
API проверки уникальности текстов — 25 коп. за проверку и дешевле!
С помощью нашего API вы можете настроить свои приложения для автоматической проверки текстов на уникальность.
Проверка одного текста стоит 25 копеек. Для оптовых клиентов мы предлагаем скидки.
Вы можете проверять страницы и тексты размером до 20.000 символов. Параллельно можно проверять в 5 потоков днем и в 10 ночью.
Для работы с API подписка не нужна! Достаточно пополнить API-счет. Деньги списываются отдельно за каждую проверку.
Готовые плагины
Плагин для WordPress CMS с готовой интеграцией нашего API
Доступ к API
Для доступа к API нужен аккаунт на нашем сайте.
Примеры использования API
- Автоматическая проверка нового контента на вашем сайте
- Аутсорсинг проверки статей на уникальность для биржи контента
- Проверка статей, не размещенных в Интернете, которые невозможно добавить к нам на регулярную проверку
- Мониторинг уникальности вашего контента с любым интервалом
- Проведение исследований, требующих данных по уникальности контента
Документация для разработчиков
Правила отправки запроса
Формат ответа
Пример кода на PHP
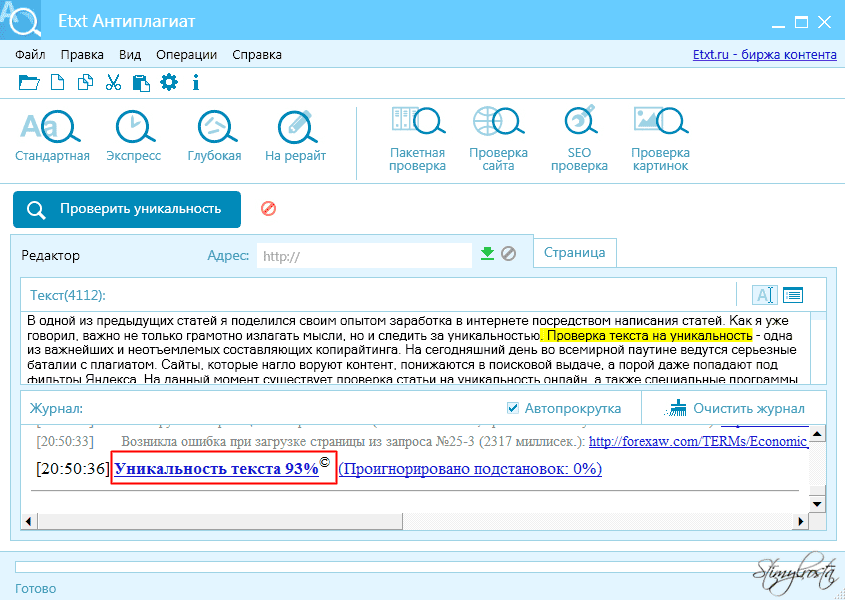
Что такое API проверки на уникальность content-watch.
 ru?
ru?Content-watch.ru предлагает вам интегрировать проверку контента на уникальность в ваши сайты и приложения. Такой подход позволит вам максимально гибко адаптировать возможности нашей системы для ваших нужд.
API уникальности контента позволяет проверять тексты и сайты на уникальность автоматически, не тратя время на ручную проверку.
Для начала работы вам потребуются услуги программиста, чтобы внедрить наш API в ваш проект.
Цены и скидки
Начальная цена проверки одного текста до 20.000 символов — 25 копеек.
Если вы отправляете (или планируете отправлять) тысячи или десятки тысяч запросов к нашему API каждый месяц, мы готовы предоставить скидку. Размер скидки зависит от количества запросов в месяц и может составлять 20%, 40% и 60%.
Проверить текст на уникальность онлайн бесплатно
Любая научная работа (дипломная, курсовая, реферат, статья, диссертация и т.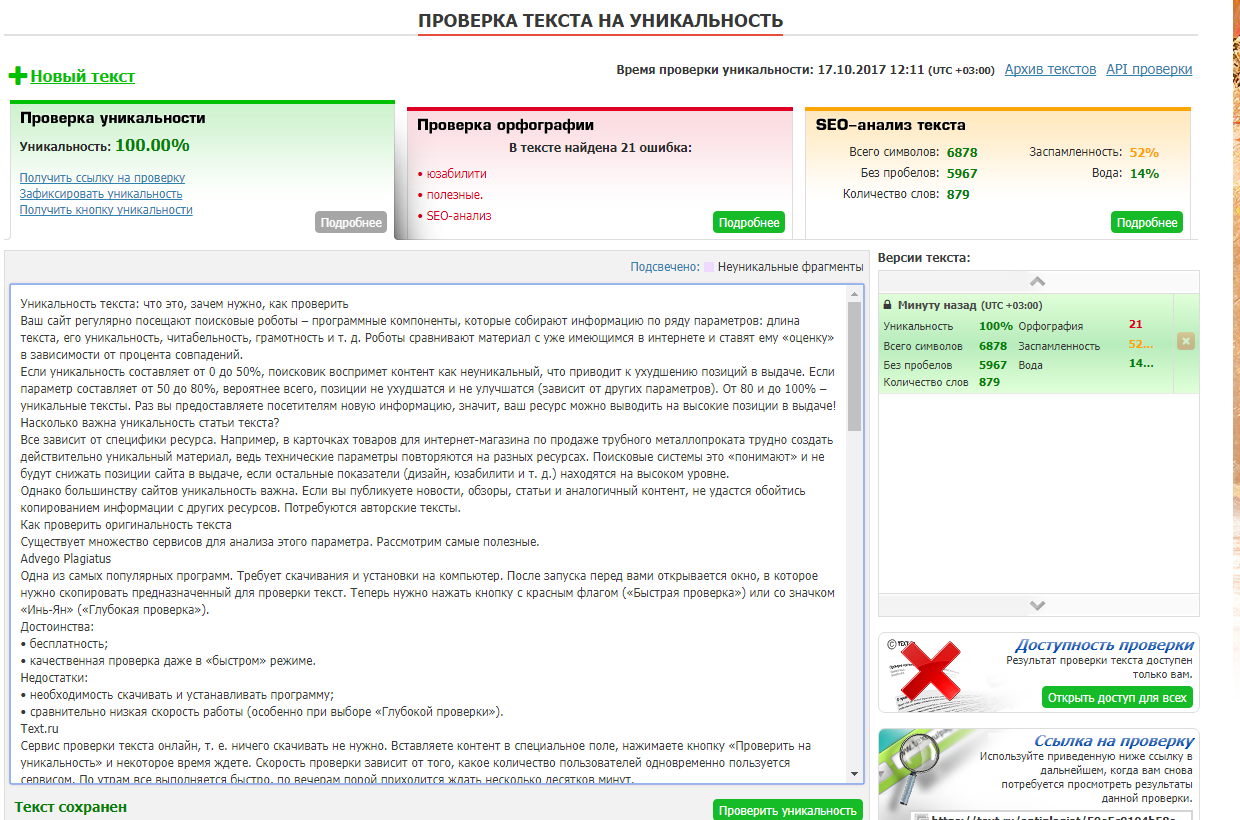
Но самостоятельное написание не является гарантией высокого процента оригинальности текста, потому что любая работа содержит ряд обязательной информации:
- теории;
- юридические законы;
- цитаты;
- распространенные речевые обороты.
Онлайн проверка текста на уникальность
Поэтому лучше проверять уникальность текста заранее — это позволит устранить все замечания еще до проверки преподавателями. В Интернете можно найти десятки платных и бесплатных антиплагиат-сервисов, но не каждому из них можно доверять. Одни программы используют устаревшие алгоритмы, другие — не предоставляют отчет, третьи — недоступны для студентов.
Поэтому мы создали свою программу для проверки уникальности текста и контента. Она полностью автоматизирована, работает круглосуточно и без регистрации. На проверку одного текста или документа требуется не более 30 секунд.
Она полностью автоматизирована, работает круглосуточно и без регистрации. На проверку одного текста или документа требуется не более 30 секунд.
Как происходит анализ уникальности документа?
За те 30 секунд, пока идет анализ, программа для проверки уникальности статьи, проделывает огромную работу. Она сопоставляет исходный текст с миллионами других документов, которые опубликованы в интернете или хранятся в закрытых базах данных библиотек и университетов.
Для этого текст разбивается на фрагменты определенной величины — шинглы. Вот «постулат теории относительности» — это шингл из 3 слов. Программа по специальным алгоритмам ищет эту фразу в других документах. Если находит, то отмечает фрагмент как заимствованный и снижает процент уникальности. К примеру, показатель оригинальности 80% означает, что в документе содержится 80% авторского материала, а оставшиеся 20% — это плагиат.
- Загружаете работу, который нужно проверить на уникальность.
 Поддерживаются все основные форматы: doc, docx, odt, pdf, rtf, txt.
Поддерживаются все основные форматы: doc, docx, odt, pdf, rtf, txt. - Выбираете алгоритм, по которому будет осуществляться проверка. Нужно использовать ту систему, которую применяют в вашем учебном заведении. Просто уточните у преподавателя — это не тайна, такая информация является открытой.
- Если нужны дополнительные опции, отметьте их галочками. Можно поискать в файле следы технического кодирования и скрытый текст. Это признаки того, что документ подвергался искусственному увеличению оригинальности. Если такие «улики» обнаружены, сервис позволяет их сразу же уничтожить.
- Работа отправляется на проверку. Анализ занимает примерно 30 секунд.
- Вы получаете подробный отчет, где указан процент оригинальности, а заимствованные словосочетания выделены цветом. Здесь же можно посмотреть, откуда, по мнению умного алгоритма, вы стащили фрагменты материала. Скорее всего, практически все цитаты, теории и названия законодательных актов будут отмечены как плагиат.
 Поддерживаются все основные форматы: doc, docx, odt, pdf, rtf, txt.
Поддерживаются все основные форматы: doc, docx, odt, pdf, rtf, txt.
Antiplagius — лучший сервис определения оригинальности текста
Преимущества нашего сервиса для проверки оригинальности текста:
- В отличие от других сервисов, мы бесплатно проверяем не только большие тексты, но и документы. Работаем с текстами до 200 000 знаков и с документами до 20 Мб.
- Массовая проверка уникальности текста без регистрации. Чтобы пройти тест на уникальность, вам не нужно создавать аккаунт на сайте.
- Нам удалось учесть алгоритмы всех современных онлайн-сервисов для проверки уникальности текста, поэтому мы можем гарантировать объективность и точность полученных результатов.
- Наша программа проверки уникальности позволяет: установить процент оригинальности, увидеть заимствованные фрагменты, получить ссылки на первоисточники.
- Система работает практически мгновенно — всего 30 секунд, и отчет готов. Другие сервисы, через которые ведется массовая проверка документов, не могут похвастаться такой оперативностью. Там ваша работа попадает в длинную очередь и может стоять в ней часами.
- Мы предоставляем возможность сохранить отчет в формате pdf и поделиться результатами с друзьями в социальных сетях или используя ссылку.
 Там ваша работа попадает в длинную очередь и может стоять в ней часами.
Там ваша работа попадает в длинную очередь и может стоять в ней часами.А еще, вы сможете получить на нашем сайте и другие услуги:
- профессиональный анализ работы — поиск плагиата и технических ошибок;
- повышение уникальности;
- глубокая проверка в других сервисах (в том числе в закрытой для студентов системе «Антиплагиат.ВУЗ»).
К нам обратились уже 1 500 000 студентов, и все они получили хорошую оценку или «зачет» на защите. Мы можем помочь и вам!
Проверка уникальности контента
Почему важно знать детали создания и защиты уникального контента? Потому что это позволит защитить ваш сайт от санкций поисковых систем по причине наличия неуникального контента. Если поисковая система определит текстовое содержание вашего сайта как неуникальное и применит свои санкции, то о конкурентной борьбе за потенциальных клиентов в Интернете можно будет забыть до тех пор, пока вы не добьетесь снятия санкций.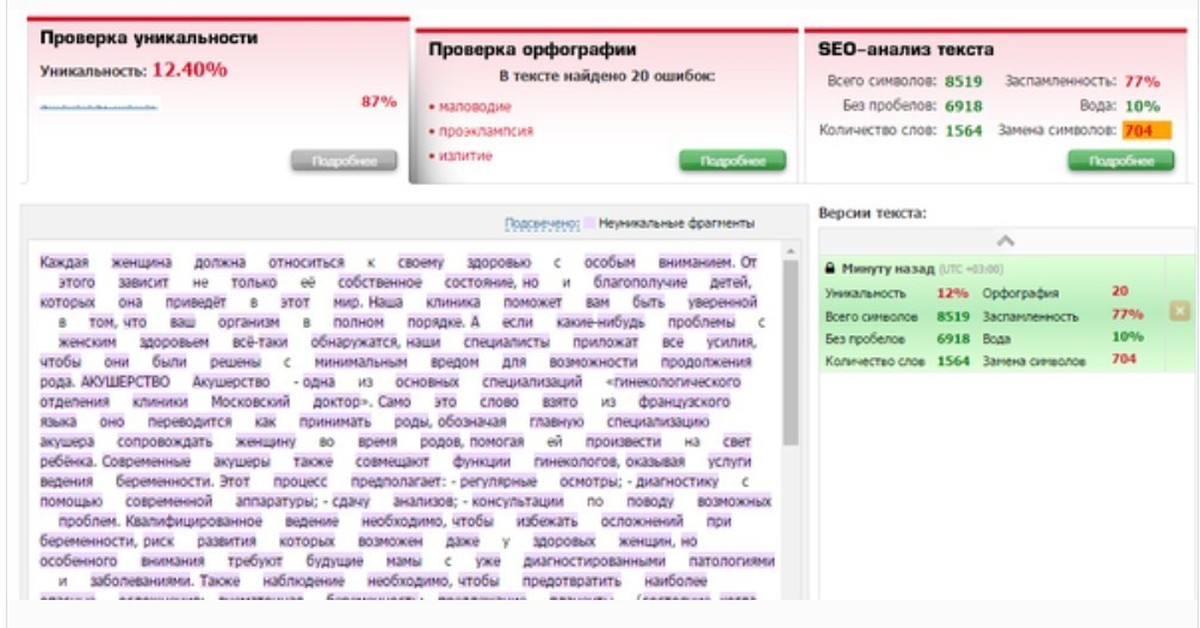
Текстовый контент (содержание) сайта — важнейший инструмент его seo-оптимизации и раскрутки. Если вы хотите на равных конкурировать в виртуальной сети, то будет недостаточно просто предоставить основную информацию о своей компании, и не заниматься написанием информативных статей.
Современные поисковые системы, к сожалению, далеки от совершенства, поэтому не могут анализировать юзабилити сайта или его дизайн для определения его качества. Другое дело — текстовая составляющая ресурса, с которой даже поисковые роботы могут работать на удовлетворительном уровне распознания и разделения качественного и уникального контента от заимствованного или несоответствующего основным требованиям современного пользователя.
Обращаясь к исследованиям поисковой системы Яндекс мы можем сразу определить, что качество контента — один из важнейших показателей ранжирования, иначе подробные исследования в этой области попросту не проводились бы.
В текстовом формате (без учета дублей) в Рунете размещено более 140 тысяч Гб данных, а с учетом дублей — более 200 тысяч Гб. Следовательно, около 60 тысяч Гб (или приблизительно 33.3%) контента — не уникален.
Информация в сети распределена неравномерно. 88% всего текста находится менее чем на одном проценте сайтов. Впрочем, мы знаем, что в мире многое распределно неравномерно, ведь даже 90% всех денег в мире принадлежит всего лишь 1% людей.
Если все слова Рунета записать на бумаге, получится куб высотой с девятиэтажный дом.
89% всех сайтов содержат совсем немного текста — в среднем по 1630 слов, как полторы журнальных страницы. На один большой сайт (таких менее 1%) приходится в среднем 18 миллионов слов — объем текста небольшой домашней библиотеки из 250-300 книг.
Орфографических ошибок и опечаток в текстах, размещенных в интернете, не так много.
Даже для тех слов, в которых часто делают ошибки (например, педиатр, агентство, геморрой), средняя доля ошибок не превышает 5-6%. Впрочем, бывает и так, что количество ошибок в одном лишь слове поражает своим количеством. Например, по исследованиям опять же Яндекса, зафиксировано около 1 200 ошибок и опечаток в запросе «одноклассники».
 Даже для тех слов, в которых часто делают ошибки (например, педиатр, агентство, геморрой), средняя доля ошибок не превышает 5-6%. Впрочем, бывает и так, что количество ошибок в одном лишь слове поражает своим количеством. Например, по исследованиям опять же Яндекса, зафиксировано около 1 200 ошибок и опечаток в запросе «одноклассники».
Даже для тех слов, в которых часто делают ошибки (например, педиатр, агентство, геморрой), средняя доля ошибок не превышает 5-6%. Впрочем, бывает и так, что количество ошибок в одном лишь слове поражает своим количеством. Например, по исследованиям опять же Яндекса, зафиксировано около 1 200 ошибок и опечаток в запросе «одноклассники».Это лишь часть данных исследования Яндекса, но и из них нас интересует, в основном, лишь первый пункт — отношение доли уникального контента к неуникальному. Напомню, что оно составляет приблизительно 67 к 33 процентам в пользу уникального содержания сайтов. Казалось бы, все не так плохо — ведь все еще уникальный контент преобладает. Тем не менее, 60 тысяч Гб информации представляют собой дубликаты уже размещенной информации.
Способы получения уникального контента
Самый очевидный способ получения уникального контента — написание его журналистами (копирайтерами).
Сканирование книг, журналов, газет. Существенные минусы — возможны претензии авторов, либо контент уже есть в сети.
Рерайт контента. Переписывание статьи своими слова, делая их уникальными для ПС и для пользователей.

Рассмотрим понятие рерайта подробнее.
Обычно под термином «рерайтинг» подразумевают работу с текстом, точнее — его литературную обработку с сохранением исходного смысла повествования. «Рерайт» же конечный результат этой работы, т.е. полностью переписанный и уникальный текст.
Несмотря на то, что рерайтинг считается более дешевой и менее творческой работой, чем его собрат — копирайтинг (то есть написание уникальных, авторских текстов), здесь тоже есть правила, которые нужно неукоснительно выполнять.
Следует сделать небольшое отступление и сказать о причинах, по которым рерайт выбирается как метод создания уникального контента. Все дело в разнообразии тематик и невозможности написания одним человеком статей на любую тему.
Если ваш интернет ресурс предназначен для рекламы и продажи специфического оборудования (например, техники для лесозаготовки), то статьи в информационном разделе не обязательно будут написаны профессионалом в деле лесозаготовки.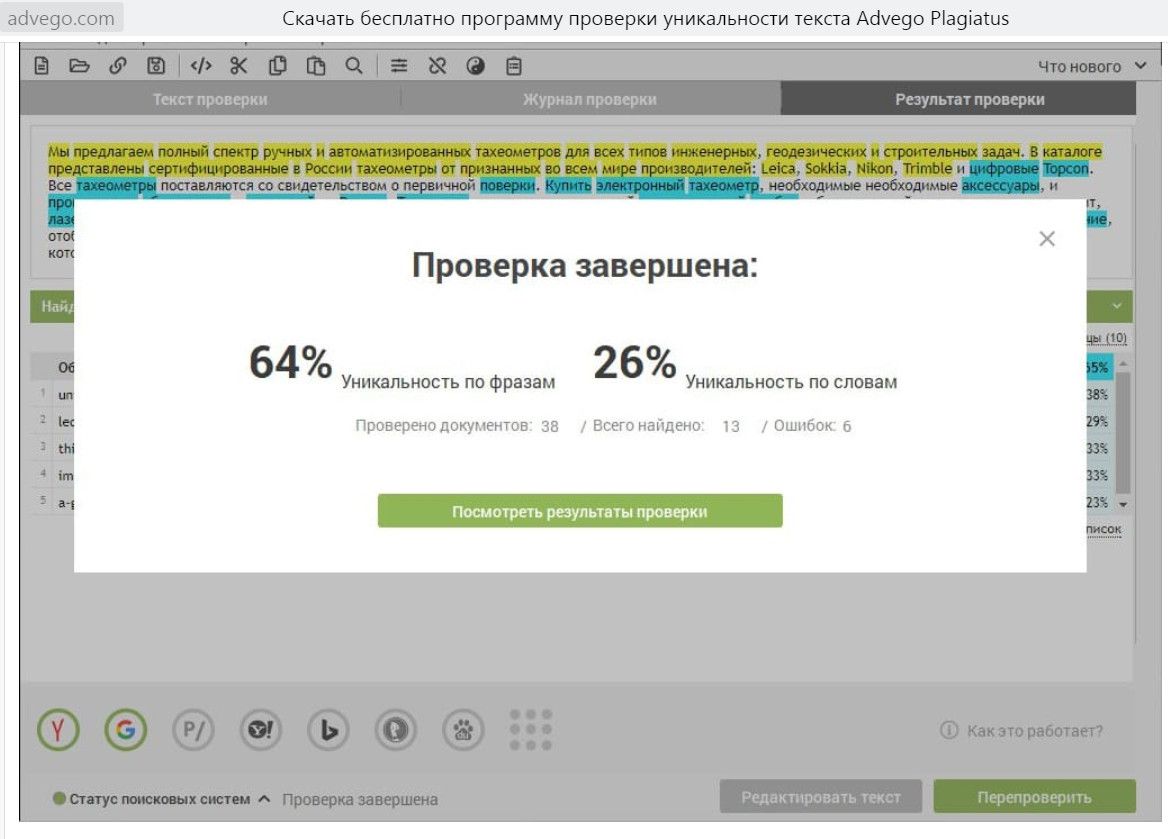
Профессиональный копирайтер при написании подобного текста скорее всего воспользуется рерайтом специализированных статей на данную тематику. Но это не означает, что в тексте лишь некоторые слова будут заменены синонимами или переставлены местами.
Как уже упоминалось, процедура рерайтинга имеет немало законов и правил, отступление от которых чревата нарушением логики в подаче материала или полную утраты смысла.
Главное правило рерайта: сначала определяются имеющиеся в тексте факты, фиксируется стиль и тип повествования, и уже на их основе создается статья.
Рассмотрим пример.
Пример рерайта
Здесь мы будем использовать прием трансформации прямой речи в косвенную — один из наиболее распространенных приемов в рерайте:
Оригинальный текст: «Я не могу, когда в доме нет мужчины, — говорила Эдит Пиаф. — Это хуже, чем день без солнечного света. Без него, в конце концов, можно обойтись — есть электричество. Но дом, в котором не висит где-нибудь мужская рубашка или галстук. .. просто убивает!»
.. просто убивает!»
Правильный рерайт: «Великая певица Эдит Пиаф утверждала, что отсутствие мужчины в доме переносить тяжелее, чем день без единого лучика солнца. Ведь солнце можно заменить электричеством. А в доме, где нет ни галстука, ни рубашки любимого мужчины — не хочется жить»
Неправильный рерайт: «Если в жилище нет мужчины, то это наводит грусть и сравнимо лишь с отсутствием дневного света. Так говорила актриса Эдит Пиаф о своем муже. Ведь свет можно заменить! Невозможно жить в доме, где нет мужских вещей»
Проанализируем ошибки во втором, не совсем верном, варианте рерайта.
Отсутствие в доме мужчины сравнивается с отсутствием света, хотя в оригинальном сообщении было сказано: отсутствие мужчины хуже дня без света.
В неправильном тексте говорится про то, что можно заменить свет. Эдит Пиаф уточняла: солнце заменимо электричеством.
Эдит Пиаф не была актрисой, и это — фактическая ошибка.
И кто сказал, что она так говорила о своем муже?
Здесь мы видим две фактически и две более тонкие ошибки, которые часто допускаются при написании рерайта неопытными копирайтерами.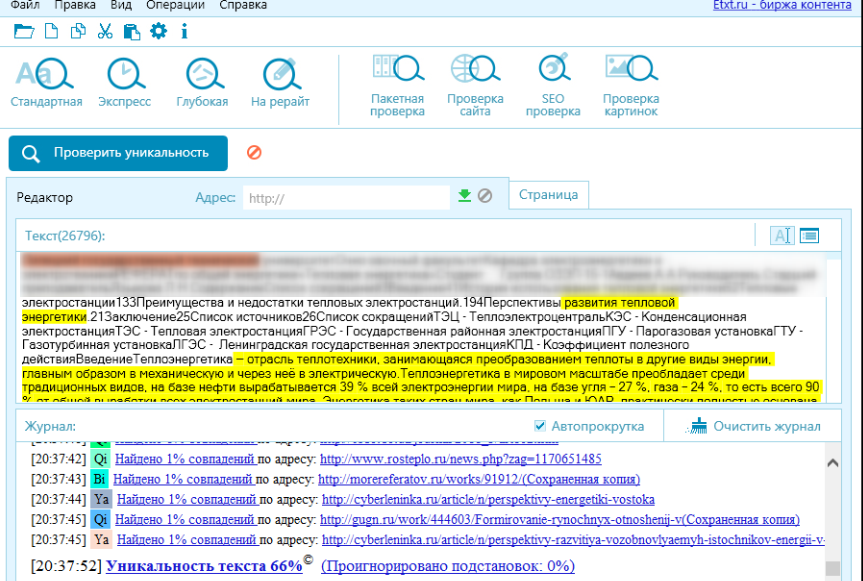
Делаем качественный рерайт. Советы и хитрости
Далее, постараемся рассмотреть процесс написания рерайт более системно и выделим основные этапы работы с ним.
