
Rech — распознавание аудио потока в телефонии, система распознавания речи
Распознавание речи (слова)На русском языке Rech распознаёт произнесенные слова:
Ноль Один Два Три Четыре Пять Шесть Семь Восемь Девять
Да Нет Вперед Назад Отмена Подтверждаю
Почему используется ограниченный набор слов?
Классические сервисы очень неточно распознают отдельные слова, используемые вне контекста, что не может удовлетворять пользователя.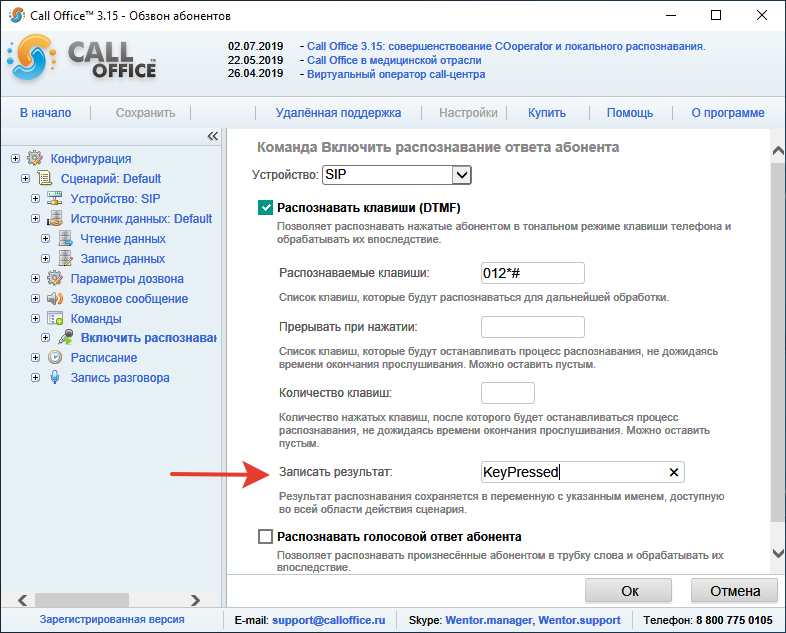
Можно ли распознавать другие слова?
Приложение может распознавать любые другие слова, для этого их нужно предварительно добавить в словарь. Для индивидуального добавления в словарь новых слов необходима доплата.
Почему Rech для телефонии работает лучше, чем классические системы распознавания голоса?
- Rech является узкоспециализированной системой, заточенной под IP-телефонию.
- Искусственный интеллект обучается не на живых разговорах, а на материалах «из телефонной трубки», использует нейросеть для адаптации слов с привязкой к контенту.
- Rech не дожидается записи ролика установленной длины, а на ходу осуществляет потоковое распознавание речи из аудофайла.


Голосовое распознавание: голосовое распознавание текста онлайн, распознавание голосовых команд, а также текста и речи
Голосовое распознавание
Больше не нужно платить call-центру или нанимать несколько сотрудников, которые могли бы отвечать на все звонки. Ни одно обращение клиента не останется пропущенным: сервис автоматически ответит на звонок и сохранит разговор в виде чата.
Перед вами – сервис голосового распознавания текста онлайн, не требующий установки программного обеспечения и специального оборудования и упрощающий работу с клиентами. Это возможность недорого увеличить конверсию и сделать компанию клиентоориентированной.
Голосовое распознавание текста
Благодаря голосовому распознаванию текста вы сможете записывать сообщения для клиентов и ответы соответствующие их запросам. Вам нужно просто набрать текст – и сервис воспроизведет его в точности. Вы сможете создать больше, чем автоответчик: программа будет вести полноценный разговор с клиентом, и тот получит всю информацию, которая его интересует. В дальнейшем ваши сотрудники могут перезвонить и уточнить данные.
Голосовое распознавание речи
Функция распознавания голосовых команд – это удобный и простой способ:
- создать голосовую навигацию для пользователя;
- сохранить запись разговора в текстовом формате;
- предоставить позвонившему информацию, которая его интересует, без прямого участия ваших сотрудников.
Конечно, сервис голосового распознавания речи не заменит консультанта, однако позволит существенно сократить затраты на прием и обработку рутинных звонков и расширить базу клиентов. Ни один из ваших потенциальных клиентов не останется без внимания – сервис работает в автоматическом режиме круглые сутки. Это «умный автоответчик», который решит ряд ваших бизнес-задач.
Ни один из ваших потенциальных клиентов не останется без внимания – сервис работает в автоматическом режиме круглые сутки. Это «умный автоответчик», который решит ряд ваших бизнес-задач.
Начало работы с распознаванием речи и python
Я хотел бы знать, с чего можно начать распознавание речи. Не с библиотекой или чем-то еще, что довольно «Black Box’ed», но вместо этого я хочу знать, где я действительно могу сделать простой скрипт распознавания речи. Я сделал некоторые поиски и нашел, не так много, но то, что я видел, это то, что есть словари ‘sounds’ или слогов, которые могут быть собраны вместе, чтобы сформировать текст. Итак, в основном мой вопрос заключается в том, с чего я могу начать с этого?
Кроме того, поскольку это немного оптимистично, я также был бы в порядке с библиотекой (на данный момент), чтобы использовать ее в своей программе. Я видел, что некоторые речи в текстовых библиотеках и APIs выплевывают только один результат.
Поделиться Источник bs7280 02 сентября 2012 в 19:31
7 ответов
- как отключить команды распознавания речи windows?
Я создаю программу с python, которая позволяет выполнять команды с windows распознаванием речи, единственная проблема заключается в том, что я не хочу, чтобы распознавание речи использовало их команды по умолчанию. Есть ли способ отключить это либо с помощью python, либо просто полностью отключить…
- Распознавание речи в Android
Я работаю над распознаванием речи, и мне нужны некоторые примеры программ.
Может ли кто-нибудь вести меня?
 Может ли кто-нибудь вести меня?
Может ли кто-нибудь вести меня?
7
Если вы действительно хотите понять распознавание речи с нуля, найдите хороший пакет обработки сигналов для python, а затем прочитайте о распознавании речи независимо от программного обеспечения.
Но распознавание речи-чрезвычайно сложная проблема (в основном потому, что звуки взаимодействуют всевозможными способами, когда мы говорим). Даже если вы начнете с лучшей библиотеки распознавания речи, которую вы можете получить в свои руки, вам ни в коем случае не придется больше ничего делать.
Поделиться alexis 02 сентября 2012 в 21:38
7
Обновление: это больше не работает
потому что google закрыл свою платформу —
вы можете использовать https:/ / pypi.python.org/pypi/pygsr
$> pip install pygsr
пример использования:
from pygsr import Pygsr
speech = Pygsr()
# duration in seconds
speech. record(3)
# select the language
phrase, complete_response = speech.speech_to_text('en_US')
print phrase
 record(3)
# select the language
phrase, complete_response = speech.speech_to_text('en_US')
print phrase
record(3)
# select the language
phrase, complete_response = speech.speech_to_text('en_US')
print phrase
Поделиться dr. Neox 14 мая 2013 в 19:33
7
Pocketsphinx также является хорошей альтернативой. Есть привязки Python, предоставляемые через SWIG, которые облегчают интеграцию в сценарий.
Например:
from os import environ, path from itertools import izip from pocketsphinx import * from sphinxbase import * MODELDIR = "../../../model" DATADIR = "../../../test/data" # Create a decoder with certain model config = Decoder.default_config() config.set_string('-hmm', path.join(MODELDIR, 'hmm/en_US/hub4wsj_sc_8k')) config.set_string('-lm', path.join(MODELDIR, 'lm/en_US/hub4.5000.DMP')) config.set_string('-dict', path.join(MODELDIR, 'lm/en_US/hub4.5000.dic')) decoder = Decoder(config) # Decode static file. decoder.decode_raw(open(path.join(DATADIR, 'goforward.raw'), 'rb')) # Retrieve hypothesis. hypothesis = decoder.hyp() print 'Best hypothesis: ', hypothesis.best_score, hypothesis.hypstr print 'Best hypothesis segments: ', [seg.word for seg in decoder.seg()] # Access N best decodings. print 'Best 10 hypothesis: ' for best, i in izip(decoder.nbest(), range(10)): print best.hyp().best_score, best.hyp().hypstr # Decode streaming data. decoder = Decoder(config) decoder.start_utt('goforward') stream = open(path.join(DATADIR, 'goforward.raw'), 'rb') while True: buf = stream.read(1024) if buf: decoder.process_raw(buf, False, False) else: break decoder.end_utt() print 'Stream decoding result:', decoder.hyp().hypstr

Поделиться toine 23 июня 2014 в 17:05
- Проблемы установки Dragonfly с распознаванием речи Windows
Я хочу сделать распознавание речи с помощью Dragonfly с распознаванием речи Windows на windows 10, но проблема в том, что он всегда отображает ошибки.
Я застрял в нем с тех пор, как несколько дней назад. Это все, что я пытался сделать.: Сначала я скачал python 2.7.6.msi, затем установил… - Распознавание речи в facebook ботах
Доступна ли опция распознавания речи при разработке facebook бота? Я не смог найти ни одного документа, связанного с распознаванием речи в developers.facebook.com Но я видел, что FB купил Wit.ai для распознавания речи. Находится ли он в стадии разработки?
 Я застрял в нем с тех пор, как несколько дней назад. Это все, что я пытался сделать.: Сначала я скачал python 2.7.6.msi, затем установил…
Я застрял в нем с тех пор, как несколько дней назад. Это все, что я пытался сделать.: Сначала я скачал python 2.7.6.msi, затем установил…
7
Я знаю, что этот вопрос стар, но только для людей в будущем:
Я использую speech_recognition-модуль, и мне это нравится. Единственное, что для этого требуется интернет, потому что он использует Google для распознавания речи. Но в большинстве случаев это не должно быть проблемой. Распознавание работает почти идеально.
EDIT:
Пакет speech_recognition может использовать для перевода не только google, но и CMUsphinx (который позволяет распознавать в автономном режиме). Единственное различие заключается в тонком изменении команды распознавания:
Единственное различие заключается в тонком изменении команды распознавания:
https:/ / pypi.python.org/pypi/SpeechRecognition/
Вот небольшой пример кода:
import speech_recognition as sr
r = sr.Recognizer()
with sr.Microphone() as source: # use the default microphone as the audio source
audio = r.listen(source) # listen for the first phrase and extract it into audio data
try:
print("You said " + r.recognize_google(audio)) # recognize speech using Google Speech Recognition - ONLINE
print("You said " + r.recognize_sphinx(audio)) # recognize speech using CMUsphinx Speech Recognition - OFFLINE
except LookupError: # speech is unintelligible
print("Could not understand audio")
Есть только одна вещь,которая плохо работает для меня: слушать в бесконечном цикле. Через несколько минут он вешает трубку. (Это не сбой, это просто не реагирует.)
EDIT:
Если вы хотите использовать микрофон без бесконечного цикла, вы должны указать длину записи. Пример кода:
Пример кода:
import speech_recognition as sr
r = sr.Recognizer()
with sr.Microphone() as source:
print("Speak:")
audio = r.listen(source, None, "time_to_record") # recording
Поделиться Noah Krasser 25 декабря 2015 в 09:42
6
Для тех, кто хочет глубже погрузиться в тему распознавания речи в Python, вот несколько ссылок:
Поделиться anatoly techtonik 17 декабря 2015 в 09:05
4
Dragonfly предоставляет чистую структуру для распознавания речи на Windows. Обратитесь к примеру употребления. Поскольку вы не ищете большой масштаб функций, предоставляемых Dragonfly, вы можете взглянуть на библиотеку PySpeech, которая больше не поддерживается .
