
Подсчет вхождений символа в строке в Python
- Используйте функцию
count()для подсчета количества символов, встречающихся в строке в Python - Используйте
collections.Counterдля подсчета вхождений символа в строку в Python - Использование регулярных выражений для подсчета вхождений символа в строку в Python
- Используйте
defaultdictдля подсчета вхождений символа в строку в Python - Используйте
pandas.value_counts()для подсчета вхождений символа в строку в Python - Используйте
lambdaвыражение для подсчета вхождений символа в строку в Python - Используйте цикл
forдля подсчета вхождений символа в строку в Python
В программировании строка — это последовательность символов.
В этом руководстве будет показано, как подсчитать количество вхождений символа в строку в Python.
Используйте функцию
count() для подсчета количества символов, встречающихся в строке в PythonМы можем подсчитать появление значения в строках с помощью функции count(). Он вернет, сколько раз значение появляется в данной строке.
Он вернет, сколько раз значение появляется в данной строке.
Например,
print('Mary had a little lamb'.count('a'))
Выход:
Помните, что верхний и нижний регистры считаются разными символами. A и a будут рассматриваться как разные символы и иметь разные значения.
Используйте
collections.Counter для подсчета вхождений символа в строку в PythonCounter — подкласс словаря, присутствующий в модуле collections. Он хранит элементы как ключи словаря, а их вхождения — как значения словаря. Вместо того, чтобы вызывать ошибку, он возвращает нулевое количество пропущенных элементов.
Например,
from collections import Counter my_str = "Mary had a little lamb" counter = Counter(my_str) print(counter['a'])
Выход:
Это лучший выбор при подсчете большого количества букв, поскольку счетчик вычисляет все значения за один раз. Это намного быстрее, чем функция 
Использование регулярных выражений для подсчета вхождений символа в строку в Python
Регулярное выражение — это специальный синтаксис, содержащийся в шаблоне, который помогает находить строки или набор строк, сопоставляя этот шаблон. Импортируем модуль re для работы с регулярными выражениями.
Мы можем использовать функцию findall() для нашей задачи.
Например,
import re
my_string = "Mary had a little lamb"
print(len(re.findall("a", my_string)))
Выход:
Используйте
defaultdict для подсчета вхождений символа в строку в PythonDefaultdict присутствует в модуле collections и является производным от класса словаря. Его функциональность примерно такая же, как у словарей, за исключением того, что он никогда не вызывает KeyError, так как предоставляет значение по умолчанию для ключа, который никогда не существует.
Мы можем использовать его, чтобы получить вхождения символа в строке, как показано ниже.
from collections import defaultdict
text = 'Mary had a little lamb'
chars = defaultdict(int)
for char in text:
chars[char] += 1
print(chars['a'])
print(chars['t'])
print(chars['w']) # element not present in the string, hence print 0
Выход:
Используйте
pandas.value_counts() для подсчета вхождений символа в строку в PythonМы можем использовать метод pandas.value_counts()
Series.Например,
import pandas as pd phrase = "Mary had a little lamb" print(pd.Series(list(phrase)).value_counts())
Выход:
4 a 4 l 3 t 2 e 1 b 1 h 1 r 1 y 1 M 1 m 1 i 1 d 1 dtype: int64
Возвращает вхождения всех символов в объекте Series.
Используйте
lambda выражение для подсчета вхождений символа в строку в PythonФункции lambda могут не только подсчитывать вхождения из данной строки, но также могут работать, когда у нас есть строка, как список подстрок.
См. Следующий код.
sentence = ['M', 'ar', 'y', 'had', 'a', 'little', 'l', 'am', 'b'] print(sum(map(lambda x : 1 if 'a' in x else 0, sentence)))
Выход:
Используйте цикл
for для подсчета вхождений символа в строку в PythonМы перебираем строку, и если элемент равен желаемому символу, переменная count увеличивается до тех пор, пока мы не дойдем до конца строки.
