
Как правильно составить семантическое ядро
В начале было слово: семантическое ядро как основа продвижения сайта
Процесс продвижения вашего сайта и привлечение трафика из поисковых систем – задача многогранная и требующая целого комплекса самых разных мер. Но все это начинается со слов – ключевых запросов, по которым пользователи поисковиков придут на страницы вашего ресурса и останутся довольны результатом, то есть найдут искомую информацию, товары или услуги. Совокупность всех ключевых запросов для конкретного сайта и именуется семантическим ядром. Именно вокруг него «вертится» последующая и едва ли не самая важная работа по продвижению вашего сайта в поисковых системах.
По сути процесс составления семантического ядра – это подбор списка ключевых запросов, наиболее релевантных содержанию вашего сайта, то есть лучше всего характеризующих профиль и тематику данного ресурса. Проявите фантазию и поставьте себя на место пользователя – какие слова вы ввели бы в строку поиска, чтобы найти предлагаемые вашим сайтом товары или услуги, каковы возможные комбинации, синонимы? В этой работе вам помогут множество онлайн-сервисов статистики ключевых запросов, самые популярные из которых – Яндекс. Подбор слов и Планировщик ключевых слов Google, а также ряд платных сервисов. Итогом этой работы станет увесистый перечень самых разных запросов самой разной частотности.
Есть несколько правил дальнейшей работы с ним:
- Все имеющиеся запросы необходимо распределить по страницам сайта так, чтобы содержание страницы в наибольше степени соответствовало той или иной группе запросов;
- Если вы обнаружили группу запросов, близких друг к другу по тематике, ноне нашли для них релевантной страницы на сайте, такую страницу предстоит создать;
- по одному запросу можно продвигать только одну страницу, лучше всего отвечающую на данный запрос пользователя;
- для продвижения главной страницы следует выбирать наиболее общие и высокочастотные запросы;
- среднечастотные и низкочастотные запросы распределяются по вторичным страницам, также наиболее подходящим по тематике.


У многих возникает вопрос, что же первичнее: исходная структура сайта или семантическое ядро? Наверное, он сродни другому извечному вопросу «что первее – курица или яйцо», и однозначного ответа нет. Во всем должен быть баланс. Ясно одно – полное и грамотно составленное семантическое ядро поможет вам выявить недостатки структуры вашего сайта и устранить их так, чтобы пользователи всегда могли найти именно то, что им нужно. В этом и заключается залог успешного SEO-продвижения и увеличения посещаемости из поисковых систем.
Урок 63. Основы работы с семантическим ядром сайта
При продвижении сайта большое значение имеет правильная работа с семантическим ядром вашего ресурса. В такое ядро входит большое количество запросов, которые в будущем будут использоваться для его продвижения. Ранее мы уже не раз говорили о значимости составления правильного семантического ядра и дальнейшей работы с запросами. Пришло время обратить больше внимания на различные аспекты составления семантического ядра. В этом уроке мы рассмотрим процессы работы с ядром в контексте одного из важных этапов продвижения сайта. Вы получите важную информацию о частотности запросов и специфике запросов-масок.
Частотность как один из основных параметров запросов в семантическом ядре
Продвигать сайт можно нескольким основным группам запросов. К ним относятся:
- Низкочастотные вопросы. Низкочастотными называются те запросы, которые имеют частоту ввода менее 1 тысячи повторений. Такого рода запросы являются одними из наиболее перспективных при продвижении сайта в ТОП, так как позволяют хорошо конкретизировать область продвижения. Это оказывает благотворное влияние на путь вашего сайта в ТОП выдачи поисковых систем.
- Среднечастотные запросы используются не менее 1 тысячи и не более 10 тысяч раз. Работать с такими запросами сложнее, так как на рынке в данном сегменте сложился очень высокий уровень конкуренции. Однако среднечастотные запросы также хорошо подходят для продвижения страниц вашего сайта.
- Высокочастотные запросы повторяются в поисковых системах более 10 тысяч раз. Это высококонкурентные запросы, которые ориентированы на плотно заполненный рынок. Продвигать по высокочастотным запросам имеет смысл только главные страницы, в остальных случаях стоит использовать низко- и среднечастотники. Пример высокочастотного запроса – «деревянные окна».
 Однако среднечастотные запросы также хорошо подходят для продвижения страниц вашего сайта.
Однако среднечастотные запросы также хорошо подходят для продвижения страниц вашего сайта.Как составить правильное семантическое ядро с учетом таких характеристик запроса? Для этого стоит учитывать несколько важных рекомендаций:
- Всегда учитывайте тематику сайта. Запросы выбираются только относительно тематики сайта.
- Обратите внимание на техническую готовность вашего ресурса к продвижению по определённой группе запросов, а также ваши собственные финансовые возможности.
- Ориентироваться при составлении семантического ядра стоит и на поставленные ранее конечные цели продвижения. В зависимости от этого также может поменяться специфика использования определенной группы запросов.
- Рассчитывайте свой бюджет при работе с запросом. Высокочастотные запросы в работе могут стоить слишком дорого, что окажется полностью нецелесообразным для большинства заказчиков.
- Учитывайте специфику вашего сайта. При работе с высокочастотными запросами, ресурс должен быть технически готов принять большое количество посетителей.
Работа с высокочастотными запросами для небольших сайтов часто оказывается нецелесообразной и не отбивающей затраты. Именно по этой причине вам стоит обратить особое внимание на свои возможности и конечные цели.
Запросы-маски и специфика работы с ними
Ранее мы не касались такого понятия как «запрос-маска». А тем временем, при продвижении, работа с этими запросами имеет большое значение. Масками называются те запросы, которые состоят из одного или двух слов. Основная их задача – отражать одно из направлений работы вашей организации. Маски могут относиться как к классу высокочастотников, так и к классу среднечастотников. Однако в некоторых случаях также встречаются и низкочастотные запросы.
Основная их задача – отражать одно из направлений работы вашей организации. Маски могут относиться как к классу высокочастотников, так и к классу среднечастотников. Однако в некоторых случаях также встречаются и низкочастотные запросы.
Получение запроса-маски для сайта сопряжено с определением четкой тематики работы компании по одному из направлений. После того, как такая тематика определена, веб-мастер пользуется одним из статистических сервисов, в которых собирается информация по запросам, и выбирает наиболее релевантные и соответствующие по своей специфике определенной области. Яркие примеры таких запросов – продажа спецодежды, страхование жизни, ремонт телевизоров.
Для того, чтобы правильно подобрать запросы-маски при работе с сайтом, вам стоит обратить внимание на выполнение нескольких основных правил:
- Не стоит использовать слишком сильные обобщения. Всегда стоит помнить о том, что на сайт нужно привлекать именно целевой трафик, тех пользователей, которые могут стать постоянными клиентами в будущем. Для этого нужно конкретизировать сферу работы вашей компании и ориентироваться на требования конечной аудитории. Выбор слишком общих понятий при работе с маской неизбежно приведет к тому, что вы привлечете большое количество нецелевого трафика. Само продвижение по таким запросам будет очень затратным и слишком трудоёмким для вас. В ряде случаев это может не оправдать работы по выводу сайта в ТОП 10.
- Всегда стоит избегать запросов, которые не соответствуют специфике вашего бизнеса. Это связано с тем, что вы привлечете на ваш сайт большое количество незаинтересованных посетителей. Они не будут находить на сайте нужной информации и просто покинут его. Это очень резко и негативно отражается на поведенческих факторах, которые, напомним, высоко ценятся при ранжировании. Помимо этого, использование нетематических запросов может расцениваться поисковой системой как попытка ввести пользователя в заблуждение.

Как правильно составить семантическое ядро
Когда идея сайта уже созрела (тематика, дизайн и программная часть), то следующим этапом должен стать подбор ключевых слов
Сам процесс построения семантического ядра состоит из следующих этапов:
1. Определение как можно более длинного списка ключевых выражений (которые подходят по тематике данного ресурса).
Для этого вы изучаете тексты своего сайта, сайты конкурентов, включая мета-теги, пользуетесь тезаурусом и другими средствами.
2. Анализ каждого словосочетания из списка посредством проверки спроса и предложения.
Во время этого этапа у вас появятся новые варианты словосочетаний, которые вы добавляете в свой список, а затем проверяете на спрос/ предложение.
На данном этапе ваша задача отобрать те словосочетания, которые часто ищут пользователи Интернет и которые используются в качестве ключевых относительно небольшим количеством других сайтов. Здесь не обойтись без специальных сервисов.
Для российского Интернета (чтобы определить популярность того или иного словосочетания) можно воспользоваться:
Для англоязычного Интернета лучше воспользоваться:
Параллельно с процессом изучения спроса нужно проводить и процесс изучения конкуренции. Чтобы получить представление о конкуренции (то есть о том, сколько примерно сайтов оптимизирует страницы под это ключевое выражение), нужно воспользоваться расширенным поиском основных поисковых систем (достаточно проверить данные в Yandex для русскоязычного сайта и в Google для англоязычного).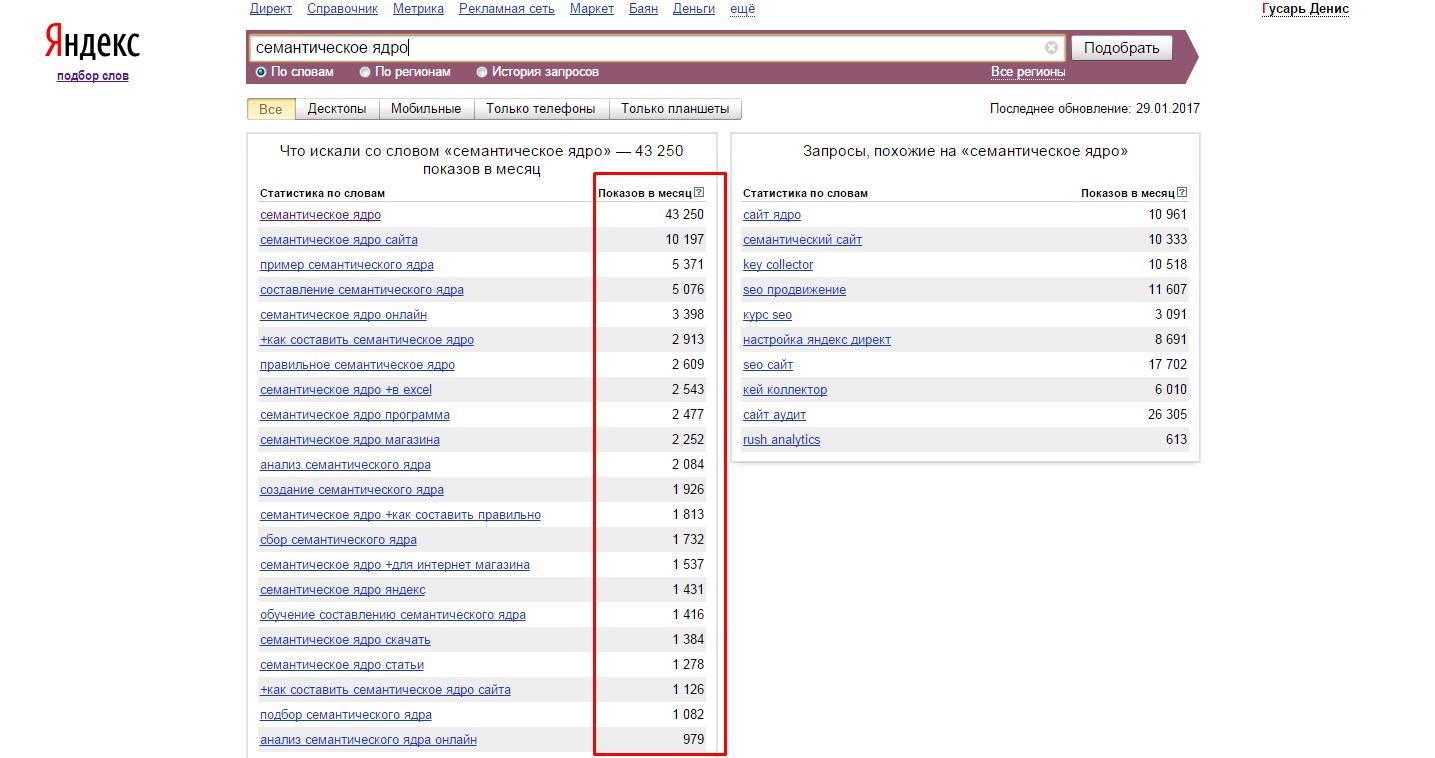
На основании полученного результата вы создаете список ключевых выражений с наилучшим отношением спрос/ предложение.
3. Размещение и оптимизация отобранных ключевых словосочетаний на страницах сайта.
Как минимум, вы должны использовать ключевые выражения в заголовке страницы, в тегах h2, h3, в тексте на странице. Рекомендуется использовать синонимы ключевых слов.
Процесс подбора ключевых слов важен на всех этапах жизнедеятельности сайта, так как является одним из способов привлечь большее количество целевых посетителей без дополнительных расходов на рекламу.
Автор Вячеслав Ивашкин, под редакцией 1PS.RU
P.S. Статья устарела, обновленную читайте по ссылке.
Как составить семантическое ядро сайта правильно в 2020 году
О том, как составить семантическое ядро, написаны мегатонны буковок, но то ли тема такая, то ли я такой, что долго не мог понять, как же это делается, в чем суть СЯ и каковы нюансы? Пришлось долго и нудно раскуривать завалы статей, результатом чего стала еще одна.
Итак, по общему мнению семантическое ядро сайта – полный список запросов, по которым продвигается сайт.
Создание семантического ядра для сайта, особенно мощного коммерческого – сложный и длительный процесс. Но с блогом проще. В случае блога СЯ носит более вальяжный характер.
Честно говоря, создавая Оружейную, я не чувствовал необходимости в каком-то там семантическом ядре. В голове я держал примерный курс развития и план написания статей. Этого, казалось, всегда будет достаточно.
Однако позже я начал задумываться… Вот, к примеру, обмен или покупка ссылок: нужно быстро выбрать запрос для продвижения, получить URL продвигаемой по этому запросу статьи и анкор. А быстро получается не всегда.
А вот другой пример: мониторинг позиций блога с программой Site Auditor. По каким запросам? Естественно, лучше по всем тем, по которым блог продвигается.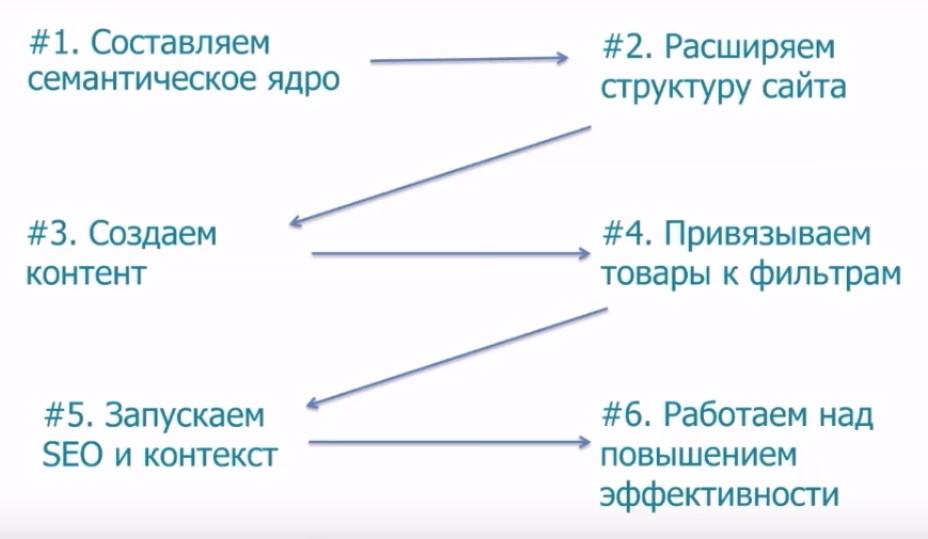 А где их взять? Листать страницы блога и вспоминать, под какой запрос написана какая статья? Нет, это не системно.
А где их взять? Листать страницы блога и вспоминать, под какой запрос написана какая статья? Нет, это не системно.
Семантическое «недоядро»
В общем, раз за разом я натыкался на мысль, что нужно иметь список или таблицу, вмещающую в себя:
- — ключевые запросы, по которым блог продвигается
- — URL статей, оптимизированных под соответствующий запрос
- — title этих статей
- — ну, и еще желательно приблизительную частотность запроса (хоть она и меняется, но хотя бы пометку: ВЧ, СЧ, НЧ)
- — а еще можно количество внешних ссылок в статье, но это уже роскошь.
Иными словами, жизнь сама подвела меня к необходимости семантического ядра.
Говоря строго, то, что я себе представлял было не совсем СЯ, а каким-то «семантическим недоядром», т. е. списком уже имеющихся статей и запросов, но до нормального СЯ от такого списка пара шагов.
Читая одну за другой статьи в интернет, я сталкивался с противоречиями. Кто-то преподносит создание ядра как легкое занятие, кто-то наоборот нагнетает, что сложность чрезвычайно высока: структура запросов в семантическом ядре должна соответствовать структуре страниц сайта и их перелинковке. Я не представлял, как применить эти рекомендации к своему блогу. Вывод, до которого я шел долго, чрезвычайно прост: создание СЯ – процесс сложный, но в отличие от коммерческих сайтов, для блога процесс может быть значительно упрощен.
СЯ – список запросов, по которым продвигается блог. И точка. Не имеет значения, как он будет представлен и что будет содержать, кроме самих запросов, но для удобства я решил делать его в электронных таблицах (Excel, Calc) и помимо запросов указывать другую информацию, перечисленную в списке выше.
Основное отличие списка статей и запросов, о котором я мечтал поначалу, от полноценного семантического ядра в том, что настоящее ядро – это еще и Ваш roadmap в наполнении блога материалами. Ведь ядро может содержать и те запросы, статьи по которым еще не написаны. То есть, выполнять функцию планирования.
То есть, выполнять функцию планирования.
Завел я, к примеру, сайтег про дыхательные методики и сразу составил список запросов (читай статей и разделов сайта), которые предстоит написать.
Или заметил, я скажем, в вордстат. яндексе забавный запрос «основатель математики», ввел его в поиск, а в ответ, – оппаньки! – ни одной более-менее релевантной статьи… «Эге, – думаю, – надо бы заполнить пустоту статейкой на skolkobudet. ru». Кто основал математику, я, разумеется, четкого представления не имею, но это не значит, что не смогу написать небольшое словоблудие исследование, оптимизированное под этот запрос.
В общем, вот. Теперь поговорим конкретнее о том, как составить семантическое ядро блога: сбор запросов
Ядро состоит из запросов. Сколько запросов для своего сайта вы придумаете сходу? У меня получалось не больше 10. К счастью, фантазия не единственный их источник. Запросы для семантического ядра можно взять в следующих местах:
1) ну, перво-наперво из головы, да. Ее никто не отменял. К примеру, я без всяких фокусов знаю, что мой сайт skolkobudet. ru отвечает запросу «деление в столбик», «системы счисления тренажер» и «тренажеры по математике». Также я знаю, что для Оружейной подойдут запросы: «летающая птичка twitter», «загнутый угол page peel» или «блоггинг». А предполагаемый бложек про дыхательные методики будет иметь в ядре запросы «дыхательные методики», «метод Бутейко», «метод Фролова», «тренажер Фролова» и т. п.