Первая задача — выбрать исходный текст
Тут важны следующие вещи.
Объем. Размер исходного текста должен примерно соответствовать размеру того текста, который должен получиться.
Соответствие заявленной теме. Очень часто рерайтеры пытаются впарить заказчику статьи, которые притянуты к заказанным темам «за уши». Это происходит не из-за того, что рерайт плохой, а из-за того, что неправильно выбран исходный материал. Не жалейте времени — не так много его уйдет на то, чтобы вникнуть в тему, на которую Вы собрались писать. Обратите внимание, самые успешные рерайтеры, в основном, специализируются на весьма ограниченном круге «любимых» тем. Поверьте, это не потому, что они не могут писать на другие. Это потому, что они борются за качество рерайта. Согласитесь, не хочется получать плохие отзывы за неплохие, в общем-то, материалы.
Разберитесь в терминологии. Этот пункт прямо вытекает из предыдущего. Прежде, чем писать на новую тему — въезжайте в неё, разбирайтесь в терминах. Уясните, что холодильная ванна — это «боннета», а не «боннет» или «бонетт», что мощность двигателя измеряют в лошадиных силах, а электрическую мощность — в джоулях. Это поможет избежать совсем уж глупых ошибок, которые могут сгубить всю вашу работу.
Сформулируйте основные вопросы, на которые должна ответить ваша статья. Исходная должна отвечать на все эти вопросы. Логично?

Вторая задача — перетасовать исходный текст
Суть рерайта в том, что результирующий текст не похож на оригинал! Соответственно, давайте для начала хотя бы перекрутим то, из чего мы будем делать свой шедевр.
Самое простое, что можно сделать. Безжалостно отрубаем вступление и развязку! Теперь делим исходный текст на смысловые абзацы и меняем их местами. Также как карты тасуют. До хаотичности. Да, кстати. Рекомендуется исходник сохранить отдельно, на случай, если вы всё-таки запутаетесь в собственном тексте или из него куда-нибудь смоются смысл и логика..png?1549983278910)
Теперь, приступаем к рерайту. Рерайтить будем те самые смысловые абзацы. Да-да, каждый из них сейчас для вас должен стать отдельным текстом. Со своей логикой, не противоречащей общей. Думаю, несколько строк текста каждый сможет пересказать своими словами.
Используйте синонимы
Меняйте конструкции предложений
Разбейте длинные предложения на несколько
Укрупните или объедините короткие
Можно и порядок предложений поменять
Комбинируйте методы. Не забывайте о том, что превращение фразы «Хлеб — всему голова» во фразу «Булка — всему башня!» — это, как бы помягче сказать-то… НЕ СОВСЕМ РЕРАЙТ. Точно также, как не совсем рерайт переработка фразы «Ночь. Улица. Фонарь. Аптека» во фразу «Ночь, улица и фонарь с аптекой». Они, как говорится в законе о защите прав потребителя «похожи до степени смешения».
Заменяя слова синонимами, не потеряйте смысл. «Варочная поверхность» и «электроплита» — не всегда тождественны, а то, что все кильки являются рыбами — совсем не значит, что все рыбы — кильки. Кроме того, будет обидно вовсе потерять все умные слова. Да, и «пластиковые окна» на «пластиковые окошки» менять, как минимум, не оригинально.
Кроме того, будет обидно вовсе потерять все умные слова. Да, и «пластиковые окна» на «пластиковые окошки» менять, как минимум, не оригинально.
Третья задача. Введение и развязка
Помните, в предыдущем пункте мы с вами безжалостно отрубили несчастному исходнику начало и конец? Чем же он будет думать? Для лучшего рерайта эти две вещи — введение и послесловие пишем заново. Сами. Когда все будет готово, на всякий случай, проверяем — не получилось ли между вашими мыслями и мыслями авторов исходника опасной близости. Если одно мучительно похоже на другое — переписываем! Теперь у нашего рерайта появилось хоть что-то уникальное.
Что же такое «дубликат» и откуда он появляется в сети?
Несмотря на то, что существует такой прекрасный метод создания уникального контента, как рерайтинг (не говоря уже о создании уникального контента с нуля), в сети интернет все еще присутствует огромное количество дубликатов, нарушающих законные права их создателей на размещение исключительно на своих ресурсах.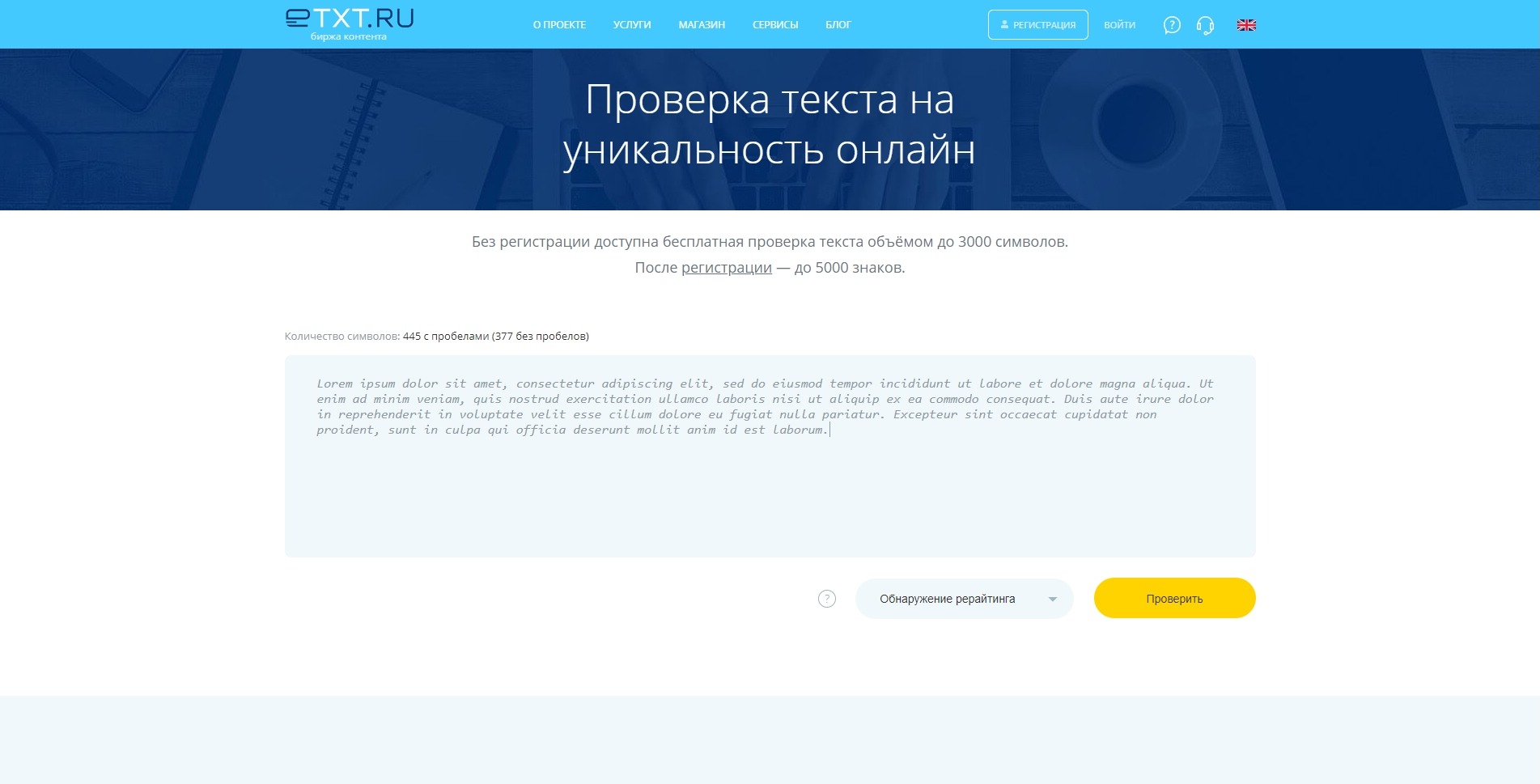
Дубликаты разделяют на полные и нечеткие.
Полные дубликаты — это документы (часть контента сайта или весь контент целиком), которые поисковые системы считают уникальными, но каждый пользователь может легко заметить их совпадение.
Нечеткие дубликаты имеют незначительные отличия даже для визуального восприятия пользователя в виде перестановки блоков навигации, новостей или других элементов сайта.
Существует немало подходов к дублированию информации, а следовательно можно дифференцировать несколько источников дубликатов контента.
Как видим, методов создания дублей весьма немало.
Для того, чтобы бороться с дубликатами, нужно сначала научиться определять их, отличать от уникального контента в сети.
Существует немало синтаксических и лексических методов определения дубликатов в сети, на которых основаны современные программы по вычислению копий исходного документа или страницы в Интернете.
Рассмотрим наиболее популярные из них.
Программы для проверки уникальности контента
1. Advego Plagiatus
Advego PlagiatusAdvego Plagiatus — программа поиска в интернете частичных или полных копий текстового документа с интуитивным интерфейсом. Плагиатус показывает степень уникальности текста, источники текста, процент совпадения текста.
Этим сервисом пользуются, наверное, все копирайтеры которые пишут тексты на заказ. Это не сервис, а программа, чем еще даже удобнее. Эта программа пока бесплатная, чем и привлекает огромное количество пользователей.
Есть некоторые нюансы, например если текст хорошо оптимизирован под определенные ключевые слова, то понятное дело что они будут повторяться и добиться уникальности в 100% практически нельзя. Нормальный уникальный текст это от 85-95%.
2.АнтиплагиатПроверить контент на уникальность достаточно просто — нужно вставить текст в окошко сервиса и нажать «Проверить». В сервисе имеется история проверок. Без регистрации разрешается проверять тексты не более 5000 символов. Есть мнения в Интернете, что база сайтов для проверки у Антиплагиата маловата, и не всегда он может вычислить скопированный текст, поиск неточный.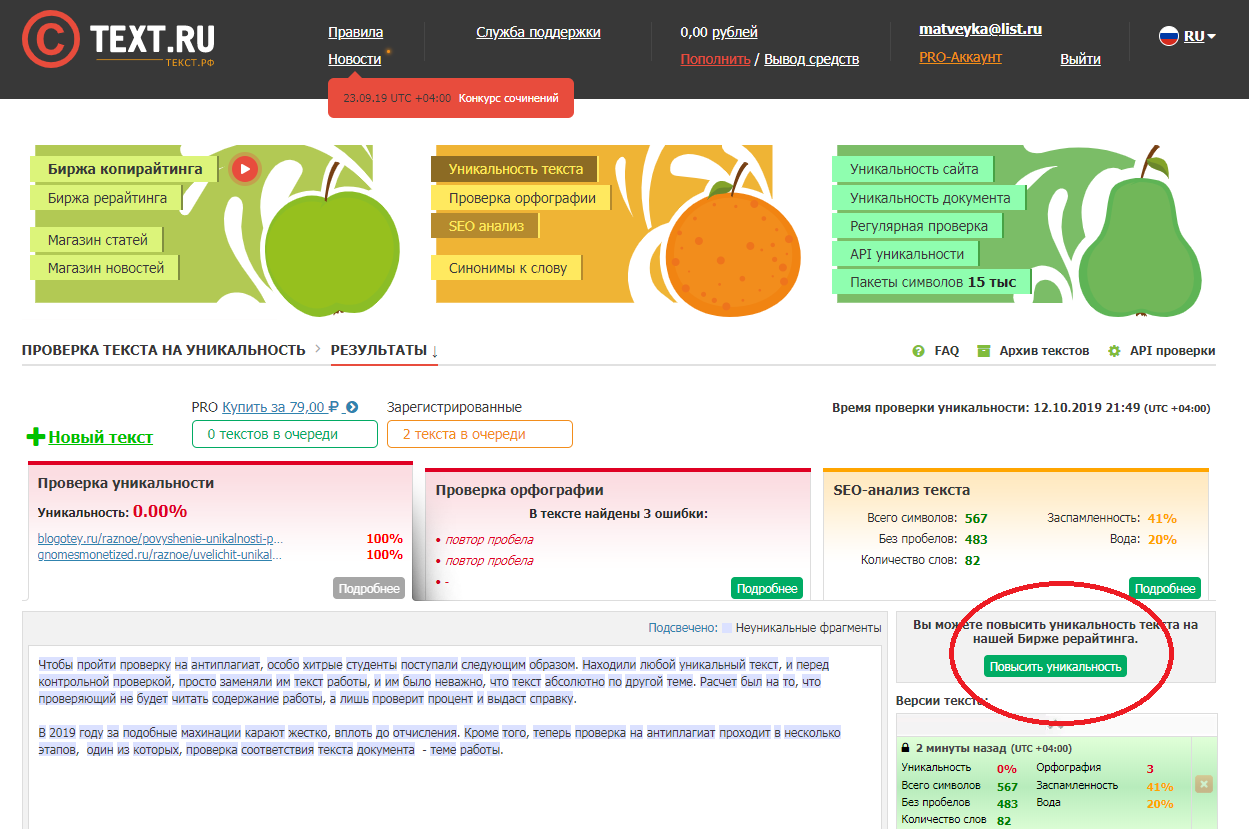 Бывает, что текст, который Антиплагиат определяет, как уникальный, при проверке другими сервисами находится на каком-нибудь сайте.
Бывает, что текст, который Антиплагиат определяет, как уникальный, при проверке другими сервисами находится на каком-нибудь сайте.
Простенький онлайн сервис (проверяет только тексты в сети), показывающий копии ваших документов во всемирной паутине WWW. Разрабатывался для европейских пользователей, но вполне успешно пользуется популярностью и в рунете. Предварительная публикация статьи на сайте для проверки — это неудобство, поэтому заказчикам статей у копирайтеров этот сервис может быть не интересен. В адресную строку вводите адрес для проверки страницы на уникальность, а сервис выведет список похожих документов в сети.
4. ПоисковикиКлючевую фразу текста в кавычках вводим в поисковик для точного поиска. Точная цитата (кавычки) поддерживаются почти всеми поисковиками. Далее смотрим, нет ли совпадений на других сайтах. Проделать эту процедуру нужно несколько раз, выбрав разные цитаты текста из статьи, при этом свои запросы следует ограничивать 3-6 словами и 90 символами. Также из текста стоит убрать все разделители (кроме запятой и точки), поисковиками они не учитываются.
Также из текста стоит убрать все разделители (кроме запятой и точки), поисковиками они не учитываются.
Самое простое — вставить небольшие отрывки из проверяемой статьи последовательно в поисковики. Это самый простой тест на уникальность текста, но самый долгий и нудный. Недостаток у него один — максимальный фрагмент текста для поиска небольшой, 160-255 знаков с пробелами.
5. AllsubmitterУдобная программа, использующая алгоритм проверки с помощью фрагментов текста по точным вхождениям в строке поисковых систем (предыдущий метод).
Кроме того, может использовать базу приложения Copyscape для проверки дубликатов.
Чрезвычайно удобна автономностью своей работы (достаточно лишь ввести ссылку на сайт, уникальность контента, на котором необходимо проверить), а также гибкими настройками.
Контент можно проверять как в форме текста, так и уже выложенный на веб-страницах.
Как защитить свой контент?
Защита контента — непростая задача, которая требует разумного подхода веб-мастера к развитию своего сайта.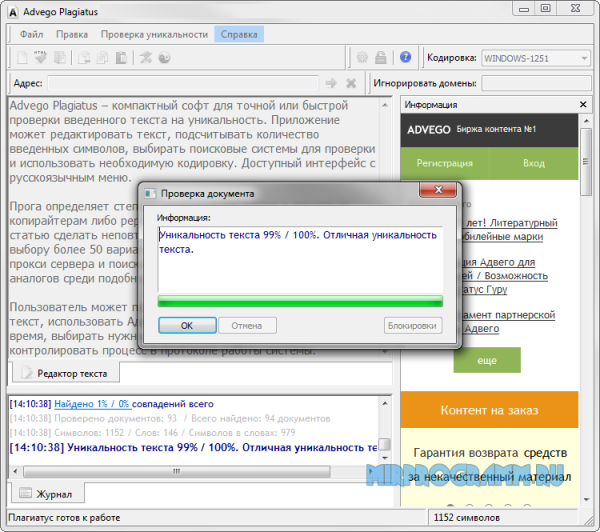 Несмотря на то, что поисковые системы призваны помогать каждому сайту в его развитии, в ситуации с тотально распространенным копированием информации они могут сыграть злую шутку с авторами уникального контента.
Несмотря на то, что поисковые системы призваны помогать каждому сайту в его развитии, в ситуации с тотально распространенным копированием информации они могут сыграть злую шутку с авторами уникального контента.
В первую очередь, здесь следует упомянуть трастовость сайтов для поисковых систем. Например, крупные новостные порталы постоянно размещают контент, который в последствии копируется на множество сайтов по всей сети Интернет. Почему же эти крупные новостные сайты не теряют трастовость в поисковых системах?
Все дело в ссылках. Если любой веб-мастер менее трастового ресурса поставит ссылку на крупный новостной ресурс после размещения его контента, то это послужит лучшей защитой от копирования в восприятии поисковой системы.
Безусловно, не каждый веб-мастер окажется порядочным человеком, который ценит авторские права новостного ресурса, с которого он взял контент.
Как быть в этом случае? Решение лежит на поверхности — необходимо размещать тот же контент на менее трастовых сайтах со ссылкой на оригинал, источник. Чем больше таких ссылок получит источник, тем меньше поисковая система будет сомневаться в его авторском праве на этот контент.
Чем больше таких ссылок получит источник, тем меньше поисковая система будет сомневаться в его авторском праве на этот контент.
Платное размещение статей на различных ресурсах сегодня не проблема для любого веб-мастера, поэтому такое решение оптимально для многих крупных новостных ресурсов, пример которых мы рассмотрели.
Кроме того, что при такой системе владельцы крупных новостных порталов могут быть уверены, что их репутация не пострадает за счет более мелких и менее добросоветсных ресурсов, владельцы менее трастовых ресурсов имеют возможность заработать на платном размещении статей со ссылкой на первоисточник контента.
Существуют и другие методы предотвращения воровства контента вашего сайта, которые можно отнести к программным. Программные методы подразумевают защиту контента от копирования на уровне скрипта сайта, в котором прописываются специальные команды или в котороый добавляются некоторые плагины. Например, для блогов системы WordPress существует плагин WP-CopyProtect, который попросту запрещает выделение текста на странице, а так же не дает использовать клики правой кнопкой мыши.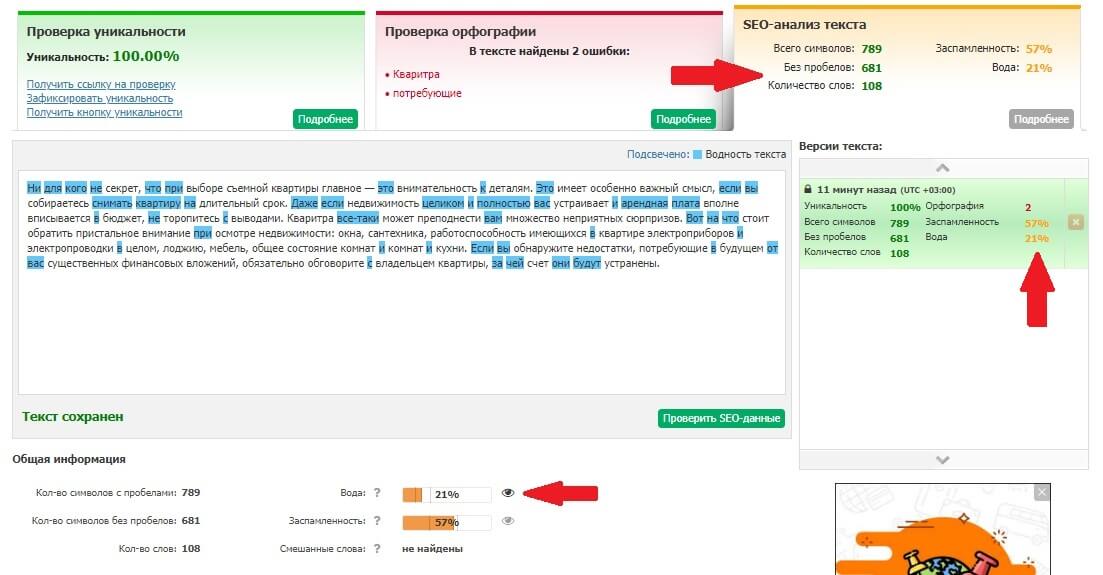
Но минус такого подхода состоит в том, что многие пользователи захотят скопировать ваш контент без всякого злого умысла, например, для прочтения в печатном варианте — и в этом случае их ждет разочарование.
Кроме того, современная судебная система Украины предполагает защиту авторских прав пользователей веб-ресурсов. Но и здесь есть существенные минусы:
Во-первых, законодательство Украины не будет рассматривать дело в том случае, если владелец сайта, который продублировал ваш контент, будет зарегистрирован на сервере другой страны.
Во-вторых, судебный процесс может сильно затянуться и отобрать огромное количество средств, в частности направленных на сбор доказательств и наем адвокатов.
В случае, если вы видите обращение к «букве закона» единственно правильным решением, советую обратиться напрямую к владельцу сайта, продублировавшего ваш контент с претензией, в случае невыполнения которой обращаться к его хостеру.
Но так или иначе, размещение контент на менее трастовых сайтах со ссылкой на себя дает самый адекватный результат и лучшие гарантии избежания санкций от поисковых систем. При этом вам не нужно производить эксперименты на своих посетителях, запрещая им копировать контент.
При этом вам не нужно производить эксперименты на своих посетителях, запрещая им копировать контент.
Суммируя все вышесказанное, хотелось бы напомнить, что работа с контентом вашего сайта — это не только его написание самостоятельно, заказ у профессиональных копирайтеров или качественный рерайт, но и постоянный контроль и защита его от дублирования другими сайтами.
Другими словами, если вы создали новый сайт, который будет представлять вашу компанию в Интернете, то для его конкурентоспособности необходимо постоянно следить за уникальностью контента, обновлять его, а также предпринимать активные меры по продвижению — иначе ваш сайт рискует остаться незамеченным вашими потенциальными клиентами, попав под санкции поисковых систем.
Если все вышеперечисленное кажется вам слишком сложным или даже недостижимым, то вы всегда можете довериться профессионалам компании Netpeak, которые проведут весь комплекс работ с контеном со всей ответственностью и профессионализмом.
Как проверить текст на уникальность: 10 онлайн сервисов
Уникальность текста – один из основных параметров, на которые обращают внимание поисковые системы при ранжировании сайтов в выдаче SERP. Однако не все относятся добросовестно к чужим текстам, и не редко можно встретить ситуацию, когда интересный материал растиражирован в сети интернет на десятках сайтах. Проверка уникальности опубликованного на сайте текста может быть полезна не только с точки зрения ранжирования. Найдя дубликаты и написав об этом владельцам ресурсов, вы можете потребовать размещение ссылки на ваш сайт, как на сайт источник материала. Это не гарантирует, что вам ответят и поставят ссылку, однако этот способ можно использовать как бесплатный метод получения обратных ссылок на сайт.
Однако не все относятся добросовестно к чужим текстам, и не редко можно встретить ситуацию, когда интересный материал растиражирован в сети интернет на десятках сайтах. Проверка уникальности опубликованного на сайте текста может быть полезна не только с точки зрения ранжирования. Найдя дубликаты и написав об этом владельцам ресурсов, вы можете потребовать размещение ссылки на ваш сайт, как на сайт источник материала. Это не гарантирует, что вам ответят и поставят ссылку, однако этот способ можно использовать как бесплатный метод получения обратных ссылок на сайт.
И здесь возникает вопрос о том, где и как проверить текст на уникальность. Для этого удобнее всего использовать онлайн сервисы, так как установленные программы все равно требуют наличие интернет-соединения при запуске проверки. Удобнее всего, когда сервис не требует регистрации и предоставляется бесплатно, так на проверку нужного текста или текстов затрачивается минимум усилий.
Таких онлайн сервисов можно найти достаточно много, однако каждый из них имеет специфику и свой набор функций. Например:
Например:
- некоторые проверяют ограниченное количество текстов без регистрации,
- некоторые имеют возможность проверки только текста, а другие могут сделать проверку по ссылке на источник,
- отдельные сервисы предоставляют возможность проверки не одного текста или ссылки, а массовой проверки разделов сайта и даже всего сайта.
- некоторые проверяют только техническую уникальность, а другие способны найти и синонимайз.
Здесь мы представляем краткий обзор 10 самых популярный онлайн сервисов для проверки текста на уникальность. Чтобы оценить их работу, мы проверили в каждом из них данный текст, который писался исключительно как копирайт. Посмотрим, что же скажут о нем сервисы.
