
Robots.txt как создать и правильно настроить
Последнее обновление: 08 ноября 2022 года
24352
Время прочтения: 6 минут
Тэги: Яндекс, Google
О чем статья?
- Зачем нужен robots.txt?
- Основные директивы файла robots.txt
- Как создать robots.txt?
- Как проверить файл?
Кому будет полезна статья?
- Веб-разработчикам.
- Техническим специалистам.
- Оптимизаторам.
- Администраторам и владельцам сайтов.
Поисковые роботы или веб-краулеры постоянно индексируют страницы сайтов, собирают информацию и заносят ее в базы данных поисковых систем. Первый файл, с которого начинается проверка, — это robots.txt. Именно в нем содержится вся необходимая и важная для краулеров информация. В статье мы расскажем, как создать, настроить и проверить robots.
Зачем нужен robots.txt?
Файл robots.txt — служебный файл, который содержит информацию о том, какие страницы сайта доступны для сканирования поисковыми роботами, а какие им посещать нельзя. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
С помощью robots.txt вы можете задать уровень доступа краулеров к сайту и его разделам: полностью запретить индексацию или ограничить сканирование отдельных папок, страниц, файлов, а также закрыть ресурс для роботов, которые не относятся к основным поисковым системам.
Таким образом, создание и правильная настройка robots.txt помогут ускорить процесс индексации сайта, снизить нагрузку на сервер, положительно отразятся на ранжировании сайта в поисковой выдаче.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«Некоторым сайтам файл robots. txt не нужен совсем или может ограничиваться малым набором директив. Например, при одностраничной структуре ресурса-лендинга зачастую файл robots.txt не требуется — поисковые системы проиндексируют одну страницу, лишние служебные файлы с малой вероятностью будут добавлены в индекс. Небольшое количество правил в robots.txt также можно наблюдать и у больших сайтов с простой структурой, например, у информационных ресурсов. Так, например, один из крупнейших зарубежных блогов по SEO https://backlinko.com/ имеет в robots.txt только две простые директивы:
txt не нужен совсем или может ограничиваться малым набором директив. Например, при одностраничной структуре ресурса-лендинга зачастую файл robots.txt не требуется — поисковые системы проиндексируют одну страницу, лишние служебные файлы с малой вероятностью будут добавлены в индекс. Небольшое количество правил в robots.txt также можно наблюдать и у больших сайтов с простой структурой, например, у информационных ресурсов. Так, например, один из крупнейших зарубежных блогов по SEO https://backlinko.com/ имеет в robots.txt только две простые директивы:
Disallow: /tag/
Disallow: /wp-admin/».
Основные директивы файла robots.txt
Чтобы поисковые роботы могли корректно прочитать robots.txt, он должен быть составлен по определенным правилам. Структура служебного файла содержит следующие директивы:
- User-agent. Директива User-agent определяет уровень открытости сайта для поисковых роботов.

Пример:
User-agent: * — сайт доступен для индексации всем краулерам
User-agent: Yandex — доступ открыт только для роботов Яндекса
User-agent: Googlebot — доступ открыт только для роботов Google - Disallow. Директива Disallow определяет, какие страницы сайта необходимо закрыть для индексации. Как правило, для сканирования закрывают весь служебный контент, но при желании вы можете скрыть и любые другие разделы проекта. Подробнее о том, каким страницам и сайтам не нужно индексирование, вы можете прочитать в статье: «Как закрыть сайт от индексации в robots.txt». Обратите внимание, что даже если на сайте нет страниц, которые вы хотите закрыть, директиву все равно нужно прописать, но без указания значения.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: /wp-admin — служебная папка со всеми вложениями закрыта для индексации
User-agent: Yandex — правила, размещенные ниже, действуют для роботов Яндекса
Disallow: / — все разделы сайта доступны для индексации - Allow. Директива Allow определяет, какие разделы сайта доступны для сканирования поисковыми роботами. Поскольку все, что не запрещено директивой Disallow, индексируется автоматически, здесь достаточно прописать только исключения из правил. Указывать все доступные краулерам разделы сайта не нужно.
Пример 1:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
Пример 2:
User-agent: * — правила, размещенные ниже, действуют для всех краулеров
Disallow: / — сайт полностью закрыт для всех поисковых роботов
User-agent: Googlebot — правила, размещенные ниже, действуют для роботов Google
Allow: / — сайт полностью открыт для роботов Google - Sitemap. Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Sitemap: https://site.ru/sitemap.xml


 Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Директива Sitemap — это карта сайта, которая представляет собой полную ссылку на файл в формате .xml и содержит перечень всех доступных для сканирования страниц, а также время и частоту их обновления.
Как создать robots.txt?
Служебный файл robots.txt можно создать в текстовом редакторе Notepad++ или другой аналогичной программе. Весь текст внутри файла должен быть записан латиницей, русские названия можно перевести с помощью любого Punycode-конвертера. Для кодировки файла выбирайте стандарты ASCII или UTF-8.
Чтобы robots.txt корректно индексировался поисковыми роботами, при создании файла следуйте данным ниже рекомендациям:
- Объединяйте директивы в группы.
- Учитывайте регистр. Прописывайте имя файла строчными буквами. Если Яндекс информирует, что для его поисковых роботов регистр не имеет значения, то Google рекомендует соблюдать регистр.
- Не указывайте несколько папок в одной директиве.
- Работайте с разными уровнями. В robots.txt вы можете задавать настройки на трех уровнях: сайта, страницы, папки. Используйте эту возможность, если хотите закрыть часть материалов для поисковиков.
- Удаляйте неактуальные директивы. Некоторые директивы robots. txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
- Проверьте соответствие sitemap.xml и robots.txt. Файлы sitemap.xml и robots.txt дополняют друг друга. Проверьте, чтобы информация в них совпадала, и sitemap был включен в одноименную директиву.
 Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта.
Так, краулеру не придется сканировать весь файл в поисках нужной инструкции, робот быстро найдет предназначенную для него строку User-agent и, следуя директивам, проверит указанные разделы сайта. txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).
txt устарели и игнорируются краулерами. Удалите их, чтобы не засорять файл. На данный момент устаревшими являются директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов), Clean-param (ограничение дублирующего контента).После создания robots.txt, обратите внимание, чтобы его размер не превышал 32 КБ. При большом объеме файла, он не будет восприниматься поисковыми роботами Яндекс.
Разместите robots.txt в корневой директории сайта рядом с основным файлом index.html. Для этого используйте FTP доступ. Если сайт сделан на CMS, то с файлом можно работать через административную панель.
Как проверить файл?
Удостовериться в том, что файл составлен корректно, можно с помощью инструментов Яндекс. Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Вебмастер и Google Robots Testing Tool. Поскольку каждая система проверяет robots.txt, основываясь только на собственных критериях, проверку необходимо выполнить в обоих сервисах.
Проверка robots.txt в Яндекс.Вебмастер
При первом запуске Яндекс.Вебмастер необходимо создать личный кабинет, добавить сайт и подтвердить свои права на него. После этого вы получите доступ к инструментам сервиса. Для проверки файла нужно зайти в раздел «Инструменты» подраздел «Анализ robots.txt» и запустить тестирование. Если в ходе проверки сервис обнаружит ошибки, он покажет, какие строки требуют корректировки, и что нужно исправить.
