
Сбор семантического ядра: 4 сервиса
Сбор семантического ядра — важный этап оптимизации сайта. Собранные таким образом ключевые слова и фразы должны стать частью заголовков и описаний отдельных страниц. Благодаря грамотно составленному ядру, можно продвинуть сайт в топ поисковых систем, не прибегая к другим SEO-инструментам.
Да, сбор семантического ядра относится к задачам SEO-специалиста, однако современные сервисы позволяют это сделать и без привлечения такового. Рассказываем, что это за сервисы и как ими пользоваться.
- Wordstat
- Key Collector
- Словоёб
- ARSENKIN TOOLS
Wordstat
Вордстат — сервис для сбора семантики вручную. Подходит для небольших материалов и других страниц, которые не требуют большого количества ключей и их синонимов.
Все запросы имеют четыре очень важных показателя, которые следует учитывать при сборе ядра:
- частотность;
- конкурентность;
- региональность;
- сезонность.


И всё это можно учесть при составлении семантического ядра в Wordstat. Региональность выбирается внизу окошка, сезонность можно определить через вкладку «История запросов», а частотность отображается в столбце «Показов в месяц»:
Конкурентность зачастую коррелирует с частотностью, поскольку чем популярнее слово, тем больше сайтов стараются его использовать.
Но всё-таки, как вычислить конкурентность ключа? Для этого существует формула:
KEI = p²/u,
где p — общая частота запроса в месяц, а u с количество результатов в поиске (просто вбиваете ключ и смотрите, сколько сайтов по нему можно найти).
Но посмотрим правде в глаза: собирать руками семантическое ядро для лонгрида или другой важной страницы, которая должна предоставлять исчерпывающую информацию, — продолжительный и трудоёмкий процесс.
Именно поэтому разработчики создали специальные приложения для автоматизации сбора.
Key Collector
Это основной инструмент автоматического составления семантических ядер в большинстве компаний. Программа платная, однако лицензия является бессрочной, то есть это единоразовая покупка. Однако приобретённый Key Collector может устанавливаться строго на 1 ПК: для других компьютеров необходимо приобретать дополнительные лицензии.
Принцип работы:
- Перед началом работы настраиваете приложение.
- Вбиваете в программу основные маркерные запросы. Пример: сайт «Типичный программист» о программировании и информационных технологиях. Создаём две категории запросов с маркерами «программирование» и «информационные технологии».
- Запускаете программу, и она парсит Wordstat.
- Из полученного вороха ключевиков удаляете нерелевантные и получаете чистое семантическое ядро.
Обновления для Key Collector выходят раз в несколько дней, что свидетельствует о постоянном развитии и доработке функционала.
Важно Почти для всех сервисов по автоматическому сбору семантики требуется покупка прокси, так как по сути это парсинг, и из-за большого количества автоматических запросов может быть забанен основной IP-адрес.
Настройка Key Collector:
Словоёб
Название странное, но мы ничего не придумывали. Словоёб — это бесплатная версия Key Collector с ограничениями по настройкам и функционалу. Обновления выходят, но редко, и для получения новой версии нужно переустановить программу. Тем не менее данный инструмент отлично подойдёт для решения несложных задач.
Это также парсер Wordstat, поэтому следует озаботиться покупкой прокси.
ARSENKIN TOOLS
Условно бесплатный набор инструментов, направленных на оптимизацию ресурса. Для работы с семантическим ядром следует выделить несколько:
- Парсинг подсветок Yandex. Сервис позволяет быстро собрать подсветки (синонимы ключевика) из поисковой системы Яндекс и дополнительные тематические ключи.
- Выгрузка ТОП-10 сайтов. Самый полезный для сеошников инструмент, с помощью которого можно выгрузить первые сайты в поисковой выдаче Google и Яндекс по заданным запросам. Это позволяет увидеть, какие страницы поисковики считают наиболее хорошо оптимизированными, проанализировать их и оптимизировать свою страницу по тому же принципу.
- Сбор частотности и сезонности. Быстрая проверка частотности и сезонности через Вордстат.
- Кластеризация запросов. Быстрая группировка необходимых ключей.
- Сбор поисковых подсказок. С помощью этого инструмента можно без труда собрать подсказки вGoogle, Яндексе и даже YouTube.
 Это позволяет увидеть, какие страницы поисковики считают наиболее хорошо оптимизированными, проанализировать их и оптимизировать свою страницу по тому же принципу.
Это позволяет увидеть, какие страницы поисковики считают наиболее хорошо оптимизированными, проанализировать их и оптимизировать свою страницу по тому же принципу.Рассмотрим работу сервиса на примере выгрузки топ-10 сайтов по нужным нам запросам. Для начала вобьём эти запросу в специальное окно, выберем поисковую систему (ПС Google доступна только по подписке), глубину проверки и регион:
Нажимаем «Начать проверку» и видим следующий результат:
Удобно, что одни и те же страницы можно подсветить, прослеживая степень оптимизации по ряду ключевых запросов. Далее можно перейти на страницы конкурентов и прогнать их уже через другие сервисы, которые позволят понять, почему поисковые системы оценивают их выше. После возвращаемся и оптимизируем свою страницу так, чтобы понравится Яндексу больше.
После возвращаемся и оптимизируем свою страницу так, чтобы понравится Яндексу больше.
Кстати, на последнем скрине вы можете видеть в топе наш оптимизированный лонгрид на тему, как стать программистом.
Остались вопросы по сбору семантики? Пишите в комментариях.
Как составить семантическое ядро для сайта
В данном руководстве мы пошагово опишем алгоритм подбора эффективного семантического ядра.
Несмотря на то, что в данном руководстве часто упоминается функционал Rush Analytics, по сути не важно, какими инструментами вы будете собирать данные.
Вы можете собирать данные даже вручную, копируя их из браузера, однако, на это уйдет в 100-300 раз больше вашего времени.
Данная методология подходит для коммерческих сайтов (сайтов услуг), для интернет-магазинов и для информационных порталов. Однако для каждого типа сайтов есть свои нюансы в поисковом спросе — вы легко их поймете в процессе составления семантического ядра онлайн.
Базовая парадигма сбора семантики
На схеме выше показана единственно верная логика сбора семантического ядра — сначала получить базовые запросы (маркерные), которые характеризуют вашу тематику, а потом расширить их дополнительными запросами и сформировать структуру сайта.
Почему именно такая методология? Все просто: при таком подходе к подбору семантического ядра вы
а) будете контролировать процесс сбора семантики и не «закопаетесь» в уйме ключевых слов
б) вам практически не придется чистить семантическое ядро вручную, семантическое ядро для сайта автоматически можно почистить с помощью наших списков стоп слов
в) Это быстрее, чем любая другая методология.
Давайте раз и навсегда разберемся в терминологии, которую наша команда использует при работе с семантикой
Фактически есть 2 типа запросов: маркерные запросы и запросы из облака ключевых слов
Маркерные запросы
Маркерные запросы — это запросы, которые четко отвечают продвигаемой странице. Такие запросы обычно имеют значимую частотность ключевых слов по Wordstat и являются средне-частотными (СЧ), или «жирными» низкочастотниками (НЧ), и могут породить «хвост» запросов, например при добавлении слов «купить», «цена», «отзывы».
Такие запросы обычно имеют значимую частотность ключевых слов по Wordstat и являются средне-частотными (СЧ), или «жирными» низкочастотниками (НЧ), и могут породить «хвост» запросов, например при добавлении слов «купить», «цена», «отзывы».
