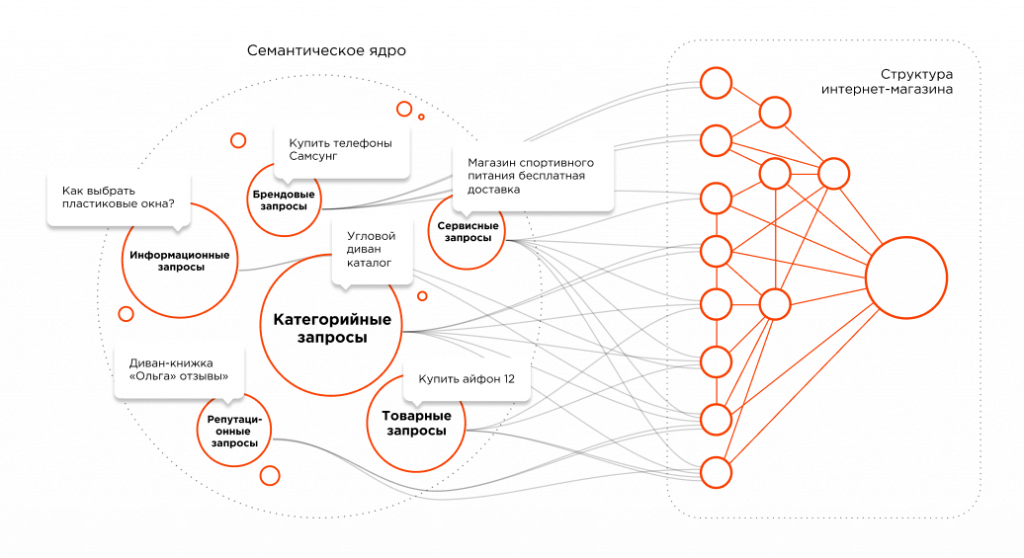
Семантическое ядро онлайн | Семантика для сайта в Rush Analytics
Доверьте рутину нам — занимайтесь реальными задачами
Зарегистрироваться
Первые 7 дней бесплатно.
Без привязки карты и лишней информации
Мы гордимся, что работаем с такими компаниями
Инструменты Основные возможностинашего сервиса
Анализ позиций
4 инструмента
Семантика
5 инструментов
Аудит сайта
2 инструмента
Инструменты PBN
6 инструментов
Анализ позиций
Отслеживайте позиции вашего сайта и конкурентов в режиме реального времени в Google и Яндекс во всех регионах и на всех языках так часто, как вы хотите.
- Проверка позиций сайта
- SERP монитор
- SERM
- Проверка индексации
Попробовать бесплатно
Аудит сайта
Проведите аудит вашего сайта по всем ключевым параметрам и получите рекомендации по устранению найденных ошибок.
- Сайт аудит
- Метасканер
Попробовать бесплатно
Начните пользоваться Rush-Analytics уже сегодня
Получи 7-ми дневный бесплатный доступ к полному функционалу.
Без привязки карты.
Попробовать бесплатно
Алексей Терехов PR директор Admitat gmbhuRush Analytics — единственный на сегодня доступный инструмент для вебмастеров, который позволяет вытворять с семантическим ядром такие вещи, которые могут присниться только в сладких снах!
 ru
ruМоя компания пользовалась этим сервисом для продвижения гипермаркета. В результате внедрения кластеризованной семантики по одному разделу посещаемость на сайте выросла на 4000 человек в сутки за 4 месяца. Помимо этого, сервис колоссально сокращает время на работу с семантикой.
Rush Analytics позволяет своевременно отслеживать эффективность поискового продвижения по категориям и качественно наблюдать за позициями конкурентов. За счет этого мы принимаем правильные решения в кратчайшие сроки и максимизируем оборот и выручку из органического поиска.
Вадим CEO Aktis Group Самый главный инструмент SEO, который я использую.
Мне нравятся инструменты проверки позиций и текстовый анализатор, они предоставляют мне реальные данные, которые помогают догнать и обогнать конкурентов.
Получите 7 дней бесплатного доступа
Здесь вы можете собрать поисковые подсказки из Яндекс, Google или YouTube
Зарегистрироваться
Карта сайта — Rush Analytics
Сайт
Блог
- Что это такое Chat GPT
- Фильтр Минусинск от поисковой системы Яндекс
- Линкбилдинг — что это такое простыми словами
- Ссылочный взрыв
- Список регионов Яндекса
- Что такое монолитный индекс
- Карьера в SEO: сколько зарабатывают SEO-специалисты, плюсы и минусы профессии
- PBN: понятие и необходимость использования
- Что такое бэклинки
- Все о поисковых подсказках Яндекса
- Что такое анкорная ссылка
- Битые ссылки
- Типы поисковых запросов
- Как найти дроп-домены
- Как проверить метатеги на сайте
- Как посмотреть индексацию сайта
- 5 шагов в поиске ниши для сайта
- Аддурилка Яндекса и Гугла
- Что такое безанкорные ссылки
- Чистим семантическое ядро от мусора в два клика
- Что такое CTA в рекламе
- Что такое информационный сайт
- Что такое качественный контент
- Что такое MX-запись домена
- Что такое пагинация
- Что такое и зачем нужна внутренняя перелинковка страниц сайта
- Что такое песочница Яндекс и Google
- Что такое позиция сайта
- Что такое продающий текст
- Что такое релевантность страниц
- Что такое ссылочное ранжирование
- Что такое тайтл (title)
- Что такое заспамленность текста и как этого избежать?
- Что ждет контентные сайты в 2023 году: тренды, прогнозы
- Что значит ссылочное продвижение сайта в 2023 году
- Идеальная страница 404, какая она?
- Подробное руководство как оптимизировать результаты в поисковой выдаче Google
- Как использовать Google Keyword Planner
- Хедер сайта
- Какой домен лучше выбрать для продвижения сайта: com, ru, net
- Парсим поисковые подсказки из Youtube в Rush Analytics
- Как удалить личную информацию из поисковика Google
- Как выбрать хостинг для сайта в 2023 году
- Как монетизировать сайт и зарабатывать на трафике?
- Как написать статью план
- Как определить своих конкурентов в поисковой выдаче
- Как оптимизировать сайт под голосовой поиск в Яндекс и Google
- Лучшие программы для исправления ошибок в тексте
- Продвижение ВК-групп в поисковой выдаче Яндекс
- Правильная структура текста на сайте
- Поведенческие факторы ранжирования
- Что такое семантическое ядро сайта
- Операторы Wordstat — как работать с ними эффективно
- Open Graph — панацея для соцсетей
- Низкочастотные запросы
- ТЗ на текст
- Как заработать на ссылках в 2023 году
- Монетизация сайтов в 2023 году
- Мобильный поиск в современном SEO
- LSI ключевые слова: что это такое, как собрать и использовать фразы в SEO
- Аналитика источников семантики
- Чем отличаются информационные и коммерческие тексты?
