
Семантическое ядро для сайта. Пошаговое руководство без воды — SEO на vc.ru
Привет. Я занимался сбором семантического ядра для своего сайта с разными перерывами на протяжении последних 3 лет. До этого лет 10 меня тошнило от самой идеи. Я приступал к этому процессу, бросал, потом пробовал снова и снова бросал. SEO казалось чем-то таким заоблачным. Типа, пришёл какой-то волшебник и что-то там насеошил.
32 747 просмотров
К моему большому сожалению, обилие тренингов, статей, лекций и видосов на YouTube не сильно облегчают понимание процесса сбора и обработки семантики. Перелопачивать все эти тонны воды могут лишь не все😊 А сеошники любят налить воды, мы все про это прекрасно знаем. Смотришь вот так разные тренинги, а у преподов в голове сплошная каша. Когда человек не может сформулировать свои мысли в краткой статье, ему явно не стоит преподавать. Я решил попробовать. Кратко не получилось 😊
На данный момент я занимаюсь внедрением собранной семантики на сайт и решил написать эту статью. Возможно, она поможет тем, кто только начинает в этом разбираться. Мне бы точно очень помогла. Это, по сути, пошаговое руководство. Что, за чем, как и в каком порядке стоит делать. «Делать» никуда не денется, работать придётся много, но зато теперь с пониманием, куда и как двигаться и где вообще конец этого бесконечного тоннеля.
Возможно, она поможет тем, кто только начинает в этом разбираться. Мне бы точно очень помогла. Это, по сути, пошаговое руководство. Что, за чем, как и в каком порядке стоит делать. «Делать» никуда не денется, работать придётся много, но зато теперь с пониманием, куда и как двигаться и где вообще конец этого бесконечного тоннеля.
Но, хватит предисловий, приступим к алогоритму.
Важная ремарка. Здесь не будет конкретных рекомендаций по работе с Excel. Будем считать по умолчанию, что интернет маркетолог хорошо знаком с этим инструментом. Key Collector тоже не должен быть для вас чем-то новым.
Также должен сказать, что читать этот мануал по диагонали бесполезно, т.к. он представляет из себя конкретный набор шагов, которые нужно выполнять. Без выполнения, всё это чтение «по буллетам» вам ничего не даст. Делюсь, потому что понимаю, что этот каторжный труд осилят единицы.
Итак, для сбора и обработки семантического ядра вам понадобится:
Доступы:
· Google search console
· Yandex метрика
· Yandex webmaster
Программы:
· Key Collector
· SEO Screaming Frog
· MS Excel
· Надстройка для парсинга yandex webmaster в google chrome
Платные сервисы и услуги:
· 10 прокси для Key Collector
· Pixeltools
· Just Magic
Cбор семантического ядра представляет из себя систему воронок, через которые просеиваются запросы.
Вам предстоит много ручной работы, много часов труда. Чем выше ваша вовлеченность в бизнес и понимание тематики, тем проще вам будет отделить мусор от полезных запросов.
Вводные данные: у вас уже есть сайт, который вы создали по своему усмотрению и пониманию того, каким должен быть идеальный поисковый спрос. Пора столкнуться с суровой реальностью. Сайт приносит какие-то деньги, но хочется больше.
Источники семантики / запросов:
· Keyso — сервис видимости конкурентов
· Счётчики на вашем сайте (метрика, вебмастер, сёрч консоль)
· Yandex wordstat
· Метатеги сайтов конкурентов
· Подсказки в Yandex и Google
ШАГ 1. Сервисы видимости
1. Находите на kwork или подобной бирже человека, который делает выгрузки из keyso за деньги. Покупаете у него выгрузку по 15 основным конкурентам. 15 будет достаточно. Если вы занимаетесь своей темой давно, 15 основных конкурентов у вас уже будут на слуху.![]() Это будет большущая таблица с запросами.
Это будет большущая таблица с запросами.
2. Делаем выгрузку из метрики и сёрч консоли
3. Собираем с помощью плагина для google chrome информацию из вебмастера
Где смотреть:
· Метрика: стандартные отчеты — источники — поисковые запросы
· Вебмастер: поисковые запросы — управление группами — все запросы
· Сёрч консоль: эффективность — запросы
Делаете выгрузку за 1 год из этих источников.
ШАГ 2. Парсинг конкурентов
Находите сайты конкурентов. Чем больше найдёте, тем лучше.
Осматриваете сайты на предмет оптимизации. Обычно сразу видно, ведется над сайтом работа или он сделан лишь бы как и не стоит внимания.
Парсите все отобранные сайты с помощью программы SEO Screaming Frog. Вам нужны данные из полей title и h2.
Как правило, у большинства сайтов эти теги сделаны по шаблонам и не составит большого труда удалить из тегов лишнюю информацию и оставить только ключевые слова.
Обрабатываете title и h2 конкурентов в Excel. Собираете всё это в одну большую таблицу.
Собираете всё это в одну большую таблицу.
ШАГ 3. Фильтрация по частотности
Загружаете результаты ваших сборов в Key Collector.
Настройки в KC — вашего региона, если бизнес сильно к нему привязан. Если он универсальный, выставляйте Москву. Там будет больше статистики.
Можно предварительно перед загрузкой в Key Collector заменить в вашей базе слов точки, запятые, тире, дефисы и слэши на знак пробела и почистить фразы от двойных пробелов.
Можно предварительно почистить вашу базу от мусора. На ваше усмотрение. Но я на этом этапе не советую этим заниматься, т.к. база очень большая и проще сначала убрать из неё всё, что можно, автоматически.
К этому моменту вам понадобятся платные прокси. Покупаете их и прописываете в настройках программы Key Collector. Настройки для парсинга не привожу. Нагуглите сами. Вы уже большие.
Итак, вы загружаете в KC вашу базу ключевых слов и парсите базовую частотность с помощью прокси. С вашего основного IP парсить бесполезно.
Если частотность собирается слишком долго, можно воспользоваться платными сервисами типа https://moab.tools/Parse/CheckWordstat
Ваша задача на этом этапе избавиться от нулевых запросов.
После парсинга базовой частотности переносите нулевые запросы в отдельную мусорную папку в Key Collector. Вы НЕ удаляете запросы. Это нужно для того, чтобы в дальнейшем мусор не попадал в вашу базу по второму кругу.
