
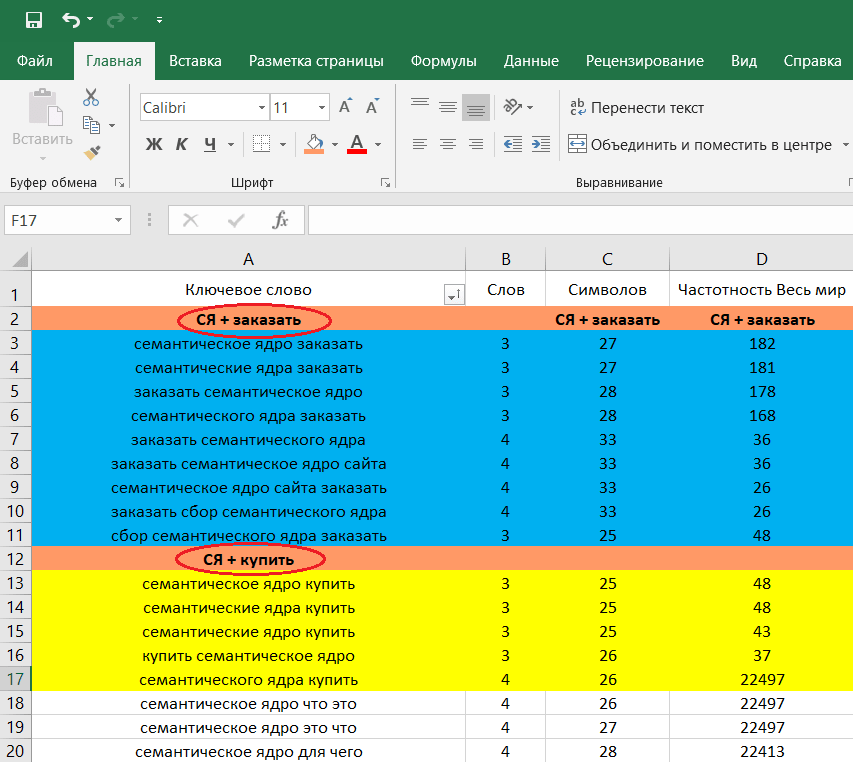
Подбор ключевых слов в Google (сбор статистики и кластеризация запросов)
Для создания успешного сайта, который будет активно привлекать посетителей из Google, Bing или Yandex — крайне важно подобрать правильные «фокусные» ключевые слова. Процесс подбора ключевых слов специалисты называют — составлением семантического ядра.
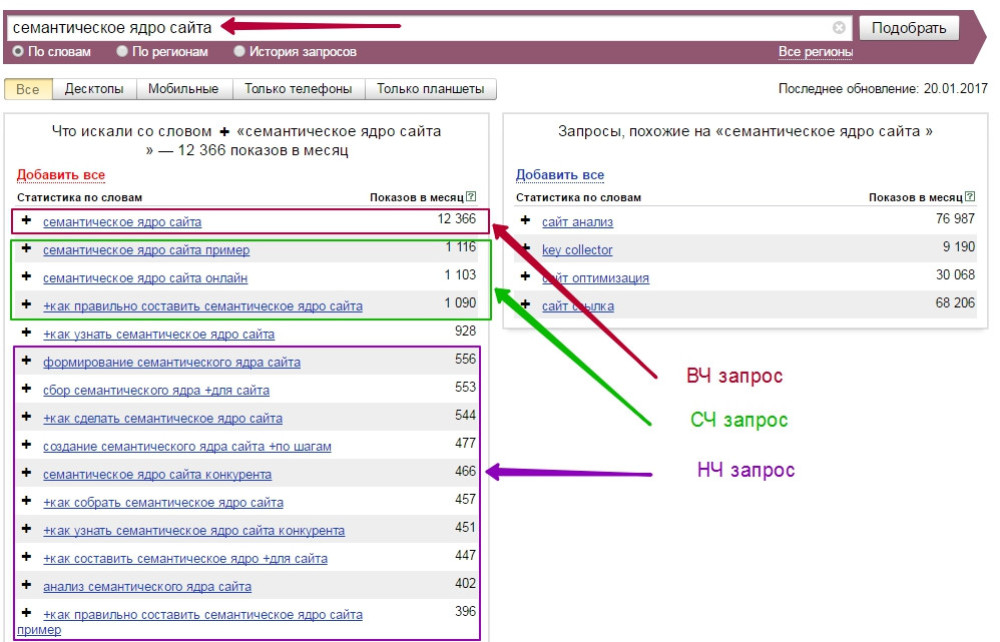
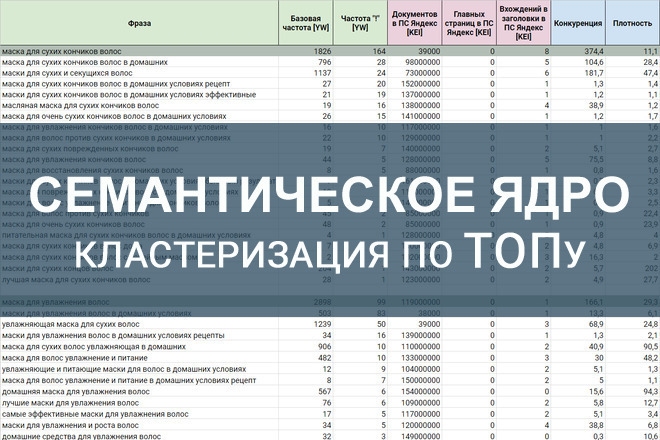
Семантическое ядро — это перечень слов и словосочетаний, которые пользователи используют при поиске в определённой теме. Будь то товары, услуги или информация. Слова и фразы из которых состоит Семантическое ядро называют поисковыми запросами или ключевыми словами. Самый пример семантического ядра — это таблица с двумя столбами данных. Первый столбец обычно содержит список поисковых запросов, при этом во втором столбце выписано количество поисков соответствующего слова или словосочетания. Эти данные SEO специалист получает используя специальные инструменты для изучения ключевых слов. Обычно такие инструменты и статистику представляют Поисковые системы.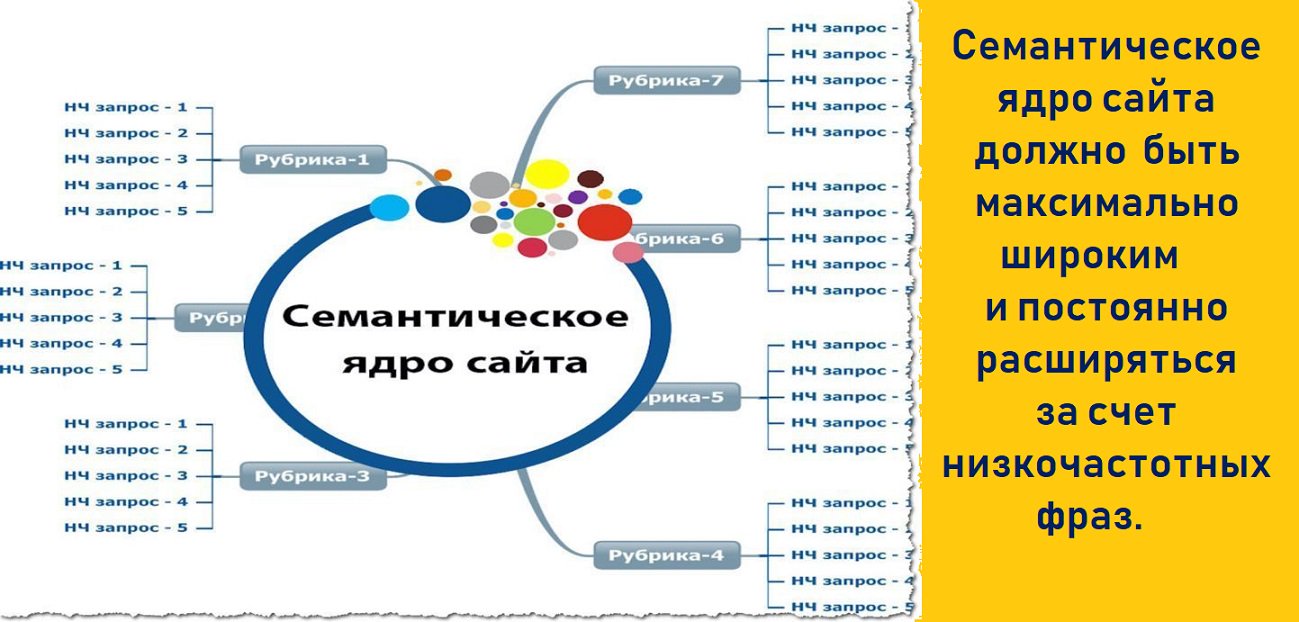
Пример фрагмента семантического ядра (часть группы «куртки коламбия»).
Как подобрать ключевые слова для сайта в Google?
- Составьте список идей ключевых слов
- Соберите статистику с помощью инструментов поисковых систем
- Удалите ключевые слова которые не касаются вашего бизнеса
- Группировка запросов по смыслам
- Расширьте статистику поисковыми подсказками и другими инструментами
- Выберите самые эффективные ключевые слова
А теперь давайте разберемся подробнее в каждом пункте плана.
Составление идей ключевых слов
Идеи ключевых слов — это, предположения, как мы считаем пользователи могут искать наши товары или услуги в Google.
Первый способ, фантазия:
Просто откройте текстовый файл и напишите в столбик как вы думаете люди будут вас искать.
Пример для магазина:
Постарайтесь максимально описать весь ассортимент товаров и услуг, используйте уточнения материалов и свойств, названия брендов.
Второй способ, изучите меню:
Посмотрите в меню своего сайта. Скопируйте название разделов и подразделов сайта и дополните их важными свойствами и названиями брендов. Такой генератор ключевых слов позволит быстро создать сотни стартовых запросов.
Так же можно использовать онлайн инструменты вида: генератор ключевых слов. Такие сервисы позволяют пересекать основную тему с коммерческими уточнениями и регионом, быстро создавая сотни запросов для предсемантики.
Третий способ, посмотрите на Википедию:
Откройте статью на Wikipedia по вашей теме и изучите свойства и уточнения которые важны в вашей теме.
На странице Википедии я узнал о размерах, материалах и видах, как результат мой список идей ключевых слов:
Совет: Используйте разные методы для составления большого количества разных идей ключевых слов.
Когда идеи ключевых слов готовы, переходим ко второму шагу.
Сбор статистики поисковых запросов
Для сбора основных ключевых слов по Google мы воспользуемся инструментом «Планировщик ключевых слов от Google» https://ads.google.com/intl/ru_ru/home/tools/keyword-planner/
Популярные платные и бесплатные инструменты которые помогу собрать вам ключевые слова.
Сбор через: Планировщик ключевых слов Google Ads
Чтобы воспользоваться инструментом необходимо зарегистрировать аккаунт гугл адвордс, пройти регистрацию в сервисе Google Ads, заполнить все необходимые поля и создать текстовую рекламную компанию. Для тестовой компании вы можете заполнить все поля любыми данными, для нас самое важное дойти до планировщика ключевых слов.
Если Google Keyword Planner не показывает вам статистику по ключевым словам или показывает всего одно слово проверьте установлен ли у вас язык «Русский» и правильный регион.
В новом Google аккаунте статистика в инструменте будет показывать для вас в виде диапазонов, вот так:
Для получения полной статистики необходимо потратить в сервисе гугл реклама минимум 10 долларов. Обратите внимание нужно не просто пополнить счёт а именно потратить средства. После базовых затрат вы получите доступ к статистике на срок около месяца. И будете видеть полную статистику.
Обратите внимание нужно не просто пополнить счёт а именно потратить средства. После базовых затрат вы получите доступ к статистике на срок около месяца. И будете видеть полную статистику.
В полной версии планировщика ключевых слов мы так же можем увидеть информацию о сезонности. Если вы хотите просмотреть сезонность по отдельному ключевому слову или теме, воспользуйтесь бесплатным инструментом Google Trends.
Google Trends — покажет вам сезонность и поможет понять перспективность темы. Изучая рост популярности отдельных запросов или темы вы сможете определить тенденции роста своей ниши.
Если вы получили ключевые слова с частотностью в виде диапазона ее всегда можно уточнить в онлайн инструментах. Так же, такие инструменты как topvisor.com или www.rush-analytics.ru позволяют снять частотность по любым регионам задав свой список ключевых слов. Данные о частотности по 150 ключевым словам обойдутся вам менее чем в 1 гривну.
Получаем слова и объединяем в один файл
Теперь поочередно вводим по 2-3 идеи ключевых слов в инструмент и скачиваем результаты нажатием на кнопку «скачать все варианты ключевых слов».
В результате мы получим несколько файлов в формате csv. Содержимое всех этих файлов нужно объединить в один большой файл.
Чтобы быстро объединить все файлы в один удобно использовать командную строку, для этого:
1. Открываем меню «пуск» и начинаем печатать cmd, выбираем из выпадающего списка нужный пункт и нажимаем «Enter».
2. Заходим в папку с файлами ключевых слов через команду cd.
3. Вводим в командную строку: copy \b *.csv all.csv
В итоге получаем один большой файл со всей статистикой. Теперь в нем нужно удалить лишние строки, а именно заголовки столбцов и даты выгрузки.
Автоматический сбор слов для сайта
Если вам нужно собрать слова быстро, хорошим решением будет использовать автоматические инструменты подбора слов. Для этого, соберите список ваших конкурентов и по очереди проанализируйте их в таких инструментах как:
Это позволит собрать список слов по которым отображаются конкуренты в поиске. Эти запросы по сути вы сразу сможете использовать как базовое семантическое ядро для старта вашего сайта.
Эти запросы по сути вы сразу сможете использовать как базовое семантическое ядро для старта вашего сайта.
Чистка семантического ядра
Давайте разберемся как удалить ненужные слова. Мы собрали много слов и словосочетаний, нам нужно оставить только те из них которые подходят нашему бизнесу.
Как быстро удалить все ненужные слова
ШАГ 1: Удалите дубликаты слов через функцию в Excel.
ШАГ 2: Удалите мусорные фразы, разложите все фразы на слова отсортировав их по популярности с помощью http://simple-seo-tools.com. Такой вид отображения называется частотная таблица. Посмотрите полученную таблицу, основная цель — обнаружить не целевые слова. Такие как не целевые регионы, бренды и типы товаров которые вы не продаёте, а так же, любые другие слова которые не касаются вашего сайта — бизнеса.
Когда вы обнаружили не нужные слова — отфильтруйте свой список фраз по этому слову и удалите все мусорные Поисковые запросы. Продолжайте эту работу пока в списке фраз не останутся только целевые слова без мусора.
При работе с большим перечнем слов более 1000 запросов, ручное удаление нецелевых запросов может занять достаточно много времени. Ускорить работу можно с помощью специальных инструментов.
Чистка семантического ядра в Key Collector
Key Collector — одна из самых популярных программ по сбору и сортировке ключевых слов. При стоимости 850 грн. за лицензию она ускоряет обработку семантики в 5-10 раз.
План работы.
- Загрузите ключевые слова в Key Collector.
- Используйте списки стоп слов для удаления самых мусорных запросов. Вот несколько списков стоп слов которые вам пригодятся.
- Используйте инструмент анализа по составу фраз. В результате вы получите ключевые слова в виде групп по определенным словам. Просматривая группы выберите не подходящие фразы или целые группы и нажмите кнопку «удалить».
Такой подход поможет вам почистить даже очень большой список ключевых слов.
Группировка запросов — Кластеризация
Посмотрим на группировку запросов она нужна нам для правильного распределения ключевых слов по страницам сайта. При группировке наша задача объединить запросы таким образом, чтобы все запросы в группе имели одинаковый смысл. Поскольку определение смыслов всех запросов не простая задача — группировку запросов чаще всего проводят с помощью специальных программ.
При группировке наша задача объединить запросы таким образом, чтобы все запросы в группе имели одинаковый смысл. Поскольку определение смыслов всех запросов не простая задача — группировку запросов чаще всего проводят с помощью специальных программ.
Обратите внимание, группировку нужно проводить именно по смыслу запросов, а не по составу слов.
Довольно часто — сложно определить смысл запроса и то намерение, которое пользователь вкладывал в запрос. В таком случае, стоит проверить смысл запроса в поисковой системе. Посмотрите, какие результаты показывает Google по вашему запросу, это поможет понять какую информацию хочет получить пользователь.
Почему поисковая система знает о запросах больше людей?
Дело в том, что поисковая система постоянно оценивает поведение людей в поиске. Алгоритмы поисковой системы запоминают какие результаты люди выбирают чаще. Так к примеру если по запросу «гольф» пользователи Google будут чаще выбирать информации о «wolksvagen golf» поисковая система поймет,что по этому запросу люди ищут не спорт, а машину.
Таким образом, поисковая система действительно понимает смысл запроса лучше чем некоторые пользователи.
Наиболее популярный метод группировки запросов также основан на понимании запроса поисковой системой. Такой метод называют группировкой по поисковой выдаче или группировкой по ТОПам. Суть метода в сравнении результатов поиска по двум запросам и сравнении страниц которые отображаются в топ 10. Если в результатах поиска по двум разным запросами отображаются достаточное количество одинаковых страниц — такие запросы объединяют в одну группу.
Сноска. Количество совпадений результатов поиска, при котором запросы считают синонимами называется порог или уровень кластеризации. Самый распространенный уровень кластеризации 4 — совпадения.
Естественно, что процесс сравнения всех запросов ядра между собой достаточно трудоемкий. И его стоит автоматизировать.
Инструменты группировки запросов по Google
Группировка ключевых слов по результатам поиска (кластеризация) позволяет правильно разделить ключевые слова по группам и сформировать структуру содержания. Пример списка групп ключевых слов после кластеризации.
Пример списка групп ключевых слов после кластеризации.
Зачем нужна Кластеризация?
Группировка ключевых слов нужна для того, чтобы правильно распределить поисковые запросы между всеми страницами сайта. А так же, определить какие страницы, категории товаров или статьи нам нужно создать дополнительно. Поиск групп запросов по которым на нашем сайте еще нет страницы и создание таких страниц, это один из самых эффективных методов быстрого роста посещаемости из поиска.
Чем отличается Семантическое ядро для лендинга и интернет магазина?
Ключевые слова для Landing Page
Основная особенность так называемых лендинг сайтов, это отсутствие внутренних страниц. По сути нам приходится продвигать всего одну страницу. А значит нужно учесть на ней как можно больше семантики.
Первый вариант. Взять не большой порог кластеризации, (к примеру 3) это позволит создать большой кластер для страницы и тем самым захватить больше ключевых слов. Хотя между этими словами буден не сильная связь, если мы создадим достаточно хорошее содержание — есть шанс выйти по ним в ТОП Google.
Хотя между этими словами буден не сильная связь, если мы создадим достаточно хорошее содержание — есть шанс выйти по ним в ТОП Google.
Второй вариант. Собрать семантику стандартным способом и выбрать наиболее интересный, с точки зрения бизнеса кластер.
Третий способ. Собрать полноценную семантику с большим количеством групп. А для охвата этой семантики сделать дополнительные страницы в виде отдельных лендингов. Такой подход не вызовет много затрат, но позволит привлечь значительно больше посетителей.
Сбор семантики для интернет магазина
Сбор семантики для интернет магазина — один из ключевых моментов при создании его структуры. Для того чтобы собрать максимально полный список запросов воспользуйтесь следующим планом.
- Полнота семантики для интернет магазина очень важна, составьте максимально полный список идей ключевых слов.
- При группировке ключевых слов используйте Хард Кластеризацию. Хард Кластеризация означает, что запросы в рамках группы будут иметь более жёсткую связь, так как сравнение результатов поиска будет происходить между всеми запросами группы.


Точность и полнота сбора семантики особенно важна для и интернет магазина или портала так как именно на основе групп вы будете строить структуру вашего каталога.
Расширение ключевых слов с помощью поисковых подсказок
Несмотря на большое количество статистики которое мы можем получить из Google Keyword Planner некоторые ключевые слова в нем просто не отображаются. Для поиска таких скрытых ключевых слов удобно использовать сбор поисковых подсказок. Собирать поисковые подсказки так же можно автоматически, таким образом расширяя количество интересных ключевых слов в нужных вам группах.
Собрать поисковые подсказки можно с помощью автоматических инструментов.
Получение ключевых слов из Google Search Сonsole и Analytics
Мы всегда можем дополнить свой список ключевых слов используя те запросы по которым уже есть позиции в поиске. Для этого нужно открыть отчет «Эффективность» в Google Search Console.