- Аудит текстов на сайте
- Что такое сохраненная копия страницы в Яндексе
- Инструменты для PBN в Rush Analytics
- Инструкция по функционалу «Учитывать порядок слов в запросе» сборщика Wordstat
- Как определить оптимальный размер статьи?
- HARD-кластеризация в Rush Analytics
- Анализ ниши и выбор темы для сайта-статейника
- 7 критериев хорошего домена
- Как повысить конверсию текста?
- Как пользоваться Google Trends
- Что такое редирект
- YML-файл: что это
- Что такое дроп-домены
- Проверка релевантности текста
- Что такое тошнота текста
- Что такое парсер простыми словами
- Что такое веб-архив сайта
- Этапы SEO-продвижения сайта
- Что такое Rewriterule
- Как вывести сайт из-под фильтра
- Что такое водяной знак на фото
- Что такое партнерская программа
- Что такое веб-страница
- Что такое PageRank
- Уровень вложенности страницы
- Что такое делегирование домена
- Съём позиций сайта
- Стоит ли заниматься SEO-продвижением в кризис
- Что такое авторский контент
- Как подготовить сайт к Core Web Vitals
- SEO тексты для сайта: зачем нужны и как заказать
- Как зарабатывать на партнерской программе от Amazon?
- Как заработать на арбитраже трафика
- Сколько стоит сделать сайт
- SEO-оптимизация изображений для сайта
- Сторителлинг — главный тренд контент-маркетинга XXI века
- Продвижение сайта в Китайском Байду
- Улучшаем скорость сайта с помощью Google PageSpeed Insights
- Правильный файл robots.
 txt
txt - Как сделать SEO-оптимизацию сайта на WordPress
- Работаем с Текстовым Анализатором в Rush Analytics
- Верстка и оформление статей на сайте
- Гид по поисковым операторам Google
 txt
txtFAQ
Инструменты
Manage consent
Разработка для семантической паутины — Smashing Magazine
- Чтение за 16 мин. Доступность
- Поделиться в Twitter, LinkedIn
Об авторе
Фред — редактор социальных навыков и профессионального развития в Smashing Magazine (предложите его!) и инженер-программист в The Guardian. Среди его интересов…
Больше о
Frederick ↬
Среди его интересов…
Больше о
Frederick ↬
В июле Фонд Викимедиа объявил об Абстрактной Википедии, попытке разметить знания, не зависящие от языка. Во многих отношениях это кульминация десятилетий наращивания, в течение которых мечта о семантической сети так и не осуществилась, но и не исчезла полностью.
На самом деле семантическая сеть растет, и по мере того, как она обновляет свою миссию, мы все выиграем от включения семантической разметки в наши веб-сайты, будь то личные блоги или гиганты социальных сетей. Независимо от того, заботитесь ли вы о сложном веб-опыте, поисковой оптимизации или отражении тирании веб-монополий, Semantic Web заслуживает нашего внимания.
Преимущества разработки для Semantic Web не всегда очевидны или очевидны, но каждый сайт, который это делает, укрепляет основы открытого, прозрачного, децентрализованного Интернета.
Семантическая сеть
Что такое Семантическая сеть? Это машиночитаемая сеть, обеспечивающая через метаданные «общую структуру, которая позволяет совместно использовать данные и повторно использовать их между приложениями, предприятиями и сообществами».
Идея так же стара, как и сама Всемирная паутина. На самом деле старше. Это было в центре внимания 19-летия Тима Бернерса-Ли.89 предложение. Как он отметил, не только документы должны образовывать сети, но и данные внутри их тоже должны: (Большое превью)
За прошедшие десятилетия семантическая паутина прошла тернистый путь. На рубеже тысячелетий он превратился в несколько концепций — открытые данные, графы знаний — все они фактически означают одно и то же: сети данных.
Больше после прыжка! Продолжить чтение ниже ↓
Как резюмирует W3C, это «расширение существующей сети, в которой информации придается четко определенное значение, что позволяет компьютерам и людям лучше работать вместе».
У этой идеи было немало сторонников. Интернет-хактивист Аарон Шварц написал рукопись книги о Semantic Web под названием A Programmable Web . В нем он написал:
«Документы нельзя объединять, интегрировать и запрашивать; они служат в основном как отдельные экземпляры, которые нужно просматривать и анализировать. Но данные разнообразны и могут принимать любую форму, которая лучше всего соответствует вашим потребностям».
По целому ряду причин Семантическая Паутина не получила такого же развития, как Сеть, хотя и наверстывает упущенное. На протяжении многих лет некоторые разметки пытались захватить мантию — RDFa, OWL и Schema, и это лишь некоторые из них, — хотя ни одна из них не стала стандартной, как, скажем, HTML или CSS. Порог входа был слишком высок.
Однако мечта о семантической паутине не сбылась, и по мере того, как все больше и больше сайтов включают ее в свои проекты, появляется все больше причин присоединиться к этой вечеринке. Чем больше сайтов попадает на борт, тем сильнее становится семантическая паутина.
Чем больше сайтов попадает на борт, тем сильнее становится семантическая паутина.
Дальнейшее чтение
- Интеллект данных
- Семантическая паутина, статья 2001 года Тима Бернерса-Ли, Джеймса Хенсли и Ора Лассила
- . в сорняки , как проектировать для Semantic Web, стоит копнуть немного глубже в , почему . Какая разница, подключены ли данные? Подключенных документов недостаточно?
Есть несколько причин, по которым Semantic Web продолжает продвигаться теми, кто заботится о свободном и открытом Интернете. Понимание этих причин имеет важное значение для процесса внедрения. Это не должно быть случаем «ешьте овощи, используйте семантическую разметку». Семантическая паутина — это то, во что нужно верить и частью чего следует быть.
К преимуществам семантического веба относятся:
- Более богатые и сложные веб-интерфейсы
- Обход разрозненности контента и интернет-монополий
- Улучшенная читаемость и ранжирование в поисковых системах
- Демократизация информации
Большинство из них можно проследить до основного принципа Semantic Web: универсальный язык для данных.
Доля языков, используемых в Интернете, не соответствует количеству языков, используемых в реальном мире. (Большое превью) Хотя Интернет уже сотворил чудеса для международного общения, нельзя не отметить тот факт, что в некоторых странах он намного лучше, чем в других. Возьмем, к примеру, языки, используемые в Интернете, и языки, используемые в реальном мире. Самые внимательные из вас могут заметить небольшой дисбаланс в приведенных ниже данных…Безграничная утопия Интернета не так близка, как может показаться тем из нас, кто находится внутри англоязычного пузыря. За это кого-то можно наказать? Не обязательно, но с этим нужно смириться. Это подчеркивает важность разметки, которая устраняет эти пробелы. Обогащая данные сети, мы снимаем нагрузку с ее языков.
