
Как составить robots.txt самостоятельно
Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots.txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено
краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта — Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается.
Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается.
- Быстро загружаются.
Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
 Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается.
Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt.
 В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами — http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
 Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
Такой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
«*» — означает любую последовательность символов в файле.
«$» — ограничивает действия «*», представляет конец строки.
«/» — показывает, что закрывают для сканирования.
«/catalog/» — закрывают раздел каталога;
«/catalog» — закрывают все ссылки, которые начинаются с «/catalog».
«#» — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.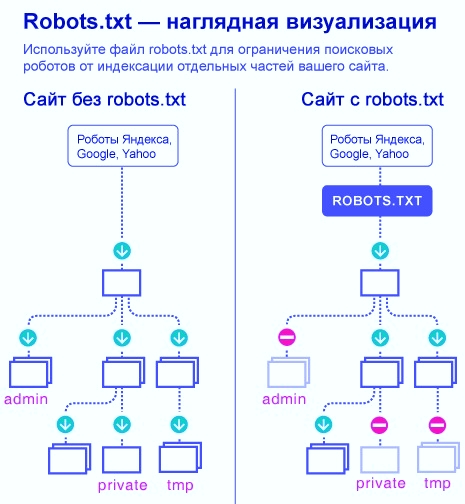
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots. txt пустым.
txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на «.pdf»:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата «Disallow: /about» без закрывающего «/» запретит доступ и к разделу
http://site. com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл «photo.html» разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.
 html
Disallow: /album1/
html
Disallow: /album1/
Заблокировать доступ к каталогам «site.com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
«www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123″
«www. site. com/some_dir/get_book.pl?ref=site_2& book_id=123″
site. com/some_dir/get_book.pl?ref=site_2& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123″
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
«www.example. com/some_dir/get_book.pl? book_id=123″
Для адресов вида:
«www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df»
«www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
«www.example1. com/forum/showthread. php? s=681498b9648949605&t=8243″
php? s=681498b9648949605&t=8243″
«www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
«www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311″
«www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без «http://» и без закрывающего слэша «/».
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже
не используют, если в ваших robots. txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке
http://site. com/sitemap, ref не меняет содержание страницы get_book:
com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
Для проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
Правильный файл robots.txt для сайта
Директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке. Таким образом, порядок следования директив в файле robots.txt не влияет на использование их роботом. Примеры:
При указании путей директив Allow и Disallow можно использовать спецсимволы * и $, задавая, таким образом, определенные регулярные выражения.
Спецсимвол * означает любую (в том числе пустую) последовательность символов.
Спецсимвол $ означает конец строки, символ перед ним последний.
Директива Sitemap
Если вы используете описание структуры сайта с помощью файла Sitemap, укажите путь к файлу в качестве параметра директивы sitemap (если файлов несколько, укажите все). Пример:
User-agent: Yandex Allow: / sitemap: https://example.com/site_structure/my_sitemaps1.xml sitemap: https://example.com/site_structure/my_sitemaps2.xml
Директива является межсекционной, поэтому будет использоваться роботом вне зависимости от места в файле robots.txt, где она указана.
Робот запомнит путь к файлу, обработает данные и будет использовать результаты при последующем формировании сессий загрузки.
Директива Crawl-delay
Директива работает только с роботом Яндекса.
Если сервер сильно нагружен и не успевает отрабатывать запросы робота, воспользуйтесь директивой Crawl-delay. Она позволяет задать поисковому роботу минимальный период времени (в секундах) между окончанием загрузки одной страницы и началом загрузки следующей.
Перед тем, как изменить скорость обхода сайта, выясните к каким именно страницам робот обращается чаще.
- Проанализируйте логи сервера. Обратитесь к сотруднику, ответственному за сайт, или к хостинг-провайдеру.
- Посмотрите список URL на странице Индексирование → Статистика обхода в Яндекс.Вебмастере (установите переключатель в положение Все страницы).
Если вы обнаружите, что робот обращается к служебным страницам, запретите их индексирование в файле robots.txt с помощью директивы Disallow. Это поможет снизить количество лишних обращений робота.
Директива Clean-param
Директива работает только с роботом Яндекса.
Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту директиву, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.example.com/some_dir/get_book.pl?ref=site_3&book_id=123Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex
Disallow:
Clean-param: ref /some_dir/get_book.plробот Яндекса сведет все адреса страницы к одному:
www.example.com/some_dir/get_book.pl?book_id=123Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска.
Синтаксис директивы
Clean-param: p0[&p1&p2&. .&pn] [path] .&pn] [path]
.&pn] [path]В первом поле через символ & перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых нужно применить правило.
Примечание. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt. В случае, если директив указано несколько, все они будут учтены роботом.
Префикс может содержать регулярное выражение в формате, аналогичном файлу robots.txt, но с некоторыми ограничениями: можно использовать только символы A-Za-z0-9.-/*_. При этом символ * трактуется так же, как в файле robots.txt: в конец префикса всегда неявно дописывается символ *. Например:
Clean-param: s /forum/showthread.phpозначает, что параметр s будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php. Второе поле указывать необязательно, в этом случае правило будет применяться для всех страниц сайта.
Регистр учитывается. Действует ограничение на длину правила — 500 символов. Например:
Действует ограничение на длину правила — 500 символов. Например:
Clean-param: abc /forum/showthread.php
Clean-param: sid&sort /forum/*.php
Clean-param: someTrash&otherTrashДиректива HOST
На данный момент Яндекс прекратил поддержку данной директивы.
Правильный robots.txt: настройка
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Правильный Robots.txt пример для WordPress
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.