Из этого отчета вы сможете получить до 1000 ключевых слов по которым пользователи видели ваш сайт в Гугл.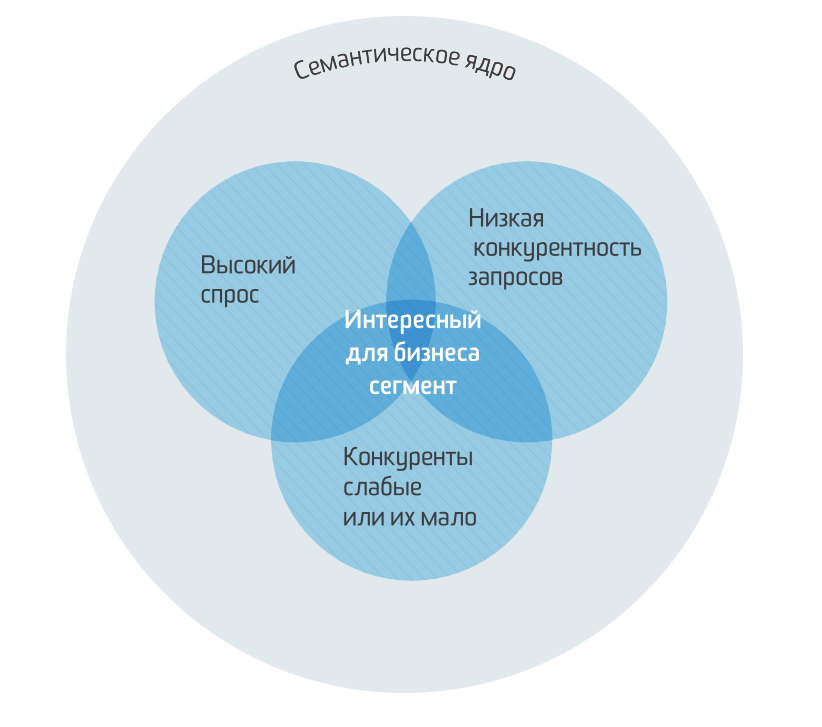 Ту же статистику вы сможете получить в Google Аналитике в отчете: Источники трафика > Search Console > Запросы. Но для этого, вам нужно связать инструменты Google Аналитикс и Search Console. Подробнее в справке Гугл.
Ту же статистику вы сможете получить в Google Аналитике в отчете: Источники трафика > Search Console > Запросы. Но для этого, вам нужно связать инструменты Google Аналитикс и Search Console. Подробнее в справке Гугл.
Как построить структуру на основе семантики
Каждая группа запросов это отдельная страница. Логически определите какие группы запросов вы посадите на существующие страницы сайта.
Определите группы для которых нет посадочных страниц, спланируйте создание недостающих страниц.
Не объединяйте группы запросов без причины. Если запросы попали в разные группы — значит они имеют разный смысл.
Составьте файл в котором за каждой группой ключевых слов будет закреплена страница, так вы не упустите ни одно ключевое слово.
Как выбрать эффективные «фокусные» ключевые слова
Часто, семантическое ядро будет содержать тысячи ключевых слов и не всегда понятно с каких именно запросов стоит начинать продвижение. Если вы хотите получить быстрый результат в виде позиций в поиске и потока посетителей на ваш сайт, нужно выбрать те ключевые слова на которые ваши конкуренты обращают меньше внимания.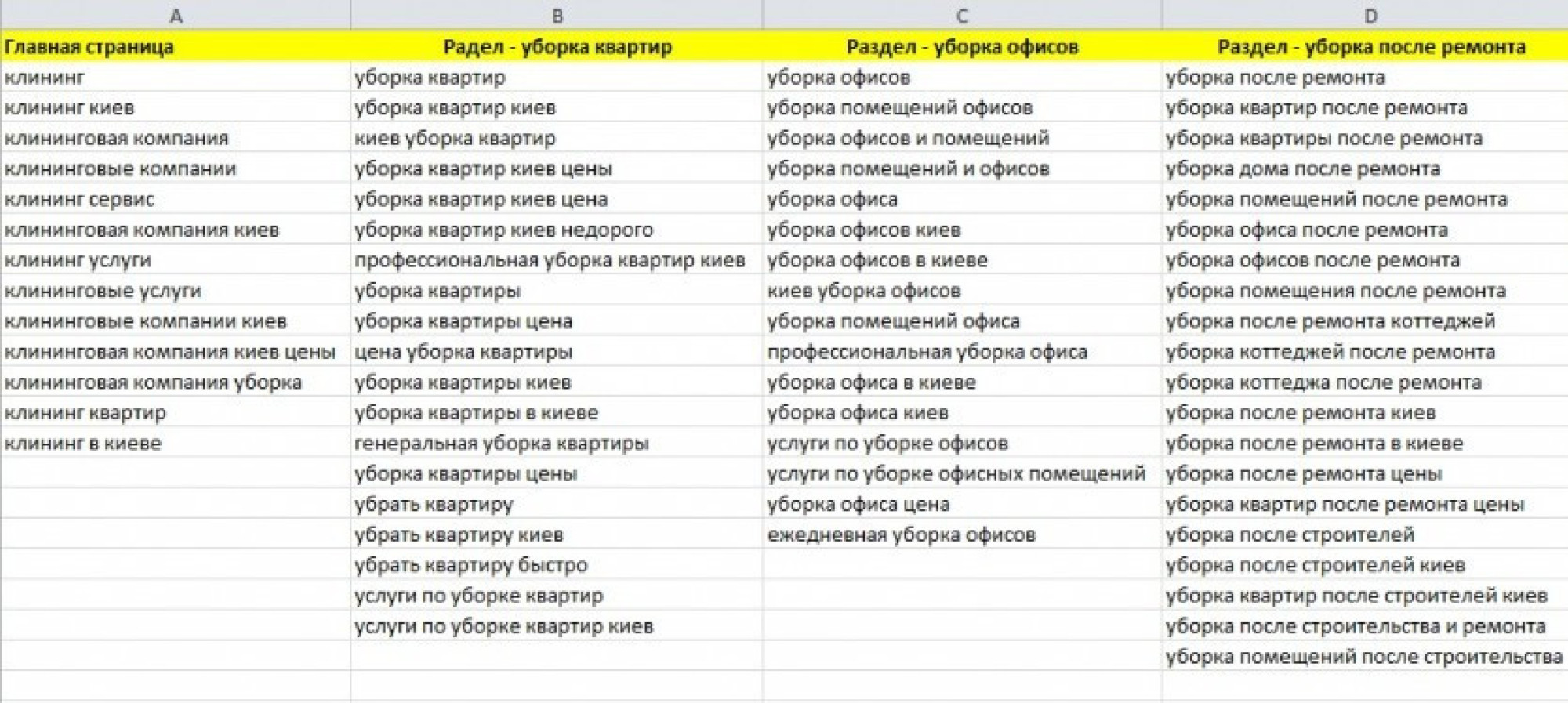 Как это сделать?
Как это сделать?
- Отберите ключевые фразы из трех и более слов, но при этом с частотностью больше 100.
- Установите бесплатное приложение https://moz.com/products/pro/seo-toolbar. Для полноценной работы нужно будет зарегистрироваться на сайте moz.com. Это приложение добавит на страницу результатов поиска Google данные о ссылках по каждому результату.
- Начните по очереди перебирать запросы которые вы отобрали в первом пункте. Нас интересуют такие ключевые слова по которым мы увидим минимум 2 результата с показателем не больше трех ссылок на страницу. Этот показатель говорит о том, что страница занимает свою позицию в основном, за счет содержания, а значит создав содержание лучше мы сможем ее обойти.
- Посмотрите на заголовки страниц в поиске. Посчитайте какое количество результатов в поиске не содержит в заголовке ключевую фразу которую вы ввели в Гугл. Заголовок страницы очень важная часть оптимизации, если конкурент не использует в заголовке фразу значит это ваша потенциальная возможность. Просто используя «не занятую» фразу в заголовке и тексте вы достаточно быстро сможете зайти в ТОП10, если напишите хороший контент.
 Просто используя «не занятую» фразу в заголовке и тексте вы достаточно быстро сможете зайти в ТОП10, если напишите хороший контент.
Просто используя «не занятую» фразу в заголовке и тексте вы достаточно быстро сможете зайти в ТОП10, если напишите хороший контент.Для примера возьмем одну из наших статей:
Такую стратегию еще называют подбором «focus keyword» фокусных ключевых слов. Это требует потратить дополнительное время, но позволяет быстро получить результат даже в конкурентных тематиках.
Что делать с собранными ключевыми словами?
После сбора ключевых слов необходимо разделить полученные группы на 3 основных типа:
- Группы ключевых слов под которые нет посадочных страниц — в этом случае, необходимо создать дополнительные посадочные страницы по заданным темам.
- Группы слов с хорошими посадочными страницами — эти страницы необходимо улучшать и проверить их текстовую оптимизацию.
- Группа слов с сомнительными посадочными страницами (смысловые дубликаты, пустые страницы) — эти страницы прежде всего требуют серьезных доработок. Создание нового релевантного содержания и хорошей текстовой оптимизации.

Зачем нужны ключевые слова и как их использовать
Собранные и разбитые на группы слова — это, основа для дальнейшего написания текстов и создание всего содержимого. Так же, на основе этих же ключевых слов строиться план для строительства ссылок. Таким образом, составление семантического ядра, просто основа всего SEO продвижения.
Общий план сбора семантического ядра
- Составьте максимально полный список идей ключевых слов.
- Соберите статистику по каждой теме отдельно, не забывайте учитывать регион и язык поиска. Если ваш сайт на нескольких языках для каждой языковой версии — вы должны собрать отдельный список ключевых слов.
- Удалите весь мусор.
- Проведите группировку запросов и определите посадочные страницы под каждую группу.
- Расширьте наиболее важные группы поисковыми подсказками.
- Выделите фокусные ключевые слова.
- Начинайте занимать позиции.
Инструменты
Онлайн сервисы
Программы (Специальный Soft для работы с ключевыми словами)
Видео инструкция
YouTube инструкция по сбору и компоновке ключевых слов.
Составление семантического ядра, сбор статистики — Урок №3, Школа SEO
Кластеризация ключевых слов — Урок №4, Школа SEO
Не забывайте !
Вы всегда можете заказать семантическое ядро сайта и аудит у нас.
Руководитель отдела продвижения SEO7. Ведущий Youtube канала Школа SEO. Автор блога о поисковой оптимизации seo-sign.com
Семантическое ядро — как собрать самостоятельно и какие инструменты использовать?
Доброго времени суток, дорогие читатели нашего блога. На моих часах 1:10 ночи, в наушниках играет очередной подкаст Neuropunk Records, а, значит, самое время написать сочную статью.
В этот раз мы затронем вопрос семантического ядра сайта (она же СЯ, она же семантика) — что это, как собрать самостоятельно и какие программы и сервисы-помощники можно использовать. Статья направлена, в первую очередь, на молодых SEO-специалистов, маркетологов и владельцев бизнеса, которые хотят развивать свой проект в интернете самостоятельно. Опытным сеошникам я вряд ли открою какие-то новые горизонты сбора СЯ, но кто знает наверняка, а? 🙂
Прим.
 автора: хочется сразу сказать, что в этих ваших интернетах существует великое множество онлайн-сервисов и скачиваемых программ, которые можно тем или иным образом использовать для сбора семантического ядра. В своей статье я хочу рассказать только о самых популярных, т.к. не вижу смысла пережевывать одни и те же функции. У всех они примерно одинаковые.
автора: хочется сразу сказать, что в этих ваших интернетах существует великое множество онлайн-сервисов и скачиваемых программ, которые можно тем или иным образом использовать для сбора семантического ядра. В своей статье я хочу рассказать только о самых популярных, т.к. не вижу смысла пережевывать одни и те же функции. У всех они примерно одинаковые.Ладно, поехали.
Семантическое ядро — определение, основные правила сбора
Итак, семантическое ядро сайта — это массив всех релевантных (тематических) запросов, по которым человек может и должен найти ваш сайт в выдаче поисковых систем. Семантическое ядро должно быть разбито на группы запросов (кластеры). Каждый кластер должен иметь привязку к какой-то релевантной посадочной странице. Т.е., проще говоря, вы должны сразу определить для себя по каким запросам и на какие страницы вашего сайта должен переходить пользователь из поиска.
Оформить СЯ можно так, как вам удобнее, мне, например, привычнее делать это в стандартном excel, используя несколько столбцов: группа запросов, сами запросы, посадочная страница кластера и title кластера.
При сборе семантики следует придерживаться нескольких правил
- Отделяйте транзакционные запросы от информационных.
Не нужно пытаться впихнуть невпихуемое на одну страницу. Например, запрос “купить дом в Анапе” — это одна посадочная страница, а запрос “Почему в Анапе жить хорошо?” — совершенно другая (вероятнее всего статья или гайд). Можно, конечно, взять продающую страницу с предложениями недвижимости и расписать там огромную простыню текста, в котором будут подробно указаны все преимущества жизни в Анапе, но далеко не факт, что это сыграет вам на руку — либо коммерческие запросы перекроют информационные, либо, наоборот, либо ни те, ни другие не выйдут в ТОП. В общем, каждому запросу должно быть свое место.
- Внимательно выбирайте посадочные страницы.
Да, в большинстве случаев и без глубокого анализа конкурентов понятно, какой запрос, на какую страницу должен вести.
Однако случается и такое, что очевидное ключевое слово на деле у 80% ТОП-конкурентов ведет не туда, куда вы планировали его “посадить”. Нужно играть по правилам поисковой выдачи, потому что бодаться с ней — себе дороже. Отсюда вывод — внимательно проверяйте посадочные под свои запросы. Ориентируйтесь на ТОП… в этом нам помогут онлайн-сервисы, но об этом мы поговорим чуть позже. - Не гоняйтесь за НЧ-запросами.
Да, низкочастотный хвост важен, но не следует усердствовать, собирая все возможные низкочастотники для страницы. Я, например, делаю следующим образом — если в кластере собирается в районе 10-30 ВЧ-СЧ запросов, то далее для него беру только НЧ с общей частотностью не ниже 5. Хотя многое, конечно, зависит от тематики. В узкоспециализированных областях, где СЯ в принципе трудно собрать (например, какая-нибудь техника для аэродромов), есть смысл рассматривать любой ключ, т.к. каждый запрос в топе, даже НЧ, будет важен.
- При сборе семантики учитывайте сезонность запросов.
Хороший пример — туристические сайты. Сезон большинства таких ресурсов выпадает на май-сентябрь. Соответственно, если вы решили собрать семантику в декабре, вы получите неточные данные — запросы с низкой частотностью, которые вы не возьмете в работу, хотя в сезон их частотность увеличивается в сотни раз.
- Анализируйте не только общую частотность запроса, но и частотность его прямого вхождения.
Это поможет определить приоритетные для оптимизации страницы ключи. Для определения частотности прямого вхождения ключа, используйте оператор “!”. Пример — запрос “ехать в турцию” (без кавычек — это тоже оператор) имеет по РБ общую частотность 326, а запрос “!ехать в турцию” в том же регионе — 0. Отсюда делаем вывод — никто не использует запрос “ехать в турцию” в прямом вхождении и скорее использует другие его словоформы. Это не значит, что такой ключ не надо брать в семантику, просто с ним нужно быть внимательнее, когда начнете оптимизировать посадочную под запросы.
 Однако случается и такое, что очевидное ключевое слово на деле у 80% ТОП-конкурентов ведет не туда, куда вы планировали его “посадить”. Нужно играть по правилам поисковой выдачи, потому что бодаться с ней — себе дороже. Отсюда вывод — внимательно проверяйте посадочные под свои запросы. Ориентируйтесь на ТОП… в этом нам помогут онлайн-сервисы, но об этом мы поговорим чуть позже.
Однако случается и такое, что очевидное ключевое слово на деле у 80% ТОП-конкурентов ведет не туда, куда вы планировали его “посадить”. Нужно играть по правилам поисковой выдачи, потому что бодаться с ней — себе дороже. Отсюда вывод — внимательно проверяйте посадочные под свои запросы. Ориентируйтесь на ТОП… в этом нам помогут онлайн-сервисы, но об этом мы поговорим чуть позже.
Ну вот из большего все, теперь поговорим про онлайн-сервисы и инструменты для сбора СЯ.
Инструменты и онлайн-сервисы для сбора семантики
Yandex.Wordstat
Онлайн-база ключевых слов от Яндекса. Источник 90% ваших запросов (для РУ-региона). Вордстат очень прост в использовании — вам нужно указать регион, по которому вы будете снимать частотность запросов, написать, собственно, исходный запрос и… все — вам предложат все связанные с исходником ключи, нужно только выбрать подходящие.
Также в Вордстате можно посмотреть сезонность запросов. Для этого выберите опцию “История запросов” и анализируйте динамику запроса за последние 12 месяцев.
Пара советов по поводу работы с YWS
Совет номер раз: так бывает, что защитная система Яндекса в какой-то момент начинает считать вас спам-ботом и на каждое действие в Яндекс.Вордстат (вплоть до перехода по страницам пагинации) требует введения капчи, от которой в районе таза разгорается пламя такой интенсивности, что при желании можно прожечь себе путь до Китая.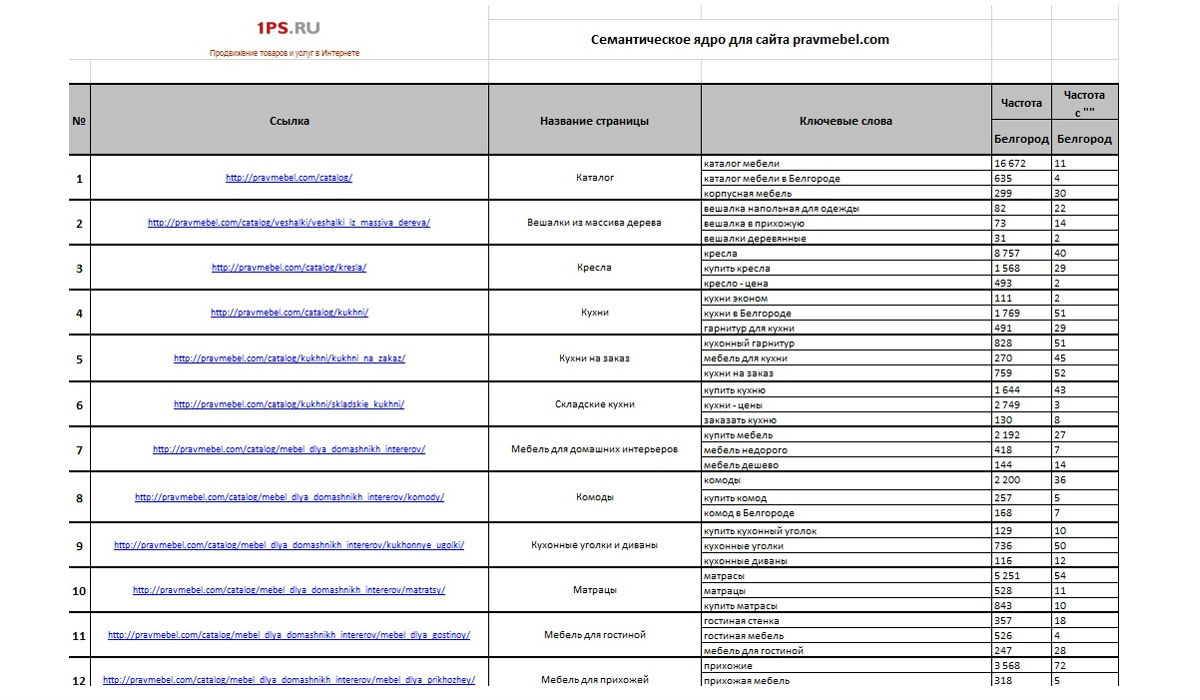
Чтобы предупредить незапланированное воспламенение, предлагаю для сбора семантики пользоваться браузером Opera — у него есть одна примечательная функция, которая раз и навсегда решает проблему капчи от Яндекса, а именно — встроенный VPN (подмена IP). Включить его — как два байта переслать. Для этого следуйте по пути
Совет номер два: для упрощения сбора нужных ключей, установите плагин Yandex Wordstat Assistant — он немного преобразует Вордстат и позволит без лишних усилий отмечать нужные ключи и копировать их целыми группами. Без него все сложнее — каждый ключ нужно вручную выделять, копировать и переносить в отдельный файл. В общем очень удобное приложение, которое экономит кучу времени вебмастера.