Это суть недавно анонсированной абстрактной Википедии, которая попытается отделить статьи от языка, на котором они написаны. Исполнительный директор Викимедиа Кэтрин Махер пишет: «Используя код, добровольцы смогут переводить эти абстрактные материалы».
статей на свои языки. В случае успеха это может в конечном итоге позволить каждому читать любую тему в Викиданных на своем родном языке».Аннотация Создатель Википедии Денни Врандечич в течение многих лет был сторонником семантической паутины, признавая ее потенциал для раскрытия неиспользованного потенциала онлайна. Важнейшее значение для этого процесса имеет разрушение национальных барьеров.
«Независимо от того, на каком языке вы публикуете свой контент, вы упустите возможность включить в него подавляющее большинство людей в мире. Интернет дал нам прекрасную возможность глобального охвата, но, полагаясь на один язык или небольшой набор языков, мы упускаем эту возможность. Хотя наиболее важной целью является создание хорошего контента, вы привлекаете больше людей к участию в разработке лучшего контента, будучи независимым от языка. Это помогает вам снизить барьеры для вклада и потребления и позволяет гораздо большему количеству людей извлечь выгоду из этих усилий».
— Денни Врандечич, создатель абстрактной Википедии
Своевременным примером этого стала визуализация данных во время пандемии COVID-19. Вирус вызвал невыразимый хаос во всем мире, но он также стал ярким моментом для открытых сетей передачи данных, позволив превосходным веб-приложениям, отчетам и многому другому стать обычным явлением в Интернете.
Информационная панель ncovid2019.live была создана американским старшеклассником Ави Шиффманом и использует данные ВОЗ, CDC и COV19. (Большое превью)И, конечно же, когда данные прозрачны и легкодоступны, легче выявлять аномалии… или прямой обман. Широкий публичный доступ к такой информации был бы немыслим еще 20 лет назад. Теперь мы ожидаем этого и чуем неладное, когда нам отказывают. Данные мощный , и если мы захотим, мы можем использовать его навсегда.
Точно так же, проверка себя из бункеров контента — отличительная черта современного веб-опыта — лишает власти веб-монополии, такие как Google, Facebook и Twitter.
Мы настолько привыкли к сторонним платформам, которые расшифровывают и представляют информацию, что забываем, что они не являются строго необходимыми.«Если бы у нас были общие форматы, общие протоколы, некоторые провайдеры все еще могли бы играть большую роль на определенных рынках — вспомните Gmail для электронной почты, — но каждый волен перейти к другому провайдеру, и рынок остается конкурентным. ”
— Денни Врандечич, создатель Абстрактной Википедии. он бесплатный, открытый и абстрактный, что позволяет общаться между разными языками и платформами, что в противном случае было бы намного сложнее.
Обработка данных онлайн-контента
Проектирование для Semantic Web сводится к обработке данных онлайн-контента — просмотру вашего контента и пониманию того, что можно (и нужно) абстрагировать. Что это означает в практическом плане, помимо смутного согласия с тем, что это стоит делать? Это зависит:
- Если вы начинаете проект с нуля, включите в свою работу соображения Semantic Web. По мере того, как веб-сайт обретает форму, вплетайте семантическую разметку в его ДНК.
- При обновлении или перестроении проекта оцените, что можно вплести в Semantic Web, чего в настоящее время нет, а затем внедрите.
Оба случая в основном сводятся к информационному содержимому. В этом разделе мы рассмотрим несколько примеров абстракции данных и то, как она может сделать контент лучше, умнее и доступнее.
Абстрагирование информации
Проектирование и разработка для семантической паутины означает просмотр онлайн-контента с использованием ваших данных. Большинство из нас воспринимает Интернет как серию связанных документов или страниц; что вы хотите сделать с Semantic Web, так это соединить информацию. Это означает оценку вашего контента для точек данных, а затем корректировку дизайна на основе того, что вы найдете.
Сторонник Semantic Web Джеймс Хендлер особенно хорошо описывает этот процесс в своем духе DIVE. ( ПОГРУЖАЙТЕСЬ в данные, а? А?).
Он разбивается следующим образом:- Обнаружение
Поиск наборов данных и/или контента (в том числе за пределами вашей организации). - Интегрировать
Свяжите отношения, используя значащие метки. - Подтвердить
Ввести входные данные для систем моделирования и имитационного моделирования. - Исследовать
Разработать подходы к превращению данных в практические знания.
Разработка для Semantic Web в значительной степени заключается в том, чтобы иметь представление о том, что вы делаете, с высоты птичьего полета, и о том, как это потенциально влияет на бесконечно более богатый веб-опыт. Как говорит Хендлер, практическое знание — это цель.
Это действительно применимо практически к любому типу веб-контента, но давайте начнем с обычного примера: рецептов . Допустим, вы ведете кулинарный блог с новыми рецептами каждый четверг.
Если вы француз и публикуете потрясающий рецепт суфле в своем личном блоге в виде обычного текста, это будет полезно только тем, кто умеет читать по-французски.Однако с помощью семантической разметки блог можно преобразовать в машиночитаемый набор данных рецептов. Синтаксис существует для абстрагирования кулинарных терминов. Например, схема, которая может работать вместе с микроданными, RDFa или JSON-LD, имеет разметку, включающую:
- Время подготовки
- Время приготовления
- Рецепт Выход
- Рецепт Ингредиент
- Ориентировочная стоимость
- Питательная ценность с разбивкой на калории и жиры Содержание
- Подходит для диетического питания.
Я мог бы продолжить. Полный набор опций с примерами можно прочитать на Schema.org. При добавлении их в формат сообщения формат рецепта вообще не должен меняться — вы просто размещаете информацию в терминах, понятных компьютерам.
Преобразовывая редакционный контент в данные, рецепты BBC значительно повышают свою потенциальную полезность. (Нажмите для просмотра в большом разрешении)Например, все, что выделено синим в рецепте BBC выше, также получило семантическую разметку — от времени приготовления до содержания питательных веществ. Вы можете увидеть, что происходит под капотом, введя URL-адрес рецепта в Google Rich Results Test. Обратите внимание на функциональность «Добавить в список покупок» — пример подключения, ставшего возможным благодаря реализации Semantic Web. Хороший контент становится полезными данными.
Пути большинства из нас сталкивались с такой изощренностью через результаты поиска, но приложения гораздо шире. Семантическая разметка рецептов облегчает поиск и использование веб-сайтов домашними помощниками. Перечисленные ингредиенты можно заказать в местном супермаркете. Рецепты можно было фильтровать самыми разными способами — по диетам, аллергиям, религии, стоимости и так далее. Или, скажем, у вас было ограниченное количество ингредиентов в доме. С помощью базы данных вы можете ввести эти ингредиенты и посмотреть, какие рецепты подходят для этого.
Диапазон возможностей действительно граничит с безграничностью. Как сказал Шварц, данные многообразны. Как только он у вас появится, вы сможете использовать его самыми странными и замечательными способами. Эта статья не столько об этих странных и чудесных способах, сколько о том, как сделать их возможными. Проектирование для Semantic Web делает последующий дизайн бесконечно богаче.
