как составить СЯ онлайн для SEO-продвижения, автоматическая разработка
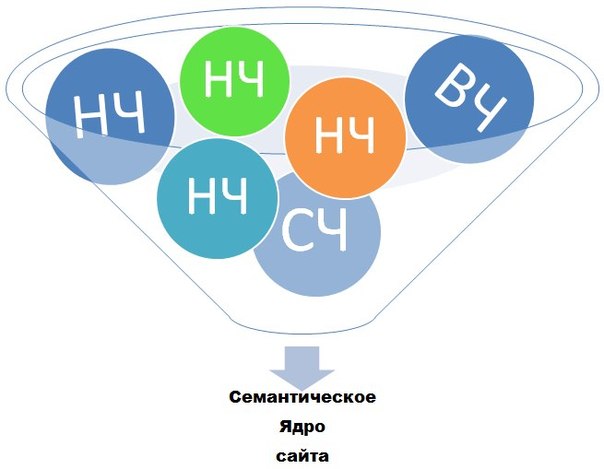
Семантическое ядро (СЯ) — это список слов и словосочетаний, описывающих направленность и тематику сайта. Для крупных сайтов такой перечень может насчитывать до нескольких тысяч слов.
Составление семантического ядра является первой ступенью в продвижении. Смысловая направленность ядра оказывает прямое влияние на оптимизацию, подбор целевых страниц и наполнение сайта.
Как составить семантическое ядро сайта?
Предлагаем вам несколько общих советов, которые помогут вам сформировать семантическое ядро вашего сайта.
Для начала нужно определить запросы, описывающие содержания сайта. Для этого можно использовать три сервиса:
- Яндекс.Вордстат.
- Google Ads.
- ROOKEE.
После этого следует отсеять неподходящие запросы — в частности, ключевые слова, не соответствующие тематике сайта.
Получившийся список запросов нужно распределить по страницам сайта. Обычно наиболее конкурентные запросы используются для продвижения главной страницы и страниц с наибольшей ссылочной массой. Остальные запросы группируются и распределяются между другими страницами сайта.
Вы можете автоматически составить семантическое ядро — для этого создайте новую рекламную кампанию.
Кроме того, в системе есть возможность составить семантическое ядро с помощью услуги «Подбор запросов для продвижения». Чтобы заказать её, перейдите в раздел «Витрина услуг».
раздел Витрина.png
Нужная вам услуга находится в пакете «Подготовка к продвижению».
Она подходит для:
— сайтов,
— сообществ ВКонтакте,
— видео и каналов на Youtube.
Кликните на название услуги. Выберите количество запросов, на которое вы хотите подобрать и нажмите на кнопку Заказать услугу.
Укажите адрес продвигаемого сайта, телефон для связи, регион продвижения, а также напишите комментарий для вашего заказа.
После этого нажмите на кнопку «Заказать». Сумма, необходимая для заказа услуги, будет списана с вашего баланса автоматически.
Что нужно учитывать при создании семантического ядра?
В состав СЯ следует включать как узкие, так и общие запросы. Использование низкочастотных (кстати, подробнее про частотность вы можете прочитать в соответствующей статье справки) запросов приводит посетителей на сайт, но такой трафик существенно ниже по объёму, чем от высокочастотных ключевых слов. Преобладание общих запросов, в свою очередь, негативно сказывается на поведенческих факторах.
Используйте ассоциативные ключевые слова из сходных тем, чтобы сделать тексты более привлекательными для поисковиков и посетителей сайта.
Не забывайте о ключевых словах, набранных с ошибками — например, «пакупка автомобиля». Поисковик может найти релевантный сайт и по такому запросу.
Количество ключевиков напрямую зависит от объёма текста на странице. Не следует перенасыщать текст ключевыми словами. Рекомендуется использовать плотность не больше 5-7% от общей длины текста.
Как сделать семантическое ядро наиболее эффективным?
Итак, вы составили семантическое ядро сайта, подобрали для него несколько тысяч ключевых слов, распределили их по категориям и группам и даже провели предварительный анализ конкурентов для составления максимально релевантного и конкурентного СЯ. И даже более того — вы не допустили самых распространенных ошибок при составлении контент-стратегии, а также учли правила составления хорошего контента. Как проверить семантическое ядро и эффективность подобранных ключевых запросов? Для решения этой задачи идеально подойдет SpySerp, который позволит не только определить эффективность самого семантического ядра, но и его эффективность с точки зрения поисковых систем.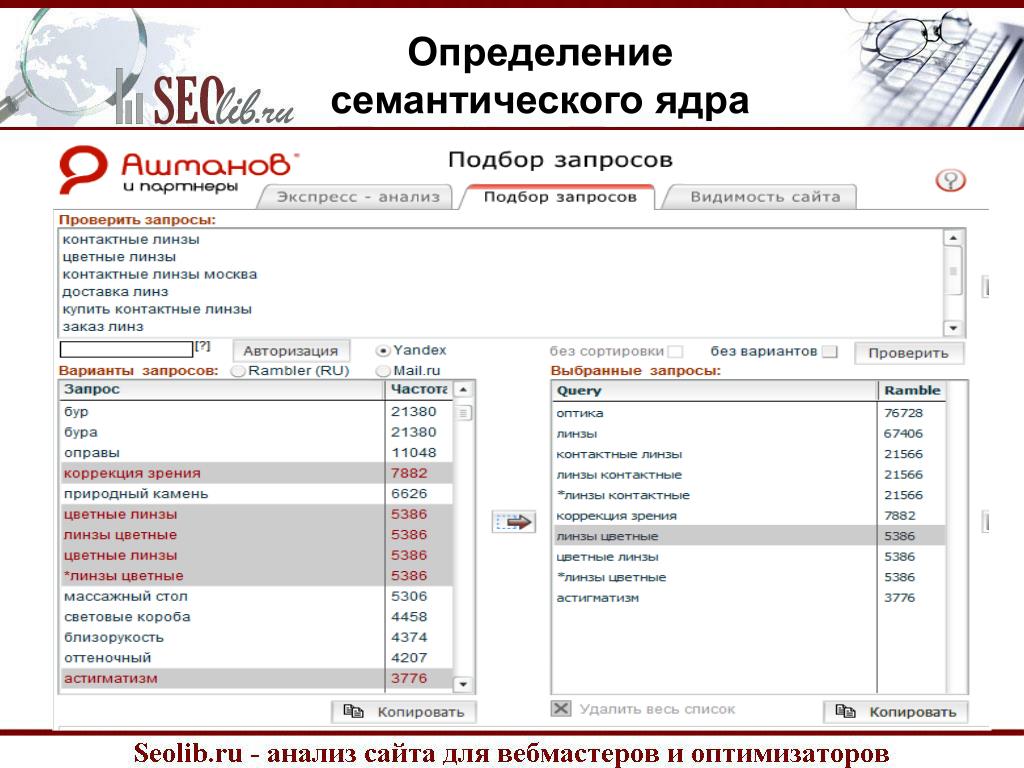
Проверяем эффективность выбранных ключевых слов
Как проверить эффективность собранных ключевых слов? Если подобранные вами ключи хорошо видны в поисковых системах и занимают высокие позиции, то это свидетельствует о том, что сбор семантического ядра был проведен правильно. Причин же, по которым КС могут быть плохо видны поисковыми системами, может быть множество — от запрета на индексацию в robots.txt до фильтров Гугла или Яндекса. Рассмотрим подробнее процесс проверки эффективности СЯ вашего сайта с помощью нашего сервиса.
Создаем проект в SpySerp
Первый шаг для проверки того, как составлено семантическое ядро, — это регистрация в системе и создание проекта. Регистрация бесплатная, а использование не составит никакой сложности даже для новичков.
Регистрация бесплатная, а использование не составит никакой сложности даже для новичков.
При создании проекта пользователю будет предложено использовать возможности мастера настроек — с его помощью проект можно создать в течение 2-3 минут.
Добавляем ключевые слова из семантического ядра
Первые три шага уже описаны в нашей статье о том, как использовать возможности SpySerp — на данном этапе остановимся на четвертом шаге — добавлении ключевых слов. Начиная с этого шага (а также с учетом предыдущих) мы размещаем КС из семантического ядра сайта, которые нужно проверить. Для примера мы взяли интернет-магазин из Google, который занимается продажей спортивной обуви и проверили его ключевые слова, после чего — добавили эти ключевые слова в соответствующее поле:
Для проверки мы выбрали только 40 ключевых слов, однако их количество может быть куда больше (для отдельных проектов допустимое количество — вплоть до 1 млн).
Последним шагом мы выставляем время проводимых настроек, выбираем режим проверок (можно выбрать автоматический/ручной режим), проверяем все настройки ещё раз и запускаем проект.
Анализ результатов
Для получения результатов по 40 ключевым словам из семантического ядра нам понадобилось около 2-3 минут. Теперь мы можем ознакомиться с результатами:
Какие выводы можно сделать из полученных результатов: в поисковой системе Google большинство проверенных ключевых слов находятся в пределах ТОП-10 — это может свидетельствовать о том, что семантическое ядро сайта качественное и материалы, размещенные на страницах, также отличаются высоким качеством, в результате чего по выбранным ключевым словам в выбранном регионе и поисковой системе сайт находится в топовых позициях.
Альтернативная проверка через SpySerp
Можно воспользоваться альтернативным методом проверки ключевых слов с помощью SpySerp. Для этого, сразу после регистрации, необходимо перейти на главную страницу сайта и в поле ввода доменного имени ввести интересующий сайт и нажать кнопку “Начать”:
На выходе вы получаете полную информацию об эффективности собранного семантического ядра сайта на основании позиций поисковых запросов и ключей из вашего семантического ядра. Желаем вам удачных проверок и высокой видимости в поисковых системах!
