Robots.txt — как настроить и загрузить на сайт
Михаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т.
 д.
д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: *
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image.

Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing. Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.

Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.![]()
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой.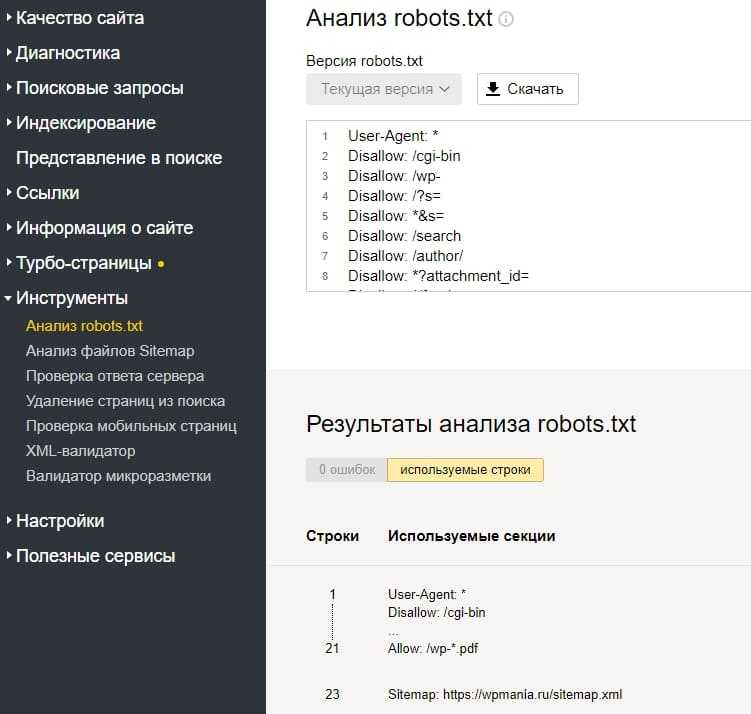 Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
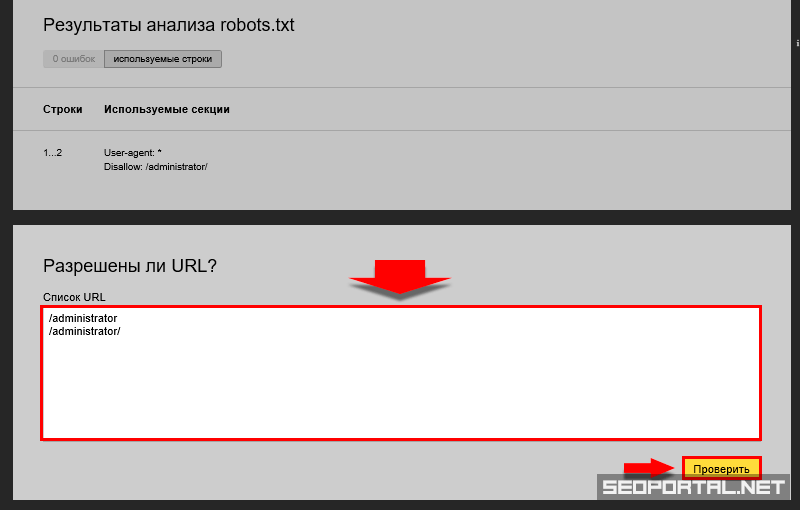
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
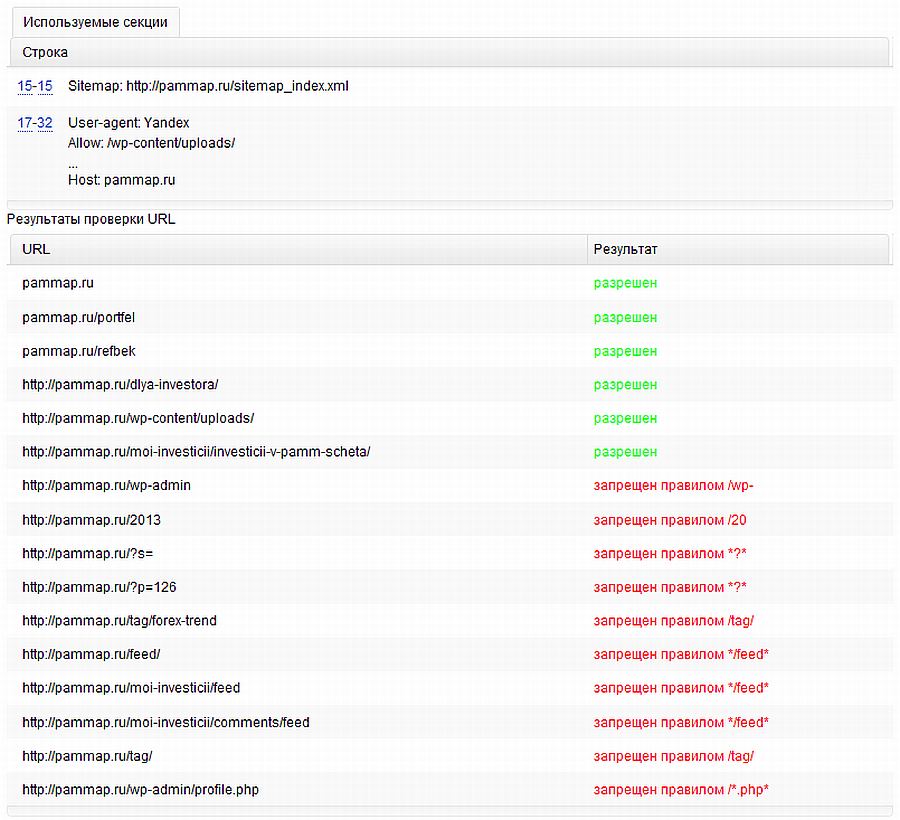
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся
шутить, но получается не всегда
Пытаемся
шутить, но получается не всегда
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
Robots.
 txt — как настроить и загрузить на сайт
txt — как настроить и загрузить на сайтМихаил Шумовский
07 октября, 2022
Кому нужен robots.txt Как настроить robots.txt Как создать robots.txt Требования к файлу robots.txt Как проверить правильность Robots.txt
Мы в Telegram
В канале «Маркетинговые щи» только самое полезное: подборки, инструкции, кейсы.