То есть, основу для семантического ядра составляет наши собственные представления о том, чему в общем посвящен сайт, или что могут на нем искать посетители. Эти запросы можно использовать как отправную точку в Wordstat. yandex и сервисах подбора ключевых запросов.
2) с сайта/блога. Если сайт уже существует, если уже есть страницы, соответствующие каким-то запросам, эти запросы, конечно, включаем в ядро.
3) из wordstat. yandex. ru и adwords. google. ru. Набираем, к примеру, запрос «математика» (взятый из головы) и видим различные варианты запросов с этим словом, а также связанные запросы (см. выше про запрос «основатель математики»). Не забываем про использование кавычек и восклицательного знака в вордстат. яндексе. Так статистика будет точной для этого словосочетания, а не для всех его словоформ. Иными словами: «! устный! счет» — 126 показов в месяц (и это точно), а устный счет — 3822 показа в месяц (это с кучей других запросов, содержавших «устный счет» в различных словоформах).
выше про запрос «основатель математики»). Не забываем про использование кавычек и восклицательного знака в вордстат. яндексе. Так статистика будет точной для этого словосочетания, а не для всех его словоформ. Иными словами: «! устный! счет» — 126 показов в месяц (и это точно), а устный счет — 3822 показа в месяц (это с кучей других запросов, содержавших «устный счет» в различных словоформах).
Я не буду здесь описывать технологию работы с wordstat. yandex и adwords. google. Я писал об этом в статье про подбор ключевых слов для статьи. Да и интерфейс, в общем-то, прозрачен.
4) с сайтов-конкурентов. Если чей-то сайт пробился в ТОП-5, значит, не худо перенять опыт. Заходим на Megaindex (или в какой-то другой ссылочный агрегатор, имеющий аналогичный функционал), выбираем раздел «Анализ сайтов», вводим URL сайта-конкурента и видим запросы, по которым продвигается сайт:
Вот таким вот нехитрым способом Megaindex позволяет узнать, по каким запросам (всего их около 850) продвигается взятый для примера блог А. Борисова. Некоторые запросы грех не позаимствовать в качестве тем для будущих статей.
Кстати, 30 мая MegaIndex проводит бесплатный семинар по аудиту сайтов:
Сервис подбора запросов от Megaindex предлагает мне вот такие запросы для семантического ядра сайта seo-armory. ru. Данные получены на основании автоматического анализа сайтов-конкурентов.
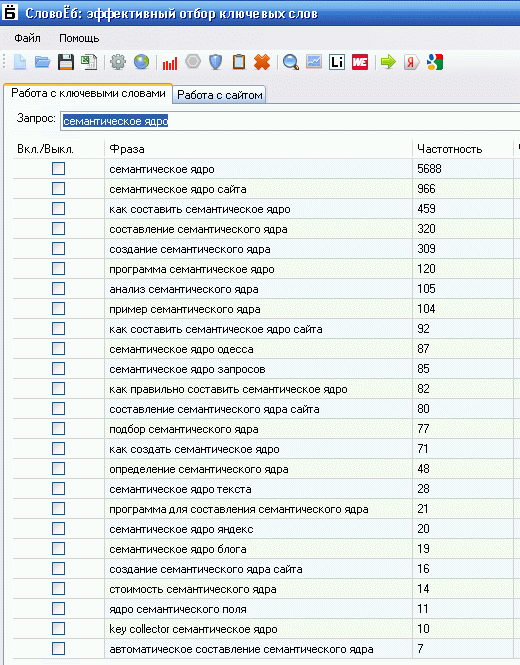
5) пользуясь парсерами ключевых слов. KeyCollector (и бесплатный младший брат его СловоЁб), Магадан (версия LITE бесплатна в отличие от PRO), Анадырь (бесплатен)… Всё это программы, позволяющие значительно упростить и ускорить сбор ключевиков с сервисов wordstat. yandex. ru и adwords. google. ru, а также с массы других сервисов (например, с ссылочных агрегаторов). Как правило, парсеры имеют массу удобных функций, значительно облегчающих жизнь составителю СЯ.
6) из готовых баз ключевых слов. Да, база Пастухова. Да, стоит в районе 500$. Да, облизнулись и читаем дальше. Ну, или купили побыренькому и читаем дальше.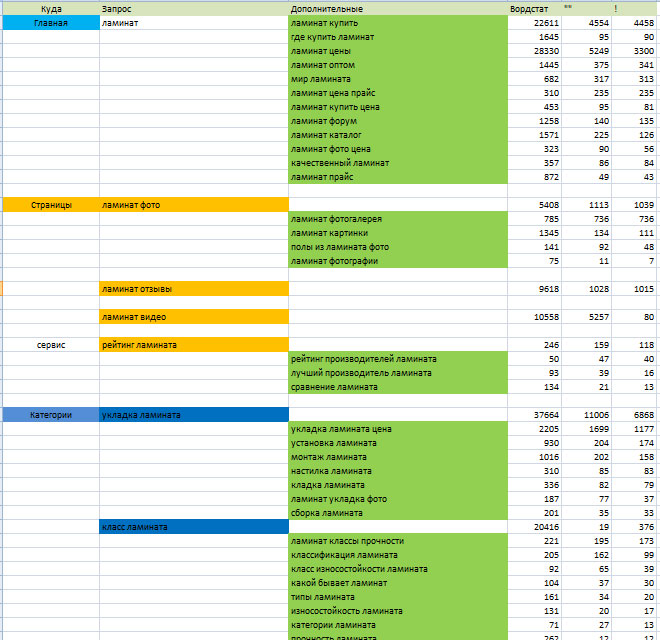 Хотя есть и бесплатные базы. Например, база, которую можно взять на keybooster. ru (на момент написания статьи URL не открывается). Кроме того, эта база интегрирована в программу Магадан, которую можно взять на magadanparser. ru (открывается нормально).
Хотя есть и бесплатные базы. Например, база, которую можно взять на keybooster. ru (на момент написания статьи URL не открывается). Кроме того, эта база интегрирована в программу Магадан, которую можно взять на magadanparser. ru (открывается нормально).
А дальше?
Итак, мы надергали изо всех указанных мест несколько сотен (или тысяч) запросов и смотрим на этот список. Что делать дальше?
Фильтрация ключевых запросов
Какие из попавшихся запросов подходят для нашего сайта/блога? Есть 5 критериев фильтрации:
1) Перво-наперво исключаем те запросы, по которым не собираемся писать статьи. Это могут быть замечательные во всех отношениях запросы, но нам с ними не по пути. Мы не будем о них писать. Например, MegaIndex предложил в числе прочих запросы «монетизация форума» и «интернет-магазин на Joomla». Я пока далек от монетизации форумов (есть у меня один форум, но ему еще расти и расти). CMS Joomla тоже пока не входит в круг моих интересов. Зачем мне эти запросы? Выкидываю их.
Часто можно сразу выкинуть запросы, содержащие слова «реферат», «бесплатно» или «скачать» (если, конечно, вы не предлагаете рефераты, халяву или файлы для скачивания).
2) Взглянем на статистику запросов (в том же вордстате). Нужен ли нам в семантическом ядре запрос, которым озадачились всего 5 человек в месяц? Не думаю. Потому, подбирая запросы, отсеиваем всё, что принесет меньше 10 человек в месяц (а хотите меньше 20 или 30, всё зависит от Вашего самомнения). Но будьте внимательны: вордстат в отличие от гугл эдвордс не учитывает сезонность. Вряд ли зимой в Москве запрос «куда выйти на шашлыки» будет так же популярен, как летом. Ориентировочно: низкочастотный (НЧ) запрос – менее 1000 в месяц, среднечастотные (СЧ) – от 1000 до 10000, высокочастотные (ВЧ) – более 10000.
3) Кстати, о Москве. Важно также настроить регион продвижения. Это позволяют сделать все сервисы, даже вордстат. Статистика запросов может сильно отличаться для разных регионов.
4) Мы не одни такие умные, что продвигаемся в инете. Конкуренция всеобъемлюща. По каждому запросу у нас будут конкуренты. Запросы делятся на высоко-, средне- и низкоконкурентные. Эдвордс показывает уровень конкуренции по запросам, правда, не расшифровывая, что такое «низкий», «средний», «высокий» в его понимании. Лезть в высококонкурентные области мне как-то страшновато. Запинают и не заметят. Или даже просто не заметят.
Конкуренция всеобъемлюща. По каждому запросу у нас будут конкуренты. Запросы делятся на высоко-, средне- и низкоконкурентные. Эдвордс показывает уровень конкуренции по запросам, правда, не расшифровывая, что такое «низкий», «средний», «высокий» в его понимании. Лезть в высококонкурентные области мне как-то страшновато. Запинают и не заметят. Или даже просто не заметят.
5) Следует также исключить из семантического ядра накрученные запросы, то есть, имеющие высокую базовую частотность, но «! крайне! малую! частотность! по! точной! словоформе» (см. выше). Скорее всего, такие запросы имеют высокую базовую частотность из-за действий оптимизаторов, мутящих воду в яндексе своими бесконечными составлениями семантических ядер. Если разница между двумя частотностями – 10-30 раз, это признак накрученного запроса.
Кроме того, полезно набрать интересующий запрос в поиске и посмотреть выдачу. Если в ТОП-10 суперпуперсайты, то ловить нечего. Плохо (для нас), когда в выдаче главные страницы сайтов («морды»). Вторые по вложенности – получше. Третьи – совсем хорошо (для нас). Если в тайтлах ТОП-10 есть прямые вхождения ключевиков – это для нас тоже плохо. Кое-где встречаются рекомендации не связываться с запросами, по которым в выдаче больше 4 «морд».
Настоятельно советую пооткрывать сайты ТОП-10 по данному запросу и на глаз оценить их конкурентный потенциал. Более подробных рекомендаций тут не даю, т. к. анализ сайтов-конкурентов – это тема для отдельного и долгого разговора.
В общем, фильтруем запросы, исходя из частотности и конкурентности. И не думайте, что второе прямо пропорционально первому.
В итоге
Итак, после мозгового штурма и фильтрации у нас в руках (в Блокноте, в gedit, в Excel, Calc или даже на бумажке) есть список ключевых слов. У меня для Оружейной получилось около трех сотен запросов. Форма их записи – свободная. Главное, чтобы вам было удобно.
Вот этих тем и ждет от Вас Общественность. Вот по этим запросам и надо выбирать тему для ВОСТРЕБОВАННЫХ статей.
Фрагмент семантического ядра Оружейной в процессе работы над ним. Не утверждаю, что это ядро — безусловный образец для подражания, но оно хотя бы дает представление о том, как МОЖЕТ выглядеть семантическое ядро..
Если вы указываете в ядре соответствующие запросам страницы, учтите, что теоретически одна страница может быть оптимизирована под несколько схожих запросов. Например, для этой статьи запросто: «семантическое ядро» и «семантическое ядро сайта».
Учтите так же, что семантическое ядро блога – это не статуя, а вполне себе живое образование, то есть, его можно и нужно менять по мере изменения вашего взгляда на собственный блог и наполнения его контентом. В этом еще одно отличие блога от коммерческого сайта, который зачастую предполагает более-менее постоянное содержимое.
Как правильно составить семантическое ядро сайта
Опубликовано: 20.05.2016г.
Успешность продвижения сайта во многом определяется правильностью составления семантического ядра (запросов пользователей в поисковиках) на самом первом этапе работы с сайтом.
Как обычно бывает
Поверхностные знания владельцев копоративных сайтов и интернет-магазинов о сути и назначении семантического ядра дает пространство для маневра со стороны недобросовестных исполнителей. В результате:
- SEO компания или фрилансер выбран по принципу обещает продвинуть «больше запросов за меньшие или такие же деньги»
- оптимизируются страницы сайта под большой спектр запросов (5-6 и более запросов на страницу)
- пишется большое количество SEO текстов, в т.ч. на новые страницы сайта
- на сайте создаются новые разделы типа «новости», «статьи», «полезная информация», которые весьма опосредованно относятся к основному коммерческому содержанию сайта
- размещаются рекламные ссылки и статьи
- растут позиции по запросам
- посещаемость сайта тоже растёт
- заказчику вручаются красивые отчеты о проделанной работе и выросших позициях
- заказчик платит каждый месяц по счетам
- а продаж как не было, так и нет
Описанная ситуация очень распространена.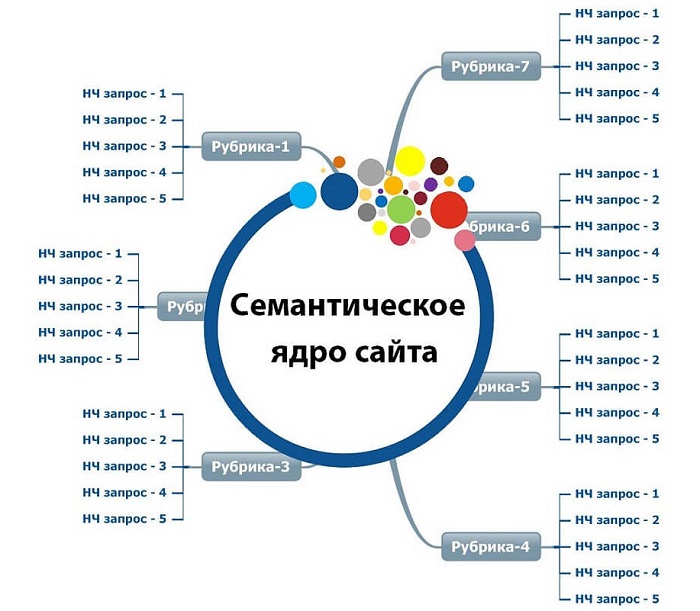 И практически каждый второй, если не первый владелец сайта, задумывается о смене подрядчика по продвижению, именно по описанной причине.
И практически каждый второй, если не первый владелец сайта, задумывается о смене подрядчика по продвижению, именно по описанной причине.
Где ошибка?
Посетители, которые заходили на сайт, не ставили своей целью покупку товара или заказ услуги.
Почему так происходит?
Причины включения «нерабочих» запросов в семантическое ядро бывают разные, но наиболее частые из них:
- «сеошник» не вник в специфику бизнеса заказчика
- действительно сложная тематика, что и сам заказчик не знает по каким запросам его товар могут искать
- заказчик «сам настоял» на включении некоторых запросов
- «обещали продвинуть по 100 запросам, вот и наскребли»
Как ни странно, но последний пример из списка, можно отнести к разряду классических, когда специалист подобрал 76 запросов, а менеджер по продажам требует подобрать ровно 100 запросов, чтобы было как в том «пакетном предложении на сайте». В итоге рождаются запросы и фразы благодаря фантазии специалиста, а не исходя из анализа данных статистики запросов поисковых систем.
Как избежать подобной ситуации заказчику?
На этапе составления семантического ядра крайне желательно:
- привлекать к работе специалистов заказчика. Только они могут обозначить товары и услуги, которые наиболее востребованы на рынке, а также дать альтернативные названия товаров (на сленге, наименования аналогов).
- запрашивать коммерческие предложения от 5 и более SEO компаний. В этом случае фактор человеской ошибки будет минимизирован и из различных предложений со списками запросов можно подготовить один перечень, который будет наиболее объективным.
- анализировать текущую выдачу по исследуемым запросам.
- использовать данные счетчиков статистики сайта Яндекс Метрика и Google Analytics.
Оценка коммерческих и информационных запросов
Для коммерческих сайтов крайне важно, чтобы семантическое ядро включало коммерческие запросы, по которым пользователи явно выражают намерение купить товар или заказать услугу.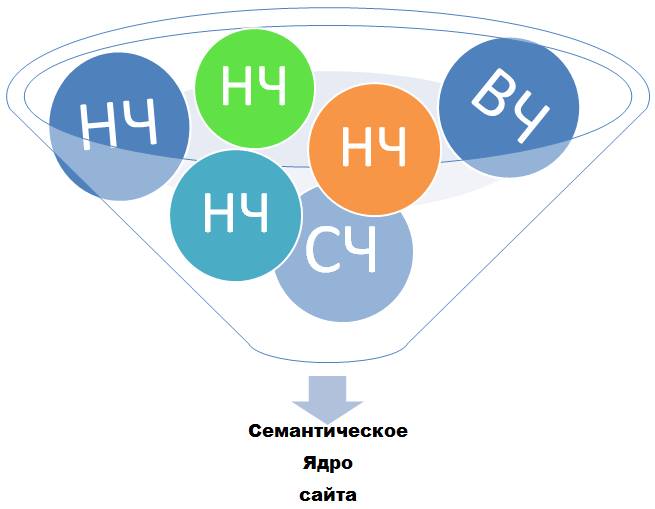
| «Плюс-слова» | «Минус-слова» |
|
|
Оценка навигационных запросов
Как правило, навигационные запросы стоит относить к коммерческим, в том случае, если пользователь вводит часть названия вашей организации или пользователь указывает регион (область, город), в котором ему интересна информация и заказчик в состоянии работать с таким клиентом.
Пример навигационного запроса: «стрижка собак на шварца» или «ремонт окон екатеринбург».
Оценка общих запросов
Порой общий запрос вида «пластиковые окна» сложно отнести к коммерческому или информационному, поскольку один пользователь может искать и информацию, а другой — товар. В этом случае следует анализировать текущую выдачу поисковой системы по данному запросу.
Принцип простой:
- Если в выдаче присутствуют главным образом новостные сайты и сайты некоммерческого формата (блоги, форумы, странички из соцсетей), то такие запросы также не стоит включать в список запросов для продвижения.
- Если в выдаче по запросу есть сайты-конкуренты или сервис Яндекс Маркет, то это хороший признак того, что большая часть пользователей ищут товар для покупки или услугу.
Оценка эффективности с учетом сезонности
Есть много тематик, где список запросов нужно составлять с учетом фактора сезонности. Например, услуга «шиномонтаж» востребована главным образом весной и осенью, поэтому при составлении семантического ядра лучше всего при сборе данных ориентироваться на пиковые показатели в сезон, т. .е. анализировать данные за март-апрель и октябрь-ноябрь.
.е. анализировать данные за март-апрель и октябрь-ноябрь.
Пример составления списка эффективных запросов
Рассмотрим тематику «продвижение сайтов» в регионе Екатеринбург. В качестве источника данных для анализа используем сервис Яндекс Вордстат.
В Вордстате данные по запросу представлены в двух столбцах.