Вот более личный пример, чтобы показать, что я имею в виду. Мы с парой друзей в качестве хобби ведем небольшой музыкальный веб-журнал. Хотя мы публикуем редкие статьи или интервью, «главным событием» являются наши еженедельные обзоры альбомов, в которых каждый из нас втроем выставляет оценки, выбирает любимые треки и пишет резюме. Мы работаем уже более пяти лет, а это значит, что у нас около 250 отзывов, а это означает очень много потенциальных данных. Мы не осознавали, насколько, пока не начали редизайн сайта.
Я упоминал об этом в статье о включении структурированных данных в процесс проектирования.
Анализируя наши обзоры, мы поняли, что они битком набиты информацией, которой можно дать семантическую разметку. Исполнители, названия альбомов, обложки, дата выпуска, индивидуальные оценки, общие оценки, тип выпуска и многое другое. Более того — и это действительно интересно — мы поняли, что можем подключиться к существующей базе данных: MusicBrainz.Этот двусторонний подход является сутью Semantic Web. Когда наш музыкальный веб-сайт перезапустится, он станет собственным открытым источником данных с тысячами уникальных точек данных. Подключение к существующей музыкальной базе данных даст нашим собственным данным больше контекста и потенциала. Тысячи точек данных становятся десятками тысяч точек данных, а может и больше.
С помощью простой семантической разметки, казалось бы, безобидные веб-страницы могут стать центром огромной информационной сети. (Большой предварительный просмотр)На приведенном выше рисунке лишь поверхностно показано, сколько информации будет связано со страницами отзывов.
Контент такой же, как и раньше, только теперь он подключен к экосистеме метаданных — Giant Global Graph, как однажды назвал ее Бернерс-Ли.Разработка для Semantic Web означает идентификацию ваших собственных данных, их разметку, а затем выяснение того, как они связаны с другими данными. Потому что это так. Это всегда так. И этот процесс таков, как это…
(Большой предварительный просмотр)… со временем становится этим…
Связанное облако открытых данных, постоянно обновляемая визуализация состояния связанных данных в Интернете. (Большой предварительный просмотр)Второе изображение — это связанное открытое облако данных, постоянно обновляемая визуализация подключенных данных в Интернете. Этот красный улей связей — это науки; остальным есть куда двигаться. Вот где мы вступаем.
Полезные семантические веб-ресурсы
- RDF на w3schools.com
- Валидатор RDF от W3C
- «Семантическая паутина стала проще» от W3C
- «Что случилось с семантической паутиной?» by Two-Bit History
- Генератор JSON-LD
- Помощник по разметке структурированных данных Google
Plugin
Идеал семантической сети — это связь.
Создавайте данные, делитесь данными, требуйте данные. Станьте частью информационной экосистемы. Когда вы создаете исходные данные, отлично. Поделиться. Когда данные уже существуют и вы хотите их использовать, извлеките их.Вот лишь несколько доступных ресурсов данных:
- DPpedia
- MusicBrainz
- WorldCat
- ISBNdb
Действительно, там, где такие базы данных существуют, я бы даже сказал, что правильно будет обновить их там, где в них не хватает информации. Зачем держать это в себе? Станьте участником, сторонником Semantic Web.
Внедрение
Что касается встраивания Semantic Webness в ваши сайты, я, конечно же, не выступаю за ручную пошаговую разметку. У кого есть на это время? Чаще всего решение заключается в стандартизации формата и шаблонов для него.
Создание шаблонов дает большие возможности. У скольких людей действительно есть время, чтобы разметить всю эту информацию вручную? Однако, если у вас есть настраиваемые входные данные, вы получаете лучшее из обоих миров.
Контент может быть заполнен удобной для людей информацией, и эта информация существует в виде данных, готовых служить любой цели, которая приходит на ум.Возьмем, к примеру, генератор статических сайтов, такой как Eleventy, который в последнее время пользуется некоторой любовью со стороны сообщества разработчиков. Вы пишете пост, запускаете его по шаблону, и вы — золото. Так почему бы не включить семантическую разметку в сам шаблон?
Как и Eleventy, новая версия нашего музыкального веб-журнала использует Markdown для своих сообщений. Хотя у нас есть те же старые текстовые сообщения, что и всегда, каждый обзор теперь также включает следующие входные метаданные, которые затем втягиваются в шаблон: минут на любую загрузку поста. (Большой предварительный просмотр)
Вместе с информацией об авторе в теле сообщения и некоторой общей информацией о веб-сайте это преобразуется в следующую семантическую разметку:
<скрипт type="application/ld+json"> { "@контекст": "https://schema. org/",
"@type": "Обзор",
"reviewBody": "Один из окончательных альбомов, выпущенных, возможно, величайшим певцом и автором песен, которого мы когда-либо видели. Тем, кто хочет исследовать пугающую дискографию Янга: начните здесь.",
"datePublished": "2020-08-14",
"автор": [{
"@type": "Человек",
"name": "Андре Дак"
},
{
"@type": "Человек",
"name": "Фредерик О'Брайен"
},
{
"@type": "Человек",
"name": "Маркус Лоуренс"
}],
"itemReviewed": {
"@type": "Музыкальный Альбом",
"name": "После золотой лихорадки",
"@id": "https://musicbrainz.org/release-group/b6a3952б-9977-351с-а80а-73е023143858",
"image": "https://audioxid.com/images/album-artwork/after-the-gold-rush-neil-young.jpg",
"albumProductionType": "https://schema.org/StudioAlbum",
"albumReleaseType": "https://schema.org/AlbumRelease",
"Артист": {
"@type": "Музыкальная группа",
"name": "Нил Янг",
"@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf"
}
},
"ОбзорРейтинг": {
"@type": "Рейтинг",
"ratingValue": 27,
"худший рейтинг": 0,
"лучший рейтинг": 30
},
"издатель": {
"@type": "Организация",
"name": "Аудиоксид",
"description": "Независимый музыкальный интернет-журнал, основанный в 2015 году. Публикует обзоры, статьи, интервью и другие странности.",
"url": "https://audioxid.com",
"логотип": "https://audioxid.com/logo-location.jpg",
"такой же как" : [
"https://facebook.com/audioxid",
"https://twitter.com/audioxid",
"https://instagram.com/audioxidcom"
]
}
}
Там, где раньше был только текст, теперь на каждой странице обзора будут машиночитаемые версии того, что читатели увидят при посещении сайта. Все слова остались на месте, содержание практически не изменилось — оно просто было дополнено данными. От расширенных результатов поиска до интерактивных страниц со статистикой отзывов — это значительно расширяет возможности. Дорога впереди широкая и открытая. Это также дает нам долю в будущем MusicBrainz. Соединяя их данные с нашими собственными данными, мы, в свою очередь, хотим, чтобы все работало хорошо, и сделаем все возможное, чтобы это произошло.