10 самых популярных сервисов для проверки уникальности текста
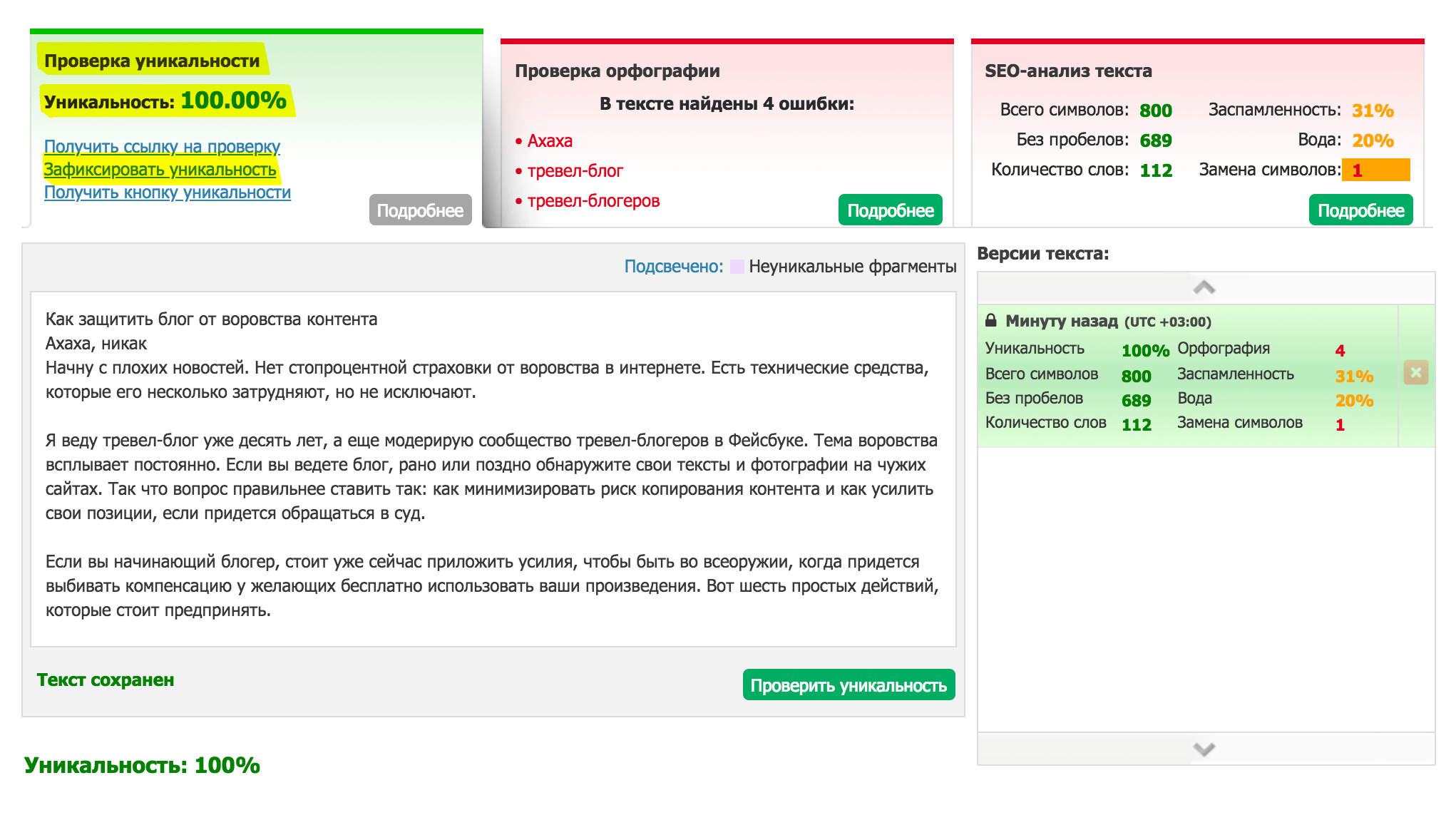
1. http://content-watch.ru/ — удобный сервис, который предоставляет возможность проверки текстов, сайтов, а также возможность защиты уже опубликованных текстов с помощью автоматической их проверки сервисом по расписанию.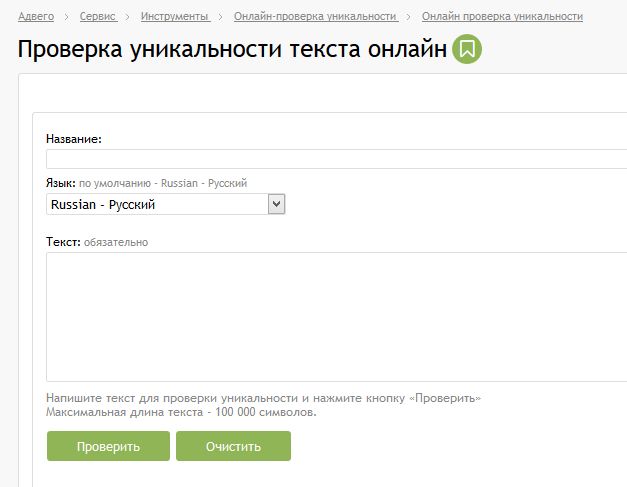 Для использования полноценного функционала требуется регистрация. Наш текст был оценен в 100%.
Для использования полноценного функционала требуется регистрация. Наш текст был оценен в 100%.
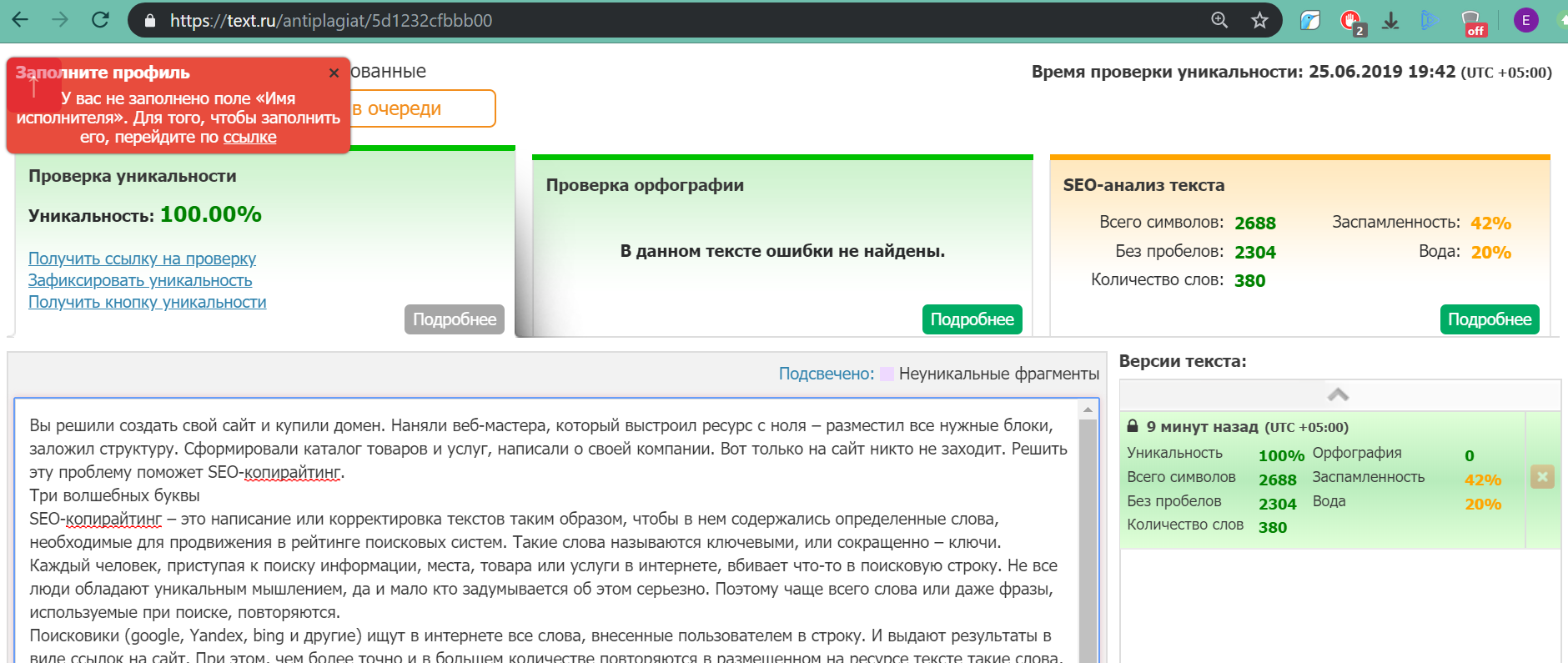
2. text.ru — также бесплатный сервис для проверки текста на уникальность. Он более медленный, так как на проекте висит много других сервисов: проверка орфографии, биржа копирайтинга и пр. Без регистрации возможно проверить только текст, после ее прохождения доступна проверка по url. Уникальность нашего текста составила 100%. Вода — 19%. Заспамленность 57%.
3. copyscape.com — известный западный сервис по проверке уже опубликованных текстов. Удобен тем, что подсвечивает неуникальный текст на стороннем сайте. Можно защитить свой сайт с помощью специального баннера сервиса:
Сopyscape не нашел совпадений по данному тексту.
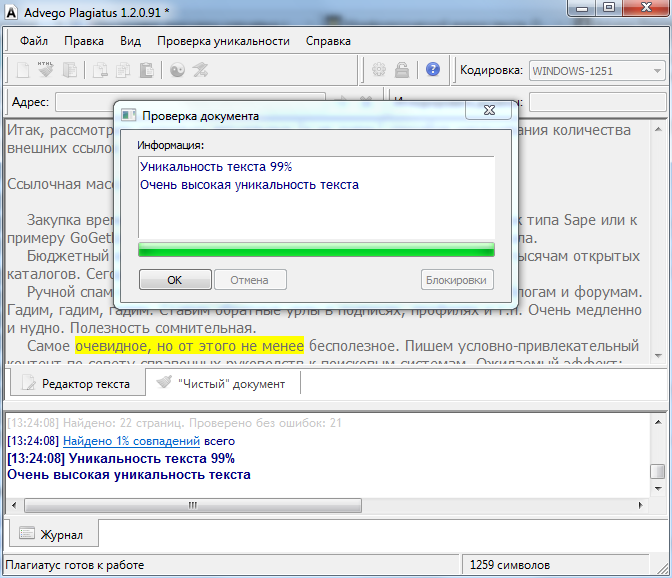
4. advego.ru — когда-то самая популярная программа по проверке текстов на уникальность, которая уже уходит на второй план. Его минус в том, что требуется установка программы, многие поисковые системы блокируются при проверке и даже иногда появляется капча.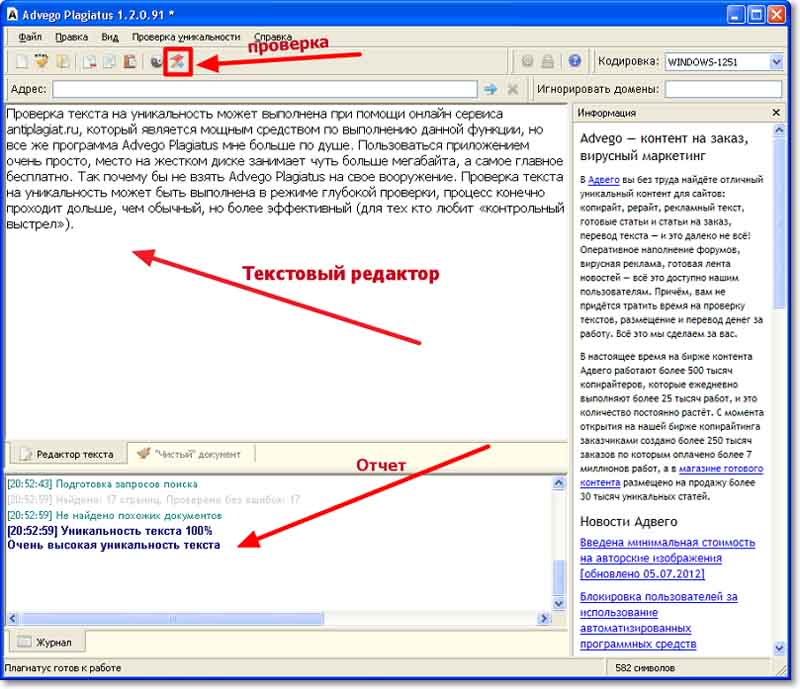 Адвего оценил текст (глубокая проверка) на 94% / 46% — возможно, рерайт; быстрая провека — 97% / 55%.
Адвего оценил текст (глубокая проверка) на 94% / 46% — возможно, рерайт; быстрая провека — 97% / 55%.
5. findcopy.ru — бесплатный сервис онлайн проверки текстов на уникальность, проверки по url страницы, семантического анализа текста (количество слов, знаков, параметра тошноты текста и плотности ключевых слов и словосочетаний). Удобно, что можно посмотреть, насколько сервис загружен в данный момент. Findcopy.ru является переработанным проектом miratools.ru биржи Миралинкс. Наш текст уникален на 100%.
6. pr-cy.ru онлайн сервис для проверки уникальности бесплатно. Из минусов – дополнительно при каждой проверке требуется вводить капчу. На самом проекте можно найти еще много других инструментов для проверки параметров сайтов, ссылок и контента. Здесь уникальность показала 97%.
7. antiplagiat.ru — доступна проверка текста, а также его загрузка через файл, но все только после предварительной регистрации на сайте. Бесплатные возможности сервиса очень ограничены, зато имеется много тарифных планов для их расширения. Наш текст уникален на 100%.
Наш текст уникален на 100%.
8. plagiarisma.ru — преимущество сервиса в том, что проверка возможна для более чем 190 языков, однако функционал без регистрации немного ограничен (проверка возможно до 2000 символов). Возможна проверка текста, по url, а также текста из загруженного файла. Показатель уникальности данного текста — 99%
9. istio.com — преимущество сервиса в наличии расширенной формы для проверки текстов, где есть возможность выделять ключевые слова, проверить орфографию, водность, посмотреть карту текста. В нашем тексте он оценил водность — 46%, а вот показателя уникальности не нашлось.
10. antiplagiat.su — еще один сервис для проверки уникальности текстов. Не понравилось в нем то, что сохраняются общедоступными последние проверки в сервисе, а раздел этот не закрыт от индексации. То есть, проверив здесь текст, можно автоматически сделать его неуникальным. Поэтому здесь мы свой текст проверять не стали.
В своей работе мы используем 2 сервиса — copyscape. com, для проверки уже опубликованных и для англоязычных текстов, а также content-watch.ru для массовой проверки или проверки еще не опубликованных текстов. Ведь привычнее всего работать там, где устраивает функционал и качество работы сервиса.
com, для проверки уже опубликованных и для англоязычных текстов, а также content-watch.ru для массовой проверки или проверки еще не опубликованных текстов. Ведь привычнее всего работать там, где устраивает функционал и качество работы сервиса.
Вернуться
Проверка уникальности ☑️ текста. Обзор сервисов
Девиз SEO последних 3-4 лет — “Контент создается для людей, а не для поисковых систем”.
Каждое обновление алгоритмов поисковиков дает понять, что контент оценивается с позиции пользователя: конкретики и сути в ответе, а не 10 прямых вхождений с водой. Посетитель вбивает запрос, смотрит SERP, кликает по ссылкам и от каждого сайта из 10 ожидает получить удовлетворительный интент.
С 2017 года авторы ориентируются на LSI-копирайтинг, а написание SEO-текстов в их первоначальном понимании уже не актуально. Но любой текст перед публикацией оптимизатор проверят в специальных автоматических сервисах-помощниках. Уникальность, заспамленность, тошнота, читабельность, ключевые вхождения, — термины, которыми оперируют контент-маркетологи, SEO-специалисты, копирайтеры и другие эксперты по работе с контентом. Текстовые сервисы помогают выявить недочеты и улучшить статьи, как бы ни хаяли Главред Ильяхова.
Текстовые сервисы помогают выявить недочеты и улучшить статьи, как бы ни хаяли Главред Ильяхова.
В статье я разберу главные показатели текстовой адекватности и проведу эксперимент — проверю часть этого текста в каждом бесплатном сервисе и сравню показатели.
В этой части — уникальность, тошнотность, читабельность и водность. А во 2 — грамотность, ключевые слова, структуру текста и другие полезные инструменты для работы.
1. Уникальность
Уникальность = оригинальность текста.
Максимум — 100%, и стремиться к нему нужно. Но если у вас очень популярная тема, узкоспециализированная ниша, или товар со специфическими характеристиками, допускается показатель уникальности от 85% (лучше 90%).
Сервисы для проверки:
Проверяет уникальность, проводит SEO-анализ текста, находит грамматические ошибки. Для ускорения проверки рекомендуется регистрация. Доступна также платная версия с ускоренной проверкой.
Рис. 1 — Проверка уникальности в text..jpg) ru
ru
Регистрация обязательна. Рассчитывает уникальность текста, количество ключевых вхождений. Подбирает синонимичные фразы. Возможна генерация ТЗ для копирайтеров.
*Что интересно — 1я редакция статьи писалась в мае 2019 и тогда после проверки уникальности я получила другие цифры (см. сравнение ниже).
Рис. 2 — Проверка уникальности в tools.pixelplus.ru
Есть веб и десктопная версии программы.
Также можно провести семантический анализ текстов: проверить орфографию, подсчитать водность, тошноту, плотность ключевых слов и их частотность. Выявить стоп-слова.
Рис. 3 — Проверка уникальности в advego.com
После нажатия на кнопку “Посмотреть результаты проверки” сервис показывает список сайтов, которые содержат похожий на проверяемый контент.
Рис. 4 — Проверка уникальности в advego.com
По моему опыту, это самый “зверский” сервис проверки — здесь всегда самый низкий процент уникальности. Именно поэтому в работе я ориентируюсь только на него. Там, где прочие сервисы покажут 100%, Адвего выдаст реальную цифру в районе 90+%.
Там, где прочие сервисы покажут 100%, Адвего выдаст реальную цифру в районе 90+%.
Без регистрации можно проверить документы объемом до 5000 символов.
Вычисляет тошноту, воду, время на чтение, плотность распределения ключевых слов. Определяет вес главной страницы сайта, релевантность заголовка и тегов h2, подсвечивает частотные слова. Показывает источники с похожим контентом.
Рис. 5 — Проверка уникальности в pr-cy.ru
Функционал позволяет проверить бесплатно без регистрации тексты длиной 3000 символов до 5 раз в сутки.
По моему опыту, это наиболее лояльный сервис из всех в статье.
Рис. 6 — Проверка уникальности в content-watch.ru
Регистрация обязательна. Система проверяет уникальность документа с использованием специализированных библиотек.
На бесплатной основе доступна только краткая версия отчета.
Рис. 7 — Проверка уникальности в antiplagiat.ru
Незарегистрированные пользователи имеют возможность проверить тексты до 3000 знаков на уникальность либо рерайт. Время ожидания — до 15 минут. Проводится SEO-анализ.
Время ожидания — до 15 минут. Проводится SEO-анализ.
После регистрации появляется возможность проверки текстов до 5000 знаков.
Рис. 8 — Проверка уникальности в etxt.ru
Для проверки текста от 1000 символов нужна регистрация.
Онлайн-сервис вычисляет уникальность, тошноту, водность. Проверяет орфографию.
Содержит массу других полезных инструментов для SEO и пользовательского анализа сайтов.
Рис. 9 — Проверка уникальности в be1.ru
Доступен после регистрации, прохождения теста, творческого задания и одобрения модератором.
Лимит — 5 документов в сутки. Больше — только на платной основе.
Рис. 10 — Проверка уникальности в contentmonster.ru
Для наглядности внесу цифры в таблицу и сравню показатель уникальности.
Результаты:
| Сервис | Уникальность (%) |
| text.ru | 100 |
| tools. pixelplus.ru | 93,9 |
| advego.com | 92 |
| pr-cy.ru | 98 |
| content-watch.ru | 100 |
| antiplagiat.ru | 100 |
| etxt.ru | 100 |
| be1.ru | 93 |
| contentmonster.ru | 100 |
Я проверила одну и ту же часть текста в 9 разных сервисах и получила разброс уникальности 92-100%. Для текста объемом 1127 символов б/п расхождение 8% критичное, хоть оригинальность и находится в допустимых пределах. Потому что чем объемнее будет статья, тем ниже станет уникальность. И расхождение между сервисами увеличится.
Жестокий Адвего редко дает 100% тексту — даже когда он взят полностью из головы, все равно встретятся фразы, которые найдутся во многих текстах, потому что люди используют устойчивые выражения или спецтермины, и это нормально.
Пример таких выражений из моего текста — «алгоритмы поисковых систем«, «SEO-специалисты«, «написание SEO-текстов» и др.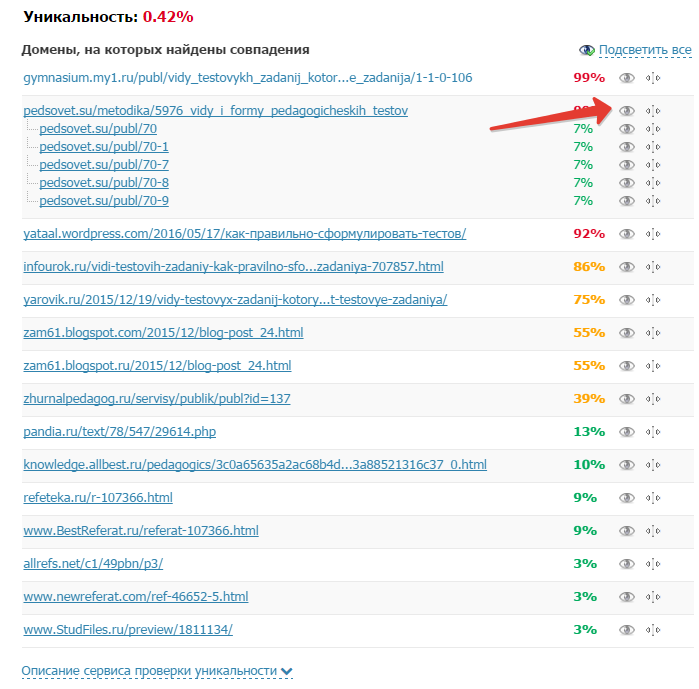 . Для Адвего лучше смотреть на 2 цифру — уникальность по словам. Чем она выше, тем больше разнообразных и отличных от общепринятых интернетовских слов вы используете в своем тексте (синонимы, похожие слова).
. Для Адвего лучше смотреть на 2 цифру — уникальность по словам. Чем она выше, тем больше разнообразных и отличных от общепринятых интернетовских слов вы используете в своем тексте (синонимы, похожие слова).
На какой сервис ориентироваться в работе — ваше личное решение.
2. Тошнота
Это процент насыщенности публикации ключевыми словами (оптимально до 10%). Естественность текста или академическая (классическая) тошнота документа рассчитывается как квадратный корень из количества повторений или фраз.
Норма — до 10%.
Инструменты:
Онлайн сервис проверки SEO-показателей текста.
Рис. 11 — Показатели тошноты текста, advego.plagiatus
Используется для статей и опубликованных материалов. Позволяет определить тошноту страниц веб-площадок.
В пункте “Уникальность” выше на рисунке 5 уже обозначена тошнота = 2%.
Помимо тошноты подсчитывает воду, заспамленность, количество знаков с пробелами и без, выискивает слова-паразиты, анализирует ключи. Проверяет правописание, распознает тематику статьи.
Проверяет правописание, распознает тематику статьи.
Рис. 12 — Показатели тошноты текста, istio.com
Кроме общей тошноты документа, подсчитывает тошноту по каждому слову-повтору.
Рис. 13 — Показатели тошноты текста, be1.ru
Сервис ориентирован на поисковик Яндекс и алгоритм “Баден-Баден”.
Определяет заспамленность, водность, тошноту, переоптимизацию, удобочитаемость текстов и др..
Рис. 14 — Показатели тошноты текста, turgenev.ashmanov
Десктопная программа студии Дениса Каплунова. Определяет статистику использования ключевых слов, показатель тошноты, при заданных параметрах позволяет рассчитать стоимость работы.
Рис. 15 — Показатели тошноты текста, textus.pro
Снова записываю данные в таблицу.
Результаты:
| Сервис | Тошнота классическая (%) | Тошнота академическая(%) |
advego. com com | 2 | 7,4 |
| pr-cy.ru | 2 | — |
| istio.com | 2,64 | — |
| be1.ru (по самому частотному слову) | 2 | 2,4 |
| turgenev.ashmanov | 2 | 9,16 |
| textus pro | 2,65 | — |
Проверка текста в 6 сервисах дала разброс значений классической тошноты 2-2,65%. Академической — 2,4-9,16% (данные всего 3х сервисов). Все цифры в пределах нормы (с поправкой на небольшой объем текста). Чем больше символов, тем выше будет тошнота.
Адвего — мой ориентир (предельное значение — 4-5%). Не потому, что Адвего дал минимальный показатель, а потому, что в нем я проверяю и другие текстовые метрики. Ведь в одном сервисе работать удобнее, чем сразу в нескольких.
