
Плагин к браузеру для решения ReCaptcha, FunCaptcha, GeeTest и других капч «2Captcha solver google chrome extension»
- Скрипты и библиотеки
бесплатно
4/5
Отзывы: 8
- Описание
Плагин для браузера Google Chrome, позволяющий автоматически распознавать такие капчи как ReCaptcha V2, V3, GeeTest, Arkose Labs FunCaptcha, Human Captcha и другие.
- Статистика
- Отзывы
#16454150 Михаил
2023-01-08
4
Geetest не видит почему то, кнопка решить не появляется
#15174933 Евгений Дмитриевич
2022-09-03
1
не работает. только зря на счет внес деньги.
не ведитесь
только зря на счет внес деньги.
не ведитесь
#12837249 DM
2021-11-03
5
Не запускаеться решение капчи….
#10105670 Кот
2021-03-04
4
Подскажите, стоит ли ждать решение капчи Яндекса?
#5713331 Рокот
2021-02-10
5
Прозондировал эту тему и пришел к такому выводу, что функция автовход после решения каптчи не будет корректно работать у большинства пользователей, по двум основным причинам.
1. Chrome — большинство пользователей пользуются подстановкой реквизитов доступа через него, но не все знают что, если например перезапустить браузер и открыть сайт с формой авторизации, то можно увидеть что реквизиты доступа подставились, но это не совсем так, если кликнуть мышью или нажать на любую клавишу на клаве, то можно увидеть что шрифт подставленных реквизитов слегка поменялся, вот тогда и происходить автоподстановка, видимо это зашита браузера чтобы не подставлять куда попало самое сокровенное.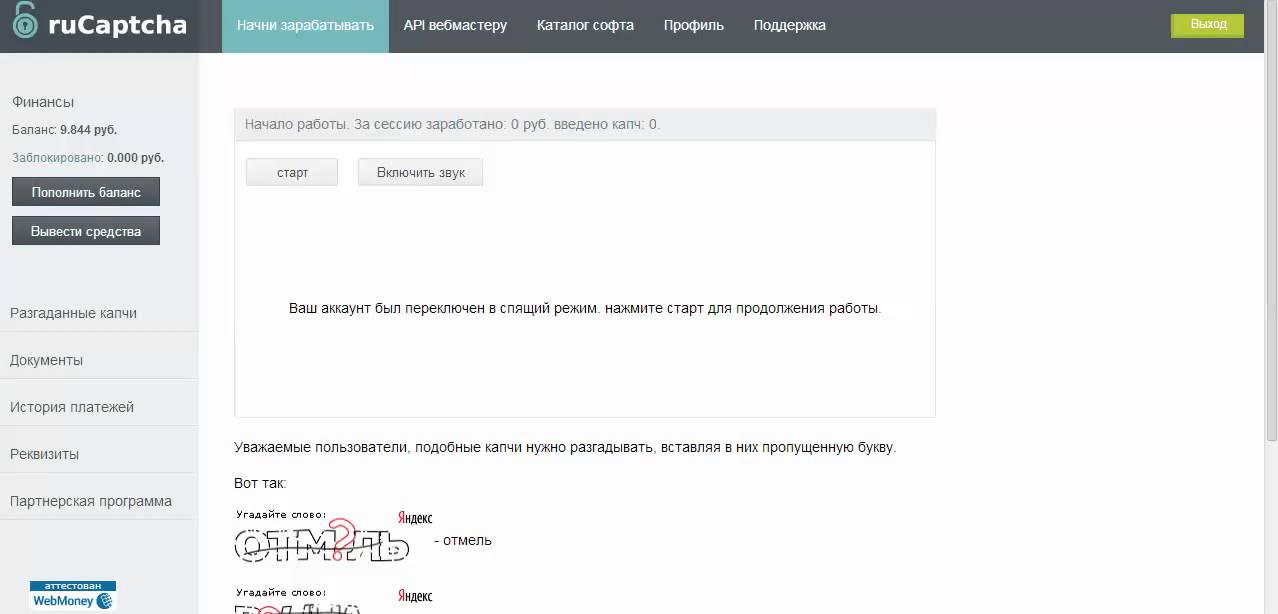
#1 Админ
2021-02-10
5
#5713331 Рокот С автосабмитом нужно быть очень осторожным, он легко может съесть баланс. Напишите на форуме https://captchaforum.com/threads/rasshirenie-dlya-brauzera-2captcha-solver.1153/ на какой странице проблема возникла. Постараюсь разобраться.
#5713331 Рокот
2021-02-09
3
По началу работало, потом начались траблы, каптча разгадывается по кругу, а вход не происходит, пока заметил она там солидно баланс отъела. …
…
#10 Андрей
2021-01-25
5
Первое расширение для браузера по решению рекапчи, которое работает идеально, как швейцарские часы )))))
Текстовая CAPTCHA в 2022 / Хабр
В этой статье я попробую пройти весь путь в распознавании text-based CAPTCHA, от эвристик до полностью автоматических систем распознавания. Попробую проанализировать, жива ли еще капча(речь про текстовую), или пора ей на покой.
Впервые текстовая капча(text-based CAPTCHA), дальше я ее буду называть просто капча, использовалась в поисковике AltaVista, это был 1997 год, она предотвращала автоматическое добавление URL в поисковую систему. В те годы это была надежная защита от ботов, но прогресс не стоял на месте, и эту защиту начали обходить, используя доступные на то время OCR(например, FineReader).
