
Инструменты для интернет-маркетинга, SEO и SMM
SEOlib – молодой сервис, с помощью которого специалисты в области SEO легко могут проводить аудит сайта, оптимизацию ресурса и его продвижение. Функционал программы удобный и простой в использовании. По сравнению с конкурентами, применение сервиса имеет несколько основных преимуществ.
Приятный интерфейс страницы. Внешний вид страницы позволяет пользователям с удовольствием выполнять все работы. Удобная навигационная панель, название блоков и разделов, привлекательная верхняя область страницы, красочные рекламные изображения – это сервис SEOlib. Структура сайта позволяет быстро выполнять установленные задания.
Прозрачная и оправданная цена. Стоимость устанавливается в зависимости от проведенного анализа и расчета показателей.
Широкий функциональный набор. Программа позволяет выполнять большое количество задач. Например, с ее помощью без проблем осуществляется анализ динамики роста места сайта в поисковых системах; сравнивание занимаемых позиций страницей в различных регионах и поисковиках; определение уровня кликабельности в процессе выдачи; диагностируется взаимозависимость сайта с регионом его расположения. SEOlib позволяет сравнить видимость ресурса с конкурентами; повышает уровень релевантности текстовой информации сайта.
Постоянное развитие сервиса. Программа постоянно поддается усовершенствованию. Регулярно проводится обновление системы, улучшается структура и функциональные возможности сервиса. Администрация делает все, чтобы клиенту было выгодно и эффективно использовать
SEOlib.
Администрация делает все, чтобы клиенту было выгодно и эффективно использовать
SEOlib.
Преимуществом сервиса является возможность привлечения партнеров. То есть, вы можете привести пользователя и зарабатывать не менее 10% от суммы его дохода.
С помощью программы реально отслеживать изменение видимости интернет-страницы в поисковиках, строить понятные графики и отправлять клиентам отчеты в формате Excel. Запросто подбираются ключевые фразы, проверяется частота и уровень конкурентоспособности основных запросов для всех регионов Yandex.ru. Сервис дает возможность провести экспресс-анализ. Он заключается в анализе главных показателей ресурса и оценивании общего фактического состояния страницы.
Если у вас возникли проблемы в процессе работы с программой, свяжитесь с администрацией сервиса. Сделать это можно по телефонному номеру, указанному на сайте, или отправить заявку с заполненными полями (имя, электронный адрес, тема сообщения и его текст).
Программа подходит для операционных систем Windows 7 , Windows, 8Linux Ubuntu (LTS), Android 4.4 и IOS 7.1. Используется для браузеров актуальных версий Mozilla Firefox и Google Chrome. Для применения сервиса необходимо пройти регистрацию на сайте и дальнейшую авторизацию.
SEOlib – мощный аналитический инструмент, который состоит из большого количества полезных для пользователя функций. Они дают возможность безопасно, оперативно анализировать веб-ресурс и алгоритмы поисковых систем. Максимальная глубина проверки составляет 500 результатов. Наибольшее количество запросов на один аккаунт не имеет ограничений.
SEOlib – эффективный сервис осуществления качественной проверки места, которое занимает сайт в поисковых системах в независимости от региона.
Назад в раздел
SEOlib — сервис анализа позиций и аудита поисковой оптимизации
Обзор SEOlib
SEOlib — набор инструментов, предназначенных для оптимизации сайта, мониторинга его позиций в поиске и анализа ключевых фраз.
Возможность проводить технический аудит, генерировать файл robots.txt и мета-теги будет полезна веб-разработчикам. SEO-специалисты могут подбирать ключевые слова и следить за изменениями позиций ресурса в поисковых системах. Стоимость пользования рассчитывается исходя из количества запрошенных отчётов и анализов, что подойдёт малому, среднему и крупному бизнесу.
SEOlib позволяет отслеживать видимость собственного портала или ресурса-конкурента в поиске с максимальной глубиной 500 строчек для Яндекса и Google. Также есть проверка сниппетов и функция определения релевантной страницы. Подбор ключевых слов для повышения сайта в выдаче производится с оценкой конкурентности запроса. Сервис отслеживает первые 100 мест в поиске по определённым фразам, а также выявляет “быстрорастущие” сайты и семантических лидеров — ресурсы, которые попадают в топы по наибольшему числу запросов. Для каждого анализа доступны отчёты, их выгрузку можно настроить автоматически, указав частоту и формат.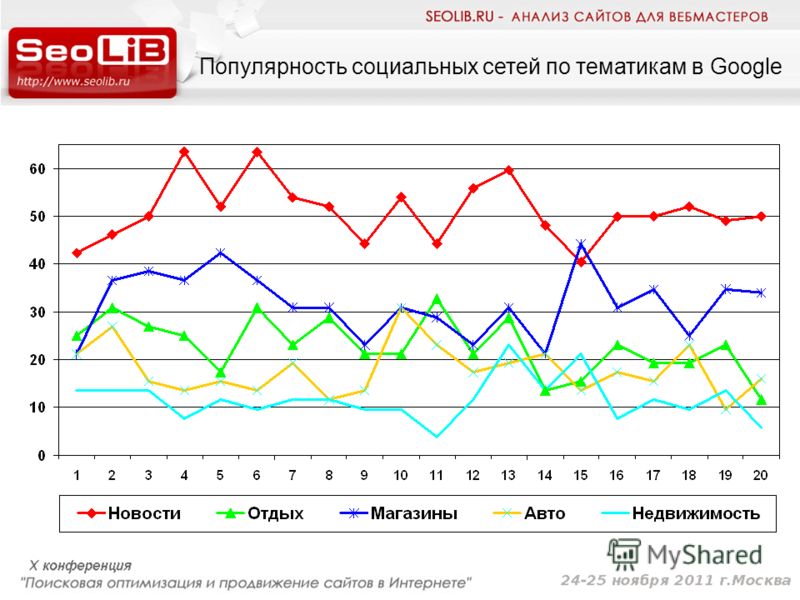
Ключевые особенности
- Проверка позиций сайта в топ-500 позиций Яндекса и Google
- Анализ для 5 сайтов-конкурентов
- SEO-аудит
- Проверка ссылок на сайтах-донорах
- Функция диагностики поисковых санкций
SEO сервисы для бизнеса
1
Сервис, предоставляющий информацию о том, как индексируются ваш сайт в Яндексе. Позволяет настроить индексирование сайта и улучшить представление сайта в результатах поиска, исправить ошибки.
Позволяет настроить индексирование сайта и улучшить представление сайта в результатах поиска, исправить ошибки.
2
Панель вебмастера для управления индексацией сайта в поисковике Google. Предоставляет поисковую аналитику
3
Cервис автоматизированного продвижения сайтов в поисковых системах Яндекс и Google, и автоматизации контекстных рекламных кампаний в Яндекс.Директе и Google AdWords. Для работы с SeoPult не обязательны специальные навыки и опыт, для удобства пользователей реализован функционал рекомендаций и преднастроек.
4
Комплексный инструмент для продвижения в интернете. В сервисе можно продвинуть сайт в Яндекс и Google, заказать профессиональные рекомендации по улучшению сайта, статьи, медийную рекламу и рекламу у блогеров. В результате вы получите новых посетителей, повысите привлекательность сайта для людей и поисковых систем.
5
Панель инструментов для веб-мастера. Проверка позиций сайта по ключевым словам. Мониторинг конкурентов.
6
Биржа вечных (контекстных) ссылок на качественных сайтах. Разовая оплата после индексации.
7
Сервис для оценки пользовательского интереса к конкретным тематикам и для подбора ключевых слов рекламодателями и вебмастерами
8
Платформа для аналитики и контроля SEO. Проверка выдачи, частотности, позиций и санкции. Анализ запросов, страниц и сайта на множество параметров. Гибкая настройка частоты съема любых данных. Возможность разграничить права не только на проекты, но и на любые модули и инструменты. Отчеты по трафику и по позициям, по отдельной странице или сайту в целом, по каждой поисковой системе, в динамике. Контроль размещения и индексации ссылок.
9
Сервис размещения платных постов в социальных сетях и блогах
10
Система размещения статей (с ссылками) на неограниченный срок.
11
Сервис для создания посадочных страниц. Галерея макетов целевых страниц. Шаблоны мобильных целевых страниц, адаптированных для операционных систем iOS и Android.
12
Сервис проверки трастовости сайтов и анализа их SEO параметров
13
Сервис для SEO и онлайн-маркетинга. Объединяет инструменты для анализа сайта, мониторинга конкурентов, проверки позиций, подбора и группирования ключевых слов, мониторинга бэклинков, автоматической профессиональной отчетности и прочее. Кроме стандартного набора SEO-инструментов, сервис оснащён рядом дополнительных функций, таких как white Label и Маркетинг План.
14
Сервис автоматического продвижения сайтов и поисковой оптимизации. Подбирает ключевые слова, составляет тексты ссылок и рекламных объявлений, рассчитывает бюджет, запускает рекламную кампанию, следит за результатами продвижения
15
Cервис для продвижения сайтовестественными ссылками. Ручная простановка и модерация. Ежедневный съем позиций и проверка ссылок. Подробная отчетность и аналитика
16
Сервис автоматического продвижения сайта. Агреггатор бирж ссылок. Проверка качества ссылок. Подбор запросов.
17
Набор SEO-инструментов: проверка позиций, ссылок и траста сайта, подбор ключевых слов, проверка индексации и поиск релевантных запросов, анализ качества ссылок.
18
Сервис для веб-мастеров для управления сайтом в поиске Mail.ru. Показывает, какие страницы находятся в индексе Поиска Mail.Ru, какие внешние ссылки ведут на ваш сайт, значения поведенческих факторов для запросов, по которым пользователи видели ваш сайт в выдаче.
19
Сервис покупки ссылок на главных страницах
20
Сервис регистрации сайта в каталогах. Услуги по SEO-раскрутке и настройке контекстной рекламы
21
Сервис определения позиций сайтов в поисковых системах и рейтингах. Позволяет узнавать позиции сайта в поисковиках по нужным вам запросам, получать отчеты по электронной почте, отслеживать изменения позиций, следить за динамикой размещения в поисковой выдаче одного или нескольких сайтов.
22
Сервис крауд-маркетинга — биржа купли-продажи естественных трафиковых крауд-ссылок с тематичных форумов и обсуждаемых тем на свой сайт.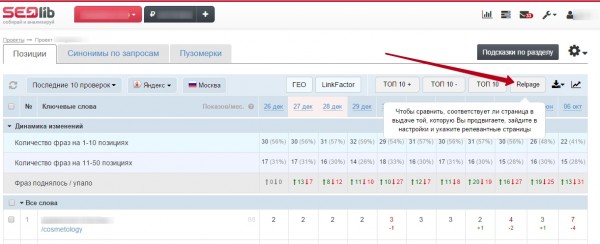
23
Биржа прямой рекламы, с помощью которой вы можете размещать статьи на качественных сайтах. Подтвержденные данные посещаемости и распределения источников трафика. Гарантия от удаления статей. Система отзывов
24
Сервис продвижения сайтов поведенческими факторами
25
Сервис определения позиций сайта по запросам в поисковых системах Яндекс и Google. Поддерживается геотаргетинг
26
Сервис автоматической закупки качественных ссылок в SAPE. Настраиваемый автоматический отсев некачественных ссылок в вашем аккаунте Sape. Качество доноров ссылок определяется с помощью сервиса XTOOL
27
Автоматизированный сервис для работы с биржами вечных ссылок с возможностью рассрочки платежа.
Проверка позиций сайта
О том, как можно заработать в интернете с помощью своего сайта в сети можно найти много информации. Специалисты, казалось бы, дословно объяснили уже и алгоритм создания сайта, и его продвижения, и способы заработка с помощью своего ресурса.
Если вы ведете свой блог или у вас есть интернет-магазин, то, следовательно, вы имеете и свой постоянный поток посетителей. Есть вариант получать деньги за каждое посещение сайта или страницы, а можно зарабатывать с помощью рекламы. Если же вы создали свой тематический сайт, то количество посетителей зависит от того, насколько он будет SEO-оптимизирован.
Выполнять проверку вручную довольно сложно, поэтому лучше воспользоваться сервисом, автоматически определяющим место сайта в SERP.
Список лучших сервисов для мониторинга позиций веб-ресурса
Topvisor.ru
Именно от правильно продуманных ключей зависит позиция вашего сайта в поисковике. Осуществляется проверка позиций сайта в поисковой системе с помощью веб-системы Топвизор. Именно с данным сервисом у вас есть возможность проверять, на каких позициях ваш ресурс находится в Яндекс и Google. Проверку можно осуществлять вручную. Также у вас есть возможность отслеживать позиции сайтов-конкурентов и сравнивать позиции.
Топвизор помогает определиться с самыми популярными запросами и вывести ваш сайт на более высокие позиции. Чем выше в поисковике стоит ваш сайт, тем больше вероятности, что к вам зайдет большое количество посетителей. Также с данной системой можно четко проследить, какие запросы работают на вас, а какие, наоборот, тормозят ваше развитие.
С Топвизор можно также и провести SEO-оптимизацию вашего сайта. Система поможет вам проанализировать ключевые слова, трафик, ваших конкурентов. Здесь тщательно ведется отслеживание позиций, а также проводится работа с рекламой и отчетами.
Данную систему одобряют как уже продвинутые пользователи сети, так и новички в этом деле. Проследить за позицией вашего сайта с Топвизор можно в восьми поисковых системах. Кроме того, система позволяет увидеть рейтинг вашего видео в YouTube. Чтобы осуществить проверку, можно установить фильтр, а можно поставить запрос на все ядро. Можно работать с отдельными запросами.
Теперь не нужно самому придумывать ключевые слова – за вас все сделает Топвизор.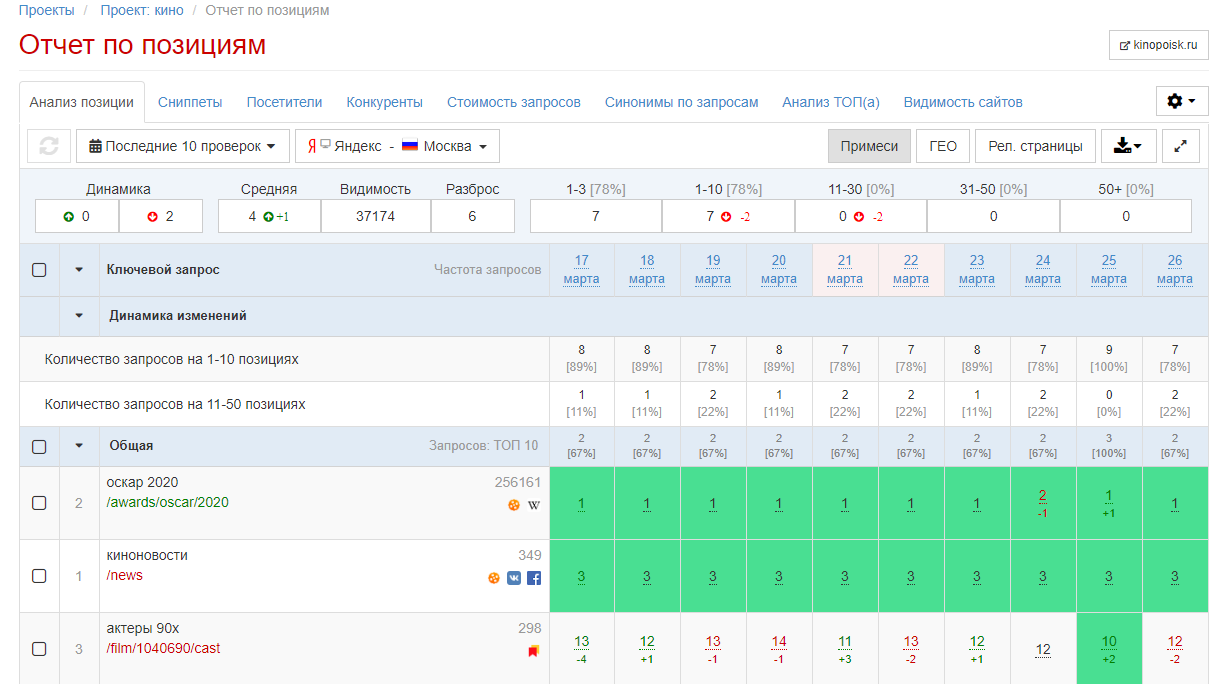 Здесь проводится группировка ключей и их анализ. А с большим количеством запросов можно работать с помощью систематических таблиц.
Здесь проводится группировка ключей и их анализ. А с большим количеством запросов можно работать с помощью систематических таблиц.
Серпхант
Серпхант – аналитический сервис, который имеет множество инструментов, помогающих комплексно проанализировать свой сайт. Имеет как платные функции, так и бесплатные. Одним из таких инструментов можно проверить позиции сайта.