Левый столбец показывает варианты от исходного запроса, которые вводили пользователи,а правый столбец показывает «похожие» запросы. С данными правого столбца следует работать в том случае, если запрос явно соответствует тематике сайта.
| Запрос | Частотность | Тип запроса |
| продвижение сайтов | 3195 | коммерческий |
| продвижение сайтов екатеринбург | 726 | коммерческий |
| создание и продвижение сайтов | 127 | коммерческий |
| самостоятельное продвижение сайта | 97 | информационный |
| продвижение сайта самостоятельно | 97 | информационный |
| seo продвижение сайта | 88 | информационный |
| поисковое продвижение сайтов | 84 | коммерческий |
| сео продвижение сайта | 69 | информационный |
| система продвижения сайта | 56 | навигационный |
| продвижение сайта цена | 53 | коммерческий |
| продвижение сайта бесплатно | 51 | информационный |
| бесплатное продвижение сайта | 51 | информационный |
| продвижение сайта в яндексе | 47 | информационный |
| продвижение сайта в поисковых системах | 44 | коммерческий |
| разработка и продвижение сайтов | 40 | коммерческий |
| заказать продвижение сайта | 35 | коммерческий |
| оптимизация и продвижение сайтов | 32 | коммерческий |
| работа продвижению сайта | 31 | коммерческий |
| создание и продвижение сайтов екатеринбург | 29 | коммерческий |
| продвижение сайта в интернете | 27 | коммерческий |
| продвижение сайта недорого | 27 | коммерческий |
| недорогое продвижение сайтов | 27 | коммерческий |
| продвижение сайта скачать | 27 | информационный |
| продвижение сайта стоит | 25 | коммерческий |
| продвижение сайта инструкция | 25 | информационный |
| пошаговое продвижение сайта | 25 | информационный |
| продвижение сайта самостоятельно пошаговая инструкция | 24 | информационный |
| продвижение статей сайта | 24 | информационный |
| продвижение сайта статьями | 24 | информационный |
| продвижение сайтов пошаговая инструкция | 24 | информационный |
| продвижение сайта самостоятельно пошаговая | 24 | информационный |
| продвижение сайтов отзывы | 23 | информационный |
| сколько стоит продвижение сайта | 21 | коммерческий |
| компании по продвижению сайта | 21 | навигационный |
| продвижение сайта ссылками | 21 | информационный |
| продвижение сайта 2016 | 21 | информационный |
| создание и продвижение сайтов недорого | 20 | коммерческий |
| недорогое создание и продвижение сайтов | 20 | коммерческий |
| стоимость продвижения сайта | 20 | коммерческий |
| договор на продвижение сайта | 19 | информационный |
| поисковая оптимизация и продвижение сайтов | 19 | информационный |
| продвижение сайта своими руками | 18 | информационный |
| продвижение сайта текстами | 18 | информационный |
| студия продвижения сайтов | 17 | навигационный |
| продвижение сайтов пермь | 17 | навигационный |
| продвижение новых сайтов | 16 | информационный |
| нова продвижение сайтов | 16 | навигационный |
| план продвижения сайта | 16 | информационный |
| технология продвижения сайтов | 16 | информационный |
| продвижение сайтов торрент | 16 | информационный |
Удаляем из списка информационные запросы и те навигационные, которые не подходят по своему содержанию.
Промежуточный результат.
| Запрос | Частотность | Тип запроса |
| продвижение сайтов | 3195 | коммерческий |
| продвижение сайтов екатеринбург | 726 | коммерческий |
| создание и продвижение сайтов | 127 | коммерческий |
| поисковое продвижение сайтов | 84 | коммерческий |
| продвижение сайта цена | 53 | коммерческий |
| продвижение сайта в поисковых системах | 44 | коммерческий |
| разработка и продвижение сайтов | 40 | коммерческий |
| заказать продвижение сайта | 35 | коммерческий |
| оптимизация и продвижение сайтов | 32 | коммерческий |
| работа продвижению сайта | 31 | коммерческий |
| создание и продвижение сайтов екатеринбург | 29 | коммерческий |
| продвижение сайта в интернете | 27 | коммерческий |
| продвижение сайта недорого | 27 | коммерческий |
| недорогое продвижение сайтов | 27 | коммерческий |
| продвижение сайта стоит | 25 | коммерческий |
| сколько стоит продвижение сайта | 21 | коммерческий |
| создание и продвижение сайтов недорого | 20 | коммерческий |
| недорогое создание и продвижение сайтов | 20 | коммерческий |
| стоимость продвижения сайта | 20 | коммерческий |
| компании по продвижению сайта | 21 | навигационный |
Добавим к данным результаты анализа по запросу-синониму «раскрутка сайтов». Процесс оценки запросов опущен и дан конечный результат с сортировкой запросов по частотности.
Процесс оценки запросов опущен и дан конечный результат с сортировкой запросов по частотности.
| Запрос | Частотность | Тип запроса |
| продвижение сайтов | 3195 | коммерческий |
| продвижение сайтов екатеринбург | 726 | коммерческий |
| раскрутка сайта | 310 | коммерческий |
| создание и продвижение сайтов | 127 | коммерческий |
| поисковое продвижение сайтов | 84 | коммерческий |
| продвижение сайта цена | 53 | коммерческий |
| продвижение сайта в поисковых системах | 44 | коммерческий |
| разработка и продвижение сайтов | 40 | коммерческий |
| раскрутка сайтов екатеринбург | 38 | коммерческий |
| заказать продвижение сайта | 35 | коммерческий |
| оптимизация и продвижение сайтов | 32 | коммерческий |
| работа продвижению сайта | 31 | коммерческий |
| создание и продвижение сайтов екатеринбург | 29 | коммерческий |
| продвижение сайта в интернете | 27 | коммерческий |
| продвижение сайта недорого | 27 | коммерческий |
| недорогое продвижение сайтов | 27 | коммерческий |
| продвижение сайта стоит | 25 | коммерческий |
| сколько стоит продвижение сайта | 21 | коммерческий |
| компании по продвижению сайта | 21 | навигационный |
| создание и продвижение сайтов недорого | 20 | коммерческий |
| недорогое создание и продвижение сайтов | 20 | коммерческий |
| стоимость продвижения сайта | 20 | коммерческий |
| раскрутка сайта цена | 7 | коммерческий |
| раскрутка сайта в интернете | 6 | коммерческий |
| раскрутка сайта в поисковых системах | 5 | коммерческий |
| поисковая раскрутка сайта | 5 | коммерческий |
| создание и раскрутка сайтов | 4 | коммерческий |
| раскрутка сайтов работа | 4 | коммерческий |
| раскрутка сайта месяц | 4 | коммерческий |
| раскрутка сайта цена в месяц | 3 | коммерческий |
| раскрутка и продвижение сайта | 3 | коммерческий |
| раскрутка веб сайта | 3 | коммерческий |
В результате анализа двух общих запросов «продвижение сайтов» и «раскрутка сайтов» был получен список из 32 коммерческих запросов, по которым можно проводить дальнейшую работу по оценке эффективности.
Стоит отметить, что при общем количестве анализируемых запросов в 100 штук, доля коммерческих запросов составила всего 32%.
Оценка запроса с учетом частотности
Очевидно, что одни запросы пользователи вводят в поисковике чаще, а другие реже. Частотность Яндекс Вордстат как раз таки помогает определить те запросы, продвижение которых даст прогнозируемый трафик из Яндекса.
Для определения реальной популярности запроса необходимо проверять частотность в строгом соответствии. Для этого используется оператор с использованием кавычек и восклицательного знака перед каждым словом в запросе «![ключ 1] ![ключ 2]».
Для данной тематики эффективным запросом для продвижения можно считать запросы с частотностью в строгом соответствии больше 5.
В итоге получаем:
| Запрос | Частотность | В строгом соответствии |
| продвижение сайтов | 3195 | 628 |
| продвижение сайтов екатеринбург | 726 | 434 |
| раскрутка сайта | 310 | 69 |
| создание и продвижение сайтов | 127 | 31 |
| раскрутка сайтов екатеринбург | 38 | 21 |
| разработка и продвижение сайтов | 40 | 18 |
| создание и продвижение сайтов недорого | 20 | 18 |
| заказать продвижение сайта | 35 | 17 |
| создание и продвижение сайтов екатеринбург | 29 | 17 |
| продвижение сайта в поисковых системах | 44 | 12 |
| продвижение сайта цена | 53 | 8 |
| поисковое продвижение сайтов | 84 | 7 |
| продвижение сайта в интернете | 27 | 7 |
| стоимость продвижения сайта | 20 | 6 |
Из исходного списка в 100 запросов были оттобраны 14 запросов, продвижение по которым может обеспечить целевых посетителей.
Как подобрать семантическое ядро. Основные принципы. Читайте на Cossa.ru
Основа поискового продвижения — грамотный и наиболее полный сбор семантического ядра. Для эффективного продвижения проекта вы должны знать, чем интересуется ваша целевая аудитория и как она ищет информацию. Такие данные помогут сделать сайт интересным для пользователей, главное — правильно их использовать.
Семантическое ядро — это набор поисковых фраз и словосочетаний, которые наиболее полно отражают тематику вашего сайта и отвечают на основной вопрос — какую информацию там можно найти. В первую очередь нужно ориентироваться на клиентов, то есть конкретизировать запросы, которые они используют для поиска ответов на свои вопросы.
Виды сбора семантики и частотность
Автоматический
Отлично подходит, если вам нужно собрать максимально полное семантическое ядро и оценить структуру сайта. Также применяется для решения узких задач, но в основном это нецелесообразно из-за больших временных затрат на очистку.
Чаще всего в него входят:
- расширенный сбор ключей из разных колонок Wordstat;
- сбор всевозможных подсказок;
- сбор ключевых фраз с сайтов-конкурентов.
Как продвигать финансовые проекты в интернете?
Спецпроект о цифровых инструментах, которые помогают банкам, стартапам и другим финкомпаниям. Тексты экспертов и ничего лишнего:
- Какие инструменты и подходы использовать для маркетинга;
- Как распределить рекламный бюджет и настроить воронку продаж;
- Какие каналы пора освоить, пока этого не сделали конкуренты;
- Как развиваться и адаптировать рекламу под горячий рынок финуслуг.
Всё про диджитал для «финансов» →
Реклама
В статье рассмотрим именно этот вид.
Ручной
Способ подходит для сбора небольшого количества ключевых фраз — например, для нескольких разделов. Вы практически не будете тратить время на очистку и сэкономите часы на кластеризацию. Ключевые фразы вручную удобно собирать при помощи сервиса Wordstat с бесплатным приложением к браузеру Yandex Wordstat Assistant.
Учитывайте частотность запросов, которая делится на 3 типа.
- Обычная — общая частотность всех ключевых запросов, содержащих фразу с вхождениями дополнительных слов и в разных словоформах.
- В кавычках — частотность всех ключевых запросов, которые содержат именно эту фразу, возможно, в разных словоформах, без вхождения дополнительных слов.
- В кавычках и с восклицательным знаком — точная частотность ключевой фразы в заданной словоформе и без вхождения дополнительных слов.
Общая частотность неточная, поэтому для SEO чаще используется в [кавычках], реже в ![кавычках] и восклицательным знаком.
Зачем нужно собирать семантического ядро
Без правильно собранной семантики вы не сможете:
- прогнозировать трафик;
- оценить видимость сайта;
- составить чёткое ТЗ на SEO-тексты;
- грамотно провести внутреннюю оптимизацию;
- составить полную структуру сайта;
- определить список ключей под контент-маркетинг;
- корректно рассчитать стоимость работ в SEO.
Сбор семантического ядра — это основа основ и путь к светлому будущему. Своеобразный фундамент для SEO-специалиста, на который он будет опираться в процессе работы над проектом.
Пример из охранной тематики, сбор маркерных запросов
Перед автоматическим сбором семантического ядра важно учесть все нишевые маркерные запросы, чётко отвечающие продвигаемой странице, иначе ядро будет неполным. Чаще всего — это высокочастотные запросы: названия разделов, категорий, рубрик и подобные.
Чаще всего — это высокочастотные запросы: названия разделов, категорий, рубрик и подобные.
У каждого сайта/тематики, как правило, свой набор услуг или товаров. Рассмотрим пример сбора семантического ядра для крупной компании по установке систем безопасности и охранных сигнализаций.
Маркерными запросами для нашего сайта будут:
- умный дом;
- охранные датчики;
- тревожная кнопка;
- пожарная сигнализация;
- установка видеонаблюдения;
- система контроля доступа.
Что необходимо, чтобы правильно собрать все маркерные запросы.
- Проанализировать структуру и собрать все маркеры с продвигаемого сайта.
- Сделать то же самое, что и в первом пункте, только по сайтам основных конкурентов.
- Уточнить у владельца сайта весь список товаров или услуг, которые у него имеются.
- Сопоставить собранные маркеры с текущими товарами/услугами сайта/компании и убрать лишнее — это сократит время на очистку.
Автоматический сбор и очистка СЯ
Вы собрали все маркерные запросы, теперь можно приступать к сбору семантического ядра, который состоит из нескольких этапов.
- Сбор ключевых фраз из левой и правой колонки Wordstat.
-
Сбор поисковых подсказок и запросов из нижней части выдачи Яндекс.
Чаще всего для этих двух пунктов используется программа Key Collector, правда, у некоторых крупных компаний есть свои внутренние разработки. -
Сбор подсказок из YouTube.
Это значительно расширит количество ключевых фраз. На данный момент можно воспользоваться бесплатным инструментом от Pixel Tools или платным от Rush Analytics. -
Сбор ключевых фраз с сайтов основных конкурентов.
Для этой цели существует масса условно-бесплатных и платных инструментов: Bukvarix, Spywords, Serpstat и другие.
Не пугайтесь огромного количества ключей после сбора ключевых фраз и подсказок — всё не так страшно. Очищать семантику сначала нужно в автоматическом режиме, при помощи стоп-слов и специальных правил фильтрации в программе Key Collector. В ней можно отделить от своего ядра запросы с «точной частотностью» = 0 или по другому условию, в зависимости от сезонности и необходимого количества ключевых фраз.
Ключевые фразы удаляются по критериям:
- опечатки и лишние символы в запросе;
- запросы с нулевой точной частотностью — необязательно удалять совсем, так как они бывают полезны при дальнейшем продвижении из-за фактора сезонности;
- запросы с названием товарных позиций/моделей, которых нет на сайте;
- одинаковые запросы, но с разным окончанием;
- навигационные запросы для других сайтов;
- запросы, включающие название страниц или услуг, которых нет на сайте — например: инструкция, отзывы, рассрочка, б/у, видео;
- запросы для другой тематики;
- запросы для других городов, регионов;
- неявные дубли.
Бо́льшая часть ненужных слов удаляется автоматически, а дальше потребуется кропотливая ручная работа. Многие специалисты пользуются инструментом «Анализ групп» в Key Collector, чтобы ускорить процесс.
На примере нашего кейса охранной тематики — после сбора семантики количество ключевых фраз было более 42 тысяч, после очистки осталось всего 924.
Кластеризация и определение посадочных страниц
Это разбиение, распределение запросов из очищенного семантического ядра по группам/кластерам на основании сходства сайтов конкурентов в выдаче поисковой системы. На сегодняшний день существует много инструментов по автоматической кластеризации, например:
- SE Ranking;
- Rush Analytics;
- Pixel Tools;
- Topvisor;
-
Serpstat.

Все они приблизительно схожи по точности, потому что основаны на одних и тех же принципах. Различие только в дополнительных функциях:
- автоматическое определение посадочных страниц;
- сбор LSI-фраз;
- сбор синонимов, тематических фраз и тому подобного.
В Key Collector также можно воспользоваться инструментом автоматической кластеризации, но придётся потратить больше времени на ручную доработку.
Есть два метода автоматической кластеризации.
- Soft — все запросы кластера связаны хотя бы с одним общим (маркерным) запросом.
- Hard — каждый запрос связан со всеми запросами в своём кластере.
Универсальной методики не существует, для каждой тематики и требований необходимы свои параметры. При кластеризации также следует указывать параметр точности — обычно он в пределах значений от 3-х до 5-ти, чаще всего наилучший результат показывает = 4. Например, для нашей цели подошла soft-кластеризация с точностью 4.
Ключевые фразы в процессе кластеризации делятся на 2 основные группы.
- Коммерческие запросы — распределяются по кластерам и группам на основе сходства из поисковой выдачи.
- Информационные запросы — в дальнейшем пойдут для задач контент-маркетинга, чтобы привлекать дополнительный целевой трафик на сайт.
Несмотря на то что процесс кластеризации частично автоматизирован, за ним всегда необходимо дорабатывать вручную.
После завершения кластеризации идёт определение посадочной страницы под каждую группу запросов. Вы должны чётко представлять структуру сайта, чтобы правильно определить посадочную страницу под каждый кластер. Если на сайте нет подходящей страницы под найденный кластер, то её необходимо создать, чтобы привлечь на ресурс больше целевого трафика.
Для ускорения процесса на помощь приходят различные сервисы по определению релевантных страниц, однако, бо́льшую часть работы следует проводить в ручном режиме, чтобы ничего не упустить и лучше ориентироваться в структуре сайта.
Создание структуры и временные затраты
На основе результатов кластеризации и определения посадочных страниц была создана структура коммерческих страниц и разделов:
Существует второй подход — создать структуру сайта ещё до сбора семантического ядра. В этом случае ключевые фразы будут распределяться по уже готовому «каркасу».
Благодаря кластеризации и новой структуре нам удалось расширить количество коммерческих страниц с 16-ти до 67 штук, что позволило в разы увеличить целевой трафик на сайт.
Временные затраты:
- сбор маркерных запросов: 1 час;
- сбор ключей и подсказок: 2,5 часа;
- очистка: 5 часов;
- кластеризация: 8 часов;
- определение посадочных страниц: 1,5 часа;
- создание структуры: 1,5 часа.
Вся работа заняла приблизительно: 20 часов.
Точность временных затрат на сбор семантики обычно зависит от трёх факторов:
- тематика сайта;
- размер сайта;
- регион продвижения.
Поэтому объём работ и трудозатраты рассчитываются индивидуально.
Напутствие
Будьте готовы со всей ответственностью подойти к кропотливому и длительному процессу, если хотите увеличить видимость сайта в поисковых системах и привлечь целевую аудиторию полезным контентом. Для того чтобы правильно собрать наиболее полное семантическое ядро вам потребуется практический опыт, аналитический склад ума и платные инструменты.
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на [email protected]. А наши требования к ним — вот тут.
Ваши статьи присылайте нам на [email protected]. А наши требования к ним — вот тут.
6 этапов составления семантического ядра :: Shopolog.ru
Принцип работы любой поисковой системы прост: в ответ на запрос пользователя она подбирает и выдает наиболее релевантные страницы сайтов. Но почему некоторые ресурсы в одной и той же тематике имеют большую посещаемость, а другие меньшую или совсем не собирают пользователей из поиска? Потому что у этих сайтов нет корректно сформированного семантического ядра. Как его правильно построить и избежать распространенных ошибок рассказывает Артем Яськов – руководитель отдела SEO-аналитики Kokoc.com (Kokoc Group).
Семантическое ядро – это набор поисковых фраз, наиболее полно характеризующих деятельность компании. Например, для интернет-магазина ими могут стать названия товаров и категорий, для сайта услуг – перечень услуг, предлагаемых ресурсом. Максимальное количество словосочетаний, составляющих семантическое ядро, обеспечивает выход ресурса в топ поисковых систем по высокочастотным и среднечастотным запросам (запросам, которые пользователи часто и, соответственно, реже задают в поисковых системах). Если же семантическое ядро отсутствует или включает минимальный набор фраз, то сайт либо не выйдет в топ, либо окажется на задворках поиска.
Молодые компании, порой, пытаются сэкономить и просят сформировать семантическое ядро сайта только по низкочастотным (самым непопулярным запросам в поисковых системах) и среднечастотным запросам. По их мнению, конкуренция по высокочастотным запросам будет стоить слишком дорого. Однако они не учитывают, что семантическое ядро напрямую влияет на структуру сайта. И если впоследствии компания решит продвигаться по высокочастотным запросам, ресурс придется переделывать.