Их исходный код выглядит легко понять, и, возможно, это то, что вы хотите посмотреть в первую очередь
Поделиться tehmisvh 02 сентября 2012 в 20:04
0
Это может быть самое важное, что нужно усвоить: элементарные понятия обработки сигналов, в частности, цифровой обработки сигналов (DSP).
Во-первых, это аналого-цифровое преобразование (ADC). Это действительно относится к области аудиотехники и в настоящее время является частью процесса записи, даже если все, что вы делаете, — это подключаете микрофон к компьютеру.
Если вы начинаете с аналоговых записей, это может быть вопрос преобразования старых лент или виниловых долгоиграющих записей в цифровую форму или извлечения звука из старых видеозаписей. Проще всего просто воспроизвести источник в гнездо аудиовхода вашего компьютера и использовать встроенное аппаратное и программное обеспечение для захвата необработанной линейной импульсно кодовой модуляции (LPCM) цифровой сигнал в файл. Дерзость, о которой Вы упомянули, — отличный инструмент для этого и даже больше.
Преобразование Фурье — ваш друг. С точки зрения науки о данных он отлично подходит для извлечения признаков и уменьшения размеров пространства признаков, особенно если вы ищете признаки, которые охватывают изменения звука в течение всего образца.
В частности, вы будете использовать быстрое преобразование Фурье (FFT), а очень эффективная форма дискретного преобразования Фурье (DFT). В настоящее время FFT обычно выполняется в аппаратном обеспечении DSP.
 Небольшое понимание абстрактных понятий подготовит вас к
ошеломляющему изобилию инструментов, скажем, в scipy.signal.
Небольшое понимание абстрактных понятий подготовит вас к
ошеломляющему изобилию инструментов, скажем, в scipy.signal. Здесь нет места для объяснений, но
необработанные данные во временной области гораздо сложнее обрабатывать алгоритмам машинного обучения
, чем необработанные данные в частотной области.
Здесь нет места для объяснений, но
необработанные данные во временной области гораздо сложнее обрабатывать алгоритмам машинного обучения
, чем необработанные данные в частотной области.Поделиться GLHF 06 января 2020 в 17:37
Похожие вопросы:
начало работы с распознаванием речи и синтезом речи
я хочу начать работу с распознаванием речи и синтезом речи в прототипе, основанном на распознавании речи , кто-то сказал мне использовать Microsoft speech server (sdk и так далее) когда у меня есть…
Какие языки поддерживает распознавание речи android
Я хочу реализовать поиск с помощью распознавания речи, но не видел информации о языках, поддерживаемых распознаванием речи.
Android: преобразование речи в текст и распознавание речи в автономном режиме
Я застрял в одном из моих автономных приложений Android, где мне нужно автономное распознавание речи и речь к Text API. Пожалуйста, поделитесь своими мнениями и вводными данными, если кто-то работал…
как отключить команды распознавания речи windows?
Я создаю программу с python, которая позволяет выполнять команды с windows распознаванием речи, единственная проблема заключается в том, что я не хочу, чтобы распознавание речи использовало их…
Распознавание речи в Android
Я работаю над распознаванием речи, и мне нужны некоторые примеры программ. Может ли кто-нибудь вести меня?
Проблемы установки Dragonfly с распознаванием речи Windows
Я хочу сделать распознавание речи с помощью Dragonfly с распознаванием речи Windows на windows 10, но проблема в том, что он всегда отображает ошибки. Я застрял в нем с тех пор, как несколько дней. ..
..
Распознавание речи в facebook ботах
Доступна ли опция распознавания речи при разработке facebook бота? Я не смог найти ни одного документа, связанного с распознаванием речи в developers.facebook.com Но я видел, что FB купил Wit.ai для…
Автоматическая система распознавания речи для python
В настоящее время я прохожу стажировку в качестве специалиста по обработке данных в стартапе и должен искать и внедрять существующие системы автоматического распознавания речи. У меня есть…
Python: получить системный звук в распознавании речи вместо микрофона
Я работаю над распознаванием речи в python, но он получает только входные данные от Микропохона. Как можно передать звук из динамиков в качестве входных данных в библиотеку распознавания речи?…
Автономное распознавание речи в реальном времени в Python
Я работаю с Python распознаванием речи уже большую часть месяца, делая JARVIS-подобного помощника. Я использовал как модуль распознавания речи с Google Speech API, так и Pocketsphinx, и я…
Я использовал как модуль распознавания речи с Google Speech API, так и Pocketsphinx, и я…
Стартап дня: движок для распознавания украинской речи Speech Recognition for Ukrainian
23 Марта, 2021, 15:04
2093
Рубрика «Стартап дня» на AIN.UA — это трибуна для основателей проектов, на которой можно познакомить потенциальных клиентов и инвесторов со своим продуктом. Редакция сохраняет прямую речь спикера. Рассказать о своем стартапе можно, заполнив анкету по ссылке.
Speech Recognition for Ukrainian — первый бесплатный движок для распознавания украинской речи. На его основе все желающие могут создать собственный умный дом, колонку Алекса или просто распознавать записанные интервью/видео и так далее.
Основатели и команда стартапа
Основатели стартапа — Лахаев Тарас, Иевлев Алексей и Смоляков Егор. На протяжении всего времени над проектом работали около 10-15 человек.
О чем стартап
Пример работы телеграм-бота для распознавания речи@ukr_stt_bot
Мы создали первый бесплатный движок для распознавания украинской речи. Этот движок позволяет переводить украинскую речь в текст. На его основе все желающие могут создать собственный умный дом, колонку Алекса или просто распознавать записанные интервью/видео и так далее.
Помимо движков мы еще собрали 1200 часов украинской речи (аудио) с текстом самих записей и выложили их как торрент, это позволяет всем желающим создать распознавание на своих собственных технологиях.
Какая модель монетизации
Она отсутствует. Тут дело в том, что мы не компания как таковая, просто люди заинтересованные собрались и сделали.
Мы создали основу/инфрасткрутную часть для будущих стартапов которые будут распознавать украинскую речь.
Сколько времени ушло на MVP? Какие ошибки допустили?
4 месяца.
Как появилась идея создать стартап?
Субтитры, созданные Speech Recognition for UkrainianИдея сделать распознавание у каждого сооснователя уже сформировалась отдельно от других. Алексей хотел приложить распознавание в своем бизнесе, Тарас хотел сделать умный дом, а я (Егор) хотел создать распознавание звонков (я работал в телеком-компании и один бизнес-запрос был в этом).
Я нашел ребят просто по их сообщениям в похожей Telegram группе и создал общую группу, где мы начали общаться на тему «Как достичь желаемого».
Тарас занимался сбором данных, Алекс информационной поддержкой, тестированием и помогал Тарасу с железом, а я занимался развитием связей с разными людьми, которые тренировали модели машинного обучения на основе собранных данных, созданием ботов и делал примеры как использовать созданные движки.
В итоге сейчас 3 готовых к использованию движка доступных всем желающим.
Как вы оцениваете рынок для вашего продукта?
Рынок применения очень широк. От голосовых ассистентов до систем речевой аналитики. Весь мир сейчас активно занимается распознаванием аудио и нам, как IT-стране, нельзя отставать.
Сколько денег/времени инвестировано?
Никаких денег, кроме оплаты сервера для ботов не было потрачено. Всё на энтузиазме и желании получить качественный движок распознавания.
Чего удалось добиться?
Например, недавно один участник нашей группы добавил нашу модель в своё Android-приложение для автоматического создание субтитров в видео. Проверить работу приложения можно скачав его по ссылке.
Создание личного офлайн ассистента на движке Speech Recognition for Ukrainian
Другой участник делал голосовое управление в звонках. Я, например, планирую делать речевую аналитику для звонков.
Я, например, планирую делать речевую аналитику для звонков.
Читайте также:
SergeyShk/Speech-to-Text-Russian: Проект для распознавания речи на русском языке на основе pykaldi.
Проект для распознавания речи на русском языке на основе pykaldi.
Установка
Самостоятельная (Linux)
- Установить kaldi:
https://kaldi-asr.org/doc/tutorial_setup.html
- Установить необходимые Python-библиотеки:
$ pip install -r requirements.txt
- Установить pykaldi:
- С помощью conda (с поддержкой GPU):
$ conda install -c pykaldi pykaldi
- С помощью conda (без поддержки GPU):
$ conda install -c pykaldi pykaldi-cpu
- Собрать из исходников (раздел From Source):
https://github. com/pykaldi/pykaldi
com/pykaldi/pykaldi
- Добавить в PATH пути к компонентам kaldi:
$ PATH /kaldi/src/featbin:/kaldi/src/ivectorbin:/kaldi/src/online2bin:/kaldi/src/rnnlmbin:/kaldi/src/fstbin:$PATH
- Склонировать репозиторий проекта:
$ git clone https://github.com/SergeyShk/Speech-to-Text-Russian.git
- Отредактировать файл model/conf/ivector_extractor.conf, указав в нем корректные директории
Docker
- Собрать docker-образ:
$ docker build -t speech_recognition:latest .
Или
$ docker pull ghcr.io/sergeyshk/stt-ru:0.2.0
- Создать docker-том для работы с внешними данными:
$ docker volume create -d local -o type=none -o o=bind -o device=[DIR] asr_volume
- Запустить docker-контейнер:
$ docker run -it --rm -p 9000:9000 -p 5000:5000 -v asr_volume:/archive speech_recognition
Структура проекта
Файлы проекта расположены в директории /speech_recognition:
- start_recognition. py — скрипт запуска процедуры распознавания;
- /tools — набор инструментов для распознавания:
- data_preparator.py — скрипт подготовки данных для распознавания;
- recognizer.py — скрипт распознавания речи;
- segmenter.py — скрипт сегментации речи;
- transcriptins_parser.py — скрипт парсинга результатов распознавания;
- /model — набор файлов для модели распознавания;
- /web — веб-приложение с демо-стендом распознавания речи;
- /examples — набор ноутбуков с примерами работы инструментов.
 py — скрипт запуска процедуры распознавания;
py — скрипт запуска процедуры распознавания;Модель
В качестве акустической и языковой модели используется русскоязычная модель от alphacep:
http://alphacephei.com/kaldi/kaldi-ru-0.6.tar.gz
При необходимости использования собственной модели, необходимо заменить соответствующие файлы в директории /model.
