
Запрет индексации в robots.txt | REG.RU
Чтобы убрать весь сайт или отдельные его разделы и страницы из поисковой выдачи Google, Яндекс и других поисковых систем, их нужно закрыть от индексации. Тогда контент не будет отображаться в результатах поиска. Рассмотрим, с помощью каких команд можно выполнить в файле robots.txt запрет индексации.
Зачем нужен запрет индексации сайта через robots.txt
Первое время после публикации сайта о нем знает только ограниченное число пользователей. Например, разработчики или клиенты, которым компания прислала ссылку на свой веб-ресурс. Чтобы сайт посещало больше людей, он должен попасть в базы поисковых систем.
Чтобы добавить новые сайты в базы, поисковые системы сканируют интернет с помощью специальных программ (поисковых роботов), которые анализируют содержимое веб-страниц. Этот процесс называется индексацией.
После того как впервые пройдет индексация, страницы сайта начнут отображаться в поисковой выдаче. Пользователи увидят их в процессе поиска информации в Яндекс и Google — самых популярных поисковых системах в рунете. Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, которые содержат соответствующую информацию:
Например, по запросу «заказать хостинг» в Google пользователи увидят ресурсы, которые содержат соответствующую информацию:
Однако не все страницы сайта должны попадать в поисковую выдачу. Есть контент, который интересен пользователям: статьи, страницы услуг, товары. А есть служебная информация: временные файлы, документация к ПО и т. п. Если полезная информация в выдаче соседствует с технической информацией или неактуальным контентом — это затрудняет поиск нужных страниц и негативно сказывается на позиции сайта. Чтобы «лишние» страницы не отображались в поисковых системах, их нужно закрывать от индексации.
Кроме отдельных страниц и разделов, веб-разработчикам иногда требуется убрать весь ресурс из поисковой выдачи. Например, если на нем идут технические работы или вносятся глобальные правки по дизайну и структуре. Если не скрыть на время все страницы из поисковых систем, они могут проиндексироваться с ошибками, что отрицательно повлияет на позиции сайта в выдаче.
Для того чтобы частично или полностью убрать контент из поиска, достаточно сообщить поисковым роботам, что страницы не нужно индексировать. Для этого необходимо отключить индексацию в служебном файле robots.txt. Файл robots.txt — это текстовый документ, который создан для «общения» с поисковыми роботами. В нем прописываются инструкции о том, какие страницы сайта нельзя посещать и анализировать, а какие — можно.
Прежде чем начать индексацию, роботы обращаются к robots.txt на сайте. Если он есть — следуют указаниям из него, а если файл отсутствует — индексируют все страницы без исключений. Рассмотрим, каким образом можно сообщить поисковым роботам о запрете посещения и индексации страниц сайта. За это отвечает директива (команда)
Как запретить индексацию сайта
О том, где найти файл robots.txt, как его создать и редактировать, мы подробно рассказали в статье. Если кратко — файл можно найти в корневой папке. А если он отсутствует, сохранить на компьютере пустой текстовый файл под названием robots. txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
txt и загрузить его на хостинг. Или воспользоваться плагином Yoast SEO, если сайт создан на движке WordPress.
Чтобы запретить индексацию всего сайта:
- 1.
Откройте файл robots.txt.
- 2.
Добавьте в начало нужные строки.
- Чтобы закрыть сайт во всех поисковых системах (действует для всех поисковых роботов):
User-agent: * Disallow: /
- Чтобы запретить индексацию в конкретной поисковой системе (например, в Яндекс):
User-agent: Yandex Disallow: /
- Чтобы закрыть от индексации для всех поисковиков, кроме одного (например, Google)
User-agent: * Disallow: / User agent: Googlebot Allow: /
- 3.
Сохраните изменения в robots.txt.
Готово. Ресурс пропадет из поисковой выдачи выбранных ПС.
Ресурс пропадет из поисковой выдачи выбранных ПС.
Запрет индексации папки
Гораздо чаще, чем закрывать от индексации весь веб-ресурс, веб-разработчикам требуется скрывать отдельные папки и разделы.
Чтобы запретить поисковым роботам просматривать конкретный раздел:
- 1.
Откройте robots.txt.
Укажите поисковых роботов, на которых будет распространяться правило. Например:
- Все поисковые системы:
User-agent: *
— Запрет только для Яндекса:
User-agent: Yandex
- 3.
Задайте правило Disallow с названием папки/раздела, который хотите запретить:
Disallow: /catalog/
Где вместо catalog — укажите нужную папку.
 org/HowToStep»>
4.
org/HowToStep»>
4.Сохраните изменения.