KeyCollector
Многим известная и очень удобная программа для парсинга Yandex.Wordstat и других семантических баз. Вот вам сразу линк на официальную страничку KC.
С помощью KeyCollector можно в режиме реального времени спарсить базу запросов по нужным ключевым словам, собрать для них частотности, фильтровать и удалять ключи, группировать их в кластеры, посмотреть список страниц-конкурентов в ТОП-10 по определенным ключам и многое другое. Все функции программы перечислять слишком долго — это тема на отдельную статью.
Pixelplus
Платный онлайн-сервис, который собрал в себе очень много полезного для анализа семантики и оптимизации страниц сайта. Сразу линк на сервис.
Так, если сейчас мы говорим о семантическом ядре, нам интересны следующие инструменты:
- Список URL в ТОП — позволяет проанализировать конкурентную выдачу запроса и определить, к какой посадочной странице лучше привязать ключ.
- Оценка интента запроса — тут мы можем узнать, чего ожидает пользователь, вводя тот или иной запрос. Выгоднее анализировать целый кластер, благо для этого есть возможность. Сервис предлагает нам следующие интенты: коммерция, отзывы, фото и видео, словари, музыка, путешествия. Прогнав кластер и поняв его интент, вы сможете лучше понимать, чего ожидает рядовой потребитель от вашей посадочной страницы, на которую ведут запросы из анализируемой группы, и подходят ли в принципе отдельные запросы для страницы.
- Детальный анализ запроса — в принципе полный анализ запроса по ряду критериев.
 Выгоднее анализировать целый кластер, благо для этого есть возможность. Сервис предлагает нам следующие интенты: коммерция, отзывы, фото и видео, словари, музыка, путешествия. Прогнав кластер и поняв его интент, вы сможете лучше понимать, чего ожидает рядовой потребитель от вашей посадочной страницы, на которую ведут запросы из анализируемой группы, и подходят ли в принципе отдельные запросы для страницы.
Выгоднее анализировать целый кластер, благо для этого есть возможность. Сервис предлагает нам следующие интенты: коммерция, отзывы, фото и видео, словари, музыка, путешествия. Прогнав кластер и поняв его интент, вы сможете лучше понимать, чего ожидает рядовой потребитель от вашей посадочной страницы, на которую ведут запросы из анализируемой группы, и подходят ли в принципе отдельные запросы для страницы.В анализе учитывается:
- Геозависимость — зависит ли результат выдачи по запросу от региона пользователя.
- Степень локализации — процент сайтов в ТОП-50 с ярко выраженной геозависимостью.
- Слова из подсветки — слова, которые подсвечиваются в поисковой выдаче. Хороший помощник для оптимизации мета Title и Description.
- Cлова СПЕКТРа — дополнительный список подсвеченных слов, выбранных по технологии СПЕКТР.
- Слова, задающие тематику — слова, которые часто встречаются в сниппетах конкурентов (кроме синонимов анализируемого запроса). Также используется для оптимизации метатегов и текста страницы.
- Общая и точная частоты — частотности запроса без операторов и с оператором “!”. Зачем оно надо? Вспоминаем мои советы по сбору семантического ядра (подсказываю — пункт 5).
- Число главных страниц в ТОП — помощь при определении посадочной страницы.
- Наличие витального ответа — показывает является ли анализируемый запрос брендовым.
- Число найденных результатов — показывает сколько всего было найдено документов (читай — страниц), соответствующих запросу.
- Бюджет по MegaIndex — показывает уровень конкуренции в Яндексе. Чем выше число, тем конкурентнее запрос.
- Число объявлений в Яндекс.Директ — кол-во платной рекламы по запросу.
- Число точных вхождений в Title и сниппеты из ТОП-50 — оцениваем корректность ключевой фразы, т. е. как часто она используется в прямом вхождении в сниппете.
- Средний возраст документов — особенно актуально для молодых сайтов. Чем старше страница конкурента, тем тяжелее ее победить.

 е. как часто она используется в прямом вхождении в сниппете.
е. как часто она используется в прямом вхождении в сниппете.Семантика в Google
Единственное, что я упустил еще в самом начале статьи, — это сбор семантики с частотностями в Google. К сожалению, данный поисковик не предлагает таких сервисов, как Яндекс.Вордстат, и частотности запросов можно узнать лишь через Google Adwords на этапе настройки рекламной кампании. Также можно воспользоваться платными онлайн-сервисами SemRush или SerpStat, которые позволяют анализировать поисковые запросы с учетом частотностей Google. Помните, что в Google частотности округляются до десятков. Т.е. запрос с частотностью 10 может на самом деле иметь частоту от 10 до 19.
К сожалению, данный поисковик не предлагает таких сервисов, как Яндекс.Вордстат, и частотности запросов можно узнать лишь через Google Adwords на этапе настройки рекламной кампании. Также можно воспользоваться платными онлайн-сервисами SemRush или SerpStat, которые позволяют анализировать поисковые запросы с учетом частотностей Google. Помните, что в Google частотности округляются до десятков. Т.е. запрос с частотностью 10 может на самом деле иметь частоту от 10 до 19.
Вывод
Семантическое ядро — это, наверное, один из важнейших отправных пунктов в оптимизации вашего сайта, поэтому подойти к сбору семантики нужно ответственно, “с головой”. От этого будет зависеть не только итоговый анализ ваших достижений, но и изначально грамотная оптимизация посадочных страниц.
Что же, я надеюсь, моя статья поможет вам грамотно собрать СЯ и двигать свой сайт в светлое коммунистическое будущее. А у меня на сегодня все, на часах 3:38 и я иду спать. Вам желаю всего хорошего, подписывайтесь на наш блог, чтобы не пропустить интересные статьи от меня и моих коллег. .. ну и не забывайте чистить кэш перед сном.
.. ну и не забывайте чистить кэш перед сном.
Владимир Еленский
Практикующий SEO-специалист MAXI.BY media.
Опыт работы более 5-ти лет. Хороший человек и просто красавчик.
Семантическое ядро для информационного сайта
Семантическое ядро – залог успешной кампании по продвижению. Неверные слова могут свести на нет все усилия по раскрутке вашего сайта. В сети много данных о составлении семантики, но крайне мало полезной информации о подборе ключей именно для информационных сайтов.
Видео о продвижении информационного сайта:
Содержание
Особенность семантики для СМИ заключается в том, что у таких сайтов нет постоянного семантического ядра. Оно с той или иной скоростью непрерывно изменяется, и предвидеть что-либо заранее практически невозможно, так как статистика поисковиков дается, как правило, за предыдущий месяц.
 По этой причине поисковые запросы для информационных ресурсов можно разделить на 2 группы:
По этой причине поисковые запросы для информационных ресурсов можно разделить на 2 группы:- Постоянные слова – неизменная часть семантики.
- Новые или меняющиеся слова – динамичная группа поисковых запросов.
Давайте подробнее разберемся во всех тонкостях SEO-продвижения информационного сайта.
Типы запросов и интент пользователя
Типичная ошибка начинающих оптимизаторов – сбор всех возможных поисковых запросов с помощью автоматических систем или специализированных программ. Пользователи идут в поиск с какой-либо целью, и эта цель всегда «скрыта» в запросе. Для того чтобы отобрать правильные запросы, нужно верно определить цель. А для этого нужно знать, какие типы запросов бывают, и какие цели преследуют пользователи, их вводящие.
Поисковые запросы принято делить на 3 основные группы, в зависимости от того, какую потребность с помощью поиска пользователь закрывает:
Пользователь ищет в сети конкретную компанию. Обычно сайты компаний на 1-х местах по таким запросам.
Обычно сайты компаний на 1-х местах по таким запросам.
[iqad агентство] – пример навигационного запроса
Можно ли использовать навигационные запросы для продвижения СМИ? В большинстве случаев нет. В том случае, если само издание готово создать специальные страницы – карточки организаций – такой вариант возможен. Но важно понимать, что первое место всегда будет отдано официальной странице.
Например, у вас интернет-СМИ, посвященное теме «Спорт и здоровье». В этом случае вы можете создать каталог медицинских и спортивных организаций и собирать соответствующий трафик.
wordstat.yandex.ru – сервис анализа и подбора ключевых слов
В алгоритме ранжирования «Андромеда», введенному поисковой системой Яндекс в конце 2018 года, сайты по ряду запросов, стали подсвечиваться значком «навигационный ответ». Такие значки появились именно для тех запросов, по которым, по мнению поисковой системы, пользователю важно найти именно официальный сайт:
Значок навигационного ответа в органической выдаче Яндекса. Алгоритм «Андромеда».Транзакционные и коммерческиеСамые простые поисковые запросы этой группы, включающие в себя такие слова как: [купить], [заказать], [скачать] — т. е. призывающие совершить действие. Для сайтов СМИ подходят слабо, только если у вас есть специальные сервисы или коммерческие разделы, так как коммерческие слова наиболее конкурентные, а значит дорогие в плане трудозатрат на их вывод в ТОП-10.
Однако, если исключить на 100% коммерческую группу запросов и оставить навигационные с меньшей конкуренцией или с уклоном в информационную составляющую, можно собирать дополнительный трафик.
Например, ваше СМИ может быть посвящено финансовой сфере. Создание сервиса расчета ипотечного платежа – «Ипотечный калькулятор» – позволит привлекать дополнительные объемы трафика.
Банки.ру – в ТОП-10 поисковой системы Яндекс сервис по расчету ипотекиИнформационные запросы
С их помощью пользователь ищет информацию в сети. Это те
запросы, на которые любое СМИ или информационный ресурс \ раздел должны делать
упор. Это ключевая группа запросов для всех информационных сайтов!
Это те
запросы, на которые любое СМИ или информационный ресурс \ раздел должны делать
упор. Это ключевая группа запросов для всех информационных сайтов!
Пример таких запросов:
- [рецепт ухи],
- [как разобрать телефон],
- [куда вложить пенсию] и т. п.
Структура поисковых запросов не всегда говорит нам о потребности пользователя, о том, что он хочет получить вводя тот или иной поисковый запрос. Например, что хотел получить пользователь, вводивший в поиск запрос [владимир путин]?
- Личный сайт президента РФ?
- Профиль в соцсетях?
- Биографию?
- Новости?
- Фотографии?
- Видео?
- Интервью?
Истинная потребность пользователя называется интентом. И для того чтобы его понять,
мы должны обратиться к результатам поиска.
Если мы видим в выдаче преобладание каких-либо определенных
сайтов, посчитав и оценив их контент, можно определить тип запроса.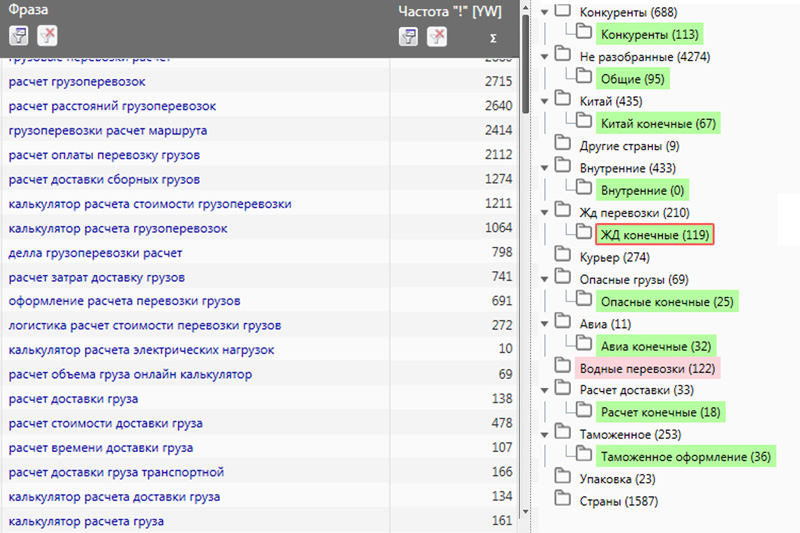
Например:
- если мы видим магазины – запрос коммерческий,
- если мы видим статьи – информационный,
- если мы видим разные сайты – смешанный.
Пример поисковой выдачи по общему или смешанному запросу
Особенности устройства поисковых сервисов
Пользователи поисковых сервисов — это самые разные люди. Об этих людях поисковые сервисы собирают информацию, строят портрет пользователя, изучают их предпочтения. Зная характер поведения пользователя и его предпочтения, можно отдавать те сайты, которые интересны именно этому пользователю. Выдача подстраивается под конкретного пользователя. Такой процесс называется – персонализация.
Подробнее о персональном поиске в справке Яндекс.
Для более точного определения типа запроса всегда отключайте
в настройках поисковой машины персональный поиск. Иначе ваши личные
предпочтения могут исказить объективную картину, и вы неверно определите тип
поискового запроса.
Персональные ответы в поиске Яндекса
Анализ поисковых запросов для СМИ
После того как мы разобрались в типах запросов, можно приступать к отбору нужных нам слов для раскрутки СМИ или информационного сайта/раздела на сайте.
Основным сервисом информации о поисковых запросах является wordstat.yandex.
Wordstat.yandex – сервис статистики поисковых запросов к поисковой системе Яндекс
Мы видим все ключевые слова и статистику того, сколько раз этот запрос вводили пользователи Яндекса. Запросы сортируются от наиболее популярных к наименее.
Вторым по популярности сервисом анализа поисковых запросов, вводимых в Google, является сервис контекстной рекламы — ads.google.com. Конкретно его раздел:
keywordplanner или планировщик ключевых слов
Планировщик ключевых слов Google показывает статистику поисковых запросов в диапазоне.
На практике такие системы неудобны для сбора больших
семантических ядер. А именно такие ядра необходимы для сайтов СМИ. Специалисты
по поисковой оптимизации прибегают к инструментам автоматизации. Такие сервисы
и программы автоматизируют рутинные процессы и многократно ускоряют работу.
А именно такие ядра необходимы для сайтов СМИ. Специалисты
по поисковой оптимизации прибегают к инструментам автоматизации. Такие сервисы
и программы автоматизируют рутинные процессы и многократно ускоряют работу.
Автоматизация по сбору поисковых запросов для информационного сайта
Программы для профессионалов
Ввиду того, что семантика сайта СМИ может включать в себя сотни, тысячи или десятки тысяч запросов, нам необходима автоматизация сбора данных о поисковых запросах. Разберем самые популярные программы и сервисы.
Key Collector
Особой популярностью у SEO-оптимизаторов пользуется программа Key Collector.
Key Collector – одна из самых популярных программ для подбора и анализа ключевых слов
Функционал программы насчитывает десятки функций. Наиболее популярные среди них:
- Сбор статистики Yandex.Wordstat.
- Сбор статистики Yandex.Metrika.
- Сбор статистики Google. Analytics.
- Сбор поисковых подсказок.
- Сбор статистики из сервисов продвижения.
- Сбор статистики Yandex.Direct.
- Сбор статистики Google.Adwords.
- Сбор статистики ВКонтакте.
- Показатели KEI.
- Определение релевантных страниц и съем позиций.
 Analytics.
Analytics.Хочется отметить, что программа – платная и для большинства пользователей ее функционал избыточен. К счастью, есть и бесплатная альтернатива. Это сокращенная версия KeyCollector – Слово*б.
Подробнее о программе Слово*б.
Ее функционала будет достаточно для большинства штатных задач по подбору и анализу ключевых слов.
Есть и другие популярные программы и сервисы. Среди них можно выделить:
Готовые базы поисковых запросов
В связи с тем, что статистика Yandex.Wordstat не полная, она
ограничена минимальной частотностью. А в периоды «не сезона» может быть крайне
незначительной. Для подбора максимальной базы можно воспользоваться готовыми
базами ключевых слов.
База поисковых запросов Пастухова – одна из самых крупных в русскоязычном сегменте.
База поисковых запросов Пастухова содержит 1,655,810,672 ключевых слов.
Группировка запросов
После сбора списка ключевых слов их принято объединять в группы или кластеры.
В группы слова объединяются по общей потребности. Для каждой потребности мы выделяем свою страницу сайта, и цель страницы – закрыть потребность. Например: цель этой страницы закрыть потребность в информации о поисковых запросах для сайта СМИ.
Пример группировки или разбивки:
Группировка запросов – важный этап при разработке семантического ядра сайта
Для автоматизации группировки запросов мы используем инструменты кластеризации. На основании того, какие страницы сейчас показываются в поиске и по каким запросам, эти сервисы способны автоматизировать всю работу по объединению слов в группы.
Среди платных инструментов это:
- Rush Analytics.
- SEMparser.
- Just Magic.
Среди бесплатных:
Coolakov – один из самых популярных бесплатных инструментов группировки слов. Но лимиты ограничены
Структура ядра для СМИ
Классический способ продвижения: подбор запросов и продвижение сайта по выбранному списку. Такой способ не в полной мере подходит для информационных сайтов. Обычно ядро для СМИ нужно составлять таким образом, чтобы оно состояло из двух частей:
- Статическая или неизменная часть семантики.
- Динамическая или изменяемая часть семантики
Неизменная часть семантики
Как правило, это могут быть страницы разделов – новости китая/новости политики и т. п.
Это ключевые разделы вашего сайта. Они всегда доступны и не теряют своей актуальности. Не забывайте подбирать запросы и для главной страницы сайта.
Главные страницы сайта чаще всего продвигают по наиболее общим и популярным ключевым словам Долгоиграющие сюжеты
Долгоиграющие сюжеты – интервью с Пугачевой, биография Галкина и т. п. Подготовка таких материалов позволит долгое время
привлекать на ваш сайт трафик. Нередко такие станицы дают большую долю
органического трафика.
п. Подготовка таких материалов позволит долгое время
привлекать на ваш сайт трафик. Нередко такие станицы дают большую долю
органического трафика.
Тренды – набирающие популярность темы, которые могут перерасти в долгоиграющие сюжеты. Для подбора и анализа можно использовать сервис — Google Trends.
Google Trends – отображает динамику популярности
На графике Google Trends мы видим уровень интереса к теме по отношению к наиболее высокому показателю в таблице для определенного региона и периода времени. Таким образом можно отбирать темы, набирающие популярность в данный момент.
Новостные или короткие по жизни сюжеты
Это то, что мы видим в ТОП-10 и те новостные сюжеты, которые имеют короткий срок жизни. Быть в ТОП-ах новостных агрегаторов – это не задача поисковой оптимизации. Семантику под такие событийные запросы не собрать даже с помощью Google Trends.
Зато без специальной оптимизации легко попасть в ТОП-10
выдачи.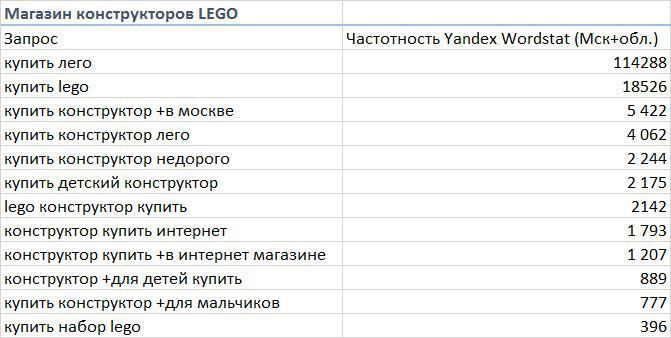 Для этого необходимо:
Для этого необходимо:
А вот быть в ТОП-10 это да, но тут не нужно специальной оптимизации, необходимо:
1. Быть добавленным в агрегаторы поисковиков.
Чтобы узнать о добавлении ресурса в агрегаторы, достаточно:
Отправить запрос на добавление в Google.Новостях – тут: https://support.google.com/news/publisher-center/answer/40787?hl=ru.
Отправить письмо на добавление сайта в Я.Новости – тут: https://yandex.ru/support/news/info-for-mass-media.html.
2. Писать новости сразу и с уникальным текстом.
3. Печатать много новостей для привлечения быстробота (робот поисковой машины, который индексирует новые материалы и выводит их в поиск в течение нескольких минут).
Персоналии
Всегда есть люди, умеющие поддерживать к себе неиссякаемый
интерес аудитории. Это знаменитости или публичные люди. Для СМИ вашей тематики
это могут быть звезды, политологи, политики, популярные авторы и т. д. Создание
таких страниц может поддержать стабильно высокий трафик для вашего сайта.