Для более точной проверки лучше учесть данные пары сайтов, особенно если текст большой (от 5000 символов).
3. Читабельность
“Текст пишется для людей, а не для поисковых систем”. Публикация должна быть:
Публикация должна быть:
- читабельна;
- понятна;
- легко восприниматься.
Инструменты для проверки:
Вычисляет “Читабельность” материала, исходя из длины слов и предложений, количества терминов и абстрактных слов, структуры предложений. Указывает предполагаемую возрастную категорию аудитории, которая будет читать текст. Чем выше значение индекса, тем сложнее текст.
Рис. 16 — Показатели читабельности текста, readability.io
Доступны 2 вкладки: чистота текста и читаемость. Сервис избавляет от словесного мусора: воды, стоп-слов, канцеляризмов, штампов, вычурности. Подсвечивает некорректные слова и выражения, предлагает перефразировать и заменить их. Максимальный балл — 10. “Проходным” для читаемости негласно принято считать 8.
Рис. 17 — Показатели читабельности текста, glvrd.ru
“Тургенев” рассчитывает индекс удобочитаемости и общий риск текста, который имеет обратную от Главреда градацию — чем меньше баллов набрал материал, тем лучше.
Рис. 18 — Показатели читабельности текста, turgenev.ashmanov
Сравниваю показатели в таблице. Результаты:
| Сервис | Читабельность (баллы) |
| readability.io | 13,64 |
| glvrd.ru | 9,5 |
| turgenev.ashmanov | 15,6 |
10 — максимум, который может набрать публикация по Главреду.
У Тургенева чем выше цифра, тем сложнее читается текст. 15 — условный проходной балл для специфических сфер (для юридических тем оценка может быть гораздо выше 15, и это приемлемое значение).
Мне привычнее и понятнее ориентироваться по Главреду, т. к. в нем я проверяю чистоту. Но знаю специалистов, для которых Тургенев — основа.
Уникальность контента: что это такое
Создание контента
Происхождение уникального контента подразделяется на три вида:
- копирайтинг — самостоятельное написание статей сотрудниками продвигаемой организации или заказ текстов у копирайтеров. В текстах должны содержаться ключевые слова, выбранные для поисковой оптимизации сайта.
- рерайтинг — переписывание статьи-источника другими словами с сохранением ее смысла и структуры.
- скан — сканирование оффлайн материалов (при профессиональной раскрутке сайтов не допускается, так как нарушает авторские права создателей).
 В текстах должны содержаться ключевые слова, выбранные для поисковой оптимизации сайта.
В текстах должны содержаться ключевые слова, выбранные для поисковой оптимизации сайта.Проверка уникальности
Перед добавлением новых текстов на сайт их необходимо проверить на уникальность. Для этого разработан ряд программных методов. Их классифицируют на 2 группы: on-line сервисы и утилиты, устанавливаемые на компьютер.
On-line сервисы
В данную группу входят такие ресурсы, как copyscape, miratools, антиплагиат и др.
- Copyscape. Проект создан компанией Indigo Stream и работает по принципу поисковых машин. Позволяет проверять тексты, размещенные на сайте (URL необходимо вводить в поле поиска). В качестве платных услуг доступен периодический мониторинг страниц для выявления плагиата, пакетное исполнение проверок (одновременно до 10 тысяч страниц), анализ оффлайновых материалов.
- Miratools. Отечественный сервис от биржи статей Miralinks. В бесплатной версии позволяет проверять не более 10 текстов в сутки размером до 3 тысяч символов. После анализа неуникальные фрагменты статьи выделяются красным цветом, при наведении на них курсора всплывает окно со ссылками, по которым найдены похожие фразы. В платном модуле доступна проверка URL, пакетный режим, планировщик, отправление результатов на e-mail. Анализ текста занимает не более 10 минут.
- Антиплагиат. Для статей размером до 5 тысяч символов используется быстрая проверка, для объемных документов до 20 Мб в форматах DOC, TXT, HTML, RTF, PDF — подробная (доступна зарегистрированным пользователям).
Устанавливаемые на компьютер
- Double Content Finder (DC Finder). Продукт биржи копирайтеров TextBroker. Текст для проверки можно загрузить из txt-файла, добавить из буфера обмена или указать ссылку. После поиска (занимает 3-10 минут) утилита сообщает, что текст уникален, или показывает перечень ссылок (до 50), где встречаются дубли. Программа запускается из файла exe и работает автономно (без настроек, параметров уточнения запросов и т.д.).
- Advego Plagiatus. Продукт текстовой биржи Advego. Показывает уникальность текста (до 10 000 символов), источники и процент совпадения. Etxt. Утилита разработана биржей контента Etxt. Позволяет искать совпадения по копиям, сохраненным поисковыми системами, в пакетном режиме, определять процент уникальности, редактировать дублированные фрагменты, настраивать число выборок, слов в шингле и другие параметры поиска, вести историю проверок.
 Программа запускается из файла exe и работает автономно (без настроек, параметров уточнения запросов и т.д.).
Программа запускается из файла exe и работает автономно (без настроек, параметров уточнения запросов и т.д.).Другие термины на букву « У»
Все термины SEO-ВикипедииТеги термина
Голосов 5, рейтинг 5 | |||||||||
Проверка курсовой на уникальность
Из-за особенностей системы российского образования, проверка на уникальность нужна даже в том случае, если ты писал работу сам.
 Важно понимать, что процент оригинальности — формальный показатель, который зависит и от самой программы проверки.
Важно понимать, что процент оригинальности — формальный показатель, который зависит и от самой программы проверки.Для большинства российских университетов стандартом проверки является программа «Антиплагиат.вуз». Университетская проверка — самая строгая. При написании курсовой работы стоит учитывать эти три особенности «Антиплагиат.вуза»:
После проверки работы загружаются в общую базу «Кольцо вузов». Это значит, что написанную тобой работу будет нельзя сдать повторно не только в твоём университете, но и в большинстве вузов России. Поэтому нельзя использовать даже те работы, которых в открытом доступе нет (например, курсовые работы знакомых). Использование собственных старых работ система тоже считает плагиатом — в этом случае нужно доказывать преподавателю свою правоту.
«Антиплагиат.
вуз» считает перефразирование плагиатом. С последними обновлениями в систему был добавлен модуль проверки «Перефразирование» — теперь система проверяет весь текст в целом. Подстановка синонимов и переписывание иными словами теперь не дают высокой уникальности.Доступ к «Антиплагиат.вуз» есть только в университете, чаще всего — только у преподавателей. Ты не сможешь проверить свою работу дома, и купить доступ к этой системе нельзя. Если у преподавателя возникают вопросы к оригинальности твоей работы — проси подробный отчёт. Повысить уникальность вслепую практически невозможно (только если знаешь наверняка, что где-то ты схитрил).
 вуз» считает перефразирование плагиатом. С последними обновлениями в систему был добавлен модуль проверки «Перефразирование» — теперь система проверяет весь текст в целом. Подстановка синонимов и переписывание иными словами теперь не дают высокой уникальности.
вуз» считает перефразирование плагиатом. С последними обновлениями в систему был добавлен модуль проверки «Перефразирование» — теперь система проверяет весь текст в целом. Подстановка синонимов и переписывание иными словами теперь не дают высокой уникальности.Есть и хорошие новости: если ты писал работу сам, следуя нашим советам, проверки на плагиат можно не бояться. В крайнем случае понадобится точечный рерайт, если уникальность нужно будет поднять на 5-10%.
Что неизбежно снижает уникальность
Даже если ты написал работу полностью сам, небольшой процент заимствований неизбежен. Эти четыре вещи негативно влияют на уникальность:
Эти четыре вещи негативно влияют на уникальность:
- Титульный лист. Титульные листы почти всегда есть в открытом доступе, а в некоторых университетах требуют прикреплять к курсовой работе 3-4 страницы такого общедоступного текста. Огромное количество титульных листов — не твоя проблема, и об этом нужно говорить.
- Список литературы. Обширный список литературы — огромный плюс, но список из 30-50 источников может существенно снизить оригинальность. Сокращать количество источников ради процента в программе не нужно — нужно доказывать научному руководителю, что ты прав.
- Формулы и стандартные формулировки. В некоторых работах никуда не деться от использования текстов законов. Если в курсовой работе нужна спецификация, то от снижения уникальности тоже никуда не деться. Не бойся доказывать, что проверять на уникальность нужно только то, что ты делал сам. То же самое касается таблиц — если в методичке даны шаблоны со словами «делать так и никак иначе», то оригинальность гарантированно упадёт.
- Приложения. В приложениях может быть всё, что угодно — от паспорта оборудования до огромной таблицы с бухгалтерской отчётностью компании за последние 10 лет. Чтобы избежать конфликтов, лучше использовать скриншоты или сканированные версии документов (сохраняя оригинал на случай возможных правок).

Процент оригинальности в отрыве от самой работы не отражает её качества. Если ты понимаешь, что писал всё честно, и в курсовой нет ничего, кроме твоего анализа проблемы, а уникальность снижают список литературы и титульный лист, то нужно доказывать свою правоту. Твоя курсовая — это не проценты в программе.
Системы проверки
Как уже было сказано, доступ к «Антиплагиат.вуз» получить практически невозможно, и итоговый процент уникальности самостоятельно ты узнать не сможешь. Но это не значит, что проверить уникальность самому нельзя (но и первой попавшейся системе проверки доверять не стоит). Самостоятельно проверить уникальность можно тут:
Но это не значит, что проверить уникальность самому нельзя (но и первой попавшейся системе проверки доверять не стоит). Самостоятельно проверить уникальность можно тут:
- Бесплатная версия сервиса «Антиплагиат.ру». Для курсовой, написанной честно, бесплатной проверки будет достаточно.
- eTXT Антиплагиат. Главное достоинство сервиса — полный отчёт о проверке тут можно получить абсолютно бесплатно. Советуем скачать десктопную версию, там доступна даже проверка с учётом перефразирования.
Чтобы перестраховаться, лучше проверять свои работы максимально строго. Помни, что именно ты должен стать своим самым строгим критиком. И это касается не только текста курсовой.
Мы рассмотрели всё, что касается работы с текстом курсовой работы. Теперь ты знаешь, как писать, чтобы не было правок или претензий к уникальности.

python — есть ли короткий способ проверить уникальность значений без использования «если» и нескольких «и»?
Это немного зависит от того, какие у вас есть ценности.
Если они хорошо работают и хешируются, то вы можете (как уже указывали другие) просто использовать набор , чтобы узнать, сколько уникальных значений у вас есть, и если это не равно количеству общих значений, которые у вас есть, по крайней мере два равных значения.
def all_distinct (* значения):
return len (set (значения)) == len (значения)
all_distinct (1, 2, 3) # Верно
all_distinct (1, 2, 2) # Ложь
Хэшируемые значения и ленивый
Если у вас действительно много значений и вы хотите прервать работу, как только будет найдено одно совпадение, вы также можете лениво создать набор.Это сложнее и, вероятно, медленнее, если все значения различны, но обеспечивает короткое замыкание в случае обнаружения дубликата:
def all_distinct (* значения):
видел = установить ()
seen_add = seen. add
last_count = 0
для элемента в значениях:
visible_add (элемент)
new_count = len (просмотрено)
если new_count == last_count:
вернуть ложь
last_count = new_count
вернуть True
all_distinct (1, 2, 3) # Верно
all_distinct (1, 2, 2) # Ложь
Однако, если значения не хэшируемые, это не сработает, поскольку set требует хешируемых значений.
Нехешируемые значения
Если у вас нет хешируемых значений, вы можете использовать простой список для хранения уже обработанных значений и просто проверить, есть ли каждый новый элемент уже в списке:
def all_distinct (* значения):
видел = []
для элемента в значениях:
если товар виден:
вернуть ложь
visible.append (элемент)
вернуть True
all_distinct (1, 2, 3) # Верно
all_distinct (1, 2, 2) # Ложь
all_distinct ([1, 2], [2, 3], [3, 4]) # Верно
all_distinct ([1, 2], [2, 3], [1, 2]) # Ложь
Это будет медленнее, потому что проверка того, находится ли значение в списке, требует сравнения его с каждым элементом в списке.
A (стороннее) библиотечное решение
Если вы не возражаете против дополнительной зависимости, вы также можете использовать одну из моих библиотек (доступных в PyPi и conda-forge) для этой задачи iteration_utilities.all_distinct . Эта функция может обрабатывать как хешируемые, так и нехешируемые значения (и их сочетание):
из iteration_utilities import all_distinct
all_distinct ([1, 2, 3]) # Верно
all_distinct ([1, 2, 2]) # Ложь
all_distinct ([[1, 2], [2, 3], [3, 4]]) # Верно
all_distinct ([[1, 2], [2, 3], [1, 2]]) # Ложь
Общие комментарии
Обратите внимание, что все вышеупомянутые подходы основаны на том факте, что равенство означает «не равно», что имеет место (почти) для всех встроенных типов, но не обязательно так!
Однако я хочу указать на ответы чепнеров, которые не требуют хэширования значений. и не полагаются на «равенство означает не равенство», явно проверяя ! = . Он также вызывает короткое замыкание, поэтому ведет себя так же, как ваш исходный подход
Он также вызывает короткое замыкание, поэтому ведет себя так же, как ваш исходный подход и .
Производительность
Чтобы получить общее представление о производительности, я использую другую свою библиотеку ( simple_benchmark )
Я использовал разные хешируемые входы (слева) и нехешируемые входы (справа). Для хэшируемых входных данных лучше всего работали подходы с использованием наборов, в то время как для нехешируемых входных данных подходы со списками работали лучше. Комбинации Подход на основе казался самым медленным в обоих случаях:
Я также проверил производительность в случае наличия дубликатов, для удобства я рассмотрел случай, когда первые два элемента были равны (в противном случае настройка была идентична предыдущему случаю):
из iteration_utilities import all_distinct
из комбинаций импорта itertools
из simple_benchmark import BenchmarkBuilder
# Первый тест
b1 = BenchmarkBuilder ()
@ b1. add_function ()
def all_distinct_set (значения):
return len (set (значения)) == len (значения)
@ b1.add_function ()
def all_distinct_set_sc (значения):
видел = установить ()
seen_add = seen.add
last_count = 0
для элемента в значениях:
visible_add (элемент)
new_count = len (просмотрено)
если new_count == last_count:
вернуть ложь
last_count = new_count
вернуть True
@ b1.add_function ()
def all_distinct_list (значения):
видел = []
для элемента в значениях:
если товар виден:
вернуть ложь
видимый.добавить (элемент)
вернуть True
b1.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
@ b1.add_function ()
def all_distinct_combinations (значения):
вернуть все (x! = y для x, y в комбинациях (значения, 2))
@ b1.add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер урожая, диапазон (размер)
r1 = b1. run ()
r1.plot ()
# Второй тест
b2 = BenchmarkBuilder ()
b2.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b2.add_functions ([all_distinct_combinations, all_distinct_list])
@Би 2.add_arguments ('количество нехешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [[i] для i в диапазоне (размер)]
r2 = b2.run ()
r2.plot ()
# Третий тест
b3 = BenchmarkBuilder ()
b3.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b3.add_functions ([all_distinct_set, all_distinct_set_sc, all_distinct_combinations, all_distinct_list])
@ b3.add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [0, * диапазон (размер)]
r3 = b3.пробег()
r3.plot ()
# Четвертый тест
b4 = BenchmarkBuilder ()
b4.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b4.add_functions ([all_distinct_combinations, all_distinct_list])
@ b4. add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [[0], * [[i] для i в диапазоне (размер)]]
r4 = b4.run ()
r4.plot ()
 add_function ()
def all_distinct_set (значения):
return len (set (значения)) == len (значения)
@ b1.add_function ()
def all_distinct_set_sc (значения):
видел = установить ()
seen_add = seen.add
last_count = 0
для элемента в значениях:
visible_add (элемент)
new_count = len (просмотрено)
если new_count == last_count:
вернуть ложь
last_count = new_count
вернуть True
@ b1.add_function ()
def all_distinct_list (значения):
видел = []
для элемента в значениях:
если товар виден:
вернуть ложь
видимый.добавить (элемент)
вернуть True
b1.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
@ b1.add_function ()
def all_distinct_combinations (значения):
вернуть все (x! = y для x, y в комбинациях (значения, 2))
@ b1.add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер урожая, диапазон (размер)
r1 = b1.
add_function ()
def all_distinct_set (значения):
return len (set (значения)) == len (значения)
@ b1.add_function ()
def all_distinct_set_sc (значения):
видел = установить ()
seen_add = seen.add
last_count = 0
для элемента в значениях:
visible_add (элемент)
new_count = len (просмотрено)
если new_count == last_count:
вернуть ложь
last_count = new_count
вернуть True
@ b1.add_function ()
def all_distinct_list (значения):
видел = []
для элемента в значениях:
если товар виден:
вернуть ложь
видимый.добавить (элемент)
вернуть True
b1.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
@ b1.add_function ()
def all_distinct_combinations (значения):
вернуть все (x! = y для x, y в комбинациях (значения, 2))
@ b1.add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер урожая, диапазон (размер)
r1 = b1. run ()
r1.plot ()
# Второй тест
b2 = BenchmarkBuilder ()
b2.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b2.add_functions ([all_distinct_combinations, all_distinct_list])
@Би 2.add_arguments ('количество нехешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [[i] для i в диапазоне (размер)]
r2 = b2.run ()
r2.plot ()
# Третий тест
b3 = BenchmarkBuilder ()
b3.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b3.add_functions ([all_distinct_set, all_distinct_set_sc, all_distinct_combinations, all_distinct_list])
@ b3.add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [0, * диапазон (размер)]
r3 = b3.пробег()
r3.plot ()
# Четвертый тест
b4 = BenchmarkBuilder ()
b4.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b4.add_functions ([all_distinct_combinations, all_distinct_list])
@ b4.
run ()
r1.plot ()
# Второй тест
b2 = BenchmarkBuilder ()
b2.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b2.add_functions ([all_distinct_combinations, all_distinct_list])
@Би 2.add_arguments ('количество нехешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [[i] для i в диапазоне (размер)]
r2 = b2.run ()
r2.plot ()
# Третий тест
b3 = BenchmarkBuilder ()
b3.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b3.add_functions ([all_distinct_set, all_distinct_set_sc, all_distinct_combinations, all_distinct_list])
@ b3.add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [0, * диапазон (размер)]
r3 = b3.пробег()
r3.plot ()
# Четвертый тест
b4 = BenchmarkBuilder ()
b4.add_function (псевдоним = 'all_distinct_iu') (all_distinct)
b4.add_functions ([all_distinct_combinations, all_distinct_list])
@ b4. add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [[0], * [[i] для i в диапазоне (размер)]]
r4 = b4.run ()
r4.plot ()
add_arguments ('количество хешируемых входов')
def arguments_provider ():
для exp в диапазоне (1, 12):
size = 2 ** exp
размер доходности, [[0], * [[i] для i в диапазоне (размер)]]
r4 = b4.run ()
r4.plot ()
панд: объедините наборы данных и проверьте уникальность
Pandas: Упражнение 69 DataFrame с решением
Напишите программу Pandas для объединения наборов данных и проверки уникальности.
Пример раствора :
Код Python:
импортировать панд как pd
df = pd.DataFrame ({
«Имя»: [«Альберто Франко», «Джино Макнейл», «Райан Паркс», «Иша Хинтон», «Сайед Уортон»],
'Date_Of_Birth': ['17.05.2002', '16.02.1999', '25.09.1998', '11.05.2002', '15.09.1997'],
«Возраст»: [18,5, 21,2, 22,5, 22, 23].
})
print ("Исходный фрейм данных:")
печать (df)
df1 = df.copy (deep = True)
df = df.drop ([0, 1])
df1 = df1.падение ([2])
print ("\ nНовые фреймы данных:")
печать (df)
печать (df1)
print ('\ n "one_to_one": проверьте, уникальны ли ключи слияния как в левом, так и в правом наборах данных: "')
df_one_to_one = pd.merge (df, df1, validate = "one_to_one")
печать (df_one_to_one)
print ('\ n "one_to_many" или "1: m": проверьте, уникальны ли ключи слияния в левом наборе данных:')
df_one_to_many = pd.merge (df, df1, validate = "one_to_many")
печать (df_one_to_many)
print ('«many_to_one» или «m: 1»: проверьте, уникальны ли ключи слияния в правильном наборе данных:')
df_many_to_one = pd.слияние (df, df1, validate = "many_to_one")
печать (df_many_to_one)
 })
print ("Исходный фрейм данных:")
печать (df)
df1 = df.copy (deep = True)
df = df.drop ([0, 1])
df1 = df1.падение ([2])
print ("\ nНовые фреймы данных:")
печать (df)
печать (df1)
print ('\ n "one_to_one": проверьте, уникальны ли ключи слияния как в левом, так и в правом наборах данных: "')
df_one_to_one = pd.merge (df, df1, validate = "one_to_one")
печать (df_one_to_one)
print ('\ n "one_to_many" или "1: m": проверьте, уникальны ли ключи слияния в левом наборе данных:')
df_one_to_many = pd.merge (df, df1, validate = "one_to_many")
печать (df_one_to_many)
print ('«many_to_one» или «m: 1»: проверьте, уникальны ли ключи слияния в правильном наборе данных:')
df_many_to_one = pd.слияние (df, df1, validate = "many_to_one")
печать (df_many_to_one)
})
print ("Исходный фрейм данных:")
печать (df)
df1 = df.copy (deep = True)
df = df.drop ([0, 1])
df1 = df1.падение ([2])
print ("\ nНовые фреймы данных:")
печать (df)
печать (df1)
print ('\ n "one_to_one": проверьте, уникальны ли ключи слияния как в левом, так и в правом наборах данных: "')
df_one_to_one = pd.merge (df, df1, validate = "one_to_one")
печать (df_one_to_one)
print ('\ n "one_to_many" или "1: m": проверьте, уникальны ли ключи слияния в левом наборе данных:')
df_one_to_many = pd.merge (df, df1, validate = "one_to_many")
печать (df_one_to_many)
print ('«many_to_one» или «m: 1»: проверьте, уникальны ли ключи слияния в правильном наборе данных:')
df_many_to_one = pd.слияние (df, df1, validate = "many_to_one")
печать (df_many_to_one)
Пример вывода:
Исходный фрейм данных:
Имя Date_Of_Birth Age
0 Альберто Франко 17.05.2002 18,5
1 Джино Макнейл 16.02.1999 21,2
2 Райан Паркс 25.09.1998 22,5
3 Иеша Хинтон 05.11.2002 22,0
4 Сайед Уортон 15. 09.1997 23,0
Новые DataFrames:
Имя Date_Of_Birth Age
2 Райан Паркс 25.09.1998 22.5
3 Иеша Хинтон 05.11.2002 22,0
4 Сайед Уортон 15.09.1997 23,0
Имя Date_Of_Birth Age
0 Альберто Франко 17.05.2002 18,5
1 Джино Макнейл 16.02.1999 21,2
3 Иеша Хинтон 05.11.2002 22,0
4 Сайед Уортон 15.09.1997 23,0
"one_to_one": проверьте, уникальны ли ключи слияния как в левом, так и в правом наборах данных: "
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23.0
«one_to_many» или «1: m»: проверьте, уникальны ли ключи слияния в левом наборе данных:
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23,0
«Many_to_one» или «m: 1»: проверьте, уникальны ли ключи слияния в правильном наборе данных:
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23,0
 09.1997 23,0
Новые DataFrames:
Имя Date_Of_Birth Age
2 Райан Паркс 25.09.1998 22.5
3 Иеша Хинтон 05.11.2002 22,0
4 Сайед Уортон 15.09.1997 23,0
Имя Date_Of_Birth Age
0 Альберто Франко 17.05.2002 18,5
1 Джино Макнейл 16.02.1999 21,2
3 Иеша Хинтон 05.11.2002 22,0
4 Сайед Уортон 15.09.1997 23,0
"one_to_one": проверьте, уникальны ли ключи слияния как в левом, так и в правом наборах данных: "
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23.0
«one_to_many» или «1: m»: проверьте, уникальны ли ключи слияния в левом наборе данных:
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23,0
«Many_to_one» или «m: 1»: проверьте, уникальны ли ключи слияния в правильном наборе данных:
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23,0
09.1997 23,0
Новые DataFrames:
Имя Date_Of_Birth Age
2 Райан Паркс 25.09.1998 22.5
3 Иеша Хинтон 05.11.2002 22,0
4 Сайед Уортон 15.09.1997 23,0
Имя Date_Of_Birth Age
0 Альберто Франко 17.05.2002 18,5
1 Джино Макнейл 16.02.1999 21,2
3 Иеша Хинтон 05.11.2002 22,0
4 Сайед Уортон 15.09.1997 23,0
"one_to_one": проверьте, уникальны ли ключи слияния как в левом, так и в правом наборах данных: "
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23.0
«one_to_many» или «1: m»: проверьте, уникальны ли ключи слияния в левом наборе данных:
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23,0
«Many_to_one» или «m: 1»: проверьте, уникальны ли ключи слияния в правильном наборе данных:
Имя Date_Of_Birth Age
0 Иеша Хинтон 05.11.2002 22,0
1 Сайед Уортон 15.09.1997 23,0
Редактор кода Python:
Есть другой способ решить эту проблему? Разместите свой код (и комментарии) через Disqus.
