
как собрать семантику для полного охвата
Александр Шараевский
SEO IM of Enterprise Department at Netpeak
Семантическое ядро — это неотъемлемая часть каждого сайта. Полнота и качество семантики определяют то, придут ли на ваш сайт целевые пользователи, и придут ли вовсе. Процесс сбора семантического ядра — трудоемкий, а иногда и бесконечный процесс, однако, зная некоторые важные приемы, можно его упростить и сэкономить время.
В данной статье я поэтапно расскажу о том, как быстро собрать семантическое ядро для сайта, кластеризовать его и расширить структуру сайта, используя комплекс инструментов. Поехали!
Содержание:
Нет подпунктов 😉
- Для сайта, который еще в разработке
- Для уже существующего сайта
- Как найти конкурентов вручную
- Как определить конкурентов с помощью Serpstat
- Анализ структуры сайтов-конкурентов
- Настройка KeyCollector
- Формирование базовых запросов
- Поиск синонимов через дополнительные сервисы
- Сбор поисковых запросов через разные источники
- Сбор стоп-слов
- Расширение семантики в Serpstat
- Сбор расширений в Вордстат
- Сбор поисковых подсказок
Кластеризация ключевых фраз
Тоже нет подпунктов 🙂
Ура! Статья подходит к концу!
Ну вот и все!
Семантическое ядро — мозг вашего сайта. Все его направления должны быть связаны с друг другом, но в то же время каждое отвечает за конкретное действие. Это сборник слов и словосочетаний, полностью охватывающий деятельность компании по разным направлениям.
Все его направления должны быть связаны с друг другом, но в то же время каждое отвечает за конкретное действие. Это сборник слов и словосочетаний, полностью охватывающий деятельность компании по разным направлениям.
Ядро состоит из ключевых фраз, по которым пользователь находит определенную страницу сайта в зависимости от своего запроса. На основании семантики составляется структура сайта, прописываются метатеги и основные заголовки страниц.
Каким должен быть размер семантического ядра
Вы не получите точный ответ на вопрос: сколько фраз нужно использовать в продвижении сайта? В узких нишах и специфических услугах это количество варьируется в пределах нескольких сотен. В обширном интернет-магазине их может быть пару сотен тысяч или миллион. На сайтах-агрегаторах используется несколько миллионов запросов.
Размер ядра напрямую зависит от типа сайта, его тематики и не определяется количеством существующих страниц. Структура сайта определяется исключительно после того, как будет завершен сбор семантического ядра.
Структура сайта определяется исключительно после того, как будет завершен сбор семантического ядра.
Но как понять, сколько запросов может быть на вашем сайте, если он был недавно создан? Вам поможет сбор семантики конкурентов. Проанализируйте ключевые фразы конкурентов в топе поисковиков. У вас должно быть не меньше. Но копировать в точности чужую семантику не следует.
Как сформировать первичную
структуру сайта
Первый этап работы над проектом — это составление первого (чернового) варианта структуры сайта. Она представляет собой костяк будущей структуры сайта и строится на основании маркерных запросов.
Маркерные запросы или маркеры — это ключевые фразы, которые определяют тематику ниши. Они должны четко отвечать тематике страницы (1 маркер — 1 страница). Зачастую маркерными запросами являются категории, разделы и рубрики на сайте. Отталкиваясь от маркерных запросов, можно расширять семантику.
Первичную структуру можно подготовить как для уже существующего сайта, так и для проекта в разработке. Но тут есть пара нюансов.
Для сайта, который еще в разработке:
Просим клиента предоставить данные об особенностях бизнеса.
Просим список всех товаров для будущего сайта в Google таблице или в формате .xls.
Анализируем данные и подготавливаем первичную структуру, учитывая также и технические страницы.
Для уже существующего сайта:
Переносим существующую структуру сайта в рабочую таблицу.
Изучаем ассортимент на сайте.
Анализируем поисковую выдачу по коммерческим маркерным запросам, которые характеризуют тематику.
Собираем список сайтов-конкурентов, которые занимаются этим направлением.
Просматриваем все сайты и набрасываем структуру сайта.
Переносим категории каждого из сайтов на таблицу и анализируем структуру каждой категории.
Обращаем внимание на фильтры, сортировки, тегирование и используем всю полезную информацию от конкурентов.
Это необходимо для максимально четкого разграничения категорий на сайте. Например, на одном из сайтов, над которым мы работаем, обнаружились разные типы товаров, находящиеся в одной категории.
Этого нужно избегать. Для этого мы доработали структуру и сформировали дополнительные категории под отдельные типы товаров. Получились такие категории:
москитные сетки;
спирали от комаров;
мухобойки;
липкие ленты;
ловушки;
палочки от комаров;
липкие листы.
Работая над расширением структуры, выделяем новые элементы другим цветом. Это помогает увидеть масштабы и объем работы при расширении, которые придется проделать.
Также при разработке первичной структуры, помимо категорий, учитываем типы и значения фильтров. Чем подробнее будет структура, тем проще и быстрее будет ее расширить.
Как определить прямых конкурентов
Искать конкурентов можно двумя способами: вручную и автоматически, с помощью специализированных сервисов. Рассмотрим оба способа.
Рассмотрим оба способа.
Как найти конкурентов вручную
Чтобы искать прямых конкурентов вручную, необходимо иметь набор фраз, по которым вы хотите продвигаться. Когда у вас есть эти фразы, можно проверять, какие еще сайты ранжируются по этим фразам в поиске, и кто из них находится в топе.
Пробейте каждый запрос в поисковой системе и посмотрите, кто находится в выдаче по тем же фразам. Важно помнить, что поисковики часто персонализируют поиск и формируют SERP (страницу выдачи) на основе ваших прошлых запросов. Поэтому для большей точности используйте режим «Инкогнито»: в Google Chrome, Яндекс или Opera — комбинация клавиш Ctrl+Shift+N, в Mozilla — Ctrl+Shift+P.
Поочередно введите запросы в каждой поисковой системе, так как выдача в них отличается.
Создайте таблицу и внесите в нее сайты, которые ранжируются по нужным ключевикам. Вы получите общую картину по вашей нише и узнаете ближайших конкурентов. После чего можно начинать анализ.
После чего можно начинать анализ.
Просмотрев выдачу по всем ключевым фразам. Так вы соберете базу основных конкурентов и сможете продумать план дальнейших действий.