Обучение журналистов
Часто авторы используют именно творческие названия разделов/колонок/публикаций. Что не поспособствует их ранжированию в ТОП-10 по популярным поисковым запросам.
Например, автор, делая обзор на новую модель BMW, может написать: «Яблочко от яблони». Понятно, что он имеет ввиду факт: новая модель от старой не отличается. Но, добавив к названию и в заголовок ключевые слова, получим шанс подняться в ТОП-10:
«Обзор нового BMW: Яблочко от яблони».
Научите журналистов (копирайтеров) пользоваться статистикой поисковых запросов.
Изучение конкурентов
Изучайте успешные СМИ (контент, разделы, перелинковка, тегирование и т. п.). Это поможет найти вектор развития для вашего сайта, подкинуть свежих идей и перенять успешный опыт.
Как найти конкурента
Для поиска сайта конкурента можно воспользоваться поисковой системой. Вбивайте в поиск наиболее популярные слова и выделяйте сайты, которые ранжируются в ТОП-10. Также можно воспользоваться платными сервисами и программами. Например, сервис SpyWords.
Также можно воспользоваться платными сервисами и программами. Например, сервис SpyWords.
Сервис SpyWords покажет наиболее близкие по семантике сайты
Выбирайте наиболее близкие к вашему сайту по видимости конкурентов или к лидеру, к которому вы стремитесь.
План публикаций
Проблема, с которой вы обязательно столкнетесь после подбора всех запросов: семантика очень большая. И не всегда понятно, как выстраивать приоритеты. Мы предлагаем простой способ составить контент-план на основании оценок групп запросов.
Мне тут не хватает инфы, как часто стоит пересобирать СЯ. Так и хочется спросить – с какой периодичностью к этому нужно возвращаться?
Оцениваем кластеры запросов по 2 параметрам:
- Конкуренция.
- Популярность.
После оценки мы выстраиваем
контент-план для сайта, основываясь на принципе: максимум трафика с меньшей конкуренцией. Для старых и трастовых
сайтов можно попробовать изменить приоритет и строить контент-план, основываясь
только на частотности кластеров.
Обновление семантического ядра
Семантическое ядро необходимо актуализировать.
Составить ядро 1 раз и на всю жизнь проекта не получится. В общем смысле, актуализация семантического ядра сводится к тому, что мы должны пересобрать или обновить нашу семантику. Дополнить ее новыми запросами. Убрать из нее более не актуальные или не интересные.
Технические аспекты продвижения информационного сайта
Технический аудит новостного сайта обязателен и имеет высокий приоритет. Дело в том, что одной из отличительных особенностей информационных сайтов является их размер. Чем больше сайт, тем больше ошибок может возникать.
Выделим основные технические ошибки, влияющие на ранжирование в поиске.
Дублирование
Дублироваться может часть контента страницы. Наиболее часты ошибки — это:
- Наличие дублей тегов, особенно TITLE.
- Дубли текста или его частей.
- Полные или частичные дубли страниц.
Любое дублирование, даже частичное, снижает уникальность
документов, а значит их ценность в глазах поисковых машин будет ниже.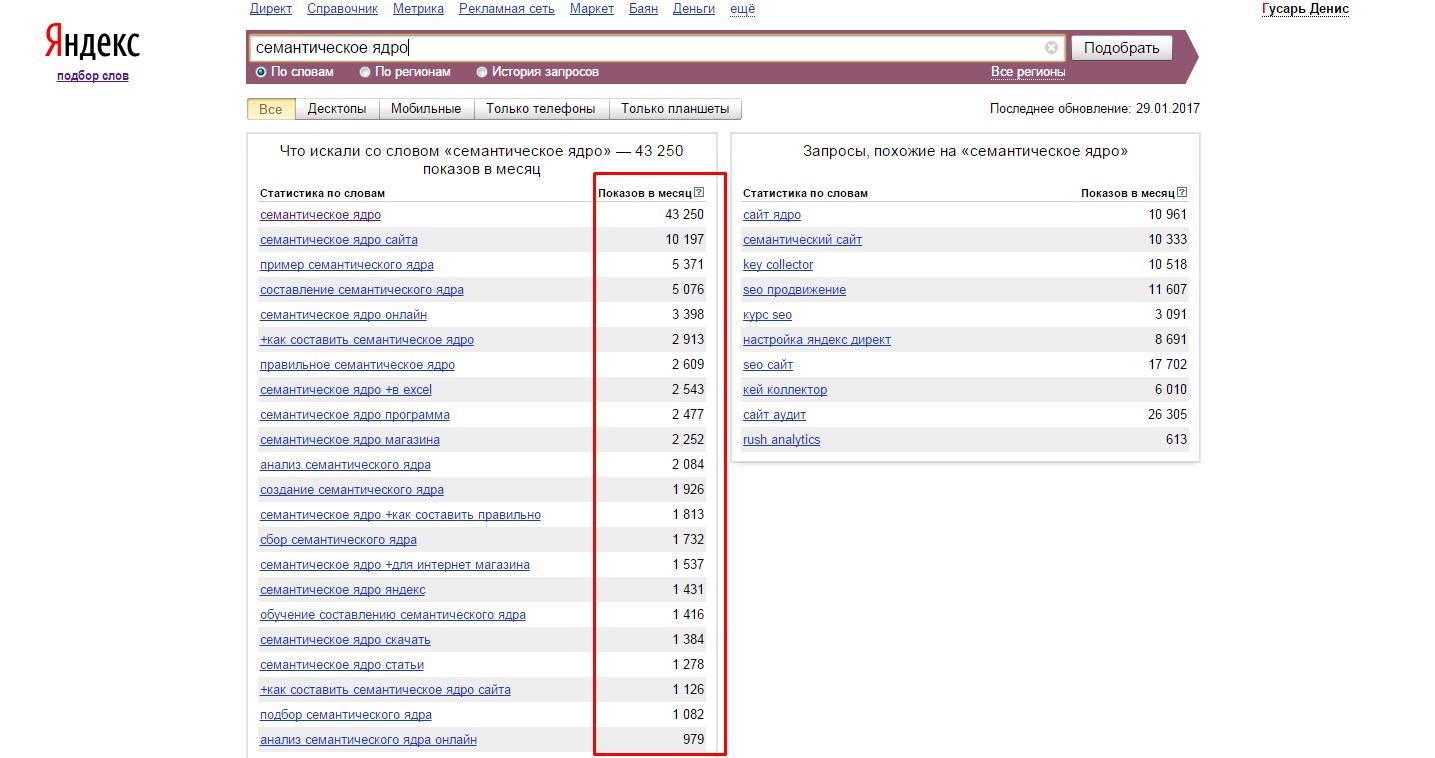
Ссылки на сайте и изображения
Битые внешние и внутренние ссылки, недоступные изображения, циклические ссылки – это все ошибки, снижающие скорость индексации ресурса, увеличивающие показатель отказов и время на сайте. Устраняйте их обязательно.
Скорость загрузки
Скорость загрузки сайта – один из факторов ранжирования. Замечено как его прямое воздействие, например, в мобильной выдаче, так и косвенное через поведенческие метрики.
До 40% посетителей сайта готовы закрыть страницу до ее полной загрузки, если скорость загрузки страницы выше 3 сек.
Турбо-страницы и AMP Google
Это специальные технологии поисковых систем, способные многократно увеличить загрузку документов за счет их упрощения. Подробнее о технологиях:
Турбо-страницы Яндекса способны
увеличить загрузку контента сайтов из поиска Яндекса, Новостей и Дзена в 15 раз в 3G-сетях
Расширенные сниппеты
Cниппет
– это текстовая часть, которая описывает ваш сайт в результатах поиска. Его
привлекательность для пользователя напрямую влияет на вероятность перехода
именно на ваш сайт.
Его
привлекательность для пользователя напрямую влияет на вероятность перехода
именно на ваш сайт.
Существует несколько способов сделать ваш сниппет привлекательным. Отметим наиболее важные.
МикроформатыНаиболее популярные и поддерживаемые Яндексом:
- hCard — стандарт разметки контактной информации вашего сайта.
- hReview — стандарт разметки отзывов.
- hRecipe — стандарт разметки рецептов. hProduct — стандарт разметки разметка товаров.
Больше о микроформатах в помощи Яндекса: https://yandex.ru/support/webmaster/microformats/what-is-microformat.html.
Семантическая разметка Schema.org
https://schema.org/
Это международный формат разметки данных, поддерживаемый большинством поисковых систем.
Если ваш сайт относится к группе специализированных,
например, рецепты, и для него есть свой формат разметки – используйте
специализированные форматы от Яндекса. Для всех общих и стандартных элементов,
например, контактная информация, лучше прибегать к стандарту Schema.
Для всех общих и стандартных элементов,
например, контактная информация, лучше прибегать к стандарту Schema.
Социальные сети
Мы не будем рассматривать вопрос раскурки СМИ в социальных сетях. Остановимся лишь на аспекте влияния социальных сетей на ранжирование вашего сайта в поиске. Поисковая система должна видеть ряд сигналов, которые укажут ей на то, что вы ведете активность в соц.сетях.
- Наличие официальных групп и сообществ в социальных сетях.
- Наличие ссылок на ваш сайт из социальных сетей.
- Наличие переходов на ваш сайт из социальных сетей.
Разрабатывая стратегию продвижения в социальных сетях, учитывайте 3 основные вышеуказанные рекомендации.
Заключение
Продвижение информационного сайта – это работа с большими объемами данных. Сбор семантики – кропотливый труд. Но в инструментах SEO сегодня появились помощники, которые сильно упрощают нашу жизнь. Собирайте наиболее полное ядро. Группируйте запросы по потребностям пользователей и раскрывайте потребность на продвигаемых страницах.
Избавляйте сайт от технических ошибок, исследуйте технологии поисковых сервисов, которые могут быть полезны вашему сайту. Улучшайте сниппет вашего сайта.
Следуйте нашим инструкциям и привлекайте максимум органического трафика.
 Научите журналистов и редакторов SEO-магии. Изучайте конкурентов. Актуализируйте ядро. Органический трафик – один из самых стабильных и недорогих, хотя и трудозатратный.
Научите журналистов и редакторов SEO-магии. Изучайте конкурентов. Актуализируйте ядро. Органический трафик – один из самых стабильных и недорогих, хотя и трудозатратный.как собрать самостоятельно семантическое ядро
Семантическое ядро сайта — это кластеры ключевых слов, сформированные на основании семантически релевантных групп. Другими словами, это ядро сайта (или группа ключей), которые после сбора и кластеризации распределяется по тематическим страницам сайта.
Как собрать семантическое ядро сайта? Можно ли сделать это в автоматическом режиме, или же сбор СЯ выполняется только в ручном режиме? Читайте далее нашу статью и используйте наиболее удобные для вас варианты.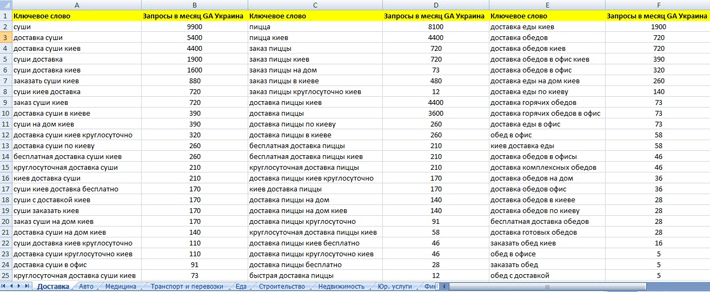
Основы кластеризации и семантики сайта
Зачем нужно делать семантическое ядро сайта?
Представьте ситуацию: вы создаете онлайн-магазин по продаже электронных товаров. У вас не менее 50 категорий (ноутбуки, компьютеры, комплектующие, смартфоны, смарт-часы, периферийные устройства и т.д.).
В каждой категории — не менее нескольких сотен позиций товара. Например: смартфоны → Apple → iPhone → iPhone 8 → iPhone 8 256gb. Аналогично — со всеми другими товарами.
Мы видим древовидную структуру, когда от категории товаров навигация переводит на конкретную модель или позицию товара.
Для каждого товара, категории или группы необходимо подобрать ключевые слова, по которым вы хотите, чтобы та или иная страница ранжировалась. И в данном случае сбор всех подходящих ключевых слов и их дальнейшая кластеризация и составляют семантическое ядро сайта.
И в данном случае сбор всех подходящих ключевых слов и их дальнейшая кластеризация и составляют семантическое ядро сайта.
Другими словами, семантическое ядро — это группа морфологически схожих словоформ и словосочетаний, которые наилучшим образом характеризуют страницу веб-сайта.
Как собрать семантическое ядро вручную?
Для ручного сбора семантического ядра необходимо выполнить следующие действия:
1. Определить центральное ключевое слово (слова)
Центральное ключевое слово — это основа вашего будущего СЯ. Центральное КС должно отвечать следующим требованиям:
- Максимально точно характеризовать сайт в целом;
- Иметь высокую частотность;
- Быть коммерческим/информационным, в зависимости от типа сайта.

Приведем пример: ваш сайт — интернет-магазин техники. Вашими главными ключами будут: купить телефон, интернет магазин, купить ноутбук, купить смартфон и т.д.
Ключевое слово может быть не одним — их может быть несколько, в зависимости от размера сайта.
2. Определить основные группы ключевых слов
Основные группы ключевых слов — это следующий уровень после центральных ключевых слов в структуре семантического ядра.
Главные группы ключевых слов используются для категорий, разделов и прочих крупных семантических кластеров.
3. Определить ключевые слова для подгрупп и страниц
Следующим шагом необходимо собрать ключи для подгрупп и страниц, которые должны группироваться по тому же принципу, который описан выше.
Остался последний вопрос: как это всё выглядит на практике? Как собрать семантическое ядро сайта и какие инструменты нужно использовать для этого? Выглядит это всё следующим образом.
Сбор СЯ с помощью Планировщика ключевых слов Google
Перейдите в Google Keyword Planner (планировщик ключевых слов) и перейдите по внутренней ссылке.
Выберите меню с поиском ключевых слов:
Выберите категории и основные ключевые слова, которые наилучшим образом характеризуют ваш сайт.
Выберите локацию и нажмите кнопку “Получить варианты”.
Перейдите во вкладку “Варианты КС”…
…и выгрузите ключевые слова в документ:
Далее вы можете отсортировать ключевые слова по конкурентности, частотности и другим параметрам.
Аналогичным образом семантическое ядро собирается для каждой группы семантически релевантных запросов.
Что делать, если все ключевые слова относятся к разным категориям?
В таком случае возможны два варианта:
1. Ручная группировка запросов. Хороший метод, когда у вас не более 100 ключевых слов. Если же у вас тысячи ключей, группировка запросов может занять недели.
2. Автоматическая группировка (кластеризация). Выполняется с помощью SpySERP. Для этого необходимо зарегистрироваться на сайте, выбрать раздел “Кластеризация”, после чего все ваши ключевые слова автоматически сгруппируются по семантически релевантным кластерам.
Семантическое ядро сайта онлайн: сервисы для автоматического сбора
Итак, вы не хотите использовать планировщик ключевых слов по каким-либо причинам. Как собрать семантическое ядро другими способами?
Как собрать семантическое ядро другими способами?
Вы можете собрать семантическое ядро сайта онлайн — специально для этого существует ряд сервисов, которые помогут справиться с задачей не хуже, чем ПКС от Google или Яндекс Вордстат.
Key Collector
Программа для комплексной работы с семантическим ядром сайта. Позволяет выполнять все возможные операции, начиная от сбора ключей и заканчивая чисткой полученного списка.
Сервис платный — лицензия на использование стоит $50.
Ahrefs Keyword Explorer
Если вам нужно быстро и просто собрать ключевые слова, вы можете воспользоваться функционалом Ahrefs. Месячная подписка стоит $99, однако если и триал-версия на неделю стоимостью $7 — такого триала вам должно более чем хватить для решения задач небольшого объема.
Semrush
Наконец, для сбора семантического ядра вы можете воспользоваться Semrush — ещё одним онлайн-сервисом, который работает по принципу, описанному выше. В бесплатной версии вы можете собрать до 10 фраз в широком и фразовом соответствии, с учетом региона запросов.
В бесплатной версии вы можете собрать до 10 фраз в широком и фразовом соответствии, с учетом региона запросов.
Семантическое ядро — это “скелет” сайта и его основа, которая в дальнейшем послужит вам базисом для развития стратегии продвижения. Именно поэтому процессу сбора ядра необходимо уделять особое внимание и мы надеемся, что информация, описанная в статье, поможет вам сделать это максимально быстро и качественно.
Как правильно собрать ключи для СЕО?
Построение семантического ядра – один из важнейших этапов продвижения сайта, ведь от него зависит то, насколько сайт будет «видимый» в поисковой выдаче и какие он будет занимать позиции по определенным запросам. Эта задача требует специфических знаний, поэтому, если вы планируете заказать комплексное продвижение сайта, рекомендуем доверять выполнение этого процесса исключительно опытным специалистам.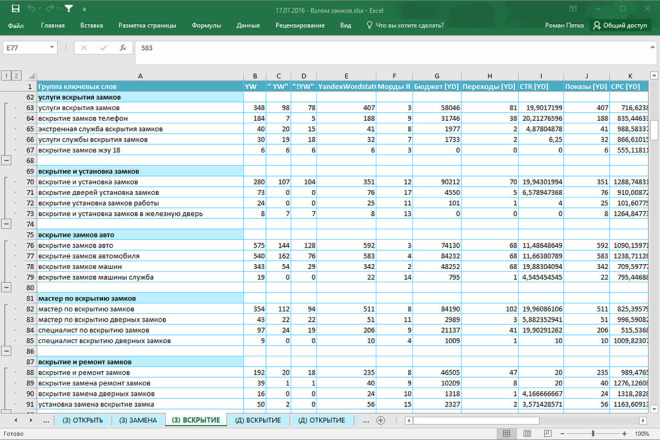 Ну а в этой статье мы рассмотрим, что именно представляет собой семантическое ядро (ключи для SEO) и как правильно его собирать.
Ну а в этой статье мы рассмотрим, что именно представляет собой семантическое ядро (ключи для SEO) и как правильно его собирать.
Семантическим ядром называют набор слов и словосочетаний, которые максимально точно отражают тематику и структуру сайта. Чтобы было понятнее, представьте, что вам нужно что-то найти в Интернете, например, фарфоровые сувениры. Вы будете вводить в строку поиска вариации словосочетания «фарфоровые сувенир» дополняя словами вроде «купить» или «на подарок».
Поисковая система проанализирует ваш запрос и предоставит перечень сайтов, на которых присутствуют именно такие ключевые слова. Вот это и есть простой и понятный ответ на вопрос о том, что такое ключевые слова и зачем они нужны.
Как правильно собирать семантику?Разумеется, сбор семантики – это важная задача, от выполнения которой напрямую зависит поисковое продвижение сайтов. Специалисты делят этот процесс на несколько этапов:
- Изучение структуры будущего или уже существующего сайта – это необходимо для того, чтобы построить логическую иерархию страниц и понимать, как именно собирать семантику. Например, главная должна содержать основной ключ, который будет обозначать направление деятельности компании, а страницы в каталоге – ключи отдельно собранные для каждой группы товаров.
- Составление семантического ядра. С помощью специальных онлайн-сервисов необходимо сначала выбрать синонимы, затем проанализировать по высокочастотным синонимам ресурсы конкурентов, а затем собрать низкочастотные остатки ключевых слов.
- Кластеризация и расширение собранной семантики – после того, как ядро собрано и с него удалили все лишние ключи, необходимо разбить его группы (кластеры) и выполнить парсинг поисковых подсказок.
 Например, главная должна содержать основной ключ, который будет обозначать направление деятельности компании, а страницы в каталоге – ключи отдельно собранные для каждой группы товаров.
Например, главная должна содержать основной ключ, который будет обозначать направление деятельности компании, а страницы в каталоге – ключи отдельно собранные для каждой группы товаров.Затем останется выбрать ключи для заголовка страницы и грамотно разместить семантику на страницах сайта. С этой целью заказывают написание сео-текстов с определенными техническими требованиями.
«Источник: bonum-studio.com»
Хотите читать новости в удобном для вас виде?
