
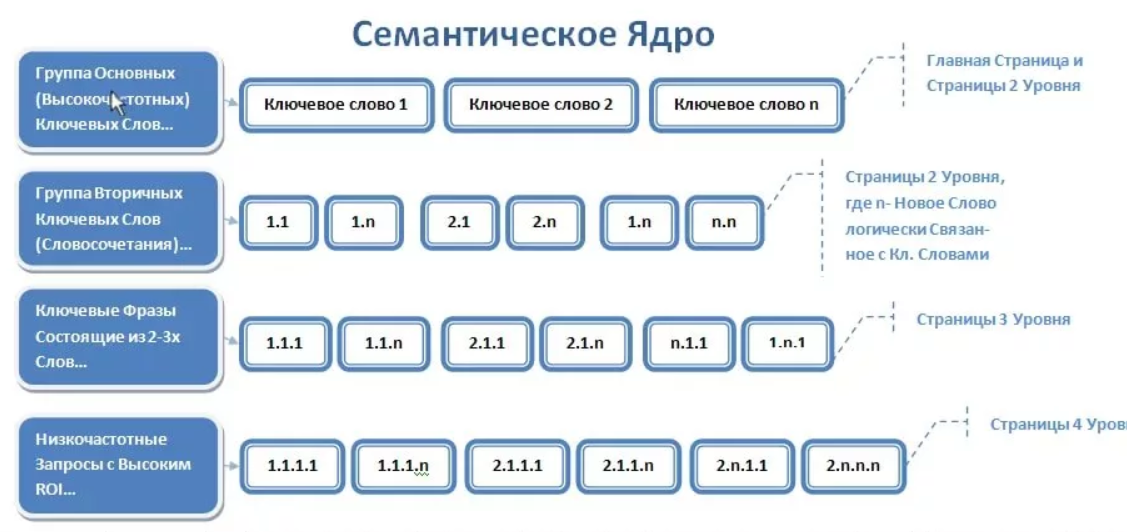
Как составить семантическое ядро сайта
Семантическое ядро сайта – упорядоченный набор ключевых слов, форм и словосочетаний, которые понятно характеризуют ваш бизнес, предлагаемые товары или услуги.
Зачем собирают семантику? Чтобы выдвинуть сайт в ТОП и провести грамотную CEO-оптимизацию ресурса – так ваши посетители в пару кликов найдут на сайте нужную информацию. Ну, а вы в итоге получите приток целевой аудитории и увеличите число заявок!
А теперь рассказываем подробнее, что такое семантическое ядро, как его собрать и правильно обработать.
Если взглянуть на нашу планету – как основа, внутри нее находится ядро. Аналогично и с нашим организмом – в основе каждой его клеточки тоже присутствует ядро. Эта основа помогает различным организмам правильно функционировать. Так и с вашим сайтом – позаботьтесь о том, чтобы внутри него было грамотно собрано и проработано семантическое ядро.
Семантика для сайта – фундамент вашего бизнеса, на котором выстраиваются все остальные этажи, помещения и комнаты. Представьте себе дерево с большой кроной и множеством листьев – оно существует только благодаря стволу, на котором и держится каждая ветка и каждая сотня или тысяча листочков. Семантическое ядро – это как корень и ствол для вашего сайта.
Представьте себе дерево с большой кроной и множеством листьев – оно существует только благодаря стволу, на котором и держится каждая ветка и каждая сотня или тысяча листочков. Семантическое ядро – это как корень и ствол для вашего сайта.
Масса известных на весь мир успешных изобретений – копии, взятые из природы. Например, самолет создан по образу и подобию птицы, а самые крепкие небоскребы построены на основе стебля пшеницы, который хоть и колеблется под гнетом ветра – но никогда не ломается за счет своей продуманной архитектуры.
Создавая семантику, вы делаете ваш бизнес устойчивым – он приобретает основательный фундамент и крепкий внутренний стержень. Если решите махнуть на семантическое ядро для сайта – можете не рассчитывать на его долгую и успешную жизнь.
А вы верите в мифы?
Есть мифы, рассказывающие о несложности сбора семантического ядра. А на самом деле – дела обстоят, как на рисунке:
Что мы видим? Громадный пласт пользовательских запросов скрыт от анализа на поверхности, нужна специальная подготовка и проработка запросов, которые ищут пользователи в нужной вам нише.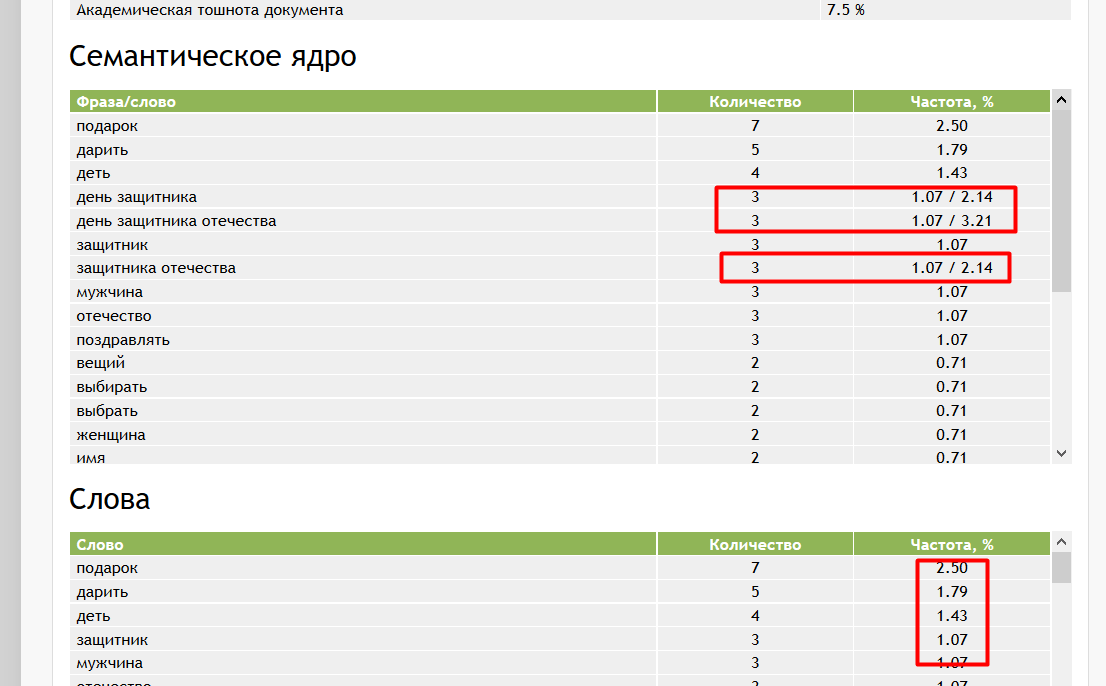
Попробуйте для начала погрузиться в интересующую вас сферу и глубоко копнуть, чтобы достать по-настоящему ценные материалы.
Важно! Без уникального предложения, построенного на полученных ключах, вы не сможете вовлечь пользователя в покупку вашей услуги или товара. Чтобы привлечь внимание аудитории – нужно понять, как мыслит та самая аудитория. Если рекламные объявления составлены на основе неправильно подобранных ключевых слов – аудитория пройдет мимо вашего предложения.
Помните, и естественный органический трафик, и контекстная реклама – все завязано на семантическом ядре и зависит от качества его проработки.
Собирать семантическое ядро – жизненно важная задача для развития вашего бизнеса в интернете
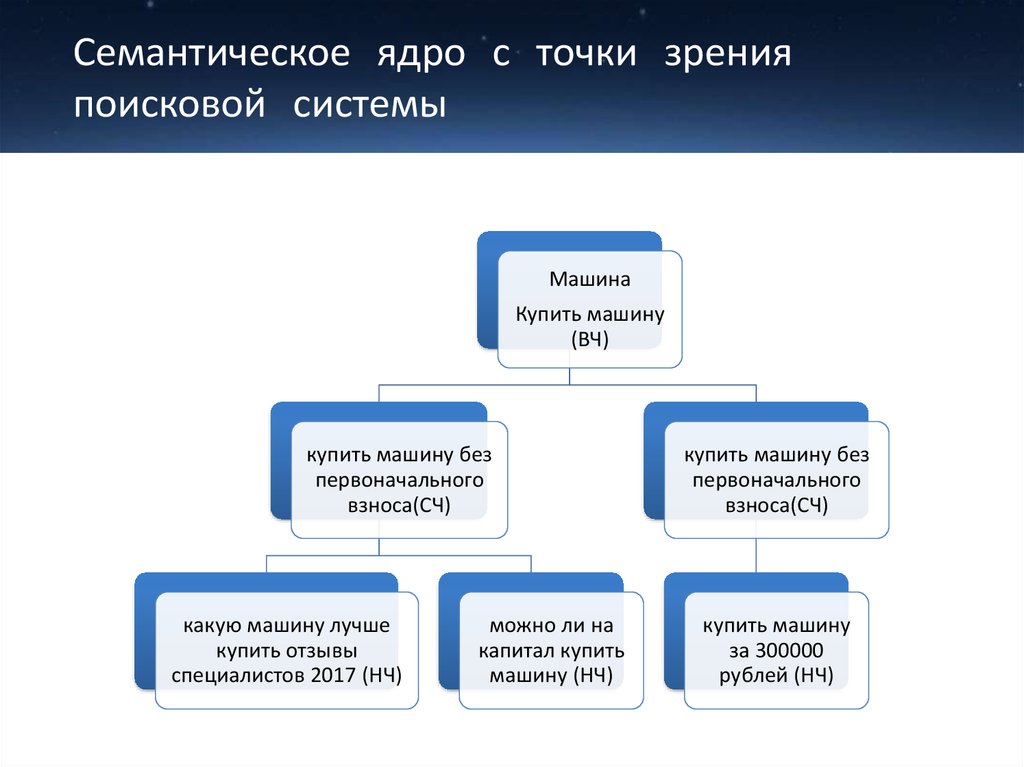
Сбор семантики – процесс поиска ключевых слов в определенной тематической области, а также исключение и фильтрация фраз, отдаленных от вашего бизнеса и не соответствующих рекламному предложению. В данной статье мы расскажем как составить семантическое ядро сайта.
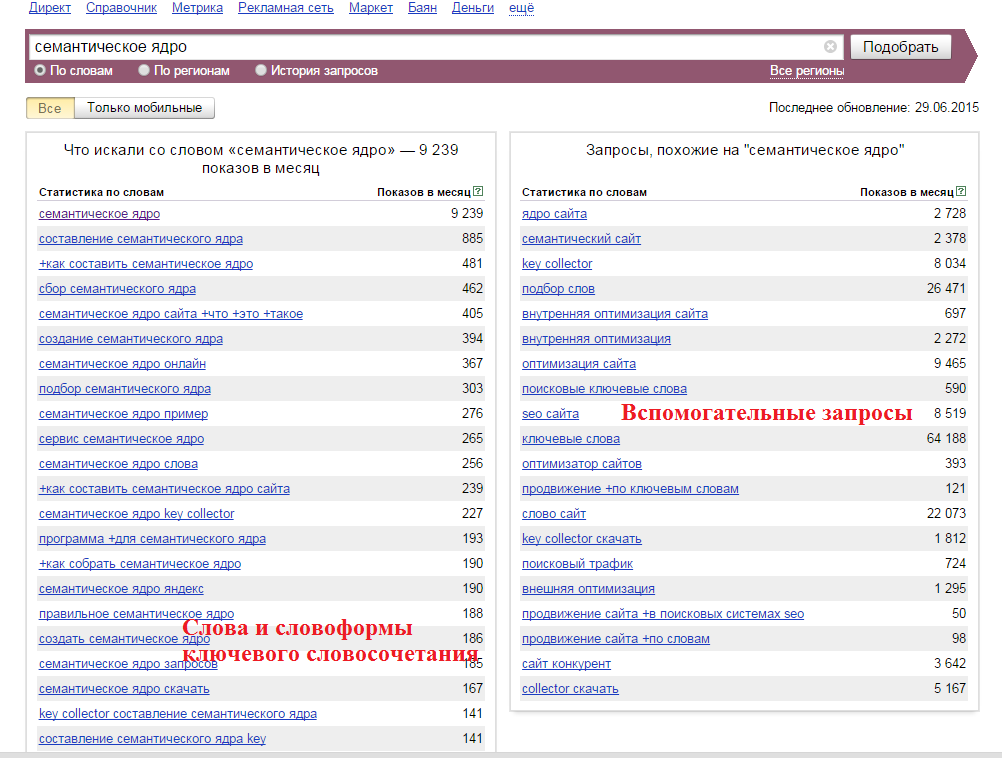
Параллельно с ключевыми словами мы находим и частоту их фигурирования в поисковых системах – получаем информацию, как часто ключевики пользователи вбивают запросы в Google, Яндекс и прочие системы.