Готово. Вы закрыли от индексации нужный каталог. Если требуется запретить несколько папок, последовательно пропишите для каждой директиву Disallow.
Как закрыть служебную папку wp-admin в плагине Yoast SEO
Как закрыть страницу от индексации в robots.txt
Если нужно закрыть от индексации конкретную страницу (например, с устаревшими акциями или неактуальными контактами компании):
- 1.
Откройте файл robots.txt на хостинге или используйте плагин Yoast SEO, если сайт на WordPress.
- 2.
Укажите, для каких поисковых роботов действует правило.
- 3.
Задайте директиву Disallow и относительную ссылку (то есть адрес страницы без домена и префиксов) той страницы, которую нужно скрыть.
 Например:
Например:User-agent: * Disallow: /catalog/page.html
Где вместо catalog — введите название папки, в которой содержится файл, а вместо page.html — относительный адрес страницы.
- 4.
Сохраните изменения.
 Например:
Например:Готово. Теперь указанный файл не будет индексироваться и отображаться в результатах поиска.
Помогла ли вам статья?
Да
раз уже
помогла
▷ Какие страницы закрыть от индексации: запрет индексации страниц
31179
| How-to | – Читать 14 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ИСПРАВЛЕНИЕ
Инструкцию одобрил
Tech Head of SEO в TRINET.Group
Рамазан Миндубаев
Контент сайта должен быть информативным и полезным для пользователя, а соответствующие страницы — открытыми для сканирования поисковым роботом. Однако есть случаи, когда нужно закрыть страницу от индексации. Разберемся в каких случаях это уместно.
Однако есть случаи, когда нужно закрыть страницу от индексации. Разберемся в каких случаях это уместно.
Содержание:
- Причины запретить индексацию страницы
- Какие страницы не индекстровать
- Как закрыть страницы от индексации
3.1. Как закрыть сайт от индексации Google - Как проверить, сколько страниц закрыто от индексации
- Заключение
FAQ
Причины запретить индексацию страниц
Владелец сайта заинтересован, чтобы потенциальный клиент находил его веб-ресурс в выдаче, а поисковая система — в том, чтобы предоставить пользователю ценную и релевантную информацию. Для индексации должны быть открыты только те страницы, которые имеет смысл выводить в результаты поиска.
Рассмотрим причины, по которым следует запретить индексацию сайта или отдельных страниц:
Контент не несет в себе смысловой нагрузки для поисковой системы и пользователей или же вводит их в заблуждение.
К такому контенту можно отнести технические и административные страницы сайта (корзина, страница оплаты, результатов поиска, авторизация и т.д.), данные с персональной информацией, наборы фильтров каталога товара в электронной коммерции (множественный выбор фильтров по цене, цвету, фактуре и другое).
Нерациональное использование краулингового бюджета.
Краулинговый бюджет — это определенное количество страниц сайта, которое периодически сканирует поисковая система. Для всех сайтов это значение количества страниц разное и не постоянное и в том числе зависит от типа сайта и частоты его обновления. В наших интересах тратить ресурсы краулеров на те страницы, которые представляют ценность и пользу как для клиента так и для нас (бизнеса). Чтобы краулер чаще посещал и обновлял контент в индексе нужных нам страниц, необходимо закрыть от сканирования те, которые вытягивают краулинговый бюджет и не приносят собственно пользы.
Схема сканирования, индексирования и ранжирования сайта
Хотите прямо сейчас проверить, какие страницы вашего сайта индексируются и находятся в топе поисковой выдачи? А по каким фразам ранжируется ваш конкурент? Попробуйте Serpstat (нужно зарегистрироваться и после вы получите доступ к бесплатным инструментам). Если хотите доминировать на своем рынке — используйте Serpstat и достигайте большей эффективности в онлайн.
Какие закрыть страницы от индексации
Страницы сайта в процессе разработки
Если проект только в процессе создания, лучше закрыть сайт от поисковых систем. Рекомендуется открыть доступ к сканированию наполненных и оптимизированных страниц, отображение которых в результатах поиска целесообразно. При разработке сайта на тестовом сервере доступ к нему должен быть ограничен с помощью файла robots.txt, мета тега noindex или пароля, однако приоритетный вариант — это именно присвоение метатега <meta name=»robots» content=»noindex, nofollow» /> ко всем страницам разрабатываемого ресурса, так как в таком случае индексация страницы невозможна, в отличие от robots. txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
txt, где директива запрета скорей рекомендация для краулера и индексация страниц все равно возможна в ряде случаев. Зачастую программисту не сложно добавить нужную логику что бы вывести дополнительный мета тег и запретить индексацию сайта. Для ворд пресса можно использовать настройки плагина Yoast SEO или другого с подобной функцией.