Скоринг запросов — оценка семантического ядра: что важно знать
{«id»:132051,»url»:»https:\/\/vc.ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat»,»title»:»\u0421\u043a\u043e\u0440\u0438\u043d\u0433 \u0437\u0430\u043f\u0440\u043e\u0441\u043e\u0432\u00a0\u2014\u00a0\u043e\u0446\u0435\u043d\u043a\u0430 \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0433\u043e \u044f\u0434\u0440\u0430: \u0447\u0442\u043e \u0432\u0430\u0436\u043d\u043e \u0437\u043d\u0430\u0442\u044c»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc. ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat&title=\u0421\u043a\u043e\u0440\u0438\u043d\u0433 \u0437\u0430\u043f\u0440\u043e\u0441\u043e\u0432\u00a0\u2014\u00a0\u043e\u0446\u0435\u043d\u043a\u0430 \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0433\u043e \u044f\u0434\u0440\u0430: \u0447\u0442\u043e \u0432\u0430\u0436\u043d\u043e \u0437\u043d\u0430\u0442\u044c»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat&text=\u0421\u043a\u043e\u0440\u0438\u043d\u0433 \u0437\u0430\u043f\u0440\u043e\u0441\u043e\u0432\u00a0\u2014\u00a0\u043e\u0446\u0435\u043d\u043a\u0430 \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0433\u043e \u044f\u0434\u0440\u0430: \u0447\u0442\u043e \u0432\u0430\u0436\u043d\u043e \u0437\u043d\u0430\u0442\u044c»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.
ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat&title=\u0421\u043a\u043e\u0440\u0438\u043d\u0433 \u0437\u0430\u043f\u0440\u043e\u0441\u043e\u0432\u00a0\u2014\u00a0\u043e\u0446\u0435\u043d\u043a\u0430 \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0433\u043e \u044f\u0434\u0440\u0430: \u0447\u0442\u043e \u0432\u0430\u0436\u043d\u043e \u0437\u043d\u0430\u0442\u044c»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat&text=\u0421\u043a\u043e\u0440\u0438\u043d\u0433 \u0437\u0430\u043f\u0440\u043e\u0441\u043e\u0432\u00a0\u2014\u00a0\u043e\u0446\u0435\u043d\u043a\u0430 \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0433\u043e \u044f\u0434\u0440\u0430: \u0447\u0442\u043e \u0432\u0430\u0436\u043d\u043e \u0437\u043d\u0430\u0442\u044c»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc. ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat&text=\u0421\u043a\u043e\u0440\u0438\u043d\u0433 \u0437\u0430\u043f\u0440\u043e\u0441\u043e\u0432\u00a0\u2014\u00a0\u043e\u0446\u0435\u043d\u043a\u0430 \u0441\u0435\u043c\u0430\u043d\u04
ru\/u\/329180-amdg\/132051-skoring-zaprosov-ocenka-semanticheskogo-yadra-chto-vazhno-znat&text=\u0421\u043a\u043e\u0440\u0438\u043d\u0433 \u0437\u0430\u043f\u0440\u043e\u0441\u043e\u0432\u00a0\u2014\u00a0\u043e\u0446\u0435\u043d\u043a\u0430 \u0441\u0435\u043c\u0430\u043d\u04
Как правильно составить семантическое ядро?
26 Апреля 2019SEO продвижение любого сайта начинается с правильно составленного семантического ядра. Не имеет значения продвигаете вы сайт услуг или интернет-магазин, наша статья поможет вам разобраться с тем, что такое семантическое ядро, как его правильно собрать и какие сервисы для этого можно использовать.
Содержание
Что такое семантическое ядро?
Семантическое ядро (СЯ) — перечень слов и их сочетаний, отражающих тематику и структуру сайта.
Оно также представляет собой список запросов, которые пользователи вводят в поисковую строку. Они хотят найти ресурс, который полностью решит их проблему, потратив на это минимум времени. Мы же хотим привести на сайт заинтересованных пользователей, которые совершают целевое действие: оформят покупку, оставят заявку, контактные данные и т.д. Поэтому очень важно правильно собрать ядро и оптимизировать страницы под поисковые фразы, которые приведут на сайт именно целевую аудиторию.
Мы же хотим привести на сайт заинтересованных пользователей, которые совершают целевое действие: оформят покупку, оставят заявку, контактные данные и т.д. Поэтому очень важно правильно собрать ядро и оптимизировать страницы под поисковые фразы, которые приведут на сайт именно целевую аудиторию.
Во время сбора семантического ядра происходит формирование списка ключевых слов и фраз. Чем больше синонимов, вариаций написания слов и терминов вы учтете, тем лучше можно будет продумать и сформировать структуру сайта, проработать контент, с учетом ключевых слов, к которому относятся заголовки страниц, описания и тексты. Таким образом, вы сможете предоставить интересную, понятную и актуальную информацию для пользователей вашего сайта.
Классификация ключевых слов
Все ключевые слова можно условно классифицировать на несколько видов, работа с каждым из которых имеет свои особенности. Мы рассмотрим 4 основных типа параметров, по которым разделяются поисковые фразы.
1. По частотности
По частотности
 По частотности
По частотности- Высокочастотные (ВЧ) – фразы, описывающие общую тему. Чаще всего посадочной для них является главная страница.
- Среднечастотные (СЧ) – отдельные направления в теме. Подходят для продвижения разделов, подразделов и каталожных страниц коммерческого сайта, а также для крупных информационных статей.
- Низкочастотные (НЧ) – запросы нацеленные на поиск конкретного ответа на вопрос. Под такие фразы чаще всего оптимизируются карточки товаров или определенные статьи.
- Микронизкочастотные (МНЧ) – это фразы, которые спрашивают один раз в месяц (по данным Яндекс.Вордстат).
ВЧ запросы стоит включать в семантическое ядро в том случае, если ваш сайт уже уверенно стоит в ТОПе по низкочастотным и среднечастотным запросам.
С них часто начинается продвижение молодого сайта, у которого пока нет позиций и трафика.
Нет смысла включать такие запросы в семантическое ядро. По ним легко выйти в ТОП, но будучи на первых позициях вы не получите трафика.
2. По коммерческости
Коммерческий запрос — фраза, которую пользователь вводит в поисковую строку с целью совершить покупку (купить самокат, велопрокат прайс).
Некоммерческий запрос — фраза, с помощью которой пользователь ищет информацию без осуществления покупки (станок характеристики, микроволновка отзывы).
Семантическое ядро интернет-магазинов и прочих продающих сайтов обязательно должно включать в себя коммерческие запросы и составлять его основу. Это не значит, что нельзя включать в СЯ некоммерческие запросы: они могут вести на страницы со статьями, советами, обзорами. Однако вы должны понимать, что такие запросы не принесут продаж.
3. По геозависимости
Геозависимые — ключевые фразы, по которым результаты выдачи в поиске отличаются при смене региона. Например:
- мультфильм шрек в кино
- заказать пиццу
- ресторан морепродуктов
Если пользователь ищет «кинотеатры», находясь в Новосибирске, то ему не интересны кинотеатры в Москве, Санкт-Петербурге и других городах.
Геонезависимые — ключевые фразы, по которым результаты выдачи в поиске НЕ отличаются при смене региона. Например:
- мультфильм шрек оценки
- купить кровать в омске
- как приготовить кулич
Если в том же Новосибирске вводится запрос «кинотеатры в москве», то становится понятно, что нужны результаты по Москве, независимо от того, в каком городе пользователь находится.
По геонезависимым запросам намного тяжелее выйти в ТОП из-за большой конкуренции. Но коммерческие запросы редко бывают геонезависимыми — ведь чем ближе географически к пользователю расположена компания предлагающая услуги или товары, тем ему удобнее. Поэтому основная часть семантического ядра коммерческого сайта будет состоять из геозависимых запросов. Однако существуют исключения, все зависит от тематики сайта. Поэтому всегда проверяйте продвигаемые фразы на геозависимость.
4. По типу
- Информационные — запросы, с помощью которых осуществляется поиск полезной информации (как связать носки).
- Брендовые — запросы включающие в себя название определенной компании. Брендовыми также являются запросы с различными вариантами написания домена, в том числе на русском и с ошибками (алиэкспересс, али экспрес, ali express).
- Транзакционные — фразы, которые используют для поиска товаров и услуг с дальнейшим желанием покупки или заказа. Транзакционные аналогичны коммерческим.
- Навигационные — ключевые слова, по которым ищут какое-то место или событие (конференция сбербанк 2018).
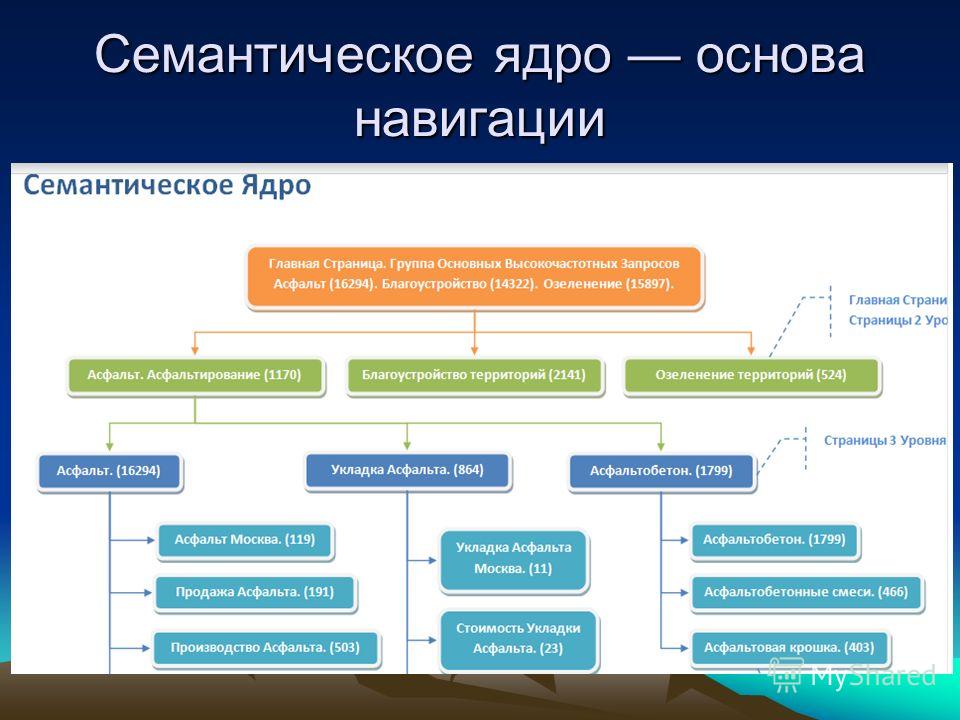
Такие запросы можно брать в семантическое ядро, если только ваш бренд, марка или компания достаточно известны и пользователи ищут вас в сети.