 к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Sitemap: http://site.
к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
Sitemap: http://site.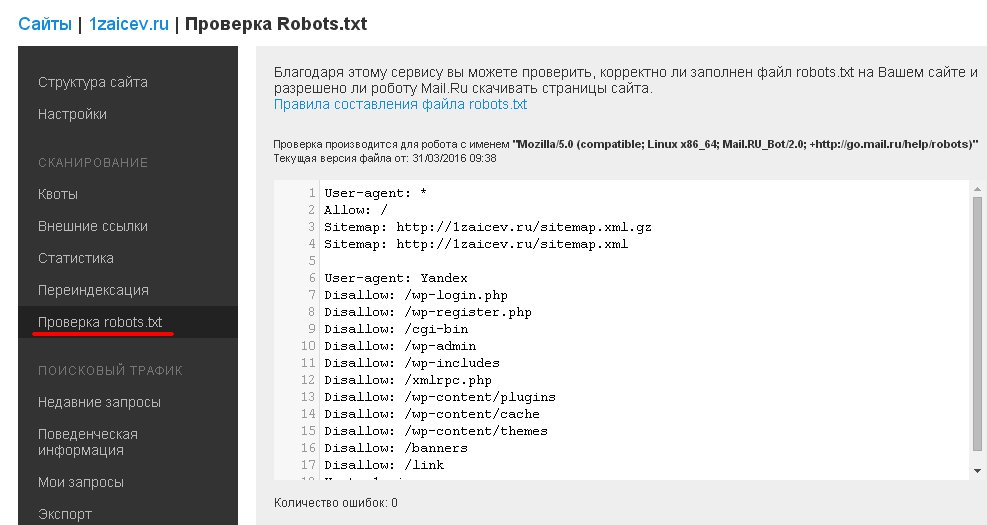 xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогичноRobots.txt пример для Joomla
User-agent: *Disallow: /administrator/Disallow: /cache/Disallow: /includes/Disallow: /installation/Disallow: /language/Disallow: /libraries/Disallow: /media/Disallow: /modules/Disallow: /plugins/Disallow: /templates/Disallow: /tmp/Disallow: /xmlrpc/Sitemap: http://путь к вашей карте XML формата
Robots. txt пример для Bitrix
 txt пример для Bitrix
txt пример для BitrixUser-agent: *Disallow: /*index.php$Disallow: /bitrix/Disallow: /auth/Disallow: /personal/Disallow: /upload/Disallow: /search/Disallow: /*/search/Disallow: /*/slide_show/Disallow: /*/gallery/*order=*Disallow: /*?print=Disallow: /*&print=Disallow: /*register=Disallow: /*forgot_password=Disallow: /*change_password=Disallow: /*login=Disallow: /*logout=Disallow: /*auth=Disallow: /*?action=Disallow: /*action=ADD_TO_COMPARE_LISTDisallow: /*action=DELETE_FROM_COMPARE_LISTDisallow: /*action=ADD2BASKETDisallow: /*action=BUYDisallow: /*bitrix_*=Disallow: /*backurl=*Disallow: /*BACKURL=*Disallow: /*back_url=*Disallow: /*BACK_URL=*Disallow: /*back_url_admin=*Disallow: /*print_course=YDisallow: /*COURSE_ID=Disallow: /*?COURSE_ID=Disallow: /*?PAGENDisallow: /*PAGEN_1=Disallow: /*PAGEN_2=Disallow: /*PAGEN_3=Disallow: /*PAGEN_4=Disallow: /*PAGEN_5=Disallow: /*PAGEN_6=Disallow: /*PAGEN_7=Disallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*PAGE_NAME=searchDisallow: /*PAGE_NAME=user_postDisallow: /*PAGE_NAME=detail_slide_showDisallow: /*SHOWALLDisallow: /*show_all=Sitemap: http://путь к вашей карте XML формата
Robots. txt пример для MODx
 txt пример для MODx
txt пример для MODxUser-agent: *Disallow: /assets/cache/Disallow: /assets/docs/Disallow: /assets/export/Disallow: /assets/import/Disallow: /assets/modules/Disallow: /assets/plugins/Disallow: /assets/snippets/Disallow: /install/Disallow: /manager/Sitemap: http://site.ru/sitemap.xml
Robots.txt пример для Drupal
User-agent: *Disallow: /database/Disallow: /includes/Disallow: /misc/Disallow: /modules/Disallow: /sites/Disallow: /themes/Disallow: /scripts/Disallow: /updates/Disallow: /profiles/Disallow: /profileDisallow: /profile/*Disallow: /xmlrpc.phpDisallow: /cron. php
phpDisallow: /update.phpDisallow: /install.phpDisallow: /index.phpDisallow: /admin/Disallow: /comment/reply/Disallow: /contact/Disallow: /logout/Disallow: /search/Disallow: /user/register/Disallow: /user/password/Disallow: *register*Disallow: *login*Disallow: /top-rated-Disallow: /messages/Disallow: /book/export/Disallow: /user2userpoints/Disallow: /myuserpoints/Disallow: /tagadelic/Disallow: /referral/Disallow: /aggregator/Disallow: /files/pin/Disallow: /your-votesDisallow: /comments/recentDisallow: /*/edit/Disallow: /*/delete/Disallow: /*/export/html/Disallow: /taxonomy/term/*/0$Disallow: /*/edit$Disallow: /*/outline$Disallow: /*/revisions$Disallow: /*/contact$Disallow: /*downloadpipeDisallow: /node$Disallow: /node/*/track$Disallow: /*&Disallow: /*%Disallow: /*?page=0Disallow: /*sectionDisallow: /*orderDisallow: /*?sort*Disallow: /*&sort*Disallow: /*votesupdownDisallow: /*calendarDisallow: /*index. php
phpAllow: /*?page=Disallow: /*?Sitemap: http://путь к вашей карте XML формата
ВНИМАНИЕ!