Закрыть сайт от индексации в robots.txt можно следующим содержимым (первая директива — означает обращение ко всем краулерам, вторая директива — запрещает сканировать все URL сайта):
User-agent: *
Disallow: /
Эти две строчки запретят доступ к сайту всем роботам поисковых систем.
Если нужно при этом разрешить сканировать конкретные URL, нужно добавить директиву Allow: /namepage$ где /namepage URL страницы разрешенной к сканированию. Директива разрешения сканирования доминирует над запретом (для конкретного URL), а значек $ отменяет применение по умолчанию не выводимывого символа «*». То есть если не поставить $ — мы разрешим сканировать вложенные URL относительно родителя, такие как /namepage/indexpage.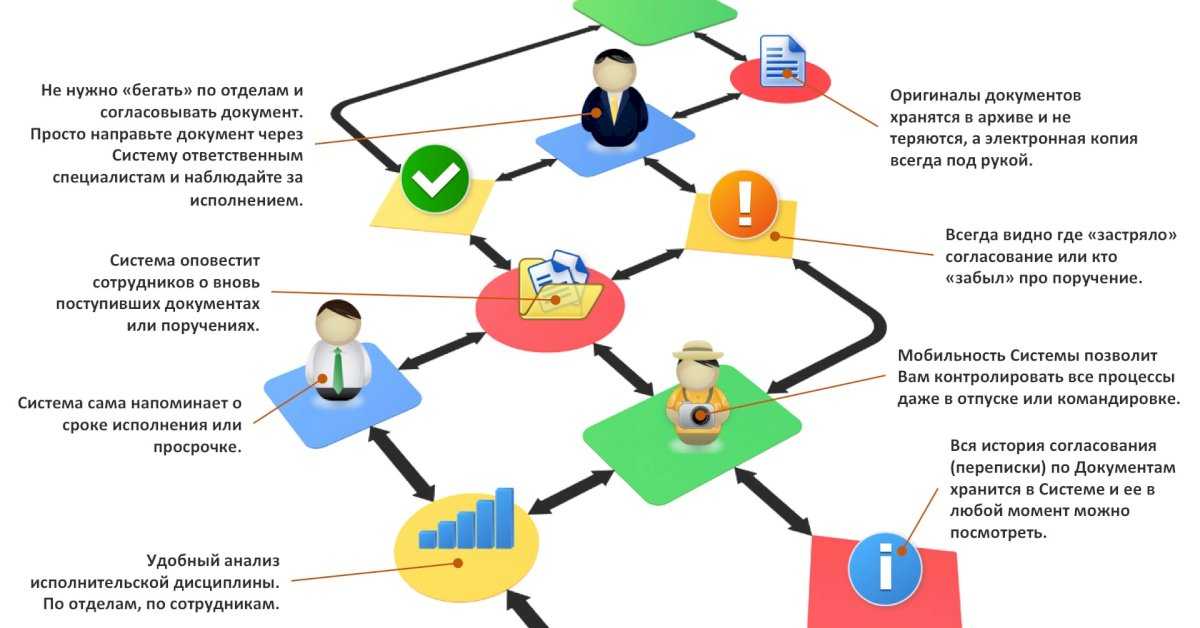 html и т.д.
html и т.д.
Запрет индексации для сайта на сервере NGINX осуществляется с помощью добавления кода add_header X-Robots-Tag «noindex, nofollow»; в файл .conf.
Копии сайта
Настраивая копию сайта, важно правильно указать зеркало с помощью 301 редиректов, либо атрибута rel= «canonical», чтобы сохранить рейтинг существующего ресурса и проинформировать поисковую систему: где сайт-первоисточник, а где его аналог. Закрывать от индексации работающий ресурс крайне нежелательно. Тем самым можно обнулить возраст сайта и наработанную репутацию.
Страницы печати
Страницы печати могут быть полезны посетителю. Нужную информацию можно распечатать в виде адаптированного текста: статью, сведения о товаре, карту расположения организации.
По сути страница печати является копией её основной версии. Если эта страница открыта для индексации, поисковый робот может выбрать ее приоритетной и более релевантной. Для правильной оптимизации сайта с большим числом страниц следует установить запрет индексации страниц для печати.
Чтобы закрыть ссылку на документ, можно использовать вывод контента с помощью AJAX, закрыть страницы с помощью метатега <meta name=»robots» content=»noindex, follow»/>, либо в роботс закрыть от индексации все страницы печати.