Частота запросов дает понять, какое словосочетание востребовано больше, какое меньше, какое вовсе неликвидно. Такая градация проста и понятна.
Читайте также: Как увеличить продажи в интернете: полное руководство
Хотите больше трафика на сайт?
Продвигайте или рекламируйте на своем ресурсе товары и услуги, используя ключевые слова с ошеломляющим спросом ☺
Исследуйте ключевые слова, согласовывайте поисковую выдачу и ваше торговое предложение, учитывая спрос и конкуренцию.
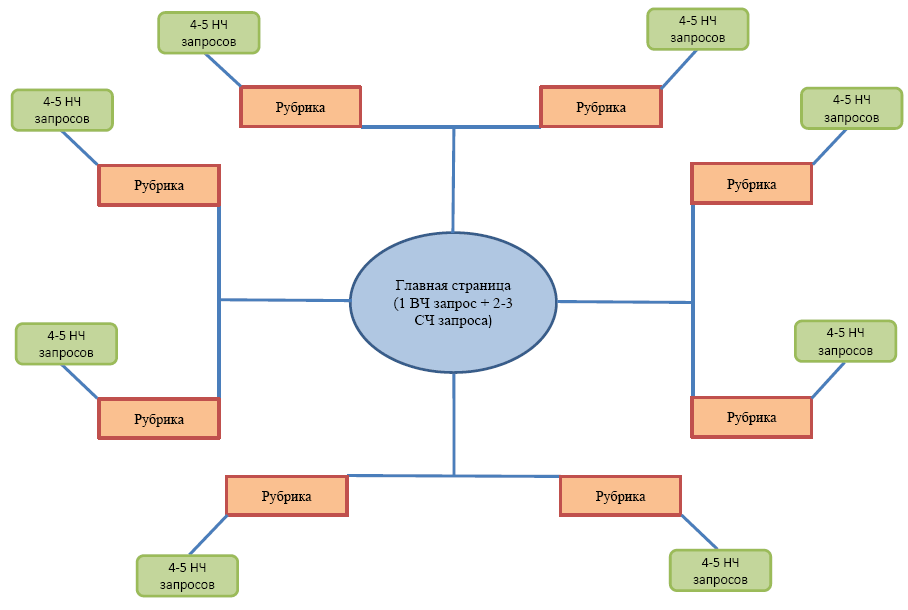
Ваше идеальное семантическое ядро релевантно задачам бизнеса и ожиданиям поисковых систем:
Задача по сбору семантики – составить и организовать структуру ключевых слов, подходящих для сайта, ваших покупателей и поисковой системы, которая разместит вас в своей выдаче.
Составляя семантическое ядро, соберите показатели по другим ключевым метрикам – в зависимости от условий работы вашего бизнеса, гео-расположения, сезонности услуг или товара. Это поможет в проведении исследований и определит приоритетность ключевых слов.
А вот и список дополнительных метрик:
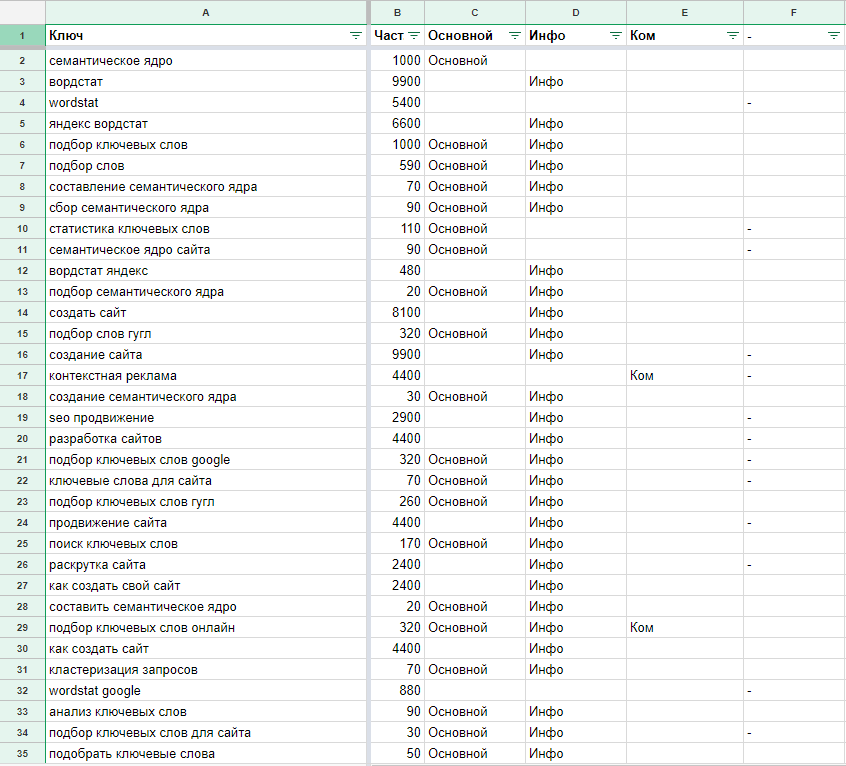
| ключевые слова | количество запросов в месяц (валово для всех нужны городов: ) | конкуренция по данным Мутаген | геозависимость запроса (по данным Яндекс) | сезонность запроса (по данным вордстат) | средняя частотность за последние 12 месяцев (по данным вордстат) | |||
| Яндекс | ||||||||
| широкое | точное “!” | широкое | точное “!” | |||||
Сбор семантики – на скорость
Для старта проведите мозговой штурм всевозможных направлений и тем, касающихся вашего бизнеса Найдите все возможные подходящие разветвления бизнеса, направления компании, синонимы, словообразования, словосочетания и прочее для охвата интересов вашей целевой аудитории. Это все поможет в качественном сео продвижение.
Это все поможет в качественном сео продвижение.
Вам нужно собрать список масок или словосочетаний – из них в итоге соберется семантическое ядро. Список масок схож со списком покупок, с которым вы идете в магазин и покупаете с его помощью все необходимое. А уже дома готовите блюдо из приобретенных продуктов.
Чтобы блюдо получилось вкусным и аппетитным –соберите необходимые для его приготовления ингредиенты. Отнеситесь к сбору масок серьезно – иначе не получится приготовить ваше семантическое ядро.
В самом начале важно понимать тонкости бизнеса и микроклимата вашего вида деятельности, как кулинарного искусства. Сделайте список вариантов, по которым ваш бизнес может быть найден в сети. Есть ключевые слова, о которых вы не подозреваете, а они прибыльные с точки зрения продвижения.
Например, краткий список направлений и синонимов для компании, которая предоставляет услуги СТО:
СТО, автосервис, станция техобслуживания, станция технического обслуживания, диагностика автомобиля, ТО автомобиля, ремонт автомобиля, обслуживание автомобилей, замена запчастей, компьютерная диагностика, шиномонтаж, элетрики, механики.
Если вы ответственный за семантическое ядро, но не собственник бизнеса, и мало разбираетесь в нише для продвижения – обратитесь за помощью к специалистам в этом направлении.
Пообщайтесь с собственником бизнеса, с менеджером по продажам и с другими сотрудниками, которые подробно опишут бизнес и расскажут о направлениях, по которым вы будете двигаться дальше.
Вот краткий список вопросов, чтобы выловить новые данные:
- Цель сбора семантического ядра? Для SEO-продвижения, для контекстной рекламы, для расширения семантического ядра?
- Чем занимается компания? Полный список услуг и товаров.
- Чем компания не занимается? (например – производит велосипеды, но не предоставляет ремонт и обслуживание)
- По какому региону/стране/городам – работает компания?
- Работает ли компания оптом или только в розницу?
- Осуществляет ли доставку?
- С кем сотрудничаем, с кем не сотрудничаем, целевая аудитория компании?
- Приоритетные и главные направления деятельности?
- Ценовая политика компании – премиум сегмент/демпинг цен?
При возможности – сделайте опрос клиентов компании:
- Как они нашли компанию в интернете?
- Какие запросы использовали при поиске?
- Что понравилось, а что нет?
Расширение ядра
Воспользуйтесь правой колонкой Яндекс Вордстат – так получите информацию о запросах, похожих на ваши.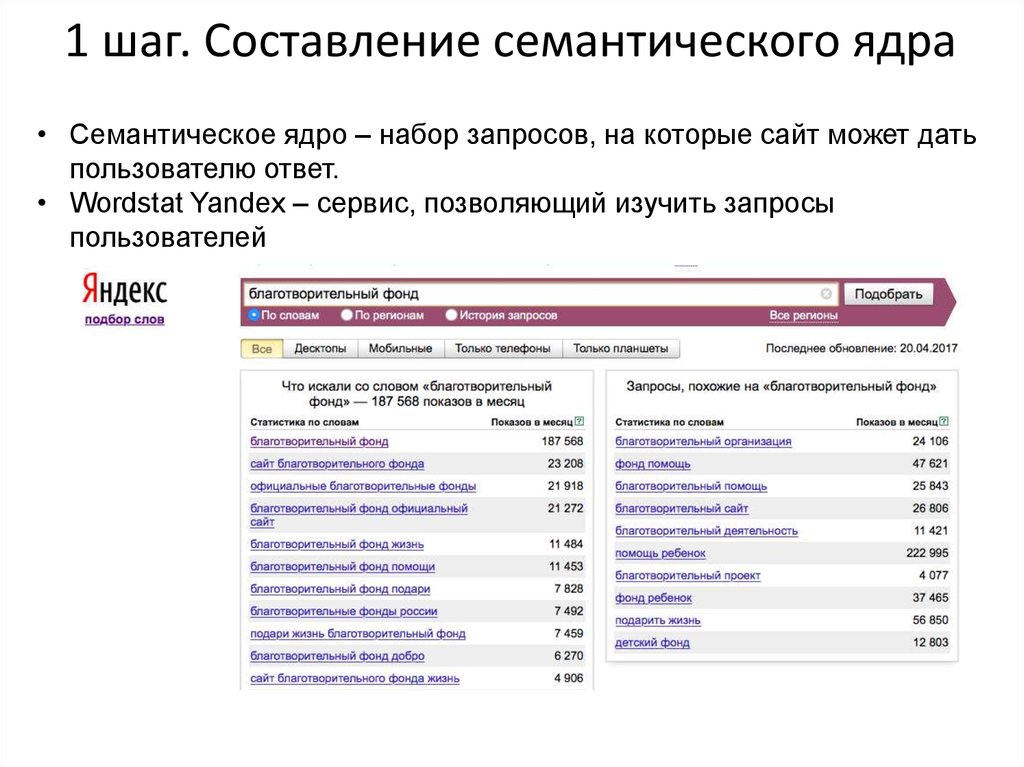
Такая информация многократно увеличит и расширит направления, по которым собираем семантическое ядро:
Используйте информацию от поисковой системы – о похожих запросах или запросах, которые ищут вместе с вашим.