Правила формирования семантического ядра1. Формирование семантического ядра сайта начинается с анализа конкурентов. Введя в поисковой системе «Яндекс» фразы, наиболее интересные компании, нужно посмотреть, какие ресурсы отображены на странице результатов.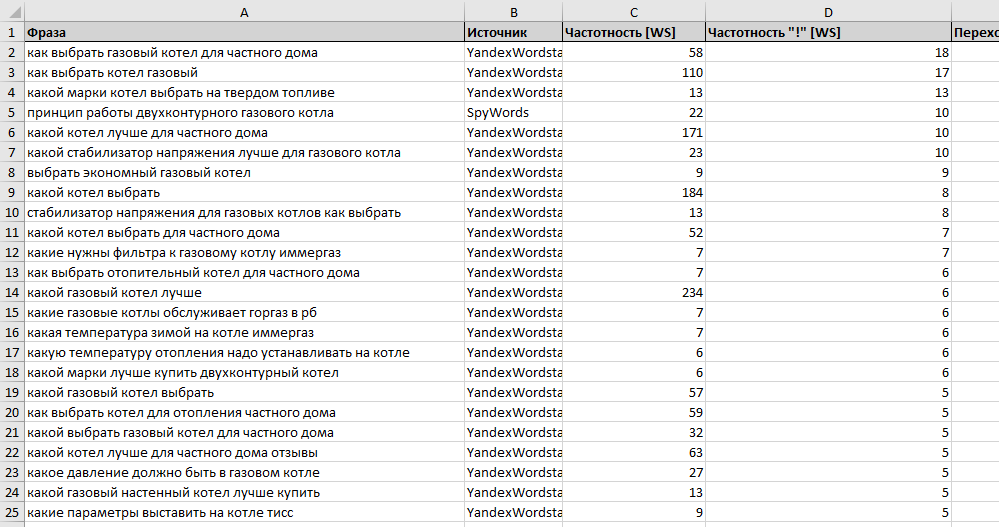 Если в топ 10 будут сайты, тематики которых соответствуют вашей, то следует составить предварительный список конкурентов и проверить их видимость в поисковиках. Для этого, например, можно использовать функционал MegaIndex «Видимость сайта». Он покажет, по каким ключевым словам видны эти ресурсы в Яндексе и Google. Далее необходимо выбрать наиболее подходящие вашему ресурсу запросы и сохранить их в отдельном файле. Пользуясь сервисом MegaIndex можно проанализировать любое количество конкурентов – их число зависит только от того, насколько полный анализ требуется.
Если в топ 10 будут сайты, тематики которых соответствуют вашей, то следует составить предварительный список конкурентов и проверить их видимость в поисковиках. Для этого, например, можно использовать функционал MegaIndex «Видимость сайта». Он покажет, по каким ключевым словам видны эти ресурсы в Яндексе и Google. Далее необходимо выбрать наиболее подходящие вашему ресурсу запросы и сохранить их в отдельном файле. Пользуясь сервисом MegaIndex можно проанализировать любое количество конкурентов – их число зависит только от того, насколько полный анализ требуется.
2. Следующий этап – анализ собственного сайта. Для этого с помощью систем веб-анализа «Яндекс.Метрика» или Google Analytics нужно проверить запросы, по которым ищут вас пользователи в поисковиках. Эти данные выгружаются из систем статистики и дополняют список ключевых слов по конкурентам.
3. Затем приходит время для использования инструментов «Яндекса» и Google. Они помогают проверить популярность выбранных ключевых слов среди пользователей, а также собрать дополнительные. Вручную процесс займет много времени, поэтому стоит воспользоваться специальными программами, которые чаще всего являются платными, например, Key Collector. Таким образом, можно расширить исходные запросы, добавив недостающие тематические слова.
4. Еще один источник, полезный при составлении семантического ядра — это подсказки поисковых систем. Когда человек формулирует поисковый запрос, система предлагает его уточнить. Например, к запросу «купить велосипед», Яндекс советует добавить «купить велосипед в Москве распродажа», «купить велосипед в интернет-магазине недорого» или «купить велосипед Стелс в Москве распродажа». Подсказки также стоит включить в список, а сделать это можно воспользовавшись тем же Key Collector, поскольку ручная работа займет много времени.
5. Не забудьте учесть регион присутствия бизнеса и добавить в список запросы, снабженные названиями городов. Например, если, находясь в Москве, ввести запрос «купить стиральную машину», то поисковик выдаст результаты, релевантные для столицы.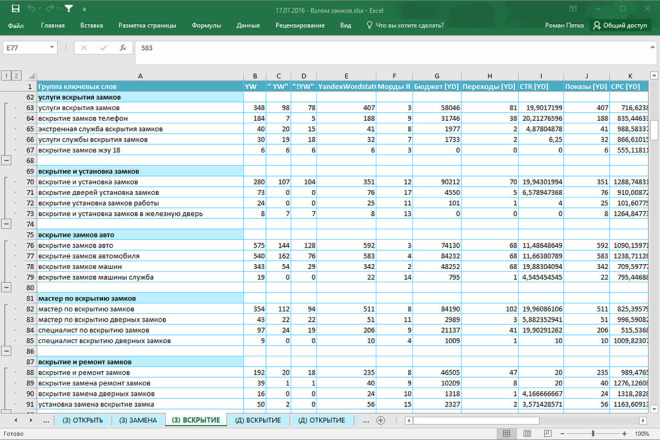 А вот если спросить «где купить стиральную машину в Нижнем Новгороде», то выдача будет соответствовать уже этому городу.
А вот если спросить «где купить стиральную машину в Нижнем Новгороде», то выдача будет соответствовать уже этому городу.
6. Далее с помощью «Яндекс.Подбор слов» и Google AdWords нужно проверить насколько собранные запросы интересны пользователям и удалить из получившегося списка непопулярные, а также те, которые не относятся к виду деятельности компании. Так, коммерческому сайту, как правило, не интересны запросы, содержащие слова «скачать», «бесплатно».
После того, как список ключевых слов составлен, их нужно распределить по страницам сайта, при необходимости, изменив его структуру.
Распространенные ошибки:
- добавление информационных запросов в ядро коммерческого сайта;
- включение в ядро непопулярных поисковых слов и фраз, а также запросов, не характеризующих деятельность компании.
Избежать ошибок легко – достаточно ответственно отнестись к вопросу формирования семантического ядра и не пропустить ни один из перечисленных пунктов.
Исследования и анализ SEO В 2021 году [Полное руководство]
Хотя инструмент Google Ads Keyword Planner — первая остановка в поиске правильных ключевых слов, Ahrefs — это чрезвычайно ценный, но платный инструмент. Вы можете использовать его для многих вещей, таких как анализ обратных ссылок, исследование конкурентов, исследование ключевых слов и многое другое.
Это продвинутый инструмент, так как вы можете использовать его, чтобы буквально шпионить за своими конкурентами, понимать их источники трафика и знать, по каким ключевым словам они ранжируются.Вот как выглядит интерфейс:
Это пример веб-сайта, на котором показаны ключевые слова, по которым он ранжируется, объем поиска и рейтинг ключевых слов по различным странам. Эти данные ценны золотом и могут предоставить достаточно данных для нескольких месяцев вашей SEO-кампании.
Убер-совет
Принадлежащий Нилу Патель, это одно из самых рентабельных и недорогих решений для исследования ключевых слов и конкурентов на рынке. Начиная всего с 12 долларов за отслеживание до 3 веб-сайтов, вы можете легко выполнять задачи SEO и отслеживать прогресс и результаты.Бесплатная версия ограничена в предоставлении данных и доступа, но должна быть достаточно хорошей для начала. В этом случае мы возьмем пример Sitewired. После запуска теста на домашней странице вот результаты:
Начиная всего с 12 долларов за отслеживание до 3 веб-сайтов, вы можете легко выполнять задачи SEO и отслеживать прогресс и результаты.Бесплатная версия ограничена в предоставлении данных и доступа, но должна быть достаточно хорошей для начала. В этом случае мы возьмем пример Sitewired. После запуска теста на домашней странице вот результаты:
Вы можете увидеть количество ключевых слов, позицию и объем. Они меняются изо дня в день в зависимости от вашего поискового трафика и от того, насколько агрессивна ваша SEO-кампания. Используя Ubsersuggest, вы можете легко определить целевые ключевые слова и провести исследование конкурентов.Таким образом, вы можете реализовать надежный план SEO, подкрепленный данными.
Намерение и влияние ключевых слов
Начиная с кампании SEO, важно найти правильные ключевые слова, но еще более важно изучить намерение и возможное влияние, которое оно может иметь. Например, веб-хостинговая компания, продвигающая планы управляемого хостинга VPS, не должна оптимизировать свой контент для «бесплатного управляемого хостинга» или «бесплатного хостинга WordPress». Почему? Тот, кто ищет «бесплатного», будет иметь минимальные шансы превратиться в платящего покупателя.
На следующем снимке экрана вы можете увидеть, как Google показал результаты, связанные с «бесплатным управляемым хостингом wp». Это отличный способ определить намерения пользователя. Поскольку в результатах поиска указаны цены, хостинговая компания должна исключить слово «бесплатно» в своих SEO-кампаниях:
Намерение «бесплатно» недостаточно убедительно для включения этого ключевого слова в SEO-кампанию.
При проведении исследования ключевых слов задайте себе следующие вопросы:
- Почему я провожу это исследование?
- Каковы намерения этих поисков?
- Какое влияние рейтинг этих ключевых слов окажет на посещаемость моего веб-сайта и конверсии?
Оптимизация по ключевым словам, не имеющим отношения к вашему бизнесу, приведет к более высокому показателю отказов, что не является жизнеспособным вариантом для вашего бизнеса.
Согласно MOZ, оптимизаторы поисковых систем не должны забывать о важности и релевантности длинных ключевых слов.
Вот поясняющий график:
Ключевые слова с длинным хвостом предназначены не только для вашего бизнеса, но также включают вопросы и разговорные фразы, которые клиенты обычно ищут в Интернете. Например:
- Как сделать сайт адаптивным?
- Как проводить исследование ключевых слов?
- Что такое исследование ключевых слов SEO?
Как упоминалось ранее, один из ЛУЧШИХ способов узнать разговорные фразы — это ввести несколько вопросов в поиске Google и получить список рекомендуемых вопросов, например:
Если бы вы писали и оптимизировали «Как проводить исследование ключевых слов», ваши шансы оказаться на вершине были бы меньше, чем если бы вы сделали то же самое для Youtube, рекламы Google или Bing и т. Д.Все сводится к конкуренции. Все занимаются исследованием ключевых слов, но как только вы выбираете длиннохвостое ключевое слово, ваши шансы на ранжирование автоматически повышаются.
Завершение!
Не существует ярлыка или волшебной формулы для ранжирования в поисковых системах, равно как и SEO не является языком программирования, на котором вы можете дать указание Google благословить вас бесплатным органическим трафиком.
Добиваться плодотворных результатов от SEO-кампании день ото дня становится все труднее из-за постоянно меняющейся алгоритмической природы большого G.С учетом сказанного, эти трудоемкие усилия определенно стоят потраченного времени. И если вы подумали, вот ответ:
Нет, SEO не умер!
Если у вас нет твердого плана SEO, в основе которого лежит семантическое ядро, вы обречены на провал в Интернете. Создание семантического ядра должно быть первой частью вашей SEO-кампании, поскольку его больше нельзя игнорировать. Без него не будет достаточно трафика и конверсий.
Многие оптимизаторы поисковых систем также не понимают, что простой оптимизации по ключевым словам недостаточно. Не менее важно писать содержательный содержательный контент, богатый ключевыми словами. Это может быть в форме сообщений в блогах, новых статей, гостевых сообщений (со ссылкой на ваш сайт), а также путем улучшения копии вашего сайта.
Не менее важно писать содержательный содержательный контент, богатый ключевыми словами. Это может быть в форме сообщений в блогах, новых статей, гостевых сообщений (со ссылкой на ваш сайт), а также путем улучшения копии вашего сайта.
SEO — это постоянно развивающаяся область. То, что работает сегодня, может не работать завтра. Кто знал еще в декабре 2019 года, что из-за COVID19 произойдет внезапный переход к удаленной работе? Теперь у нас есть множество ключевых слов и поисковых запросов, связанных с коронавирусом.
Не забывайте пересматривать свои ключевые слова каждые несколько недель.Никогда не угадаешь, когда появятся новые поисковые запросы!
А теперь перехожу к вам! Мы хотели бы услышать ваш ответ на это руководство. Поделитесь с нами своим опытом, и давайте извлечем из этого что-то взаимовыгодное 🙂
Семантическое знание — обзор
V Обсуждение
Семантическое знание организовано таким образом, что оно дает значимые и адаптивные выводы (например, яблоки и апельсины являются фруктами и поэтому могут играть аналогичные функциональные роли). Исследования, представленные в этой главе, показывают, что такие объектно-ориентированные выводы влияют на то, как люди решают проблемы, переносят ранее изученные решения в новые проблемы или оценивают сходство.Таким образом, настоящие результаты не очень удивительны — неудивительно, что люди предпочитают сравнивать или комбинировать яблоки и апельсины, а не яблоки и корзины. Однако что довольно удивительно, так это то, что такие эффекты были упущены из виду исследователями, изучающими познание более высокого порядка.
Дело не в том, что исследователи не заметили, что объектные умозаключения влияют на рассуждения. Классическим примером таких эффектов может служить работа Дункера (1945) о «функциональной неподвижности», в которой функциональная роль коробки как контейнера отталкивала людей от использования коробки как платформы, на которой они могли бы установить свечу. В более свежем примере исследование Котовски, Хейса и Саймона (1985) сравнило человеческие решения двух версий проблемы Ханойской башни. Они обнаружили, что испытуемым было несложно положить большой диск поверх маленького, но когда на дисках было написано «акробаты», испытуемые не позволяли большому акробату прыгать на плечах маленького акробата. К сожалению, такие демонстрации были просто добавлены к списку исследований, показывающих, что поверхностные аспекты содержания и формулировки приводят к ошибкам или делают некоторые изоморфы проблем более сложными, чем другие.Они не инициировали исследования, которые ищут закономерности в том, как люди выбирают или адаптируют свои инструменты рассуждения (например, сравнение против интеграции) к семантическим различиям, которые они считают важными (например, функциональная симметрия против асимметрии).
В более свежем примере исследование Котовски, Хейса и Саймона (1985) сравнило человеческие решения двух версий проблемы Ханойской башни. Они обнаружили, что испытуемым было несложно положить большой диск поверх маленького, но когда на дисках было написано «акробаты», испытуемые не позволяли большому акробату прыгать на плечах маленького акробата. К сожалению, такие демонстрации были просто добавлены к списку исследований, показывающих, что поверхностные аспекты содержания и формулировки приводят к ошибкам или делают некоторые изоморфы проблем более сложными, чем другие.Они не инициировали исследования, которые ищут закономерности в том, как люди выбирают или адаптируют свои инструменты рассуждения (например, сравнение против интеграции) к семантическим различиям, которые они считают важными (например, функциональная симметрия против асимметрии).
Направление исследований, которое по своей сути, вероятно, наиболее близко к исследованиям, описанным здесь, ищет закономерности в том, как семантическое знание влияет на рассуждения об условных силлогизмах (например, Cheng & Holyoak, 1985,1989; Cheng, Holyoak, Nisbett , & Oliver, 1986; Cosmides, 1989; Cosmides & Tooby, 1994; Cummins, 1995; Gigerenzer & Hug, 1992).Эта работа показала, что различные содержательные экземпляры материальной импликации («если p , то q ») вызывают правила рассуждения различных прагматических и / или социальных схем. Согласно Cheng и Holyoak (1985), инициировавшим это направление исследований, люди применяют разные правила рассуждений к формально изоморфным утверждениям, таким как «если есть облака, то идет дождь» или «если вы пьете пиво, то вы должны быть как минимум 21 год.» В первом случае люди руководствуются знанием того, что облака — необходимая, но недостаточная причина для дождя (напр.g., причинно-следственная схема), тогда как во втором они руководствуются знанием того, что возраст употребления алкоголя устанавливается законом, которому можно не подчиняться (то есть схемой разрешений).
Как и в случае арифметических операций (Bassok et al., 1997), правила формальной логики семантически совместимы с правилами одних схем, но не с другими. Например, Modus Tollens («если не q , то не p ») совместим с правилами схемы разрешений (например, если вам меньше 21 года [ не q ], то вам не разрешается пить. спирт [, не стр. ]).Однако это правило иногда конфликтует с правилами причинно-следственной схемы (например, если не идет дождь [, не q ], из этого не обязательно следует, что нет облаков [, не стр. ]). Cheng et al. . (1986) обнаружили, что, как и математически сложные предметы в Bassok et al. которые иногда «не могли» построить задачи сложения или деления слов для семантически несовместимых наборов объектов, субъекты, которые были обучены оценке достоверности условных силлогизмов, совершали «логические ошибки» в тестовых задачах, которые вызывали правила несовместимых прагматических схем.
Cheng et al. (1996) убедительно доказали, что соблюдение семантических и прагматических ограничений (то есть эффектов содержания) защищает людей от произвольных и аномальных выводов. Фактически, результаты Bassok et al. (1997) настоятельно предполагают, что, когда применение формальных правил противоречит семантическим и прагматическим знаниям людей, они могут предпочесть приходить к разумным и логически неверным выводам, чем приходить к логически верным, но аномальным выводам. К сожалению, представление о том, что абстрагирование структуры от содержания является признаком интеллектуальных достижений, кажется настолько привлекательным, что даже разумные ответы на семантические ограничения могут быть классифицированы исследователями как ошибки рассуждения.Объяснительная экономия, которую подразумевает это понятие, может также объяснить, почему исследователи предпочитают строить и проверять независимые от содержания объяснения рассуждений. При тестировании таких учетных записей они обычно усредняют реакции людей на стимулы, которые различаются по содержанию, рассматривая такие ответы как ошибки измерения, которые скрывают основные закономерности обработки (см. Goldstein & Weber, 1995, для проницательного обсуждения и исторического анализа этой точки зрения). Эта практика, скорее всего, усреднит те самые эффекты, которые были в центре внимания исследований, описанных в этой главе.
Goldstein & Weber, 1995, для проницательного обсуждения и исторического анализа этой точки зрения). Эта практика, скорее всего, усреднит те самые эффекты, которые были в центре внимания исследований, описанных в этой главе.
Выводы на основе объектов, которые отражают соблюдение семантических и прагматических различий, подразумеваемых содержанием, являются скорее присущими, чем отклонением от нормальной обработки. Кроме того, такие выводы не указывают на плохое понимание, незрелость или недостаточные познавательные ресурсы. Следовательно, влияние объектно-ориентированных умозаключений на рассуждение плохо согласуется с «скрытым сокровищем» или любым другим вариантом метафоры «ошибочная абстракция от содержания». Вместо этого такие эффекты, кажется, предполагают метафору «инструментария», посредством которой люди пытаются найти наилучшее соответствие между своими инструментами обработки и ограничениями, налагаемыми стимулами, с которыми они сталкиваются.Я твердо верю, что, приняв метафору набора инструментов, исследователи могут обнаружить интересные закономерности в том, как люди приспосабливают обработку к своим высокоорганизованным семантическим и прагматическим знаниям.