Не всегда на серьёзных щах — шуточки тоже шутим =)
Подписаться
Станьте email-рокером 🤘
Пройдите бесплатный курс и запустите свою первую рассылку
Подробнее
Robots.txt — документ, который нужен для индексирования и продвижения сайта. С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
С помощью этого файла владелец сайта подсказывает поисковым системам, какие разделы ресурса нужно учитывать, а какие — нет. Объясняю особенности его составления и настройки такого текстового файла.
Если у сайта нет robots.txt, поисковые роботы считают все страницы ресурса открытыми для индексирования. Если файл есть, владелец сайта может запретить роботам индексировать определённые страницы.
Например, контентным ресурсам или медиа можно работать без robots.txt — тут все страницы участвуют в индексации.
На других ресурсах могут быть страницы, которые не нужно показывать поисковым роботам:
- Админ-панели сайта: пути, которые начинаются с /user, /admin, /administrator и т.д.
- Пустые страницы ресурса: если на них нет контента, в индексации они не помогут.
- Формы регистрации.
- Личные страницы в интернет-магазинах: кабинеты пользователей, корзины и т. д.
 д.
д.Начну с основных параметров.
User-agent: Yandex
Disallow: catalog/
Allow: /catalog/cucumbers/
Sitemap: http://www.example.com/sitemap.xml
User-agent — указывает название робота, к которому применяется правило. Например, User-agent: Yandex означает, что правило применяется к роботу Яндекса.
А user-agent: * означает, что правило применяется ко всем роботам. Но о звёздочках поговорим ниже.
Основные типы роботов, которые можно указать в User-agent:
- Yandex. Все роботы Яндекса.
- YandexBot. Основной робот Яндекса
- YandexImages. Индексирует изображения.
- YandexMedia. Индексирует видео и другие мультимедийные данные.
- Google. Все роботы Google.
- Googlebot. Основной робот Google.
- Googlebot-Image. Индексирует изображения.
 Индексирует изображения.
Индексирует изображения.Disallow. Указывает на каталог или страницу ресурса, которые роботы индексировать не будут. Если нельзя индексировать конкретную страницу, например, определённый раздел в каталоге, нужно указывать полный путь к ней — как в поисковой строке браузера.
В начале строки должен быть символ /. Если правило касается каталога, строка должна заканчиваться символом /.
Например, disallow: /catalog/gloves. Так мы запретим индексацию раздела с перчаткам.
Если оставить disallow пустым, роботы будут индексировать все страницы сайта.
Allow. Указывает на каталог или страницу, которые можно сканировать роботу. Его используют, чтобы внести исключения в пункт disallow и разрешить сканирование подкаталога или страницы в каталоге, который закрыт для обработки.
Если требуется индексировать конкретную страницу, нужно указывать к ней полный путь. Как и в disallow. Например, allow: /story/marketing.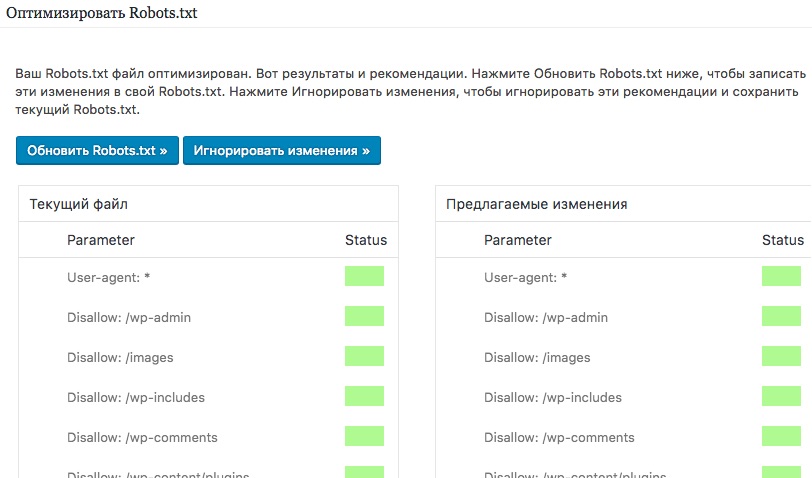 Так мы разрешили индексировать статью о маркетинге.
Так мы разрешили индексировать статью о маркетинге.
Если правило касается каталога, строка должна заканчиваться символом /.
Если allow пустой, робот не будет индексировать никакие страницы.
Sitemap. Необязательная директива, которая может повторяться несколько раз или не использоваться совсем. Её используют, чтобы описать структуру сайта и помочь роботам индексировать страницы.
Лендингам и небольшим сайтам sitemap не нужен. А вот таким ресурсам без sitemap не обойтись:
- Cайтам без хлебных крошек (навигационных цепочек).
- Большим ресурсам. Например, если сайт содержит большой объём мультимедиа или новостного контента.
- Сайтам с глубокой вложенностью. Например, «Главная/Каталог/Перчатки/Резиновые».
- Молодым ресурсам, на которые мало внешних ссылок, — их роботам сложно найти.
- Сайтам с большим архивом страниц, которые изолированы или не связаны друг с другом.
Файл нужно прописывать в XML-формате. Создание sitemap — тема для отдельной статьи. Подробную инструкцию читайте на Google Developers или в Яндекс.Справке.
Основные моменты robots.txt разобрали. Теперь расскажу про дополнительные параметры, которые используют в коде.
