
Собираем семантическое ядро через смартфон на Android
😼
Выборредакции
В свое время, когда я только начинал работать специалистом по контекстной рекламе, мне часто приходилось пользоваться программой KeyCollector и сервисом Wordstat для сбора семантики. И зачастую мне было любопытно, а есть ли аналогичный сервис, но только для мобильного телефона?
Ведь это было бы так удобно! Пока ты не в офисе и под рукой нет ноутбука, вместо бесполезных игрушек можно частично или полностью собрать семантику для своих проектов. Долгое время эта мысль не выходила у меня из головы, а решения все не было.
Это приложение, конечно, по функционалу не сравнится с KeyCollector, но может частично помочь вам собрать семантику на телефоне, пока вы в пути. Судя по всему, парсинг ключевых слов происходит из прогнозировщика Google Ads. Интерфейс достаточно прост. Все, что вам нужно сделать:
1) Установить приложение на телефон по ссылке.
2) В меню приложения выбрать «Add keyword to suggest»
3) Затем выбрать страну и язык, по которым будет происходить поиск ключевых слов. Указать по одной маске парсинга в строке и нажать кнопку «SAVE»
4) Откроется следующее меню, в котором вы можете запустить сбор семантики по заданным маскам.
5) Когда парсинг семантики будет окончен, вы сможете перейти вглубь маски, увидеть все собранные по ней ключи и удалить ненужные.
6) После чего вы сможете экспортировать полученный результат в .csv файл и отправить его себе на почту.
Но как всегда в бочке мёда всегда найдется своя ложка дёгтя 🙂
Есть пару нюансов:
1) Приложение доступно только для Android. На iOS его, к сожалению, нет.
На iOS его, к сожалению, нет.
2) Парсить вы можете только по всей стране. Ограничить сбор семантики конкретными городами не получится.
3) За раз можно собрать не больше 500 ключей. Затем удалять старые собранные маски и добавлять новые.
4) Экспортированный файл сохраняется в кодировке utf-8. Это не будет проблемой, если у вас Mac и вы пользуетесь приложением Numbers для работы с таблицами. В Microsoft Excel может возникнуть проблема с отображением ключей, и тогда вам нужно будет воспользоваться функцией импорта данных. Как это сделать можно посмотреть по ссылке.
Если же эти нюансы вас не смущают, то ставьте приложение и пользуйтесь им для решения рабочих задач в дороге 🙂
KeyCollector – лучшая программа для составления семантического ядра
Если мы говорим о программе для составления семантического ядра, то вполне естественно, возникает вопрос: что такое семантическое ядро?
Семантическое ядро – это термин вебмастеров и сео оптимизаторов, и представляет собой подбор слов и словосочетаний, которые с максимальной точностью указывают на рассматриваемую тему сайта, характеризуют предложения, рекомендуемые данным ресурсом.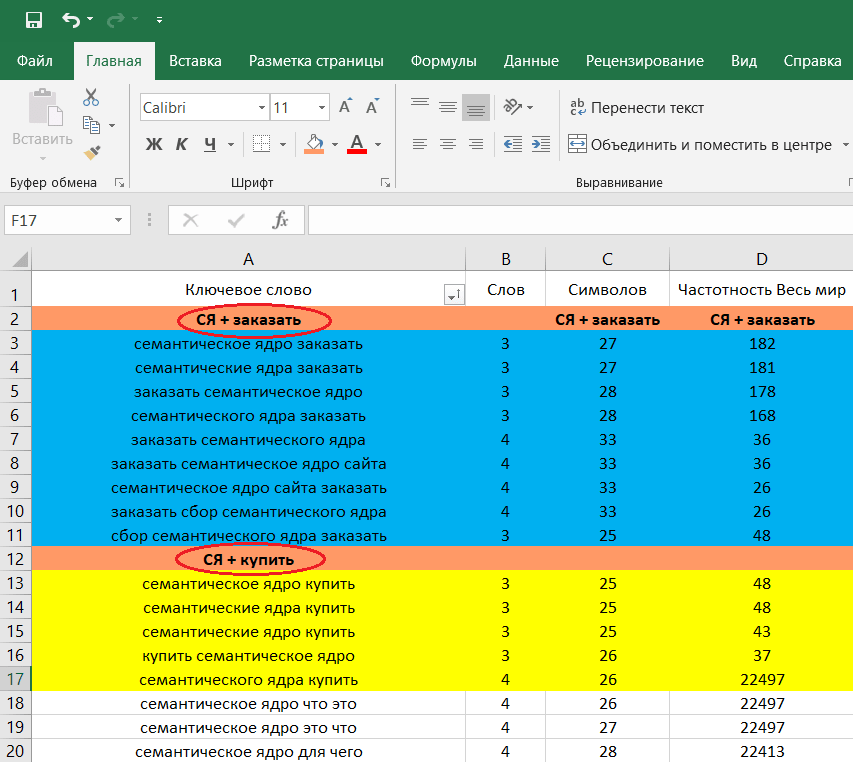
Реалити-шоу по продвижению крупного проекта
Как профессионал шаг за шагом продвигает самый разные страницы и запросы в ТОП. За год посещаемость выросла с 1000 человек до 7000 человек в сутки.
Это возможно.
Почему выбираем Key Collector?
Программа для составления семантического ядра Key Collector и служит сео оптимизатору помощником в создании и подборе ключевых фраз. Название программы можно перевести как собиратель ключей.
Кей-коллектор – приложение, устанавливаемое на компьютер. Программа разработана компанией LegatoSoft.
Она не только автоматизирует процесс составления семантического ядра страницы, она собирает информацию с сервисов-источников ключей, благодаря чему вы получаете самые актуальные фразы высокой, средней и низкой частоты запросов. В числе сервисов – Яндекс, Google? Liveinternet, Rambler adstat, MegaIndex, В Контакте и др.
Собирая семантическое ядро, вы устанавливаете свой регион, или расширяете географию, указываете страну, СНГ, Европу.
Все предложенные программой ключи оцениваются по нескольким параметрам:
- Популярность,
- Конкурентность,
- Геозависимость,
- Сезонность,
- Стоимость продвижения
Кей-коллектор определяет релевантные страницы на анализируемом сайте, выполняет быстрый анализ позиций в поисковой выдаче.
И что еще замечательно в этой программе, она собирает рекомендации по внутренней перелинковке.
Получаемые с программы результаты экспортируются в формат Microsoft Excel и CSV. С ними можно работать и в самой программе.
Таким образом, с программой кей-колллектор вы получите верного помощника в работе над сео оптимизацией сайтов, который сэкономит ваше время для более важных и актуальных дел.
Основные функции программы Key Collector: как ею пользоваться?
После загрузки и установки программы на рабочем столе появляется иконка
Базовая настройка Кей Коллектора.
Сначала в верхнем левом углу нажимаете на шестеренку, и в выпавшем окне – парсинг и Word stat. Затем выставляете настройки, как на скриншоте. Не забудьте внизу сохранить изменения.
Затем выставляете настройки, как на скриншоте. Не забудьте внизу сохранить изменения.
Создайте в Яндексе дополнительный аккаунт, и вставьте его в поле ввода настроек.
Обратите внимание на двоеточие между логином и паролем.
Далее следуют настройки во вкладке интерфейс – экспорт:
В программе имеется антигейт, который берет на себя функцию распознавания каптчи. Как ее проплатить и активировать, вы узнаете из этого видео. Теперь, когда программа настроена, можно переходить к работе в ней.План работы с программой для составления семантического ядра.
Создаете проект файла. И прописываете название. Для работы удобно, когда в файле прописано название сайта и дата начала работы.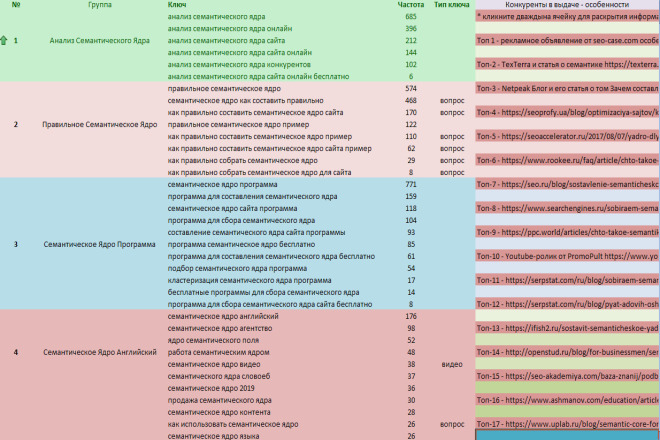
Файл сохраняете, указываете – название файла. Kcdb (тип файла).
Обязательно указываете таргетинг. Если ваш сайт целенаправлен на конкретно ваш регион, нажимаете на глобус.
В выпавшем окошке напротив страны Россия жмете на плюсик, и выбираете нужный регион. Снова жмете на плюсик, выбираете область. Те же самые действия выполняют жители ближнего зарубежья и Европы. Если сайт географически не ограничен, то в первом выпавшем окошке ставите галочки. И, конечно, не забывайте сохранять изменения.Ну вот, теперь, когда программа готова, переходим непосредственно к парсингу. Для информации, парсинг – это синтаксический (структурный) анализ сайтов. Парсингом также называется скачивание необходимой информации.
Выбираем сервис для сбора слов.
Выбрав сервис, и вписав запрос, нажимаете начать парсинг. С помощью программы вы легко осуществите поиск слов из Яндекс Wordstat, Liveinternet, Rambler adstat и др. Внизу журнал событий показывает? как идет парсинг. Отсюда вы узнаете и о завершении работы.
Внизу журнал событий показывает? как идет парсинг. Отсюда вы узнаете и о завершении работы.Зачистка списка слов
Следующий шаг – анализ частотностей и удаление ненужных ключей. В выделенном на скрине разделе можно провести анализ статистики по отдельным сервисам.
В примере на скрине выбран Яндекс директ.
Обратите внимание на предупреждение, сделанное программой. Оно выдается в каждой вкладке:
Для того чтобы проанализировать частнотности и в других сервисах, надо зарегистрироваться в них.Для некоторых сайтов и соответственно, некоторых ключей имеет значение сезонность. Например, спрос на тур путевки в Таиланд возрастает зимой, а на ремонт холодильников, или продажу мороженого, напротив, летом.
Число запросов также изменяется в зависимости от времени года. Программа позволяет создать фильтр с учетом сезонности.
Вкладка стоп-слова позволяет отсортировать и удалить нецелевые запросы. Нажимаете на иконку стоп-слова, и в выпавшее окошко вписываете слова, которые на ваш взгляд, не соответствуют тематике сайта.
Эта мера позволяет отсеять до 60% нецелевых запросов.
Фильтры вы найдете во вкладках частотности, сезон и других, расположенных в линию.Не забудьте перемещать ползунок снизу, чтобы увидеть все сервисы, предлагаемые программой
Нажимая на значки правой и левой мышкой, вы вызовите контекстное меню. Наводите курсор на значок и нажимаете левой мышкой Также наводите курсор на значок и жмете правой мышкой На этом скрине показан фильтр для поля сезон. Примерно также оформляете фильтры и в остальных вкладках. Здесь же вы найдете вкладки, позволяющие оценить стоимость продвижения, просчитать его сроки.Конкурентность по Яндексу и Google
Но вебмастеру не лишним будет знать, что Яндекс любит сайты, которые часто обновляются. Но это не значит, что нужно сбрасывать одновременно по несколько страниц. Достаточно по странице в день, а если времени не хватает, то 2-3 раза в неделю, но регулярно.
Гугл менее чувствителен к частоте обновления страниц, но он отдает предпочтение сайтам, имеющим входящую ссылочную массу.
Поэтому, чтобы успешно продвигаться в Google, надо приобретать ссылки на соответствующих сервисах – Miralinks, Sape, Mainlink.
Заключение
В общем, Key Collector – программа многофункциональная, и необходима вебмастеру, решившему играть по-крупному.
В одной статье сложно описать весь ее функционал. Но с основными принципами работы в этой программе, вы здесь ознакомитесь.
1 урок сбора семантического ядра
Перед созданием РК нам необходимо собрать семантическое ядро.
Что такое семантическое ядро – это набор ключевых фраз по которым будет продвигаться наш сайт в поисковых системах, либо, в нашем случае, по которым будет настраиваться контекстная реклама.
Сбор семантического ядра я разделил на 3 этапа:
- сбор масок
- парсинг (сбор) ключевых фраз
- сортировка ключевых фраз
Сбор масок – базисов для парсинга
Маски (или базисы) – это ключевые слова (фразы) по которым будет осуществляться парсинг наших основных ключей в сервисе Wordstat. По таким ключам мы рекламироваться на поиске не будем, так как они несут в себе общий характер без конкретики и не отражают конкретных намерений пользователя. Маски мы будем вводить в поле для поиска в Вордстате. Иногда по базисам настраивают рекламу в РСЯ. Базисы в вордстате:
По таким ключам мы рекламироваться на поиске не будем, так как они несут в себе общий характер без конкретики и не отражают конкретных намерений пользователя. Маски мы будем вводить в поле для поиска в Вордстате. Иногда по базисам настраивают рекламу в РСЯ. Базисы в вордстате:
“автосервис ремонт” это маска
В левом столбце находятся наши ключи, которые мы будем собирать, рядом с каждым ключом указано число – это частотность (сколько раз тот или иной ключ набираю в поисковике)
Как я уже говорил маски состоят из 1-2 слов и редко используется для настройки рекламной кампании, они нужны только для поиска ключевых фраз и как правило имеют высокую частотность, это общие слова относящиеся к нашему бизнесу, без конкретизации цвета, материала, размера и других уточнений. Все собранные маски записываем в файл Excel или блокнот.
Способы поиска масок:
- “Мозговой штурм”. Думаем как нас могут искать в поисковых системах и вводим этот запрос в Вордстат.
 Смотрим какие ключи появились в выдаче (в левом столбце), если тематика наша, то записываем маску.
Смотрим какие ключи появились в выдаче (в левом столбце), если тематика наша, то записываем маску. - Правый столбец Wordstat (Его называют эхо Вордстата). В этом столбце сервис показывает похожие запросы, которые могут стать нашими масками. Вводим каждую маску в поиск и проверяем правый столбец
- “Подсказки Яндекс Директ”. Заходим в Директ, создаем тестовую РК и объявление, нажимаем редактировать объявление. Прокручиваем вниз, видим поле “ключевые фразы” и справа колонку “подсказки”. В поле “ключевые фразы” вводим наши маски по-одной, после этого в столбце “подсказки” будут появляться дополнительные ключевые фразы, которые возможно подойдут нам.
- Синонимы. Заходим в сервис поиска синонимов, забиваем наши маски, ищем синонимы.
- Составление mind map (карта мыслей) о них мы поговорим дальше.
 Смотрим какие ключи появились в выдаче (в левом столбце), если тематика наша, то записываем маску.
Смотрим какие ключи появились в выдаче (в левом столбце), если тематика наша, то записываем маску.Создаем Mindmap карты для сбора семантики
Mindmap карты играют ключевую роль при сборе семантики (не только для контекстной рекламы, но и для seo). При этом совершенно не каждый директолог их использует, но если у вас узкая ниша или вы хотите собрать все ключевые фразы вашей тематики, без нее не обойтись.