Внимание! Размер файла HCLG.
 fst составляет более 500МБ, поэтому для корректного клонирования репозитория необходимо установить на свой компьютер GitHub LFS. Также можно скачать данный файл вручную с соответствующей страницы проекта.
fst составляет более 500МБ, поэтому для корректного клонирования репозитория необходимо установить на свой компьютер GitHub LFS. Также можно скачать данный файл вручную с соответствующей страницы проекта.Запуск
Распознавание речи
- Подготовить директорию для размещения WAV-файлов;
- Для запуска процедуры распознавания речи выполнить команду:
$ ./start_recognition.py /archive/wav /archive/output -dw -l
- Для запуска режима мониторинга директории выполнить команду:
$ ./start_recognition.py /archive/wav /archive/output -l -t 60 -d 1
Описание параметров запуска доступно по команде:
$ ./start_recognition.py -h
usage: start_recognition.py [-h] [-rm REC_MODEL] [-rg REC_GRAPH]
[-rw REC_WORDS] [-rc REC_CONF] [-ri REC_ICONF]
[-sm SEGM_MODEL] [-sc SEGM_CONF] [-sp SEGM_POST]
[-p PROCESSES] [-l] [-dw] [-t TIME] [-d DELTA]
WAV OUT
Запуск процедуры распознавания речи
positional arguments:
WAV Путь к . WAV файлам аудио
OUT Путь к директории с результатами распознавания
optional arguments:
-h, --help show this help message and exit
-rm REC_MODEL, --rec_model REC_MODEL
Путь к .MDL файлу модели распознавания
-rg REC_GRAPH, --rec_graph REC_GRAPH
Путь к .FST файлу общего графа распознавания
-rw REC_WORDS, --rec_words REC_WORDS
Путь к .TXT файлу текстового корпуса
-rc REC_CONF, --rec_conf REC_CONF
Путь к .CONF конфигурационному файлу распознавания
-ri REC_ICONF, --rec_iconf REC_ICONF
Путь к .CONF конфигурационному файлу векторного
экстрактора
-sm SEGM_MODEL, --segm_model SEGM_MODEL
Путь к .RAW файлу модели сегментации
-sc SEGM_CONF, --segm_conf SEGM_CONF
Путь к .CONF конфигурационному файлу сегментации
-sp SEGM_POST, --segm_post SEGM_POST
Путь к . VEC файлу апостериорных вероятностей
сегментации
-p PROCESSES, --processes PROCESSES
Количество процессов для обработки файлов
-l, --log Логировать результат распознавания
-dw, --delete_wav Удалять .WAV файлы после распознавания
-t TIME, --time TIME Пауза перед очередным сканированием директории в
секундах
-d DELTA, --delta DELTA
Дельта, выдерживаемая до чтения файла в минутах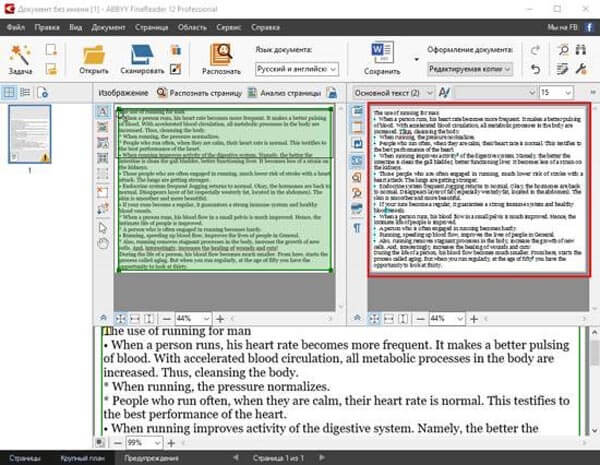 WAV файлам аудио
OUT Путь к директории с результатами распознавания
optional arguments:
-h, --help show this help message and exit
-rm REC_MODEL, --rec_model REC_MODEL
Путь к .MDL файлу модели распознавания
-rg REC_GRAPH, --rec_graph REC_GRAPH
Путь к .FST файлу общего графа распознавания
-rw REC_WORDS, --rec_words REC_WORDS
Путь к .TXT файлу текстового корпуса
-rc REC_CONF, --rec_conf REC_CONF
Путь к .CONF конфигурационному файлу распознавания
-ri REC_ICONF, --rec_iconf REC_ICONF
Путь к .CONF конфигурационному файлу векторного
экстрактора
-sm SEGM_MODEL, --segm_model SEGM_MODEL
Путь к .RAW файлу модели сегментации
-sc SEGM_CONF, --segm_conf SEGM_CONF
Путь к .CONF конфигурационному файлу сегментации
-sp SEGM_POST, --segm_post SEGM_POST
Путь к .
WAV файлам аудио
OUT Путь к директории с результатами распознавания
optional arguments:
-h, --help show this help message and exit
-rm REC_MODEL, --rec_model REC_MODEL
Путь к .MDL файлу модели распознавания
-rg REC_GRAPH, --rec_graph REC_GRAPH
Путь к .FST файлу общего графа распознавания
-rw REC_WORDS, --rec_words REC_WORDS
Путь к .TXT файлу текстового корпуса
-rc REC_CONF, --rec_conf REC_CONF
Путь к .CONF конфигурационному файлу распознавания
-ri REC_ICONF, --rec_iconf REC_ICONF
Путь к .CONF конфигурационному файлу векторного
экстрактора
-sm SEGM_MODEL, --segm_model SEGM_MODEL
Путь к .RAW файлу модели сегментации
-sc SEGM_CONF, --segm_conf SEGM_CONF
Путь к .CONF конфигурационному файлу сегментации
-sp SEGM_POST, --segm_post SEGM_POST
Путь к .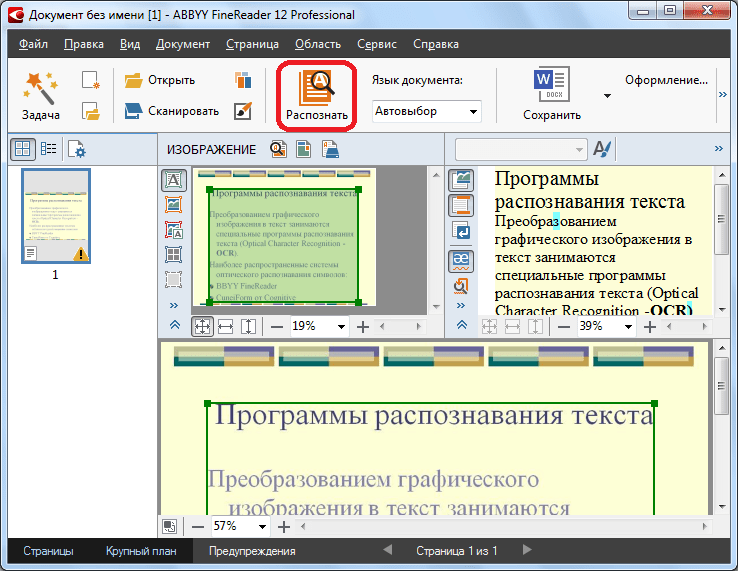 VEC файлу апостериорных вероятностей
сегментации
-p PROCESSES, --processes PROCESSES
Количество процессов для обработки файлов
-l, --log Логировать результат распознавания
-dw, --delete_wav Удалять .WAV файлы после распознавания
-t TIME, --time TIME Пауза перед очередным сканированием директории в
секундах
-d DELTA, --delta DELTA
Дельта, выдерживаемая до чтения файла в минутах
VEC файлу апостериорных вероятностей
сегментации
-p PROCESSES, --processes PROCESSES
Количество процессов для обработки файлов
-l, --log Логировать результат распознавания
-dw, --delete_wav Удалять .WAV файлы после распознавания
-t TIME, --time TIME Пауза перед очередным сканированием директории в
секундах
-d DELTA, --delta DELTA
Дельта, выдерживаемая до чтения файла в минутахДемонстрационный стенд
- Запустить веб-сервер:
$ cd web
$ ./app.py
- Перейти по адресу:
http://0.0.0.0:5000
Сервис ноутбуков
- Запустить сервис:
$ jupyter notebook --no-browser --ip=0.0.0.0 --port=9000 --allow-root
- Перейти по адресу:
http://0.0.0.0:9000
Google Cloud обновила свои сервисы расшифровки аудио и синтеза речи — новости на Tproger
Команда Google Cloud объявила в своем блоге о стабильном выпуске API для синтеза речи Cloud Text-to-Speech с экспериментальной функцией аудиопрофилей и поддержкой нескольких новых языков. А сервис для расшифровки аудио Cloud Speech-to-Text научился распознавать разных спикеров и самостоятельно определять язык записи из нескольких возможных.
А сервис для расшифровки аудио Cloud Speech-to-Text научился распознавать разных спикеров и самостоятельно определять язык записи из нескольких возможных.
Cloud Text-to-Speech
Голоса
Вместе с переходом на стабильный рабочий режим API для перевода письменной речи в устную получил поддержку ряда новых языков и голосов, созданных с помощью технологии WaveNet. В общей сложности доступно 14 языков и диалектов (русского среди них нет), на которых говорит 30 стандартных «голосов» и 26 тех, что основаны на WaveNet.
Аудиопрофили
В бета-режиме запущена функция аудиопрофилей. Она позволяет автоматически оптимизировать аудиофайл для конкретного устройства: «умных» часов и других носимых гаджетов, смартфонов, наушников, обычных и стереоколонок, аудиосистем «умного» дома, автомобильных динамиков. Также можно установить режим «по умолчанию».
Cloud Speech-to-Text
Распознавание спикера
API для перевода аудио в текст, Cloud Speech-to-Text, получило функцию распознавания спикеров по голосу. Используя машинное обучение, система при транскрибировании разделяет реплики разных людей и помечает их номерами. Однако в начале обработки аудиофайла необходимо указать количество спикеров.
Используя машинное обучение, система при транскрибировании разделяет реплики разных людей и помечает их номерами. Однако в начале обработки аудиофайла необходимо указать количество спикеров.
Распознавание языка
Также команда Google Cloud добавила функцию автоопределения языка на записи. Используя API для своих приложений, разработчик может указывать до 4 языков в одном запросе. На момент написания новости инструмент поддерживает 120 языков (включая русский).
Распознавание важных слов
С обновленным Cloud Speech-to-Text разработчики могут присваивать уровни важности отдельным специфическим словам. Команда Google Cloud привела в пример такую команду пользователя: «Занеси, пожалуйста, в календарь встречу с Джоном на завтра, в 2 часа дня». В этом предложении «пожалуйста» значит меньше, чем «Джон» или «2 часа дня», поэтому приложение при необходимости попросит человека повторить время или имя, но не пустые слова вежливости.
Технологию синтеза речи Google долгое время использовала лишь в собственных продуктах. Сторонним разработчикам она стала доступна в марте 2018 года с выбором из 32 голосов и 12 языков. А сервис расшифровки устной речи раньше назывался Cloud Speech API, и нынешнее имя получил в апреле 2018 года вместе с новыми моделями для анализа звонков и видео.
Сторонним разработчикам она стала доступна в марте 2018 года с выбором из 32 голосов и 12 языков. А сервис расшифровки устной речи раньше назывался Cloud Speech API, и нынешнее имя получил в апреле 2018 года вместе с новыми моделями для анализа звонков и видео.
via TechCrunch Source: блог Google Cloud
Нейросети научились распознавать устную речь не хуже человека
Microsoft / Youtube
Компания Microsoft усовершенствовала систему распознавания устной речи, работа которой основана на использовании нейросетей. Теперь система делает меньше ошибок, чем профессиональный специалист по набору текста. Статья ученых, описывающая программу, выложена на сервере препринтов ArXiv.
Теперь система делает меньше ошибок, чем профессиональный специалист по набору текста. Статья ученых, описывающая программу, выложена на сервере препринтов ArXiv.