Для начала посмотрим на robots.txt Unisender. Для этого в поисковой строке браузера пишем Unisender.com/robots.txt.
По такой же формуле можно проверять файлы на всех сайтах: URL сайта + домен/robots.txt.
Robots.txt Unisender отличается от файла, который я приводил в пример. Дело в том, что здесь использованы дополнительные параметры:
Директива # (решётка) — комментарий. Решётки прописывают для себя, а поисковые роботы комментариев не видят.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Звёздочку роботы видят, а решётку — нет
Директива * (звёздочка) — любая последовательность символов после неё.
Например, если поставить звёздочку в поле disallow, то всё, что находится на её месте, будет запрещено.
User-agent: Yandex
Disallow: /example/* # запрещает ‘/example/blog’
# запрещает ‘/example/blog/test’
Disallow: */shop # запрещает не только ‘/shop’,
# но и ‘/example/shop’
Также и с полем allow: всё, что стоит на месте звёздочки, — разрешено для индексации.
User-agent: Yandex
Allow: /example/* # разрешает ‘/example/blog’
# разрешает ‘/example/blog/test’
Allow: */shop # разрешает не только ‘/shop’,
# но и ‘/example/shop’
Например, у Google есть особенность: компания рекомендует не закрывать от поисковых роботов файлы с css-стилями и js-скриптами. Вот как это нужно прописывать:
User-agent: Googlebot
Disallow: /site
Allow: *.css
Allow: *. js
js
Директива $ (знак доллара) — точное соответствие указанному параметру.
Например, использование доллара в disallow запретит доступ к определённому пути.
User-agent: Yandex
Disallow: /example # запрещает ‘/example’,
# запрещает ‘/example.html’
Disallow: /example$ # запрещает ‘/example’,
# не запрещает ‘/example.html’
# не запрещает ‘/example1’
# не запрещает ‘/example-new’
Таким способом можно исключить из сканирования все файлы определённого типа, например, GIF или JPG. Для этого нужно совместить * и $. Звёздочку ставим до расширения, а $ — после.
User-agent: Yandex
Disallow: / *.gif$ # вместо * могут быть любые символы,
# $ запретит индексировать файлы gif
Директива Clean-param — новый параметр Яндекс-роботов, который не будет сканировать дублированную информацию и поможет быстрее анализировать ресурс.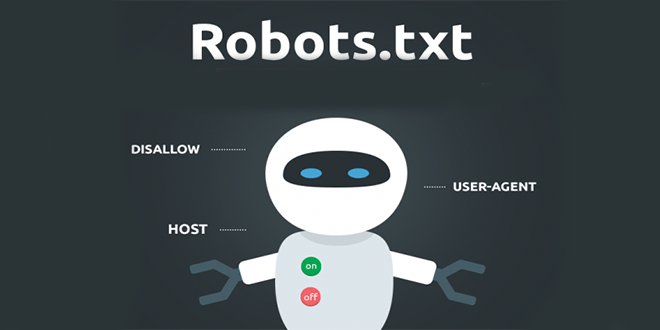
Дело в том, что из-за повторяющейся информации роботы медленнее проверяют сайт, а изменения на ресурсе дольше попадают в результаты поиска. Когда роботы Яндекса увидят эту директиву, не будут несколько раз перезагружать дубли информации и быстрее проверят сайт, а нагрузка на сервер снизится.
www.example.com/dir/get_card.pl?ref=site_1&card_id=10
www.example.com/dir/get_card.pl?ref=site_2&card_id=10
Параметр ref нужен, чтобы отследить, с какого ресурса сделан запрос. Он не меняет содержимое страницы, значит два адреса покажут одну и ту же страницу с книгой card_id=10. Поэтому директиву можно указать так:
User-agent: Yandex
Disallow:
Clean-param: ref /dir/get_card.pl
Робот Яндекса сведёт страницы к одной: www.example.com/dir/get_card.pl?card_id=10
Чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес:
User-agent: Yandex
Disallow:
Clean-param: utm
Директива Crawl-delay — устанавливает минимальный интервал в секундах между обращениями робота к сайту. Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Это помогает снизить нагрузку на сервер ресурса. Чем выше указанное значение, тем меньше страниц робот загрузит за сессию.
Значения можно указывать целыми или дробными числами через точку.
User-agent: Yandex
Disallow:
Crawl-delay: 0.5
Для Яндекса максимальное значение в crawl-delay — 2. Более высокое значение можно установить инструментами Яндекс.Вебмастер.
Для Google-бота можно установить частоту обращений в панели вебмастера Search Console.
Директива Host — инструкция для робота Яндекса, которая указывает главное зеркало сайта. Нужна, если у сайта есть несколько доменов, по которым он доступен. Вот как её указывают:
User-agent: Yandex
Disallow: /example/
Host: example.ru
Если главное зеркало сайта — домен с протоколом HTTPS, его указывают так:
Host: https://site.ru
Как создать robots.txtСпособ 1. Понадобится текстовый редактор: блокнот, TextEdit, Vi, Emacs или любой другой. Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Не используйте приложения Microsoft Office, потому что они сохраняют файлы в неподходящем формате или добавляют в них лишние символы, которые не распознаются поисковыми роботами.
Способ 2. Создать на CMS с помощью плагинов — в этом случае robots.txt установится сам.
Если вы используете CMS хостинга, редактировать файл robots.txt не потребуется. Скорее всего, у вас даже не будет такой возможности. Вместо этого провайдер будет указывать поисковым системам, нужно ли сканировать контент, с помощью страницы настроек поиска или другого инструмента.
Способ 3. Воспользоваться генератором robots.txt — век технологий всё-таки.
Сгенерировать файл можно на PR-CY, IKSWEB, Smallseotools.