Подходящая семантическая разметка зависит от характера веб-сайта, но есть вероятность, что она существует.
Начните с очевидных входных данных (дата, автор, тип контента и т. д.) и продвигайтесь вглубь контента. Первый шаг может быть таким же простым, как hCard (разновидность цифрового удостоверения личности) для вашего личного веб-сайта. Распечатайте скриншоты страниц и начните комментировать. Вы будете поражены тем, сколько контента может быть обработано данными.За гранью воображения
Проектирование и разработка для Semantic Web — это практика, восходящая к основополагающим идеалам Интернета. Независимо от того, цените ли вы красивую информативную визуализацию данных, хотите получить более сложные результаты поиска, лишить власти веб-монополии или просто верите в бесплатную и открытую информацию, Semantic Web — ваш союзник.
Аарон Шварц завершил свою рукопись призывом надежды:
«Семантическая паутина основана на пари, пари, что предоставление миру инструментов для простого сотрудничества и общения приведет к таким замечательным возможностям, что мы едва ли можем себе представить их прямо сейчас.
».Абстрактная Википедия Денни Врандечич разделяет сегодняшние настроения, говоря:
«Необходима веб-инфраструктура, которая облегчит взаимодействие между сервисами, что требует общего набора стандартов для представления данных и общих протоколов для всех провайдеров».
Семантическая паутина хромала достаточно долго, чтобы стало ясно, что язык-серебряная пуля вряд ли появится, но сейчас их достаточно, чтобы мирно сосуществовать, чтобы мечта Бернерса-Ли стала реальностью для большей части сети. Каждый из нас может быть адвокатом в своем районе.
Будьте лучше, требуйте лучшего
Как сказал Тим Бернерс-Ли, Semantic Web — это не только техническое препятствие, но и культура. В 2009 году на TED Talk он прекрасно резюмировал: создавать связанные данные, требовать связанные данные . Сейчас это вернее, чем когда-либо. Всемирная паутина открыта, взаимосвязана и хороша настолько, насколько мы ее заставляем. Всякий раз, когда вы делаете что-то онлайн, спросите себя: «Как это может подключиться к Semantic Web?» Ответы добавят новые измерения к вещам, которые мы создаем, и создадут невообразимо прекрасные новые возможности на долгие годы.
7 Семантические веб-инструменты для вашего веб-сайта
Содержание
Содержание
Содержание
Как мы уже говорили ранее, включение принципов семантического веба может иметь огромные преимущества для вашего контент-маркетинга, локального SEO и ваш онлайн-бизнес. Но как на самом деле «сделать» семантическую паутину? Какие инструменты существуют, чтобы помочь вам использовать его?
Больше не удивляйся!
В этом посте мы собрали 7 отличных инструментов, которые вы можете использовать для создания, проверки и добавления семантических объектов на свой веб-сайт.
Создание семантической разметки
Добавление семантической разметки для связи вашего контента с вашими объектами является основным строительным блоком семантической сети.
А если вы не программист?
Используйте эти инструменты для создания семантической разметки для вашего сайта.
Инструмент метаданных WooRank
Метаданные схемы — отличный способ указать поисковым системам и другим роботам на другие ваши онлайн-профили:
- Google+
- Foursquare
- Yelp
Все они могут быть источниками данных для Google Knowledge Graph, и многие расширенные фрагменты будут содержать ссылки на профили социальных сетей, которые Google может найти.
Инструмент метаданных WooRanks — отличный способ создать разметку, необходимую для того, чтобы поисковые роботы указывали на ваши страницы в социальных сетях. Просто введите свои URL-адреса в соответствующие поля, а затем скопируйте предоставленный код на свой веб-сайт.
URL вводятся, семантическая разметка выходит. Это легко и бесплатно.
Генератор схем JSON-LD
Генератор схем от Hall Analysis — еще один бесплатный инструмент для создания семантической разметки, которую вы можете добавить на свой сайт. Генератор схем создаст код для контекста вашего сайта для
- Местные предприятия
- Люди
- Продукты
- События
- Организация
- Веб-сайты
Генератор
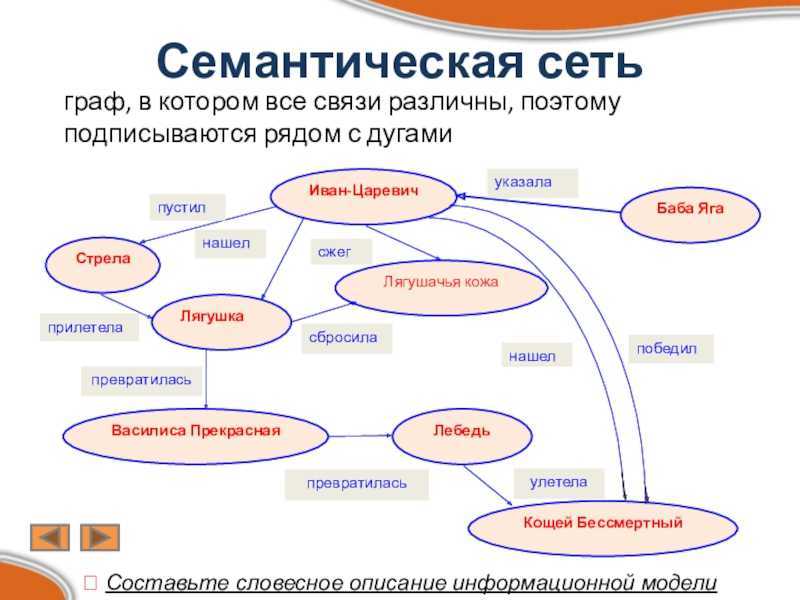 Хотя Интернет уже сотворил чудеса для международного общения, нельзя не отметить тот факт, что в некоторых странах он намного лучше, чем в других. Возьмем, к примеру, языки, используемые в Интернете, и языки, используемые в реальном мире. Самые внимательные из вас могут заметить небольшой дисбаланс в приведенных ниже данных…
Хотя Интернет уже сотворил чудеса для международного общения, нельзя не отметить тот факт, что в некоторых странах он намного лучше, чем в других. Возьмем, к примеру, языки, используемые в Интернете, и языки, используемые в реальном мире. Самые внимательные из вас могут заметить небольшой дисбаланс в приведенных ниже данных…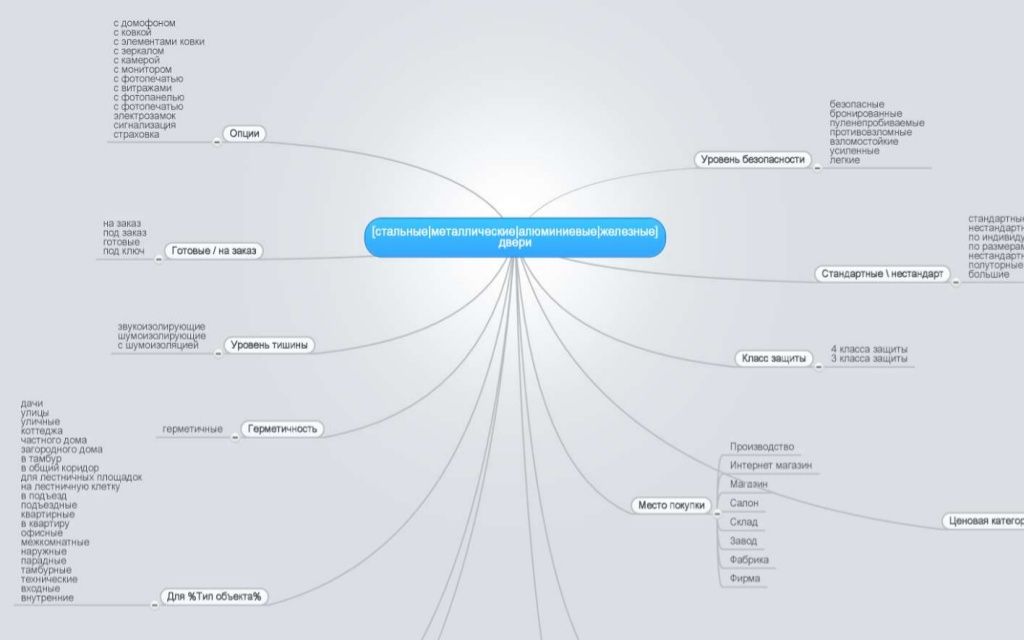 статей на свои языки. В случае успеха это может в конечном итоге позволить каждому читать любую тему в Викиданных на своем родном языке».