Как правильно составить семантическое ядро для сайта
Семантическое ядро (СЯ) — перечень сгруппированных ключевых слов, которые используются для продвижения сайта в поисковых системах.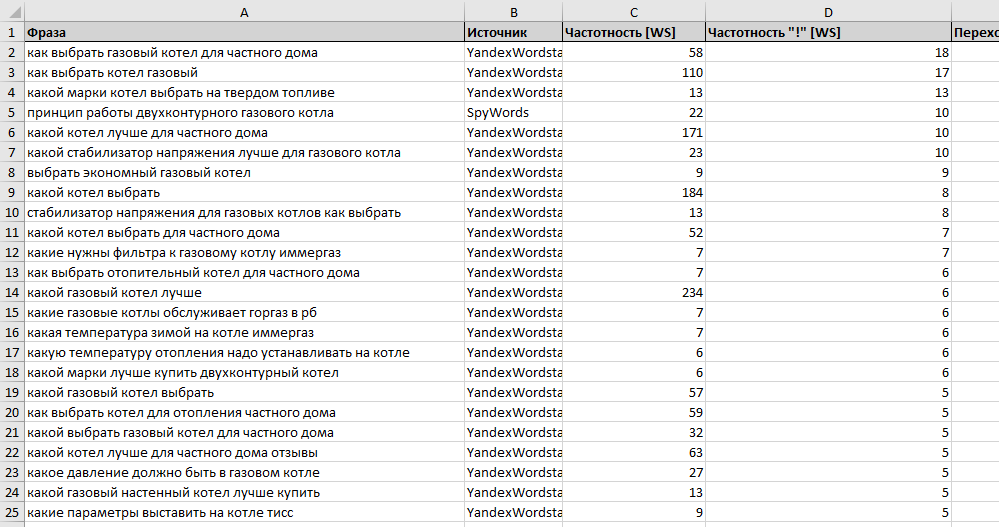 От правильного составления семантики зависят позиции вашего ресурса в Яндексе и Google и его посещаемость.
От правильного составления семантики зависят позиции вашего ресурса в Яндексе и Google и его посещаемость.
Во многих случаях сбор СЯ лучше доверить SEO-специалисту, но если вы хотите заняться этим самостоятельно в целях экономии или просто из интереса, внимательно изучите данную статью и следуйте приведенным в ней рекомендациям.
Собираем первичные ключи в Яндекс Вордстат
Перед тем, как составлять полноценное СЯ, нам нужно выявить первичные ключевые слова. На их основе соберем их дополнительные и модифицированные версии. В этом поможет сервис Яндекс Вордстат. Чтобы им воспользоваться, зарегистрируйте почту в Яндексе и авторизуйтесь в ней.
Теперь подумайте, какие слова отражают то, что вы продаете или предлагаете. Например, у вас интернет-магазин по продаже женской одежды. Введите в поисковую строку Вордстат запрос «женская одежда» и нажмите на кнопку «Подобрать». Вы увидите самые популярные первичные запросы.
Таких запросов обычно несколько десятков в левой колонке и около 10-15 в правой. Справа отображаются те слова, которые похожи на ваш запрос с точки зрения тематики. Нас же больше интересует список слева, так как он самый релевантный.
Справа отображаются те слова, которые похожи на ваш запрос с точки зрения тематики. Нас же больше интересует список слева, так как он самый релевантный.
Те фразы, которые мы видим в Вордстате, ― самые высокочастотные. Не стоит полагаться только на них при раскрутке в поисковиках. Продвижение начинается с низкочастотных и среднечастотных запросов. По ним проще всего попасть в ТОП того же Яндекса и нарастить трафик. А что касается высокочастотных, обычно здесь огромная конкуренция и для видимых результатов продвижения понадобится много месяцев упорной работы и хорошие вложения. Отберите из первичных фраз самые естественные — те, что читаются легко и не вызывают недоумения от искусственного нагромождения слов. Сохраните отобранные запросы в текстовый файл.
Формируем семантическое ядро с помощью программы «СловоЁБ»
Не обращайте внимание на немного нецензурное название софта. Это всё креативность разработчиков или тех, кто отвечал за нейминг продукта.
Программа предназначена для автоматизации работы с большим объемом данных от 1000 ключевых слов. Это крайне удобно для интернет магазинов, сайтов с рецептами, кинопорталов, а также ряда других сайтов где количество слов в Yandex Wordstat достигает десятки тысяч. Ручной сбор семантики в этих случаях станет неэффективным, и без использования специального программного обеспечения (СловоЁБ, KeyCollector) для автоматизации займет значительно больше времени.
Настраиваем софт
Скачайте «СловоЁБ». Распакуйте архив и запустите главный исполняемый файл.
Откроется программа. Зайдите в настройки, кликнув по иконке шестеренки вверху софта. В разделе «Парсинг» откройте подраздел «Yandex.Direct», вставьте туда несколько аккаунтов Яндекса, которые предварительно необходимо создать. Свою личную учетную запись туда вводить не стоит, так как ее могут забанить.
Формат добавления аккаунтов простой — логин:пароль. Просто вставьте аккаунты в поле «Настройки аккаунтов Yandex», затем отыщите пункт «Использовать основной IP-адрес» и снимите с него галочку. Сохраните изменения.
Перейдите в раздел настроек «Сеть», поставьте галочку на пункте «Использовать прокси-серверы» и добавьте сами прокси в формате ip:port или ip:port@login:pass, если у вас включена авторизация по логину и паролю. Прокси помогут избежать блокировки Яндексом вашего IP адреса и позволят ускорить сбор ключевых слов. Работать можно без использования прокси серверов, особенно если вы планируете собирать небольшое ядро на 1000 слов. Прокси лучше покупать индивидуальные, но могут подойти и бесплатные или пакетные, если они не заблокированы поисковыми системами и имеют хорошую скорость соединения. Найти прокси можно на форумах или на сайте SPYS.ONE.
Не забудьте снять галочку с пункта «Использовать основной IP-адрес» в разделе настроек «Парсинг», во вкладке «Yandex.Wordstat», чтобы исключить свой реальный адрес из процесса сбора ключевых слов и избежать наложения ограничений со стороны системы.
Далее перейдите в раздел настроек «Антикапча». Введите ключ от любой из систем, которая помогает с распознаванием капчи и нажмите на кнопку «Сохранить изменения». Рекомендуем использовать ruCaptcha или Antigate.
Рекомендуем использовать ruCaptcha или Antigate.
Создаем проект и запускаем сбор
Теперь, когда все основные настройки сконфигурированы, создайте проект, нажав на кнопку с соответствующим названием в главном окне программы.
Вам будет предложено сохранить создаваемый проект на компьютер. Сделайте это. Нажмите на красную иконку вверху программы (сбор фраз из левого блока Вордстата), в пустое окно введите первичные ключевые слова, которые вы ранее собрали. Затем воспользуйтесь кнопкой «Начать сбор».
Перед тем, как появятся первые результаты, может пройти несколько минут. Время занимает распознавание капчи работниками сервиса, ключ к которому вы указали в настройках. В нижней вкладке «Журнал событий» вы можете отслеживать все действия программы. Запросы появляются в таблице программы постепенно, по несколько десятков за раз. Сбор занимает немало времени, но так как нам нужно было лишь показать на примере, мы его остановили и будем использовать те фразы, что успели собраться.
Напротив ключевых слов отображается базовая частотность. Ее не стоит учитывать, ведь она не показывает реального количества запросов пользователей. Чтобы выявить настоящую частотность, нажмите на кнопку, где нарисована лупа и кликните по варианту «Собрать частотности » «».
Процесс занимает немало времени, поэтому запаситесь терпением. Когда он будет завершен, вы увидите реальные показатели частотности и поймете, какие запросы менее конкурентные, а какие более, и что с ними делать.
При помощи фильтра вы можете удалить лишние запросы, оставив только нужные. Просто введите в поисковую строку фильтра слово, которое присутствует в лишних ключевых фразах и нажмите Enter. В окне отобразятся те запросы, которые содержат данное слово. Выделите их мышкой и во вкладке «Данные» нажмите на кнопку удаления фраз. Затем кликните по иконке с красным крестиком в фильтре, чтобы вернуть отображение оставшихся поисковых запросов.
После удаления лишних фраз экспортируйте те, которые остались, в файл Excel. Для этого в левом верхнем меню программы найдите значок табличного документа, кликните по нему и сохраните файл на компьютер.
Для этого в левом верхнем меню программы найдите значок табличного документа, кликните по нему и сохраните файл на компьютер.
На этом сбор семантики закончен. Далее идет группировка запросов. Это можно делать вручную или автоматически, используя сервисы. Чаще всего группируются ключевые фразы по частотности. Такая разбивка нужна, чтобы разграничивать продвижение. Например, сначала проработать низкочастотные и среднечастотные запросы. А когда по ним сайт окажется в ТОП, перейти к высокочастотным и наиболее конкурентным.
Как именно выполнять группировку, мы расскажем в одной из наших следующих публикаций, а пока что — желаем вам удачного сбора семантического ядра!
Как составить семантическое ядро сайта
Семантическое ядро сайта – упорядоченный набор ключевых слов, форм и словосочетаний, которые понятно характеризуют ваш бизнес, предлагаемые товары или услуги.
Зачем собирают семантику? Чтобы выдвинуть сайт в ТОП и провести грамотную CEO-оптимизацию ресурса – так ваши посетители в пару кликов найдут на сайте нужную информацию.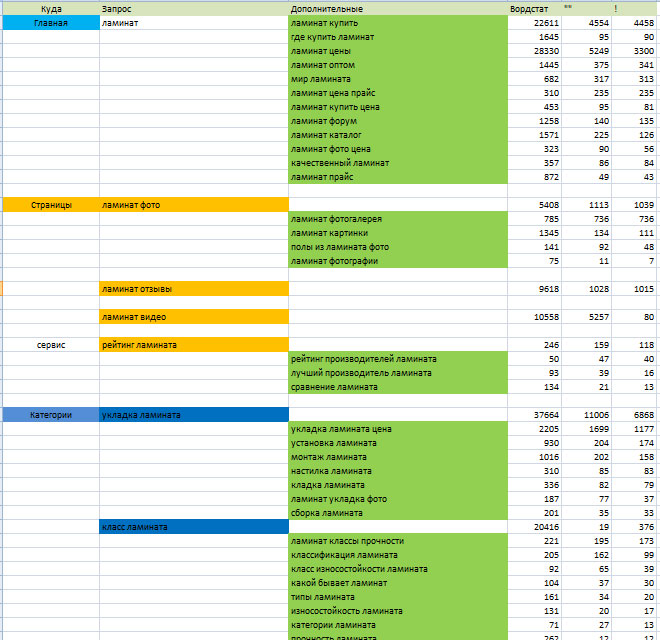 Ну, а вы в итоге получите приток целевой аудитории и увеличите число заявок!
Ну, а вы в итоге получите приток целевой аудитории и увеличите число заявок!
А теперь рассказываем подробнее, что такое семантическое ядро, как его собрать и правильно обработать.
Если взглянуть на нашу планету – как основа, внутри нее находится ядро. Аналогично и с нашим организмом – в основе каждой его клеточки тоже присутствует ядро. Эта основа помогает различным организмам правильно функционировать. Так и с вашим сайтом – позаботьтесь о том, чтобы внутри него было грамотно собрано и проработано семантическое ядро.
Семантика для сайта – фундамент вашего бизнеса, на котором выстраиваются все остальные этажи, помещения и комнаты. Представьте себе дерево с большой кроной и множеством листьев – оно существует только благодаря стволу, на котором и держится каждая ветка и каждая сотня или тысяча листочков. Семантическое ядро – это как корень и ствол для вашего сайта.
Масса известных на весь мир успешных изобретений – копии, взятые из природы. Например, самолет создан по образу и подобию птицы, а самые крепкие небоскребы построены на основе стебля пшеницы, который хоть и колеблется под гнетом ветра – но никогда не ломается за счет своей продуманной архитектуры.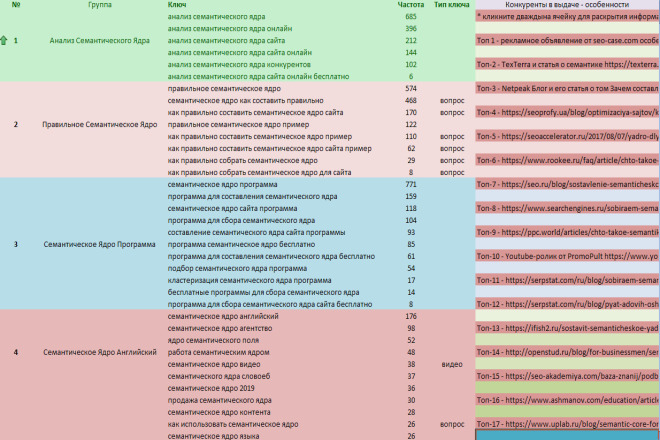
Создавая семантику, вы делаете ваш бизнес устойчивым – он приобретает основательный фундамент и крепкий внутренний стержень. Если решите махнуть на семантическое ядро для сайта – можете не рассчитывать на его долгую и успешную жизнь.
А вы верите в мифы?
Есть мифы, рассказывающие о несложности сбора семантического ядра. А на самом деле – дела обстоят, как на рисунке:
Что мы видим? Громадный пласт пользовательских запросов скрыт от анализа на поверхности, нужна специальная подготовка и проработка запросов, которые ищут пользователи в нужной вам нише.
Попробуйте для начала погрузиться в интересующую вас сферу и глубоко копнуть, чтобы достать по-настоящему ценные материалы.
Важно! Без уникального предложения, построенного на полученных ключах, вы не сможете вовлечь пользователя в покупку вашей услуги или товара. Чтобы привлечь внимание аудитории – нужно понять, как мыслит та самая аудитория. Если рекламные объявления составлены на основе неправильно подобранных ключевых слов – аудитория пройдет мимо вашего предложения.
Помните, и естественный органический трафик, и контекстная реклама – все завязано на семантическом ядре и зависит от качества его проработки.
Собирать семантическое ядро – жизненно важная задача для развития вашего бизнеса в интернете
Сбор семантики – процесс поиска ключевых слов в определенной тематической области, а также исключение и фильтрация фраз, отдаленных от вашего бизнеса и не соответствующих рекламному предложению. В данной статье мы расскажем как составить семантическое ядро сайта.
Параллельно с ключевыми словами мы находим и частоту их фигурирования в поисковых системах – получаем информацию, как часто ключевики пользователи вбивают запросы в Google, Яндекс и прочие системы.
Частота запросов дает понять, какое словосочетание востребовано больше, какое меньше, какое вовсе неликвидно. Такая градация проста и понятна.
Читайте также: Как увеличить продажи в интернете: полное руководство
Хотите больше трафика на сайт?
Продвигайте или рекламируйте на своем ресурсе товары и услуги, используя ключевые слова с ошеломляющим спросом ☺
Исследуйте ключевые слова, согласовывайте поисковую выдачу и ваше торговое предложение, учитывая спрос и конкуренцию.
Ваше идеальное семантическое ядро релевантно задачам бизнеса и ожиданиям поисковых систем:
Задача по сбору семантики – составить и организовать структуру ключевых слов, подходящих для сайта, ваших покупателей и поисковой системы, которая разместит вас в своей выдаче.
Составляя семантическое ядро, соберите показатели по другим ключевым метрикам – в зависимости от условий работы вашего бизнеса, гео-расположения, сезонности услуг или товара. Это поможет в проведении исследований и определит приоритетность ключевых слов.
А вот и список дополнительных метрик:
| ключевые слова | количество запросов в месяц (валово для всех нужны городов: ) | конкуренция по данным Мутаген | геозависимость запроса (по данным Яндекс) | сезонность запроса (по данным вордстат) | средняя частотность за последние 12 месяцев (по данным вордстат) | |||
| Яндекс | ||||||||
| широкое | точное “!” | широкое | точное “!” | |||||
Сбор семантики – на скорость
Для старта проведите мозговой штурм всевозможных направлений и тем, касающихся вашего бизнеса Найдите все возможные подходящие разветвления бизнеса, направления компании, синонимы, словообразования, словосочетания и прочее для охвата интересов вашей целевой аудитории. Это все поможет в качественном сео продвижение.
Это все поможет в качественном сео продвижение.
Вам нужно собрать список масок или словосочетаний – из них в итоге соберется семантическое ядро. Список масок схож со списком покупок, с которым вы идете в магазин и покупаете с его помощью все необходимое. А уже дома готовите блюдо из приобретенных продуктов.
Чтобы блюдо получилось вкусным и аппетитным –соберите необходимые для его приготовления ингредиенты. Отнеситесь к сбору масок серьезно – иначе не получится приготовить ваше семантическое ядро.
В самом начале важно понимать тонкости бизнеса и микроклимата вашего вида деятельности, как кулинарного искусства. Сделайте список вариантов, по которым ваш бизнес может быть найден в сети. Есть ключевые слова, о которых вы не подозреваете, а они прибыльные с точки зрения продвижения.
Например, краткий список направлений и синонимов для компании, которая предоставляет услуги СТО:
СТО, автосервис, станция техобслуживания, станция технического обслуживания, диагностика автомобиля, ТО автомобиля, ремонт автомобиля, обслуживание автомобилей, замена запчастей, компьютерная диагностика, шиномонтаж, элетрики, механики.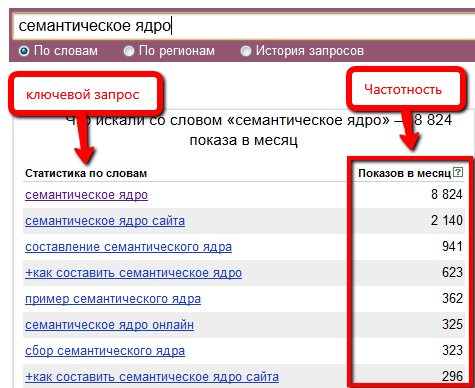
Если вы ответственный за семантическое ядро, но не собственник бизнеса, и мало разбираетесь в нише для продвижения – обратитесь за помощью к специалистам в этом направлении.
Пообщайтесь с собственником бизнеса, с менеджером по продажам и с другими сотрудниками, которые подробно опишут бизнес и расскажут о направлениях, по которым вы будете двигаться дальше.
Вот краткий список вопросов, чтобы выловить новые данные:
- Цель сбора семантического ядра? Для SEO-продвижения, для контекстной рекламы, для расширения семантического ядра?
- Чем занимается компания? Полный список услуг и товаров.
- Чем компания не занимается? (например – производит велосипеды, но не предоставляет ремонт и обслуживание)
- По какому региону/стране/городам – работает компания?
- Работает ли компания оптом или только в розницу?
- Осуществляет ли доставку?
- С кем сотрудничаем, с кем не сотрудничаем, целевая аудитория компании?
- Приоритетные и главные направления деятельности?
- Ценовая политика компании – премиум сегмент/демпинг цен?
При возможности – сделайте опрос клиентов компании:
- Как они нашли компанию в интернете?
- Какие запросы использовали при поиске?
- Что понравилось, а что нет?
Расширение ядра
Воспользуйтесь правой колонкой Яндекс Вордстат – так получите информацию о запросах, похожих на ваши.
Такая информация многократно увеличит и расширит направления, по которым собираем семантическое ядро:
Используйте информацию от поисковой системы – о похожих запросах или запросах, которые ищут вместе с вашим.
Здесь находятся актуальные для компании ключевики – они популярны, используйте их при продвижении:
Минус- слова
В каждом виде деятельности есть разветвления, которые%
- не интересны бизнесу
- неактуальны
- не релевантны
Это – минус-слова или стоп-слова.
Например, мы производим велосипеды и продаем их. Но – мы не продаем велосипеды Б/У, хотя просмотров по этим запросам масса – около 25 тысяч/ месяц:
В нашем случае слово «бу» – минус-слово или стоп-слово. Добавьте это слово в список игнорируемых фраз – так словосочетания, содержащие «бу», удалятся при сборе ядра.
Чтобы правильно составить список минус-слов, определите цель сбора семантического ядра для:
- Информационных, новостных ресурсов и порталов
- Ecommerce проектов
- Агентств и сайтов-визиток
- Лендингов, созданных специально для рекламы в Я. Директ
 Директ
ДиректВокруг каждого сайта – большое облако ключевых запросов, которые делятся на группы. Мы рассмотрим деление на 2 группы – коммерческие, например «купить велосипед» и информационные – например «как выбрать велосипед».
Вам интересны интернет-маркетинг и продвижение бизнеса в интернете? Подписывайтесь на наш Telegram-канал!Мы можем собрать все ключевики, которые находятся в нише, но чаще это нецелесообразно.