Ненужные документы
На сайте, кроме страниц с основным контентом, могут присутствовать документы PDF, DOC, XLS, доступные для чтения и загрузки. В результатах поиска на ряду со страницами сайта можно увидеть заголовки pdf-файлов.
Возможно, содержимое этих файлов не отвечает запросам целевой аудитории сайта. Или же документы появляются в поиске выше html-страниц сайта. В этом случае индексация документов нежелательна, и их лучше закрыть от сканирования в файле robots.txt.
Пример индексации pdf-файла на сайте
Пользовательские формы и элементы
Сюда относят все страницы, которые полезны для клиентов, но не несут информационной ценности для других пользователей и, как следствие, поисковых систем. Это могут быть формы регистрации и оформления заявок, корзина, личный кабинет. Доступ к таким страницам следует ограничить.
Это могут быть формы регистрации и оформления заявок, корзина, личный кабинет. Доступ к таким страницам следует ограничить.
Технические данные сайта
Технические страницы нужны исключительно для служебного использования администратором. Например, форма авторизации для входа в панель управления.
Форма авторизации в админку OpenCart
Персональная информация о клиентах
Эти данные могут содержать не только только имя и фамилию зарегистрированного пользователя, но и контактные и платежные данные, оставленные при оформлении заказа. Эта информация должна быть надежно защищена от просмотра.
Страницы сортировки
Особенности структуры таких страниц делают их похожими друг на друга. Чтобы снизить риск санкций от поисковых систем за дублированный контент, рекомендуем закрывать к ним доступ.
Страницы пагинации
Данные страницы хоть частично и дублируют содержание основной страницы, закрывать от индексации их не рекомендуется, для них необходимо настроить атрибут rel=»canonical», атрибуты rel=»prev» и rel=»next», указать в Google Search Console в разделе «Параметры URL», какие параметры разбивают страницы, либо целенаправленно их оптимизировать.
- Как провести анализ индексации сайта
- SEO-аудит сайта с помощью Serpstat: обзор инструмента
- Как автоматизировать поиск ошибок на сайте: Аудит сайта теперь доступен в API Serpstat
Как закрыть страницы от индексации
Метатег robots со значением noindex в html-файле
Чтобы закрыть страницу от индексации, используйте атрибут noindex в html-коде страницы — это сигнал поисковой системе о том, что ее следует исключить из результатов поиска. Чтобы использовать метатеги, необходимо в заголовок <head> соответствующего html-документа добавить <meta name=»robots» content=»noindex, follow»/>.
Это позволяет полностью закрыть страницу, оставив роботам возможность переходить по размещенным на странице ссылкам. Если это не нужно, замените follow на nofollow:
<meta name=»robots» content=»noindex, nofollow»/>
При использовании данных методов страница будет закрыта для сканирования даже при наличии внешних ссылок на нее.
Как закрыть сайт от индексации Google
Вы можете также закрыть доступ к сайту только ботам Google. Добавьте для этой цели данный метатег внутри <head> </head> всех страниц ресурса:
<meta name=»googlebot» content=»noindex, nofollow»/>
Через robots доступ к сайту ботам Google закрывается так:
User-agent: googlebot
Disallow: /
Еще можно запретить доступ к каким-либо статьям сайта роботам Google Новостей, тогда они не появятся в Google News:
<meta name=»Googlebot-News» content=»noindex, nofollow»>.
Файл robots.txt
В этом документе можно заблокировать доступ ко всем выбранным страницам или указать поисковикам не индексировать сайт.
Ограничить индексацию страниц через файл robots.txt можно так:
User-agent: * #название поисковой системы Disallow: /catalog/ #частичный или полный URL закрываемой страницы
Чтобы использование этого метода было эффективным, следует проверить, нет ли внешних ссылок на раздел сайта, который нужно скрыть, а также изменить все внутренние ссылки, ведущие на него.
Файл конфигурации .htaccess
Используя этот документ можно ограничить доступ к сайту с помощью пароля. Необходимо указать Username пользователей, которые смогут попасть к нужным страницам и документам, в файле паролей .htpasswd. Затем указать путь к этому файлу с помощью специального кода в файле .htaccess.
AuthType Basic AuthName "Password Protected Area" AuthUserFile путь к файлу с паролем Require valid-user
Удаление URL через сервисы веб-мастеров
В Google Search Console можно убрать страницу из результатов поиска, указав URL в специальной форме и обозначив причину ее удаления. Функция удаления страниц доступна в разделе «Индекс Google». Обработка запроса может занять некоторое время.