При этом совершенно не каждый директолог их использует, но если у вас узкая ниша или вы хотите собрать все ключевые фразы вашей тематики, без нее не обойтись.
Mindmap карты – что это?
В переводе с английского Mindmap – это карта мыслей. Применяя её можно в простом и доступом формате для глаз законспектировать большую базу ключевых запросов, и, при
этом, что самое важное, спокойно в них разбираться, а при необходимости добавить что-то не дублируя.
Стоит подчеркнуть, что интеллект-карты используются не только для получения семантики. В такие карты можно заносить все что угодно: от плана на день до плана презентации. Но сегодня я расскажу лишь о формате для директологов и сеошников.
Какие бывают Mindmap карты:
• Online-карты.
• Программы на PC/MAC/Linux.
• Мобильные mindmap карты.
Я пользовался всевозможными бесплатными видами и предпочёл на простой компьютерной программе xmind. Мне кажется, что так намного проще и удобнее работать с обширными интеллект-картами.
Существуют как платные, так и бесплатные программы для построения mindmap карт. Но наибольшей популярностью пользуются следующие: Xmind, MindJet и Freemind.
Я остановился на Xmind за множество достоинств: удобный дизайн, автоматическое сохранение и, к тому же, программа бесплатная. Установить её можно на любую известную операционную систему, а скачать абсолютно бесплатно можно с сайта разработчика.
Настройка Xmind
Первое, что необходимо сделать, установить программу и запустить её, далее всплывёт окно, в котором можно выбрать тему новой mindmap карты. Я рекомендую остановиться на базовой(кликните дважды по плашке), однако это никак не влияет на конечный результат. Можно выбрать любую тему, которая вам нравится.
После этого, автоматически, создаётся плашка «Центральный раздел». Ей можно дать новое название, соответствующее названию проекта (нужно кликнуть дважды по плашке). К примеру, назовём«Дизайн интерьеров».
Чтобы было удобно работать, необходимо держать в уме всего две важные клавиши: Enter (создаёт родительскую плашку) и Tab (создаёт дочернюю плашку). Не забывайте, что одну из плашек, при этом, обязательно нужно выделить. У нас это «Дизайн интерьеров».
Не забывайте, что одну из плашек, при этом, обязательно нужно выделить. У нас это «Дизайн интерьеров».
xmind создание вкладок
Теперь начнётся самое увлекательное и важное. Необходимо обдумать тему и распределить вероятные поисковые запросы на главные группы и подгруппы.
Сбор семантики в xmind
В этом примере я показал упрощённую схему. Вам стоит рассмотреть всевозможные варианты запросов. Я затрачиваю на это от 30 минут до целых суток, всё зависит от трудности тематики.
Далее следует сформировать первичную семантику способом пересечения первоначальных ключевых слов. Для этого существует большое количество инструментов, но я использую инструмент ppc-help. Пример mind map можно скачать здесь.
Теперь мы переходим ко 2му уроку, где мы будем собирать наши основные ключевые фразы.
Смотрите также:
Проектирование и разработка баз данных. Технология программирования ORM. Распределенные, параллельные и гетерогенные базы данных.
Проектирование баз данных — процесс создания схемы базы данных и определения необходимых ограничений целостности.
Основные задачи проектирования баз данных:
• Поддержка хранения в БД всей необходимой информации.
• Возможность сбора данных по всем необходимым запросам.
• Сокращение от избыточности и дублирования данных.
• Поддержка целостности базы данных.
Основные этапы проектирования баз данных
Концептуальный дизайн — создание модели семантической области, то есть информационной модели самого высокого уровня абстракции. Такая модель создается без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» являются синонимами.
Конкретный тип и содержание концептуальной модели базы данных определяется формальным устройством, выбранным для этой цели.Обычно используются графические обозначения, похожие на диаграммы ER.
Чаще всего в концептуальную модель БД входят:
• описание информационных объектов или концепций предметной области и связи между ними.
• описание ограничений целостности, то есть требований к допустимым значениям данных и связям между ними.
Логический дизайн — создание схемы базы данных на основе определенной модели данных, например, реляционной модели данных.Для реляционной модели данных логическая модель данных — набор диаграмм отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющими внешние ключи.
Преобразование концептуальной модели в логическую, как правило, осуществляется по формальным правилам. Этот этап можно существенно автоматизировать.
На этапе логического проектирования учитывается специфика конкретной модели данных, но не может быть учтена специфика конкретной СУБД.
Physical design — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения для поддерживаемых типов данных и т. Д. Кроме того, специфика конкретной СУБД в случае физической конструкции включает в себя выбор решений, связанных с физическим носителем хранения данных (выбор методов управления дисковой памятью, разделения БД по файлам и устройствам, методов доступа к данным), создания индексов и т. д.
Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения для поддерживаемых типов данных и т. Д. Кроме того, специфика конкретной СУБД в случае физической конструкции включает в себя выбор решений, связанных с физическим носителем хранения данных (выбор методов управления дисковой памятью, разделения БД по файлам и устройствам, методов доступа к данным), создания индексов и т. д.
Что такое ORM?
ORM или Объектно-реляционное отображение — это технология программирования, которая позволяет преобразовывать несовместимые типы моделей в ООП, в частности, между хранилищем данных и предметами программирования. ORM используется для упрощения процесса сохранения объектов в реляционной базе данных и их извлечения, при этом ORM сам заботится о преобразовании данных между двумя несовместимыми состояниями. Большинство инструментов ORM в значительной степени полагаются на метаданные базы данных и объектов, поэтому объектам не нужно ничего знать о структуре базы данных, а базе данных — ничего о том, как данные организованы в приложении. ORM обеспечивает полное разделение задач на хорошо запрограммированные приложения, в случае которых и база данных, и приложение могут работать с данными каждое в корневой форме.
Fugure1- Работа ОРМ
Принцип работы ORM- Ключевой особенностью ORM является отображение, которое используется для привязки объекта к его данным в БД. ORM как бы создает «виртуальную» схему базы данных в памяти и позволяет манипулировать данными уже на уровне объекта. Дисплей отображается как объект, а его свойства связаны с одной или несколькими таблицами и их полями в базе данных.ORM использует информацию этого дисплея для управления процессом преобразования данных между базой и формами объектов, а также для создания SQL-запросов для вставки, обновления и удаления данных в ответ на изменения, которые приложение вносит в эти объекты.
Распределенная база данных — набор логически связанных между собой разделенных данных (и их описаний), которые физически распределены в некоторой компьютерной сети. Распределенная СУБД — программный комплекс, предназначенный для управления распределенными базами данных и позволяющий сделать распространение информации прозрачным для конечного пользователя.
Распределенная СУБД — программный комплекс, предназначенный для управления распределенными базами данных и позволяющий сделать распространение информации прозрачным для конечного пользователя.
Пользователи взаимодействуют с распределенной базой данных через приложения. Приложения можно разделить на те, которым не требуется доступ к данным на других веб-сайтах (локальные приложения), и те, которые требуют аналогичного доступа (глобальные приложения).
Один из подходов к интеграции объектно-ориентированных приложений с реляционными базами данных заключается в разработке разнородных информационных систем . Гетерогенные информационные системы способствуют интеграции разнородных источников информации, структурированных (с наличием регулярной (нормализованной) диаграммы), полуструктурированных, а иногда и неструктурированных.Любая разнородная информационная система строится по схеме глобальной базы данных над базами данных компонентов, поэтому пользователи получают преимущества диаграммы, то есть единые интерфейсы доступа (например, интерфейс в стиле sql) к данным, сохраненным в разных базах данных, и богатые функциональные возможности. . Такая разнородная информационная система называется системой интегрированных мультибаз данных.
. Такая разнородная информационная система называется системой интегрированных мультибаз данных.
Становление систем управления базами данных (СУБД) по времени совпало со значительным прогрессом в развитии технологий распределенных вычислений и параллельной обработки.В результате появились базы данных распределенных систем управления и параллельные системы управления базами данных. Эти системы становятся доминирующими инструментами для создания приложений с интенсивной обработкой данных.
Параллельный компьютер, или мультипроцессор сам по себе — это распределенная система, составленная из узлов (процессоров, компонентов памяти), соединенных быстрой сетью в общем корпусе. Технология распределенных баз данных может быть естественно пересмотрена и широко распространена в параллельных системах баз данных, т.е.е. системы баз данных на параллельных компьютерах
Распределенная и параллельная СУБД предоставляют те же функциональные возможности, что и хост-СУБД, за исключением того факта, что они работают в среде, где данные распределяются по узлам компьютерной сети или многопроцессорной системе.
Вопросы:
1. Почему отношения являются важным аспектом баз данных?
2. В чем разница между плоскими файлами и другими моделями баз данных?
3.Что такое ORM?
4. Принцип работы ORM?
5. ORM или объектно-реляционное отображение?
Список литературы
1. Джун Дж. Парсонс и Дэн Ожа, Новые перспективы компьютерных концепций, 16-е издание — всеобъемлющее, Thomson Course Technology, подразделение Thomson Learning, Inc. Кембридж, Массачусетс, АВТОРСКОЕ ПРАВО © 2014.
2. Лоренцо Кантони (Университет Лугано, Швейцария) Джеймс А. Дановски (Университет Иллинойса в Чикаго, Иллинойс, США) Коммуникация и технологии, 576 страниц.
Лекция №11 . Анализ данных.
Цель: дать общие понятия корреляции, регрессии, а также познакомиться с описательной статистикой.
План:
1. Базы анализа данных.
2. Методы сбора, классификации и прогнозирования. Деревья решений.
Методы сбора, классификации и прогнозирования. Деревья решений.
Базы анализа данных.
Интеллектуальный анализ данных — это процесс автоматического извлечения и генарификации прогнозной информации из больших банков данных.DM включает в себя анализ наборов данных наблюдений для поиска неожиданных, ранее неизвестных взаимосвязей и обобщения данных по-новому, понятным и полезным для владельца данных.
Отношения и сводки, полученные с помощью интеллектуального анализа данных, часто называют моделями или шаблонами. Примеры включают линейные уравнения, правила, кластеры, графики, древовидные структуры и повторяющиеся шаблоны во временных рядах. Следует отметить, что дискриплайн обычно имеет дело с данными, которые уже были собраны для какой-либо цели, кроме анализа интеллектуального анализа данных (например, они могли быть собраны для поддержания актуальной записи всех транзакций в банке).Это означает, что цели интеллектуального анализа данных обычно не играют никакой роли в стратегии сбора данных..jpg) Это один из способов его отличия от многих статистических данных, в которых данные часто собираются с использованием эффективных стратегий для ответа на конкретные вопросы.
Это один из способов его отличия от многих статистических данных, в которых данные часто собираются с использованием эффективных стратегий для ответа на конкретные вопросы.
DM, широко известный как «Обнаружение знаний в базах данных» (KDD), представляет собой автоматизированное или удобное извлечение шаблонов, представляющих знания, неявно сохраненные или захваченные в больших базах данных, которые могут содержать миллионы строк, связанных с предметом базы данных, хранилищами данных, Интернетом и другой массивной информацией. репозитории или потоки данных.
Итак, читатели (которые, как мы полагаем, знают о структуре системы баз данных) могут распознать основные различия между традиционной системой баз данных и DWH, которые включают интеллектуальный анализ данных, анализ (как части обнаружения знаний в базах данных), механизм OLAP (процессы онлайн-аналитики вместо или дополнительно к процессам онлайн-транзакций) Серверы DW / Marts (набор серверов для разных отделов предприятий), Back Ground process / preprocessing (например, Очистка — решение проблемы с отсутствующими данными, данными шума) и т. д.
Замечание об истории терминов
[с https: // en. wikipedia.org/wiki/Data_mining]:
Грегори Пятецкий-Шапиро ввел термин «открытие знаний в базах данных» для первого семинара по той же теме (KDD-1989), и этот термин стал более популярным в сообществе AI и машинного обучения. Однако термин Data Mining (1990) стал более популярным в деловых кругах и в прессе. В настоящее время интеллектуальный анализ данных и обнаружение знаний взаимозаменяемы. Для описания этой области также используются термины «прогнозная аналитика» (с 2007 г.) и «Наука о данных» (с 2011 г.).
Фактически, мы можем сказать, что DM — это шаг в процессе KDD, связанный с алгоритмами, разнообразием методов для определения поддержки принятия решений, предсказанием, прогнозированием и оценкой с использованием методов распознавания образов, а также статистических и математических методов.
Базовые модели и задачи интеллектуального анализа данных
DM включает в себя множество различных алгоритмов для выполнения различных задач. Все эти алгоритмы пытаются подогнать модель под данные. Создаваемая модель может быть по своей природе прогнозирующей или описательной .На рис. 6.2 представлены основные задачи DM, используемые в этом типе модели.
Все эти алгоритмы пытаются подогнать модель под данные. Создаваемая модель может быть по своей природе прогнозирующей или описательной .На рис. 6.2 представлены основные задачи DM, используемые в этом типе модели.
Predictive позволяет прогнозировать значения данных, используя известные результаты из различных наборов выборочных данных.
Классификация позволяет классифицировать данные из большого банка данных по заранее определенному набору классов. Классы определяются до изучения или изучения данных в банке данных. Задачи классификации позволяют не только изучать и исследовать существующие выборочные данные, но и предсказывать будущее поведение этих выборочных данных.Например, обнаружение мошенничества при транзакции с кредитной картой для предотвращения материальных потерь; оценка вероятности ухода сотрудника из организации до завершения проекта — вот некоторые из задач, которые вы решаете, применяя метод классификации.
Регрессия — это один из статистических методов, который позволяет прогнозировать будущие значения данных на основе текущих и прошлых значений данных. Задача регрессии проверяет значения данных и вырабатывает математическую формулу.Результат, полученный при использовании этой математической формулы, позволяет предсказать будущее значение существующих или даже пропущенных данных. Основным недостатком регрессии является то, что вы можете реализовать регрессию на количественных данных, таких как скорость и вес, чтобы предсказать их поведение в будущем.
Анализ временных рядов является частью Temporal Mining , позволяя прогнозировать будущие значения для текущего набора значений, которые зависят от времени. Анализ временных рядов позволяет использовать текущие и прошлые выборочные данные для прогнозирования будущих значений.Значения, которые вы используете для анализа временных рядов, равномерно распределяются по часам, дням, неделям, месяцам, годам и так далее. Вы можете нарисовать график временных рядов, чтобы визуализировать количество изменений в данных для определенных изменений во времени. Вы можете использовать анализ временных рядов для изучения тенденций на фондовом рынке для различных компаний за определенный период и, соответственно, для осуществления инвестиций.
Вы можете нарисовать график временных рядов, чтобы визуализировать количество изменений в данных для определенных изменений во времени. Вы можете использовать анализ временных рядов для изучения тенденций на фондовом рынке для различных компаний за определенный период и, соответственно, для осуществления инвестиций.