Однако поиск конкурентов вручную имеет ряд недостатков, которые следует учитывать:
большие временные затраты;
неточная картина по нише;
риск упустить важного конкурента или ключевой запрос;
сложно уследить за изменениями в нише и сохранять актуальность данных.
Как определить конкурентов с помощью Serpstat
Чтобы ускорить поиск прямых конкурентов и получить более точные и актуальные данные, можно автоматизировать процесс и использовать специальные SEO-сервисы. Я покажу, как быстро собрать базу конкурирующих сайтов с помощью Serpstat.
Если сайт уже есть и по нему достаточно информации
Вводим адрес домена в поисковую строку→ выбираем необходимую базу данных→ нажимаем «Поиск». В Суммарном отчете видим график конкурентов.
На нем показаны ближайшие конкуренты вашего домена на основе пересечения семантики. Анализируемый домен всегда будет в правом верхнем углу графика. Прямыми конкурентами являются те сайты, которые расположены ближе всего к нему на пересечении осей.
Чтобы получить полный список релевантных конкурентов, перейдите в раздел «Анализ сайта → Анализ доменов → SEO-анализ → Конкуренты».
Для дальнейшей работы выгружаем данные в удобном формате:
После выгрузки чистим список и оставляем только коммерческие сайты:
API Serpstat: конкуренты
Можно найти конкурентов с помощью API Serpstat, через дополнение для Google таблиц. API Serpstat экономит время и доступен на любом тарифе. Просто скопируйте домен(ы) в таблицу→ подключите дополнение→ выберите нужный метод→ получите результат! Подробнее об использовании читайте в инструкции.
УСТАНОВИТЬ ДОПОЛНЕНИЕ
Если сайт новый или по нему недостаточно данных
Если работа ведется над новым сайтом, либо по нему нет достаточного количества данных, можно прибегнуть к анализу отдельных категорий. Вводим в поисковую строку ключевую фразу (например, под категорию «Удобрения») и переходим в отчет «Анализ ключевых фраз→ SEO-анализ→ Конкуренты».
Вводим в поисковую строку ключевую фразу (например, под категорию «Удобрения») и переходим в отчет «Анализ ключевых фраз→ SEO-анализ→ Конкуренты».
Данные экспортируем и чистим по аналогии с предыдущим способом.
Анализ сайтов-конкурентов: масштабный путеводитель
| Читать |
API Serpstat: ключевые фразы
По аналогии с первым методом: вводим ключевые слова→ выбираем метод→ загружаем данные!
Получаем полный список конкурентов по фразам из топ-100 Google или топ-50 Яндекс:
Дополнение Serpstat Batch Analysis для Google Spreadsheets
| Читать |
Анализ структуры сайтов-конкурентов
На этапе анализа структуры, тщательно изучаем структуру сайтов-конкурентов, уделяем особое внимание категориям и фильтрам. Ищем интересные фишки и элементы, добавляем в структуру своего сайта для дальнейшей разработки.
Например, у одного из конкурентов мы нашли интересные фильтры в категории «Инсектициды»:
вредитель;
болезнь.
Сразу же добавили их и в свою структуру:
Как собрать семантическое ядро
На этапе сбора семантического ядра необходимо максимально охватить нишу: собрать максимум фраз, кластеризовать их и распределить по категориям, доработать структуру, категории, фильтры.
Под каждую категорию собираем маркерные ключевые фразы в соответствии с названием категории. Отталкивая от этого, расширяем семантику с помощью синонимов.
Чтобы собрать синонимы, используем такие сервисы:
Serpstat
API Консоль и дополнение для Google таблиц
KeyCollector
Яндекс.Вордстат
Планировщик ключевых слов Google Рекламы
Когда предстоит работа с большим количеством ключевых фраз, для всех операций лучше использовать KeyCollector.
Настройка KeyCollector
Прежде чем начать работу с KeyCollector:
Подключаем прокси. Чтобы избежать бана в сервисах лучше использовать платные персональные прокси.
Чтобы избежать бана в сервисах лучше использовать платные персональные прокси.
Подключаем аккаунт Яндекс.Директ и Google Ads. Нужно создать специальные аккаунты для KeyCollector, а не использовать основные, так как их могут забанить.
Подключаем API.
Указываем ключ для распознавания капчи.
Указываем регион для Яндекс.Вордстат и Директа.
Важно: чтобы сделать работу по сбору и кластеризации ключей в KeyCollector более удобной, мы создаем папку под каждую категорию, подкатегорию, фильтр. Такие группы упрощают дальнейшую работу с семантическим ядром.
Формирование базовых запросов
Анализируем каждую категорию и страницу и подбираем по несколько ключевых фраз, которые будут описывать их содержимое. Например, запросы для категории «Препараты защиты растений»:
препараты защиты растений;
средства для защиты растений.
Далее расширяем семантику. Для этого смотрим отчет Serpstat «Анализ ключевых фраз→ SEO-анализ→ Подбор фраз», в нем собраны все фразы, включающие анализируемую:
Также берем фразы из отчета «Анализ ключевых фраз→SEO-анализ→ Похожие фразы», в нем собраны ключевики из топ-20, семантически связанные с анализируемой фразой (синонимы, альтернативное название и т. д.):
д.):
Чтобы получить эти данные сразу в таблице, можно выгрузить из через API-дополнение, пользуясь аналогичными методами:
Далее заимствуем семантику конкурентов. Для этого в поисковую строку Serpstat вводим отдельные страницы конкурента и смотрим, по каким фразам они ранжируются в топ-100:
Чтобы получить еще больше данных, комбинируем результаты по нескольким регионам и поисковым системам. Переносим всю информацию в KeyCollector.
Кстати, чтобы не переносить фразы вручную, мы используем функционал, который позволяет собирать фразы по URL или домену напрямую из Serpstat. Можно указать несколько URL и добавить запросы в проект. Это экономит массу времени:
Как за 10 минут собрать семантическое ядро и еще 5 крутых SEO-кейсов
| Читать |
Поиск синонимов через дополнительные сервисы
Для расширения семантики также можно использовать правую колонку в Вордстат.
Также подходит планировщик ключевых слов в Google Ads. Для этого открываем Планировщик→ кликаем на «Поиск новых ключевых слов по фразе, сайту или категории»→ вписываем запросы→ выбираем язык и регион→ кликаем «Получить варианты».