Если у вас интернет-магазин – собирайте ключевые запросы с фразами:
купить, цена, стоимость, магазин и так далее…
При этом используйте уже готовые списки минус-слов, они давно собраны и находятся в свободном доступе в сети.
Например, универсальный список минус-слов для интернет-магазина, который исключает всякие мусорные запросы, а также информационные фразы.
скачать, скачивать, бесплатно, бесплатный, онлайн, видео, клип, видеоклип, фотография, фото, video, photo, книга, смотреть, слушать, песня, музыка, mp3, альбом, запись, remix, ремикс, слова, текст, минусовка, dj, торрент, торент, torent, torrent, мультфильм, мультик, мультсериал, анекдот, прикол, фильм, сериал, сезон, серия, телесериал, программа, игра, играть, выиграть, gameadmin_Ja, симулятор, покер, казино, photoshop, фотошоп, вики, википедия, wikipedia, сонник, сон, сниться, присниться, форум, порно, порн, секс, сексуальный, sex, adult, porno, porn, эротика, эротический, голый, обнаженный, бу, б у, б/у
Если у вас новостной сайт – сделайте наоборот, возьмите фразы для парсинга, которые внутри содержат такого рода слова:
как, что это, какие, почему, лучшие, можно ли, и так далее. .
.
Регион работы компании
Определите региональность вашего бизнеса – все ключевые слова имеют разный спрос индивидуально для каждого региона.
Исключения: Если это информационный сайт – региональность можно не указывать, тогда по умолчанию ключевикам будет присваиваться частотность их спроса по всему миру.
Выберите город, страну или несколько городов/стран – где вы будете работать.
Названия городов, где вы не фигурируете – внесите в список стоп-слов.
Например, если работаете по СНГ, но не работаете в Беларуси – используйте список городов Беларуси в качестве минус-слов:
Минск, Гомель, Витебск, Гродно, Брест, Барановичи, Борисов, Пинск, Орша, Мозырь, Солигорск, Новополоцк, Лида, Молодечно, Полоцк, Жлобин, Светлогорск, Речица, Жодино, Слуцк, Кобрин, Слоним, Волковыск, Калинковичи, Сморгонь, Рогачёв, Рогачев, Берёза, Береза, Новогрудок, Вилейка, Дзержинск, Лунинец, Ивацевичи, Марьина Горка, Поставы, Пружаны, Добруш, Глубокое, Лепель, Мосты, Иваново, Житковичи, Столбцы, Смолевичи, Щучин, Ошмяны, Дрогичин, Заславль, Несвиж, Ганцевичи, Новолукомль, Хойники, Жабинка, Микашевичи, Городок, Фаниполь, Белоозёрск, Белоозерск, Столин, Березино, Малорита, Барань, Любань, Старые Дороги, Ляховичи, Клецк, Логойск, Скидель, Берёзовка, Березовка, Воложин, Петриков, Толочин, Червень, Копыль, Узда, Ельск, Браслав, Чашники, Буда-Кошелёво, Буда Кошелёво, Буда-Кошелево, Буда Кошелево, Крупки, Каменец, Островец, Миоры, Наровля, Ивье, Дубровно, Сенно, Ветка, Чечерск, Дятлово, Верхнедвинск, Мядель, Свислочь, Докшицы, Давид-Городок, Давид Городок, Высокое, Василевичи, Туров, Дисна, Коссово
Как подготовиться к сбору ядра на примере
Наш бизнес – это сервис по поиску баз данных компаний. Для него нужно создать семантическое ядро.
Для него нужно создать семантическое ядро.
У нас крайне мало информации и подробностей о проекте – собирать семантику на основе таких абстрактных данных будет проблематично.
Мы запрашиваем дополнительные данные о проекте.
Полученные ответы:
Наша компания работает в России и СНГ с контактными данными юридических лиц и ИП.
База данных включает в себя следующие контактные данные компаний:
- наименование,
- адрес,
- телефоны стационарные и мобильные,
- e-mail,
- ссылки на сайты.
На сайте есть возможность сформировать базу компаний по собственным требованиям с помощью фильтра:
- город/страна,
- рубрики (сферы деятельности),
- выбор только производителей,
- компаний с e-mail,
- стационарными или мобильными телефонами.
Целевая аудитория компании
Проект нацелен на компании, которые стремятся расширить свою клиентскую базу, расширить географию поставок для увеличения продаж.
Главная цель – увеличение продаж. Соответственно, компании ищут контактные данные своих потенциальных клиентов – телефоны для обзвона и e-mail для рассылки коммерческих предложений.
Данные в базе есть только по юридическим лицам – другим компаниям. В базе нет физических лиц – потребителей, обывателей.
Какие задачи решает проект?
Проект дает пользователю контактные данные компаний за минимальное время и небольшую стоимость.
Преимущества компании.
Экономия времени. При поиске контактов компаний пользователь ищет их в известных онлайн-справочниках. Так тратится много времени на сбор данных и их обработку, а также пользователь может получить неполную базу.
В базе много других баз. Наш сервис собирает данные из разных источников, тем самым мы добиваемся наиболее полной и актуальной информации. Также для формирования пользователем базы в нашем сервисе понадобится гораздо меньше времени. Достаточно потратить 5 минут и у пользователя уже есть готовая база.
Что относится к нашей работе, а что не относится?
- На сайте нет контактов физических лиц, есть только юр. лица и ИП.
- Также нет информации по ОКВЭД, ЕГРЮЛ и контактных данных ЛПР (лицо принимающее решение о покупке ФИО и телефоны).
- 2Gis – отношения не имеем (минус-слова).
- Не интересны запросы связанные с возможность бесплатно получить базы (бесплатно, справочник и так далее). Слова скачать походят, а вот “бесплатно” нет.
- Базы клиентов компаний – не занимаемся (нет данных, незаконно)
- Для смс рассылок – не продаем для такой услуги.
- Личные данные физических лиц – нет
- Данные руководителей организаций – нет
- Пароли и доступы к данным компаний и физических лиц – нет
- Если речь идет про смс рассылку, то это физ. лица – не подходит
- И данные каких-либо конкретных лиц компании (любые их данные: номера секретаря компании или номера отдела снабжения компаний)
- Телефонный справочник – нет
- Все что относится к одной организации – не подходит. У нас база email и телефонов компаний (выборка по рубрикам).
- Все что касается физических лиц – не подходит. Когда человек вводит к примеру “список аквапарков” – это запрос физика.
- Справочники чего-либо не относящегося к “контактам” – не подходит. Пример “медицинский справочник”.
- Оптовая база если речь про 1 конкретную – не наше.
- Все что не касается “база контактов компаний” – не наше. Пример: база по продаже бизнеса. Все что не связано с получением списка контактов нескольких компаний из определенной ниши.
- Страховые компании – спрашивают физ. Лица.
- Застройщики – спрашивают физ. Лица.
 У нас база email и телефонов компаний (выборка по рубрикам).
У нас база email и телефонов компаний (выборка по рубрикам).После запроса информации мы получили практически полную картину функционирования нашего проекта. Мы знаем, какие задачи решает наш бизнес, а какие задачи мы не решаем, хотя они находятся якобы тоже в нашей нише.
Все эти данные должны быть предоставлены от собственника бизнеса или любого другого компетентного лица.
В итоге при подготовке к сбору ядра мы получили следующую информацию:
Регион работы:
Россия и СНГ
Краткий список минус-слов:
1с, 2Гис, 2Gis, смс, страховые, застройщики, физ, физических, бесплатно, справочник.
Мозговой штурм направлений, синонимов и прочее:
| Основа | Чего? | Кого? | Какие? | Для чего? | Продающее | ГЕО | Формат |
|---|---|---|---|---|---|---|---|
| База | емайлов | предприятий | актуальные | Обзвон | Недорого | Россия | Эксель |
| компаний | свежие | Звонки | Дешево | Москва | Эксел | ||
| e mail | фирм | текущие | Холодные звонки | Купить | Областям | Excel |
Как видно из таблицы, мы нашли несколько вариаций, которые могут идти вместе с ключом «База» – предприятия, компании, фирмы. Это схожие по определению слова – но в поисковой выдаче будут совершенно разные сайты по этим запросам. Такие словосочетания есть практически в каждом виде бизнеса.
Мы должны учесть максимум возможных вариаций и внести их в таблицу масок. В результате – получен список ключевых фраз, которые мы будем использовать как основу для парсинга.
Для примера возьмем следующий список слов:
База емайлов, база email, база e mail, база предприятий, база компаний, база фирм
Топ сервисов при сборе ядра
- Бесплатный вариант и самый простой – Яндекс Вордстат (ссылка сюда https://wordstat.yandex.ru/).
Сначала выбираем регион, по которому осуществляем поиск:
Далее по очереди вбиваем наши ключи в адресную строку в следующем формате:
(База емайлов | база email | база e mail | база предприятий | база компаний | база фирм)
Если ключей будет больше, по аналогии добавьте их внутрь скобок ( ).
Символ | – который разделяет фразы и означает, что будут собраны данные сразу для нескольких ключей, без него нам пришлось бы собирать каждый ключ в отдельности по порядку.
Так мы получим данные по всем ключам сразу – это сэкономит время.
Важно! Не забываем добавить стоп-слова в следующем формате:
(База емайлов | база email | база e mail | база предприятий | база компаний | база фирм) -бесплатно -1с -2Гис -2Gis -смс -страховые -застройщики -физ -физических -бесплатно -справочник
Получаем выдачу, сразу отфильтрованную от ненужных ключевых запросов:
Для сравнения – выдача без фильтрации, со всеми ключами:
Видим наличие фраз, которые не подходят по роду деятельности.
Для комфортного сбора ключей из Wordstat – установите себе в браузер дополнительное расширение для работы с ключами – Yandex Wordstat Assistant
Оно доступно для многих браузеров:
Это расширение помогает легко выбирать ключи и копировать их – нажмите на знак плюс «+» напротив нужного ключа, обработав весь список ключей – нажмите на кнопку, которая показана на картинке под пунктом 5, эта операция добавит список ключей в буфер обмена:
Дальше заходим в Excel или в другой сервис по обработке семантики и копируем туда наши ключи:
Минусы сервиса:
- Нет возможности получить сразу несколько видов частотности
- Просматривать можно только по 50 запросов на странице
- Отсутствует выгрузка данных, только сторонние методы сбора
Бесплатный сервис «Букварикс» (bukvarix.com) – еще один хороший вариант сбора семантического ядра, так как содержит огромную базу из 2 миллиардов ключей, при этом постоянно обновляется:
Сервис предоставляет возможность получать семантику исходя не только из ключевой фразы, но и с помощью доменного имени сайта. То есть можно проанализировать сайты конкурентов, которые уже проиндексированы и содержат интересующие нас запросы.
То есть можно проанализировать сайты конкурентов, которые уже проиндексированы и содержат интересующие нас запросы.
Также присутствует база рекламных объявлений, топ поисковых запросов, английская база ключей и многое другое.
Сервис имеет более простой интерфейс и не требует дополнительных знаний и инструкций, в отличие от Wordstat. Здесь все понятно, без слов:
Вводим список слов в окно поиска слева, список минус-слов добавляем в окно справа и жмем кнопку найти:
Получаем список ключевых слов вместе с дополнительной информацией, которую можно будет использовать в продвижении:
количество слов в фразе,количество символов,
общая частотность весь мир,
точная частотность весь мир.
Чтобы скачать всю информацию по ключам из букварикса – воспользуйтесь соответствующей кнопкой:
Получаем результат в формате .csv:
Минусы сервиса:
- Рациональность запроса нельзя выбрать, частота собирается только по всему миру
- Много ненужных запросов с нулевой частотой
- Очень много дублей одних и тех же запросов
Автоматические сервисы по сбору ядра
На рынке также есть сервисы, которые автоматизируют сбор семантического ядра.
Например, RushAnalytics:
Сервис использует тот же Wordstat для сбора ключевых запросов, но все настраивается в несколько кликов и не требует от вас дополнительных знаний.
1. Добавляем проект, выбрав нужный регион:
2. Настраиваем глубину парсинга, максимум 40 страниц из Wordstat:
3. Указываем список масок и список минус слов
Запускаем проект. По готовности можно будет скачать таблицу с расширением .xlsx
Сервисы, которые имеют собственные мульти-язычные базы ключевых слов:
Например – seranking
В нашем распоряжении – ядра для стран Европы, СНГ, США, Канады, Австралии. Это весомый повод использовать их собственные наработки, так как с помощью их баз можно расширить свое семантическое ядро и получить ценные ключевики, которых нет у конкурентов.
Сервисы для сбора ядра конкурентов
На рынке много ресурсов для сбора семантического ядра конкурентов, рассмотрим наиболее актуальные для русскоязычного сегмента рынка.
https://www. keys.so/
keys.so/
https://serpstat.com/ru/
https://spywords.ru/
Используя эти три сервиса, вы получаете доступ к множеству данных, вот список только некоторых:
- Выгрузка семантики конкурентов
- Разбивка семантики сразу по страницам, согласно данным конкурентов
- Органическая и рекламная выдача по ключам или доменам конкурентов
- Групповые отчеты для сравнения сайтов конкурентов
- Выборки по списку запросов конкурентов
Минимальный план действий по сбору ядра конкурентов:
- Найдите минимум 5 самых близких и конкурентов в вашей нише.
- Обязательно проверьте чтобы они занимали топовые позиции (топ 1-3 ) в поисковой органической выдаче по вашему региону.
- Сделайте выгрузку органического выдачи всех 5 сайтов конкурентов
- Объедините полученные данные с вашим семантическим ядром.
Проведем анализ одного сайта – компании по продаже квадрокоптеров – idrone.ru.
С помощью сервиса кейсо мы сделаем выгрузку страниц сайта, которые присутствуют в органической выдаче.
Данные из этого сервиса выгружаются в виде Excel документа в следующем формате:
Особенно ценно – что кейс дает возможность сразу определить релевантность фразы и ее место в архитектуре сайта. Это ценная информация, которую используем при распределении нашего семантического ядра по сайту.
Организовав правильно работу фильтров в Excel, отсортируем ключи по группам для более ясного восприятия:
Как обработать семантическое ядро
Существует множество вариантов анализа данных в бесплатных и платных сервисах.
Всю эту информацию можно выгрузить в таблицы Excel. Но как обработать этот огромный массив данных, состоящий из отчетов, выгрузок, группировок и множества других файлов?
Профессиональный, платный вариант для обработки семантического ядра – KeyCollector.
Сразу о минусах:
- Программу нужно установить на компьютер, более того – есть привязка по железу, после переустановки Windows нужно будет писать в поддержку, чтобы снова получить лицензию
- Нет поддержки MacOs и Linux – только Windows
- Для нормальной работы нужно покупать прокси-серверы и антикапчу
- Нельзя работать с файлами из облака – зависает, выдает критическую ошибку
Плюсы:
- Единоразовая оплата, пожизненное использование
- Постоянные обновления
- Техподдержка по любым вопросам
- Интеграция и возможность работать практически со всеми сервисами, рассмотренными ранее в статье.
- Встроенные функции для работы со стоп словами, с дублями ключей, кластеризацией

Загрузка данных в проект
В программе есть функция, которая позволяет загружать файлы с расширением .csv и подтягивать всю информацию из них.
Далее выбираем нужные нам данные и делаем загрузку:
Проделываем эту операцию со всем массивом файлов, которые мы собрали при парсинге. Обратите внимание на возможность не добавлять фразу, если она уже есть в ядре:
Этот функционал не запутает вас в ядре и спасет от дублей фраз.
Чистка ядра от мусора
Кейколлектор предоставляет не идеальные, но вполне хорошие варианты фильтрации и чистки семантического ядра:
Выберите следующие параметры, которые изображены на рисунке снизу для оптимальной чистки мусорных запросов. Будьте внимательны при выборе колонки частоты, там необходимо указать именно то что актуально для вашего проекта. Если вы собирали фразовую частотность, а не точную – то сделайте соответствующий выбор.
После выбора параметров – можно использовать умную отметку, которую мы настроили под наш проект, и удалить все дубли ключевых фраз:
Чистка пустых значений и значений с очень маленькой частотностью:
Выделяем и удаляем ключи – которые сверх низкочастотные. Для каждого проекта это будет своя цифра. В нашем случае это точная частота «!» которая идет меньше 5.
Если вам нужны полностью все запросы, то просто удалите все пустые значения и ключи с нулевой точной частотой.
Кластеризация ключевых фраз
Можно использовать встроенные методы кластеризации Кей коллектора.
С их помощью вы получите кластеры фраз, исходя из нескольких условий:
Вариант 1, который идет по умолчанию – это группировка по отдельным словам:
В зависимости от того, сколько раз и где используется каждое отдельное слов – идет построение древовидной структуры:
Такая структура поможет правильно распределить семантику по страницам нашего сайта и составить верную архитектуру:
Вариант-1. Более продвинутый, он основан на данных конкурентов и поисковой выдачи.
Более продвинутый, он основан на данных конкурентов и поисковой выдачи.
Этот метод подразумевает использование уже проиндексированных сайтов из поисковой выдачи в качестве сортировщиков для наших ключевиков. Каждое слово проверяется по выдаче топ 10, 20, 30,50 – и анализируется под какие виды страниц оно подходит лучше всего. В итоге на основе этих данных фразы собираются в похожие группы и образуют кластеры.
ВАЖНО! Для работы этого метода вам необходимо будет получить данные из поисковых систем
В зависимости от того, какую поисковую систему вы определили как главную для построения групп ключей – из этой системы соберите данные.
Группировка такого рода похожа на группировку по составу фраз:
Ключевые слова уже не просто выведены по количеству вхождений в фразу, каждая группа является индивидуальной и после уточнения может быть вынесена как отдельная страница для сайта.
Автоматизированные сервисы Rush Analytics и Seranking также открывают технологию кластеризации, с помощью которой приходит понимание – какие ключи на какую страницу нужно вставлять:
Выгрузка данных в итоговый файл.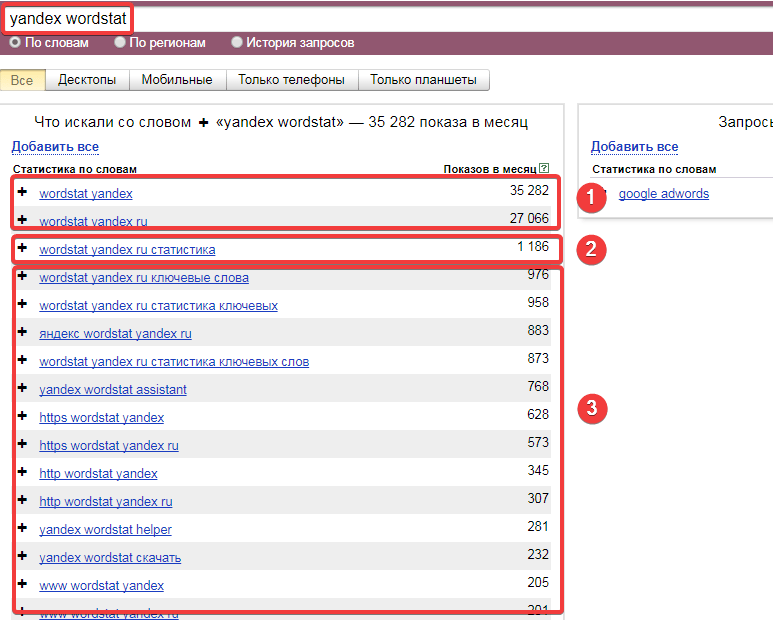
В итоге мы должны образовать из полученных данных – файл примерно такого вида:
Этот вариант содержит в себе ключевую информацию и необходимые данные для старта работ по рекламе и продвижению.
Пример части готового собранного ядра:
Теперь вы знаете, как грамотно собрать семантическое ядро для своего сайта, при этом сэкономив время и личные ресурсы. Надеемся, наши рекомендации помогут вам в решении вопроса семантики, а ваш сайт выполнит задачи бизнеса и непременно будет в топе поисковых систем! ☺
Автор: Максим Глотов — MaxGlot
Подпишитесь на рассылку FireSEO
и получайте подборки статей, полезных сервисов, анонсы и бонусы. Присоединяйтесь!
Как выбрать семантическое «ядро» для вашего сайта | по ключевому слову не указано
Поисковый запрос Google изменился с годами. Если вы онлайн-маркетолог и серьезный профессионал в области SEO, вам жизненно необходимо соответствовать текущим изменениям и улучшениям. Базовое исследование ключевых слов становится более сложной задачей, порождающей семантическую поисковую систему. Для исследования ключевых слов вы можете попробовать использовать инструмент исследования ключевых слов Bing, и не забывайте о многочисленных инструментах Google.