В программе, созданной компанией Microsoft, используются сверточные и LSTM нейросети. Сверточные нейросети представляют собой класс нейросетей, которые хорошо справляются с распознаванием изображений, звуков и другими подобными задачами (мы писали об этом подробнее). Если в обычных перцептронах каждый нейрон предыдущего слоя связан с каждым нейроном последующего слоя, в сверточных сетях связь между разными уровнями осуществляется через операцию свертки. В ходе этой операции используется ограниченная матрица весов небольшого размера, которая двигается по предыдущему слою. Такая архитектура позволяет наращивать большое число слоев без слишком больших вычислительных затрат, что необходимо для решения абстрактных задач, вроде распознавания речи. LSTM нейросети, в свою очередь, представляют собой подвид рекуррентных нейросетей, для которых характерно наличие обратной связи. Их ключевая особенность состоит в том, что они способны обучаться долговременным зависимостям. На практике это означает, что LSTM-нейросети по умолчанию хранят информацию в течение продолжительного периода времени и способны работать с контекстом в длинных предложениях.
Если в обычных перцептронах каждый нейрон предыдущего слоя связан с каждым нейроном последующего слоя, в сверточных сетях связь между разными уровнями осуществляется через операцию свертки. В ходе этой операции используется ограниченная матрица весов небольшого размера, которая двигается по предыдущему слою. Такая архитектура позволяет наращивать большое число слоев без слишком больших вычислительных затрат, что необходимо для решения абстрактных задач, вроде распознавания речи. LSTM нейросети, в свою очередь, представляют собой подвид рекуррентных нейросетей, для которых характерно наличие обратной связи. Их ключевая особенность состоит в том, что они способны обучаться долговременным зависимостям. На практике это означает, что LSTM-нейросети по умолчанию хранят информацию в течение продолжительного периода времени и способны работать с контекстом в длинных предложениях.
В своей системе авторы использовали сверточные сети VCG Net из 14 слоев, Residual-Net из 49 слоев и LACE из 22 слоев. LSTM-нейросеть состояла из шести слоев, в каждом из которых было по 512 скрытых нейронов. Кроме того, при создании программы использовались лингвистическая модель N-грамм и такие инструменты, как Computational Network Toolkit, что позволило ускорить работу графического процессора. Лингвистическая модель была обучена с помощью нескольких баз данных расшифрованных разговоров, состоящих в совокупности из примерно 350 миллионов слов. Для тренировки нейросетей использовались три похожие базы данных, в которых было 85 миллионов слов. Обучение программы заняло в совокупности две тысячи часов.
LSTM-нейросеть состояла из шести слоев, в каждом из которых было по 512 скрытых нейронов. Кроме того, при создании программы использовались лингвистическая модель N-грамм и такие инструменты, как Computational Network Toolkit, что позволило ускорить работу графического процессора. Лингвистическая модель была обучена с помощью нескольких баз данных расшифрованных разговоров, состоящих в совокупности из примерно 350 миллионов слов. Для тренировки нейросетей использовались три похожие базы данных, в которых было 85 миллионов слов. Обучение программы заняло в совокупности две тысячи часов.
Согласно результатам тестов, частота ошибок системы в метрике Word Error Rate составляет всего 5,9 процента, что сопоставимо с аналогичным показателем для людей, которые профессионально занимаются расшифровкой аудиозаписей. В прошлом месяце лучший результат системы составлял 6,3 процента. Наибольшую трудность у нее вызывали междометия, выражающие сомнение («хмм»), и слова, которые использовались людьми для поддержания беседы («ага», «ох» и т. д.).
д.).
Разработчики Microsoft планируют использовать систему в голосовом помощнике Cortana, игровой приставке Xbox One и других программах, использующих распознавание речи. Однако теперь программистам предстоит выяснить, как будет работать созданная ими система в реальных условиях. В местах, где много фонового шума, качество распознавания речи может существенно снизиться. В перспективе исследователи планируют научить систему не только транскрибировать речь, но и разговаривать с пользователями и выполнять их команды.
Технологии машинного обучения используются также и для решения обратной задачи — перевода написанного текста в устную речь. Например, недавно компания Google DeepMind представила новый алгоритм для синтеза человеческой речи под названием WaveNet. В его основе лежит использование нейросети, архитектура которой также была вдохновлена рекуррентной и сверточной нейросетью. Это позволяет добиться более реалистичной имитации голоса. В отличие от классических систем преобразования текста в речь, WaveNet не использует готовые библиотеки «живой» речи, а поточечно генерирует профиль звуковой волны.
Кристина Уласович
Как автоматически преобразовать аудио в текст
Ищете профессиональный преобразователь голосовой записи в текст?
После семинара, вебинара, конференции, лекции вам может потребоваться преобразовать голосовые записи в текст для дальнейшей обработки. Это лучший вариант для сохранения информации в текстовом формате. Затем его можно использовать в оригинальной или переведенной форме для написания книг, руководств, использовать на сайте для написания статей, подкастов и т. Д.
Audext — это интеллектуальный расшифровщик аудио, который помогает преобразовывать ваши голосовые записи в текст и предоставляет их в удобном формате для редактирования.
Наши лучшие специалисты работали над программой транскрипции Audext, что гарантирует высокое качество предоставляемых услуг. Это удобное решение для обработки любых транскрипций голосовых записей:
- Когда нужно перевести речь в текст во время конференции или встречи, деловой беседы.
- Если вы хотите преобразовать голосовые заметки iPhone в текст.
- Если вы хотите преобразовать видеоконтент в текстовый формат.
- YВам необходимо транскрибировать телефонные звонки в текст во время разговора с потенциальным клиентом; или проверьте, как сотрудники используют скрипты продаж по телефону.

Что нужно знать, чтобы преобразовать аудиозапись голоса в текст?
Во-первых, вам необходимо предоставить аудиозапись в правильном формате для транскрипции; это могут быть MP3, WAV и другие. Если у вас есть аудиозапись в другом формате, вы всегда можете преобразовать ее, прежде чем начать расшифровку. Существует множество программ, позволяющих перекодировать онлайн или офлайн. Но не волнуйтесь, Audext работает с наиболее распространенными аудиоформатами 🙂
Как происходит транскрипция голосовой записи в текст?
Это основной вид деятельности нашей службы.Перед преобразованием голоса с диктофона в текст Audext распознает голоса, определяет наличие дополнительных шумов и, наконец, транскрибирует!
Транскрибирование записи голоса в текст больше не является сложной и трудоемкой задачей. Вам не нужны какие-то особые знания или навыки. Просто загрузите свою голосовую запись в Audext и получите синхронизированный текст с четкими репликами. Используя наш редактор, вы можете ввести имена выступающих и при необходимости отредактировать текст, потому что даже машины могут ошибаться.
Вам не нужны какие-то особые знания или навыки. Просто загрузите свою голосовую запись в Audext и получите синхронизированный текст с четкими репликами. Используя наш редактор, вы можете ввести имена выступающих и при необходимости отредактировать текст, потому что даже машины могут ошибаться.
Получите тридцать минут транскрипции онлайн бесплатно, начните пробную версию СЕЙЧАС, чтобы увидеть все функции, которые может предоставить Audext!
Получите 30 минут бесплатноАвтоматический онлайн-конвертер MP3 в текст
Как использовать онлайн-конвертер MP3 в текст
Раньше исследователи и журналисты самостоятельно сталкивались с проблемой автоматической транскрипции MP3 в текст. Сегодня существует более эффективный способ получить необходимый формат текстового файла из вашей аудиозаписи.Он называется Audext.
Процесс преобразования файлов MP3 в Audext прост и удобен. Вы можете редактировать текстовый файл результатов на той же странице, где вы загружаете свой MP3 для преобразования. Более того, есть возможность отредактировать его в удобном для вас темпе и скачать готовую версию текстового файла.
Более того, есть возможность отредактировать его в удобном для вас темпе и скачать готовую версию текстового файла.
Автоматическая транскрипция — это проблема, с которой большинство исследователей столкнется на определенном этапе своего качественного исследования. Если вы имеете дело с часами записанных интервью или фокус-групп, это может быть непросто.
Хотя расшифровка ваших собственных данных может принести значительную аналитическую пользу (познакомьтесь с материалом ближе и ближе), это может оказаться нецелесообразным для всех. Особенно, если вы ограничены во времени, не можете вручную преобразовать речевые заметки в текст или у вас низкий порог скуки. Здесь вам нужно как можно быстрее преобразовать MP3 в текст!
Когда журналист проводит полевые исследования, важно записывать каждое слово ответов респондентов. Что касается того, почему так важно конвертировать аудио MP3 вашего интервью в текст, есть несколько причин.
Когда вы проводите интервью, это дает вам свободу слушать. Так что все, на чем вам действительно нужно сосредоточиться, — это делать заметки и обращать внимание на человека, с которым вы разговариваете. Лучший онлайн-конвертер Audext MP3 в текст здесь, чтобы помочь вам на следующих этапах вашей работы по собеседованию — транскрибирование вашей записи в текст онлайн.
Так что все, на чем вам действительно нужно сосредоточиться, — это делать заметки и обращать внимание на человека, с которым вы разговариваете. Лучший онлайн-конвертер Audext MP3 в текст здесь, чтобы помочь вам на следующих этапах вашей работы по собеседованию — транскрибирование вашей записи в текст онлайн.
Почему стоит попробовать программу для транскрипции текста Audext MP3 в Интернете?
Транскрипты файлов MP3 доступны для поиска: Расшифровка подкастов означает, что владелец может генерировать огромный объем трафика на веб-сайт, поскольку текст становится доступным для поиска для читателя.
Люди могут наткнуться на записанные подкасты во время просмотра веб-страниц, связанных с контентом, который доставляют подкасты. Поисковые машины подбирают ключевые слова. Однако записи шоу в аудиофайлах в формате MP3 недоступны для поиска, в отличие от транскриптов.
Может использоваться как контент блога: Возможно, подкастер не может решить, что разместить в блоге. Автоматическая транскрипция аудио из MP3 в текст может быть скопирована и мгновенно преобразована в новый пост в блоге без дополнительных усилий.
Автоматическая транскрипция аудио из MP3 в текст может быть скопирована и мгновенно преобразована в новый пост в блоге без дополнительных усилий.
Можно также использовать Audext audio to text converter онлайн для создания информационного бюллетеня для подписчиков или множества коротких статей за короткий период времени.
Поскольку существует огромный спектр преимуществ, использование приложения Audext для конвертации MP3 в текст онлайн стоит трудозатратных усилий. Это может сэкономить вам не только время, но и много денег.
Как мне преобразовать MP3 в текстовый файл с моего мобильного телефона?
Существуют различные способы использования автоматического преобразования речи в текст в формате MP3.Самый простой — подключить смартфон к ПК или ноутбуку и передать файл MP3 физически . Вы также можете просто отправить свои аудиофайлы по электронной почте, Gmail или Bluetooth.
Другой способ — это сохранить их на Google Диске или напрямую загрузить в онлайн-конвертер MP3 в текст с помощью мобильного браузера. Таким образом, вы также можете загрузить свою запись MP3 со своего устройства Android или iOS прямо в Audext Cloud Editor .
Таким образом, вы также можете загрузить свою запись MP3 со своего устройства Android или iOS прямо в Audext Cloud Editor .
Audext корректно работает как на настольных, так и на мобильных устройствах, поэтому вам не нужно беспокоиться, если вам нужно быстро преобразовать речь MP3 в текст, а ПК нигде нет.Audext поможет вам!
Онлайн-конвертераудио в текст [2021]
Все мы знаем, что набор текста отнимает много времени. Чтобы печатать, нужно гораздо больше времени, чем думать. Эта процедура может привести к снижению производительности. My Voice 2 Text — ваше решение этой проблемы.