статей на свои языки. В случае успеха это может в конечном итоге позволить каждому читать любую тему в Викиданных на своем родном языке».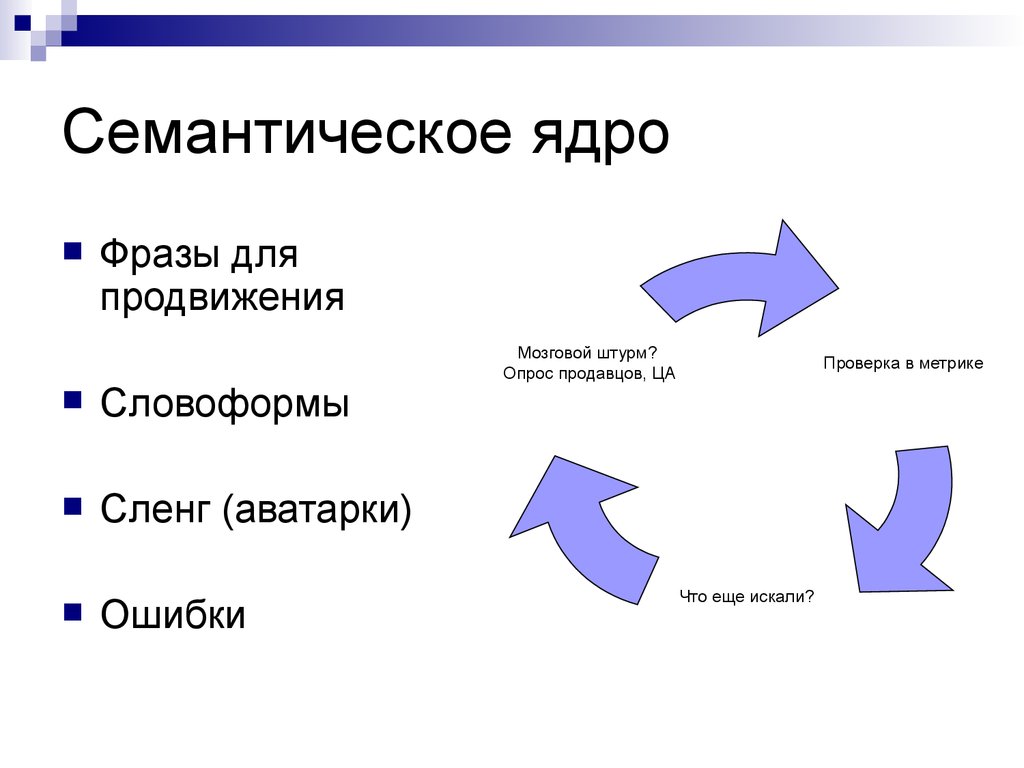
 Мы настолько привыкли к сторонним платформам, которые расшифровывают и представляют информацию, что забываем, что они не являются строго необходимыми.
Мы настолько привыкли к сторонним платформам, которые расшифровывают и представляют информацию, что забываем, что они не являются строго необходимыми. По мере того, как веб-сайт обретает форму, вплетайте семантическую разметку в его ДНК.
По мере того, как веб-сайт обретает форму, вплетайте семантическую разметку в его ДНК. Он разбивается следующим образом:
Он разбивается следующим образом: Если вы француз и публикуете потрясающий рецепт суфле в своем личном блоге в виде обычного текста, это будет полезно только тем, кто умеет читать по-французски.
Если вы француз и публикуете потрясающий рецепт суфле в своем личном блоге в виде обычного текста, это будет полезно только тем, кто умеет читать по-французски. (Нажмите для просмотра в большом разрешении)
(Нажмите для просмотра в большом разрешении)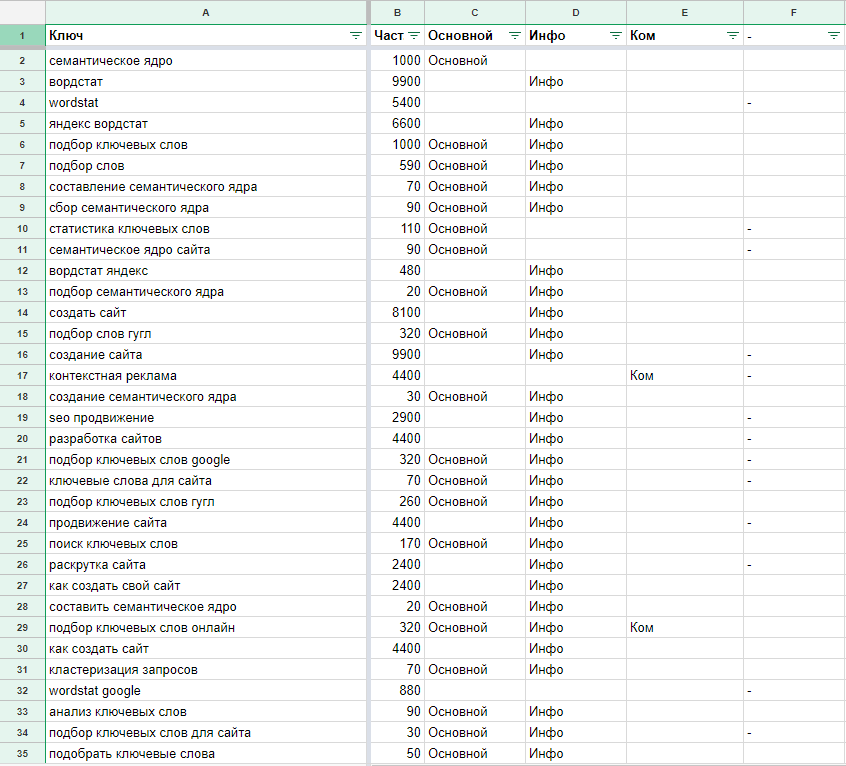
 Анализируя наши обзоры, мы поняли, что они битком набиты информацией, которой можно дать семантическую разметку. Исполнители, названия альбомов, обложки, дата выпуска, индивидуальные оценки, общие оценки, тип выпуска и многое другое. Более того — и это действительно интересно — мы поняли, что можем подключиться к существующей базе данных: MusicBrainz.