Примеры:
Платья
Красные платья
Красные платья в пол
Телевизоры
Телевизоры Samsung
Телевизоры Самсунг
LED телевизоры Samsung
Стиральные машины
Стиральные машины для дачи
Стиральные машины шириной 40 см
Другими словами, эти ключевые слова часто являются названием страниц/категорий/статей/карточек товара и прочих типов страниц, которые вообще можно продвигать в поисковых системах.
Часто задаваемые вопросы про маркеры:
Q: Могут ли для страницы быть несколько маркеров?
A: Да — конечно — это довольно частый случай.
Например, на одну страницу могут идти такие маркеры как:
Телевизоры Samsung
Телевизоры Samsung купить
Телевизоры Самсунг
Телевизоры Самсунг купить
Телевизоры самсунг цена
Все эти запросы четко отвечают одной странице
Так же на одну страницу могут идти два маркера-синонима, не связанных лингвистически:
Спецоджеда
Рабочая одежда
или
электроплита бош
электрическая плита bosch
Это вполне нормально и логично.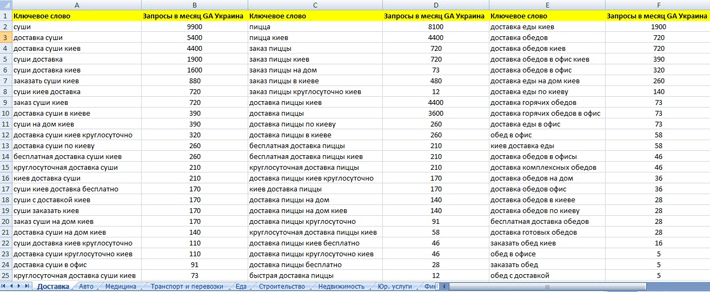
НЕ маркеры — облако запросов. Это все второстепенные запросы, которые уточняют маркерные запросы — т.е. по факту это маркеры + 1/2/3 слова или синонимы маркеров. Как правило запросы из облака — менее частотные и поэтому мы будем привязывать их к маркерам.
Как найти маркерные запросы?
Сразу скажем, что получить маркерные запросы для сайта любого объема ПОЛНОСТЬЮ автоматически не получится по ряду причин. Это на данный момент основной фронт ручной работы при подборе семантики. Мы работаем над автоматизированным алгоритмом и сообщим вам о его выходе.
Вариант №1: можно получить поисковые запросы из Яндекс Метрики. Плюсы такого метода — что вы сразу будете знать релевантные URL для этих запросов.
Вариант №2: Берем названия категорий/услуг своего сайта и расширяем их логическими гипотезами:
«Как, по каким запросам пользователи еще могут искать эту страницу моего сайта? Какие есть синонимы?»
NB!: Отличным подспорьем в определении маркеров является старый добрый Яндекс Wordstat, при всех его недостатках. Рекомендуем использовать браузерный плагин Yandex Wordstat Assistant от компании Semantica — очень удобный — выполняет роль своего рода «заметок на полях» — в него можно в один клик добавить интересующие слова.
Рекомендуем использовать браузерный плагин Yandex Wordstat Assistant от компании Semantica — очень удобный — выполняет роль своего рода «заметок на полях» — в него можно в один клик добавить интересующие слова.
Мы понимаем, что не у каждого оптимизатора/владельца бизнеса есть под рукой департамент разработки, который быстро сможет выгрузить для сайта связку URL — название категории/страницы.
Что такое связка URL-название категории/страницы?Поэтому есть 3 варианта как получить связку URL — название категории/страницы:
- Запросить у программистов — идеальный 🙂
- Самому спарсить это с сайта. В этом поможет отличный и простой инструмент — Screaming Frog (официальный сайт Screaming Frog). Это парсер сайта, который в итоге отдаст вам в формате Excell таблицу вида URL — заголовок h2 (это и есть название категории/страницы).
- Если структура сайта еще только проектируется — резонно вручную придумать связки URL-название категории.
Фактически маркеры для вашего сайта будут состоять из:
- Запросов, выгруженных из Яндекс Метрики
- Названий категорий/страниц, взятых с сайта
- Расширений названий категорий/страниц т. е. логических гипотез
 е. логических гипотез
е. логических гипотезВажно выполнить эту часть работы по подбору семантического ядра максимально тщательно т.к. если вы потеряете большую часть маркеров — вы потеряете большую часть семантического ядра.
Часто задаваемые вопросы по подбору маркеров:
Q: У меня большой сайт и маркеров сотни или тысячи — как быть?!
A: В таком случае нужно работать итерациями, собирая семантику начиная с самых приоритетных категорий.
Реалии таковы, что собрать семантику для большого интернет-магазина или портала «за раз» невозможно — вы просто «закопаетесь».
Определите самые приоритетные категории по принципу самой высокой маржинальности и принципу сезонности — эффективнее всего начинать продвигать категории за 6 месяцев до их пикового сезонного спроса. Сезонность можно оценить в Яндекс Wordstat. Пример запроса:
Q: На сколько низкочастотное слово может быть маркером?
A: Здесь все зависит от тематики. В узких тематиках даже ключевые слова с частотностью 15 по кавычкам «» могут быть маркерными запросами. Главное правило — спросите себя — хотел бы мой пользователь видеть отдельную страницу под этот запрос (и связанные с ним?). Удобно ли ему будет пользоваться той структурой, что я создаю?
В узких тематиках даже ключевые слова с частотностью 15 по кавычкам «» могут быть маркерными запросами. Главное правило — спросите себя — хотел бы мой пользователь видеть отдельную страницу под этот запрос (и связанные с ним?). Удобно ли ему будет пользоваться той структурой, что я создаю?
NB:! Для интернет магазинов нужно сразу же скрестить все маркеры со словами «купить» и «цена» — это тоже будут маркеры. Таким образом все запросы точно попадут на нужные страницы.
Q: Как мне держать маркеры в Excell, чтобы потом мне было удобно с ними работать?
A: Идеальный и единственно правильный вариант — всегда держать связку URL-маркер в Excel — так вы всегда сможете понимать какие маркеры идут на один URL, даже если ваш список перемешается.
В дальнейшем таким образом вы сможете фильтровать целые кластеры, которые идут на одну страницу — это может быть и 10 и 50 ключевых слов. Очень удобно.
Пример правильного оформления маркеров в Excel
Итак, после N времени работы мы собрали маркеры для всего сайта (или части сайта), что дальше?
Естественно, что маркеры, это далеко не полная семантика — теперь нам нужно собрать облако запросов — расширить наше семантическое ядро.
Облако запросов — расширение семантического ядра
Облако запросов — это все ключевые слова, полученные парсингом поисковых подсказок и Яндекс Wordstat по маркерным запросам.
По нашему опыту эффективнее всего получать расширения запросов из поисковых подсказок Яндекса + поисковые подсказки Google и левой колонки Яндекс Wordstat.
Почему?
Не потому, что в Rush Analytics есть парсинг только Яндекс Wordstat и поисковых подсказок 🙂
Потому, что эти источники семантики: а) Обладают максимальной полнотой б) Подсказки изначально трастовый источник семантики т.к. сам Яндекс исправляет орфографию и добавляет в подсказки ТОЛЬКО реальные запросы пользователей. Что нам и нужно.
Часто задаваемые вопросы по сбору облака запросов
Q: У меня есть база Пастухова, есть аккаунт в SeoPult и Sape — там тоже есть ключевые слова — чем они плохи?
A: Если говорить о готовых базах данных (например, База Пастухова), то плохи они вот чем а) непонятно откуда взяты эти запросы — реальные ли это запросы или же это «кривые» запросы горе-оптимизаторов б) Большинство запросов в готовых базах данных банального сгенерированы или уже потеряли актуальность.