В результате получаем список синонимов:
Как найти ключевые фразы, которых нет в Google Adwords?
| Читать |
Сбор поисковых запросов через разные источники
В качестве дополнительного источника семантики мы используем инструменты Яндекс, Вордстат, Serpstat, в KeyCollector. Также собираем поисковые подсказки, для этого подходит отчет «Поисковые подсказки» в интерфейсе Serpstat:
Или через API:
Такого инструментария будет вполне достаточно.
Хотите узнать, как с помощью интерфейса и API Serpstat собрать семантическое ядро?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
Сбор стоп-слов
Для составления качественного семантического ядра необходим также список стоп-слов. Он поможет избавиться от всех мусорных фраз и избежать двойной работы при обновлении семантического ядра в будущем.
Он поможет избавиться от всех мусорных фраз и избежать двойной работы при обновлении семантического ядра в будущем.
В список стоп-слов включаем:
Приставки, характеризующие информационные запросы: что, это, как, фото, видео, смотреть, своими руками и т.д.
Топонимы, не соответствующие вашим целям.
Фразы, предполагающие бесплатное получение: дешево, недорого, бесплатно, скачать и т.д.
Названия популярных сайтов и брендов: розетка, olx, vk, шафа.
Субъективные понятия: самый качественный/ лучший и т.д.
Список стоп-слов будет постоянно расширяется по мере работы над семантическим ядром. Для работы с большим массивом стоп-слов подойдет специальный инструмент в KeyCollector:
Расширение семантики в Serpstat
Чтобы собрать расширения, в KeyCollector выбираем «Serpstat→ Сбор расширений ключевых фраз»:
Добавляем фразы и получаем список расширений:
Как собрать семантическое ядро самостоятельно с помощью Serpstat
| Читать |
Сбор расширений в Вордстат
Следующий этап — сбор расширений в Вордстат. Используем «Пакетный сбор» слов из левой колонки Yandex Wordstat:
Используем «Пакетный сбор» слов из левой колонки Yandex Wordstat:
Перед сбором применяем стоп-слова (список стоп-слов не должен превышать 7000 символов):
Так мы избавимся от лишних фраз. Если же ваш список свыше 7000 символов, этот шаг можно пропустить и вернуться к нему после сбора данных.
Сбор поисковых подсказок
Далее собираем поисковые подсказки из Google и Яндекс. Тут подойдет Serpstat (как уже упоминалось выше) и KeyCollector.
Собрать подсказки в Serpstat можно двумя способами.
Через интерфейс
Вводим ключевую фразу→ выбираем поисковую систему и регион→ переходим в отчет «Поисковые подсказки»→ скачиваем отчет.
Также можно воспользоваться пакетной выгрузкой:
Через API
Чтобы выгрузить подсказки через API, можно перейти в API Консоль — ее использование не требует знаний в программировании — и следуем инструкции:
Выбираем поисковую систему.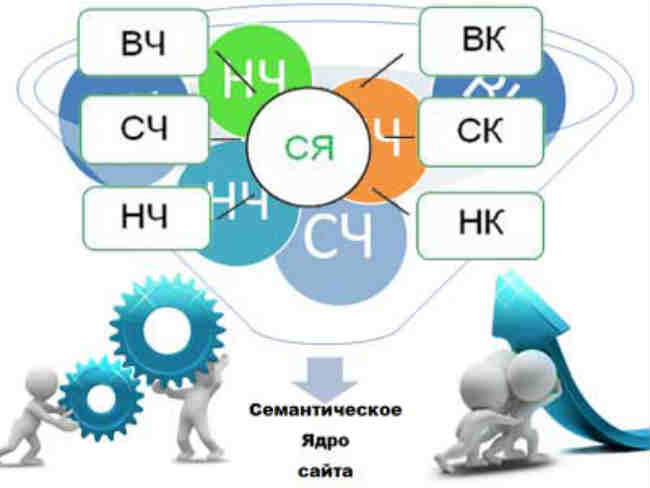
Выбираем API-метод.
Вводим запросы.
Загружаем данные.
Получаем отчет и экспортируем его.
Как за 10 минут собрать семантическое ядро и еще 5 крутых SEO-кейсов
| Читать |
Помимо API Консоли можно воспользоваться Дополнением для Google Таблиц «Serpstat Batch Analysis» на базе API Serpstat. Подробнее читайте в статье.
Дополнение Serpstat Batch Analysis для Google Spreadsheets
| Читать |
Хотите узнать, как с помощью API Serpstat собрать семантическое ядро?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
Как почистить семантику
Далее чистим семантическое ядро от мусорных фраз, нерелевантных и низкоэффективных ключей.
Если на этапе сбора расширений ваш список стоп-слов превышал 7000 символов, и вы не воспользовались опцией чистки запросов, то на данном этапе нужно применить инструмент «Стоп-слова»:
Собираем частотность фраз: переходим в инструмент «Сбор статистики Яндекс.Директ»→ берем статистику за год, чтобы не привязываться к сезонности→ отмечаем чек-бокс «Целью запуска сбора….» → нажимаем «Получить данные».
Далее настраиваем инструмент «Анализ неявных дублей»:
Искать дубли во всех видимых группах.
Отметить все, кроме самых высокочастотных в каждой группе.
Снять отметку со всех неявных дублей.
Отметить все, кроме 1 элемента в каждой группе.
Задать частотность, но основе которой будут анализироваться неявные дубли.
Нажимаем на «Выполнить поиск дублей повторно» и получаем дубли, которые нужно удалить:
Далее переходим к инструменту «Анализ групп»:
Удаляем оставшиеся неподходящие фразы, отмечая ненужные группы. В меню выбираем «Отправить все слова из определений групп, в которых хотя бы одна фраза отмечена, в окно стоп-слов»:
В меню выбираем «Отправить все слова из определений групп, в которых хотя бы одна фраза отмечена, в окно стоп-слов»:
Переносим все неподходящие фразы в список стоп-слов.
Чистим фразы, у которых частотность («») за год ниже 10 (однако, для разных тематик этот показатель может отличаться). Такие ключевики несут информационный шум, поэтому стоит от них избавить с помощью фильтров в KeyCollector:
Кластеризация ключевых фраз
Сгруппировать фразы можно как вручную, так и автоматически. Для автоматической группировки можно использовать Кластеризацию Serpstat или группировку в KeyCollector.