Например,
sentence = 'Mary had a little lamb'
count = 0
for i in sentence:
if i == "a":
count = count + 1
print(count)
Выход:
Мы можем увидеть еще один способ использования этого метода с функцией
my_string = "Mary had a little lamb" print(sum(char == 'a' for char in my_string))
Выход:
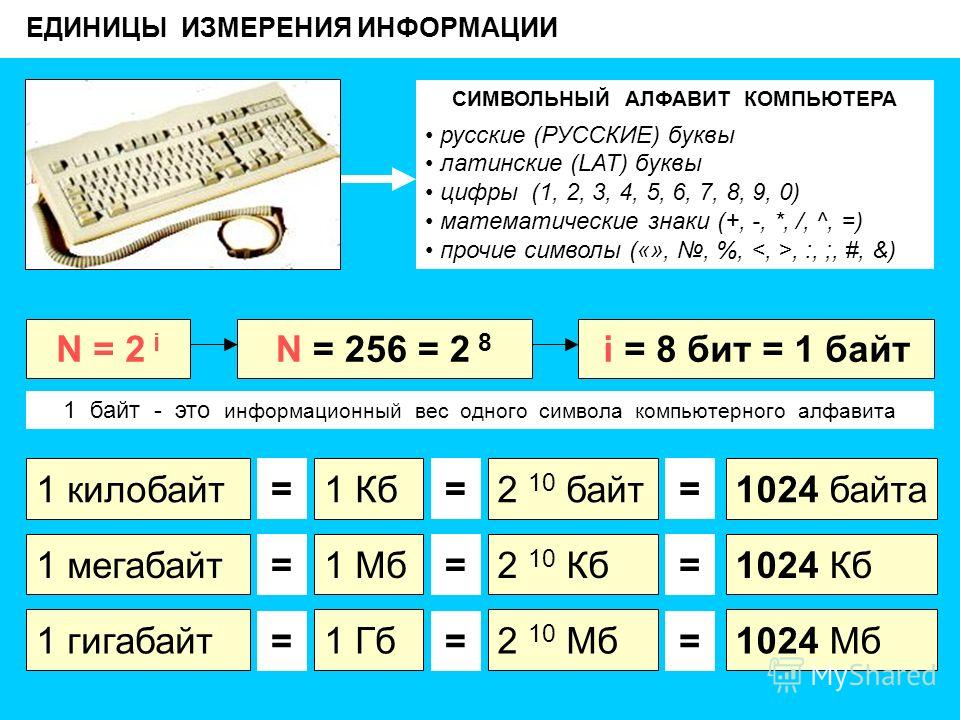
как выполняется подсчет знаков, алгоритм проведения процедуры
- Главная
- #83510 (без названия)
войти в систему
Добро пожаловат!Войдите в свой аккаунт
Ваше имя пользователя
Ваш пароль
Вы забыли свой пароль?
восстановление пароля
Восстановите свой пароль
Ваш адрес электронной почты
Домой Hi-Tech Как узнать количество символов в тексте и зачем требуется подсчет
1 Зачем может потребоваться подсчет
2 Как проводится процедура
Чтобы узнать количество символов в тексте онлайн, необходимо воспользоваться специализированным сервисом. Существует множество ресурсов, на которых предлагается возможность осуществления глубокого анализа. Достаточно большой популярностью пользуется сервис Серпхант. Здесь можно проводить проверки документа по нескольким критериям.
Существует множество ресурсов, на которых предлагается возможность осуществления глубокого анализа. Достаточно большой популярностью пользуется сервис Серпхант. Здесь можно проводить проверки документа по нескольким критериям.
Зачем может потребоваться подсчет
Определять количество знаков необходимо для точного понимания размера текста и дальнейшей работы с документом. При помощи онлайн-сайта становится возможным в короткие сроки уточнить весь спектр параметров текста. Удается понять, сколько символов с пробелами и без них, а также какие изменения необходимо внести для достижения целевых результатов.
Подробная оценка символов необходима при оптимизации. В таком случае важными параметрами, помимо знаков, считаются:
- академическая и классическая тошнота;
- водность;
- общее количество слов и стоп-слов.
Благодаря SEO-оценке, удается получить более оптимизированный и читабельный текст. Если на сайте размещается качественный контент, это помогает продвигать его в поисковой выдаче, что положительно сказывается на общем показателе посещаемости.
Как проводится процедура
Если определение количества осуществляется через Серпхант, то подсчет символов не занимает много времени. Он включает в себя следующие этапы:
- Переход на главную страницу сайта.
- Вход в раздел инструменты и выбор нужного варианта.
- Копирование текста в отдельное окно.
- Клик по кнопке «Проверить».
В течение 10-15 секунд будет представлена подробная информация о скопированном документе. Преимуществом использования данного сервиса является возможность проведения неограниченных бесплатных проверок. Таким образом удается достигать нужных значений при помощи внесения корректировки и повторной оценки. Для взаимодействия с ресурсом не требуется регистрация. На сайте представлены как бесплатные, так и платные услуги. Некоторые инструменты значительно упрощают поисковую оптимизацию, другие позволяют детально оценивать отдельные интернет-порталы.
Проведение детальной проверки через Серпхант — крайне простая и точная процедура. С ее помощью удается уточнять количество недопустимых выражений и символов в текстовом файле за короткий промежуток времени. Также при необходимости можно оценивать вхождение ключевых слов (ключевики заранее копируются в соответствующие поля).