По некоторым транзакционным запросам в ТОПе выдачи находится большое количество сайтов-агрегаторов. И для обычных интернет-магазинов остается 1-2 места, либо его вообще нет. Поэтому лучше подобрать более реальный запрос для продвижения.
Сервисы для составления семантического ядра
Есть большое количество онлайн сервисов, которые ускоряют и автоматизируют процесс сбора семантического ядра. Вы можете воспользоваться как платными, так и бесплатными программами. Рассмотрим несколько таких сервисов и их принцип работы.
Вы можете воспользоваться как платными, так и бесплатными программами. Рассмотрим несколько таких сервисов и их принцип работы.
Key Collector
Эта программа окажет вам непосильную помощь, если вы хотите собрать обширное ядро для большого сайта с достаточно разветвленной структурой. Список основных функций этого сервиса:
- Сбор ключевых слов через Яндекс.Вордстат.
- Парсинг подсказок поисковых систем.
- Удаление неподходящих слов с помощью стоп-слов.
- Определение базовой и точной частотности.
- Фильтрация запросов по различным показателям.
- Определение сезонности.
Сервис Key Collector платный. Все эти задачи можно выполнить и в бесплатных аналогах, но придется использовать несколько программ.
SlovoEB
Это бесплатный сервис от разработчиков Key Collector. Его основные функции — это сбор ключевиков через Wordstat, парсинг подсказок и определение частотности фраз.
Интерфейс будет достаточно понятен даже для людей, которые не имеют опыта работы с подобными сервисами. Для начала работы нужно создать новый проект, а затем на вкладке “Данные” перейти на “Добавить фразу”. Отметьте там предполагаемые фразы по которым пользователи могут найти ваш сайт, продукт или услуги на нем.
Сервис сам подберет ключевые фразы, а также поможет автоматизировать задачи для последующего анализа и очистки будущего ядра.
Wordstat Яндекса
Яндекс.Вордстат — сервис с помощью которого вы сможете бесплатно собрать и проанализировать семантическое ядро вашего сайта онлайн. Давайте немного подробнее рассмотрим функционал сервиса:
Предоставляет статистику показов в месяц по ключевому слову, а также поисковым фразам, которые включают указанное вами ключевое слово. Можно проанализировать общие данные или заострить внимание на запросах именно мобильной аудитории.
- Показывает данные по регионам
- Предоставляет историю показов фраз в динамике
- Предоставляет статистику запросов по определенным регионам
Этот сервис очень удобен для подборки ключевых фраз для семантического ядра, но дальше проводить анализ и группировать запросы придется вручную.
Системы аналитики
При сборе семантического ядра для уже существующего сайта можно воспользоваться такими системами аналитики, как Яндекс.Вебмастер, Яндекс.Метрика или Google Analytics. Там вы сможете найти с помощью каких фраз посетители находят ваш сайт и выбрать из них подходящие для продвижения.
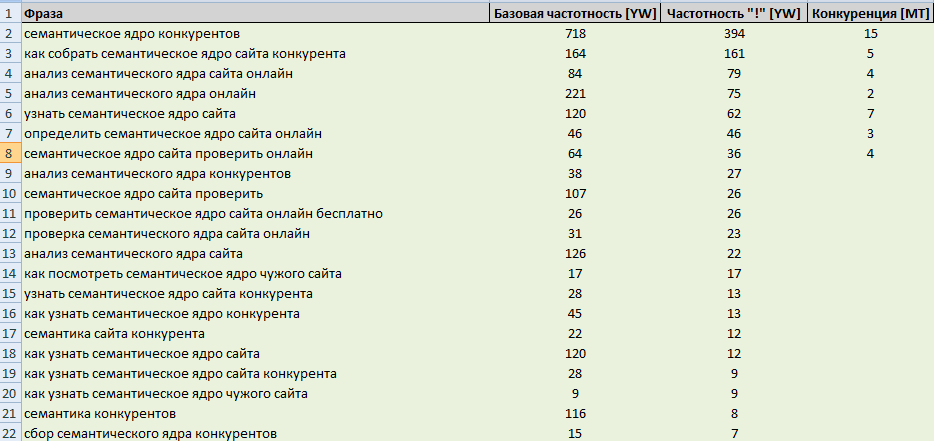
Анализ семантического ядра конкурентов
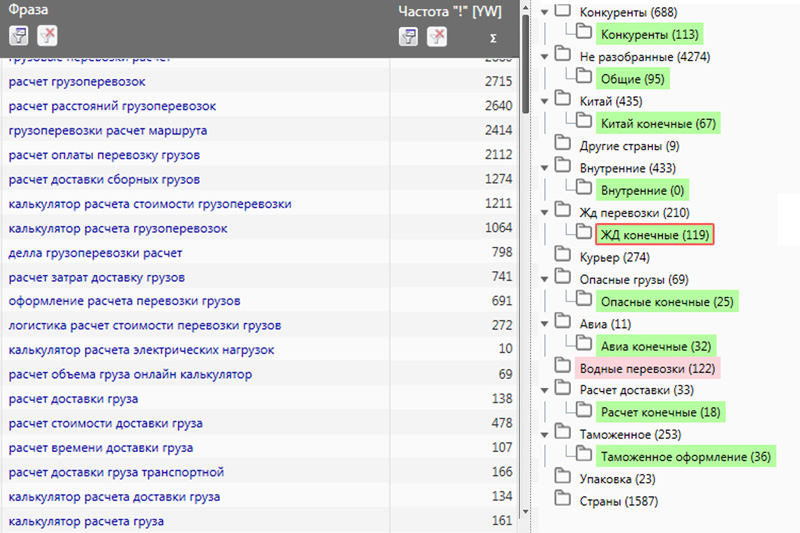
Для сбора семантического ядра есть немного другой подход. Можно провести анализ семантического ядра конкурентов. В итоге вы получите список фраз, который можно использовать при продвижении сайта. В большинстве своем такие сервисы платные.
Принцип работы сервисов
Сервисы для анализа семантики конкурентов не имеют прямого доступа к статистике сайта. Алгоритм их работы основывается на периодическом сборе и анализе информации с поисковых систем. Информация записывается в базу и выдается пользователю инструмента по запросу. Следовательно, если база сервиса обновляется редко — есть шанс получить уже устаревшую, не актуальную и бесполезную информацию.
Megaindex Premium Analytics
Модуль «Видимость сайта» платформы Megaindex дает нам достаточно обширный набор инструментов для получения ключевых фраз конкурентов: можно посмотреть и выгрузить ключевые фразы по которым ранжируется сайт; найти схожие по семантике сайты, которые тоже могут быть использованы в качестве доноров. Сервис платный.
Keys.so
Был создан как инструмент для анализа семантики конкурентов. Необходимо ввести url интересующего нас сайта, отобрать доноров по количеству общих ключей, проанализировать их сайты и выгрузить ключи. Все делается быстро и без лишних телодвижений. Приятный, свежий интерфейс, только нужная информация.
Spywords.ru
Помимо анализа видимости предоставляет статистику по объявлениям в директе. Интерфейс немного перегружен, но если разобраться, то сервис свою задачу в целом решает. Можно проанализировать сайты конкурентов, посмотреть пересечения по семантическому ядру, выгрузить фразы по которым продвигаются конкуренты. К недостаткам можно отнести довольно слабую базу — всего 23 млн ключевых слов.
К недостаткам можно отнести довольно слабую базу — всего 23 млн ключевых слов.
Бесплатные сервисы
XTool – популярный сервис которым пользуется большое количество новичков. Он может показывать видимость сайтов в поисковых системах, их траст, а также некоторые другие данные. Количество проверок лимитировано. Стоимость каждой проверки, которая превышает этот лимит – 1 рубль.
Букварикс – бесплатно позволяет анализировать семантическое ядро чужих ресурсов, что в конечном итоге позволяет пользователям получать доступ к нужной информации, не заплатив ни копейки. Очень распространен среди фрилансеров на всевозможных биржах, т. к. даже бесплатный аккаунт позволяет пользоваться инструментом на достаточно приличном уровне.
Сбор семантического ядра пошагово
Разберем основные этапы через которые нужно пройти для составления будущего семантического ядра.
Шаг 1. Подбор основных фраз
Определитесь что именно будет продавать ваш сайт, наметьте основные разделы товаров.
Для начала нужно собрать первичный список общих основных слов и словосочетаний, охватывающих тематику (ВЧ). Также такие запросы называются маркерами. Это могут быть названия направлений сайта (можно использовать названия разделов и подразделов).
При подборе маркерных фраз удобнее всего использовать Яндекс.Вордстат. Вбивая в него ключевую фразу, слева вы можете увидеть вариации этого словосочетания с использованием различных слов, а справа — похожие запросы, которые можно взять для дальнейшего расширения темы.
Также показывается базовая частотность фразы за месяц во всех словоформах и с добавлением любых слов. Но нам такая частотность в данный момент не нужна, ведь нас будет интересовать частота всех итоговых фраз ядра “в кавычках”, т. е. учитывается частота во всех словоформах, но без добавления дополнительных слов.
Представьте, что вы решили продвигать свой блог для сео, значит часть основных запросов будет примерно такая:
Для наглядности разберем как на каждом шагу происходит подбор фраз на основе маркерной фразы “семантическое ядро”, а для остальных тем всё можно сделать аналогично примеру..jpg)
Шаг 2. Поиск синонимов
Пользователи при написании запроса в поисковой строке могут использовать слова близкие по смыслу. Чтобы максимально охватить ядро тематики нам нужно найти все возможные синонимы и словоформы к основным словам. Для этого можно воспользоваться следующим:
- Мозговой штурм. Поставьте себя на место пользователя и подумайте какими другими словами вы могли бы сформулировать вопрос.