Суть описательной модели — определение закономерностей и взаимосвязей в выборочных данных:
Кластеризация — это обработка данных, в некотором смысле противоположная классификациям, которая позволяет создавать новые группы и классы на основе изучения закономерностей и взаимосвязей между значениями данных в банке данных.Это похоже на классификацию, но не требует предварительного определения групп или классов. Метод кластеризации иначе известен как сегментирование обучения без учителя . Все эти элементы данных, которые более похожи друг на друга, объединены в одну группу, также известную как кластеры. Примеры включают группы компаний, производящих похожие продукты или почвы с одинаковыми свойствами (например, чернозем), группу людей с одинаковыми привычками и т. Д.
Примеры включают группы компаний, производящих похожие продукты или почвы с одинаковыми свойствами (например, чернозем), группу людей с одинаковыми привычками и т. Д.
Суммирование — это метод, который позволяет суммировать большой фрагмент данных, содержащихся на веб-странице или в документе.Изучение этих обобщенных данных позволяет понять суть всей веб-страницы или документа. Таким образом, обобщение также известно как характеристика или обобщение. Обобщение ищет определенные характеристики и атрибуты данных в большом наборе данных, а затем суммирует их. Примером использования технологии реферирования являются такие поисковые системы, как Google. Другие примеры включают резюмирование документа, резюмирование коллекции изображений и резюмирование видео. Резюмирование документа пытается автоматически создать репрезентативное резюме или реферат всего документа, находя наиболее информативные предложения.
Правила ассоциации позволяют установить ассоциацию и отношения между большими неклассифицированными элементами данных на основе определенных атрибутов и характеристик. Правила ассоциации определяют определенные правила ассоциативности между элементами данных, а затем используют эти правила для установления отношений. Обнаружение последовательности определяет последовательные шаблоны, которые могут существовать в большом и неорганизованном банке данных. Вы обнаруживаете последовательность в банке данных, используя фактор времени, то есть связываете элементы данных со временем, в которое они были созданы.Изучение последовательности событий при раскрытии и анализе преступлений позволяет службам безопасности и полицейским организациям раскрыть тайну преступления и принять превентивные меры, которые могут быть приняты против таких странных и неизвестных болезней.
Правила ассоциации определяют определенные правила ассоциативности между элементами данных, а затем используют эти правила для установления отношений. Обнаружение последовательности определяет последовательные шаблоны, которые могут существовать в большом и неорганизованном банке данных. Вы обнаруживаете последовательность в банке данных, используя фактор времени, то есть связываете элементы данных со временем, в которое они были созданы.Изучение последовательности событий при раскрытии и анализе преступлений позволяет службам безопасности и полицейским организациям раскрыть тайну преступления и принять превентивные меры, которые могут быть приняты против таких странных и неизвестных болезней.
§ 23. Результаты семантического изменения
Результаты семантического изменения могут
обычно наблюдаются в изменении денотационного значения
слово (ограничение и расширение значения) или в изменении
его коннотационного компонента (улучшение и ухудшение
имея в виду).
Изменения
в
денотационный
имея в виду
может привести к ограничению типов или диапазон
референтов, обозначаемых словом. Это можно проиллюстрировать
смысловое развитие слова гончая (OE. сот) который
раньше обозначал «собаку любой породы», но теперь обозначает только «собаку»
используется в погоне ». То же самое и со словом fowl (OE. фузол,
fuzel) который
на древнеанглийском обозначается «любая птица», но в современном английском обозначает
«Домашняя курица или петух».Обычно это описывается как
«Ограничение значения» и если слово с новым значением
начинает использоваться в специализированном словаре некоторой ограниченной группы
в речевом сообществе принято говорить о специализации
из
имея в виду.
Например, мы можем наблюдать ограничение и специализацию значения
в случае глагола to
скольжение (OE. глидан) который
имел значение «двигаться мягко и плавно» и теперь
приобрела ограниченное и специализированное значение «чтобы
летать без двигателя »(ср. а планер).
Изменения в денотационном значении может также привести к применению слово к более широкому кругу референтов. Обычно это описывается как расширение смысла и может быть проиллюстрирован словом target который первоначально означало «маленький круглый щит» (уменьшительное от targe, с ф. НА. тарга) но теперь означает «все, во что стреляют», а также в переносном смысле «любое результат, направленный на ‘.
Если
слово с расширенным значением переходит из специализированного
словарный запас в обиход, мы описываем результат семантического
изменить как обобщение
смысла.
Слово лагерь, например,
который первоначально использовался только как военный термин и означал »
место размещения войск в палатках (ср. L. кампус
— ‘упражнения
земля для армии) расширила и обобщила ее
значение и теперь обозначает «временное жилище» (путешественников,
кочевники и др.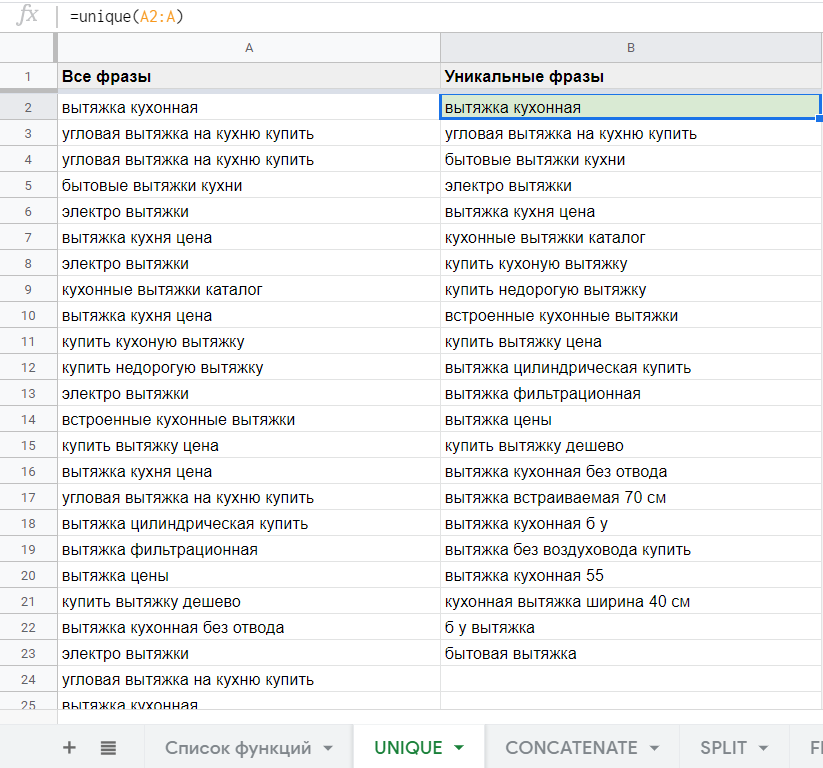 ).
).
В виде как видно из рассмотренных выше примеров, это в основном денотационный компонент лексического значения, который затрагивается при коннотационный компонент остается неизменным.Есть и другие случаи, однако, когда изменения в коннотационном значении приходят к перед. Эти изменения, как правило, сопровождаются изменением денотационный компонент ‘можно разделить на две основные группы: а) уничижительный развитие или приобретение словом некоторого унизительного эмоционального заряда, и б) мелиоративный развитие или же улучшение коннотационной составляющей значения. В семантическое изменение в слове хам май служат для иллюстрации первой группы. Это слово изначально использовалось для обозначают «крестьянин, крестьянин» (ср. OE. z ebur « житель») а затем приобрел уничижительный, презрительный коннотационный смысл и стало обозначать «неуклюжего или невоспитанного человека». В может наблюдаться мелиоративное развитие коннотационного значения в изменении смысловой структуры слова министр который в одном из своих значений первоначально означало «слуга, дежурный,
31
но
в настоящее время —
‘A
государственный служащий высшего ранга, лицо, руководящее отделом
государства или аккредитованы одним государством другому ».
Это Интересно отметить, что в деривационных кластерах изменение коннотационное значение одного члена не обязательно влияет на другие. Эту особенность можно проследить в словах авария и случайно. Лексическое значение существительного авария претерпела уничижительное развитие и означает не только то, что происходит случайно », но обычно« что-то неудачное ». Производные прилагательное случайное не имеет в своей семантической структуре этого отрицательное коннотационное значение (ср.также удача: неудача, удача удача и удача).
Типы семантических компонентов
Ведущий семантический компонент в семантической структуре слова обычно называется денотативным компонентом (также может использоваться термин ссылочный компонент ). Денотативный компонент выражает концептуальное содержание слова.
В следующем списке представлены денотативные компоненты некоторых английских прилагательных и глаголов:
Обозначение компонентов
одинокий, прил. > в одиночку, без компании
> в одиночку, без компании
пресловутый, прил. > широко известный
празднование, прил. > широко известный
в блики, в.> Смотреть
смотреть, v. > смотреть
дрожать, v.> Дрожать
дрожать, v.> Дрожать
Совершенно очевидно, что определения, приведенные в правом столбце, лишь частично и не полностью описывают значения соответствующих им слов.Чтобы дать более или менее полную картину значения слова, необходимо включить в схему анализа дополнительные семантические компоненты, которые именуются коннотациями, или коннотативными компонентами.
Дополним семантические структуры приведенных выше слов, введя коннотативные компоненты в схемы их семантических структур.
Приведенные выше примеры показывают, как, выделяя денотативные и коннотативные компоненты, можно получить достаточно ясную картину того, что на самом деле означает это слово. Схемы, представляющие семантические структуры glare, shiver, shudder , также показывают, что значение может иметь два или более коннотативных компонента.
Приведенные примеры не исчерпывают все типы коннотаций, но представляют лишь некоторые из них: эмоциональные, оценочные коннотации, а также коннотации продолжительности и причины. (Более подробную классификацию коннотативных компонентов значения см. В главе 10.)
Значение и контекст
В начале параграфа «Многозначность» мы обсудили достоинства и недостатки этого языкового явления.Один из наиболее важных «недостатков» многозначных слов состоит в том, что иногда существует вероятность недопонимания, когда слово используется в одном значении, но принимается слушателем или читателем в другом. Вполне естественно, что в таких ящиках есть материал, из которого сделаны анекдоты, например, следующие:
Заказчик. Я бы хотел книгу, пожалуйста.
Книготорговец. Что-нибудь легкое?
Заказчик. Это не имеет значения.Моя машина со мной.
В этом разговоре покупателя честно вводит в заблуждение многозначность прилагательного свет , понимая его в буквальном смысле, тогда как продавец книг использует это слово в переносном значении «несерьезно; развлекательно».
В следующем анекдоте один из выступающих делает вид, что неправильно понял собеседника, основываясь на своей гневной реплике на многозначности существительного kick:
Критик начал уходить в середине второго акта пьесы.
«Не уходи», — сказал менеджер. «Я обещаю, что в следующем акте будет потрясающий удар».
«Хорошо», — был ответ, — «отдай автору». 1
Вообще говоря, общеизвестно, что контекст является мощным средством предотвращения любого неправильного понимания значений. Например, прилагательное унылый, , если оно используется вне контекста, будет означать разные вещи для разных людей или вообще ничего. Только в сочетании с другими словами он раскрывает свое истинное значение: тусклый зрачок, тупая игра, тупое лезвие, мутная погода, и т. Д.Однако иногда такой минимальный контекст не раскрывает значение слова, и он может быть правильно истолкован только через то, что профессор Н. Амосова назвала контекстом второй степени [1], как в следующем примере: Мужчина был крупный, но жена была еще толще. Слово толще здесь служит своеобразным индикатором, указывающим на то, что большой описывает толстого человека, а не большого.
Только в сочетании с другими словами он раскрывает свое истинное значение: тусклый зрачок, тупая игра, тупое лезвие, мутная погода, и т. Д.Однако иногда такой минимальный контекст не раскрывает значение слова, и он может быть правильно истолкован только через то, что профессор Н. Амосова назвала контекстом второй степени [1], как в следующем примере: Мужчина был крупный, но жена была еще толще. Слово толще здесь служит своеобразным индикатором, указывающим на то, что большой описывает толстого человека, а не большого.
Текущие исследования семантики в значительной степени основаны на предположении, что одним из наиболее многообещающих методов исследования семантической структуры слова является изучение линейных отношений слова с другими словами в типичных контекстах, т.е.е. его совместимость или совместимость.
Ученые установили, что семантика слов, характеризующихся общими встречами (т. Е. Слова, которые регулярно встречаются в общих контекстах), коррелирована, и, следовательно, одно из слов в такой паре может быть изучено через другое.
Таким образом, если кто-то намеревается исследовать семантическую структуру прилагательного, лучше всего рассмотреть прилагательное в его наиболее типичных синтаксических образцах A + N (прилагательное + существительное) и N + l + A (существительное + связать глагол + прилагательное) и тщательно изучить значения существительных, с которыми часто используется прилагательное.
Например, изучение типичных контекстов прилагательного яркий в первом шаблоне даст нам следующие наборы: а) яркий цвет (цветок, платье, шелк и т. Д.), Б) яркий металл ( золото, драгоценности, доспехи и т. д.), в) ярких, учеников (ученик, мальчик, товарищ и т.д.), г) ярких, лиц (улыбка, глаза и т.д.) и некоторые другие. Эти наборы приведут нас к выделению значений прилагательного, относящегося к каждому набору комбинаций: а) интенсивный по цвету, б) сияющий, в) способный, г) веселый и т. Д.
Для переходного глагола, с другой стороны, рекомендуемый образец будет: V + N (глагол + прямой объект, выражаемый существительным).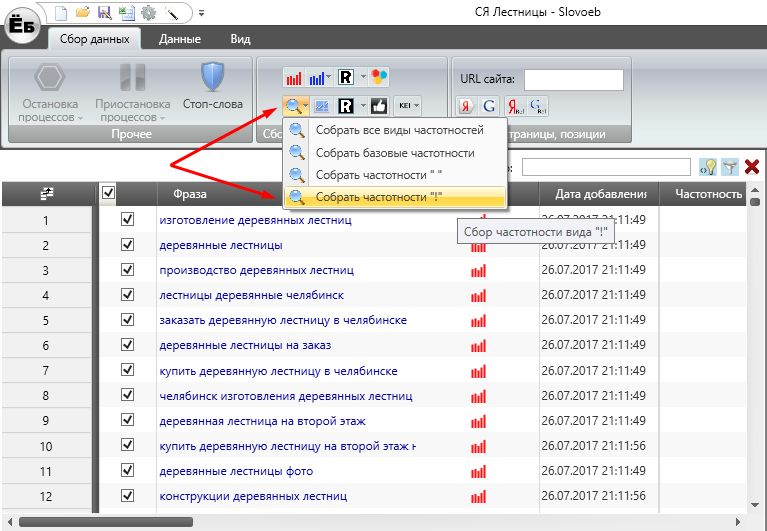 Если, например, нашим объектом исследования являются глаголы производить, создавать, составлять, , правильной процедурой будет рассмотрение семантики существительных, которые используются в шаблоне с каждым из этих глаголов: что это такое что производится? создано? составлен?
Если, например, нашим объектом исследования являются глаголы производить, создавать, составлять, , правильной процедурой будет рассмотрение семантики существительных, которые используются в шаблоне с каждым из этих глаголов: что это такое что производится? создано? составлен?
