Перевод аудио в текст онлайн
Опубликовано: 14.05.2020 Обновлено: 30.12.2022 Категория: Руководства Автор: myWEBpc
Многие пользователи ищут легкий способ как перевести видео mp4 или аудио mp3 в текст за бесплатно в онлайн режиме. В свою очередь, извлеченный текст из аудио сразу может быть переведен на другой язык. К примеру, вы нашли видео на английском языке и вам нужно извлечь текст, чтобы в дальнейшим перевести его на другой язык. Это касается и обычных аудио музыки, которые могут быть переведены в текст для дальнейшего перевода на другой язык или других нужд.
Также разберем еще один немаловажный момент, как перевести текст в аудио формат и скачать его. Смотрите внимательно каждый способ, так как они все уникальны для каждого пользователя.
- Транскрибация — это перевод аудио или видеоинформации в текст.
- Транскрипция — это запись каких-либо символов, в данном случае текста в звук.
Перевести аудио в текст —
ТранскрибацияGoogle Translate
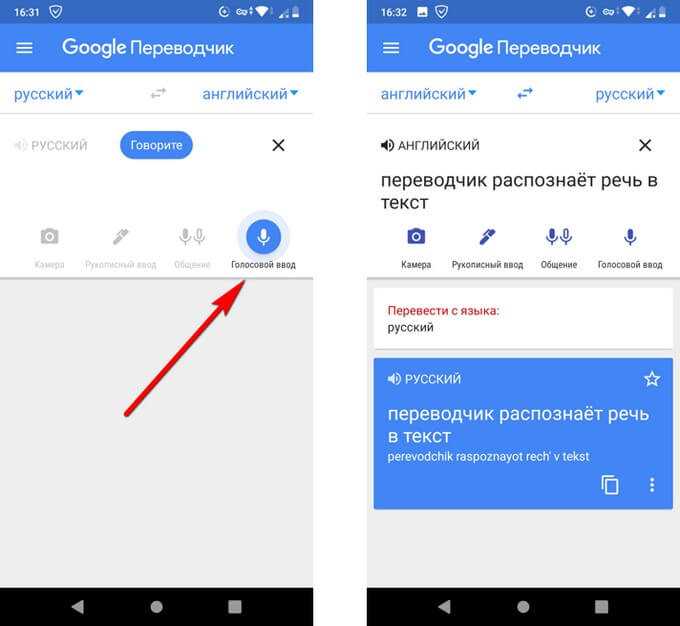
Вам понадобиться микрофон.
- Выбираем видео или аудио с которого нужно извлечь, запускаем его и ставим на паузу.
- Далее переходим на гугл переводчик https://translate.google.com.
- Выберите язык и нажмите на кнопку микрофона.
Примечание: Имеется ограничение в 5000 символов.
Google Docs
Если выше способом мы имеет ограничение в 5000 символов, то можем воспользоваться гугл документами.
- Перейдите в Googele Docs
- Нажмите на вкладку «Инструменты» и выберите «Голосовой ввод«.
Microsoft Word онлайн
Аналогичный способ, только в Word онлайн. Если у вас есть премиум версия, то нажав на язычок микрофона вы сможете скачать аудио файл в формате mp3.
- Перейдите на сайт Microsoft Word
- Нажмите сверху на иконку «Микрофона» и запись будет начата.


Перевести текст в аудио —
ТранскрипцияOneNote
Воспользуемся OneNote, чтобы преобразовать текст в аудио-речь. Мы сможем просто вставить готовый текст и озвучить его голосовым ассистентом. Программа OneNote встроена в Windows 10, что позволит нам не пользоваться сторонними программами и онлайн сервисами. Также, она есть и онлайн версия. OneNote также есть и на мобильных устройствах IOS и Android, но я буду пример показывать для Windows 10.
- Наберите в поиске меню пуск «OneNote» и запустите приложение.
- Создайте разделы в левом столбце, если в этом есть необходимость.
- Справа напишите или вставьте текст, который нужно озвучить.
- Нажмите сверху на вкладку «Иммерсивное средство чтения» и текст будет озвучен.
Если вам нужно нужно преобразовать текст в аудио формат, чтобы скачать аудио файл, то нажмите на вкладку «Вставка» > «Звук» (иконка микрофона).