- Правая часть в Яндекс.Вордстат.
- Запросы сформулированные на кириллице (seo/сео, polaris/поларис).
- Аббревиатуры, сленговые фразы и различные термины, относящиеся к тематике.
- Подсказки в поисковой строке Яндекс и Google, а также фразы в блоке “Вместе с … ищут”.
После всех действий по выбранной теме получится подобный список фраз:
Шаг 3. Расширение ядра
Этот шаг удобно выполнять с помощью уже знакомого инструмента Wordstat. С помощью этого сервиса нужно провести анализ по всем фразам, которые были получены на прошлом этапе, и скопировать всё, что будет находиться в левой колонке в отдельный файл. Также иногда нужно поглядывать и на правую колонку, потому что иногда Яндекс будет предлагать вам и другие слова, которые вы могли пропустить ранее.
Также иногда нужно поглядывать и на правую колонку, потому что иногда Яндекс будет предлагать вам и другие слова, которые вы могли пропустить ранее.
В результате выполнения этого шага у вас должен получиться список фраз из Yandex.Wordstat для каждого ключа, полученного на втором этапе.
Шаг 4. Удаление лишних фраз
Этот этап для вас будет самым долгим и трудозатратным, т. к. выполняется он вручную. Нужно внимательно просмотреть каждую поисковую фразу и удалить неподходящие по смыслу.
Рассмотрим примеры запросов, которые нужно сразу убирать из будущего ядра:
- ключи с названиями брендов конкурентов;
- ключи с названиями товаров или услуг, которые вы не предоставляете и не собираетесь с ними работать в дальнейшем;
- ключи с использованием неподходящих регионов и адресов;
- фразы написанные с ошибками и опечатками.
После удаления лишних фраз получится перечень запросов для маркерного ключа “семантическое ядро”. Далее рассмотрим ещё несколько шагов, в процессе которых будут вноситься корректировки в полученный список.
Далее рассмотрим ещё несколько шагов, в процессе которых будут вноситься корректировки в полученный список.
Шаг 5. Определение точной частотности для фраз
Для массового определения точной частотности “в кавычках” нужно воспользоваться сервисами, например, Key Collector или SlovoEB. Подробнее о них мы разберем в этой статье позже.
После определения точной частотности всех фраз, нужно удалить все нулевики, т. к. такие запросы в точности никто не вводит, а значит трафик они вам не принесут.
Шаг 6. Проверка конкурентности
Здесь нужно анализировать выдачу в ТОП-10 по запросам. Обратите внимание на количество главных страниц (морд сайтов), тип контента конкурентов (статья, товар или каталожная страница), вложенность адресов страниц и их формат, а также тип сайтов конкурентов (информационные, коммерческие, агрегаторы). После анализа выдачи вы сможете понять, насколько жесткая борьба за позиции по определенному запросу и на сколько велика вероятность попадания в ТОП вашего сайта. Если становится понятным, что ваш сайт не сможет составить конкуренцию в выдаче, то такие запросы нужно убирать из ядра.
Если становится понятным, что ваш сайт не сможет составить конкуренцию в выдаче, то такие запросы нужно убирать из ядра.
После прохождения всех шагов, представленных выше, для каждой базовой поисковой фразы, вы получите готовое ядро для сайта.
Итоговый чек-лист
- Подбираем базовые запросы, которые описывают тематику. Берез за основу структуру сайта и типы предоставляемых товаров или услуг.
- Ищем синонимы ключевых слов с помощью Яндекс.Вордстат и парсинга подсказок поисковых систем.
- Расширяем ядро с помощью левой части в Wordstat.
- Очищаем список от лишних фраз.
- Определяем точную частотность для всех запросов и удаляем нулевики.
- Проверяем конкурентность запросов и проводим окончательную чистку семантического ядра.
Пример семантического ядра интернет-магазина
Здесь вы можете увидеть пример части семантического ядра интернет-магазина.
Такое представление помогает оценить всю ситуации продвижения, а также увидеть подобные проблемы:
- нет страницы, которая подходит для продвижения по данному запросу, нужно создать новую
- эффективность продвижения страниц сайта
- соответствуют ли посадочные и ранжируемые страницы
Что делать с семантическим ядром после составления?
Вы составили семантическое ядро для своего сайта, но затем возникают вопросы: “Что делать после сбора ядра?”, “Как размещать семантическое ядро на сайте?”.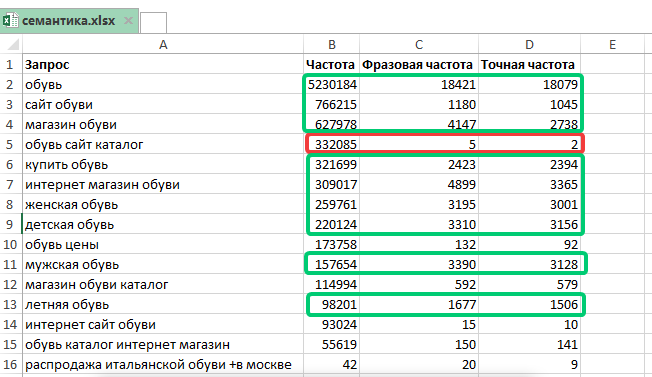 Давайте рассмотрим следующие шаги продвижения сайта:
Давайте рассмотрим следующие шаги продвижения сайта:
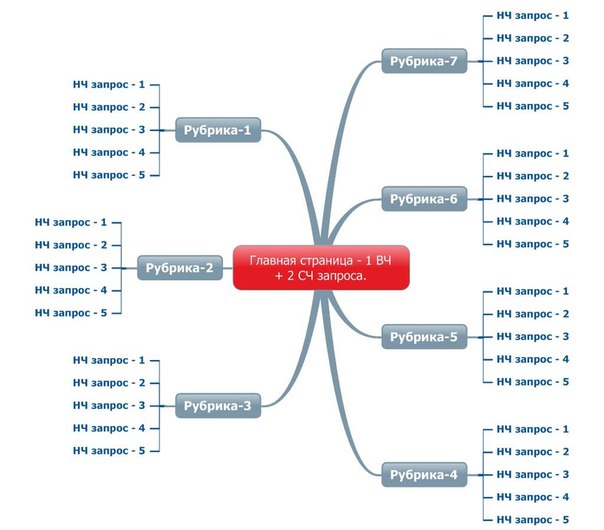
- Кластеризация запросов и распределение их по посадочным страницам. На данный момент ваше семантическое ядро является разрозненным списком фраз. Для дальнейшей работы вам необходимо провести их кластеризацию, т. е. объединить в группы по смыслу. А затем уже подобрать для каждой группы страницу продвижения (выбрать из существующих на сайте или создать новую).
- Составление оптимизированных заголовков и описаний для посадочных страниц. Используем самый высокочастотный запрос, описывающий содержимое страницы для заголовка h2. Менее частотные фразы добавляем в заголовок title и описание description с разбавлением дополнительными словами, не относящимися к тематике.
- Наполнение страницы контентом. Проанализируйте запросы, подобранные для продвигаемых страниц. Необходимо выявить потребности пользователей, которые вводят эти поисковые фразы. Какую информацию они хотят найти, перейдя на ваш сайт? Далее составляем план текста и пишем его сами, либо отправляем задание копирайтеру. Только после этого вбиваете основную поисковую фразу, продвигаемую на выбранную вами страницу, и смотрите наполняемость страниц конкурентов, чтобы сделать похожее.
 Только после этого вбиваете основную поисковую фразу, продвигаемую на выбранную вами страницу, и смотрите наполняемость страниц конкурентов, чтобы сделать похожее.
Только после этого вбиваете основную поисковую фразу, продвигаемую на выбранную вами страницу, и смотрите наполняемость страниц конкурентов, чтобы сделать похожее.Теперь ваши посадочные страницы оптимизированы под фразы из семантического ядра.
Заключение
В этой статье мы рассмотрели все этапы по сбору качественного и полного семантического ядра для сайта, а также некоторые сервисы, которые помогут вам в этом деле. Выполняя каждый шаг в описанной выше инструкции вы сможете собрать ядро, которое будет максимально охватывать тематику вашего сайта, а это значит, что вы сможете составить правильную стратегию продвижения и быстро выбраться в ТОП выдачи поисковых систем.
что это, как собрать, примеры / ИНТЕРНЕТ-МАРКЕТИНГ
Семантическое ядро – это набор фраз, соответствующих поисковым запросам пользователей в поисковых системах, которые характеризуют определенную тематику (товары, услуги, вид деятельности и т. д.).
д.).
Собранная (полная) семантика сайта называется семантическим ядром (СЯ).
Семантика – это то, с чего стоит начать поисковое продвижение. Без семантики невозможно представить, каким образом интересуются той или иной информацией, товаром или услугой в интернете.
Ключевые правила семантики
- Семантическое ядро сайта должно включать группы запросов: НЧ (низкочастотные), СЧ (среднечастотные) и ВЧ (высокочастотные), чтобы полностью охватить тематику сайта
- Ключевые слова семантического ядра должны соответствовать тематике сайта
- Один запрос – одна страница. Недопустимо, чтобы одному запросу соответствовало несколько страниц. Но можно, чтобы одной странице соответствовало несколько поисковых запросов
- Группировка запросов по соответствующим страницам. При формировании семантики и кластеризации запросов нужно разбивать запросы на группы, которые соответствуют одной конкретной странице сайта
- Сайт должен давать ответ на любой запрос, который есть в семантическом ядре (!)
- Структуру сайта должна отражать семантическое ядро (!)
Этапы создания семантического ядра
- Составьте список услуг, товаров, информации, которая размещается или будет размещаться на сайте. Проанализируйте целевую аудиторию (далее «ЦА»), их группы и их потребности. Выявите спрос ЦА и сезонность (например, с помощью Яндекс.Wordstat). Важно просмотреть общий спрос.
- Подберите запросы, которые соответствуют тематике вашего сайта. Самостоятельно. Как вы бы искали тот или иной товар? Услугу? Устройте мозговой штурм.