В вашем проекте в KC теперь будет три папки для мусора:
1. базовая частотность = 0
2. «точная частотность» = 0
3. «!точная !частотность» = 0
Как вы уже поняли, после того, как вы уберете запросы по первому параметру, нужно будет спарсить частотности по двум остальным
После каждого из этапов чистки, запросов в вашей семантике будет оставаться всё меньше, а мусора будет становиться всё больше.
При сборе базовой частотности может оказаться, что для каких-то запросов она не собирается. Это нормально. Запускайте сбор частотности повторно. То, что не собралось, соберется. Останутся:
Это нормально. Запускайте сбор частотности повторно. То, что не собралось, соберется. Останутся:
· запросы слишком длинные (больше 7 слов).
· запросы со спец символами
Кто-то заморачивается и пытается оставить длинные запросы в ядре. У меня не настолько конкурентная тематика, поэтому я их просто переношу в мусор. Поверьте, вам хватит работы и без них. И при желании в дальнейшем к ним можно будет вернуться.
ШАГ 4. ГЕО
После того, как в вашей базе остались запросы с «!точной !частотностью» > 0, мы чистим их по ГЕО. Удаляем гео запросы.
Для этого вы лично формируете свою первую базу минус слов для KC – ГЕО.
Там будут города, населенные пункты, регионы, области, страны в различных вариантах склонений и описаний. Для склонения можно использовать сервис https://morpher.ru/Opt/
ШАГ 5. Мусор, часть 1
После чистки по ГЕО вы составляете собственный словарь мусорных «минус слов». Вы собираете ваш персональный список минус слов, таких как: порно, скачать, форум и прочее.
Список будет постепенно расширяться, упрощая вам первичную фильтрацию в дальнейшем. Не ленитесь добавлять в него частотные мусорные слова. Для каждой тематики такой список минус слов свой собственный. Поэтому не стоит искать какие-то универсальные списки. Создавайте свой собственный.
Слова, которые наиболее часто встречаются в вашем списке запросов можно посмотреть с помощью инструмента «анализ групп» в KC. Да, там можно искать не только что-то полезное, но и мусор. Вообще именно с поиска мусора в этом инструменте и стоит начать. Сканировать список запросов глазами – так вы далеко не уедете.
Удаляем из нашего списка самый очевидный мусор.
ШАГ 6. Бренды
Отделяем брендовые и товарные запросы от чистых категорийных. Для этого вы составляете собственный список брендовых «минус слов». Сюда входят различные варианты написания брендов, транслит, опечатки.
Отсеиваете список запросов по брендам, вынося все такие запросы в отдельную папку «Брендовые запросы».
ШАГ 7. Инфо
Отделение инфо запросов. Составляете ваш собственный словарь минус слов, которые позволят отделить информационные запросы от коммерческих. Сюда входя такие слова как отзывы, топ, рейтинг, лучший, обзор, и т.д.
Убирайте информационку в отдельную папку «информационные запросы»
ШАГ 8. Товарка
Отделяете бренды от товаров. Часто в названиях товаров используются цифры — это один из простейших способов отделить бренды от товаров.
Если брендовый трафик для вас имеет большое значение, работайте с этой папкой в KC.
Используйте возможности KC для поиска: «анализ групп» — это очень мощный инструмент
Также вам пригодятся инструменты фильтрации, такие как «фраза содержит / не содержит»:
· цифры
· латинские буквы
· буквы кириллицы
· повторы слов
ШАГ 9. Первичная структура
Составление первичной структуры сайта в Key Collector. Это необходимо для упрощения дальнейшей фильтрации.
Создавая структуру сайта в KC, вы также упрощаете себе в дальнейшем парсинг и обработку запросов, т. к. они будут собираться примерно из одной и той же темы / группы запросов и отсеять мусор из одной такой пачки намного проще, чем пытаться убрать его из одной большой общей кучи.
к. они будут собираться примерно из одной и той же темы / группы запросов и отсеять мусор из одной такой пачки намного проще, чем пытаться убрать его из одной большой общей кучи.
Чем детальнее вы создадите структуру проекта в KC, тем проще вам будет работать
Данная структура нужна только для парсинга и фильтрации. То, что вы будете внедрять на сайт, от этой предварительной структуры будет очень сильно отличаться
ШАГ 10. Сортировка
Работаете со «структурой», сортируя запросы по папкам, параллельно избавляясь от мусора. Это самый длительный и занудный процесс, но его нужно пройти.
Параллельно вы будете находить гео, мусор, информационку, брендовые и товарные запросы, а ваши словари минус слов будут пополняться. Структура будет становиться более детальной и понятной. У проекта начнут вырисовываться черты, вы наконец-то поймете, сколько всего вы упустили.
Вы научитесь работать с «анализом групп» и фильтрами в KC, помимо структуры создадите необходимые лично вам подпапки в KC.
В целом уже начнёт складываться понимание как это всё работает, что удобно, а что — нет.
Заодно, поковырявшись в меню КС, вы найдете способы простого перемещения списков запросов по папкам. и в целом поднатореете в тематике.
Заодно увидите сколько новых вариантов написания уже известных вам запросов существует, а вы о них и не догадывались.
ШАГ 11. Отдохните
Итак вы разгребли вот это всё: метрика, вебмастер, сёрч консоль, keyso, метатеги конкурентов.
Это уже большое достижение. У вас уже также создана структура сайта в KC для парсинга запросов, которая позволит эффективно собирать вам нужные группы запросов.
К этому моменту вы должны уже ненавидеть KC и его мелкие буковки, правая рука — стонать от приближающегося тоннельного синдрома, а глаза — просить пощады.
Ну что, же, приступим к парсингу.
ШАГ 12. Парсинг запросов
Благодаря сформированной структуре, вы можете зайти в любую из папок с запросами, включить анализ групп и найти там все существительные.
Существительные — это основа маркеров для парсинга.
«Анализ групп» позволяет легко найти самые частотные слова и легко составить небольшой список маркерных фраз для последующего парсинга Wordstat.
Итак вы составили список маркеров для конкретной папки. Берете их и все запросы, которые уже есть в этой папке и собираете вордстат по всем этим фразам.
Далее повторяете перечисленные выше этапы с чисткой. Теперь чистка будет проходить уже намного проще, ведь вы работаете с небольшими участками сем ядра. И мусор в таких условиях чистить гораздо проще. Ведь то, что является мусором в одной категории, в другой – совсем не мусор. В общем, вы меня поймете, когда поработаете в KC хоть немного.
Чистку опять начинаете с частотности, потом гео, мусор, бренды, информационка. В итоге останется не так много рабочих запросов.