Yandex SpeechKit
Yandex SpeechKit — онлайн сервис для бета-тестирования синтеза речи. Также можно скачать озвученный файл в формате OGG для прослушивания в проигрывателях.
- Перейдите на сервис Яндекса speechkit.
- Добавьте нужный вам текст в левом столбце.
- Справа вы можете настроить скорость голоса, эмоцию и выбрать ассистента.
- Ниже нажмите на «Синтезировать речь
- Если вам нужно скачать озвученный текст, то нажмите на конку скачивания.
- Преобразованный текст в аудио будет в формате .ogg.
Any Text to Voice
Any Text to Voice бесплатное приложение UWP из Microsoft Store, которое переведет текст в аудио и позволит сохранить в формате mp3.
- Перейдите в Microsoft Store и установите приложение.
- Выберите обязательно ассистента для озвучки. Если текст русский, и ассистент должен быть русский. Приложение берет встроенную озвучку в Windows 10. Если вам нужен арабский, то в параметрах языка ввода Windows 10 установите нужный вам арабский.
- Нажав на «Save as audio» вы сможете сохранить озвученный файл в формате mp3.

Перевод аудио в текст на телефоне IOS и Android
Если вам нужно перевести речь в текст или расшифровать аудио файл в текст на телефоне IOS или Android, то имеется очень хорошее приложение «Голосовой блокнот«, которое можно скачать ниже для своего устройства.
- Скачать «Голосовой блокнот» для IOS с AppStore
- Скачать «Голосовой блокнот» для Android с GooglePlay
Перевод аудио в текст в Teleram
Просто запустите бота VoiceTextRobot и начните аудиозапись. В дальнейшим она преобразуется в текст. Кроме того, бота можно привязать к групповому чату.
Удобный диктофон и транскрипция текста — переводчик
Код товара: 70-018 У меня есть вопрос
новое
Описание товара Удобный диктофон и транскрипция текста — переводчик
Удобный диктофон и транскрипция-переводчик текста через bluetooth-наушники . Синхронный перевод текста на 112 языков мира . Диктофон с функцией транскрипции текста и переводом на 112 языков мира, встроенная память 16Гб. Это удобное, действительно миниатюрное устройство размером всего 6см x 2,2см записывает окружающий звук с помощью двух высококачественных микрофонов в HD качестве. Запись хранится на встроенной памяти объемом 16 Гб. Встроенный аккумулятор емкостью 220 мАч позволяет записывать до 10 часов. Запись звука начнется сразу после начала записи. Диктофон работает с ПК, а также со смартфонами на Android и iOS через мобильное приложение. Вы просто синхронизируете диктофон с ПК или телефоном и можете воспроизводить и редактировать сохраненные записи.
Синхронный перевод текста на 112 языков мира . Диктофон с функцией транскрипции текста и переводом на 112 языков мира, встроенная память 16Гб. Это удобное, действительно миниатюрное устройство размером всего 6см x 2,2см записывает окружающий звук с помощью двух высококачественных микрофонов в HD качестве. Запись хранится на встроенной памяти объемом 16 Гб. Встроенный аккумулятор емкостью 220 мАч позволяет записывать до 10 часов. Запись звука начнется сразу после начала записи. Диктофон работает с ПК, а также со смартфонами на Android и iOS через мобильное приложение. Вы просто синхронизируете диктофон с ПК или телефоном и можете воспроизводить и редактировать сохраненные записи.
Записанный звук можно сразу переписать в текст . Сохраняются как аудио, так и текстовый формат. Распознанный текст можно сразу перевести на 112 языков мира. Он сохранит исходный текст, а также перевод. Запись автоматически сохраняется в качестве резервной копии в облачном хранилище. Произнесенное слово превращается в текст в реальном времени, и вы можете немедленно поделиться им, например, в Twitter или Facebook. Встроенный аккумулятор заряжается через кабель USB типа C. Соединение с ПК или телефоном осуществляется через Bluetooth. Он может преобразовать 2-часовую аудиозапись в текстовую форму всего за 5 минут.
Он сохранит исходный текст, а также перевод. Запись автоматически сохраняется в качестве резервной копии в облачном хранилище. Произнесенное слово превращается в текст в реальном времени, и вы можете немедленно поделиться им, например, в Twitter или Facebook. Встроенный аккумулятор заряжается через кабель USB типа C. Соединение с ПК или телефоном осуществляется через Bluetooth. Он может преобразовать 2-часовую аудиозапись в текстовую форму всего за 5 минут.