Здесь находятся актуальные для компании ключевики – они популярны, используйте их при продвижении:
Минус- слова
В каждом виде деятельности есть разветвления, которые%
- не интересны бизнесу
- неактуальны
- не релевантны
Это – минус-слова или стоп-слова.
Например, мы производим велосипеды и продаем их. Но – мы не продаем велосипеды Б/У, хотя просмотров по этим запросам масса – около 25 тысяч/ месяц:
В нашем случае слово «бу» – минус-слово или стоп-слово. Добавьте это слово в список игнорируемых фраз – так словосочетания, содержащие «бу», удалятся при сборе ядра.
Чтобы правильно составить список минус-слов, определите цель сбора семантического ядра для:
- Информационных, новостных ресурсов и порталов
- Ecommerce проектов
- Агентств и сайтов-визиток
- Лендингов, созданных специально для рекламы в Я.
 Директ
Директ
 Директ
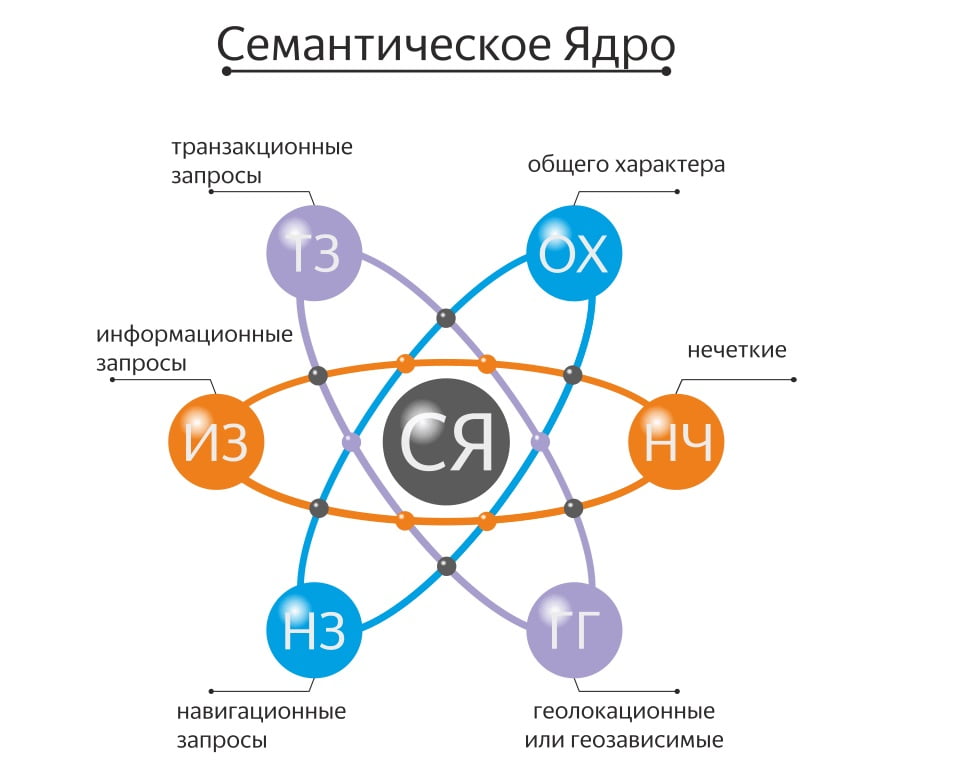
ДиректВокруг каждого сайта – большое облако ключевых запросов, которые делятся на группы. Мы рассмотрим деление на 2 группы – коммерческие, например «купить велосипед» и информационные – например «как выбрать велосипед».
Подпишитесь на авторский телеграм-канал про предпринимательство в России.
Мы можем собрать все ключевики, которые находятся в нише, но чаще это нецелесообразно.
Если у вас интернет-магазин – собирайте ключевые запросы с фразами:
купить, цена, стоимость, магазин и так далее…
При этом используйте уже готовые списки минус-слов, они давно собраны и находятся в свободном доступе в сети.
Например, универсальный список минус-слов для интернет-магазина, который исключает всякие мусорные запросы, а также информационные фразы.
скачать, скачивать, бесплатно, бесплатный, онлайн, видео, клип, видеоклип, фотография, фото, video, photo, книга, смотреть, слушать, песня, музыка, mp3, альбом, запись, remix, ремикс, слова, текст, минусовка, dj, торрент, торент, torent, torrent, мультфильм, мультик, мультсериал, анекдот, прикол, фильм, сериал, сезон, серия, телесериал, программа, игра, играть, выиграть, gameadmin_Ja, симулятор, покер, казино, photoshop, фотошоп, вики, википедия, wikipedia, сонник, сон, сниться, присниться, форум, порно, порн, секс, сексуальный, sex, adult, porno, porn, эротика, эротический, голый, обнаженный, бу, б у, б/у
Если у вас новостной сайт – сделайте наоборот, возьмите фразы для парсинга, которые внутри содержат такого рода слова:
как, что это, какие, почему, лучшие, можно ли, и так далее. .
.
Регион работы компании
Определите региональность вашего бизнеса – все ключевые слова имеют разный спрос индивидуально для каждого региона.
Исключения: Если это информационный сайт – региональность можно не указывать, тогда по умолчанию ключевикам будет присваиваться частотность их спроса по всему миру.
Выберите город, страну или несколько городов/стран – где вы будете работать.
Названия городов, где вы не фигурируете – внесите в список стоп-слов.
Например, если работаете по СНГ, но не работаете в Беларуси – используйте список городов Беларуси в качестве минус-слов:
Минск, Гомель, Витебск, Гродно, Брест, Барановичи, Борисов, Пинск, Орша, Мозырь, Солигорск, Новополоцк, Лида, Молодечно, Полоцк, Жлобин, Светлогорск, Речица, Жодино, Слуцк, Кобрин, Слоним, Волковыск, Калинковичи, Сморгонь, Рогачёв, Рогачев, Берёза, Береза, Новогрудок, Вилейка, Дзержинск, Лунинец, Ивацевичи, Марьина Горка, Поставы, Пружаны, Добруш, Глубокое, Лепель, Мосты, Иваново, Житковичи, Столбцы, Смолевичи, Щучин, Ошмяны, Дрогичин, Заславль, Несвиж, Ганцевичи, Новолукомль, Хойники, Жабинка, Микашевичи, Городок, Фаниполь, Белоозёрск, Белоозерск, Столин, Березино, Малорита, Барань, Любань, Старые Дороги, Ляховичи, Клецк, Логойск, Скидель, Берёзовка, Березовка, Воложин, Петриков, Толочин, Червень, Копыль, Узда, Ельск, Браслав, Чашники, Буда-Кошелёво, Буда Кошелёво, Буда-Кошелево, Буда Кошелево, Крупки, Каменец, Островец, Миоры, Наровля, Ивье, Дубровно, Сенно, Ветка, Чечерск, Дятлово, Верхнедвинск, Мядель, Свислочь, Докшицы, Давид-Городок, Давид Городок, Высокое, Василевичи, Туров, Дисна, Коссово
Как подготовиться к сбору ядра на примере
Наш бизнес – это сервис по поиску баз данных компаний. Для него нужно создать семантическое ядро.
Для него нужно создать семантическое ядро.
У нас крайне мало информации и подробностей о проекте – собирать семантику на основе таких абстрактных данных будет проблематично.
Мы запрашиваем дополнительные данные о проекте.
Полученные ответы:
Наша компания работает в России и СНГ с контактными данными юридических лиц и ИП.
База данных включает в себя следующие контактные данные компаний:
- наименование,
- адрес,
- телефоны стационарные и мобильные,
- e-mail,
- ссылки на сайты.
На сайте есть возможность сформировать базу компаний по собственным требованиям с помощью фильтра:
- город/страна,
- рубрики (сферы деятельности),
- выбор только производителей,
- компаний с e-mail,
- стационарными или мобильными телефонами.
Целевая аудитория компании
Проект нацелен на компании, которые стремятся расширить свою клиентскую базу, расширить географию поставок для увеличения продаж.
Главная цель – увеличение продаж. Соответственно, компании ищут контактные данные своих потенциальных клиентов – телефоны для обзвона и e-mail для рассылки коммерческих предложений.
Данные в базе есть только по юридическим лицам – другим компаниям. В базе нет физических лиц – потребителей, обывателей.
Какие задачи решает проект?
Проект дает пользователю контактные данные компаний за минимальное время и небольшую стоимость.
Преимущества компании.
Экономия времени. При поиске контактов компаний пользователь ищет их в известных онлайн-справочниках. Так тратится много времени на сбор данных и их обработку, а также пользователь может получить неполную базу.
В базе много других баз. Наш сервис собирает данные из разных источников, тем самым мы добиваемся наиболее полной и актуальной информации. Также для формирования пользователем базы в нашем сервисе понадобится гораздо меньше времени. Достаточно потратить 5 минут и у пользователя уже есть готовая база.
Что относится к нашей работе, а что не относится?
- На сайте нет контактов физических лиц, есть только юр. лица и ИП.
- Также нет информации по ОКВЭД, ЕГРЮЛ и контактных данных ЛПР (лицо принимающее решение о покупке ФИО и телефоны).
- 2Gis – отношения не имеем (минус-слова).
- Не интересны запросы связанные с возможность бесплатно получить базы (бесплатно, справочник и так далее). Слова скачать походят, а вот “бесплатно” нет.
- Базы клиентов компаний – не занимаемся (нет данных, незаконно)
- Для смс рассылок – не продаем для такой услуги.
- Личные данные физических лиц – нет
- Данные руководителей организаций – нет
- Пароли и доступы к данным компаний и физических лиц – нет
- Если речь идет про смс рассылку, то это физ. лица – не подходит
- И данные каких-либо конкретных лиц компании (любые их данные: номера секретаря компании или номера отдела снабжения компаний)
- Телефонный справочник – нет
- Все что относится к одной организации – не подходит. У нас база email и телефонов компаний (выборка по рубрикам).
- Все что касается физических лиц – не подходит. Когда человек вводит к примеру “список аквапарков” – это запрос физика.
- Справочники чего-либо не относящегося к “контактам” – не подходит. Пример “медицинский справочник”.
- Оптовая база если речь про 1 конкретную – не наше.
- Все что не касается “база контактов компаний” – не наше. Пример: база по продаже бизнеса. Все что не связано с получением списка контактов нескольких компаний из определенной ниши.
- Страховые компании – спрашивают физ. Лица.
- Застройщики – спрашивают физ. Лица.
 У нас база email и телефонов компаний (выборка по рубрикам).
У нас база email и телефонов компаний (выборка по рубрикам).После запроса информации мы получили практически полную картину функционирования нашего проекта. Мы знаем, какие задачи решает наш бизнес, а какие задачи мы не решаем, хотя они находятся якобы тоже в нашей нише.
Все эти данные должны быть предоставлены от собственника бизнеса или любого другого компетентного лица.
В итоге при подготовке к сбору ядра мы получили следующую информацию:
Регион работы:
Россия и СНГ
Краткий список минус-слов:
1с, 2Гис, 2Gis, смс, страховые, застройщики, физ, физических, бесплатно, справочник.
Мозговой штурм направлений, синонимов и прочее:
| Основа | Чего? | Кого? | Какие? | Для чего? | Продающее | ГЕО | Формат |
|---|---|---|---|---|---|---|---|
| База | емайлов | предприятий | актуальные | Обзвон | Недорого | Россия | Эксель |
| компаний | свежие | Звонки | Дешево | Москва | Эксел | ||
| e mail | фирм | текущие | Холодные звонки | Купить | Областям | Excel |
Как видно из таблицы, мы нашли несколько вариаций, которые могут идти вместе с ключом «База» – предприятия, компании, фирмы. Это схожие по определению слова – но в поисковой выдаче будут совершенно разные сайты по этим запросам. Такие словосочетания есть практически в каждом виде бизнеса.