С ее помощью удается уточнять количество недопустимых выражений и символов в текстовом файле за короткий промежуток времени. Также при необходимости можно оценивать вхождение ключевых слов (ключевики заранее копируются в соответствующие поля).
Предыдущая статьяЛукашенко находится в положении победителя
Следующая статьяПредприятие «Ростеха» за сотни миллионов локализует в Москве выпуск китайских умных счетчиков
БОЛЬШЕ ИСТОРИЙ
Подсчитать количество символов в каждом слове в серии Pandas
Улучшить статью
Сохранить статью
- Последнее обновление: 28 июл, 2020
Улучшить статью
Сохранить статью
Для подсчета количества символов мы используем Series.
Синтаксис: Series.str.len()
Тип возвращаемого значения: Серия целочисленных значений. Значения NULL также могут присутствовать в зависимости от серии вызывающего абонента.
Еще один способ найти количество символов с помощью функции len() (которая заключена в функцию карты), чтобы заданный ряд заменял значение длины, взяв ряд данных в качестве входных данных, используя pandas.series( ) .
Давайте посмотрим несколько примеров:
Пример 1: Мы берем ввод слов и считаем каждый символ слова с помощью Series.map() , которые заменяют значения и выдают результат с помощью функции с именем calc.
|
Выход:
Пример 2: .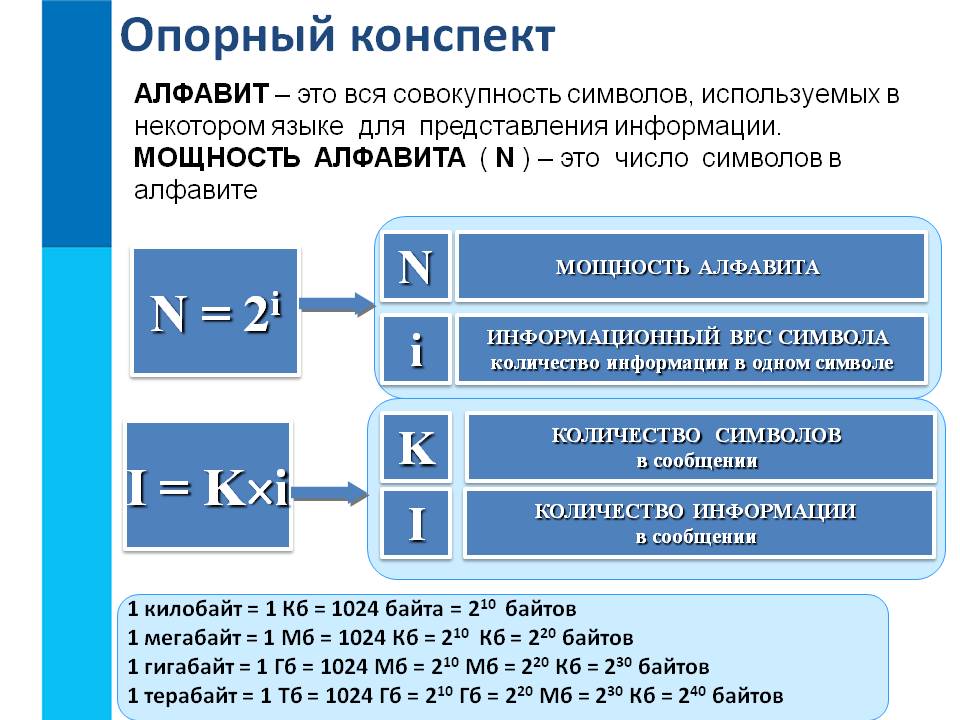 используйте Series.apply() для одиночных значений.
используйте Series.apply() для одиночных значений.
. |

Выход:
Пример 3: к печати в Специфической форме.
|
 0053 .
0053 . Выход:
Связанные статьи
Рассчитайте номер. символов, которые могут поместиться в элемент HTML, где ширина целевого элемента HTML и текста не являются статическими, тогда этот пост для вас. Чтобы решить эту проблему, я расскажу о пользовательских хуках реагирования и немного о веб-API. И, в конце концов, я собираюсь показать вам, что разработчику внешнего интерфейса нужны некоторые алгоритмы и навыки решения проблем, чтобы решать чисто проблемы внешнего интерфейса.
На работе дизайнеры просят меня сократить тексты кнопок на три точки от середины. Как показано ниже:
Проблема в том, что ширина кнопок не была фиксированной, и текст внутри них тоже не был фиксированным. Вкратце, мне пришлось сделать следующее:
Вы можете найти полный код и демонстрацию для темы этого блога, динамически вычисляющую подходящую длину символа, из этого репозитория
Так как ширина кнопки является динамической, и сама загружается асинхронно; мы не можем вычислить ширину, используя componentDidMount или useEffect ловушка. Вместо этого нам нужно использовать хук
Вместо этого нам нужно использовать хук useLayoutEffect из-за асинхронного эффекта пользовательского интерфейса.