Синхронный перевод текста на 112 языков
Благодаря небольшому размеру, легкому весу и практичному зажиму на задней стороне вы можете прикрепить диктофон в любом месте на одежде. Применение универсальное и он обязательно найдет свое применение на деловых встречах, лекциях, занятиях, обработке текстов, а также в поездках или сразу записи творческих идей.
Дальность действия микрофонов до 3 метров.Функции:
Транскрипция аудио (речевой) записи в текст
Синхронный перевод на 112 языков
HD-запись
2 микрофона для идеальной записи звука
Практичный зажим для крепления
Элегантный высокотехнологичный дизайн
Мгновенный обмен в социальных сетях
Мобильное приложение работает со смартфонами Android и iOS и ПК с Windows.
Соединение Bluetooth + USB тип C
Встроенная внутренняя память 16 ГБ
Технические характеристики:
Память: внутренняя — 16 ГБ
Процессор: ATS2837, двухъядерный 240 МГц, CK802 + 400 МГц, 32-битный DSP
Время работы от батареи при записи: до 10 часов
Способ подключения: двойной режим, Bluetooth 5.0
Поддержка операционных систем: Android 5 и новее, iOS 9.0, Windows XP, Vista, 7 и новее
Аккумулятор: 220 мАч
Диапазон микрофона: до 3 м
Рабочая температура: от -10 до 55°C
Размеры: 60x22x12 мм
Содержимое пакета:
1x диктофон + переводчик
1x USB-кабель — тип C
1x руководство
Комментарии
Audio Translator — переводите аудио на более чем 80 языков
Преодолейте языковой барьер и позвольте своему контенту достичь глобальной аудитории посредством перевода. Аудиопереводчик Maestra имеет обширный список языков, и его можно попробовать бесплатно!
Начните бесплатно Запросить демонстрацию
1 Загрузка аудиофайлов в облако Maestra
Пользователи могут загружать различные типы файлов в облако Maestra. Помимо другого файла
форматы, вы также можете загрузить их из Instagram, Youtube, Google Drive или Dropbox напрямую в
Maestra или перетащите файл прямо из ваших папок.
Помимо другого файла
форматы, вы также можете загрузить их из Instagram, Youtube, Google Drive или Dropbox напрямую в
Maestra или перетащите файл прямо из ваших папок.
2 Автоматический аудио переводчик
После загрузки аудиофайла в программу транскрипции Maestra транскрипция процесс начнется автоматически. Пользователи могут выбрать целевой язык для одновременного закончить транскрипцию и перевод. Вы также можете перевести аудиофайлы на более языки после этого шага при использовании расширенного редактора Maestra.
3 Редактировать и экспортировать
В редакторе Maestra пользователи могут корректировать текст и предварительно просматривать аудиофайлы после внесения изменений.
Чтобы перевести аудио в текст, нажмите «Перевести» и выберите один из более чем 80 языков. Затем,
экспортируйте аудиофайл в различные форматы, доступные в Maestra.
Затем,
экспортируйте аудиофайл в различные форматы, доступные в Maestra.
Преимущества автоматического аудиоперевода
Являетесь ли вы создателем контента, профессиональным переводчиком, или работник, которому время от времени требуется голосовой перевод, голосовой онлайн-переводчик Maestra может автоматически транскрибировать голосовые записи, аудио или голосовые заметки и переводить аудио в текст для несколько языков всего за несколько минут.
Экономия времени
Расшифровка и перевод голоса или аудиозаписи может занять некоторое время, но Маэстра
программное обеспечение для автоматической транскрипции позволяет пользователям транскрибировать запись голоса или звуковую дорожку
за считанные минуты с впечатляющей точностью благодаря программному обеспечению для распознавания речи.
В переводческом бизнесе работа с объемными файлами может занять много времени. Что может быть даже дольше, если вы делаете контроль качества после перевода. Если вы заканчиваете длинные переводы в меньшее количество времени, у вас будет больше времени, чтобы исправить ошибки, которые приведут к выполнению больше работы за меньшее время. Аудиопереводчик Maestra позволит вам добиться этого благодаря к его точному программному обеспечению для распознавания речи.