CMS постоянно обновляются. Возможно, понадобиться закрыть от индексации другие страницы. В зависимости от цели, запрет на индексацию может сниматься или, наоборот, добавляться.
Проверить robots.txt
У каждого поисковика свои требования к оформлению файла robots.txt.
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка robotx.txt для поискового робота Яндекса
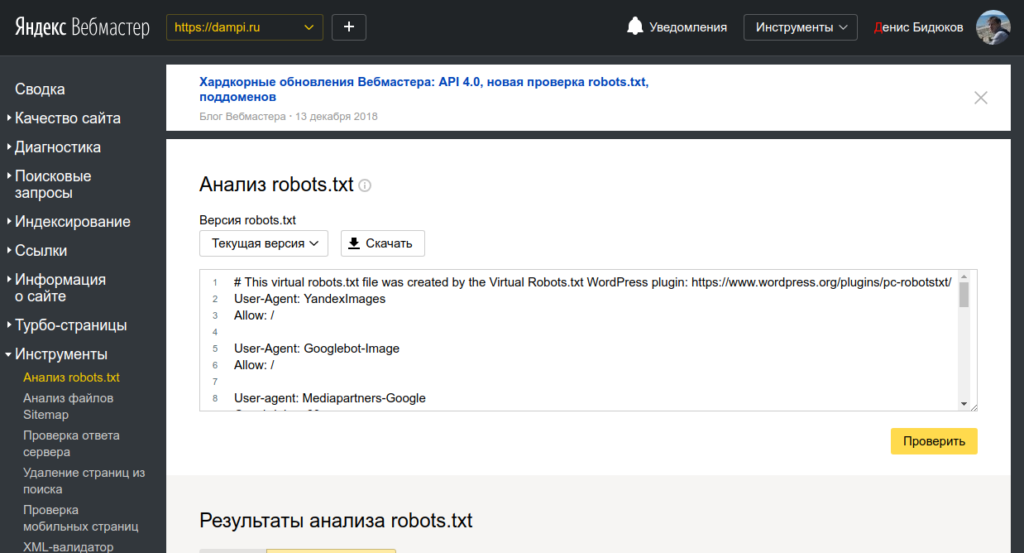
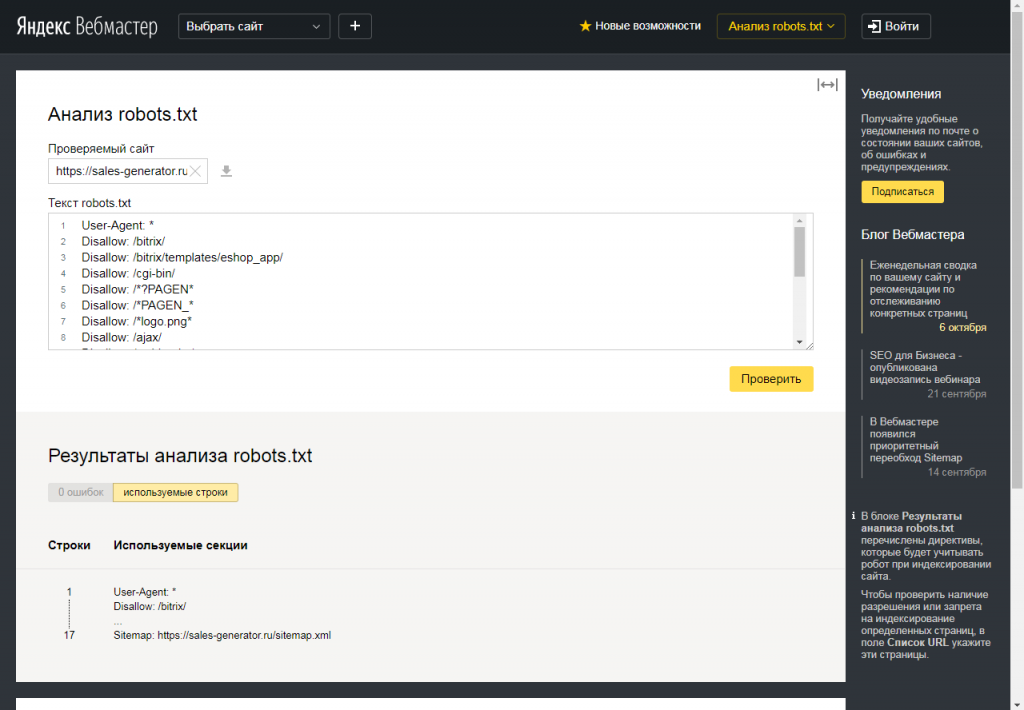
Сделать это можно при помощи специального инструмента от Яндекс — Яндекс.Вебмастер, еще и двумя вариантами.
Вариант 1:
Справа вверху выпадающий список – выберите Анализ robots. txt или по ссылке http://webmaster.yandex.ru/robots.xml
txt или по ссылке http://webmaster.yandex.ru/robots.xml
Вариант 2:
Этот вариант подразумевает, что ваш сайт добавлен в Яндекс Вебмастер и в корне сайта уже есть robots.txt.
Слева выберите Инструменты — Анализ robots.txt
Не стоит забывать о том, что все изменения, которые вы вносите в файл robots.txt, будут доступны не сразу, а спустя лишь некоторое время.