Для исследования ключевых слов вы можете попробовать использовать инструмент исследования ключевых слов Bing, и не забывайте о многочисленных инструментах Google.
Семантическое ядро может показаться новым пользователям сложным, но на самом деле это не так.Здесь давайте рассмотрим технологию семантического поиска и то, как она помогает создавать более интеллектуальный и доступный для поиска контент.
Начнем с определения семантики. Семантика из словаря описывает семантику как значение или интерпретацию слова, знака или предложения. С точки зрения маркетологов, семантика — это то, как вы интерпретируете конкретный термин.
Когда пользователь ищет термин, у него есть четкое представление о слове, которое он хотел найти. Например, кто-то искал «динамик».
- Вы имеете в виду того, кто предстает перед толпой?
- Это потоковое устройство?
- Преимущества и функции динамика?
- Что? Google не знает.
Итак, чтобы получить идеальный результат поиска, необходимо ввести определенные группы ключевых слов. Ваш поиск может быть более конкретным, набрав водонепроницаемый динамик Bluetooth. В этом случае поисковая система предоставит варианты результатов, специфичные для водонепроницаемого динамика Bluetooth. Однако результаты поиска будут широкими и общими.Введите более подробный поисковый запрос, чтобы получить желаемые результаты.
Ваш поиск может быть более конкретным, набрав водонепроницаемый динамик Bluetooth. В этом случае поисковая система предоставит варианты результатов, специфичные для водонепроницаемого динамика Bluetooth. Однако результаты поиска будут широкими и общими.Введите более подробный поисковый запрос, чтобы получить желаемые результаты.
Вот здесь-то и вступает в игру семантическое ядро. Поисковые системы разработаны с алгоритмами, которые помогают им понимать запрос, поэтому конкретность очень важна.
Определение основных терминов важно для начала работы над аффективным семантическим исследованием ключевых слов. Вы можете использовать Google Keyword Tool, чтобы помочь вам составить соответствующий список основных ключевых слов и фраз. Использование ключевых слов Google Analytics — тоже хорошая практика. Если вы ищете «как не покупать лимон?» вам будут предоставлены ключевые фразы, связанные с этим.
Основными ключевыми словами могут быть:
- Предотвратить покупку плохой машины
- Избегать покупки плохой машины
- Избегать покупки неисправных автомобилей
Абсолютное определение слов повышает шансы получить авторитет и актуальность. Получив основные ключевые слова, вы сможете составить приблизительный план содержания вашего веб-сайта.
Вы придумали релевантные ключевые слова с помощью технологии семантического поиска. Пришло время сесть и написать свой контент.Однако всегда помните, что вы пишете для людей. Они изначально вас здесь беспокоят. Убедитесь, что содержание не содержит спама со всеми имеющимися семантическими ключевыми словами. Пишите естественно, пока не напишете ядро. Затем настройте некоторые части для оптимизации. При необходимости вставьте ключевые слова. При необходимости удалите немного. Пишите, корректируйте, читайте, а затем публикуйте.
Исследование семантического ядра имеет жизненно важное значение для оптимизации. Разумно используйте ключевые слова для разработки полезного, релевантного и удобного для поисковых систем содержания для создания авторитетного веб-сайта.Технология семантического исследования предоставляет отличный список ключевых слов для повышения рейтинга и авторитета сайта. Однако, как и в случае с другими стратегиями поисковой оптимизации, всегда имеет смысл сделать его естественным. Работайте над своим контентом профессионально и дружелюбно, и вы удивитесь, насколько болит ваша веб-страница.
Однако, как и в случае с другими стратегиями поисковой оптимизации, всегда имеет смысл сделать его естественным. Работайте над своим контентом профессионально и дружелюбно, и вы удивитесь, насколько болит ваша веб-страница.
Ключевые слова SEO или семантическое ядро
Мы рады представить всем нашим клиентам и не только — результат нашей многолетней работы — новые онлайн-сервисы
Даем каждому по 150 $ для сбора любой семантики условий акции на официальном сервисе.Просто зарегистрируйтесь по ссылке .
Создание семантического ядра или seo-ключа с помощью WebCoreLab включает онлайн-сервисы сбора и группировки семантических запросов. Мы можем получить мета-ключевые слова с сотен веб-сайтов для использования в текстовом маркетинге.
Теперь продвигать сайты стало проще. : просто воспользуйтесь нашими техническими условиями для написания контента (текстов) для своих сайтов. Вам не нужно быть профессиональным редактором или SEO-специалистом, просто возьмите техническое задание и с его помощью раскройте тему. И как только материал попадет в индекс Google, вы начнете получать тысячи, а может и десятки тысяч уникальных посетителей.
И как только материал попадет в индекс Google, вы начнете получать тысячи, а может и десятки тысяч уникальных посетителей.
Мы занимаемся только ручным сбором семантического ядра и используем профессиональные семантические инструменты на основе нейронных сетей, с привлечением семантических экспертов в конкретной сфере бизнеса клиента!
Почему выбирают нас:
- 10 лет на рынке.
- Обширный опыт работы в индустрии семантического ядра и построения профессиональной архитектуры сайта.
- Собственные сервисы по сбору и кластеризации семантических ядер под управлением нейронных сетей
- Собственные автоматические сервисы по формированию технического задания на копирайтеров
- Вы платите только за результат.
- Вы можете контролировать и управлять всем процессом сбора и кластеризации семантического ядра в нашей уникальной системе.
- Онлайн-поддержка 24 \ 7 — в личном кабинете, индивидуальный чат на сайте, а также поддержка по телефону.
- Перед тем, как начать пользоваться сервисом, вы можете попробовать его бесплатно: https://home.webcorelab.com/test
- Любые способы оплаты — Visa, Mastercard, Pay Pal, Payoneer, банковский перевод.

Наши технические характеристики основаны на ключах LSI и 27 метриках префикса.
Мы готовим технические спецификации с использованием LSI Keywords.
Для более полного и качественного сбора ключевых слов бизнес-аккаунты используются в таких сервисах, как semrush.com, serpstat.com, советы Google, Moz, Google Реклама, Google Trends. Мы также используем наши собственные ключевые базы данных (900 миллионов в США и 4,2 миллиарда во всех других регионах).
Почему работать с нами выгодно и безопасно:
- Вы платите только за семантическое ядро в любом количестве и качестве, то есть платите только за одобренные вами ключевые слова и не более
- Фиксированный платеж за готовое разгруппированное ключевое слово составляет всего 0 долларов. 35 и без скрытых комиссий
- Бесплатные тестовые системы перед запуском
- Чтобы начать и получить результат за четыре дня, достаточно нескольких минут.
 35 и без скрытых комиссий
35 и без скрытых комиссийНачать сбор в 2 этапа:
Просто заполните бриф и внесите фиксированный залог в размере 150 долларов (на брифе должна быть кнопка)
После того, как мы сделаем за вас всю работу, вы сможете наблюдать и контролировать весь процесс сбора семантического ядра в личном кабинете сервиса.
Все работы ведутся в несколько этапов:
- Перед тем, как приступить к любому проекту, мы детально выясняем сферу бизнеса, в которой работает клиент, и особенности его бизнеса. Первичный анализ бизнес-сферы занимает от 2-х дней, после чего к клиенту назначается профильный специалист, который ведет его до конца проекта.
Для выполнения этого анализа нам потребуется введение от клиента, которое клиент должен заполнить, после анализа деловой сферы вам может потребоваться личный контакт через мессенджеры или по телефону.
По завершении анализа клиент получит отдельный отчет «Competitive Intelligence».
- Второй этап — это первичный парсинг всей бизнес-сферы.
Сканируем всех ТОП конкурентов с детальным анализом качества ресурса в сфере бизнеса.
- Третий этап — первичная очистка ядра, согласование окончательного списка ключевых слов для последующей группировки и подготовка технического задания для копирайтеров.
- Четвертый этап — согласование ключей для группировки; На этом этапе клиент выбирает оптимальное количество и качество ключевых слов для последней версии семантического ядра. Необязательно просматривать весь список ключевых запросов, вы просто указываете нам направление, остальную работу мы сделаем за вас.
- Пятый этап — ручная группировка ключевых слов с учетом вводного клиента.На этом этапе мы окончательно согласовываем с клиентом окончательный список ключевых слов.
- Шестой этап — формирование технического задания на копирайтеров с учетом LSI. Каждое Техническое задание представляет собой отдельный документ с определенным набором ключей LSI для Заголовка — h2 — Body и оптимальной длиной текста в символах.
 Каждое Техническое задание представляет собой отдельный документ с определенным набором ключей LSI для Заголовка — h2 — Body и оптимальной длиной текста в символах.
Каждое Техническое задание представляет собой отдельный документ с определенным набором ключей LSI для Заголовка — h2 — Body и оптимальной длиной текста в символах.Нравится:
Нравится Загрузка …
Руководство по семантическому поиску для начинающих: примеры и инструменты
Еще со времен появления Google Hummingbird термин «семантический поиск» использовался очень часто.Тем не менее, эту концепцию часто понимают неправильно. Что такое семантический поиск и как он помогает в SEO?
Когда люди говорят друг с другом, они понимают больше, чем просто слова. Они понимают контекст, невербальные сигналы (выражения лица, нюансы голоса и т. Д.) И многое другое.
Это происходит естественно, поэтому мы не очень понимаем, насколько сложно объяснить то, что передается без помощи всех «запредельных» сигналов.
Факторы, которые делают жизнь как Google, так и SEO такой сложной
- Google пытается (и часто изо всех сил) понять, чего хотят их пользователи (фактически не видя и не слыша их)
- SEO-специалисты пытаются реконструировать то, что Google удалось понять из запросов их пользователей, и как создавать страницы, соответствующие этим таинственным критериям. По мере того, как алгоритм Google становится все более зрелым, становится все труднее расшифровать то, что ему нужно, или, что более важно, то, что Google считает нужным своим пользователям при использовании любого конкретного поискового запроса.
Здесь вступает в игру семантический поиск.
«Семантика» относится к концепциям или идеям, передаваемым словами, а семантический анализ делает любую тему (или поисковый запрос) простой для понимания машиной.
Проще говоря (я не являюсь профессиональным экспертом по семантическому анализу, хотя у меня есть степень в области когнитивной лингвистики), Google (и, следовательно, оптимизаторы поисковых систем) имеют дело с двумя основными концепциями семантического поиска:
- Семантическое отображение, то есть исследование связей между любым словом / фразой и набором связанных слов или концепций.
- Семантическое кодирование, то есть использование кодирования для лучшего объяснения Google, какие типы информации можно найти на каждой странице.

Поскольку в нашей отрасли мы склонны подбрасывать термины налево и направо (и часто придумываем свои собственные), возникает большая путаница, когда дело доходит до семантического поиска и того, как это делать.
Итак, эта статья — моя попытка устранить эту путаницу и помочь вам лучше понять семантический анализ и его применение в SEO.
Семантическое отображение
Семантическое отображение — это визуализация отношений между концепциями и сущностями (а также отношений между взаимосвязанными концепциями и сущностями).
Вот пример семантической карты (или модели), взятой из статьи Раманатана Гуха из Google, будущего создателя проекта Schema:
Источник изображения
[Часть семантической карты для поискового запроса [Йо-Йо Ма]]
Эта модель помогает Google лучше понимать любой из связанных запросов и предоставлять полезные подсказки для поиска (например, граф знаний, быстрые ответы и другие).
Источник изображения: Скриншот автора (декабрь 2019 г.)
Семантический анализ также помогает Google лучше обслуживать пользователей голосового поиска, предоставляя им немедленные ответы на основе их общего понимания темы.
Но как можно использовать семантический анализ в поисковой оптимизации?
Лучший способ понять семантику предлагает Text Optimizer — инструмент, помогающий понять эти отношения.
Если кто-то ищет [пицца], он может искать:
- Заказать пиццу
- Приготовить пиццу
За годы предоставления пользователям результатов поиска и анализа их взаимодействия с этими результатами, Google, похоже, знает, что большинство людей, которые ищут [пиццу], заинтересованы в заказе пиццы.
Источник изображения: Скриншот автора (декабрь 2019 г.)
Следовательно, все, что нам нужно сделать, — это расшифровать понимание Google любого запроса, на создание и уточнение которого у них были годы.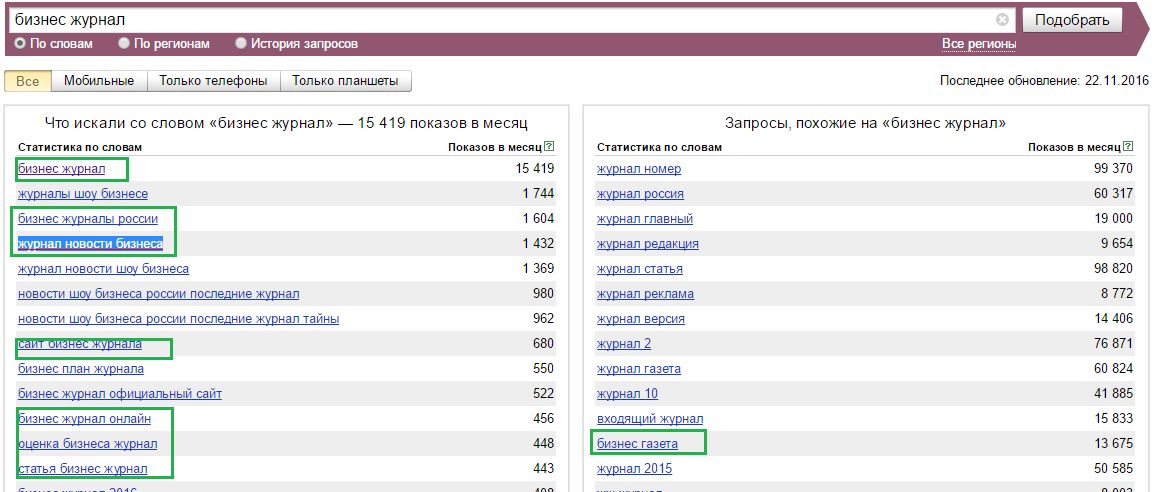
Таким образом, Text Optimizer собирает эти результаты поиска и группирует их по связанным темам и объектам, что дает вам четкое представление о том, как лучше оптимизировать поисковые запросы.
Источник изображения: Снимок экрана, созданный автором (декабрь 2019 г.)
Идея состоит в том, что использование нескольких из этих терминов в вашем тексте помогает правильно включить их в семантическую модель Google.Таким образом, Google будет знать, что ваш документ будет соответствовать намерениям пользователя.
Семантическое кодирование
Идея использования кода для выражения смысла (а не только представления) возникла много лет назад, задолго до запуска проекта Schema.org.
В течение многих лет мы использовали семантический HTML для передачи смысла содержания:
- Подзаголовки h2-H6 отображают основные темы документа
- Другие теги HTML будут выражать больше семантики, в том числе:
Эти теги помогают различным машинам лучше понимать и передавать информацию, которую они находят на веб-странице.
Например, для обеспечения доступности рекомендуется использовать следующую разметку для вспомогательных технологий, чтобы знать, где начинается (и заканчивается) цитата и на кого ссылаются.
Источник изображения: Снимок экрана, созданный автором (декабрь 2019 г.)
Вот как теги HTML добавляют значение документа и почему мы называем их семантическими тегами.
Когда в 2011 году был создан Schema.org, владельцам веб-сайтов было предложено еще больше способов передать значение документа (и его различных частей) машине.С тех пор мы можем указывать поисковому роботу автора страницы, тип контента (статья, часто задаваемые вопросы, обзор и другие подобные страницы) и его цель (проверка фактов, контактные данные и т. Д.) .
Так зачем кому-то заниматься семантическим кодированием?
Семантическая разметка существует по одной причине —
Желание общаться Мы хотим объяснить цель и структуру нашего контента поисковой системе.
С помощью семантической разметки Google может идентифицировать и использовать ключевую информацию со страницы.Взамен веб-издатели получают «расширенные описания», то есть более подробные списки поиска, чем те, которые не используют семантику.
Чтобы помочь вам с семантическим кодированием, существует множество инструментов:
- Schema App помогает практически с любой существующей разметкой структурированных данных
- Для пользователей WordPress создано множество плагинов, включая схему обзора, схему часто задаваемых вопросов и многое другое.
Наконец, недавний проект под названием inLinks помогает добавлять структурированные данные на ваши страницы на основе их собственного семантического анализа.
Источник изображения: Снимок экрана, созданный автором (декабрь 2019 г.)
Заключение
Проще говоря, семантический анализ — это попытка преодолеть разрыв между поисковым алгоритмом, веб-страницами, которые он возвращает, и пользователями поисковой системы:
- Человек хочет что-то найти, и перед поисковой системой нужно решить две задачи: понять, чего хочет пользователь, и сопоставить это намерение с веб-документами, которые лучше всего справляются с этой задачей.
- Поисковая машина должна понимать, что они хотят найти.Семантический анализ используется для лучшего понимания цели поискового запроса
- Поисковая машина должна сопоставить это намерение запроса с веб-страницами, которые она имеет в индексе. Семантическое кодирование можно использовать, чтобы объяснить поисковой системе, что это за страница и соответствует ли она цели запроса.
Как видите, семантика используется для упрощения взаимодействия между поисковой системой и ее пользователями, но она также помогает поисковой системе лучше понимать (и использовать) информацию на любой странице.
Энн Смарти — блоггер и менеджер сообщества Internet Marketing Ninjas. Ее можно найти в твиттере @seosmarty
Как оптимизировать свой сайт для семантического поиска
Способы поиска информации в Интернете быстро меняются.
На заре SEO большинство поисковых запросов состояло из фрагментов отрывочных предложений, таких как «бесплатные ссуды до зарплаты» или «лучшая пицца в Нью-Йорке». В результате большинство веб-сайтов были оптимизированы для нацеливания на определенные ключевые слова.Именно так Google решал, какой контент наиболее релевантен конкретному поисковому запросу.
В результате большинство веб-сайтов были оптимизированы для нацеливания на определенные ключевые слова.Именно так Google решал, какой контент наиболее релевантен конкретному поисковому запросу.
Однако теперь, когда Google способен понимать контекст этих ключевых слов, поиск становится более интерактивным и диалоговым. По мере того, как Google продолжает свой путь к семантическому поиску, с точки зрения SEO все становится немного сложнее.
Семантический поиск обеспечивает более персонализированный поиск, определяя цель и контекстное значение поискового запроса.Google может сделать это за счет включения множества факторов, таких как местоположение пользователя, ежедневные / еженедельные тенденции, синонимы, разговорный язык и другие элементы естественного языка.
В этой статье я расскажу, как оптимизаторы поисковых систем и онлайн-маркетологи могут оптимизировать свое присутствие в Интернете, чтобы воспользоваться преимуществами семантического поиска.
Использовать семантическую разметку
Семантический поиск основан на совокупности объектов, разбросанных по сети — людей, мест, вещей, идей и концепций и т. Д.Один из наиболее эффективных способов определения этих сущностей — использование структурированной разметки. Когда поисковая система сканирует ваш сайт, структурированная разметка помогает поисковой системе понять контекст вашего содержания. По сути, это способ для веб-мастеров маркировать свой контент, чтобы помочь поисковым системам отсортировать отдельные атрибуты объектов и предоставить пользователю более точные результаты поиска.
Д.Один из наиболее эффективных способов определения этих сущностей — использование структурированной разметки. Когда поисковая система сканирует ваш сайт, структурированная разметка помогает поисковой системе понять контекст вашего содержания. По сути, это способ для веб-мастеров маркировать свой контент, чтобы помочь поисковым системам отсортировать отдельные атрибуты объектов и предоставить пользователю более точные результаты поиска.
Например, если я ищу «даты тура Fleetwood Mac», первый органический результат будет с www.ticketmaster.com. Вы заметите, что в нем перечислены несколько предстоящих дат тура, и каждая связана с уникальным URL-адресом, по которому вы можете приобрести билеты на эту дату / место проведения. Это достигается с помощью структурированных данных.
Наиболее широко используемые форматы разметки — микроданные, RDFa и JSON-LD. Если вы не знакомы со структурированными данными, я бы рекомендовал проверить schema.org. Там вы найдете надежную общую библиотеку словаря разметки и несколько примеров, которые проведут вас через процесс реализации.