Поиск общего семантического ядра всех языков
Используйте этот идентификатор для цитирования или ссылки на этот элемент: https: // hdl.handle.net/1959.11/2173
| Название: | Поиск общего семантического ядра всех языков | Автор (и): | Годдард, Клифф (автор) | Дата публикации: | 2002 | Ссылка на ручку: | https://hdl.handle.net/1959.11/2173 | Abstract: | Каждая теория начинается с определенных предположений. | Тип публикации: | Книжная глава | Источник публикации: | Значение и универсальная грамматика: теория и эмпирические результаты, т.1, стр. 5-40 5-40 | Издатель: | Издательская компания Джона Бенджамина | Место публикации: | Амстердам, Нидерланды | ISBN: | 30633 1588112640 | Область исследований (FOR): | 200408 Лингвистические структуры (включая грамматику, фонологию, лексику, семантику) | Социально-экономическая цель (SEO): | 950201 Общение на разных языках и культурах | HERDC Описание категории: | B1 Глава в научной книге | Другие ссылки: | http: // www.benjamins.com/cgi-bin/t_bookview.cgi?bookid=SLCS%2060 http://books.google.com.au/books?id=TM3_HBV7mcQC&lpg=PP1&pg=PA5 http://trove.nla.gov. au / work / 33389879 | Название серии: | Исследования в серии Language Companion (SLCS) | Серийный номер: | 60 | Статистика на октябрь 2018: | Посетителей: 112 | Редактор: | Редактор (ы): Клифф Годдард и Анна Вежбицка |
|---|---|
| Встречается в коллекциях: | Глава книги |
 Первоначальное предположение теории естественного семантического метаязыка состоит в том, что значения, выражаемые на любом языке, могут быть адекватно описаны в рамках ресурсов этого языка, т.е.е. что любой естественный язык адекватен как свой собственный семантический метаязык. Теория начиналась как метод лексико-семантического анализа, основанный на редуктивном перефразировании; то есть на идее, что значение любого семантически сложного слова может быть объяснено посредством точного пересказа, составленного из более простых и понятных слов, чем оригинал (Wierzbicka 1972). Метод редуктивного перефразирования позволяет избежать путаницы в круговороте и терминологической неясности — двух проблемах, с которыми сталкивается большинство других семантических методов.Простота и ясность являются лозунгами, и с этой целью в редуктивных экспликациях перефразирования не допускаются никакие технические термины, неологизмы, логические символы или аббревиатуры — только простые слова из обычного естественного языка. Если возможно провести семантический анализ с использованием редуктивного перефразирования и в то же время избежать цикличности, то из этого следует, что каждый естественный язык должен содержать непроизвольное и нередуцируемое семантическое ядро, которое останется после того, как будут обработаны все разложимые выражения.Это семантическое ядро должно иметь языковую структуру с лексиконом неопределимых выражений (семантических простых чисел) и грамматикой, то есть некоторыми принципами, определяющими, как можно комбинировать лексические элементы. Семантические простые числа и их принципы комбинирования составят своего рода мини-язык с такой же выразительной силой, что и полный естественный язык; отсюда и термин «естественный семантический метаязык».
Первоначальное предположение теории естественного семантического метаязыка состоит в том, что значения, выражаемые на любом языке, могут быть адекватно описаны в рамках ресурсов этого языка, т.е.е. что любой естественный язык адекватен как свой собственный семантический метаязык. Теория начиналась как метод лексико-семантического анализа, основанный на редуктивном перефразировании; то есть на идее, что значение любого семантически сложного слова может быть объяснено посредством точного пересказа, составленного из более простых и понятных слов, чем оригинал (Wierzbicka 1972). Метод редуктивного перефразирования позволяет избежать путаницы в круговороте и терминологической неясности — двух проблемах, с которыми сталкивается большинство других семантических методов.Простота и ясность являются лозунгами, и с этой целью в редуктивных экспликациях перефразирования не допускаются никакие технические термины, неологизмы, логические символы или аббревиатуры — только простые слова из обычного естественного языка. Если возможно провести семантический анализ с использованием редуктивного перефразирования и в то же время избежать цикличности, то из этого следует, что каждый естественный язык должен содержать непроизвольное и нередуцируемое семантическое ядро, которое останется после того, как будут обработаны все разложимые выражения.Это семантическое ядро должно иметь языковую структуру с лексиконом неопределимых выражений (семантических простых чисел) и грамматикой, то есть некоторыми принципами, определяющими, как можно комбинировать лексические элементы. Семантические простые числа и их принципы комбинирования составят своего рода мини-язык с такой же выразительной силой, что и полный естественный язык; отсюда и термин «естественный семантический метаязык».Файлы в этом элементе:
2 файла| Файл | Описание | Размер | Формат |
|---|
Элементы в Research UNE защищены авторским правом, все права сохранены, если не указано иное.
Как проводить исследование ключевых слов: полное руководство для начинающих
Поисковые запросы по ключевым словам являются неотъемлемой частью SEO. Даже в то время, когда используются продвинутые поисковые алгоритмы, такие как Google Hummingbird, ключевые слова определяют тему веб-сайта для поисковых роботов. Ниже мы подробно обсудим, как проводить исследование ключевых слов, и поговорим об инструментах, которые помогут вам с этой задачей. Вы можете узнать больше об алгоритмах в статьях Google BERT Update и Google Algorithms, которые влияют на SEO.
Даже в то время, когда используются продвинутые поисковые алгоритмы, такие как Google Hummingbird, ключевые слова определяют тему веб-сайта для поисковых роботов. Ниже мы подробно обсудим, как проводить исследование ключевых слов, и поговорим об инструментах, которые помогут вам с этой задачей. Вы можете узнать больше об алгоритмах в статьях Google BERT Update и Google Algorithms, которые влияют на SEO.
Ключевые слова как инструмент поисковой оптимизации
Прежде чем ответить на вопрос о том, как работает исследование ключевых слов, давайте разберемся с концепциями.
Ключевые слова могут помочь повлиять на рейтинг сайта. Они делают это, сообщая поисковым системам, какие запросы будут влиять на рейтинг страницы. Ключевые слова образуют смысловое ядро. Для получения дополнительной информации см. Что такое SERP в 2020 году?
Семантическое ядро составляют слова и словосочетания, определяющие профиль сайта и его специализацию.Более подробную информацию по теме можно найти в разделе Что такое семантический поиск? Для составления ключевых слов обычно анализируются сайты конкурентов и определяются типичные поисковые запросы с помощью специальных программных инструментов. О том, как провести полный анализ конкурентов и получить все необходимые данные, читайте в статье SEO Competitive Analysis.
В следующих параграфах мы более подробно остановимся на этом.
Базовое исследование запросов — обязательный шаг при составлении семантического ядра
Базовые запросы или запросы маркеров — это запросы пользователей, которые точно соответствуют теме вашего сайта.Например, если мы говорим об интернет-магазине автомобильных запчастей и аксессуаров, будут запросы типа: «автомобильные шины», «крыло для BMW x6» и т. Д. В общем, просто изучите, какие фразы будут вводить ваша целевая аудитория. поисковик и запишите их.
Второй шаг — собрать вторичные или немаркерные запросы. Это те же самые основные поисковые запросы или их синонимы с дополнительными уточняющими словами (обычно от одного до трех слов). Эти поисковые запросы создаются при добавлении таких слов, как «купить», «купить в Нью-Йорке», «цена», «купить подержанный».Если вы даже приблизительно не понимаете, что может подпадать под эту категорию поиска, воспользуйтесь такими инструментами поиска, как Google AdWords. О них поговорим позже.
Эти поисковые запросы создаются при добавлении таких слов, как «купить», «купить в Нью-Йорке», «цена», «купить подержанный».Если вы даже приблизительно не понимаете, что может подпадать под эту категорию поиска, воспользуйтесь такими инструментами поиска, как Google AdWords. О них поговорим позже.
Также может быть полезно изучение содержания популярных сайтов схожей тематики. В описаниях продуктов или статьях вы определенно можете найти хотя бы пару ранее невиданных запросов. Для получения информации о том, как правильно анализировать ваш контент, см. Аудит контента веб-сайта.
Ключевые слова везде
И, наконец, в качестве дополнительной меры, чтобы подтвердить свои предположения, вы можете ввести интересные поисковые запросы в Google и посмотреть, что показывает категория «Люди также спрашивают».Дополнительную информацию по теме можно найти в статье «Люди тоже спрашивают».
Почему разнообразие ключевых слов важно для привлечения органического трафика?
Несмотря на то, что SEO-специалисты выступают за качество, а не за количество, очень важно, чтобы ключевые слова были разными. Процедура поиска по ключевым словам подразумевает разделение семантического ядра на кластеры или группы запросов по схожим нишам и направлениям.
Благодаря этому можно правильно распределять ключевые слова по страницам сайта.Например, информационный поиск лучше подходит для страниц блога, а коммерческий поиск лучше для целевых страниц товаров или категорий).
Как часто вам нужно проводить исследования?
Обычно самая глобальная работа по составлению семантического ядра проводится в самом начале продвижения сайта. Однако со временем ядро может пополняться новыми запросами, которые могут содержать тенденции.
Например, когда был представлен iPhone XS, в мире технического оснащения был резонанс.Все сайты по продаже смартфонов начали создавать огромное количество отзывов об этой новинке. Конечно, это отразилось на семантическом ядре торговых площадок — оно пополнилось как минимум одним новым ключевым словом — iPhone XS
.
Поэтому однозначного ответа на частоту ревизии семантического ядра нет. Это нужно делать сразу же, как только какая-то новая тенденция затронула вашу нишу.
Как составлять ключевые слова: типы настраиваемых запросов
А теперь пора выяснить, как найти лучшие ключевые слова для SEO.По сути, вам необходимо знать, какие типы запросов поступают в поисковые системы от пользователей.
Оттуда вы можете использовать их как часть различных фраз, чтобы уменьшить их частоту и повысить релевантность страниц сайта.
Есть пять типов ключевых слов:
- Коммерческий : это широкая категория различных ключевых слов, которые обеспечивают большой процент органического трафика. Для веб-сайта туристического агентства ключевое слово «путеводитель» будет бесполезным.Однако, если вы предоставите некоторую информацию о туризме, это слово будет более подходящим. Чтобы понять, попадает ли ваше потенциальное ключевое слово в эту категорию, просто введите его в поиск и посмотрите, какие сайты по этой теме отображаются в поисковой выдаче. Если их бизнес-ниша идентична вашей, значит, все в порядке, и вы можете смело использовать это ключевое слово. Для получения дополнительной информации по этой теме прочтите статью Что такое поисковая выдача.
- Transactional : это еще один тип ключевого слова, который также идеально подходит для использования на коммерческих сайтах.Ключевые слова транзакции описывают целевые действия для тех пользователей, которые намереваются купить продукт или услугу. Они идеальны в тех случаях, когда человек уже искал информацию, сумел принять положительное решение и наконец приступил к процессу покупки. Такие ключевые слова всегда содержат «купить», «продать», «подписаться» и т. Д.
- Информативный : этот тип ключевых слов используется для привлечения пользователей, которые ищут информацию. Например, чтобы сравнить продукты с похожими моделями, чтобы узнать их характеристики, мы можем говорить не только о продукте, но и об общих образовательных запросах, таких как «Достопримечательности Нью-Джерси». Часто такие ключевые слова содержат вспомогательные слова, такие как «нравится», «против», «сравнивать» и т. Д.
- Навигационный : это еще один вид ключевых слов, которые напрямую относятся к определенному бренду, компании или известному сайту. В этом случае пользователи обращаются к поисковику с конкретным запросом и упоминают название сайта. Такие ключевые слова обычно полезны, когда бренд хорошо известен и популярен.
- Локальный : И, наконец, у нас есть локальные ключевые слова. Это ключевые слова, ориентированные на конкретное место.Чаще всего они содержат название определенного географического местоположения, например «купи обувь в Орегоне». Для получения дополнительной информации по теме см. Местный контрольный список SEO 2020.
 Часто такие ключевые слова содержат вспомогательные слова, такие как «нравится», «против», «сравнивать» и т. Д.
Часто такие ключевые слова содержат вспомогательные слова, такие как «нравится», «против», «сравнивать» и т. Д.6 шагов по ключевым словам
А теперь рассмотрим шесть последовательных шагов, которые объяснят, как найти ключевые слова для SEO.
Шаг первый: проведите терминологическое исследование
Если вы прекрасно понимаете нишу, в которой продвигаете сайт, вы уже сделали первый шаг. Вам необходимо провести масштабное терминологическое исследование ключевых слов SEO.В любой нише, будь то косметика, автомобили или ракетостроение, есть ряд брендов, определенные ключевые термины и поисковые запросы, которые чаще всего возникают среди вовлеченных в нее интернет-пользователей. Поэтому вам придется изучить терминологию, чтобы досконально разобраться в специфике того или иного вида бизнеса.
Например, если вы планируете продвигать косметический веб-сайт, введите следующие запросы: «Самые популярные косметические бренды», «Популярные косметические ингредиенты», «Типы средств по уходу за кожей», «Процедуры по уходу за кожей», «Уход за кожей» и т. Д.поможет вам в этом.
Шаг второй: начните с высокочастотных ключевых слов
Этот шаг называется базовым исследованием ключевых слов. Следовательно, вам нужно будет определить наиболее часто встречающиеся ключевые слова. Обычно они содержат от одного до трех слов. Если мы продолжим тему косметического сайта, то наиболее часто встречающимися ключевыми словами будут такие варианты, как «губная помада на покупку», «L’Oreal», «маска для волос» и т. Д.
Обычно они содержат от одного до трех слов. Если мы продолжим тему косметического сайта, то наиболее часто встречающимися ключевыми словами будут такие варианты, как «губная помада на покупку», «L’Oreal», «маска для волос» и т. Д.
Конечно, когда речь идет о сборе семантического ядра для очень большого сайта с большим ассортиментом продукции, таких запросов могут быть тысячи.В этом случае имеет смысл выбрать основные поисковые запросы, начиная с наиболее важных категорий для продвижения (наиболее маржинальных и актуальных для сезонного спроса).
Шаг третий: отслеживание конкурентов по ключевым словам
Следуя SEO-исследованию наиболее и наименее популярных ключевых слов, вы узнаете, какие ключевые слова используют ваши конкуренты. Для этого вы можете использовать один из программных инструментов, о котором мы расскажем ниже.
Шаг четвертый: рассмотрите геолокацию
Также при составлении семантического ядра важно ориентироваться на локации, в которых проживает ваша целевая аудитория.В конце концов, те же статьи о солнцезащитном креме будут намного популярнее в более теплых местах с большим количеством солнца.
Шаг пятый: создание запросов Longtail и LSI
После сбора основных ключевых слов вы должны сформулировать средне- и низкочастотный поиск. К ним относятся поиск с длинным хвостом и поиск LSI (латентное семантическое индексирование). И LSI, и длиннохвостый очень хорошо влияют на контекстный (семантический) поиск, что особенно важно с момента вступления в силу алгоритма поиска Google Hummingbird на основе искусственного интеллекта (подробнее читайте в статье Ключевые слова LSI).Поговорим о них подробнее.
LSI — косвенные ключевые слова. Это ключевые слова, которые контекстуально связаны с основным составом вашего семантического ядра, но имеют другую словоформу. Обычно это синонимы, геозависимые слова или другие слова, относящиеся к тому же предмету.
Самый простой способ найти их — использовать специальные сервисы (их список представлен в следующем абзаце), но вы также можете попробовать ручной выбор, если вы знакомы с тематикой продвигаемого веб-сайта. Вы можете установить флажки PAA (Люди также спрашивают) и SRT (Поиск по теме), чтобы узнать возможные варианты LSI без использования стороннего программного обеспечения.
Вы можете установить флажки PAA (Люди также спрашивают) и SRT (Поиск по теме), чтобы узнать возможные варианты LSI без использования стороннего программного обеспечения.
Например, если ваше семантическое ядро содержит ключевое слово Android, фразу Google Play можно отнести к LSI.
Что еще можно сказать о длиннохвостых запросах? Фактически, мы неоднократно упоминали о них выше: это поиск по маркерам с квалифицирующими префиксами. Самый простой способ найти их — ввести один из основных поисковых запросов в Google и просмотреть все варианты автозаполнения.
Например, при вводе запроса «скинни в джинсах женщины» вы увидите следующие длиннохвостые ключевые слова:
На их основе уже можно составлять целые кластеры ключевых слов, о которых пойдет речь на следующем шаге.
Шаг шестой: Кластер
Как только ключевые слова, потенциально полезные для вашего сайта, найдены, стоит начать кластеризацию запросов (группировку). Это необходимо для того, чтобы не складывать все ключевые слова вместе и не создавать мегаобзоры.Таким образом, вы можете добавить максимальное количество ключевых слов, а также распределить слова из группы по отдельным целевым страницам.
Кроме того, кластеризация позволяет сузить специфику определенных веб-страниц, поскольку объединение запросов в группы происходит по темам и словоформам. Такой подход повышает актуальность.
Как сгруппировать? Очень просто. Для этого вы берете любое ключевое слово с высокой частотой и добавляете к нему хвосты, чтобы сформировать ключевые слова со средней и низкой частотой. Эти хвосты обычно представляют собой слова, описывающие местоположение, действие (например, покупку), цвет, время года и другие определяющие характеристики.Мы подробно объяснили, как это сделать, на предыдущем шаге.
И чтобы не гадать, какие слова можно использовать в качестве ключевых слов, мы предлагаем больше узнать об инструментах автоматического поиска. Они помогут провести максимально информированное исследование ключевых слов.
Популярные инструменты поиска по ключевым словам
Рассмотрим десять самых популярных программных решений для поиска по ключевым словам.
Google Adwords
Google AdWords, пожалуй, самый популярный инструмент поиска по ключевым словам и группировки.Несмотря на это, SEO-специалисты это не очень любят. Это потому, что планировщик очень навязчиво предлагает запустить рекламу. Несмотря на то, что это его основная задача, Google AdWords также очень хорошо ищет ключевые слова. Кроме того, нет возможности просматривать ежемесячную частоту поиска по ключевым словам.
Все недостатки полностью окупаются тем, что вы можете найти ключевые слова, которые не покажет ни один другой инструмент. Вы также можете научиться обходить предложение о запуске кампании, не платя Google ни цента.
Вы можете узнать больше о том, как Google AdWords работает как инструмент подсказки ключевых слов, из этого видео на Youtube.
Google Тренды
Это еще один достойный инструмент подсказки ключевых слов Google. Использование данных из поисковой системы определяет частоту поиска определенных терминов в зависимости от местоположения пользователей, их языка и определенного периода времени.
В целом это очень полезное решение для тех, кто постоянно ломает голову над обновлением семантического ядра.Чтобы узнать, как использовать этот инструмент и сделать SEO более эффективным, см. Как использовать Google Trends для SEO.
Исследование ключевых слов Semrush
SEMrush — еще одно приложение для поиска по ключевым словам, которое предоставит вам бесплатную 30-дневную пробную версию.