Капча начала усложняться, в неё добавляли небольшой шум, искажения, чтобы распространенные OCR не могли распознать текст. Тогда начали появляться написанные под конкретные капчи OCR, что требовало дополнительных затрат и знаний у атакующей стороны. И от разработчиков капчей требовалось понимание, в чем сейчас трудности у атакующего, и какие искажения нужно внести, чтобы было сложно автоматизировать распознавание капчи. Часто из-за непонимания, как работает OCR, вносились искажения, которые больше создавали проблем человеку, чем машине. OCR для разных типов капч писались с использованием эвристик, и одним из сложных этапов была сегментация капчи на отдельные символы, которые потом можно было легко распознать с помощью тех же CNN(например LeNet-5), да и SVM покажут неплохой результат даже на сырых пикселях.
И от разработчиков капчей требовалось понимание, в чем сейчас трудности у атакующего, и какие искажения нужно внести, чтобы было сложно автоматизировать распознавание капчи. Часто из-за непонимания, как работает OCR, вносились искажения, которые больше создавали проблем человеку, чем машине. OCR для разных типов капч писались с использованием эвристик, и одним из сложных этапов была сегментация капчи на отдельные символы, которые потом можно было легко распознать с помощью тех же CNN(например LeNet-5), да и SVM покажут неплохой результат даже на сырых пикселях.
В качестве объекта распознавания возьму капчу Яндекса с сайта Yandex.com. На русскоязычной версии сайта капчи немного сложнее из-за того, что используются как русские, так и английские слова.
Примеры капчНа первый взгляд, достаточно правильно бинаризировать картинку(перевести в черно-белый вариант) и дело в шляпе, можно получить большой процентов правильных распознаваний, так как сегментация на отдельные буквы выглядит довольно простой.
Для снижения эффективности эвристических алгоритмов Яндекс сделал упор на сложность бинаризации: есть капчи, для которых в каждой области изображения будет свой порог бинаризации, и надо подбирать его адаптивно. В среднем капча содержит 14 символов. Даже если мы сделаем классификатор с точностью 99%, и все капчи будем правильно сегментировать, то это нам даст точность в 87% распознавания всей капчи из двух слов. Здесь еще стоит упомянуть, что на сложность модели влияет количество классов(букв, цифр, знаков), используемых во всем наборе капч — чем их больше, тем сложнее достичь высоких процентов распознавания отдельных символов на простых моделях, поэтому капча на яндекс.ру будет сложнее, т.к. в ней используются русские и английские слова.
Из слабых мест этой капчи можно отметить, что буквы легко сегментируются при правильной бинаризации, и можно использовать проверку по словарю.
Далее будет описан эвристический алгоритм распознавания, а также я оставлю здесь ссылку на обучающую и тренировочную выборки.
Подготовительный этап
Для начала скачаем капчи и разделим их на тренировочную выборку и тестовую. Скачивание изображений капчи происходило через ВПН(с сайта yandex.com). При попытке сделать аккаунт вручную через браузер система меня распознавала ботом(думаю, из-за ВПН). Поэтому, предполагаю, я получил капчи с повышенной сложностью — «Если на втором этапе мы по-прежнему считаем запрос подозрительным, но степень уверенности в этом не такая высокая, то показываем простейшую капчу. А вот если мы уверены, что перед нами робот, то можем сложность и приподнять. Простое, но эффективное решение. » https://habr.com/ru/company/yandex/blog/549996/ Тип браузера, похоже, на результат не влиял (Opera, Chrome, Edge).
Итого набралось 4847 капч в тренировочную выбрку, и 354 — в тестовую. На распознавание обеих выборок было потрачено несколько долларов на сервисе decaptcher.com.
Эвристический алгоритм распознавания
Алгоритм будет состоять из нескольких шагов, это бинаризация, очистка от шума, извлечение двух слов, при необходимости — нормализация наклона для каждого слова, потом сегментация и распознавание.
1. Бинаризируем картинку — перевод цветного изображения, или изображения в градациях серого в черно-белое изображения. Цель — получение фона(0) и объекта(1), и уменьшение шума после бинаризации. Алгоритмы бинаризации будут описаны ближе к концу. Далее для каждого этапа сформируем параметры, которые будем потом оптимизировать. С этого момента работаем только с бинарным изображением.
2. Бинарное изображение очищаем от шума. Извлекаем связанные области из изображения — это наши объекты. Далее по количеству пикселей, которые входят в объект, разделяем их на шум и полезный объект. Все, что входит в наш интервал от А до В (по числу пикселей), это полезные объекты, остальное отсеиваем. В этом случае, например, у буквы i точка может быть определена как шум, чтобы этого не происходило, введем еще третью величину, расстояние С, это расстояние шума малого размера(эту величину мы тоже будем подбирать) до полезного объекта. Параметры А,В и С найдем простым перебором на тренировочном наборе, где максимизируем количество правильно распознанных капч.
3. Извлекаем из изображения 2 слова. Пробел между словами находится примерно по центру изображения. Величину «примерно» будем искать в окне ширины X, это будет еще одним параметром для оптимизации. Далее получаем горизонтальную гистограмму яркости в этом окне, вводим еще одно значение — порог, который будет нам показывать в этом столбце пробел, или объект, наибольшее кол-во пробелов подряд будут нам говорить о том, что это место разделения двух слов. В этой процедуре нам нужно подобрать 2 параметра, оптимальная ширина окна в центре изображения, и порог, который нам показывает, объект это, или пробел.
4. Нормализация наклона текста(для тех капч, где она нужна). Чтобы получить точность распознавания отдельных букв выше, нужно в некоторых капчах нормализовать наклон. Для этого мы проводим морфологическую операцию закрытие, и у нас получается единый объект. Далее находим ориентацию этого объекта, это угол между осью Х и главной осью элипса, в который вписывается наш объект.
5. Сегментация. На этом этапе у нас есть изображения 2-х слов, теперь нужно разбить их на отдельные буквы, для дальнейшего распознавания. Так как в нашем случае буквы не соприкасаются вместе, то можем извлечь связные области из изображения, это и будут наши символы, пригодные для дальнейшего распознавания.
Примеры символов извлеченные из двух изображений6. Распознавание символов. Для распознавания я использовал сверточную сеть Lenet-5, только в моем случае классов было 26, в оригинале — 10. Для предобучения сети я сделал выборку в 52 тыс. изображений букв(по 2 тыс. на класс), отобрал несколько шрифтов, добавил различные искажения и обучил сверточную сеть. Подбирая параметры к алгоритму бинаризации и сегментации, мы получаем выборку для обучения классификатора. Эта выборка будет использована на втором и последующих шагах обучения классификатора, первый шаг обучения проходил с искуственно сгенерированными символами.![]() Процесс итерационный, итого я смог насобирать 47 тыс. изображений букв с капч. Классы распределялись неравномерно, но это ожидаемо, так как в капче используют слова, а не случайные наборы букв. Итоговый классификатор имел точность 98.48%.
Процесс итерационный, итого я смог насобирать 47 тыс. изображений букв с капч. Классы распределялись неравномерно, но это ожидаемо, так как в капче используют слова, а не случайные наборы букв. Итоговый классификатор имел точность 98.48%.
Теперь, в зависимости от метода бинаризации, я представлю результаты распознаваний. Сначала я использовал один порог бинаризации для всех капч, порог подобрал на тренировочной выборке, и получил 15% правильно распознанных капч на тренировочной и 15% на тестовой.
Использование алгоритма Оцу дало 13.6% на тренировочной и 12.25% на тестовой.
Метод бинаризации Sauvola, после подбора параметров он дал 26.01% на тренировочной и 25.8% на тестовой.
Подметив, что капчи можно разделить по фону на группы, сделаем кластеризацию. Признаки извлечем с помощью метода Zoning. Суть метода такова — изображение делится на непересекающиеся области заданного размера, после чего извлекаем из каждой области среднее значение яркости. Чем меньше у нас размер окна, тем точнее описывается изображение.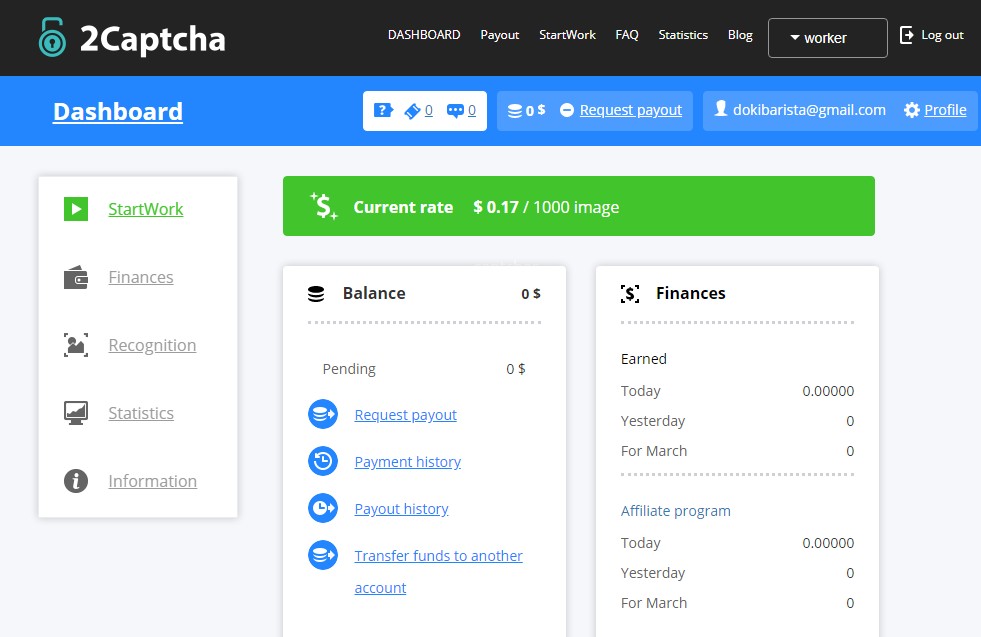 Для разделения на кластеры используем алгоритм кластеризации k-means. Классические методы определения оптимального количества кластеров показывали 2 кластера. Эмпирически я выбрал количество кластеров равное 5. Разбивка по кластерам получилась такая: в первом — 842 шт, во втором — 1300 шт, в третьем -1237 шт, в четвертом — 770 шт, в — пятом 698 шт изображений. Для каждого кластера подбираем свои параметры бинаризации алгоритма Sauvola на тренировочном наборе. В итоге получаем точность в 31.22%, на тестовом — 30.8%.
Для разделения на кластеры используем алгоритм кластеризации k-means. Классические методы определения оптимального количества кластеров показывали 2 кластера. Эмпирически я выбрал количество кластеров равное 5. Разбивка по кластерам получилась такая: в первом — 842 шт, во втором — 1300 шт, в третьем -1237 шт, в четвертом — 770 шт, в — пятом 698 шт изображений. Для каждого кластера подбираем свои параметры бинаризации алгоритма Sauvola на тренировочном наборе. В итоге получаем точность в 31.22%, на тестовом — 30.8%.
Примеры кластеров:
Кластер 1Кластер 2Кластер 3Кластер 4Кластер 5Теперь у нас есть капчи, которые мы правильно бинаризировали, можно попробовать что-нибудь потяжелее, например U-Net для бинаризации, сеть с 13.5+ млн. параметров. Получили на тренировочных данных 39,2% правильных ответов, на тесте — 38.7%.
Для каждого нового типа капч, нам приходилось бы придумывать какие то новые схемы бинаризации, сегментации, что делает задачу трудоемкой в зависимости от капчи, но не невозможной. И затраты на разработку такой системы был порогом, который не каждый мог преодолеть для автоматического распознавания капчи и использования сервиса ботами.
И затраты на разработку такой системы был порогом, который не каждый мог преодолеть для автоматического распознавания капчи и использования сервиса ботами.
А что на счет полностью автоматизированного процесса создания модели для распознавания, где не надо ничего придумывать, никакой эвристики? На вход — капчи с ответами, на выходе — готовая модель. Относительно недавно на сайте библиотеки Keras появились исходники, которые, при небольшой модификации, можно использовать для распознавания любых текстовых капч https://keras.io/examples/vision/captcha_ocr/
На Яндекс капче у меня получились такие цифры: на тренировочных данных сеть показала точность 55%, на тестовых — 39%. Из-за слишком маленькой тренировочной выборки для такой большой сети происходило быстро переобучение, но при правильно подобранных параметрах регуляризации сеть могла обучаться. Если увеличить тренировочную выборку, добавив туда отраженные картинки, то получим на тренировочных 58% точности, а на тесте — 43%. Увеличение тренировочной выборки новыми капчами даст еще прирост правильных ответов.
Увеличение тренировочной выборки новыми капчами даст еще прирост правильных ответов.
Сеть чаще всего ошибается на капчах такого вида:
Типы капч на которых система чаще всего ошибаетсяЭто коррелирует с тезисом авторов Яндекс капчи, в своей статье они писали -«Наиболее сложные датасеты с распознаванием слов на сегодняшний день представляют собой сильно искривлённые тексты (irregular text recognition).» Но в данном случае это скорее ограничение архитектуры используемой сети. Полученные фичи после слоев CNN мы распознаем lstm слоем последовательно слева направо, и в некоторых срезах возможного символа у нас находится сразу несколько символов. Это легко показать, сделав набор вот таких «капч»(рис. 1 ) в 10 тыс тренеровочных и 1 тыс тестовых. Обучив сетку, получим правильных ответов всего 20%, и 80% ошибок.
Рис. 1Но если сделать капчи, написав текст в одну строчку и добавив в текст искажения, усложняя ее (рис. 2), то получим 97% правильных ответов и 3% ошибочных.
Рис. 2
2Для увеличения процента успешных распознаваний яндекс капч можно использовать детектор текста, после чего нормализовать наклон и далее распознать нейронной сетью. Примеры сложных яндекс капч и детектора текста(рис. 3)
Рис. 3Если использовать детектор текста, то мы получим на тренировочных 60% точности, а на тесте — 51%. Я использовал уже предобученный на синтетике детектор текса — CRAFT: Character-Region Awareness For Text detection, а распознаванием отдельных слов занималась уже обученная модель на самой Яндекс капче.
Разработчики из Яндекса при проектировании капчи решали сразу две проблемы — уменьшение потенциальной эффективности ОЦР при «дружелюбности» для человека. Но чаще встречается такой подход к созданию текстовых капч — если человеку трудно ее распознать, то сложно и машине(рис. 4)
Рис. 4Но это не так, нейронные сети без труда «ломают» такие капчи и могут показать уровень расознавания выше человеческого. При этом не нужно придумывать какие-то эвристические алгоритмы, достаточно скачать готовую сетку и обучить, 99% текстовых капч она решит.
Если подвести итог, то проектирование текстовой капчи в текущих реалиях требует понимания методов и подходов, которыми будет пользоваться злоумышленник для ее распознавания и исходя из этого проектировать капчу, которая эффективно сможет противостоять роботам, и при этом будет простой для восприятия человеком.
Прошу вас поделиться своими мыслями в комментариях, как может выглядеть текстовая капча, которая будет сложной для распознавания машиной.
Login No Captcha reCAPTCHA — Плагин для WordPress
- Детали
- отзывов
- Монтаж
- Развитие
Опора
Добавляет флажок Google No Captcha ReCaptcha на страницы входа в WordPress и Woocommerce, забытого пароля и страницы регистрации пользователя. Отказывает в доступе к автоматическим сценариям, но упрощает вход в систему для людей, установив флажок. Как говорит Google, это «сложно для ботов, легко для людей».
- Экран параметров конфигурации
- Экран входа в систему после настройки
Установите как обычно для плагинов WordPress.
Зачем мне устанавливать этот плагин?
Многие сайты Worpdress бомбардируются автоматическими сценариями, которые снова и снова пытаются войти в систему администратора.