Существует интересная гипотеза о том, что семантика слов, регулярно используемых в общих контекстах (например,г. ярких цветов, чтобы построить дом, создать произведение искусства, и т. Д.) Настолько тесно взаимосвязаны, что каждый из них как бы постоянно размышляет о значении своего соседа. Если глагол для создания часто используется с объектом music, , не естественно ли ожидать, что определенные музыкальные ассоциации сохранятся в значении глаголов — compose?
Отметьте также, насколько тесно отрицательная оценочная коннотация прилагательного пресловутого связана с отрицательной коннотацией существительных, с которыми оно обычно ассоциируется: печально известный преступник, вор, гангстер, игрок, сплетник, лжец, скупец, и др.
Все это приводит нас к выводу, что контекст — хороший и надежный ключ к значению слова. Тем не менее, даже приведенные выше шутки показывают, насколько вводящий в заблуждение этот ключ может оказаться в некоторых случаях. И здесь перед нами две опасности. Первый — это явное непонимание, когда говорящий имеет в виду одно, а слушатель принимает слово в другом значении.
Вторая опасность связана не с процессом коммуникации, а с исследовательской работой в области семантики.Распространенная ошибка неопытных исследователей — видеть разные значения в каждом новом наборе комбинаций. Вот загадочный вопрос, чтобы проиллюстрировать, что мы имеем в виду. Ср .: злой человек, гневное письмо. прилагательное злой употребляется в одном и том же значении в обоих контекстах или в двух разных значениях? Некоторые люди скажут «два» и будут утверждать, что, с одной стороны, сочетаемость различна: (мужчина имя человека; буква имя объекта), а с другой стороны, буква не может вызывать гнев.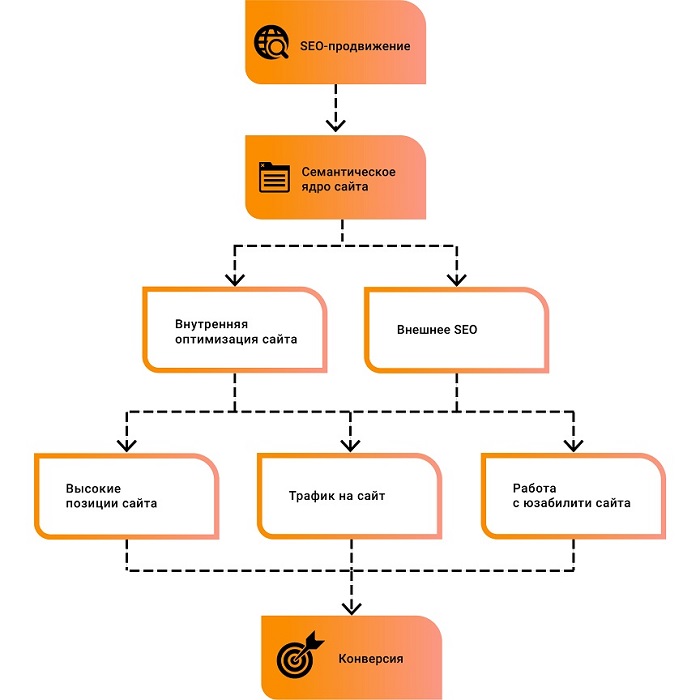 Правда, не может; но он может очень хорошо передать гнев человека, написавшего его. Что касается возможности комбинирования, главное, что слово может иметь одно и то же значение в различных наборах сочетаемости. Например, в парах веселые дети, веселый смех, веселые лица, веселые песни прилагательное веселый передает одно и то же понятие хорошего настроения, независимо от того, испытываются ли они непосредственно детьми (в первой фразе) или косвенно выражаются через веселые лица, смех и песни других словесных групп.
Правда, не может; но он может очень хорошо передать гнев человека, написавшего его. Что касается возможности комбинирования, главное, что слово может иметь одно и то же значение в различных наборах сочетаемости. Например, в парах веселые дети, веселый смех, веселые лица, веселые песни прилагательное веселый передает одно и то же понятие хорошего настроения, независимо от того, испытываются ли они непосредственно детьми (в первой фразе) или косвенно выражаются через веселые лица, смех и песни других словесных групп.
Задача различения различных значений слова и различных вариаций сочетаемости (или, в традиционной терминологии, различных употреблений слова), на самом деле является вопросом выделения различных значений в семантической структуре слова.
См .: 1) грустная женщина,
2) грустный голос,
3) мешок? рассказ,
4) негодяй унылый (= неисправимый мерзавец)
5) грустная ночь (= темная, черная ночь, арка.поэт.)
Сколько значений sad вы можете распознать в этих контекстах? Очевидно, что первые три контекста имеют общее обозначение печали, тогда как в четвертом и пятом контекстах обозначения различны. Итак, в этих пяти контекстах мы можем выделить три значения sad.
Все это приводит нас к выводу, что контекст не является окончательным критерием значения и его следует использовать в сочетании с другими критериями.В настоящее время в семантических исследованиях широко используются различные методы компонентного анализа: дефиниционный анализ, трансформационный анализ, распределительный анализ. Тем не менее, контекстный анализ остается одним из основных исследовательских методов определения семантической структуры слова.
Упражнения
Курсы информатики
Следующие курсы рассчитаны на один семестр (по четыре кредита каждый), если не указано иное.Для получения дополнительной информации, касающейся описания курсов, предварительных условий и расписания, обратитесь в Офис заместителя декана по инженерным и компьютерным наукам.
Примечание: Некоторые курсы для аспирантов по содержанию эквивалентны конкретным курсам бакалавриата. Эти аспирантские курсы, отмеченные (*) ниже, не предоставляются студентам, получившим эквивалент бакалавриата.
COMP 6231 Проектирование распределенной системы (4 кредита)
Принципы распределенных вычислений: масштабируемость, прозрачность, параллелизм, согласованность, отказоустойчивость.Технологии взаимодействия клиент-сервер: межпроцессное взаимодействие, сокеты, групповое взаимодействие, удаленный вызов процедур, удаленный вызов метода, брокер объектных запросов, CORBA, веб-сервисы. Методы проектирования распределенных серверов: репликация процессов, отказоустойчивость за счет пассивной репликации, высокая доступность за счет активной репликации, координация и согласование транзакций и контроль параллелизма. Разработка программных отказоустойчивых распределенных систем высокой доступности с использованием репликации процессов.Лаборатория: два часа в неделю.
COMP 6281 Параллельное программирование (*) (4 кредита)
Переход от фон Неймана к архитектурам параллельной обработки: парадигмы разделяемой памяти и передачи сообщений; массивно-параллельные компьютеры; последние тенденции в области параллельной обработки товаров; кластеры, многоядерные, гетерогенные вычисления на базе CPU-GPU. Проблемы согласованности памяти и балансировки нагрузки. Параллельные алгоритмы для платформ с общей памятью и передачи сообщений; эффективность и масштабируемость; проблемы накладных расходов на производительность.Среды параллельного программирования: модели параллельного программирования; языки; программные инструменты. Лаборатория: два часа в неделю. Требуется проект.
COMP 6311 Анимация для компьютерных игр (*) (4 кредита)
Предварительное условие: COMP 6761 или эквивалент, ранее или одновременно.
Введение в алгоритмы, структуры данных и методы, используемые при моделировании и визуализации динамических сцен. Темы включают принципы традиционной анимации, производственный конвейер, оборудование и программное обеспечение для анимации, представление ориентации и интерполяцию, моделирование физических и шарнирных объектов, прямую и обратную кинематику, управление движением и захват, ключевые кадры, процедурную и поведенческую анимацию, анимацию камеры, создание сценариев. системы и деформации произвольной формы.Требуется проект. Лаборатория: два часа в неделю.
COMP 6321 Машинное обучение (4 кредита)
Введение в основы машинного обучения. Линейные модели: линейная и полиномиальная регрессия, переоснащение, выбор модели, логистическая регрессия, наивный байесовский метод. Нелинейные модели: деревья решений, обучение на основе экземпляров, бустинг, нейронные сети. Поддержка векторных машин и ядер. Теория вычислительного обучения. Экспериментальная методология, источники ошибок. Структурированные модели: графические модели, сети глубоких убеждений.Обучение без учителя: k-средние, модели смеси, оценка плотности, максимизация математического ожидания, анализ основных компонентов, собственные карты и другие методы уменьшения размерности. Обучение в динамических системах: скрытые марковские модели и другие типы временных / последовательных моделей. Обучение с подкреплением. Обзор машинного обучения и его приложений. Требуется проект. Лаборатория: два часа в неделю.
COMP 6331 Advanced Game Development (*) (4 кредита)
Необходимое условие: Разрешение преподавателя.
Введение в сложные аспекты компьютерных игр. Дизайн игрового движка. Искусственный интеллект (AI): движение персонажей, не являющихся игроками, скоординированное движение, поиск пути, представления мира; принятие решений; тактический AI, стратегический AI, обучение в играх. Физические методы: обнаружение столкновений и реагирование. Сетевые игры: многопользовательские игры, создание сетей и распределенных игр, мобильные игры. Повышение реалистичности: кат-сцены, 3D-звук. Требуется проект. Лаборатория: два часа в неделю.
COMP 6341 Компьютерное зрение (*) (4 кредита)
Этот курс знакомит с основными методами и концепциями компьютерного зрения, включая формирование изображения, группировку и подгонку, геометрическое видение, распознавание, организацию восприятия и новейшее программное обеспечение инструменты. Студенты изучают фундаментальные алгоритмы и методы и получают опыт программирования компонентов, основанных на видении; в частности, как программировать в OpenCV, мощном программном интерфейсе, используемом для обработки данных, полученных с пассивных и активных датчиков.Требуется проект. Лаборатория: два часа в неделю.
Примечание: Студенты, получившие зачет по COMP 691 (компьютерное зрение), не могут пройти этот курс в качестве кредита.
COMP 6351 Темы научных вычислений (4 кредита)
Отдельные элементы численных методов, которые имеют центральное значение для научных вычислений. Точное содержание курса может несколько отличаться от одного предложения к другому, но будет включать следующие темы: введение в численное решение нелинейных уравнений, методы продолжения, численное решение задач начального значения в обыкновенных дифференциальных уравнениях, метод конечных разностей. , численная теория устойчивости, жесткие уравнения, краевые задачи в обыкновенных дифференциальных уравнениях, методы коллокаций, введение в численное решение уравнений в частных производных, с акцентом на нелинейные задачи диффузии.Требуется проект.
COMP 6361 Численный анализ нелинейных уравнений (4 кредита)
Введение в численные алгоритмы для нелинейных уравнений, включая дискретные и непрерывные системы. Акцент делается на компьютерный численный анализ, а не на численное моделирование. Этот курс подходит для ученых и инженеров, имеющих практический интерес к нелинейным явлениям. Темы включают вычислительные аспекты: методы гомотопии и продолжения, неподвижные точки и стационарные решения, асимптотическая устойчивость, бифуркации, периодические решения, переход к хаосу, консервативные системы, решения с бегущей волной, методы дискретизации.Будут рассмотрены самые разные приложения. Будут доступны пакеты числового программного обеспечения. Требуется проект.
COMP 6371 Иммерсивные технологии (*) (4 кредита)
Этот курс охватывает основы иммерсивных технологий и предлагает краткую историю и обзор иммерсивных технологий. Студенты анализируют тематические исследования интерактивного опыта с использованием иммерсивных технологий и определяют основные проблемы современного состояния. Кроме того, этот курс охватывает фундаментальные принципы 3D-графики для создания виртуальных ресурсов и сред, а также базовые концепции и технологии взаимодействия.Требуется проект.
COMP 6381 Цифровое геометрическое моделирование (4 кредита)
Этот курс знакомит с конвейером моделирования цифровой геометрии с упором на фундаментальные структуры данных и алгоритмы для цифрового представления и обработки трехмерной геометрии. Студенты изучают широкий спектр приложений и решений в области автоматизированного проектирования, инженерии, обратного проектирования архитектуры и медицинских приложений. Поскольку треугольные сетки на сегодняшний день являются наиболее популярным представлением трехмерной геометрии, в этом курсе основное внимание уделяется представлениям треугольной сетки и структурам данных, которые позволяют программисту эффективно запрашивать и редактировать геометрию.Кроме того, курс охватывает моделирование сплайнов: шлицы Эрмита, шлицы Безье и B-сплайны. Требуется проект.
COMP 6411 Сравнительное исследование языков программирования (4 кредита) Сравнение нескольких языков программирования высокого уровня в отношении областей применения, дизайна, эффективности и простоты использования. Выбранные языки продемонстрируют парадигмы программирования, такие как функциональные, логические и сценарии. Статическая и динамическая типизация. Составление и интерпретация.Продвинутые методы реализации. Требуется проект.
COMP 6421 Дизайн компилятора (*) (4 кредита)
Организация и реализация компилятора: лексический анализ и синтаксический анализ, синтаксически-управляемый перевод, оптимизация кода. Системы поддержки. Требуется проект.
COMP 6461 Компьютерные сети и протоколы (4 кредита)
Сети прямого соединения: кодирование, формирование кадров, обнаружение ошибок, управление потоком, примеры сетей. Коммутация и пересылка пакетов: мосты, коммутаторы.Межсетевое взаимодействие: Интернет-протокол, маршрутизация, адресация, IPv6, многоадресная рассылка, мобильный IP. Сквозные протоколы: UDP, TCP. Концепции сетевой безопасности. Протоколы прикладного уровня. Лаборатория: два часа в неделю.
COMP 6481 Программирование и решение проблем (4 кредита)
Этот курс дает обзор программирования, решения проблем, широко используемых структур данных и разработки фундаментальных и сложных алгоритмов с использованием объектно-ориентированного программирования. Студенты узнают о массивах, списках и основных понятиях итераторов; алгоритмы сортировки и поиска; тестирование программного обеспечения, включая граничное и модульное тестирование; анализ сложности; рекурсия; деревья и алгоритмы обхода деревьев; карты и хеш-таблицы; деревья поиска; и графики и алгоритмы на основе графов.Чтобы получить проходной балл, ученик должен пройти один или несколько компьютерных тестов на компетенцию в области программирования. Учебник: один час в неделю. Лаборатория: 3 часа в неделю.
Примечание 1: Только студенты MApCompSc и MEng (SOEN) могут пройти этот курс в качестве кредита.
Примечание 2: Студенты, получившие кредит за COMP 5481, не могут пройти этот курс для получения кредита.
COMP 6521 Advanced Database Technology and Applications (4 кредита)
Обзор стандартных реляционных баз данных, языков запросов.Обработка запросов и оптимизация. Параллельные и распределенные базы данных. Информационная интеграция. Системы хранилищ данных. Интеллектуальный анализ данных и OLAP. Веб-базы данных и XML Активные и логические базы данных, управление пространственными и мультимедийными данными. Лаборатория: два часа в неделю.
COMP 6531 Основы семантической паутины (4 кредита)
языков разметки сети, стандарты Консорциума всемирной паутины (W3C), структура описания ресурсов расширяемого языка разметки (XML), схема для языков разметки, семантическая сеть, онтология разработка, языки разметки для онтологий, язык веб-онтологий (OWL), логические основы онтологий, логика описания, рассуждения с онтологиями.Требуется проект.