Мы должны учесть максимум возможных вариаций и внести их в таблицу масок. В результате – получен список ключевых фраз, которые мы будем использовать как основу для парсинга.
Для примера возьмем следующий список слов:
База емайлов, база email, база e mail, база предприятий, база компаний, база фирм
Топ сервисов при сборе ядра
- Бесплатный вариант и самый простой – Яндекс Вордстат (ссылка сюда https://wordstat.yandex.ru/).
Сначала выбираем регион, по которому осуществляем поиск:
Далее по очереди вбиваем наши ключи в адресную строку в следующем формате:
(База емайлов | база email | база e mail | база предприятий | база компаний | база фирм)
Если ключей будет больше, по аналогии добавьте их внутрь скобок ( ).
Символ | – который разделяет фразы и означает, что будут собраны данные сразу для нескольких ключей, без него нам пришлось бы собирать каждый ключ в отдельности по порядку.
Так мы получим данные по всем ключам сразу – это сэкономит время.
Важно! Не забываем добавить стоп-слова в следующем формате:
(База емайлов | база email | база e mail | база предприятий | база компаний | база фирм) -бесплатно -1с -2Гис -2Gis -смс -страховые -застройщики -физ -физических -бесплатно -справочник
Получаем выдачу, сразу отфильтрованную от ненужных ключевых запросов:
Для сравнения – выдача без фильтрации, со всеми ключами:
Видим наличие фраз, которые не подходят по роду деятельности.
Для комфортного сбора ключей из Wordstat – установите себе в браузер дополнительное расширение для работы с ключами – Yandex Wordstat Assistant
Оно доступно для многих браузеров:
Это расширение помогает легко выбирать ключи и копировать их – нажмите на знак плюс «+» напротив нужного ключа, обработав весь список ключей – нажмите на кнопку, которая показана на картинке под пунктом 5, эта операция добавит список ключей в буфер обмена:
Дальше заходим в Excel или в другой сервис по обработке семантики и копируем туда наши ключи:
Минусы сервиса:
- Нет возможности получить сразу несколько видов частотности
- Просматривать можно только по 50 запросов на странице
- Отсутствует выгрузка данных, только сторонние методы сбора
Бесплатный сервис «Букварикс» (bukvarix.com) – еще один хороший вариант сбора семантического ядра, так как содержит огромную базу из 2 миллиардов ключей, при этом постоянно обновляется:
Сервис предоставляет возможность получать семантику исходя не только из ключевой фразы, но и с помощью доменного имени сайта. То есть можно проанализировать сайты конкурентов, которые уже проиндексированы и содержат интересующие нас запросы.
То есть можно проанализировать сайты конкурентов, которые уже проиндексированы и содержат интересующие нас запросы.
Также присутствует база рекламных объявлений, топ поисковых запросов, английская база ключей и многое другое.
Сервис имеет более простой интерфейс и не требует дополнительных знаний и инструкций, в отличие от Wordstat. Здесь все понятно, без слов:
Вводим список слов в окно поиска слева, список минус-слов добавляем в окно справа и жмем кнопку найти:
Получаем список ключевых слов вместе с дополнительной информацией, которую можно будет использовать в продвижении:
количество слов в фразе,количество символов,
общая частотность весь мир,
точная частотность весь мир.
Чтобы скачать всю информацию по ключам из букварикса – воспользуйтесь соответствующей кнопкой:
Получаем результат в формате .csv:
Минусы сервиса:
- Рациональность запроса нельзя выбрать, частота собирается только по всему миру
- Много ненужных запросов с нулевой частотой
- Очень много дублей одних и тех же запросов
Автоматические сервисы по сбору ядра
На рынке также есть сервисы, которые автоматизируют сбор семантического ядра.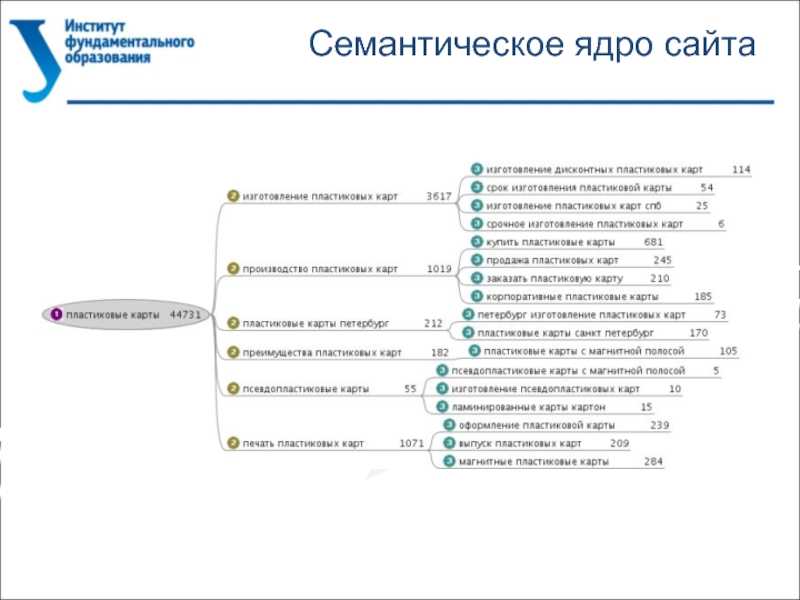
Например, RushAnalytics:
Сервис использует тот же Wordstat для сбора ключевых запросов, но все настраивается в несколько кликов и не требует от вас дополнительных знаний.
1. Добавляем проект, выбрав нужный регион:
2. Настраиваем глубину парсинга, максимум 40 страниц из Wordstat:
3. Указываем список масок и список минус слов
Запускаем проект. По готовности можно будет скачать таблицу с расширением .xlsx
Сервисы, которые имеют собственные мульти-язычные базы ключевых слов:
Например – seranking
В нашем распоряжении – ядра для стран Европы, СНГ, США, Канады, Австралии. Это весомый повод использовать их собственные наработки, так как с помощью их баз можно расширить свое семантическое ядро и получить ценные ключевики, которых нет у конкурентов.
Сервисы для сбора ядра конкурентов
На рынке много ресурсов для сбора семантического ядра конкурентов, рассмотрим наиболее актуальные для русскоязычного сегмента рынка.
https://www. keys.so/
keys.so/
https://serpstat.com/ru/
https://spywords.ru/
Используя эти три сервиса, вы получаете доступ к множеству данных, вот список только некоторых:
- Выгрузка семантики конкурентов
- Разбивка семантики сразу по страницам, согласно данным конкурентов
- Органическая и рекламная выдача по ключам или доменам конкурентов
- Групповые отчеты для сравнения сайтов конкурентов
- Выборки по списку запросов конкурентов
Минимальный план действий по сбору ядра конкурентов:
- Найдите минимум 5 самых близких и конкурентов в вашей нише.
- Обязательно проверьте чтобы они занимали топовые позиции (топ 1-3 ) в поисковой органической выдаче по вашему региону.
- Сделайте выгрузку органического выдачи всех 5 сайтов конкурентов
- Объедините полученные данные с вашим семантическим ядром.
Проведем анализ одного сайта – компании по продаже квадрокоптеров – idrone.ru.
С помощью сервиса кейсо мы сделаем выгрузку страниц сайта, которые присутствуют в органической выдаче.
Данные из этого сервиса выгружаются в виде Excel документа в следующем формате:
Особенно ценно – что кейс дает возможность сразу определить релевантность фразы и ее место в архитектуре сайта. Это ценная информация, которую используем при распределении нашего семантического ядра по сайту.
Организовав правильно работу фильтров в Excel, отсортируем ключи по группам для более ясного восприятия:
Как обработать семантическое ядро
Существует множество вариантов анализа данных в бесплатных и платных сервисах.
Всю эту информацию можно выгрузить в таблицы Excel. Но как обработать этот огромный массив данных, состоящий из отчетов, выгрузок, группировок и множества других файлов?
Профессиональный, платный вариант для обработки семантического ядра – KeyCollector.
Сразу о минусах:
- Программу нужно установить на компьютер, более того – есть привязка по железу, после переустановки Windows нужно будет писать в поддержку, чтобы снова получить лицензию
- Нет поддержки MacOs и Linux – только Windows
- Для нормальной работы нужно покупать прокси-серверы и антикапчу
- Нельзя работать с файлами из облака – зависает, выдает критическую ошибку
Плюсы:
- Единоразовая оплата, пожизненное использование
- Постоянные обновления
- Техподдержка по любым вопросам
- Интеграция и возможность работать практически со всеми сервисами, рассмотренными ранее в статье.
- Встроенные функции для работы со стоп словами, с дублями ключей, кластеризацией
Загрузка данных в проект
В программе есть функция, которая позволяет загружать файлы с расширением .csv и подтягивать всю информацию из них.
Далее выбираем нужные нам данные и делаем загрузку:
Проделываем эту операцию со всем массивом файлов, которые мы собрали при парсинге. Обратите внимание на возможность не добавлять фразу, если она уже есть в ядре:
Этот функционал не запутает вас в ядре и спасет от дублей фраз.
Чистка ядра от мусора
Кейколлектор предоставляет не идеальные, но вполне хорошие варианты фильтрации и чистки семантического ядра:
Выберите следующие параметры, которые изображены на рисунке снизу для оптимальной чистки мусорных запросов. Будьте внимательны при выборе колонки частоты, там необходимо указать именно то что актуально для вашего проекта. Если вы собирали фразовую частотность, а не точную – то сделайте соответствующий выбор.
После выбора параметров – можно использовать умную отметку, которую мы настроили под наш проект, и удалить все дубли ключевых фраз:
Чистка пустых значений и значений с очень маленькой частотностью:
Выделяем и удаляем ключи – которые сверх низкочастотные. Для каждого проекта это будет своя цифра. В нашем случае это точная частота «!» которая идет меньше 5.
Если вам нужны полностью все запросы, то просто удалите все пустые значения и ключи с нулевой точной частотой.
Кластеризация ключевых фраз
Можно использовать встроенные методы кластеризации Кей коллектора.
С их помощью вы получите кластеры фраз, исходя из нескольких условий:
Вариант 1, который идет по умолчанию – это группировка по отдельным словам:
В зависимости от того, сколько раз и где используется каждое отдельное слов – идет построение древовидной структуры:
Такая структура поможет правильно распределить семантику по страницам нашего сайта и составить верную архитектуру:
Вариант-1. Более продвинутый, он основан на данных конкурентов и поисковой выдачи.
Более продвинутый, он основан на данных конкурентов и поисковой выдачи.
Этот метод подразумевает использование уже проиндексированных сайтов из поисковой выдачи в качестве сортировщиков для наших ключевиков. Каждое слово проверяется по выдаче топ 10, 20, 30,50 – и анализируется под какие виды страниц оно подходит лучше всего. В итоге на основе этих данных фразы собираются в похожие группы и образуют кластеры.
ВАЖНО! Для работы этого метода вам необходимо будет получить данные из поисковых систем
В зависимости от того, какую поисковую систему вы определили как главную для построения групп ключей – из этой системы соберите данные.
Группировка такого рода похожа на группировку по составу фраз:
Ключевые слова уже не просто выведены по количеству вхождений в фразу, каждая группа является индивидуальной и после уточнения может быть вынесена как отдельная страница для сайта.
