
Как правильно собрать семантическое ядро для сайта — Маркетинг на vc.ru
Всем привет, наша веб-студия Mad Design готовит презентацию для выступления по seo-оптимизации и продвижению сайта в топ 10 и решили поделиться с вами материалом о том, как собрать семантическое ядро для сайта.
Семантическое ядро сайта – это полный набор ключевых слов, соответствующих тематике веб-ресурса, по которым пользователи смогут найти его в поисковой системе.
К примеру, семантическое ядро для ремонта телефонов iphone будут примерно такими: ремонт iphone X 64 гб, замена стекла iPhone, замена батарейки iPhone X 64 гб, ремонт телефонов iPhone любых моделей и т.д.
Перед началом работ по продвижению вашего сайта сначала необходимо найти все ключевые запросы, по которым его могут искать целевые посетители. На основании семантики составляется структура, распределяются ключи, прописываются мета-теги, заголовки документов, описания к изображениям, а также разрабатывается анкор-лист для работы со ссылочной массой.
При составлении семантического ядра важно решить главную задачу: определить, какую информацию следует опубликовать, чтобы привлечь потенциального клиента.
Составление списка ключевых запросов решает еще одну важную задачу: для каждой поисковой фразы вы определяете релевантную страницу, которая полно сможет ответить на вопрос пользователя.
Данная задача решается следующим образом:
· Вы создаете структуру сайта на основе семантического ядра.
· Вы распределяете подобранные термины по готовой структуре ресурса.
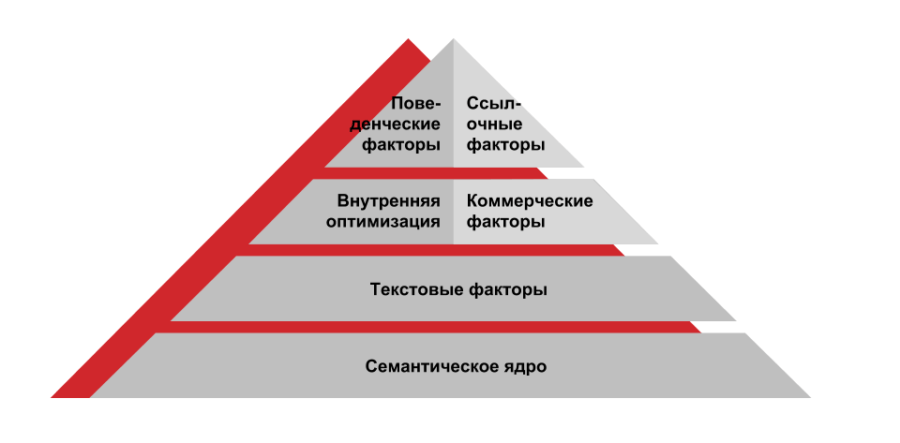
Виды ключевых запросов (КЗ) по количеству просмотров:
· НЧ – низкочастотные. До 100 показов в месяц.
· СЧ – среднечастотные. От 101 до 1 000 показов.
· ВЧ – высокочастотные. Более 1000 показов.
Виды КЗ по типу поиска:
· Информационные нужны при поиске информации. «Как жарить картофель» или «сколько звезд на небе».
· Транзакционные используются для совершения действия. «Заказать пуховый платок», «скачать песни Высоцкого»
· Навигационные используются для поиска связанного с какой-то конкретной фирмой или привязкой к сайту. «Хлебопечь МВидео» или «смартфоны Связной».
· Прочие — расширенный список, по которому невозможно понять конечную цель поиска. К примеру, запрос «торт Наполеон» – возможно, человек ищет рецепт его приготовления, а, возможно, хочет купить торт.
Как составить семантику:
· Необходимо выделить главные термины вашего бизнеса и нужд пользователей. К примеру, клиенты прачечной интересуются стиркой и чисткой.
· Затем следует определить хвосты и спецификацию (более 2 слов в запросе), которые пользователи добавляют к главным терминам. Этим вы увеличите охват целевой аудитории и снизите частотность терминов (стирка пледов, стирка курток и т.п.)
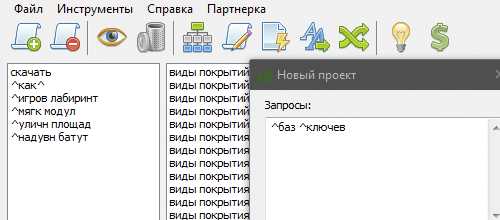
Сбор семантического ядра вручную.
Яндекс Wordstat:
· Выберите регион веб-ресурса.
· Введите ключевую фразу. Сервис выдаст вам количество запросов с данным ключевиком за последний месяц и список «родственных» терминов, которые интересовали посетителей. Имейте ввиду, что если вы вводите, к примеру, «купить окна», то получаете результаты по точному вхождению ключевика. Если вводите данный ключ без кавычек, то получаете общие результаты, и запросы типа «купить окна в воронеже» и «купить окно пластиковое» также будут отражены в данной цифре. Для сужения и уточнения показателя можно воспользоваться оператором «!», который ставится перед каждым словом: !купить !окна. Вы получите число, показывающее точную выдачу по каждому слову. Получится список типа: купить пластиковые окна, купить и заказать окна, при этом слова «купить» и «окна» будут отражаться в неизменном виде. Для получения абсолютного показателя по запросу «купить окна» следует применять следующую схему: вводим в кавычках «!купить !окна». Вы получите самые точные данные.
· Соберите слова из левой колонки и проанализируйте каждое из них. Составьте начальную семантику. Обращайте внимание на правую колонку, содержащую КЗ, которые пользователи вводили до или после поиска слов из левой колонки. Вы найдете еще немало нужных фраз.
· Пройдите по вкладке «История запросов». На графике вы сможете проанализировать сезонность, популярность фраз в каждом месяце. Неплохие результаты дает работа с поисковыми подсказками Яндекса. Каждый КЗ вводится в поисковое поле, и на основе всплывающих подсказок расширяется семантика.
Google-планировщик КЗ:
· Введите главный ВЧ запрос.
· Выберите «Получить варианты».
· Отберите самые релевантные варианты.
Изучение сайтов-конкурентов.
Используйте этот метод как дополнительный, чтобы определить правильность выбора того или иного КЗ. В этом вам помогут инструменты BuzzSumo, Searchmetrics, SEMRush, Адвсе.
Программы для составления семантического ядра.
· Key Collector. Если вы составляете очень объемную семантику, то без этого инструмента вам не обойтись. Программа подбирает семантику, обращаясь к Яндекс Wordstat, собирает поисковые подсказки данного поисковика, фильтрует КЗ со стоп-словами, очень низкой частотой, дублированные, определяет сезонность фраз, изучает статистику счетчиков и соцсетей, подбирает релевантные страницы к каждому запросу.
· SlovoEB. Бесплатный сервис от Key Collector. Инструмент подбирает ключевые слова, группирует и анализирует их.
· Allsubmitter. Помогает подобрать КЗ, показывает сайты-конкуренты.
· KeySO. Анализирует видимость веб-ресурса, его конкурентов и помогает в составлении СЯ.
Что нужно учитывать при подборе ключевых фраз:
· Показатели частотности.
· Большая часть КЗ должна быть НЧ, остальные — СЧ и ВЧ.
· Релевантные поисковым запросам страницы.
· Конкурентов в ТОП.
· Конкурентность фразы.
· Прогнозируемое количество переходов.
· Сезонность и геозависимость.
· КЗ с ошибками.
· Ассоциативные ключи.
Правильное семантическое ядро.
1. Прежде всего, необходимо определиться с понятиями «ключевые слова», «ключи», «ключевые или поисковые запросы» – это слова или фразы, при помощи которых потенциальные клиенты вашего сайта ищут необходимую информацию.
2. Составьте следующие списки: категории товаров или услуг (далее -ТУ), названия ТУ их бренды, коммерческие хвосты ( «купить», «заказать» и т.п.), синонимы, транслитерацию на латинице (или на русском соответственно), профессиональные жаргонизмы ( «клавиатура» – «клава» и т.п.), технические характеристики, слова с возможными опечатками и ошибками ( «оренбуржский» вместо «оренбургский» и т.п.), привязки к местности (город, улицы и т.п.).
3. При работе со списками ориентируйтесь на КЗ из договора по продвижению, структуру веб-ресурса, информацию, прайс-листы, сайты-конкуренты, опыт предшествующего SEO.
4. Приступайте к подбору семантики путем смешения выбранных на предыдущем шаге словосочетаний, используя ручной метод или при помощи сервисов.
5. Сформируйте список стоп-слов и удалите неподходящие КЗ.
6. Сгруппируйте КЗ по релевантным страницам. Под каждый ключ подбирается наиболее релевантная страница или создается новый документ. Желательно данную работу проводить вручную. Для крупных проектов предусмотрены платные сервисы типа Rush Analytics.
7. Идите от большего к меньшему. Сначала распределите ВЧ по страницам. Затем то же самое проделайте с СЧ. НЧ можно добавить к страницам с распределенными по ним ВЧ и НЧ, а также подобрать для них индивидуальные страницы.
После анализа первых результатов работ мы можем увидеть, что:
· продвигаемый сайт не виден по всем заявленным ключевым словам;
· по КЗ выдаются не те документы, которые вы предполагали релевантными;
· мешает неправильная структура веб-ресурса;
· для некоторых КЗ релевантны несколько веб-страниц;
· не хватает релевантных страниц.
При группировке КЗ работайте со всеми возможными разделами на веб-ресурсе, наполняйте каждую страницу полезной информацией, не создавайте дублированный текст.
Распространенные ошибки при работе с КЗ.
· была подобрана только очевидная семантика, без словоформ, синонимов и т.д;
· оптимизатор распределил слишком много КЗ на одну страницу;
· одинаковые КЗ распределены на разные страницы.
При этом ранжирование ухудшается, сайт может быть наказан за «переспам», а если у веб-ресурса неправильная структура, то продвигать его будет очень сложно.
Не важно, каким образом вы будете подбирать семантику. При правильном подходе вы получите правильное СЯ, необходимое для успешного продвижения сайта.
Команда веб-студии Mad Design благодарит вас за внимание. Всем успехов и продаж!)
Материал опубликован пользователем. Нажмите кнопку «Написать», чтобы поделиться мнением или рассказать о своём проекте.
Написатьvc.ru
Правильно собрать семантическое ядро для продвижения сайта — SEO на vc.ru
Подробная инструкция от руководителя оптимизаторов в «Ашманов и партнёры» Никиты Тарасова.
Семантическое ядро — основа поискового продвижения. Если допустить ошибки на этом этапе, дальнейшая работа по SEO пойдёт под откос. Это руководство поможет собрать семантику для проекта любого масштаба и ничего не упустить.
Этапы работы
Сбор семантического ядра состоит из четырёх последовательных этапов:
*Маркером (или маркерным запросом) называют слово или словосочетание наиболее точно отражающее суть конкретной страницы сайта. Обычно в качестве основного «маркерного» запроса для страницы берётся содержимое заголовка h2. У одной страницы может быть несколько маркерных запросов.
Получение маркеров и работа с ними
На рисунке изображена последовательность действий по подбору и обработке маркеров:
Последовательность подбора и обработки маркеровСобираем список заголовков h2
Собирать заголовки вручную долго и муторно, особенно если сайт состоит из тысяч страниц. Процесс можно автоматизировать и ускорить с помощью «пауков».
«Пауки» — программы, которые эмулируют роботов поисковых систем: обходят все страницы на сайте, получают список URL-адресов и заголовков h2. Список экспортируется в любой удобный формат, например, в Excel. Вот ссылки на наиболее популярные программы:
Корректируем заголовки
Убедитесь, что собранные маркерные запросы обладают частотностью. Если частотность вызывает сомнения, сверьтесь с «Вордстатом», а потом скорректируйте запрос или найдите более частотный.
Не используйте несколько интентов (потребностей пользователей) для продвижения на одной странице. Например, на сайте магазина мебели есть раздел «Кресла и стулья». Но пользователи так не ищут, поэтому эффективней создать два отдельных раздела «Кресла» и «Стулья».
Не проектируйте структуру сайта так, чтобы в разных разделах дублировались одинаковые страницы, как на скриншоте ниже.
Страница «Смесители» дублируется в разделах «Ванная» и «Душ»В примере выше для раздела «Душ» можно оставить ссылку на раздел «Смесители для ванны и душа», но она должна вести на страницу: http://www.domain.ru/catalog/vannaya/smesiteli-dlya-vanny-i-dusha/.
Не создавайте отдельные страницы под синонимичные группы запросов вроде «дешевые матрасы», «недорогие матрасы». Они могут быть восприняты поисковыми системами как нечёткие дубли. Это может привести к проблемам с индексацией сайта: часть страниц будет исключена из поиска.
Чтобы определить, какие запросы можно продвигать на одной странице, а какие — нет, воспользуйтесь сервисом кластеризации*.
*Кластеризация — принцип группировки запросов на основании общего числа URL в поисковой выдаче.
Суть кластеризации в том, чтобы изучить, как распределены запросы у сайтов, уже находящихся в верхней десятке поисковых систем. Для определения совместимости интентов идеально подойдёт такой сервис. А про методы кластеризации подробнее расскажу ниже.
Расширяем заголовки за счёт интентов и дополнительных слов
Когда мы получили маркеры, дальше собираем ключевые слова с помощью «Вордстата». Стоит учесть, что «Вордстат» отображает только 41 страницу со статистикой по запросу.
Если мы имеем дело с частотным маркером (например, «Диван»), то есть вероятность, что весь пул запросов мы не охватим.
Как видно, запросы ещё есть, но на следующей странице результаты не отображаются
Поэтому стоит подготовить список уточняющих запросов, характерных для конкретной тематики: например, «диван купить», «диван цена» и так далее.
Готовые тематические подборки можно найти на этой странице.
Получить маркеры, сцепленные с дополнительными словами, можно при помощи формулы =СЦЕПИТЬ(A1;» «;$E$1).
Маркеры не должны содержать символы .,»?!()- и другие знаки. Замените символы в Excel на пробел, используя сочетание клавиш Ctrl и H, а затем проверьте список маркерных запросов на орфографию.
Собираем заголовки с сайтов конкурентов
Проанализируйте сайты конкурентов, находящиеся в топе выдачи по интересующим вас запросам. В ходе анализа особенно интересно получить заголовки «теговых страниц», которые заточены под конкретный пользовательский интент.
Заголовки сайтов-конкурентов можно просканировать «пауками», о которых говорилось выше (например, Screaming frog SEO spider).
Этот подход поможет расширить структуру сайта и подобрать новые запросы для семантического ядра.
Нормализуем запросы
Под нормализацией понимается определение наиболее частотной формы запроса. Это нужно, чтобы не упустить запросы с высокой частотой, приносящие больше трафика на сайт.
Если запросов немного, они состоят из двух слов, то определить наиболее частотный запрос можно в «Вордстате» при помощи операторов: «[!поисковый !запрос]».
Например:
Если запрос состоит из трех и более слов, а запросов больше ста, проверка вручную займёт много времени. Чтобы автоматически выявлять наиболее частотную словоформу, я сделал специальный парсер на базе А-parser.
Логика работы парсера в следующем:
- в «Вордстате» запросы выводятся в порядке убывания частоты;
- каждый запрос, подаваемый на вход, заключается в кавычки, тем самым анализируются все словоформы запроса;
- в качестве результата берётся первый запрос из левой колонки, то есть наиболее частотная из словоформ.
Как видно из примера ниже, наиболее частотной словоформой является «купить диван», что подтверждается точной частотой запросов из примеров выше.
Когда мы провели работы, описанные в разделе, у нас получается список маркерных запросов, удовлетворяющий следующим критериям:
- нет опечаток;
- нет символов и знаков препинания;
- все маркерные запросы частотные;
- часть маркеров содержит дополнительные слова и словосочетания, характерные для конкретной тематики;
- в списке присутствуют наиболее частотные словоформы запросов;
Парсинг запросов
Список маркеров, который мы получили, нужно расширить дополнительными словами — «хвостами». Это поможет нам максимально охватить семантику в поисковой нише, в которой продвигается сайт. Дополнительные слова можно взять из источников, указанных на схеме ниже.
Наиболее популярные источники для парсинга поисковых запросовКоротко разберу особенности некоторых источников.
Поисковые подсказки «Яндекса» и Google
Основное преимущество подсказок в том, что их база намного больше, чем база того же «Вордстата».
В подсказки попадают запросы, обладающие частотой, которые реально запрашивают пользователи. В «Вордстате» же есть доля мусорных и автосгенерированных запросов, не обладающих реальным поисковым спросом.
Подсказки в «Яндексе» можно получать в формате json. В этом случае каждой поисковой подсказке присваивается определенный тип.
Ниже приведены наиболее часто встречающиеся типы подсказок:
- B и T обозначают «обычные» подсказки;
- W — это перестановка слов;
- In — автодополнение;
- Pb — порно-подсказка;
- Nav — навигационный запрос;
- Rich — расширенная подсказка-сниппет, появляется для «Википедии»;
- Tail_word — как правило, означает, что подсказка дополняется не с конца, а с начала;
- Art, Fast_w, Fresh_console, Fast — неизвестные типы.
Например, после сбора можно сразу удалить все подсказки с типом «In», что существенно уменьшит число мусорных запросов. Для сбора подсказок с указанием типов я использую парсер.
«Яндекс.Вебмастер»
В «Вебмастере» есть раздел, в котором можно получить рекомендованные поисковые запросы. Достаточно нажать на кнопку и через некоторое время список будет доступен для скачивания.
Рекомендованные поисковые запросы в «Яндекс.Вебмастере»«Яндекс.Метрика» и Google Analytics
Часть запросов можно выгрузить из отчёта «Яндекс.Метрики»: «Стандартные отчеты» → «Источники» → «Поисковые запросы».
Выгрузка поисковых запросов из «Яндекс.Метрики»В Google Analytics также есть данные о запросах, но с 2011 года Google начал шифровать запросы пользователей, поэтому собрать большой объём информации из данного источника не получится.
Выгрузка поисковых запросов из Google AnalyticsГотовые базы ключевых слов
На рынке есть готовые базы ключевых слов для различных тематик. Например:
У готовых баз есть два недостатка: они обновляются нерегулярно и содержат много мусорной и автосгенерированной семантики.
Тем не менее предпочтительнее использовать базу «Букварикс». Как показали исследования коллег из Rush Analytics, она содержит минимум мусорных запросов и к тому же бесплатная.
SaaS-решения
SaaS-решения (software as a service) помогают выгружать списки запросов, по которым находится в выдаче ваш сайт или сайты конкурентов. Ниже список наиболее популярных сервисов:
Когда получим «хвосты» для маркерных запросов, нужно объединить данные из всех источников в один список и избавиться от дублей.
Для автоматизации сбора запросов можно воспользоваться программами:
И сервисами:
Чистка запросов
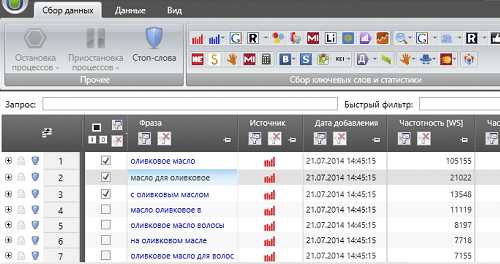
Удаляем мусорные фразы
В процессе сбора хвостов в списки неизбежно попадают мусорные запросы. Избавится от них можно с помощью функции «Стоп слова» программы Key collector.
В качестве стоп-слов можно использовать готовые тематические подборки.
С помощью функции «Анализ групп» можно найти и удалить нецелевую семантику.
Удаление низкочастотных запросов
Часть собранных запросов может быть автосгенерированными или низкочастотными (менее трех запросов). Если такие запросы попадут в семантическое ядро, то с высокой вероятностью для них будут созданы отдельные страницы на сайте. Значимого объема трафика они не принесут, но будут отнимать краулинговый бюджет.
Краулинговый бюджет — количество страниц, которые поисковый бот может обойти за период времени.
Нижний порог частоты запроса определяется отдельно для каждой тематики. Брать в работу микро- и низкочастотные запросы стоит лишь в исключительных ситуациях (например, если продукт супермаржинальный). Пример: разработка и внедрение ERP-систем, продажа нефтеперерабатывающего оборудования и так далее.
Для определения точной частоты запросов можно воспользоваться одной из программ — Key collector или A-parser, либо сервисами:
После чистки вы получите список целевых запросов, обладающих достаточной частотой.
Распределение запросов и кластеризация
Основная идея кластеризации — выяснить, как распределены запросы у сайтов, находящихся в первой десятке поисковой выдачи.
Наиболее широкое распространение данная методология получила около четырёх лет назад. Правда, некоторые оптимизаторы до сих пор предпочитают распределять запросы вручную, а зря.
Кластеризация позволяет решить ряд проблем при распределении запросов по страницам сайта. Она особенно полезна на больших объемах — от 1000 запросов и более.
Определяем тип запроса (коммерческий, информационный)
Запросы «пудра» и «пудра купить» на первый взгляд про одно и тоже. Но в первом случае поисковая выдача заполнена преимущественно информационными сайтами.
Исключение составляют два сайта: pudra.ru и «Подружка»: https://www.podrygka.ru/catalog/makiyazh/litso-1/pudra/. Их в расчет не берем, так как первый ранжируется за счет вхождения запроса в домен. А второй — за счёт своей популярности и больших объёмов прямого трафика на сайт.
По запросу «пудра» лидируют в основном информационные сайтыПо запросу «пудра купить» десятку результатов поисковой выдачи занимают в основном интернет-магазины.
Можно сделать вывод, что продвинуть оба запроса на одной странице не получится. Для продвижения запроса «пудра» нужна информационная статья с достаточным объемом текста и иллюстрациями. А для продвижения запроса «пудра купить» — небольшой текст и каталог товаров с ценами.
Результаты выдачи поисковых систем — особенно «Яндекса» — достаточно сильно типизированы. Выдача состоит либо преимущественно из коммерческих сайтов, либо из информационных. Кластеризация позволяет с большой точностью отделить коммерческие запросы от информационных.
Определяем типы страниц (главная, внутренняя)
Теперь проанализируем выдачу по запросы «люстры купить» и «люстры интернет-магазин», которые также похожи. Видно, что по запросу «люстры купить» топ занимают внутренние страницы сайтов, а по запросу «люстры интернет-магазин» — главные страницы.
По запросу типа «люстры купить» приоритет отдается внутренним страницам сайтовСледовательно, по запросу «люстра купить» продвигаем внутренние страницы с каталогом люстр, а по запросу «люстры интернет магазин» — главную страницу сайта.
Определяем совместимость продвижения запросов на одной странице
На скриншоте ниже видно, что запросы «угловые диваны» и «недорогие диваны» не имеют между собой ни одного общего URL. Для достижения лучших результатов эти запросы стоит продвигать на отдельных страницах.
Кластеризация — инструмент аналитики, который не даёт готового решения. Он собирает данные в удобном отображении для дальнейшей постобработки и анализа.
Существует два метода кластеризации:
- Hard — используется для продвижения по позициям, а также для продвижения в конкурентных тематиках. Количество запросов в кластере меньше, но точность выше.
Условие, соблюдаемое при hard-кластеризации, — у всех запросов в кластере должен быть общий набор URL.
- Soft — в основном используется для трафикового продвижения. Количество запросов в кластере больше, но точность ниже.
Условие, соблюдаемое при soft-кластеризации, — запросы сравниваются на предмет общих URL у всех запросов в группе. Например, у запроса А есть общий набор URL с запросом В, у запроса В есть общий набор URL с запросом С.
Схематичное изображение методов hard- и soft-кластеризацииПриведу несколько популярных сервисов кластеризации:
Для постобработки кластеризованной семантики можно воспользоваться бесплатной надстройкой для Excel.
Сбор семантики для больших проектов
Если проект содержит тысячи посадочных страниц, лучше собирать семантику отдельно для каждого раздела, учитывая приоритеты бизнеса и сезонность. А затем последовательно собирать семантическое ядро для двух–трёх разделов за каждую итерацию. Такой подход позволит собрать качественное семантическое ядро и не упустить целевые запросы
Если же собирать семантическое ядро сразу под весь проект, то на выходе получатся тысячи или даже десятки тысяч кластеров запросов, которые будет сложно обработать.
Как сохранить наследственность «Маркерный запрос — URL»
На первом шаге, описанном в статье, мы выгружали табличный список «Маркерный запрос — URL». Если сохранить URL после всех корректировок с маркерными запросами, то с помощью функции ВПР в Excel можно привязать часть URL-адресов к уже раскластеризованной семантике.
То есть — если маркерный запрос находится в кластере с другими запросами и у маркерного запроса уже известен URL, то можно считать, что все запросы кластера принадлежат к этому URL.
Не стоит бояться развивать структуру сайта. Если по результатам сбора запросов и их кластеризации вы понимаете, что под часть запросов не хватает посадочных страниц, лучше создать их или в крайнем случае отказаться от продвижения части запросов. Это будет эффективнее, чем вести несколько групп запросов (часто с несовместимыми интентами) на одну страницу сайта.
Материал опубликован пользователем. Нажмите кнопку «Написать», чтобы поделиться мнением или рассказать о своём проекте.
Написатьvc.ru
Сбор семантики для контекстной рекламы — руководство от Ильи Исерсона
Владелец базы ключевых слов MOAB и спикер конференции Baltic Digital Days о том, что важно учесть при составлении семантического ядра.
Как собрать правильное семантическое ядро
Если вы думаете, что собрать правильное ядро способен некий сервис или программа, то вы будете разочарованы. Единственный сервис, способный собрать правильную семантику, весит около полутора килограмм и потребляет около 20 ватт мощности. Это мозг.
Причем в этом случае у мозга есть вполне конкретное практическое применение вместо абстрактных формул. В статье я покажу редко обсуждаемые этапы процесса сбора семантики, которые невозможно автоматизировать.
Существует два подхода к сбору семантики
Подход первый (идеальный):
- Вы продаете заборы и их монтаж в Москве и Московской области.
- Вам нужны заявки из контекстной рекламы.
- Вы собираете всю семантику (расширенные фразы) по запросу «заборы» откуда угодно: от WordStat до поисковых подсказок.
- Получаете много запросов — десятки тысяч.
- Затем несколько месяцев чистите их от мусора и получаете две группы: «нужные» запросы и «минус-слова».
Плюсы: в этом случае вы получаете 100% охват — вы взяли все реальные запросы с трафиком по главному запросу «заборы» и выбрали оттуда всё, что вам нужно: от элементарного «заборы купить» до неочевидного «установка бетонных парапетов на забор цена».
Минусы: прошло два месяца, а вы только закончили работать с запросами.
Подход второй (механический):
Бизнес-школы, тренеры и агентства по контексту долго думали, что с этим делать. С одной стороны, действительно проработать весь массив по запросу «заборы» они не могут — это дорого, трудозатратно, людей не получится научить этому самостоятельно. С другой стороны, деньги учеников и клиентов тоже надо как-то забрать.
Так было придумано решение: берем запрос «заборы», умножаем на «цены», «купить» и «монтаж» — и вперед. Ничего не надо парсить, чистить и собирать, главное — перемножить запросы в «скрипте-перемножалке». При этом возникающие проблемы мало кого волновали:
- Все придумывают плюс-минус одинаковые перемножения, поэтому запросы вида «монтаж заборов» или «заборы купить» моментально «перегреваются».
- Тысячи качественных запросов вида «заборы из профнастила в Долгопрудном» вообще не попадут в семантическое ядро.
Подход с перемножениями себя полностью исчерпал: наступают трудные времена, победителями выйдут только те компании, которые смогут для себя решить проблему качественной обработки действительно большого реального семантического ядра — от подбора базисов до очистки, кластеризации и создания контента для сайтов.
Задача этой статьи — научить читателя не только подбирать правильную семантику, но и соблюдать баланс между трудозатратностью, размером ядра и личной эффективностью.
Что такое базис и как искать запросы
Для начала договоримся о терминологии. Базис — это некий общий запрос. Если вернуться к примеру выше, вы продаете любые заборы, значит, «заборы» — главный для вас базис. Если же вы продаете только заборы из профнастила, то вашим главным базисом будет «заборы из профнастила».
Но если вы один, запросов много, а кампании надо запускать, то можно взять в качестве базиса «заборы из профнастила цена» или «заборы из профнастила купить». Функционально базис служит не столько как рекламный запрос, сколько как основа для сбора расширений.
Например, по запросу «заборы» более 1,3 млн показов в месяц по РФЭто — не пользователи, не клики и не запросы. Это количество показов рекламных блоков «Яндекса» по всем запросам, включающим слово «заборы». Это мера охвата, применимая к некоему большому массиву запросов, объединенных вхождением в него слова «заборы».
В то же время по запросу «заборы из профнастила» — только 127 тысяч показов, то есть охват сжался в десять раз. Сопоставимым образом уменьшится и количество запросов, и трафик на сайт.
Таким образом, можно сказать, что базис — это общий запрос, описывающий товар, услугу или нечто иное, за счет самой своей формулировки определяющий меру охвата потенциальной аудитории.
- Хотим «геноцида» конкурентов — берем огромный массив запросов по базису «забор», несколько лет его чистим и группируем — и вуаля — у вас лучшая рекламная кампания на рынке.
- Хотим сделать скромно, но эффективно, продавая только высокомаржинальные заборы из профнастила ограниченной аудитории — берем меньшую в десять раз выборку по запросу «заборы из профнастила» и работаем только с ней.
Итак, первый этап любой рекламной кампании — подбор семантики. А первый этап подбора семантики — это подбор базисов. Важно подобрать базисные запросы, которые:
- Описывают товар или услугу.
- Дадут такой объем расширенных запросов, который вы можете обработать в приемлемые для себя сроки.
Теперь попробуем разобраться с проблемой поиска базисов как таковых.
1. Как вы сами называете товар или услугу
Если вы — подрядчик, то спросите об этом у клиента. Например, заказчик говорит вам: «Я продаю спортивные покрытия в Москве и области». Выбросьте из формулировки заказчика Москву и область, а также подберите синонимы.
Базисы в таком случае будут такимиЦифры — это данные частотности по Москве и области по WordStat. Нетрудно заметить, что каждый из запросов при парсинге WordStat в глубину даст разную выборку расширенных запросов, и каждая выборка — это сегмент целевого спроса.
Пример с синонимами посложнее: «небольшой» медиаплан на сотню с лишним базисов с частотностью по Москве для продажи элитной недвижимости:
Вывод: собирать семантику сложно. Но сам сбор низкочастотных запросов довольно прост — есть куча сервисов от Key Collector до MOAB и других. Дело не в сервисе. Дело в том, что подобрать корректные базисы сервисом невозможно — это можно сделать только руками и мозгом человека, это самая трудная и тяжелая операция.
Итак, мы уже вспомнили определения товара или услуги «из головы» и привели их к укороченным формам. То есть если мы продаем «грузовики камаз», то пишем в файл просто — «камаз».
2. Посмотрите сайты конкурентов
Важно понять ключевой принцип — выборка по запросу «камаз» и по запросу «65115 -камаз» дает разные запросы, частично непересекающиеся. Это разные сущности.
Поэтому не нужно мучительно читать тайтлы конкурентов или анализировать их в сомнительных сервисах. Расслабьтесь, включите фантазию, налейте бокал хорошего коньяка и почитайте сайты конкурентов. Вот список артикулов, каждый из которых — отдельная выборка.
3. Сервисы поисковых систем
Здесь буду краток: проверяйте найденные в первых пунктах базисы вручную через правую колонку WordStat и блок «искали вместе с этим»
Пример: в правой колонке WordStat содержатся так называемые запросы, которые пользователи искали вместе с указанным. Глядя на правую колонку по запросу из примера выше, можно увидеть запрос с вхождением слова «самосвал».
Отлично. Запрос «купить камаз самосвал» нам не нужен, так как он и так попадет в расширенные запросы по базису «камаз», а вот запрос «самосвал» — это новый сегмент с отдельными новыми запросами, новым спросом и новой семантикой.
Берем его в проект. Аналогичным образом анализируем и блок «искали вместе с этим» в выдаче «Яндекса» и Google.
Google, к примеру, подсказывает запрос «сельхозник» Вот что можно получить по нему в WordStatПроверим, что говорит «Яндекс». Даже если предположить, что вы не продаете ничего, кроме «КамАЗов», то ваши усилия все равно не пропадут даром.
Можно взять запрос «тягач» и получить новый спрос на ваши грузовики и по немуВ целом, думаю, принцип понятен: задача — найти как можно больше целевых базисов, которые выступают инициаторами, драйверами новых длинных семантических хвостов.
Конечно, тут можно дать ещё много советов: посмотреть анкор-файл конкурентов, посмотреть выгрузки из SpyWords или Serpstat. Всё это, конечно, хорошо. Вернее, было бы хорошо, если бы не было так грустно. Потому что в сущности работа еще даже не началась: насобирать каждый может, а попробуйте-ка всё это очистить, сгруппировать и грамотно управлять.
Вышеописанного вполне достаточно, чтобы, имея светлую голову, собрать семантику на порядок качественнее и лучше, чем у 99% ваших конкурентов.
Как не потратить всю жизнь на сбор ключевых слов
Многие спрашивают: как грамотно управлять семантикой, как её «резать». Если вы продаете могильные камни из буйволиного рога в Нарьян-Маре, вы вряд ли столкнетесь с этой проблемой — у вас семантики всегда будет мало. В то же время, в «горячих» популярных тематиках семантики всегда валом: названия брендов, категорий, моделей, их синонимы и так далее.
Мы решаем эту проблему за счет многоуровневой приоритизации семантики.
1. Приоритизация семантики до сбора запросов
Посмотрите на разделы и категории, по которым собираете семантику, оцените среднюю маржинальность каждой категории. Выкиньте те разделы, где маржинальность меньше 20%. Чаще всего (почти всегда в b2c и чуть реже в b2b) на марже 20% вы будете крутить рекламу в ноль.
Если всё равно остается много — уберите и те разделы, где маржинальность меньше 25-30%, там вы тоже, скорее всего, много не заработаете — максимум немного мелочи в карман плюс покажете производителю больше оборота и выбьете новые скидки. Зарабатывать интересные деньги получается на товарах и услугах с маржой от 30% — не всегда и не везде конечно, но эти цифры я видел десятки раз на самых разных проектах.
2. Сбор базисов и расширенной семантики по ним
Собрали? Все равно получается много? Проранжируйте запросы. Ставьте 1, 2 или 3 рядом с каждым базисом. Заставьте себя это сделать, вот так:
Я специально ограничиваюсь тремя значениями — это просто. Если у вас будет десять уровней приоритета, вы сойдете с ума, думая о том, поставить 6 или 7 конкретному базису, — а так решения очень простые и очевидные.
Кроме того, это помогает структурировать свой бизнес для самого себя — взглянуть на него сквозь призму спроса и маржинальности: фильтруем по столбцу «Приоритет» и видим, что поставили «1» тем базисам, по которым мало спроса.
Значит, надо либо активнее работать с другими товарными направлениями, снижать закупочные цены, либо стимулировать спрос — но это уже другая история.
3. Отсекли всё неприоритетное и всё равно семантики слишком много
Когда говорят про «резать» семантику, те, кто с этим поработал, как правило, имеют в виду удаление низкочастотных запросов с частотностью ниже определённой отсечки. В тематических дискуссиях в Facebook и на форумах я регулярно вижу цифры от 5 до 10 (имеется в виду общая частотность по запросу).
То есть намеренно убирается из массива всё, что по частотности меньше 10.
Понятно, что так делать можно, если у вас всё равно очень много семантики. Но это всегда вопрос выбора между поеданием рыбы и сидением на неудобных для сидения предметах. Слишком много уберете — недосчитаетесь каких-то минус-слов, получите больше «грязного» трафика на запуске, но выиграете в трудозатратности.
Моё мнение таково: условная точка баланса здесь находится на уровне «убираем всё, что не имеет частотности». Это позволяет выкинуть примерно половину массивов, полученных из различных источников, в то же время трафик на запуске остается очень чистым, с погрешностью буквально 1-3% и быстро дочищается.
Что значит «дочищается»
Представьте, что вы собрали рекламную кампанию для поискового размещения в «Яндекс.Директе», запустили ее, и вам нужно оценить эффективность проделанной работы. Как это сделать? Оценивать по продажам? Не совсем правильно, ведь продажи — это результат работы цепочки «кампания-сайт-менеджеры».
Звонки? Тоже нет, ведь огромное влияние на количество звонков оказывает сайт: может быть, с кампанией всё хорошо, просто сайт сделан неправильно.
Быстро проверить эффективность поисковой кампании можно в «Яндекс.Метрике». Для этого нам надо через два-три дня после запуска кампании получить отчет о фразах, послуживших источниками перехода. Как найти этот отчет в «Метрике»:
А затем:
Кликаем на крестик на всех группировках, кроме «Поисковая фраза», и нажимаем «Применить». Мы получим отчет о тех фразах, по которым пользователи увидели наши объявления, кликнули по ним и перешли к нам на сайт. Что делать с этим отчетом?
Внимательно просмотреть и выделить нерелевантные фразы, которые не относятся к вашему бизнесу. На жаргоне их называют «мусором». В профессионально сделанных кампаниях в первое время после запуска доля «мусора» может составлять от 1 до 4%, в кампаниях, собранных «на коленке», — до 20-40%.
Как вы уже, наверное, поняли, процедуру с дополнительной очисткой от мусора стоит проводить регулярно — как минимум, два-три раза в месяц. Почему так часто?
У нас был интересный пример из практики. Мы работали с кампанией, в которую включили для клиента высокомаржинальный запрос «черный дым дизель». Клиент работал с дизельными двигателями, и такой запрос означает, что у клиента есть серьезная проблема с двигателем, и, вероятно, потребность в квалифицированных услугах.
Одновременно с этим в сентябре 2016 года, когда группировка российского флота направилась в Сирию, ТАКР «Адмирал Кузнецов» привлек внимание международных СМИ сильным черным дымом из выхлопной трубы. Это неизбежно спровоцировало запросы вроде «черный дым дизель адмирал кузнецов».
Ранее таких запросов просто не было, поэтому и не было минусов формата «–адмирал, –кузнецов». Поэтому мало того, что наше объявление показалось по таким запросам, так оно ещё и сгенерировало бессмысленные переходы, не имеющие для бизнеса никакой ценности.
Отследить такие запросы оперативно можно только в «Метрике»: поэтому возьмите себе за правило на старте кампании почаще (позже — реже) проверять семантику и дополнительно минусовать новый мусор.
Разумеется, возникает вопрос: а что вообще влияет на количество мусора. Всё просто — статистическая достоверность семантики.
На что влияет объем семантики
Далеко не всегда люди понимают, о чем говорят, когда обсуждают влияние обширного семантического ядра на цену клика, качество кампании и прочее. Сама по себе обширная семантика не вызывает ни снижения цены клика, ни увеличения качества кампании. На что же реально влияют сотни и тысячи собранных НЧ-запросов?
1. Чистота трафика на запуске кампании
Чем больше запросов вы соберете — тем больше найдете минус-слов. На бесконечно большой выборке запросов вы найдете все возможные минус-слова, потратив на это бесконечный период времени.
На практике стоит ограничиться запросами, как я уже говорил, с частотностью от 1 по нужному региону — это даст «мусорность» в районе 3-4% при запуске, после чего вы быстро дочистите оставшиеся мусорные запросы, минусы, по которым почему-то не попали в выборку.
При этом стоит использовать и WordStat, и советы поисковых систем, собирая подсказки для каждого запроса, полученного в WordStat. Использование одного только WordStat даст высокую мусорность — 10-15% на запуске как минимум (если не больше). Но все мы понимаем — чем больше мусора, тем больше расход средств, тем меньше лидов на единицу расхода.
2. Релевантность объявлений запросам
Здесь важно понять системообразующий принцип: запросы, которые вы добавили в кампанию, по большому счету, ничего не значат. Они не важны.
Реальный трафик, который будет попадать к вам на сайт, приходит большей частью не по тем запросам, которые вы добавили в кампанию, а по расширениям от них. На один запрос, добавленный в кампанию, приходится как минимум три-четыре расширенных варианта — это ультра-НЧ, которые вообще никак не предскажешь, пользователи генерируют их прямо в момент поиска.
Поэтому не столь важен сам запрос: так много стало трафика по ультра-НЧ с частотой перехода в один-два раза в месяц или в год, что привязываться к конкретному запросу нет смысла. Важно собрать статистически значимую семантику, разбить её на мелкие группы похожих запросов и составить под них объявления.
Больше семантика — больше групп, больше точность соответствий и ниже цена кампаний на поиске. В конкретной группе похожих ультра-НЧ, из которых сформируется объявление, может быть пять-десять запросов — а если вы выудите из «Метрики» фразы по этому объявлению через полгода, получите список на 30-40 фраз как минимум.
Повторюсь: семантика — не панацея от всего и не божество. Семантика влияет на многое: на чистоту трафика, на релевантность объявлений запросам — но не на всё. Не имеет смысла собирать огромные выборки «нулевок» в надежде получить трафик дешевле — этого не будет.
Семантика влияет:
- На охват рекламной кампании.
- На чистоту трафика.
- На релевантность «запрос-объявление».
Вот те факторы, про которые вам стоит помнить в первую очередь. Впрочем, попробуем суммировать итоги в двух словах.
Кратко
- Соберите базисные запросы — общие фразы, описывающие ваши товары и услуги.
- Проверьте, все ли синонимы и переформулировки вы собрали: в помощь вам WordStat и блок «похожие запросы» в SERP.
- Соберите расширения по полученным запросам: WordStat, поисковые подсказки, база MOAB — всё идет в дело.
- Составьте табличку, где рядом с каждым базисом будет указана его частотность и количество расширенных запросов.
- Если запросов слишком много, и вы не успеваете их обработать — выполните приоритизацию базисов в зависимости от маржи, частотности и количества запросов.
- Окончательный семантический план сформирован. Теперь дело за очисткой и кластеризацией семантики.
#Кейсы
vc.ru
что это, как составить и проработать ее
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Семантика сайта – это ключевые слова соответствующие подходящим поисковым запросам пользователей, на основе которых строится структура определенного ресурса.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Ключевые слова существуют не обособленно, а формируют между собой взаимосвязанную сеть для полного охвата всех запросов, касающихся тематики портала. Таким образом создается семантическое ядро, в котором предусмотрены все запросы, актуальные для конкретного сайта.
Рассмотрим семантику для продвижения сайтов на примере.
Вы занимаетесь созданием web-ресурсов. Пользователь вводит запрос в поиске: «Как сделать сайт». Если на вашем сайте нет ответа на этот вопрос, то налицо проблемы с семантикой, т.е. вы плохо составили семантическое ядро, без которого сложно раскручивать сайт и поднимать его в ТОП поисковой выдачи по интересным для вас ключам.
Что представляет собой семантика сайта
Любой вид деятельности, представленный в интернете, подпадает под поисковую оптимизацию. В числе ключевых инструментов, с помощью которых проводится продвижение – семантика сайта или создание семантического ядра для конкретного ресурса. Это перечень словосочетаний и фраз, которые полностью описывают тематику и направленность ресурса. От того, насколько большим является проект, зависит и величина ядра. Задача, как проработать семантику сайта, считается актуальной и востребованной, когда его владелец решил начать продвижение в поиске с целью увеличения трафика клиентов.
Как собрать семантику для сайта
Чтобы правильно составить семантическое ядро, нужно принимать во внимание два вопроса:
- В чем нуждается целевая аудитория.
- Какие услуги и товары вы собираетесь продавать.
Составляя семантическое ядро и на его основе структуру сайта, помните о важных фактах:
- Содержимое должно оправдывать ожидания пользователей ресурса.
- Страница сайта – ответ на вопрос посетителя.
- Сайт в целом должен давать максимум ответов на все вопросы по тематике.
- Полная семантика сайта повторяет его структуру.
Основные группы запросов по частотности
В процессе формирования семантики для продвижения сайтов необходимо понимать частотность запросов, которые могут отличаться особенностями продвижения по ним, но в целом способствуют увеличению трафика.
Выделяют:
- высокочастотные;
- среднечастотные;
- низкочастотные запросы.
Такое разделение производится для понимания структуры сайта в целом, формирования метатегов, поиска запросов для внутренней оптимизации страниц.
Ключевые правила семантики
- Один запрос – одна страница. Нельзя, чтобы одному запросу соответствовало несколько страниц ресурса. Зато одной странице может быть присвоено несколько ключей для продвижения.
- Семантическое ядро должно включать в себя все типы запросов по частотности.
- В процессе расстановки запросов по группам, необходимо включать только те, по которым осуществляется продвижение конкретной страницы.
В топе Яндекса может быть предусмотрено всего 1-2 места по определенной тематике, что усиливает конкуренцию. Кроме этого, Яндекс.Директ и прочие рекламные инструменты смещают результаты органичной выдачи вниз. В этом случае одной только семантики будет недостаточно для успешной оптимизации сайта.
Этапы создания семантического ядра
- Составьте список товаров, услуг и другой информации, которая освещается на сайте. Проанализируйте потенциальных посетителей и ЦА в целом. Например, при продаже дорогих товаров не имеет смысла использовать фразу «купить дешево» и т.д.
- Подберите запросы, которые соответствуют вашей тематике. Учтите все запросы, по которым могут искать предложение на сайте.
- Подберите запросы из поисковых систем при помощи специальных сервисов (например, Яндекс.Wordstat).
- Отфильтруйте запросы. Исключите пустые фразы и повторы. Объедините все списки фраз, собранные различными способам, для последующего анализа. Используйте специальные программы. Наиболее популярная – Key Collector.
- Сгруппируйте запросы в отдельные категории, по которым будут продвигаться разделы и страницы конкретного ресурса.
Как получить дополнительные преимущества перед конкурентами
Вопрос, как собрать семантику сайта, одним лишь подбором поисковых запросов не решается. Для продвижения необходимо грамотно применять и SEO-теги. Они содержат ключевые данные для поисковых систем, пренебрегать которыми не рекомендуется.
SEO-теги для семантики сайта:
- Title – заголовок страницы, отображаемый в статусной строке. Заголовок обязательно понятный, поскольку привлекает к себе внимание пользователей.
- Description – краткое содержание страницы. Тег имеет служебное значение – он оказывает помощь поисковой системе в процессе выдачи.
- IMG – текстовое описание картинки на странице.
- А – тег ссылки.
- Noindex – применяется, когда индексация страницы сайта не нужна в течение определенного периода.
- Robots – тег, дающий указание поисковому роботу.
- Revesit – определение периодичности индексирования ресурса для робота.
Крайне важно знать, как составить семантику сайта и следовать изложенным стандартам в процессе работы. Это существенно облегчит процесс и поможет пресечь многие проблемы, связанные с оптимизацией сайта для поиска.
Создав семантику один раз, не оставляйте ее неизменной на протяжении длительного периода. Новые товары и услуги появляются регулярно, а старые утрачивают свою актуальность. Поэтому вы не только должны знать, как проработать семантику сайта, но и проводить ее актуализацию один раз в полгода или год, чтобы внедрять новые поисковые запросы и удалять старые, утратившие свою актуальность.
semantica.in
Как составить семантическое ядро для сайта
Полное руководство по подбору семантического ядра
В данном руководстве мы пошагово опишем алгоритм подбора эффективного семантического ядра.
Несмотря на то, что в данном руководстве часто упоминается функционал Rush Analytics, по сути не важно, какими инструментами вы будете собирать данные.
Вы можете собирать данные даже вручную, копируя их из браузера, однако, на это уйдет в 100-300 раз больше вашего времени.
Данная методология подходит для коммерческих сайтов (сайтов услуг), для интернет-магазинов и для информационных порталов. Однако для каждого типа сайтов есть свои нюансы в поисковом спросе — вы легко их поймете в процессе создания семантического ядра.
Оглавление
1. Базовая парадигма сбора семантики2. Маркерные запросы
— FAQ по маркерным запросам (что такое маркер etc..)
— Как найти маркерные запросы?
— FAQ по подбору маркерных запросов
3. Облако запросов — расширение семантического ядра — FAQ по сбору облака запросов
— Алгоритм сбора облака запросов
4. Построение финальной структуры сайта — кластеризация ключевых слов — Часто задаваемые вопросы по кластеризации ключевых слов
— Алгоритмы кластеризации в Rush Analytics
— Определение релевантных URL для кластеров
— Финализируем структуру сайта — делаем комбинированную кластеризацию
5. Вместо заключения
Базовая парадигма сбора семантики

На схеме выше показана единственно верная логика сбора семантического ядра — сначала получить базовые запросы (маркерные), которые характеризуют вашу тематику, а потом расширить их дополнительными запросами и сформировать структуру сайта.
Почему именно такая методология? Все просто: при таком подходе к подбору семантического ядра вы
а) будете контролировать процесс сбора семантики и не «закопаетесь» в уйме ключевых слов
б) вам практически не придется чистить семантическое ядро вручную
в) Это быстрее, чем любая другая методология.
Давайте раз и навсегда разберемся в терминологии, которую наша команда использует при работе с семантикой
Фактически есть 2 типа запросов: маркерные запросы и запросы из облака ключевых слов
Маркерные запросы
Маркерные запросы — это запросы, которые четко отвечают продвигаемой странице. Такие запросы обычно имеют значимую частотность по Wordstat и являются средне-частотными (СЧ), или «жирными» низкочастотниками (НЧ), и могут породить «хвост» запросов, например при добавлении слов «купить», «цена», «отзывы».
Примеры:Платья
Красные платья
Красные платья в пол
Телевизоры
Телевизоры Samsung
Телевизоры Самсунг
LED телевизоры Samsung
Стиральные машины
Стиральные машины для дачи
Стиральные машины шириной 40 см
Другими словами, эти ключевые слова часто являются названием страниц/категорий/статей/карточек товара и прочих типов страниц, которые вообще можно продвигать в поисковых системах.
Часто задаваемые вопросы про маркеры:
Q: Могут ли для страницы быть несколько маркеров?
A: Да — конечно — это довольно частый случай.
Например, на одну страницу могут идти такие маркеры как:Телевизоры Samsung
Телевизоры Samsung купить
Телевизоры Самсунг
Телевизоры Самсунг купить
Телевизоры самсунг цена
Все эти запросы четко отвечают одной странице
Так же на одну страницу могут идти два маркера-синонима, не связанных лингвистически:
Спецоджеда
Рабочая одежда
или
электроплита бош
электрическая плита bosch
Это вполне нормально и логично.
НЕ маркеры — облако запросов. Это все второстепенные запросы, которые уточняют маркерные запросы — т.е. по факту это маркеры + 1/2/3 слова или синонимы маркеров. Как правило запросы из облака — менее частотные и поэтому мы будем привязывать их к маркерам
Как найти маркерные запросы?
Сразу скажем, что получить маркерные запросы для сайта любого объема ПОЛНОСТЬЮ автоматически не получится по ряду причин. Это на данный момент основной фронт ручной работы при подборе семантики. Мы работаем над автоматизированным алгоритмом и сообщим вам о его выходе.
Вариант №1: можно получить маркеры для страниц своего сайта из Яндекс Метрики 2.0 — как это сделать — детально описано в этой статье. Плюсы такого метода — что вы сразу будете знать релевантные URL для этих запросов.
Вариант №2: Берем названия категорий/услуг своего сайта и расширяем их логическими гипотезами:
«Как, по каким запросам пользователи еще могут искать эту страницу моего сайта? Какие есть синонимы?»
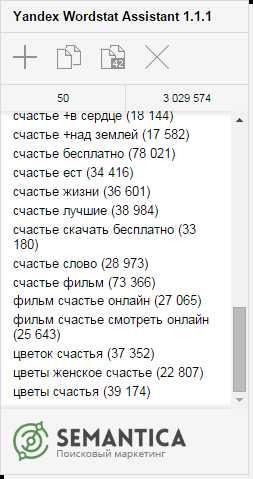
NB!: Отличным подспорьем в определении маркеров является старый добрый Яндекс Wordstat, при всех его недостатках. Рекомендуем использовать браузерный плагин Yandex Wordstat Assistant от компании Semantica — очень удобный — выполняет роль своего рода «заметок на полях» — в него можно в один клик добавить интересующие слова.
Мы понимаем, что не у каждого оптимизатора/владельца бизнеса есть под рукой департамент разработки, который быстро сможет выгрузить для сайта связку URL — название категории/страницы.
Что такое связка URL-название категории/страницы?
Поэтому есть 3 варианта как получить связку URL — название категории/страницы:
- Запросить у программистов — идеальный 🙂
- Самому спарсить это с сайта. В этом поможет отличный и простой инструмент — Screaming Frog (официальный сайт Screaming Frog). Это парсер сайта, который в итоге отдаст вам в формате Excell таблицу вида URL — заголовок h2 (это и есть название категории/страницы).
- Если структура сайта еще только проектируется — резонно вручную придумать связки URL-название категории.
Фактически маркеры для вашего сайта будут состоять из:
- Запросов, выгруженных из Яндекс Метрики
- Названий категорий/страниц, взятых с сайта
- Расширений названий категорий/страниц т.е. логических гипотез
Важно выполнить эту часть работы по подбору семантического ядра максимально тщательно т.к. если вы потеряете большую часть маркеров — вы потеряете большую часть семантического ядра.
Часто задаваемые вопросы по подбору маркеров:
Q: У меня большой сайт и маркеров сотни или тысячи — как быть?!
A: В таком случае нужно работать итерациями, собирая семантику начиная с самых приоритетных категорий.
Реалии таковы, что собрать семантику для большого интернет-магазина или портала «за раз» невозможно — вы просто «закопаетесь».
Определите самые приоритетные категории по принципу самой высокой маржинальности и принципу сезонности — эффективнее всего начинать продвигать категории за 6 месяцев до их пикового сезонного спроса. Сезонность можно оценить в Яндекс Wordstat. Пример запроса:
Q: На сколько низкочастотное слово может быть маркером?
A: Здесь все зависит от тематики. В узких тематиках даже ключевые слова с частотностью 15 по кавычкам «» могут быть маркерными запросами. Главное правило — спросите себя — хотел бы мой пользователь видеть отдельную страницу под этот запрос (и связанные с ним?). Удобно ли ему будет пользоваться той структурой, что я создаю?
NB:! Для интернет магазинов нужно сразу же скрестить все маркеры со словами «купить» и «цена» — это тоже будут маркеры. Таким образом все запросы точно попадут на нужные страницы.
Q: Как мне держать маркеры в Excell, чтобы потом мне было удобно с ними работать?
A: Идеальный и единственно правильный вариант — всегда держать связку URL-маркер в Excel — так вы всегда сможете понимать какие маркеры идут на один URL, даже если ваш список перемешается.
В дальнейшем таким образом вы сможете фильтровать целые кластеры, которые идут на одну страницу — это может быть и 10 и 50 ключевых слов. Очень удобно.
Пример правильного оформления маркеров в Excel
Итак, после N времени работы мы собрали маркеры для всего сайта (или части сайта), что дальше?
Естественно, что маркеры, это далеко не полная семантика — теперь нам нужно собрать облако запросов — расширить наше семантическое ядро.
Облако запросов — расширение семантического ядра
Облако запросов — это все ключевые слова, полученные парсингом поисковых подсказок и Яндекс Wordstat по маркерным запросам.
По нашему опыту эффективнее всего получать расширения запросов из поисковых подсказок Яндекса + Google и левой колонки Яндекс Wordstat.
Почему?
Не потому, что в Rush Analytics есть парсинг только Яндекс Wordstat и поисковых подсказок 🙂
Потому, что эти источники семантики: а) Обладают максимальной полнотой б) Подсказки изначально трастовый источник семантики т.к. сам Яндекс исправляет орфографию и добавляет в подсказки ТОЛЬКО реальные запросы пользователей. Что нам и нужно.
Часто задаваемые вопросы по сбору облака запросов
Q: У меня есть база Пастухова, есть аккаунт в SeoPult и Sape — там тоже есть ключевые слова — чем они плохи?
A: Если говорить о готовых базах данных (например, База Пастухова), то плохи они вот чем а) непонятно откуда взяты эти запросы — реальные ли это запросы или же это «кривые» запросы горе-оптимизаторов б) Большинство запросов в готовых базах данных банального сгенерированы или уже потеряли актуальность.
SeoPult и Sape можно использовать, чтобы прикинуть свои маркеры — иногда там можно найти интересные ключевые слова
Таким образом, проще собрать свежие и актуальные ключевые слова для своей тематики, чем «копаться в мусоре».
Более подробно ознакомиться с обзором источников ключевых слов можно в этой статье из нашей базы знаний
Поверьте — все пригодные запросы этих баз данных есть в Яндекс Wordstat и поисковых подсказках. Мы проверяли.
Итак — у нас есть 2 потенциальных источника семантики — Яндекс Wordstat и поисковые подсказки.
Алгоритм сбора облака запросов
- Берем маркерные запросы и собираем по ним левую колонку Яндекса Wordstat.
Подробное руководство по сбору Яндекс Wordstat в Rush Analytics можно найти здесь
- После сбора ключевых слов — очищаем полученные данные от мусорных и нецелевых запросов.
В нашем сервисе мы реализовали алгоритм автоматической очистки стоп-слов в Яндекс Wordstat — воспользуйтесь готовыми списками стоп-слов по гео-запросам и списками популярных мусорных слов по различным тематикам. Вы так же можете добавить свой список стоп-слов «под себя». - По полученному списку ключевых слов собираем поисковые подсказки — ставим второй уровень перебора и перебор русского алфавиты.
Для интернет-магазинов/коммерческих сайтов, у которых в семантике есть иностранные бренды крайне рекомендуем поставить и перебор английского алфавита.
Для всех сайтов, у которых есть числовые артикулы — рекомендуем поставить перебор цифр. ВАЖНО: в поисковых подсказках вам будут встречаться нецелевые ключевые слова. Избежать ручной чистки этих слов довольно просто — для этого в Rush Analytics есть функционал стоп-слов, который вырезает нецелевые ключевые слова «на лету» — указав список стоп-слов для вашей тематики — в финальной выгрузке вы получите список только нужных и целевых ключевых слов. - После сбора поисковых подсказок вам будет доступен итоговый файл — это как раз то, что нам нужно.
Как работать со стоп-словами и как определить их для вашей тематики, мы подробно рассказали в этой статье.
Также в статье представлен обширный список стоп-слов, который подходит для большинства тематик.
Тематические списки стоп-слов и гео запросы интегрированы непосредственно в интерфейс Rush Analytics — во все типы проектов (Wordstat, сбор подсказок и в кластеризацию).
Формируем финальное облако запросов:
Финальное облако запросов будет включать в себя:а) Ключевые слова, собранные с левой колонки Wordstat
б) Ключевые слова, полученные из поисковых подсказок
Т.е. вам нужно объединить 2 массива данных (2 файла), которые мы получили из поисковых подсказок и из Яндекс Wordstat.
Не забудьте проверить частотность собранных подсказок по Wordstat — это пригодится вам в дальнейшей работе.
Здесь вы должны иметь от нескольких тысяч до нескольких сотен тысяч целевых ключевых слов + знать их частотность по Wordstat. Уже на данном этапе понятно, что собранная база ключевых слов в 10-50 раз превышает то, что имеют конкуренты 🙂
Построение финальной структуры сайта — кластеризация ключевых слов.
Понятно, что привязать полученное облако запросов к маркерам вручную очень трудоемкая задача, требующая нечеловеческой концентрации и уйму времени. Именно это явилось одной из причин, по которой мы реализовали в Rush Analytics функционал кластеризации запросов по методу подобия выдачи поисковых систем.
Как работает алгоритм кластеризации ключевых слов в Rush Analytics?
Мы собираем ТОП10 результатов поисковый выдачи (Яндекса или Google — на выбор), далее сравниваем — какие запросы имеют несколько (от 3 до 8ми) общих URLв ТОПе и исходя из этих данных автоматически группируем запросы в кластеры.
Часто задаваемые вопросы по кластеризации ключевых слов:
Q: Какая еще цель кластеризации, кроме облегчения рутинной работы по группировке ключевых слов?
A: Кластеризация ключевых слов на основе данных из поисковой выдачи — гарантирует то, что запросы, которые попали в один кластер будут УСПЕШНО продвигаться на одну страницу. Кластеризация по методу подобия ТОПов исключает попадание коммерческих и информационных запросов в один кластер.
Коммерческие запросы никогда не продвинутся на одну страницу с информационными. Частая ошибка при продвижении интернет-магазинов, которая приводит к печальным последствиям — это продвижении коммерческих и информационных запросов на одну страницу.
Q: Почему часть ключевых слов в моем проекте некластеризована?
A: Изначально сервис Rush Analytics создавался для внутренних нужд агентства Rush Agency. Наш основной профиль — продвижение крупных Ecommerce проектов, где основная задача не сгруппировать запросы «абы как», а сгруппировать их так, чтобы они успешно попадали в ТОП поисковой выдачи уже в момент индексации страниц, сделанных под семантику. Таким образом — мы кластеризуем только те ключевые слова, для которых нашлась пара, и которые реально будут продвигаться на одну страницу. Остальные ключевые слова мы оставляем некластеризованными, чтобы не вводить в заблуждение специалистов, которые работают с семантикой.
Q: Почему в кластеризации есть настройки точности? Зачем они?
A: В каждой тематике есть свой, необходимый и достат
www.rush-analytics.ru
Что делать с семантическим ядром сайта?
Добрый день. В последнее время на почту падает очень много писем в стиле:
- «В прошлый раз тупо не успел зарегистрироваться на марафон из-за того что был в отпуске, а как таковых анонсов было мало…»
- «Петь, увидел что готовится какой-то курс, можешь сказать точные даты и сколько будет занятий?»
- «Сколько будет стоить курс? Какой будет материал? Это марафон или электронная запись?»
И так далее и тому подобное. Таких писем пришло уже 27 штук. В предварительную регистрацию вписалось 100 человек (регистрация в конце опроса).
Постараюсь ответить на часть вопросов:
- Точную дату выхода курса сказать не могу. Это будет точно в октябре и скорее всего в конце.
- Курс будет открыт в продаже максимум 5 дней, я наберу группу c которой мне интересно будет работать и достигать конкретных цифр, потом закрою доступ. Так что не проспите даты регистрации.
- На последнем марафоне некоторые участники достигли невероятных результатов (графиками поделюсь в следующих уроках), но этих результатов достигли только те, кто делал все домашние задания и посещал все занятия, поэтому регистрация будет ограничена по времени и по количеству. Скорее всего первым 30-ти сделаю какой-нибудь существенный бонус.
Пока всё, вы можете задать мне вопрос на почту ([email protected]), в комментариях или записаться в предварительную регистрацию пройдя этот опрос.
А теперь перейдем к вкусному. 🙂
Семантическое ядро собрано, что дальше?
Все оптимизаторы твердят вокруг, что нужно собирать семантическое ядро сайта. Это безусловно правда, но, к сожалению, многие даже не представляют, что делать с этим добром? Ну собрали мы его, что дальше-то? Я не удивлюсь, если вы тоже относитесь к этой категории. Вообще, некоторые клиенты заказывают семантическое ядро, и даже собрав его максимально качественно, они выкидывают ваш труд на ветер. Хочется плакать, когда видишь подобное. Сегодня я расскажу про то, что делать с семантическом ядром на самом деле.
Если вы вдруг еще его не создали так, как положено, то вот ссылки на уроки по составлению семантического ядра.
- Составление структуры сайта.
- Составление семантического ядра с помощью Базы Пастухова и Key Collector. Часть 1
- Составление семантического ядра с помощью Базы Пастухова и Key Collector. Часть 2
Я буду демонстрировать все на простейшем примере, чтобы облегчить ваше понимание в этом нелегком деле. Допустим, нам нужно было бы собрать семантическое ядро для сайта, который рассказывает про WordPress. Вполне естественно, одной из рубрик данного сайта будет «Плагины WordPress».
Кстати, не забывайте, когда парсите ключевые слова искать фразы и на русском. То есть для рубрики «плагины WordPress» нужно парсить не только фразу «плагин wordpress», но и фразу «плагин вордпресс». Часто бывает, что на русском название бренда или продукта ищут даже больше, чем в оригинальном написании на английском. Помните об этом.
После сбора СЯ (сокращенно от «семантическое ядро») для данной рубрики, получаем примерно такой Excel’овский файл:
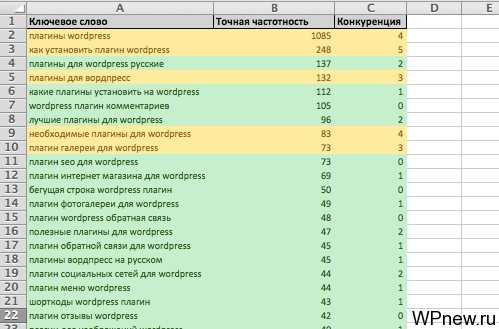
Как видите, довольно много запросов и все разбито в кучу. Дальше мы просто группируем в Excel путем вырезания/вставки схожие по смыслу ключевые слова. Группы ключевых слов разделяем какой-нибудь пустой строчкой для наглядности.
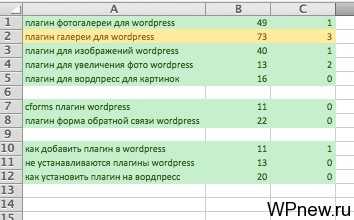
Дальше слева создаем пустой столбец и даем заголовок данной группе и это даже будет черновым вариантом для будущего заголовка статей.
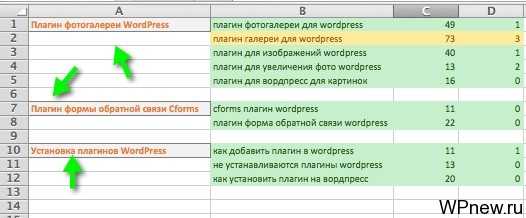
Тут было бы еще великолепно если ключевые слова в подгруппах отсортировать по точной частотности (для будущего это пригодится). Получается так, что эти подгруппы — ключевые слова, которые содержатся в этих статьях. Если семантическое ядро составлено довольно качественно мы не упустим ничего и охватим ВСЕ запросы, которые входят в данную рубрику.
Общие слова, такие как «плагины wordpress» мы оставляем для страницу с рубрикой, то есть прямо в рубрике размещаем необходимый SEO оптимизированный текст. Обязательно прочитайте мою статью про SEO оптимизацию рубрик в WordPress, чтобы знать, как это делать правильно.
Даже, если вы пишите статью не сами, то этот файл с разбивкой семантического ядра на группы — идеальное пособие для копирайтера. То есть он уже видит структуру статьи и понимает то, о чем он должен писать. Стоит ли говорить сколько трафика можно собрать таким образом?
В идеале, если, конечно, вы пишите сами статьи или у вас есть толковый SEO копирайтер. В любом случае, обязательно прочитайте статью про то, как писать SEO оптимизированный текст. Если даже пишете не вы сами — покажите эту статью копирайтеру и эффект от вашего контента не заставит вас ждать. Уже через некоторое время вы будете приятно удивлены над ростом трафика.
Кстати, подходящие ключевые слова при возможности нужно сделать заголовками, конечно в более естественной форме. То есть, примерно так:
Я тут показал наглядно, как примерно должен выглядеть тег h2 и h3. И, снова, обязательно прочитайте про правильное использование заголовков h2-h6 в SEO.
Запомните, никакого спама, друзья мои, переоптимизация — это зло. Тут важна, как и во всей структуре сайта, правильно составленная структура статьи. Запомните раз и навсегда: поисковые системы очень сильно любят хорошо структурированные сайты, а про людей я вообще молчу. Все мы любим, когда на сайте все разложено по полчкам, понятно, внятно, красиво.
Что ж, ребята, на сегодня все, встретимся в следующем уроке, которая вам тоже должен понравится. Вам же нравится, что я пишу? Я прав? 🙂 Если да, не забываем про ретвиты, лайки и прочие «вкусняшки», а особенно я люблю комментарии. Для вас мелочь, а для меня все это очень приятно. Вы же «добряки», друзья мои? 🙂
P.s. Вам нужен сайт? Тогда создание сайта Киев возможно то, что нужно именно вам. Доверьтесь профессионалам.
wpnew.ru
50 лучших инструментов для работы с семантическим ядром — Devaka SEO Блог
Составление и обработка семантического ядра – одна из ключевых задач в SEO. Ниже представлен список инструментов и сервисов для работы с семантикой: подбор, группировка, фильтрация, кластеризация ключевых слов и другое.
Собственные системы аналитики
Собственные счетчики и системы аналитики позволяют собирать списки ключевых слов, по которым люди уже заходили на сайт. Самые популярные из них, и бесплатные:
— Google Analytics
Не покажет зашифрованные запросы Яндекса, а также скроет многие ключи, по которым люди переходили из Google, но какой-то полезный список ключевых слов все же можно получить. При связи с панелью для вебмастеров можно получить больше информации по запросам.
— Яндекс.Метрика
Статистика переходов и ключевых слов из Яндекса и других поисковиков, в том числе из Яндекс.Картинок.
— LiveInternet
Полезно использовать вместе с другими системами аналитики, чтобы собирать как можно больше данных.
Сервисы поисковых систем
Поисковики предоставляют собственные бесплатные сервисы для анализа и подбора ключевых слов.
— Яндекс Вордстат
Подбор ключевых слов от Яндекса. Можно задавать регион и искать связанные слова, смотреть популярность запросов.
— Рамблер Вордстат
Статистика по запросам от Рамблера. Можно выбирать период и проверять сезонность запросов. Также позволяет узнать популярность запроса в разных странах и российских регионах.
— Keyword Planner от Google
Подбор запросов от Google. Можно настроить поиск не только слов из органики, но и видео-запросов с YouTube.
— Статистика запросов от Mail.ru
Реальные запросы в Mail с демографической статистикой. Хорошо показывает, что некоторые высокочастотные фразы не такие уж высокочастотные.
— Тренды Google
Поиск трендовых (быстрорастущих) запросов, текущих, за период или в разных странах.
— Google Correlate
Поиск слов, коррелирующих с заданным. Производится на основе поведенческих данных (одинаковой активности пользователей по разным запросам).
Готовые оффлайн и онлайн базы
Готовая база ключевых слов – также хороший источник семантики. Все базы обычно платные.
— База Пастухова [платная]
База русскоязычных ключевых слов с данными по количеству запросов в Яндексе и цене кликов в Бегуне. Автоматизированные фильтры и разные функции для работы со списками ключевиков через программный интерфейс.
— UP Base [платная]
Русская и английская базы ключевых слов из различных доступных источников, очищенные от мусора. Программа имеет ряд требований и ограничений.
— Мутаген [платная]
Онлайн-база, где можно подобрать эффективные ключевики. Показывает для запросов уровень конкуренции, имеет API.
— KeyBooster [платная]
Хранит запросы, которые люди парсили из вордстата сервисом «Магадан».
— RooStat [платная]
База запросов из Рунета для интеграции в свой софт. Ежемесячные обновления.
Сервисы анализа конкурентов
Эти сервисы предназначены для анализа конкурентов и имеют широкий функционал, в том числе здесь можно быстро составить семантическое ядро, основываясь на семантике заданных сайтов.
— АДВСЁ [платная]
Статистика поисковой рекламы в Яндексе и Google. Подбор семантики, исходя из конкретных сайтов (поиск запросов, по которым эти сайты размещают контекстную рекламу).
— advODKA [платная]
Анализ ключевых слов, по которым показываются объявления сайта, видимость домена в ТОП20 Яндекса и Google (регионы «Москва» и «Питер») с различной статистикой.
— SpyWords [платная]
Анализ семантики сайтов-конкурентов, поиск уникальных запросов видимости домена в поиске (по московскому региону), по сравнению с другими заданными доменами.
— SemRush [платная]
Собирает ТОП20 Google и Bing по 100 млн. запросов. Удобный инструмент для тех, кто продвигает сайт под русскоязычный или зарубежный Google.
— Prodvigator [платная]
Анализ украинского, российского, болгарского и казахстанского Google, а также поисковой выдачи Яндекса (Мск) по базе реальных запросов. Быстрая выборка не только поисковых запросов, но и подсказок.
— TopVisor [платная]
Парсинг контекста (Яндекс, Гугл), поисковых подсказок (в т.ч. из Mail и Спутника) или выгрузка ключевиков из панели для вебмастеров или системы аналитики для анализируемых проектов.
— Spy Fu [платная]
Подбор англоязычных запросов для зарубежных проектов. Итоговая статистика имеет параметр сложности продвижения запросов.
— Keyword Eye [платная]
Просмотр конкурентости заданных англоязычных ключевых слов в виде облака. Формирование предложений (выгрузка из готовой базы по заданной фразе).
— SimilarWeb [условно бесплатно]
Отображает разные параметры сайта, в том числе, по каким запросам он получает трафик из органического поиска или контекста.
— Alexa [условно бесплатно]
Подобный сервису SimilarWeb. В бесплатной версии можно узнать лишь 5 трафиковых запросов сайта. Берет данные из своего тулбара.
Специализированные сервисы подбора семантики
— keywordtool.io [бесплатно]
Удобная альтернатива AdWords Planner. 750 предложений для каждого ключевого слова, основанные на подсказках Google для разных языков (83 доступных языка) и регионов (192 домена Google). Подбор семантики из YouTube, AppStore и Bing.
— fastkeywords.biz [условно бесплатно]
Поиск по базе ключевых слов. Имеет возможность задавать маску, чтобы находить слова с разными окончаниями. Неизвестно, как часто обновляется.
— actualkeywords.com [платная]
Поиск по готовой базе англоязычных ключевых слов, готовые тематические подборки.
— keywords.megaindex.ru [бесплатно]
Подбор ключевых слов для сайта от MegaIndex. Неудобно, но бесплатно.
—wordtracker.com [платная]
Популярный зарубежный инструмент анализа ключевых слов.
—ubersuggest.org [бесплатно]
Парсер поисковых подсказок Google. Можно задать язык и вертикаль поиска – например, спарсить семантику из поиска по изображениям или новостям.
—wordpot.com [бесплатно]
Бесплатный подбор англоязычных запросов.
—words.elama.ru [бесплатно]
Удобный подбор поисковых запросов. Правда нет возможности экспортировать список.
—keywordtooldominator.com/k/amazon-keyword-tool/ [бесплатно]
Семантика из интернет-магазина Амазон. Очень удобный инструмент для сбора коммерческих (транзакционных) запросов.
Программы для работы с семантическим ядром
— Key Collector [платная]
Многофункциональная программа под Windows для работы с семантическим ядром.
— Yandex Wordstat Helper [бесплатно]
Расширение для Mozilla Firefox и Google Chrome, ускоряющее сбор ключевых слов в Яндекс.Вордстате.
— export.yandex.ru/inflect.xml [бесплатно]
Склонятор ключевых слов от Яндекса.
— Mystem [бесплатно]
Программа от Яндекса для морфологического анализа текста на русском языке. Можно использовать для приведения ключевых слов в нормальную форму.
— Магадан [платная]
Парсер ключевых слов Яндекс.Директа (Вордстата). Помогает составлять семантическое ядро и подготавливать рекламные кампании.
— tools.k50project.ru/lemma/ [бесплатно]
Лемматизатор для лингвистических экспериментов. Приведение ключевых слов к нормальной форме.
— kg.ppc-panel.ru [бесплатно]
Создание групп запросов по общим вхождениям. Удобный и простой инструмент.
— Макрос от Devaka [бесплатно]
Макрос для OpenOffice, упрощающий классификацию поисковых запросов.
Другие инструменты для работы с семантическим ядром
— Keyword Organizer [платно]
Удобный инструмент для группировки ключевых слов, создания контента под определенные группы.
— Just Magic [платно]
Авто-подбор семантики для SEO и контекста, подбор релевантных страниц под запросы.
— Key Assistant [бесплатно]
Ручная группировка ключевых слов по страницам.
— МегаЛемма [платно]
Очистка семантического ядра от мусора, группировка ключевых слов, экспорт результатов в удобном формате.
— Rush Analytics [платно]
Парсинг вордстата и поисковых подсказок, кластеризация поисковых запросов на основе подобия ТОПа. На выходе – практически готовая структура сайта.
— s:toolz [платно]
Кластеризация поисковых запросов на основе поисковой выдачи. Ещё один сервис по автоматизации подбора семантического ядра для сайта.
— Кейса [платно]
Фильтрация ключевых слов, быстрое распределение по группам, возможности внесения дополнительных данных. Ускоряет работу с большими списками запросов.
Если этот список инструментов оказался для вас полезным, поделитесь ссылкой на него с друзьями.
devaka.ru