Мнение эксперта
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры»:
«В пункте «Анализ robots.txt» вы также можете «протестировать» написание директив и их влияние на статус индексации. Если Вы сомневаетесь в правильности написания директив, то укажите в поле «Разрешены ли URL?» нужные Вам URL, после чего Вебмастер покажет вам статус индексации этих адресов при указанном robots.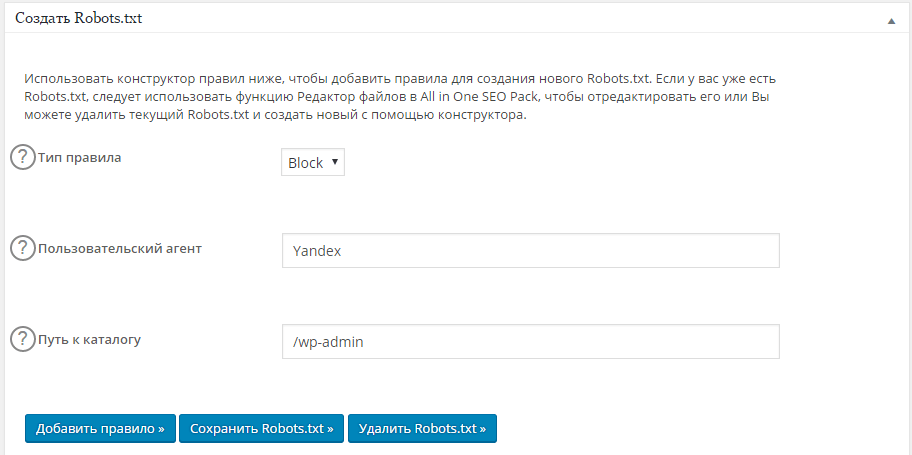 txt.».
txt.».
Проверка robots.txt в Google Robots Testing Tool
Проверять robots.txt в Google можно в административной панели Search Console. Просто перейдите на страницу проверки, и система автоматически протестирует файл. Если на странице вы увидите неактуальную версию robots.txt, нажмите кнопку «Отправить» и действуйте согласно инструкциям поисковой системы. Если Google найдет ошибки, вы можете исправить их в сервисе проверки. Однако учтите, что система не сохраняет правки автоматически. Чтобы исправления не пропали, их нужно внести вручную на хостинге или в административной панели CMS и сохранить.
Выводы
- Файл robots.txt — это служебный документ, который создается для корректной индексации сайта поисковыми роботами. Он не является обязательным элементом, но от его наличия зависит скорость индексации страниц и позиции ресурса в поисковой выдаче.
- Файл создается в Notepad++ или любом другом текстовом редакторе. Структура robots. txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
- Заполнять файл следует по правилам, начиная с кода User-agent. Директивы необходимо объединять в группы, отделяя блоки пустой строкой. С помощью директив Disallow и Allow можно запрещать и разрешать индексацию страниц, папок и отдельных файлов.
- Размер robots.txt не должен превышать 32 КБ. Размещать файл необходимо в корневой директории сайта рядом с основным файлом index.html.
- Проверить robots.txt на наличие ошибок можно с помощью инструментов Яндекс.Вебмастер и Google Robots Testing Tools.
 txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.
txt содержит директивы: User-agent, Disallow, Allow и Sitemap. Чтобы поисковые роботы могли корректно прочитать robots.txt, они должны быть прописаны правильно.Статья
Поисковые подсказки в Яндекс
#SEO, #Яндекс
СтатьяКак размещать рекламу в поисковых подсказках Яндекс
#SEO, #Яндекс
СтатьяЯндекс обновил алгоритмы: как улучшить ранжирование сайта?
#SEO, #Яндекс
Статью подготовили:
Прокопьева Ольга. Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Работает копирайтером, в свободное время пишет прозу и стихи. Ближайшие профессиональные цели — дописать роман и издать книгу.
Алексей Губерман, руководитель отдела поисковой оптимизации в компании «Ашманов и партнеры».
Теги: SEO, Яндекс, Google
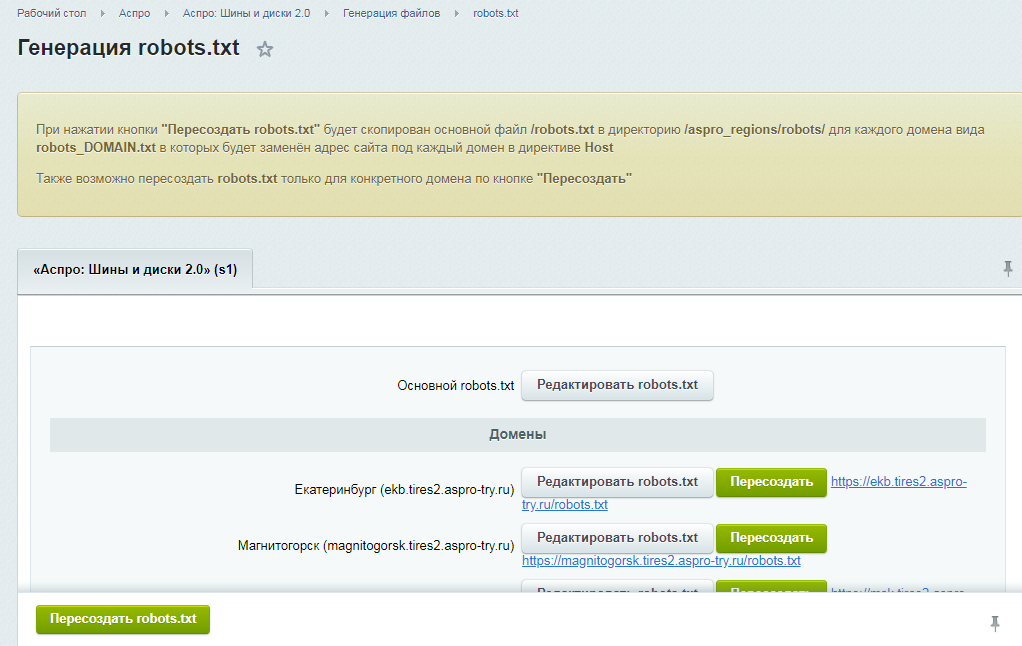
Как настроить и добавить robots.txt на сайт
Поисковые системы ранжируют страницы согласно заданным параметрам. Если не прописать условия ранжирования с помощью специальных инструментов, в топ выдачи попадут ненужные страницы, а нужные — останутся в тени. Чтобы этого избежать, необходимо настроить robots.txt.
Что такое файл robots.txt, для чего он нужен и за что отвечает
Robots.txt — простой, но важный файл для SEO-продвижения. Он содержит команды и инструкции по индексации сайта.
Правильный robots.txt позволит закрыть от индексации, например, технические страницы. Это нужно для того, чтобы оптимизировать сайт под поисковые системы и повысить его позиции в выдаче.
Как создать и добавить robots.
 txt на сайт
txt на сайтЕсли у вашего сайта нет robots.txt, то он считается полностью открытым для индексирования.
Robots.txt сайта yandex.ru
Создаем файл в блокноте или любой текстовой программе — подойдет Word, NotePad и т. д. Главное, чтобы вы сохранили файл в формате “.txt” и назвали его “robots”. В тексте нужно будет прописать страницы, которые можно и нельзя индексировать, указать нужные директивы.
Разрешили сканировать все, что начинается с “/catalog”, запретили доступ к разделам “about”, “info”, “album1”
Исключать из индексации нужно те страницы, которые не содержат полезной и релевантной для целевой аудитории информации:
- страницы авторизации и регистрации;
- результаты поиска;
- служебные разделы;
- страницы фильтров;
- PDF-документы;
- разрабатываемые страницы;
- формы заказа, корзина и т. д.
Файл загрузите в корень сайта через панель администратора.