Включает полный набор инструментов для цифрового маркетинга и инструмент для поиска по ключевым словам. Это также очень мощное решение вместе с Google Adwords. Справедливости ради отметим, что он намного удобнее, и вы не найдете агрессивных предложений по запуску платных рекламных кампаний.
Это также очень мощное решение вместе с Google Adwords. Справедливости ради отметим, что он намного удобнее, и вы не найдете агрессивных предложений по запуску платных рекламных кампаний.
Ответ
AnswerThePublic — это надстройка для вашего браузера Chrome или Firefox. С его помощью вы можете постоянно отслеживать такие показатели, как ежемесячный объем поиска и цена за клик. Вы также получите подробные данные о конкуренции ключевых слов на нескольких сайтах.
Все это появится по нажатию всего одной кнопки. Один щелчок — и любые страницы конкурирующих сайтов покажут вам используемые ключевые слова.
Инструмент исследования ключевых слов SpyFu
Инструмент подсказки ключевых словSpyFu предлагает колоссальный список полезных данных по очень большому количеству ключевых слов.
Чтобы начать работу, вам нужно будет ввести одно ключевое слово в строку поиска. После вы получите целый список релевантных фраз. Выберите любой из них для своего сайта, ориентируясь на частоту и тематику вашего бизнеса.
Убер-совет
Ubersuggest — еще один инструмент поиска по ключевым словам, который дает вам представление о стратегиях, которые эффективно работают для ваших конкурентов. Это решение тоже абсолютно бесплатное.
Нужны дополнительные варианты ключевых слов? С помощью этого инструмента вы получите все, от основных ключевых слов до длинных фраз.Вы также увидите объем, конкуренцию и даже сезонные тенденции для каждого выбранного вами ключевого слова. Кроме того, чтобы упростить работу с ключевыми словами, Ubersuggest создает список ключевых слов, который основан не только на стратегии SEO для поиска ключевых слов, заимствованных у ваших конкурентов, но и на том, что люди вводят в поиске Google.
SEO книга
Это еще один отличный бесплатный инструмент для подсказки ключевых слов. Среди его основных функций — охват поиска по ключевым словам, параметрам поиска (локализация пользователя, период и т. Д.).), оценочная стоимость поиска (цена предложения, умноженная на ежемесячный объем поиска), данные по рынкам Великобритании и США и быстрый экспорт 1000 ключевых слов с наибольшим весом.
Д.).), оценочная стоимость поиска (цена предложения, умноженная на ежемесячный объем поиска), данные по рынкам Великобритании и США и быстрый экспорт 1000 ключевых слов с наибольшим весом.
WordStream
Это бесплатный инструмент, который использует последние данные поиска Google для создания наиболее точных и релевантных ключевых слов. Вместо случайного составления ключевых фраз, основанных исключительно на автоматических предложениях Google, вы можете использовать простой и интуитивно понятный WordStream, не выходя за рамки бюджета на SEO.
Серпстат
Этот инструмент подсказки ключевых слов использует уникальный древовидный алгоритм.Он проверяет положение страниц вашего сайта в результатах поиска и помогает оптимизировать их, используя правильно подобранные ключевые слова. Кроме того, с его помощью вы можете определить связанные ключевые слова, условия поиска и фразы, которые семантически связаны с запрошенным ключевым словом.
И, наконец, с помощью настраиваемых фильтров вы можете задать собственные параметры, чтобы получить набор оптимальных ключевых слов для вашего региона.
Чего не делать с ключевыми словами: Anti Trends 2020
Следуя рекомендациям по проведению исследования ключевых слов, мы решили дать список манипуляций, которые не стоит делать.Существуют плохие методы SEO, при которых игнорируются все усилия по поиску ключевых слов. Вот они:
- Подчеркнуть только один тип ключевого слова, либо только высокочастотные ключевые слова, либо только низкочастотные ключевые слова : Иногда новички в области SEO слепо следуют рекомендациям и стараются избегать высокочастотного поиска. Это негативно сказывается на позиционировании сайта в поисковой выдаче и препятствует его продвижению. Поэтому высокочастотные ключи должны присутствовать хотя бы один раз на каждой целевой странице.Когда игнорируются ключевые слова с небольшим процентом поисковых запросов пользователей, бывает и наоборот. Из-за этого теряются ценные идеи по созданию контента, а объем потенциального органического трафика снижается. Отсюда вывод: при продвижении сайта стоит использовать всевозможные ключевые слова, не упуская из виду источники потенциального трафика.
- Создание контента ради использования самих ключевых слов : Многие копирайтеры, даже в наше время, любят спамить ключевыми словами, создавая совершенно неинформативные и плохо читаемые текстовые холсты.Сделайте основной акцент на качестве и полезности контента, а не на том факте, что он содержит слишком много ключевых слов.
- Передача ответственности за поиск программных средств : Считается, что такие инструменты, как Google Adwords, способны выполнять всю грязную работу SEO-специалистов, включая работу, связанную с поиском по ключевым словам. Конечно, это очень полезные инструменты, но пренебрегать ручным анализом ключевых слов точно не стоит. Дело в том, что пока нет ни одного машинного алгоритма, который мог бы работать на одном уровне с человеком при отслеживании отраслевых тенденций и интересов целевой аудитории.
- Слишком большой набор ключевых фраз : Иногда программные инструменты для поиска по ключевым словам довольно сложны и требуют много времени при использовании. Если вы новичок и только запускаете свой сайт, имеет смысл следить за конкурентами и ключевыми словами, которые они используют на своем сайте.
Теперь вы знаете, как подбирать ключевые слова для SEO. Поиск по ключевым словам требует комплексного подхода и требует подробного анализа. В противном случае вы вряд ли сможете достичь оптимальных позиций в результатах поиска, если вместо этого не будете использовать черный SEO, о котором вы можете узнать больше в White Hat VS Gray Hat VS Black Hat SEO.
Расскажите нам в комментариях ниже о своем опыте поиска по ключевым словам. Насколько это было продуктивно? Вы использовали программные средства, описанные в статье? Как быстро вам удалось повысить позиции вашего сайта в поисковой выдаче?
Что это и как работает?
Для людей разобраться в тексте просто: мы узнаем отдельные слова и контекст, в котором они используются. Если вы читаете этот твит:
Если вы читаете этот твит:
«Ваше обслуживание клиентов — это шутка! Я ждал 30 минут и считаю!»
Вы понимаете, что клиент разочарован тем, что агент службы поддержки слишком долго отвечает.
Однако сначала необходимо научить машины понимать человеческий язык и понимать контекст, в котором используются слова; в противном случае они могут неправильно истолковать слово «шутка» как положительное.
На основе алгоритмов машинного обучения системы семантического анализа могут понимать контекст естественного языка, обнаруживать эмоции и сарказм и извлекать ценную информацию из неструктурированных данных, достигая точности человеческого уровня.
Прочтите, чтобы узнать больше о семантическом анализе и о том, как он может помочь вашему бизнесу:
Что такое семантический анализ?
Проще говоря, семантический анализ — это процесс извлечения значения из текста.Это позволяет компьютерам понимать и интерпретировать предложения, абзацы или целые документы, анализируя их грамматическую структуру и выявляя отношения между отдельными словами в определенном контексте.
Это важная подзадача обработки естественного языка (NLP) и движущая сила таких инструментов машинного обучения, как чат-боты, поисковые системы и анализ текста.
Инструменты семантического анализа могут помочь компаниям автоматически извлекать значимую информацию из неструктурированных данных, таких как электронные письма, заявки в службу поддержки и отзывы клиентов.Ниже мы объясним, как это работает.
Как работает семантический анализ
Лексическая семантика играет важную роль в семантическом анализе, позволяя машинам понимать отношения между лексическими элементами (словами, фразовыми глаголами и т. Д.):
- Гипонимы: конкретных лексических элементов общей лексической элемент (гипернимое) например апельсин — гипоним фрукта (гиперним).
- Мерономия: логическое расположение текста и слов, обозначающее составную часть или член чего-либо. е.g., сегмент апельсина
- Многозначность: отношения между значениями слов или фраз, хотя и немного отличаются, но имеют общее основное значение. например Я прочитал статью и написал статью)
- Синонимы: слов, которые имеют то же или почти такое же значение, что и другие, например, счастливый, довольный, восторженный, безмерно обрадованный
- Антонимы: слов, близких друг к другу. к противоположным значениям например, счастливый, грустный
- Омонимы : два слова, которые звучат одинаково и пишутся одинаково, но имеют разное значение е.g., оранжевый (цвет), оранжевый (фрукт)
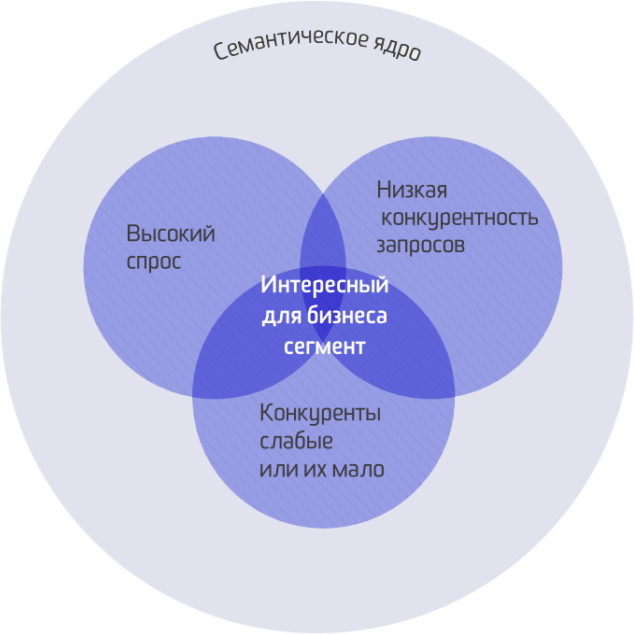 е.g., сегмент апельсина
е.g., сегмент апельсинаСемантический анализ также принимает во внимание знаки и символы (семиотика) и словосочетания (слова, которые часто идут вместе).
Автоматический семантический анализ работает с помощью алгоритмов машинного обучения.
Подавая семантически усовершенствованные алгоритмы машинного обучения образцами текста, вы можете обучать машины делать точные прогнозы на основе прошлых наблюдений. В семантическом подходе к машинному обучению задействованы различные подзадачи, включая устранение неоднозначности смысла слова и извлечение взаимосвязей:
Устранение неоднозначности смысла слова
Автоматический процесс определения значения слова, используемого в соответствии с его контекстом .
Естественный язык неоднозначен и многозначен; иногда одно и то же слово может иметь разные значения в зависимости от того, как оно используется.
Слово «апельсин», например , может относиться к цвету, фрукту или даже городу во Флориде!
То же самое происходит со словом «дата», , которое может означать либо конкретный день месяца, либо плод, либо встречу.
В семантическом анализе с машинным обучением компьютеры используют устранение неоднозначности смысла слова, чтобы определить, какое значение является правильным в данном контексте.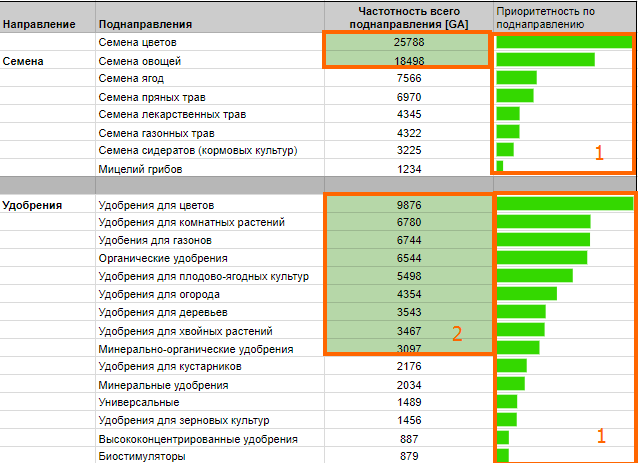
Извлечение отношений
Эта задача состоит из обнаружения семантических отношений, присутствующих в тексте. Отношения обычно включают два или более объекта (которые могут быть именами людей, мест, названиями компаний и т. Д.). Эти сущности связаны семантической категорией, такой как «работает в», «живет в», «является генеральным директором», «имеет штаб-квартиру».
Например, фраза «Стив Джобс — один из основателей Apple со штаб-квартирой в Калифорнии» содержит два разных отношения:
Методы семантического анализа
В зависимости от типа информации, которую вы хотите получить из данных, вы можете использовать один из двух методов семантического анализа: модель классификации текста (которая присваивает тексту предопределенные категории) или текст экстрактор (вытаскивающий конкретную информацию из текста).
Модели семантической классификации
- Классификация тем: сортировка текста по предопределенным категориям на основе его содержания. Команды обслуживания клиентов могут захотеть классифицировать заявки в службу поддержки по мере их поступления в службу поддержки. С помощью семантического анализа инструменты машинного обучения могут определить, следует ли классифицировать билет как «Проблема с оплатой», или «Проблема с доставкой».
- Анализ тональности: обнаружение в тексте положительных, отрицательных или нейтральных эмоций для обозначения срочности.Например, отметьте упоминания в Twitter по настроениям, чтобы получить представление о том, что клиенты думают о вашем бренде, и иметь возможность идентифицировать недовольных клиентов в режиме реального времени.
- Классификация намерений: классификация текста на основе того, что клиенты хотят делать дальше. Вы можете использовать это, чтобы пометить электронные письма с продажами как «Интересно» и «Не интересно» , чтобы активно обращаться к тем, кто может захотеть попробовать ваш продукт.

Модели семантического извлечения
- Извлечение ключевых слов: поиск подходящих слов и выражений в тексте.Этот метод используется отдельно или вместе с одним из вышеперечисленных методов для получения более детальной информации. Например, вы можете проанализировать ключевые слова в группе твитов, которые были отнесены к категории «негативных», и определить, какие слова или темы упоминаются чаще всего.
- Извлечение сущностей: идентификация именованных сущностей в тексте, таких как имена людей, компаний, мест и т. Д. Группа обслуживания клиентов может найти это полезным для автоматического извлечения названий продуктов, номеров доставки, электронных писем и любых других соответствующих данных из службы поддержки. Билеты.
Автоматическая классификация заявок с использованием инструментов семантического анализа освобождает агентов от повторяющихся задач и позволяет им сосредоточиться на задачах, которые представляют большую ценность, одновременно улучшая качество обслуживания клиентов.
Заявки можно мгновенно направить в нужные руки, а срочные вопросы можно легко определить по приоритетам, что сокращает время ответа и поддерживает высокий уровень удовлетворенности.
Выводы, полученные на основе данных, также помогают командам выявлять области, в которых можно улучшить, и принимать более обоснованные решения.Например, вы можете решить создать надежную базу знаний, определив наиболее частые запросы клиентов.
Заключение
В сочетании с машинным обучением семантический анализ позволяет вам вникать в данные ваших клиентов, позволяя машинам извлекать значение из неструктурированного текста в масштабе и в реальном времени.
Мощные инструменты машинного обучения с расширенной семантикой предоставят ценную информацию, которая способствует более эффективному принятию решений и повышению качества обслуживания клиентов.
MonkeyLearn упрощает начало работы с инструментами автоматического семантического анализа. Используя пользовательский интерфейс с низким кодом, вы можете создавать модели для автоматического анализа вашего текста на предмет семантики и выполнять такие методы, как анализ тональности и темы или извлечение ключевых слов, всего за несколько простых шагов.
Используя пользовательский интерфейс с низким кодом, вы можете создавать модели для автоматического анализа вашего текста на предмет семантики и выполнять такие методы, как анализ тональности и темы или извлечение ключевых слов, всего за несколько простых шагов.
Запросите у наших экспертов персонализированную демонстрацию и сразу же приступайте к работе!
Выучить RDF
Введение
Этот набор уроков представляет собой введение в RDF, основную модель данных семантической паутины и основу всех других технологий семантической паутины.Уроки вводят RDF, представляют дополнительные детали, а затем помещают RDF в контекст других технологий, таких как XML и JSON. Покрытие предназначено для новичков, плохо знакомых с RDF, но технический опыт очень поможет вам изучить материал.
Если вы еще не прошли уроки прикладных семантических технологий, сейчас самое время это сделать. Они обеспечивают критический контекст для этого набора уроков.
RDF 101
RDF (Resource Description Framework) — одна из трех основополагающих технологий семантической паутины, две другие — SPARQL и OWL.
В частности, RDF — это модель данных семантической паутины. Это означает, что все данные в технологиях семантической паутины представлены в виде RDF. Если вы храните данные семантической паутины, они находятся в RDF. Если вы запрашиваете данные семантической паутины (обычно с использованием SPARQL), это данные RDF. Если вы отправляете данные Семантической паутины своему другу, это RDF.
В этом уроке мы познакомимся с RDF.
Цели
В этом уроке вы выучите:
- Что такое RDF и чем он принципиально отличается от XML и реляционных баз данных
- Что подразумевается под «моделью данных графа»
- Как RDF обычно представляется визуально
- Важность URI и значимость (или ее отсутствие) «универсальности» идентичности
Сегодняшний урок
RDF является основой семантической паутины и обеспечивает ее врожденную гибкость. Все данные в семантической сети представлены в RDF, включая схему, описывающую данные RDF.
Все данные в семантической сети представлены в RDF, включая схему, описывающую данные RDF.
RDF не похож на табличную модель данных реляционных баз данных. И это не похоже на деревья мира XML. Вместо этого RDF — это граф.
Графики RDF
В частности, это маркированный ориентированный граф. Я имею в виду не график, как «диаграммы и графики», а скорее «точки и линии».
Следовательно, вы можете думать о RDF как о группе узлов (точек), соединенных друг с другом ребрами (линиями), где и узлы, и ребра имеют метки.
Термин «ориентированный граф» будет много значить для математиков из аудитории, но для остальных из вас я привел здесь простой пример.
Это полное, действительное, визуальное представление небольшого графа RDF. Покажите его любому специалисту по семантической паутине, и он сразу поймет, что он представляет.
Узлами графа являются овалы и прямоугольники (овалы и прямоугольники — это условное обозначение, к которому мы скоро вернемся). Ребра помечены стрелками, которые соединяют узлы друг с другом.Ярлыки — это URI (это очень важно, и мы рассмотрим его более подробно).
Примечание: графическая природа RDF является причиной того, что логотипы компаний, занимающихся семантической паутиной, почти всегда имеют некоторые ссылки на графы. Посмотрите, сможете ли вы найти график в логотипах Revelytix, Ontoprise, Ontotext, Apache Jena и Cambridge Semantics, не говоря уже о логотипе RDF, изображенном вверху на этом уроке.
В ориентированном графе RDF есть три типа узлов:
- Ресурсные узлы.Ресурс — это все, о чем можно что-то сказать. Ресурс легко представить как вещь, а не как ценность. В визуальном представлении ресурсы представлены овалами.
- Буквальные узлы. Термин «литерал» — это модное слово для обозначения ценности. В приведенном выше примере это ресурс http://www.cambridgesemantics.com/people/about/rob (еще раз, URI), а значением свойства foaf: name является строка «Роб Гонсалес». В визуальном представлении литералы представлены прямоугольниками.
- Пустые узлы.Пустой узел — это ресурс без URI. Пустые узлы — это расширенная тема RDF, которую мы рассмотрим в другом уроке. Обычно я рекомендую избегать их вообще, особенно если вы новичок в этой сфере. Они перечислены здесь просто для полноты.