Получите больше зрителей благодаря специальным возможностям
Любой вид контента может выиграть от аудиоперевода просто потому, что нарушает язык
барьер позволяет контенту достичь международной аудитории.
 Аудиопереводчик Maestra может переводить аудио в
минут, что позволяет большему количеству людей потреблять контент. Пользователи могут загружать несколько аудиоформатов
и получите переведенное аудио на более чем 80 поддерживаемых языках. Большое разнообразие
языков гарантирует, что клиенты могут переводить голоса на менее распространенные языки, если они захотят
поэтому с помощью нашего голосового переводчика.
Аудиопереводчик Maestra может переводить аудио в
минут, что позволяет большему количеству людей потреблять контент. Пользователи могут загружать несколько аудиоформатов
и получите переведенное аудио на более чем 80 поддерживаемых языках. Большое разнообразие
языков гарантирует, что клиенты могут переводить голоса на менее распространенные языки, если они захотят
поэтому с помощью нашего голосового переводчика.Раскройте потенциал вашего контента
Аудиоконтент можно использовать где угодно. Люди слушают подкасты, видео и записи во время
они ездят на работу, отдыхают или даже работают. Это форма контента, которую легко потреблять где угодно и где угодно.
в любой момент. Вот почему аудио переводчик может быть чрезвычайно полезным. Умение переводить
аудио на иностранный язык в несколько кликов мгновенно позволяет вашему контенту достичь нового
аудитория, которая может вывести уровень доступности контента на новый уровень.
Голосовой переводчик Маэстры
Мы все знаем о переводе субтитров, но перевод текста и добавление сгенерированных ИИ нейронных
голоса с помощью программного обеспечения для преобразования текста в речь — отличное дополнение к контенту, который многие
люди не пользуются. Дополнительный доступ к субтитрам и озвучке просто
слишком здорово, чтобы пропустить.
Голосовой переводчик Маэстры является автоматическим
генератор озвучки, который также может переводить сгенерированные озвучки более чем на 80
языки. Это отличный способ добавить доступность и рост любому контенту без
необходимость фактически выполнять ручную работу, которая необходима в традиционном дубляже. С помощью нескольких кликов
и за считанные минуты создавайте контент с искусственно созданным голосом за кадром и значительно расширяйте
потенциал вашего контента.
Программа распознавания речи точно определяет голоса и переводит звук. В
Кроме того, пользователи могут регулировать громкость как закадрового голоса, так и исходного звука файла.
через наш редактор озвучивания.
Текстовый редактор
Простое редактирование текста
С помощью текстового редактора Maestra вы можете легко вносить изменения в текст и автоматически переводить текст на 80+ иностранных языков без дополнительной оплаты.
- Экспорт видео в формате MP4 с пользовательским стилем текста!
- Экспорт текста в виде файла Word, PDF или TXT
- Синхронизация стенограммы аудио
- Автоматически генерируемые метки времени
- Обнаружение разных динамиков
Пользовательский стиль
В то время как вы автоматически добавляете субтитры к видео, Maestra также позволяет вам стилизовать ваше видео, предлагая несколько шрифтов, размеров и цветов, а также дополнительные настраиваемые инструменты для оформления субтитров.

После добавления субтитров к видео, затем вы можете отображать видеоконтент на облачных серверах Maestra, чтобы ваше устройство не должен рушиться между интенсивной нагрузкой кодирования мультимедиа. Ваш видеофайл должен быть готов к загрузке в течение нескольких минут, и как только он будет готов, вы можете скачать файл с субтитрами прямо через ваш браузер.
Встроить плеер
Используйте встроенный проигрыватель Maestra, чтобы делиться своими видео с автоматически генерируемыми субтитрами и закрытые субтитры без необходимости загружать или экспортировать видео.
Щелкните значок, чтобы просмотреть автоматически созданные подписи.
Начните бесплатно
Команды Маэстра
Создавайте групповые каналы с разрешениями на просмотр и редактирование для всей вашей команды и компании. Совместная работа и редактирование общих файлов с вашими коллегами в режиме реального времени. Перевести субтитры с помощью
Онлайн-переводчик субтитров Maestra.
Совместная работа и редактирование общих файлов с вашими коллегами в режиме реального времени. Перевести субтитры с помощью
Онлайн-переводчик субтитров Maestra.
Попробуйте бесплатно
Совместная работа и редактирование файла субтитров
Аудиопереводчик Maestra позволяет редактировать и делиться переведенным текстом в совместной среда.
Начните бесплатно
Безопасность
Процесс полностью автоматизирован. Ваши аудио- и мультимедийные файлы зашифрованы в состоянии покоя и в транзитом и не может быть доступен кому-либо еще, если вы не разрешите. Как только вы удалите файл, все данные, включая медиафайлы и текст, будут немедленно удалены. Посетите нашу страницу безопасности, чтобы узнать больше!
Многоканальная загрузка
Переводите аудиофайлы после загрузки с вашего устройства, Google Диска, Dropbox, Instagram или
в качестве альтернативы, вставив ссылку на YouTube или в общедоступные СМИ.
Отзывы клиентов
Что говорят о Маэстре
★ ★ ★ ★ ★
4,7 из 5 звезд
Читать все отзывы
Готовое решение «все в одном» для Автоматические расшифровки, субтитры и озвучка»
Что приходит на ум, когда Maestra является оптимальным решением для Наша компания заключается в том, что это такая экономия времени и денег.
★ ★ ★ ★ ★
Читать отзывы полностью
«идеально подходит для любых потребностей в стенограмме»
Лучшее в Maestra — это то, насколько хорошо она создает
стенограммы.![]() Это так полезно для меня. Это делает мой день намного легче.
Это так полезно для меня. Это делает мой день намного легче.
★ ★ ★ ★ ★
Читать отзывы полностью
«MAESTRA — ИДЕАЛЬНЫЙ СУБТИТРОВ. ОБОЖАЮ ЭТО!»
Маэстра просто великолепна! Мы смогли сделать субтитры на нескольких языках с помощью их платформы. Несколько пользователей могли работать и сотрудничать благодаря их супер-дружественному интерфейсу.
★ ★ ★ ★ ★
Читать отзывы полностью
«Освойте медиа с Маэстрой»
Лучшая сторона этого продукта — автоматические субтитры.![]() И большинство
важно, он поддерживает несколько языков.
И большинство
важно, он поддерживает несколько языков.
★ ★ ★ ★ ☆
Читать отзывы полностью
«Карманный удобный создатель контента»
Это облачная версия. Это позволяет автоматически транскрибировать, субтитры, а также озвучивание видео- и аудиофайлов на сотни языков. Это помогает достичь и обучать людей по всему миру.
★ ★ ★ ★ ★
Читать отзывы полностью
регистр
Начните использовать аудиопереводчик Maestra уже сегодня.

Зарегистрируйтесь в Maestra сегодня, чтобы легко переводить аудиофайлы на более чем 50 языков.
Попробуйте бесплатно
Идеально подходит для преподавателей, исследователей, маркетологов, лекторов, журналистов, медиа-компаний и Ты!
SimulSpeech: Сквозной одновременный перевод речи в текст
Йи Рен, Цзинлин Лю, Сюй Тан, Чен Чжан, Тао Цинь, Чжоу Чжао, Tie-Yan Liu
Abstract
В этой работе мы разрабатываем SimulSpeech, сквозную систему синхронного перевода речи в текст, которая одновременно переводит речь на исходном языке в текст на целевом языке. SimulSpeech состоит из речевого кодировщика, речевого сегментатора и текстового декодера, где 1) сегментатор основан на кодере и использует потерю временной классификации соединения (CTC) для разделения входной потоковой речи в реальном времени, 2) кодер-декодер внимание принимает стратегию ожидания-k для синхронного перевода. SimulSpeech сложнее, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и синхронным нейронным машинным переводом (NMT)). Мы вводим два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножения матриц внимания одновременных моделей NMT и ASR, чтобы помочь в обучении механизма внимания в SimulSpeech; 2) Дистилляция знаний на уровне данных передает знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценок BLEU и задержки перевода.
SimulSpeech сложнее, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и синхронным нейронным машинным переводом (NMT)). Мы вводим два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножения матриц внимания одновременных моделей NMT и ASR, чтобы помочь в обучении механизма внимания в SimulSpeech; 2) Дистилляция знаний на уровне данных передает знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценок BLEU и задержки перевода.- Anthology ID:
- 2020. acl-main.350
- Volume:
- Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
- Month:
- July
- Year:
- 2020
- Address :
- онлайн
- Место:
- ACL
- SIG:
- Издатель:
- Ассоциация для вычислительной лингвистики
- .6
- Язык:
- URL:
- https://aclanthology.org/2020.Acl-main.350
- DOI:
- 10.18653/v1/2020.AC-main.350.
- Процитируйте (ACL):
- Йи Рен, Цзинлинь Лю, Сюй Тан, Чэнь Чжан, Тао Цинь, Чжоу Чжао и Те-Янь Лю. 2020. SimulSpeech: сквозной одновременный перевод речи в текст. В материалах 58-го ежегодного собрания Ассоциации компьютерной лингвистики , страницы 3787–379.6, Интернет. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- SimulSpeech: Сквозной одновременный перевод речи в текст (Ren et al., ACL 2020)
- Копия цитирования:
- PDF:
- https://aclanthology. org/2020.acl-main.350.pdf
- Видео:
- http://slideslive.com/38929241
 acl-main.350
acl-main.350 org/2020.acl-main.350.pdf
org/2020.acl-main.350.pdfPDF Процитировать Поиск Видео
- BibTeX
- МОДЫ XML
- Сноска
- Предварительно отформатированная
@inproceedings{ren-etal-2020-simulspeech,
title = "{S}imul{S}peech: сквозной одновременный перевод речи в текст",
автор = "Рен, Йи и
Лю, Цзинлин и
Тан, Сюй и
Чжан, Чен и
Цинь, Тао и
Чжао, Чжоу и
Лю, Те-Ян",
booktitle = "Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики",
месяц = июль,
год = "2020",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology.org/2020.acl-main.350",
doi = "10.18653/v1/2020.acl-main.350",
страницы = "3787--3796",
abstract = "В этой работе мы разрабатываем SimulSpeech, сквозную систему синхронного перевода речи в текст, которая одновременно переводит речь на исходном языке в текст на целевом языке. SimulSpeech состоит из кодировщика речи, сегментатора речи и декодера текста. , где 1) сегментатор опирается на кодировщик и использует потерю временной классификации соединения (CTC) для разделения входной потоковой речи в реальном времени, 2) внимание кодировщика-декодера использует стратегию ожидания $k$ для синхронного перевода. является более сложным, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и одновременным нейронным машинным переводом (NMT)). Мы представляем два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножение матриц внимания одновременных моделей NMT и ASR для обучения механизма внимания в SimulSpeech; 2) Данные Дистилляция знаний на уровне переносит знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценок BLEU и задержки перевода. ",
}
 SimulSpeech состоит из кодировщика речи, сегментатора речи и декодера текста. , где 1) сегментатор опирается на кодировщик и использует потерю временной классификации соединения (CTC) для разделения входной потоковой речи в реальном времени, 2) внимание кодировщика-декодера использует стратегию ожидания $k$ для синхронного перевода. является более сложным, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и одновременным нейронным машинным переводом (NMT)). Мы представляем два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножение матриц внимания одновременных моделей NMT и ASR для обучения механизма внимания в SimulSpeech; 2) Данные Дистилляция знаний на уровне переносит знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценок BLEU и задержки перевода.
SimulSpeech состоит из кодировщика речи, сегментатора речи и декодера текста. , где 1) сегментатор опирается на кодировщик и использует потерю временной классификации соединения (CTC) для разделения входной потоковой речи в реальном времени, 2) внимание кодировщика-декодера использует стратегию ожидания $k$ для синхронного перевода. является более сложным, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и одновременным нейронным машинным переводом (NMT)). Мы представляем два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножение матриц внимания одновременных моделей NMT и ASR для обучения механизма внимания в SimulSpeech; 2) Данные Дистилляция знаний на уровне переносит знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценок BLEU и задержки перевода. ",
}
",
}
<моды> <информация о заголовке> SimulSpeech: сквозной одновременный перевод речи в текст <название типа="личное">И Рен <роль>автор <название типа="личное">Цзинлин Лю <роль>автор <название типа="личное">Сюй Загар <роль>автор <название типа="личное">Чен Чжан <роль>автор <название типа="личное">Дао Цинь <роль>автор <название типа="личное">Чжоу Чжао <роль>автор <название типа="личное">Тие-Ян Лю <роль>автор <информация о происхождении>2020-07 текст <информация о заголовке> Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции В этой работе мы разрабатываем SimulSpeech, сквозную систему синхронного перевода речи в текст, которая одновременно переводит речь на исходном языке в текст на целевом языке. ren-etal-2020-simulspeech 10.18653/v1/2020.acl-main.350 <местоположение> https://aclanthology.org/2020.acl-main.350 <часть> <дата>2020-07 <единица экстента="страница">3787 <конец>3796
 SimulSpeech состоит из речевого кодировщика, речевого сегментатора и текстового декодера, где 1) сегментатор основан на кодере и использует потерю временной классификации соединения (CTC) для разделения входной потоковой речи в реальном времени, 2) кодер-декодер внимание принимает стратегию ожидания-k для синхронного перевода. SimulSpeech сложнее, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и синхронным нейронным машинным переводом (NMT)). Мы вводим два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножения матриц внимания одновременных моделей NMT и ASR, чтобы помочь в обучении механизма внимания в SimulSpeech; 2) Дистилляция знаний на уровне данных передает знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценки BLEU и задержки перевода.
SimulSpeech состоит из речевого кодировщика, речевого сегментатора и текстового декодера, где 1) сегментатор основан на кодере и использует потерю временной классификации соединения (CTC) для разделения входной потоковой речи в реальном времени, 2) кодер-декодер внимание принимает стратегию ожидания-k для синхронного перевода. SimulSpeech сложнее, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и синхронным нейронным машинным переводом (NMT)). Мы вводим два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножения матриц внимания одновременных моделей NMT и ASR, чтобы помочь в обучении механизма внимания в SimulSpeech; 2) Дистилляция знаний на уровне данных передает знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценки BLEU и задержки перевода.
%0 Материалы конференции %T SimulSpeech: Сквозной одновременный перевод речи в текст %А Рен, Йи %А Лю, Цзинлин %А Тан, Сюй %А Чжан, Чен %А Цинь, Тао %А Чжао, Чжоу %А Лю, Ти-Ян %S Материалы 58-го ежегодного собрания Ассоциации компьютерной лингвистики %D 2020 %8 июля %I Ассоциация компьютерной лингвистики %С онлайн %F ren-etal-2020-simulspeech %X В этой работе мы разрабатываем SimulSpeech, сквозную систему синхронного перевода речи в текст, которая одновременно переводит речь на исходном языке в текст на целевом языке. SimulSpeech состоит из речевого кодировщика, речевого сегментатора и текстового декодера, где 1) сегментатор основан на кодере и использует потерю временной классификации соединения (CTC) для разделения входной потоковой речи в реальном времени, 2) кодер-декодер внимание принимает стратегию ожидания-k для синхронного перевода.
 SimulSpeech сложнее, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и синхронным нейронным машинным переводом (NMT)). Мы вводим два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножения матриц внимания одновременных моделей NMT и ASR, чтобы помочь в обучении механизма внимания в SimulSpeech; 2) Дистилляция знаний на уровне данных передает знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценок BLEU и задержки перевода.
%R 10.18653/v1/2020.
SimulSpeech сложнее, чем предыдущие каскадные системы (с одновременным автоматическим распознаванием речи (ASR) и синхронным нейронным машинным переводом (NMT)). Мы вводим два новых метода дистилляции знаний для обеспечения производительности: 1) дистилляция знаний на уровне внимания передает знания из умножения матриц внимания одновременных моделей NMT и ASR, чтобы помочь в обучении механизма внимания в SimulSpeech; 2) Дистилляция знаний на уровне данных передает знания из модели NMT с полным предложением, а также снижает сложность распределения данных, чтобы помочь в оптимизации SimulSpeech. Эксперименты с наборами данных MuST-C англо-испанский и англо-немецкий разговорный язык показывают, что SimulSpeech достигает разумных оценок BLEU и меньшей задержки по сравнению со сквозным переводом речи в текст (без синхронного перевода) и более высокой производительностью, чем двухэтапная каскадная модель синхронного перевода с точки зрения оценок BLEU и задержки перевода.
%R 10.18653/v1/2020.