При парсинге сюда будут прилетать запросы из других групп, сортируем всё это дело по своим местам.
ШАГ 13. Глубокий парсинг
Если вы хотите максимально глубоко погрузиться в тему, вы берете высокочастотные слова и парсите их в таких вариантах
· «слово слово слово слово слово слово»
· «слово слово слово слово слово»
· «слово слово слово слово»
· «слово слово слово»
· «слово слово»
· «слово»
Таким образом вы максимально обходите ограничения Wordstat по выводу слов, ведь глубина просмотра статистики у него всего лишь 41 страница и в больших тематиках этого часто не хватает.
Для этого вы и парсите 6-5-4-3-2-1-словники по-отдельности.
ШАГ 14. Сбор подсказок
После того как пройдены все 13 предыдущих этапов, вы берете все запросы из любой папки и парсите по ним подсказки.
Далее чистите, фильтруете и сортируете.
Работа довольно муторная как и всё что связано с сем ядром, но зато вы можете быть уверены, что мало кто из конкурентов способен пройти через весь этот ад. Ну и фильтровать подсказки по конкретным группам – это детский сад по сравнению с тем, что вы уже проделали ранее.
ШАГ 15. Just Magic
Ура. вы собрали сем ядро. Радоваться, однако, рано. Собранная и внедрённая семантика — это две больших разницы. Приступим к следующему этапу.
На данном этапе основная работа с KC закончена и мы переносим собранное сем ядро / а точнее ту часть, с которой вы решаете работать, в Excel.
Работайте с отдельными группами, относительно большими кластерами, которые вы бы вынесли на первый / максимум на второй уровень в меню вашего сайта.
Не стоит сильно углубляться в подпапки но и не стоит сразу хвататься за весь сайт.
Берём группу запросов, с которой мы решили работать.
Регистрируемся в Just Magic и парсим там частотность [«!слово !слово»] — это самая точная словоформа и порядок слов, именно её стоит использовать в работе.
JM любит сортировать запросы по алфавиту. Учитывайте это и используйте формулы Vlookup / ВПР в Excel.
Убираем из нашего списка в Excel все запросы, у которых [«!слово !слово»] = 0.
Создаём новый пустой (!) проект в KС.
Загружаем в него оставшиеся запросы и супер точную частотность, полученную в Just Magic.
Используя инструмент KC «анализ неявных дублей», отмечаем в списке «неявные дубли».
Выгружаем полученный список в Excel, вставляем эти данные в нашу таблицу
Убираем из списка запросов в Excel неявные дубли.
Вы только что сократили вашу табличку примерно на 30-40%.
Для оставшихся запросов используем сервис «тематический классификатор» Just Magic.
Он позволяет еще более точно просеять оставшийся список и найти потенциально проблемные запросы, которые стоит убрать из ядра.
Проходимся по списку глазами/руками еще раз, отмечая лишнее.
ШАГ 16. PixelTools
Итак у нас остались запросы без дублей, с максимальной точной частотностью, просеянные через тематический классификатор.
Регистрируемся в Pixeltools и собираем там параметры «Гео/коммерциализация», а также делаем кластеризацию запросов в Just magic.
Это всё платные инструменты. Но если вы когда-нибудь сливали деньги в контексте, суммы за эти услуги не должны вас шокировать. Экономить тут не стоит. И стоит это совсем не космических денег, ведь вы делаете семантику для себя любимого.
Почему кластеризация в JM? Потому что там очень удобно за один проход делается кластеризация на нескольких уровнях. Это очень наглядно и выглядит в Excel позволяет быстро перегруппировать запросы в случае необходимости, не прибегая к повторной кластеризации.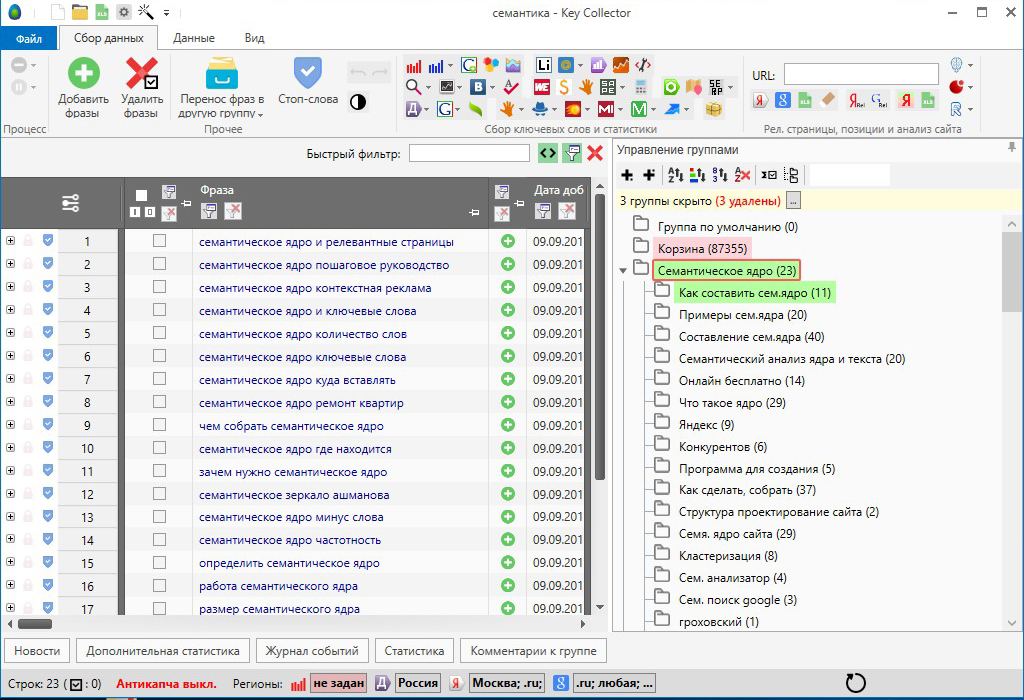
Не нужно возиться с кучей настроек в Key Assort, не нужно по нескольку раз перекластеризовывать ядро, ища подходящий вариант, в Pixeltools тоже кластеризация не наглядная. JM на данный момент в табличном виде мне кажется самым удобным.
Почему идёт работа с 2 сервисами? Это упрощает аналитику и помогает сделать выбор, основываясь на показаниях в 2 разных источниках. В таблицах с такими данными работать намного проще.