Предыдущая: Напишите программу Pandas для переименования всех столбцов с тем же шаблоном данного DataFrame.
Далее: Напишите программу Pandas для преобразования непрерывных значений столбца в данном DataFrame в категориальные.
Python: советы дня
Python: использование тернарного оператора для условного присваивания
Пример:
def test (x, y, z): вернуть x, если x <= y и x <= z else (y, если y <= x и y <= z else z) print (test (1, 0, 1)) print (test (1, 2, 2)) print (test (2, 2, 3)) print (test (5, 4, 3))
Выход:
0 1 2 3
Проверка уникальности в классах.Выявить и удалить повторяющиеся объекты… | автор: Арун Суреш
Сценарий:
Рассмотрим массив из объектов того же класса, который содержит один или несколько повторяющихся объектов.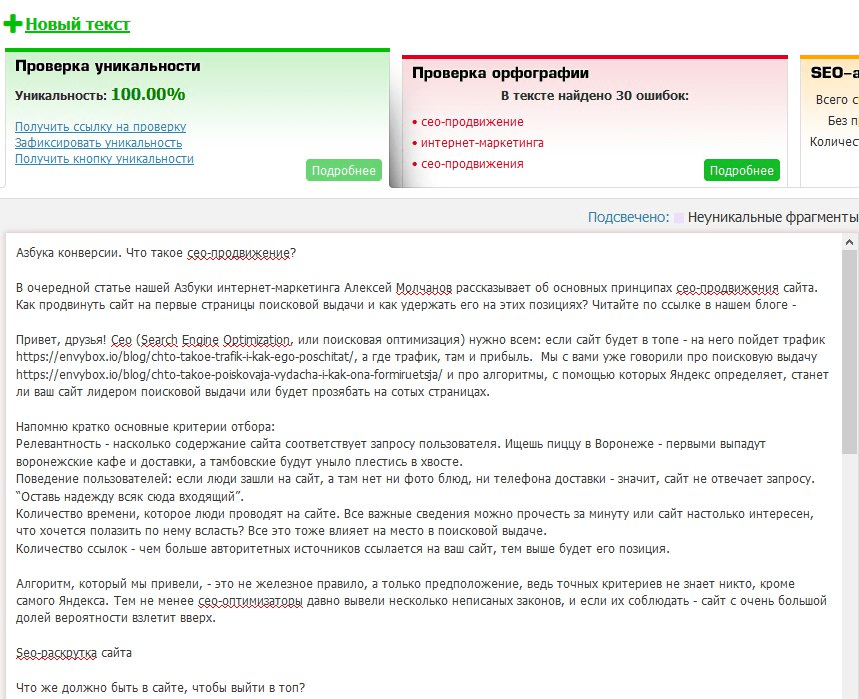 Требуется эффективное удаление дубликатов из списка без потери данных, но с высокой производительностью.
Требуется эффективное удаление дубликатов из списка без потери данных, но с высокой производительностью.
Допущения:
- Вы можете получить доступ к родительскому классу и изменить его реализацию.
- Порядок или длина списка не имеет значения.
- Решение не зависит от языка, хотя в примерах будет использоваться python 3.7
Решение
Идеальный способ удаления дубликатов из любого контейнера данных - создать новый контейнер данных и итеративно добавлять элементы в этот новый контейнер во время проверки. если он уже существует. Для проверки существования, очевидно, потребуется внутренняя проверка на равенство, которая определит уникальность каждого элемента.
Эту стратегию можно повторно использовать для удаления дубликатов из списка объектов определенного пользователем класса.Для этого в классе должен быть доступен метод equals в качестве компаратора. В этой проверке равенства мы должны определить, насколько один объект равен другому.
Эту проверку можно сделать более эффективной, выполнив группировку хэшей перед проверкой равенства. Это необходимо для идентификации и группировки элементов для сравнения. В хэше должны использоваться те же параметры, что и при проверке равенства. Помните, что одинаковые объекты всегда будут иметь один и тот же хэш, но объекты с одинаковым хешем не обязательно должны быть равными.
Реализация
Мы реализуем класс Book с тремя параметрами, как показано ниже.Реализуйте метод равенства и переопределите метод хеширования по умолчанию, используя тот же набор параметров.
В приведенном ниже примере в списке книг указано 13 книг, 4 из которых являются дубликатами. Используя понимание этого списка, мы создадим список объектов object_list с 13 объектами Book .
В качестве нового контейнера мы будем использовать набор Python, который представляет собой неупорядоченный набор уникальных элементов.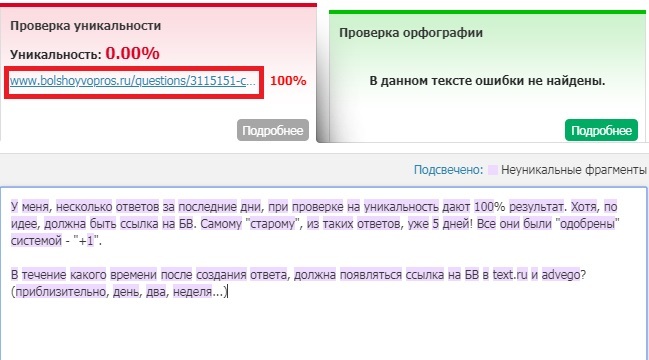 Таким образом, нам не нужно реализовывать проверку уникальности, поскольку она изначально доступна в наборе, и мы будем использовать метод
Таким образом, нам не нужно реализовывать проверку уникальности, поскольку она изначально доступна в наборе, и мы будем использовать метод __eq__ , который мы реализовали в классе.
Единственное ограничение для использования set - это элементы, которые должны быть хешируемыми, что мы включили, реализовав __hash__ . Проверка уникальности набора будет использовать методы __eq__ и __hash__ из класса Book . Это в точности похоже на контракт хэш-кода equals в java.
Список object_list можно преобразовать в набор object_set , используя любой из методов, показанных в примере. Это преобразование эффективно удалит все дубликаты и представит коллекцию уникальных объектов Book , эффективно решая исходный сценарий проблемы.
Заключение
- Структура данных Set выполняет проверку на равенство с использованием метода объекта
__eq__, и именно здесь мы определили, как объект совпадает с другим объектом. -
__hash__используется для эффективной идентификации и группировки элементов для сравнения. - Всегда помните, что методы
__eq__и__hash__должны быть реализованы с использованием одних и тех же параметров.
Проверка уникальности IP-адреса
Как я могу использовать протокол разрешения адресов (или что-то еще), чтобы определить, является ли назначенный мне IP-адрес уникальным, не заставляя все другие хосты обновлять свой кеш и терять связь с первоначальным владельцем?
Как я могу использовать протокол разрешения адресов (или что-то еще), чтобы определить, является ли назначенный мне IP-адрес уникальным, не заставляя все другие хосты обновлять свой кеш и терять связь с первоначальным владельцем?
Если у вас есть доступ ко второму компьютеру в сети, используйте его для проверки связи с рассматриваемым IP-адресом, чтобы узнать, активен ли он в настоящее время в сети, прежде чем загружать систему с этим адресом.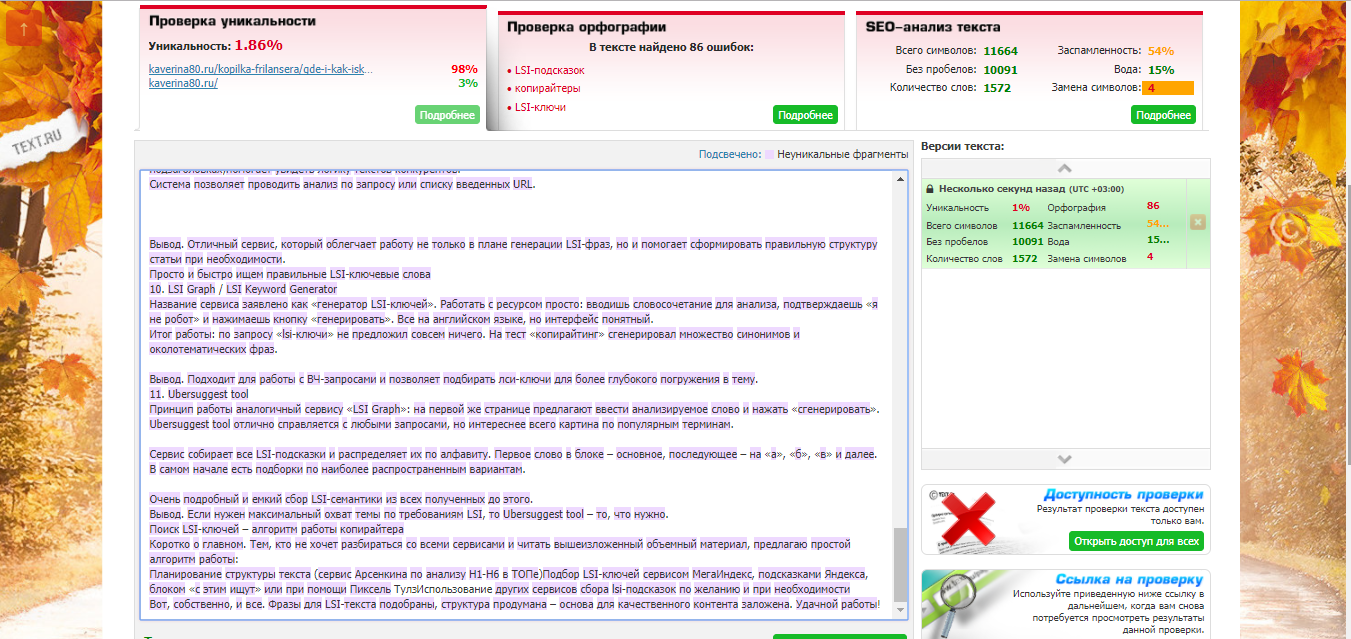
Ввод
arp -a
из командной строки должен отобразить локальный кеш протокола разрешения адресов и указать адрес управления доступом к среде для активного IP-адреса, если он находится в том же сегменте сети (даже если это система не отвечает на пинги).
Если вы попытаетесь обнаружить это после запуска вашей системы в сети с сомнительным IP-адресом, вы должны увидеть на экране ошибки «дублированный IP-адрес».
Как конечный пользователь сети, ваши возможности ограничены, если у вас нет доступного программного обеспечения сетевого сниффера, которое перечисляет и просматривает активные IP-адреса.Если IP-связь медленная, обратитесь к администратору локальной сети.
Если вы являетесь администратором локальной сети, выключите сомнительную систему, немного подождите и пропингуйте интересующий IP-адрес с другой машины, чтобы узнать, получите ли вы ответ.
Присоединяйтесь к сообществам Network World на Facebook и LinkedIn, чтобы комментировать самые важные темы.Copyright © 2003 IDG Communications, Inc.
Проверок Active Record - Руководства по Ruby on Rails
1 Обзор валидации
Вот пример очень простой валидации:
класс Person класс Person irb> Person.create (имя: "Джон Доу"). Действителен?
=> правда
irb> Человек.создать (name: nil) .valid?
=> ложь
Person.create (имя: "Джон Доу"). Действителен?
Person.create (name: nil) .valid?
Копировать Как видите, наша проверка позволяет нам узнать, что наш Person недействителен.
без атрибута name . Второй человек не будет сохранен в
база данных.
Прежде чем углубляться в подробности, давайте поговорим о том, как проверки вписываются в общая картина вашего приложения.
1.1 Зачем нужны валидации?
Проверки используются, чтобы гарантировать, что на вашем
база данных. Например, для вашего приложения может быть важно убедиться, что
каждый пользователь предоставляет действующий адрес электронной почты и почтовый адрес. Уровень модели
проверки - лучший способ гарантировать, что в ваш
база данных. Они не зависят от базы данных, не могут быть обойдены конечными пользователями и
удобно тестировать и поддерживать. Rails предоставляет встроенные помощники для общих
потребности, а также позволяет создавать свои собственные методы проверки.
Например, для вашего приложения может быть важно убедиться, что
каждый пользователь предоставляет действующий адрес электронной почты и почтовый адрес. Уровень модели
проверки - лучший способ гарантировать, что в ваш
база данных. Они не зависят от базы данных, не могут быть обойдены конечными пользователями и
удобно тестировать и поддерживать. Rails предоставляет встроенные помощники для общих
потребности, а также позволяет создавать свои собственные методы проверки.
Есть несколько других способов проверки данных перед их сохранением на вашем база данных, включая собственные ограничения базы данных, проверки на стороне клиента и проверки на уровне контроллера.Вот краткое изложение плюсов и минусов:
- Ограничения базы данных и / или хранимые процедуры делают механизмы проверки
зависит от базы данных и может затруднить тестирование и обслуживание.
Однако, если ваша база данных используется другими приложениями, это может быть хорошим
идея использовать некоторые ограничения на уровне базы данных. Кроме того,
проверки на уровне базы данных могут безопасно обрабатывать некоторые вещи (например, уникальность
в часто используемых таблицах), что может быть трудно реализовать в противном случае.
- Проверки на стороне клиента могут быть полезны, но обычно ненадежны, если используются один.Если они реализованы с использованием JavaScript, их можно обойти, если В браузере пользователя отключен JavaScript. Однако в сочетании с другие методы, проверка на стороне клиента может быть удобным способом обеспечения пользователи с немедленной обратной связью, когда они используют ваш сайт.
- Проверки на уровне контроллера могут быть заманчивыми для использования, но часто становятся громоздкий и сложный в тестировании и обслуживании. По возможности, это хорошо идея сделать ваши контроллеры тонкими, так как это сделает ваше приложение удовольствие работать в долгосрочной перспективе.
 Кроме того,
проверки на уровне базы данных могут безопасно обрабатывать некоторые вещи (например, уникальность
в часто используемых таблицах), что может быть трудно реализовать в противном случае.
Кроме того,
проверки на уровне базы данных могут безопасно обрабатывать некоторые вещи (например, уникальность
в часто используемых таблицах), что может быть трудно реализовать в противном случае. Выбирайте их в определенных случаях. Это мнение команды Rails
что проверки на уровне модели являются наиболее подходящими в большинстве случаев.
1.2 Когда происходит валидация?
Есть два типа объектов Active Record: те, которые соответствуют строке
внутри вашей базы данных и тех, которые этого не делают. Когда вы создаете новый объект, для
пример с использованием метода new , этот объект не принадлежит базе данных
пока что. Как только вы позвоните по номеру , сохраните для этого объекта, он будет сохранен в
соответствующая таблица базы данных.Active Record использует new_record? экземпляр
чтобы определить, находится ли объект уже в базе данных или нет.
Рассмотрим следующий класс Active Record:
класс Person класс Person bin / rails : irb> p = Person.new (имя: "Джон Доу")
=> # <Идентификатор человека: nil, name: "John Doe", created_at: nil, updated_at: nil>
irb> p.новый рекорд?
=> правда
irb> p. save
=> правда
irb> p.new_record?
=> ложь
p = Person.new (имя: "Джон Доу")
p.new_record?
p.save
p.new_record?
Копировать.png) save
=> правда
irb> p.new_record?
=> ложь
save
=> правда
irb> p.new_record?
=> ложь
При создании и сохранении новой записи на сервер будет отправлена операция SQL INSERT .
база данных. При обновлении существующей записи будет отправлена операция SQL UPDATE .
вместо. Валидации обычно выполняются перед отправкой этих команд в
база данных. Если какие-либо проверки не пройдут, объект будет помечен как недопустимый и
Active Record не будет выполнять операцию INSERT или UPDATE .Это позволяет избежать
сохранение недопустимого объекта в базе данных. Вы можете выбрать конкретный
проверки выполняются при создании, сохранении или обновлении объекта.
Есть много способов изменить состояние объекта в базе данных.
Некоторые методы запускают проверки, а некоторые нет. Это означает, что это
возможно сохранить объект в базе данных в недопустимом состоянии, если вы не
осторожный.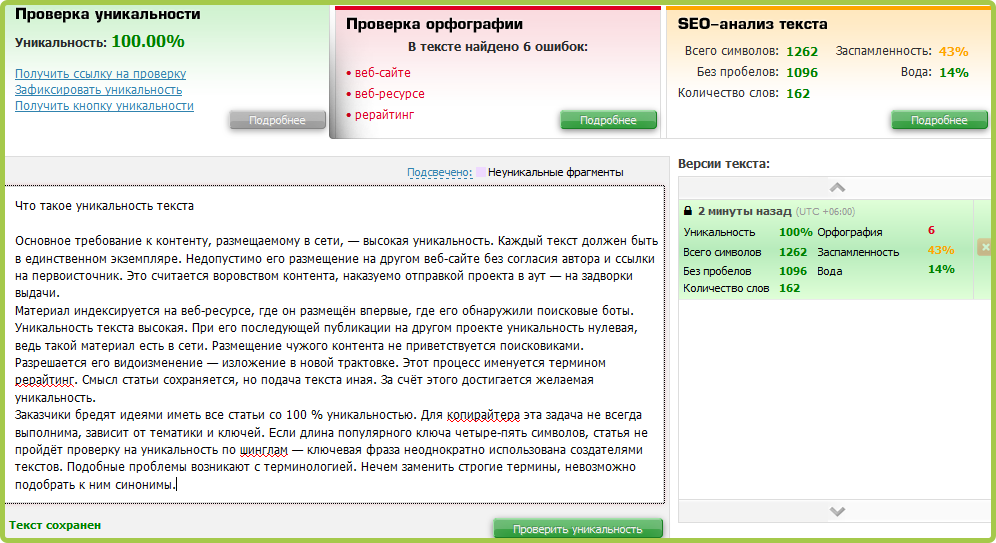
Следующие методы запускают проверки и сохраняют объект в база данных только если объект действительный:
-
создать -
создать! -
экономия -
экономия! -
обновить -
обновление!
Версии Bang (e.грамм. экономия! ) вызывают исключение, если запись недействительна.
В версиях без взрыва нет: сохраняет и обновляет возвращает false и create возвращает объект.
1.3 Пропуск проверок
Следующие методы пропускают проверки и сохраняют объект в база данных независимо от ее действительности. Их следует использовать с осторожностью.
-
декремент! -
декремент_счетчик -
инкремент! -
счетчик инкремента -
вставка -
вставка! -
вставка_все -
insert_all! -
переключить! -
сенсорный -
touch_all -
update_all -
атрибут_обновления -
update_column -
update_columns -
счетчики обновлений -
упсерт -
upsert_all
Обратите внимание, что save также может пропускать проверки, если передано validate:
false в качестве аргумента. Эту технику следует использовать с осторожностью.
Эту технику следует использовать с осторожностью.
1,4
действителен? и недействительны? Перед сохранением объекта Active Record Rails выполняет ваши проверки. Если эти проверки вызывают какие-либо ошибки, Rails не сохраняет объект.
Вы также можете запустить эти проверки самостоятельно. действителен? запускает ваши проверки
и возвращает true, если в объекте не было обнаружено ошибок, и false в противном случае.
Как вы видели выше:
класс Person класс Person irb> Человек.create (имя: "Джон Доу"). действителен?
=> правда
irb> Person.create (name: nil) .valid?
=> ложь
Person.create (имя: "Джон Доу"). Действителен?
Person.create (name: nil) .valid?
Копировать После того, как Active Record выполнил валидацию, можно получить доступ ко всем найденным ошибкам. через метод экземпляра
через метод экземпляра errors , который возвращает коллекцию ошибок.
По определению объект действителен, если эта коллекция пуста после запуска
проверки.
Обратите внимание, что объект, созданный с помощью new , не будет сообщать об ошибках.
даже если это технически недействительно, потому что проверки выполняются автоматически
только при сохранении объекта, например, с методами create или save .
класс Person класс Person irb> p = Person.new
=> # <Идентификатор человека: ноль, имя: ноль>
irb> p.errors.size
=> 0
irb> p.valid?
=> ложь
irb> p.errors.objects.first.full_message
=> «Имя не может быть пустым»
irb> p = Person.create
=> # <Идентификатор человека: ноль, имя: ноль>
irb> p.errors.objects.first.full_message
=> «Имя не может быть пустым»
irb> p. save
=> ложь
irb> p.save!
ActiveRecord :: RecordInvalid: проверка не удалась: имя не может быть пустым
irb> Person.create!
ActiveRecord :: RecordInvalid: проверка не удалась: имя не может быть пустым
p = Person.new
p.errors.size
p.valid?
p.errors.objects.first.full_message
p = Person.create
p.errors.objects.first.full_message
p.save
p.save!
Person.create!
Копировать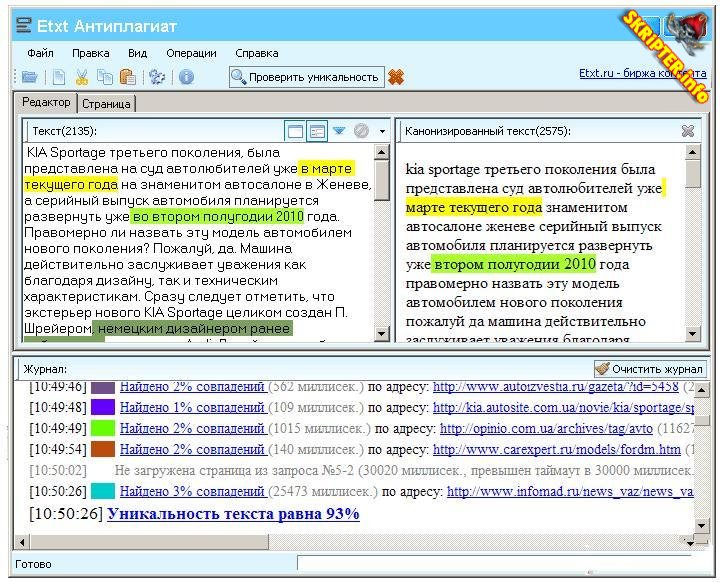 save
=> ложь
irb> p.save!
ActiveRecord :: RecordInvalid: проверка не удалась: имя не может быть пустым
irb> Person.create!
ActiveRecord :: RecordInvalid: проверка не удалась: имя не может быть пустым
save
=> ложь
irb> p.save!
ActiveRecord :: RecordInvalid: проверка не удалась: имя не может быть пустым
irb> Person.create!
ActiveRecord :: RecordInvalid: проверка не удалась: имя не может быть пустым
недействительно? действительно ли ? . Это вызывает ваши проверки,
возвращает true, если в объекте были обнаружены ошибки, и false в противном случае.
1,5
ошибок [] Чтобы проверить, является ли конкретный атрибут объекта допустимым, вы можете
использовать ошибки [: атрибут] . Он возвращает массив всех сообщений об ошибках для : атрибут . Если по указанному атрибуту ошибок нет, пустой массив
возвращается.
Этот метод используется только после выполнения проверок, потому что он только
проверяет коллекцию ошибок и не запускает саму проверку. Это
отличается от
Это
отличается от ActiveRecord :: Base # недействительно? Метод объяснен выше, потому что
он не проверяет достоверность объекта в целом.Он только проверяет, чтобы увидеть
есть ли ошибки, обнаруженные в отдельном атрибуте объекта.
класс Person класс Person irb> Person.new.errors [: name] .any?
=> ложь
irb> Person.create.errors [: name] .any?
=> правда
Person.new.errors [: name] .any?
Person.create.errors [: name] .any?
КопироватьМы рассмотрим ошибки валидации более подробно в разделе Работа с валидацией. Раздел ошибок.
2 Помощника по валидации
Active Record предлагает множество предопределенных помощников по валидации, которые вы можете использовать
прямо внутри определения вашего класса. Эти помощники обеспечивают общую проверку
правила. Каждый раз, когда проверка завершается неудачно, к объекту добавляется ошибка.
ошибок Коллекция , и это связано с тем, что атрибут
подтверждено.
Каждый помощник принимает произвольное количество имен атрибутов, поэтому с одним В строке кода вы можете добавить такую же проверку к нескольким атрибутам.
Все они принимают параметры : на и : сообщение , которые определяют, когда
проверка должна быть запущена и какое сообщение следует добавить в ошибок сборник, если он не работает, соответственно. Параметр : на принимает одно из значений : создать или : обновить . Ошибка по умолчанию
сообщение для каждого из помощников проверки. Эти сообщения используются, когда
опция : message не указана. Давайте посмотрим на каждый из
доступные помощники.
2,1
принятие Этот метод проверяет, что флажок в пользовательском интерфейсе был установлен, когда
форма была отправлена. Обычно это используется, когда пользователь должен согласиться с вашим
условия обслуживания приложения, подтвердите, что какой-то текст прочитан, или любой аналогичный
концепция.
класс Person класс Person terms_of_service не равно nil .Сообщение об ошибке по умолчанию для этого помощника: «необходимо принять» .