Чтобы кластеризовать фразы в Serpstat:
Перейдите в раздел «Инструменты» и кликните кнопку «Открыть» в ячейке «Кластеризация и текстовая аналитика».
Нажмите кнопку «Создать проект».
Введите в полученной ячейке название проекта и домен (если собираетесь проводить текстовую аналитику по конкретному домену) нажмите «Далее».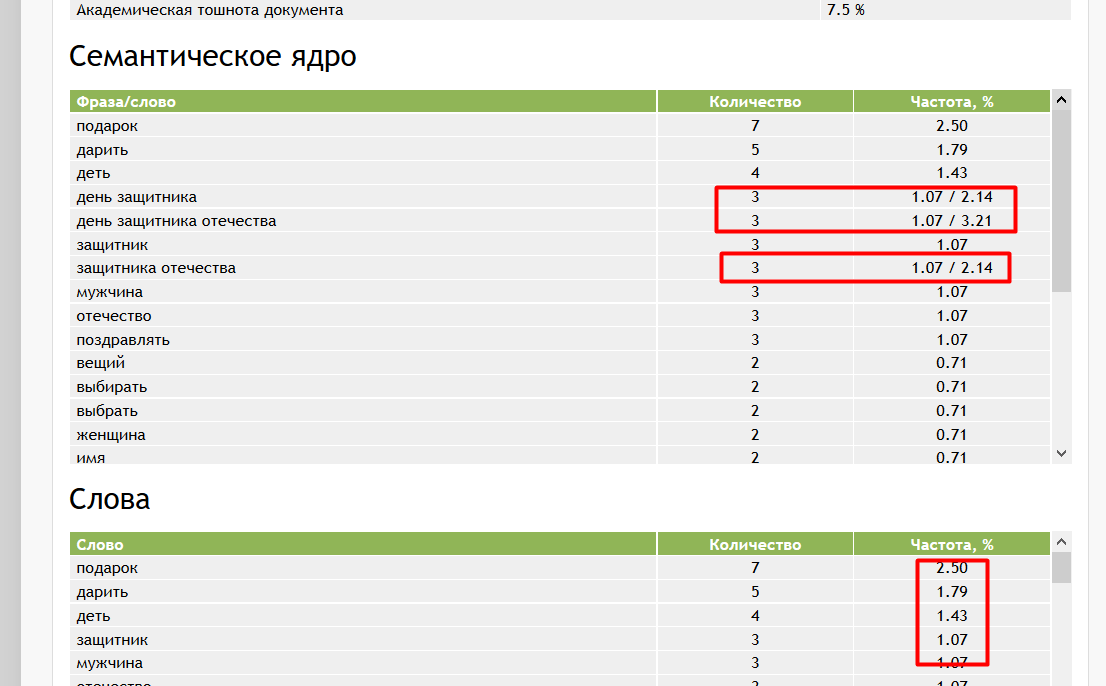
Задайте список фраз или загрузите их в окошко в файле CSV или TXT.
Добавьте поисковую систему, страну, регион и город.
Выберите силу связи, тип кластеризации и нажмите «Готово».
Чтобы сгруппировать фразы в KeyCollector:
Переходим в раздел «Вычисление KEI» и выбираем «Получить данные для ПС Google».
Чтобы не попасть в бан вам потребуется много платных прокси.
Используем инструмент «Анализ групп» и настраиваем группировку как на скриншоте:
Вручную обрабатываем все группы запросов и «доводим ее до ума». После ручной проработки получается практически готовая семантика.
Хотите узнать, как с помощью API Serpstat разбить семантическое ядро по страницам?
Заказывайте бесплатную персональную демонстрацию сервиса, и наши специалисты вам все расскажут! 😉
| Оставить заявку! |
| Узнать подробнее! |
Как автоматизировать и ускорить SEO-задачи с помощью API Serpstat — инструкция от Flatfy
| Читать |
Как сформировать структуру сайта
Когда собраны и кластеризованы все ключевые фразы, приступаем к формированию структуры сайта. Здесь мы уже окончательно оформляем категории, подкатегории, сортировки и фильтры.
Здесь мы уже окончательно оформляем категории, подкатегории, сортировки и фильтры.
Все данные анализируем и переносим в таблицу. Вот небольшая часть того, что должно получиться:
Подробнее о том, как составить структуру, читайте в статье.
Как создать структуру сайта на основе семантики
| Читать |
Бонус: распространенные ошибки при составлении семантического ядра
При составлении семантического ядра может быть допущена масса ошибок. Вот основные из них:
Соединение разных по смыслу ключей на одной странице.
Игнорирование синонимов и смежных по смыслу слов.
Отсутствие страниц геолокации (например, продажа скутеров в Екатеринбурге), если вы продаете в разных городах.
Комбинация информационных и коммерческих запросов на одной странице.
Игнорирование последовательности слов во фразах. Например, «купить автомобиль» и «автомобиль купить» дают разный итог в выдаче.
Отсутствие низкочастотных запросов. Лучше продвинуть сто страниц по словам с запросами менее 10 показов в месяц, чем использовать только 10 страниц с запросами более 1000 показов в месяц.
Полное исключение странных на первый взгляд комбинаций ключевых фраз. Например, если вы продаете одежду, то запрос «куртка с тигром» может быть очень полезен для вашего сайта.
Полное копирование семантики у конкурентов. Вместе с запросами вы можете скопировать и их ошибки.
Добавление новых поисковых фраз на существующие страницы.
Пять адовых ошибок при работе с семантическим ядром
| Читать |
Заключение
Для составления семантического ядра нужно использовать все доступные каналы подбора ключевых фраз. После сбора семантик, вам потребуется удалить минус-слова, мусорные сочетания, добавить названия городов (если есть потребность) и провести группировку по релевантным страницам.
Посмотрите, сколько всего фраз у конкурентов. Проанализируйте их структуру и процент показов. Из имеющихся запросов проведите грамотную кластеризацию по принципу «один запрос = одна страница». Обратите внимание на последовательность слов во фразах, не путайте информационные запросы с коммерческими.