Для его применения не требуется регистрация и оплата. Но имеется дневное ограничение по числу лимитов – в день можно проверить 50 запросов. Съем позиций можно выполнять с региональной привязанностью, в двух поисковых системах Я и Г. Он имеет простой интерфейс и удобную форму отчета.
Если бесплатных лимитов недостаточно, можно зарегистрироваться и использовать все инструменты сервиса в платном формате, где стоимость 1 проверки позиций составляет от 0,02 р до 0,04 р, все зависит от тарифного плана. Для тестирования предоставляются бесплатные лимиты!
Top-inspector.ru
Система имеет простой и понятный интерфейс.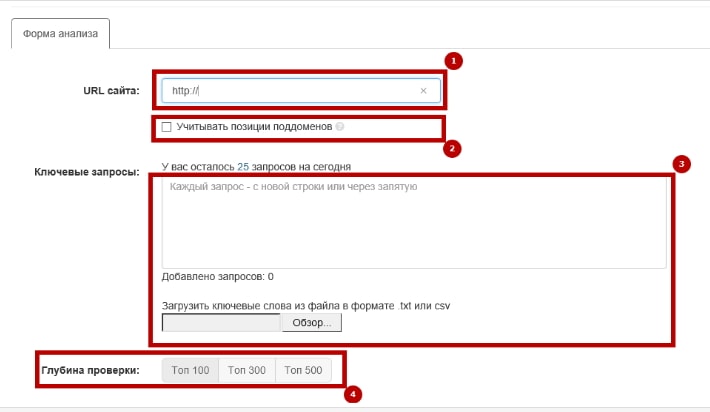 Ключевики можно не только вводить вручную, но и переносить из Google Analytics или Яндекс.Метрики.
Ключевики можно не только вводить вручную, но и переносить из Google Analytics или Яндекс.Метрики.
Проверка позиций сайта онлайн в этом сервисе выполняется всего в 2 поисковиках – Google и Яндекс. Однако для одного проекта разрешено выбирать до 4 регионов. Здесь также доступен бесплатный мониторинг 2 конкурирующих доменов.
Система предоставляет отчеты по позициям за любую дату и автоматически пересылает их на E-mail клиента.
Цена проверки позиций по одному слову равна 0,0009$.
SEOlib.ru
Сервис работает с Google, Яндекс и Mail.ru. Для всех поисковиков доступен выбор региона. К функциям системы относятся сравнение видимости домена с сайтами-конкурентами, определение кликабельности веб-ресурса, анализ переходов посетителей по ключевым словам и виду поиска, проверка релевантности текстов.
Ежедневно пользователь сможет проверить позиции сайта в Яндекс и Google бесплатно по 25 запросам. В дальнейшем, стоимость одной проверки будет составлять 0,004$.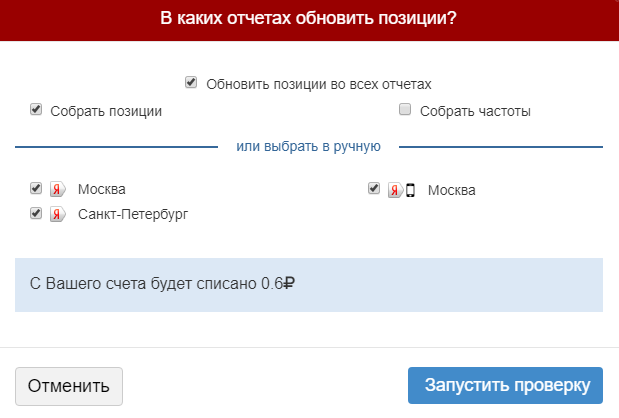
Сервис имеет калькулятор, позволяющий рассчитать цену мониторинга за месяц с учетом количества регионов и ключевых слов, а также глубины и частоты проверок.
Seranking.ru
В перечень используемых системой поисковиков входят Яндекс, Yahoo, Bing, Google (в том числе Google Maps и Google Mobile).
Здесь также можно подключить Google Analytics, чтобы определять количество трафика, пришедшего по тем или иным ключевым запросам.
В сервисе доступны проверки не только всего домена, но и отдельных URL, что позволяет веб-мастеру мониторить группы и страницы в соцсетях, лендинги, ролики в YouTube.
В течение 14 дней система может использоваться в тестовом режиме, однако функциональность бесплатной версии ограничена.
Allpositions
Мониторинг позиций сайта по ключевым словам в этом сервисе выполняется на базе Яндекс, Google и Mail.ru. Система собирает статистику посетителей при активации Google Analytics и анализирует конкурентов в поисковой выдаче.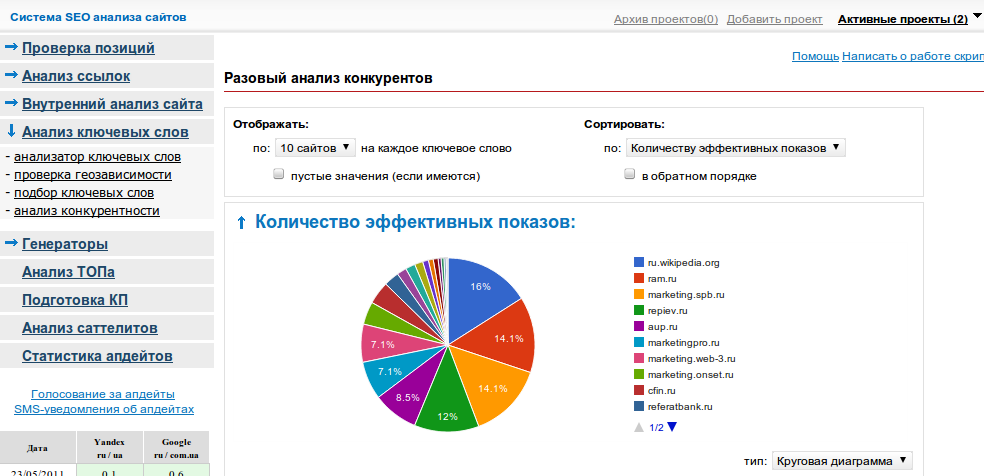
В сервисе действует внутренняя валюта – монета. При регистрации пользователю сразу же выдается 1000 монет. За одну проверку позиции веб-ресурса необходимо заплатить 1 монету (0,002$). При закупке большого количества внутренней валюты действует система скидок.
Все указанные сервисы позволяют веб-мастеру мониторить домен с оптимальной частотой, достигая необходимой глубины результатов поисковой выдачи.
Для использования этих систем достаточно указать адрес проекта, определить ключевые запросы и выбрать периодичность проверок.
Где занять деньги онлайн: как быстро взять микрозайм без отказа в УкраинеЧитайте обзоры:
Платная и бесплатная проверка позиций сайта, онлайн сервисы.
Здесь рассказывается про SEO инструменты: офлайн и онлайн сервисы, позволяющие проверить позиции сайта по ключевым словам в Гугл, Яндекс и других поисковиках.
В интернете существует множество сервисов, предоставляющие необходимую услугу для SEO — проверка позиций сайта по ключевым словам (запросам) в поисковых системах как платных, так и бесплатных, по которым можно проверить результаты поискового продвижения сайта. В последнее время качаственные сервисы снятия позиций в Яндекс и Google и других поисковых систем перешли с бесплатных условий пользования на платные. Практически все подобные сервисы требуют регистрации. Многие сервисы анализа сайта позволяют проверить позиции сайта по ключевым словам, по статистике, взятой у некоторых ниже перечисленных сервисов.
В последнее время качаственные сервисы снятия позиций в Яндекс и Google и других поисковых систем перешли с бесплатных условий пользования на платные. Практически все подобные сервисы требуют регистрации. Многие сервисы анализа сайта позволяют проверить позиции сайта по ключевым словам, по статистике, взятой у некоторых ниже перечисленных сервисов.
Бесплатная проверка позиций сайта.
Бесплатный сервис для проверки позиций сайта.
до 100 запросов за 1 раз, до 100 позиции в выдаче. Возможность проверить позиции по регионам. Показ урлов страниц по этим запрорсам. Сводка по ТОП-1, 5, 10, 50, 100. Чтобы проверять позиции в Гугле, необходима регистрация и установка расширения анализа сайтов в браузер (что может быть полезным). Скачивание отчета в .csv.
https://be1.ru/position-yandex-google/
В последнее время, в связи с изменениями условий работы поисковых систем, уменьшилось количество онлайн сервисов, производящих бесплатную проверку позиций сайта. Некоторые из них:
Некоторые из них:
SpySerp- довольно точный и гибкий. 2 бесплатных проекта по 50 запросов в день.
с 25 февраля лимиты для БЕСПЛАТНОГО тарифного плана будут изменены.
Ключевые изменения:
— 5 поисковых систем на проект;
— 5 ключевых слов на проект;
— 1000 проверок в месяц.
Все остальные лимиты остаются прежними.
analizsaita.com/proverit-pozicii — инструмент проверки позиций сайта сервиса анализатора. Позволяет проверить 30 запросов. В день апдейта 25.
webmasters.ru — достаточно точное снятие позиций, но ограничено до 30 ключевых запросов, не показывает улучшение и ухудшение позиций. Необходимо каждый раз вводить ключевые слова. При проверке позиций в Яндексе могжет выйти ошибка.
seogadget.ru — до 30 запросов. Работает довольно качественно. Наваерное, на сегодняшний день, лучший бесплатный сервис проверки позиций. Необходимо каждый раз вводить список ключевых слов.
seolib.ru/tools/positions/analysis — еще один сервис, включающий как бесплатную (25 запросов в сутки) так и платную проверку позиций сайта с большим функционалом. Работает надежней выше перечисленных.
Работает надежней выше перечисленных.
На настоящий момент довольно качественную услугу бесплатной проверки позиций сайта предоставляют сайты: сервис автоматического продвижения megaindex.ru. Есть погрешности. Рост и понижение позиций не показывает. Основное преимущество -нет ограничения количества ключевых слов.
sitexpert.org — бесплатно до 10 выражений. Проверки в Яндексе отключил. Бывают погрешности. Автоматическа проверка.
Многофункциональная программа оффлайн анализа сайта и проверки позиций на локальном компьютере SiteAuditor. программа позволяет получать статистику систем Яндекс, Рамблер, Апорт, Google и Yahoo. Скачать SiteAuditor можно па адресу site-auditor.ru. На сайте подробное описание программы.
SESpider была еще одна программа бесплатной проверки позиций на локальном компьютере. Но сервис перестал обновляться.
Платная проверка позиций сайта по ключевым словам.
Преимуществом платных сервисов является больший функционал, автоматическая проверка (ввод ключевых слов один раз), можно добавлять запросы до указанного на сайте ограничения количества, показывают рост и понижение позиций, больший выбор поисковых систем.
allpositions.ru, есть бесплатные пробные периоды.
top-inspector.ru — есть бесплатные пробные периоды.
Биржа ссылок setlinks.ru также предоставляет очень качественную проверку до 50 запросов, но недавно перешла на платную основу — сервисом могут пользоваться клиенты, которые тратят средства. Тем, кто здесь закупает ссылки — лучше проверять позиции на этом сайте. Во время сотрудничества с одним крупным каталогом, бесплатный вариант этого сервиса был очень полезен.
siteposition.ru — предоставляет платную и бесплатную проверку. Бесплатная -простая проверка: 1 запрос в 2 поисковых системах, платная -автоматическая проверка: список запросов. Во всех случаях необходима регистрация.
topvisor.ru- регистрируемся, создаем проект, в настройках выбираем поисковые системы. Пробный период на 200 запросов.
seranking.ru — регистрируемся, создаем проект, в настройках выбираем поисковые системы. Пробный период 15 дней.
Некоторые из этих платных сервисов можно использовать бесплатно, прибегнув к хитрости — после окончания пробных периодов заново регистрироваться под другим аккаунтом и продолжать проверку позиций уже в новом проекте.
Как проверить позиции сайта в поисковиках
Знание сервисов или программ, позволяющих проверить позиции сайта в поисковиках Яндекс и Гугл, очень важно, если Вы хотите добиться высокой посещаемости.
Конечно, можно просто писать оптимизированные под ключевики статьи, полезные и интересные, изо дня в день, и наблюдать за тем, как посещаемость Вашего сайта растет. Но это — путь для терпеливых, и для тех, у кого есть время, потому что заработок будет расти очень постепенно, пропорционально количеству Ваших статей.
Высокой посещаемости, а следовательно, и хорошего заработка с сайта, можно добиться быстрее, если продвигать статьи по ключевым словам, используя платные и бесплатные методы продвижения.
А для этого нужно знать позиции Вашего сайта на текущий момент: ведь бессмысленно продвигать ключевик, который и так находится на первом месте в выдаче. Или гораздо проще продвинуть ключевые слова, которые находятся близко к ТОПу, чем те, которые не попали даже в ТОП100.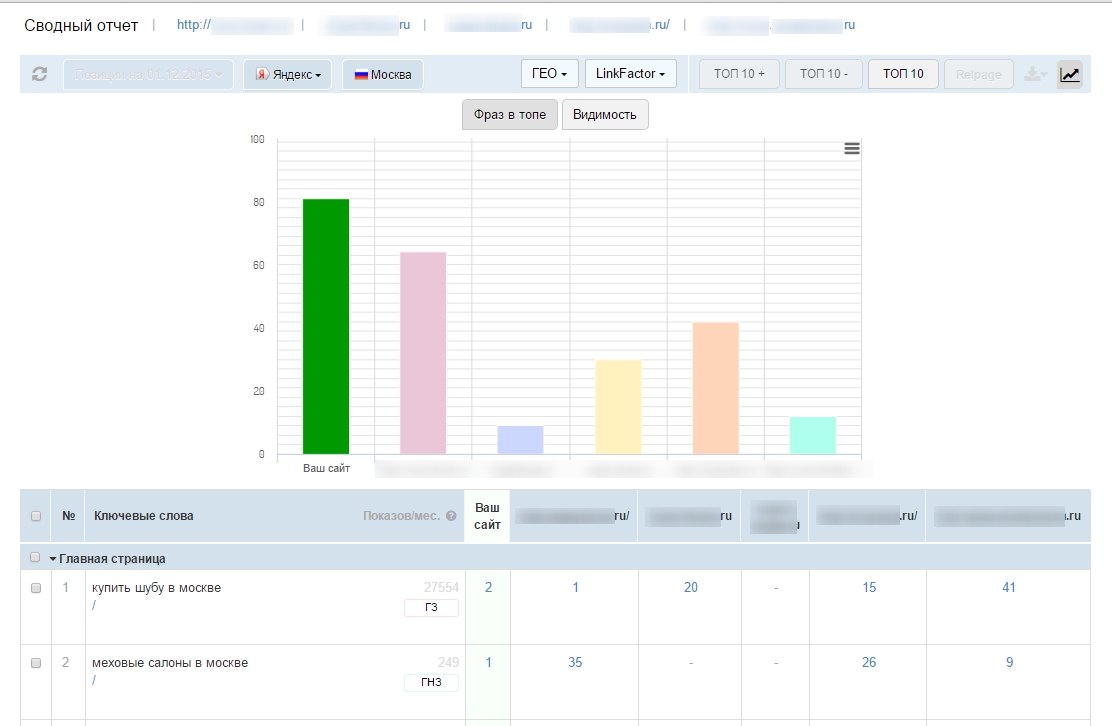
Посетители редко заглядывают на вторую-третью страницу, не говоря уже о том, чтобы заходить еще глубже. Потому, если продвинуть ключевик со второй страницы на первую, это даст ощутимо больший эффект, чем если Вы продвинете ключевик с тридцатой страницы на двадцатую. Это если не брать в расчет релевантность. Также нужно учитывать конкуренцию, или по крайней мере иметь ее в виду.
Чем больше Вы получаете информации и чем больше Вы можете ее понять и осмыслить, тем осознаннее Вы действуете. Совсем разный результат получается, когда Вы делаете что-то наугад, вслепую, или когда делаете дело, представляя себе конечный результат.
Итак, нужно отслеживать позиции ключевых фраз, по которым Ваш сайт находится в выдаче поисковых систем. Увидев, что какие-то ключевые слова находятся на невысоких позициях, Вы всегда можете их попробовать поднять.
Сайт Seolib.ru
Один из способов — проверить позиции сайта с помощью сервиса SeoLib. Заходите на сервис, и нажимаете на пункт Анализ позиций — Разовая проверка позиций. Здесь Вы действуете следующим образом: вводите URL сайта, выбираете глубину проверки и вводите ключевые слова, каждое с новой строки. Ниже выбираете поисковые системы, по которым будет осуществляться проверка позиций сайта, и нажимаете Начать проверку.
Здесь Вы действуете следующим образом: вводите URL сайта, выбираете глубину проверки и вводите ключевые слова, каждое с новой строки. Ниже выбираете поисковые системы, по которым будет осуществляться проверка позиций сайта, и нажимаете Начать проверку.
Сайт XSeo.in
Работает аналогично. Заходите на сайт, и выбираете пункт Проверить позицию сайта. Вводите URL своего сайта, поисковый запрос, и поисковик. Затем нажимаете Проверить позиции. Сервис отличается быстротой и отсутствием глюков. По крайней мере, во время работы с ним у меня их не было. Приятно с ним работать, хотя и загружает только один ключевик и один поисковик за раз.
Сайт Webmasters.ru
Заходите на сайт, и заходите в пункт Определение позиций. Вводите адрес, определяете глубину анализа страниц — определяются только ключевые слова, находящиеся на двух первых страницах. И проверяете место Вашего сайта по нужным Вам запросам. Ключевики прописываются каждый с новой строки, до 30 штук.
Вводите адрес, определяете глубину анализа страниц — определяются только ключевые слова, находящиеся на двух первых страницах. И проверяете место Вашего сайта по нужным Вам запросам. Ключевики прописываются каждый с новой строки, до 30 штук.
Сайт MainSpy.ru
По образу действий похож на предыдущие. Заходите на сайт MainSpy.ru, и нажимаете на пункт меню Позиции сайта. Вводите в большом поле ключевики, каждый с новой строки, указываете адрес сайта в поле под словом Домен, вводите код региона Яндекса, и нажимаете кнопку Проверить. На сервисе также присутствуют другие функции. Можно, например, проверить скорость загрузки сайта.
Программа Site-Auditor
Теперь поговорим о программах, которые Вы скачиваете себе на компьютер. За этой программой заходите на сайт Site-Auditor, и переходите на закладку Скачать. Выбираете эту программу для своей операционной системы, скачиваете и запускаете. Программа не требует установки, и сразу начинает работать.
В окне программы вводите на закладке Экспресс-анализ адрес своего сайта. Переходите на закладку Подбор запросов, прописываете запросы, каждый с новой строки, и нажимаете на стрелку справа от окна. Затем нажимаете на кнопку Проверить, и смотрите, на каких позициях по данному ключевому запросу находится Ваш сайт в выдаче Яндекса и Google.
Вы можете отследить динамику движения позиций Вашего сайта в запросах по данным ключевым словам. В закладке Видимость сайта слева внизу Вы увидите даты Ваших проверок, и перейдя по ним, сможете посмотреть, какие позиции занимал Ваш сайт в те дни.
Более подробные сведения Вы можете получить в разделах «Все курсы» и «Полезности», в которые можно перейти через верхнее меню сайта. В этих разделах статьи сгруппированы по тематикам в блоки, содержащие максимально развернутую (насколько это было возможно) информацию по различным темам.
Также Вы можете подписаться на блог, и узнавать о всех новых статьях.
Это не займет много времени. Просто нажмите на ссылку ниже:
Подписаться на блог: Дорога к Бизнесу за Компьютером
Проголосуйте и поделитесь с друзьями анонсом статьи на Facebook:
Проверка позиций сайта в AllPositions от А до Я
06.06.2019
Ярослав Рушковский, SEO-специалист Webpromo
Так сложилось, что лучший способ оценить эффективность продвижения сайта в органическом поиске — замерить позиции. И сделать это можно в сервисе AllPositions. Причем работать там можно не только со своими проектами, но и с сайтами конкурентов. Впрочем, давайте лучше мы детально расскажем как это работает.
Содержание:- Начало работы
- Создаем проект
- Создание отчета позиций ключевых слов
- Добавляем ключевые запросы в отчет
- Полезные фишки системы
- Альтернативные сервисы замера позиций ключевых слов
- Выводы
Начало работы
Как и везде, все начинается с регистрации — http://allpositions.ru/user/registration/.
Стандартное окно регистрации:
Три поля для заполнения и можно приступать к работе. Не забудьте подтвердить регистрацию по отправленной на почту ссылке.
После регистрации вам достанется 1000 монет для тестирования работы сервиса. Монеты — это внутренняя валюта. Один замер одного ключевого слова стоит 1 монету. Потом монеты придется покупать за реальные деньги, но об этом позже.
Создаем проект
Каждый сайт, позиции по которому вы будете замерять, в сервисе называется проектом. После создания проекта переходите в отчеты http://allpositions.ru/reports/site_position/
На странице смело нажимайте кнопку “Добавить”.
Вo всплывающем окне заполните следующие поля:
- Название проекта (если оставить пустым, проект будет иметь название адреса сайта)
- Url проекта
После снова жмите на кнопку “Добавить”.
Новый проект создан. Теперь нужно создать отчет.
Создание отчета позиций ключевых слов
Позиции по интересующим ключевым запросам можно посмотреть только в отчете. Нажмите на “Добавить отчет”
Выполните три простых шага:
- Указывайте все домены сайта. Не забывайте отметить соответствующий пункт, если есть поддомены.
Если нет, оставляйте поле пустым и нажимайте “Далее”
- На втором шаге выбирайте поисковую систему, по которой будет происходить замер.
На данный момент из предустановленных стран доступны:
- Россия
- Украина
- Беларусь
Из поисковых систем:
- Яндекс
- Mail.ru
- Rambler
- Tut.by
Если интересует замер позиций по другим регионам, огорчаться не нужно. Это всего лишь предустановки. Более гибкую настройку можно выполнить нажав на кнопку “Добавить Яндекс”
Или “Добавить Google”
И да, замер позиций можно проводить сразу по нескольким поисковым системам. Потому никаких проблем не будет, если ваш сайт продвигается сразу на несколько регионов.
Для примера я выберу 4 системы — это Яндекс и Google в Украине и России
После выбора поисковых систем переходим к следующему шагу “Далее”.
- На третьем шаге указываем частоту сканирования.
Небольшая ремарка. Сервис AllPositions в большей степени интегрирован с поисковой системой Яндекс, поэтому в нем больше настроек связанных с ней.
Например, “Проверка позиций после апдейта Яндекса” и т.д.
Если хотите избежать автоматического списания средств системой, указывайте частоту “по требованию”.
Нажимаем “Добавить”.
Добавляем ключевые запросы в отчет
После настройки открывается возможность добавить в него ключевые запросы.
Кликайте на Добавить отчет” и указывайте интересующие поисковые запросы в появившемся окне. Каждый запрос с новой строки.
Если есть файл с собранным семантическим ядром для сайта, можно использовать функцию Импорта запросов.
После того как внесли все интересующие ключи, нажимайте на “Добавить”.
Сразу запуститься процесс замера позиций по указанным ключевым запросам. Останется лишь немного подождать… или много, если у вас большое количество запросов. Но, нужно отдать сервису должное, он работает довольно быстро.
О ходе работы сигнализирует индикатор в правой части страницы
Вот как выглядит отчет по позициям:
- Запросы, которые мы добавили сами.
- Частота (по умолчанию данные берутся из wordstat.yandex.ru).
- Поисковые системы (которые мы выбрали для отчета).
- Колонка с прочерками. В ней будет выводится информация, когда по запросам будет 2 и более замера позиций. Сама информация будет показывать тенденцию роста или спада запроса.
- Дата замера позиции.
Ссылка на сам отчет — http://allpositions.ru/reports/guest/index/860583/8e111a7cea1a82f553c3cfc8f14b19f3
Для создания подобной ссылки выбирайте “Отчет для клиентов” и нажимайте на “Отчет”
Полезные фишки системы
- В отчете можете посмотреть, какую страницу обнаружила система по каждому из запросов. Для этого необходимо нажать на цифру позиции напротив запроса.
- Каждому запросу можно задать целевой URL. Для этого нажимайте на сам ключевой запрос.
В появившемся окне прописывайте необходимый адрес страницы.
Поисковая система может отображать не ту страницу, которую вы продвигаете по целевому запросу, поэтому лучше это сделать.
Ускорить процесс поможет файл в формате .csv, в котором нужно прописать Запрос;URL. Обязательно разделите через точку с запятой. Каждый запрос с целевым урлом должны быть с новой строки. Например:
википедия;https://ru.wikipedia.org
кавказкая пленица;https://ru.wikipedia.org/wiki/
После используйте систему Импорта
- Используйте группировку запросов по посадочным страницам. Если кластеризованная семантика находится в соответствующих группах, анализ упрощается (особенно при больших объемах).Для этого создавайте файл в формате .csv и повторяйте все действия из пункта 2 (только вместо URL указывайте название группы).Или выбирайте нужные запросы в самом отчете.
Ниже выбирайте “Переместить в другую группу”.
После нажатия на “Применить” можете выбрать группу или создать новую.
После перемещения отфильтровать запросы можно в “Группе запросов”.
- Для изменения уже созданного отчета можно использовать:
- Добавить запрос (добавление новых запросов через интерфейс системы).
- Обновить отчет (запуск измерения позиций).
- Настройки (вызывает окно из пункта “Создание отчета позиций ключевых слов”).
- Свяжите аналитику и AllPositions. Это позволит вам видеть еще более полную картину по сайту. Сделать это можно в разделе “Статистика”.
- Пользуйтесь справкой, если непонятен какой-то из разделов.
Альтернативные сервисы замера позиций ключевых слов
Приведу альтернативные сервисы позволяющие замерять позиции:
- Search Console и/или Яндекс.Вебмастер
- Seranking.ru
- Topvisor.ru
- Serpstat.com
- Rush-Analytics.ru
- Rankinity.ru
- Seolib.ru
- Line.pr-cy.ru
У каждого из этих сервисов, несмотря на специфику и направленность, есть возможность замера позиций. Но только AllPositions является узконаправленным инструментом, позволяющим максимально просто замерять позиции как своего сайта, так и сайтов конкурентов.
Выводы
Сервис AllPositions прост в освоении и использовании. В нем можно получить ключевую информацию для анализа эффективности продвижения в органическом поиске. Гибкая система настройки и автоматизации отчетов делает сервис полезным и для SEO-специалистов, и для владельцев сайта.
Дом | Библиотечная система Юго-Восточной Оклахомы
Из New York Times, автор бестселлеров , Кристин Ханна выходит мощный роман о любви, потерях и волшебстве дружбы. . . .
Бурным летом 1974 года Кейт Муларки заняла свое место в конце восьмого класса социальной пищевой цепи. Затем, к ее изумлению, «самая крутая девушка в мире» переезжает через улицу и хочет стать ее другом. У Талли Харта, кажется, есть все — красота, ум, амбиции.На первый взгляд, они настолько противоположны, насколько могут быть два человека: Кейт, обреченная на вечную некрутью, с любящей семьей, которая унижает ее на каждом шагу. Талли, окутанная гламуром и таинственностью, но обладающая секретом, который ее разрушает. Они заключают договор, что навсегда останутся лучшими друзьями; к концу лета они стали TullyandKate. Неразлучный.
Так начинается новый великолепный роман Кристин Ханна. Firefly Lane , охватывающая более трех десятилетий и разыгрывающая постоянно меняющееся лицо Тихоокеанского Северо-Запада, — это трогательная, яркая история двух женщин и дружбы, которая становится переборкой в их жизни.
С самого начала Талли отчаянно пытается доказать миру свою ценность. Брошенная матерью в раннем возрасте, она жаждет безоговорочной любви. В блестящую эпоху восьмидесятых с длинными волосами она смотрит на мужчин, чтобы заполнить пустоту в ее душе. Но в застегнутые девяностые ее увлекают телевизионные новости. Она будет следовать своим слепым амбициям в Нью-Йорке и по всему миру, обретая славу и успех. . . и одиночество.
Кейт рано понимает, что в ее жизни не будет ничего особенного.Во время учебы в колледже она делает вид, что ее движет потребность в успехе, но на самом деле все, чего она хочет, — это влюбиться, завести детей и жить обычной жизнью. По-своему тихо Кейт такая же целеустремленная, как и Талли. Чего она не знает, так это того, как быть женой и матерью ее изменит. . . как она потеряет из виду то, кем была когда-то и чего хотела. И как сильно она позавидует своей знаменитой лучшей подруге. . . .
В течение тридцати лет Талли и Кейт поддерживают друг друга на протяжении всей жизни, преодолевая бури дружбы — ревность, гнев, обиду, негодование.Они думают, что пережили все это, пока один-единственный акт предательства не разлучит их на части. . . и подвергает их храбрость и дружбу последнему испытанию.
Firefly Lane для всех, кто когда-либо пил яблочное вино Boone’s Farm, слушая Abba или Fleetwood Mac. Это больше, чем роман о взрослении, это история о поколении женщин, которые были одновременно благословлены и прокляты своим выбором. Речь идет об обещаниях, секретах и предательствах. И, наконец, об одном человеке, который действительно, действительно знает вас — и знает, что может причинить вам боль.. . и исцелить вас. Firefly Lane — это история, которую вы никогда не забудете. . . тот, который вы захотите передать своему лучшему другу.
Как использовать Python для анализа данных SEO: справочное руководство
Вы обнаруживаете, что выполняете одни и те же повторяющиеся задачи SEO каждый день или сталкиваетесь с проблемами, когда нет инструментов, которые могут вам помочь?
Если да, возможно, вам пора выучить Python.
Начальные затраты времени и пота окупятся значительным увеличением производительности.
Пока я пишу эту статью в первую очередь для профессионалов SEO, которые плохо знакомы с программированием, я надеюсь, что она будет полезна тем, у кого уже есть опыт работы в программном обеспечении или Python, но кто ищет простой для сканирования ссылка для использования в проектах анализа данных.
Оглавление
Реклама
Продолжить чтение ниже
Основы Python
Python прост в освоении, и я рекомендую вам потратить день на изучение официального руководства.Я собираюсь сосредоточиться на практических приложениях для SEO.
При написании программ на Python вы можете выбрать между Python 2 или Python 3. Лучше писать новые программы на Python 3, но возможно, что ваша система может поставляться с уже установленным Python 2, особенно если вы используете Mac. Пожалуйста, также установите Python 3, чтобы использовать эту шпаргалку.
Вы можете проверить свою версию Python, используя:
$ python --version
Использование виртуальных сред
По завершении работы важно убедиться, что другие люди в сообществе могут воспроизвести ваши результаты.Им нужно будет установить те же сторонние библиотеки, которые вы используете, часто с теми же версиями.
Python поощряет создание для этого виртуальных сред.
Если ваша система поставляется с Python 2, загрузите и установите Python 3 с помощью дистрибутива Anaconda и выполните эти шаги в командной строке.
Объявление
Продолжить чтение ниже
$ sudo easy_install pip $ sudo pip install virtualenv $ mkdir seowork $ virtualenv -p python3 seowork
Если вы уже используете Python 3, выполните следующие альтернативные шаги в командной строке:
$ mkdir seowork $ python3 -m venv seowork
Следующие шаги позволяют работать с любой версией Python и позволяют использовать виртуальные среды.
$ cd seowork $ исходный бункер / активировать (seowork) $ deactivate
Когда вы деактивируете среду, вы возвращаетесь в командную строку, и библиотеки, которые вы установили в среде, не работают.
Полезные библиотеки для анализа данных
Каждый раз, когда я начинаю проект анализа данных, мне нравится иметь как минимум следующие установленные библиотеки:
Большинство из них входят в состав дистрибутива Anaconda. Давайте добавим их в нашу виртуальную среду.
(seowork) Запросы на установку $ pip3 (seowork) $ pip3 установить matplotlib (seowork) $ pip3 install requests-html (seowork) $ pip3 install pandas
Вы можете импортировать их в начале кода следующим образом:
запросов на импорт из requests_html импорта HTMLSession import pandas as pd
Поскольку вам требуется больше сторонних библиотек в ваших программах, вам нужен простой способ отслеживать их и помогать другим легко настраивать ваши скрипты.
Вы можете экспортировать все библиотеки (и их номера версий), установленные в вашей виртуальной среде, используя:
(seowork) $ pip3 freeze> requirements.txt
Когда вы делитесь этим файлом с вашим проектом, кто-либо другой из сообщество может установить все необходимые библиотеки с помощью этой простой команды в своей виртуальной среде:
(peer-seowork) $ pip3 install -r requirements.txt
Использование Jupyter Notebooks
При анализе данных я предпочитаю использовать Jupyter ноутбуки, поскольку они обеспечивают более удобную среду, чем командная строка.Вы можете проверить данные, с которыми вы работаете, и написать свои программы в исследовательской манере.
(seowork) $ pip3 install jupyter
Затем вы можете запустить ноутбук, используя:
(seowork) $ jupyter notebook
Вы получите URL-адрес для открытия в вашем браузере.
В качестве альтернативы вы можете использовать Google Colaboratory, который является частью GoogleDocs и не требует настройки.
Форматирование строк
В своих программах вы потратите много времени на подготовку строк для ввода в различные функции.Иногда вам нужно объединить данные из разных источников или преобразовать из одного формата в другой.
Допустим, вы хотите программно получить данные Google Analytics. Вы можете создать URL-адрес API с помощью Google Analytics Query Explorer и заменить значения параметров в API заполнителями с помощью скобок. Например:
Объявление
Продолжить чтение ниже
api_uri = "https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&" \
"start-date = {start} & end-date = {end} & metrics = {metrics} &" \
"sizes = {sizes} & segment = {segment} & access_token = {token} &" \
"max-results = {max_results}" {gaid} — это учетная запись Google, т.е.например, «ga: 12345678»
{start} — это дата начала, то есть «2017-06-01»
{end} — дата окончания, то есть «2018-06-30»
{metrics } — это список числовых параметров, например «ga: users», «ga: newUsers»
{sizes} — это список категориальных параметров, например, «ga: landingPagePath», «ga: date»
{ сегмент} — это маркетинговые сегменты. Для SEO нам нужен органический поиск, который представляет собой «gaid :: — 5»
{token} — это токен доступа безопасности, который вы получаете из Google Analytics Query Explorer.Срок его действия истекает через час, и вам нужно снова запустить запрос (во время аутентификации), чтобы получить новый.
{max_results} — максимальное количество результатов для возврата до 10 000 строк.
Вы можете определить переменные Python для хранения всех этих параметров. Например:
gaid = "ga: 12345678" . start = "2017-06-01" end = "2018-06-30"
Это позволяет довольно легко получать данные с нескольких веб-сайтов или диапазонов данных.
Наконец, вы можете объединить параметры с URL-адресом API для создания действительного запроса API для вызова.
api_uri = api_uri.format ( gaid = gaid, старт = старт, конец = конец, метрики = метрики, размеры = размеры, сегмент = сегмент, токен = токен, max_results = max_results )
Python заменит каждый заполнитель соответствующим значением из передаваемых нами переменных.
Объявление
Продолжить чтение ниже
String Encoding
Encoding — еще один распространенный метод обработки строк. Многие API требуют определенного формата строк.
Например, если один из ваших параметров является абсолютным URL-адресом, вам необходимо закодировать его, прежде чем вставлять его в строку API с заполнителями.
из синтаксического анализа импорта urllib url = "https://www.searchenginejournal.com/" parse.quote (url)
Результат будет выглядеть так: ‘https% 3A // www.searchchenginejournal.com/ ’, который можно безопасно передать в запрос API.
Другой пример: предположим, вы хотите создать теги заголовков, содержащие амперсанд (&) или угловые скобки (<,>). Их нужно избегать, чтобы не сбивать с толку парсеры HTML.
импорт HTML title = "SEO <Новости и учебные пособия>" html.escape (title)
Результат будет выглядеть так:
'SEO & lt; News & amp; Учебники & gt; '
Аналогичным образом, если вы читаете закодированные данные, вы можете вернуть их обратно.
html.unescape (escaped_title)
Результат будет снова читаться, как оригинал.
Форматирование даты
Анализ данных временных рядов очень распространен, и значения даты и времени могут иметь множество различных форматов. Python поддерживает преобразование дат в строки и обратно.
Например, после того, как мы получим результаты из Google Analytics API, мы можем захотеть проанализировать даты в объектах datetime. Это упростит их сортировку или преобразование из одного строкового формата в другой.
Объявление
Продолжить чтение ниже
от даты, времени, импорта, даты и времени
dt = datetime.strptime ('5 января 2018 г. 18:33', '% b% d% Y% I:% M% p') Здесь% b,% d и т. Д. — это директивы, поддерживаемые strptime ( используется при чтении дат) и strftime (используется при их записи). Вы можете найти полную ссылку здесь.
Создание запросов API
Теперь, когда мы знаем, как форматировать строки и создавать правильные запросы API, давайте посмотрим, как мы на самом деле выполняем такие запросы.
r = requests.get (api_uri)
Мы можем проверить ответ, чтобы убедиться, что у нас есть действительные данные.
печать (r.status_code) print (r.headers ['content-type'])
Вы должны увидеть код состояния 200. Типом содержимого большинства API-интерфейсов обычно является JSON.
При проверке цепочек переадресации можно использовать параметр истории переадресации, чтобы увидеть всю цепочку.
print (r.history)
Чтобы получить окончательный URL, используйте:
print (r.url)
Извлечение данных
Большая часть вашей работы — это сбор данных, необходимых для проведения анализа. Данные будут доступны из разных источников и форматов. Давайте рассмотрим самые распространенные.
Чтение из JSON
Большинство API-интерфейсов возвращают результаты в формате JSON. Нам нужно разобрать данные в этом формате в словарях Python. Для этого вы можете использовать стандартную библиотеку JSON.
Объявление
Продолжить чтение ниже
import json
json_response = '{"website_name": "Журнал поисковой системы", "website_url": "https: // www.searchchenginejournal.com/ "} '
parsed_response = json.loads (json_response) Теперь вы можете легко получить доступ к любым нужным вам данным. Например:
print (parsed_response ["website_name"])
Результатом будет:
"Search Engine Journal"
Когда вы используете библиотеку запросов для выполнения вызовов API, вам не нужно сделать это. Объект ответа предоставляет для этого удобное свойство.
parsed_response = r.json ()
Чтение со страниц HTML
Большая часть данных, необходимых для SEO, будет на клиентских веб-сайтах. Несмотря на то, что недостатка в отличных поисковых роботах для SEO нет, важно научиться сканировать себя, чтобы делать такие необычные вещи, как автоматическая группировка страниц по типам страниц.
из requests_html import HTMLSession
сеанс = HTMLSession ()
r = session.get ('https://www.searchenginejournal.com/') Вы можете получить все абсолютные ссылки, используя это:
print (r.html.absolute_links)
Частичный вывод будет выглядеть так:
{'http://jobs.searchenginejournal.com/', 'https://www.searchenginejournal.com/what-i-learned-about -seo-this-year / 281301 / ',…} Затем давайте извлечем некоторые общие теги SEO с помощью XPATH:
Заголовок страницы
r.html.xpath (' // title / text () ') Результат:
[' Журнал поисковых систем - SEO, новости и учебные пособия по поисковому маркетингу ']
Мета-описание
r.html.xpath ("// meta [@ name = 'description'] / @ content") Обратите внимание, что я изменил стиль кавычек с одинарных на двойные, иначе я получу ошибку кодирования.
Результат:
[«Search Engine Journal посвящен выпуску последних новостей поиска, лучших руководств и практических рекомендаций для сообщества SEO и маркетологов».]
Canonical
r. html.xpath ("// ссылка [@ rel = 'canonical'] / @ href") Результат:
['https: // www.searchchenginejournal.com/ ']
URL AMP
r.html.xpath ("// ссылка [@ rel =' amphtml '] / @ href") Search Engine Journal не имеет URL AMP.
Meta Robots
Реклама
Продолжить чтение ниже
r.html.xpath ("// meta [@ name = 'ROBOTS'] / @ content") Результат:
['NOODP']
h2s
r.html.xpath ("// h2") На домашней странице журнала поисковой системы нет h2s.
Значения атрибутов HREFLANG
r.html.xpath ("// link [@ rel = 'alternate'] / @ hreflang") Search Engine Journal не имеет атрибутов hreflang.
Проверка сайта Google
r.html.xpath ("// meta [@ name = 'google-site-verify'] / @ content") Результат:
['NcZlh5TFoRGYNheLXgcrcx9g ', 'd0L0giSu_RtW_hg8i6GRzu68N3d4e7nmPlZNA9sCc5s', 'S-Orml3wOAaAplwsb19igpEZzRibTtnctYrg46pGTzA']
Рендеринг JavaScript
Если страница, которую вы анализируете, требует рендеринга JavaScript, вам нужно только добавить дополнительную строку кода для поддержки этого.
из requests_html import HTMLSession
сеанс = HTMLSession ()
r = session.get ('https://www.searchenginejournal.com/')
r.html.render () Первый запуск render () займет некоторое время, поскольку будет загружен Chromium. Рендеринг Javascript намного медленнее, чем без рендеринга.
Чтение из запросов XHR
Поскольку отрисовка JavaScript выполняется медленно и требует много времени, вы можете использовать этот альтернативный подход для веб-сайтов, которые загружают содержимое JavaScript с помощью запросов AJAX.
Снимок экрана, показывающий, как проверить заголовки запроса файла JSON с помощью инструментов разработчика Chrome. Путь к файлу JSON будет выделен, как и заголовок x-request-with.ajax_request = 'https: //www.searchenginejournal.com/location.json' г = requests.get (ajax_request) results = r.json ()
Вы получите нужные данные быстрее, поскольку не требует рендеринга JavaScript или даже анализа HTML.
Реклама
Продолжить чтение ниже
Чтение журналов сервера
Google Analytics — мощный инструмент, но он не регистрирует и не отображает посещения от большинства сканеров поисковых систем.Мы можем получить эту информацию прямо из файлов журнала сервера.
Давайте посмотрим, как мы можем анализировать файлы журналов сервера, используя регулярные выражения в Python. Вы можете проверить регулярное выражение, которое я использую здесь.
импорт по log_line = '66 .249.66.1 - - [06 / Янв / 2019: 14: 04: 19 +0200] "GET / HTTP / 1.1" 200 - "" "Mozilla / 5.0 (совместимый; Googlebot / 2.1; + http: / /www.google.com/bot.html) "' регулярное выражение = '([(\ d \.)] +) - - \ [(. *?) \] \ "(. *?) \" (\ D +) - \ "(. *?) \" \ "(. *?) \" ' группы = re.совпадение (регулярное выражение, строка) .groups () печать (группы)
В выводе каждый элемент записи журнала красиво разбивается:
('66 .249.66.1 ', '06 / январь / 2019: 14: 04: 19 +0200', 'GET / HTTP /1.1 ',' 200 ',' ',' Mozilla / 5.0 (совместимый; Googlebot / 2.1; + http: //www.google.com/bot.html) ') Вы получаете доступ к строке пользовательского агента в группе шесть, но списки в Python начинаются с нуля, так что это пять.
печать (группы [5])
Результат:
'Mozilla / 5.0 (совместимый; Googlebot / 2.1; + http: //www.google.com/bot.html) '
Вы можете узнать о регулярных выражениях в Python здесь. Обязательно ознакомьтесь с разделом о жадных и нежадных выражениях. Я использую нежадный при создании групп.
Проверка робота Googlebot
При выполнении анализа журнала для понимания поведения поискового бота важно исключить любые поддельные запросы, поскольку любой может выдать себя за робота Google, изменив строку пользовательского агента.
Google предлагает простой способ сделать это здесь.Давайте посмотрим, как это автоматизировать с помощью Python.
Объявление
Продолжить чтение ниже
импортный разъем bot_ip = "66.249.66.1" хост = socket.gethostbyaddr (bot_ip) print (host [0])
Вы получите crawl-66-249-66-1.googlebot.com
ip = socket.gethostbyname (host [0])
Получите ‘ 66.249.66.1 ‘, что показывает, что у нас есть реальный IP-адрес робота Googlebot, поскольку он соответствует нашему исходному IP-адресу, который мы извлекли из журнала сервера.
Чтение с URL-адресов
Часто упускаемый из виду источник информации — это фактические URL-адреса веб-страниц. Большинство веб-сайтов и систем управления контентом содержат обширную информацию в URL-адресах. Посмотрим, как это извлечь.
Можно разбить URL-адреса на их компоненты с помощью регулярных выражений, но гораздо проще и надежнее использовать для этого стандартную библиотеку urllib .
из urllib.parse import urlparse url = "https: //www.searchenginejournal.com /? s = google & search-orderby = релевантность & searchfilter = 0 & search-date-from = январь + 1% 2C + 2016 & search-date-to = январь + 7% 2C + 2019 " parsed_url = urlparse (url) print (parsed_url)
Результат:
ParseResult (scheme = 'https', netloc = 'www.searchenginejournal.com', path = '/', params = '', query = 's = google & search -orderby = релевантность & searchfilter = 0 & search-date-from = январь + 1% 2C + 2016 & search-date-to = январь + 7% 2C + 2019 ', fragment =' ')
Например, вы можете легко получить доменное имя и путь к каталогу, используя:
print (parsed_url.netloc) print (parsed_url.path)
Это приведет к тому, что вы ожидаете.
Мы можем дополнительно разбить строку запроса, чтобы получить параметры URL и их значения.
parsed_query = parse_qs (parsed_url.query) print (parsed_query)
На выходе вы получаете словарь Python.
{'s': ['google'],
'search-date-from': ['1 января 2016'],
'search-date-to': ['7 января 2019'],
"порядок поиска": ["релевантность"],
'searchfilter': ['0']} Мы можем продолжить и проанализировать строки даты в объектах Python datetime, что позволит вам выполнять операции с датой, такие как вычисление количества дней между диапазоном.Я оставлю это вам в качестве упражнения.
Реклама
Продолжить чтение ниже
Другой распространенный метод, который можно использовать в вашем анализе, — разбить часть пути URL-адреса с помощью «/», чтобы получить части. Это просто сделать с помощью функции разделения.
url = "https://www.searchenginejournal.com/category/digital-experience/"
parsed_url = urlparse (url)
parsed_url.path.split ("/") Результатом будет:
['', 'category', 'digital-experience', '']
Когда вы разделите пути URL таким образом, вы можете использовать это, чтобы сгруппировать большую группу URL-адресов по их верхним каталогам.
Например, вы можете найти все продукты и все категории на веб-сайте электронной торговли, если это позволяет структура URL.
Выполнение базового анализа
Большую часть времени вы потратите на приведение данных в правильный формат для анализа. Часть анализа относительно проста, если вы знаете, какие вопросы задавать.
Давайте начнем с загрузки сканирования Screaming Frog в фреймворк pandas.
импорт панд как pd
df = pd.DataFrame (pd.read_csv ('internal_all.csv', header = 1, parse_dates = ['Last Modified']))
print (df.dtypes) Вывод показывает все столбцы, доступные в файле Screaming Frog, и их типы Python. Я попросил pandas преобразовать столбец Last Modified в объект datetime Python.
Давайте проведем несколько примеров анализа.
Объявление
Продолжить чтение ниже
Группировка по каталогу верхнего уровня
Во-первых, давайте создадим новый столбец с типом страниц, разделив пути URL-адресов и извлекая имя первого каталога.
df ['Тип страницы'] = df ['Адрес']. Apply (lambda x: urlparse (x) .path.split ("/") [1])
aggregated_df = df [['Тип страницы', 'Количество слов']]. Groupby (['Тип страницы']). Agg ('сумма')
print (aggregated_df) После создания столбца «Тип страницы» мы группируем все страницы по типу и общему количеству слов. Частично результат выглядит так:
seo-guide 736 SEO-внутренние-ссылки-лучшие-практики 2012 SEO-ключевое слово-аудит 2104 SEO-риски 2435 SEO-инструменты 588 SEO-тренды 3448 seo-Trends-2019 2676 seo-value 1528
Группировка по коду состояния
status_code_df = df [['Код состояния', 'Адрес']].groupby (['Код состояния']). agg ('count')
печать (status_code_df)
200 218
301 6
302 5 Листинг временных перенаправлений
temp_redirects_df = df [df ['Status Code'] == 302] ['Address'] печать (temp_redirects_df) 50 https: //www.searchenginejournal.com/wp-content ... 116 https: //www.searchenginejournal.com/wp-content ... 128 https://www.searchenginejournal.com/feed 154 https: //www.searchenginejournal.com/wp-content ... 206 https: //www.searchenginejournal.com / wp-content ...
Страницы с пустыми списками
no_content_df = df [(df ['Status Code'] == 200) & (df ['Word Count'] == 0)] [[ «Адрес», «Количество слов»]] 7 https: //www.searchenginejournal.com/author/cor ... 0 9 https: //www.searchenginejournal.com/author/vic ... 0 66 https: //www.searchenginejournal.com/author/ada ... 0 70 https: //www.searchenginejournal.com/author/ron ... 0
Публикационная активность
Давайте посмотрим, в какое время дня в SEJ публикуется больше всего статей.
lastmod = pd.DatetimeIndex (df ['Последнее изменение']) writing_activity_df = df.groupby ([lastmod.hour]) ['Адрес']. Count () 0,0 19 1.0 55 2,0 29 10,0 10 11,0 54 18,0 7 19,0 31 20,0 9 21,0 1 22.0 3
Интересно отметить, что в обычное рабочее время не так много изменений.
Мы можем построить это прямо из панд.
writing_activity_df.plot.bar ()Столбиковая диаграмма, показывающая время дня, когда статьи публикуются в журнале Search Engine Journal.Гистограмма была создана с использованием Python 3.
Сохранение и экспорт результатов
Теперь мы переходим к простой части — сохранению результатов нашей тяжелой работы.
Объявление
Продолжить чтение ниже
Сохранение в Excel
writer = pd.ExcelWriter (no_content.xlsx ') no_content_df.to_excel (писатель, "Результаты") writer.save ()
Сохранение в CSV
Временный_редиректс_df.to_csv ('временный_редирект.csv ') Дополнительные ресурсы для получения дополнительных сведений
Мы едва коснулись поверхности того, что возможно, если вы добавите скрипты Python в свою повседневную работу по поисковой оптимизации. Вот несколько ссылок для дальнейшего изучения.