Проверка robotx.txt для поискового робота Google
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
- В Google Search Console выберите ваш сайт, перейдите к инструменту проверки и просмотрите содержание файла
robots.txt. Синтаксические и логические ошибки в нем будут выделены, а их количество – указано под окном редактирования. - Внизу на странице интерфейса укажите нужный URL в соответствующем окне.
- В раскрывающемся меню справа выберите робота.
- Нажмите кнопку ПРОВЕРИТЬ.
- Отобразится статус ДОСТУПЕН или НЕДОСТУПЕН. В первом случае роботы Google могут переходить по указанному вами адресу, а во втором – нет.
- При необходимости внесите изменения в меню и выполните проверку заново. Внимание! Эти исправления не будут автоматически внесены в файл robots.txt на вашем сайте.
- Скопируйте измененное содержание и добавьте его в файл robots.txt на вашем веб-сервере.

Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Генераторы robots.txt
- Сервис от SEOlib.ru.С помощью данного инструмента можно быстро получить и проверить ограничения в файле Robots.txt.
- Генератор от pr-cy.ru.В результате работы генератора Robots.txt вы получите текст, который необходимо сохранить в файл под названием Robots. txt и загрузить в корневой каталог вашего сайта.
 txt и загрузить в корневой каталог вашего сайта.
txt и загрузить в корневой каталог вашего сайта.Настройка robots.txt для Joomla 3
25.05.2019 | Категория: SEO и маркетингРассмотрим как создать для Joomla 3+ правильный файл для поисковых роботов — robots.txt
Этот файл нужен для указания роботам того, что нужно индексировать на вашем сайте и чего НЕ нужно.
Изначально robots.txt имеет такой вид:
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /images/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Чтобы понимать суть этого файла, давайте слегка разберём что здесь написано и какие операторы (команды) он поддерживает.
User-agent — это имя робота, для которого предназначена инструкция. По умолчанию в Joomla стоит * (звёздочка) — это означает, что инструкция предназначена для абсолютно всех поисковых роботов.
Наиболее распространённые имена роботов:
- Yandex — все роботы поисковой системы Яндекса
- YandexImages — индексатор изображений
- Googlebot — робот Гугла
- BingBot — робот системы Bing
- YaDirectBot — робот системы контекстной рекламы Яндекса
Использовать отдельные инструкции для каждого робота в большинстве случаем нет необходимости. Если только на каких то специфичных проектах и для особенных задач.
Каждый робот понимает большую часть команд, и только для некотрых, например для робота Яндекса существуют собственные команды.
Поэтому смело можно ставить * (звёздочку) и писать инструкции для всех. Если какой-то робот не поёмёт что-то, он просто проигнорирует эту команду и будет работать дальше.
Disallow — запрещает индексировать содержимое указанной папки или URL.
Пример:
Disallow: /images/ — запрет индексации всего содержимого папки images
Disallow: /index.php* — запрет индексации всех URL адресов, начинающихся с index.php
Allow — наоборот, разрешает индексацию папки или URL.
Пример:
Allow: /index.php?option=com_xmap&sitemap=1&view=xml — разрешает индексацию карты сайта, созданной при помощи Xmap.
Такая директива необходима если у вас стоит запрет на индексацию адресов с index.php, а чтобы робот мог получить доступ к карте сайта, нужно разрешить этот конкретный URL.
Host — указание основного зеркала сайта (с www или без www)
Пример:
Host: www.joomlatown.net — основной адрес этого сайта с www
Sitemap — указание на адрес по которму находиться карта сайта
Пример:
Sitemap: http://www.joomlatown.net/index.php?option=com_xmap&sitemap=1&view=xml
По этому адресу находится карта сайта в формате xml
Clean-param — специальная директива, которая запрещает роботам Яндекса индексировать URL адреса с динамическими параметрами.
Динамические параметры, это различные переменные и цифры, которые подставляются к адресу, например при поиске по сайту.
Пример таких параметров:
http://www.joomlatown.net/poisk?searchword=robots.txt&ordering=newest&searchphrase=all&limit=20
И чтобы Яндекс не учитывал такие служебные страницы, в robots.txt задаётся директива Clean-param.
Всё тот же пример с поиском по сайту:
Clean-param: searchword / — директива запрещает индексировать все URL с параметром ?searchword
Crawl-delay — директива пока знакомая только Яндексу. Она указывает с каким интервалом сканировать страницы, интервал задаётся в секундах.
Может быть полезно если у вас много страниц и достаточно высокая нагрузка на сервер, поскольку каждое обращение робота к странице вашего сайта — это нагрузка на сервер. Робот может сканировать по несколько страниц в секунду и тем самым загрузить серврер.
Пример:
Crawl-delay: 5 — интервал для загрузки страницы — 5 секунд.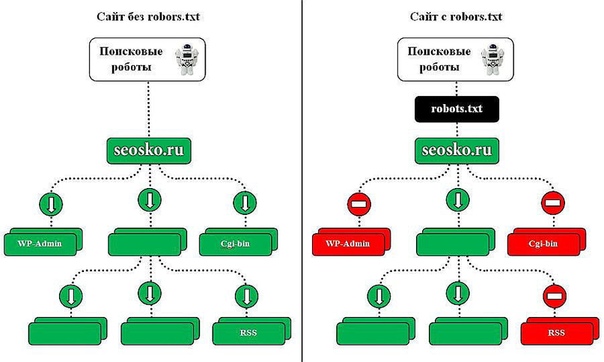
Прим: Но с crawl-delay нужно быть осторожнее, он может замедлить индексацию страниц сайта.
Специфичные директивы для Яндекса вы можете посмотреть здесь >>
Все директивы пишутся с новой строки, без пропуска.
Таким образом для Joomla 3, со включенным SEF (красивыми ссылками без index.php) можно вывести такой файл robots.txt
User-agent: *
Disallow: /administrator/
Disallow: /bin/
Disallow: /cache/
Disallow: /cli/
Disallow: /components/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /layouts/
Disallow: /libraries/
Disallow: /logs/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /index.php*
Allow: /index.php?option=com_xmap&sitemap=1&view=xml
Host: ваш_домен.ru
Sitemap: http://ваш_адрес_карты_сайта
Clean-param: searchword /
Здесь мы запретили индексацию URL адресов с index. php — это можно применить только если у вас включен SEF.
php — это можно применить только если у вас включен SEF.
Разрешили индексацию картинок, xml-карты сайта, указали главное зеркало сайта, путь до карты сайта, запретили (очистили) параметр searchword, который используется в поиске Joomla.
Желаю хорошей и быстрой индексации!
Создать robots.txt онлайн
Чтобы активировать PRO версию программы достаточно только нажать и поделиться страницей через социальные сети выше.
Robots.txt является обыкновенным текстовым файлом, располагающимся в корне вашего сайта, просмотреть и отредактировать его можно используя любой текстовый редактор. В данном файлике записаны инструкции, которыми должны руководствоваться поисковые машины (роботы). Собственно, отсюда и пошло название этого документа. Инструкции эти указывают поисковику, что подлежит индексированию, а что трогать не нужно. Наверное, каждый вебмастер хотел бы, чтобы созданный им сайт как можно быстрее был проиндексирован поисковой системой, причем чтобы этот процесс прошел правильно и без ошибок. Поэтому, нужно понимать, что без грамотно составленного файла robots.txt это маловероятно, следовательно, нужно позаботиться о его создании. Конечно же вы можете самостоятельно написать данный файл, к тому же примеров в сети очень много. Но, намного правильнее и быстрее будет воспользоваться нашим инструментом создания robots.txt – это самый эффективный способ. Все что от Вас требуется это заполнить форму на нашем сайте и все. В результате вы получите уже готовый текст, который нужно просто вставить в документ и сохранить в корне вашего сайта под именем Robots.txt. При этом у вас есть возможность полностью запретить индексирование своего сайта, хотя вряд ли это кому-то понадобится. Здесь вам нужно будет указать местонахождение карты вашего сайта, а если у вас ее нету, то можно просто не заполнять данное поле. Далее вы можете выбрать поисковые системы, которым дадите право проводить индексирование страниц вашего ресурса. Рекомендуется выбирать все, это даст наиболее положительный эффект в плане посещаемости сайта.
Поэтому, нужно понимать, что без грамотно составленного файла robots.txt это маловероятно, следовательно, нужно позаботиться о его создании. Конечно же вы можете самостоятельно написать данный файл, к тому же примеров в сети очень много. Но, намного правильнее и быстрее будет воспользоваться нашим инструментом создания robots.txt – это самый эффективный способ. Все что от Вас требуется это заполнить форму на нашем сайте и все. В результате вы получите уже готовый текст, который нужно просто вставить в документ и сохранить в корне вашего сайта под именем Robots.txt. При этом у вас есть возможность полностью запретить индексирование своего сайта, хотя вряд ли это кому-то понадобится. Здесь вам нужно будет указать местонахождение карты вашего сайта, а если у вас ее нету, то можно просто не заполнять данное поле. Далее вы можете выбрать поисковые системы, которым дадите право проводить индексирование страниц вашего ресурса. Рекомендуется выбирать все, это даст наиболее положительный эффект в плане посещаемости сайта. В перечне присутствуют все основные поисковые машины. Далее вам предлагается указать те страницы, которые вы бы не хотели видеть в индексе поисковиков. На этом все, ваш файлик готов, можете выкладывать его к себе на сайт.
В перечне присутствуют все основные поисковые машины. Далее вам предлагается указать те страницы, которые вы бы не хотели видеть в индексе поисковиков. На этом все, ваш файлик готов, можете выкладывать его к себе на сайт.Есть ли какие-то отличия Robots.txt для Яндекса в сравнении с файлами для других роботов?
На самом деле каждая поисковая машина использует разные методы индексирования, и вообще работают они по-разному. Каждый поисковик имеет свои методики ранжирования, присвоения сайтам определенного места в своем списке. Однако, практически все они одинаково индексируют и понимают файл Robots.txt. Практика свидетельствует, что один файл Robots.txt подходит абсолютно ко всем поисковым системам и с ним не возникает никаких проблем.Есть ли возможность проверить существующий файл Robots.txt?
Если вы сами писали данный файл, или использовали другой генератор, и сомневаетесь в его работоспособности, то можете проверить его с помощью специального сервиса на нашем сайте.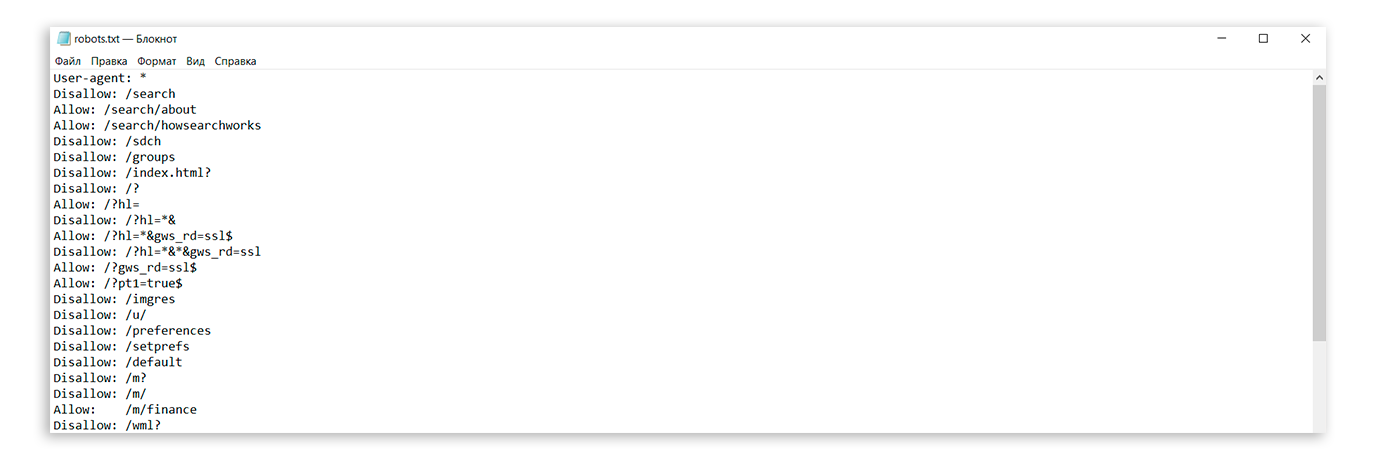 Если в ходе такой проверки обнаружатся те или иные проблемы, то вы с легкостью сможете сгенерировать новый файлик воспользовавшись нашим инструментом. Специалисты всегда рекомендуют проверять самодельные файлы Robots.txt с помощью уже проверенных генераторов, чтобы избежать возможных проблем в будущем.
Если в ходе такой проверки обнаружатся те или иные проблемы, то вы с легкостью сможете сгенерировать новый файлик воспользовавшись нашим инструментом. Специалисты всегда рекомендуют проверять самодельные файлы Robots.txt с помощью уже проверенных генераторов, чтобы избежать возможных проблем в будущем.Страницы веб-роботов
О /robots.txt
В двух словах
Владельцы веб-сайтов используют файл /robots.txt для получения инструкций по их сайт для веб-роботов; это называется Исключение роботов Протокол .
Это работает так: робот хочет перейти по URL-адресу веб-сайта, скажем, http://www.example.com/welcome.html. Прежде чем это произойдет, он первым проверяет http://www.example.com/robots.txt и находит:
Пользовательский агент: * Запретить: /
«User-agent: *» означает, что этот раздел применим ко всем роботам.»Disallow: /» сообщает роботу, что он не должен посещать никакие
страницы на сайте.
При использовании /robots.txt следует учитывать два важных момента:
- роботы могут игнорировать ваш /robots.txt. Особенно вредоносные роботы, которые сканируют Интернет на наличие уязвимостей безопасности и сборщики адресов электронной почты, используемые спамерами не обращаю внимания.
- файл /robots.txt является общедоступным. Все могут видеть, какие разделы вашего сервера вы не хотите, чтобы роботы использовали.
Так что не пытайтесь использовать /robots.txt для сокрытия информации.
Смотрите также:
Реквизиты
/Robots.txt является стандартом де-факто и не принадлежит никому орган по стандартизации. Есть два исторических описания:
Вдобавок есть внешние ресурсы:
Стандарт /robots.txt активно не развивается. См. Как насчет дальнейшего развития /robots.txt? для дальнейшего обсуждения.
На оставшейся части этой страницы дается обзор того, как использовать / robots. txt на
ваш сервер, с несколькими простыми рецептами. Чтобы узнать больше, смотрите также FAQ.
txt на
ваш сервер, с несколькими простыми рецептами. Чтобы узнать больше, смотрите также FAQ.
Как создать файл /robots.txt
Где поставить
Краткий ответ: в каталоге верхнего уровня вашего веб-сервера.
Более длинный ответ:
Когда робот ищет URL-адрес в файле «/robots.txt», он удаляет компонент пути из URL-адреса (все, начиная с первой косой черты), и помещает на его место «/robots.txt».
Например, для http: // www.example.com/shop/index.html, он будет удалите «/shop/index.html» и замените его на «/robots.txt», и в итоге будет «http://www.example.com/robots.txt».
Итак, как владельцу веб-сайта вам необходимо разместить его в нужном месте на своем веб-сервер для работы полученного URL. Обычно это то же самое место, куда вы помещаете главный «index.html» вашего веб-сайта страница. Где именно это и как поместить файл, зависит от программное обеспечение вашего веб-сервера.
Не забудьте использовать строчные буквы для имени файла:
«роботы.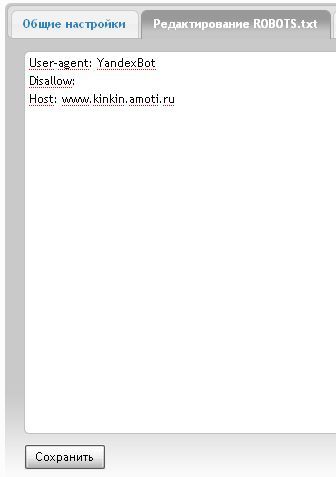 txt », а не« Robots.TXT.
txt », а не« Robots.TXT.
Смотрите также:
Что туда класть
Файл «/robots.txt» — это текстовый файл с одной или несколькими записями. Обычно содержит одну запись следующего вида:Пользовательский агент: * Disallow: / cgi-bin / Запрещение: / tmp / Запретить: / ~ joe /
В этом примере исключены три каталога.