Удаление URL-адресов из индекса в Search Console
Как проверить, сколько страниц закрыто от индексации
С помощью Аудита сайта Serpstat можно быстро проверить сайт на наличие технических ошибок и узнать, сколько страниц не проиндексировано.
Для того, чтобы это сделать нужно всего лишь нажать на кнопку ниже, и у вас будет возможность создать проект для сайта ↓
В появившихся настройках можно указать имя домена и количество страниц, которые нужно просканировать краулеру:
Запуск аудита в Serpstat
Выбор типа сканирования и указание лимита страниц
Когда сканирование будет закончено, на графике в Суммарном отчете можно проверить, какое количество страниц из указанных не проиндексировано:
Проверка индексации страниц в Аудите Serpstat
Хотите узнать, как с помощью Serpstat найти и исправить технические ошибки на сайте?
Оставьте заявку и наши специалисты проконсультируют вас по продвижению вашего проекта, поделятся учебными материалами и инсайтами рынка!
| Заказать бесплатную консультацию |
Error get alias
Заключение
Управление индексацией — важный этап SEO. Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Следует не только оптимизировать перспективные для трафика страницы, но и скрывать от индексации контент, продвижение которого не несет никакой пользы.
Ограничение доступа к ряду страниц и документов сэкономит ресурсы поисковой системы и ускорит индексацию сайта в целом.
Как запретить индексацию сайта?
Запретить доступ ботов поисковых систем к сайту можно с помощью нескольких способов: добавления метатега robots со значением noindex в html-код; указания директивы Disallow в файле robots.txt; установки пароля для доступа к сайту в конфигурационном файле .htaccess. Также можно блокировать доступ к отдельным каталогам и документам.
Как временно закрыть сайт от индексации
Чтобы закрыть сайт от индексации, добавьте метатег name=»robots» content=»noindex, nofollow» в раздел всех веб-страниц или добавьте директиву User-agent: * Disallow: / в файл robots.txt.
Как закрыть сайт от индексации WordPress
Чтобы закрыть сайт WordPress от индексации, зайдите в админку CMS, выберите раздел «Настройки» → «Чтение». Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Найдите подраздел «Видимость для поисковых систем» и отметьте галочкой «Попросить поисковые системы не индексировать сайт». После этого WordPress автоматически внесет коррективы в файл robots.txt для запрета индексации.
Задавайте вопросы в комментариях или пишите в техподдержку.:) А также вступайте в чат любителей Серпстатить и подписывайтесь на наш канал в Telegram.
Serpstat — набор инструментов для поискового маркетинга!
Находите ключевые фразы и площадки для обратных ссылок, анализируйте SEO-стратегии конкурентов, ежедневно отслеживайте позиции в выдаче, исправляйте SEO-ошибки и управляйте SEO-командами.
Набор инструментов для экономии времени на выполнение SEO-задач.
Получить бесплатный доступ на 7 дней
Оцените статью по 5-бальной шкале
4.11 из 5 на основе 45 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Анастасия Сотула
Как включить HTTP/2 для сайта
How-to
Анастасия Сотула
Как проверить посещаемость сайта в системах аналитики и без счетчика
How-to
Анастасия Сотула
Что такое SEO продвижение сайтов: SEO оптимизация сайта пошагово
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе.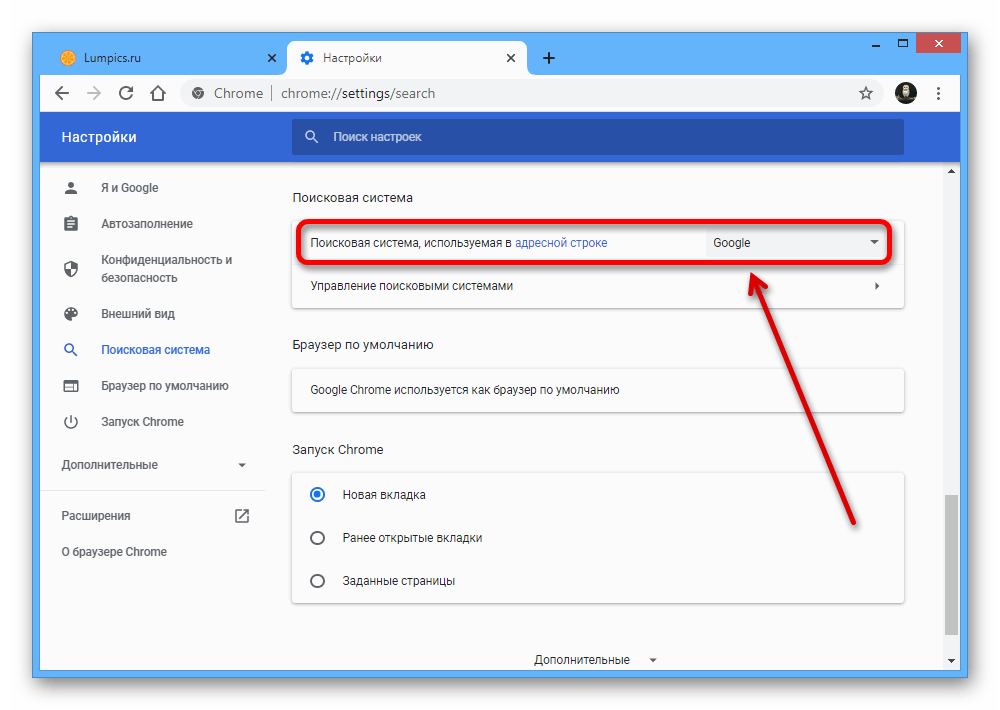 Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
5 способов заблокировать веб-сайт в результатах поиска Google
Рекомендуемые
Это руководство покажет вам, как действовать в определенных ситуациях в результатах поиска Google. Вы хотите удалить список доменов из поиска? Это возможно.