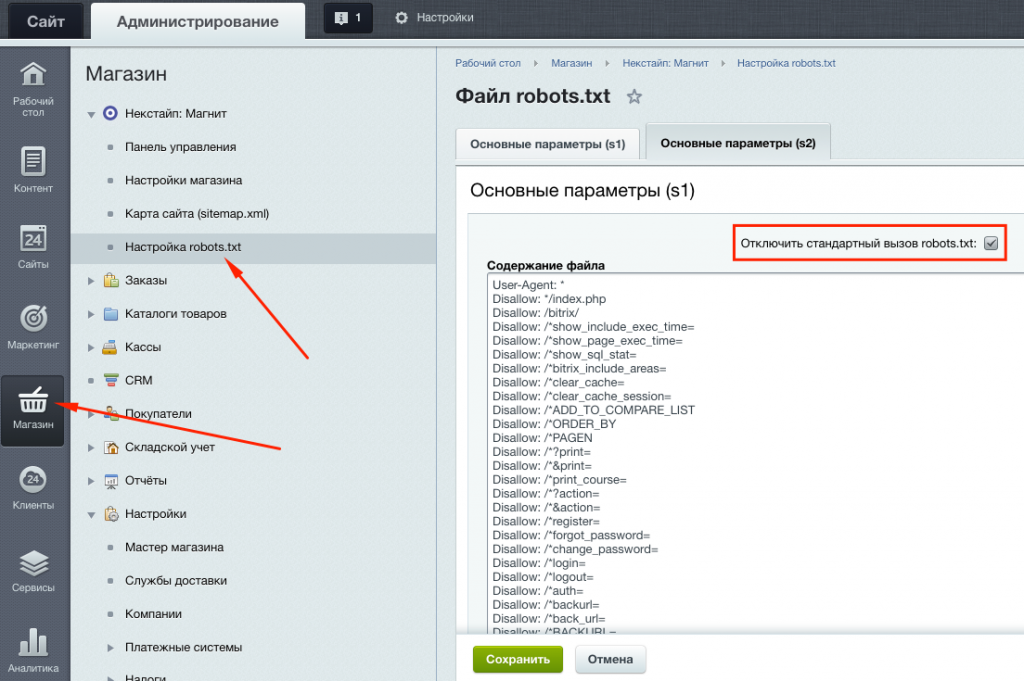
Затем установить галочку в строке «Включить robots. txt» и внести в поле необходимые правила, нажать «Применить». Проверьте, открывается ли файл по адресу ваш_домен/robots.txt.
txt» и внести в поле необходимые правила, нажать «Применить». Проверьте, открывается ли файл по адресу ваш_домен/robots.txt.
Как настроить файл robots.txt вручную
Для этого не нужно быть программистом или верстальщиком — достаточно разобраться, за что отвечает каждый параметр, который мы будем вносить в файл.
- User-agent. С этой директивы должен начинаться каждый robots.txt. Она показывает, для бота какой поисковой системы предназначается инструкция.
User-agent: YandexBot — для Яндекса,
User-agent: Googlebot — для Гугла,
User-Agent: * — общий для всех роботов.
https://vk.com/robots.txt предназначается для всех роботов поисковых систем
- Allow. Эта директива показывает, какие страницы может индексировать робот поисковых систем.
Например, в этом файле Яндексу разрешается индексировать весь сайт:
User-Agent: YandexBot
Allow: /
- Disallow. Полная противоположность предыдущей директивы — закрывает те страницы, которые запрещается индексировать.
Директивы в файле robots.txt на сайте apple.com
- Sitemap. Этот параметр показывает, где находится карта сайта в формате XML, если такая у вас есть. Добавляется данная строчка в конец файла. Прописывается так:
Sitemap: http://www.вашсайт.ru/sitemap.xml
- Clean Param. Закрывает от индексации страницы с дублирующимся контентом. Это нужно для того, чтобы снизить нагрузку на сервер, — так робот поисковой системы не будет раз за разом перезагружать дублирующуюся информацию. Например, у вас есть три страницы с одинаковым содержанием, которые отличаются только параметром “get=”. Он нужен, чтобы понять, с какого сайта к вам пришел пользователь. В этом случае URL страниц разные, но все они ведут на одну и ту же страницу. Чтобы робот не индексировал всё как дубли, прописываем:
Clean-param: option /index.php
Готовые шаблоны файлов: где взять и как редактировать
Если нет желания или времени прописывать директивы вручную, можно воспользоваться сервисами для создания готовых файлов robots.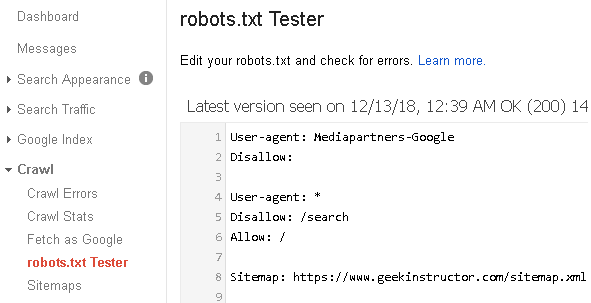 txt для сайта. Однако, у этого способа есть свои плюсы и минусы.
txt для сайта. Однако, у этого способа есть свои плюсы и минусы.
Экономия времени — если у вас много сайтов, не придется для каждого вручную прописывать параметры
Директивы будут настроены однотипно, в них не учитываются особенности именно вашего сайта
Рассмотрим самые популярные сервисы:
- CY-PR. Интерфейс довольно простой — все, что требуется сделать, выбрать нужные поля и задать ваши значения. Готовый файл нужно перенести в корень сайта.
Интерфейс CY-PR
- Seo-auditor. Выбираете нужные поля и вводите ваши значения. Можно указать зеркало сайта, запретить скачивание сайта программами и адаптировать robots.txt под движок WordPress.
Интерфейс Seo-auditor
- IKSWEB. Еще один генератор с более разнообразной адаптацией настроек под CMS сайта — доступны WordPress, 1C-Bitrix, Blogger, uCoz и многие другие.
Интерфейс IKSWEB
После создания файла вы можете его редактировать под себя. Для этого достаточно открыть файл в блокноте и внести необходимые изменения в директивы.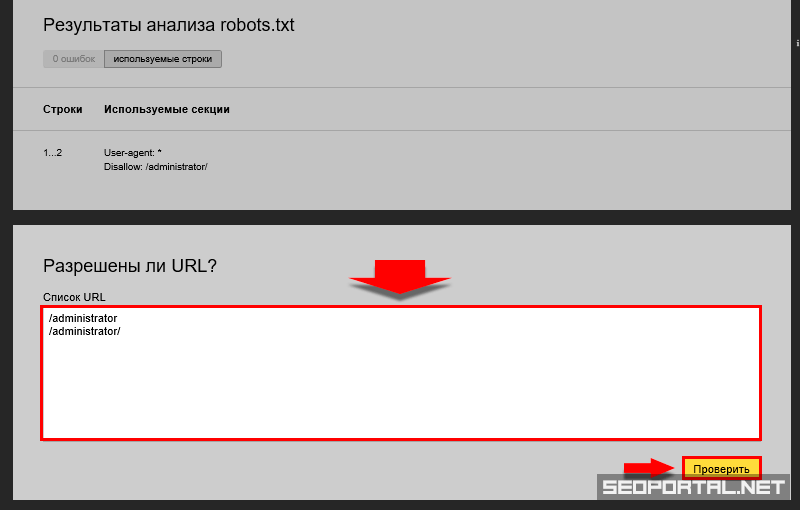 Не забудьте загрузить обновленный документ в корень сайта.
Не забудьте загрузить обновленный документ в корень сайта.
Как исправить ошибки при проверке robots.txt
В первой части статьи мы писали, как проверить корректную работу файла. Рассмотрим, как исправить ошибки, которые могут возникнуть.
Чек-лист для настройки файла robots.txt
- Файл имеет расширение “.txt” и называется “robots”.
- Файл загружен в корень сайта.
- Файл начинается с директивы User-agent и содержит не более 2 048 правил.
- Каждое правило длиной не более 1 024 символа.
- Файл содержит только одну директиву типа “User-agent: *”.
- После каждой директивы проставлено двоеточие, а затем прописан параметр.
- Файл успешно прошел проверку на сервисе, ошибок не обнаружено.
Перейти ко всем материалам блога
Что такое файл robots.txt? Рекомендации по синтаксису Robot.txt
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем) о том, как сканировать страницы на их веб-сайте. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как метароботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).
Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как метароботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «follow» или «nofollow»).
На практике файлы robots.txt указывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта. Эти инструкции по обходу указываются путем «запрета» или «разрешения» поведения определенных (или всех) пользовательских агентов.