Учтите тот факт, что люди в процессе поиска находятся на разных стадиях. Ваша задача — учесть все возможные запросы на каждой из этих стадий. Не забывайте о низкочастотных запросах, которые помогут вам быстрее выбраться в топ. Размещайте их во вложенных страницах, а в описаниях разделов и категорий применяйте более частотные фразы. Регулярно расширяйте семантику на вашем сайте.
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
все способы. Часть 2 — SEO на vc.ru
Первая часть вот здесь. Во второй части статьи рассмотрим, как собрать СЯ для сайта услуг, как спроектировать семантику и кластеризовать её; а также как узнать пул запросов вашего конкурента.
1300 просмотров
Содержание:
1. Как собрать семантическое ядро для сайта услуг?
1.1. Проектирование структуры
1.2. Приоритизация и детализация
2. Кластеризация семантического ядра. Способы кластеризации
2.1. Ручной метод кластеризации запросов
2.2. Автоматический метод
3. Как понять семантическое ядро сайта-конкурента
3.1. Как получить семантику конкурентов?
3.2. Используем семантику конкурента с наибольшей эффективностью
4. Способы сбора семантического ядра
Как собрать семантическое ядро для сайта услуг?
С СЯ для интернет-магазина мы разобрались в предыдущей части. Ещё хороший гайд есть у SERPStat, но под нишу медицинского ИМ. Теперь рассмотрим, как собрать семантическое ядро для сайта услуг.
Услуги представляют собой огромный сегмент рынка. Более того – на практике каждый процент трафика для таких сайтов важнее, чем для e-commerce ресурсов.
Проектирование структуры
Чтобы подобрать ключи, нужно учитывать уже существующий перечень услуг. В качестве примера возьмем компанию, занимающуюся строительством деревянных домов. Алгоритм следующий:
- Запрашивается информация у клиента по направлениям работы.
- Проанализировать конкурентов через любой доступный сервис. Выявить синонимы поможет правая колонка Вордстата.
Проанализировав конкурентов, составим первичную структуру:
пример первичной структуры
В перечне не отображены стандартные страницы «О компании», «Наши специалисты», «Контакты» и т.д. Дело в том, что сейчас нам интересны только посадочные, генерирующие трафик – именно для них мы собираем и распределяем семантику. Перечисленные выше страницы к таковым не относятся, но на сайте они в любом случае будут присутствовать.
Перечисленные выше страницы к таковым не относятся, но на сайте они в любом случае будут присутствовать.
Приоритизация и детализация
У нас есть перечень предлагаемых компанией услуг, есть запросы, характерные для выбранной ниши. Теперь можем выстраивать приоритеты. С чем работаем?
Выделяем основные и второстепенные страницы; определяем, для каких направлений сбор запросов первостепенен, для каких – может подождать. Затем выстраиваем порядок оптимизации страниц, разделов.
Так мы оказываем себе неоценимую услугу – составляем конкретную стратегию, структурируем процесс, благодаря чему становимся более последовательными и эффективными.
Будьте внимательны! Важно собрать максимально полное семантическое ядро, это важно и для интернет-магазина, и для ресурса, представляющего услуги. Именно от этого зависит количество вероятных точек входа по аналогии с тегами в каталоге товаров.
Пример распределения по подкатегориям (плашки сверху) на сайте re-forma. ru
ru
Во-первых, это более четкая релевантность для поиска, во-вторых, это удобство для пользователей. Анализируйте конкурентов, подсматривайте идеи, перерабатывайте информацию и генерируйте новое. Впрочем, в заимствовании структуры ничего незаконного нет 🙂
Вернемся к примеру, который рассматривали ранее – с компанией, занимающейся строительством домов. «Присваиваем» конкретной группе запросов свою страницу исходя из того, какова частотность запросов по той или иной услуге – то есть определяем посадочные.
Учитывайте маржинальность – так вы добьетесь более широкого охвата по запросам, точно попадая в нужный нам сегмент бизнеса.
Например, каталог проектов, цены на строительство (в этот раздел вкладываем отдельные страницы по каркасным домам, баням и проч.), типы фундамента (в этот раздел вкладываем отдельные страницы по свайному, столбчатому, ленточному и другим), вопросы и ответы.
В этом плане работать с семантическим ядром для интернет магазинов проще.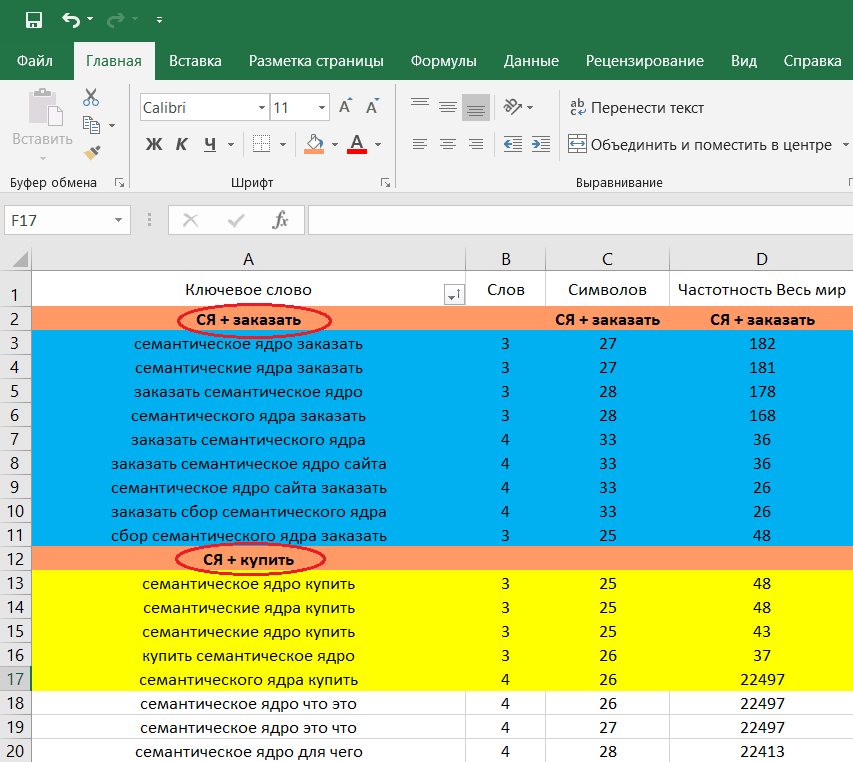 Вы можете создавать посадочные страницы в виде страниц тегов, опций фильтрации. С сайтами услуг маневров меньше, ведь большое число страниц может перегрузить ресурс, сделать его запутанным для пользователей, не говоря о том, что каждую страницу нужно хорошо проработать в плане наполнения.