No Captcha — это очень простой тест, поддерживаемый Google, для быстрого отказа в доступе к автоматизированным сценариям. Это здорово само по себе, чтобы мгновенно сделать ваш сайт WordPress более безопасным, или его можно использовать с другими плагинами (такими как Google Authenticator, ограничение попыток входа в систему и т. Д.) Как часть стратегии глубокой защиты.
Для этого есть куча других плагинов, зачем мне ставить
этот ?Я приложил немало усилий, чтобы убедиться, что этот плагин прост в использовании и установке, совместим с различными конфигурациями WordPress, поддерживает несколько языков и что вы случайно не заблокируете себя от администратора, используя это. Я сам использую его на своих сайтах. Пока это просто работает.

Поддерживает ли этот подключаемый модуль подключаемый модуль пользовательской страницы входа [insert name]?
Вероятно, нет. Многие плагины настраиваемых форм входа в систему не вызывают стандартный хук действия login_form из своих форм входа, что делает невозможным правильное отображение капчи после запроса пароля. По этой причине этот плагин поддерживает только стандартные формы wp-login.php и WooCommerce. Многие такие плагины предлагают поля с капчей (иногда в качестве платного обновления). Этот плагин пытается хорошо делать всего несколько вещей.
Нет. Этот плагин предназначен для предотвращения попыток автоматического взлома, а не для предотвращения спама в комментариях. У большинства хороших плагинов для комментариев есть собственные методы защиты от спама. Этот плагин пытается хорошо делать всего несколько вещей.
Добавляет ли этот плагин CAPTCHA в пользовательские формы?
Нет.
Этот подключаемый модуль предназначен для предотвращения попыток автоматического взлома, а не для предотвращения спама из пользовательских форм. Большинство хороших плагинов для пользовательских форм имеют свои собственные методы защиты от спама. Многие из них уже поддерживают поле CAPTCHA. Этот плагин пытается хорошо делать всего несколько вещей.Могу я помочь?
Да, пожалуйста. Отправьте запрос на включение на github.
У меня проблемы с reCAPTCHA в Internet Explorer
См. эту страницу для помощи от Google.
Я все еще вижу множество атак грубой силы на /wp-login.php в моих файлах журналов
Плагин reCAPTCHA не предотвратит попытки атак методом грубой силы, а просто гарантирует, что они не увенчаются успехом. То есть скрипты все равно могут пытаться проводить прямые POST-атаки на /wp-login.php, но без правильных данных reCAPTCHA они не пройдут (даже если правильно угадали логин и пароль).
Чтобы предотвратить повторные попытки доступа к /wp-login.php, рассмотрите возможность использования плагина, который ограничивает количество попыток входа в систему в сочетании с этим плагином. Другие подходы, такие как брандмауэр веб-приложений, также должны стать частью вашей комплексной стратегии глубокоэшелонированной защиты.Где я могу узнать больше о Google reCAPTCHA?
https://www.google.com/recaptcha/intro/index.html
Какие у вас скучные юридические оговорки?
Этот плагин никоим образом не связан с Google и не поддерживается им. Google является зарегистрированным товарным знаком Google, Inc. Используя reCAPTCHA, вы соглашаетесь с условиями обслуживания, установленными Google. Автор не дает никаких гарантий относительно пригодности этого программного обеспечения для каких-либо целей. Вы соглашаетесь использовать его исключительно на свой страх и риск.
 Этот подключаемый модуль предназначен для предотвращения попыток автоматического взлома, а не для предотвращения спама из пользовательских форм. Большинство хороших плагинов для пользовательских форм имеют свои собственные методы защиты от спама. Многие из них уже поддерживают поле CAPTCHA. Этот плагин пытается хорошо делать всего несколько вещей.
Этот подключаемый модуль предназначен для предотвращения попыток автоматического взлома, а не для предотвращения спама из пользовательских форм. Большинство хороших плагинов для пользовательских форм имеют свои собственные методы защиты от спама. Многие из них уже поддерживают поле CAPTCHA. Этот плагин пытается хорошо делать всего несколько вещей. Чтобы предотвратить повторные попытки доступа к /wp-login.php, рассмотрите возможность использования плагина, который ограничивает количество попыток входа в систему в сочетании с этим плагином. Другие подходы, такие как брандмауэр веб-приложений, также должны стать частью вашей комплексной стратегии глубокоэшелонированной защиты.
Чтобы предотвратить повторные попытки доступа к /wp-login.php, рассмотрите возможность использования плагина, который ограничивает количество попыток входа в систему в сочетании с этим плагином. Другие подходы, такие как брандмауэр веб-приложений, также должны стать частью вашей комплексной стратегии глубокоэшелонированной защиты. Вау, работает! Я был так разочарован в течение нескольких недель контактной формой, чья reCAPTCHA не работала из-за конфликта с плагином NoCaptcha ReCaptcha для WooCommerce.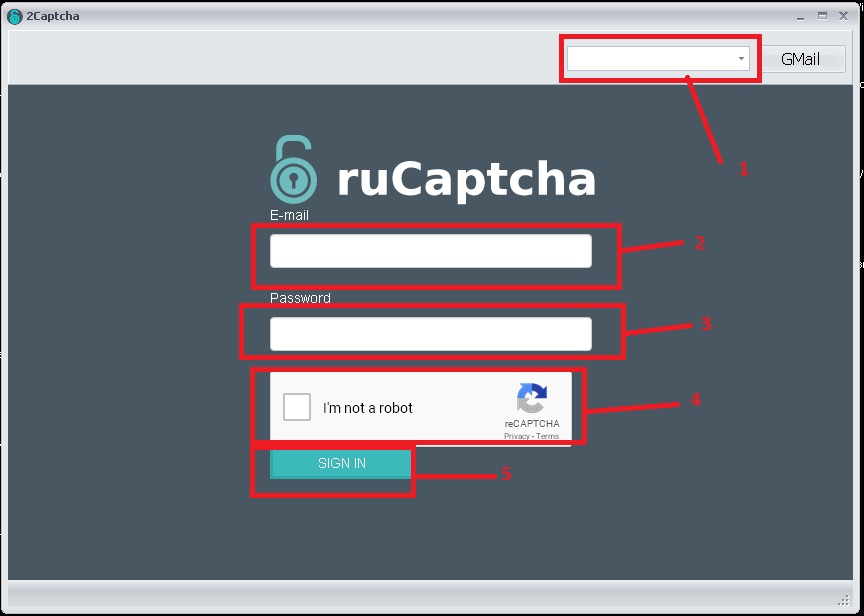 Этот плагин больше не поддерживается, как они сказали мне, когда я связался с ними. Я не знал, куда обратиться за заменой. Мы получали тонны поддельных регистраций на странице нашей учетной записи WooCommerce, и этот плагин остановил их.
Так или иначе, я нашел этот плагин, прочитал несколько обзоров и решил попробовать его на нашем сценическом сайте. Он только что установлен там, поэтому мое волнение, возможно, преждевременно, но я так взволнован, увидев, что наша контактная форма WPForms reCAPTCHA снова работает, даже на сценическом сайте, что я хотел, чтобы разработчики знали, как я благодарен. Я опубликую еще несколько мыслей, как только установлю его на живом сайте и опробую в течение нескольких дней.
Это было НАСТОЛЬКО легко установить, и инструкции также были простыми. Мне понравилось их предупреждение протестировать в другом браузере, чтобы убедиться, что вы можете войти на свой сайт перед сохранением ключей. Отличный совет!
Спасибо за создание этого плагина. Я в восторге от него.
Этот плагин больше не поддерживается, как они сказали мне, когда я связался с ними. Я не знал, куда обратиться за заменой. Мы получали тонны поддельных регистраций на странице нашей учетной записи WooCommerce, и этот плагин остановил их.
Так или иначе, я нашел этот плагин, прочитал несколько обзоров и решил попробовать его на нашем сценическом сайте. Он только что установлен там, поэтому мое волнение, возможно, преждевременно, но я так взволнован, увидев, что наша контактная форма WPForms reCAPTCHA снова работает, даже на сценическом сайте, что я хотел, чтобы разработчики знали, как я благодарен. Я опубликую еще несколько мыслей, как только установлю его на живом сайте и опробую в течение нескольких дней.
Это было НАСТОЛЬКО легко установить, и инструкции также были простыми. Мне понравилось их предупреждение протестировать в другом браузере, чтобы убедиться, что вы можете войти на свой сайт перед сохранением ключей. Отличный совет!
Спасибо за создание этого плагина. Я в восторге от него.
Заранее спасибо за вашу хорошую работу, работает очень хорошо Пять звезд!
Отличный плагин, но действительно нуждается в поддержке подстановочных знаков для настройки «Белый список IP». Многие интернет-провайдеры постоянно меняют IP-адреса, поэтому постоянно заходить и вручную добавлять другой IP-адрес в список неудобно. Около 10 месяцев назад я отправил тему поддержки с просьбой о поддержке подстановочных знаков, но разработчик плагина не ответил. Поддержка подстановочных знаков легко изменила бы мой рейтинг на 5 звезд. В противном случае я в конечном итоге разветвлю этот плагин и сам добавлю подстановочный знак (это тривиально). Спасибо разработчикам за этот замечательный плагин.
Хороший плагин!
Придраться не к чему, все работает исправно.
Отличный и простой плагин. Я надеюсь, что reCAPTCHA V3 будет поддерживаться в будущем.
Прочитать все 58 отзывов
«Вход без капчи reCAPTCHA» — это программное обеспечение с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
Следующие люди внесли свой вклад в этот плагин.
Авторы
- Роберт Пик
1.7.1
Нарушенная совместимость
1.7 =
— Показать информацию о последствиях для безопасности использования функции белого списка
1.6.11
- Исправление обратной совместимости для PHP <= 5.5 Причуда/ошибка empty(): https ://www.php.net/manual/en/function.empty.php
1.6.10
- Устранена проблема, из-за которой можно было обходить капчу при регистрации новых пользователей, появившуюся в версии 1.6.9
- Добавить опцию для полного отключения CSS по умолчанию
1.6.9
- Устранена проблема с зависимостями CSS, вызывающая конфликты на страницах без входа
1.6.8
- Предотвратить раскрытие информации, возвращая только ошибку о пустой капче, а не статус входа в систему
1.6.7
- Отменить изменения стиля CSS после нескольких сообщений о проблемах
- Добавить поддержку немецкого языка
1.
 6.6
6.6- Улучшение стиля CSS
1.6.5
- Испытано с 5.3
1.6.4
- Испытано с 5.2
- Использование обратного вызова для отключения кнопок отправки
1.6.3
- Устранить проблему с отображением капчи во встроенной форме входа на странице оформления заказа WooCommerce
1.6.2
- Устранить фатальную ошибку в старых версиях PHP (сообщено в 5.4.45)
1.6.1
- Отключить кнопки отправки через javascript в формах Woo
- Улучшение обмена сообщениями об ошибках
1.6
- Добавлена функция белого списка IP-адресов (спасибо @farley1122)
- Более полная защита конечных точек регистрации, включая wp-signup.php и страницу моей учетной записи
1.5
- Решить проблему, появившуюся в 1.4x, из-за которой вводилась проверка
- ВСЕМ ПОЛЬЗОВАТЕЛЯМ НАСТОЯТЕЛЬНО РЕКОМЕНДУЕТСЯ ОБНОВИТЬ ИЗ ПРИЧИН БЕЗОПАСНОСТИ И НЕ ИСПОЛЬЗОВАТЬ 1. 4x
 4x
4x1.4.1
- Выровнять текстовый домен языка с тегом плагина, чтобы разрешить добавление переводов
1.4
- Добавлена поддержка регистрационных форм (спасибо d2roth)
- Выравнивание вызовов фильтра/перехвата с кодексом
- Увеличить приоритет (более раннее выполнение) проверки входа (предотвращает ненужные предупреждения, например, от WordFence)
1.3.3
- Исправлена ошибка с откатом к cURL в случаях неправильной настройки TLS
1.3.2
- Исправление совместимости для использования языковой конструкции empty() в php 5.x
1.3.1
- Добавлена экспериментальная поддержка v3 (пока скрыта)
1.3
- Добавлена reCaptcha в форму восстановления пароля
- Добавлен русский перевод
- Проверено с 5.0
1.2.5
- Отменить изменение формы утерянного пароля, так как это было только для внешнего интерфейса
1.
 2.4
2.4- Добавить reCaptcha в форму восстановления пароля
1.2.3
- Улучшенное соответствие разделу 508
- Не проверять значения noCaptcha при использовании метода аутентификации, отличного от WordPress, кроме WooCommerce
- Добавить стандартный эффект встряхивания WordPress к неверному ответу на вход
1.2.2
- Не проверять значения noCaptcha при использовании метода аутентификации, отличного от WordPress
- Исправлена ошибка с серой кнопкой отправки на странице настроек
1.2.1
- Реализовать noCaptcha для формы входа клиента WooCommerce
1.2
- Исправлена важная проблема безопасности (спасибо jezevec10 за отчет), чтобы защитить страницу входа с поддержкой reCaptcha от умных ботов
1.1.11
- Добавлен французский перевод (спасибо fdinh)
1.1.10
- Незначительное исправление для отчетов об ошибках
1.
 1.7
1.7- Исправлена ошибка отображения формы входа в админку, тестирование на 4.5
1.1.6
- Отключить вход с помощью js, пока NoCaptcha не вернет
1.1.5
- Совместимость с 4,4x
1.1.4
- Лучшее отображение капчи при отключенном javascript (спасибо webmasteral)
1.1.3
- Улучшена обработка некоторых ответов Google
1.1.2
- Улучшенная регистрация скрипта точно в срок (только для администратора/логина)
1.1.1
- Удалить предупреждение о слишком ранней постановке css/js в очередь
1.1
- Значительное улучшение безопасности: теперь поддерживается проверка reCaptcha с отключенным javascript (спасибо mfjtf)
1.0.3
- Решить проблему с WordPress, размещенным на недоступном домене (например, localhost)
1.0.2
- Устранить ошибку с полезной нагрузкой wp_remote_post()
1.
 0.1
0.1- Решить проблему связывания из-за того, что сопровождающие репозитория переименовали плагин
1.0.0
- Первый выпуск
Мета
- Версия: 1.7.1
- Последнее обновление: 3 месяца назад
- Активные установки: 90 000+
- Версия WordPress: 4.6 или выше
- Протестировано до: 6.1.1
- Языки:
китайский (Китай), датский, голландский, голландский (Бельгия), английский (США), галисийский, немецкий, испанский (Эквадор), испанский (Испания), испанский (Венесуэла) и шведский.
Перевести на ваш язык
- Теги:
googleloginnocaptcharecaptchasecurity
- Расширенный просмотр
Служба поддержки
Проблемы, решенные за последние два месяца:
3 из 4
Посмотреть форум поддержки
Аутентификация— полезно ли иметь капчу на экране входа в систему?
спросил
Изменено 7 лет, 9 месяцев назад
Просмотрено 23 тысячи раз
Я добавил recaptcha на экран входа в систему.
Моя цель была связана с вопросами безопасности, такими как атаки по словарю/ботами или что-то в этом роде.
Пользователи теперь его ненавидят, Некоторые даже не поняли, и мне пришлось его удалить.
Когда я смотрю вокруг, я не вижу многих систем с этим на экране входа в систему, в большинстве случаев в других формах, таких как свяжитесь с нами, или иногда, например, в обмене стеками, когда вы хотите опубликовать.
Это заставило меня задуматься, стоит ли отображать его на экране входа в систему?
- аутентификация
- капча
8
В некоторых крупных системах я видел, как это делают: капча требуется только после последовательных неудачных попыток входа в систему (т. е. сброс счетчика после действительного входа в систему). Если вы беспокоитесь об автоматическом взломе, вы можете поставить капчу на какое-то большое количество неудачных попыток, таких как 20, 50, 100 неудачных попыток. Почти ни один законный пользователь не увидит капчу, но автоматическая атака будет поражена ею.
Почти ни один законный пользователь не увидит капчу, но автоматическая атака будет поражена ею.
Стоит ли добавлять эту сложность? Безопасность и UX — это компромисс. Вам нужно найти правильный компромисс для вашего профиля риска.
12
Капча на экране входа не имеет смысла. Я не удивлен, что ваши пользователи ненавидели это. Назначение полей с капчей в формах — предотвратить их отправку ботами. Бот не должен иметь возможность войти через ваш экран входа, так как у него не должно быть действительных учетных данных. Если бот может угадать действительные учетные данные, вам необходимо повысить надежность пароля.
Пользователи теперь его ненавидят, Некоторые даже не поняли, и мне пришлось его удалить.
Здесь вам придется сделать выбор между удобством использования и безопасностью. Хотя полезно иметь капчу на страницах входа, это невероятно неудобно для пользователя.
Мой лучший совет — регистрировать каждую неверную попытку входа в базу данных и перед аутентификацией пользователя проверять, пытался ли этот IP-адрес войти X раз за последний час.
Вы также можете добавить некоторую форму системы подделки межсайтовых запросов на каждую страницу входа. Это означает, что при каждой попытке входа в систему будет создаваться скрытое поле с токеном, а это означает, что злоумышленнику придется сделать два запроса, чтобы попытаться войти в систему.
1
Добавление Captcha или ReCaptcha не является решением, это просто препятствие как для хакеров, так и для пользователей.
У меня очень хорошее зрение в очках, и иногда я едва могу разобрать текст на изображении. Я полагаю, что кто-то, кто отрицает свое видение, придет в ярость.
Все, что вы реализуете, должно иметь конкретную цель, иначе вы просто подбрасываете в небо пироги с какашками, и эти пироги в конечном итоге приземляются прямо на ваших пользователей.
Вот пища для размышлений:
1
Проблема
Учетные записи пользователей взламываются из-за попыток автоматического подбора
Раствор
Учетные записи теперь блокируются после 3 неудачных попыток входа в систему
2
Проблема
Все учетные записи пользователей были раскрыты, и теперь бот пытается взломать все учетные записи
Все учетные записи блокируются в течение нескольких секунд из-за 3 неудачных попыток входа в систему
Решения? Много, но нужно ли нам вообще доходить до этого шага? Является ли это проблемой в настоящее время?
2
Другим способом атаки может быть установка «приманки». Это обычное поле ввода, которое включается в HTML вместе с полями для входа (имя пользователя, пароль), но это дополнительное поле скрыто с помощью CSS.
Как правило, боты пытаются ввести текст во все поля, показанные в HTML, поэтому в PHP я проверил, что если поле honeypot не будет пустым — я бы забанил этот IP.
(Это была домашняя страница клуба прыжков с парашютом с крошечной функцией администратора для обновления дат, когда мы собираемся прыгать и т. д. Я бы не рекомендовал это для чувствительных приложений)
2
Системы CAPTCHA предназначены для того, чтобы различать автоматических ботов и реальных пользователей. К сожалению, как вы заметили, они не очень удобны (в частности, для пользователей с ограниченными возможностями).
Является ли это «хорошей идеей» или нет, зависит от вашего варианта использования, на самом деле, хотя они не очень эффективны при входе пользователей в систему: они не очень полезны для предотвращения атак с подбором пароля, а реализация ограничителя скорости в приложении больше удобно для пользователя, в то время как реализация PIN-кода TOTP обеспечивает лучшую безопасность.
Получение некой формы «доказательства работы» от вашего клиента может быть очень хорошей идеей, если вы собираетесь тратить на них ресурсы сервера и если эти ресурсы ограничены. Типичным вариантом использования такого запроса является система, которая будет выполнять работу для анонимных пользователей (например, веб-приложение WHOIS может использовать это для сохранения ресурсов).
Задумайтесь на мгновение о том, что ваша капча пытается выполнить. Вот цель, о которой я могу думать:
- Предотвратить широкомасштабную автоматизированную атаку на слабые учетные записи
Вот способ сделать то, что, вероятно, сделает ваших пользователей счастливее:
Если компьютер успешно входит в систему (как Боб), установите файл cookie на этом компьютере, чтобы сервер знал, что компьютер получает 5 бесплатных попыток входа в систему. Аккаунт Боба без капчи.
Если компьютер, пытающийся войти в систему, принадлежит последнему известному IP-адресу Боба, дайте этому IP-адресу 5 бесплатных попыток войти в учетную запись Боба без ввода капчи.
Идея здесь в том, что массовый подбор пароля обычно происходит с компьютеров или IP-адресов, которые не вошли в учетную запись законным образом.
Это, вероятно, можно улучшить, объединив его с идеями из других ответов, где вы даете несколько «бесплатных попыток» учетным записям или ips.
1
Добавлять капчу после 10 или 100 неудачных попыток бесполезно, так как большинство современных ботов имеют учетную запись deathbycaptcha, а API для dbc действительно прост в использовании. Так что показывать капчу каждый второй раз — это хорошо, я думаю.
Чтобы предотвратить атаки методом полного перебора, вам лучше сделать следующее.
1) Убедитесь, что пароли достаточно сложны. Если будет возможность, многие пользователи будут использовать чрезвычайно простые пароли, такие как их имя и т. д. Пароли должны состоять как минимум из 8 символов и должны включать цифры, буквы и смешанный регистр.