Обратите внимание, что для каждого префикса URL-адреса вам нужна отдельная строка «Disallow». хотите исключить — нельзя сказать «Disallow: / cgi-bin / / tmp /» на одна линия.Кроме того, в записи может не быть пустых строк, так как они используются для разграничения нескольких записей.
Также обратите внимание, что подстановка и регулярное выражение не поддерживается ни в User-agent, ни в Disallow
линий. ‘*’ В поле User-agent — это специальное значение, означающее «любой
робот «. В частности, у вас не может быть таких строк, как» User-agent: * bot * «,
«Запрещать: / tmp / *» или «Запрещать: * .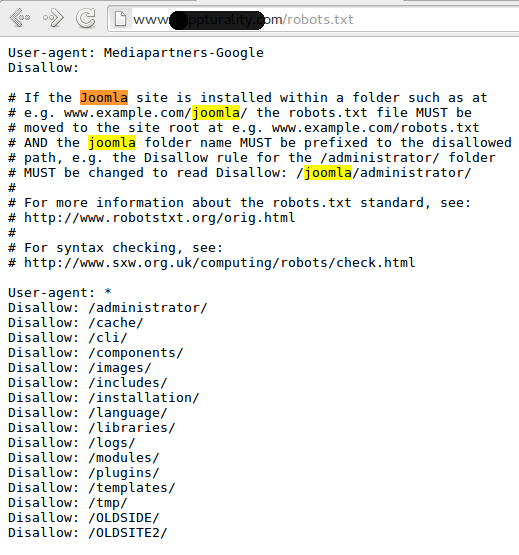 gif».
gif».
Что вы хотите исключить, зависит от вашего сервера. Все, что не запрещено явно, считается справедливым игра для извлечения.Вот несколько примеров:
Чтобы исключить всех роботов со всего сервера
Пользовательский агент: * Запретить: /
Разрешить всем роботам полный доступ
Пользовательский агент: * Запретить:
(или просто создайте пустой файл «/robots.txt», или не используйте его вообще)
Чтобы исключить всех роботов из части сервера
Пользовательский агент: * Disallow: / cgi-bin / Запрещение: / tmp / Запретить: / junk /
Для исключения одного робота
Пользовательский агент: BadBot Запретить: /
Чтобы позволить одному роботу
Пользовательский агент: Google Запретить: Пользовательский агент: * Запретить: /
Для исключения всех файлов, кроме одного
В настоящее время это немного неудобно, так как нет поля «Разрешить». В
простой способ — поместить все файлы, которые нельзя разрешить, в отдельный
директорию, скажите «вещи» и оставьте один файл на уровне выше
этот каталог:
В
простой способ — поместить все файлы, которые нельзя разрешить, в отдельный
директорию, скажите «вещи» и оставьте один файл на уровне выше
этот каталог:Пользовательский агент: * Запретить: / ~ joe / stuff /В качестве альтернативы вы можете явно запретить все запрещенные страницы:
Пользовательский агент: * Запретить: /~joe/junk.html Запретить: /~joe/foo.html Запретить: /~joe/bar.html
Просканировано роботом Googlebot? | появляется в указателе? | Потребляет PageRank | Риски? Трата? | Формат | |
robots. txt txt | нет | Если на документ есть ссылка, он может отображаться только по URL-адресу или с данными из ссылок или доверенных сторонних источников данных, таких как ODP | да | Люди могут смотреть на ваших роботов.txt, чтобы увидеть, какой контент вы не хотите индексировать. Многие новые запуски обнаруживаются людьми, отслеживающими изменения в файле robots.txt. Неправильное использование подстановочных знаков может быть дорогостоящим! | Агент пользователя: * ИЛИ Агент пользователя: * Также можно использовать сложные подстановочные знаки. |
| мета тег noindex роботов | да | нет | Да, но может передать большую часть своего PageRank, ссылаясь на другие страницы | Ссылки на странице noindex по-прежнему сканируются поисковыми пауками, даже если страница не отображается в результатах поиска (если они не используются вместе с nofollow). Страница, использующая мета-nofollow роботов (1 строка ниже) в сочетании с noindex, может накапливать PageRank, но не передавать его другим страницам. | ИЛИ может использоваться с nofollow likeo |
| метатег nofollow для роботов | целевая страница сканируется, только если на нее есть ссылки из других документов | Целевая страницаотображается, только если на нее есть ссылка из других документов | нет, PageRank не передан по назначению | Если вы увеличиваете значительный PageRank на странице и не позволяете PageRank исходить с этой страницы, вы можете потерять значительную долю ссылочного рейтинга. | ИЛИ можно использовать с noindex likeo |
| ссылка rel = nofollow | целевая страница сканируется, только если на нее есть ссылки из других документов | Целевая страницаотображается, только если на нее есть ссылка из других документов | Использование этого может привести к потере некоторого PageRank. Рекомендуется использовать в областях контента, создаваемых пользователями. Рекомендуется использовать в областях контента, создаваемых пользователями. | Если вы делаете что-то на грани спама и используете nofollow для внутренних ссылок для увеличения PageRank, то вы больше похожи на оптимизатора поисковых систем и, скорее всего, будете наказаны инженером Google за «поисковый спам» | текст ссылки |
| rel = canonical | да.может сканироваться несколько версий страницы, и они могут появиться в индексе | В индексе все еще отображаетсястраниц. это воспринимается скорее как подсказка, чем как директива. | PageRank должен накапливаться на целевой цели | При использовании таких инструментов, как переадресация 301 и rel = canonical, может возникнуть небольшое снижение рейтинга страниц, особенно с rel = canonical, поскольку обе версии страницы остаются в поисковом индексе. | |
| Ссылка Javascript | в целом да, если целевой URL легко доступен в частях ссылки a href или onclick. | Страница назначенияотображается, только если на нее есть ссылка из других документов | в целом да, PageRank обычно передается получателю | Хотя многие из них отслеживаются Google, другие поисковые системы могут не отслеживать их. |
|
 html
html txt, они могут по-прежнему отображать эти страницы как списки только URL-адресов в своих результатах поиска.Лучшее решение для полной блокировки индекса конкретной страницы — использовать метатег robots noindex для каждой страницы. Вы можете сказать им не индексировать страницу или не индексировать страницы и , чтобы не переходить по исходящим ссылкам, вставив один из следующих битов кода в заголовок HTML вашего документа, который вы не хотите индексировать.