Вы можете создавать посадочные страницы в виде страниц тегов, опций фильтрации. С сайтами услуг маневров меньше, ведь большое число страниц может перегрузить ресурс, сделать его запутанным для пользователей, не говоря о том, что каждую страницу нужно хорошо проработать в плане наполнения.
Итак, выделяя отдельные группы запросов в виде отдельных посадочных, повышаем релевантность для поиска, не говоря уже об удобстве для посетителей. Ограничение страниц приводит к потере немалых возможностей по привлечению дополнительного трафика.
Кластеризация семантического ядра. Способы кластеризации
Рассмотрим методы кластеризации ключевых запросов, а именно, – ручной и автоматический.
Кластер представляет собой отдельную группу запросов, которая соответствует исключительно одной страницу, на которой и будет продвигаться эта группа запросов. Кластеризовать – значит «разбить» семантическое ядро, разделить полученные запросы в семантике по кластерам.
Почему это важно? Корректное распределение фраз на страницам – один из главных факторов успеха продвижения в целом.
Существует ручная и автоматическая кластеризация, а также смешанный метод. Способ выбирают в зависимости от объема СЯ.
Ручной метод кластеризации запросов
Если у вас небольшая семантика, например, 500 запросов, вы можете воспользоваться ручной кластеризацией.
Итак, запросы необходимо распределять по интенту. Под интентом поискового запроса подразумевается потребность пользователя, ищущего услугу или продукт в поисковике.
Допустим, есть запросы:
- доставка корейской косметики мск.
- доставка корейской косметики по россии.
- доставка корейской косметики москва.
Каждый кластер может содержать до 7-10 запросов. Не стремитесь заполнить страницу максимумом разноплановых ключей – это не только не принесет ожидаемого эффекта, но и даже ухудшит позиции ресурса в выдаче. Чтобы не совершать ошибок, придерживайтесь простого принципа: одна посадочная страница – один кластер.
Чтобы не совершать ошибок, придерживайтесь простого принципа: одна посадочная страница – один кластер.
Используйте получившуюся структуру для оформления меню и внутренних ссылок на сайте и не забывайте проверять запросы в поисковой выдаче. Порой запросы имеют идентичное знание, но конкуренты продвигаются на разных страницах.
Важно! Один кластер не должен объединять и коммерческие, и информационные запросы. В противном случае страница потеряет позиции по этим запросам, и о ТОП-10 можно забыть.
Кластеризованные вручную запросы
Автоматический метод
Автоматический метод предполагает использование программных инструментов. Основа алгоритмов таких сервисов – группировка по топу.
- Rush Analytics. Инструмент платный. Включает множество опций по автоматизации работы с семантикой.

- Упоминаемый вчера Keys.so – помимо базы запросов, обладает достаточно мощным кластеризатором с тонкими настройками.
- Также интересная десктопная программа, созданная для кластеризации СЯ – KeyAssort.

Вариантов, разумеется, больше, и вопрос выбора достаточно индивидуален.
Как понять семантическое ядро сайта-конкурента
Для начала поговорим о семантике видимой и фактической.
Например, создан сайт, в него заложена определенная структура, опубликованы тексты, оптимизированные под заданные ключевые слова. То есть все ключи конкурента – это и есть семантическое ядро сайта. Это
Ресурс ранжируется, отображается в выдаче по определенным запросам. При этом по некоторым запросам сайт продвинуть не удастся – по ним он просто не покажется в результатах поиска, если запросы группировались неправильно. Вместе с тем – некоторые страницы ресурса не попадают в выдачу по другим причинам. И тогда получается, что из фактической семантики, изначально закладываемой специалистом, считается релевантной лишь определенная часть запросов. Это и есть
И тогда получается, что из фактической семантики, изначально закладываемой специалистом, считается релевантной лишь определенная часть запросов. Это и есть
Если говорить о соотношении, то чем больше доля видимой по отношению к фактической, тем качественней была проведена оптимизация.
Как получить семантику конкурентов?
Нам на помощь приходит автоматизация. Сервисы, позволяющие выделить ключи конкурентов, работают следующим образом:
- формируется база запросов;
- по каждой фразе – до десяти страниц выдачи;
- периодически повторяется сбор выдачи по всем фразам.
Мы не зря начали с примера по видимой и фактической семантике. Дело в том, что описанные сервисы выдают исключительно видимую семантику. Известна видимость только для тех фраз, которые присутствуют в базе. Сервис выявляет только ту семантику, которая ему известна.
Примерное соотношение видимой семантики к базе сервиса
К чему мы приходим?
- Чтобы оценить, насколько актуальна семантика конкурента, необходимо уточнить, когда собирались позиции.
- Часть попросту не видна – страницы еще не индексируются, поисковая система исключила их из выдачи в силу разных причин. То есть мы не видим то, что фактически есть на сайте.
- И главное, нам неизвестно, какие ключи составляют базу того или иного сервиса.
В итоге нам доступен лишь тот фрагмент ядра, который отображается поисковиком или инструментом.
Каковы выводы?
- Ключи, собранные у конкурентов, полную семантику не отображают. Эти данные не вполне актуальны.
- Собранная семантика – не основной, лишь вспомогательный инструмент. Эта информация вполне может использоваться для общего анализа.
- Наличие большой базы не обеспечивает актуальность информации – напротив. Чем больше число фраз, глубже сбор, тем больше времени уходит. Пока собиралась выдача по началу, по концу уже потеряла актуальность. Чем больше фраз в базе сервиса, тем выше вероятность получить наиболее полное ядро.
- Есть и преимущество – в нашем распоряжении появляется обширный кластер запросов от основных конкурентов. Часть запросов может интегрировать в собственную семантику. Так ядро становится более полным.
Стоит ли вообще использовать семантику конкурентов? Конечно, стоит.
Вы запускаете новый проект
Ваш проект – совершенно свежий, и вам необходимо начинать с самого начала. По мере сбора мы используем ключи конкурентов, чтобы дополнить собственное ядро.
Учитывайте, что полностью перенимать семантику у другого ресурса не стоит – она может просто не подойти. Допустим, вы работаете над нишевым сайтом, а ваши конкуренты – порталы, у которых гигантские ядра.