В итоге у вас будут собраны вот эти параметры:
Pixel tools:
· геозависимость
· локализация
· комерциализация
· витальный ответ
Just Magic:
· «[!проверяемая !фраза]»
· тематика
· группировка по 4 уровням
· наличие главных страниц в выдаче
· комерциализация
· геозависимость
К сожалению, в JM нет возможности собрать гео и коммерцию отдельно, это работает только при кластеризации. Ну, работаем с тем, что есть.
ШАГ 17. Excel
Обработка таблиц с полученными данными в Excel.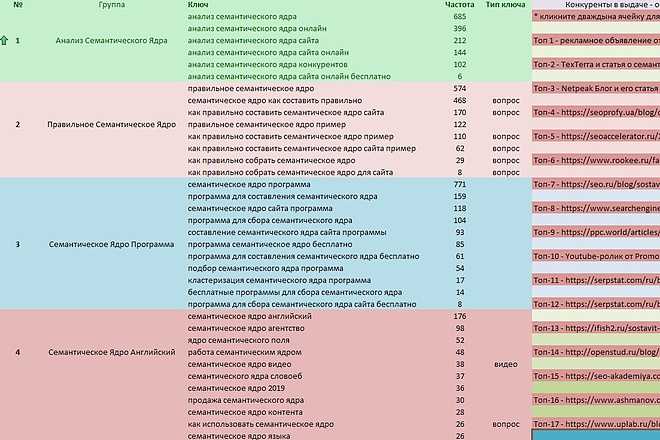 Сортируете всё это чудо, используете условное форматирование столбцов с необходимыми вам данными, чтобы проще их читать.
Сортируете всё это чудо, используете условное форматирование столбцов с необходимыми вам данными, чтобы проще их читать.
На этом этапе из списков ваших запросы отсеются потенциальные инфо запросы, которые вы посчитали коммерцией.
А также вы быстро пройдётесь по названиям групп, которые уже были выгружены из KC и сравните их с данными, полученными в JM.
Это первичная кластеризация с первой ручной корректировкой данных
ШАГ 18. Чистовая кластеризация
После отсева мусора в результате первичной кластеризации, берете оставшийся у вас список запросов из разных подгрупп одного большого раздела, сваливаете их в кучу и на этот раз делаете кластеризацию уже всего списка запросов в JM.
Она пройдёт более качественно, т.к. мусор вы уже убирали руками. Он всё равно будет, но уже в единичных случаях. В целом это и есть ваш финальный список запросов.
Далее вы проходитесь по нему вручную и решаете, нужно ли дробить какие-то кластеры на отдельные, переносить ли какие-то запросы из одной группы в другую.
Сортировка по группам в JM + ваша личная сортировка запросов по группам, которую вы сначала сделали в KC, а потом перепроверили в Excel, сделает обработку финального списка запросов простой и наглядной.
В итоге у вас получится таблица, которая называется «карта релевантности». В ней будут сгруппированы запросы для каждого из кластеров. Вам останется только проставить для них продвигаемые URL.
У многих групп запросов таких URL / страниц не будет, их придётся создавать на сайте.
Проанализировав получившиеся группы / кластеры, вы поймете для каких из них нужны отдельные страницы, а для каких хватит настроек в фильтрах категорий на сайте.
Далее, работая уже с конкретным ассортиментом на сайте, вы поймете, что некоторые из полученных в результате кластеризации групп просто нельзя использовать, потому что в каталоге нет таких товаров, соответственно, список рабочих кластеров станет еще меньше.
Всё. Создаете страницы и следите за апдейтами.
В итоге у вас есть:
1.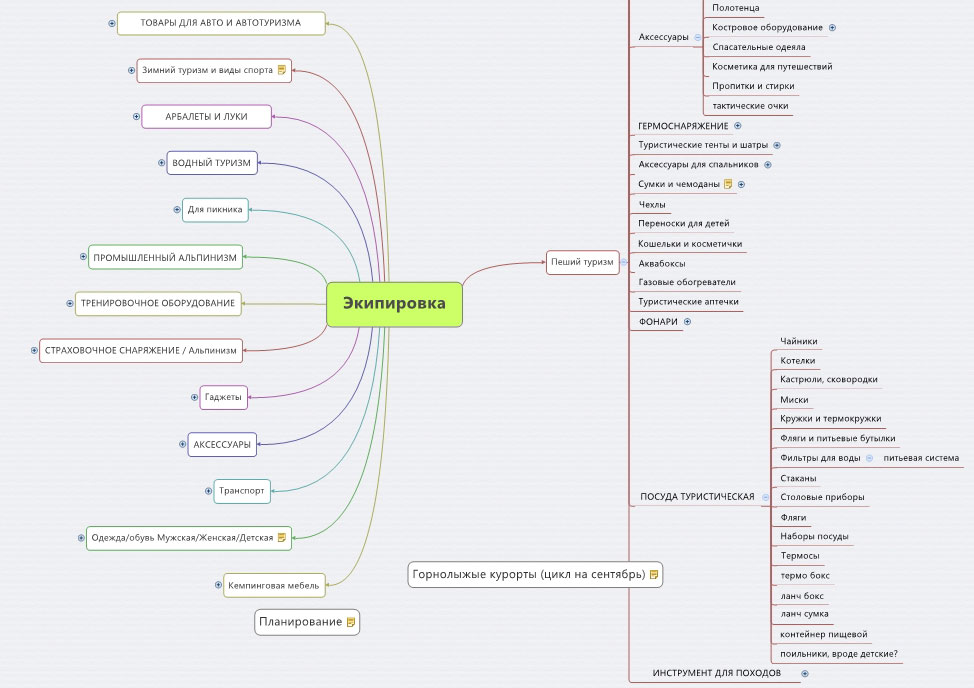 Проект в KC который вы можете пополнять новыми запросами, ведь конкуренты не спят и стоит периодические заглядывать к ним, смотреть, что у них новенького. Парсить их и ваши маркеры.
Проект в KC который вы можете пополнять новыми запросами, ведь конкуренты не спят и стоит периодические заглядывать к ним, смотреть, что у них новенького. Парсить их и ваши маркеры.
2. Карта релевантности — вещь, которая есть далеко не у каждого.
3. Благодаря карте релевантности у вас есть чёткое понимание, какие страницы нужно создать, какого ассортимента не хватает на сайте, как его стоит там разместить, как изменить структуру каталога для удобства навигации, какие страницы наиболее популярны и значит должны быть наиболее заметны в меню и навигации. Всё это было бы невозможно без описанных выше шагов.
4. Если вы захотите написать инфо статью, у вас уже будут собраны инфо запросы в вашем проекте. Останется только немного их доработать.