COMP 6591 Введение в системы баз знаний (4 кредита)
Обзор логики первого порядка, реляционной алгебры и реляционного исчисления. Основы логического программирования. Логика представления знаний. Архитектура системы базы знаний. Основы дедуктивных баз данных. Обработка запросов сверху вниз и снизу вверх. Некоторые важные стратегии обработки запросов и их сравнение. Проектная или курсовая работа по актуальным темам исследований.
COMP 6621 Дискретная математика Пола Эрдеша (4 кредита)
Введение в методы и методы доказательства Пола Эрдеша, которые особенно применимы к информатике.Доказательство постулата Бертрана. Теоремы Эрдеша-Секереса и де Брейна-Эрдеша. Теорема Рамсея и числа Рамсея. Теорема Ван дер Вардена и числа Ван дер Вардена. Дельта-системы и доказательство гипотезы Эрдеша-Ловаса. Теорема Эрдеша-Ко-Радо. Экстремальная теория графов. Случайные графы и раскраска графов. Вероятностный метод и его приложения в теоретической информатике. Требуется проект.
COMP 6631 Крупномасштабная оптимизация (4 кредита)
Математическое моделирование крупномасштабных моделей оптимизации.Разработка и реализация крупномасштабных методов оптимизации: методы декомпозиции (Бендерса, Данцига-Вульфа, лагранжева релаксации, генерация столбцов), методы ветвей и цен. Методы крупномасштабного линейного и нелинейного программирования для оптимизации сети и целочисленного / дискретного программирования. Методы нелинейной невыпуклой непрерывной оптимизации: методы ветвей и границ, программирование DC (разности выпуклых функций), билинейная и двояковыпуклая оптимизация. Эвристика и метаэвристика.Требуется проект.
Примечание: Студенты, получившие кредит по этой теме под номером COMP 691Y, не могут пройти этот курс для получения кредита.
COMP 6641 Теория вычислений (4 кредита)
Общие свойства алгоритмических вычислений. Машины Тьюринга, универсальные машины Тьюринга. Вычислимые функции Тьюринга как стандартное семейство алгоритмов. Примитивные рекурсивные функции. Тезис Черча, рекурсивные множества. Рекурсивно перечислимые множества и их свойства.Теорема Райса. Меры временной и пространственной сложности. Иерархия мер сложности. Продвинутые темы по теории сложности. Требуется проект.
COMP 6651 Методы разработки алгоритмов (4 кредита)
Предварительные математические задания; Эмпирические и теоретические меры эффективности алгоритмов; Оптимизация и комбинаторные методы и алгоритмы, включая жадные алгоритмы, динамическое программирование, методы ветвей и границ и алгоритмы графовой сети; Анализ амортизированной сложности; Алгоритмы сопоставления строк; NP-полные задачи и приблизительные решения; Вероятностные алгоритмы.Требуется проект.
COMP 6661 Комбинаторные алгоритмы (4 кредита)
Представление и генерация комбинаторных объектов; методы поиска; подсчет и оценка. Проекты по избранным приложениям из комбинаторики и теории графов.
COMP 6711 Computational Geometry (4 кредита)
Эффективные алгоритмы и структуры данных для решения геометрических задач. Обсуждаемые проблемы включают выпуклые оболочки, пересечения линий, триангуляцию многоугольников, расположение точек, поиск по дальности, диаграммы Вороного, триангуляции Делоне, деревья интервалов и деревья сегментов, компоновку, планирование движения роботов, двоичные пространственные разделы, квадродеревья и посещаемость.Алгоритмические методы включают развертку плоскости, инкрементную вставку, рандомизацию, разделяй и властвуй. Акцент будет сделан на вычислениях и сложности, с приложениями в компьютерной графике, автоматизированном проектировании, географических информационных системах, сетях, создании сетей, базах данных и планировании движения роботов. Требуется проект.
COMP 6721 Прикладной искусственный интеллект (*) (4 кредита)
Курс охватывает эвристический и состязательный поиск конкретных приложений.Затем обсуждаются автоматизированные рассуждения, расширенное представление знаний и работа с неопределенностью для приложений искусственного интеллекта. Наконец, он вводит автоэнкодеры, рекуррентные нейронные сети и модели последовательности. Требуется проект. Лаборатория: два часа в неделю.
COMP 6731 Распознавание образов (*) (4 кредита)
Предварительная обработка. Извлечение и выбор признаков. Сходство между образцами и измерениями расстояния. Синтаксический и статистический подходы.Кластерный анализ. Байесовская теория принятия решений и дискриминантные функции. Методы кластеризации и классификации. Приложения. Требуется проект. Лаборатория: два часа в неделю.
COMP 6741 Интеллектуальные системы (*) (4 кредита)
Представление знаний и рассуждения. Неопределенность и разрешение конфликтов. Проектирование интеллектуальных систем. Архитектура на основе грамматики, правил и классной доски. Требуется проект. Лаборатория: два часа в неделю.
COMP 6751 Анализ естественного языка (4 кредита)
Введение в обработку естественного языка.Структура английского языка. Грамматики и синтаксический анализ. Лексическая и композиционная семантика. Прагматические вопросы. Приложения для интеллектуального анализа текста и извлечения информации. Требуется проект.
Примечание: Студенты, получившие кредит за COMP 7741 до сентября 2011 года, не могут пройти этот курс для получения кредита.
COMP 6761 Расширенная трехмерная графика для программирования игр (4 кредита)
Фундаментальные алгоритмы, методы и принципы разработки программного обеспечения для трехмерной графики. Введение в архитектуру графических приложений реального времени; обзор основных 3D-концепций моделирования, просмотра и рендеринга.Функции трехмерной графики, конвейер и производительность. Иерархическая 3D графика. Алгоритмы отсечения окклюзии, обнаружения столкновений, фотореализма, теней и текстур. Современные тенденции и новейшие алгоритмы графики и физики. Лаборатория: два часа в неделю.
COMP 6771 Обработка изображений (*) (4 кредита)
Основы цифровых изображений; улучшение изображения: обработка гистограмм, фильтрация в пространственной области, фильтрация в частотной области; восстановление и реконструкция изображений; сегментация изображения: обнаружение линий, преобразование Хафа, обнаружение и связывание краев, пороговая обработка, разделение и объединение областей; сжатие изображений; введение в вейвлет-преобразование и обработку с несколькими разрешениями.Требуется проект. Лаборатория: два часа в неделю.
COMP 6781 Статистическая обработка естественного языка (4 кредита)
Курс охватывает надежные методы обработки естественного языка (NLP) и их приложения для управления большими коллекциями текста. В этом курсе рассматриваются следующие темы: закон Ципфа, поиск информации, статистический машинный перевод, языковые модели N-грамм и методы сглаживания, устранение неоднозначности смысла слов, тегирование частей речи, вероятностные грамматики и синтаксический анализ.Требуется проект.
COMP 6791 Поиск информации и веб-поиск (*) (4 кредита)
Основы поиска информации (IR): логические модели, векторное пространство и вероятностные модели. Токенизация и создание инвертированных файлов. Схемы взвешивания. Оценка ИК-систем: точность, отзыв, электронная мера. Обратная связь по релевантности и расширение запроса. Применение IR в поисковых системах: XML, анализ ссылок, алгоритм PageRank. Методы категоризации текста и кластеризации, используемые при фильтрации спама.Требуется проект. Лаборатория: два часа в неделю.
COMP 6811 Алгоритмы биоинформатики (4 кредита)
Основные цели курса — охватить основные алгоритмы, используемые в биоинформатике; выравнивание последовательностей, выравнивание множественных последовательностей, филогения; классификация паттернов в последовательностях; прогноз вторичной структуры; Прогнозирование трехмерной структуры; анализ данных экспрессии генов. Сюда входят алгоритмы динамического программирования, машинного обучения, имитации отжига и кластеризации.Особое внимание будет уделено алгоритмам. Требуется проект.
COMP 6821 Базы данных и системы биоинформатики (4 кредита)
Основные цели курса — изучить потребности биоинформатики в управлении данными, управлении знаниями и вычислительной поддержке; предоставить подробное описание примера каждого типа базы данных и системы; и внедрить передовые технологии баз данных и программное обеспечение, соответствующие потребностям биоинформатики.Требуется проект.
COMP 691 Темы по информатике I (4 кредита)
Тематика будет меняться от семестра к семестру и из года в год. Студенты могут повторно зарегистрироваться на этот курс при условии, что содержание курса изменилось. Изменения в содержании будут обозначены буквой, следующей за номером курса, например, COMP 691A, COMP 691B и т. Д.
COMP 6961 Семинар для аспирантов по информатике (1 кредит)
Студенты должны будут посетить выбранный набор ведомственных семинаров и представить исчерпывающий отчет по темам, представленным на одном из семинаров.Этот курс оценивается по принципу «прошел / не прошел».
COMP 6971 Проект и отчет I (4 кредита)
Предпосылка: Завершение 16 кредитов; CGPA 3,40 или выше; разрешение отдела.
См. Раздел «Требования к магистратуре прикладных компьютерных наук» (MApCompSc). Проект: 8 часов в неделю.
Примечание: Студенты, получившие зачетные баллы за SOEN 6951 или SOEN 6971, не могут пройти этот курс для получения кредита.
COMP 6981 Проект и отчет II (4 кредита)
Необходимое условие: COMP 6971.
Описание курса такое же, как у COMP 6971.
Примечание: Студенты, получившие зачетные баллы за ENCS 6931, не могут пройти этот курс для получения кредита.
COMP 7241 Параллельные алгоритмы и архитектуры (4 кредита)
Предварительное условие: COMP 6281 или разрешение преподавателя.
Параллельные архитектуры; организация памяти, структуры взаимосвязей, методы маршрутизации данных. Параллельные алгоритмы; парадигмы и методы проектирования, анализ сложности, алгоритмы для различных моделей вычислений.Требуется проект.
COMP 7251 Мобильные вычисления и беспроводные сети (4 кредита)
Предварительные требования: COMP 6461.
Введение в мобильные вычисления и беспроводные сети: локальные (LAN), персональные (PAN) и городские (MAN). Мобильные одноранговые сети и сенсорные сети. Алгоритмы и протоколы для доступа к среде, маршрутизации, управления топологией и надежного транспорта. Требуется проект.
COMP 7451 Семантика языков программирования (4 кредита)
Предварительное условие: COMP 6411.
Необходимость семантического описания языков программирования. Классификация семантики: операциональная, аксиоматическая, теоретико-модельная, алгебраическая, денотационная. Классификация языков: процедурные, функциональные, логические, эквациональные. Приложения: проверка, построение, языковое проектирование, временная логика для распределенных систем, семантика для продвинутых языков.
COMP 7521 Криптография и безопасность данных (4 кредита)
Предварительное условие: COMP 6651.
Традиционная криптография.Теория информации. Криптографические алгоритмы с закрытым ключом (симметричный ключ) и открытым ключом (асимметричный ключ). Расширенный стандарт шифрования (Rijndael). Криптографические хеш-функции. Цифровые подписи. Аутентификация источника данных и целостность данных. Аутентификация объекта. Распределение ключей, управление, восстановление и исчерпание. Протоколы аутентификации. Услуги безопасности (конфиденциальность, аутентификация, целостность, контроль доступа, неотказуемость и доступность) и механизмы (шифрование, механизмы целостности данных, цифровые подписи, хэши с ключами, механизмы контроля доступа, аутентификация запрос-ответ, заполнение трафика и маршрутизация контроль).Проекты будут предлагаться по избранным темам в криптографии.
COMP 7531 Принципы систем баз данных (4 кредита)
Предварительное условие: COMP 6521.
Модели баз данных. Алгебраические, логические и дедуктивные языки баз данных. Эквивалентность запросов и оптимизация. Переписывание запросов, интеграция информации и обмен данными. Неполная информация и сложные значения. Введение в актуальные темы исследований. Требуется проект.
COMP 7651 Расширенный анализ алгоритмов (4 кредита)
Предварительное условие: COMP 6651.
Амортизированный анализ алгоритмов, NP-твердость и аппроксимационные алгоритмы, онлайн-алгоритмы, рандомизированные алгоритмы. Избранные актуальные темы. Проектная или курсовая работа.
COMP 7661 Расширенный рендеринг и анимация (4 кредита)
Предварительные требования: COMP 6761.
Расширенные концепции рендеринга и анимации с упором на вычислительные методы для синтеза сложных реалистичных изображений, как статических, так и динамических. Темы включают: обзор комп
Работа | Семантическое искусство
L&I, как и большинство организаций, реализовала безопасность отдельно для каждого из своих приложений.Чем больше приложений вы получите, тем больше будет избыточности и тем больше вероятность того, что вы непоследовательно применяете закон и свою собственную внутреннюю политику.
Мы начали этот проект с упражнения, которое мы назвали «экзегезой». В данном случае это было толкование всех законов, постановлений и политик, применяемых к безопасности данных в Департаменте. В дополнение к частому чтению и извлечению отрывков требовался семантический анализ, поскольку каждый из законов имел свой аспект. В некоторых законах (например, HIPAA) обсуждаются права пациентов.Особый подкласс рабочих — травмированные рабочие, которых лечили медицинские работники, — это пациенты согласно этому определению. Таких тонких различий было множество.
Из этого мы построили набор правил, которые необходимо было реализовать, чтобы приложения соответствовали им. Это было также в то время, когда штат начал открывать свою систему для широкой аудитории, и поэтому количество пользователей собиралось вырасти с 3000, в основном, внутренних пользователей, до 3000000 общих пользователей (работники, работодатели и поставщики в штат).
Мы создали набор требований и включили всех обычных подозреваемых в программном обеспечении безопасности. В то время бизнес-модели этих компаний не позволяли им отделять аутентификацию от авторизации (они оценивали свои продукты в зависимости от количества аутентифицированных пользователей). Однако штат обязал использовать собственную службу аутентификации. Мы не нашли поставщика, который мог бы удовлетворить наши требования к авторизации без включения избыточной службы аутентификации. Хотя мы были разочарованы, один из аналитиков этого проекта был в приподнятом настроении.«Раньше мы все равно выбирали бы один и имели дело с тем фактом, что не могли обрабатывать наши требования отдельно».
В результате наших исследований мы разработали индивидуальную общую службу безопасности, которая затем была передана внедренческой компании на конкурсной основе. В нашем первоначальном дизайне служба полагалась бы на механизм правил для оценки правил авторизации. Возможно, из-за того, что мы так хорошо поработали над толкованием и значительно сократили количество правил, группа внедрения жестко запрограммировала правила.Сервис используется более пяти лет; все новые приложения используют его, а существующие системы модернизируются.
6. Что необходимо для сбора данных — шесть шагов к успеху
Если организация рассматривает вопрос о том, собирать ли данные самостоятельно или получить помощь от внешнего консультанта, ей потребуется достаточно информации, чтобы принять обоснованное решение о том, как продолжать.