Базовый формат:User-agent: [имя user-agent]Disallow: [строка URL не сканируется]
Вместе эти две строки считаются полным файлом robots.txt — хотя один файл robots может содержать несколько строк пользовательских агентов и директив (например, запрещает, разрешает, задержки сканирования и т.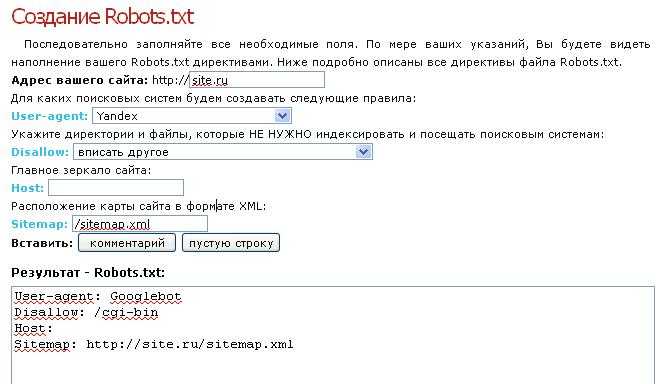 д.).
д.).
В файле robots.txt каждый набор директив агента пользователя отображается как отдельный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами агента пользователя каждое правило запрещает или разрешает Только применяется к агентам пользователя, указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется к более чем одному пользовательскому агенту, сканер будет обращать внимание (и следовать директивам) только на наиболее конкретные группа инструкций.
Вот пример:
Msnbot, discobot и Slurp вызываются специально, поэтому эти пользовательские агенты будут только обращать внимание на директивы в своих разделах файла robots.txt. Все остальные пользовательские агенты будут следовать директивам в группе пользовательских агентов: *.
Пример robots.txt:
Вот несколько примеров robots. txt в действии для сайта www.example.com:
txt в действии для сайта www.example.com:
Агент пользователя: * Disallow: /
Использование этого синтаксиса в файле robots.txt означает, что все поисковые роботы не будут сканировать какие-либо страницы на www.example. com, включая домашнюю страницу.
Разрешение всем поисковым роботам доступа ко всему контентуАгент пользователя: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам просканировать все страницы на www.example.com, включая главную страницу.
Блокировка определенного поискового робота из определенной папкиАгент пользователя: Googlebot Запретить: /example-subfolder/
Этот синтаксис указывает только сканеру Google (имя пользовательского агента Googlebot) не сканировать любые страницы, которые содержать строку URL www.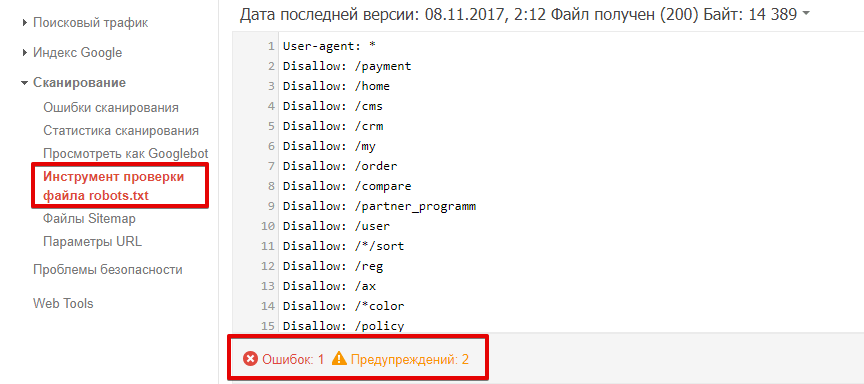 example.com/example-subfolder/.
example.com/example-subfolder/.
Агент пользователя: Bingbot Запретить: /example-subfolder/blocked-page.html сканирование конкретной страницы по адресу www.example.com/example-subfolder/blocked-page.html.Как работает файл robots.txt?
Поисковые системы выполняют две основные функции:
- Просматривают веб-страницы в поисках контента;
- Индексация этого контента, чтобы его можно было предоставить тем, кто ищет информацию.
Для обхода сайтов поисковые системы следуют ссылкам, чтобы перейти с одного сайта на другой — в конечном счете, сканируя многие миллиарды ссылок и веб-сайтов. Такое поведение сканирования иногда называют «пауками».
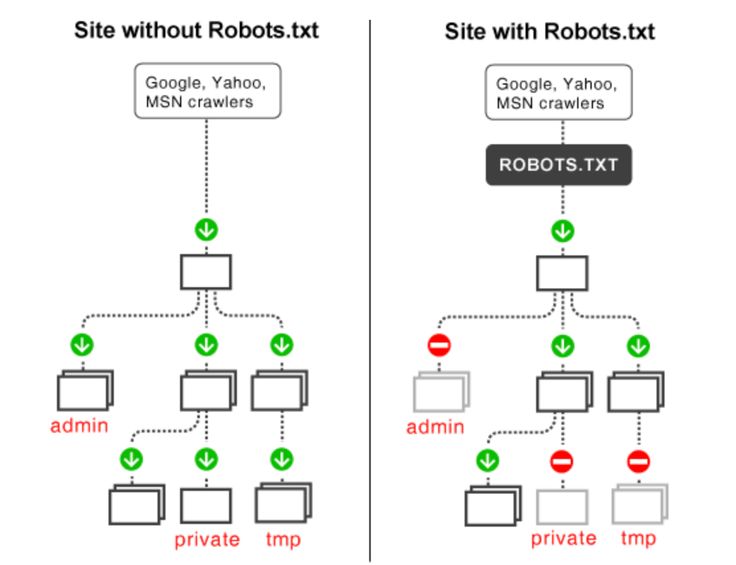
После перехода на веб-сайт, но до его сканирования поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы.
Другие необходимые сведения о robots.txt:
(более подробно обсуждается ниже)
 Поскольку файл robots.txt содержит информацию о как поисковая система должна сканировать, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt , а не содержит какие-либо директивы, запрещающие деятельность пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Поскольку файл robots.txt содержит информацию о как поисковая система должна сканировать, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt , а не содержит какие-либо директивы, запрещающие деятельность пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте. -
Чтобы найти файл robots.txt, его необходимо поместить в каталог верхнего уровня веб-сайта.
-
Robots.txt чувствителен к регистру: файл должен иметь имя «robots.txt» (не Robots.txt, robots.TXT или другое).
-
Некоторые пользовательские агенты (роботы) могут игнорировать ваш файл robots.txt. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или скребки адресов электронной почты.
-
Файл /robots.
txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого сайта (если этот сайт имеет файл robots.txt!). Это означает, что любой может видеть, какие страницы вы сканируете или не хотите, поэтому не используйте их для сокрытия личной информации пользователя. -
Каждый поддомен в корневом домене использует отдельные файлы robots.txt. Это означает, что и у blog.example.com, и у example.com должны быть свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
-
Обычно рекомендуется указывать местоположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:
Идентификация критических предупреждений robots.txt с помощью Moz Pro
Функция сканирования сайта Moz Pro проверяет ваш сайт на наличие проблем и выделяет срочные ошибки, которые могут помешать вам появиться в Google. Воспользуйтесь 30-дневной бесплатной пробной версией и посмотрите, чего вы можете достичь:
Воспользуйтесь 30-дневной бесплатной пробной версией и посмотрите, чего вы можете достичь:
Начать мою бесплатную пробную версию
Технический синтаксис robots.txt
Синтаксис robots.txt можно рассматривать как «язык» файлов robots.txt . Есть пять общих терминов, которые вы, вероятно, встретите в файле robots. Среди них:
-
Агент пользователя: Конкретный поисковый робот, которому вы даете инструкции по сканированию (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
-
Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL-адрес. Для каждого URL разрешена только одна строка «Запретить:».
-
Разрешить (применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или вложенной папке, даже если ее родительская страница или вложенная папка могут быть запрещены.
-
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что Googlebot не подтверждает эту команду, но скорость сканирования можно установить в Google Search Console.
-
Карта сайта: Используется для вызова местоположения любой карты сайта XML, связанной с этим URL-адресом. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.

Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов, которые нужно блокировать или разрешать, файлы robots.txt могут оказаться довольно сложными, поскольку они позволяют использовать сопоставление с шаблоном для охвата диапазона возможных вариантов URL-адресов. Google и Bing поддерживают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Этими двумя символами являются звездочка (*) и знак доллара ($).