Ян Онесорк
• 3 минуты чтения
Их даже можно пометить. Или, может быть, вы хотите удалить личную информацию из результатов поиска. Отметьте, какая из приведенных ниже ситуаций относится к вам.
Отметьте, какая из приведенных ниже ситуаций относится к вам.
Исключить веб-сайт из результатов поиска навсегда
Если есть конкретный сайт, который вас так сильно беспокоит, что вы больше не хотите видеть его в результатах поиска Google, существует бесплатное расширение для Chrome, которое делает именно это. .
Это называется «Персональный черный список» (не Google). Он добавит простую ссылку «Заблокировать (домен)» в результаты поиска. Вы также можете импортировать весь свой личный черный список.
Заблокировать отображение выбранных доменов в результатах поиска Google с помощью расширенияПосле этого расширение удалит выбранные сайты из результатов поиска Google, чтобы вам больше не приходилось их видеть.
Хотите верьте, хотите нет, но в 2011 году эта функция была встроена в результаты поиска Google и была доступна каждому.
Однократное исключение веб-сайта из результатов поиска
Если вы хотите удалить определенный домен из определенного поиска, вы можете использовать параметр site:. Допустим, вы хотите использовать Google [техническое SEO], но не хотите видеть результаты поиска с neilpatel.com.
Допустим, вы хотите использовать Google [техническое SEO], но не хотите видеть результаты поиска с neilpatel.com.
Ваш поиск будет выглядеть следующим образом:
технический поиск -site:neilpatel.com
«Сайт:» означает, что вы хотите искать в указанном домене. — знак означает, что вы хотите, чтобы этот сайт был исключен из результатов поиска.
Исключить домен из одного поиска по сайту: параметрНе удалять, только добавить метку!
Есть один тип результатов поиска, который беспокоит большинство людей, — контент с платным доступом. Кто хочет увидеть результат поиска, нажмите на него и увидите, что сначала нужно заплатить за доступ к нему. Пользователи редко заинтересованы в подписке только для того, чтобы получить доступ к одной статье, поэтому это часто приводит к ухудшению пользовательского опыта.