Требования к файлу robots.txtКогда создадите текстовый файл, сохраните его в кодировке utf-8. Иначе поисковые роботы не смогут прочитать документ. После создания загрузите файл в корневую директорию на сайте хостинг-провайдера. Корневая директория — это папка public. html.
html.
Папка, в которой нужно искать robots.txt. Источник
Если файла нет, его придётся создавать самостоятельно.
Требования, которым должен соответствовать robots.txt:
- Каждая директива начинается с новой строки.
- Одна директива в строке, сам параметр также написан в одну строку.
- В начале строки нет пробелов.
- Нет кавычек в директивах.
- Директивы не нужно закрывать точкой или точкой с запятой.
- Файл должен называться robots.txt. Нельзя называть его Robots.txt или ROBOTS.TXT.
- Размер файла не должен превышать 500 КБ.
- robots.txt должен быть написан на английском языке. Буквы других алфавитов не разрешаются.
Если файл не соответствует одному из требований, весь сайт считается открытым для индексирования.
Как проверить правильность Robots.txtПроверить robots. txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
txt помогают сервисы от Яндекс и Google. В Яндексе можно проверять файл даже без сайта — например, если вы написали robots.txt, но пока не загрузили его на сайт.
Вот как это сделать:
- Перейдите на Яндекс.Вебмастер.
- В открывшееся окно вставьте текст robots.txt и нажмите проверить.
Если файл написан правильно, Яндекс.Вебмастер не увидит ошибок.
А если увидит ошибку — подсветит её и опишет возможную проблему.
На Яндекс.Вебмастер можно проверить robots.txt и по URL сайта. Для этого нужно указать запрос: URL сайта/robots.txt. Например, unisender.com/robots.txt.
Ещё один вариант — проверить файл robots.txt через Google Search Console. Но сначала нужно подтвердить владение сайтом. Пошаговый алгоритм проверки robots.txt описан в видеоинструкции:
Поделиться
СВЕЖИЕ СТАТЬИ
Другие материалы из этой рубрики
Не пропускайте новые статьи
Подписывайтесь на соцсети
Делимся новостями и свежими статьями, рассказываем о новинках сервиса
Статьи почтой
Раз в неделю присылаем подборку свежих статей и новостей из блога. Пытаемся
шутить, но получается не всегда
Пытаемся
шутить, но получается не всегда
Наш юрист будет ругаться, если вы не примете 🙁
Как запустить email-маркетинг с нуля?
В бесплатном курсе «Rock-email» мы за 15 писем расскажем, как настроить email-маркетинг в компании. В конце каждого письма даем отбитые татуировки об email ⚡️
*Вместе с курсом вы будете получать рассылку блога Unisender
Оставляя свой email, я принимаю Политику конфиденциальностиНаш юрист будет ругаться, если вы не примете 🙁
ФайлRobots.
 txt — что это такое? Как это использовать? // WEBRIS
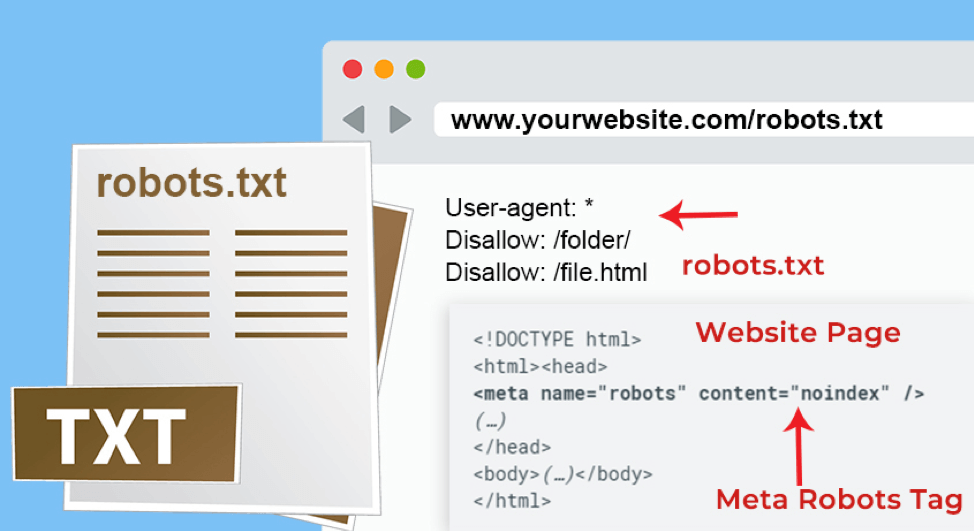
txt — что это такое? Как это использовать? // WEBRISКороче говоря, файл Robots.txt управляет доступом поисковых систем к вашему веб-сайту.
Этот текстовый файл содержит «директивы», которые указывают поисковым системам, какие страницы должны быть «разрешены» и «запрещены» для поисковых систем.
Скриншот нашего файла Robots.txt
Добавление сюда неправильных директив может негативно сказаться на вашем рейтинге, поскольку это может помешать поисковым системам сканировать страницы (или весь ваш сайт).
Ваш сайт теряет деньги…
Узнайте, сколько именно клиентов вы ДОЛЖНЫ получать от органического поиска.
Что такое «роботы» (в отношении SEO)?
Роботы — это приложения, которые «сканируют» веб-сайты, документируя (т. е. «индексируя») информацию, которую они охватывают.
В отношении файла Robots.txt эти роботы называются агентами пользователя.