Его приложение представляет собой чистый онлайн-конвертер аудио в текст, который вы можете использовать для голосового набора на английском языке и просмотра его преобразования в текст в реальном времени. Это экономит много времени и повышает вашу производительность.
Инструмент использует High-End AI технологию для преобразования произнесенных слов в текст со 100% точностью. Это революция в области распознавания речи.
Это революция в области распознавания речи.
Часто задаваемые вопросы о преобразовании аудио в текст
Как преобразовать аудиофайл в текст?
Существует множество приложений, которые автоматически преобразуют звук в текст. Хотя рекомендуется использовать MyVoice2Text.com Free Audio o программа для преобразования текста, позволяющая мгновенно расшифровать аудиофайл.
Как я могу бесплатно преобразовать аудио в текст?
Одним из способов преобразования аудиофайлов в текст является Myvoice2Text.com. Вы можете попробовать использовать MyVoice2Text для преобразования голоса в текст с большей точностью, хотя в основном они предназначены для личного, а не коммерческого использования из-за ограничений авторских прав.
Есть ли программное обеспечение для преобразования аудио в текст?
MyVoice2Text — отличный вариант преобразования текста в речь, который можно использовать для преобразования ваших аудиофайлов в текст. Все, что вам нужно, это аудиофайл для загрузки, и он преобразует ваш звук в текст за считанные минуты с точностью около 95%.
Все, что вам нужно, это аудиофайл для загрузки, и он преобразует ваш звук в текст за считанные минуты с точностью около 95%.
Есть ли приложение для преобразования аудио в текст?
Несколько приложений предлагают услуги преобразования звука в текст; Хотя большинство из них бесплатны, вы также можете выбрать платные функции, что упрощает процесс преобразования звука в текст. Однако, хотя приложения — отличный способ сделать это, у них также есть некоторые проблемы с конфиденциальностью, поскольку они установлены на вашем телефоне. Таким образом, используя онлайн-платформу, такую как MyVoice2Text.com для более безопасной и точной расшифровки ваших аудиофайлов.
Какое бесплатное приложение для преобразования голоса в текст самое лучшее?
Технология распознавания речи растет в геометрической прогрессии, что позволяет более точно преобразовывать голос в текст. В Интернете доступно много программного обеспечения, такого как MyVoice2Text.com, с помощью которого вы можете удобно и точно бесплатно конвертировать ваши аудиофайлы и речь в текст.
Как преобразовать звук в текст в Интернете?
Вам просто нужно поискать в Google, и вы найдете множество приложений и программного обеспечения, доступных в Интернете, которые позволят вам без проблем транскрибировать аудио в текст.Вы можете попробовать использовать MyVoice2Text.com, который позволит вам транскрибировать все ваши аудиофайлы в режиме реального времени, и, что самое приятное, это абсолютно бесплатно. Давай, попробуй !!!
Есть ли в Microsoft Word перевод текста?
Коснитесь значка микрофона на клавиатуре, чтобы начать диктовать. Говорите столько времени, сколько хотите, а затем коснитесь другой области экрана, когда закончите.
Можете ли вы преобразовать речь в текст в Word?
Благодаря функции Microsoft Word «Диктовать» все, что вам нужно сделать, это говорить в любой микрофон, как если бы вы произносили устную презентацию, одновременно печатая на клавиатуре для знаков препинания.Вы также можете создавать новые абзацы, произнося «новая строка».
Как расшифровать аудио в iTunes?
Шаг 1. Откройте iTunes и нажмите кнопку «iTunes Store» на верхней панели навигации.
Шаг 2: Найдите альбом или песню, которую вы хотите расшифровать, в выбранном вами жанре.
Шаг 3: Прокрутите вниз до нижней вкладки с надписью «Еще» и нажмите «TRANSCRIBE AUDIO».
Шаг 4: Нажмите начать транскрипцию внизу экрана. Имейте в виду, что некоторые песни могут перестать транскрибироваться, в то время как другие могут занять час или больше, в зависимости от длины и сложности.
Шаг 5: После того, как вы закончите перевод, наведите указатель мыши на метку завершенной дорожки (выделенную жирным шрифтом), снова прокрутите вниз до нижней вкладки с надписью «Еще» и нажмите «Показать стенограмму».
Теперь ваши аудиофайлы расшифрованы и готовы к использованию! »
Может ли Mac преобразовывать аудио в текст?
Функция диктовки в OS X позволяет легко печатать, не используя руки. Чтобы использовать его, просто нажмите назначенную вами комбинацию клавиш или выберите «Начать диктовку» в меню «Правка» и начните говорить.
Как использовать голос в текст на моем Macbook?
Выскажи свои мысли миру! Голосовая диктовка теперь доступна практически на всех устройствах Android. Чтобы запустить голосовую команду, откройте любое приложение и коснитесь значка микрофона в нижней части клавиатуры. Начни говорить, когда будешь готов к тому, чтобы окружающие услышали, что у тебя на уме! Для более сложной и точной транскрипции вы можете использовать MyVoice2Text.com, который преобразует все ваши аудио в текст в режиме реального времени.
Может ли Siri расшифровывать аудиофайлы?
Программное обеспечение Siri Assistant, встроенное в iOS, может открывать приложение «Заметки» и расшифровывать ваши слова, когда вы их произносите. Кроме того, многие приложения для диктовки загружают запись вашего голоса на свои серверы для транскрипции.
Как преобразовать видеозаписи в текст?
Чтобы расшифровать видеозаписи, вам понадобится программное обеспечение для преобразования видео в текст и HTML. Adobe CS6 может сделать это с помощью титров в качестве языка разметки (.scc), но доступно множество других вариантов. Чтобы найти тот, который лучше всего подходит для ваших нужд, выполните поиск «расшифруйте видеозаписи» в поисковой системе вашего браузера.
Adobe CS6 может сделать это с помощью титров в качестве языка разметки (.scc), но доступно множество других вариантов. Чтобы найти тот, который лучше всего подходит для ваших нужд, выполните поиск «расшифруйте видеозаписи» в поисковой системе вашего браузера.
Есть ли в Word 2013 озвучивание текста?
Нет, Word 2013 не поддерживает преобразование голоса в текст. Однако, если вы хотите использовать свой голос и преобразовать его в слова для редактирования, вы можете использовать MyVoice2Text.com. Этот онлайн-конвертер речи в текст абсолютно бесплатный; кроме того, они экономят время и создают более читаемую копию.
Есть ли в Word 2010 преобразование речи в текст?
Нет, Word 2010 не поддерживает преобразование голоса в текст. Однако, если вы хотите диктовать и транскрибировать свой голос в слова для целей редактирования, вы можете использовать MyVoice2Text.com, онлайн-конвертер речи в текст.
Как преобразовать речь в текст в Документах Google?
Вам понадобится микрофон, подключенный к вашему компьютеру. Затем вы можете выбрать раскрывающееся меню «Инструменты» в любом поле редактирования текста в Документах Google и нажать «Голосовой ввод».»Кроме того, вы можете искать голосовой ввод с помощью сочетания клавиш Ctrl + Shift + S. Затем осторожно говорите со своим компьютером, пока он не распознает все, что вы хотите ввести — единственное требование — его микрофон должен слышать все что вы говорите. Программное обеспечение для распознавания голоса будет слушать каждый звук, исходящий из вашего рта. Каждые пару секунд это программное обеспечение будет делать паузу, чтобы вы продиктовали больше слов — оно не различает отдельные слова, поэтому убедитесь, что все в порядке. произносится правильно, прежде чем продолжить работу!
Затем вы можете выбрать раскрывающееся меню «Инструменты» в любом поле редактирования текста в Документах Google и нажать «Голосовой ввод».»Кроме того, вы можете искать голосовой ввод с помощью сочетания клавиш Ctrl + Shift + S. Затем осторожно говорите со своим компьютером, пока он не распознает все, что вы хотите ввести — единственное требование — его микрофон должен слышать все что вы говорите. Программное обеспечение для распознавания голоса будет слушать каждый звук, исходящий из вашего рта. Каждые пару секунд это программное обеспечение будет делать паузу, чтобы вы продиктовали больше слов — оно не различает отдельные слова, поэтому убедитесь, что все в порядке. произносится правильно, прежде чем продолжить работу!
Как мне вручную расшифровать аудио?
Существует бесплатное программное обеспечение, которое позволяет вводить звук в программное обеспечение, такое как Myvoice2Text.com изнутри, который затем можно вручную расшифровать.
Какое программное обеспечение для преобразования речи в текст самое лучшее?
MyVoice2Text.![]() com на сегодняшний день является лучшим программным обеспечением для преобразования речи в текст. Он быстрый, эффективный и точный — все, что можно представить в средстве распознавания речи. MyVoice2Text попал в новости более десяти месяцев назад, поэтому можно с уверенностью сказать, что на данный момент это отраслевой стандарт!
com на сегодняшний день является лучшим программным обеспечением для преобразования речи в текст. Он быстрый, эффективный и точный — все, что можно представить в средстве распознавания речи. MyVoice2Text попал в новости более десяти месяцев назад, поэтому можно с уверенностью сказать, что на данный момент это отраслевой стандарт!
Как активировать преобразование голоса в текст на Android?
Чтобы активировать преобразование голоса в текст, вы должны сначала настроить ярлык голосового поиска — в вашем распоряжении Google Search.После активации перейдите в «Настройки» и найдите «Настройки голосового ввода и вывода». Вы также можете настроить режим текстового сообщения в том же месте. Это удовольствие использовать, и не нужно много времени, чтобы научиться. Вы можете получить к нему доступ, удерживая кнопку «Домой» на телефоне, пока не услышите два звуковых сигнала. Оттуда вы увидите клавиатуру и микрофон, которые будут оставаться открытыми столько, сколько они вам понадобятся!
Как включить преобразование голоса в текст на моем iPhone?
Выполните следующие действия, чтобы включить преобразование голоса в текст на iPhone:
1. Откройте приложение «Настройки» на iPhone
Откройте приложение «Настройки» на iPhone
2. Нажмите «Общие».
3. Прокрутите вниз и нажмите «Специальные возможности».
4. Найдите параметр «VoiceOver» или «Управление голосом», включите его, затем нажмите «Говорить на экране», чтобы выбрать голос для голосовой обратной связи из этого параметра. Вы также можете изменить эти настройки позже, вернувшись в раздел «Специальные возможности»; прокрутите вниз, пока не дойдете до VoiceOver -> Выбран экран «Говорить» -> При желании изменить голоса -> Готово.
Как преобразовать голос в текст на iPhone?
С помощью нескольких касаний и смахиваний на iPhone вы можете включить режим диктовки, чтобы он автоматически преобразовывал то, что вы говорите, в текст, когда вы начинаете говорить.Ниже приведены несколько шагов по преобразованию голоса в текст на iPhone. Выберите «Настройки»> «Основные»> «Клавиатура». Включите «Включить диктовку».
Как я могу быстрее преобразовать аудио в текст?
Расшифровка аудио — непростая задача. Это требует много времени и внимания к деталям, но есть несколько способов увеличить скорость транскрипции с помощью игр с набором текста, которые помогут улучшить скорость вашего слова в минуту (WPM), или найти доступную службу автоматического распознавания голоса, такую как MyVoice2Text, которая расшифровывает тексты бесплатно.