Автоматизированные сервисы Rush Analytics и Seranking также открывают технологию кластеризации, с помощью которой приходит понимание – какие ключи на какую страницу нужно вставлять:
Выгрузка данных в итоговый файл.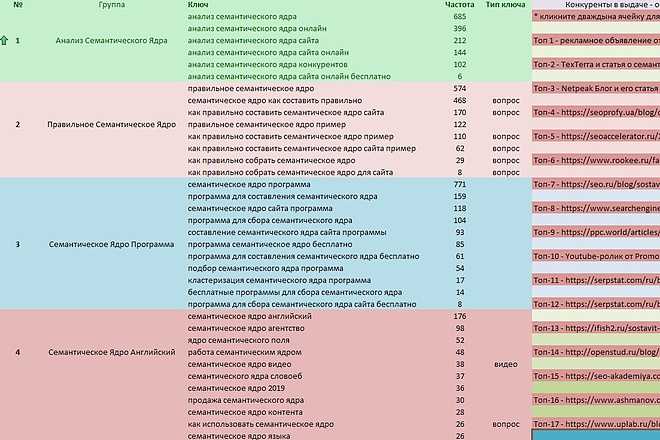
В итоге мы должны образовать из полученных данных – файл примерно такого вида:
Этот вариант содержит в себе ключевую информацию и необходимые данные для старта работ по рекламе и продвижению.
Пример части готового собранного ядра:
Теперь вы знаете, как грамотно собрать семантическое ядро для своего сайта, при этом сэкономив время и личные ресурсы. Надеемся, наши рекомендации помогут вам в решении вопроса семантики, а ваш сайт выполнит задачи бизнеса и непременно будет в топе поисковых систем! ☺
Автор: Максим Глотов — MaxGlot
Подпишитесь на рассылку FireSEO
и получайте подборки статей, полезных сервисов, анонсы и бонусы. Присоединяйтесь!
Настоящим подтверждаю, что я ознакомлен и согласен с условиями политики конфиденциальности на отправку данных.
Как собирать и как составить семантическое ядро
- Анастасия Киселевич
Как собирать и как составить семантическое ядро? Все о том, как правильно собрать семантическое ядро для сайта интернет магазина
- Ключові запити
- семантичне ядро
Содержание:
-
Как собирать и как составить семантическое ядро? Все о том, как правильно собрать семантическое ядро для сайта интернет магазина
-
Алгоритм действий как же все такие правильно составить семантическое ядро сайта
-
Как выглядит семантическое ядро сайта?
-
Как составить семантическое ядро для сайта интернет-магазина – на примере интернет-магазина медицинских товаров для дома и детей
-
Как правильно создать семантическое ядро для сайта интернет магазина – сделаем краткий вывод о том, как сформировать семантическое ядро
На скриншоте пример семантического ядра интернет магазина для популярных сегодня пульсоксиметров.
Обучение составлению семантического ядра – это первое что проходит джун.
Давайте разберем этот процесс на примере и узнаем, как правильно подобрать ключевые слова для интернет-магазина.
Алгоритм действий как же все такие правильно составить семантическое ядро сайта
-
Ознакомляемся с содержимым ресурса, то есть смотрим какие товарные группы представлены в магазине
-
Выбираем инструмент для сбора семантического ядра – это может быть Планировщик, Яндекс Вордстат, Key Collector, Serpstat (не забывайте выставлять правильный географический регион)
-
Для интернет-магазина мы берем только те запросы, которые приведут к транзакциям – то есть либо к покупке или же к регистрации пользователя
-
Собираем только те запросы для каждой категории или подкатегории, которые являются ее информационной потребностью
-
Настоятельно рекомендуем не использовать следующие запросы: фото, картинка, видео, дешево, недорого, по низкой цене, бесплатно и их похожие вариации
-
Настоятельно рекомендуем не собирать информационные запросы и запросы типа «форум», «выбор» итд.
-
Аккуратно собираем эпитеты, так как зачастую они субъективные (красивый, модный)
-
Брендовые запросы нужно собирать как на языке оригинала, так и в русском варианте и транслитерации – например Adidas – Адидас, адики…
-
Не забываем про синонимы, а также народные названия товаров, например – термометр, градусник, измеритель температуры тела, и вот тут можно допустить уточнение «медицинский»
-
Берем во внимание множественное число и географическую принадлежность.

Стоит также остановиться на таком термине как «Интент» что же это значит в нашем случае?
Интент поискового запроса — это то что пользователь поисковой системы вкладывает в запрос, то есть какая цель движет им, когда человек вводит запрос тот или иной запрос в поисковую строку.
Боты поисковика проанализирую ключ, который написал пользователь и сформируют для него выдачу максимально соответствующую цели. И из этого вытекает одна из самых важных задач для Seo специалиста после того как семантическое ядро собрано и кластеризовано, нужно верно распознать цель этих запросов. Потому как это увеличит качество материала, размещенного на сайте в будущем, так как он будет соответствовать интенту, то есть цели пользователя.
Как выглядит семантическое ядро сайта?
Мы используем в работе Google таблицы – создаем столбцы по типу как на примере
Страница это название категории, подкатегории или карточки товара
Все этим мелкие рабочие нюансы помогают нам в ответе на вопрос о том, как быстро и правильно собрать семантическое ядро для сайта под СЕО
Как составить семантическое ядро для сайта интернет-магазина – на примере интернет-магазина медицинских товаров для дома и детей
Как составлять семантическое ядро в общем мы узнали, теперь перейдем к тому, как собрать ключевые слова для сайта на практике.
Так как данный проект строился с 0, то в первую очередь нам понадобиться ответ от заказчика по поводу категория товаров — запросов много, собирать на перед не нужно. Категорий на сайте на данный момент много – давайте остановимся на одной: приоритетная категория «Аспираторы назальные». Если вы не в курсе – то аспиратор, это такой прибор, который используют для того, чтоб убрать сопли из носа грудничков.
Первым делом почитаем что такое Аспиратор, какие они бывают, посмотрим, как эта категория организована у конкурентов как построить семантическое ядро для категории Аспиратор смогли ТОПы выдачи
Далее воспользуемся одним из ранее предложенных инструментов для сбора семантики – мы обязательно поделимся с Вами позже информацией, как собрать качественное ядро семантики для сайта при помощи разных сервисов, так как у каждого из них есть свои нюансы работы.
Не забываем про синонимы и уточнения:
У конкурентов и из массива ключей, полученного из сервисов для сбора семантического ядра мы узнали, что аспираторы бывают двух типов – механические и электронные.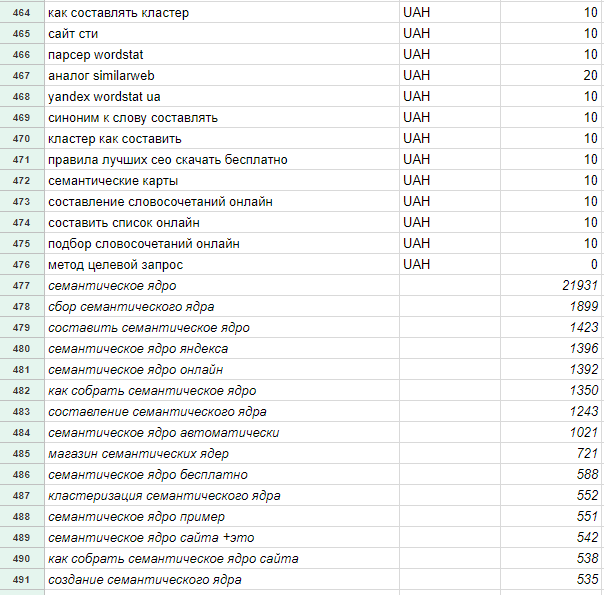 Как же составить ключевые слова для подкатегории сайта, спросите Вы – ответим, так же как для категории, то есть берем запросы, которые отвечают за информационную потребность для данной страницы:
Как же составить ключевые слова для подкатегории сайта, спросите Вы – ответим, так же как для категории, то есть берем запросы, которые отвечают за информационную потребность для данной страницы:
Также учитываем синонимы, уточнения, география и все вариации транзакционных запросов – купить, заказать, цена, стоимость и тд.
Стоит учитывать также и то, что аспираторы производят много компаний. Как собирать семантику для брендов мы кратко рассказали в начале статьи. Напоминаем, что у нас есть аспиратор двух типов – поэтому надо прорабатывать брендовые запросы как для общей категории, так и для каждого из типов.
Как собирать семантическое ядро для карточек товара для сайта интернет магазина
Во-первых, вам понадобиться список товаров, если же заказчик его не предоставил всегда можно посмотреть у конкурентов. Во-вторых, запросы, которые соответствуют карточкам товара можно посмотреть в общем пуле семантики, которую вы взяли на сервисах. Ну и теперь надо обработать такие запросы как на языке оригинала, так и на русском, со всеми возможными вариациями и уточнениями.
Как правильно создать семантическое ядро для сайта интернет магазина – сделаем краткий вывод о том, как сформировать семантическое ядро
Семантическое ядро – это фундамент качественного продвижения Вашего сайта и залог его попадания в ТОП выдачи поисковых систем. От того как правильно подобрать семантическое ядро сайта и как составить ключевые слова для сайта зависит успех Вашего проекта. Мы надеемся, что этот материал дал Вам ответы как сделать семантическое ядро для сайта.
П.С. Для того, чтоб написать данный материал мы тоже собирали семантику. Как собрать семантическое ядро для информационных статей также расскажем Вам в нашем блоге.
Разработка для семантической паутины — Smashing Magazine
- Чтение за 16 мин. Доступность
- Поделиться в Twitter, LinkedIn
Об авторе
Фред — редактор программных навыков и профессионального развития в Smashing Magazine (предложите его!) и инженер-программист в The Guardian.
В июле Фонд Викимедиа объявил об Абстрактной Википедии, попытке разметить знания, не зависящие от языка. Во многих отношениях это кульминация десятилетий наращивания, в течение которых мечта о семантической сети так и не осуществилась, но и не исчезла полностью.
На самом деле семантическая сеть растет, и по мере того, как она обновляет свою миссию, мы все выиграем от включения семантической разметки в наши веб-сайты, будь то личные блоги или гиганты социальных сетей. Независимо от того, заботитесь ли вы о сложном веб-опыте, поисковой оптимизации или отражении тирании веб-монополий, Semantic Web заслуживает нашего внимания.
Преимущества разработки для Semantic Web не всегда очевидны или очевидны, но каждый сайт, который это делает, укрепляет основы открытого, прозрачного, децентрализованного Интернета.
Семантическая сеть
Что такое Семантическая сеть? Это машиночитаемая сеть, обеспечивающая через метаданные «общую структуру, которая позволяет совместно использовать данные и повторно использовать их между приложениями, предприятиями и сообществами».
Идея так же стара, как и сама Всемирная паутина. На самом деле старше. Это было в центре внимания 19-летия Тима Бернерса-Ли.89 предложение. Как он отметил, не только документы должны образовывать сети, но и данные внутри их тоже должны: (Большое превью)
За прошедшие десятилетия семантическая паутина прошла тернистый путь. На рубеже тысячелетий он превратился в несколько концепций — открытые данные, графы знаний — и все они фактически означают одно и то же: сети данных.
Больше после прыжка! Продолжить чтение ниже ↓
Как резюмирует W3C, это «расширение существующей сети, в которой информации придается четко определенное значение, что позволяет компьютерам и людям лучше работать вместе».
У этой идеи было немало сторонников. Интернет-хактивист Аарон Шварц написал рукопись книги о Semantic Web под названием A Programmable Web . В нем он написал:
«Документы нельзя объединять, интегрировать и запрашивать; они служат в основном как отдельные экземпляры, которые нужно просматривать и анализировать. Но данные разнообразны и могут принимать любую форму, которая лучше всего соответствует вашим потребностям».
По целому ряду причин Семантическая Паутина не получила такого же развития, как Сеть, хотя и наверстывает упущенное. На протяжении многих лет некоторые разметки пытались захватить мантию — RDFa, OWL и Schema, и это лишь некоторые из них, — хотя ни одна из них не стала стандартной, как, скажем, HTML или CSS. Порог входа был слишком высок.
Однако мечта о семантической паутине не сбылась, и по мере того, как все больше и больше сайтов включают ее в свои проекты, появляется все больше причин присоединиться к этой вечеринке. Чем больше сайтов попадает на борт, тем сильнее становится семантическая паутина.