Расширяете ядро для действующего проекта
Вы развиваете ресурс, семантика которого собиралась давно и не вполне корректно. А сейчас вам необходимо дополнять сайт новыми разделами и категориями, расширять перечень товаров или услуг, добавлять информационные тексты.
Но за что браться в первую очередь? Стоит воспользоваться рассмотренными ниже сервисами, чтобы в итоге сориентироваться по ключам ресурсов-конкурентов.
Приобретаете готовый сайт для дальнейшего развития
Перед покупкой нам необходимо оценить потенциал ресурса, стоит ли вообще его приобретать. Наиболее простой способ – опять же узнать СЯ сайта. Так мы оцениваем текущий охват тематики в сравнении с конкурентами.
Если показатели видимости проверяемого ниже более чем в 2 раза, то делаем вывод, что у первого есть существенный невыработанный потенциал для наращивания и расширения семантики. В данном случае вы сравниваем исключительно с нишевыми конкурентами, а порталы в расчет не берем.
Используем семантику конкурента с наибольшей эффективностью
Как использовать семантику конкурента с наибольшей эффективностью? Во-первых, смотрим на процент пересечений по ключам между собственным сайтом и донорами.
Если готового ресурса нет, выберите конкурента, проанализируйте, и если сайт приглянулся, берите его за эталон. Точно так же оцениваем процент пересечений по ключам между эталоном и донором. Автоматизируйте эту работу, воспользовавшись сервисами, выгружающими ядра конкурентов.
Из заинтересовавших нас доноров выбираем близких по тематике, имеющих максимальное число пересечений по ключам.
Кластеризация в сервисе Keys.so
Способы сбора семантического ядра
Сервисов множество, вот лишь некоторые из них:
- SEMrush;
- SpyWords;
- Keys.so;
- Яндекс.Вордстат;
- Serpstat;
- Rush Analytics;
- Arsenkin;
- Key Collector;
- PPC Help;
- Coolakov;
- Megaindex;
- Semantist.
Key Collector
- Возможность поиска неявных дублей. Удаление запросов, которые состоят из идентичных ключевых слов.
- Заполнение фильтра минус-слов.
- Работа с регулярными выражениями.
- Достойный функционал – есть все необходимо для работы с семантикой. Удобное удаление неявных дублей.
- Удобно настраивать инструменты для отбора и выгрузки результатов.
- Можете подключать к другим сервисам посредством платного API.
Serpstat
- Есть возможность подбора органических ключевых слов.
- Анализ предложений из поисковой выдачи.
- Подбор связанных ключевых слов.
- Программа позволяет собрать ключи и спарсить подсказки для расширения семантики.
- Возможность работать с частотностью, анализом конкурентов. Вы сразу определяете, стоит ли добавлять ключевую фразу в ядро.
- Бесплатная версия подойдет только для небольших проектов. Для работы с многостраничными ресурсами придется оформлять платную подписку
Rush Analytics
- Есть инструмент Вордстат. Rush Analytics избавляет от необходимости ввода капчи или подключения прокси.
- Собираются ключевые фразы, анализируется их частотность благодаря инструменту Adwords.
- Благодаря «Сборке подсказок» осуществляется парсинг поисковых подсказок из поисковых систем. Можно устанавливать стоп-слова, ставить геофильтр.
- Гибкий инструментарий. Возможно создание семантики под ключ. Точная настройка по нише рынка и по гео.
- Возможность бесплатно тестировать программу в течение недели.
Резюмируем, что вопрос выбора сугубо индивидуален, все зависит конкретно от вашей ситуации, мы рассмотрели только 3 самых популярных сервиса.
Также если у вас есть свои способы сбора семантического ядра, делитесь ими в комментариях – будет полезно для остальных SEO-специалистов.
Как сгруппировать фразы для семантического ядра сайта
И так мы пытаемся разобраться что такое семантическое ядро и как его собрать. Но эта информация абсолютно бесполезна без знания правил группировки и кластеризации фраз.
Почему групповая фраза?
Главное, семантическое ядро должно учитывать не сколько основных факторов, а именно желание, интересы пользователей и соответствие бизнес-целям проекта. Необходимо семантическое ядро группировки фраз:
- создание семантического ядра структуры сайта помогает определить форму, в которой необходимо организовать меню сайта и внутреннюю перелинковку страниц;
- маркетинговый анализ — анализ текущего спроса на товары и услуги;
- создание контент-плана — подбор тем, интересующих пользователя, а также подбор запросов для оптимизации конкретных страниц сайта;
- создать правильную ссылку на сайт;
- разделение запросов на коммерческие и информационные, которые запрашивает пользователь, наилучшим образом соответствуют бизнес-целям веб-сайта.
Грамотная группа поисковых запросов позволяет максимально увеличить трафик поисковых систем.
Существует несколько способов кластеризации ключевых фраз в семантическом ядре.
Группировка также может быть выполнена по типу
Запросы на информацию следует сразу выделить в отдельную группу. Когда человек вводит запрос, он хочет найти информацию для решения того или иного вопроса. Такие запросы характерны для информационных порталов, новостных изданий, в целом для информационных, научно-популярных, образовательных сайтов.
К информационным запросам относятся ключевые фразы с «что», «когда», «где», «как» и «инструкция» и «отзывы», «форум» и так далее.
Например:
- отзывы о качестве трафика
- настроенный график трафика до и после
- трафик
- трафик сделай сам
- Форум отзывов о качественном трафике
Транзакционные (коммерческие) запросы помогают пользователю совершить какое-либо действие — скачать, купить, скачать. Для интернет-магазинов запросы на транзакцию приводят к целевой и эффективной аудитории.
Примеры:
- стоимость трафика
- сколько стоит трафик на сайт
- значение трафика
- стоимость трафика по гео
В отдельную группу выделены геозависимые запросы. Это запросы, по которым пользователь ожидает увидеть локальные или региональные сайты.
Например:
- ремонтные услуги
- внутренняя отделка дома
- специалисты по ремонтным работам
Общие или нечеткие запросы могут быть как информационными, так и транзакционными. При этом неясна цель пользователя. Конверсия по этому типу запросов гораздо меньше, чем по транзакционным.