txt, они могут по-прежнему отображать эти страницы как списки только URL-адресов в своих результатах поиска.Лучшее решение для полной блокировки индекса конкретной страницы — использовать метатег robots noindex для каждой страницы. Вы можете сказать им не индексировать страницу или не индексировать страницы и , чтобы не переходить по исходящим ссылкам, вставив один из следующих битов кода в заголовок HTML вашего документа, который вы не хотите индексировать.


 asp$
asp$ txt: Я случайно потерял более 10 000 долларов прибыли из-за одной ошибки robots.txt!
txt: Я случайно потерял более 10 000 долларов прибыли из-за одной ошибки robots.txt! Google предлагает hreflang, чтобы помочь им узнать, какие URL-адреса являются эквивалентами для разных языков и рынков.
Google предлагает hreflang, чтобы помочь им узнать, какие URL-адреса являются эквивалентами для разных языков и рынков. txt не позволит Google создавать такие страницы
txt не позволит Google создавать такие страницы htaccess он предлагает советы о том, как предотвратить индексирование вашей SSL-версии https вашего сайта. За годы, прошедшие с момента его первоначальной публикации, Google указывал на предпочтение ранжирования HTTPS-версии сайта над HTTP-версией сайта. Есть способы выстрелить себе в ногу, если он не будет перенаправлен или канонизирован должным образом.
htaccess он предлагает советы о том, как предотвратить индексирование вашей SSL-версии https вашего сайта. За годы, прошедшие с момента его первоначальной публикации, Google указывал на предпочтение ранжирования HTTPS-версии сайта над HTTP-версией сайта. Есть способы выстрелить себе в ногу, если он не будет перенаправлен или канонизирован должным образом.
 Правило их всех таково:
Правило их всех таково:
 txt и Sitemap
txt и Sitemap 

 Например, страницы входа или страницы ресурсов не должны даже запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл.
Например, страницы входа или страницы ресурсов не должны даже запрашиваться сканерами поисковых систем. Подобные URL-адреса следует скрыть от поисковых систем, добавив их в файл Robots.txt файл. Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
Эти директивы могут быть указаны для всех поисковых систем или для определенных пользовательских агентов, идентифицированных HTTP-заголовком пользовательского агента. В диалоговом окне «Добавить запрещающие правила» вы можете указать, к какому искателю поисковой системы применяется директива, введя пользовательский агент искателя в поле «Робот (пользовательский агент)».
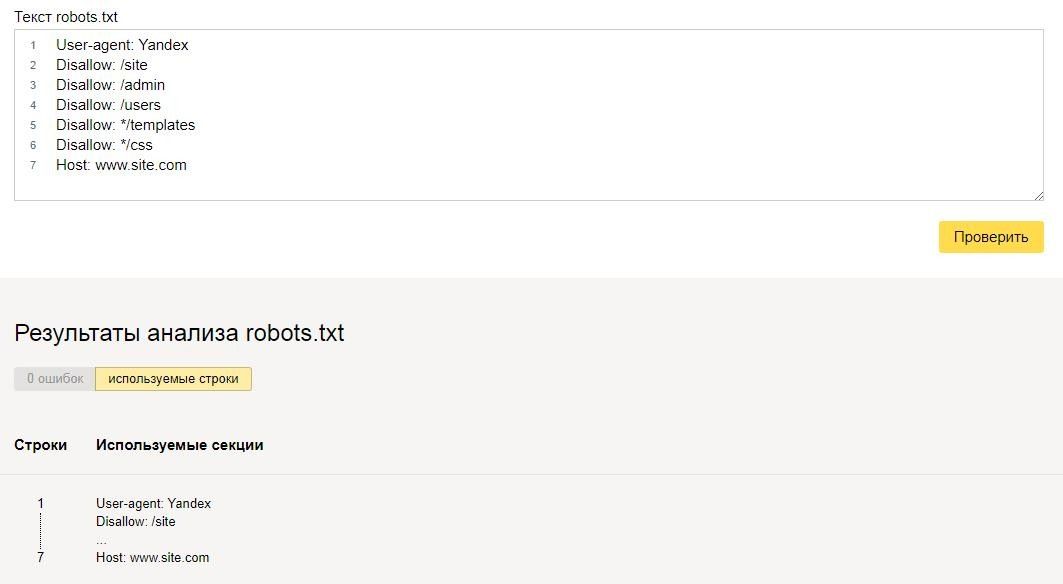 txt . В этом отчете будут отображены все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
txt . В этом отчете будут отображены все ссылки, которые не были просканированы, поскольку они были запрещены только что созданным файлом Robots.txt.
 Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»:
Вы можете выбрать один из нескольких вариантов, используя раскрывающийся список «Структура URL»: Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом:
Файл sitemap.xml будет обновлен (или создан, если он не существует), и его содержимое будет выглядеть следующим образом: txt на панели Actions :
txt на панели Actions :