Загрузите это бесплатное расширение для браузера Chrome, которое добавляет ярлык ко всем сайтам с платным контентом в результатах поиска Google, Facebook и Twitter.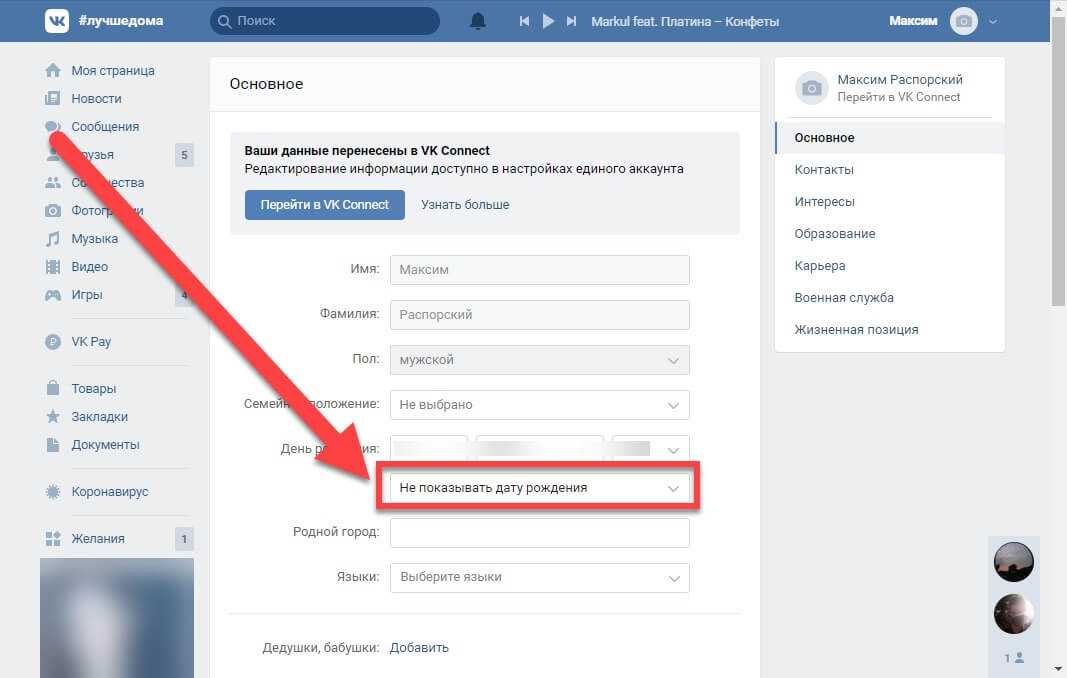
Вы можете настроить список помеченных доменов, чтобы удалить те, на которые вы подписаны, или добавить в список другие сайты. Поскольку список полностью настраиваемый, вы даже можете изменить назначение расширения и пометить любые сайты по своему усмотрению (например, сайты, распространяющие фальшивые новости и т. д.)
Полностью заблокируйте доступ к веб-сайту и повысьте производительность
Некоторые приложения и расширения не позволяют вам получить доступ к выбранным сайтам в течение заданного времени. Разумеется, для повышения производительности.
Вы можете попробовать расширение Block Site для браузера Chrome или попробовать одно из труднообходимых приложений — например, Cold Turkey — одно из самых популярных.
Но эти приложения не блокируют отображение сайтов в результатах поиска, но не позволяют вам получить к ним доступ.
Собственный сайт: как удалить что-то из поиска Google?
Отображает ли Google какую-либо информацию в результатах поиска, которую вы не хотите показывать публично? Вы контролируете сайт? Если вы можете редактировать код HTML, добавьте этот метатег в раздел
страницы, которую вы хотите удалить из Google:
Здесь вы вы найдете дополнительную информацию о том, как запретить поисковым системам индексировать ваш контент.
Имейте в виду, что это приведет к удалению информации только из результатов поиска Google, и потребуется некоторое время, чтобы тег вступил в силу. Безопаснее просто удалить саму страницу или хотя бы добавить защиту паролем. Защиту паролем может быть трудно настроить. Тем не менее, на многих веб-хостингах эта функция встроена и доступна через администратора хостинга.
Обновлено 11 ноября 2020 г.: Компания Google недавно опубликовала видео об удалении/блокировке страниц из поиска Google. Проверьте это ниже:
Google объясняет, как скрыть веб-сайт из результатов поиска
Google говорит, что лучший способ скрыть веб-сайт из результатов поиска — это пароль, но есть и другие варианты, которые вы можете рассмотреть.
Эта тема освещена в последнем выпуске серии видеороликов Ask Googlebot на YouTube.
Джон Мюллер из Google отвечает на вопрос о том, как предотвратить индексацию контента в поиске и разрешено ли это делать веб-сайтам.
«Короче говоря, да, можете, — говорит Мюллер.
Есть три способа скрыть сайт из результатов поиска:
- Использовать пароль
- Обход блока
- Индексация блока
Веб-сайты могут либо полностью отказаться от индексации, либо проиндексироваться и скрыть контент от робота Googlebot с помощью пароля.
Блокирование контента роботом Googlebot не противоречит правилам для веб-мастеров, если в то же время он заблокирован для пользователей.
Например, если сайт защищен паролем при сканировании роботом Googlebot, он также должен быть защищен паролем для пользователей.
В качестве альтернативы сайт должен иметь директивы, запрещающие роботу Googlebot сканировать или индексировать сайт.
Вы можете столкнуться с проблемами, если ваш веб-сайт предоставляет другой контент для робота Googlebot, чем для пользователей.
Это называется «маскировкой» и противоречит рекомендациям Google.