Чем больше сайтов попадает на борт, тем сильнее становится семантическая паутина.
Дальнейшее чтение
- Интеллект данных
- Семантическая паутина, статья 2001 года Тима Бернерса-Ли, Джеймса Хенсли и Ора Лассила
- Дополнившуюся группу веб-сообщества на W3C
Знание без Borders
перед Gate Gate Gate Gate в сорняки , как проектировать для Semantic Web, стоит копнуть немного глубже в , почему . Какая разница, подключены ли данные? Подключенных документов недостаточно?
Есть несколько причин, по которым Semantic Web продолжает продвигаться теми, кто заботится о свободном и открытом Интернете. Понимание этих причин имеет важное значение для процесса внедрения. Это не должно быть случаем «ешьте овощи, используйте семантическую разметку». Семантическая паутина — это то, во что нужно верить и частью чего следует быть.
К преимуществам семантического веба относятся:
- Более богатые и сложные веб-интерфейсы
- Обход разрозненности контента и интернет-монополий
- Улучшенная читаемость и ранжирование в поисковых системах
- Демократизация информации
Большинство из них можно проследить до основного принципа Semantic Web: универсальный язык для данных.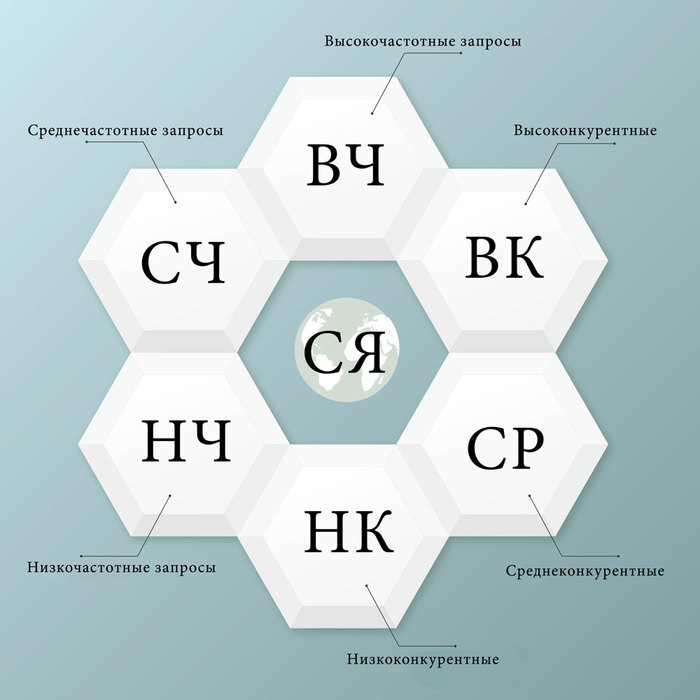 Хотя Интернет уже сотворил чудеса для международного общения, нельзя не отметить тот факт, что в некоторых странах он намного лучше, чем в других. Возьмем, к примеру, языки, используемые в Интернете, и языки, используемые в реальном мире. Самые внимательные из вас могут заметить небольшой дисбаланс в приведенных ниже данных…
Хотя Интернет уже сотворил чудеса для международного общения, нельзя не отметить тот факт, что в некоторых странах он намного лучше, чем в других. Возьмем, к примеру, языки, используемые в Интернете, и языки, используемые в реальном мире. Самые внимательные из вас могут заметить небольшой дисбаланс в приведенных ниже данных…
Безграничная утопия Интернета не так близка, как может показаться тем из нас, кто находится внутри англоязычного пузыря. За это кого-то можно наказать? Не обязательно, но с этим нужно смириться. Это подчеркивает важность разметки, которая устраняет эти пробелы. Обогащая данные сети, мы снимаем нагрузку с ее языков.
Это суть недавно анонсированной абстрактной Википедии, которая попытается отделить статьи от языка, на котором они написаны. Исполнительный директор Викимедиа Кэтрин Махер пишет: «Используя код, добровольцы смогут переводить эти абстрактные материалы».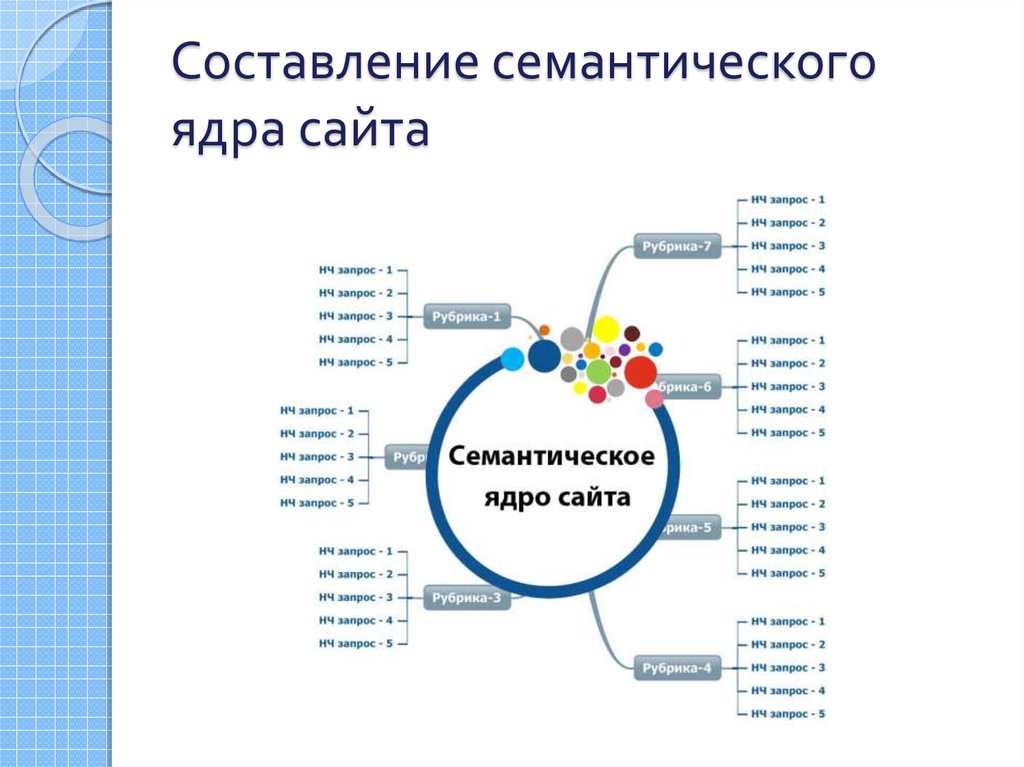 статей на свои языки. В случае успеха это может в конечном итоге позволить каждому читать любую тему в Викиданных на своем родном языке».
статей на свои языки. В случае успеха это может в конечном итоге позволить каждому читать любую тему в Викиданных на своем родном языке».
Аннотация Создатель Википедии Денни Врандечич в течение многих лет был сторонником семантической паутины, признавая ее потенциал для раскрытия неиспользованного потенциала онлайна. Важнейшее значение для этого процесса имеет разрушение национальных барьеров.
«Независимо от того, на каком языке вы публикуете свой контент, вы упустите возможность включить в него подавляющее большинство людей в мире. Интернет дал нам прекрасную возможность глобального охвата, но, полагаясь на один язык или небольшой набор языков, мы упускаем эту возможность. Хотя наиболее важной целью является создание хорошего контента, вы привлекаете больше людей к участию в разработке лучшего контента, будучи независимым от языка. Это помогает вам снизить барьеры для вклада и потребления и позволяет гораздо большему количеству людей извлечь выгоду из этих усилий».— Денни Врандечич, создатель абстрактной Википедии

Своевременным примером этого стала визуализация данных во время пандемии COVID-19. Вирус вызвал невыразимый хаос во всем мире, но он также стал ярким моментом для открытых сетей передачи данных, позволив превосходным веб-приложениям, отчетам и многому другому стать обычным явлением в Интернете.
Информационная панель ncovid2019.live была создана американским старшеклассником Ави Шиффманом и использует данные ВОЗ, CDC и COV19. (Большое превью)И, конечно же, когда данные прозрачны и легкодоступны, легче выявлять аномалии… или прямой обман. Широкий публичный доступ к такой информации был бы немыслим еще 20 лет назад. Теперь мы ожидаем этого и чуем неладное, когда нам отказывают. Данные мощный , и если мы захотим, мы можем использовать его навсегда.
Точно так же, проверка себя из бункеров контента — отличительная черта современного веб-опыта — лишает власти веб-монополии, такие как Google, Facebook и Twitter. Мы настолько привыкли к сторонним платформам, которые расшифровывают и представляют информацию, что забываем, что они не являются строго необходимыми.
Мы настолько привыкли к сторонним платформам, которые расшифровывают и представляют информацию, что забываем, что они не являются строго необходимыми.
«Если бы у нас были общие форматы, общие протоколы, некоторые провайдеры все еще могли бы играть большую роль на определенных рынках — вспомните Gmail для электронной почты, — но каждый волен перейти к другому провайдеру, и рынок остается конкурентным. ”— Денни Врандечич, создатель Абстрактной Википедии. он бесплатный, открытый и абстрактный, что позволяет общаться между разными языками и платформами, что в противном случае было бы намного сложнее.
Обработка данных онлайн-контента
Проектирование для Semantic Web сводится к обработке данных онлайн-контента — просмотру вашего контента и пониманию того, что можно (и нужно) абстрагировать. Что это означает в практическом плане, помимо смутного согласия с тем, что это стоит делать? Это зависит:
- Если вы начинаете проект с нуля, включите в свою работу соображения Semantic Web.
- При обновлении или перестроении проекта оцените, что можно вплести в Semantic Web, чего в настоящее время нет, а затем внедрите.
Оба случая в основном сводятся к информационному содержимому. В этом разделе мы рассмотрим несколько примеров абстракции данных и то, как она может сделать контент лучше, умнее и доступнее.
Абстрагирование информации
Проектирование и разработка для семантической паутины означает просмотр онлайн-контента с использованием ваших данных. Большинство из нас воспринимает Интернет как серию связанных документов или страниц; что вы хотите сделать с Semantic Web, так это соединить информацию. Это означает оценку вашего контента для точек данных, а затем корректировку дизайна на основе того, что вы найдете.
Сторонник Semantic Web Джеймс Хендлер особенно хорошо описывает этот процесс в своем духе DIVE. ( ПОГРУЖАЙТЕСЬ в данные, а? А?).
- Обнаружение
Поиск наборов данных и/или контента (в том числе за пределами вашей организации).- Интегрировать
Свяжите отношения, используя значащие метки.- Подтвердить
Ввести входные данные для систем моделирования и имитационного моделирования.- Исследовать
Разработать подходы к превращению данных в практические знания.Разработка для Semantic Web в значительной степени заключается в том, чтобы иметь представление о том, что вы делаете, с высоты птичьего полета, и о том, как это потенциально влияет на бесконечно более богатый веб-опыт. Как говорит Хендлер, практическое знание — это цель.
Это действительно применимо практически к любому типу веб-контента, но давайте начнем с обычного примера: рецептов . Допустим, вы ведете кулинарный блог с новыми рецептами каждый четверг.
Однако с помощью семантической разметки блог можно преобразовать в машиночитаемый набор данных рецептов. Синтаксис существует для абстрагирования кулинарных терминов. Например, схема, которая может работать вместе с микроданными, RDFa или JSON-LD, имеет разметку, включающую:
- Время подготовки
- Время приготовления
- Рецепт Выход
- Рецепт Ингредиент
- Ориентировочная стоимость
- Питательная ценность с разбивкой на калории и жиры Содержание
- Подходит для диетического питания.
Я мог бы продолжить. Полный набор опций с примерами можно прочитать на Schema.org. При добавлении их в формат сообщения формат рецепта вообще не должен меняться — вы просто размещаете информацию в терминах, понятных компьютерам.