Дополнительные ресурсы:
Кредиты изображений
Снимок экрана, сделанный автором, январь 2019 г.
Гистограмма, созданная автором, январь 2019 г.
garmeeh / next-seo: Следующий SEO — это плагин, который упрощает управление вашим SEO в Next.js проектов.
Next SEO — это плагин, который упрощает управление SEO в проектах Next.js.
Запросы на вытягивание приветствуются. Также не забудьте проверить проблемы для запросов функций, если вы ищу вдохновение, что добавить.
Хотите поддержать этот бесплатный плагин?
Содержание
Использование
NextSeo работает, включая его на страницы, где вы хотите добавить атрибуты SEO.После включения на страницу вы передаете ей объект конфигурации со свойствами SEO страницы. Это может быть динамически сгенерировано на уровне страницы, или в некоторых случаях ваш API может возвращать объект SEO.
Настройка
Сначала установите:
npm install --save next-seo
или
Добавить SEO на страницу
Затем нужно импортировать NextSeo и добавить нужные свойства. Это отобразит теги в для SEO.Как минимум, вы должны добавить заголовок и описание.
Пример с заголовком и описанием:
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
Простое использование
);
экспортировать страницу по умолчанию; Но NextSeo дает вам гораздо больше возможностей, которые вы можете добавить. См. Ниже типичный пример страницы.
Пример типовой страницы:
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
SEO добавлено на страницу
);
экспортировать страницу по умолчанию; Заметка в Твиттере Теги
Twitter будет читать теги og: title , og: image и og: description своей карты. next-seo опускает twitter: title , twitter: image и twitter: description , чтобы избежать дублирования.
Некоторые инструменты могут сообщать об ошибке. См. Выпуск № 14
.Конфигурация SEO по умолчанию
NextSeo позволяет вам установить некоторые свойства SEO по умолчанию, которые будут отображаться на всех страницах, без необходимости включать в них что-либо. При необходимости вы также можете переопределить их для каждой страницы.
Для этого вам необходимо создать собственный .В каталоге страниц создайте новый файл _app.js . См. Документацию Next.js здесь для получения дополнительной информации о пользовательском .
В этом файле вам нужно будет импортировать DefaultSeo из next-seo и передать ему props.
Вот типичный пример:
импорт приложения, {контейнер} из следующего / приложения;
импортировать {DefaultSeo} из 'next-seo';
// импортируем вашу конфигурацию seo по умолчанию
импортировать SEO из '../next-seo.config';
экспорт класса по умолчанию MyApp extends App {
оказывать() {
const {Component, pageProps} = это.реквизит;
возвращаться (
<Контейнер>
Для правильной работы DefaultSeo должен быть размещен над (перед) Компонент из-за поведения Next.js внутренности.
Кроме того, вы также можете создать файл конфигурации для хранения значений по умолчанию, таких как next-seo.config.js
экспорт по умолчанию {
openGraph: {
тип: 'сайт',
локаль: 'en_IE',
url: 'https://www.url.ie/',
site_name: 'SiteName',
},
twitter: {
ручка: '@handle',
site: '@site',
cardType: 'summary_large_image',
},
}; импорт вверху _app.js
импортировать SEO из '../next-seo.config';
и компонент DefaultSeo можно использовать как это вместо
С этого момента на всех ваших страницах будут применяться указанные выше значения по умолчанию.
Обратите внимание, что Контейнер устарел в Next.js v9.0.4, поэтому вам следует заменить этот компонент здесь на React.Fragment в этой версии и более поздних версиях — см. Здесь
Опции NextSeo
| Имущество | Тип | Описание |
|---|---|---|
Заголовок Шаблон | строка | Позволяет вам установить шаблон заголовка по умолчанию, который будет добавлен к вашему заголовку Подробнее |
титул | строка | Установить мета-заголовок страницы |
по умолчанию Название | строка | Если на странице не задан заголовок, эта строка будет использоваться вместо пустого titleTemplate Подробнее |
noindex | логическое (по умолчанию false) | Устанавливает, нужно ли индексировать страницу. Подробнее |
nofollow | логическое (по умолчанию false) | Устанавливает, следует ли переходить на страницу или нет. Подробнее |
дополнение | ||
описание | строка | Установить мета-описание страницы |
канонический | строка | Установить канонический url страницы |
мобильный Альтернативный.СМИ | строка | Установите размер экрана, на котором должен отображаться мобильный веб-сайт, начиная с | .
mobileAlternate.href | строка | Установить альтернативный URL мобильной страницы |
языкАльтернаты | массив | Установите язык альтернативных URL-адресов. Ожидает массив объектов с формой: {hrefLang: string, href: string} |
дополнительные метатеги | массив | Позволяет добавить метатег, который здесь не задокументирован.Подробнее |
дополнительная ссылка Теги | массив | Позволяет добавить тег ссылки, который здесь не задокументирован. Подробнее |
twitter.cardType | строка | Тип карты, который будет одним из summary , summary_large_image , app или player |
twitter.site | строка | @ имя пользователя веб-сайта, используемого в нижнем колонтитуле карты |
twitter.ручка | строка | @username для создателя / автора контента (выводится как twitter: creator ) |
facebook.appId | строка | Используется для Facebook Insights, вы должны добавить на свою страницу идентификатор приложения facebook. Подробнее |
openGraph.url | строка | Канонический URL вашего объекта, который будет использоваться в качестве его постоянного идентификатора на графике |
openGraph.тип | строка | Тип вашего объекта. В зависимости от указанного типа могут потребоваться и другие свойства. Подробнее |
openGraph.title | строка | Заголовок открытого графика, он может отличаться от вашего мета-заголовка. |
openGraph.description | строка | Описание открытого графика, оно может отличаться от вашего метаописания. |
openGraph.изображения | массив | Массив изображений (объект), который будет использоваться платформами социальных сетей, Slack и т. Д. В качестве предварительного просмотра. Если предоставлено несколько, вы можете выбрать один при совместном использовании. См. Примеры |
openGraph.videos | массив | Массив видео (объект) |
openGraph.locale | строка | Локаль, в которой размечены теги открытого графика. Формат language_TERRITORY.По умолчанию en_US. |
openGraph.site_name | строка | Если ваш объект является частью большого веб-сайта, имя, которое должно отображаться для всего сайта. |
openGraph.profile.firstName | строка | Имя человека. |
openGraph.profile.lastName | строка | Фамилия человека. |
openGraph.profile.username | строка | Имя пользователя. |
openGraph.profile.gender | строка | Пол человека. |
openGraph.book.authors | строка [] | Авторы статьи. См. Примеры |
openGraph.book.isbn | строка | ISBN |
openGraph.book.releaseDate | дата и время | Дата выпуска книги. |
openGraph.book.tags | строка [] | Отметьте слова, связанные с этой книгой. |
openGraph.article.publishedTime | дата и время | Когда статья была впервые опубликована. См. Примеры |
openGraph.article.modifiedTime | дата и время | Время последнего изменения статьи. |
openGraph.article.expirationTime | дата и время | Когда статья устарела после. |
openGraph.article.authors | строка [] | Авторы статьи. |
openGraph.article.section | строка | Имя раздела высокого уровня. Например. Технологии |
openGraph.article.tags | строка [] | Ключевые слова, связанные с этой статьей. |
Шаблон заголовка
Заменяет % s на строку заголовка
title = 'Это мой титул'; titleTemplate = 'Следующее SEO | % s '; // выходы: Следующее SEO | Это мой титул
title = 'Это мой титул'; titleTemplate = '% s | Следующее SEO '; // выводит: Это мой заголовок | Следующее SEO
Название по умолчанию
заголовок = undefined; titleTemplate = 'Следующее SEO | % s '; defaultTitle = 'Следующее SEO'; // выводит: Следующее SEO
Без индекса
Установка этого значения на true установит noindex, следуйте за (чтобы установить nofollow , обратитесь к nofollow ).Это работает постранично. Это свойство работает в тандеме со свойством nofollow , и вместе они заполняют метатеги robots и googlebot .
Примечание: Свойства noindex и nofollow немного отличаются от всех остальных в том смысле, что их установка по умолчанию не работает должным образом. Это связано с тем, что Next SEO уже имеет индекс по умолчанию , следуйте за , потому что next-seo в конце концов является плагином SEO.Поэтому, если вы хотите глобально использовать эти свойства, см. ОпасныеSetAllPagesToNoIndex и опасноSetAllPagesToNoFollow.
Пример без индекса на одной странице:
Если у вас есть одна страница, которую вы не хотите проиндексировать, вы можете добиться этого с помощью:
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
Эта страница не проиндексирована
);
экспортировать страницу по умолчанию;
/ *
* / опасноSetAllPagesToNoIndex
Он имеет префикс , опасно , потому что он будет noindex для всех страниц.Поскольку это плагин для SEO, это довольно опасное действие. Это , а не плохо использовать это, просто убедитесь, что вы хотите noindex КАЖДУЮ страницу . Вы все равно можете переопределить это на уровне страницы, если у вас есть вариант использования для индексирования страницы. Это можно сделать, установив noindex: false .
Единственный способ отключить это - удалить опору из DefaultSeo в вашем пользовательском .
Нет подписки
Установка этого значения на true установит индекс , nofollow (чтобы установить noindex , обратитесь к noindex ).Это работает постранично. Это свойство работает в тандеме со свойством noindex , и вместе они заполняют метатеги robots и googlebot .
Примечание: В отличие от других свойств, установка noindex и nofollow по умолчанию не работает должным образом. Это потому, что Next SEO по умолчанию имеет индекс , следуйте за , поскольку next-seo в конце концов является плагином SEO. Если вы хотите разрешить эти свойства глобально, см. «ОпасноSetAllPagesToNoIndex» и «опасноSetAllPagesToNoFollow».
Пример № Следуйте на одной странице:
Если у вас есть одна страница, которую вы не хотите проиндексировать, вы можете добиться этого с помощью:
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
На эту страницу не подписаны
);
экспортировать страницу по умолчанию;
/ *
* / опасноSetAllPagesToNoFollow
Он имеет префикс , опасно , потому что nofollow всех страниц.Поскольку это плагин для SEO, это довольно опасное действие. Это , а не плохо использовать это, просто убедитесь, что вы хотите nofollow КАЖДУЮ страницу. Вы все равно можете переопределить это на уровне страницы, если у вас есть вариант использования, чтобы следовало за страницей. Это можно сделать, установив nofollow: false .
Единственный способ отключить это - удалить опору из DefaultSeo в вашем пользовательском .
noindex | nofollow | мета содержание роботов , googlebot |
|---|---|---|
| – | – | индекс , следовать за (по умолчанию) |
| ложь | ложь | индекс , следовать |
| правда | – | noindex, следовать |
| правда | ложь | noindex, следовать |
| – | правда | индекс, nofollow |
| ложь | правда | индекс, nofollow |
| правда | правда | noindex, nofollow |
роботов Опоры
В дополнение к индексу , следуйте за , метатег robots принимает больше свойств, чтобы архивировать более точное сканирование и предоставлять лучшие фрагменты для роботов SEO, которые сканируют вашу страницу.
Пример:
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
Дополнительные реквизиты для роботов в Next-SEO !!
);
экспортировать страницу по умолчанию;
/ *
* / Доступные объекты
| Имущество | Тип | Описание |
|---|---|---|
нет архива | логический | Не показывать кешированную ссылку в результатах поиска. |
носниппет | логический | Не показывать фрагмент текста или превью видео в результатах поиска для этой страницы. |
max-snippet | номер | Используйте максимум [число] символов в качестве текстового фрагмента для этого результата поиска. Узнать больше |
max-image-preview | «нет», «стандартный», «большой» | Установите максимальный размер предварительного просмотра изображения для этой страницы в результатах поиска. |
max-video-preview | номер | Используйте максимум [число] секунд в качестве фрагмента видео для видео на этой странице в результатах поиска. Узнать больше |
notranslate | логический | Не предлагать перевод этой страницы в результатах поиска. |
noimageindex | логический | Не индексируйте изображения на этой странице. |
недоступен_после | строка | Не показывать эту страницу в результатах поиска после указанной даты / времени.Дата / время должны быть указаны в широко распространенном формате, включая, помимо прочего, RFC 822, RFC 850 и ISO 8601. |
Для получения дополнительной информации о X-Robots-Tag посетите Центр поиска Google - Управление сканированием и индексированием
Твиттер
Twitter будет читать теги og: title , og: image и og: description для своей карты, поэтому next-seo опускает twitter: title , twitter: image и twitter : description так что не дублировать.
Некоторые инструменты могут сообщать об ошибке. См. Выпуск № 14
. facebook = {{
appId: '1234567890',
}} Добавьте это в конфигурацию SEO, чтобы включить мета fb: app_id, если вам нужно включить аналитику Facebook для вашего сайта. Информацию об этом можно найти в документации facebook
.Канонический URL
Добавьте это для каждой страницы на странице, если вы хотите объединить повторяющиеся URL-адреса.
canonical = 'https: //www.canonical.т.е. / ';
Заместитель
Это отношение ссылки используется для обозначения связи между настольным компьютером и мобильным веб-сайтом для поисковых систем.
Пример:
mobileAlternate = {{
media: 'только экран и (max-width: 640px)',
href: 'https://m.canonical.ie',
}} languageAlternates = {[{
hrefLang: 'де-АТ',
href: 'https://www.canonical.ie/de',
}]} Дополнительные метатеги
Это позволяет вам добавлять любые другие метатеги, которые не включены в конфигурацию .
содержание является обязательным. Затем либо name , property , либо httpEquiv . (Только по одному на каждую)
Пример:
additionalMetaTags = {[{
свойство: 'dc: creator',
содержание: "Джейн Доу"
}, {
имя: 'имя-приложения',
содержание: 'NextSeo'
}, {
httpEquiv: 'x-ua-совместимый',
содержание: 'IE = edge; хром = 1 '
}]} Неверные примеры:
Они недействительны, поскольку они содержат более одного из name , property и httpEquiv в одной и той же записи.
additionalMetaTags = {[{
свойство: 'dc: creator',
name: 'dc: creator',
содержание: "Джейн Доу"
}, {
свойство: 'имя-приложения',
httpEquiv: 'имя-приложения',
содержание: 'NextSeo'
}]} Следует отметить, что в настоящее время он поддерживает только уникальные теги.
Это означает, что он будет отображать только один тег на одно уникальное имя / свойство / httpEquiv . Будет отображен последний определенный.
Пример:
Если вы сдадите:
additionalMetaTags = {[{
свойство: 'dc: creator',
content: 'Джон Доу'
}, {
свойство: 'dc: creator',
содержание: "Джейн Доу"
}]} это приведет к рендерингу:
,
Дополнительные теги ссылок
Это позволяет добавлять любые другие теги ссылок, которые не включены в конфигурацию .
rel и href .
Пример:
additionalLinkTags = {[
{
rel: 'значок',
href: 'https://www.test.ie/favicon.ico',
},
{
rel: 'яблоко-сенсорный-значок',
href: 'https://www.test.ie/touch-icon-ipad.jpg',
размеры: 76x76
},
{
rel: 'манифест',
href: '/manifest.json'
}
]} это приведет к рендерингу:
<ссылка rel = "значок касания яблока" href = "https: // www.test.ie/touch-icon-ipad.jpg " />
Открыть график
Полную спецификацию можно найти на http://ogp.me/
Next SEO в настоящее время поддерживает:
Примеры открытых графиков
Базовый
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
Базовый
);
экспортировать страницу по умолчанию; Примечание
Несколько образов доступно в next.js версии 7.0.0-canary.0
Для версий 6.0.0 - 7.0.0-canary.0 вам просто нужно указать один массив элементов:
изображений: [
{
url: 'https://www.example.ie/og-image-01.jpg',
ширина: 800,
высота: 600,
alt: 'Og Image Alt',
},
], Подача нескольких изображений ничего не сломает, но только одно будет добавлено к голове.
Видео
Вся информация на http://ogp.me/
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
SEO страницы видео
);
экспортировать страницу по умолчанию; Примечание
Несколько образов доступно в версии next.js 7.0.0-canary.0
Для версий 6.0.0 - 7.0.0-canary.0 вам просто нужно указать один массив элементов:
изображений: [
{
url: 'https: // www.example.ie/og-image-01.jpg ',
ширина: 800,
высота: 600,
alt: 'Og Image Alt',
},
], Подача нескольких изображений ничего не сломает, но только одно будет добавлено к голове.
Статья
. импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
Статья
);
экспортировать страницу по умолчанию; Примечание
Множественные изображения, авторы, теги доступны из следующего.js версия 7.0.0-canary.0
Для версий 6.0.0 - 7.0.0-canary.0 вам просто нужно указать один массив элементов:
изображений:
изображений: [
{
url: 'https://www.example.ie/og-image-01.jpg',
ширина: 800,
высота: 600,
alt: 'Og Image Alt',
},
], авторов:
авторов: [ 'https://www.example.com/authors/@firstnameA-lastnameA', ],
теги:
Подача нескольких из любого из вышеперечисленных ничего не сломает, но только один будет добавлен в голову.