Примеры:
- трафик для бизнес-сайта
- трафик на сайт
- быстро поднять трафик на сайт
- вариантов трафика
Продвигать сайт по запросам сложно, так как непонятно, что нужно пользователю: информация о «трафике» или порядок обслуживания.
Необходимо идентифицировать синонимичный запрос:
- заказать трафик
- для заказа посетителей сайта
И профессионализмы:
- цена трафика
- цена быстрого трафика
Группировка по смыслу в первую очередь предназначена для удобства пользователя. Мы должны понимать уровень требований к продукту или услуге и вести к цели.
Группировка запросов по типу страницы
Основные типы страниц:
- main — слова и словосочетания, которые в целом характеризуют сайт, например: качественный трафик для сайта из Эстонии;
- категорий/подкатегорий товаров и услуг — суммарные запросы на товары и услуги, например: цена трафика, трафик из Эстонии;
- карточка товаров/услуг — групповые запросы, релевантные конкретному товару или услуге, например: CPC, CPM;
- информационные страницы (блоги/статьи) страницы, которые будут отвечать на конкретный информационный запрос, например: что такое SEO и почему это важно; для других страниц.
Правила группировки ключевых слов:
1. Один запрос токена перемещает сайт на одну страницу. Это не значит, что для каждого запроса на сайте должна быть отдельная страница. Просто один и тот же запрос не позволяет оптимизировать несколько страниц. В противном случае на сайте будут появляться похожие по смыслу страницы, что приведет к затруднениям в навигации.
2. Подобранные ключевые слова для страницы должны давать исчерпывающий ответ пользователю. Например, появление в запросе слова «купить» должно приводить к покупке товара на сайте. По запросу «цена» пользователь должен увидеть прайс-лист.
3. Высокочастотные запросы должны быть не дальше одного-двух кликов от главной страницы, в категориях.
4. На главной странице рекомендуется делать общие запросы, более конкретные запросы товаров, услуг необходимо выделять на страницы категорий и товаров.
5. Недопустимо совмещать посещение коммерческих и информационных запросов. Коммерческие запросы — каталоги, прайс-листы, страницы, услуги, информация, статьи, новости, посты в блогах.
6. В одну группу лучше всего добавлять слова, очень близкие по смыслу и структуре к другим в пределах слов-запросов. Например, такими запросами могут быть «посещаемость сайта», «быстрый трафик», «качество трафика».
В чем обычно ошибаются при группировке фраз
1. Не используйте низкочастотные запросы
Создание фильтра низкочастотных запросов позволяет сделать страницу более полезной и удобной. Низкочастотные запросы более точны и указывают на конкретный товар или услугу, которые, в свою очередь, ведет к дальнейшим успешным конверсиям.
Например:
- мастер по дизайну интерьера дома
- внутренняя отделка без мастера
2. Смешение коммерческих и информационных запросов
Эти два типа запросов имеют разные цели — привлечение готовых к покупке клиентов и расширение спектра запросов, по которым можно обнаружить сайт.
3. Для объединения разных групп на одной странице
Возвращаясь к тому, что для каждой группы запросов должна быть своя посадочная страница.
Первый и второй запрос сгруппировать и разместить на одном лендинге, четвертый и пятый на другом. Каждый последующий запрос должен иметь свою целевую страницу.
Так пользователь увидит страницу с нужной информацией.
Insights
- Семантическое ядро должно полностью определять объем проекта.
- Группа ключевых слов нужна для многих целей — от анализа рынка товаров и услуг до создания оптимальной структуры сайта;
- При группировке запросы должны исходить из бизнес-целей проекта;
Основные правила при группировке ключевых слов:
- одна группа поисковых запросов на одной целевой странице;
- целевая страница должна соответствовать запросам пользователя и давать исчерпывающий ответ;
- Не стоит продвигать проект в общих чертах, а также смешивать в одной группе информационные и коммерческие запросы.
Правильно группируйте запросы и привлекайте максимум трафика из поисковых систем.
Семантическое ядро для вашего сайта 2022 %: сбор и кластеризация
Семантическое ядро представляет собой структурированный список поисковых запросов, по которым потенциальные клиенты могут найти сайт в поисковых системах. Семантика для сайта помогает сформировать его логичную и эффективную структуру, собрать максимум органического трафика в своей нише.
Успешное продвижение сайта в поисковых системах зависит от правильности и полноты семантического ядра. Если вы хотите заказать семантику или улучшить уже собранное ядро, обращайтесь в WebSeo.
Оставить заявку
Какие задачи решает сервис?
Разработка правильной структуры
Грамотно собранное и разбитое на тематические блоки семантическое ядро поможет создать эффективную структуру для дальнейшего продвижения сайта.
Сбор нишевого трафика
Собрав максимальное количество запросов по тематике можно получить больше трафика. Для этого важно правильно оптимизировать страницы под собранную семантику и вывести их в топ.
Основа контент-стратегии
Любое семантическое ядро включает в себя информационные запросы. На основе таких фраз можно построить план публикаций для блога, который принесет больше конверсий.
Составление технического задания для копирайтеров
На основе семантики для сайта создается техническое задание для копирайтеров. Список запросов часто определяет структуру текста на странице. Правильное использование поисковых фраз в тексте позволяет собрать больше трафика.
Сбор и анализ семантического ядра от WebSeo: ваши преимущества от сервиса
Что вы получаете сотрудничая с WebSeo?
- Гибкий подход к задаче. Мы можем собрать семантику для сайта с нуля, провести аудит или обновить его. Благодаря этому польза от работы будет максимальной, а цена – разумной.
- Полный охват семантики. Мы собираем поисковые фразы из нескольких источников, охватывая максимальное количество запросов и трафика.
- Эффективная структура. Очистка и правильная группировка поисковых фраз повышает эффективность сайта.
- Доступ ко всему спектру услуг. У нас вы можете заказать сбор семантики или полный комплекс работ по интернет-маркетингу в любой нише рынка.
Что включает сбор семантики?
- Анализ ниши и конкурентов.
- Сбор поисковых фраз из нескольких источников.
- Формирование и очистка полного списка заявок.
- Кластеризация семантического ядра.
- Согласование дальнейших работ с заказчиком.
От чего зависит цена?
Стоимость семантического ядра зависит от количества страниц и тематики сайта. Количество собираемых запросов может быть разным, в указанных пределах, например, от 500 до 1000 фраз.