В этом разделе описаны некоторые ключевые моменты, которые могут возникнуть на различных этапах процесса сбора данных.Нет требования, чтобы эти шаги выполнялись или выполнялись в том порядке, в котором они написаны. Представленная модель предлагается в качестве справочного инструмента. То, как собираются и анализируются данные, зависит от многих факторов, включая контекст, проблему, которую необходимо отслеживать, цель сбора данных, а также характер и размер организации.
Главное соображение — убедиться, что любая собранная информация осуществляется способом и для целей, которые соответствуют Кодексу и соответствуют законодательству о свободе информации и защите конфиденциальности.В интересах эффективности и действенности рекомендуется приложить усилия для сбора данных, которые проливают свет на проблемы или возможности. Чтобы защитить достоверность и надежность данных, информацию следует собирать с использованием общепринятых методов сбора данных.
Шаг 1. Определите проблемы и / или возможности для сбора данных
Первый шаг — выявить проблемы и / или возможности для сбора данных и решить, какие дальнейшие шаги предпринять. Для этого может быть полезно провести внутреннюю и внешнюю оценку, чтобы понять, что происходит внутри и за пределами вашей организации.
Некоторым организациям, таким как FCP и Законодательный план обеспечения равноправия в сфере занятости (LEEP) [21] работодателей, даются конкретные указания относительно того, какие вопросы следует изучить и как следует собирать данные. У других организаций может быть больше гибкости, чтобы решить, когда и как собирать информацию для достижения определенных целей. Некоторые из приведенных ниже неполных вопросов могут относиться к широкому кругу организаций и аудиторий, включая сотрудников и пользователей услуг. В зависимости от организации эти вопросы могут рассматриваться на этапе 1 или на разных этапах процесса сбора данных.
Провести анализ всех политик, практик и процедур, применимых к сотрудникам, пользователям услуг или другой соответствующей аудитории:
- Есть ли в организации политика, практика и процедуры в области людских ресурсов и прав человека, доступные для всех сотрудников или людей, которым они служат?
- Имеются ли в организации четкие, прозрачные и справедливые процедуры подачи жалоб для рассмотрения заявлений о дискриминации, преследовании или системных барьерах?
- Были ли поданы или получены какие-либо претензии, жалобы или утверждения, касающиеся дискриминации, преследований или системных барьеров?
- Имеются ли какие-либо сигнальные барьеры для лиц, защищенных согласно Кодексу и / или другим лицам / группам в обществе, основаны на заземлении, отличном от кода Код ?
- Были ли решены какие-либо вопросы надлежащим образом и в соответствии с существующими политиками, практикой и процедурами?
Изучите организационную культуру через призму прав человека, разнообразия и равноправия:
- Каковы полномочия, цели и основные ценности организации?
- Какова история организации?
- Поддерживаются ли, отражаются и продвигаются ли высшие руководители во всей организации справедливость, разнообразие и инклюзивность?
- Имеются ли показатели эффективности для мотивации достижения стратегических целей организации в области людских ресурсов, прав человека, равенства и разнообразия?
- Считают ли сотрудники, что организация разнообразна, инклюзивна и предоставляет равные возможности для обучения и развития?
- Как принимаются решения?
- Как рекламируются возможности трудоустройства, программирования или предоставления услуг?
- Имеются ли в организации формальные, прозрачные и справедливые процессы набора, найма, продвижения по службе, увольнения и выхода на пенсию сотрудников?
- Есть ли в организации четкая система дисциплины?
- Считается ли, что эта система применяется справедливо и последовательно?
- Считают ли пользователи услуг, что их приветствуют, ценят и могут ли пользоваться услугами, предлагаемыми организацией?
Оценить внешний контекст:
- Есть ли лучшие практики в отрасли / секторе или среди аналогичных организаций, у которых можно поучиться?
- Есть ли объективные данные или исследования, показывающие, что дискриминация или системные барьеры существуют или не существуют в организации, отрасли / секторе или аналогичных организациях?
- Есть ли доказательства от других организаций или юрисдикций, что политика, программа или практика, аналогичная действующей в организации, оказала положительное или отрицательное влияние на лиц, находящихся под защитой Кодекса, или других маргинализированных лиц в обществе?
- Как организация воспринимается сообществом, в котором она работает?
- Делали ли средства массовой информации или группы защиты комплименты или критику организации по вопросам прав человека, человеческих ресурсов или справедливости?
- Каковы демографические данные людей, которым служит организация, или сообщества, в котором она работает?
- Демографические данные меняются или, по прогнозам, изменятся в будущем?
- Проактивно ищет ли организация способы убедиться, что у нее есть навыки и знания, необходимые для удовлетворения потенциальных потребностей и проблем этой меняющейся демографической группы?
Проверить представительство:
- Сравните состав персонала организации с доступностью рабочей силы или демографическими данными пользователей услуг в сообществе, городе, регионе, провинции и / или стране, в которой она работает.
- Является ли организация представительной и реагирующей на потребности сообщества, которое она обслуживает?
- На данном этапе подробное сравнение не требуется. Здесь цель состоит в том, чтобы определить ключевые проблемы и / или возможности, которые могут потребовать дальнейшего изучения, отметив очевидные пробелы, различия или тенденции.
- Организации могут:
- Оцените, как люди или группы, определенные по основанию Кодекса , и другие лица / группы представлены и распределяются между их сотрудниками или пользователями услуг по уровням ответственности, профессии, филиалам, отделам или другим подходящим параметрам.
- Есть ли в организации или в сфере оказания услуг какие-либо области, где люди или группы кажутся явно перепредставленными или недопредставленными?
Поиск вышеуказанной информации может быть сложной задачей для небольших организаций, но Интернет предлагает множество ресурсов на выбор. Сообщения средств массовой информации могут содержать полезные сведения, а также ресурсы в Интернете, предлагаемые Управлением по правам человека, Статистическим управлением Канады, [22] города Торонто, [23] правительственными учреждениями и общественными организациями, которые сосредоточены на коде , и других. — Код наземных тем.Информация также может быть собрана из различных источников с использованием общепринятых исследовательских методологий сбора данных, обсуждаемых на этапе 3.
Ожидается, что внутренняя и внешняя оценка организации в свете вопросов, перечисленных выше, может привести к ряду потенциальных проблем и / или возможностей для изучения сбора данных. Прежде чем перейти к Шагу 2, организации могут пожелать рассмотреть, есть ли какие-либо предварительные действия, которые можно предпринять для решения этих проблем и / или возможностей без сбора данных ( e.г. обучение, разработка политики).
Пример: Обзор на этапе 1 мог выявить следующие проблемы и / или возможности для сбора данных:
- Положительные отзывы общественности о пилотном проекте по охране общественного порядка в районах с высоким уровнем преступности
- Неясные и непоследовательные политики и процедуры в области прав человека для решения проблемы сексуальных домогательств.
Приведенные выше примеры представляют собой потенциальную возможность или проблемную проблему с правами человека, соответственно, и могут подойти для сбора данных.На основе оценок на Шаге 1 (вместо или вместе с дальнейшим сбором данных) необходимо принять решения о том, как лучше всего решить выявленные возможности и / или проблемы и будет ли целесообразно действовать.
Если результаты внутренней и внешней оценки показывают, что организация не имеет серьезных проблем с дискриминацией и / или системными барьерами и в целом соблюдает нормы Кодекса и политики OHRC, подумайте, может ли организация по-прежнему извлекать выгоду из упреждающей реализации инициативы по сбору данных (например, для помощи в мониторинге текущей эффективности и пригодности политики, программ и стратегий вмешательства).
Шаг 2. Выберите проблемы и / или возможности и установите цели
На этапе 2 основное внимание уделяется выбору приоритетных вопросов и / или возможностей для сбора данных, а затем постановке целей и задач.
Организация рассматривает проблемы и / или возможности, выявленные в результате внутренней и внешней оценки, выполненной на Шаге 1, и выбирает одну или несколько конкретных проблем и / или возможностей для начала проекта сбора данных из списка приоритетов. Некоторые из вопросов, которые организация может рассмотреть при принятии решения о расстановке приоритетов для проблемы и / или возможности для сбора данных, включают:
- Есть ли фундаментальная причина или возможность для сбора данных, из которых могут возникнуть другие проблемы и / или возможности?
Пример: Стареющая база налогоплательщиков дает государственному органу серьезную причину для сбора данных о предполагаемом размере, потребностях и доходной базе этой группы.Это меняющееся демографическое положение также дает государственному органу возможность убедиться в том, что он активно разрабатывает политику, программы и услуги, которые доступны и соответствуют потребностям и интересам этих налогоплательщиков.
- Выявила ли внутренняя и внешняя оценка организации на этапе 1 какие-либо критические пробелы или тенденции, которые очевидны в организации, отрасли / секторе или аналогичных организациях?
- Есть ли какая-то конкретная область, которая привлекла положительное / отрицательное внимание средств массовой информации или стала предметом многочисленных жалоб, внутренних слухов и опасений?
- Кажется, что в одной области больше или меньше разнообразия по сравнению с другими?
Целеполагание
Хотя организация может намереваться собирать данные, относящиеся к нескольким проблемам и / или возможностям одновременно, следующие шаги, включая постановку целей, должны быть индивидуализированы для каждой проблемы и / или возможности.
Конкретная цель (цели), определенная для каждой проблемы и / или возможности, может зависеть от гипотезы или предположения о том, что происходит, что можно проверить с использованием методов сбора и анализа данных.
Пример: Отель в центре Торонто получает жалобы от гостей, которые идентифицируют себя как геи, на нежелательное обращение со стороны персонала. Гипотеза может заключаться в том, что персонал отеля недостаточно осведомлен и не обучен тому, как уважительно обращаться с гостями, которые являются геями или считаются представителями более широкого ЛГБТ-сообщества.Цель состоит в том, чтобы получить достаточно доказательств для проверки этой гипотезы.
Шаг 2 также может включать в себя мозговой штурм организации для небольшого набора вопросов, на которые можно ответить путем сбора данных. Вместо того, чтобы задавать общий вопрос вроде: «Есть ли в этом отеле какие-либо доказательства дискриминации по признаку сексуальной ориентации или гендерной идентичности?» Можно спросить: «Какой процент гостей отеля идентифицирует себя как часть ЛГБТ-сообщества?» и «Каково восприятие услуг, оказываемых самоидентифицирующимися покровителями ЛГБТ?» В конечном итоге собираемые данные должны быть рационально связаны с поставленными целями и общей целью сбора данных.
Шаг 3. Спланируйте подход и методы
На Шаге 3 организации будут принимать решения о том, кто будет опрашиваться, как будут собираться данные, источники данных, которые будут использоваться, и продолжительность проекта сбора данных, среди других вопросов. Эти решения могут быть приняты после консультации со специалистом. Методы и подходы будут исходить из целей, установленных на шаге 2, и будут существенно различаться в зависимости от ряда факторов, включая контекст организации, размер, ресурсы, а также цель и сложность проблемы (вопросов) или возможности (возможностей). выбрано.
Некоторые из вопросов, которые следует рассмотреть на этом этапе, включают:
О ком будут собираться данные?
«Группа интересов» (например, пользователи молодежных услуг местного общественного центра, которые не могут читать и говорить по-английски в качестве второго языка) будет в центре внимания исследования, а используемые методы сбора данных будут относиться к этой группе или лиц, входящих в его состав, в зависимости от целей проекта.
Понимание дискриминации
- Размышляя о том, о ком будут собираться данные, важно учитывать, кто, по вашему мнению, больше всего пострадает, например, от дискриминации или неравенства, которые вы хотите измерить.Это широкая категория (например, все пользователи услуг, которые не могут читать ) или подмножество этой категории (например, молодежь, пользователей услуг, которые не могут читать )? Выделенные курсивом слова относятся к уникальной характеристике более широкой группы, о которой организация может пожелать собрать информацию.
- В зависимости от таких факторов, как цели проекта сбора данных, размер организации, ресурсы и время, данные могут быть собраны о многих подмножествах в рамках более широкой группы интересов (например,г. молодежи пользователей услуг, которые не умеют читать и говорят английский как второй язык ().
- Сбор данных о группе интересов с общими характеристиками на основе нескольких признаков Code или отличных от Code может помочь организации понять поведение, восприятие, ценности и демографический состав пользователей услуг и других представляющих интерес субъектов. Вообще говоря, сбор данных, которые отражают более одного основания с кодом Code и / или не с кодом Code , может позволить получить более обширную, подробную информацию и более сложный анализ.
- Важно осознавать, что на основании уникального сочетания идентичностей люди могут подвергаться определенным формам дискриминации. Множественные формы дискриминации могут пересекаться и объединяться, создавая уникальный опыт дискриминации. Эта точка зрения называется «перекрестным» анализом дискриминации.
Пример: Мужчина, использующий молодежные услуги из Южной Азии, который не умеет читать и ограниченно говорит по-английски, может столкнуться с дискриминацией по любому из признаков возраста, расы, цвета кожи, происхождения, этнического происхождения, места происхождения, пола, инвалидности или воспринимаемая инвалидность ( e.г. можно рассматривать как имеющего неспособность к обучению). Однако он также может подвергаться дискриминации по пересекающимся признакам на основании того, что его идентифицируют как «молодого, неграмотного индийского мужчины из другой страны» на основании различных предположений или стереотипов, которые однозначно связаны с этим социально значимым взаимодействием множества факторов идентичности. .
Чтобы лучше понять потенциальное влияние нескольких факторов идентичности или пересечения при сборе и анализе данных о группе интересов, может быть полезно проконсультироваться с сообществами и просмотреть соответствующие исследования и другие соответствующие документы, которые подчеркивают, как динамика Дискриминация и ущемление прав могут иметь практическое значение для лиц, определенных по признакам Кодекса и не по признакам Кодекса .Недавнее издание книги «Права человека на работе» УВКПЧ является полезным справочным материалом для этой цели. OHRC также разработало политику и руководящие принципы, которые содержат более подробное описание того, как Код применяется к различным основаниям (см. Приложение G, где приведен список руководств, политик и инструкций OHRC).
С кем будет сравниваться интересующая вас группа?
«Группа сравнения» [24] должна состоять из лиц, которые разделяют одну или несколько характеристик с лицами в интересующей группе, но различаются ключевыми характеристиками, изучаемыми (например,г. пользователи молодежных служб, которые не умеют читать, но могут свободно говорить по-английски (). Опыт пользователей молодежных услуг, которые не умеют читать и которые говорят на английском как втором языке, можно сравнить с опытом пользователей молодежных услуг, которые не умеют читать, но свободно говорят по-английски.
Из каких мест или географических областей будут собираться данные?
Некоторые инициативы по сбору данных требуют сбора данных из разных размеров, групп или сообществ, расположенных в разных местах и географических областях.При определении того, откуда собирать информацию, следует учитывать ключевые факторы, включая то, о ком будут собираться данные и с кем эти данные будут сравниваться.
Пример: Местный общественный центр заинтересован в том, чтобы его текущая программа повышения грамотности молодежи более отвечала потребностям растущего числа молодых людей в окрестностях, которые не умеют читать и говорят на английском как на втором языке. Общественный центр планирует собрать информацию о сообществе, которое он обслуживает, и о географическом регионе, в котором он расположен.Данные собираются из уже существующих записей общинного центра о пользователях его услуг, включая людей, которые посещают программу повышения грамотности молодежи или проявили к ней интерес. Помимо других источников данных, также изучается общедоступная информация о характеристиках окрестностей.