Schema.org также является одним из немногих словарей разметки, санкционированных основными поисковыми системами, такими как Google, Bing, Yahoo! и Яндекс. Google даже создал этот отличный инструмент, который позволяет вам выделять определенные элементы на вашем веб-сайте, а затем генерировать HTML-код с включенной разметкой, что упрощает реализацию. После этого вы также можете использовать Инструмент проверки структурных данных Google, чтобы проверить правильность реализации разметки.
Разбейте ключевые слова на несколько уровней
При семантическом поиске вы должны сосредоточиться на контексте, а не только на ключевых словах.При оптимизации по намерениям пользователя это помогает разделить ключевые слова на три отдельных уровня в зависимости от их контекста.
Уровень 1 — Первый уровень состоит из ваших «основных» ключевых слов — это ключевые слова, которые не сильно отклоняются от вашего целевого набора. Хороший способ идентифицировать эти ключевые слова — использовать функцию «похожих поисковых запросов» Google.
Например, если бы мы настроили таргетинг на «обувь Nike», то по соответствующим поисковым запросам мы увидели бы следующее:
Уровень 2 — Второй уровень должен включать ваши «тематические» ключевые слова — это ключевые слова, не связанные напрямую с вашим целевым набором, но все же связанные с центральной темой или концепцией.Например, если ваше ключевое слово — «обувь Nike», то некоторые тематические ключевые слова будут включать «кроссовки» или «мужские спортивные туфли».
Уровень 3 — Третий уровень предназначен для всех ваших «основных» ключевых слов — это второстепенные ключевые слова, которые обычно отвечают на вопрос пользователя. Если мы снова воспользуемся примером «обувь Nike», основным ключевым словом может быть «обзор обуви Nike» или «цена обуви Nike».
Учитывайте свою аудиторию
Ваша маркетинговая стратегия всегда должна быть адаптирована к вашей конкретной аудитории, особенно при оптимизации для семантического поиска. Чтобы определить и понять вашу целевую аудиторию, я бы порекомендовал вам начать с оценки следующих критериев:
Чтобы определить и понять вашу целевую аудиторию, я бы порекомендовал вам начать с оценки следующих критериев:
- Сектор — Вы B2B или B2C?
- Идентификационный номер — Установить основы: возраст, пол, средний доход и т. Д.
- Расположение — Где живут ваши клиенты? Определите свою территорию.
- Настроение — Как клиенты реагируют на ваш бренд?
После того, как вы определите свою целевую демографическую группу, вы сможете отодвинуть слои и проанализировать психологические факторы.Эти факторы обычно называют психографией , и они помогают маркетологам и владельцам бизнеса понять, что движет покупателем.
Психография может выявить такие характеристики, как:
- Личные ценности
- Образ жизни
- Тип личности
- Поведение в сети
- Личные интересы
Millward Brown опубликовал две действительно потрясающих графики, которые разрушают архетипы бренда. Ваши типы должны быть более конкретными, но это отличная отправная точка.
Ваши типы должны быть более конкретными, но это отличная отправная точка.
На первом рисунке показаны архетипы:
А второй график показывает силу каждого архетипа:
Вы можете создать аналогичную диаграмму, используя свои собственные данные, чтобы выяснить, как каждый архетип преобразуется независимо. Чем более целенаправленно, тем лучше.
Я бы рекомендовал по возможности разбивать большие наборы данных на более мелкие.Например, если вы обнаружите, что 90 процентов вашей демографической группы составляют люди от 40 до 40 лет, я бы рекомендовал разбить возрастную группу на меньшую группу, чтобы вы могли собрать больше данных.
Вы можете начать сбор данных, изучив поведение пользователей и демографические данные в Google Analytics. Вы также можете получить некоторое представление об анализе данных о платном поиске и социальных сетях. Чем больше вы узнаете о своей целевой демографической группе, тем лучше вы поймете, как они ищут в Интернете.
Будущее поиска
В семантическом поиске нет ничего нового, но я все же думаю, что мы видели лишь небольшую часть того, что он может делать — не только для потребителей, но и для предприятий.
Google продолжает добавлять семантические функции, такие как Google Now (прогнозный поиск), разговорный поиск (голосовой поиск) и Google Knowledge Graph. По мере того, как Google настраивает свою способность понимать намерения пользователей, компании и маркетологи будут вынуждены делать то же самое.
Следуя советам, изложенным в этой статье, вы можете стать конкурентом и начать оптимизацию своего сайта для семантической сети.Если есть что добавить, дайте нам знать в комментариях.
Лучшие практики и способы их реализации
Это руководство дает глубокое понимание основ семантического SEO. Поисковые системы в Интернете и, в частности, Google все больше сосредотачиваются на семантическом индексировании и поиске контента, основанном на концепции «сущностей» (или «вещей»), а не на концепции «слов» (или «строк»). С другой стороны, это гораздо более эффективный способ хранения мировой информации.С другой стороны, иногда он теряет цвет и разнообразие результатов. Это руководство даст вам прочную основу как для концепций семантического поиска, так и для стратегий SEO, которые вы можете использовать для использования семантического или объектно-ориентированного поиска.
С другой стороны, это гораздо более эффективный способ хранения мировой информации.С другой стороны, иногда он теряет цвет и разнообразие результатов. Это руководство даст вам прочную основу как для концепций семантического поиска, так и для стратегий SEO, которые вы можете использовать для использования семантического или объектно-ориентированного поиска.
Что такое семантическое SEO?
Семантический поиск имеет несколько аспектов, а семантическое SEO — это искусство оптимизации базовых данных. В одном контексте семантический поиск — это поиск информации, который использует сущности, а не URL-адреса веб-страниц в качестве первичной структуры записи в системе поиска информации.Семантический поиск эффективен для машин благодаря структурированным форматам и относительно конкретному словарю. Специалисты по поисковой оптимизации начинают осознавать глубокую разницу между подходом сущности к ключевому слову в контент-стратегиях. Теперь у Google есть большая и сложная «Сеть знаний», которая помогает ему понимать отношения между концепциями.
Теперь у Google есть большая и сложная «Сеть знаний», которая помогает ему понимать отношения между концепциями.
Теперь задача вашей стратегии интернет-маркетинга состоит в том, чтобы понять, как оптимизировать присутствие организации в сети таким образом, чтобы основные компетенции организации были выражены в пределах этого графа знаний.Это «Семантический поиск» или «Семантическое SEO», и эта серия публикаций представляет собой исчерпывающее учебное руководство, которое поможет специалистам по цифровому маркетингу включить этот аспект искусственного интеллекта в поисковый маркетинг.
Другой способ описания семантического поиска состоит в том, что поисковая машина пытается извлечь значение из содержимого, которое она сканирует на странице, не просто путем подсчета слов, но и с учетом разметки, которая определяет способ представления страницы. Система веб-поиска по-прежнему может связывать этот контент со смыслом, но есть несколько атрибутов разметки, которые сканер может легко использовать для определения смысла, например:
- Теги заголовка (от h2 до h4) для определения важных концепций
- Bullet указывает, что помогает группировать концепции
- Таблицы для помощи в организации данных
В последнее время JSON-LD стал распространенным способом добавления структурированных данных в контент.
Как семантический поиск влияет на поисковую оптимизацию
Прошли те времена, когда не было лишних слов. Семантический поиск использует концепции глубокого обучения. Алгоритмы поиска, известные как Hummingbird и RankBrain, являются частью набора инструментов, которые полностью изменили значение термина «ранжирование в поисковой выдаче». Это руководство по семантическому поиску предоставит бесценный и обновляемый ресурс. Мы уверены, что это окажется бесценным для оптимизаторов поисковых систем.
Как семантическое SEO улучшает взаимодействие с пользователем
Семантическое SEO улучшает взаимодействие с пользователем, поскольку оно предоставляет пользователям новые концепции, тесно связанные с исходным запросом, отвечая на поисковое намерение Алгоритм Google постепенно узнает, что вы предоставили отличного пользователя опыта и, таким образом, имеет тенденцию повышать рейтинг вашего контента в результатах поиска.
Руководство по семантическому поиску Содержание
Переходите к разделу или читайте как книгу, щелкая <Далее> на каждой странице.
Целевая аудитория и вклад
Для кого предназначено это руководство.
Объяснение графа знаний
Разберитесь, что такое граф знаний. Получите обоснованное представление о том, что такое таблица знаний Google, без необходимости иметь докторскую степень в области систем поиска информации. Подробнее…
Развитие поиска
Первая поисковая система на самом деле была просто списком веб-сайтов, организованных людьми в тематические деревья.Неужели все действительно так отличается в мире графов знаний и семантической разметки? Подробнее…
Использование инструмента поиска объектов Google
У Google есть инструмент поиска объектов. Если вы не можете использовать API, они также создали для вас веб-интерфейс. Практический способ ТОЧНО узнать, что Google считает сущностью. Подробнее …
Стратегии семантического SEO
Как создать стратегию семантического SEO? Знание о графе знаний и объектах само по себе не улучшит ваше присутствие в Интернете. Вам нужно по-другому подходить к SEO к дням ключевых слов. На стратегическом уровне есть несколько подходов. Подробнее…
Вам нужно по-другому подходить к SEO к дням ключевых слов. На стратегическом уровне есть несколько подходов. Подробнее…
Получение листинга в Википедии
Стать объектом в Википедии — это самый известный способ попасть в список в сети знаний Google, который довольно хорошо определяет вас как сущность. Однако Википедия полна ловушек для неосторожных. Мы спросили группу экспертов о том, как, по их мнению, вам следует подходить к размещению в Википедии. Подробнее…
Разверните сеть знаний, чтобы попасть в список
Если у вас нет прямой возможности иметь запись в Википедии, вы можете стать объектом в графе знаний посредством ассоциации с существующей сущностью в Википедии.Подробнее…
Другие способы стать сущностью
Помимо Википедии, существуют другие базы данных, к которым Google обращается для построения своего графа знаний. Вот несколько идей относительно других подходов к тому, чтобы стать Сущностью. Подробнее…
Совместите свое присутствие в сети со своей нишей
Компании обычно не соглашаются с тем сообщением, которое они хотят изобразить, и нишей, в которой они хотят достаточно лаконично доминировать. Хорошо определяя свой собственный бренд, вы привязываете его к семантически близкой сущности.Например, Nike ассоциируется с обувью. Подробнее…
Хорошо определяя свой собственный бренд, вы привязываете его к семантически близкой сущности.Например, Nike ассоциируется с обувью. Подробнее…
Создание цифровых активов
Как вы относитесь к созданию цифровых активов за пределами ваших веб-страниц? Подробнее…
Как добавить структурированную разметку
Добавление структурированной разметки на ваши веб-страницы легко выполняется с помощью инструментов inLinks, но также помогает понять основные идеи. Правильный код важен, потому что известно, что Google наказывает сайты, злоупотребляющие структурированной разметкой. Подробнее…
Использование внутренних ссылок в семантическом поиске
Внутренние ссылки помогают как пользователю, так и поисковым системам соединять концепции и темы.Ссылки на страницы по определенным темам из основного текста могут значительно улучшить ваши усилия по поисковой оптимизации. Подробнее…
Руководство по внутренним ссылкам
Пошаговое руководство по оптимизации внутренних ссылок на вашем сайте. Подробнее…
Подробнее…
Семантическое SEO-написание и алгоритм Flesh-Kincaid
Читаемость семантического seo-написания основана на алгоритме Flesh-Kincaid, который помогает вам определить, на каком уровне должен быть читатель, чтобы понимать ваш контент. Алгоритм Флеша-Кинкейда учитывает несколько элементов, таких как длина ваших предложений и абзацев, использование заголовков и уровень словарного запаса.
InLinks использует шкалу Флеша-Кинкейда от 1 до 100, чтобы дать вам оценку удобочитаемости вашего контента; чем выше этот балл, тем легче читать.
раскрытие преимуществ семантического ядра, фактического и дополненного продукта с помощью интеллектуального анализа текста
Таблица 2. Периферийные измерения оценок доставки фаст-фуда
F # Retrieved Factor Ключевые слова Измерение продукта
1
Управление услугами
(84 слова)
46,8% экспл. отклонение
Для звонка, ответа, связи, ответа, поддержки, на
получение, заказ, подтверждение, информация, телефон, чат,
отмена, создание, ресторан, личный, платформа,
приложение, проблема, после, номер , подтверждение, время, почта,
касание, точка, хочу, заявка, ошибка, ночь, средний,
адрес, покрытие, ужасно, шанс, заказ,
неудобно, клиент, с опозданием (просрочено), вернуть,
ужасно (ужасно), момент, медленный, худший, часть, причина,
сейчас, высота, дом, уважение, внимание, голод,
неполный, сообщение, опыт, день, было,
запрос, недостаток, то же , напиток, вещь, полный, заряд, господин,
место, то же, кроме того, курьер доставки, только, чаевые,
доставщик, боль, меню, вид, простой, другой,
срок службы, продукт, эмбарго, компания , опция,
дорого, половина, реклама
Дополненный продукт
2
Проблемы продукта
(60 слов)
8. 6% объясненная разница
6% объясненная разница
Мясо, курица, картофель, старый, некрасивый, твердый, ужасный, сырой,
вкус, жирный, спросил, соус, рис, на Соль, салат, сыр,
дорого, качество, гамбургер, есть , приходите, количество,
ингредиент, отправляйте, хлеб, макароны, сайт, порция, нравится,
тарелка, початки, арепа, суп, цена, сухие, маленькие, красивые, салфетки,
нормальные, обычные, сок, коробка , кусок, содовая, презентация,
пицца, сумка, французская, покрытая, собака, сдача, крыло,
акция, комбо, тесто, большая, терияки, креветки,
лимонад, помидор
Фактический товар
3
Удовлетворенность бренда
(25 слов)
4.0% экспл. дисперсия
Вкусно, идеально, спасибо, отлично, богато, хорошо, быстро,
горячо, супер, люблю, рекомендую, суши, своевременно, круто,
доставить, пунктуально, соблюдать, вкусно, температура,
дружелюбно, улучшить , размер, комментарий, остальное, хорошо
Фактический продукт
4
Процесс оплаты
(13 слов)
2,6% объясн. отклонение
отклонение
Наличные, карта, оплата, деньги, устройство для чтения карт, сдача, билет,
песо, счет, стоимость, дополнительный, форма, серебро. Дополненный продукт
коммуникация.Это относится к опыту потребителей, когда они взаимодействуют как с электронной платформой
, так и с соответствующими службами физической доставки.
важных слов в этом факторе (слова, отмеченные желтым на рис. 2) относятся к
каналам связи, которые клиенты используют для подтверждения проблем с физическим адресом
, неполного заказа или отказа электронных и физических средств. . Темы
этого типа разговора и связанных слов могут охватывать бренд, продукт, услугу
или организацию (Chen & Xie, 2008; Raassens & Haans, 2017), что приводит к намерению переключения
(Wangenheim, 2016) .Поразительно, что клиенты
заявляют об уважении и личной поддержке своих заказов, показывая, что не только качество еды, но и обслуживание клиентов
является жизненно важным элементом.
Фактор 2 (проблемы с производством) Второй фактор отражает реальный продукт, который наследует
, и показывает лексическое разнообразие, заключенное в количестве уникальных слов. Обозначенные
в Таблице 2 (слова, отмеченные зеленым), эти слова связаны с проблемами продукта, а
выражают чувствительные мнения клиентов с точки зрения разнообразия продуктов питания, подачи продуктов питания
и условий доставки еды.Например, наиболее важные слова в этом факторе
относятся к мясу, курице и картофелю, что показывает, что потребители
рассматривают как измерение проблем продукта или уровня качества.
Фактор 3 (Удовлетворенность бренда) Третий фактор, отражающий реальный продукт, связывает
со словами удовлетворенности клиентов в отношении брендов продуктов питания и услуг (слова, отмеченные
голубым цветом на Рисунке 2). Этот параметр относится к набору комментариев, в которых
вербализирует важность температуры и вкуса пищи как критических условий, которые менеджеры
и владельцы ресторанов должны учитывать при доставке своих продуктов. Например,
Например,
, это измерение включает такие слова, как вкусно, идеально, спасибо, отлично, богато, хорошо,
10
Шесть основных аспектов семантического ИИ
В этом докладе я представлю гибридный подход и сосредоточусь на нем. называется «Семантический ИИ», который использует машинное обучение, как и большинство современных усилий ИИ, но в сочетании с обработкой естественного языка и семантическими технологиями. Мы обсудим, почему предприятиям нужно управление ИИ, и чем семантический ИИ отличается в этом отношении от других фреймворков.
Семантический ИИ — это подход, который имеет технические и организационные преимущества. Это больше, чем «еще один алгоритм машинного обучения». Это скорее стратегия искусственного интеллекта, основанная на технических и организационных мерах, которые реализуются на протяжении всего жизненного цикла данных. Семантический ИИ обеспечивает основу для развертывания ИИ в масштабах всего предприятия. В этом выступлении я также представлю «Шесть основных аспектов семантического ИИ», и мы обсудим, почему этот подход, как интегрированная стратегия ИИ, проявляет свое влияние на различных уровнях.
В частности, я приведу примеры и более подробную информацию о шести основных аспектах, а именно:
- Гибридный подход: семантический ИИ — это комбинация методов, полученных из символического ИИ и статистического ИИ.
- Качество данных: семантически обогащенные данные служат основой для повышения качества данных и предоставляют больше возможностей для извлечения признаков.
- Data as a Service: Связанные данные, основанные на стандартах W3C Semantic Web, могут служить платформой данных в масштабе предприятия и помогают предоставлять обучающие данные для машинного обучения более экономичным способом.
- Структурированные данные соответствуют тексту: большинство алгоритмов машинного обучения хорошо работают как с текстом, так и со структурированными данными, но эти два типа данных редко объединяются, чтобы служить как единое целое.
- Нет черного ящика: в отличие от технологий искусственного интеллекта, которые «работают как по волшебству», где лишь несколько экспертов действительно понимают лежащие в их основе методы, семантический ИИ стремится предоставить инфраструктуру для преодоления информационной асимметрии между разработчиками систем искусственного интеллекта и другими заинтересованными сторонами. .
- На пути к самооптимизирующимся машинам: семантический ИИ — это искусственный интеллект нового поколения. Машинное обучение может помочь расширить графы знаний, а, в свою очередь, графы знаний могут помочь улучшить алгоритмы машинного обучения (например, посредством «дистанционного наблюдения»).
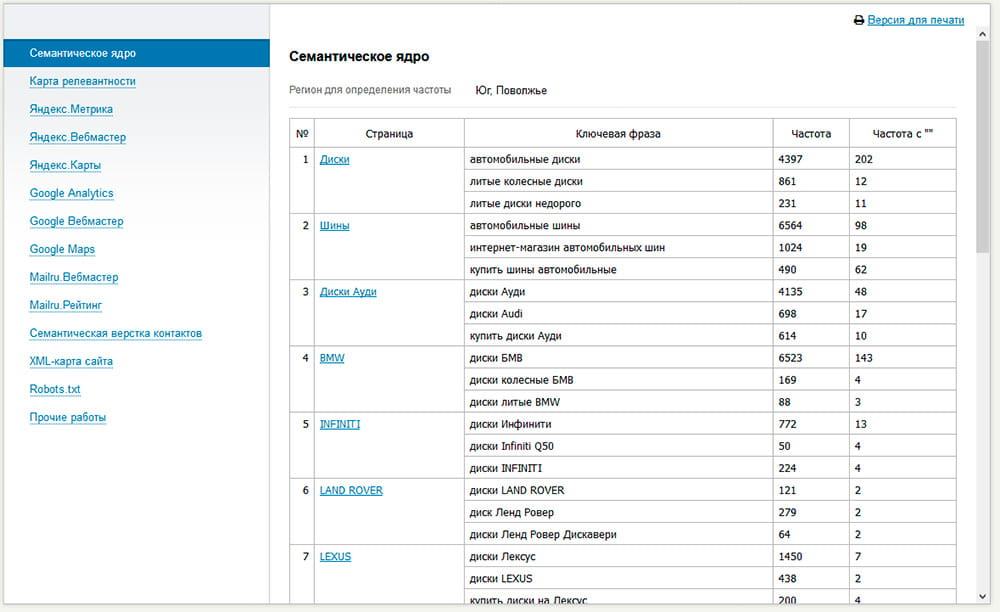 .
.«Управление данными в поддержку ИИ — это не разовый проект, а текущая деятельность, которая должна быть формализована как часть вашей стратегии управления данными» (Gartner 2018)
.