С учетом этого различия, вот правильные способы скрыть контент от поисковых систем.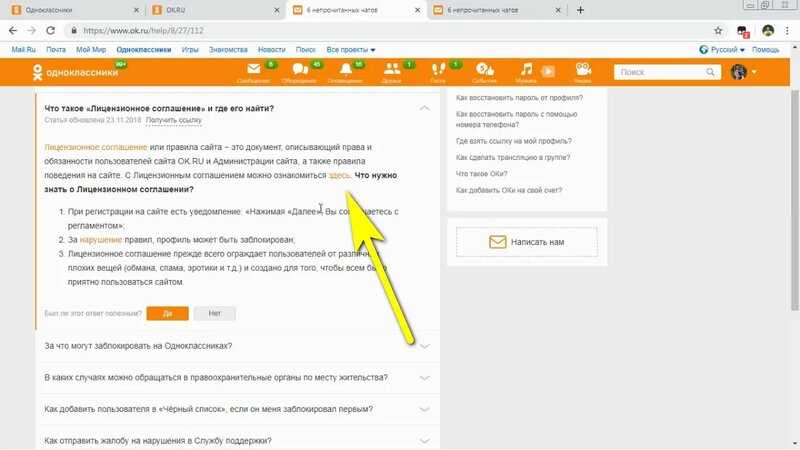
1. Защита паролем
Блокировка веб-сайта паролем часто является лучшим подходом, если вы хотите сохранить конфиденциальность своего сайта.
Пароль гарантирует, что ни поисковые системы, ни случайные пользователи сети не смогут увидеть ваш контент.
Это обычная практика для веб-сайтов в разработке. Публикация веб-сайта в режиме реального времени — это простой способ поделиться с клиентами незавершенной работой, не позволяя Google получить доступ к веб-сайту, который еще не готов к просмотру.
2. Заблокировать сканирование
Еще один способ запретить роботу Googlebot доступ к вашему сайту — заблокировать сканирование. Это делается с помощью файла robots.txt.
С помощью этого метода люди могут получить доступ к вашему сайту по прямой ссылке, но она не будет обнаружена «приличными» поисковыми системами.
По словам Мюллера, это не лучший вариант, потому что поисковые системы могут индексировать адрес веб-сайта, не обращаясь к его содержимому.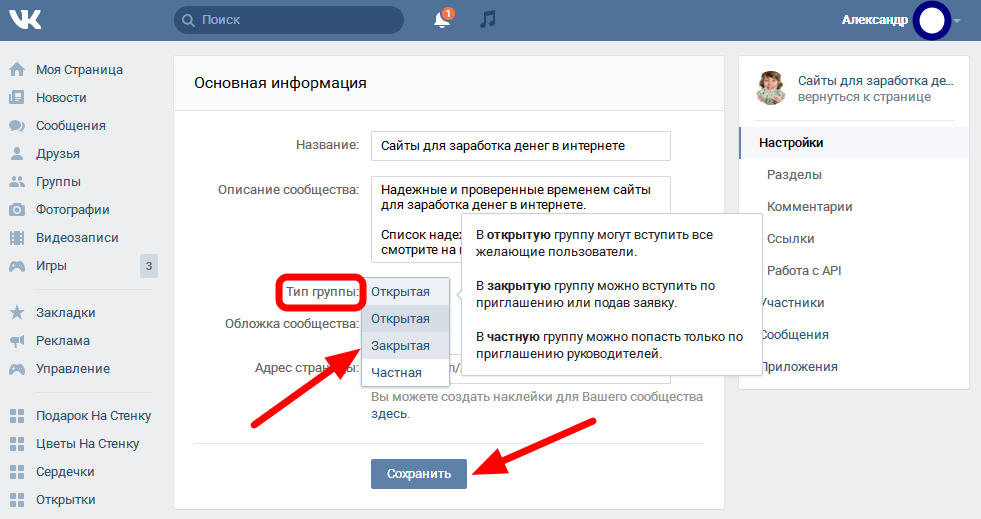
Такое случается редко, но о такой возможности вам следует знать.
3. Заблокировать индексирование
Третий и последний вариант — заблокировать индексирование вашего веб-сайта.
Для этого вы добавляете на свои страницы метатег noindex robots.
Тег noindex указывает поисковым системам не индексировать эту страницу до тех пор, пока после они ее не просканируют.
Пользователи не видят метатег и могут нормально открывать страницу.
Заключительные мысли Мюллера
Мюллер завершает видео, говоря, что главная рекомендация Google — использовать пароль:
«В целом, для частного контента мы рекомендуем использовать защиту паролем. Легко проверить, работает ли он, и он не позволяет никому получить доступ к вашему контенту.
Блокировка сканирования или индексации — хорошие варианты, когда контент не является частным. Или если есть только части веб-сайта, которые вы не хотите отображать в поиске».