- Подберите запросы из поисковых систем с помощью сервисов сбор запросов (например, Яндекс.Wordstat, Google Trends)
- Отфильтруйте полученные запросы. Исключите пустые фразы и повторы. Объедините список фраз в один список и сделайте поиск дополнительных ключевых слов с помощью Key Collector – наиболее популярная программа сбора ключей для семантики
- Сгруппируйте полученные запросы по основным разделам сайта, которые потом будут продвигаться
 Проанализируйте целевую аудиторию (далее «ЦА»), их группы и их потребности. Выявите спрос ЦА и сезонность (например, с помощью Яндекс.Wordstat). Важно просмотреть общий спрос.
Проанализируйте целевую аудиторию (далее «ЦА»), их группы и их потребности. Выявите спрос ЦА и сезонность (например, с помощью Яндекс.Wordstat). Важно просмотреть общий спрос.Если у Вас возникли сложности в сборе семантического ядра, Вы всегда можете обратиться к нам за этой услугой.
Пример собранной семантики по теме «Продвижение в поисковых системах» в программе KeyCollector
Классификация поисковых запросов
Поисковые запросы могут быть:
- Информационные. По таким запросам пользователи обычно ищут ответ на какой-либо вопрос, который они задают в поисковой строке
- Транзакционные (коммерческие). По таким запросам пользователи ищут сайты, на которых они могут что-то купить или приобрести.
- Навигационные. По таким запросам пользователи ищут сайт, на котором, по их мнению, есть ответ на их вопрос.
- Геозависимые и геонезависимые – информационные и транзакционные запросы, которые имеют свойство менять органическую выдачу по регионам, но при этом иметь схожесть по типу. Например, геозавизимые: купить ботинки в Москве или куда сходить в кино. Геонезависимые: как пришить пуговицу или как делать оригами т.д.
 По таким запросам пользователи обычно ищут ответ на какой-либо вопрос, который они задают в поисковой строке
По таким запросам пользователи обычно ищут ответ на какой-либо вопрос, который они задают в поисковой строкеВ каждой поисковой системе тип запроса может отличаться. Для того, чтобы понять к какому типу отнести запрос, нужно вручную проверить выдачу по этому запросу в конкретном регионе.
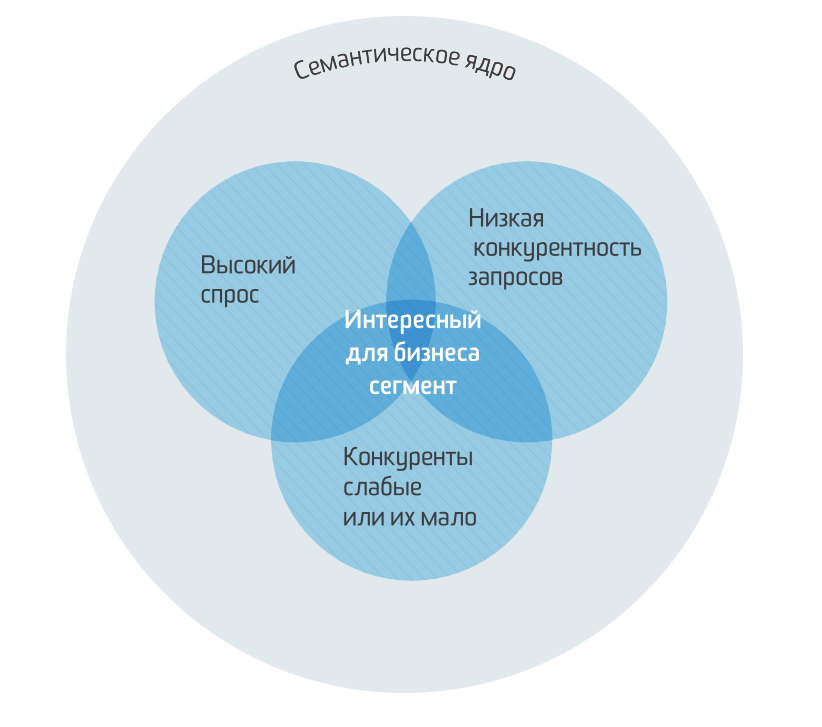
Пример готовой семантики для 4 страниц сайта
Пример класстеризации запросов с определением посадочных страниц на реальном проекте
Сколько ключей должно быть в cемантике
Первое, от чего зависит размер семантики — это тематика сайта. Тематика может быть узкая (например, лазерная резка) или широкой (например, продукты питания). Чем шире тематика, тем больше запросов она содержит.
Тематика может быть узкая (например, лазерная резка) или широкой (например, продукты питания). Чем шире тематика, тем больше запросов она содержит.
«Ширина» является неким показателем спроса пользователей. Как правило, чем шире тематика, тем она конкурентней, т.к. в ней участвуют больше конкурентов.
Чтобы понять, сколько ключей должно быть в семантике, нужно понять количество запросов в тематике и определится со своими целями и ограничениями.
Рамер тематики покажет вам количество запросов в ней, ваши цели ограничат нужный объем ключевых слов (эффективные для вас), а конкурентность подскажет, какие запросы будут для вас легкими, а за какие придется побороться.
Следует помнить, что для интернет-магазинов продвижение по запросам неэффективно, поэтому много ключевых слов для таких сайтов не нужно, достаточно ограничиться запросами по категориям товаров.
Важно! Чем больше семантика, тем больше работы потребуется больше, чтобы оптимизировать сайт под неё.
Что делать после сбора семантического ядра
После сбора семантики приступайте к определению посадки каждой из групп (как мы это сделали на примере, выше) — определите для каждой семантической группы одну страницу на сайте, которую будете продвигать по этой группе запросов. И приступайте к общей оптимизации по каждой из страниц. Но перед этим обязательно сделайте аудит сайта.
как составить и зачем это нужно?
Корректно составленное семантическое ядро способно отправить на ваш сайт только нужных пользователей, а неудачное — похоронить его в недрах поисковой выдачи. Попробуем разобраться, как сделать его вашим верным помощником в деле продвижения сайта.
Что такое семантическое ядро?
Семантическое ядро (СЯ) — это совокупность слов, их форм и фраз, описывающих сайт или блог в целом и с разбивкой по его разделам. При этом все выбранные слова или словосочетания подбираются на основании актуальной статистики поисковых запросов и распределяются по группам согласно структуре сайта, частотности и другим характеристикам.
Зачем сайту семантическое ядро?
Основное назначение сайта, и маркетинга в целом, — привлекать клиентов и подводить их к принятию решения о покупке товара или заказе услуги. СЯ с этой точки зрения — это детализированный ответ на вопрос «что мы найдем на этом сайте?». Поэтому две основные задачи, которые можно решить с его помощью — это:
- попадание сайта в поисковую выдачу
- описание товара или услуги с учетом их особенностей в контекстной рекламеКлюч — основа объявления в контекстной рекламе
Однако этим дело не ограничивается, СЯ можно использовать и как перечень тем для контент-плана. Контент-план — это список тематик планируемого контента с указанием графика его подготовки
Почитать по теме:
3 популярных мифа о топовой семантике
Что первично: семантическое ядро или структура сайта?
Здесь мы неизбежно столкнемся с вопросом, который задает себе любой собственник или менеджер бизнеса, намечающий план оптимизации существующего сайта или разработки нового: что эффективнее — планирование структуры сайта исходя из грамотно собранного (читай работающего на продвижение бизнеса) СЯ или сбор семантического ядра на основе уже существующей структуры сайта? Обе точки зрения возможны, что выбрать — решать вам. Однако стоит помнить, что распределение СЯ по готовому каркасу — это результат вашего видения работы с клиентом, а организация сайта исходя из запросов — ответ на текущую ситуацию в поведении пользователей, которая может со временем измениться.
Однако стоит помнить, что распределение СЯ по готовому каркасу — это результат вашего видения работы с клиентом, а организация сайта исходя из запросов — ответ на текущую ситуацию в поведении пользователей, которая может со временем измениться.
О структуре сайта
Так или иначе сайт, структура которого соответствует верно выбранным запросам (о том, как их выбирать, поговорим чуть позже), не будет вступать в противоречие с логикой пользователя. Это одинаково важно и при первичной, и при функциональной навигации по сайту. Цель первичной навигации для владельца сайта — возвращение пользователя для принятия решения о покупке товара, заказе услуги или получении информации. Функциональной навигацией называют прохождение процессов выбора, покупки и оплате товара, подписки на персональные предложения производителя и т.д. Так, например, сайт по изготовлению сувениров с фотопечатью может иметь следующую структуру, отвечающую запросам пользователей:
Структура сайта
Почитать по теме:
15 советов по seo-архитектуре сайта
Подбор ключевых слов и фраз
Определив цель сбора СЯ, попробуем разобраться, что и как следует собирать. Слова и словосочетания, которые вводят в строке поисковика потенциальные гости сайта, чтобы найти нужную им информацию, называют ключевыми запросами или просто ключами. Например, чтобы заказать подушку с фотографией в подарок, пользователь может использовать запросы «подушка с фото заказать», «подушка с фотографией цена» и т.д.
Слова и словосочетания, которые вводят в строке поисковика потенциальные гости сайта, чтобы найти нужную им информацию, называют ключевыми запросами или просто ключами. Например, чтобы заказать подушку с фотографией в подарок, пользователь может использовать запросы «подушка с фото заказать», «подушка с фотографией цена» и т.д.
Для того, чтобы сформулировать маску подбора ключей для вашего СЯ необходимо запомнить, что ключи состоят из 3 частей:
- тело — главная часть запроса, его тема,
- спецификатор — то, что пользователь собирается сделать в рамках данной темы,
- хвост — детализация этого намерения или особые обстоятельства.
Например, у запроса «заказать лимузин в Санкт-Петербурге онлайн» будут следующие части: «лимузин» — тело, «заказать» — спецификатор, «в Санкт-Петербурге онлайн» — хвост.