Вы также можете передать собственное сообщение с помощью опции сообщение . класс Person класс Person : accept , которая определяет допустимые значения
это будет считаться принятым.По умолчанию ['1', true] и может быть
легко меняется. класс Person класс Person  если ты
нет поля для него, помощник создаст виртуальный атрибут. Если
поле действительно существует в вашей базе данных, параметр
если ты
нет поля для него, помощник создаст виртуальный атрибут. Если
поле действительно существует в вашей базе данных, параметр accept должен быть установлен на
или укажите true , иначе проверка не будет запущена.2.2
validates_associated Вы должны использовать этот помощник, когда ваша модель связана с другими моделями
и они также нуждаются в валидации. При попытке сохранить объект действителен? будет вызываться для каждого из связанных объектов.
Библиотека классов библиотека классов Не используйте validates_associated на обоих концах ваших ассоциаций.
Они будут звать друг друга в бесконечном цикле.
Сообщение об ошибке по умолчанию для validates_associated - «недействительно» .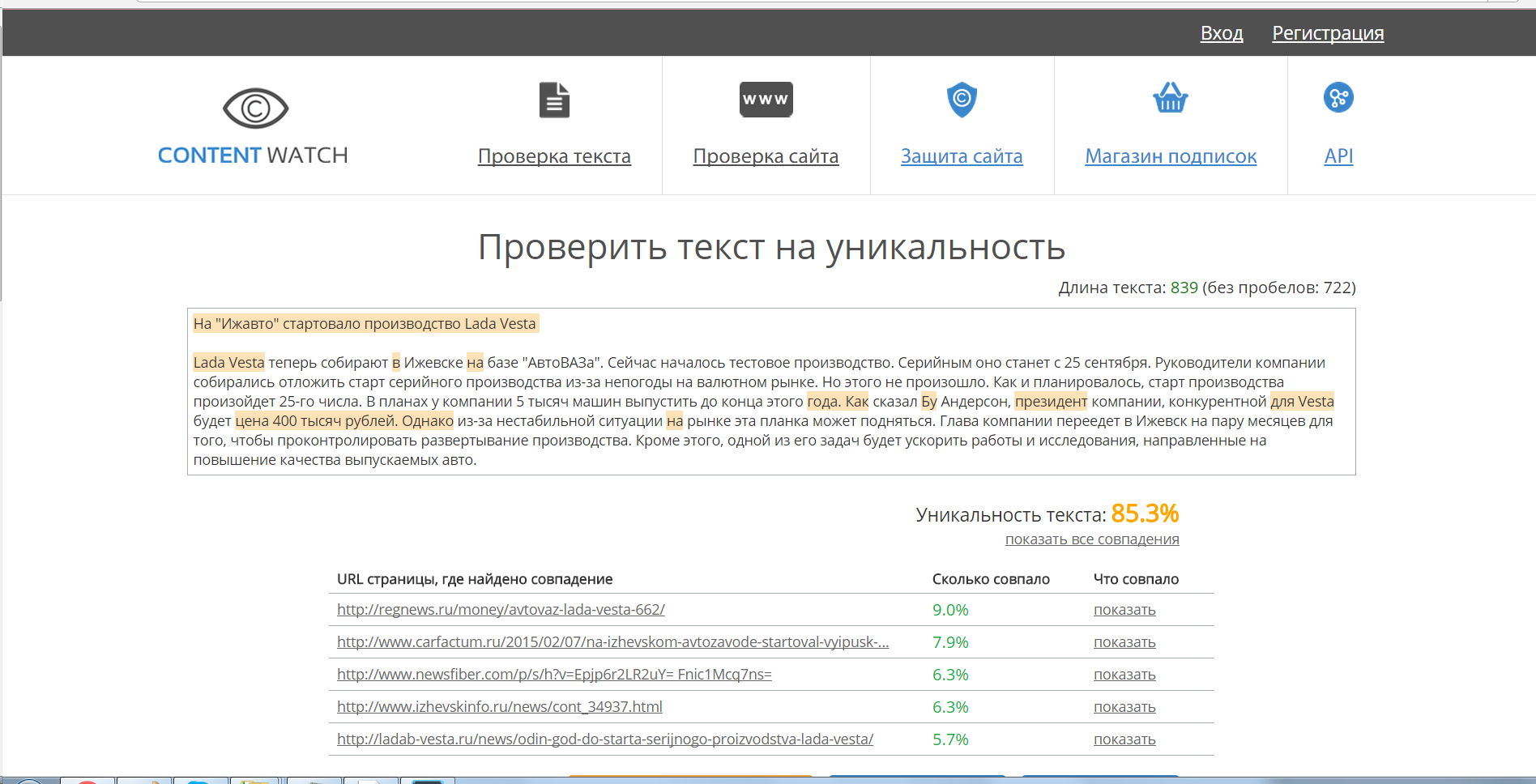 Примечание
что каждый связанный объект будет содержать свою собственную коллекцию
Примечание
что каждый связанный объект будет содержать свою собственную коллекцию ошибок ; ошибки делают
не пузыриться до вызывающей модели.
2.3
подтверждение Вы должны использовать этот помощник, когда у вас есть два текстовых поля, которые должны получить точно такой же контент. Например, вы можете подтвердить адрес электронной почты. или пароль. Эта проверка создает виртуальный атрибут, имя которого имя поля, которое необходимо подтвердить с добавлением «_confirmation».
класс Person класс Person <% = text_field: person,: email%>
<% = text_field: person,: email_confirmation%>
<% = text_field: person,: email%> <% = text_field: person,: email_confirmation%> Копировать Эта проверка выполняется, только если email_confirmation не равно nil . Требовать
подтверждение, обязательно добавьте проверку присутствия для атрибута подтверждения
(мы рассмотрим
Требовать
подтверждение, обязательно добавьте проверку присутствия для атрибута подтверждения
(мы рассмотрим присутствие позже в этом руководстве):
класс Person класс Person : case_sensitive , которую можно использовать, чтобы определить,
ограничение подтверждения будет чувствительно к регистру или нет.По умолчанию эта опция
истинный. класс Person класс Person 
2,4
исключение Этот помощник проверяет, что значения атрибутов не включены в данный набор.Фактически, этот набор может быть любым перечислимым объектом.
класс Учетная запись класс Account есть опция : в , которая получает набор значений, которые
не будут приняты для проверенных атрибутов.Вариант : в имеет
псевдоним : в пределах , который вы можете использовать для той же цели, если хотите.
В этом примере используется параметр : message , чтобы показать, как можно включить
значение атрибута. Полные параметры аргумента сообщения см. В
документация сообщения.
Сообщение об ошибке по умолчанию: «зарезервировано» .
2,5
формат Этот помощник проверяет значения атрибутов, проверяя, соответствуют ли они
заданное регулярное выражение, которое задается с помощью опции : with .
класс Продукт class Product : без .Сообщение об ошибке по умолчанию: "недействительно" .
2,6
включение Этот помощник проверяет, включены ли значения атрибутов в данный набор.
Фактически, этот набор может быть любым перечислимым объектом.
класс Кофе class Coffee есть опция : в , которая получает набор значений, которые
будут приняты.Параметр : в имеет псевдоним : в пределах , который вы можете
используйте для той же цели, если хотите. В предыдущем примере используется : опция сообщения , чтобы показать, как вы можете включить значение атрибута. Для полного
параметры см. в документации к сообщениям.Сообщение об ошибке по умолчанию для этого помощника: "не включено в список" .
2,7
длина Этот помощник проверяет длину значений атрибутов. Он обеспечивает
множество опций, поэтому вы можете указать ограничения длины по-разному:
Он обеспечивает
множество опций, поэтому вы можете указать ограничения длины по-разному:
класс Person класс Person -
: минимум- длина атрибута не может быть меньше указанной. -
: максимум- Атрибут не может иметь длину больше указанной. -
: в(или: в пределах) - длина атрибута должна быть включена в данное интервал. Значение этого параметра должно быть диапазоном. -
: is- длина атрибута должна быть равна заданному значению.
Сообщения об ошибках по умолчанию зависят от типа проверки длины
выполнила. Вы можете настроить эти сообщения, используя : неправильная_длина , : too_long и : опции too_short и % {count} в качестве заполнителя для
число, соответствующее используемому ограничению длины. Вы все еще можете использовать : сообщение - параметр для указания сообщения об ошибке.
класс Person класс Person : минимум равен 1, вам следует
предоставьте собственное сообщение или используйте вместо этого присутствие: истина .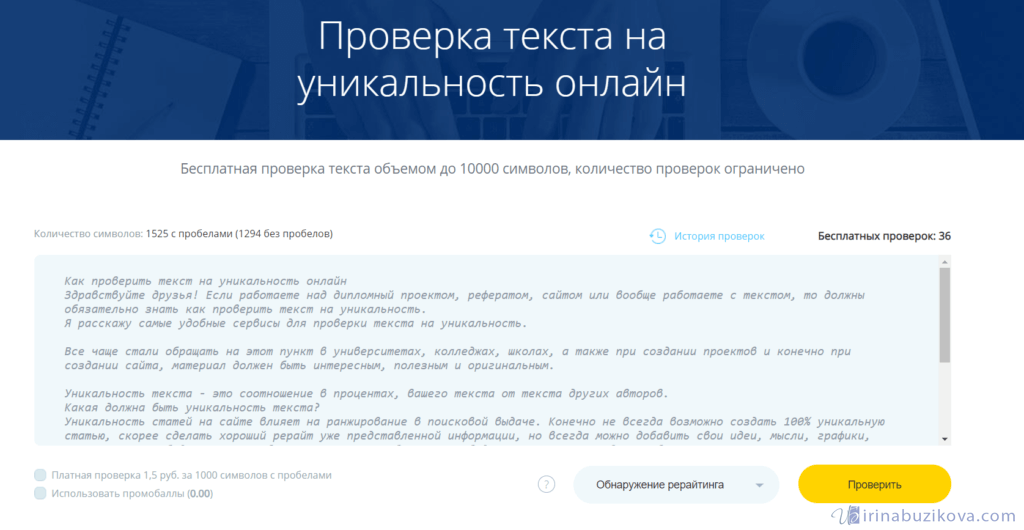 Когда
Когда : в или : в пределах имеет нижний предел 1, вы должны либо указать
заказное сообщение или вызов присутствие до длины .2,8
числовое значение Этот помощник проверяет, что ваши атрибуты имеют только числовые значения. К по умолчанию, он будет соответствовать необязательному знаку, за которым следует целое или плавающее номер точки.
Чтобы указать, что разрешены только целые числа,
установите : only_integer в значение true. Тогда он будет использовать
/ \ A [+ -]? \ D + \ z /
/ \ A [+ -]? \ D + \ z /
Копировать регулярное выражение для проверки значения атрибута. В противном случае он попытается
преобразовать значение в число, используя Float . Float преобразуются в BigDecimal с использованием значения точности столбца или 15.
класс Player класс Player : only_integer - "должно быть целым числом" .
Помимо : only_integer , этот помощник также принимает следующие параметры для добавления
ограничение допустимых значений:
-
: больше_тан- Указывает, что значение должно быть больше указанного. ценить. Сообщение об ошибке по умолчанию для этого параметра: "должно быть больше, чем % {count} ". -
: better_than_or_equal_to- указывает, что значение должно быть больше или равно предоставленному значению. Сообщение об ошибке по умолчанию для этой опции: "должно быть больше или равно% {count}" . -
: equal_to- указывает, что значение должно быть равно предоставленному значению. В сообщение об ошибке по умолчанию для этой опции: "должно быть равно% {count}" . -
: less_than- Указывает, что значение должно быть меньше предоставленного значения. В сообщение об ошибке по умолчанию для этой опции: "должно быть меньше% {count}" . -
: less_than_or_equal_to- указывает, что значение должно быть меньше или равно предоставленное значение. Сообщение об ошибке по умолчанию для этого параметра - "должно быть
меньше или равно% {count} ". -
: other_than- Указывает, что значение должно отличаться от указанного. Сообщение об ошибке по умолчанию для этого параметра - "должно быть отличным от% {count}" . -
: odd- указывает, что значение должно быть нечетным, если установлено значение true. В сообщение об ошибке по умолчанию для этой опции - "должно быть нечетным" . -
: even- указывает, что значение должно быть четным, если установлено значение true. В сообщение об ошибке по умолчанию для этого параметра: "должно быть четным" .
 Сообщение об ошибке по умолчанию для этого параметра - "должно быть
меньше или равно% {count} ".
Сообщение об ошибке по умолчанию для этого параметра - "должно быть
меньше или равно% {count} ". По умолчанию число не допускает значений nil . Вы можете использовать опцию allow_nil: true , чтобы разрешить это.
Сообщение об ошибке по умолчанию, когда не указаны параметры: "не число" .
2.9
присутствие Этот помощник проверяет, что указанные атрибуты не пусты.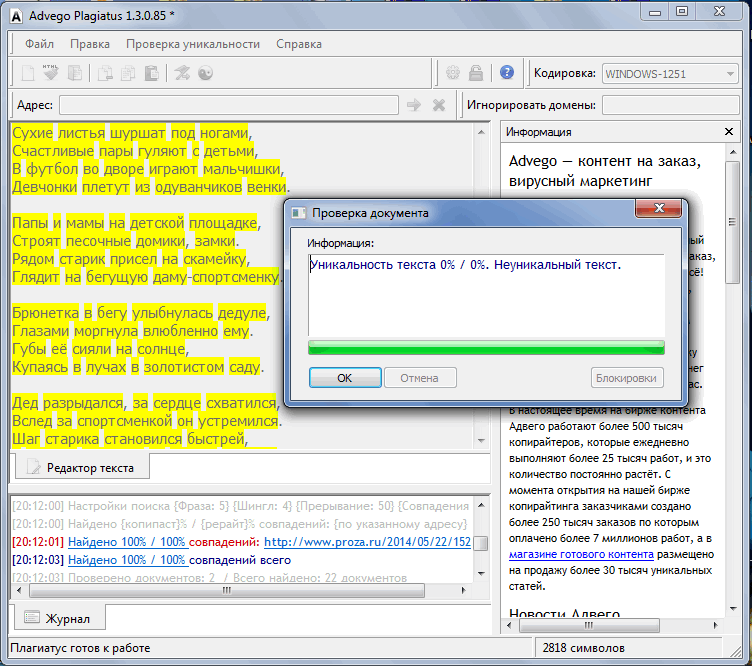 Он использует
Он использует пусто? , чтобы проверить, является ли значение nil или пустой строкой,
есть, строка, которая либо пуста, либо состоит из пробелов.
класс Person класс Person класс Поставщик класс Поставщик : inverse_of для ассоциации: Если вы хотите убедиться, что ассоциация присутствует и действительна, вам также необходимо использовать validates_associated .
класс Заказ класс Order has_one или has_many , он проверит, не является ли объект пустым? ни отмечен_для разрушения? . С ложно. Пусто? верно, если вы хотите проверить наличие логического
вы должны использовать одну из следующих проверок:
проверяет: логическое_имя_поля, включение: [истина, ложь]
проверяет: логическое_имя_поля, исключение: [ноль]
проверяет: логическое_имя_поля, включение: [истина, ложь]
проверяет: boolean_field_name, исключение: [nil]
Копировать Используя одну из этих проверок, вы убедитесь, что значение НЕ будет nil что в большинстве случаев приведет к значению NULL .
2.
 10
10 отсутствие Этот помощник проверяет отсутствие указанных атрибутов. Он использует присутствует? , чтобы проверить, не является ли значение нулевым или пустой строкой,
есть, строка, которая либо пуста, либо состоит из пробелов.
класс Person класс Person класс LineItem класс LineItem : inverse_of для ассоциации: класс Заказ класс Order has_one или has_many , он проверит, нет ли объекта ? ни отмечен_для разрушения? .
С ложно. Присутствует? ложно, если вы хотите проверить отсутствие логического
field вы должны использовать validates: field_name, exclusion: {in: [true, false]} .
Сообщение об ошибке по умолчанию: «должно быть пустым» .
2.11
уникальность Этот помощник проверяет уникальность значения атрибута прямо перед объект сохраняется. Он не создает ограничения уникальности в базе данных, поэтому может случиться так, что два разных подключения к базе данных создают две записи с тем же значением для столбца, который вы хотите сделать уникальным.Чтобы этого избежать, вы должны создать уникальный индекс для этого столбца в своей базе данных.
класс Учетная запись класс Account 
Существует опция : scope , которую можно использовать для указания одного или нескольких атрибутов, которые
используются для ограничения проверки уникальности:
класс Holiday класс Holiday : scope , вы должны создать уникальный индекс для обоих столбцов в вашей базе данных.См. Руководство по MySQL для получения более подробной информации о нескольких индексах столбцов или руководство PostgreSQL для примеров уникальных ограничений, которые относятся к группе столбцов. Существует также опция : case_sensitive , которую можно использовать, чтобы определить,
ограничение уникальности будет чувствительно к регистру или нет. По умолчанию эта опция
истинный.
По умолчанию эта опция
истинный.
класс Person класс Person Сообщение об ошибке по умолчанию - «уже принято» .
2.12
validates_with Этот помощник передает запись в отдельный класс для проверки.
класс GoodnessValidator класс GoodnessValidator записи. Ошибки [: base] относятся к состоянию записи
в целом, а не по конкретному атрибуту.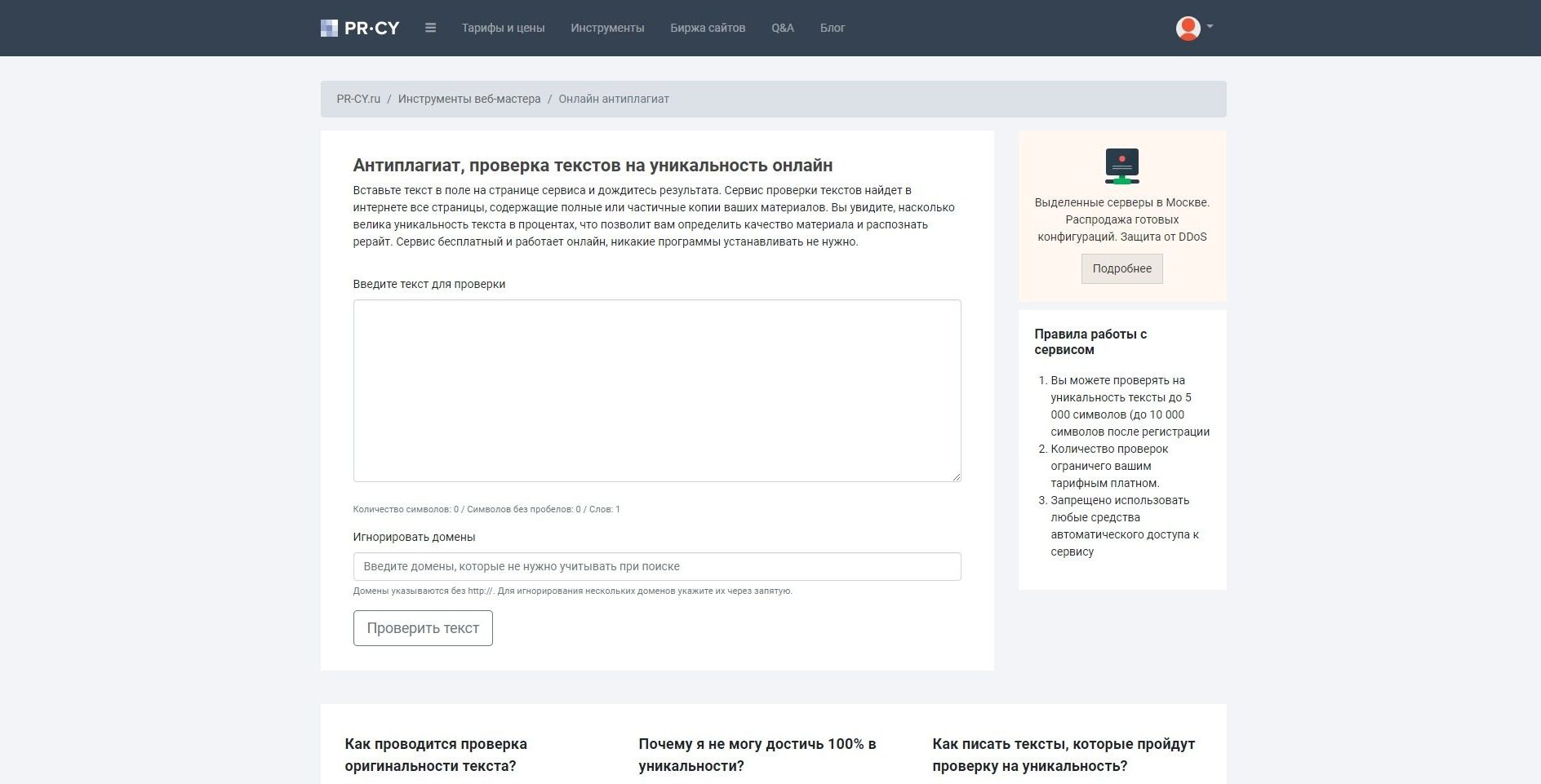 Ошибки [: base]
Ошибки [: base] Помощник validates_with принимает класс или список классов для использования
Проверка. Сообщение об ошибке по умолчанию для validates_with отсутствует. Вы должны
вручную добавить ошибки в коллекцию ошибок записи в классе валидатора.
Чтобы реализовать метод проверки, у вас должен быть определен параметр записи ,
которая является записью, которая подлежит проверке.
Как и все другие проверки, validates_with принимает : if , : if и : на опций. Если вы передадите какие-либо другие параметры, он отправит эти параметры в
класс валидатора как варианты :
класс GoodnessValidator класс GoodnessValidator 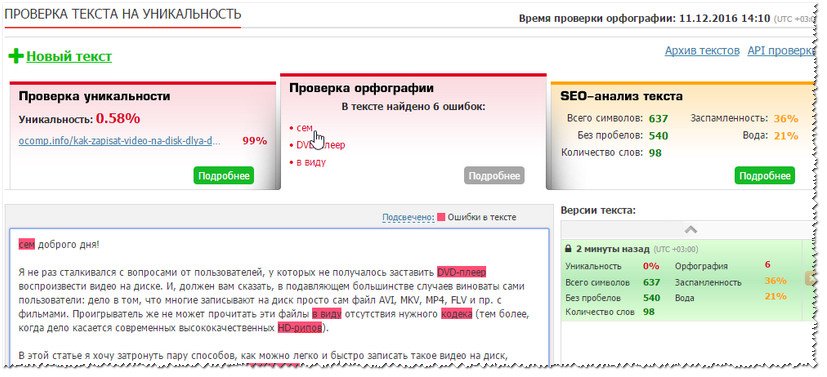 любой? {| поле | record.send (field) == "Зло"}
record.errors.add: base, "Этот человек злой"
конец
конец
конец класс Person
любой? {| поле | record.send (field) == "Зло"}
record.errors.add: base, "Этот человек злой"
конец
конец
конец класс Person Если ваш валидатор достаточно сложен и вам нужны переменные экземпляра, вы можете легко использовать вместо этого простой старый объект Ruby:
класс Person  ..
конец
..
конец
класс Person validates_each Этот помощник проверяет атрибуты блока. У него нет предопределенного
функция проверки.Вы должны создать его, используя блок, и каждый атрибут
передано на validates_each будет протестировано против него. В следующем примере
мы не хотим, чтобы имена и фамилии начинались с нижнего регистра.
класс Person класс Person  errors.add (attr, 'должно начинаться с верхнего регистра') if value = ~ / \ A [[: lower:]] /
конец
конец
Копировать
errors.add (attr, 'должно начинаться с верхнего регистра') if value = ~ / \ A [[: lower:]] /
конец
конец
КопироватьБлок получает запись, имя атрибута и значение атрибута. Вы можете делать все, что угодно, чтобы проверить правильность данных в блоке. Если твой проверка не удалась, вы должны добавить ошибку в модель, поэтому делая его недействительным.
3 Общие параметры проверки
Это общие параметры проверки:
3.1
: allow_nil Параметр : allow_nil пропускает проверку, когда проверяемое значение равно ноль .
класс Кофе class Coffee  В
документация сообщения.
В
документация сообщения.3,2
: allow_blank Параметр : allow_blank аналогичен параметру : allow_nil .Этот вариант
позволит пройти проверку, если значение атрибута пустое? , например ноль или
пустая строка, например.
класс Тема класс Тема irb> Topic.create (title: "") .valid?
=> правда
irb> Topic.create (title: nil) .valid?
=> правда
Тема.create (title: "") .valid?
Topic.create (title: nil) .valid?