Преобразовывая редакционный контент в данные, рецепты BBC значительно повышают свою потенциальную полезность.Например, все, что выделено синим в рецепте BBC выше, также получило семантическую разметку — от времени приготовления до содержания питательных веществ. Вы можете увидеть, что происходит под капотом, введя URL-адрес рецепта в Google Rich Results Test. Обратите внимание на функциональность «Добавить в список покупок» — пример подключения, ставшего возможным благодаря реализации Semantic Web. Хороший контент становится полезными данными.
Пути большинства из нас сталкивались с такой изощренностью через результаты поиска, но приложения гораздо шире. Семантическая разметка рецептов облегчает поиск и использование веб-сайтов домашними помощниками. Перечисленные ингредиенты можно заказать в местном супермаркете. Рецепты можно было фильтровать самыми разными способами — по диетам, аллергиям, религии, стоимости и так далее. Или, скажем, у вас было ограниченное количество ингредиентов в доме. С помощью базы данных вы можете ввести эти ингредиенты и посмотреть, какие рецепты подходят для этого.
Диапазон возможностей действительно граничит с безграничностью. Как сказал Шварц, данные многообразны. Как только он у вас появится, вы сможете использовать его самыми странными и замечательными способами. Эта статья не столько об этих странных и чудесных способах, сколько о том, как сделать их возможными. Проектирование для Semantic Web делает последующий дизайн бесконечно богаче.
Вот более личный пример, чтобы показать, что я имею в виду. Мы с парой друзей в качестве хобби ведем небольшой музыкальный веб-журнал. Хотя мы публикуем редкие статьи или интервью, «главным событием» являются наши еженедельные обзоры альбомов, в которых каждый из нас втроем выставляет оценки, выбирает любимые треки и пишет резюме. Мы работаем уже более пяти лет, а это значит, что у нас около 250 отзывов, а это означает очень много потенциальных данных. Мы не осознавали, насколько, пока не начали редизайн сайта.
Я упоминал об этом в статье о включении структурированных данных в процесс проектирования.
Этот двусторонний подход является сутью Semantic Web. Когда наш музыкальный веб-сайт перезапустится, он станет собственным открытым источником данных с тысячами уникальных точек данных. Подключение к существующей музыкальной базе данных даст нашим собственным данным больше контекста и потенциала. Тысячи точек данных становятся десятками тысяч точек данных, а может и больше.
С помощью простой семантической разметки, казалось бы, безобидные веб-страницы могут стать центром огромной информационной сети. (Большой предварительный просмотр)На приведенном выше рисунке лишь поверхностно показано, сколько информации будет связано со страницами отзывов.
Разработка для Semantic Web означает идентификацию ваших собственных данных, их разметку, а затем выяснение того, как они связаны с другими данными. Потому что это так. Это всегда так. И этот процесс таков, как это…
(Большой предварительный просмотр)… со временем становится этим…
Связанное облако открытых данных, постоянно обновляемая визуализация состояния связанных данных в Интернете. (Большой предварительный просмотр)Второе изображение — это связанное открытое облако данных, постоянно обновляемая визуализация подключенных данных в Интернете. Этот красный улей связей — это науки; остальным есть куда двигаться. Вот где мы вступаем.
Полезные семантические веб-ресурсы
- RDF на w3schools.com
- Валидатор RDF от W3C
- «Семантическая паутина стала проще» от W3C
- «Что случилось с семантической паутиной?» by Two-Bit History
- Генератор JSON-LD
- Помощник по разметке структурированных данных Google
Plugin
Идеал Semantic Web — это связь.
Вот лишь несколько доступных ресурсов данных:
- DPpedia
- MusicBrainz
- WorldCat
- ISBNdb
Действительно, там, где такие базы данных существуют, я бы даже сказал, что правильно будет обновить их там, где в них не хватает информации. Зачем держать это в себе? Станьте участником, сторонником Semantic Web.
Внедрение
Что касается встраивания Semantic Webness в ваши сайты, я, конечно же, не выступаю за ручную пошаговую разметку. У кого есть на это время? Чаще всего решение заключается в стандартизации формата и шаблонов для него.
Создание шаблонов дает большие возможности. У скольких людей действительно есть время, чтобы разметить всю эту информацию вручную? Однако, если у вас есть настраиваемые входные данные, вы получаете лучшее из обоих миров.
Возьмем, к примеру, генератор статических сайтов, такой как Eleventy, который в последнее время пользуется некоторой любовью со стороны сообщества разработчиков. Вы пишете пост, запускаете его по шаблону, и вы — золото. Так почему бы не включить семантическую разметку в сам шаблон?
Как и Eleventy, новая версия нашего музыкального веб-журнала использует Markdown для своих сообщений. Хотя у нас есть те же старые текстовые сообщения, что и всегда, каждый обзор теперь также включает следующие входные метаданные, которые затем втягиваются в шаблон: минут на любую загрузку поста. (Большой предварительный просмотр)
Вместе с информацией об авторе в теле сообщения и некоторой общей информацией о веб-сайте это преобразуется в следующую семантическую разметку:
<скрипт type="application/ld+json"> { "@контекст": "https://schema.org/", "@type": "Обзор", "reviewBody": "Один из окончательных альбомов, выпущенных, возможно, величайшим певцом и автором песен, которого мы когда-либо видели. Тем, кто хочет исследовать пугающую дискографию Янга: начните здесь.", "datePublished": "2020-08-14", "автор": [{ "@type": "Человек", "name": "Андре Дак" }, { "@type": "Человек", "name": "Фредерик О'Брайен" }, { "@type": "Человек", "name": "Маркус Лоуренс" }], "itemReviewed": { "@type": "Музыкальный Альбом", "name": "После золотой лихорадки", "@id": "https://musicbrainz.org/release-group/b6a3952б-9977-351с-а80а-73е023143858", "image": "https://audioxid.com/images/album-artwork/after-the-gold-rush-neil-young.jpg", "albumProductionType": "https://schema.org/StudioAlbum", "albumReleaseType": "https://schema.org/AlbumRelease", "Артист": { "@type": "Музыкальная группа", "name": "Нил Янг", "@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf" } }, "ОбзорРейтинг": { "@type": "Рейтинг", "ratingValue": 27, "худший рейтинг": 0, "лучший рейтинг": 30 }, "издатель": { "@type": "Организация", "name": "Аудиоксид", "description": "Независимый музыкальный интернет-журнал, основанный в 2015 году. Публикует обзоры, статьи, интервью и другие странности.", "url": "https://audioxid.com", "логотип": "https://audioxid.com/logo-location.jpg", "такой же как" : [ "https://facebook.com/audioxid", "https://twitter.com/audioxid", "https://instagram.com/audioxidcom" ] } } Там, где раньше был только текст, теперь на каждой странице обзора будут машиночитаемые версии того, что читатели увидят при посещении сайта. Все слова остались на месте, содержание практически не изменилось — оно просто было дополнено данными. От расширенных результатов поиска до интерактивных страниц со статистикой отзывов — это значительно расширяет возможности. Дорога впереди широкая и открытая. Это также дает нам долю в будущем MusicBrainz. Соединяя их данные с нашими собственными данными, мы, в свою очередь, хотим, чтобы все работало хорошо, и сделаем все возможное, чтобы это произошло.
Подходящая семантическая разметка зависит от характера веб-сайта, но есть вероятность, что она существует.
За гранью воображения
Проектирование и разработка для Semantic Web — это практика, восходящая к основополагающим идеалам Интернета. Цените ли вы красивую информативную визуализацию данных, хотите получить более сложные результаты поиска, лишить власти веб-монополии или просто верите в бесплатную и открытую информацию, Semantic Web — ваш союзник.
Аарон Шварц завершил свою рукопись призывом надежды:
«Семантическая паутина основана на пари, пари, что предоставление миру инструментов для простого сотрудничества и общения приведет к таким замечательным возможностям, что мы едва ли можем себе представить их прямо сейчас.Абстрактная Википедия Денни Врандечич разделяет сегодняшние настроения, говоря:
«Необходима веб-инфраструктура, которая облегчит взаимодействие между сервисами, что требует общего набора стандартов для представления данных и общих протоколов для всех провайдеров».Семантическая паутина хромала достаточно долго, чтобы стало ясно, что язык-серебряная пуля вряд ли появится, но сейчас их достаточно, чтобы мирно сосуществовать, чтобы мечта Бернерса-Ли стала реальностью для большей части сети. Каждый из нас может быть адвокатом в своем районе.
Будьте лучше, требуйте лучшего
Как сказал Тим Бернерс-Ли, семантическая паутина — это не только техническое препятствие, но и культура. В 2009 году на TED Talk он прекрасно резюмировал: создавать связанные данные, требовать связанные данные . Сейчас это вернее, чем когда-либо. Всемирная паутина открыта, взаимосвязана и хороша настолько, насколько мы ее заставляем.
Связанные данные и семантическая сеть — метаданные и обнаружение @ Pitt
Связанные открытые данные (LOD)
Связанные данные, выпущенные под открытой лицензией, которая не препятствует их бесплатному повторному использованию. — Тим Бернерс-Ли, Связанные данные.
Примеры больших связанных наборов открытых данных включают DBpedia и Wikidata.
Структура описания ресурсов (RDF)
Набор стандартов семантической сети, разработанный консорциумом Worldwide Web Consortium (W3C). Эти стандарты создают структуру для создания простых утверждений о ресурсах, чтобы машины могли интерпретировать отношения. Эти операторы называются триплетами, которые представляют собой операторы субъект-предикат-объект, используемые для описания отношений между сущностями в среде связанных данных.
Ресурсы: RDF 1.1 Primer
Схема
Набор элементов для структурирования данных (например, MARC, MODS, EAD, RDFS).
URI
URI или унифицированный идентификатор ресурса — это уникальный контролируемый термин, используемый для идентификации чего-либо.
Одним из типов URI является URN или унифицированное имя ресурса, которое представляет собой установленную стандартизированную метку для конкретного объекта. Другой тип URI — это URL-адрес, который указывает местоположение ресурса в Интернете. Машинно интерпретируемые URI обычно имеют форму URL. Эти URL-адреса могут привести пользователей к дополнительной информации об этих ресурсах, но не все URI должны указывать на удобочитаемую веб-страницу.
Примером URI неподвижного изображения (изображения, карты и т. д.) из словаря типов Dublin Core является http://purl.org/dc/dcmitype/StillImage. Другой пример дает URI для американского автора по имени Марк Твен как https://viaf.
Тройки
Тройки, также известные как семантические тройки, представляют собой операторы субъект-предикат-объект, используемые для описания отношений между сущностями в связанной среде данных. Они являются строительными блоками связанных данных. Например, для описания книги под названием «Какая-то книга», написанной автором по имени Джейн Доу, тройка может быть чем-то вроде Джейн Доу — автора «Какой-то книги». В Semantic Web каждый компонент триплета обычно задается в URI.
Семантическая паутина
Семантическая паутина считается следующей стадией развития после Всемирной паутины и представляет собой представление Всемирной паутины связанных данных. В семантической сети все данные в сети структурированы и машиночитаемы. Это позволяет компьютерам делать выводы о взаимосвязях между ресурсами, расширяя возможности человека для открытия новых областей знаний. Одним из современных предшественников Semantic Web является панель знаний Google, которая объединяет данные из многих источников в компактное и простое информационное окно.
 По мере того, как веб-сайт обретает форму, вплетайте семантическую разметку в его ДНК.
По мере того, как веб-сайт обретает форму, вплетайте семантическую разметку в его ДНК. Он разбивается следующим образом:
Он разбивается следующим образом: Если вы француз и публикуете потрясающий рецепт суфле в своем личном блоге в виде обычного текста, это будет полезно только тем, кто умеет читать по-французски.