Анализируя наши обзоры, мы поняли, что они битком набиты информацией, которой можно дать семантическую разметку. Исполнители, названия альбомов, обложки, дата выпуска, индивидуальные оценки, общие оценки, тип выпуска и многое другое. Более того — и это действительно интересно — мы поняли, что можем подключиться к существующей базе данных: MusicBrainz. Контент такой же, как и раньше, только теперь он подключен к экосистеме метаданных — Giant Global Graph, как однажды назвал ее Бернерс-Ли.
Контент такой же, как и раньше, только теперь он подключен к экосистеме метаданных — Giant Global Graph, как однажды назвал ее Бернерс-Ли.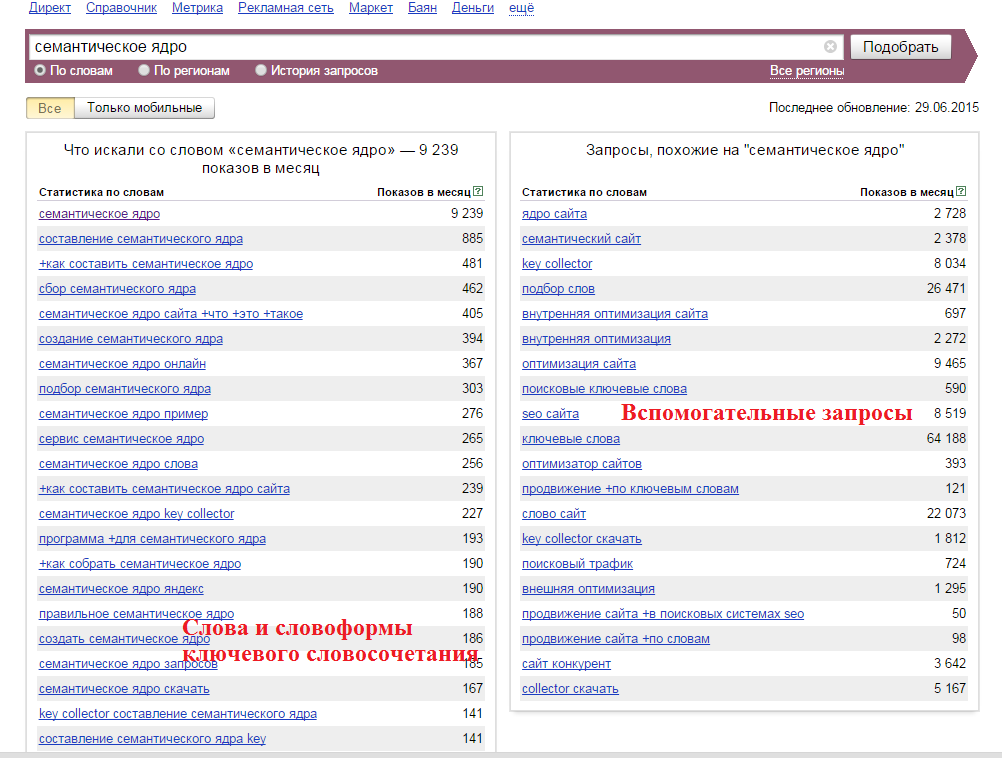 Создавайте данные, делитесь данными, требуйте данные. Станьте частью информационной экосистемы. Когда вы создаете исходные данные, отлично. Поделиться. Когда данные уже существуют и вы хотите их использовать, извлеките их.
Создавайте данные, делитесь данными, требуйте данные. Станьте частью информационной экосистемы. Когда вы создаете исходные данные, отлично. Поделиться. Когда данные уже существуют и вы хотите их использовать, извлеките их. Контент может быть заполнен удобной для людей информацией, и эта информация существует в виде данных, готовых служить любой цели, которая приходит на ум.
Контент может быть заполнен удобной для людей информацией, и эта информация существует в виде данных, готовых служить любой цели, которая приходит на ум. org/",
"@type": "Обзор",
"reviewBody": "Один из окончательных альбомов, выпущенных, возможно, величайшим певцом и автором песен, которого мы когда-либо видели. Тем, кто хочет исследовать пугающую дискографию Янга: начните здесь.",
"datePublished": "2020-08-14",
"автор": [{
"@type": "Человек",
"name": "Андре Дак"
},
{
"@type": "Человек",
"name": "Фредерик О'Брайен"
},
{
"@type": "Человек",
"name": "Маркус Лоуренс"
}],
"itemReviewed": {
"@type": "Музыкальный Альбом",
"name": "После золотой лихорадки",
"@id": "https://musicbrainz.org/release-group/b6a3952б-9977-351с-а80а-73е023143858",
"image": "https://audioxid.com/images/album-artwork/after-the-gold-rush-neil-young.jpg",
"albumProductionType": "https://schema.org/StudioAlbum",
"albumReleaseType": "https://schema.org/AlbumRelease",
"Артист": {
"@type": "Музыкальная группа",
"name": "Нил Янг",
"@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf"
}
},
"ОбзорРейтинг": {
"@type": "Рейтинг",
"ratingValue": 27,
"худший рейтинг": 0,
"лучший рейтинг": 30
},
"издатель": {
"@type": "Организация",
"name": "Аудиоксид",
"description": "Независимый музыкальный интернет-журнал, основанный в 2015 году.