Копировать3,3
: сообщение Как вы уже видели, параметр : сообщение позволяет указать сообщение, которое
будет добавлен в коллекцию ошибок в случае сбоя проверки. Когда это
опция не используется, Active Record будет использовать соответствующее сообщение об ошибке по умолчанию.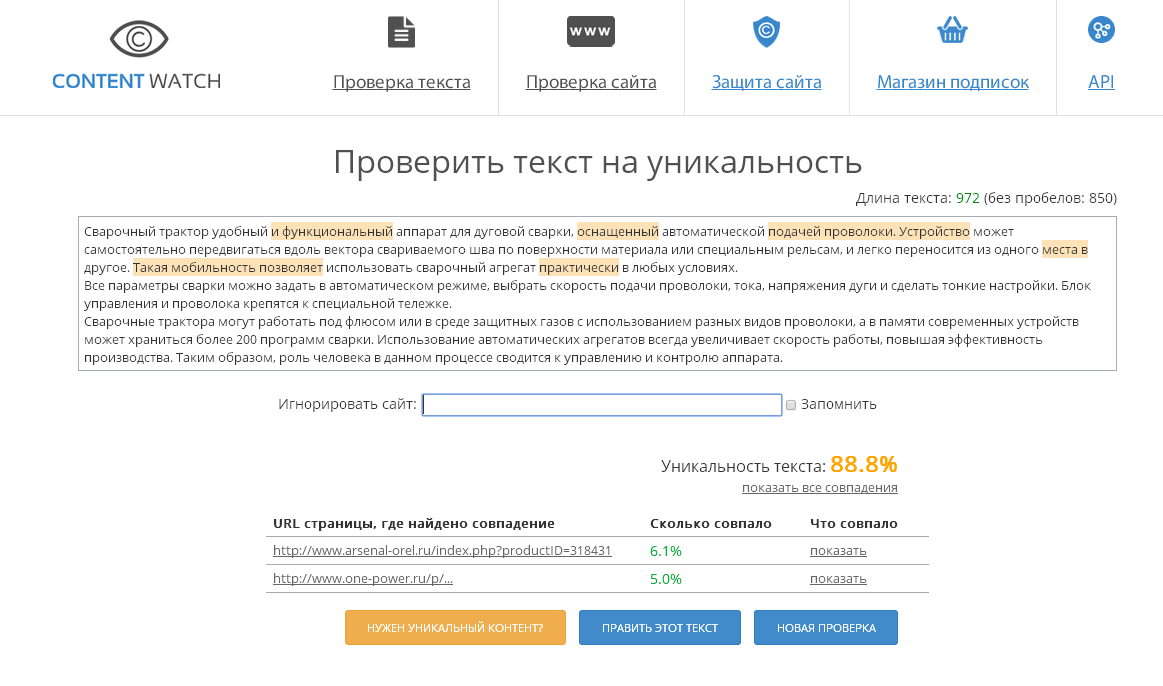 для каждого помощника по проверке. Параметр
для каждого помощника по проверке. Параметр : message принимает String или Proc .
A String : значение сообщения может дополнительно содержать любое / все из % {value} , % {attribute} и % {model} , которые будут динамически заменены, когда
проверка не удалась.Эта замена выполняется с помощью драгоценного камня I18n, а
заполнители должны точно совпадать, пробелы не допускаются.
A Proc : значение сообщения получает два аргумента: проверяемый объект и
хэш с : модель , : атрибут и : значение пар ключ-значение.
класс Person  проверяет: возраст, численность: {сообщение: "% {значение} кажется неправильным"}
# Proc
проверяет: имя пользователя,
уникальность: {
# object = person проверяемый объект
# data = {модель: "Человек", атрибут: "Имя пользователя", значение: <имя пользователя>}
сообщение: -> (объект, данные) сделать
"Привет, # {object.name}, # {data [: value]} уже заняты".
конец
}
конец
проверяет: возраст, численность: {сообщение: "% {значение} кажется неправильным"}
# Proc
проверяет: имя пользователя,
уникальность: {
# object = person проверяемый объект
# data = {модель: "Человек", атрибут: "Имя пользователя", значение: <имя пользователя>}
сообщение: -> (объект, данные) сделать
"Привет, # {object.name}, # {data [: value]} уже заняты".
конец
}
конец
класс Person name}, # {data [: value]} уже заняты".
конец
}
конец
Копировать3.4
: на Параметр : на позволяет указать, когда должна произойти проверка. В
поведение по умолчанию для всех встроенных помощников проверки должно запускаться при сохранении
(как при создании новой записи, так и при ее обновлении). если ты
хотите изменить его, вы можете использовать на:: create для запуска проверки только тогда, когда
создается новая запись или on:: update для запуска проверки только тогда, когда запись
обновлено.
класс Person класс Person на: для определения пользовательских контекстов. Пользовательские контексты должны быть
запускается явным образом путем передачи имени контекста в
Пользовательские контексты должны быть
запускается явным образом путем передачи имени контекста в действителен? , г. недействителен? , или с сохранением . класс Person класс Person irb> person = Человек.новый (возраст: 'тридцать три')
irb> person.valid?
=> правда
irb> person.valid? (: account_setup)
=> ложь
irb> person.errors.messages
=> {: email => ["уже занято"],: age => ["не число"]}
person = Person.new (возраст: 'тридцать три')
person.valid?
person.valid? (: account_setup)
person.errors.messages
Копировать person.valid? (: Account_setup) выполняет обе проверки без сохранения
модель.
person.save (context:: account_setup) проверяет person.save в account_setup контекст перед сохранением.
Когда запускается явным контекстом, проверки выполняются для этого контекста, как и любые проверки без контекста.
класс Person класс Person irb> person = Человек.новый
irb> person.valid? (: account_setup)
=> ложь
irb> person.errors.messages
=> {: email => ["уже занято"],: age => ["не является числом"],: name => ["не может быть пустым"]}
person = Person.new
person.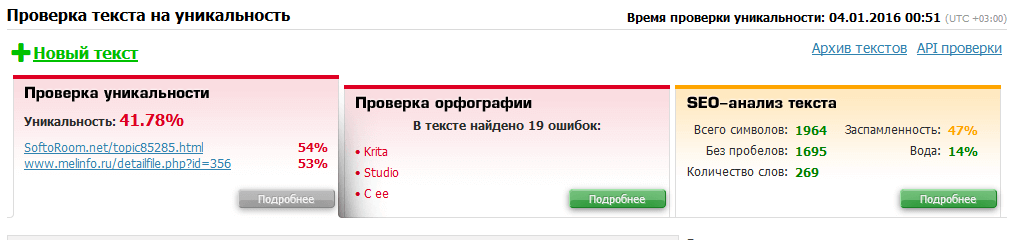 valid? (: account_setup)
person.errors.messages
Копировать
valid? (: account_setup)
person.errors.messages
Копировать4 строгих проверки
Вы также можете указать строгие проверки и повысить ActiveModel :: StrictValidationFailed , если объект недействителен.
класс Person класс Person irb> Человек.новый. действительный?
ActiveModel :: StrictValidationFailed: имя не может быть пустым.
Person.new.valid?
Копировать Существует также возможность передать настраиваемое исключение в параметр : strict .
класс Person класс Person irb> Человек. новый. действительный?
TokenGenerationException: токен не может быть пустым
Person.new.valid?
Копировать новый. действительный?
TokenGenerationException: токен не может быть пустым
новый. действительный?
TokenGenerationException: токен не может быть пустым
5 Условная проверка
Иногда имеет смысл проверять объект только при заданном предикате.
доволен. Вы можете сделать это, используя опции : if и : except , которые
может принимать символ, Proc или Array . Вы можете использовать : if вариант, если вы хотите указать, когда проверка должна произойти .если ты
хотите указать, когда проверка не должна происходить , тогда вы можете использовать : кроме опции .
5.1 Использование символа с
: если и : кроме Вы можете связать : если и : если варианты с символом, соответствующим
к имени метода, который будет вызван прямо перед проверкой.
Это наиболее часто используемый вариант.
класс Заказ класс Order  2 Использование Proc с
2 Использование Proc с : если и : если Можно связать : если и : если не с объектом Proc который будет называться. Использование объекта Proc дает вам возможность писать
встроенное условие вместо отдельного метода. Этот вариант лучше всего подходит для
однострочные.
класс Учетная запись класс Account Lambdas являются типом Proc , их также можно использовать для записи в строку
условия короче. проверяет: пароль, подтверждение: true, если: -> {password.blank? }
проверяет: пароль, подтверждение: true, если: -> {password.blank? }
Копировать5.
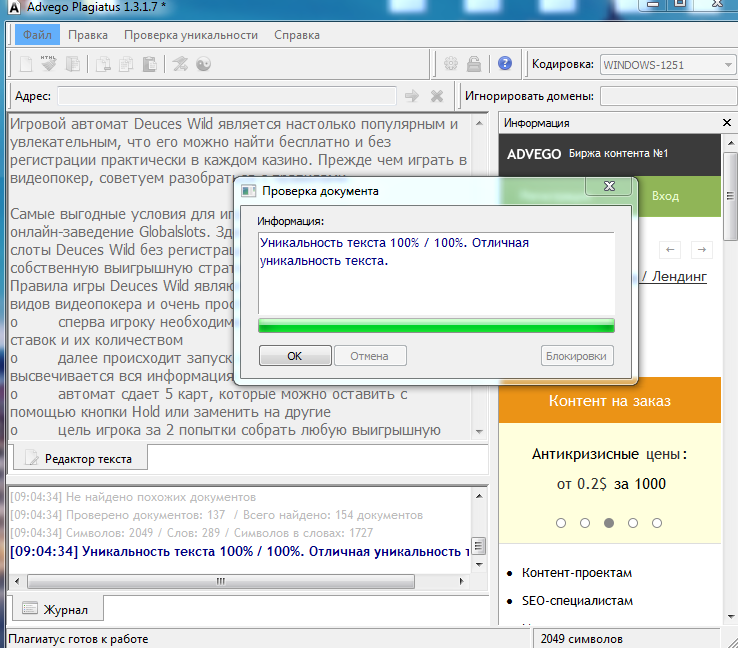 3 Группировка условных проверок
3 Группировка условных проверок Иногда бывает полезно, чтобы несколько проверок использовали одно условие.Может
легко достигается с помощью with_options .
класс Пользователь класс User with_options будут автоматически
выполнено условие , если:: is_admin? 5.4 Объединение условий проверки
С другой стороны, когда несколько условий определяют, будет ли проверка
Если это произойдет, можно использовать массив . Причем можно применить как : если , так и : если не с той же проверкой.
класс Компьютер класс Computer : если условий и ни одно из : если условий не оцениваются как истинно .6 Выполнение пользовательских проверок
Когда встроенных помощников проверки недостаточно для ваших нужд, вы можете напишите свои собственные валидаторы или методы проверки по своему усмотрению.
6.1 Пользовательские валидаторы
Пользовательские валидаторы - это классы, унаследованные от ActiveModel :: Validator .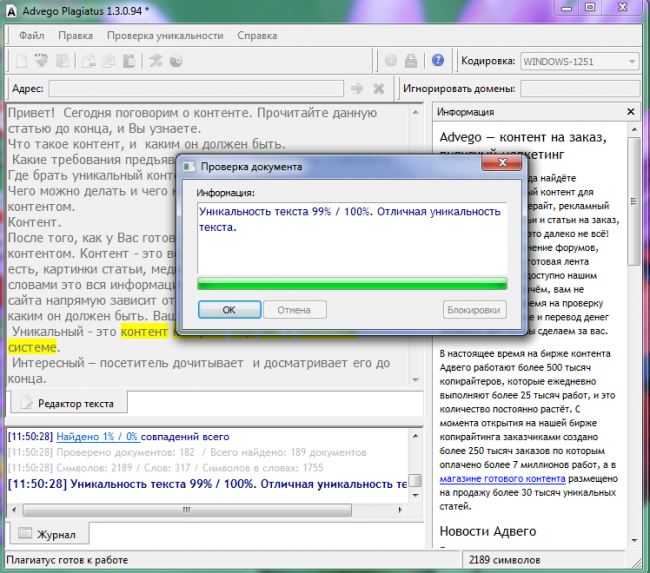 Эти
классы должны реализовывать метод
Эти
классы должны реализовывать метод validate , который принимает запись в качестве аргумента
и выполняет проверку на нем. Пользовательский валидатор вызывается с помощью validates_with метод.
класс MyValidator класс MyValidator ActiveModel :: EachValidator . В этом случае обычай
класс валидатора должен реализовывать метод
В этом случае обычай
класс валидатора должен реализовывать метод validate_each , который занимает три
аргументы: запись, атрибут и значение. Они соответствуют экземпляру,
атрибут, который нужно проверить, и значение атрибута в переданном
пример.@ \ s] +) @ ((?: [- a-z0-9] + \.) + [a-z] {2,}) \ z / i
атрибут record.errors.add, (options [: message] || «не является адресом электронной почты»)
конец
конец
конец класс Person 6.2 Пользовательские методы
Вы также можете создавать методы, которые проверяют состояние ваших моделей и добавляют
ошибки в коллекцию ошибок , если они недопустимы.Тогда вы должны
зарегистрируйте эти методы с помощью , проверьте class, передавая символы для имен методов проверки.
Вы можете передать более одного символа для каждого метода класса и соответствующего проверки будут выполняться в том же порядке, в котором они были зарегистрированы.
действителен? проверит, что коллекция ошибок пуста,
поэтому ваши собственные методы проверки должны добавлять к нему ошибки, когда вы
желаю, чтобы проверка не прошла:
класс Счет-фактура total_value
errors.add (: скидка, «не может быть больше общей суммы»)
конец
конец
конец
класс Invoice  настоящее время? && expiration_date
настоящее время? && expiration_date По умолчанию такие проверки будут запускаться каждый раз, когда вы звоните по номеру . Действительно? или сохраните объект. Но также можно контролировать, когда запускать эти
пользовательские проверки путем предоставления опции : on методу validate ,
с помощью: : создать или : обновить .
класс Счет-фактура класс Invoice  add (: customer_id, "не активен"), если customer.active?
конец
конец
Копировать
add (: customer_id, "не активен"), если customer.active?
конец
конец
Копировать7 Работа с ошибками проверки
действителен? и недействительны? Методы предоставляют только сводный статус действительности.Однако вы можете глубже изучить каждую отдельную ошибку, используя различные методы из коллекции errors .
Ниже приводится список наиболее часто используемых методов. Пожалуйста, обратитесь к документации ActiveModel :: Errors за списком всех доступных методов.
7.1
ошибок Шлюз, через который вы можете получить подробную информацию о каждой ошибке.
Возвращает экземпляр класса ActiveModel :: Errors , содержащий все ошибки,
каждая ошибка представлена объектом ActiveModel :: Error .
класс Person класс Person irb> person = Person. new
irb> person.valid?
=> ложь
irb> person.errors.full_messages
=> [«Имя не может быть пустым», «Имя слишком короткое (минимум 3 символа)»]
irb> person = Person.new (имя: "Джон Доу")
irb> person.valid?
=> правда
irb> человек.errors.full_messages
=> []
person = Person.new
person.valid?
person.errors.full_messages
person = Person.new (имя: "Джон Доу")
person.valid?
person.errors.full_messages
Копировать.png?1549983342654) new
irb> person.valid?
=> ложь
irb> person.errors.full_messages
=> [«Имя не может быть пустым», «Имя слишком короткое (минимум 3 символа)»]
irb> person = Person.new (имя: "Джон Доу")
irb> person.valid?
=> правда
irb> человек.errors.full_messages
=> []
new
irb> person.valid?
=> ложь
irb> person.errors.full_messages
=> [«Имя не может быть пустым», «Имя слишком короткое (минимум 3 символа)»]
irb> person = Person.new (имя: "Джон Доу")
irb> person.valid?
=> правда
irb> человек.errors.full_messages
=> []
7.2
ошибок [] ошибок [] используется, когда вы хотите проверить сообщения об ошибках для определенного атрибута. Он возвращает массив строк со всеми сообщениями об ошибках для данного атрибута, каждая строка с одним сообщением об ошибке. Если с атрибутом нет ошибок, он возвращает пустой массив.
класс Person класс Person irb> person = Person. new (имя: "Джон Доу")
irb> person.valid?
=> правда
irb> person.errors [: имя]
=> []
irb> person = Person.new (имя: "JD")
irb> person.valid?
=> ложь
irb> person.errors [: имя]
=> ["слишком короткое (минимум 3 символа)"]
irb> person = Человек.новый
irb> person.valid?
=> ложь
irb> person.errors [: имя]
=> ["не может быть пустым", "слишком короткое (минимум 3 символа)"]
person = Person.new (имя: "Джон Доу")
person.valid?
person.errors [: имя]
person = Person.new (имя: "JD")
person.valid?
person.errors [: имя]
person = Person.new
person.valid?
person.errors [: имя]
Копировать new (имя: "Джон Доу")
irb> person.valid?
=> правда
irb> person.errors [: имя]
=> []
irb> person = Person.new (имя: "JD")
irb> person.valid?
=> ложь
irb> person.errors [: имя]
=> ["слишком короткое (минимум 3 символа)"]
irb> person = Человек.новый
irb> person.valid?
=> ложь
irb> person.errors [: имя]
=> ["не может быть пустым", "слишком короткое (минимум 3 символа)"]
new (имя: "Джон Доу")
irb> person.valid?
=> правда
irb> person.errors [: имя]
=> []
irb> person = Person.new (имя: "JD")
irb> person.valid?
=> ложь
irb> person.errors [: имя]
=> ["слишком короткое (минимум 3 символа)"]
irb> person = Человек.новый
irb> person.valid?
=> ложь
irb> person.errors [: имя]
=> ["не может быть пустым", "слишком короткое (минимум 3 символа)"]
7.3
ошибок. Где и объект ошибки Иногда нам может потребоваться дополнительная информация о каждой ошибке рядом с ее сообщением. Каждая ошибка инкапсулируется как объект ActiveModel :: Error и , где метод является наиболее распространенным способом доступа.
, где возвращает массив объектов ошибок, отфильтрованных по различным условиям.
класс Person класс Person irb> person = Person.new
irb> person.valid?
=> ложь
irb> person.errors.where (: имя)
=> [...] # все ошибки для: name attribute
irb> человек.errors.where (: name,: too_short)
=> [...] #: too_short ошибок для: name attribute
person = Person.new
person.valid?
person.errors.where (: имя)
person.errors.where (: имя,: too_short)
КопироватьВы можете прочитать различную информацию из этих объектов ошибок:
irb> error = person.errors.where (: name) .last
irb> error.attribute
=>: имя
irb> error.type
=>: too_short
irb> error.options [: count]
=> 3
error = person.errors.where (: имя).последний
error.attribute
error.type
error.options [: count]
КопироватьТакже можно сгенерировать сообщение об ошибке:
irb> сообщение об ошибке
=> "слишком короткое (минимум 3 символа)"
irb> error. full_message
=> «Имя слишком короткое (минимум 3 символа)»
сообщение об ошибке
error.full_message
Копировать full_message
=> «Имя слишком короткое (минимум 3 символа)»
full_message
=> «Имя слишком короткое (минимум 3 символа)»
Метод full_message создает более удобное для пользователя сообщение с добавлением имени атрибута с заглавной буквы.
7,4
errors.add Метод add создает объект ошибки, используя атрибут , ошибку типа и дополнительный хэш параметров.Это полезно для написания собственного валидатора.
класс Person класс Person irb> person = Person.create
irb> person.errors.where (: имя) .first.type
=>: too_plain
irb> person.errors.where (: name) .first.full_message
=> «Имя недостаточно крутое»
person = Person. create
person.errors.where (: имя) .first.type
person.errors.where (: имя) .first.full_message
Копировать
create
person.errors.where (: имя) .first.type
person.errors.where (: имя) .first.full_message
Копировать7,5
ошибок [: base] Вы можете добавить ошибки, которые связаны с состоянием объекта в целом, а не с конкретным атрибутом. Вы можете добавить ошибки в : base , если хотите сказать, что объект недействителен, независимо от значений его атрибутов.
класс Person класс Person irb> person = Person.create
irb> person.errors.where (: base) .first.full_message
=> «Этот человек недействителен, потому что ...»
person = Person.create
person.errors.where (: base) .first.full_message
Копировать7,6
ошибок. clear  clear
clear Метод clear используется, когда вы намеренно хотите очистить коллекцию ошибок . Конечно, вызов errors.clear для недопустимого объекта на самом деле не сделает его действительным: коллекция ошибок теперь будет пустой, но в следующий раз, когда вы вызовете valid? или любой другой метод, который пытается сохранить этот объект в базе данных, проверка будет запущена снова. Если какая-либо из проверок завершится неудачно, коллекция ошибок будет заполнена снова.
класс Person класс Person irb> person = Person.new
irb> person.valid?
=> ложь
irb> person.errors.empty?
=> ложь
irb> person.errors.clear
irb> person.errors.empty?
=> правда
irb> person.save
=> ложь
irb> person. errors.empty?
=> ложь
person = Человек.новый
person.valid?
person.errors.empty?
person.errors.clear
person.errors.empty?
person.save
person.errors.empty?
Копировать errors.empty?
=> ложь
errors.empty?
=> ложь
7,7
errors.size Метод size возвращает общее количество ошибок для объекта.
класс Person класс Person irb> person = Человек.новый
irb> person.valid?
=> ложь
irb> person.errors.size
=> 2
irb> person = Person.new (имя: «Андреа», электронная почта: «[email protected]»)
irb> person.valid?
=> правда
irb> person.errors.size
=> 0
person = Person.new
person.valid?
person.errors.size
person = Person.new (имя: «Андреа», электронная почта: «[email protected]»)
person.valid?
person.errors.size
Копировать8 Отображение ошибок проверки в представлениях
После создания модели и добавления проверок, если эта модель создана с помощью
веб-формы, вы, вероятно, захотите отобразить сообщение об ошибке, когда один из
проверки не пройдут.
Поскольку каждое приложение обрабатывает такие вещи по-разному, Rails делает
не включайте помощников просмотра, которые помогут вам напрямую генерировать эти сообщения.
Однако из-за большого количества методов, которые Rails предоставляет вам для взаимодействия,
валидации в целом, вы можете создавать свои собственные. Кроме того, когда
генерируя каркас, Rails поместит некоторый ERB в _form.html.erb , который
он генерирует, который отображает полный список ошибок этой модели.
Предполагая, что у нас есть модель, сохраненная в переменной экземпляра с именем @article , это выглядит так:
<% если @article.ошибки. любые? %>
<% = pluralize (@ article.errors.count, "error")%> запретил сохранение этой статьи:
<% @ article.errors.each do | error | %>
- <% = error.full_message%>
<% конец%>
<% конец%>
<% if @ article.errors.any? %> errors.count, "error")%> запретил сохранение этой статьи:
errors.count, "error")%> запретил сохранение этой статьи:- <% @article.errors.each do | error | ошибка | %>
- <% = error.full_message%> <% конец%>
Кроме того, если вы используете помощники форм Rails для генерации ваших форм, когда
ошибка проверки возникает в поле, будет сгенерировано лишнее Затем вы можете стилизовать этот div по своему усмотрению.Эшафот по умолчанию, который
Rails генерирует, например, добавляет это правило CSS: Это означает, что любое поле с ошибкой заканчивается красной рамкой в 2 пикселя. Вам предлагается помочь улучшить качество этого руководства. Пожалуйста, внесите свой вклад, если вы заметите какие-либо опечатки или фактические ошибки.Для начала вы можете прочитать наш раздел документации. Вы также можете найти неполный контент или устаревшие вещи.
Пожалуйста, добавьте недостающую документацию для main. Обязательно проверьте
Edge Guides сначала проверят
если проблемы уже исправлены или нет в основной ветке.
Ознакомьтесь с Руководством по Ruby on Rails.
для стиля и условностей. Если по какой-либо причине вы заметили, что нужно исправить, но не можете исправить это самостоятельно, пожалуйста,
открыть вопрос. И последнее, но не менее важное: любые обсуждения Ruby on Rails.