Вы также можете услышать, как их называют:
- Пауки
- Боты
- Поисковые роботы
Это , а не официальные имена агентов пользователей поисковых роботов.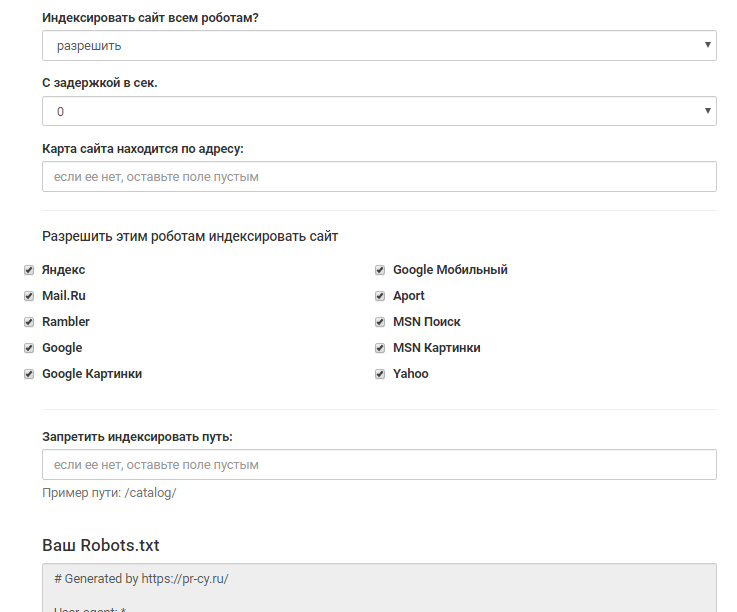 Другими словами, вы бы не «запретили» «сканера», вам нужно было бы получить официальное название поисковой системы (сканер Google называется «Googlebot»).
Другими словами, вы бы не «запретили» «сканера», вам нужно было бы получить официальное название поисковой системы (сканер Google называется «Googlebot»).
Полный список веб-роботов можно найти здесь.
Изображение предоставлено
Эти боты находятся под влиянием различных способов, включая создаваемый вами контент и ссылки, указывающие на ваш веб-сайт.
Ваш файл Robots.txt – это средство прямого общения с роботами поисковых систем , давая им четкие указания о том, какие части вашего сайта вы хотите сканировать (или не сканировать).
Как использовать файл Robots.txt?
Вам необходимо понять «синтаксис» создания файла Robots.txt.
1. Определите User-agent
Укажите имя робота, на которого вы ссылаетесь (например, Google, Yahoo и т. д.). Опять же, вы захотите обратиться за помощью к полному списку пользовательских агентов.
2. Запретить
Если вы хотите заблокировать доступ к страницам или разделу вашего сайта, укажите URL-адрес здесь.
3. Разрешить
Если вы хотите напрямую разблокировать URL-адрес внутри заблокированного родителя, введите этот путь к подкаталогу URL-адреса здесь.
Файл Robots.txt Википедии.
Короче говоря, вы можете использовать robots.txt, чтобы сказать этим поисковым роботам: «Индексируйте эти страницы, но не индексируйте другие».
Почему файл robots.txt так важен
Может показаться нелогичным «блокировать» страницы от поисковых систем. Для этого есть ряд причин и случаев:
1. Блокирование конфиденциальной информации
Хорошим примером являются каталоги.
Вероятно, вы захотите скрыть те, которые могут содержать конфиденциальные данные, такие как:
- /cart/
- /cgi-bin/
- /скрипты/
- /вп-админ/
2. Блокировка страниц низкого качества
Компания Google неоднократно заявляла, что важно, чтобы ваш веб-сайт был «очищен» от страниц низкого качества.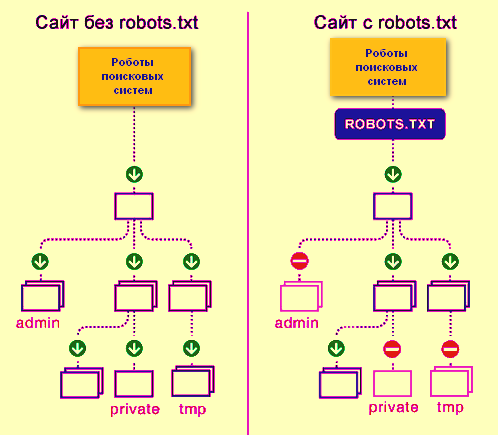 Наличие большого количества мусора на вашем сайте может снизить производительность.
Наличие большого количества мусора на вашем сайте может снизить производительность.
Ознакомьтесь с нашим аудитом контента для получения более подробной информации.
3. Блокировка повторяющегося содержимого
Вы можете исключить все страницы, содержащие повторяющееся содержимое. Например, если вы предлагаете «печатные версии» некоторых страниц, вы бы не хотели, чтобы Google индексировал повторяющиеся версии, поскольку дублированный контент может повредить вашему рейтингу.
Однако имейте в виду, что люди по-прежнему могут посещать эти страницы и ссылаться на них, поэтому, если вы не хотите, чтобы другие видели информацию, вам нужно будет использовать защиту паролем, чтобы сохранить ее конфиденциальность.
Это потому, что, вероятно, некоторые страницы содержат конфиденциальную информацию, которую вы не хотите показывать в поисковой выдаче.
Форматы robots.txt для разрешения и запрета
На самом деле файл robots.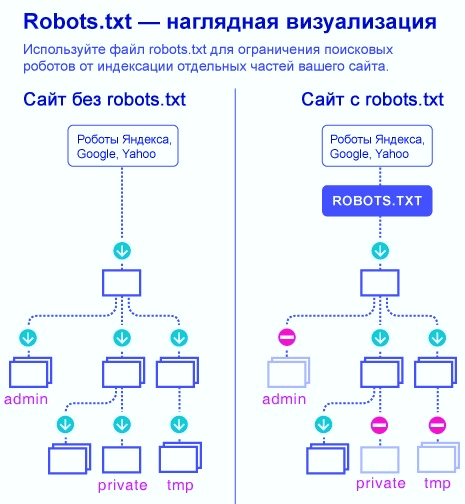 txt довольно прост в использовании.
txt довольно прост в использовании.