Понимание строения запроса позволит вам подобрать нужную маску.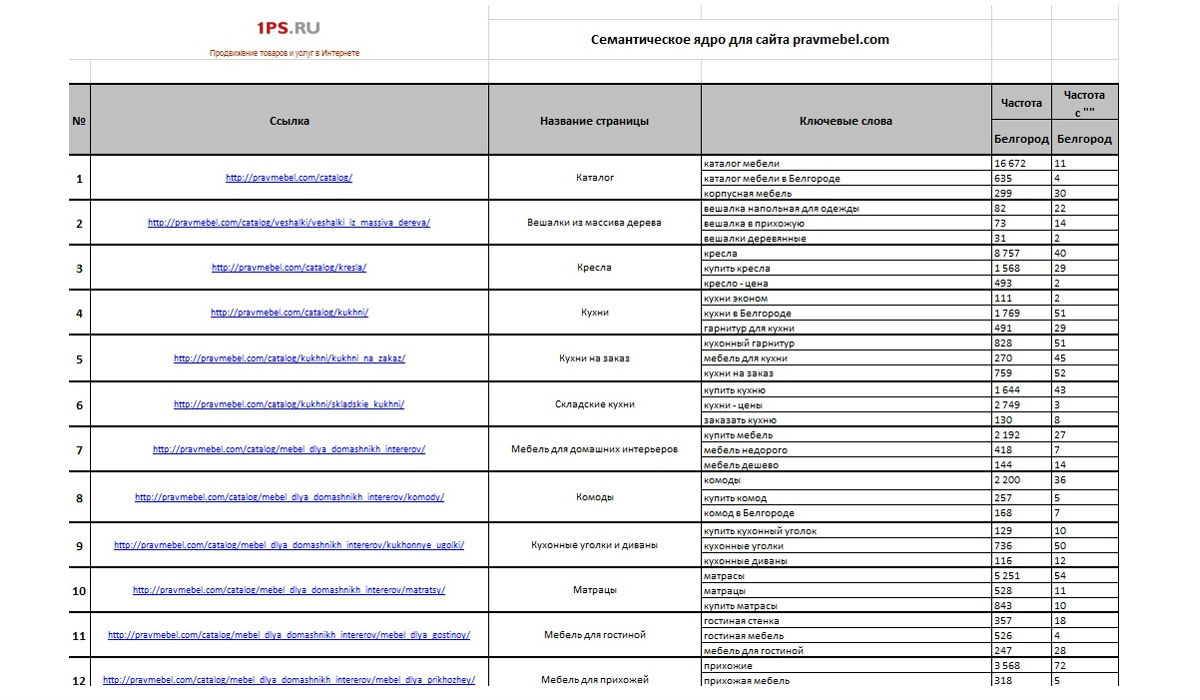 Компания по прокату лимузинов будет выбирать все запросы с телами «лимузин», «автомобиль», «кортеж», «машина» и подобными им, а также хвостами «заказать», «взять на прокат», «фотосессия с» и различными подходящими к их предложению хвостами.
Компания по прокату лимузинов будет выбирать все запросы с телами «лимузин», «автомобиль», «кортеж», «машина» и подобными им, а также хвостами «заказать», «взять на прокат», «фотосессия с» и различными подходящими к их предложению хвостами.
Ключи можно классифицировать по двум критериям: по популярности и по целям поиска.
По популярности их принято делить на:
- низкочастотные (до 100 в месяц, иногда — до 1000*)
- среднечастотные (100-1000, иногда — до 5000*)
- высокочастотные (от 1000, иногда от 5000 или даже от 10000*)
* — Сдвиг границы категорий с 100 до 1000 и с 1000 до 5000 и даже до 10000 обусловлен разницей в общем количестве запросов по конкретным темам. Если речь идет о СЯ для интернет-магазина, продающего электронику или бытовую технику, то общее количество запросов, потенциально подходящих для СЯ будет очень велико вследствие высокой популярности темы и того, что подобные покупки требуют сравнения большого количества параметров товара (а значит процесс выбора зачастую начинается в интернете).
Согласно исследованиям наибольшую конверсию приносят низкочастотные запросы, поэтому именно они должны составлять основу СЯ. Следовательно СЯ, которое можно эффективно использовать в маркетинге продукта, должно быть максимально широким. Один из способов — добавить низкочастотные фразы. Среднечастотные и высокочастотные запросы при этом тоже могут быть полезны, однако их следует включать в СЯ с наименьшим приоритетом.
Наибольшую конверсию дают низкочастотные запросы(по материалам исследования М.Успенской)
По целям поиска выделяют следующие группы запросов:
- транзакционные (цель пользователя — совершить какое-либо действие). Примеры запросов этой группы: «дизайн-проект детской сделать онлайн», «Желязны Хроники Амбера читать онлайн», «фурнитура для браслетов с буквами заказать»
- информационные (цель пользователя — найти информацию). Например: «как установить электросчетчик», «как сохранить открытые краски» и т.д.
- прочие (ключи, по которым нельзя установить цель пользователя). Например «женская одежда весна-осень 2017» — речь может идти о покупке одежды, либо о поиске выкройки или объявлений о показах этих коллекций
- навигационные, иногда их выделяют в отдельную группу (цель пользователя — поиск информации на определенном ресурсе). Например: «доставка с примеркой Ламода», «Как отследить почтовое отправление по id Алиэкспресс» и т.д.
 Например: «как установить электросчетчик», «как сохранить открытые краски» и т.д.
Например: «как установить электросчетчик», «как сохранить открытые краски» и т.д.
Запросы разных групп в данном случае должны быть учтены при оптимизации/проектировании соответствующих страниц сайта и наполнении их контентом: транзакционные запросы — в разделах «Купить/Заказать» (или их аналогах «Магазин» и др.), а информационные запросы — в разделах, предназначенных для сбора контента, например «Новости из мира дизайна мебели», «Советы тем, кто приобрел серебряные изделия» и т.д. Т.н. «прочие» запросы также могут быть полезны, если они отвечают назначению раздела сайта и могут расширить ваше СЯ, например приведенный выше запрос «женская одежда весна-осень 2017» может быть использован на сайте аксессуаров в статье, посвященной предметам, которые «будут отлично смотреться вместе с женской одеждой сезона весна-осень 2017, в которой используются бирюзовый и синий, а также аналогичная клетка с линией цвета шоколада».
Программы и сервисы для поиска ключей
Для сбора СЯ существует много платных и бесплатных программ — выбрать подходящее можно согласно конкретной задаче.
Key Collector подбирает ключевые слова через Wordstat «Яндекса» и позволяет:
- отсечь лишние словосочетания с помощью стоп-слов;
- проверить корректность форм слова;
- фильтровать запросы по частотности;
- найти неочевидные дубли запросов;
- определить сезонность конкретных ключей;
- собрать статистику из следующих сервисов: Google Analytics, Google Adwords, ВКонтакте, «Метрика» и других;
- определить стоимость слов по контексту и агрегаторам;
- работать с поисковыми подсказками;
- найти страницы, релевантные запросу и выгрузить результаты в формате SAPE, MainLink, Rookee и Excel;
- получить рекомендации по внутренней перелинковке.

Для парсинга большого объема ключей разработчики программы рекомендуют использовать прокси. Они помогают защитить ваш основной IP от блокировки, справиться с большим количеством капчи и ускорить парсинг. Оптимальный вариант — покупка российских прокси с разбросом по городам и регионам.
Это платный инструмент, объединяющий в себе много инструментов. Для каждого из них можно найти отдельный бесплатный аналог, но возникнет необходимость выстроить цепочку выгрузки и обработки данных самостоятельно.
Rookee — сервис автоматизированного управления интернет-рекламой для малого и среднего бизнеса. Помимо прочих услуг, в Rookee есть бесплатная услуга автоматического сбора семядра для продвижения сайта. Для этого потребуется лишь указать регион и адрес ресурса. Система подберет подходящие запросы и сделает прогноз по трафику и бюджету по каждому из них.
Также в Rookee вы можете бесплатно проанализировать тексты на страницах конкурентов в топе и посмотреть запросы, по которым они продвигаются. Такой анализ позволит выявить:
Такой анализ позволит выявить:
- количество точных и неточных вхождений ключей в текст на странице;
- число вхождений ключевиков в различные теги;
- частоту повторения одних и тех же слов в тексте.
СловоЕб — бесплатный инструмент для сбора ключей через Wordstat с дополнительными функциями от разработчиков Key Collector. Она может:
- отсечь лишние словосочетания с помощью стоп-слов
- фильтровать запросы по частотности
- определить сезонность конкретных ключей
- работать с поисковыми подсказками
- найти страницы, релевантные запросу и выгрузить результаты в формате Excel
Сервис подбора слов от Яндекса, Wordstat — также абсолютно бесплатная возможность подобрать ключи для СЯ. Его возможности:
- статистика по словам отдельно (для этого заданный ключ нужно взять в кавычки, а для исключения форм поставить до него восклицательный знак), их формам и словосочетаниям в том числе с разбивкой по регионам и устройствам, с которых был сформирован запрос (мобильные, десктопные, планшеты)
- история запросов пользователей в абсолютном и относительном выражении
- учет минус-слов (необходимо указать их после минуса в поисковой строке, например «самый известный салат-оливье»)
- статистика по группам запросов или с использованием только заданного вами предлога
Почитать по теме:
Как пользоваться Яндекс Вордстат: операторы, расширения и секреты
Планировщик ключевых слов от Google — сервис сбора СЯ на основе требований этого поисковика. К его возможностям можно отнести:
К его возможностям можно отнести:
- загрузка ключевых слов для анализа через CSV-файл или ввод вручную
- получение статистики по имеющимся запросам с геотаргетингом
- представление результата для заданного диапазона дат
- использование минус-слов
Аналитика от Google и Яндекс — еще один способ выяснить как пользователи составляют запросы, а также проанализировать их в динамике. Так, например, авторы отчета «Анализ поисковых запросов» в Search Console от Google предлагают использовать его так: «сравнить значения для двух точных показателей в одной группе» для того, чтобы:
- сортировать данные по величине разницы (определяя запросы, в последнее время демонстрирующие высокую активность)
- сравнить число запросов, полученных для мобильной версии сайта и для десктопной
В Яндекс Метрике можно воспользоваться «Отчетом по поисковым фразам» (Отчеты-Стандартные отчеты-Источники) и получить запросы, по которым приходят новые пользователи, а с помощью отчета «Директ-Сводка» увидеть отчет по каждой кампании (по какому запросу пользователь пришел на сайт). Таким образом, вы можете оценить эффективность ключей, использованных в рекламе и заменить их при необходимости.