Ребра могут переходить от любого ресурса к любому другому ресурсу или к любому литералу, с единственным ограничением, что ребра вообще не могут переходить от литерала к чему-либо.
Подумайте об этом на секунду.
Это означает, что все в RDF можно связать с чем угодно, просто нарисовав линию.
Эта идея является ключевой. Когда мы говорим о технологиях семантической паутины, которые фундаментально более гибки, чем другие технологии (XML, реляционные базы данных, кубы бизнес-аналитики и т. Д.), Это является причиной этого. Говоря абстрактно, вы просто проводите линии между вещами. Причем создать обновку так же просто, как нарисовать овал.
Если вы мысленно сравните это с моделью, которую вы, возможно, знаете по работе с реляционной базой данных, она кардинально отличается. Даже для базовых отношений, таких как отношения «многие ко многим», абстрактная модель реляционной базы данных усложняется.В конечном итоге вы добавляете дополнительные таблицы и столбцы (например, внешние ключи, таблицы соединений и т. Д.), Просто чтобы обойти внутреннюю жесткость системы.
Возможность соединять все вместе в любое время является революционной. Это похоже на гиперссылки в Интернете, но для любых данных, которые у вас есть! Следующее видео было во введении в семантическую сеть, но я также включу его сюда, поскольку оно подчеркивает этот момент.
Эта связь между вещами является фундаментальной возможностью семантической паутины и обеспечивается URI.
Центральное значение URI
Если вы хотите соединить две вещи в реляционной базе данных, вам нужно добавить внешние ключи к таблицам (или, если у вас есть отношение «многие ко многим», создать таблицы соединения) и т. Д. Если вы хотите связать вещи между базами данных, вам нужно задание ETL с использованием чего-то вроде Informatica. Это просто нелегко.
Если рассматривать мир XML, то то же самое. Соединение вещей в XML-документе возможно, хотя и утомительно. Связывание вещей между XML-документами требует реальной работы.Если вы не один из тех немногих, кто просто любит XSLT, вы делаете это нечасто.
Фундаментальная ценность и отличительная способность Семантической паутины — это возможность соединять вещи.
URI делает это возможным.
URI означает универсальный идентификатор ресурса. Универсальная часть этого является ключевой. Вместо того, чтобы создавать специальные идентификаторы для вещей в одной базе данных (подумайте о первичных ключах), в семантической сети мы создаем универсальные идентификаторы для вещей, согласованных в разных базах данных.Это позволяет нам создавать связи между всеми вещами (задержите на секунду скептицизм, мы доберемся до этого!).
В RDF ресурсы и ребра являются URI. Литералы — нет; это простые ценности. Пустые узлы не являются (это то, что означает «пустой» в названии). Все остальное есть, включая края.
Если вы посмотрите на наш пример выше, есть несколько примеров URI.
- http://www.cambridgesemantics.com/
- http://www.cambridgesemantics.com/people/about/rob
- foaf: member (это сокращение от http: // xmlns.com / foaf / 0.1 / member)
- foaf: name (опять же, сокращение для http://xmlns.com/foaf/0.1/name)
Первый — это URI для компании Cambridge Semantics. Второй — это URI Роба, автора этой статьи. Два других — это URI для ребер, которые соединяют ресурсы (мы подробнее поговорим об URI ребер через минуту).
Вы должны заметить, что некоторые из приведенных выше URI являются URL-адресами. Вы можете нажать на них. Это действительные веб-адреса. Так что же делает их URI?
Короче говоря, все URL-адреса являются URI, но не все URI являются URL-адресами.Конечно, это немного сбивает с толку, но подавляющее большинство практиков семантической паутины придерживаются использования URL-адресов для всех своих URI. См. Статью URL, URI и URN для краткого объяснения различий, если вам интересно.
Вернуться к концепции универсальности идентичности. Если у меня есть база данных, содержащая информацию обо мне, я бы использовал URI http://www.cambridgesemantics.com/people/about/rob для ссылки на любые данные, относящиеся ко мне. Если у вас есть другая база данных, в которой есть другая информация обо мне, вы также можете использовать тот же URI.Таким образом, если бы мы хотели найти все факты обо мне в обеих базах данных, мы могли бы запросить, используя единый универсальный URI.
Легко, правда?
Как и все теоретически простые модели, в реальном мире все иначе.
На границах универсальности и дизайн схемы RDF
Есть большая проблема с концепцией универсальности, представленной выше.
Невозможно заставить всех повсюду согласовать единый ярлык для каждой конкретной вещи, которая когда-либо была, есть или будет.
Если вы прочитаете введение в технологии семантической паутины в Интернете, вы увидите, что многие люди обращают внимание на важность URI. В конце концов, как можно соединить вещи, если вы не согласны с их ярлыками? Акцент на определении URI особенно актуален для тех, кто создает словари RDF.
Под словарём RDF мы понимаем, по сути, набор URI для ребер, составляющих графы RDF. Ребра — это то, что связывает объекты в графе, и то, что придает ему смысл.Использование определенных URI похоже на разговор на определенном языке — отсюда и термин «словарь». Например, чтобы два приложения семантической паутины могли совместно использовать данные, они должны согласовать общий словарь. (Примечание: мы собираемся рассмотреть создание RDF-словаря и схемы в будущих уроках по RDFS и OWL.)
Итак, если два приложения должны согласовать словарь для всех понятий, тогда само собой разумеется, что все словари должны быть установлены заранее, верно? К счастью, априорное существование общего словарного запаса оказывается полезным, но отнюдь не необходимым.В нашем примере foaf: name — не первый когда-либо созданный URI, который представляет концепцию имени, и нормально, что другой URI для концепции имени не использовался повторно.
К счастью, как вы увидите в руководствах по SPARQL, очень легко перевести RDF, написанный в одном словаре, в другой словарь. Технологии семантической паутины были построены исходя из предположения, что разные люди в разных приложениях, написанных для разных целей в разное время, будут создавать связанные концепции, которые пересекаются любым количеством способов, и поэтому существуют положения и методы, позволяющие заставить все это работать вместе с небольшими усилиями .Такого положения нет в мире XML или реляционных баз данных.
Другими словами, вам не нужно согласовывать все URI заранее. На самом деле этого гораздо проще не делать. Повторно используйте словарный запас, когда это возможно и удобно, и не беспокойтесь об этом, когда это не сработает.
Та же самая головоломка универсальной идентичности случается и с ресурсами. Например, вы можете рассматривать мой URL-адрес профиля Linked In как URI, представляющий меня. Это явно отличается от URI, который использует Cambridge Semantics, но, опять же, Semantic Web предлагает очень простые способы объединения идентичных концепций, чтобы они универсально отображались как одно целое.
Мы подробно рассмотрим, как это работает, в будущих уроках, а пока давайте вернемся к основам RDF.
Утверждения и тройки
Теперь, когда вы ознакомились с основами, я должен ввести некоторый жаргон сообщества, который поможет вам понять материал, который вы читаете в Интернете о технологиях семантической паутины.
Вместо того, чтобы говорить на языке узлов и ребер, специалисты по семантической паутине обращаются к операторам или тройкам, которые являются представлениями ребер графа.
Утверждение или тройка (они синонимы) относятся к тройке (следовательно, тройке) формы (субъект, предикат, объект).Из-за этой лингвистической, сентенциальной формы схемы RDF часто называют словарями.
Как упоминалось, субъект — это URI, предикат — это URI, а объект — либо URI, либо буквальное значение.
Если мы представим наш пример графика как набор троек, это будет:
- (csipeople: rob, foaf: name, «Роб Гонсалес»)
- (csipeople: rob, foaf: member, http://www.cambridgesemantics.com/)
(обратите внимание, что для краткости я использую псевдоним пространства имен csipeople для пространства имен URI http: // www.cambridgesemantics.com/people/about/).
Следовательно,RDF-графы — это просто наборы троек. По этой причине базу данных RDF часто называют тройным хранилищем.
Однако практикам семантической паутины было очень трудно иметь дело с большим количеством троек при разработке приложений. Существует множество причин, по которым вы захотите сегментировать разные подмножества троек друг от друга (упрощенный контроль доступа, упрощенное обновление, доверие и т. Д.), А ванильный RDF сделал сегментацию утомительной.
Сначала сообщество пыталось использовать реификацию для решения этой проблемы сегментации данных (мы рассмотрим реификацию в другом уроке, но концепция по существу состоит из троек относительно троек), но сегодня все сошлись на использовании именованных графов.
Именованные графики и квадраты
Именованный граф — это просто набор операторов RDF с именем (которое, как вы уже догадались, является URI).
Modern Triple хранит все поддерживаемые именованные графы, и они встроены в SPARQL 1.1, последняя спецификация языка запросов SPARQL.
При ссылке на тройку в именованном графе вы часто будете использовать нотацию с четырьмя кортежами вместо нотации с тремя кортежами. Четверка имеет вид:
(именованный граф, субъект, предикат, объект)
По этой причине тройное хранилище, которое поддерживает именованные графы, часто называется четырехъядерным хранилищем, хотя, что несколько сбивает с толку, сами тройные хранилища в любом случае часто являются четырехместными. То есть, если база данных RDF объявляет себя хранилищем троек, она, вероятно, поддерживает именованные графы.Термин «четырехъядерный магазин» не так важен.
Глядя на 4-кортежи, довольно очевидно, что один и тот же оператор может существовать в нескольких именованных графах. Это сделано специально и является очень важной особенностью. Организуя оператор в именованные графы, приложение семантической паутины может очень четко реализовать управление доступом, доверие, происхождение данных и другие функции.
Точно лучшие способы сегментирования троек в вашем приложении — это сложная тема, которая будет рассмотрена в будущих уроках, и это большая часть ценности, которую приносят платформы семантической сети, которые часто скрывают детали и логику создания и сегментации именованных графов. для упрощения разработки приложений.На данный момент просто важно знать, что именованные графы являются сегментацией и организационным механизмом Семантической паутины.
Заключение
Это большой объем информации, который нужно охватить за один урок, особенно на таком уровне детализации. Однако все сводится к очень простому резюме, которое станет вашей второй натурой, если вы потратите какое-то время на внедрение технологий семантической паутины:
- RDF — это модель данных графа.
- Данные RDF представляют собой ориентированные помеченные графы.
- Одно ребро в графе RDF — это кортеж из трех элементов, который называется оператором или тройкой.
- Тройки организованы в именованные графы, образующие кортежи из 4 или четырехугольников.
- RDF-ресурсы (узлы), предикаты (ребра) и именованные графы помечены URI.
- Хотя предпочтительнее повторно использовать URI, когда это возможно, технологии семантической паутины, включая OWL и SPARQL, упрощают разрешение конфликтов URI, как мы увидим в будущих уроках.
Неявное обязательство арифметических теорий и их семантическое ядро
Как отметили несколько авторов, Footnote 12 , прибегая к схемам, таким как \ ({\ mathsf {RFN}} (S) \) выше, можно с уверенностью рассматривать как суррогат для отдельных предложений формы
$$ \ begin {выровнено} \ quad \ forall x \, ({\ mathsf {Pr}} _ S (x) \ rightarrow \ mathsf {T} x) \ end {выравнивается} \ quad \ mathsf {GRP} (S) $$
где \ (\ mathsf {T} \) — унарный предикат истинности.Эти суррогаты становятся необходимыми только тогда, когда понятие истины не является частью сигнатуры теории. Любое заявление о разумности, по-видимому, внутренне связано с понятием истины. Если кто-то хочет выразить на объектном языке, что, например, все нелогические аксиомы S истинны, можно, конечно, прибегнуть к схеме вида
$$ \ mathsf {Ax} _S (\ ulcorner \ varphi \ urcorner) \ rightarrow \ varphi $$
где \ (\ mathsf {Ax} _S (\ cdot) \) — представление всех нелогических аксиом S .Тем не менее, этот вариант просто подчеркивает тот факт, что мы опускаем понятие истины в метатеорию.
Очевидно, у кого-то может быть независимая мотивация придерживаться выразительных ограничений арифметического языка при утверждении обоснованности теории. Теннант (2002), например, использовал хорошо известный факт, что схематические версии отражения, такие как \ ({\ mathsf {RFN}} (S) \), позволяют нам выйти за рамки того, что можно доказать в S , чтобы защитить возможность дефляционного объяснения понятия истины, используемого в этих утверждениях о разумности.Однако Теннант не полностью формулирует обоснование этих принципов, хотя и намекает на схематическую версию рефлексии как на достаточную для фиксации норм для утверждения этих утверждений о разумности (Tennant 2002, p. 574). В более общем плане, в то время как это бесспорный, что расширение Обоснованность S будет содержать формы отражения, такие как \ ({\ mathsf {RFN}} (S) \), остается проблематичным ли присутствие \ ({\ mathsf { RFN}} (S) \) является достаточным для определения расширения надежности в том смысле, что его принципы сводятся к последовательной формулировке концепций, необходимых для утверждения требований о надежности для S .Хорошей иллюстрацией того, как утверждения о разумности могут быть получены в рамках адекватной основы доказуемости и истинности, является рефлексивное замыкание Феферманом PA (\ (\ mathsf {Ref} (S) \)), ныне широко известного как KF из «Крипке- Феферман » Сноска 13 :
Какие утверждения на базовом языке L из S [\ (\ dots \)] следует принять, если вы приняли основные аксиомы и правила S ? Ответ дается в виде обычной теории ( S ), сформулированной на языке L ( T , F ) [\ (\ dots \)], где T и F являются частичной истиной и предикаты ложности, которые самоприменимы в том смысле, что они применяются к (кодам) утверждений L ( T , F ) […] Таким образом, например, мы можем рассуждать в Ref (PA) по индукции об истинности утверждений, содержащих понятие истины, и таким образом прийти к утверждениям вида: \ (\ forall x [Prov_ {PA} ( x) \ rightarrow T (x)] \), и, повторяя аргументы такого рода, вывести принципы повторного отражения для арифметики (Феферман, 1991, стр. 2).
Обратите внимание на то, что мы не предполагаем невозможность убедительных аргументов, подтверждающих отсутствие понятия истины из расширений обоснованности данной теории; мы просто считаем, что при обычном способе представления и обоснования утверждений о разумности теории S , без понятия истины трудно обойтись.Такие предложения, как предложение Теннанта, и последовавшие за ним дискуссии (Ketland 2005; Cieśliński 2010; Piazza and Pulcini 2015) ясно показывают, насколько трудно искоренить интуицию о том, что принципы отражения концептуально зависят от понятия истины. Но бремя ответственности лежит на тех, кто не разделяет эту интуицию, рассказывать принципиальную историю о заявлениях о разумности, прибегая к суррогатам, которые могут играть роль семантических понятий. Трудно сказать, к чему могла привести эта история. Таким образом, на протяжении всей статьи мы будем придерживаться широко распространенного мнения и считать, что утверждения о разумности лучше всего формулировать, используя понятие истины, регулируемое подходящими аксиомами.
Однако это не сразу означает, что эти аксиомы, добавленные к S , должны привести к , влекут за собой \ (\ mathsf {GRP} (S) \). Такое требование действительно было бы слишком сильным для произвольного S (а именно, когда S также изменяется, например, в теориях с ограниченной индукцией). Случай, сделанный Тэтом для PRA с точки зрения финитизма, действительно является одним из примеров, когда нужно быть осторожным при калибровке силы принципов для предиката истинности.1_2} \) — , язык которого расширен новым предикатом \ (\ mathsf {T} \) — со схемой Footnote 14
$$ \ begin {align} \ quad \ forall x \, (\ mathsf {T} \, \ ulcorner \ varphi (\ dot {x}) \ urcorner \, \ leftrightarrow \ varphi (x)) \ end {align} \ quad (\ mathsf {utb}) $$
для всех формул \ ({\ mathcal {L}} \) \ (\ varphi (v) \) выводит полную схему индукции \ ({\ mathcal {L}} \). 1_2} \) в \ (\ mathcal L_ \ mathsf {T}: = {{\ mathcal {L}}} \ cup \ {\ mathsf {T} \} \) содержит \ (\ mathsf {I} \ Delta _0 \) в \ (\ mathcal L_ \ mathsf {T} \), следующее выводится в бывшем
$$ \ begin {align} \ mathsf {T} \ ulcorner \ varphi (0) \ urcorner \ wedge \ forall x \, (\ mathsf {T} \ ulcorner \ varphi (\ dot {x}) \ urcorner \ rightarrow \ mathsf {T} \ ulcorner \ varphi (\ dot {x + 1}) ) \ urcorner) \ rightarrow \ forall x \, \ mathsf {T} \ ulcorner \ varphi (\ dot {x}) \ urcorner \ end {align} $$
(3)
для формулы \ (\ varphi (v) \) из \ ({\ mathcal {L}} \) произвольной сложности, потому что \ (\ mathsf {T} \ ulcorner \ varphi (\ dot {x}) \ urcorner \) — это \ (\ Delta _0 \) — формула \ (\ mathcal L_ \ mathsf {T} \).Используя (utb), (3) дает желаемый результат. □
Аргумент, использованный в предложении 3, одинаково хорошо применим — с очевидными модификациями — к другим подсистемам PA, полученным ограничением индукции, таким как \ (\ mathsf {EA} \), \ (\ mathsf {PRA} \), of \ ( \ mathsf {I} \ Sigma _n \) на каждые n . Footnote 15 В любом случае предложение 3, кажется, уменьшает наши шансы найти разумное теоретико-истинное расширение произвольной арифметической теории S , которое фиксирует набор разумных аксиом истинности, совместимых с принципами, которые мы неявно придерживаемся обязуется, когда мы одобряем S .1_2} \), \ (\ mathsf {EA} \) или \ (\ mathsf {PRA} \) до полного \ ({\ mathsf {PA}} \), то, похоже, нет никакой надежды на гармонизацию (ICT ) и базовые позиции, которые не допускают арифметические последствия, превышающие таковые для систем, связанных с такими позициями.
Тем не менее, такой вывод был бы просто торговлей на путанице в значении «аксиомы истины». Теория истины, используемая в предложении 3, получается расширением математических схем индукции базовой теории на предикат истинности.Если аксиомы (utb) однозначно теоретичны по своему характеру, естественно думать о расширенной индукции как о математической , а не как о теоретико-истинной аксиоме. Похоже, что на самом деле существует существенная разница между металингвистическими принципами, объявляющими условия истинности для предложения \ ({{\ mathcal {L}}} \), как (utb), как кажется (частично), и расширением до предикат истинности схемы, обоснование которой очевидно неметалингвистическое. Как заметил Хартри Филд, такое обоснование по существу зависит от «факта о натуральных числах, а именно от того, что они линейно упорядочены, причем каждый элемент имеет конечное число предшественников» (Field 1999, стр.{\ dot {x}}> \ dot {x} \ urcorner \), строго говоря, неотличимы. Однако с внешней точки зрения нашей неформальной метаматематической практики они явно различны. Только потому, что арифметика играет двойную роль теории синтаксиса и теории объектов, мы можем рассматривать оба случая как принадлежащие по существу к одному и тому же классу. Это наблюдение даже привело к формулировке теорий истины, которые отделяют область синтаксических объектов от математической или, в более общем плане, объектно-теоретической вселенной (см. Halbach 2011; Heck 2015; Nicolai 2015).Мы не собираемся здесь рассматривать детали этой альтернативной схемы: мы будем неявно проводить различие между металингвистическими и объектно-лингвистическими примерами индукционной схемы. Однако в дальнейшем мы не будем расширять индукционную схему S на предикат истинности, чтобы избежать какого-либо смешения между двумя уровнями.
Однако это не означает, что мы не сможем заявить истину индукционных схем S : если на самом деле расширенная индукционная схема в сочетании с аксиомами естественной истины приведет нас к очень сильным теории, предположение об истинности всех ее примеров довольно невинно.Как мы вскоре увидим, действительно, результат добавления к широкому классу базовых теорий S утверждения «все экземпляры индукционной схемы S истинны» по-прежнему совместим с альтернативным прочтением (ICT), которое мы предложили в предыдущем разделе, и это нацелено на гармонизацию (ИКТ) с основополагающими точками зрения, такими как Тейта, Исааксона и Нельсона.
Семантическое ядро
Мы видели, что сильное прочтение (ICT) может противоречить основополагающим точкам зрения, основанным на форме «арифметической полноты» или «эпистемической стабильности» некоторой арифметической системы S .Фактически, если (ICT) влечет за собой принципы отражения для S и, следовательно, утверждения на арифметическом языке, которые недоказуемы только в S , то, принимая S , человек также обязан принять арифметические следствия, выходящие за рамки S , что противоречит его предполагаемой полноте.
В заключительной части разд. 2, мы предусмотрели возможность альтернативного прочтения (ICT), которое могло бы быть защищено от этой проблемы. Но как могло выглядеть это альтернативное чтение? Может быть поспешная мысль позволить (ИКТ) зависеть исключительно от фундаментальной точки зрения.Это очень проблематично. Давайте рассмотрим, например, человека, который принимает только то, что можно вывести или интерпретировать в ПА: согласно хорошо известному результату Фефермана, он также примет \ (\ lnot \ mathsf {Con (PA)} \). Footnote 16 Напротив, мы видели, что есть несколько авторов, склонных принять \ (\ mathsf {Con (PA)} \) после принятия PA. Таким образом, согласно этому релятивистскому взгляду на (ИКТ), его разные толкования приведут не только к альтернативным наборам принципов, но, скорее, к наборам принципов, несовместимым друг с другом.В конкретном случае только что упомянутого \ (\ lnot \ mathsf {Con (PA)} \), кроме того, есть явное отклонение от того, что мы ранее защищали как необходимое условие для любого правдоподобного чтения (ICT), а именно правда принципов играют. Интерпретация (ICT), которую мы сейчас представляем, сохранит прочную связь с понятием истины, отвергая при этом жесткость, обнаруженную в прочтении (ICT) Феферманом. Наш подход обосновывает динамическое чтение (ICT) как отображение фиксированного семантического компонента — называемого семантическим ядром неявной приверженности — и переменного компонента, относящегося к основополагающей точке зрения.
Семантическое ядро представляет собой набор принципов метатеоретической природы, которые позволяют нам естественным и единообразным образом размышлять о нашем принятии различных арифметических теорий. Чтобы представить его, мы рассуждаем в три этапа. На первом этапе нам нужно расширить язык S семантическими ресурсами, в частности предикатом истинности \ (\ mathsf {T} \), и охарактеризовать его минимальным набором принципов, отражающих его дисквотационный характер. Точнее, при подходящем S теория \ (\ mathsf {TB} [S] \) получается расширением \ ({\ mathcal {L}} _ S \) предикатом \ (\ mathsf {T} \) и расширяет свои аксиомы схемой
$$ \ begin {выравнивается} \ quad \ mathsf {T} \ ulcorner \ varphi \ urcorner \, \ leftrightarrow \ varphi \ end {выравнивается} \ quad (\ mathsf {tb} ) $$
для всех \ (\ mathcal {L} _S \) — предложений \ (\ varphi \).Непосредственным следствием tb является истинность каждой аксиомы из S ; поэтому ясно, что если S имеет конечное число нелогических аксиом, tb достаточно, чтобы заключить \ (\ forall x \, (\ mathsf {Ax} _S (x) \ rightarrow \ mathsf {T} x) \), это единственное предложение, выражающее истинность всех (нелогичных) аксиом S . Дальнейшие утверждения четкой металингвистической природы также подтверждаются в табл. Например, \ (\ mathsf {TB} [S] \) доказывает утверждение, что принцип глобального отражения для S влечет за собой согласованность S .Формально:
$$ \ begin {align} \ forall x \, ({\ mathsf {Pr}} _ {S} (x) \ rightarrow \ mathsf {T} x) \ rightarrow \ mathsf {Con} (S) \ end {align} $$
(4)
Это следствие просто получается путем создания экземпляра (кода) ложности S в GRP ( S ).
Уже на этом первом этапе должно быть ясно, что мы стремимся к семантическим расширениям S в смысле согласованных формулировок концепции истины над базовой теорией S .Например, можно просто расширить S предложениями \ (\ forall x \, (\ mathsf {Ax} _S (x) \ rightarrow \ mathsf {T} x) \) или GRP ( S ) как новые аксиомы. Приведенных выше предложений явно недостаточно, чтобы считать аксиомы для предиката истинности \ (\ mathsf {T} \): в первом случае результирующая теория ясно интерпретируется в S , принимая рассматриваемый предикат истинности как определил самим \ (\ mathsf {Ax} _S (x) \); во втором случае полная схема tb не требуется для вывода (4), поскольку достаточно «модальной» аксиомы \ (\ mathsf {T} \ ulcorner \ phi \ urcorner \ rightarrow \ phi \).Это говорит о том, что в этих расширениях S концепции, отличные от истины, могут использоваться в качестве естественного прочтения для предиката \ (\ mathsf {T} \).
С точки зрения теорем из S , \ (\ mathsf {TB} [S] \) выглядит довольно невинно. Во-первых, она консервативна по сравнению с S . Более того, если S является рефлексивным [т.е. непротиворечивость любых конечных подтеорий S доказуема в S , (Mostowski 1952)], \ (\ mathsf {TB} [S] \) также относительно интерпретируема в S .Это связано с тем, что в любом данном доказательстве в S предикат истинности \ (\ mathsf {T} \) может быть заменен на S -определяемый предикат истинности. Этого достаточно, чтобы засвидетельствовать консервативность и, согласно теореме Ори о компактности (см. Lindstrom 1997, §7), интерпретируемость \ (\ mathsf {TB} [S] \) в S для рефлексивного S .
Дисквотационные принципы, однако, не соответствуют многим дальнейшим пожеланиям, которые мы хотели бы отнести к семантическому ядру неявной приверженности.n _ {{{\ mathcal {L}}}} (x) \) выражает, что x является предложением \ ({{\ mathcal {L}}} \) сложности \ (\ le n \) для любого задано n , но не для произвольных предложений \ ({{\ mathcal {L}}} \) и выражения \ (\ underset {\ cdot} {\ rightarrow} \) (и \ (\ underset {\ cdot} {f} \) в более общем виде) представляет в S синтаксическую операцию вывода (соответственно f ). Footnote 17
Таким образом, для наших целей недостаточно простого обсуждения.В качестве второго шага можно подумать о расширении \ (\ mathsf {TB} [S] \) дальнейшими теоретическими принципами, чтобы получить неограниченные версии (5). Очевидными кандидатами являются так называемые композиционные аксиомы истины , такие как «\ (\ lnot \ varphi \) истинно тогда и только тогда, когда \ (\ varphi \) не истинно», которые управляют взаимодействием предиката истинности и логические константы. Например, поскольку мы можем с уверенностью предположить, что S сформулирован в исчислении, в котором modus ponens является единственным логическим правилом вывода [см., Например, Enderton (2001)], нам нужно только добавить к S предложение
$$ \ begin {выровнено} \ forall x, y \, (\ mathsf {Sent} _ {{{\ mathcal {L}}}} (x) \ wedge \ mathsf {Sent} _ {{{ \ mathcal {L}}}} (y) \ wedge \ mathsf {T} (x \ underset {\ cdot} {\ rightarrow} y) \ wedge \ mathsf {T} x \ rightarrow \ mathsf {T} y) \ конец {выровнен} $$
(6)
, чтобы получить сохраняющий истину характер modus ponens.
Если S конечно аксиоматизирован, то \ (\ mathsf {TB} [S] \) + (6) позволяет нам доказать, что все нелогические аксиомы S верны и что — если логика правильно выбрано — что все правила вывода S сохраняют истину. Однако у этой теории есть как минимум две проблемы: во-первых, она не формулирует связное семантическое понятие, поскольку мы обычно требуем, чтобы истинность составного предложения зависела от истинности его составных частей, а эта теория не имеет такого особенность.Короче говоря, теория не является (полностью) композиционной. Во-вторых, если S не является конечно аксиоматизируемым, он не может доказать, что все нелогические аксиомы S верны. Фактически, как показывает следующая лемма, этого не может быть, даже если мы добавим к S полностью композиционную теорию истины:
Лемма 1Пусть S сформулировать как \ (\ mathcal L_ \ mathsf {T} \) и предположим, что он удовлетворяет полной индукции для \ ({{\ mathcal {L}}} _ S \) — это значит, что предикат истинности не может использоваться в индукции.Эта теория расширилась предложениями
$$ \ begin {align} & \ mathsf {Cterm} _ {{{\ mathcal {L}}} _ S} (x_1) \ wedge \ cdots \ wedge \ mathsf {Cterm} _ {{{\ mathcal {L }}} _ S} (x_n) \ rightarrow \ big (\ mathsf {T} \ ulcorner R (\ dot {x} _1, \ ldots, \ dot {x} _n) \ urcorner \ leftrightarrow R (x_1, \ ldots, x_n) \ big) \ end {align} $$
(7)
$$ \ begin {align} & \ mathsf {Sent} _ {{\ mathcal {L}}} _ S} (x) \ rightarrow \ big (\ mathsf {T} (\ underset {\ cdot} {\ lnot } x) \ leftrightarrow \ lnot \ mathsf {T} x \ big) \ end {align} $$
(8)
$$ \ begin {align} & \ mathsf {Sent} _ {{{\ mathcal {L}}} _ S} (x \ underset {\ cdot} {\ rightarrow} y) \ rightarrow \ big (\ mathsf {T } (x \ underset {\ cdot} {\ rightarrow} y) \ leftrightarrow (\ mathsf {T} x \ rightarrow \ mathsf {T} y) \ big) \ end {align} $$
(9)
$$ \ begin {align} & \ mathsf {Sent} _ {{{\ mathcal {L}}} _ S} (\ underset {\ cdot} {\ forall} vx) \ rightarrow \ big (\ mathsf {T} (\ underset {\ cdot} {\ forall} vx) \ leftrightarrow \ forall y \, \ mathsf {T} x (\ dot {y} / v) \ big) \ end {align} $$
(10)
не может доказать, что все аксиомы S верны.
В (7) R пробегает символы отношения \ ({{\ mathcal {L}}} _ S \).
ПробаПредположим, что S \ (+ \) (7–10) доказывает
$$ \ begin {align} \ forall x \, (\ mathsf {Ax} _ {S} (x) \ rightarrow \ mathsf {T } x), \ end {align} $$
(11)
Затем мы можем показать, что формула
$$ \ begin {align} \ mathcal K (x): \ leftrightarrow (\ forall y \ le x) \, (\ mathsf {Prv} _ {S} (y) \ rightarrow \ mathsf {T} \ mathsf {end} (y)) \ end {align} $$
(12)
в нем прогрессивный.b \) — функция, выводящая последний элемент из S -доказательства. Следовательно, по-прежнему с помощью результата Соловея о подключаемых частях (см. Предложение 2), мы находим начальный сегмент S -чисел, удовлетворяющий свойству, выраженному как \ (\ mathcal K (x) \), в котором все логические аксиомы S верны, а затем доказать непротиворечивость S относительно этого начального сегмента. Footnote 18 Усилением второй теоремы Гёделя о неполноте, полученным Пудлаком (1985, Cor.3.5), поэтому этого достаточно, чтобы показать, что S не может интерпретировать S \ (+ \) (7–10). Однако известно, что S \ (+ \) (7–10) можно интерпретировать в S (см. Enayat and Visser 2015, §16.5). □
Полные составные предложения (7–10), без сомнения, являются желательными характеристиками для понятия истины. Более того, это понятие истины является естественным компонентом принятия S посредством утверждений о разумности, а утверждения о разумности, в свою очередь, являются неотъемлемой частью многих утверждений о неявных обязательствах.Однако, как мы видели, существуют также ограничения, на которые можно полагать утверждения о разумности, в зависимости от основополагающей позиции. Мы уже рассмотрели примеры таких ограничений: например, связанные с принципами отражения \ (\ mathsf {RFN (EA)} \) или \ (\ mathsf {RFN (PA)} \) — и, тем более, их глобальные версии — для таких позиций, как финитизм или первопорядок а ля Isaacson. Тем не менее, как мы вскоре отметим, таких ограничений для композиционных предложений истинности не существует.Что еще более удивительно, так это то, что мы можем допускать явные утверждения о разумности относительно нелогических аксиом произвольной теории S , не вторгаясь в сферу того, что недоказуемо в S . Это можно установить в целом.
В качестве третьего и последнего шага построения семантического ядра мы рассматриваем теорию \ (\ mathsf {CT} [S] \), полученную путем расширения языка теории S с помощью предиката истинности , а не допускаются в примеры нелогических схем аксиом и расширения S с помощью принципов (7–11).
Хальбах (2011) пытается доказать консервативность \ (\ mathsf {CT} [S] \ setminus \) (11) с помощью аргумента исключения разреза. Его аргумент основан на переформулировке \ (\ mathsf {CT} [S] \) в (конечном) двустороннем исчислении секвенций с сокращением путем переписывания (7–10) в качестве правил вывода, например
, а затем переходит к попытке устранить сокращения в формулах вида \ (\ mathsf {T} s \) из выводов в этой теории. Leigh (2015) показывает, что эта стратегия может удалять разрезы только доказуемо фиксированной сложности (см.Ли 2015, §3.7). Затем он показывает, как исправить стратегию Хальбаха, найдя подходящие границы сложности \ (\ mathsf {c} (\ cdot) \) формул, отсекающих истину в \ (\ mathsf {CT} [S] \) — выводах— для S интерпретирующий EA — так что \ (\ mathsf {CT} [S] \) может быть встроен в систему в результате замены полного правила сокращения для формул вида \ (\ mathsf {T} s \) на более слабый набор правил
для каждого n и подходящая ограниченная версия (11). Важно отметить, что в этой системе используется стандартная версия исключения сокращений для сокращений приписываний правды.Выведение свободных от истинности секвенций вида \ (\ Gamma \ Rightarrow \ Delta \) затем систематизируется с помощью понятия аппроксимации секвенции, впервые рассмотренной Котларски и др. (1981), что позволяет контролировать такие доказательства в \ (\ mathsf {CT} [S] \) и преобразовывать их в доказательства той же секвенции, где используются только применения модифицированных правил. Наконец, стандартным образом устраняются сокращения в формулах вида \ (\ mathsf {T} s \). Эта стратегия дает следующее:
Предложение 4(Leigh 2015, Thm.2) Для \ (S \ supseteq \ mathsf {EA} \), \ (\ mathsf {CT} [S] \) является консервативным расширением S .
Предложение 4 говорит нам, что семантические принципы теории \ (\ mathsf {CT} [S] \) могут быть безопасно включены в семантическое ядро неявного обязательства S . Наш главный тезис сейчас обретает форму: принимая арифметическую теорию S , мы всегда неявно привержены теории \ (\ mathsf {CT} [S] \), которая составляет фиксированный, неизменный компонент нашей обязательство.Принципиально важно, исчерпывает ли \ (\ mathsf {CT} [S] \) наши обязательства или нет, зависит от конкретной фундаментальной точки зрения, которая в первую очередь привела нас к принятию данной теории S . Footnote 19
Это завершает представление семантического ядра для неявной приверженности: оно сводится к расширению S композиционными аксиомами истинности и утверждением, что все (нелогические) аксиомы S истинны. По нашему мнению, является необходимым условием для неявной приверженности, но, возможно, недостаточным. : это будет зависеть от основополагающей точки зрения, которую принимают при обосновании конкретной формальной системы S .
Прежде чем привести конкретные примеры того, как наше прочтение (ICT) в свете семантического ядра применимо к рассмотренным выше позициям, мы предвидим два возможных возражения против структуры семантического ядра. Footnote 20 Семантическое ядро можно обвинить в том, что оно слишком искусственно, учитывая (1) отсутствие естественных принципов правильности, таких как \ (\ mathsf {Con} (S) \), и (2) отсутствие замыкания при первом -Порядок рассуждений. Мы рассматриваем два возражения по отдельности.
На первое возражение естественным ответом будет то, что мы не ставим задачу, которую мы возлагаем на семантическое ядро, — решать, какое расширение разумности базовой теории S является естественным или нет.Вопрос, к которому мы обращаемся, заключается в том, действительно ли тот, кто считает базовую теорию S эпистемически стабильной в смысле разд. 1 может последовательно принимать (ICT): с помощью семантического ядра мы стремимся предоставить основу для утвердительного ответа на этот вопрос. Другими словами, мы не утверждаем, что, скажем, \ (\ mathsf {Con} (S) \) не является естественным принципом для подтверждения после того, как кто-то одобрил S , но мы разделяем с Дином мнение, что , если оправдание \ (\ mathsf {Con} (S) \) эквивалентно принципам, несовместимым с предполагаемой эпистемической стабильностью S , как мы видели в случае финитизма и первопорядка, тогда такое обоснование не может подразумеваться в простом принятии S , но должно исходить из более общих соображений.Например, как мы вскоре увидим, хотя Исааксон считает \ (\ mathsf {Con} (\ mathsf {PA}) \) принципом бесконечного характера, это не означает, что его принятие должно быть отклонено: этот принцип просто следует из принятия подходящей части бесконечной математики, хотя это не подразумевается в принятии PA, которое — согласно первопорядку — ограничивает границы конечной математики. Все это совместимо со структурой, предоставляемой семантическим ядром.
Чтобы ответить на второе возражение, можно использовать аналогичную цепочку рассуждений: закрытие истины с помощью логических рассуждений не является принципом, который мы считаем неправильным или нежелательным. Однако при условии эпистемической устойчивости теории S принцип отражения для логики влечет за собой принципы, несовместимые с этим эпистемическим статусом, такие как \ (\ mathsf {Con} (S) \). Тем не менее, мы показали, что есть более слабых форм разумности, таких как истинность всех аксиом S , которые, с одной стороны, недоступны в S , но с другой стороны, дедуктивно невиновны по отношению к S. : это делает, мы будем утверждать, что эти более слабые утверждения о разумности соответствуют требованиям тезиса о неявной приверженности (ICT), не становясь жертвой возражений Дина.Еще раз, дело в том, что кто-то может быть неявно привязан к семантическому ядру, даже если он считает, что, принимая S , он неявно обязуется принимать принципы, недоказуемые в S : в свою очередь, это не исключить, что у нее также могло быть независимое обоснование этих недоказуемых утверждений, таких как \ (\ mathsf {Con} (S) \) или принцип отражения для логики.