SeoPult и Sape можно использовать, чтобы прикинуть свои маркеры — иногда там можно найти интересные ключевые слова
Таким образом, проще собрать свежие и актуальные ключевые слова для своей тематики, чем «копаться в мусоре».
Более подробно ознакомиться с обзором источников ключевых слов можно в этой статье из нашей базы знаний
Поверьте — все пригодные запросы этих баз данных есть в Яндекс Wordstat и поисковых подсказках. Мы проверяли.
Итак — у нас есть 2 потенциальных источника семантики — Яндекс Wordstat и поисковые подсказки.
Алгоритм сбора облака запросов
- Берем маркерные запросы и собираем по ним левую колонку Яндекса Wordstat.
Подробное руководство по сбору ключевых слов из Wordstat.
- 2. После сбора ключевых слов — очищаем полученные данные от мусорных и нецелевых запросов. В нашем сервисе мы реализовали алгоритм автоматической очистки стоп-слов в Яндекс Wordstat — воспользуйтесь готовыми списками стоп-слов по гео-запросам и списками популярных мусорных слов по различным тематикам. Вы так же можете добавить свой список стоп-слов «под себя».
- 3. По полученному списку ключевых слов собираем поисковые подсказки — ставим второй уровень перебора и перебор русского алфавиты. Для интернет-магазинов/коммерческих сайтов, у которых в семантике есть иностранные бренды крайне рекомендуем поставить и перебор английского алфавита. Для всех сайтов, у которых есть числовые артикулы — рекомендуем поставить перебор цифр.
- 4. ВАЖНО: в поисковых подсказках вам будут встречаться нецелевые ключевые слова. Избежать ручной чистки этих слов довольно просто — для этого в Rush Analytics есть функционал стоп-слов, который вырезает нецелевые ключевые слова «на лету» — указав список стоп-слов для вашей тематики — в финальной выгрузке вы получите список только нужных и целевых ключевых слов.
 Вы так же можете добавить свой список стоп-слов «под себя».
Вы так же можете добавить свой список стоп-слов «под себя».Как работать со стоп-словами и как определить их для вашей тематики, мы подробно рассказали в этой статье.
Также в статье представлен обширный список стоп-слов, который подходит для большинства тематик.

Тематические списки стоп-слов и гео запросы интегрированы непосредственно в интерфейс Rush Analytics — во все типы задач (парсер Wordstat, сбор подсказок и в кластеризацию).
- После сбора поисковых подсказок вам будет доступен итоговый файл — это как раз то, что нам нужно.
Формируем финальное облако запросов:
Финальное облако запросов будет включать в себя:
а) Ключевые слова, собранные с левой колонки Wordstat
б) Ключевые слова, полученные из поисковых подсказок
Т.е. вам нужно объединить 2 массива данных (2 файла), которые мы получили из поисковых подсказок и из Яндекс Wordstat.
Не забудьте проверить частотность собранных подсказок по Wordstat — это пригодится вам в дальнейшей работе.
Здесь вы должны иметь от нескольких тысяч до нескольких сотен тысяч целевых ключевых слов + знать их частотность по Wordstat. Уже на данном этапе понятно, что собранная база ключевых слов в 10-50 раз превышает то, что имеют конкуренты 🙂
Построение финальной структуры сайта — кластеризация ключевых слов
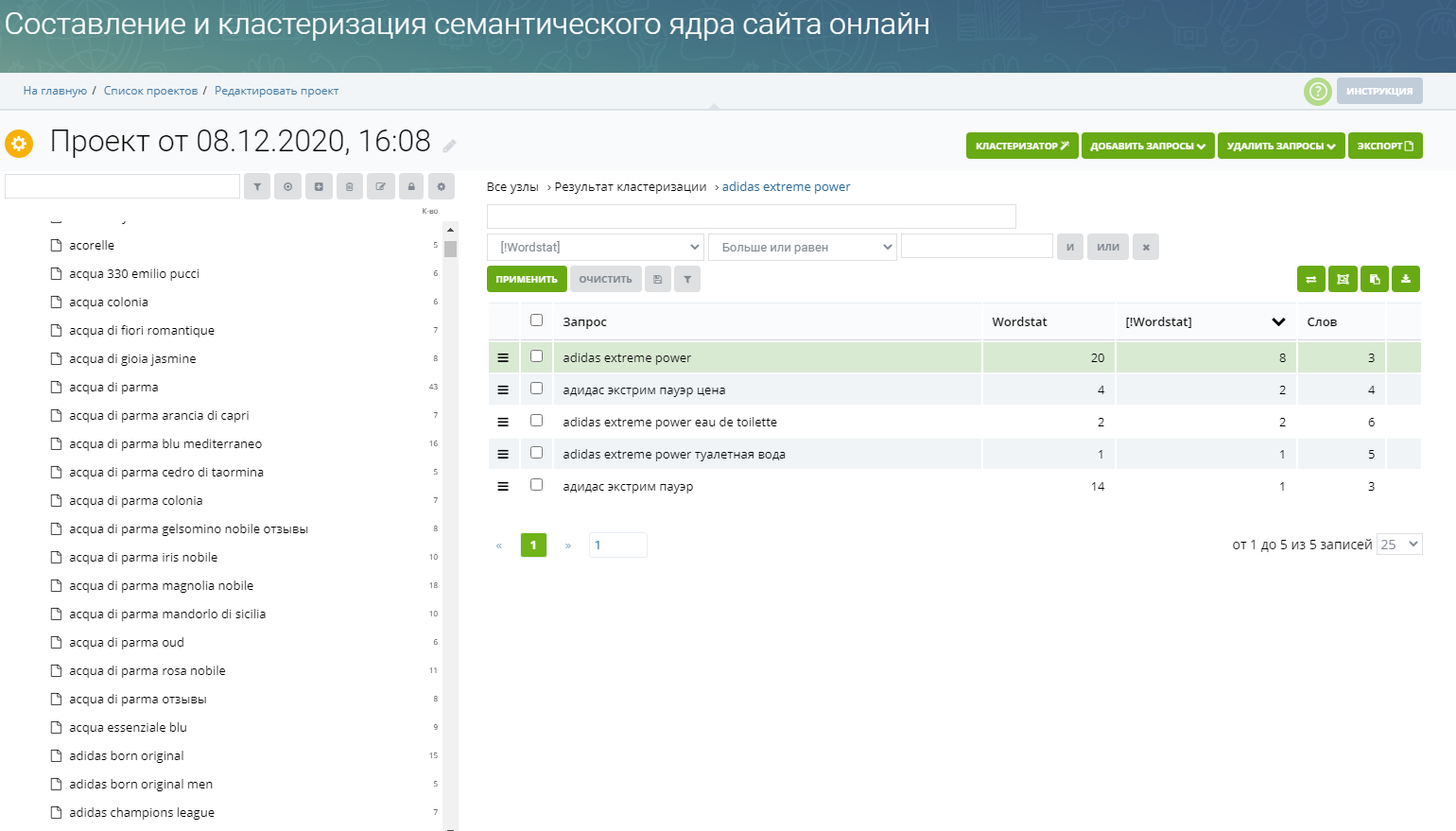
Понятно, что привязать полученное облако запросов к маркерам вручную очень трудоемкая задача, требующая нечеловеческой концентрации и уйму времени. Именно это явилось одной из причин, по которой мы реализовали в Rush Analytics функционал кластеризации запросов по методу подобия выдачи поисковых систем.
Именно это явилось одной из причин, по которой мы реализовали в Rush Analytics функционал кластеризации запросов по методу подобия выдачи поисковых систем.
Как работает алгоритм кластеризации ключевых слов в Rush Analytics?
Мы собираем ТОП10 результатов поисковый выдачи (Яндекса или Google — на выбор), далее сравниваем — какие запросы имеют несколько (от 3 до 8ми) общих URLв ТОПе и исходя из этих данных автоматически группируем запросы в кластеры.
Часто задаваемые вопросы по кластеризации ключевых слов:
Q: Какая еще цель кластеризации, кроме облегчения рутинной работы по группировке ключевых слов?
A: Кластеризация запросов на основе данных из поисковой выдачи — гарантирует то, что запросы, которые попали в один кластер будут УСПЕШНО продвигаться на одну страницу. Кластеризация по методу подобия ТОПов исключает попадание коммерческих и информационных запросов в один кластер.
Коммерческие запросы никогда не продвинутся на одну страницу с информационными. Частая ошибка при продвижении интернет-магазинов, которая приводит к печальным последствиям — это продвижении коммерческих и информационных запросов на одну страницу.
Частая ошибка при продвижении интернет-магазинов, которая приводит к печальным последствиям — это продвижении коммерческих и информационных запросов на одну страницу.
Q: Почему часть ключевых слов в моей задаче некластеризована?
A: Изначально сервис Rush Analytics создавался для внутренних нужд агентства Rush Agency. Наш основной профиль — продвижение крупных Ecommerce проектов, где основная задача не сгруппировать запросы «абы как», а сгруппировать их так, чтобы они успешно попадали в ТОП поисковой выдачи уже в момент индексации страниц, сделанных под семантику. Таким образом — мы кластеризуем только те ключевые слова, для которых нашлась пара, и которые реально будут продвигаться на одну страницу. Остальные ключевые слова мы оставляем некластеризованными, чтобы не вводить в заблуждение специалистов, которые работают с семантикой.
Q: Почему в кластеризации есть настройки точности? Зачем они?
A: В каждой тематике есть свой, необходимый и достаточный порог схожести выдачи, чтобы получить качественное семантическое ядро. Например в кластеризации интернет-магазинов будет большой проблемой, если при кластеризации запросов ключевые слова «мультиварка Redmond RX500» и «Мультиварка Redmond RX500-1» будут попадать в один кластер — т.к. это разные товары и они должны продвигаться на разные карточки товара. Здесь мы рекомендуем использовать точность = 5
Например в кластеризации интернет-магазинов будет большой проблемой, если при кластеризации запросов ключевые слова «мультиварка Redmond RX500» и «Мультиварка Redmond RX500-1» будут попадать в один кластер — т.к. это разные товары и они должны продвигаться на разные карточки товара. Здесь мы рекомендуем использовать точность = 5
Для инфо-тематик, например, для сайтов скидок или рецептов, такая точность не нужна — здесь задача получить максимальное количество сгруппированных кластеров для написания статей. Для таких сайтов мы рекомендуем точность 3 или 4. А для сайтов в очень конкурентных тематиках, где борьба за ТОП идет в основном по конкурентным ВЧ запросам — мы рекомендуем использовать повышенную точность кластеризации — 6 или 7, а под некластеризованные запросы создавать отдельные страницы.
Q: В чем разница в ваших алгоритмах кластеризации? Какой для какого случая использовать?
A: У нас есть 3 алгоритма кластеризации:
- Кластеризация с ручными маркерами
- Кластеризация по Wordstat
- Комбинированный алгоритм кластеризации (ручные маркеры + Wordstat)
Работают они по одному и тому же базовому принципу — сравнению подобия ТОПов поисковых систем, но предназначены для решения несколько различных задач.
Алгоритм с использование ручных маркеров:
Данный алгоритм эффективнее всего использовать когда у вас есть готовая и довольно разветвленная семантическая структура сайта (каталога), и вы наперед знаете все маркеры и вам нужно просто понять по каким запросам вы собираетесь продвигать существующие страницы, а задачи расширения структуры сайта не стоит. В таком случае вы берете свои маркеры (названия категорий/страниц), собираете по ним подсказки, размечаете маркеры как 1, собранное облако как 0 и отправляете на кластеризацию. На выходе вы получите готовую семантику для своих категорий, а слова, которые не привязались к вашей структуре останутся некластеризованными.
Алгоритм кластеризации по Wordstat
Этот алгоритм скорее решает обратную алгоритму ручных маркеров задачу: вы еще не знаете структуры своего сайта и не можете выделить маркеры — вы просто собрали Wordstat, подсказки и частотность по подсказкам. Теперь вам нужно структурировать эту семантику, чтобы получить группы запросов под страницы будущего сайта или будущих категорий существующего сайта. В таком случае алгоритм кластеризации по Wordstat подойдет как нельзя лучше, работает он следующим образом:
В таком случае алгоритм кластеризации по Wordstat подойдет как нельзя лучше, работает он следующим образом:
Весь список ключевых слов сортируется по убыванию частотности, алгоритм пытается привязать все возможные слова из списка к самому частотному слову и формирует кластер, далее все повторяется итерационно для следующих по частотности ключевых слов.
Не волнуйтесь за то, что ключевые слова могут при первом проходе алгоритма привязаться к неверному кластеру — мы используем алгоритмы машинного обучения, построенные на бинарных деревьях, чтобы предотвратить это 🙂
Комбинированный алгоритм (ручные маркеры + Wordstat) — сочетает подходы двух предыдущих методов.
Этот алгоритм подходит для задачи одновременного подбора ключевых слов для существующей структуры сайта и ее расширения. Работает он следующим образом: сначала мы пытаемся привязать все возможные запросы к вашим маркерным запросам и формируем готовую структуру, привязанную к вашим маркерам. Далее, все запросы, что не были привязаны к маркерам — сортируются по убыванию частотности и группируются между собой.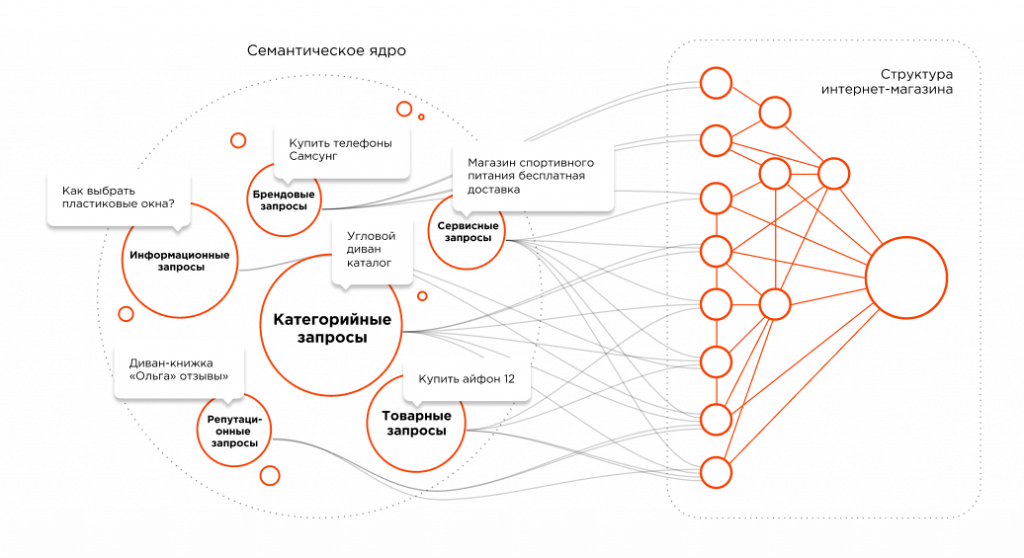 В результате вы получаете:
В результате вы получаете:
а) Готовую семантику для существующих категорий сайта
б) Расширение семантики для вашего сайта.
Мы настоятельно рекомендуем использовать комбинированный алгоритм — он дает наилучший результат.
Финализируем структуру сайта — делаем комбинированную кластеризацию
Так как мы изначально собирали семантику правильно (формируя маркерные запросы для нашего сайта) — будем использовать комбинированный алгоритм кластеризации.
Для выполнения кластеризации ваш список запросов должен выглядеть так:
Где в первой колонке находятся ключевые слова, в второй разметка маркер/не маркер (1/0), а в третьей любая частотность Wordstat (та, которую вы обычно используете для продвижения). Скачать пример файла для загрузки в кластеризатор
Подробные рекомендации, по вопросу какую частотность использовать для продвижения, приведены в этой статье
Определение релевантных URL для кластеров
В результате кластеризации вы получите готовый список кластеров, под которые нужно продвигать страницы вашего сайта. Теперь главный вопрос состоит в принятии решения — на какую страницу продвигать тот или иной кластер.
Теперь главный вопрос состоит в принятии решения — на какую страницу продвигать тот или иной кластер.
Мы в Rush Agency, предпочитаем сразу продумывать структуру сайта и URL страниц и сразу привязывать маркерные запросы (а соответственно и кластеры) к страницам. Но это требует большой подготовки и просчета на этапе создания семантики — не всегда на это есть время и ресурсы. Так же для информационных порталов и интернет-магазинов не всегда можно предугадать все поисковые желания пользователей используя логические гипотезы и приходится делать кластеризацию списка ключевых слов используя только частотность Wordstat.
Специально для этого случая — мы предусмотрели функционал автоматического определения релевантных URL для кластеров.
Работает алгоритм следующим образом:ВАЖНО!: для автоматического определения релевантных URL необходимо ввести адрес вашего сайта при создании задачи по кластеризации
После кластеризации наши алгоритмы проверят, не находится ли ваш сайт уже ТОПе по маркерному запросу — если да, то мы присвоим кластеру и всем его запросам URL вашего сайта, который уже в ТОПе и подсветим его зеленым цветом в веб-интерфейсе и в XLSX выгрузке.
Если ваш сайт не в ТОПе по маркерному запросу — мы попытаемся определить релевантную страницу на вашем сайте используя поиск по вашему сайту с оператором «site:». Найденный URL с вашего сайта будет присвоен кластеру и всем входящим в него запросам. Такие URL имею обычный цвет — черный.
Не понятно на какой URL продвигать кластер и его ключевые слова? Не можете принять решение — продвигать старую страницу или делать новую?
Не беда — мы подробно рассмотрели этот злободневный вопрос в этой статье
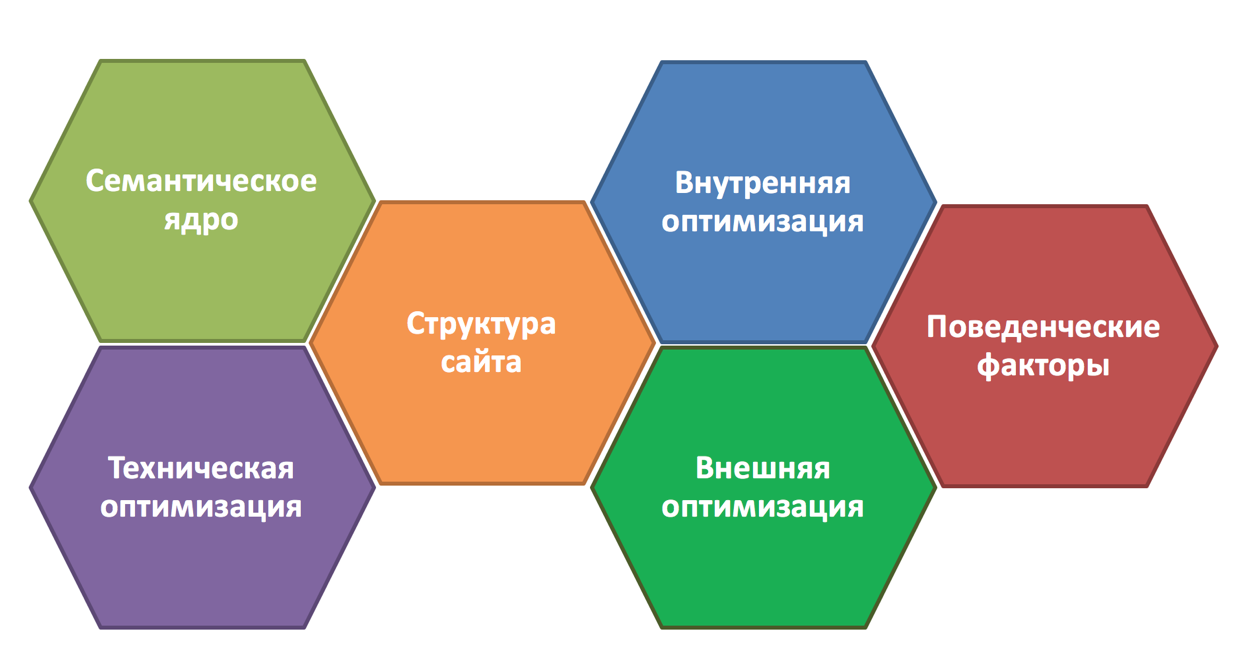
Вместо заключения
В результате, при правильном подходе к созданию семантического ядра, описанном в данном руководстве, а также нашим советам по SEO — вы в кратчайшие сроки получите максимально полное семантическое ядро для вашего сайта. К тому же запросы, сгруппированные по методу подобия поисковой выдачи с большой вероятностью попадут в ТОП выдачи поисковых систем уже в момент индексации (или переиндексации) страниц, на которые они продвигаются.
Помните, что попадание в ТОП напрямую зависит от правильной внутренней оптимизации страниц вашего сайта — об этом мы рассказываем в этой статье
Успехов при работе с семантическим ядром. Мы рады, что вы с нами и используете наши инструменты, в которые мы вкладываем очень много труда!
Надеемся, что статья оказалась для вас полезной и будем рады, если вы поделитесь ей с друзьями в социальных сетях.
____
Команда Rush Analytics
Посмотрите также:
Получаем маркерные запросы из Яндекс Метрики: руководство
Как подобрать URL для кластера ключевых слов: руководство
Обзор источников ключевых слов
Поиск ниши для сайта
Чистка семантического ядра
Порядок слов в запросе
Позиции сайта в мобильной выдаче
Сбор семантического ядра
Оформление статей на сайте
Как правильно парсить подсказки
Сбор подсказок Яндекса
Вместо заключения
В результате, при правильном подходе к созданию семантического ядра, описанном в данном руководстве, а также нашим советам по SEO — вы в кратчайшие сроки получите максимально полное семантическое ядро для вашего сайта. К тому же запросы, сгруппированные по методу подобия поисковой выдачи с большой вероятностью попадут в ТОП выдачи поисковых систем
К тому же запросы, сгруппированные по методу подобия поисковой выдачи с большой вероятностью попадут в ТОП выдачи поисковых систем
Помните, что попадание в ТОП напрямую зависит от правильной внутренней оптимизации страниц вашего сайта — об этом мы рассказываем в этой статье
Успехов при работе с семантическим ядром. Мы рады, что вы с нами и используете наши инструменты, в которые мы вкладываем очень много труда!
Надеемся, что статья оказалась для вас полезной и будем рады, если вы поделитесь ей с друзьями в социальных сетях.
____
Команда Rush Analytics
Посмотрите также:
Получаем маркерные запросы из Яндекс Метрики: руководство
Как подобрать URL для кластера ключевых слов: руководство
Обзор источников ключевых слов
Поиск ниши для сайта
Чистка семантического ядра
Порядок слов в запросе
Позиции сайта в мобильной выдаче
Сбор семантического ядра
Оформление статей на сайте
Как правильно парсить подсказки
Сбор подсказок Яндекса
FAQ для функционала «Проекты»
Была ли статья полезной?
5
0
ASO: Как создать семантическое ядро для вашего приложения | Анатолий Шарифулин | AppFollow
Оптимизация App Store — это процесс оптимизации метаданных, направленный на улучшение видимости приложения в результатах поиска.
Семантическое ядро — это набор ключевых слов и фраз, наиболее точно и понятно описывающих приложение.
Прежде всего, важно подчеркнуть, что семантическое ядро и процесс его создания — одна из самых ответственных и трудоемких задач в ASO. Далее на основе семантического ядра выбираем, какие ключевые слова использовать.
Ключевые слова могут иметь:
- высокая частота,
- средняя частота,
- низкая частота.
В отличие от веб-разработчиков, команды мобильных приложений не могут точно знать, какую частоту получают те или иные ключевые слова. Даже Apple Search Ads не дает доступа к такой информации в абсолютных значениях. Поэтому мы можем только предполагать, насколько частым является тот или иной поисковый запрос.
Для большей наглядности рассмотрим каждый шаг создания семантического ядра на примере реального приложения. Наш хороший друг любезно согласился предоставить нам всю необходимую информацию о своем новом приложении Travel Quests (на момент публикации приложение еще не было запущено в App Store).
Перед построением семантического ядра задайте себе несколько вопросов.
Кто ваша целевая аудитория?
Вы должны четко понимать, кто ваши пользователи. Например, ваше приложение — это игра, в которой пользователи должны выбирать наряды для кукол. Скорее всего, ваша основная аудитория — девочки в возрасте до 12 лет. Девочек или мальчиков постарше это вряд ли заинтересует. Прежде чем приступить к созданию семантического ядра, попробуйте определить свой потребительский сегмент.
Какую ценность представляет ваше приложение для пользователей?
О чем ваше приложение? Какова его цель? Зачем пользователю устанавливать его? Ответы на эти вопросы — ваши первые релевантные ключевые слова.
Чем ваше приложение отличается от конкурентов?
Попробуйте сформулировать, что делает ваше приложение особенным. Ваши идеи — это средне- или низкочастотные поисковые запросы, которые могут использовать клиенты. Они могут быть не самыми популярными, но здесь скрыта ценность. В то время как ваши конкуренты сосредотачиваются на наиболее часто используемых ключевых словах, вы можете достичь более высоких позиций, применяя менее популярные, но хорошо нацеленные запросы.
В то время как ваши конкуренты сосредотачиваются на наиболее часто используемых ключевых словах, вы можете достичь более высоких позиций, применяя менее популярные, но хорошо нацеленные запросы.
Кто ваши конкуренты?
На этом этапе не полагайтесь только на имена, которые первыми приходят вам в голову. Проведите хорошее исследование и выясните, кто ваши прямые и косвенные конкуренты. После проверки каждого из них составьте список ключевых слов, которые они используют чаще всего. Вы можете «позаимствовать» некоторые из них и генерировать собственные идеи.
Каков основной рынок для вашего приложения?
Возможно, вы удивитесь, но ключевые слова, используемые в британском и австралийском App Store, могут подойти и для российского рынка. Как вы можете это использовать? Даже если ваша основная клиентская база находится в России, вы можете добавить ключевые слова, которые не подошли в русской версии (из-за ограничений по символам) для магазинов приложений Великобритании и Австралии. Более подробная информация о дополнительных локалях и индексации в Google Play будет доступна в одной из следующих статей.
Более подробная информация о дополнительных локалях и индексации в Google Play будет доступна в одной из следующих статей.
Возможно, вы уже ответили на все выделенные вопросы ранее. Скорее всего, вы сделали это еще до создания приложения. Даже лучше! Эта информация необходима для создания семантического ядра и подбора правильных ключевых слов.
Подбор ключевых слов является основой создания семантического ядра, поэтому важно выбрать наиболее релевантные для дальнейшего продвижения. Вернемся к нашему примеру — приложению Travel Quests. По названию приложения легко понять, что оно связано с путешествиями и квестами. Это означает, что мы должны сосредоточить наши ASO-усилия на людях, которые любят путешествовать и ищут интересные и активные способы провести время за границей.
В данном случае релевантными запросами являются: «путешествие», «гид», «советы» и т.д. Кроме того, стоит обратить внимание на похожие запросы, т.е. слова, которые не описывают напрямую основные функции приложения, но все же имеют потенциал для привлечения трафика . Для туристических квестов это могут быть следующие ключевые слова: «музеи», «экскурсии», «достопримечательности». Анализируемое приложение не является туристическим агентством, однако его клиентами могут стать люди, планирующие поездку. Актуальность запроса очень субъективна, поэтому чем больше альтернатив вы проверите, тем выше шансы, что вы создадите качественное семантическое ядро.
Для туристических квестов это могут быть следующие ключевые слова: «музеи», «экскурсии», «достопримечательности». Анализируемое приложение не является туристическим агентством, однако его клиентами могут стать люди, планирующие поездку. Актуальность запроса очень субъективна, поэтому чем больше альтернатив вы проверите, тем выше шансы, что вы создадите качественное семантическое ядро.
Если у вас закончились идеи, используйте следующие методы для поиска релевантных ключевых слов:
- Спросите текущих и потенциальных клиентов, как они нашли ваше приложение, какие слова и фразы они использовали. Небольшой опрос среди ваших друзей и коллег также может дать вам много полезной информации;
- ознакомьтесь с названиями и описаниями приложений конкурентов. Это очень важный шаг, уделите ему достаточно времени;
- использовать аналитические и статистические инструменты, ориентированные на мобильные рынки: App Annie, Mobile Action, Sensor Tower и т. д. Там вы можете найти некоторые ключевые слова, которые ваши конкуренты используют для получения высоких результатов поиска;
- если ваше приложение уже есть в магазине, изучите комментарии пользователей;
- попробуйте инструменты для исследования ключевых слов: Google Keyword Planner, Google Trends, Яндекс.Wordstat. Последнее очень полезно, если ваш основной рынок — Россия. Однако не обращайте особого внимания на значения частоты. Из опыта мы знаем, что между веб и мобильными устройствами есть большая разница;
- используйте синонимы и языковые словари, если вам нужно подобрать ключевые слова для иностранных рынков. Multitran, например, хороший инструмент, чтобы попробовать.
 д. Там вы можете найти некоторые ключевые слова, которые ваши конкуренты используют для получения высоких результатов поиска;
д. Там вы можете найти некоторые ключевые слова, которые ваши конкуренты используют для получения высоких результатов поиска;Расчетная частота
Как было сказано выше, App Store и Google Play не предоставляют общедоступных данных о частоте поисковых запросов. Однако это не значит, что мы не можем его оценить.
Основным инструментом для этого является список поисковых предложений. Когда вы начинаете вводить запрос в строке поиска, список формируется магазином автоматически. Самые популярные ключевые слова и фразы размещаются вверху. Если запросы, которые вы планируете использовать, не отображаются там, скорее всего, они не будут привлекать трафик в ваше приложение.
Когда вы начинаете вводить запрос в строке поиска, список формируется магазином автоматически. Самые популярные ключевые слова и фразы размещаются вверху. Если запросы, которые вы планируете использовать, не отображаются там, скорее всего, они не будут привлекать трафик в ваше приложение.
Есть еще один инструмент для App Store — Search Ads, недавно представленный Apple для улучшения видимости приложения в поиске. Используя его, становится возможным дать приблизительные оценки того, сколько трафика могут генерировать разные ключевые слова. В настоящее время инструмент доступен только для рынка США. Если ваше приложение нацелено на США, у вас есть преимущество. Таким образом, получите доступ к Search Ads как можно скорее!
Собирать поисковые подсказки вручную, проверяя каждый запрос на планшете или смартфоне, очень трудоемко. AppFollow упрощает этот процесс. Этот инструмент может программно генерировать список предложений для вашего приложения, если вы подписаны на план Premium. На этом примере мы проиллюстрируем, как оценить частоту и построить семантическое ядро.
На этом примере мы проиллюстрируем, как оценить частоту и построить семантическое ядро.
Сбор подсказок — наиболее правильный способ построения семантического ядра.
Если вы еще не там, зарегистрируйтесь на AppFollow.io . В верхней панели выберите «Инструменты ASO», затем «Предложить и найти». Вы увидите следующую страницу:
Выберите необходимое устройство: iPhone/iPad или Android . В поле за ним введите интересующие вас ключевые слова. Выберите нужную локаль в списке справа.
В результате вы увидите список предложений в левой колонке. Если вы сравните его со списком на своем смартфоне, вы обнаружите, что они идентичны. В правой колонке вы можете увидеть результаты поиска по введенному ключевому слову в выбранной стране. Мы вернемся к этой части позже в статье.
Стоит заметить, что если вы просматриваете предложения для Android, Google Play корректирует их в соответствии с вашим IP-адресом.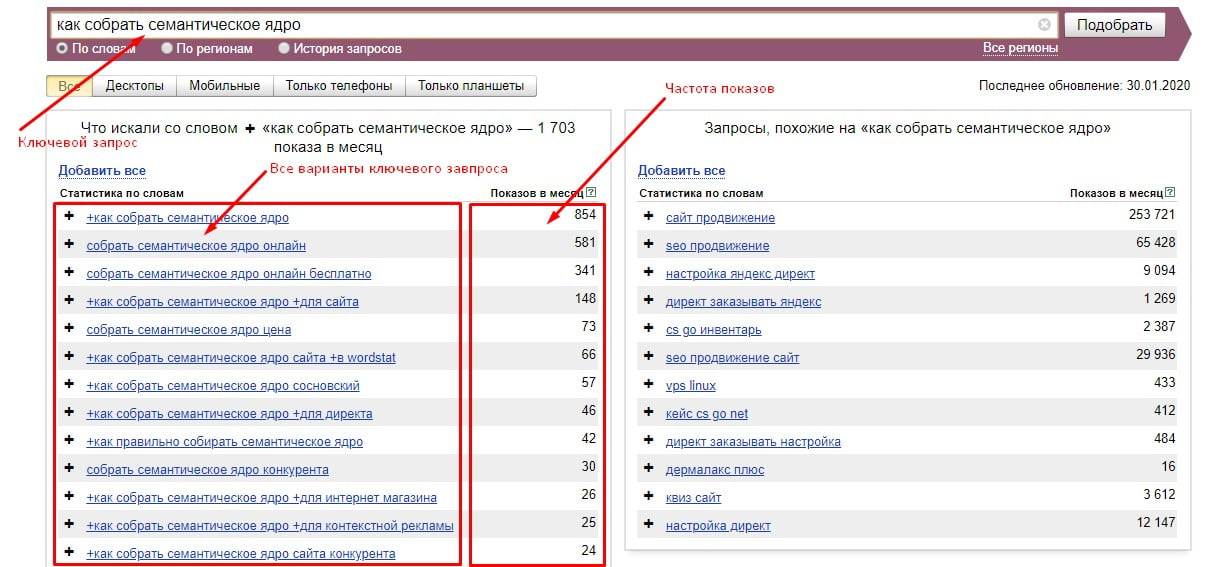 Это означает, что если вы находитесь в России и вам нужно увидеть предложения для США, вам нужно изменить свой IP на американский. Бесплатные инструменты VPN могут помочь вам в этом. В противном случае вы увидите данные поиска для страны, в которой вы сейчас находитесь.
Это означает, что если вы находитесь в России и вам нужно увидеть предложения для США, вам нужно изменить свой IP на американский. Бесплатные инструменты VPN могут помочь вам в этом. В противном случае вы увидите данные поиска для страны, в которой вы сейчас находитесь.
Все запросы с разумной частотой будут отображаться в предложениях. Они показаны в порядке убывания. Ключевое слово или фраза на первом месте имеют наибольшую частотность, а нижние — наименьшую.
AppFollow предлагает простой и удобный способ экспорта предложений — через надстройку Google Sheets , доступную для всех пользователей Google Docs.
Надстройка AppFollow для Google ТаблицЧтобы просмотреть список предложений, добавьте в любую ячейку следующую формулу: =getSuggest(«запрос»). Вместо «запрос» введите интересующее вас ключевое слово или фразу. Не забудьте добавить кавычки.
Как описано выше, вы можете собирать предложения либо с помощью ручного поиска, либо с помощью AppFollow и Google Sheets. В итоге у вас будет таблица со списками различных подсказок по каждому поисковому запросу. Важно отметить, к какому рынку или региону относятся эти списки. Примерно так должно получиться:
В итоге у вас будет таблица со списками различных подсказок по каждому поисковому запросу. Важно отметить, к какому рынку или региону относятся эти списки. Примерно так должно получиться:
После того, как вы соберете подсказки для каждого ключевого слова, отметьте их разными цветами. В нашем примере наиболее релевантные предложения выделены синим цветом, а менее релевантные — желтым.
Не учитывать заголовки с «-» , «:» или «&». Эти подсказки являются именами приложений.
Вуаля! Ваше семантическое ядро готово. Следующим шагом будет анализ наиболее релевантных и менее релевантных ключевых слов. Это будет основой для названия приложения и ключевых слов на странице приложения в App Store и Google Play. Впрочем, это тема для отдельной статьи, которую мы опубликуем в будущем.
P.S.
Уважаемые читатели, если эта статья была вам полезна, ставьте лайк 💚 или рекомендуйте ее. Мы считаем, что это ценно для многих разработчиков приложений.
Не стесняйтесь задавать вопросы, высказывать свое мнение или комментировать неясные шаги.
Первоначально опубликовано на Блог AppFollow
Суперэффективный анализ ключевых слов
Построение семантического ядра — один из важнейших этапов создания контекстной рекламной кампании. Именно на семантическом уровне начинается настоящая борьба за клиента. Успех вашей рекламы зависит от нахождения как можно большего количества поисковых запросов, не занятых конкурентами, и искоренения минус-слов. Сегодня я расскажу вам, как мы это делаем в LeadMachine.
Шаг 1. Подготовьтесь к созданию семантического ядра
Для подготовки к построению семантического ядра создайте таблицу, которая впоследствии будет заполнена ключевыми словами, которые ваши клиенты будут использовать для поиска вашего продукта. См. пример таблицы ниже.
Поместите продукт или услугу в первую колонку. Возьмем в качестве примера срочные кредиты. Как люди ищут кредиты в поисковых системах? Они могут искать «кредиты», «кредитные средства», «кредитные карты» и т. д.
Как люди ищут кредиты в поисковых системах? Они могут искать «кредиты», «кредитные средства», «кредитные карты» и т. д.
Второй столбец предназначен для того, что клиенты могут делать с вашим продуктом или услугой. Что можно сделать с кредитом? Вы можете получить, получить или получить его. Поместите местоположения в третий столбец и помните, что клиенты могут указывать их по-разному. Например, человек в Сент-Поле, штат Миннесота, может также называть свое местоположение как Сент-Пол, так и Сент-Пол, штат Миннесота.
Четвертая колонка содержит характеристики вашего продукта. На что это похоже? Какие виды кредитов существуют на рынке? Кредиты без поручителей, кредиты только ИД, кредиты без справок… Занесите в таблицу все возможные варианты поисковых запросов.
Поскольку наш товар имеет дополнительный атрибут срочности, мы добавляем еще один столбец для этого качества. Как люди выражают свою потребность в срочных деньгах? Они могут искать срочные кредиты, быстрые кредиты, экспресс-кредиты, одночасовые кредиты. Придумайте все возможные запросы и добавьте их в таблицу.
Придумайте все возможные запросы и добавьте их в таблицу.
Где взять все эти параметры запроса? Во-первых, вы их придумываете. Организуйте сеанс мозгового штурма и придумайте различные варианты запросов, которые люди могут использовать. Когда у вас закончатся идеи, вам на помощь придет отчет «Поисковые запросы» Яндекс.Метрики, а также отчеты «Обычный поиск» и «SEO-запросы» Google Analytics. Иногда они предоставляют совершенно невероятные запросы, которые приводят людей на ваш сайт.
Используйте Яндекс.Метрику, Google Analytics, Google AdWords, SpyWords и AdVse для поиска необычных ключевых слов.
Не игнорируйте Планировщик ключевых слов от Google AdWords: укажите свой продукт и веб-сайт и просмотрите предложенные варианты. Они часто включают нестандартные ключевые слова, которые могут вам подойти. Также найти ключевые слова можно с помощью SpyWords (умный подбор запросов и ключевых слов конкурентов) и AdVse (запросы конкурентов).
Шаг 2.
 Составьте список ключевых слов
Составьте список ключевых словМы собираемся составить семантическое ядро, используя только что созданную таблицу. Берите по одному ключевому слову и создавайте все возможные комбинации, используя слова из других столбцов. Эта работа занимает слишком много времени в MS EXCEL, поэтому вам лучше использовать генератор ключевых фраз. Существует большой выбор таких инструментов, выберите тот, который подходит вам лучше всего. Нам нравится Promotools.ru (это русскоязычный сервис, но их полно и на английском, как этот).
Генераторы ключевых слов очень просты в использовании. Введите ключевые слова в соответствующие ячейки по одному, и инструмент автоматически покажет вам все возможные комбинации.
Скопируйте результат в новый файл MS Excel. После того, как вы прогоните все свои ключевые слова через программу, вы получите большой список, содержащий несколько тысяч ключевых слов. Конечно, некоторые из них — мусор. Мы отсеем их на следующем этапе.
Шаг 3. Избавьтесь от ненужных запросов
Используйте инструмент Key Collector для фильтрации ненужных запросов. Загрузите список ключевых фраз в программу и запустите сбор статистики из WordStat. В списке результатов будут все запросы пользователей, в том числе те, по которым нежелательно показывать вашу рекламу. Минус-слова должны быть удалены из списка.
Используйте сборщик ключей, чтобы очистить ядро от ненужных запросов. Перейдите на вкладку «Данные» и выберите «Групповой анализ». Инструмент создаст группы слов, которые составляют ваши ключевые запросы.
Отметьте слова, которые нельзя использовать в рекламе, и скопируйте их в отдельный файл MS Excel. Это будет список ваших минус-слов. Галочки будут автоматически перенесены в основной список минус-слов. Удалить все проверенные запросы. Экспортируйте список, который у вас теперь есть после удаления минус-слов. Это готовые ключевые слова для настройки контекстной рекламной кампании.
Шаг 4. Сгруппируйте ключевые запросы
Сегментируйте окончательный список ключевых слов, чтобы упростить настройку кампании. Просмотрите готовый список и выберите слова, которые лягут в основу групп ключевых слов. Затем отфильтруйте список, чтобы отобразить ячейки с этими словами. Таким образом, вы найдете все фразы, содержащие данное слово.
Переместите найденные фразы на новый лист. Каждый лист должен соответствовать одной группе ключевых слов. В дальнейшем каждый лист будет использоваться для отдельной группы объявлений.
Используйте фильтр MS Excel для быстрой группировки запросов.
Когда все ключевые слова разбиты на группы и перенесены на отдельные листы, ваше семантическое ядро для Яндекс.Директа готово. Не забудьте добавить в итоговый документ список минус-слов. Если вы собираетесь размещать рекламу в Google AdWords, следует учитывать некоторые особенности формирования семантического ядра.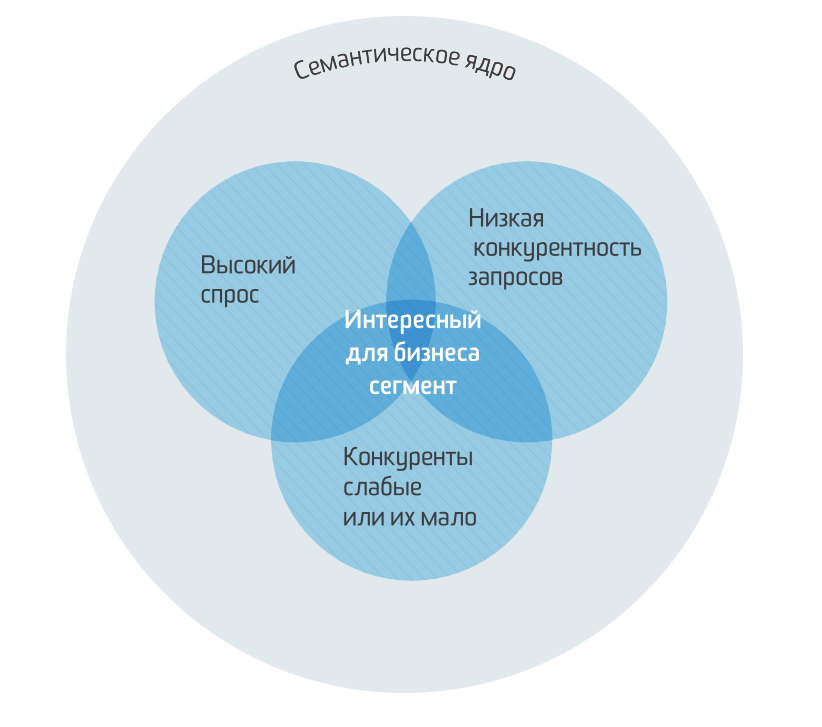
Шаг 5. Освойте хитрый Google AdWords
Первое правило Google AdWords: минус-слова должны включать все словоформы. Отклоняем минус-слова с помощью инструмента HTraffic. Опять же, это российский сервис. В английском вам нужно генерировать множественное число и опечатки. Одним из способов создания форм множественного числа является ASAP Utilities, надстройка для Excel. Для опечаток используйте Генератор опечаток ключевых слов от SEO Book или любой другой вариант по вашему выбору.
Зачем это нужно? Как это бывает, ваши объявления будут остановлены только в том случае, если поиск содержит точные формы ключевых слов. Например, если вы добавили слово «получить» в качестве минус-слова, ваше объявление по-прежнему будет отображаться по таким поисковым запросам, как «получено» или «получено».