Если сайт и ассортимент большой, эти все описанные шаги нужно будет проделать для каждого из больших разделов. Невозможно осилить всё сразу, но у вас уже есть очень мощная база, к работе над которой вы можете вернуться в любой момент, как только у вас появится вдохновение.
Пример предварительной группировки одной большой группы товаров в KC для мотивации. По цифрам в мусоре вы можете понять сколько всего пришлось отсеять.
Автор мануала https://www.facebook.com/gtrplayer
Что такое семантическое ядро и как его собрать
Чтобы сайт посещало больше людей и росла конверсия покупки, необходимо продвижение. Сделать продвижение эффективным помогает качественное семантическое ядро (СЯ). В этой статье расскажем, что же такое СЯ и чем оно полезно для вашего сайта. Вы узнаете о ключевых словах, поймете, как создается правильное ядро, и получите инструменты для сбора семантики.
Что такое семантическое ядро и зачем оно сайту
Семантическое ядро, сокращенно СЯ — это набор слов и словосочетаний для описания тематики сайта. Термин «семантическое ядро» вышел из раздела языкознания «семантика», который изучает смысл слов или речевых оборотов.
СЯ имеет определяющее значение для продвижения сайта: именно с него начинается работа над любым проектом. Без ядра невозможно запустить контекстную рекламу и создать SEO-стратегию. Структура сайта на основе СЯ помогает поисковикам лучше ранжировать ресурс и показывать пользователям релевантные результаты. Подробнее об этом в нашей статье «Как сделать правильную структуру сайта для SEO».
Без ядра невозможно запустить контекстную рекламу и создать SEO-стратегию. Структура сайта на основе СЯ помогает поисковикам лучше ранжировать ресурс и показывать пользователям релевантные результаты. Подробнее об этом в нашей статье «Как сделать правильную структуру сайта для SEO».
Анализ семантики позволяет изучить нишу, лучше понять клиента и использовать опыт конкурентов для развития собственного ресурса.
Ключевые слова и их виды
Чтобы создать ядро, нужно собрать пользовательские запросы к поисковикам. Эти запросы называются ключами. Например, чтобы узнать, как создать свой бизнес, пользователь введет в поиске «как открыть бизнес» — это и есть ключ.
Ключевые слова бывают:
● Низкочастотные (НЧ). Наименее популярные запросы; их регулярность — до 500 в месяц. Например, «купить квартиру в районе черемушки москва» — 112 запросов. По статистике, две трети запросов — низкочастотные. Конкуренция по таким фразам обычно меньше, чем по высокочастотным, поэтому продвигаться по ним легче и быстрее.
Но бывают исключения, когда низкочастотный запрос оказывается высококонкурентным. Как правило, такое происходит в специфических нишах. Например, «акриловые вывески» — это низкочастотный и узконаправленный ключ, но конкуренция в этой сфере большая. Все потому, что есть много ресурсов, которые производят акриловые и другие виды вывесок.
● Среднечастотные (СЧ). Это ключи частотностью от 500 до 5 000 показов в месяц. Например, «магазин чая в москве» — 2 716 запросов, «частная школа английского языка» — 2 964 запроса.
● Высокочастотные (ВЧ). Самые популярные поисковые запросы с частотой от 5 000 показов и выше. Например, «тур в египет» — 181 650 запросов в месяц, «купить смартфон самсунг» — 52 046 запросов.
Крупнейшие сайты делают акцент на ВЧ-запросах и вытесняют друг друга с первых позиций в выдаче. Такое продвижение стоит больших денег. Если вы не относитесь к компаниям-гигантам, то рекомендуется использовать малое количество ВЧ-запросов и сконцентрироваться на НЧ- и СЧ-запросах.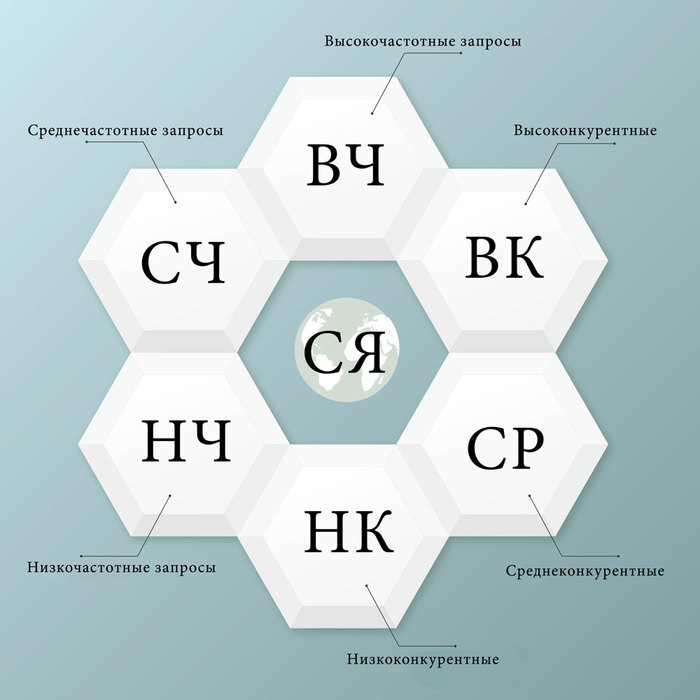 Эти ключи выводить в топ проще всего.
Эти ключи выводить в топ проще всего.
Этапы сбора семантического ядра
Для начала необходимо понять, с каких ключевых слов люди переходят на ваш сайт, чем они интересуются. Далее вы должны расширить семантическое ядро и очистить его от лишних фраз. Самый последний этап — распределить ключи по группам.
Составляем базовые ключи
Запишите основные слова и словосочетания, которые описывают ваши продукты или услуги. Чтобы удобно оформить информацию и не упустить важное, советуем заносить данные в Excel или Google Таблицы.
Обычно на этом этапе собираются высокочастотные ключи с низкой уникальностью. Пример: мы открыли пиццерию в Мытищах и Королеве. Основное направление — доставка пиццы. За основу возьмем базовый ключ «доставка пиццы».