- * — это подстановочный знак, представляющий любую последовательность символов.
- $ соответствует концу URL-адреса.
Куда идет файл robots.txt на сайте?
Всякий раз, когда они заходят на сайт, поисковые системы и другие поисковые роботы (например, поисковый робот Facebook, Facebot) знают, что нужно искать файл robots.txt. Но они будут искать этот файл только в одном конкретном месте : в основном каталоге (обычно это ваш корневой домен или домашняя страница). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файл robots, он предполагает, что на сайте его нет, и продолжает сканировать все на странице (и, возможно, даже на всем сайте). Даже если страница robots.txt существует по адресу , скажем, example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами, и, следовательно, сайт будет рассматриваться так, как если бы у него вообще не было файла robots.
Чтобы ваш файл robots.txt был найден, всегда включайте его в свой основной каталог или корневой домен.
Зачем вам robots.txt?
Файлы robots.txt контролируют доступ поисковых роботов к определенным областям вашего сайта. Хотя это может быть очень опасно, если вы случайно запретите роботу Googlebot сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может оказаться очень полезным.
Некоторые распространенные варианты использования включают:
- Предотвращение дублирования контента в поисковой выдаче (обратите внимание, что метароботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей инженерной группы)
- Предотвращение отображения страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (карт) сайта
- Предотвращение индексации поисковыми системами определенные файлы на вашем веб-сайте (изображения, PDF-файлы и т. д.)
- Указание задержки сканирования, чтобы предотвратить перегрузку ваших серверов, когда сканеры загружают несколько фрагментов контента одновременно
Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, возможно, вам вообще не нужен файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл robots Moz находится по адресу moz.com/robots.txt.
Если страница .txt не отображается, у вас в настоящее время нет (действующей) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создать его — простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов robots? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Лучшие практики SEO
-
Убедитесь, что вы не блокируете какой-либо контент или разделы вашего веб-сайта, которые вы хотите сканировать.
-
Ссылки на страницы, заблокированные robots.txt, не будут переходить. Это означает, что 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. е. страницы, не заблокированные через robots.txt, meta robots или иным образом), связанные ресурсы не будут сканироваться и не могут быть проиндексированы. 2.) Никакой вес ссылок не может быть передан с заблокированной страницы на место назначения ссылки. Если у вас есть страницы, на которые вы хотите передать право собственности, используйте другой механизм блокировки, отличный от robots.txt.
-
Не используйте robots.txt, чтобы предотвратить появление конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.
txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex. -
Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность сделать это позволяет вам точно настроить сканирование содержимого вашего сайта.
-
Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день. Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить URL-адрес robots.txt в Google.
Robots.
txt против мета-роботов против x-роботов Так много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt — это настоящий текстовый файл, тогда как meta и x-robots — это метадирективы. Помимо того, чем они на самом деле являются, все три выполняют разные функции. Robots.txt определяет поведение сканирования сайта или всего каталога, тогда как meta и x-robots могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте обучение
- Robots Meta Directives
- Каноникализация
- Перенаправление
- Robots Exclusion Protocol
- Руководство для начинающих в SEO. Moz Pro определяет, блокирует ли ваш файл robots.txt доступ поисковой системы к вашему веб-сайту. Попробуйте >>
Полное руководство по robots.txt • Yoast
Файл robots.txt является одним из основных способов указать поисковой системе, где она может и не может находиться на вашем сайте.
Все основные поисковые системы поддерживают основные функции, которые они предлагают, но некоторые из них реагируют на некоторые дополнительные правила, которые также могут быть полезны. В этом руководстве описаны все способы использования robots.txt на вашем веб-сайте. Внимание!
Любые ошибки, допущенные вами в файле robots.txt, могут серьезно повредить вашему сайту, поэтому убедитесь, что вы прочитали и поняли всю эту статью, прежде чем погрузиться в нее.
Содержание
- Что такое файл robots.txt?
- Что делает файл robots.txt?
- Куда мне поместить файл robots.txt?
- Плюсы и минусы использования robots.txt
- Синтаксис robots.txt
- Не блокировать файлы CSS и JS в robots.txt
- Проверка и исправление в Google Search Console
- Подтвердите файл robots.txt
- См. код
Что такое файл robots.txt?
Директивы сканирования
Файл robots.txt является одной из нескольких директив сканирования.
У нас есть руководства по всем из них, и вы найдете их здесь. Файл robots.txt — это текстовый файл, читаемый поисковыми системами (и другими системами). Файл robots.txt, также называемый протоколом исключения роботов, является результатом консенсуса среди первых разработчиков поисковых систем. Это не официальный стандарт, установленный какой-либо организацией по стандартизации, хотя его придерживаются все основные поисковые системы.
Базовый файл robots.txt может выглядеть примерно так:
Агент пользователя: * Запретить: Карта сайта: https://www.example.com/sitemap_index.xml
Что делает файл robots.txt?
Кэширование
Поисковые системы обычно кэшируют содержимое файла robots.txt, поэтому им не нужно его постоянно загружать, но обычно они обновляют его несколько раз в день. Это означает, что изменения в инструкциях обычно отражаются довольно быстро.
Поисковые системы обнаруживают и индексируют Интернет, просматривая страницы.
По мере сканирования они обнаруживают ссылки и переходят по ним. Это занимает их от сайт A до сайт B до сайт C и так далее. Но прежде чем поисковая система посетит любую страницу в домене, с которым она раньше не сталкивалась, она откроет файл robots.txt этого домена. Это позволяет им узнать, какие URL-адреса на этом сайте им разрешено посещать (а какие нет).Подробнее: Бот-трафик: что это такое и почему вы должны о нем заботиться »
Куда мне поместить файл robots.txt?
Файл robots.txt всегда должен находиться в корне вашего домена. Итак, если ваш домен
www.example.com, сканер должен найти его по адресуhttps://www.example.com/robots.txt.Также важно, чтобы ваш файл robots.txt назывался robots.txt. Имя чувствительно к регистру, поэтому сделайте это правильно, иначе оно не будет работать.
Плюсы и минусы использования robots.txt
Плюсы: управление краулинговым бюджетом
Общеизвестно, что поисковый паук заходит на веб-сайт с заранее определенным «допуском» на то, сколько страниц он будет сканировать (или сколько ресурс/время, которое он потратит, в зависимости от авторитета/размера/репутации сайта и того, насколько эффективно отвечает сервер).
SEO-специалисты называют это краулинговый бюджет .Если вы считаете, что у вашего веб-сайта проблемы с краулинговым бюджетом, то запрет поисковым системам «тратить» энергию на несущественные части вашего сайта может означать, что вместо этого они сосредоточатся на тех разделах, которые имеют значение. Используйте настройки очистки сканирования в Yoast SEO Premium, чтобы помочь Google сканировать то, что важно.
Иногда может быть полезно запретить поисковым системам сканировать проблемные разделы вашего сайта, особенно на сайтах, где необходимо выполнить большую SEO-очистку. После того, как вы прибрали вещи, вы можете впустить их обратно.
Примечание о блокировке параметров запроса
Одной из ситуаций, когда краулинговый бюджет имеет решающее значение, является ситуация, когда ваш сайт использует множество параметров строки запроса для фильтрации или сортировки списков. Допустим, у вас есть десять различных параметров запроса, каждый из которых имеет разные значения, которые можно использовать в любой комбинации (например, футболки разных цветов и размеров).