org/",
"@type": "Обзор",
"reviewBody": "Один из окончательных альбомов, выпущенных, возможно, величайшим певцом и автором песен, которого мы когда-либо видели. Тем, кто хочет исследовать пугающую дискографию Янга: начните здесь.",
"datePublished": "2020-08-14",
"автор": [{
"@type": "Человек",
"name": "Андре Дак"
},
{
"@type": "Человек",
"name": "Фредерик О'Брайен"
},
{
"@type": "Человек",
"name": "Маркус Лоуренс"
}],
"itemReviewed": {
"@type": "Музыкальный Альбом",
"name": "После золотой лихорадки",
"@id": "https://musicbrainz.org/release-group/b6a3952б-9977-351с-а80а-73е023143858",
"image": "https://audioxid.com/images/album-artwork/after-the-gold-rush-neil-young.jpg",
"albumProductionType": "https://schema.org/StudioAlbum",
"albumReleaseType": "https://schema.org/AlbumRelease",
"Артист": {
"@type": "Музыкальная группа",
"name": "Нил Янг",
"@id": "https://musicbrainz.org/artist/75167b8b-44e4-407b-9d35-effe87b223cf"
}
},
"ОбзорРейтинг": {
"@type": "Рейтинг",
"ratingValue": 27,
"худший рейтинг": 0,
"лучший рейтинг": 30
},
"издатель": {
"@type": "Организация",
"name": "Аудиоксид",
"description": "Независимый музыкальный интернет-журнал, основанный в 2015 году. Публикует обзоры, статьи, интервью и другие странности.",
"url": "https://audioxid.com",
"логотип": "https://audioxid.com/logo-location.jpg",
"такой же как" : [
"https://facebook.com/audioxid",
"https://twitter.com/audioxid",
"https://instagram.com/audioxidcom"
]
}
}
Публикует обзоры, статьи, интервью и другие странности.",
"url": "https://audioxid.com",
"логотип": "https://audioxid.com/logo-location.jpg",
"такой же как" : [
"https://facebook.com/audioxid",
"https://twitter.com/audioxid",
"https://instagram.com/audioxidcom"
]
}
}
 Начните с очевидных входных данных (дата, автор, тип контента и т. д.) и продвигайтесь вглубь контента. Первый шаг может быть таким же простым, как hCard (разновидность цифрового удостоверения личности) для вашего личного веб-сайта. Распечатайте скриншоты страниц и начните комментировать. Вы будете поражены тем, сколько контента может быть обработано данными.
Начните с очевидных входных данных (дата, автор, тип контента и т. д.) и продвигайтесь вглубь контента. Первый шаг может быть таким же простым, как hCard (разновидность цифрового удостоверения личности) для вашего личного веб-сайта. Распечатайте скриншоты страниц и начните комментировать. Вы будете поражены тем, сколько контента может быть обработано данными. ».
».
Схемы предоставит вам информацию о лайках и метаданные WooRank. превращает его в данные, структурированные для машиночитаемости.
Проверка семантической разметки
После того как вы пометили свои метаданные разметкой, вам необходимо проверить код. Проверка является важным шагом — добавление неработающего и неправильного кода на ваш сайт не принесет вам никакой пользы и, скорее всего, приведет к неприятным последствиям.
Проверка является важным шагом — добавление неработающего и неправильного кода на ваш сайт не принесет вам никакой пользы и, скорее всего, приведет к неприятным последствиям.
Если, конечно, вы не использовали инструмент метаданных WooRank, чтобы связать свой бренд с профилями в социальных сетях. Тогда вы можете быть уверены, что это идеальный код.
Инструмент тестирования структурированных данных Google
Если вы добавляете семантическую разметку для помощи в поисковой оптимизации, нет причин не использовать сам Google для проверки кода. Инструмент тестирования структурированных данных Google работает двумя способами:
- Скопируйте и вставьте код, который вы хотите проверить, в инструмент
- Введите URL-адрес страницы, которую вы хотите протестировать это связано с.
Итак, по коду, созданному инструментом метаданных WooRank, Google может найти сущности для организации (в данном случае Acme.org) и ее блога. Инструмент также обнаруживает ссылки на профили в социальных сетях.
(Видите? Ни ошибок, ни предупреждений. Совершенство.)
Yandex Semantic Markup Validator
Этот бесплатный инструмент, как и инструмент Google, проверяет URL-адрес вашей страницы или фрагмент кода и возвращает ссылки JSON-LD, которые он может прочитать.
Вот пример того, что происходит, когда вы пытаетесь использовать поле, не связанное со схемой:
Структурированный линтер данных
Есть несколько вещей, которые отличают структурированный линтер данных от других инструментов семантической разметки. Во-первых, вы можете загрузить локальные файлы в валидатор, а также вставить код или отправить URL-адрес.
Во-вторых, Линтер может создавать расширенные фрагменты из метаданных, которые он находит на вашей странице, так что вы можете увидеть свою разметку в действии.
Наконец, у вас также есть программный доступ к Линтеру, поэтому вам фактически не нужно вручную проверять страницы или блоки кода. ЛИНТЕР вернет запрос со следующей информацией о метаданных страницы:
- Сниппет: ЛИНТЕРовский макет расширенного сниппета страницы
- Извлеченные данные: Таблица семантических данных, которые ЛИНТЕР может обнаружить в файле
- Статистика: Информация об использовании шаблонов сниппетов и проанализированных троек
- Отладка: «Обширная информация» по отладке проблем, обнаруженных Линтером при проверке разметки создали и проверили свою семантическую разметку, вам просто нужно добавить ее на свой веб-сайт и подождать, пока Google найдет и просканирует ее.
Однако семантическая разметка не является фактором ранжирования, и просто наличие кода на ваших страницах не позволяет в полной мере использовать возможности семантической сети. Для этого вам нужно создайте свои собственные объекты и используйте их для создания семантической сети для вашего веб-сайта .
WordLift
Wordlift.io — это плагин WordPress для создателей контента, которые хотят использовать преимущества семантической сети для своего контент-маркетинга. Wordlift использует технологию обработки естественного языка (NLP), которая анализирует текст и обогащает его настраиваемой семантической разметкой.
По сути, если вы вернетесь к примеру, который мы использовали в первой части нашей семантической веб-серии, WordLift увидит это предложение:
Грег родился в Мичигане, а я живу в Брюсселе.
И обнаруживает объекты для «Грег», «Мичиган» и «Брюссель». Затем он использует открытые источники данных для разметки страницы, чтобы добавить контекст для этих сущностей.
WordLift также позволяет создавать собственные объекты для вашего веб-сайта и автоматически определяет ваш словарный запас, чтобы обогатить ваш контент. Итак, это предложение:
Добавьте местоположение вашей карты сайта xml в файл robots.txt.
Добавлена ссылка на данные для «xml sitemap» и «файла robots.txt».
TextRazor
TextRazor — это инфраструктура для анализа и обогащения текста, которая добавляет к вашему контенту семантическую сеть. Он читает ваш текст, анализирует его, а затем добавляет к нему контекст, ссылаясь на соответствующие источники в Интернете. Вы можете увидеть простую демонстрацию его анализа в действии на их веб-сайте.
TextRazor также извлекает актуальность объектов на странице для широких тем. В случае их демонстрации статьи BBC вы можете увидеть объекты и темы, для которых статья семантически релевантна.
С точки зрения SEO, это темы запросов, для которых Google считает релевантной эту страницу. Эта информация очень важна при оптимизации контента на странице и должна информировать вас о том, как вы формируете словарный запас своего веб-сайта.