Какие категории будут использоваться для определения группы интересов и группы сравнения?
Выбор категорий позволяет организовать собираемую информацию.Это можно сделать либо до сбора данных, как описано в этом шаге, либо после сбора данных (см. Шаг 5).
В некоторых случаях, хотя это и не требуется, предпочтительно использовать заранее определенные категории, например, разработанные Статистическим управлением Канады. У такого подхода есть определенные преимущества.
Пример: Организации могут быть уверены, что 12 расовых групп, используемых Статистическим управлением Канады, будут представлять, как большинство канадцев классифицируют себя по расовой принадлежности.Кроме того, использование этих категорий, скорее всего, даст надежные и достоверные результаты и позволит исследователям напрямую сравнивать результаты своих исследований с данными переписи, собранными Статистическим управлением Канады. [25]
Ограничения состоят в том, что при использовании этих категорий некоторые респонденты могут не идентифицировать себя с ними или могут возражать против них. Еще одно ограничение заключается в том, что Статистическое управление Канады не предоставляет данные переписи по всем признакам (например, по сексуальной ориентации). [26]
Статистическое управление Канады изменит свои данные за определенную плату.Например, он может разбить его на «дезагрегированные» данные для местного рынка труда или для конкретной профессиональной категории. [27]
Еще одно ограничение состоит в том, что категории Статистического управления Канады могут быть слишком широкими в зависимости от целей, выбранных на этапе 2.
Пример: Использование широкой категории, такой как «расовый», может скрыть важные различия между расовыми группами. , поскольку расовые группы не подвержены точно такому же опыту, расовым стереотипам и типам дискриминации. [28] Однако, когда необходимо описать людей коллективно, термин «расовый человек» или «расовая группа» предпочтительнее таких терминов, как «расовое меньшинство», «видимое меньшинство», «цветное лицо» или «не -Белый », поскольку он выражает расу как социальную конструкцию, а не как описание, основанное на предполагаемых биологических чертах. Кроме того, эти другие термины трактуют «белых» как норму, с которой следует сравнивать расовых людей, и имеют тенденцию объединять всех расовых людей в одну категорию, как если бы они все были одинаковыми. [29]
Рассмотрите другие категории для описания выбранных групп (например, относящиеся к категориям должностей или услуг). В конечном итоге организации могут выбрать категории, которые лучше всего отражают положение организации с точки зрения достижения ее целей в области прав человека, равенства и разнообразия.
Как следует собирать данные?
В контексте прав человека исследователей социальных наук [30] обычно просят возглавить или помочь в проектах сбора данных.В исследованиях социальных наук используются два типа данных: качественные и количественные. Хорошее исследование предполагает использование обоих типов. Оба подхода, хотя и отличаются друг от друга, могут частично совпадать и полагаться на другой для получения значимых данных, анализа и результатов.
Качественные данные:
- Обычно данные называются «качественными», если они представлены в форме слов, но могут также включать любую информацию, не имеющую числовой формы, например фотографии, видео и звукозаписи.
- Качественные методы нацелены на описание конкретного контекста, события, людей или отношений в широком контексте, пытаясь понять основные причины поведения, мыслей и чувств.
- Общие методы качественного исследования включают наблюдение, индивидуальные интервью, фокус-группы и интенсивные тематические исследования.
Пример: Сеть ресторанов хочет улучшить обслуживание и доступ к клиентам с ограниченными возможностями. Руководство решает собирать качественную информацию с помощью фокус-групп, состоящих из ряда заинтересованных сторон, включая клиентов и представителей организаций из сообщества людей с ограниченными возможностями.
Возможные сильные стороны:
- качественные данные превосходно «рассказывают историю» с точки зрения участника (это помогает участникам почувствовать, что их услышали)
- может помочь другим лучше понять проблему или проблему, предоставляя подробные описательные детали, которые объясняют человеческий контекст численных результатов
Возможные недостатки:
- считает, что на точность качественных данных могут влиять ложные, субъективные или сфабрикованные свидетельства.Хорошие качественные данные, проверенные профессиональным исследователем и собранные с использованием общепринятых методов исследования сбора данных, могут устранить влияние таких факторов
- в зависимости от характера и размера проекта, а также сложности используемых методов и анализа, может занять значительное время, быть очень трудоемким и дать результаты, которые могут быть недостаточно общими для принятия решений и цели принятия решений.
Количественные данные:
- Обычно данные называются «количественными», если они представлены в форме чисел.
- Количественный подход может использоваться для подсчета событий или количества людей, представляющих определенный фон.
- Общие количественные инструменты включают опросы, анкеты и статистические данные (например, данные переписи Статистического управления Канады).
- Важно отметить, что все количественные данные основаны на качественной оценке. Другими словами, числа нельзя интерпретировать сами по себе без понимания лежащих в их основе допущений.
Пример: Простая оценочная переменная от 1 до 5 для утверждения опроса «Мой профсоюз чутко и эффективно рассматривает жалобы, связанные с нарушением прав человека», дает респондентам возможность обвести кружком: 1 (Совершенно не согласен), 2 (Не согласен), 3 (нейтральный), 4 (согласен) и 5 (полностью согласен).
Респондент кружит «2 = не согласен». Чтобы понять значение «2» здесь, исследователь должен принять во внимание некоторые суждения и предположения, лежащие в основе этого выбора. Понимал ли респондент термин «жалоба на нарушение прав человека»? Был ли у респондента опыт подачи жалобы в профсоюз? Нравится ли респонденту профсоюзы в целом?
Возможные сильные стороны:
- воспринимаются как более достоверные и надежные, чем качественные данные из-за использования чисел, которые рассматриваются как объективный источник данных.Это не обязательно так. На точность количественных данных могут влиять манипуляции и предвзятость исследователя, среди других факторов, если только они не проверены профессионализмом исследователя и использованием принятых методов исследования сбора данных
- количественные данные превосходно подходят для обобщения, систематизации и сравнения больших объемов информации, а также для создания общих выводов по интересующей теме исследования
- может помочь измерить прогресс и успех
- хорошо умеет определять тенденции и определять масштабы интересующей темы исследования.
Возможные недостатки:
сосредоточение внимания только на цифрах и рейтингах может чрезмерно упростить или привести к неточному пониманию сложных ситуаций и реалий, если не будет предоставлен более широкий контекст
Пример: Обследование данных о занятости Отдела кастодиальных услуг крупной организации показывает, что 80% уборщиц — женщины и что 6 из 7 руководителей кастодиальных служб — мужчины. Сравнение этих цифр с данными о пробелах Канады по развитию людских ресурсов и навыков (HRSDC) показывает, что, несмотря на чрезмерную представленность женщин в рядах уборщиков, пробелов в рядах руководителей нет.
Причина кажущегося несоответствия заключается в том, что данные об отсутствии HRSDC основаны на доступности. На национальном уровне так мало женщин являются руководителями опекунских служб, что статистически незначительно, что позволяет сделать вывод об отсутствии численного разрыва в отношении женщин-надзирателей. Этот вывод, однако, не имеет смысла, поскольку организация знает, что соотношение женщин и мужчин, занимающихся уборкой, 200: 40 контролируется соотношением мужчин и женщин в руководящем составе 6: 1.Организация решает игнорировать данные HRSDC и руководствоваться здравым смыслом, создав наставничество по продвижению по службе и другие политики и программы для увеличения числа женщин-руководителей в своей рабочей силе.
- подлежат множественной интерпретации того, что на самом деле означают числа, что может привести к искаженному пониманию интересующей темы исследования. Эту потенциальную слабость можно свести к минимуму, используя принятые количественные методы исследования и определяя соответствующие предупреждения для объяснения параметров и предположений, лежащих в основе исследования
- В зависимости от характера и размера проекта, а также сложности используемых методов и анализа сбор необходимой информации может быть дорогостоящим.
- в областях исследований, которые являются относительно новыми или в которых инструменты, индикаторы, процедуры и источники далеки от устоявшихся данных, статистические данные могут отсутствовать или иметь неравное качество, что вызывает проблемы для сравнения.Эти трудности часто усугубляются другими проблемами, такими как проблемы с определением (например, значение слова «свобода» — в зависимости от толкования выбранного слова оно может приводить к различным проблемам и результатам).
Какие источники данных следует использовать для сбора информации?
Качественные и количественные данные обычно собираются из более чем одного источника. По возможности, для повышения надежности и согласованности результатов следует использовать вместе два или более из следующих источников.
Существующие ранее или официальные данные
Существующие ранее или официальные данные — это информация, которая уже была задокументирована (например, вырезки из газет, прецедентное право, данные переписи Статистического управления Канады, фотографии) или создана организацией в ходе ее повседневных деловых операций (например, файлы сотрудников, регистрационные формы студентов, годовые отчеты, отчеты о происшествиях). Эти данные могут содержать информацию, которая напрямую относится к конкретным признакам Code , таким как раса, но чаще будет иметь отношение только косвенно (например, в форме имен, места происхождения или этнической принадлежности).Этот тип информации может использоваться в качестве заместителя или заместителя для расы, но он будет менее надежным, чем фактические расовые данные, сообщаемые самими людьми.
Возможные сильные стороны:
- работоспособен. Избегает времени, энергии, затрат и сбоев, связанных со сбором данных как отдельным этапом от выполнения повседневных операций
Пример: Результаты приема на работу, приема на работу, продвижения по службе и увольнений могут быть записаны, а также такие события, как вмешательство охранников и жалобы клиентов.При записи этих событий также могут быть включены соответствующие наземные классификации Code и отличные от Code . Затем эти данные можно было бы изучить на предмет тенденций с течением времени, чтобы показать, существуют ли дискриминационные или системные барьеры, могут существовать или не существуют.
Возможные недостатки:
- Чтобы быть полезным источником информации, организации должны быть готовы собирать данные в рамках своих обычных процедур ведения документации
- надежность этих данных будет зависеть от тщательности и точности отчетов, сделанных людьми, которые их собирают.
Данные обследования
Опросное исследование — это обширная область, которая обычно включает в себя любые процедуры измерения, связанные с заданием респондентам вопросов. «Опрос» может варьироваться от короткой анкеты на бумаге и карандаше до подробного индивидуального интервью (интервью будет обсуждаться ниже).
При разработке опроса важно учитывать конкретные характеристики респондентов, чтобы убедиться, что вопросы актуальны, ясны, доступны и легки для понимания.Следует помнить о некоторых практических соображениях: умеют ли респонденты читать, сталкиваются ли они с языковыми или культурными барьерами, имеют ли они инвалидность и с ними легко связаться.
Возможные сильные стороны:
- очень полезен для документирования восприятия и восприятия человеком культуры работы организации, предоставления услуг или других областей интересов
Пример: Перепись учащихся TDSB 2006 г., обзор системы 7–12 классов включала в себя компонент о том, как старшие и средние школы в целом воспринимали свое обучение и внеклассное обучение в 10 областях, включая безопасность в школе и поддержку на дому и участие.
- может содержать вопросы количественного или качественного характера либо их комбинацию
- можно проводить в малых или больших масштабах.
Возможные недостатки:
- качество и надежность данных обследования зависит от таких факторов, как опыт людей, проводящих их, дизайн и уместность задаваемых вопросов, а также надежность методов, используемых для анализа и интерпретации результатов
- может не дать точной оценки того, как другие воспринимают происхождение или опыт человека.
Пример: Сотрудник-трансгендер может идентифицировать себя как женщину, но третья сторона может идентифицировать ее как мужчину.
Фокус-группы и интервью
Интервью и фокус-группы (также называемые «групповыми интервью») позволяют предоставлять информацию устно, индивидуально или в группе. Данные могут быть записаны самыми разными способами, включая письменные заметки, аудиозаписи и видеозаписи.
Фокус-группы:
В фокус-группах интервьюер ведет сессию.Собирают избранную группу людей, задают вопросы, поощряют их выслушивать комментарии друг друга и записывают их ответы. Один и тот же набор вопросов может использоваться для ряда разных групп, каждая из которых составлена немного по-своему, и для разных целей.
Фокус-группы могут проводить профессионалы, но это не всегда необходимо. Решение нанять профессионального фасилитатора может зависеть от целей исследования фокус-группы, характера задаваемых вопросов, навыков и опыта участвующих сотрудников, а также необходимости соблюдения конфиденциальности или анонимности.
Пример: Чтобы получить уникальное видение каждой группы, организация может пожелать провести отдельные фокус-группы для представителей каждой из внутренних и внешних групп заинтересованных сторон, таких как высшее руководство, непосредственные сотрудники, пользователи услуг и т. Д. представители профсоюзов и общественные группы. Или может оказаться более полезным организовать группу, в которую войдут люди, представляющие все ключевые внутренние и внешние заинтересованные стороны, чтобы можно было выразить и обсудить противоположные идеи.
Какой бы формат ни был выбран, важно, чтобы фокус-группа была структурирована и управлялась таким образом, чтобы создать «безопасное пространство» для людей, чтобы они могли поделиться своим опытом. В некоторых случаях это может быть невозможно без создания отдельных фокус-групп или найма профессионального фасилитатора, не связанного с организацией.
Возможные сильные стороны:
- фокус-группы позволяют озвучить несколько повествований в одном «интервью» по интересующей теме исследования
- выступают в качестве инструментов для обучения, поскольку обсуждение между участниками может пролить свет на точки зрения участников и исследователя, помогая в дальнейшем уточнить исследования по конкретной интересующей теме.
Потенциальная слабость:
- не позволяет участникам полностью выражать свои индивидуальные мнения и рассказы или задавать вопросы, когда они сразу приходят в голову, из-за необходимости слышать и учитывать другие голоса.
Интервью:
Как правило, интервью включают набор стандартных вопросов, которые задают всем респондентам индивидуально, чтобы на основе данных можно было выявить точные тенденции и пробелы. Собеседования обычно проводятся лицом к лицу, но для более быстрых результатов их также можно проводить по телефону или, по мере развития технологий, с помощью видеоконференцсвязи и других средств.
Возможные сильные стороны:
- интервью могут предоставить богатую, подробную перспективу, впечатление или историю по интересующей теме исследования
- интервьюер обычно имеет возможность исследовать более глубоко или задать уточняющие вопросы, чем в фокус-группе Данные
- , полученные как из фокус-групп, так и из интервью, могут предоставить ценный контекст для понимания и информирования исследований, цифр, событий, поведения и других целей исследования
- В зависимости от размера организации, цели сбора данных, имеющейся внутренней экспертизы и других факторов, фокус-группы и интервью могут проводиться с относительно небольшими затратами.