Книга
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
Книга
);
экспортировать страницу по умолчанию; Примечание
Множественные изображения, авторы, теги доступны в next.js версии 7.0,0-канарейка 0
Для версий 6.0.0 - 7.0.0-canary.0 вам просто нужно указать один массив элементов:
изображений:
изображений: [
{
url: 'https://www.example.ie/og-image-01.jpg',
ширина: 800,
высота: 600,
alt: 'Og Image Alt',
},
], авторов:
авторов: [ 'https://www.example.com/authors/@firstnameA-lastnameA', ],
теги:
Подача нескольких из любого из вышеперечисленных ничего не сломает, но только один будет добавлен в голову.
Профиль
импортировать {NextSeo} из 'next-seo';
const Page = () => (
<>
Профиль
);
экспортировать страницу по умолчанию; Примечание
Несколько образов доступно в версии next.js 7.0.0-canary.0
Для версий 6.0.0 - 7.0.0-canary.0 вам просто нужно указать один массив элементов:
изображений: [
{
url: 'https: // www.example.ie/og-image-01.jpg ',
ширина: 800,
высота: 600,
alt: 'Og Image Alt',
},
], Подача нескольких изображений ничего не сломает, но только одно будет добавлено к голове.
JSON-LD
Next SEO теперь имеет возможность установить JSON-LD в виде структурированных данных. Структурированные данные - это стандартизированный формат для предоставления информации о странице и классификации содержимого страницы.
У Google отличный контент на JSON-LD -> ЗДЕСЬ
Ниже вы найдете очень простую страницу, реализующую каждый из доступных типов JSON-LD:
Запрос на извлечение приветствуется, чтобы добавить любой из списка, найденного здесь
Обработка нескольких экземпляров
Если для вашей страницы требуется несколько экземпляров данного компонента JSON-LD, вы можете указать уникальные свойства keyOverride , а next-seo выполнит все остальное.
Это удобно для обзоров блогов, результатов поиска и обзорных страниц.
Пожалуйста, внимательно изучите, когда следует и не следует добавлять несколько экземпляров JSON-LD.
Артикул
. импортировать {ArticleJsonLd} из 'next-seo';
const Page = () => (
<>
Статья JSON-LD
<СтатьяJsonLd
url = "https://example.com/article"
title = "Заголовок статьи"
images = {[
https: // example.com / photos / 1x1 / photo.jpg ',
'https://example.com/photos/4x3/photo.jpg',
'https://example.com/photos/16x9/photo.jpg',
]}
datePublished = "2015-02-05T08: 00: 00 + 08: 00"
dateModified = "2015-02-05T09: 00: 00 + 08: 00"
authorName = {['Джейн Блоги', 'Мэри Стоун']}
publisherName = "Гэри Михан"
publisherLogo = "https://www.example.com/photos/logo.jpg"
description = "Это очень хорошее описание этой статьи."
/>
);
экспортировать страницу по умолчанию; Панировочные сухари
import {BreadcrumbJsonLd} из next-seo;
const Page = () => (
<>
Наверх JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
itemListElements | |
itemListElements.позиция | Положение хлебной крошки в следе хлебных крошек. Позиция 1 обозначает начало следа. |
itemListElements.name | Название строки навигации, отображаемой для пользователя. |
itemListElements.item | URL-адрес веб-страницы, которая представляет собой хлебную крошку. |
Блог
импорт {BlogJsonLd} из 'next-seo';
const Page = () => (
<>
Блог JSON-LD
Рецепт
импортировать {RecipeJsonLd} из 'next-seo';
const Page = () => (
<>
Рецепт JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
название | Название рецепта |
описание | Описание рецепта |
Автор Имя | Имя автора рецепта.Может быть строкой или массивом строк. |
ингредиенты | Список строк ингредиентов |
инструкции | – |
инструкция. Имя | Имя шага инструкции. |
инструкции. Текст | Направления шага инструкции. |
Поле поиска дополнительных ссылок
импортировать {SiteLinksSearchBoxJsonLd} из "next-seo";
const Page = () => (
<>
Окно поиска дополнительных ссылок JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
url | URL-адрес веб-сайта, связанного с окном поиска дополнительных ссылок |
потенциал Действия | Массив из одного или двух объектов SearchAction.Описывает URI для отправки запроса и синтаксис отправляемого запроса |
possibleActions.target | Для веб-сайтов - URL-адрес обработчика, который должен получать и обрабатывать поисковый запрос. для приложений - URI обработчика намерений для вашей поисковой системы, которая должна обрабатывать запросы |
PotentialActions.queryInput | Заполнитель, используемый в цели, заменяется запросом, заданным пользователем |
Курс
импортировать {CourseJsonLd} из 'next-seo';
const Page = () => (
<>
Курс JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
Название курса | Название курса. |
описание | Описание курса. Предел отображения 60 символов. |
Имя провайдера | Имя провайдера курса. |
Рекомендуемые свойства
| Имущество | Информация |
|---|---|
providerUrl | URL-адрес провайдера курса. |
Набор данных
import {DatasetJsonLd} из next-seo;
const Page = () => (
<>
Набор данных JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
описание | Краткое описание набора данных. Должно быть от 50 до 5000 символов. |
наименование | Лицензия, по которой распространяется набор данных. |
Рекомендуемые свойства
| Имущество | Информация |
|---|---|
лицензия | URL-адрес провайдера курса. |
Корпоративный контакт
импортировать {CorporateContactJsonLd} из next-seo;
const Page = () => (
<>
Корпоративный контакт JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
url | Ссылка на главную страницу официального сайта компании. |
contactPoint | |
contactPoint.telephone | Интернационализированная версия телефонного номера, начинающаяся с символа «+» и кода страны | .
contactPoint.contactType | Описание назначения номера телефона т.е. Служба технической поддержки . |
Рекомендуемые свойства ContactPoint
| Имущество | Информация |
|---|---|
contactPoint.areaServed | Строка или Массив географических регионов, обслуживаемых компанией. Пример «США» или [«США», «Калифорния», «MX»] |
contactPoint.availableЯзык | Подробная информация о используемом языке. Пример «английский» или [«английский», «французский»] |
gecontactPointo.contactOption | Подробная информация о номере телефона. Пример «TollFree» |
Страница часто задаваемых вопросов
импортировать {FAQPageJsonLd} из next-seo;
const Page = () => (
<>
Страница часто задаваемых вопросов JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
mainEntity | |
mainEntity.questionName | Полный текст вопроса.Например, «Сколько времени занимает доставка?». |
mainEntity.acceptedAnswerText | Полный ответ на вопрос. |
Объявление о вакансии
импорт {JobPostingJsonLd} из "next-seo";
const Page = () => (
<>
Публикация вакансии JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
datePosted | Исходная дата, когда работодатель разместил вакансию в формате ISO 8601 |
описание | Полное описание вакансии в формате HTML |
Организация по найму | |
Организация найма.название | Название компании, предлагающей вакансию |
hiringOrganization.sameAs | URL-адрес справочной веб-страницы |
титул | Название должности (не название публикации) |
действующий Через | Дата истечения срока действия объявления о вакансии в формате ISO 8601 |
Поддерживаемые объекты
| Имущество | Информация | |
|---|---|---|
заявитель Местоположение Требования | Географическое положение (а), в котором могут находиться сотрудники, чтобы иметь право на удаленную работу | |
базовая зарплата | ||
базовая зарплата.валюта | Валюта, в которой выражена денежная сумма | |
baseSalary.value | Значение количественного значения. Вы также можете указать минимальную и максимальную заработную плату. . | |
baseSalary.unitText | Строка, указывающая единицу измерения Норма базовой заработной платы | |
занятость Тип | Тип занятости Указание по типу занятости | |
рабочее место | Физическое (ые) местонахождение (а) предприятия, в котором сотрудник будет приходить на работу (например, офис или рабочее место), а не место, где была размещена вакансия. | |
jobLocation.streetAddress | Почтовый адрес. Например, 1600 Amphitheatre Pkwy | .|
jobLocation.addressLocality | Населенный пункт. Например, Маунтин-Вью. | |
jobLocation.addressRegion | Регион. Например, CA. | |
jobLocation.postalCode | Почтовый индекс. Например, | |
jobLocation.адресСтрана | Страна. Например, США. Вы также можете указать двухбуквенный код страны ISO 3166-1 alpha-2. | |
jobLocationType | Описание места работы Типовое руководство | |
hiringOrganization.logo | Логотипы на сторонних сайтах по поиску работы Руководство организации по найму |
Местный бизнес
Местный бизнес поддерживается подмножеством свойств.
', долгота: '-121.988331', }} images = {[ https: // example.com / photos / 1x1 / photo.jpg ', 'https://example.com/photos/4x3/photo.jpg', 'https://example.com/photos/16x9/photo.jpg', ]} sameAs = {[ 'www.company-website-url1.dev', 'www.company-website-url2.dev', 'www.company-website-url3.dev', ]} openHours = {[ { открывается: '08: 00 ', закрывается: '23: 59 ', день недели: [ 'Понедельник', 'Вторник', 'Среда', 'Четверг', 'Пятница', 'Суббота', ], действительно с: '2019-12-23', validThrough: '2020-04-02', }, { открывается: '14: 00 ', закрывается: '20: 00 ', dayOfWeek: 'Воскресенье', действительно с: '2019-12-23', validThrough: '2020-04-02', }, ]} рейтинг = {{ ratingValue: '4.5 ', ratingCount: '2', }} обзор = {[ { автор: 'Джон Доу', Дата публикации: '2006-05-04', название: 'Шедевр литературы', reviewBody: 'Я действительно наслаждался этой книгой. В нем отражены основные проблемы, с которыми сталкиваются люди, пытаясь осмыслить свою жизнь и взрослеть », reviewRating: { bestRating: '5', худший рейтинг: '1', reviewAspect: 'Ambiance', ratingValue: '4', }, }, { автор: 'Боб Смит', Дата публикации: '2006-06-15', name: «Хорошее чтение.', reviewBody: «Над пропастью во ржи - забавная книга. Это хорошая книга для чтения.», reviewRating: { ratingValue: '4', }, }, ]} makeOffer = {[ { priceSpecification: { тип: 'UnitPriceSpecification', priceCurrency: 'EUR', цена: '1000-10000', }, itemOffered: { название: 'Услуги моушн-дизайна', описание: «Мы являемся экспертом в области анимации и моушн-дизайна», }, }, { priceSpecification: { тип: 'UnitPriceSpecification', priceCurrency: 'EUR', цена: '2000-10000', }, itemOffered: { name: 'Услуги по брендингу', описание: «Реальные кадры - мощный инструмент, чтобы показать, чем занимается бизнес.Может использоваться для презентации вашей компании, демонстрации фабрики, рекламы упаковки продукта или просто рассказа любой истории. Это может помочь создать эмоциональные связи с вашей аудиторией, показывая яркие изображения. ', }, }, ]} areaServed = {[ { geoMidpoint: { широта: '41 .108237 ', долгота: '-80.642982', }, geoRadius: '1000', }, { geoMidpoint: { широта: '51 .108237 ', долгота: '-80.642982', }, geoRadius: '1000', }, ]} action = {{ actionName: 'possibleAction', actionType: 'ReviewAction', target: 'https: // www.example.com/review/this/business ', }} />
Обязательные объекты
| Имущество | Информация |
|---|---|
@id | Глобальный уникальный идентификатор конкретного местоположения компании в виде URL-адреса. |
тип | LocalBusiness или любой подтип |
адрес | Адрес местонахождения конкретного предприятия |
адрес.адресСтрана | Двухбуквенный код страны ISO 3166-1 alpha-2 |
адрес. Адрес Местность | Город |
адрес. АдресРегион | Штат или провинция, если применимо. |
адрес. Почтовый индекс | Почтовый индекс. |
address.streetAddress | Номер улицы, название улицы и номер квартиры. |
наименование | Фирменное наименование. |
Поддерживаемые объекты
| Имущество | Информация |
|---|---|
описание | Описание местонахождения предприятия |
geo | Географические координаты предприятия. |
географическая широта | Широта местонахождения предприятия |
географическая долгота | Долгота местонахождения предприятия |
рейтинг | Средняя оценка компании на основе нескольких оценок или отзывов. |
рейтинг. Номинальное значение | Рейтинг контента. |
рейтинг.Рейтинг Количество | Подсчет общего количества оценок. |
цена Ассортимент | Относительный ценовой диапазон бизнеса. |
обслуживает Кухня | Тип кухни, которую обслуживает ресторан. |
изображений | Изображение или изображения компании.Требуется для действующей разметки в зависимости от типа |
телефон | Рабочий телефонный номер, который будет основным средством связи для клиентов. |
url | Полный URL-адрес конкретного местоположения компании. |
как | Массив URL-адресов, представляющих эту компанию |
Часы работы | График работы бизнеса.Вы можете предоставить это как один объект или как массив объектов со свойствами, указанными ниже. |
часов открывания | Время работы заведения или услуги в данный день (дни) недели. |
открытиеЧасов закрытие | Время закрытия заведения или услуги в данный день (дни) недели. |
открытиеЧасов.деньНедели | День недели, для которого действительны эти часы работы.Может быть строкой или массивом строк. Обратитесь к DayOfWeek |
часов открытия действителен От | Дата, когда элемент становится действительным. |
часов открытия. Действ. Через | Дата, после которой позиция недействительна. |
обзор | Обзор местного бизнеса. |
отзыв. Автор | Автор этого материала или рейтинга. |
обзор. ОтзывBody | Собственно тело обзора. |
отзыв Дата публикации | Дата первого эфира / публикации. |
отзыв. Имя | Название предмета. |
обзор. Рейтинг | Оценка в этом обзоре |
обзор. Номинальное значение | Рейтинг контента. |
обзор. Рейтинг. Обзор Aspect | Этот отзыв или рейтинг имеет отношение к этой части или аспекту проверяемого элемента. |
review.rating.worstRating | Наименьшее значение, разрешенное в этой рейтинговой системе. Если худший рейтинг опущен, предполагается, что 1. |
review.rating.bestRating | Наибольшее значение, разрешенное в этой рейтинговой системе. Если bestRating не указан, предполагается, что 5 |
областей Обслужено | Географическая область, в которой предоставляется услуга или предлагаемый товар. |
областей Обслужено.GeoCircle | GeoCircle - это GeoShape, представляющий круговую географическую область. |
областейServed.GeoCircle.geoMidpoint | Указывает географические координаты в центре GeoShape, например. GeoCircle. |
областейServed.GeoCircle.geoMidpoint.latitude | Широта места. Например 37,42242 |
обслуженных площадей.GeoCircle.geoMidpoint.longitude | Название предмета. |
областейServed.GeoCircle.geoRadius | Указывает приблизительный радиус GeoCircle (в метрах, если иное не указано в обозначении расстояния). |
марокПредложение | Указатель на продукты или услуги, предлагаемые организацией или лицом. |
производителейПредложение | Предложение передать права на товар или оказать услугу |
марокПредложение.offer.priceSpecification | Одна или несколько подробных ценовых спецификаций с указанием цены за единицу и стоимости доставки или оплаты. |
марокПредложение.предложение.ценаСпецификация.ценаВалюта | Валюта цены или ценовой компонент, если он привязан к PriceSpecification и ее подтипам. |
производитПредложение.предложение.ценаСпецификация.цена | Цена предложения продукта или ценового компонента, прикрепленная к PriceSpecification и ее подтипам. |
делаетПредложение.Предлагаемый товар | Товар, который предлагается (или требуется) |
делаетOffer.offer.itemOffered.name | Наименование товара |
производитПредложение.предложение.описание | Описание товара. |
действие | Действие, выполняемое прямым агентом и косвенными участниками над прямым объектом. |
action.target | Указывает целевую точку входа для действия. |
ПРИМЕЧАНИЕ:
Изображения рекомендуются для большинства типов, которые вы можете использовать для LocalBusiness , в случае сомнений вам следует добавить изображение. Вы можете проверить сгенерированный JSON в Инструменте проверки структурированных данных Google
Логотип
импортировать {LogoJsonLd} из next-seo;
const Page = () => (
<>
Логотип JSON-LD
| Имущество | Информация |
|---|---|
url | URL-адрес веб-сайта, связанного с логотипом. Руководство по логотипу |
логотип | URL-адрес логотипа, представляющего организацию. |
Продукт
импорт {ProductJsonLd} из next-seo;
const Page = () => (
<>
Продукт JSON-LD
Также доступны: артикул , gtin8 , gtin13 , gtin14 .
Допустимые значения для предложений. Item Условие :
Действительные значения для предложений. Доступность :
Недвижимость агрегатПредложение также доступно:
(Игнорируется, если установлено предложений )
Обязательные объекты
| Имущество | Информация |
|---|---|
низкая Цена | Самая низкая цена из всех доступных предложений. Используйте число с плавающей запятой. | Цена
Валюта | Валюта, используемая для описания цены продукта в трехбуквенном формате ISO 4217. |
Рекомендуемые свойства
| Имущество | Информация |
|---|---|
высокая Цена | Самая высокая цена из всех доступных предложений. Используйте число с плавающей запятой. |
предложение Количество | Количество предложений по товару. |
Более подробную информацию о типе данных продукта можно найти здесь.
Социальный профиль
импортировать {SocialProfileJsonLd} из next-seo;
const Page = () => (
<>
Социальный профиль JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
тип | Лицо или организация |
наименование | Имя человека или организации |
url | URL-адрес официального веб-сайта человека или организации. |
как | Массив URL-адресов официальных страниц профиля человека или организации в социальных сетях |
Социальные профили, поддерживаемые Google
- Твиттер
- Google+
- YouTube
- Myspace
- SoundCloud
- Tumblr
Новость Артикул
импортировать {NewsArticleJsonLd} из next-seo;
const Page = () => (
<>
Новостная статья JSON-LD
Документы Google для социального профиля
Видео
импортировать {VideoJsonLd} из next-seo;
const Page = () => (
<>
Видео JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
название | Название видео. |
описание | Описание видео. HTML-теги игнорируются. |
thumbnailUrl | URL-адрес, указывающий на файл миниатюрного изображения видео. |
Дата загрузки | Дата первой публикации видео в формате ISO 8601. |
Рекомендуемые свойства
| Имущество | Информация |
|---|---|
contentUrl | URL-адрес, указывающий на фактический медиафайл видео в одном из поддерживаемых форматов кодирования. |
продолжительность | Продолжительность видео в формате ISO 8601 |
embedUrl | URL-адрес, указывающий на проигрыватель определенного видео. |
срок действия истекает | Если применимо, дата, после которой видео больше не будет доступно. |
Взаимодействие Статистика | Количество просмотров видео. |
публикация | Если ваше видео транслируется в прямом эфире, и вы хотите иметь право на значок LIVE. |
регионов Разрешено | Регионы, в которых разрешено видео. |
Событие
импорт {EventJsonLd} из "next-seo";
const Page = () => (
<>
Событие JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
название | Название события |
Дата начала | Дата начала и время события в формате iso8601 |
конечная дата | Дата и время окончания события в формате iso8601 |
местонахождение | Тип места с вложенным типом адреса |
Поддерживаемые объекты
| Имущество | Информация |
|---|---|
описание | Описание события |
расположение.то же, что | Описание места проведения |
изображений | Изображение или изображения события. |
url | Полный URL-адрес события. |
предложений | Предложение передать права на объект или предоставить услугу. Вы можете предоставить это как один объект или как массив объектов со свойствами, указанными ниже. |
исполнителей | Все артисты, которые выступают на этом мероприятии.Вы можете предоставить это как один объект или как массив объектов со свойствами, указанными ниже. |
исполнителей. Наименование | Имя исполнителя |
предлагает Обязательные объекты
| Имущество | Информация |
|---|---|
предложений. Цена | Стоимость оферты |
предложений.ценаВалюта | Валюта предложения |
предложений Рекомендуемые свойства
| Имущество | Информация |
|---|---|
предложений.priceValidДо | До истечения срока действия цены предложения |
предлагает. ТоварСостояние | Состояние товара или услуги |
предложений. Наличие | Наличие этого товара - например, «В наличии», «Нет в наличии», «Предзаказ» и т. Д. |
предложений.url | URL товара |
предложений. Продавец | Лицо, продающее этот товар |
предложений.seller.name | Имя человека |
Собственность совокупностьПредложение также доступно:
(Игнорируется, если установлено предложений )
Обязательные объекты
| Имущество | Информация |
|---|---|
низкая Цена | Самая низкая цена из всех доступных предложений. Используйте число с плавающей запятой. | Цена
Валюта | Валюта, используемая для описания цены продукта в трехбуквенном формате ISO 4217. |
Рекомендуемые свойства
| Имущество | Информация |
|---|---|
высокая Цена | Самая высокая цена из всех доступных предложений. Используйте число с плавающей запятой. |
предложение Количество | Количество предложений по товару. |
Для справки и дополнительной информации см. Google Search Event DataType
Вопросы и ответы
Страницы вопросов и ответов - это веб-страницы, содержащие данные в формате вопросов и ответов, то есть один вопрос, за которым следуют ответы.
import {QAPageJsonld} из next-seo;
const Page = () => (
<>
Страница вопросов и ответов JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
mainEntity | Вопрос для этой страницы должен быть вложен в свойство mainEntity компонента QAPageJsonld. |
mainEntity Обязательные свойства
| Имущество | Информация |
|---|---|
answerCount | Общее количество ответов на вопрос. |
принято Ответить или предложено Ответить | Чтобы иметь право на расширенный результат, вопрос должен иметь по крайней мере один ответ - acceptAnswer или предложенныйAnswer. |
наименование | Полный текст краткой формы вопроса. |
mainEntity Поддерживаемые свойства
| Имущество | Информация |
|---|---|
автор | Автор вопроса. |
дата создания | Дата добавления вопроса на страницу в формате ISO-8601. |
текст | Полный текст развернутой формы вопроса. |
проголосовать за | Общее количество голосов, полученных за этот вопрос. |
принято Ответить / предложено Ответ Обязательные свойства
| Имущество | Информация |
|---|---|
текст | Полный текст ответа. |
принято Ответить / предложено Ответ Поддерживаемые свойства
| Имущество | Информация |
|---|---|
автор | Автор вопроса. |
дата создания | Дата добавления вопроса на страницу в формате ISO-8601. |
проголосовать за | Общее количество голосов, полученных за этот вопрос. |
url | URL-адрес, который ведет непосредственно на этот ответ. |
Для справки и дополнительной информации см. Google Search Q&A DataType
Страница коллекции
Страницы коллекции - это веб-страницы. Неявно предполагается, что каждая веб-страница имеет тип WebPage, поэтому могут использоваться различные свойства этой веб-страницы, такие как хлебные крошки. Мы рекомендуем явное объявление, если эти свойства указаны, но если они находятся за пределами области элементов, предполагается, что они относятся к странице.
импорт {CollectionPageJsonLd} из 'next-seo';
const Page = () => (
<>
Страница коллекции JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
название | Название предмета. |
имеет часть | Обозначает элемент или CreativeWork, который является частью этого элемента, или CreativeWork (в некотором смысле). |
Поддерживаемые объекты
| Имущество | Информация |
|---|---|
hasPart.creativeWork | Самый общий вид творческой работы, включая книги, фильмы, фотографии, программы и т. Д. |
creativeWork Обязательные свойства
| Имущество | Информация |
|---|---|
имеет Деталь.creativeWork.author | Автор этого материала или рейтинга. Обратите внимание, что особенность автора заключается в том, что HTML 5 предоставляет специальный механизм для указания авторства с помощью тега rel. Это эквивалентно этому и может использоваться как взаимозаменяемые. |
hasPart.creativeWork. Около | Предмет содержания. |
hasPart.creativeWork.date Дата публикации | Дата первого эфира / публикации. |
hasPart.creativeWork.name | Название предмета. |
creativeWork Поддерживаемые свойства
| Имущество | Информация |
|---|---|
hasPart.creativeWork.audience | Целевая аудитория, т.е. группа, для которой что-то было создано. |
hasPart.creativeWork.keywords | Ключевые слова или теги, используемые для описания этого содержания.Несколько записей в списке ключевых слов обычно разделяются запятыми. |
hasPart.creativeWork.thumbnailUrl | Уменьшенное изображение, относящееся к Вещи. |
hasPart.creativeWork.image | Изображение предмета. Это может быть URL-адрес или полностью описанный ImageObject. |
Для справки и дополнительной информации см. Тип данных
страницы сбора.Профильная страница
Страницы профиля - это веб-страницы.Неявно предполагается, что каждая веб-страница имеет тип WebPage, поэтому могут использоваться различные свойства этой веб-страницы, такие как хлебные крошки. Мы рекомендуем явное объявление, если эти свойства указаны, но если они находятся за пределами области элементов, предполагается, что они относятся к странице.
импортировать {ProfilePageJsonLd} из "next-seo";
const Page = () => (
<>
Страница профиля JSON-LD
Обязательные объекты
| Имущество | Информация |
|---|---|
панировочные сухари | Набор ссылок, которые могут помочь пользователю понять и перемещаться по иерархии веб-сайта, представленной в виде строки или BreadcrumbList. |
Поддерживаемые объекты
| Имущество | Информация |
|---|---|
последняя просмотренная | Дата последней проверки содержимого этой веб-страницы на точность и / или полноту. |
Для справки и дополнительной информации проверьте страницу профиля DataType
Карусель
Обязательные свойства компонента карусели
| Имущество | Информация |
|---|---|
тип | Тип карусели |
данные | Данные в виде массива для списка элементов в карусели |
По умолчанию (Сводный список)
импортировать React из React;
импортировать {CarouselJsonLd} из "next-seo";
экспорт по умолчанию () => (
<>
Карусель по умолчанию JSON-LD
Требуемые данные Свойства
| Имущество | Информация |
|---|---|
url | URL-адрес страницы с подробным описанием товара. |
Курс
импортировать React из React;
импортировать {CarouselJsonLd} из "next-seo";
экспорт по умолчанию () => (
<>
Карусельный курс JSON-LD
Требуемые данные Свойства
| Имущество | Информация |
|---|---|
Название курса | Название курса. |
описание | Описание курса.Предел отображения 60 символов. |
Имя провайдера | Имя провайдера курса. |
url | URL-адрес страницы с подробным описанием товара. |
Данные Рекомендуемые свойства
| Имущество | Информация |
|---|---|
providerUrl | URL-адрес провайдера курса. |
Фильм
импортировать React из React;
импортировать {CarouselJsonLd} из "next-seo";
экспорт по умолчанию () => (
<>
Фильм "Карусель" JSON-LD
Требуемые данные Свойства
| Имущество | Информация |
|---|---|
название | Название фильма. |
изображение | Изображение, представляющее фильм. |
url | URL-адрес страницы с подробным описанием товара. |
Данные Рекомендуемые свойства
| Имущество | Информация |
|---|---|
директор | Режиссеры фильма. |
дата создания | Дата выхода фильма в прокат. |
агрегат Рейтинг | Объект совокупного рейтинга для фильма. |
обзор | Рецензия на фильм. |
Рецепт
импортировать React из React;
импортировать {CarouselJsonLd} из "next-seo";
экспорт по умолчанию () => (
<>
Рецепт карусели JSON-LD
Требуемые данные Свойства
| Имущество | Информация |
|---|---|
название | Название блюда. |
описание | Описание рецепта |
Автор Имя | Имя автора рецепта |
ингредиенты | Список строк ингредиентов |
инструкции | – |
инструкция. Имя | Имя шага инструкции. |
инструкции.текст | Направления шага инструкции. |
url | URL-адрес страницы с подробным описанием товара. |
Программное обеспечение
импортировать React из React;
импортировать {SoftwareAppJsonLd} из 'next-seo';
экспорт по умолчанию () => (
<>
Программное приложение JSON-LD
Требуемые данные Свойства
| Имущество | Информация |
|---|---|
название | Название приложения. |
цена | Цена апп. Если приложение бесплатное, установите offer.price на 0 | . Цена
Валюта | Если цена приложения больше 0, вы должны включить предложения.валюта. |
агрегат Рейтинг | Средняя оценка приложения по отзывам. (Не требуется при наличии обзора.) |
обзор | Единый обзор приложения. (Не требуется, если присутствует aggregateRating.) |
Данные Рекомендуемые свойства
| Имущество | Информация |
|---|---|
Операционная система | Режиссеры фильма. |
приложение Категория | Дата выхода фильма в прокат. |
Чтобы получить справку и дополнительную информацию, обратитесь к документации Google для программного обеспечения
.Авторы
Спасибо этим замечательным людям (смайлик):
Этот проект соответствует спецификации всех участников. Любые пожертвования приветствуются!
8+ лучших сервисов по отслеживанию позиций на сайте. Выберите тот, который вам подходит
Руководство покупателя по отслеживанию рейтинга сайта
Отслеживание позиции (также называемое отслеживанием рейтинга или отслеживанием поисковой выдачи) позволяет отслеживать ежедневный рейтинг веб-сайта для настраиваемого набора целевых ключевых слов.Вы можете настроить таргетинг на просмотр любого конкретного географического местоположения и любого типа устройства (мобильный телефон, планшет или компьютер). Инструмент поставляется с множеством функций, таких как теги, сортировка, фильтрация и экспорт отчетов, которые позволяют маркетологам легко находить именно то, что они ищут, с точки зрения эффективности SEO или PPC.
- Возможность отслеживать любое ключевое слово и домен - даже те, которых нет в основной базе данных SEMrush
- отслеживание и сравнение нескольких географических местоположений или типов устройств в одном проекте
- Отчет по избранным сниппетам для поиска возможностей использования избранных сниппетов
- Простое отслеживание локального SEO и обнаружение местных конкурентов
- Простая отчетность в формате PDF для обмена результатами с коллегами и клиентами
Почему вам следует использовать отслеживание позиции?
Независимо от вашей специализации в области SEO, вы можете выполнять поисковую оптимизацию на странице, писать контент, создавать ссылки или проводить технические аудиты. Скорее всего, вам придется измерить влияние своей работы на рейтинг веб-сайта.Это особенно верно, если ваш веб-сайт работает в локальном пространстве, поскольку результаты Google могут сильно измениться в зависимости от геолокации.
Кроме того, поскольку мир мобильного поиска продолжает расти, вы, вероятно, увидите большой потенциальный трафик, исходящий от мобильных пользователей. Чтобы узнать, где находится ваш веб-сайт в мобильных и локальных результатах, необходимо отслеживать позицию.
Во время проведения кампании вы можете использовать отслеживание позиции, чтобы увидеть, как ваши усилия отражаются на изменениях рейтинга, и узнать, какие страницы получают наибольший трафик по вашим целевым ключевым словам.Вы сможете определять самые слабые страницы, которые нужно улучшить, и отслеживать позиции конкурентов из одного места.
Чтобы помочь вам не отставать от функций поисковой выдачи в вашей нише, функция отслеживания позиции определит все уникальные функции поисковой выдачи, которые можно найти в поисковой выдаче по вашим ключевым словам. Мы также предлагаем отчет, в котором показаны возможности вашего веб-сайта после использования избранных фрагментов.
Ежедневные обновления и еженедельные отчеты по электронной почте помогут вам расставить приоритеты в работе, когда вы попытаетесь своевременно достичь своих целей.Если вы обслуживаете клиентов, SEMrush упрощает создание экспорта данных и чистых PDF-файлов, чтобы сообщать о ваших успехах напрямую клиентам.
«Воспоминаний о округе Джефферсон» | Новости, Спорт, Работа
ГОТОВ, УСТАНОВЛЕН, ЗАПИСАТЬ ИСТОРИЮ - Эрика Граббс, местный специалист по генеалогии / библиотекарь в филиале Скьяппа Публичной библиотеки Стьюбенвилля и округа Джефферсон, рада запуску «Воспоминаний округа Джефферсон», устного исторического проекта для постоянных посетителей, чтобы поделиться своими рассказы через аудиозаписи, загруженные в базу данных библиотеки Digital Shoebox.- Дженис Киаски,
STEUBENVILLE - Публичная библиотека Стьюбенвилля и округа Джефферсон надеется, что жители района захотят ностальгировать по старым добрым временам и поделиться своими историями с помощью аудиозаписей как уникального способа сохранить местную историю.
Это часть текущего проекта устной истории под названием «Воспоминания округа Джефферсон», и он готов к запуску.
Все, что ему нужно, - это покровители библиотечной системы, которые заинтересованы и готовы обсудить любое количество тем в уединении своего дома или, если они того пожелают, в обстановке библиотечного собеседования с Эрикой Граббс, специалистом по генеалогии / библиотекарем в Филиал Скьяппа.
Так или иначе, Граббс в восторге от нового предприятия - его возможностей и влияния.
«Он еще не начался, и у него нет ограничений по времени», - сказал Граббс в недавнем интервью о том, как цель проекта состоит в сборе, сохранении и передаче воспоминаний и историй жителей с помощью аудиозаписей. Рассказы будут доступны общественности для прослушивания на долгие годы.
Они будут загружены в базу данных библиотеки Digital Shoebox.Digital Shoebox предлагает оцифрованные фотографии, книги и документы, собранные библиотеками на юго-востоке Огайо. Его можно получить, посетив веб-сайт www.steubenvillelibrary.org во вкладке «Услуги», затем нажмите «История и генеалогия».
Пятнадцать диктофонов и футляры для них были приобретены для «Воспоминаний округа Джефферсон» благодаря «щедрому пожертвованию», сделанному библиотеке.
«Человек, который хочет остаться неизвестным, пожертвовал деньги в честь Алана Холла в качестве благодарности за все годы службы, которые он отдал библиотеке и сообществу в целом», - сказал Граббс о ныне вышедшем на пенсию директоре, который работал в библиотеке. библиотеке уже почти четыре десятилетия, и у кого была любовь и страсть к истории.
«Я всегда думал, что это будет здорово, - сказал Граббс. «У меня так много постоянных посетителей, которые будут рассказывать мне о своих воспоминаниях о детстве в разных общинах округа Джефферсон, и мне всегда хотелось записать их, так что это была хорошая возможность для начала», она сказала.
Четырнадцать комплектов звукозаписи поступят в обращение в различных местах библиотечной системы, так что люди смогут проверить их в течение недели и забрать домой.Это означает, что они будут доступны в Главной библиотеке и филиалах в Адене, Бриллианте, Диллонвейл-Маунт-Плезант, Скьяппе, Тилтонсвилле и Торонто. Их можно забрать домой на семь дней. По словам Граббса, «Воспоминания округа Джефферсон» рассчитаны больше на взрослых, и, по словам Граббса, диктофоны будут проверять их только на библиотечных карточках для взрослых.
Другой остается с Граббс для тех, кто не хочет записывать самостоятельно и предпочел бы вместо этого назначить сеанс с ней в отделе краеведения и генеалогии в филиале Скьяппа.
«Я полагаю, что большинство людей захотят посидеть с другом или членом семьи и вести запись непринужденного разговорного стиля, но если они предпочитают более структурированные вопросы и ответы, они всегда могут запланировать время со мной, и мы запланировали бы это здесь, в Скьяппе », - сказала она.
Регистратор удобен в использовании. «Его довольно легко использовать, и в каждом пакете у меня есть список инструкций для людей», - сказал Граббс.
Пакеты набора для записи обеспечивают основу для дальнейших действий, по словам Граббса, который сказал, что участник может говорить пять или десять минут, если это все, что нужно.«Мы действительно не хотим, чтобы они тратили слишком много времени на час, поэтому для каждого человека он будет разным. Это может быть кратко или дольше ».
О чем говорить, содержится в брошюре, прилагаемой к записывающему комплекту, в том числе:
¯ Детство и семейная жизнь: где и когда вы родились? Где ты вырос? Где Вы ходили в школу? Были ли в вашей семье традиции?
¯ Предыдущие поколения: знали ли вы своих бабушек и дедушек или прадедов? Вы помните какие-нибудь истории, рассказанные вам родителями, бабушками и дедушками об их жизни и опыте?
¯ Жизнь в родном городе: Какие у вас самые любимые воспоминания из сообщества, в котором вы жили? Какие тусовки были самыми популярными среди молодежи и подростков?
¯ Религия: Играла ли религия большую роль в вашей семье, когда вы росли? Вы посещали местную церковь? Церковь еще существует?
¯ Военные: Вы служили в армии? К какой ветви вы присоединились и когда служили? Вы служили на войне? Как это повлияло на вас и вашу семью? Вы знаете предков, которые служили во время войны?
¯ Работа: Вы помните свою первую работу? Какую работу вы выполняли в обществе на протяжении многих лет?
¯ Исторические события: Какие важные исторические события произошли при вашей жизни?
¯ Изменение времени: Какие изменения вы заметили в своем сообществе за эти годы? Какие школы, предприятия, местные мероприятия и т. Д.вы помните из прошлого, которого больше нет?
«Я надеюсь, что многие пожилые люди поделятся своими воспоминаниями», - сказал Граббс. «Несмотря на то, что там написано« Воспоминания округа Джефферсон », будут случаи, когда их опыт произошел за пределами округа Джефферсон, например, как у ветеранов. Если они хотят рассказать о своей войне или военном опыте, мы приветствуем что-нибудь подобное или семейные истории. У меня были люди, которые спрашивали, могу ли я рассказать о воспоминаниях моей прабабушки, которыми она поделилась со мной, и, возможно, она никогда не жила в округе Джефферсон, но это все еще часть их истории, поэтому они также могут делиться такими вещами.Это не должно быть просто опытом, который произошел здесь », - объяснила она.
Помимо обмена историями и воспоминаниями, люди также могут делиться фотографиями для Digital Shoebox со сканерами, доступными в каждой библиотеке, чтобы сделать это возможным.
Граббс с энтузиазмом продвигает текущий проект, отмечая, что история каждого уникальна, «предоставляя ценную информацию об истории нашего округа и опыте наших жителей.
«Я считаю особенным возможность услышать личный опыт людей, которые здесь жили», - сказала она.«В наших учебниках по истории есть отличная информация, но, чтобы послушать кого-то, кто действительно пережил определенные события, у меня так много людей, которые говорят о старых предприятиях, которые я никогда не мог посетить, но просто имея их точку зрения, у всех разный опыт. не только для того, чтобы поделиться им с сообществом, но и для того, чтобы члены их семей могли получить к ним доступ, будущие поколения смогут услышать воспоминания своих дедушек или своих тетушек », - сказала она.
«Надеюсь, это сработает - я очень рад», - сказал Граббс, отметив, что посетители библиотеки могут записывать больше одного раза.
Холл тем временем польщен тем, что пожертвование делает возможным начинание, ориентированное на историю.
«Для меня большая честь и радость, что кто-то пожертвовал средства Публичной библиотеке Стьюбенвилля и округа Джефферсон в честь моей 36-летней карьеры в качестве директора библиотечной системы», - прокомментировал Холл. «Эрика рада разработать« Jefferson County Memories », в рамках которого будут приобретены 15 устройств для записи местной истории, которые будут сохранены в онлайн-системе библиотеки Digital Shoebox».
Он добавил: «Компьютерное оборудование также является частью пожертвования, чтобы этот отдел оставался на переднем крае технологий.Когда я приехал в 1983 году, в библиотечной системе было около 150 книг по краеведению, а когда я вышел на пенсию, в отделе краеведения и генеалогии было более 7000 единиц хранения, а также более 80 000 онлайн-документов и 2500 фотографий онлайн ».
Вопросы о «Воспоминаниях округа Джефферсон» можно направить в краеведческий отдел в филиале Скьяппа по телефону (740) 264-6166 и по электронной почте Граббсу по адресу [email protected].
(с Киаски можно связаться по адресу jkiaski @ heraldstaronline.ком.)
Последние новости сегодня и многое другое в вашем почтовом ящике
Как отправлять отказы
Мы все подавали заявки на вакансии, но нам отказали. Даже самый деликатно сформулированный и уважительный отказ может уколоть вас, особенно если вы действительно хотели получить эту должность. Как работодатель вы хотите создать позитивную и уважительную рабочую среду. Для этого все начинается с процесса найма.Конечно, здорово сказать новому сотруднику, что его наняли. Однако это простая часть процесса. Быть ответственным за то, чтобы говорить людям, что они не были выбраны на должность, может быть намного сложнее. К счастью, есть несколько вещей, которые вы можете сделать, чтобы смягчить потенциальный удар.
Если вы являетесь работодателем, подумайте об использовании National Recruiting, чтобы помочь вам быстро разобраться и организовать приемы и отклонения. Выбирая Lir Lii System, вы можете развивать свою команду с уверенностью, что выбрали правильных кандидатов.Зарегистрироваться!
Отправка отказов
В процессе набора вы неизбежно откажетесь от большего количества кандидатов, чем наняли. То, как вы отклоняете кандидатов, многое говорит о вашей компании и вашей культуре. Грубый или неуместный отказ может легко навредить репутации вашей компании и вашего бренда. Вот почему National Recruiting собрал некоторые из самых важных советов, которые следует учитывать при отправке отказов.
Будьте честны
Мы все слышали что-то подобное, когда получали отказ в приеме на работу: «Хотя мы думаем, что вы квалифицированы и можете выполнить эту работу, было так много отличных кандидатов, и мы, к сожалению, должны сказать вам, что вас не выбрали.«Такая фраза хороша, если она верна. Кандидаты знают, когда вы ведете себя нечестно, и от этого у них во рту будет неприятный привкус. Если вы скажете им, что искренне интересовались ими, все, что вы сделаете, - это необоснованно возродить их надежды. Честная обратная связь - это то, что поможет им в долгосрочной перспективе стать более конкурентоспособными для будущей работы.
Действовать незамедлительно
Кандидаты часто тратят более часа на написание сопроводительных писем, изменение своих резюме и подготовку к собеседованию.Они заслуживают уважения. Когда вы примете решение, сообщите об этом кандидату. Вытягивание процесса или создание ложной надежды редко приносит пользу.
Не переусердствуйте
Не увлекайтесь, когда просматриваете все получаемые резюме и начинаете говорить кандидатам, что, по вашему мнению, они находятся наверху списка. Вы можете непреднамеренно вселить в них надежду, когда при ближайшем рассмотрении вы можете обнаружить, что есть более подходящие кандидаты на эту должность.Когда кандидат испытывает это ложное чувство надежды, он может почувствовать себя ошеломленным, когда получит отказ, особенно если он безличный. Это может привести к тому, что квалифицированные кандидаты не захотят работать с вашей компанией в будущем, потому что они больше не будут чувствовать, что могут вам доверять.
Будьте кратки
Не пишите сочинение из трех абзацев о том, как близко они подошли и в чем все их недостатки. Объясните в предложении или абзаце, почему вы их отклоняете. Например: «Несмотря на то, что мы были впечатлены вашим опытом в области маркетинга, мы решили нанять кандидата, который также имеет опыт работы в сфере управления персоналом.Однако краткость не означает, что вы должны быть краткими. Хотя вы не хотите приукрашивать сообщение, вы также не хотите, чтобы он выглядел исключительно негативным. Будьте твердыми, но справедливыми.
Сохраняйте индивидуальность
Отправка общих отказов - это один из способов сообщить всем отклоненным кандидатам, что они вас не волнуют. Не забывайте всегда указывать имя человека в электронном письме или в телефонном звонке, когда отказываетесь ему в должности. Помните, что вы, вероятно, разбиваете надежды человека на то, что он получит работу, поэтому вы должны быть по крайней мере уважительными и внимательными.Это старый лозунг воплощения в жизнь: относитесь к другим так, как вы хотите, чтобы относились к вам.
Рассмотрите преимущества электронной почты по сравнению с отказом по телефону
Когда пришло время отклонять кандидатов, что лучше отклонять по телефону или по электронной почте? Это зависит от обстоятельств. Хотя телефонный звонок может быть более личным, электронная почта может быть более желательным способом узнать плохие новости. Как правило, если кандидат не доходит до фазы собеседования, электронное письмо будет наиболее подходящим способом отправки отказа.Однако, если кандидат прошел собеседование, но не получил работу, рассказав ему о результатах по телефону, он почувствует, что его ценят, а вы уважаете его и их время.
Запросить отзыв
Вы не хотите, чтобы кандидаты чувствовали, что общение между вами - улица с односторонним движением. Предоставив им возможность связаться с вами по любым вопросам или проблемам, которые у них есть, они не только поймут, что вы их цените и уважаете, но и получите полезные отзывы, которые вы сможете учесть для улучшения процесса найма.
Поддерживать дальнейшее развитие связи
В будущем будет больше рабочих мест, и бессмысленно сжигать мосты между вашей компанией и предыдущими потенциальными сотрудниками - плохая идея. Если у вас есть кандидаты, которых вы искренне хотите побудить подавать больше заявок в будущем, есть несколько способов помочь им принять участие. Вы можете:
- Приглашайте их на мероприятия, например на ярмарки вакансий
- Отправляйте им дополнительные электронные письма в будущем
- Поощряйте их подписываться на вас в социальных сетях и взаимодействовать с ними там
Don’t Burn Your Bridges
Процесс найма может быть сложной задачей, особенно когда дело доходит до вежливого и уважительного отказа.National Recruiting поможет вам легко отслеживать всех ваших кандидатов. Попрощайтесь с бумажными приложениями и почтовым ящиком, полным случайных файлов PDF. Используя наш портал для размещения сообщений, вы можете быстро и легко сравнивать кандидатов, ускоряя процесс поиска подходящего кандидата на вашу должность. Посетите наш портал со списком кандидатов сегодня! Возможность быстро найти подходящего кандидата для вашего бизнеса также поможет вам избавиться от надежд на отказ от кандидатов. Наш сайт приема на работу поможет вам сделать этот процесс лучше для всех участников!
lib mail ✔️ mail.seolibraries.org - Услуги электронной почты SEO
Ищете lib для входа в почту ? Вот лучший способ получить доступ к почтовой учетной записи lib.
mail.seolibraries.org - SEO услуги электронной почтыhttp://mail.seolibraries.org/
Благодарим вас за выбор услуг электронной почты SEO. Нажмите кнопку ниже, чтобы перейти к экрану входа в веб-почту. Продолжить
Публичная библиотека Лос-АнджелесаПубличная библиотека Лос-Анджелеса обслуживает самую многочисленную и разнообразную библиотеку США.Публичная библиотека Лос-Анджелеса через свою Центральную библиотеку и 72 филиала обеспечивает свободный и легкий доступ к информации, идеям, книгам и технологиям, которые обогащают, просвещают и расширяют возможности каждого человека в разнообразных сообществах нашего города.
Публичная библиотека Цинциннати и округа Гамильтонhttps://www.cincinnatilibrary.org/account/
Моя учетная запись. Подать заявку на библиотечный билет ... Воспользуйтесь нашей онлайн-формой заявки.Часто задаваемые вопросы о библиотечных билетах Узнайте, как подать заявку на получение бесплатного библиотечного билета. PIN-код вашей библиотеки Инструкции по использованию и изменению PIN-кода. ... лимиты заимствования, возврат материалов и т. д. Уведомление о просрочке и задержке Получение уведомлений о просрочке и удержании по телефону, электронной почте или текстовым сообщением ...
Доступ к моей учетной записи - библиотеки Делавэра Библиотеки Делавэраhttps://lib.de.us/help/my-account/
Доступ к моей учетной записи. Каталог библиотеки Делавэра.Шаг 1. Посетите каталог библиотеки Делавэра. Шаг 2: Вверху страницы нажмите «Моя учетная запись», после чего вам будет предложено ввести номер вашей библиотечной карточки и ПИН-код. ... Спросите в местной библиотеке или напишите нам по электронной почте. Отдел библиотек штата Делавэр ...
Войти в мою учетную запись Публичная библиотека Квинсаhttp://www.queenslibrary.org/user/login
Для навигации по сайту используются вкладки и вводятся ключевые команды. Для прокрутки страницы используйте стрелки вверх и вниз.Слайд-шоу и карусели можно управлять с помощью клавиш табуляции, стрелок влево и вправо.
Библиотека Квинса - Публичная библиотека Квинса QPLhttps://queenslibrary.org/
Публичная библиотека Квинса - одна из крупнейших и наиболее загруженных систем публичных библиотек в Соединенных Штатах, предназначенная для обслуживания самого разнообразного в этническом и культурном отношении района страны. Независимо от того, кто вы, откуда или куда хотите поехать, мы говорим на вашем языке.
UBITName Login: требуется аутентификация - университет в ...https://ubmail.buffalo.edu/cgi-bin/login.pl
UBIT Имя Логин. UBITName Login возникла проблема с вашим текущим сеансом браузера. Если вы: Вход в систему: Часть процесса входа в систему могла быть неудачной. Полностью выйдите из браузера и попробуйте еще раз. Все еще не работает? Проверьте UBIT Alerts. Возможно, произошел сбой в обслуживании. Нужна дополнительная помощь? Обратитесь в справочный центр UBIT по телефону 716-645-3542.
Yahoo - логинYahoo позволяет легко получать удовольствие от того, что важнее всего в вашем мире. Лучшая в своем классе почта Yahoo, последние местные, национальные и мировые новости, финансы, спорт, музыка, фильмы…
Gmail - Электронная почта от Googlehttps://mail.google.com/mail/
Gmail - это электронная почта, которая интуитивно понятна, эффективна и полезна. 15 ГБ хранилища, меньше спама и мобильный доступ.
Yahoo MailСовершите путешествие в обновленный, более организованный почтовый ящик. Войдите в систему и начните изучать все бесплатные организационные инструменты для своей электронной почты. Просматривайте новые темы, отправляйте GIF-файлы, находите все фотографии, которые вы когда-либо отправляли или получали, и выполняйте поиск в своем аккаунте быстрее, чем когда-либо.
Почему вы должны доверять AhmsPro?
- Мы используем только официальные сайты и ссылки
- У нас работают опытные программисты, писатели, создатели контента и другие специалисты.
- AhmsPro производится в США командой специалистов из США
- AhmsPro защищен Cloudflare, поэтому данные в Интернет не попадут
- Наш бизнес был создан в 2012 году и работает до сих пор, и за эти годы у нас тысячи счастливых пользователей