Это приводит к множеству возможных допустимых URL-адресов, и все они могут быть просканированы. Блокировка параметров запроса от сканирования поможет гарантировать, что поисковая система просматривает только основные URL-адреса вашего сайта и не попадет в огромную ловушку для пауков, которую вы в противном случае создали бы.Против: не удалять страницу из результатов поиска
Несмотря на то, что вы можете использовать файл robots.txt, чтобы сообщить сканеру, куда он не может попасть на вашем сайте, вы не можете использовать его, чтобы сказать поиску движок, URL-адреса которого не показывать в результатах поиска – другими словами, его блокировка не остановит его индексацию. Если поисковая система найдет достаточное количество ссылок на этот URL, она включит его; он просто не будет знать, что находится на этой странице. Таким образом, ваш результат будет выглядеть так:
Если вы хотите надежно заблокировать страницу от появления в результатах поиска, вам нужно использовать мета robots
тег noindex. Это означает, что для того, чтобы найти тег noindex, поисковая система должна иметь доступ к этой странице, поэтому не блокирует ее с помощью robots.txt.Директивы Noindex
Раньше можно было добавить директивы noindex в файл robots.txt, чтобы удалить URL-адреса из результатов поиска Google и избежать появления этих «фрагментов». Это больше не поддерживается (и технически никогда не было).
Con: не распространяется значение ссылки
Если поисковая система не может просканировать страницу, она не может распределить значение ссылки по ссылкам на этой странице. Это тупик, когда вы заблокировали страницу в robots.txt. Любое значение ссылки, которое могло пройти на эту страницу (и через нее), теряется.
Синтаксис robots.txt
WordPress robots.txt
У нас есть целая статья о том, как лучше настроить файл robots.txt для WordPress. Не забывайте, что вы можете редактировать файл robots.txt вашего сайта в разделе Инструменты Yoast SEO → Редактор файлов.
Файл robots.txt состоит из одного или нескольких блоков директив, каждый из которых начинается со строки пользовательского агента. «User-agent» — это имя конкретного паука, к которому он обращается. У вас может быть либо один блок для всех поисковых систем, используя подстановочный знак для пользовательского агента, либо отдельные блоки для определенных поисковых систем. Поисковый паук всегда выберет блок, который лучше всего соответствует его названию.
Эти блоки выглядят так (не пугайтесь, мы объясним ниже):
User-agent: *
Disallow: /User-agent: Googlebot
Disallow:User-agent: bingbot
Disallow: /not-for-bing/Такие директивы, как
AllowиDisallow, не должны учитывать регистр, поэтому вам решать писать их строчными буквами или заглавными буквами. Значения – с учетом регистра, поэтому/photo/не совпадает с/Photo/. Нам нравится писать директивы с большой буквы, потому что это облегчает чтение файла (для людей).Директива агента пользователя
Первый бит каждого блока директив — это агент пользователя, который идентифицирует конкретного паука. Поле user-agent соответствует пользовательскому агенту этого конкретного паука (обычно более длинному), поэтому, например, наиболее распространенный паук от Google имеет следующий пользовательский агент:
Mozilla/5.0 (совместимый; Googlebot/2.1; +http ://www.google.com/bot.html)
Если вы хотите указать этому сканеру, что делать, относительно простой
User-agent: Googlebot 9Строка 0354 поможет.Большинство поисковых систем имеют несколько пауков. Они будут использовать определенный паук для своего обычного индекса, рекламных программ, изображений, видео и т. д.
Поисковые системы всегда выбирают наиболее конкретный блок директив, который они могут найти. Допустим, у вас есть три набора директив: один для
*, один дляGooglebotи один дляGooglebot-News. Если приходит бот, чей пользовательский агент Googlebot-Video, он будет следовать ограничениямGooglebot 9.0354 . Бот с пользовательским агентомGooglebot-Newsбудет использовать более конкретные директивыGooglebot-News.Наиболее распространенные пользовательские агенты для поисковых роботов
Вот список пользовательских агентов, которые вы можете использовать в файле robots.txt для соответствия наиболее часто используемым поисковым системам:
Поисковая система Поле Агент пользователя Baidu Общие baiduspiderBaidu Images baiduspider-imageBaidu Mobile baiduspider-mobileBaidu News baiduspider-newsBaidu Видео baiduspider-videoBing Общие bingbotBing General msnbotBing Images & Video msnbot-mediaBing Ads adidxbotGoogle Общие GooglebotGoogle Изображения Googlebot-ImageGoogle Mobile Googlebot-MobileGoogle News Googlebot-NewsGoogle Video Googlebot-VideoGoogle AdSense Mediapartners-GoogleGoogle AdWords AdsBot-GoogleYahoo! Общие SLURPYandex Общий Yandex.
Дис. Дис. У вас может быть одна или несколько таких строк, указывающих, к каким частям сайта не может получить доступ указанный паук. Пустая строка
Disallowозначает, что вы ничего не запрещаете, чтобы паук мог получить доступ ко всем разделам вашего сайта.В приведенном ниже примере блокируются все поисковые системы, которые «прослушивают» файл robots.txt, и не могут сканировать ваш сайт.
User-agent: *
Disallow: /В приведенном ниже примере все поисковые системы могут сканировать весь ваш сайт, пропуская один символ.
User-agent: *
Disallow:В приведенном ниже примере Google не сможет сканировать каталог
Photoна вашем сайте и все, что в нем содержится.Агент пользователя: googlebot
Запретить: /ФотоЭто означает, что все подкаталоги каталога
/Photoтакже не будут сканироваться. Это , а не , заблокирует Google от сканирования каталога/photo, так как эти строки чувствительны к регистру.Это и заблокирует доступ Google к URL-адресам, содержащим
/Photo, например/Photography/.Как использовать подстановочные знаки/регулярные выражения
«Официально» стандарт robots.txt не поддерживает регулярные выражения или подстановочные знаки; однако все основные поисковые системы это понимают. Это означает, что вы можете использовать такие строки для блокировки групп файлов:
Запретить: /*.php
Запретить: /copyrighted-images/*.jpgВ приведенном выше примере
*расширяется до любого имени файла, которому оно соответствует. Обратите внимание, что остальная часть строки по-прежнему чувствительна к регистру, поэтому вторая строка выше не блокирует сканирование файла с именем/copyrighted-images/example.JPG.Некоторые поисковые системы, такие как Google, позволяют использовать более сложные регулярные выражения, но имейте в виду, что другие поисковые системы могут не понимать эту логику.
Самая полезная функция, которую это добавляет, - это $, что указывает на конец URL-адреса. В следующем примере вы можете увидеть, что это делает:Disallow: /*.php$
Это означает, что
/index.phpнельзя индексировать, но/index.php?p=1можно. быть. Конечно, это полезно только в очень специфических обстоятельствах и довольно опасно: легко разблокировать то, чего вы не хотели.Нестандартные директивы сканирования robots.txt
А также
DisallowиДирективы User-agent, есть пара других директив сканирования, которые вы можете использовать. Все сканеры поисковых систем не поддерживают эти директивы, поэтому убедитесь, что вы знаете их ограничения.Директива allow
Хотя в исходной «спецификации» ее не было, в самом начале речь шла о директиве allow. Похоже, что большинство поисковых систем понимают его, и он позволяет использовать простые и очень читаемые директивы, такие как:
Запретить: /wp-admin/
Разрешить: /wp-admin/admin-ajax. php Единственным другим способом достижения того же результата без директивы
allowбыло бы конкретнозапретитькаждый отдельный файл в папкеwp-admin.Директива Crawl-delay
Crawl-delay является неофициальным дополнением к стандарту, и не многие поисковые системы его придерживаются. По крайней мере, Google и Яндекс им не пользуются, а с Bing непонятно. Теоретически, поскольку поисковые роботы могут быть довольно прожорливыми, вы можете попробовать .0353 crawl-delay направление, чтобы замедлить их.