Возможные недостатки:
- Индивидуальные интервью позволяют изложить только одно повествование или точку зрения на интересующую тему исследования
- может быть очень трудоемким и ресурсоемким 90 800 респондентов на интервью и в фокус-группах в целом хотят «хорошо выглядеть» в глазах окружающих. В зависимости от заданных вопросов они могут «раскрутить» свой ответ, чтобы не смущаться, особенно при личной встрече. Квалифицированные интервьюеры могут устранить эту потенциальную слабость, выполнив несколько действий, например составив хорошие вопросы, проявив проницательность, задав уточняющие вопросы и сверя ответы с другими достоверными источниками информации Интервьюеры
- , как индивидуальные, так и фокус-группы, могут исказить интервью, например, не задавая вопросов, которые вызывают у них дискомфорт, или не выслушивают внимательно респондентов по темам, по которым они имеют твердое мнение.Воздействие этой потенциальной слабости можно устранить, приняв такие меры, как обеспечение надлежащей подготовки интервьюеров и использование стандартных вопросов для интервью.
Наблюдаемые данные
Обученный персонал или внешние эксперты могут собирать данные, выявляя и записывая характеристики и поведение субъектов исследования посредством наблюдения как внутри организации, так и за ее пределами. Наблюдаемые данные могут включать информацию, собранную с использованием всех органов чувств, доступных исследователю, включая зрение, слух, обоняние, вкус и осязание.
Пример: Правозащитная организация, предлагающая услуги посредничества, нанимает эксперта по посредничеству для наблюдения за посредниками и пользователями услуг и предоставления обратной связи по любым вопросам, вызывающим озабоченность, связанным с правами человека. Чтобы свести к минимуму потенциальный стресс и беспокойство, испытываемые людьми, за которыми наблюдают, персонал и пользователи услуг заранее информируются о целях и задачах учений. Требуется согласие пользователей сервиса. Персоналу сообщается, что собранные данные наблюдений будут использоваться только в исследовательских целях и не будут переданы их руководителям.Эксперт поддерживает доступ к данным, а результаты представляются в агрегированном виде, чтобы предотвратить идентификацию лиц.
Наем экспертов, хотя и потенциально дорогостоящий, может повысить достоверность и доверие к анализу исследования, поскольку часто считается, что они не заинтересованы в результатах исследования.
Информация, собранная с использованием методов наблюдения, отличается от интервью, поскольку наблюдатель не задает активно вопросы респонденту.Наблюдаемые данные могут включать все: от полевых исследований, когда кто-то живет в другом контексте или культуре в течение определенного периода времени (включенное наблюдение), до фотографий, демонстрирующих взаимодействие между поставщиками услуг и пользователями услуг (прямое наблюдение). Данные могут быть записаны во многом так же, как интервью (заметки, аудио, видео), а также в виде изображений, фотографий или рисунков.
Возможные сильные стороны:
- эффективный и способный наблюдатель может предоставить объективную третью точку зрения на то, что происходит, и выявить последствия, которые не очевидны или о которых люди не знают
- может быть относительно недорогим в зависимости от таких факторов, как размер проекта, его цели, ресурсы организации и продолжительность проекта.
Возможные недостатки:
- обученный или иной наблюдатель может влиять на поведение наблюдаемых людей (например, люди могут быть мотивированы вести себя лучше во время наблюдения), что в конечном итоге может повлиять на точность наблюдаемых результатов
- может вызвать потенциальный стресс и беспокойство у наблюдаемых людей больше, чем использование других методов сбора данных. Можно приложить усилия для минимизации стресса и беспокойства, используя эффективные коммуникационные стратегии для заблаговременного информирования участников о цели, целях, мерах конфиденциальности, продолжительности проекта и другой ключевой информации
- наблюдатель, обученный или иной, не всегда может быть в состоянии точно различать внутри или между определенными группами людей, особенно когда идентичность (-ы) неочевидна (например,г. религия, психическое заболевание, сексуальная ориентация). В этом отношении более эффективным может быть опрос с запросом информации для самоидентификации.
Каждый источник данных, используемый для сбора информации, имеет свои сильные и слабые стороны. Были выделены некоторые из наиболее общих потенциальных сильных и слабых сторон, указанных выше. Анализ данных с разных точек зрения и использование данных из разных источников может укрепить выводы, сделанные в результате исследования. Комбинация статистического анализа, данных наблюдений, юридического анализа, документального анализа, углубленных интервью и внешних и / или внутренних консультаций может помочь в максимальном понимании данной ситуации. [31] Организации должны выбирать источники данных, которые лучше всего соответствуют их программным целям, контексту, ресурсам и организационной культуре.
Как долго будут собираться данные (объем сбора данных)?
Данные можно собирать и анализировать на краткосрочной или проектной основе в ответ на ситуации или потребности, которые время от времени возникают. Краткосрочный проект по сбору данных будет включать дату начала и дату окончания с установленными результатами, которые должны быть выполнены в течение определенного периода времени.
Лучшая практика заключается в том, чтобы собирать данные на постоянной, постоянной основе и анализировать эти данные так часто, как это необходимо для выявления, устранения и мониторинга препятствий на пути к лицам, защищенным кодом , или другим лицам, на основании кода , отличного от . основания.
Данные, собранные в рамках ограниченного по времени исследования, могут быть менее полными, чем данные, собранные в ходе постоянного мониторинга. Это связано с тем, что краткосрочные исследования не позволяют оценить тенденции, закономерности или изменения во времени. Однако там, где важными факторами являются затраты, время и ресурсы, краткосрочные исследования могут быть предпочтительным выбором для удовлетворения потребностей и целей проекта.
Другие факторы также могут влиять на надежность данных. Например, в период сбора данных люди могут изменять поведение, находясь под наблюдением.
Шаг 4. Сбор данных
При планировании наилучшего сбора данных на этапе 4 важно знать о практических соображениях и передовых методах решения логистических проблем, с которыми организации часто сталкиваются на этой стадии процесса. Выполнение плана сбора данных требует внимания к таким вопросам, как:
- Получение поддержки от высшего руководства и ключевых заинтересованных сторон внутри или за пределами организации.Эта группа может включать советы директоров, комитеты управления, представителей профсоюзов, сотрудников, общественные группы, арендаторов, клиентов и пользователей услуг.
- Создание руководящего комитета или выбор лиц, с которыми будут проводиться консультации и которые будут нести ответственность за все основные решения по процессу сбора данных, такие как дизайн, логистика, управление коммуникациями, координация и финансы.
- Определение того, кто будет собирать данные (например, эксперты или обученные сотрудники).
- Определение логистики, ресурсов, технологий и людей, необходимых для разработки и реализации инициативы по сбору данных.
- Предвидение и решение основных проблем и вопросов заинтересованных сторон по проекту.
- Разработка стратегии коммуникации и консультаций, которая объяснит инициативу по сбору данных и будет способствовать максимально возможному уровню участия.
- Защита конфиденциальности и личной информации с помощью тщательно контролируемых процедур сбора, хранения и доступа к данным, которые соответствуют законодательству о конфиденциальности, правах человека и другим законам. Необходимо уважать достоинство и конфиденциальность.
- Сведение к минимуму воздействия и неудобств для людей на рабочем месте или в среде обслуживания, что включает выбор наилучшего времени для сбора данных.
- Стремление к гибкости, позволяющей вносить изменения без больших затрат и неудобств.
- Рассмотрение периода тестирования или пилотной фазы, чтобы вы могли улучшить и изменить методы сбора данных, если это может потребоваться.
Шаг 5: Анализ и интерпретация данных
Шаг 5 включает анализ и интерпретацию собранных данных.Независимо от того, используются ли количественные и / или качественные методы сбора данных, анализ может быть сложным или менее сложным, в зависимости от используемых методов и количества собранных данных.
Объяснение технических шагов, связанных с анализом и интерпретацией данных, выходит за рамки данного руководства. Организация должна будет определить, обладает ли она внутренним потенциалом и опытом для анализа и интерпретации данных, или ей потребуется помощь внешнего консультанта.
Небольшая организация, у которой есть основные потребности в сборе данных, может полагаться на внутренний опыт и существующие ресурсы для интерпретации значения собранных данных.
Пример: Организация с 50 сотрудниками хочет выяснить, достаточно ли в ней женщин, работающих на руководящих должностях, и существуют ли препятствия для равных возможностей и продвижения по службе. Организация подсчитывает количество работающих в ней женщин (25) и определяет, сколько из этих сотрудников работают на руководящих и руководящих должностях (две). Некоторые мотивированные сотрудники определяют некоторые проблемы, вызывающие беспокойство, например гендерную дискриминацию, которые могут иметь более широкие последствия для организации в целом.
После принятия решения о проведении внутренней и внешней оценки (шаг 1) и сбора качественных данных с помощью фокус-групп и интервью с нынешними и бывшими сотрудниками высшее руководство решает, что существуют препятствия для женщин в сфере найма, найма, продвижения по службе и кадровой политики , процессы и практики. Прилагаются усилия для работы с женщинами-сотрудниками, человеческими ресурсами и другим персоналом, чтобы устранить эти препятствия. Организация обязуется способствовать созданию более справедливой и инклюзивной рабочей среды для всех сотрудников.
Шаг 6. Действия по результатам
После того, как организация проанализировала и интерпретировала результаты собранных данных, она может решить действовать в соответствии с этими данными, собрать больше данных того же типа или изменить свой подход.
Количественная и качественная информация может обеспечить прочную основу для создания эффективного плана действий, разработанного для достижения стратегических целей в области человеческих ресурсов, прав человека, справедливости и разнообразия, определенных в процессе сбора данных.Если организация считает, что у нее достаточно информации для разработки плана действий, ей следует рассмотреть возможность включения следующих элементов:
- сводка результатов анализа и интерпретации данных
- выявление препятствий, пробелов и возможностей, которые существуют или могут существовать для лиц, находящихся под защитой Кодекса, и других лиц / групп на основании оснований, отличных от Кодекса
- шагов, которые будут предприняты для устранения этих препятствий, пробелов или возможностей сейчас и в будущем
- реалистичных, достижимых целей с краткосрочными и долгосрочными сроками
- Запрошено мнение заинтересованных сторон и затронутых сообществ
- , как будет отслеживаться, оцениваться и сообщаться прогресс в достижении этих целей.
В некоторых случаях организация может решить, что ей необходимо собрать больше информации, потому что в собранных данных есть пробелы или области, в которых данные неясны или неубедительны. Это может побудить их провести более подробную внутреннюю и внешнюю оценку (вернуться к шагу 1) или попробовать другой подход.
В конце концов, не существует единственного или «правильного способа» для проведения инициативы по сбору данных. Опыт госпиталя Mount Sinai, КПМГ в Канаде, школьного совета округа Киватин-Патрисия, финансовой группы TD Bank, Университета Гвельфа и проекта DiverseCity Counts , представленного в приложениях, отражает это утверждение, но также показывает некоторое сходство в терминах. передового опыта и извлеченных уроков.
Шесть шагов к успеху
Шаг 1: Определите проблемы и / или возможности для сбора данных
Шаг 2: Выберите проблему (и) и / или возможность (и) и установите цели
Шаг 3: Планируйте подход и методы
- О ком будут собираться данные?
- С кем сравнивать интересующую группу?
- Из каких мест или географических регионов будут собираться данные?
- Какие категории будут использоваться для определения группы интересов и группы сравнения?
Как следует собирать данные?
- Качественные данные
- Количественные данные
Какие источники данных следует использовать для сбора информации?
- Существующие ранее или официальные данные
- Данные обследования
- Интервью и фокус-группы
- Наблюдаемые данные
Как долго будут собираться данные (объем сбора данных)?
Шаг 4: Сбор данных
Шаг 5: Анализ и интерпретация данных
Шаг 6: Действуйте в соответствии с результатом
[21] Закон о равенстве занятости (Закон ) применяется к федеральным работодателям, таким как банки, транспортные и коммуникационные компании со 100 или более сотрудниками, а также к корпорациям Crown и федеральной государственной службе.Работодатели, подпадающие под действие Закона № , известны как работодатели Законодательного плана обеспечения равноправия в сфере занятости (LEEP).
[22] Статистическое управление Канады онлайн: www.statcan.gc.ca.
[23] Город Торонто предлагает на своем веб-сайте множество публикаций и отчетов по множеству тем по секторам или темам, включая рабочую силу. См. City of Toronto, Publications and reports , online: www.toronto.ca/business_publications/publications.htm.
[24] Термин «группа сравнения» используется для определения того, действительно ли существует «дискриминация» прав человека в сценарии.Сравнение проводится между группой, заявляющей о дискриминации, и другой группой, которая разделяет соответствующие характеристики, для определения того, были ли в ней неблагоприятные условия, отрицание, девальвация, угнетение или маргинализация. Группа компаратора должна иметь общие характеристики с группой интересов в исследуемой области, чтобы сравнение было значимым. Подходящая группа компараторов будет зависеть от контекста и часто оспаривается сторонами в судебном процессе. Часто группа сравнения — более привилегированная группа в обществе, часто доминирующая группа.
[25] S. Wortley, Сборник расовой статистики в рамках систем уголовного правосудия и образования: отчет для Комиссии по правам человека Онтарио, (Центр криминологии, Университет Торонто) [неопубликовано], онлайн: www.ohrc.on.ca.
[26] Сбор данных по определенным признакам, таким как этническое происхождение, пол и инвалидность, проводился в течение многих лет в соответствии с федеральным законодательством о равенстве занятости, национальной переписью, которая проводится каждые пять лет или в соответствии с международными требованиями.Для сравнения, сбор данных по другим признакам, таким как сексуальная ориентация, в прошлом не проводился. Примечательно, что национальная перепись не включает вопрос о сексуальной ориентации, хотя сексуальная ориентация была включена в другие необязательные обследования и была предметом тестирования. Статистическое управление Канады, Министерство промышленности, «Консультационный отчет по переписи 2006 г., Каталог № 92-130-XE (2003 г., пересмотрен в феврале 2004 г.)».
[27] К. Агокс, «Преодоление расизма на рабочем месте: качественные и количественные свидетельства системной дискриминации» (2004) 3: 3 Canadian Diversity at 26, онлайн: www.ohrc.on.ca. Для получения дополнительной информации о «таможенных службах» Статистического управления Канады см. Statistics Canada, supra note 27.
[28] S. Wortley, Сбор расовой статистики в рамках систем уголовного правосудия и образования: отчет для Комиссия по правам человека Онтарио, (Центр криминологии, Университет Торонто) [неопубликовано], онлайн: www.ohrc.on.ca, 6.
[29] См. Политику и руководящие принципы борьбы с расизмом и расовой дискриминацией Комиссии по правам человека Онтарио (2005 г.), онлайн: www.ohrc.on.ca, 9-10.
[30] Социальные науки определяются как научные исследования человеческого общества и социальных отношений. Краткий Оксфордский словарь, девятое издание , s.v. «социальная наука.»
[31] J.-C. Икарт, М. Лабелль, Р. Антониус , Показатели для оценки муниципальной политики, направленной на борьбу с расизмом и дискриминацией, доклад, представленный ЮНЕСКО, Секция борьбы с дискриминацией и расизмом, Отдел прав человека и борьбы с дискриминацией Сектор социальных и гуманитарных наук (MontréaI, Québec: International Observatory of Racism and Discrimination: Center for Research on Immigration, Ethnicity and Citizenship (CRIEC), Université du Québec à Montréal, 2005) на 47, онлайн: CRIEC www.criec.uqam.ca/pdf/CRIEC%20Cahier%2028%20(en).pdf.