Если вы француз и публикуете потрясающий рецепт суфле в своем личном блоге в виде обычного текста, это будет полезно только тем, кто умеет читать по-французски. (Нажмите для просмотра в большом разрешении)
(Нажмите для просмотра в большом разрешении)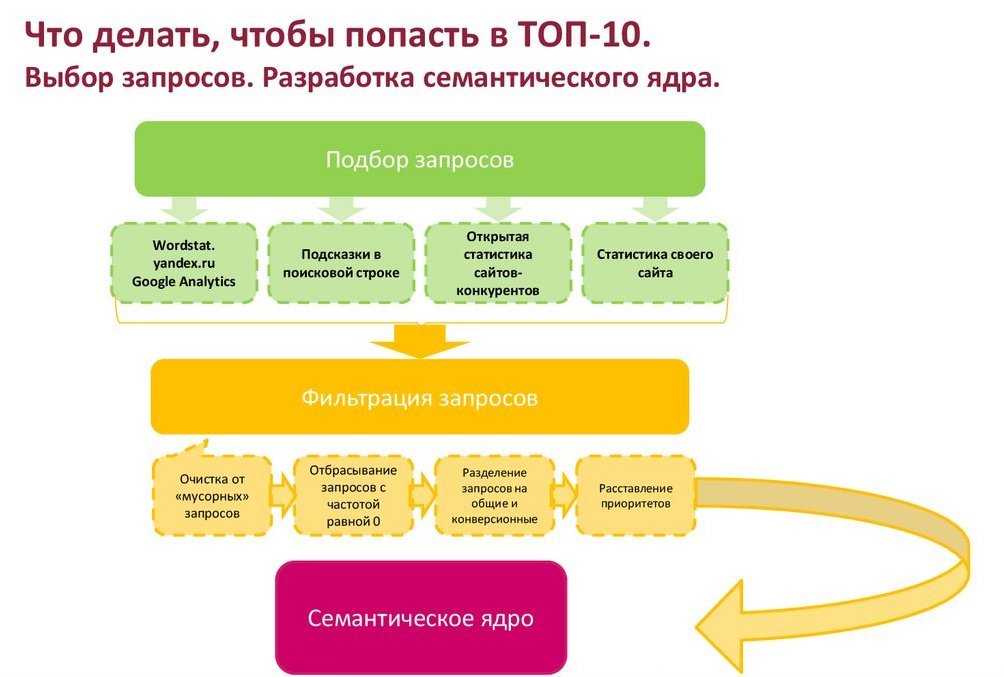
 Анализируя наши обзоры, мы поняли, что они битком набиты информацией, которой можно дать семантическую разметку. Исполнители, названия альбомов, обложки, дата выпуска, индивидуальные оценки, общие оценки, тип выпуска и многое другое. Более того — и это действительно интересно — мы поняли, что можем подключиться к существующей базе данных: MusicBrainz.
Анализируя наши обзоры, мы поняли, что они битком набиты информацией, которой можно дать семантическую разметку. Исполнители, названия альбомов, обложки, дата выпуска, индивидуальные оценки, общие оценки, тип выпуска и многое другое. Более того — и это действительно интересно — мы поняли, что можем подключиться к существующей базе данных: MusicBrainz. Контент такой же, как и раньше, только теперь он подключен к экосистеме метаданных — Giant Global Graph, как однажды назвал ее Бернерс-Ли.
Контент такой же, как и раньше, только теперь он подключен к экосистеме метаданных — Giant Global Graph, как однажды назвал ее Бернерс-Ли.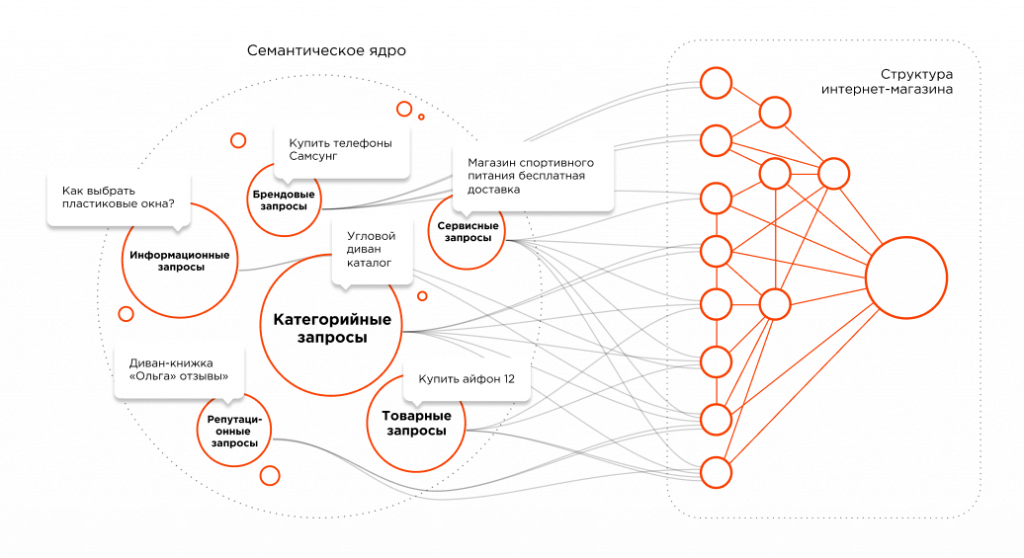 Создавайте данные, делитесь данными, требуйте данные. Станьте частью информационной экосистемы. Когда вы создаете исходные данные, отлично. Поделиться этим. Когда данные уже существуют и вы хотите их использовать, извлеките их.
Создавайте данные, делитесь данными, требуйте данные. Станьте частью информационной экосистемы. Когда вы создаете исходные данные, отлично. Поделиться этим. Когда данные уже существуют и вы хотите их использовать, извлеките их. Контент может быть заполнен удобной для людей информацией, и эта информация существует в виде данных, готовых служить любой цели, которая приходит на ум.
Контент может быть заполнен удобной для людей информацией, и эта информация существует в виде данных, готовых служить любой цели, которая приходит на ум.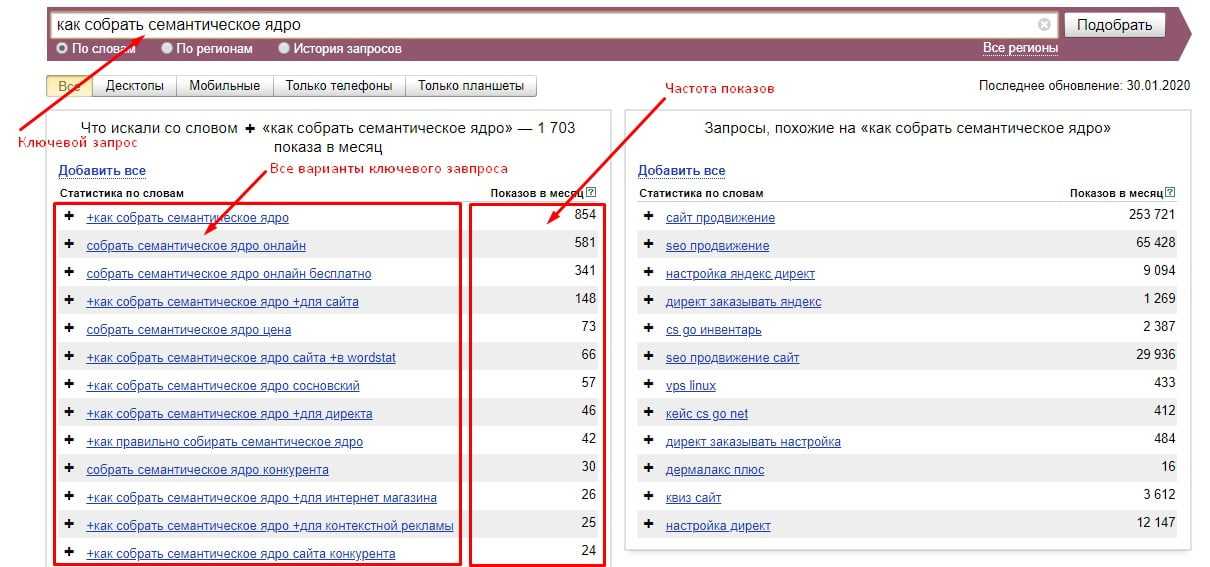
 Начните с очевидных входных данных (дата, автор, тип контента и т. д.) и продвигайтесь вглубь контента. Первый шаг может быть таким же простым, как hCard (разновидность цифрового удостоверения личности) для вашего личного веб-сайта. Распечатайте скриншоты страниц и начните комментировать. Вы будете поражены тем, сколько контента может быть обработано данными.
Начните с очевидных входных данных (дата, автор, тип контента и т. д.) и продвигайтесь вглубь контента. Первый шаг может быть таким же простым, как hCard (разновидность цифрового удостоверения личности) для вашего личного веб-сайта. Распечатайте скриншоты страниц и начните комментировать. Вы будете поражены тем, сколько контента может быть обработано данными.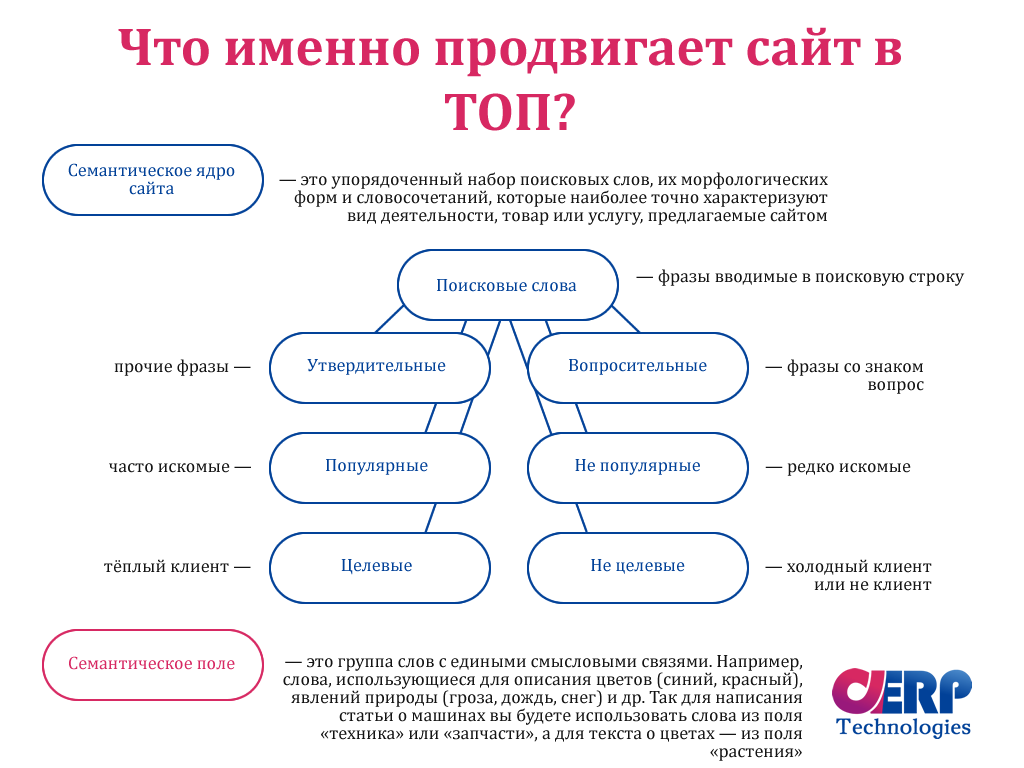 ».
». Всякий раз, когда вы делаете что-то онлайн, спросите себя: «Как это может подключиться к Semantic Web?» Ответы добавят новые измерения к вещам, которые мы создаем, и создадут невообразимо прекрасные новые возможности на долгие годы.
Всякий раз, когда вы делаете что-то онлайн, спросите себя: «Как это может подключиться к Semantic Web?» Ответы добавят новые измерения к вещам, которые мы создаем, и создадут невообразимо прекрасные новые возможности на долгие годы.
 org/viaf/50566653.
org/viaf/50566653.