Строка, подобная приведенной ниже, сообщит этим поисковым системам, как часто они будут запрашивать страницы на вашем сайте.
crawl-delay: 10
Будьте осторожны при использовании директивы
crawl-delay. Установив задержку сканирования в десять секунд, вы разрешаете этим поисковым системам доступ только к 8640 страницам в день. Это может показаться достаточным для небольшого сайта, но не очень для больших сайтов. С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это может быть хорошим способом сэкономить трафик.Директива карты сайта для XML-карты сайта
Используя директиву
карты сайта, вы можете указать поисковым системам — Bing, Yandex и Google — где найти вашу карту сайта XML. Конечно, вы можете отправить свои XML-карты сайта в каждую поисковую систему, используя их инструменты для веб-мастеров. Мы настоятельно рекомендуем вам это сделать, потому что инструменты для веб-мастеров предоставят вам массу информации о вашем сайте. Если вы не хотите этого делать, добавление строкикарты сайтав файл robots.txt является хорошей быстрой альтернативой. Yoast SEO автоматически добавит ссылку на вашу карту сайта, если вы позволите ему сгенерировать файл robots.txt. В существующий файл robots.txt вы можете добавить правило вручную через редактор файлов в разделе «Инструменты».Карта сайта: https://www.example.com/my-sitemap.
xml Не блокировать файлы CSS и JS в robots.txt
С 2015 года Google Search Console предупреждает владельцев сайтов не блокировать CSS и JS файлы. Мы давно говорим вам одно и то же: не блокируйте файлы CSS и JS в файле robots.txt. Объясним, почему не следует блокировать эти файлы от робота Googlebot.
Блокируя файлы CSS и JavaScript, вы запрещаете Google проверять правильность работы вашего веб-сайта. Если вы заблокируете файлы CSS и JavaScript в своем
robots.txt, Google не может отобразить ваш веб-сайт должным образом. Теперь Google не может понять ваш сайт, что может привести к снижению рейтинга. Более того, даже такие инструменты, как Ahrefs, отображают веб-страницы и выполняют JavaScript. Поэтому не блокируйте JavaScript, если хотите, чтобы ваши любимые SEO-инструменты работали.Это идеально согласуется с общим предположением, что Google стал более «человечным». Google хочет видеть ваш сайт таким, каким его видит посетитель, поэтому он может отличить основные элементы от дополнительных.
Google хочет знать, улучшает ли JavaScript взаимодействие с пользователем или портит его.Проверка и исправление в Google Search Console
Google поможет вам найти и исправить проблемы с файлом robots.txt, например, в разделе «Индексирование страниц» в Google Search Console. Просто выберите параметр «Заблокировано robots.txt»:
Проверьте в Search Console, какие URL-адреса заблокированы вашим robots.txtЧтобы разблокировать заблокированные ресурсы, нужно изменить файл
robots.txt. Вам нужно настроить этот файл так, чтобы он больше не запрещал Google доступ к файлам CSS и JavaScript вашего сайта. Если вы работаете на WordPress и используете Yoast SEO, вы можете сделать это напрямую с нашим плагином Yoast SEO.Проверьте файл robots.txt
Различные инструменты могут помочь вам проверить файл robots.txt, но когда дело доходит до проверки директив сканирования, мы всегда предпочитаем обращаться к источнику. Google имеет инструмент тестирования robots.
Тестирование файла robots.txt в консоли поиска Google txt в своей консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем использовать его:Обязательно проверьте свои изменения. тщательно, прежде чем поставить их жить! Вы не будете первым, кто случайно использует robots.txt, чтобы заблокировать весь ваш сайт и попасть в забвение поисковой системы!
За кулисами синтаксического анализатора robots.txt
В июле 2019 года Google объявил, что делает свой синтаксический анализатор robots.txt открытым исходным кодом. Если вы хотите разобраться в гайках и болтах, вы можете увидеть, как работает их код (и даже использовать его самостоятельно или предложить его модификации).
Йост де Валк
Йост де Валк является основателем Yoast. После продажи Yoast он перестал быть активным на постоянной основе и теперь выступает в качестве советника компании. Он интернет-предприниматель, который вместе со своей женой Марике активно инвестирует и консультирует несколько стартапов.

 д.)
д.) 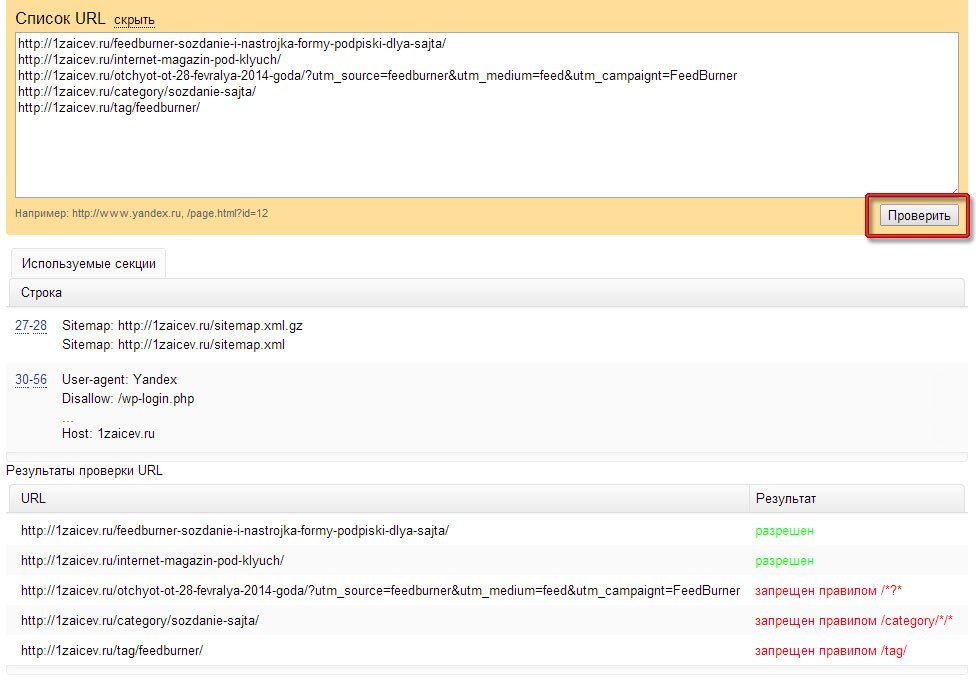
 txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.
txt на вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу в результатах поиска, используйте другой метод, например защиту паролем или мета-директиву noindex.  txt против мета-роботов против x-роботов
txt против мета-роботов против x-роботов 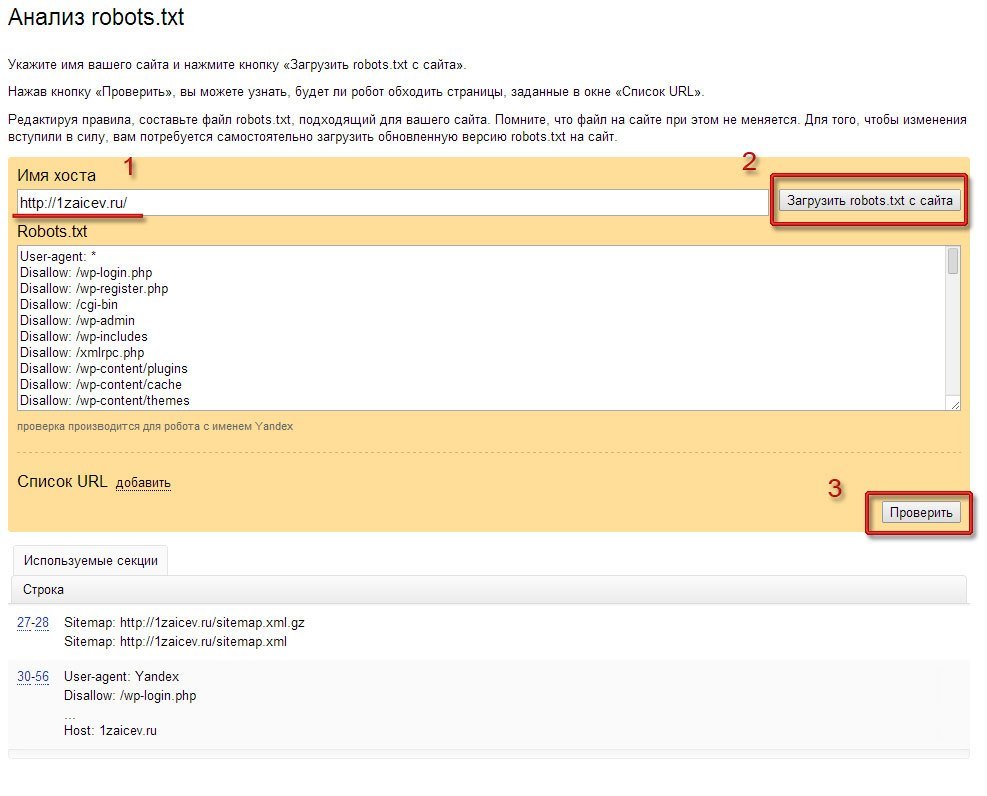 Все основные поисковые системы поддерживают основные функции, которые они предлагают, но некоторые из них реагируют на некоторые дополнительные правила, которые также могут быть полезны. В этом руководстве описаны все способы использования robots.txt на вашем веб-сайте.