Таким образом, вы можете оценить эффективность ключей, использованных в рекламе и заменить их при необходимости.
Сервисы анализа сайтов конкурентов также готовы предоставить вам варианты ключевых слов для оценки. Если речь идет о конкретной статье или разделе страницы — определить ключевые слова, которые в ней используются зачастую можно «на глаз», просто внимательно прочитав текст либо из мета-тега keywords сайта. Для автоматического сбора данных можно воспользоваться специальными сервисами, которые предоставляют разные возможности:
Кроме того есть многофункциональные сервисы, решающие задачи различной специфики, например SEM Rush, который не только анализирует ключевые слова, но также анализирует позиции конкурентов в соцсетях, ищет рекламу, а также фиксирует обратные ссылки и низкочастотные запросы. Помимо этого, подобрать актуальные ключи помогут Google Trends, WordStream и Топвизор.
Google Trends — перечень актуальных трендовПочитать по теме:
Как составить семантическое ядро: обзор инструментов
Очистка результатов и группировка ключей
После того как нужные ключи собраны с помощью любого удобного для вас сервиса необходимо подготовить полученный список к группировке:
- максимально расширить СЯ, дополнив его низкочастотными поисковыми фразами
- удалить неподходящие слова и фразы (не соответствующие вашему предложению, содержащие упоминание конкурентов, дубли, содержащие другие города или регионы, ошибки и опечатки*)
* — Что касается ключей, содержащих ошибки и опечатки, то тут нужно быть осторожными: орфографические ошибки поисковая система «понимает» и отправит пользователя по верному ключу, поэтому их стоит исключить, а вот ошибки в названиях и именах, в случае, если произнести их можно по-разному, следует оставить
После очистки оставшиеся ключи группируются в т. н. «семантические кластеры» — близкие по смыслу перечни ключей. Внутри группы возможна многоуровневая структура, либо одинарные запросы.
н. «семантические кластеры» — близкие по смыслу перечни ключей. Внутри группы возможна многоуровневая структура, либо одинарные запросы.
Следующий этап — составление таблицы соответствия «Раздел сайта — URL — Ключи» и Контент-плана:
Таблица соответствия «Раздел сайта — URL — Ключи»
Использование ключей в контенте
Органичное применение ключей
Помните, что и в данном случае лучшее — враг хорошего: избыток ключей в статьях и на странице может привести к обратному эффекту, даже если СЯ было собрано правильно. Соответственно, распределяя ключи из таблицы соответствия по заголовкам и пунктам меню или добавляя их в контент старайтесь, чтобы они смотрелись органично. Для оценки контента в этом случае также подойдут сервисы семантического анализа текста, такие как
Advego — показатели тошноты и воды с расшифровкой по количеству конкретных ключевых слов.
Анализ текста с помощью Advego
Подведем итог
Работа с СЯ — постоянный и кропотливый процесс: необходимо периодически выгружать актуальный для вашей сферы деятельности перечень ключей (с помощью одного или нескольких сервисов и аналитических отчетов), сопоставлять их с продуктом компании и оптимизировать как корпоративный сайт, лендинг или блог, так и стратегию поведения в интернете в целом (рекламные объявления, посты в соцсетях, представление продукта на торговых площадках).
Семантический интерфейс
UI Docs Начало работы Новое в версии 2.4Введение
Интеграции Инструменты сборки Рецепты ГлоссарийИспользование
Тематика МакетыГлобал
Сброс СайтЭлементы
Кнопка Контейнер Делитель Флаг Заголовок Икона Образ Ввод метка Список Загрузчик Заполнитель Железная дорога Выявить Сегмент ШагКоллекции
Панировочные сухари Форма Сетка Меню Сообщение СтолПросмотры
Реклама Карта Комментарий Подача Вещь СтатистикаМодули
Аккордеон Флажок Диммер Падать Встроить Модальный Выскакивать Прогресс Рейтинг Поиск Форма Боковая панель Липкий Вкладка ПереходПоведение
API Проверка формы ВидимостьМеню
МенюПубликации с описанием системы (или расширений системы)
| Публикации с описанием применения системы
|
 и Rayson, P. (1993).
Автоматический контент-анализ разговорного дискурса.
В: C. Souter и E. Atwell (ред.), Corpus Based Computational Linguistics . Амстердам: Родопи. pp215-226
(текст)
и Rayson, P. (1993).
Автоматический контент-анализ разговорного дискурса.
В: C. Souter и E. Atwell (ред.), Corpus Based Computational Linguistics . Амстердам: Родопи. pp215-226
(текст) Лонгман, Лондон, стр. 53-65.
Лонгман, Лондон, стр. 53-65. 22 — 31.
22 — 31. , Лиссабон, Португалия, том II, стр. 499-502.
ISBN 2-9517408-1-6.
, Лиссабон, Португалия, том II, стр. 499-502.
ISBN 2-9517408-1-6.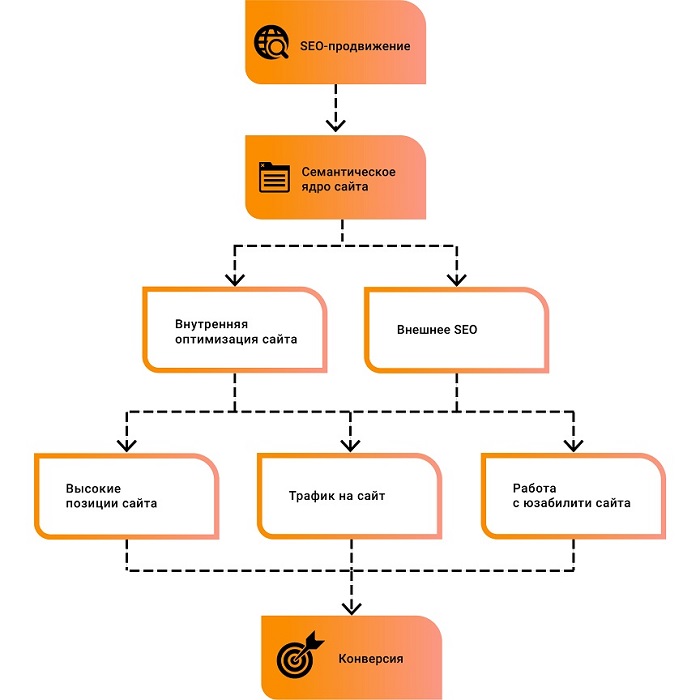 (слайды)
(слайды) 378 — 397, Elsevier.DOI: 10.1016 / j.csl.2004.11.002
378 — 397, Elsevier.DOI: 10.1016 / j.csl.2004.11.002 (2016)
Оценка лексического охвата крупномасштабных многоязычных семантических лексиконов для двенадцати языков.
В трудах 10-го издания конференции по языковым ресурсам и оценке (LREC2016), Порторож, Словения, стр. 2614-2619.
(2016)
Оценка лексического охвата крупномасштабных многоязычных семантических лексиконов для двенадцати языков.
В трудах 10-го издания конференции по языковым ресурсам и оценке (LREC2016), Порторож, Словения, стр. 2614-2619.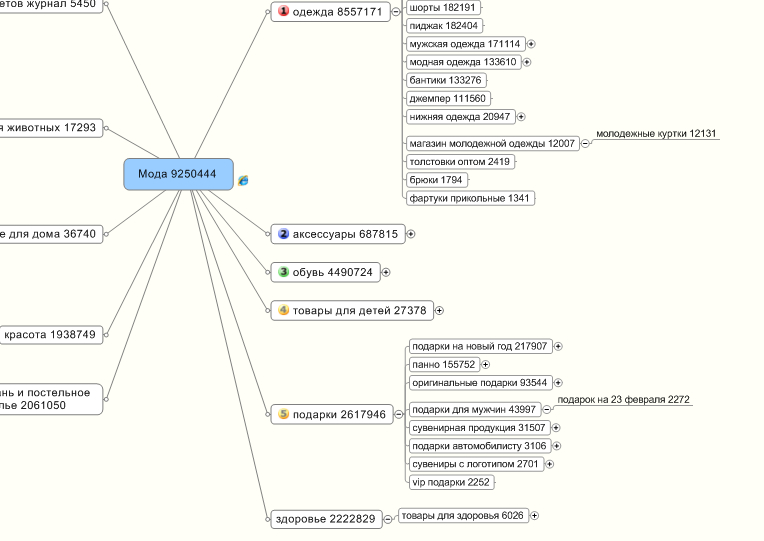 , Гейдельберг, Германия. Опубликовано Университетом Намюра, стр. 49-54. ISBN 2 87037 307 4.
, Гейдельберг, Германия. Опубликовано Университетом Намюра, стр. 49-54. ISBN 2 87037 307 4. В Хендерсоне, П. (ред.) Системная инженерия для изменения бизнес-процессов: сборник статей
из исследовательской программы EPSRC .
Springer-Verlag, Лондон, стр. 251 — 263.
ISBN 1-85233-2220
В Хендерсоне, П. (ред.) Системная инженерия для изменения бизнес-процессов: сборник статей
из исследовательской программы EPSRC .
Springer-Verlag, Лондон, стр. 251 — 263.
ISBN 1-85233-2220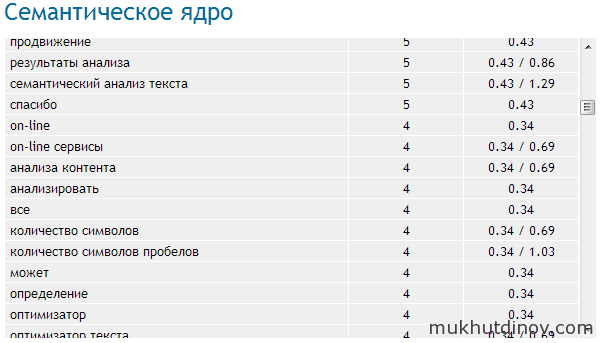 Vol. 8, №2.