документация приветствуется в списке рассылки rubyonrails-docs. В этой статье на примерах объясняются ограничения SQL NOT NULL, Unique и SQL Primary Key в SQL Server. Ограничения в SQL Server - это предопределенные правила и ограничения, которые применяются к одному или нескольким столбцам в отношении значений, разрешенных в столбцах, для поддержания целостности, точности и надежности данных этого столбца.Другими словами, если вставленные данные соответствуют правилу ограничения, они будут вставлены успешно. Если вставленные данные нарушают определенное ограничение, операция вставки будет прервана. Ограничения в SQL Server могут быть определены на уровне столбца, где они указаны как часть определения столбца и будут применяться только к этому столбцу, или объявлены независимо на уровне таблицы. В этом случае правила ограничения будут применяться к более чем одному столбцу в указанной таблице.Ограничение может быть создано с помощью команды CREATE TABLE T-SQL при создании таблицы или добавлено с помощью команды ALTER TABLE T-SQL после создания таблицы. Есть шесть основных ограничений, которые обычно используются в SQL Server, которые мы подробно опишем на примерах в этой и следующей статье. Эти ограничения: В этой статье мы рассмотрим первые три ограничения; SQL NOT NULL, UNIQUE и SQL PRIMARY KEY, а остальные три ограничения мы завершим в следующей статье.Давайте начнем обсуждение каждого из этих ограничений SQL Server с краткого описания и практической демонстрации. По умолчанию столбцы могут содержать значения NULL. Ограничение NOT NULL в SQL используется для предотвращения вставки значений NULL в указанный столбец, считая его недопустимым значением для этого столбца. Предположим, что у нас есть приведенный ниже простой оператор CREATE TABLE, который используется для определения таблицы ConstraintDemo1. Эта таблица содержит только два столбца: ID и Имя. В операторе определения столбца идентификатора принудительно применяется ограничение уровня столбца SQL NOT NULL, учитывая, что столбец идентификатора является обязательным столбцом, которому должно быть предоставлено допустимое значение SQL NOT NULL. Случай отличается для столбца Name, который можно игнорировать в инструкции INSERT, с возможностью предоставить ему значение NULL.Если при определении столбца не указана возможность NULL, по умолчанию он примет значение NULL: ИСПОЛЬЗОВАТЬ SQLShackDemo GO СОЗДАТЬ ТАБЛИЦУ ConstraintDemo1 ( ID INT NOT NULL, Имя VARCHAR (50) NULL ) Если мы попытаемся выполнить следующие три операции вставки: INSERT INTO ConstraintDemo1 ([ID], [NAME]) VALUES (1, 'Ali') GO INSERT INTO ConstraintDemo1 ([ID]) ЗНАЧЕНИЯ (2) GOintDemo1 INTO [ИМЯ]) ЗНАЧЕНИЯ ('Fadi') GO Вы увидите, что первая запись будет успешно вставлена, поскольку значения столбцов ID и Name указаны в инструкции INSERT. Проверив вставленные данные, вы увидите, что вставлены только две записи, а отсутствующее значение для столбца Name во втором операторе INSERT будет NULL, что является значением по умолчанию, как показано в результате ниже: Предположим, что нам нужно запретить столбцу Name в предыдущей таблице принимать значения NULL после создания таблицы, используя оператор ALTER TABLE T-SQL ниже: ALTER TABLE ConstraintDemo1 ALTER COLUMN [Имя] VARCHAR (50) NOT NULL Вы увидите, что команда завершится ошибкой, так как она сначала проверит существующие значения столбца Name на наличие значений NULL перед созданием ограничения, как показано в сообщении об ошибке ниже: Чтобы обеспечить соблюдение ограничений NOT NULL в SQL, мы должны удалить все значения NULL столбца Name из таблицы, используя приведенный ниже оператор UPDATE, который заменяет значения NULL пустой строкой: UPDATE ConstraintDemo1 SET [Name] = '' WHERE [Name] IS NULL Если вы снова попытаетесь создать ограничения в SQL, он будет успешно создан, как показано ниже: Ограничение SQL NOT NULL также можно создать с помощью SQL Server Management Studio, щелкнув правой кнопкой мыши нужную таблицу и выбрав параметр «Дизайн». Ограничение UNIQUE в SQL используется, чтобы гарантировать, что никакие повторяющиеся значения не будут вставлены в определенный столбец или комбинацию столбцов, которые участвуют в ограничении UNIQUE, а не являются частью ПЕРВИЧНОГО КЛЮЧА.Другими словами, индекс, который автоматически создается при определении ограничения UNIQUE, гарантирует, что никакие две строки в этой таблице не могут иметь одинаковое значение для столбцов, участвующих в этом индексе, с возможностью вставки только одного уникального значения NULL в эти столбцы, если столбец допускает NULL. Давайте создадим небольшую таблицу с двумя столбцами, ID и Name. ИСПОЛЬЗОВАТЬ SQLShackDemo GO СОЗДАТЬ ТАБЛИЦУ ConstraintDemo2 ( ID INT UNIQUE, Имя VARCHAR (50) NULL ) Если мы попытаемся запустить четыре инструкции INSERT ниже: INSERT INTO ConstraintDemo2 ([ID], [NAME]) VALUES (1, 'Ali') GO INSERT INTO ConstraintDemo2 ([ID], [NAME]) VALUES (2, 'Ali') GO INSERT INTO ConstraintDemo2 ([ID], [NAME]) VALUES (NULL, 'Adel') GO INSERT INTO ConstraintDemo2 ([ID], [NAME]) VALUES (1, 'Faris') ГО Первые две записи будут вставлены успешно, без каких-либо ограничений, предотвращающих дублирование значений столбца Name. Три вставленные строки будут такими, как показано ниже: Системный объект INFORMATION_SCHEMA.TABLE_CONSTRAINTS можно легко использовать для получения информации обо всех определенных ограничениях в конкретной таблице с помощью сценария T-SQL ниже: ВЫБРАТЬ ИМЯ ОГРАНИЧЕНИЯ, ТАБЛИЦА_СХЕМА, ИМЯ ТАБЛИЦЫ, ТИП_ОГРАНИЧЕНИЯ ИЗ ИНФОРМАЦИИ_СХЕМЫ.TABLE_CONSTRAINTS WHERE TABLE_NAME = 'ConstraintDemo2' Результат предыдущего запроса покажет определенное ограничение UNIQUE в SQL в предоставленной таблице, что будет иметь вид: Используя имя ограничения, полученное из системного объекта INFORMATION_SCHEMA. ALTER TABLE ConstraintDemo2 DROP CONSTRAINT [UQ__Constrai__3214EC26B928E528] Если вы попытаетесь выполнить ранее неудачный оператор INSERT, запись с повторяющимся значением идентификатора будет успешно вставлена: Попытка снова добавить ограничение UNIQUE в SQL с помощью команды T-SQL ALTER TABLE… ADD CONSTRAINT ниже: ALTER TABLE ConstraintDemo2 ДОБАВИТЬ ОГРАНИЧЕНИЕ UQ__Constrai UNIQUE (ID) GO Ограничение при создании SQL не будет выполнено из-за наличия повторяющихся значений этого столбца в таблице, как показано в сообщении об ошибке ниже: При проверке вставленных данных повторяющиеся значения будут очищены, как показано ниже: Чтобы добавить ограничение UNIQUE, вы можете удалить или изменить повторяющиеся значения. ОБНОВЛЕНИЕ [SQLShackDemo]. [Dbo]. [ConstraintDemo2] SET ID = 3 WHERE NAME = 'FARIS' Теперь ограничение UNIQUE в SQL можно добавить в столбец ID без ошибок, как показано ниже: Ключ UNIQUE можно просмотреть с помощью SQL Server Management Studio, развернув узел «Ключи» под выбранной таблицей.Вы также можете увидеть автоматически созданный индекс, который используется для обеспечения уникальности значений столбца. Обратите внимание, что вы не сможете удалить этот индекс, не сбросив сначала ограничение UNIQUE: В дополнение к ранее показанным командам T-SQL ограничение UNIQUE можно также определить и изменить с помощью SQL Server Management Studio. Щелкните правой кнопкой мыши нужную таблицу и выберите «Дизайн». Ограничение PRIMARY KEY состоит из одного или нескольких столбцов со значениями, которые однозначно идентифицируют каждую строку в таблице. Ограничение SQL PRIMARY KEY объединяет ограничения UNIQUE и SQL NOT NULL, когда столбец или набор столбцов, участвующих в PRIMARY KEY, не могут принимать значение NULL. Если PRIMARY KEY определен в нескольких столбцах, вы можете вставить повторяющиеся значения в каждый столбец по отдельности, но значения комбинации всех столбцов PRIMARY KEY должны быть уникальными. Учтите, что вы можете определить только один ПЕРВИЧНЫЙ КЛЮЧ для каждой таблицы, и рекомендуется использовать небольшие столбцы или столбцы INT в ПЕРВИЧНОМ КЛЮЧЕ. Помимо обеспечения быстрого доступа к данным таблицы, индекс, который создается автоматически при определении ПЕРВИЧНОГО КЛЮЧА SQL, будет обеспечивать уникальность данных. Ограничение PRIMARY KEY отличается от ограничения UNIQUE тем, что; вы можете создать несколько ограничений UNIQUE в таблице с возможностью определения только одного ПЕРВИЧНОГО КЛЮЧА SQL для каждой таблицы.Другое отличие состоит в том, что ограничение UNIQUE допускает одно значение NULL, но PRIMARY KEY не допускает значения NULL. Предположим, что у нас есть приведенная ниже простая таблица с двумя столбцами; идентификатор и имя. Столбец ID определяется как ПЕРВИЧНЫЙ КЛЮЧ для этой таблицы, который используется для идентификации каждой строки в этой таблице, гарантируя, что в этот столбец ID не будут вставлены значения NULL или повторяющиеся значения. Таблица определяется с помощью сценария CREATE TABLE T-SQL ниже: ИСПОЛЬЗОВАТЬ SQLShackDemo GO СОЗДАТЬ ТАБЛИЦУ ConstraintDemo3 ( ID INT PRIMARY KEY, Имя VARCHAR (50) NULL ) Если вы попытаетесь выполнить три инструкции INSERT ниже: INSERT INTO ConstraintDemo3 ([ID], [NAME]) VALUES (1, 'John') GO INSERT INTO ConstraintDemo3 ([NAME]) VALUES ('Fadi') GO GO GO GO GO Вы увидите, что первая запись будет успешно вставлена, поскольку значения идентификатора и имени действительны. Проверив вставленные значения, вы увидите, что только первая запись вставлена успешно, как показано ниже: Если вы не предоставите ограничение SQL PRIMARY KEY с именем во время определения таблицы, SQL Server Engine предоставит ему уникальное имя, как вы можете видеть при запросе INFORMATION_SCHEMA.Системный объект TABLE_CONSTRAINTS ниже: SELECT CONSTRAINT_NAME, TABLE_SCHEMA, TABLE_NAME, CONSTRAINT_TYPE FROM INFORMATION_SCHEMA. С приведенным ниже результатом в нашем примере: Оператор T-SQL ALTER TABLE… DROP CONSTRAINT можно легко использовать для удаления ранее определенного ПЕРВИЧНОГО КЛЮЧА, используя имя, полученное из предыдущего результата: ALTER TABLE ConstraintDemo3 DROP CONSTRAINT PK__Constrai__3214EC27E0BEB1C4; Если вы попытаетесь выполнить два ранее неудачных оператора INSERT, вы увидите, что первая запись не будет вставлена, поскольку столбец ID не допускает значений NULL. Попытка снова добавить ограничение SQL PRIMARY KEY с помощью запроса ALTER TABLE T-SQL ниже: ALTER TABLE ConstraintDemo3 ДОБАВИТЬ ПЕРВИЧНЫЙ КЛЮЧ (ID); Операция завершится неудачно, так как при первой проверке существующих значений идентификатора на наличие NULL или повторяющихся значений SQL Server обнаруживает повторяющееся значение идентификатора 1, как показано в сообщении об ошибке ниже: Проверка данных таблицы также покажет вам повторяющееся значение: Чтобы добавить ограничение PRIMARY KEY, мы должны сначала очистить данные, удалив или изменив повторяющуюся запись.Здесь мы изменим значение идентификатора второй записи, используя инструкцию UPDATE ниже: UPDATE ConstraintDemo3 SET ID = 2 WHERE NAME = 'Saeed' Затем попытайтесь добавить ПЕРВИЧНЫЙ КЛЮЧ SQL, который теперь будет успешно создан: Ограничение SQL PRIMARY KEY также можно определить и изменить с помощью SQL Server Management Studio. Пожалуйста, ознакомьтесь со следующей статьей из серии Часто используемые ограничения SQL Server: FOREIGN KEY, CHECK и DEFAULT, в которой описаны три других ограничения SQL Server. Он является сертифицированным экспертом по решениям Microsoft в области управления данными и аналитикой, сертифицированным партнером по решениям Microsoft в области администрирования и разработки баз данных SQL, партнером разработчика Azure и сертифицированным инструктором Microsoft. Кроме того, он публикует свои советы по SQL во многих блогах. Посмотреть все сообщения от Ahmad Yaseen Python | Проверить, содержит ли список все уникальные элементы Некоторые операции со списком требуют от нас проверки уникальности всех элементов в списке.Обычно это происходит, когда мы пытаемся выполнить заданные операции в списке. Следовательно, именно эта полезность необходима в настоящее время. Давайте обсудим некоторые методы, с помощью которых это можно сделать. Метод № 1: Наивный метод Выход: Метод № 2: Использование Выход: Метод № 3: Использование счетчика Выход: Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы. Для начала подготовьтесь к собеседованию.
.field_with_errors {
отступ: 2 пикселя;
цвет фона: красный;
дисплей: таблица;
}
Копировать .field_with_errors {
отступ: 2 пикселя;
цвет фона: красный;
дисплей: таблица;
}

Обратная связь

SQL NOT NULL, UNIQUE и ПЕРВИЧНЫЙ КЛЮЧ SQL
.jpg) При добавлении ограничения после создания таблицы существующие данные будут проверяться на соответствие правилу ограничения перед созданием этого ограничения.
При добавлении ограничения после создания таблицы существующие данные будут проверяться на соответствие правилу ограничения перед созданием этого ограничения. NOT NULL ограничение в SQL
 Это означает, что вы должны предоставить допустимое значение SQL NOT NULL для этого столбца в операторах INSERT или UPDATE, поскольку столбец всегда будет содержать данные.
Это означает, что вы должны предоставить допустимое значение SQL NOT NULL для этого столбца в операторах INSERT или UPDATE, поскольку столбец всегда будет содержать данные. Указание идентификатора только во втором операторе INSERT не помешает успешному завершению процесса вставки из-за того, что столбец Name не является обязательным и принимает значения NULL. Последняя операция вставки завершится неудачно, поскольку мы предоставляем только инструкцию INSERT со значением для столбца Name, без указания значения для столбца ID, которое является обязательным и не может быть присвоено значение NULL, как показано в сообщении об ошибке ниже:
Указание идентификатора только во втором операторе INSERT не помешает успешному завершению процесса вставки из-за того, что столбец Name не является обязательным и принимает значения NULL. Последняя операция вставки завершится неудачно, поскольку мы предоставляем только инструкцию INSERT со значением для столбца Name, без указания значения для столбца ID, которое является обязательным и не может быть присвоено значение NULL, как показано в сообщении об ошибке ниже: Рядом с каждым столбцом вы найдете небольшой флажок, который вы можете использовать, чтобы указать возможность нулевого значения этого столбца. Если снять флажок рядом с столбцом, автоматически будет создано ограничение SQL NOT NULL, предотвращающее вставку любого значения NULL в этот столбец, как показано ниже:
Рядом с каждым столбцом вы найдете небольшой флажок, который вы можете использовать, чтобы указать возможность нулевого значения этого столбца. Если снять флажок рядом с столбцом, автоматически будет создано ограничение SQL NOT NULL, предотвращающее вставку любого значения NULL в этот столбец, как показано ниже: УНИКАЛЬНЫЕ ограничения в SQL
 Столбец ID не может содержать повторяющиеся значения из-за ограничения UNIQUE, указанного в определении столбца.Для столбца Name не задано никаких ограничений, как в операторе CREATE TABLE T-SQL ниже:
Столбец ID не может содержать повторяющиеся значения из-за ограничения UNIQUE, указанного в определении столбца.Для столбца Name не задано никаких ограничений, как в операторе CREATE TABLE T-SQL ниже: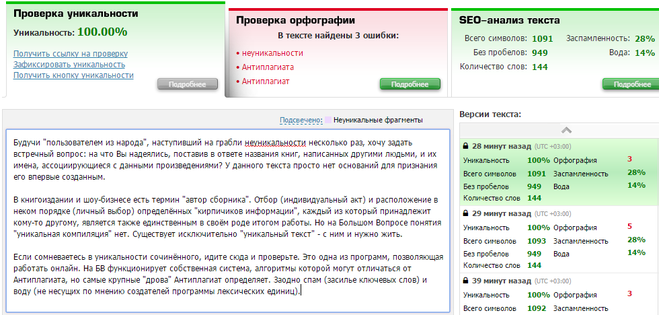 Третья запись также будет успешно вставлена, поскольку столбец уникального идентификатора допускает только одно значение NULL. Последний оператор INSERT завершится ошибкой, поскольку столбец идентификатора не допускает повторяющихся значений, а предоставленное значение идентификатора уже вставлено в этот столбец, как показано в сообщении об ошибке ниже:
Третья запись также будет успешно вставлена, поскольку столбец уникального идентификатора допускает только одно значение NULL. Последний оператор INSERT завершится ошибкой, поскольку столбец идентификатора не допускает повторяющихся значений, а предоставленное значение идентификатора уже вставлено в этот столбец, как показано в сообщении об ошибке ниже: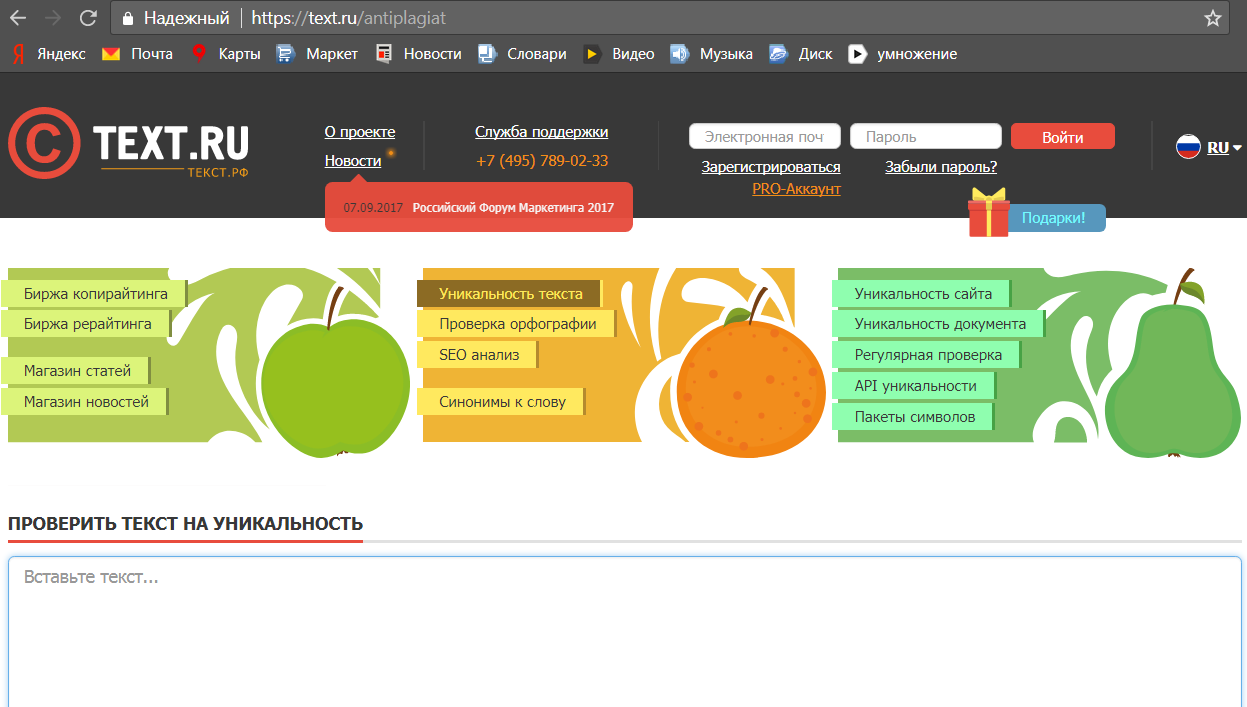 TABLE_CONSTRAINTS, мы можем отбросить ограничение UNIQUE с помощью команды ALTER TABLE… DROP CONSTRAINT в SQL T-SQL ниже:
TABLE_CONSTRAINTS, мы можем отбросить ограничение UNIQUE с помощью команды ALTER TABLE… DROP CONSTRAINT в SQL T-SQL ниже: В нашем случае мы обновим значение второго повторяющегося идентификатора, используя инструкцию UPDATE ниже:
В нашем случае мы обновим значение второго повторяющегося идентификатора, используя инструкцию UPDATE ниже: В окне «Дизайн» щелкните это окно правой кнопкой мыши и выберите «Индексы / ключи», откуда вы можете пометить ограничение как УНИКАЛЬНОЕ, как показано ниже:
В окне «Дизайн» щелкните это окно правой кнопкой мыши и выберите «Индексы / ключи», откуда вы можете пометить ограничение как УНИКАЛЬНОЕ, как показано ниже: Ограничение ПЕРВИЧНОГО КЛЮЧА SQL
 PRIMARY KEY используется в основном для обеспечения целостности объекта таблицы. Целостность объекта гарантирует, что каждая строка в таблице является однозначно идентифицируемым объектом.
PRIMARY KEY используется в основном для обеспечения целостности объекта таблицы. Целостность объекта гарантирует, что каждая строка в таблице является однозначно идентифицируемым объектом. Вторая операция вставки завершится ошибкой, поскольку столбец ID является обязательным и не может иметь значение NULL, поскольку столбец ID является ПЕРВИЧНЫМ КЛЮЧОМ SQL. Последний оператор INSERT также завершится ошибкой, поскольку указанное значение идентификатора уже существует, а повторяющиеся значения не допускаются в ПЕРВИЧНОМ КЛЮЧЕ, как показано в сообщении об ошибке ниже:
Вторая операция вставки завершится ошибкой, поскольку столбец ID является обязательным и не может иметь значение NULL, поскольку столбец ID является ПЕРВИЧНЫМ КЛЮЧОМ SQL. Последний оператор INSERT также завершится ошибкой, поскольку указанное значение идентификатора уже существует, а повторяющиеся значения не допускаются в ПЕРВИЧНОМ КЛЮЧЕ, как показано в сообщении об ошибке ниже: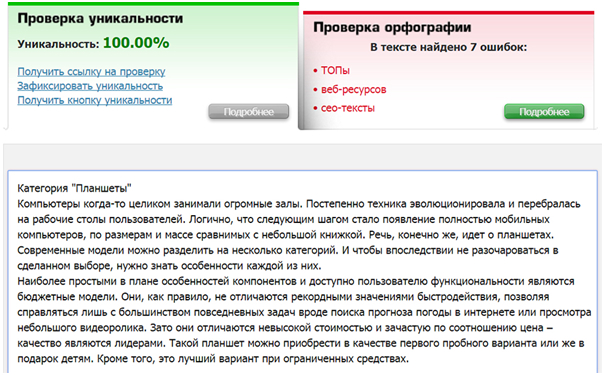 Вторая запись будет успешно вставлена, поскольку это ничто не препятствует вставке повторяющихся значений после удаления ПЕРВИЧНОГО КЛЮЧА SQL, как показано ниже:
Вторая запись будет успешно вставлена, поскольку это ничто не препятствует вставке повторяющихся значений после удаления ПЕРВИЧНОГО КЛЮЧА SQL, как показано ниже: Щелкните таблицу правой кнопкой мыши и выберите «Дизайн». В окне «Дизайн» щелкните правой кнопкой мыши столбец или набор столбцов, которые будут участвовать в ограничении PRIMARY KEY и опции Set PRIMARY KEY , которая автоматически снимет флажок Разрешить NULL, как показано ниже:
Щелкните таблицу правой кнопкой мыши и выберите «Дизайн». В окне «Дизайн» щелкните правой кнопкой мыши столбец или набор столбцов, которые будут участвовать в ограничении PRIMARY KEY и опции Set PRIMARY KEY , которая автоматически снимет флажок Разрешить NULL, как показано ниже: Полезные ссылки
Ахмад Ясин (Ahmad Yaseen) - инженер Microsoft по большим данным с глубокими знаниями и опытом в областях SQL BI, администрирования баз данных SQL Server и разработки.
Python | Проверить, содержит ли список все уникальные элементы
Решения обычно начинаются с простейшего метода, который можно применить для выполнения конкретной задачи. Здесь вы можете использовать вложенный цикл, чтобы проверить, существует ли после этого элемента аналогичный элемент в оставшемся списке.
test_list = [ 1 , 3 , 4 , 6 , 7 print ( "Исходный список:" + str (test_list)) флаг = 0 для i в диапазоне ( len (test_list)): для i1 в диапазоне ( len (test_list)): если i! = i1: если test_list [i] = = test_list [i1]: флаг = 1 если ( не флаг): печать ( «Список содержит все уникальные элементы» ) еще : печать ( «Список содержит не все уникальные элементы» )
Исходный список: [1, 3, 4, 6, 7]
Список содержит все уникальные элементы
len () + set ()
Это наиболее элегантный способ решения этой проблемы, используя всего одну строку. Это решение преобразует список в набор, а затем проверяет исходный список, если он содержит аналогичные номера. элементов.
Это решение преобразует список в набор, а затем проверяет исходный список, если он содержит аналогичные номера. элементов. test_list = [ 1 , 3 , 4 , 6 , 7 print ( "Исходный список:" + str (test_list)) флаг = 0 флаг = len ( набор (test_list)) = = len (test_list) если (флаг): печать ( «Список содержит все уникальные элементы» ) еще : печать ( «Список содержит не все уникальные элементы» )
Исходный список: [1, 3, 4, 6, 7]
Список содержит все уникальные элементы
.  itervalues ()
itervalues ()
Это один из различных методов, который использует частоту, полученную для всех элементов с помощью счетчика, и проверяет, не превышает ли какая-либо частота больше 1. из коллекций импорт Счетчик test_list = [ 1 , 3 , 4 , 6 , 7 print ( "Исходный список:" + str (test_list)) флаг = 0 счетчик = счетчик (test_list) для значений в счетчике . itervalues ():
itervalues (): если значений> 1 : флаг = 1 если ( не флаг): печать ( «Список содержит все уникальные элементы» ) еще : печать ( «Список содержит не все уникальные элементы» )
Исходный список: [1, 3, 4, 6, 7]
Список содержит все уникальные элементы