Все основные поисковые системы поддерживают основные функции, которые они предлагают, но некоторые из них реагируют на некоторые дополнительные правила, которые также могут быть полезны. В этом руководстве описаны все способы использования robots.txt на вашем веб-сайте. 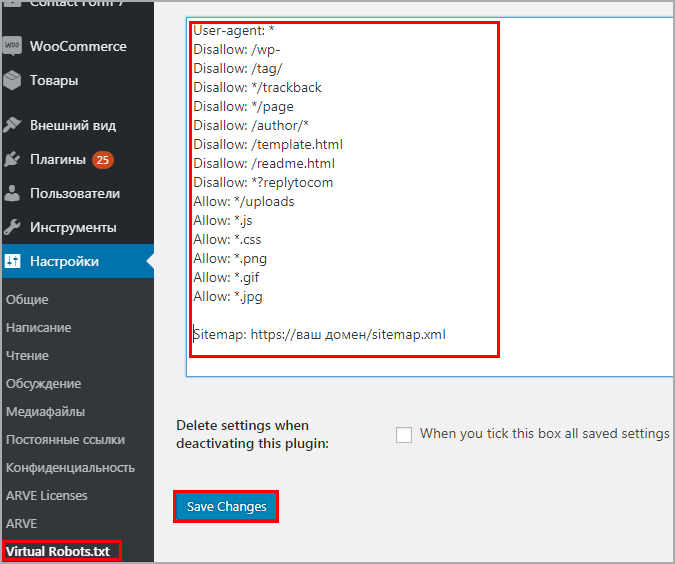 У нас есть руководства по всем из них, и вы найдете их здесь.
У нас есть руководства по всем из них, и вы найдете их здесь. 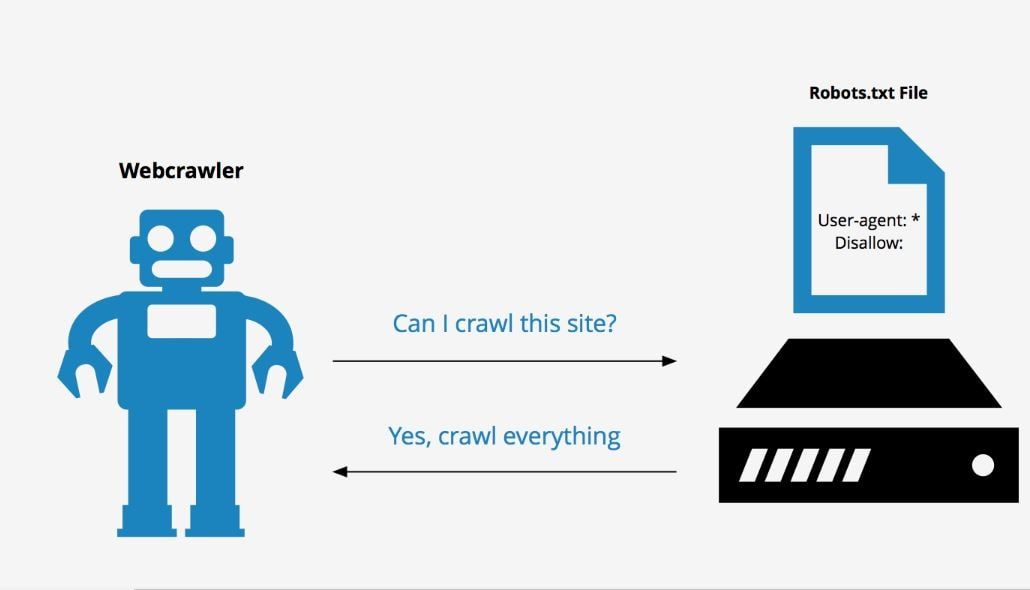 По мере сканирования они обнаруживают ссылки и переходят по ним. Это занимает их от сайт A до сайт B до сайт C и так далее. Но прежде чем поисковая система посетит любую страницу в домене, с которым она раньше не сталкивалась, она откроет файл robots.txt этого домена. Это позволяет им узнать, какие URL-адреса на этом сайте им разрешено посещать (а какие нет).
По мере сканирования они обнаруживают ссылки и переходят по ним. Это занимает их от сайт A до сайт B до сайт C и так далее. Но прежде чем поисковая система посетит любую страницу в домене, с которым она раньше не сталкивалась, она откроет файл robots.txt этого домена. Это позволяет им узнать, какие URL-адреса на этом сайте им разрешено посещать (а какие нет). SEO-специалисты называют это краулинговый бюджет .
SEO-специалисты называют это краулинговый бюджет . Это приводит к множеству возможных допустимых URL-адресов, и все они могут быть просканированы. Блокировка параметров запроса от сканирования поможет гарантировать, что поисковая система просматривает только основные URL-адреса вашего сайта и не попадет в огромную ловушку для пауков, которую вы в противном случае создали бы.
Это приводит к множеству возможных допустимых URL-адресов, и все они могут быть просканированы. Блокировка параметров запроса от сканирования поможет гарантировать, что поисковая система просматривает только основные URL-адреса вашего сайта и не попадет в огромную ловушку для пауков, которую вы в противном случае создали бы. Это означает, что для того, чтобы найти тег
Это означает, что для того, чтобы найти тег 
 Если приходит бот, чей пользовательский агент
Если приходит бот, чей пользовательский агент  Дис
Дис
 Самая полезная функция, которую это добавляет, - это
Самая полезная функция, которую это добавляет, - это  С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это может быть хорошим способом сэкономить трафик.
С другой стороны, если вы почти не получаете трафика от этих поисковых систем, это может быть хорошим способом сэкономить трафик. xml
xml 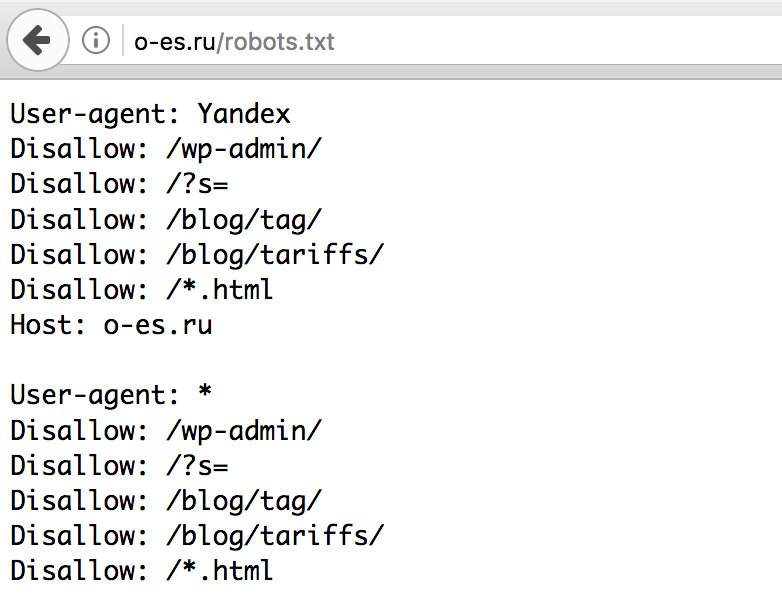 Google хочет знать, улучшает ли JavaScript взаимодействие с пользователем или портит его.
Google хочет знать, улучшает ли JavaScript взаимодействие с пользователем или портит его. txt в своей консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем использовать его:
txt в своей консоли поиска Google (в меню «Старая версия»), и мы настоятельно рекомендуем использовать его: