Как подсчитать количество ячеек, содержащих определенный текст
Вы когда-нибудь хотели посмотреть, сколько раз определенная текстовая строка появляется в наборе данных? Хотя вы можете использовать Ctrl + F для поиска значений, вам может понадобиться более проницательная и отзывчивая функция поиска. К счастью, есть несколько (гораздо более быстрых!) способов подсчета ячеек, содержащих определенный текст в Excel.
Использование функций COUNT в Excel
В Excel доступно несколько функций подсчета:
- COUNT – Подсчитывает количество ячеек, содержащих числа
- COUNTA – Подсчитывает количество непустых ячеек
- COUNTIF & COUNTIFS — подсчитывает ячейки, соответствующие определенным критериям
- COUNTBLANK – подсчитывает количество пустых ячеек
Чтобы увидеть, как они работают, предположим, что вы отвечаете за покупку фруктов для продавца и хотите узнать, сколько ящиков яблок у вас есть на складе.
Мы можем использовать функцию СЧЁТЕСЛИ, чтобы подсчитать количество ячеек, равных яблоко (без учета регистра). Если бы мы хотели ввести искомое значение apple непосредственно в формулу:
=СЧЁТЕСЛИ(B2:B13,"яблоко")
Или, если бы мы хотели обратиться к ячейке (например, B2), содержащей значение яблоко вместо:
=СЧЁТЕСЛИ(B2:B13, B2)
Примечание: СЧЁТЕСЛИ оценивает одно условие; если вам нужно подсчитать ячейки на основе нескольких условий, вместо этого используйте COUNTIFS.
Вы заметите, что этот считает ячейки , которые соответствуют яблоку . Он не считает, сколько раз встречается слово яблоко . Другими словами, ячейка должна содержать только слово яблоко , чтобы быть включенным в подсчет. Например, любые ячейки, содержащие значение ананас или красное яблоко , будут исключены.
Итак, следующий логический вопрос: что, если мы ДЕЙСТВИТЕЛЬНО хотим подсчитать ячейки, содержащие яблоко в любом месте внутри ячейки? То есть, что если ячейка содержит частичное совпадение, такое как 
Использование подстановочных знаков для подсчета ячеек, содержащих определенный текст
Подстановочные знаки Excel — это уникальные символы, которые можно использовать в формулах для представления других символов. Они используются для поиска совпадений, которые следуют определенному шаблону.
Подстановочные знаки:
- Вопросительный знак (?) — представляет один символ. Например, ?n может соответствовать в или в .
- Звездочка (*) — Звездочка обозначает неопределенное количество символов. Например, Be* может относиться к после , до , между и так далее.
- Тильда (~) — Находит подстановочные знаки в текстовой строке. Подробнее об этом ниже.
Мы можем использовать эти подстановочные знаки для частичного совпадения. То есть, когда мы подсчитываем ячейки, содержащие определенный текст, даже если ячейка содержит и другие символы.
Использование подстановочного знака вопросительного знака
Подстановочный знак вопросительного знака (?) представляет один символ в текстовой строке. Вы можете использовать несколько вопросительных знаков для представления определенного количества символов, например:
=СЧЁТЕСЛИ(B2:B13,"b???na")
Это будет соответствовать значениям, начинающимся с b , а затем включающим ровно 3 других символа, затем заканчивается na . В нашем случае это будет соответствовать 2 ячейкам, поскольку банан — единственное значение в нашем списке, которое соответствует критериям соответствия.
Если вы хотите подсчитать количество ячеек, содержащих текстовую строку определенной длины, вы можете повторить ? заданное количество раз. Например, чтобы подсчитать количество ячеек, содержащих текст длиной 4:
=СЧЁТЕСЛИ(B2:B13;"????")
И так далее!
Использование подстановочного знака звездочки для частичного совпадения
Ранее мы упоминали, что при назначении значения яблоко будут подсчитаны ячейки, которые только содержат яблоко (не больше и не меньше символов). Но что, если вы хотите включить ячейки, содержащие текстовую строку 9?0003 apple в любом месте ячейки?
Но что, если вы хотите включить ячейки, содержащие текстовую строку 9?0003 apple в любом месте ячейки?
Для этого мы будем использовать подстановочный знак звездочки в такой формуле:
=СЧЁТЕСЛИ(B2:B13,"*яблоко*")
B2), который содержал поисковый запрос apple, мы могли бы соединить подстановочные знаки со ссылкой на ячейку следующим образом:
=СЧЁТЕСЛИ(B2:B13, "*"&B2&"*")
Это подсчитает ячейки, начинающиеся с любой количество символов (включая отсутствие символов), за которыми следует яблоко , за которым следует любое количество символов (или без символов). В нашем случае количество учитываемых клеток увеличилось до трех. Это связано с тем, что подстановочный знак звездочки (*) соответствует неопределенному количеству символов до и после слова яблоко , поэтому ананас теперь включается в подсчет.
Обратите внимание, что вы можете изменить расположение звездочки по желанию. Например, *яблоко будет соответствовать любой текстовой строке, оканчивающейся на яблоко, а яблоко* будет соответствовать любой текстовой строке, которая начинается с яблока.
Например, *яблоко будет соответствовать любой текстовой строке, оканчивающейся на яблоко, а яблоко* будет соответствовать любой текстовой строке, которая начинается с яблока.
Подсчет пустых и непустых ячеек
Чтобы подсчитать общее количество непустых ячеек в диапазоне, вы можете просто использовать звездочку в следующей формуле:
=СЧЁТЕСЛИ(B:B,"*")
Или вы можете использовать COUNTA для подсчета непустых ячеек, например:
=COUNTA(B:B)
В качестве альтернативы, если вы хотите подсчитать пустые ячейки:
=COUNTBALK(B:B)
Теперь вернемся к тильде ~.
Использование символа тильды
Тильда позволяет нам искать символ подстановки (вместо того, чтобы рассматривать символ как подстановочный знак). Другими словами, если вы хотите, чтобы Excel искал звездочку вместо того, чтобы рассматривать звездочку как подстановочный знак. Например, предположим, вам нужно найти точное слово киви* .
Любая строка, начинающаяся с киви , будет возвращена, если вы использовали строку киви* (например, киви 9).0004). Это связано с тем, что Excel увидит звездочку и использует ее как подстановочный знак. Мы можем поставить перед звездочкой тильду, чтобы предотвратить такое поведение.
Таким образом, чтобы указать буквальную строку kiwi* , мы можем использовать kiwi~* следующим образом:
=СЧЁТЕСЛИ(B2:B15,"kiwi~*")
звездочка как часть текстовой строки и , а не , как подстановочный знак.
Как подсчитать количество ячеек, содержащих определенный текст — с учетом регистра
Описанный выше метод СЧЁТЕСЛИ не работает, если вам нужно выполнить поиск с учетом регистра. То есть, когда вы хотите различать прописные и строчные символы. Вместо этого вы можете комбинировать функции СУММПРОИЗВ и ТОЧНОЕ для подсчета количества ячеек, содержащих текст с учетом регистра:
=СУММПРОИЗВ(--ИСЧИСЛ("текст", диапазон)) Два дефиса в формуле преобразуют ИСТИНА и ЛОЖЬ значения (возвращаемые функцией EXACT) на 1 и 0 соответственно. Затем функция СУММПРОИЗВ суммирует эти результаты и предоставляет общее количество совпадающих ячеек.
Затем функция СУММПРОИЗВ суммирует эти результаты и предоставляет общее количество совпадающих ячеек.
Примечание: при желании вы можете использовать функцию N вместо двух дефисов, чтобы преобразовать ИСТИНА/ЛОЖЬ в 1/0.
Чтобы применить это на практике, давайте сопоставим значение нижнего регистра в ячейке B2 ( яблоко ):
=СУММПРОИЗВ(--ИСЧИСЛ(B2, B2:B14))
Формула вернула число 2. Это включала ячейки B2 и B14 (яблоко в нижнем регистре) и не включала ячейку B11 (яблоко с буквой A в верхнем регистре).
Частичное совпадение — с учетом регистра
Чтобы выполнить частичное совпадение с учетом регистра, мы можем использовать следующую формулу:
=СУММПРОИЗВ(--ЕСЧИСЛО(НАЙТИ("текст",диапазон))) Функция НАЙТИ с учетом регистра возвращает массив чисел (если текст найден в диапазоне) и ошибки (если текст не найден В диапазоне). Затем функция ISNUMBER преобразует числа в TRUE, а ошибки в FALSE. Двойное отрицание преобразует значения TRUE/FALSE в значения 1/0.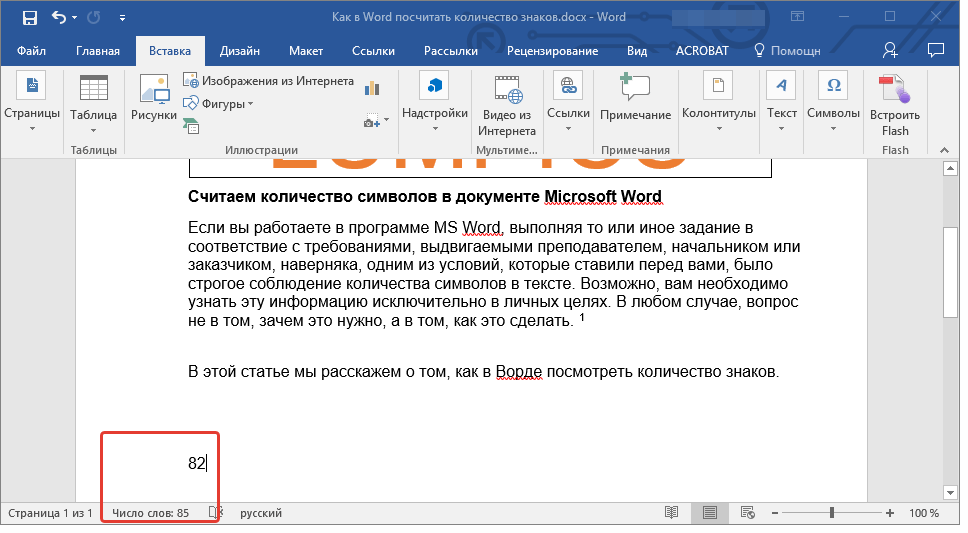 Затем функция СУММПРОИЗВ суммирует результаты и предоставляет общее количество ячеек.
Затем функция СУММПРОИЗВ суммирует результаты и предоставляет общее количество ячеек.
Вот как формула выглядит в действии:
=СУММПРОИЗВ(--(ЧИСЛО(НАЙТИ(D2, B2:B14))))
Формула подсчитывала количество ячеек, в которых значение DFF в верхнем регистре (с учетом регистра) совпадало с любым значением ячейки (частичное совпадение).
С этими формулами интересно поэкспериментировать, и они пригодятся, когда вы сортируете большие объемы данных.
Есть ли у вас другие советы по быстрому подсчету конкретных клеток? Дайте нам знать об этом в комментариях!
Как подсчитать количество строк, слов и символов в текстовом файле из терминала?
по cmdlinetips
количество слов в termimal Как мы можем получить количество строк или количество слов в файле? Самый простой способ подсчитать количество строк, слов и символов в текстовом файле — использовать команду Linux « wc » в терминале.
Команда « wc » в основном означает «счетчик слов», и с различными необязательными параметрами ее можно использовать для подсчета количества строк, слов и символов в текстовом файле.
Чтобы подсчитать количество линий, используйте « wc » с « l » как
wc -l ваштекстовый файл
Чтобы подсчитать количество слов, используйте « wc » с опцией « w » как
wc -w ваш текстовый файл
А для подсчета общего количества символов используйте « wc » с « c » как
wc -m ваш текстовый файл
Использование wc без параметров даст вам количество байтов, строк и слов (параметры -c, -l и -w).
>туалет файл1.txt 1065 5343 40559 файл1.txt
Подсчет слов, символов и строк в нескольких файлах
Команда wc может обрабатывать несколько файлов одновременно и выдавать количество слов, символов и строк.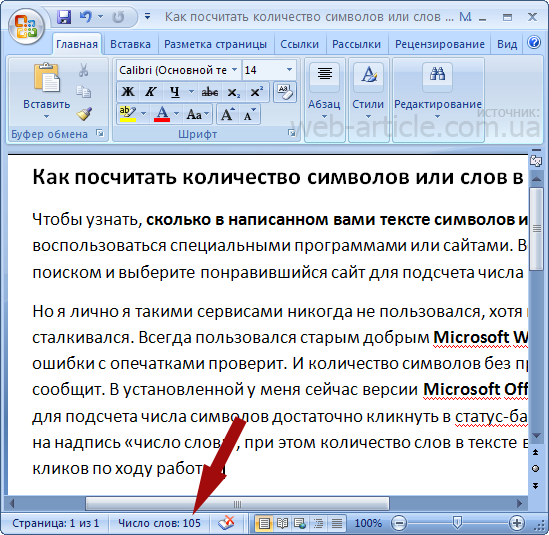 Чтобы получить количество из нескольких файлов, вы просто называете файлы с пробелом между ними. Также это даст вам общее количество. Например, чтобы подсчитать количество символов (-m), слов (w) и строк (-l) в каждом из файлов file1.txt и file2.txt и суммы для обоих, мы просто использовали бы
Чтобы получить количество из нескольких файлов, вы просто называете файлы с пробелом между ними. Также это даст вам общее количество. Например, чтобы подсчитать количество символов (-m), слов (w) и строк (-l) в каждом из файлов file1.txt и file2.txt и суммы для обоих, мы просто использовали бы
>wc -mlw файл1.txt файл2.txt
Мы получили бы результаты в красивой табличной форме
1065 5343 40454 файл1.txt 296 1075 11745 файл2.txt 1361 6418 52199 всего
Как подсчитать файлы определенного типа в каталоге?
Можно также с умом использовать команду « wc » на терминале и найти количество файлов (или файлов определенного типа) в каталоге. Например, чтобы найти количество файлов PDF в каталоге
лс -л *.pdf | туалет -л
И помните, что первая строка оператора «ls -l» — это описание. Следовательно, общее количество pdf-файлов на один меньше результата « ls -l *.