Расширяем ядро
Теперь нам нужно получить средне- и низкочастотные запросы. Здесь вам поможет сервис поиска ключей, например Яндекс Wordstat. С его помощью вы узнаете, насколько популярны слова, которые вы записали на первом этапе.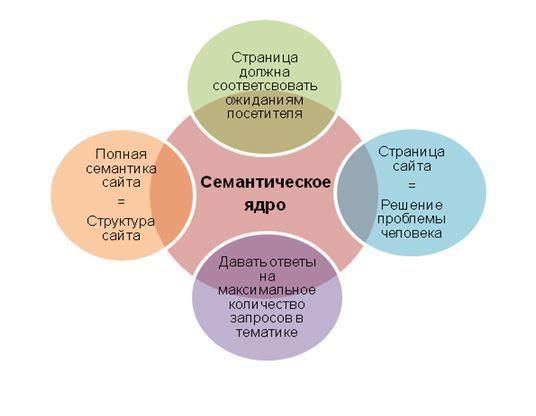 Если ваш бизнес относится к определенной локации, выберите в настройках нужный регион. После того как вы введете запрос, сервис покажет две таблицы.
Если ваш бизнес относится к определенной локации, выберите в настройках нужный регион. После того как вы введете запрос, сервис покажет две таблицы.
Найденные запросы в Яндекс Wordstat по ключу «доставка пиццы». Города: Королев, Мытищи
Слева видно, в каких вариациях люди пишут слова в поисковике. Нужно скопировать ключи из этой колонки и вставить их себе в таблицу. В колонке справа указаны фразы, которые похожи на ваши основные запросы. Подберите подходящие ключи из этой колонки и также вставьте в таблицу (на скриншотах выделены запросы, которые можно взять работу).
У вас получится список фраз для каждого базового запроса. В списках могут оказаться сотни или тысячи ключей.
Комбинируем слова. Увеличить ядро помогают запросы с уточняющими словами:
- «заказать», «цена», «стоимость», «доставка» и прочие;
- названия товаров, услуг;
- названия бренда, компании;
- информация о моделях и их характеристиках;
- акции, скидки, промокоды;
- запросы по срочности: быстрая, быстро, круглосуточно;
- по местам продажи: на дом, в офис;
- по мероприятиям и праздникам: на день рождения, Новый год, на корпоратив и прочие;
- по названию города, района доставки/обслуживания.


Изучаем конкурентов. Полезно знать и применять ключи, по которым ранжируются конкуренты. Это повышает видимость сайта в поисковой выдаче и контекстной рекламе. Определите лидеров ниши, и вы найдете у них качественные запросы. Есть специальные инструменты, которые делают эту работу автоматически и экономят время. Например, сервисы Serpstat, Мегаиндекс, Topvisor.
Регулярность расширения ядра зависит от тематики бизнеса, частоты обновления товаров и услуг, а также региона, в котором компания работает. Для сезонных сфер, например магазина трендовой одежды, обновлять ядро нужно не реже одного раза в сезон. Для новостных каналов — каждый день.
Удаляем лишние фразы
Это крайне трудоемкий этап создания семантического ядра. Не все варианты ключей, которые показали сервисы, подойдут вашему бизнесу. Нужно вручную убрать неподходящие по смыслу фразы.
Удаляйте запросы, которые содержат:
- Названия конкурентов. Для таких ключей поисковики ищут самый релевантный результат, а значит, сайт конкурента вам вряд ли обойти — он будет выше вас в выдаче. Упоминать другие бренды можно, только когда ресурс содержит материалы о конкуренте, например обзор его товара.
- Товары и услуги, которых у вас нет. Эти ключи не соответствуют ожиданию пользователя. Если использовать их на сайте, снижаются переходы по страницам и растут показатели отказов.
- Дубли. Например, из трех словосочетаний «подарок на день рождения», «подарок на день», «подарок на рождение», нужно сохранить только первое.
- Слова для другой локации. Например, если продаете только для жителей Измайловского района, вам не пригодится ключ с названием Останкинского района.
- Ошибки и опечатки. Поисковик знает, что человек ищет смартфон, даже если написано «смарфон». Поэтому на оптимизацию такие запросы не влияют.
 Упоминать другие бренды можно, только когда ресурс содержит материалы о конкуренте, например обзор его товара.
Упоминать другие бренды можно, только когда ресурс содержит материалы о конкуренте, например обзор его товара.Объединяем в группы
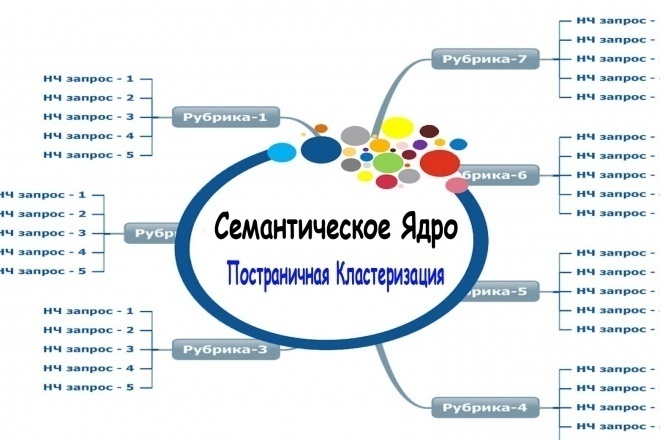
Готовое семантическое ядро следует хорошо структурировать. Метод, когда запросы разделяются на тематические группы, называется кластеризацией. Это важнейший этап, без которого семантическое ядро будет лишь набором не связанных между собой фраз.
Это важнейший этап, без которого семантическое ядро будет лишь набором не связанных между собой фраз.
Каждая группа запросов должна иметь свой интент — намерение пользователя. Выделяют следующие интенты:
- Информационные. С их помощью пользователи находят нужные сведения. Например, «как вложить деньги в акции», «как построить дом». Под такие запросы стоит писать посты и выкладывать их на сайт в разделе «Статьи» или «Блог».
- Транзакционные. Главные ключи для развития бизнеса. Это самые дорогие запросы для продвижения. Они используются, когда люди хотят совершить какое-то действие. Например, «купить автомобиль», «скачать книгу», «заказать роллы». Добавляйте их в разделы «Каталог», «Магазин», «Витрина».
- Навигационные. Эти запросы помогают найти конкретный ресурс или сайт. Например, «сайт госуслуг», «официальный сайт компании N». Размещайте их на тематических страницах: «Контакты», «Доставка», «О компании».
Кластеризацию можно проводить вручную или автоматически. Ручной метод удобен для небольшого ядра в пределах 500 запросов. Для крупного ядра лучше использовать специальные программы. За несколько минут они сделают то, на что у человека ушел бы месяц. При этом группировщики могут ошибаться, и идеальный результат получается, когда за ними перепроверяет человек.
Ручной метод удобен для небольшого ядра в пределах 500 запросов. Для крупного ядра лучше использовать специальные программы. За несколько минут они сделают то, на что у человека ушел бы месяц. При этом группировщики могут ошибаться, и идеальный результат получается, когда за ними перепроверяет человек.
Сервисы для кластеризации:
https://www.keys.so/ru/
https://just-magic.org/
https://seranking.ru/
https://arsenkin.ru/
https://ru.megaindex.com/a/keywords
Сервисы для создания семантического ядра
Key Collector
Многофункциональная программа, которая автоматизирует создание семантического ядра. Она подбирает запросы, быстро сегментирует и фильтрует ключи, собирает статистику и прочее. Приложение интегрировано с большим количеством сервисов, включая сервисы Яндекса и Гугла, что значительно упрощает работу.
Программа Key Collector
Яндекс Wordstat
Бесплатный сервис, который помогает найти и проанализировать запросы пользователей Яндекса. С его помощью можно узнать, сколько людей в месяц ищет конкретную фразу, и увидеть ключи, схожие по смыслу с вашими.
С его помощью можно узнать, сколько людей в месяц ищет конкретную фразу, и увидеть ключи, схожие по смыслу с вашими.
Сервис Яндекс Wordstat
Планировщик ключевых слов Google
Бесплатный сервис для подбора и группировки ключевых слов. Он также прогнозирует бюджет и результаты рекламной кампании.
Сервис «Планировщик ключевых слов Google»
Serpstat
Платная SEO-платформа для интернет-маркетинга. Она состоит пяти модулей: мониторинг позиций, анализ ссылок, анализ конкурентов, SEO-аудит сайта и анализ ключевых слов. Serpstat позиционирует себя как инструмент быстрого роста в SEO, PPC, контент-маркетинге и поисковой аналитике.
Сервис Serpstat
Megaindex
Платный сервис для автоматизированного продвижения сайтов. Он анализирует видимость запросов, по которым сайт занимает позиции в поисковой выдаче. Megaindex помогает выгрузить ключи топовых конкурентов и расширить ваше семантическое ядро.
Сервис Megaindex
Как использовать готовое семантическое ядро
Когда вы сделали кластеризацию, ядро готово к использованию. Собранная семантика позволяет:
Собранная семантика позволяет:
- Создавать структуру сайта. На основе СЯ создаются страницы и разделы ресурса. Поисковые системы лучше индексируют такой сайт, а пользователи быстрее находят на нем нужную информацию.
- Делать контент. Используйте ключи, когда пишете материалы для сайта. Запросы помогают создавать полезный контент, который отвечает на вопросы людей и приводит к вам целевой трафик.
- Оптимизировать теги. Ключи используют для создания важнейших мета-тегов: основного заголовка (title) и описания страницы сайта (description). Поисковики сканируют эти элементы страниц и учитывают их при индексации. Правильно прописанные title и description улучшают позиции ресурса.
- Запускать контекстную рекламу. В платной выдаче Яндекса и Google ключи применяются для контекстной и баннерной рекламы. Чтобы собрать рекламные объявления, можно взять кластеры, которые вы подготовили для SEO, или же сделать отдельную сортировку ключей.
- Продвигать визуальное содержание. Если вы вставляете ключевые слова в названия и alt-теги изображений, то это повышает вероятность их появления в разделе «Картинки» у поисковиков.
Развивать другие каналы. Использовать ключи можно везде, где пользователи вводят запросы в строку поиска. Понимание запросов в конкретной нише помогает развивать ресурс в социальных сетях, YouTube, интернет-агрегаторах и прочих каналах.
Кратко: как не допустить ошибок при создании ядра
- Ищите любые способы пополнить СЯ качественными ключами. Если собирать только очевидные запросы и никак не расширять ядро, можно лишиться большой части трафика.
- Тематика ключей не должна обманывать пользователя. Если юзер зашел на сайт по фразе «установка windows», вряд ли он останется на нем, если страница рассказывает об установке macOS.
- Не стоит оставлять «пустые» ключи с крайне низкой или нулевой частотностью. Они почти неэффективны для продвижения ресурса.
- Регулярно обновляйте ядро и учитывайте сезонность. Некоторые запросы эффективны только в определенный период. Если какой-то ключ сейчас не работает, это не значит, что так будет всегда.
- Используйте несколько инструментов для создания СЯ. Когда вы ограничиваетесь каким-то одним сервисом, список запросов может оказаться неполным.
- Обязательно делайте кластеризацию. Именно этот этап превращает тысячи ключей в грамотную структуру, которая разбита на категории, страницы, статьи и т. д.
- Не используйте слишком много запросов на одной странице и не смешивайте разные тематики. Это снижает релевантность страницы и приводит нецелевой трафик. Важно, чтобы одна страница соответствовала одному интересу человека.
Перейти ко всем материалам блога
Как самостоятельно создать семантическое ядро сайта
Оглавление
- Что такое семантическое ядро
- Как собрать семантическое ядро
- Серпстат
- Ключевое словоShitter
- Инструмент подсказки ключевых слов
- Анализ ключевых слов Ahrefs
- Вывод
 org/ListItem»> Зачем делать семантическое ядро
org/ListItem»> Зачем делать семантическое ядроЧто такое семантическое ядро
Семантическое ядро представляет собой набор ключевых слов и словосочетаний, подобранных и составленных в соответствии с тематикой сайта. На основе этих данных проводится оптимизация сайта, в частности составляется техническое задание на написание контента.
Зачем делать семантическое ядро
Как мы уже говорили, подбор ключевых слов необходим для SEO сайта. Однако семантика также важна для создания контекстной рекламы и объявлений. Специалисты отслеживают популярные фразы по запросам пользователей, а также анализируют семантические ядра конкурентов.
Как собрать семантическое ядро
Для того чтобы собрать семантическое ядро необходимо использовать специальные инструменты. В том числе:
- Серпстат;
- Ключевое словоShitter;
- Инструмент подсказки ключевых слов;
- Анализ ключевых слов Ahrefs.
Подробнее о каждом из них мы узнаем ниже.
Serpstat
Serpstat — платформа для автоматизации анализа конкурентов, ключевых слов, ссылок, аудита сайта и оптимизации. Его используют более 200 000 пользователей, включая Uber, Shopify, Samsung, Philips и Deloitte. Инструмент был разработан в 2013 году как собственный продукт, но позже превратился в полнофункциональную SEO-платформу. База данных Serpstat содержит более 5 миллиардов фраз.
База данных Serpstat содержит более 5 миллиардов фраз.
KeywordShitter
Также можно автоматически собрать семантическое ядро с помощью KeywordShitter. Это бесплатная программа. Вам даже не нужно регистрироваться, чтобы использовать его.
Keyword Tool
Еще одной программой для подбора семантики является Keyword Tool. Инструмент имеет две версии для использования – платную и бесплатную. Инструмент подсказки ключевых слов поможет вам использовать функцию автозаполнения Google для поиска ключевых слов. Программа также извлекает советы по поиску Google и представляет их в понятном формате.
Ahrefs Keywords Explorer
Если вам необходимо собрать семантическое ядро, в этом также поможет онлайн-сервис Ahrefs Keywords Explorer. Инструмент подбирает ключи как для Google, так и для других систем — Baidu, YouTube, Bing, Amazon и т. д. Также программу можно использовать для анализа других SEO-показателей — процент возврата, количество кликов на поиск, процент кликов, в том числе платных и т.![]() д.
д.
Заключение
Без использования ключевых слов невозможно осуществить качественное продвижение сайта. Поэтому необходимо собрать семантику и применить ее по назначению. Если вы не уверены, что сможете разобраться сами, то можно привлечь SEO-специалиста или обратиться в digital-агентство для сбора семантического ядра. Ни в коем случае нельзя игнорировать и откладывать это действие, ведь без него сайт не займет топовые позиции.
Формирование семантического ядра сайта.
Ключи к ТОПу!
25 долларов США в час
45 долларов США в час
ЗАКАЗАТЬ СЕЙЧАС
Продажа
-45%
Подберем ключи для вашего сайта, которые откроют дверь в ТОП!
Аналитика семантики бизнес-ниши.
Поиск по всем похожим ключевым фразам из ТОП-20.
Аналитика сложности семантики.
Проверенная система сбора семантики.

Очистка семантического ядра от стоп-слов.
Кластеризация поисковых фраз.
Рекомендации по распределению ключевых слов на сайте.
Заказать сбор семантики
Свяжитесь мгновенно через мессенджер!
Выберите свой любимый мессенджер для
Бесплатная консультация по вашему проекту.Связаться с Viber
Свяжитесь с WhatsApp
Связаться с Telegram
Для чего необходимо формирование семантического ядра сайта?
Семантическое ядро – это слова, описывающие деятельность компании, ее продукты и услуги. По ним поисковик определяет, что сайт соответствует запросу пользователя. Это основные части фраз, которые пользователи вводят при поиске в браузере. Google и Яндекс показывают сайты, содержащие ключевые слова на первых двух страницах. Это означает, что они удовлетворяют потребности людей, которые ищут продукт, услугу или информацию. Если не использовать такие «маркеры» для программ, попасть в Топ невозможно. Это основа SEO-продвижения.
Если не использовать такие «маркеры» для программ, попасть в Топ невозможно. Это основа SEO-продвижения.
Что важно учитывать при формировании семантического ядра?
Эти основные фразы отражают интересы потенциальных покупателей. Чем разнообразнее и точнее они будут, тем шире охват интернет-пользователей. Если собрать все реалистичные варианты, система покажет сайт большей целевой аудитории. Используя все формулировки, которые могут ввести пользователи, можно будет максимально увеличить охват по ключевым запросам.
Очистка семантического ядра от «мусорных» слов, не относящихся к системе, способствует продвижению. Сайт показывается только по целевым запросам. Кластеризация семантики — это распределение слов по смысловым группам и основа для создания seo-контента.
Как построить семантическое ядро?
Подберем ключевые слова, чтобы Ваш сайт был впереди конкурентов в ТОПе. Это увеличит органический поисковый трафик и увеличит продажи. TopUser.PRO гарантирует такие результаты, потому что наши специалисты:
- знакомятся с особенностями бизнеса клиента, согласовывают с ним задачу;
- анализ ниши, изучение страниц конкурентов заказчика;
- маркеры формы, выделение слов и словосочетаний, характеризующих сферу деятельности клиента;
- владеют инструментами для разбора запросов, поэтому собирают все подходящие варианты;
- избавиться от лишних слов и словосочетаний, не способствующих продвижению в поисковой выдаче;
- сгруппировать результаты по категориям в соответствии с намерениями или потребностями тех, для кого предназначены веб-страницы;
- доработка структуры семантического ядра вручную;
- формирование отчетов по этапам работ и предоставление их заказчику;
- дать совет, как оптимизировать ваш сайт, используя полученный список ключевых слов и предложить такую услугу.

Комплексный подход гарантирует, что семантическое ядро покроет все возможные запросы и не будет отягощено стоп-словами, которые снижают ранжирование и отнимают ресурсы на нецелевые показы. Такая основа позволит создавать контент, который будет не только отвечать интересам целевой аудитории6, но и хорошо ранжироваться поисковыми роботами. Это первое, что необходимо для успешного SEO-продвижения. Быстрый путь в ТОП вашего сайта!
Заказывайте и обгоняйте конкурентов уже сегодня
Часто задаваемые вопросы (FAQ)
✔️ Почему при формировании семантического ядра сайта иногда требуется использование вопросительных слов?
Google оценивает слова «как», «где» и другие как признак интереса аудитории. Особенно важно использовать их в вопросах вместе с основными ключевыми словами.
✔️ Как по результатам, которые дали формирование семантического ядра сайта, оптимизировать ваш контент на вопросы?
Используйте их в тексте как риторические. Создайте блок «Вопрос – Ответ».
Создайте блок «Вопрос – Ответ».
✔️ Какой самый простой инструмент для формирования семантического ядра сайта?
Google Планировщик ключевых слов. Все подобные сервисы просты в использовании.
✔️ Включаются ли длинные ключевые слова при формировании семантического ядра сайта?
Краткие формулировки являются основными. Ключевые слова с длинным хвостом — это дополнительные фразы. Они реже используются в поиске. Конкуренция для них ниже. Они также используются.
✔️ Как аналитика влияет на формирование семантического ядра сайта?
Исследование ключевых слов может помочь вам «заглянуть в головы ваших клиентов», найдя темы для включения в вашу контент-стратегию. Как только вы узнаете, что ищет ваша целевая аудитория, вы сможете оптимизировать свой контент, чтобы предоставить ответы, которые ей нужны.
✔️ Как правильно дополнить ключевые слова контекстом, применяя формирование семантического ядра сайта?
Есть несколько полезных советов.