Вы буквально говорите роботам, какие страницы «разрешить» (что означает, что они будут их индексировать), а какие «запретить» (которые они будут игнорировать).
Последний вы будете использовать только один раз, чтобы составить список страниц, которые вы не хотите, чтобы пауки сканировали. Команда «Разрешить» используется только в том случае, если вы хотите, чтобы страница сканировалась, но ее родительская страница «Запрещена».
Вот как выглядит файл robot.txt для моего веб-сайта:
Начальная команда агента пользователя сообщает всем веб-роботам (т. их.
Как настроить robots.txt для вашего веб-сайта
Во-первых, вам нужно записать свои директивы в текстовый файл.
Затем загрузите текстовый файл в каталог верхнего уровня вашего сайта — его необходимо добавить через Cpanel.
Изображение предоставлено
Ваш живой файл всегда будет идти сразу после «. com/» в вашем URL-адресе. Наш, например, находится по адресу https://webris.org/robot.txt.
com/» в вашем URL-адресе. Наш, например, находится по адресу https://webris.org/robot.txt.
Если бы он находился по адресу www.webris.com/blog/robot.txt, поисковые роботы даже не стали бы его искать, и ни одна из его команд не выполнялась бы.
Если у вас есть поддомены, убедитесь, что у них есть собственные файлы robots.txt. Например, наш поддомен training.webris.org имеет собственный набор директив — это невероятно важно проверять при проведении SEO-аудитов.
Проверка файла robots.txt
Google предлагает бесплатный инструмент для проверки robots.txt, который можно использовать для проверки.
Он находится в Google Search Console в разделе Crawl > Robots.txt Tester.
Использование файла Robots.txt для улучшения поисковой оптимизации
Теперь, когда вы понимаете этот важный элемент поисковой оптимизации, проверьте свой собственный сайт, чтобы убедиться, что поисковые системы индексируют страницы, которые вам нужны, и игнорируют те, которые вы хотите убрать из поисковой выдачи. .
.
В дальнейшем вы можете продолжать использовать файл robot.txt для информирования поисковых систем о том, как они должны сканировать ваш сайт.
Как правильно настроить robots.txt для вашего сайта
Если вы запускаете веб-сайт, вы, вероятно, слышали о файле robots.txt (или «стандарте исключения роботов»). Есть у вас или нет, пришло время узнать об этом, потому что этот простой текстовый файл является важной частью вашего сайта. Это может показаться незначительным, но вы можете быть удивлены тем, насколько это важно.
Давайте посмотрим, что такое файл robots.txt, для чего он нужен и как его правильно настроить для вашего сайта.
Что такое файл robots.txt?
Чтобы понять, как работает файл robots.txt, вам нужно немного узнать о поисковых системах. Короткая версия заключается в том, что они рассылают «краулеров», то есть программы, которые рыщут в Интернете в поисках информации. Затем они сохраняют часть этой информации, чтобы позже направить людей к ней.
Эти поисковые роботы, также известные как «боты» или «пауки», находят страницы на миллиардах веб-сайтов. Поисковые системы дают им указания, куда идти, но отдельные веб-сайты также могут общаться с ботами и сообщать им, какие страницы им следует просматривать.
В большинстве случаев они на самом деле делают обратное и говорят им, какие страницы им не следует просматривать. Такие вещи, как административные страницы, серверные порталы, страницы категорий и тегов и другие вещи, которые владельцы сайтов не хотят отображать в поисковых системах. Эти страницы по-прежнему видны пользователям и доступны всем, у кого есть на это разрешение (часто всем).
Но, говоря этим паукам не индексировать некоторые страницы, файл robots.txt делает всем одолжение. Если бы вы искали «MakeUseOf» в поисковой системе, хотели бы вы, чтобы наши административные страницы отображались высоко в рейтинге? Нет. Это никому не принесет пользы, поэтому мы просим поисковые системы не отображать их. Его также можно использовать, чтобы поисковые системы не проверяли страницы, которые могут не помочь им классифицировать ваш сайт в результатах поиска.
Его также можно использовать, чтобы поисковые системы не проверяли страницы, которые могут не помочь им классифицировать ваш сайт в результатах поиска.
Короче говоря, файл robots.txt указывает поисковым роботам, что делать.
Могут ли сканеры игнорировать robots.txt?
Игнорируют ли сканеры файлы robots.txt? Да. На самом деле, многие сканеры и игнорируют его. Однако, как правило, эти сканеры не принадлежат авторитетным поисковым системам. Они исходят от спамеров, сборщиков электронной почты и других типов автоматических ботов, которые бродят по Интернету. Важно помнить об этом: использование стандарта исключения роботов, чтобы сообщить ботам, чтобы они держались подальше, не является эффективной мерой безопасности 9.0004 . На самом деле, некоторые боты могут запускать со страниц, на которые вы запретили им переходить.