ISSN 1093-5371.
Vol. 8, №2.
ISSN 1093-5371.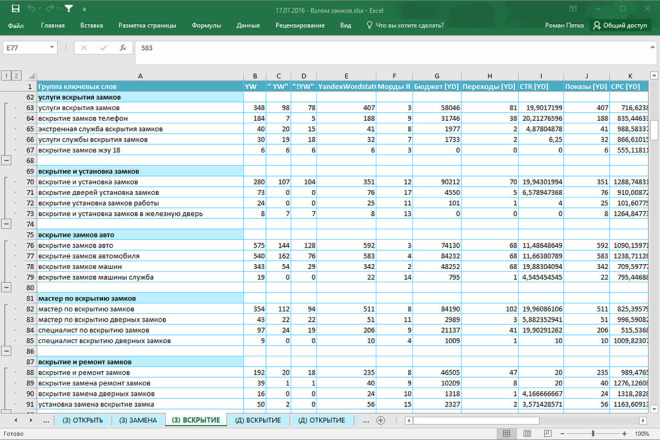
 Родопи, Амстердам.
Родопи, Амстердам.ASO: Как создать семантическое ядро для вашего приложения | Блог №
Основы
Перед построением семантического ядра задайте себе несколько вопросов.
Кто ваша целевая аудитория?
Вы должны четко понимать, кто ваши пользователи. Например, ваше приложение — это игра, в которой пользователи должны выбирать наряды для кукол.Скорее всего, ваша основная аудитория — девочки до 12 лет. Девушкам и мальчикам постарше это вряд ли интересно. Прежде чем приступить к созданию семантического ядра, постарайтесь определить свой сегмент клиентов.
Какую ценность ваше приложение приносит пользователям?
О чем ваше приложение? Какова его цель? Зачем пользователю его устанавливать? Ответы на эти вопросы — ваши первые релевантные ключевые слова.
Чем ваше приложение отличается от конкурентов?
Попытайтесь сформулировать, что делает ваше приложение особенным.Ваши идеи — это средне- или низкочастотные поисковые запросы, которые могут использовать клиенты. Возможно, они не самые популярные, но здесь есть скрытая ценность. Пока ваши конкуренты сосредотачиваются на наиболее часто используемых ключевых словах, вы можете достичь лучших позиций, применяя менее популярные, но хорошо ориентированные запросы.
Кто ваши конкуренты?
На этом этапе не полагайтесь только на имена, которые приходят вам в голову в первую очередь. Проведите хорошее исследование и выясните, кто ваши прямые и косвенные конкуренты. Проверив каждый из них, составьте список наиболее часто используемых ключевых слов.Вы можете «позаимствовать» некоторые из них и генерировать свои собственные идеи.
Каков основной рынок для вашего приложения?
Вы можете быть удивлены, но ключевые слова, используемые в британских и австралийских App Store, могут также хорошо подойти для российского рынка. Как это можно использовать? Даже если ваша основная клиентская база находится в России, вы можете добавлять ключевые слова, которые не подходят для русской версии (из-за ограничений символов) для магазинов приложений в Великобритании и Австралии. Более подробная информация о дополнительных локали и индексации в Google Play будет доступна в одной из следующих статей.
Как это можно использовать? Даже если ваша основная клиентская база находится в России, вы можете добавлять ключевые слова, которые не подходят для русской версии (из-за ограничений символов) для магазинов приложений в Великобритании и Австралии. Более подробная информация о дополнительных локали и индексации в Google Play будет доступна в одной из следующих статей.
Возможно, вы уже ответили на все выделенные вопросы ранее. Скорее всего, вы сделали это еще до создания приложения. Даже лучше! Эта информация важна для создания семантического ядра и выбора правильных ключевых слов.
Как подбирать ключевые слова
Подбор ключевых слов — основа построения семантического ядра, поэтому важно выбрать наиболее актуальные для дальнейшего продвижения. Вернемся к нашему примеру — приложению Travel Qests. Просто прочитав название приложения, легко понять, что оно связано с путешествиями и квестами.Это означает, что мы должны сосредоточить наши усилия в ASO на людях, которые любят путешествовать и ищут интересные и активные способы провести время за границей.
В данном случае релевантными запросами являются: «путешествия», «гид», «советы» и т. Д. Кроме того, стоит обратить внимание на похожие запросы, то есть слова, которые напрямую не описывают основные функции приложения, но все же могут привлечь трафик. . Для Travel Quests это могут быть следующие ключевые слова: «музеи», «туры», «достопримечательности». Анализируемое приложение не является туристическим агентством, однако его клиентами могут стать люди, которые планируют поездку.Релевантность запроса очень субъективна, поэтому чем больше альтернатив вы проверите, тем выше шансы, что вы создадите высококачественное семантическое ядро.
Когда у вас заканчиваются идеи, используйте следующие методы для поиска релевантных ключевых слов:
- спросите текущих и потенциальных клиентов, как они нашли ваше приложение, какие слова и фразы они использовали. Короткий опрос среди ваших друзей и коллег также может дать вам много полезной информации;
- Ознакомьтесь с названиями и описаниями приложений конкурентов. Это очень важный шаг, уделите ему достаточно времени;
- используйте аналитические и статистические инструменты, ориентированные на мобильные рынки: App Annie, Mobile Action, Sensor Tower и т. Д. Здесь вы можете найти некоторые ключевые слова, которые используют ваши конкуренты для достижения высоких результатов поиска;
- , если ваше приложение уже есть в магазине, изучите комментарии пользователей;
- попробуйте инструменты исследования ключевых слов: Google Keyword Planner, Google Trends, Yandex.Wordstat. Последний очень полезен, если ваш основной рынок сбыта — Россия.Однако не обращайте особого внимания на значения частоты. По нашему опыту мы знаем, что в Интернете и на мобильных устройствах они сильно отличаются;
- используйте синонимы и языковые словари, если вам нужно выбрать ключевые слова для зарубежных рынков. Например, Multitran — хороший инструмент, который стоит попробовать.
 Это очень важный шаг, уделите ему достаточно времени;
Это очень важный шаг, уделите ему достаточно времени;Оценка частоты
Как упоминалось выше, App Store и Google Play не предоставляют общедоступных данных о частоте поисковых запросов. Однако это не значит, что мы не можем его оценить.
Однако это не значит, что мы не можем его оценить.
Основной инструмент для этого — список поисковых предложений.Когда вы начинаете набирать запрос в строке поиска, список автоматически формируется магазином. Самые популярные ключевые слова и фразы размещены вверху. Если запросы, которые вы планируете использовать, там не отображаются, скорее всего, они не будут привлекать трафик в ваше приложение.
В App Store есть еще один инструмент — Search Ads, недавно представленный Apple для улучшения видимости приложений в поиске. Используя его, становится возможным дать приблизительные оценки того, сколько трафика могут генерировать разные ключевые слова.В настоящее время инструмент доступен только для рынка США. Если ваше приложение нацелено на США, у вас есть преимущество. Таким образом, получите доступ к поисковой рекламе как можно скорее!
Сбор поисковых предложений вручную путем проверки каждого запроса на планшете или смартфоне занимает очень много времени. AppFollow упрощает этот процесс. Этот инструмент может программно сгенерировать список предложений для вашего приложения, если вы подписаны на план Premium. На этом примере мы покажем, как оценить частоту и построить семантическое ядро.
AppFollow упрощает этот процесс. Этот инструмент может программно сгенерировать список предложений для вашего приложения, если вы подписаны на план Premium. На этом примере мы покажем, как оценить частоту и построить семантическое ядро.
предложений и поиска
Сбор предложений является наиболее подходящим способом построения семантического ядра.
Если вы еще не там, зарегистрируйтесь на AppFollow.io . В верхней панели выберите «Инструменты ASO», затем «Предложить и поиск». Вы увидите следующую страницу:
Выберите необходимое устройство: iPhone / iPad или Android . В поле за ним введите интересующие вас ключевые слова. Выберите нужный языковой стандарт в списке справа.
В результате вы увидите список предложений в левом столбце. Если вы сравните его со списком на вашем смартфоне, вы обнаружите, что они идентичны. В правом столбце вы можете увидеть результаты поиска по введенному ключевому слову в выбранной стране. Мы вернемся к этой части позже в статье.
Мы вернемся к этой части позже в статье.
Стоит отметить, что если вы проверите предложения для Android, Google Play подстраивает их в соответствии с вашим IP-адресом. Это означает, что если вы находитесь в России и вам нужно увидеть предложения для США, вам необходимо изменить свой IP на американский.Бесплатные инструменты VPN могут помочь вам в этом. В противном случае вы увидите данные поиска для страны, в которой находитесь.
Все запросы с разумной частотой отображаются в подсказках. Они показаны в порядке убывания. Ключевое слово или ключевая фраза на первом месте имеет наибольшую частоту, а нижние — наименьшую.
Google Таблицы
AppFollow предлагает простой и удобный способ экспорта предложений — с помощью надстройки Google Таблиц , доступной для всех пользователей Документов Google.
Надстройка AppFollow для Google Таблиц Чтобы просмотреть список предложений, добавьте следующую формулу в любую ячейку: = getSuggest («запрос»). Вместо «запрос» введите интересующее вас ключевое слово или ключевую фразу. Не забудьте поставить кавычки.
Вместо «запрос» введите интересующее вас ключевое слово или ключевую фразу. Не забудьте поставить кавычки.
Выберите наиболее важные
Как описано ранее, вы можете собирать подсказки либо с помощью ручного поиска, либо с помощью AppFollow и Google Sheets. В итоге у вас будет таблица с различными списками предложений по каждому поисковому запросу. Важно отметить, к какому рынку или региону относятся эти списки.Это должно примерно выглядеть так:
После того, как вы соберете предложения для каждого ключевого слова, отметьте их разными цветами. В нашем примере наиболее релевантные предложения выделены синим, а менее релевантные — желтым.
Не учитывайте заголовки с «-» , «:» или «&». Предлагаемые названия приложений.
Вуаля! Ваше семантическое ядро готово. Следующим шагом будет анализ наиболее релевантных и менее релевантных ключевых слов.