Это требует много времени и внимания к деталям, но есть несколько способов увеличить скорость транскрипции с помощью игр с набором текста, которые помогут улучшить скорость вашего слова в минуту (WPM), или найти доступную службу автоматического распознавания голоса, такую как MyVoice2Text, которая расшифровывает тексты бесплатно.
Есть ли приложение для преобразования голоса в текст для Android?
Для Android доступно несколько приложений для преобразования голоса в текст. Эту услугу предлагают несколько брендов, самыми популярными из которых являются Google Voice Typing, Dragon Dictation, MyVoice2Text. Однако все эти приложения будут работать только при наличии подключения к Интернету.
Если вы не хотите подключаться к Интернету, другой тип приложения под названием «Text Magnifier» может переводить то, что вы говорите, в текст полностью в автономном режиме. Он не улавливает ваш голос так отчетливо или мощно, как некоторые другие приложения (поскольку он был создан для тех, кто испытывает трудности со зрением из-за физических препятствий), но, тем не менее, это альтернатива — что-то, когда все остальное терпит неудачу!
Можно ли преобразовать речь в текст?
MyVoice2Text — это программа для диктовки на основе браузера, которая преобразует вашу речь в текст прямо в браузере Chrome.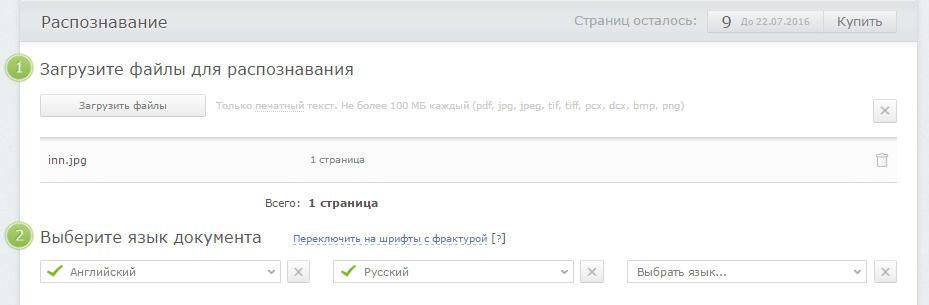 Его легко настроить, и как только вы разрешите ему использовать свой микрофон, все, что вам нужно сделать, это щелкнуть значок микрофона и начать говорить!
Его легко настроить, и как только вы разрешите ему использовать свой микрофон, все, что вам нужно сделать, это щелкнуть значок микрофона и начать говорить!
Как бесплатно преобразовать речь в текст?
MyVoice2Text.com доступен для бесплатного преобразования речи в текст, и это очень просто. Просто введите небольшой образец того, что вы хотите преобразовать в текст, и нажмите «Отправить», и вот оно что! С этого момента набор текста не должен быть проблемой после того, как MyVoice2Text сделал все, что работал за нас!
Какое приложение для преобразования речи в текст самое лучшее?
Лучшие приложения для преобразования голоса в текст в 2021 году
Dragon Anywhere: лучшее приложение для преобразования голоса в текст
Google Assistant: помощник, который отлично подходит для быстрых текстов и напоминаний
Transcribe — Speech to Text: служба транскрипции с человеческим прикосновением, это самая точная программа в этом списке и та, которая вам нужна при работе со звуком дольше часа или около того за один раз.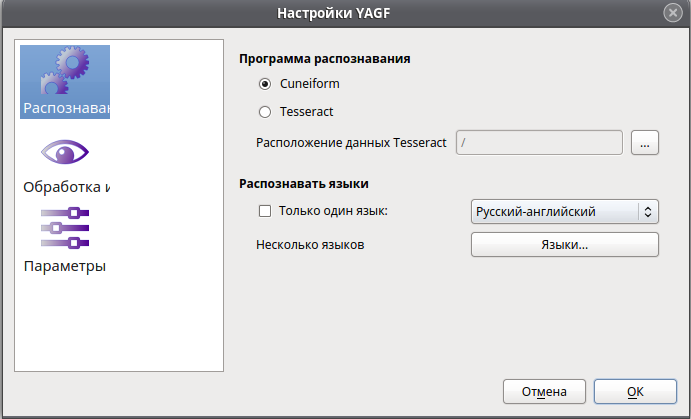
Speech notes — Speech to Text — Speechnotes позволит вам захватывать как можно больше информации во время разговоров, сохраняя при этом возможность расшифровать позже быстро!
iTranslate Converse — Переводите целые разговоры на любой язык, который только можно вообразить, просто разговаривая.
Что такое говорить в текст?
ТехнологияDictation дает пользователям возможность преобразовывать произнесенные ими слова в цифровой текст на экране. С инструментами диктовки, доступными на таких устройствах, как ноутбуки, смартфоны и планшеты, вы можете записывать свои мысли на бумаге, не набирая их самостоятельно!
Как добавить голос к тексту?
Включение / выключение голосового ввода — Android. На главном экране перейдите: значок «Приложения»> «Настройки», затем нажмите «Язык и ввод» или «Язык и клавиатура».На экранной клавиатуре коснитесь Google Keyboard / Gboard. Откроется страница настроек, на которой при необходимости можно отключить голосовой ввод.
Есть ли приложение для преобразования речи в текст для iPhone?
Диктовка — это новая технология, которая позволяет диктовать, расшифровывать и переводить текст, не набирая его на iPhone. Он использует новейшее программное обеспечение для распознавания речи, которое имеет расширенные возможности перевода голоса. Так что больше не печатайте! Вместо этого просто начните диктовать, что у вас на уме.
Какое приложение для свободного преобразования текста в текст лучше всего для iPhone?
Все лучшие приложения для преобразования свободы слова в текст для iPhone имеют примерно одинаковые функции, поэтому вам нужно будет изучить другие факторы, прежде чем выбрать тот, который подходит для ваших нужд. Что хорошего в Evernote, так это то, что он, вероятно, уже установлен на вашем iPhone и позволяет диктовать, не печатая, что может быть очень полезно. Запись разговоров с помощью NoNotes тоже может работать хорошо, потому что иногда люди хотят расшифровку телефонных разговоров, когда они пытаются, например, в судебных процессах, где записи не могут быть использованы. Тем не менее, это приложение также включает возможность записи через Skype, что может пригодиться.
Тем не менее, это приложение также включает возможность записи через Skype, что может пригодиться.
Как использовать голос для перевода текста на моем компьютере?
Доступно множество браузерных платформ для преобразования голоса в текст на компьютере. Например, вы можете использовать MyVoice2Text.com, который конвертирует ваш голос в текст в режиме реального времени с максимальной точностью и совершенно бесплатно.
Могу ли я печатать голосом?
Когда вы в пути, Gboard — находка. Он отлично подходит для набора и диктовки текста с помощью голоса! Если у вас есть Android-устройство (или планшет), то настоятельно рекомендуется скачать это приложение; это сделает текстовые сообщения намного проще, чем когда-либо прежде.
Можно ли преобразовывать текст в голосовой текст в Документах Google?
Да! Чтобы преобразовать голос в текст в документах Google, просто нажмите значок микрофона и говорите. Google Docs будет преобразовывать ваши устные слова в письменные по ходу дела. Это действительно так просто.
Это действительно так просто.
Какое бесплатное приложение для преобразования голоса в текст самое лучшее?
Gboard — одно из лучших бесплатных программ преобразования текста в речь. Он также имеет множество привлекательных функций, таких как плавный набор текста и режим работы одной рукой.
Как преобразовать речь в текст в Python
Абду Рокикз · Читать 7 мин · Обновлено октябрь 2020 · Машинное обучение · Интерфейсы прикладного программирования · Спонсируемые Распознавание речи — это способность компьютерного программного обеспечения определять слова и фразы в устной речи и преобразовывать их в текст, читаемый человеком. В этом руководстве вы узнаете, как преобразовать речь в текст на Python с помощью библиотеки SpeechRecognition.
В этом руководстве вы узнаете, как преобразовать речь в текст на Python с помощью библиотеки SpeechRecognition.
В результате нам не нужно создавать какую-либо модель машинного обучения с нуля, эта библиотека предоставляет нам удобные оболочки для различных хорошо известных API-интерфейсов распознавания публичной речи (таких как Google Cloud Speech API, IBM Speech To Text и т. Д.).
Узнайте также: Как переводить текст в Python.
Хорошо, приступим, установим библиотеку с помощью pip :
pip3 установить SpeechRecognition pydub Хорошо, откройте новый файл Python и импортируйте его:
импортировать распознавание речи как sr Самое приятное в этой библиотеке то, что она поддерживает несколько механизмов распознавания:
Здесь мы будем использовать распознавание речи Google, так как это просто и не требует ключа API.
Чтение из файла
Убедитесь, что у вас есть аудиофайл в текущем каталоге, который содержит английскую речь (если вы хотите следовать вместе со мной, получите аудиофайл здесь):
filename = "16-122828-0002. wav"  wav"
wav" Этот файл был взят из набора данных LibriSpeech, но вы можете использовать любой аудиофайл WAV, который хотите, просто измените имя файла, давайте инициализируем наш распознаватель речи:
# инициализировать распознаватель
r = sr.Recognizer () Приведенный ниже код отвечает за загрузку аудиофайла и преобразование речи в текст с помощью распознавания речи Google:
# открыть файл
с sr.AudioFile (имя файла) в качестве источника:
# прослушиваем данные (загружаем звук в память)
audio_data = r.record (источник)
# распознать (преобразовать из речи в текст)
text = r.recognize_google (audio_data)
печать (текст) Это займет несколько секунд, так как он загружает файл в Google и получает вывод, вот мой результат:
Кажется, вы несете чушь Приведенный выше код хорошо работает для аудиофайлов малого или среднего размера. В следующем разделе мы напишем код для больших файлов.
Чтение больших аудиофайлов
Если вы хотите выполнить распознавание речи для длинного аудиофайла, то функция ниже справится с этим достаточно хорошо:
# импорт библиотек
импортировать распознавание речи как SR
импорт ОС
из pydub импортировать AudioSegment
из pydub.silence import split_on_silence
# создать объект распознавания речи
r = sr.Recognizer ()
# функция, которая разбивает аудиофайл на куски
# и применяет распознавание речи
def get_large_audio_transcription (путь):
"" "
Разделение большого аудиофайла на части
и применить распознавание речи к каждому из этих фрагментов
"" "
# открываем аудиофайл с помощью pydub
звук = Аудио сегмент.from_wav (путь)
# разделить звук, когда тишина составляет 700 миллисекунд или более, и получить фрагменты
chunks = split_on_silence (звук,
# поэкспериментируйте с этим значением для вашего целевого аудиофайла
min_silence_len = 500,
# отрегулируйте это в соответствии с требованиями
тишина_порога = звук. dBFS-14,
# сохранять тишину в течение 1 секунды, также регулируется
keep_silence = 500,
)
folder_name = "аудио-фрагменты"
# создать каталог для хранения аудио фрагментов
если не os.path.isdir (имя_папки):
os.mkdir (имя_папки)
весь_текст = ""
# обрабатываем каждый кусок
для i audio_chunk в enumerate (chunks, start = 1):
# экспортируем аудиофрагмент и сохраняем его в
# каталог `имя_папки`.
chunk_filename = os.path.join (имя_папки, f "фрагмент {i} .wav")
audio_chunk.export (chunk_filename, format = "wav")
# распознать кусок
с sr.AudioFile (chunk_filename) в качестве источника:
audio_listened = r.record (источник)
# попробуйте преобразовать его в текст
пытаться:
текст = r.распознать_google (audio_listened)
кроме sr.UnknownValueError как e:
print ("Ошибка:", str (e))
еще:
text = f "{text.capitalize ()}."
print (chunk_filename, ":", текст)
весь_текст + = текст
# вернуть текст для всех обнаруженных чанков
вернуть весь_текст  dBFS-14,
# сохранять тишину в течение 1 секунды, также регулируется
keep_silence = 500,
)
folder_name = "аудио-фрагменты"
# создать каталог для хранения аудио фрагментов
если не os.path.isdir (имя_папки):
os.mkdir (имя_папки)
весь_текст = ""
# обрабатываем каждый кусок
для i audio_chunk в enumerate (chunks, start = 1):
# экспортируем аудиофрагмент и сохраняем его в
# каталог `имя_папки`.
chunk_filename = os.path.join (имя_папки, f "фрагмент {i} .wav")
audio_chunk.export (chunk_filename, format = "wav")
# распознать кусок
с sr.AudioFile (chunk_filename) в качестве источника:
audio_listened = r.record (источник)
# попробуйте преобразовать его в текст
пытаться:
текст = r.распознать_google (audio_listened)
кроме sr.UnknownValueError как e:
print ("Ошибка:", str (e))
еще:
text = f "{text.capitalize ()}."
print (chunk_filename, ":", текст)
весь_текст + = текст
# вернуть текст для всех обнаруженных чанков
вернуть весь_текст
dBFS-14,
# сохранять тишину в течение 1 секунды, также регулируется
keep_silence = 500,
)
folder_name = "аудио-фрагменты"
# создать каталог для хранения аудио фрагментов
если не os.path.isdir (имя_папки):
os.mkdir (имя_папки)
весь_текст = ""
# обрабатываем каждый кусок
для i audio_chunk в enumerate (chunks, start = 1):
# экспортируем аудиофрагмент и сохраняем его в
# каталог `имя_папки`.
chunk_filename = os.path.join (имя_папки, f "фрагмент {i} .wav")
audio_chunk.export (chunk_filename, format = "wav")
# распознать кусок
с sr.AudioFile (chunk_filename) в качестве источника:
audio_listened = r.record (источник)
# попробуйте преобразовать его в текст
пытаться:
текст = r.распознать_google (audio_listened)
кроме sr.UnknownValueError как e:
print ("Ошибка:", str (e))
еще:
text = f "{text.capitalize ()}."
print (chunk_filename, ":", текст)
весь_текст + = текст
# вернуть текст для всех обнаруженных чанков
вернуть весь_текст Примечание: Вам необходимо установить Pydub, используя pip , чтобы приведенный выше код работал.
Вышеупомянутая функция использует функцию split_on_silence () из pydub.Модуль silent для разделения аудиоданных на фрагменты без звука. min_silence_len Параметр — это минимальная длина паузы, которая будет использоваться для разделения.
silent_thresh — это порог, при котором все, что тише, будет считаться тишиной, я установил его на среднее значение dBFS минус 14, keep_silence аргумент — это количество тишины, которое нужно оставить в начале и в конце каждого обнаруженного фрагмента в миллисекундах.
Эти параметры не подходят для всех звуковых файлов, попробуйте поэкспериментировать с этими параметрами с вашими крупными потребностями в аудио.
После этого мы перебираем все фрагменты и преобразуем каждый речевой звук в текст и складываем их все вместе, вот пример выполнения:
путь = "7601-291468-0006.wav"
print ("\ nПолный текст:", get_large_audio_transcription (путь)) Примечание : Вы можете получить файл 7601-291468-0006.wav здесь.
Выход:
audio-chunks \ chunk1.wav: Его жилище, которое вы устроили в беседке или загородном доме.audio-chunks \ chunk2.wav: недалеко от города.
audio-chunks \ chunk3.wav: Как раз на том, что сейчас называется голландской улицей.
audio-chunks \ chunk4.wav: Рано ограничено доказательствами его изобретательности.
audio-chunks \ chunk5.wav: Патентованные дымовые куртки.
audio-chunks \ chunk6.wav: потребовалась лошадь, чтобы немного поработать.
audio-chunks \ chunk7.wav: мясо, запеченное в голландской печи без огня.
audio-chunks \ chunk8.wav: Тележки, которые шли раньше лошадей.
audio-chunks \ chunk9.wav: Погодный рульщик, который повернулся против ветра и других заблуждений.audio-chunks \ chunk10.wav: Так что поймите, все это можно найти.
Полный текст: Его жилище, которое вы устроили в беседке или загородной резиденции. Недалеко от города. Как раз на том, что сейчас называется голландской улицей. Рано ограничился доказательствами его изобретательности. Патентованные коптильни. Чтобы немного поработать, требовалась лошадь. Мясо, запеченное в голландской печи без огня. Телеги, которые шли впереди лошадей. Кокс погоды, который повернулся против ветра и других заблуждений. Так что просто поймите, можно это найти всем наблюдателям. Итак, эта функция автоматически создает для нас папку и помещает фрагменты исходного аудиофайла, которые мы указали, а затем запускает распознавание речи для всех из них.
Чтение с микрофона
Для этого требуется, чтобы PyAudio был установлен на вашем компьютере, вот процесс установки в зависимости от вашей операционной системы:
Windows
Вы можете просто установить его с помощью пипса:
pip3 установить pyaudio Linux
Вам необходимо сначала установить зависимости:
sudo apt-get install python-pyaudio python3-pyaudio
pip3 установить pyaudio MacOS
Вам нужно сначала установить portaudio, затем вы можете просто установить его через pip:
brew установить portaudio
pip3 установить pyaudio Теперь давайте воспользуемся микрофоном, чтобы преобразовать нашу речь:
с ср.Микрофон () в качестве источника:
# читать аудиоданные с микрофона по умолчанию
audio_data = r.record (источник, продолжительность = 5)
print ("Узнавая ...")
# преобразовать речь в текст
text = r.recognize_google (audio_data)
печать (текст) Это будет звучать из вашего микрофона в течение 5 секунд, а затем попытается преобразовать эту речь в текст!
Он очень похож на предыдущий код, но здесь мы используем объект Microphone () для чтения звука с микрофона по умолчанию, а затем мы использовали параметр длительности в функции record (), чтобы прекратить чтение через 5 секунд, а затем загружаем звук. данные в Google, чтобы получить выходной текст.
Вы также можете использовать параметр смещения в функции record (), чтобы начать запись после смещения секунд.
Кроме того, вы можете распознавать разные языки, передав параметр языка в функцию распознавания_google (). Например, если вы хотите распознать испанскую речь, вы должны использовать:
text = r.recognize_google (audio_data, language = "es-ES") Проверьте поддерживаемые языки в этом ответе stackoverflow.
Заключение
Как видите, использовать эту библиотеку для преобразования речи в текст довольно просто.Эта библиотека широко используется в дикой природе, проверьте их официальную документацию.
Если вы не хотите использовать Python и хотите, чтобы служба делала это автоматически, я рекомендую вам использовать audext, который быстро и с минимальными затратами преобразует аудио в текст в Интернете. Проверьте это!
Если вы также хотите преобразовать текст в речь на Python, ознакомьтесь с этим руководством.
Читайте также: Как распознавать оптические символы в изображениях в Python.
Счастливое кодирование ♥
Просмотр полного кодаЧитайте также
Панель комментариев
Топ-8 лучших преобразователей речи в текст и способы их использования
Программа преобразования речи в текст конвертирует аудио- и видеофайлы в текстовый формат.Обычно такое программное обеспечение изначально создавалось для настольных компьютеров. Однако по мере того, как мобильные телефоны расширяются, появилась возможность транскрибировать файлы на вашем смартфоне или планшете.
Это означает, что преобразователи речи в текст могут использоваться профессионалами из всех слоев общества. Более того, их доступность, особенно те, которые работают на мобильных устройствах, делает их полезными для студентов. Сегодня вместо того, чтобы писать заметки, все, что нужно сделать студенту, — это записать лектора или получить голосовой или аудиофайл, а затем преобразовать его в текст.
В этой статье мы рассмотрим 10 самых популярных преобразователей речи в текст и способы их использования. Мы разделили их на 2 группы, показав:
- Лучшая платная программа преобразования речи в текст
- Лучшее программное обеспечение преобразования речи в текст, которое можно использовать бесплатно
Здесь каждый найдет что-то для себя, так что прочтите и сделайте свой выбор:
Самые популярные конвертеры речи в текст
1. Dragon Professional
Если вы ищете профессиональное платное решение для преобразования речи в текст, Dragon Professional для вас.
При цене 300 долларов Nuance позаботилась о том, чтобы ничего не упустить на волю случая, и наполнила это приложение мощными функциями. Dragon Professional выполняет расшифровку со скоростью, эквивалентной скорости набора текста 160 слов в минуту, для отличного делового опыта.
Это приложение также отлично подходит для частных лиц. Функция голосового набора особенно полезна для фрилансеров и других профессионалов, которым может постоянно приходиться печатать документы и управлять ими в пути.
Вы можете делать полезные вещи с профессионалом дракона, например:
- Редактирование документов
- Создание электронных таблиц
- Голосовой поиск в браузере
- Импорт пользовательских списков слов
- Расшифруйте файлы на своем мобильном телефоне и перенесите на компьютер
- Голосовой набор
Если вам нужно приложение, которое гарантирует точность 99% прямо из коробки, это приложение для вас.Это, конечно, если вы можете позволить себе значительные 300 долларов по цене приложения. Но для приложения, которое обеспечивает такие точные результаты без какого-либо обучения, это приложение стоит вложенных средств. Просто подключи и работай, и он естественным образом адаптируется к вашему голосу и словам
2. Verbit
Verbit — это приложение для транскрипции, которое не только быстрое и простое, но и умное благодаря искусственному интеллекту. Он отлично подходит для улучшения командной работы между корпоративными командами и крупными учреждениями, такими как школы.
Некоторые ключевые особенности включают:
- Высокая точность. Это происходит не только из-за использования разнообразных речевых моделей, но и из-за того, что Verbit использует человеческие транскриберы
- Умение переводить вне зависимости от акцента
- Вы можете использовать его в режиме реального времени и получать результаты после сеанса.
- Используйте с увеличением. Комната Verbit Live с функцией масштабирования позволяет отображать стенограммы и подписи к вашим встречам с масштабированием.
- Устраняет фоновый шум
- Он может интегрировать контекстную информацию, такую как новости, в запись
- Для импортированных записей вы можете в любое время отслеживать ход выполнения и статус вашего задания.
- Доступ к отчетам, включая отчеты об использовании и выставление счетов
- Редактировать, обновлять и обмениваться файлами.Возможности редактирования включают добавление комментариев и запрос обзоров
- Доступ к менеджеру по работе с клиентами
- Вы можете управлять пользователями и разрешениями, чтобы ваша работа была в высшей степени защищенной
- Время обработки транскрипции может составлять от 4 часов до нескольких дней в зависимости от отрасли.
Цены и планы: свяжитесь с командой Verbit
3. Речевые вопросы
Speechmatics — это программное обеспечение для автоматического распознавания речи и преобразования речи в текст, «гибкое для развертывания где угодно».Это означает, что он подходит для локального использования, если вы беспокоитесь о безопасности своих файлов, или вы также можете использовать программное обеспечение Speechmatics в качестве сервисного решения (SaaS). Он имеет широкий спектр приложений, включая транскрипцию мультимедийного вещания и использование в центрах обработки вызовов.
Speechmatics работает с живым аудио и видео, а также с существующими файлами.
Ключевые особенности:
- Автоматическое распознавание речи
- Высокая точность записи и транскрипции независимо от акцента
- Использование триггеров по ключевым словам
- Идентификация динамика
- Генерировать стенограммы, доступные для поиска и редактирования
- Регулируемые метки времени
- Вы можете выделить или добавить комментарии
- Пользовательский словарь
- Время выполнения расшифровки в минутах
- Охватывает несколько языков
Цена: Связаться с командой
4.Просто нажмите запись
Just press record — это простой в использовании облачный инструмент для записи голоса и транскрипции, который одним касанием поддерживает запись и транскрипцию голоса на 30 языках на устройствах iOS.
Just press record может использоваться кем угодно с устройством iOS для управления всем, от списков дел до календаря, документов и электронной почты.
Основные характеристики:
- Простота установки и использования; не нужно создавать аккаунт
- Он предлагает неограниченное время записи, что делает его отличным компаньоном для учебы и работы.
- Преобразование речи в текст, доступный для поиска, редактирования и совместного использования
- Обменивайтесь аудио и текстовыми файлами с другими приложениями iOS
- Комплексная организация и просмотр записей и файлов
- Редактировать прямо из приложения
- Отлично подходит для совместной работы, если вы работаете с многоязычными командами
- Распознавание знаков препинания
Хорошо работает и на Apple Watch:
- Если у вас нет iPhone, записывайте на Apple Watch
- Простота использования и отзывчивость даже на маленьком экране
- Автоматическая синхронизация записей, сделанных на Apple Watch
- Воспроизведение до 12 записей
Цена: 4 доллара.99.
Преобразователи свободной речи в текст
Если вы хотите расшифровать свои файлы, но не хотите тратить деньги на программное обеспечение, вот несколько отличных вариантов на выбор:
5. Клавиатура Google Gboard
Gboard — это бесплатный и простой в использовании преобразователь текста в речь, созданный для устройств Android и iOS. Gboard изначально разрабатывался как виртуальная клавиатура, но его возможность ввода речи и высокая скорость отклика делают его довольно мощным, поэтому он попал в этот список.
Gboard сам по себе не является инструментом для транскрипции, но он делает все, что делает инструмент для транскрипции, а также кое-что. А поскольку это клавиатура, она позволит вам набирать текст физически или голосом, редактировать, переводить, сохранять и экспортировать работу практически для любого программного обеспечения, установленного на вашем смартфоне.
Некоторые замечательные и полезные функции, которые поставляются с Gboard, включают:
- Используйте голосовую команду для запуска и ввода изображений в текст
- Захват аудио и перевод файлов с помощью Google Translate для более чем 900 языков
- Голосовой поиск в Интернете
- Простой поиск с прогнозирующими результатами
- Вы можете делиться графикой, включая GIF и смайлики
- Предиктивный набор текста на основе контекста
- В отличие от других приложений, Gboard не показывает рекламы, поэтому вам не нужно беспокоиться, когда вы хотите записывать файлы на свои мобильные устройства во время движения.
6. Распознавание речи в Windows 10 (WSR)
Источник изображения ( Windows Central )
Это программа для распознавания речи, полностью интегрированная в ОС Microsoft Windows 10. Если вы уже используете Windows на своем рабочем столе, то WSR будет поставляться бесплатно
Единственным недостатком распознавания речи Windows является то, что оно не соответствует уровням точности, характерным для большинства других приложений.Однако, если у вас нет ограничений по времени и вы собираетесь использовать программное обеспечение чаще, вы можете обучить его, предоставив ему доступ к своим файлам или прочитав к нему дополнительный текст.
В отличие от Кортаны (голосовой помощник Windows), распознавание речи Windows имеет гораздо больше возможностей, в том числе:
- Выполнение голосовых команд в тексте, сообщениях электронной почты, формах и пользовательском интерфейсе рабочего стола
- Диктант
- Пользовательский словарь, включая пользовательские языковые модели
Чтобы использовать распознавание речи Windows, необходимо включить его на панели управления и выполнить несколько шагов, чтобы настроить его.
7. Расшифровать
Если вы проводите много времени на собраниях или собеседованиях, вы, несомненно, сочтете полезным записывать то, что говорится. Проблема в том, что после встречи или собеседования сделать запись голоса может быть довольно сложно. Вот где на помощь приходит расшифровка. Если ваше записывающее устройство — iPad или iPhone, вы можете использовать расшифровку для преобразования любых аудио- или видеофайлов в текст.
Transcribe работает на базе искусственного интеллекта. Он имеет следующие характеристики:
- Запись голоса с одновременной расшифровкой
- Автоматическая транскрипция голоса и видео
- Добавление титров к видео, даже на иностранных языках
- Транскрибирует более чем на 120 языков
- Поддерживает импорт файлов из Dropbox
- Вы можете экспортировать транскрибированный текст в файлы различных форматов
Если вы используете профессиональную версию, вы получаете 3 часа бесплатной транскрипции ежемесячно и можете синхронизировать до 50 ГБ файлов
8.Lilyspeech
Lilyspeech — это легкий инструмент преобразования речи в текст, который работает в Google Chrome. Он прост в установке, не требует регистрации для использования и расшифровывает текст с точностью 99,5%.
Чтобы использовать LilySpeech, нажмите Ctrl + D и начните говорить обычным голосом. Лили будет диктовать в режиме реального времени, использовать знаки препинания, такие как запятая и точка, и отвечать на голосовые команды, такие как «следующий абзац».
После того, как вы закончите диктовку и расшифровку, вы можете давать дальнейшие голосовые инструкции для выполнения различных операций, таких как копирование и вставка расшифрованного текста в электронную почту.
Использование пользовательских слов делает Lilyspeech еще более точным, поскольку вы можете научить приложение распознавать веб-адреса, отраслевой жаргон, имена людей и предприятий, среди других необычных слов.
Цена: Вы можете использовать бесплатный пакет или купить LilySpeech Premium за 29,99 долларов США в год
Заключительные слова
Вот и все! Как видите, существует множество вариантов на выбор, хотите ли вы транскрибировать на своем устройстве iOS, Android или Windows.Большинство этих приложений впишутся в ваш естественный рабочий процесс, а это значит, что вы можете просто начать их использовать без особого обучения.
Речь в текст в App Store
Новинка! Поддержка записи аудиофайлов
Диктовка — Преобразование текста в текст позволяет диктовать, записывать, переводить и расшифровывать текст вместо набора текста. Он использует новейшую технологию распознавания голоса в текст, и его основная цель — преобразование речи в текст и перевод для обмена текстовыми сообщениями.Никогда не набирайте текст, просто диктуйте и переводите своей речью! Почти каждое приложение, которое может отправлять текстовые сообщения, можно настроить для работы с «Диктовкой — преобразованием речи в текст». Диктовка использует встроенный механизм распознавания речи для текста.
Диктовка — Функции преобразования речи в текст:
► Более 40 языков диктовки
Диктовка — Преобразование речи в текст поддерживает более 40 языков. Dictate предлагает 3 текстовые зоны, обозначенные флажками языка, для которых вы можете настроить другой язык в настройках.Таким образом, вы можете переключаться между разными языковыми проектами одним щелчком мыши.
► Более 40 языков перевода
Перевод — это просто нажатие кнопки перевода. Вы можете указать целевой язык перевода в настройках приложения. Затем вы нажимаете кнопку перевода, чтобы он был переведен.
► Аудиозапись
И ваши аудиозаписи, и текстовые файлы доступны через приложение Apple «Файлы».
► Транскрипция записанных аудиофайлов
Используя транскрипцию аудиофайлов, вы можете транскрибировать записанные аудиофайлы, содержащие речь, в текст одним щелчком мыши.Поддерживаются все основные форматы аудиофайлов.
► Синхронизация iCloud
После включения iCloud ваш текст автоматически синхронизируется между всеми вашими устройствами, на которых запущен Dictate, например iPhone, iPad, macOS и Apple Watch.
► Поддержка людей с ограниченными возможностями
Dictate теперь поддерживает настройку размера системного шрифта и предоставляет настраиваемые размеры кнопок для пользователей с ослабленным зрением. Также тщательно настроен VoiceOver.
► Простое совместное использование текста
Для быстрой отправки продиктованных текстовых сообщений есть кнопка «Поделиться», которая позволяет запустить целевое приложение, т.е.е. Twitter, Facebook, WhatsApp, Flickr, Email или что-то еще, способное получать текст из системы.
► Подписка на версию Pro
Если вы собираетесь чаще использовать диктовку — преобразование текста в текст, вам необходимо подписаться на версию Pro. В версии Pro нет рекламы.
► Важные примечания относительно подписок
Все вышеперечисленное Диктовка — подписка на голосовой текст возобновляется в течение 24 часов до окончания текущего периода, и с вас будет взиматься плата через вашу учетную запись iTunes.Любая неиспользованная часть бесплатного пробного периода, если таковая предлагается, будет аннулирована при покупке подписки. Управляйте подпиской или отмените ее в настройках учетной записи iTunes. См. Наши Условия и положения (https://www.ibn-software.com/app-terms-conditions) и Политику конфиденциальности (https://www.ibn-software.com/app-privacy-policy).
Online, приложение, программное обеспечение, коммерческая лицензия с естественным звучанием голосов.
«Как родитель ученика средней школы, страдающего дислексией, чтение всегда было вызов.Мы используем программное обеспечение NaturalReader и функцию экспорта в MP3 почти ежедневно, чтобы помогите ему выполнить длительные задания по чтению. NaturalReader сыграл важную роль в помогая ему преуспеть в школе! »
— Мэри Хардин«Я больше не напрягаю глаза, пытаясь читать крошечные шрифты в электронной почте или на веб-страницах или тратить время записывать свой голос в учебных целях. У меня есть «двуязычный» NaturalReader и это стало очень полезным инструментом.Кстати, мои ученики не заметили, что мои «подруга» Кейт, которая так хорошо читает уроки, — это компьютер … »
— Ариэль Миранда«Как защитник вспомогательных технологий в Центре независимой жизни в Риверсайде. Графство Калифорния, я считаю, что Nature Reader — замечательная и доступная программа для дети с нарушением обучаемости и дислексией. У меня тоже церебральный паралич, и это программное обеспечение повысило мою продуктивность больше, чем я мог себе представить.Что мне нравится больше всего про программное обеспечение интерфейс, из-за плохого зрения пришлось увеличить шрифт, он делает чтение более увлекательным и приятным ».
— Чи-Хунг Люк Се«Эта программа помогает мне произносить слова, которые я не могу грамматические ошибки при написании записок и сочинений. Мне нравится то, что я могу конвертировать мои онлайн-учебники в MP3 и слушать их на своем смартфоне или ехал в моей машине.”
— Данита Моисей«Я использую NaturalReader для чтения вслух отрывков из купленных мной электронных книг, документов PDF, веб-страницы с большим количеством текста, и чтобы прочитать мне то, что я напечатал, чтобы «услышать их». Это очень помогает мне, так как, хотя я визуально / кинетический ученик, слова — это не изображения.