Однако поисковые системы будут действовать так, как указано в файле robots.txt, если он правильно отформатирован.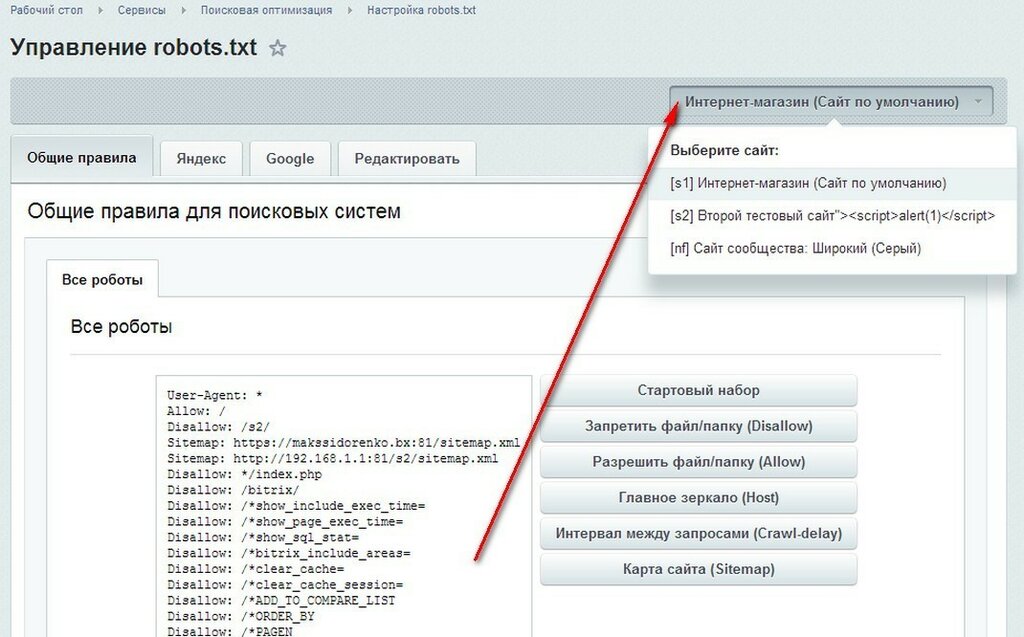
Как написать файл robots.txt
Стандартный файл исключения роботов состоит из нескольких частей. Я разобью их здесь по отдельности.
Декларация пользовательского агента
Прежде чем указывать боту, какие страницы ему не следует просматривать, необходимо указать, с каким ботом вы разговариваете. В большинстве случаев вы будете использовать простое объявление, означающее «все боты». Это выглядит так:
User-agent: *
Звездочка означает «все боты». Однако вы можете указать страницы для определенных ботов. Для этого вам нужно знать имя бота, для которого вы разрабатываете рекомендации. Это может выглядеть так:
Агент пользователя: Googlebot[список страниц, которые нельзя сканировать] Агент пользователя: Googlebot-Image/1.0[список страниц, которые нельзя сканировать]Агент пользователя: Bingbot[список страниц, которые нельзя сканировать ]
И так далее. Если вы обнаружите бота, который вообще не хочет сканировать ваш сайт, вы также можете указать это.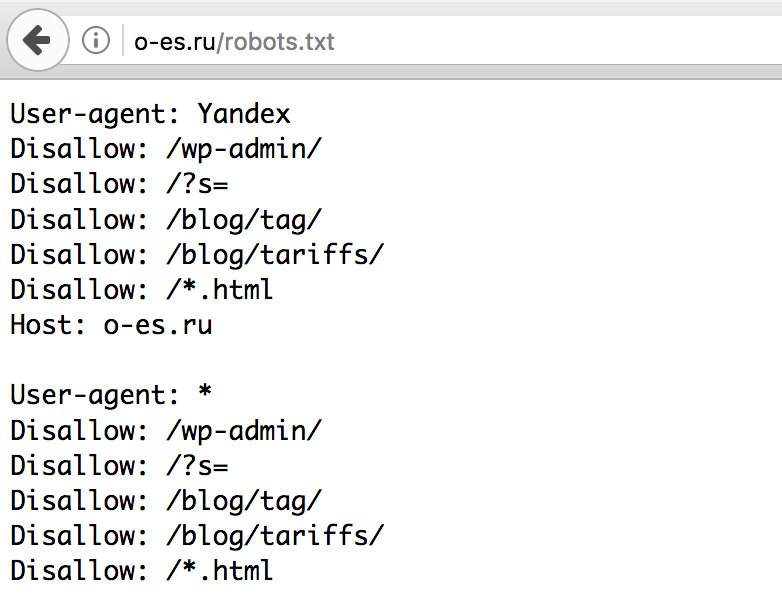
Чтобы найти имена пользовательских агентов, посетите useragentstring.com [Больше не доступно].
Запрет страниц
Это основная часть вашего файла исключения роботов. С помощью простого объявления вы говорите боту или группе ботов не сканировать определенные страницы. Синтаксис прост. Вот как вы можете запретить доступ ко всему в каталоге «admin» вашего сайта:
Disallow: /admin/
Эта строка не позволит ботам сканировать yoursite.com/admin, yoursite.com/admin/login, yoursite. .com/admin/files/secret.html и все остальное, что попадает в каталог admin.
Чтобы запретить одну страницу, просто укажите ее в строке запрета:
Запретить: /public/exception.html
Теперь страница «исключение» не будет прорисовываться, но все остальное в «общедоступной» папке будет .
Чтобы включить несколько каталогов или страниц, просто перечислите их в следующих строках:
Disallow: /private/Disallow: /admin/Disallow: /cgi-bin/Disallow: /temp/
Эти четыре строки будут применяться к любому пользователю агент, которого вы указали в верхней части раздела.
Если вы хотите, чтобы боты не просматривали какую-либо страницу вашего сайта, используйте это:
Запретить: /
Установка разных стандартов для ботов
Как мы видели выше, вы можете указать определенные страницы для разных ботов. Объединив два предыдущих элемента, вот как это выглядит:
User-agent: googlebotDisallow: /admin/Disallow: /private/User-agent: bingbotDisallow: /admin/Disallow: /private/Disallow: /secret/
Разделы «admin» и «private» будут невидимы в Google и Bing, но Google увидит «секретный» каталог, а Bing — нет.
Вы можете указать общие правила для всех ботов с помощью пользовательского агента asterisk, а затем также дать конкретные инструкции ботам в последующих разделах.
Собираем все вместе
Обладая вышеизложенными знаниями, вы можете написать полный файл robots.txt. Просто запустите свой любимый текстовый редактор (мы фанаты Sublime) и начните сообщать ботам, что они не приветствуются в определенных частях вашего сайта.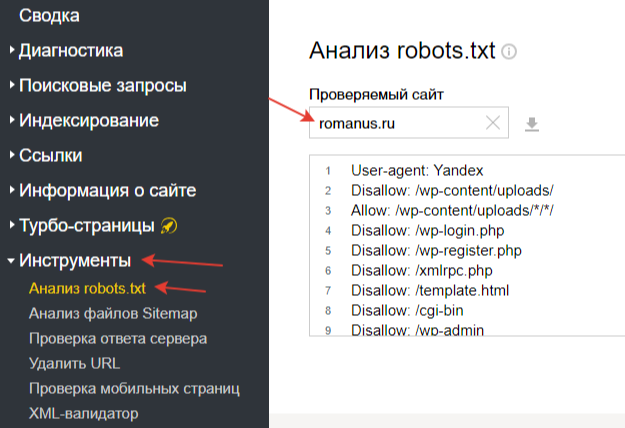
Если вы хотите увидеть пример файла robots.txt, просто перейдите на любой сайт и добавьте «/robots.txt» в конец. Вот часть файла robots.txt Giant Bicycles:
Как видите, есть довольно много страниц, которые они не хотят показывать в поисковых системах. Они также включили несколько вещей, о которых мы еще не говорили. Давайте посмотрим, что еще вы можете сделать в своем файле исключения роботов.
Расположение вашей карты сайта
Если ваш файл robots.txt сообщает ботам, куда , а не , ваша карта сайта делает обратное и помогает им найти то, что они ищут. И хотя поисковые системы, вероятно, уже знают, где находится ваша карта сайта, не помешает сообщить им об этом еще раз.
Объявление местоположения карты сайта простое:
Карта сайта: [URL карты сайта]
Вот и все.
В нашем собственном файле robots.txt это выглядит так:
Карта сайта: https://www.makeuseof.com/sitemap_index.xml
Вот и все.
Установка задержки сканирования
Директива задержки сканирования сообщает определенным поисковым системам, как часто они могут индексировать страницу на вашем сайте.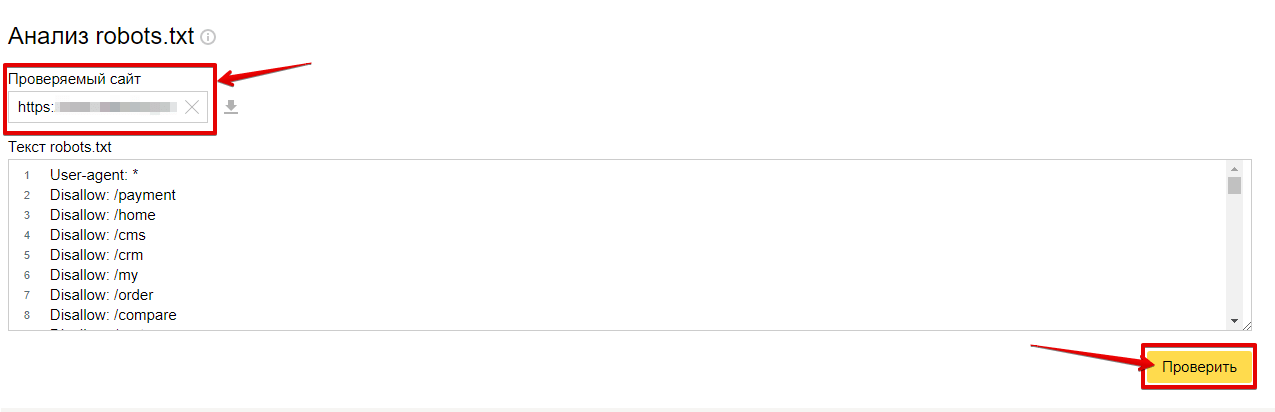 Он измеряется в секундах, хотя некоторые поисковые системы интерпретируют его несколько иначе. Некоторые считают, что задержка сканирования в 5 – это указание им ждать пять секунд после каждого сканирования, чтобы начать следующее. Другие интерпретируют это как указание сканировать только одну страницу каждые пять секунд.
Он измеряется в секундах, хотя некоторые поисковые системы интерпретируют его несколько иначе. Некоторые считают, что задержка сканирования в 5 – это указание им ждать пять секунд после каждого сканирования, чтобы начать следующее. Другие интерпретируют это как указание сканировать только одну страницу каждые пять секунд.
Почему вы говорите краулеру не ползать как можно дольше? Для сохранения пропускной способности. Если ваш сервер не справляется с трафиком, вы можете установить задержку сканирования. В общем, большинству людей не нужно беспокоиться об этом. Однако крупные сайты с высокой посещаемостью могут захотеть немного поэкспериментировать.
Вот как можно установить задержку сканирования в восемь секунд:
Задержка сканирования: 8
Вот и все. Не все поисковые системы будут подчиняться вашей директиве. Но спросить не помешает. Как и в случае с запрещенными страницами, вы можете установить разные задержки сканирования для определенных поисковых систем.
Загрузка файла robots.txt
Когда все инструкции в файле настроены, вы можете загрузить его на свой сайт. Убедитесь, что это обычный текстовый файл с именем robots.txt. Затем загрузите его на свой сайт, чтобы его можно было найти по адресу yoursite.com/robots.txt.
Если вы используете систему управления контентом, такую как WordPress, вам, вероятно, понадобится особый способ. Поскольку в каждой системе управления контентом он разный, вам необходимо обратиться к документации по вашей системе.
Некоторые системы также могут иметь интерактивные интерфейсы для загрузки вашего файла. Для этого просто скопируйте и вставьте файл, созданный на предыдущих шагах.
Не забудьте обновить свой файл
Последний совет, который я дам, — время от времени просматривать файл исключения роботов. Ваш сайт меняется, и вам может потребоваться внести некоторые коррективы. Если вы заметили странные изменения в трафике вашей поисковой системы, рекомендуется также проверить файл.