И чтобы отслеживать изменения размера элемента, я использовал ResizeObserver , который представляет собой интерфейс веб-API, доступный в большинстве браузеров.
Существует еще один способ отслеживания изменения размера элемента, который addEventListener('resize',()=>{}) подход. Однако вместо этого я предлагаю использовать ResizeObserver, потому что он более надежен, так как проще отключить наблюдателя и остановить прослушивание обратных вызовов. На самом деле, я предлагаю вам провести собственное исследование того, когда использовать ResizeObserver вместо Resize Event Listener, вы можете начать с чтения комментариев в этом выпуске.
import { useLayoutEffect, useState } from 'react'
/**
* Возвращает текущую ширину указанного элемента.
*
* @param {Ref} элемент ref для использования при вычислении ширины = new ResizeObserver((entries) => {
for (постоянная запись записей) {
if (entry.
contentBoxSize) {
setWidth(entry.contentRect.width)
}
}
})
useLayoutEffect(() => {
if (!ref?.current) return
90.002 Observerreturn () => {
elobserver.disconnect ()
}
}, [])
Ширина возврата
}
Экспорт по умолчанию UseeelementWidth
 contentBoxSize) {
contentBoxSize) { Организации, мы уверен, что для знания 333 333 3
. текста, но такой прямой информации о ширине текста нет. Чтобы рассчитать ширину текста, нам нужно использовать 9 веб-API.0053 Интерфейс TextMetrics . Этот интерфейс дает нам значение ширины текста, доступное только для чтения, на основе информации о нем. Вы можете догадаться, что текст, выделенный жирным шрифтом и крупным шрифтом, имеет большую ширину, чем мелкий шрифт.
Однако этот интерфейс вычисляет ширину текста, который заполняется только элементом canvas . Но наш элемент кнопка . Для этого мы собираемся скопировать стиль шрифта текста нашей кнопки с помощью window. getComputedStyle 9.0054 и заполнить холст этим текстом, а затем вычислить его ширину. И при таком подходе мы сможем узнать, больше ли ширина текста ширины содержимого кнопки, и если она больше, то ее следует обрезать.
getComputedStyle 9.0054 и заполнить холст этим текстом, а затем вычислить его ширину. И при таком подходе мы сможем узнать, больше ли ширина текста ширины содержимого кнопки, и если она больше, то ее следует обрезать.
Кстати, дело может быть и в другом, я имею в виду, что речь идет не только об усечении текста как расчете его ширины, речь идет о расчете количества символов, которые могут поместиться в данный элемент кнопки, усечение от середины - это просто случай из моей работы и используется в качестве примера. Далее мы собираемся написать собственный хук, который дает количество символов, вписывающихся в элемент, на основе расчета ширины.
Теперь мы можем рассчитать ширину кнопки и рассчитать ширину текста.
Здесь мы собираемся создать цикл for , который находится в пределах длины текста кнопки, мы собираемся получать символ на каждой итерации из текста кнопки и заполнять его на холсте с его стилем шрифта, как с использованием окна . .computedStyle() , а затем рассчитайте ширину текста. Если он больше, чем ширина содержимого кнопки, то разорвите цикл и верните количество подходящих символов, то есть значение индекса предыдущей итерации.
Если он больше, чем ширина содержимого кнопки, то разорвите цикл и верните количество подходящих символов, то есть значение индекса предыдущей итерации.
import { useMemo } from 'react'
/**
* Вычисляет максимальное количество символов, которое может поместиться в заданную максимальную ширину.
* Вычисляет ширину текста с заданным семейством шрифтов с помощью объекта ref, в пикселях т. е. '...' многоточие
* @return количество символов текста ссылки, включая количество символов заданного/по умолчанию
* возвращаемое значение — нечетное число, первая часть содержит +1 символ
*/
// создать элемент холста и получить его содержимое
const getContext = () => {
const fragment = document.createDocumentFragment ()
const canvas = document.createElement('canvas')
fragment.appendChild(canvas)
return canvas.getContext('2d')
}
const useFitCharacterNumber = (options) => 3 {
2 const {ref, maxWidth, middleChars} = параметры
return useMemo(() => {
if (ref.
const context = getContext()
const calculatedStyles = window.getComputedStyle(ref.current)
context.font = ComputedStyles.font
? ComputedStyles.font
: `${computedStyles.fontSize}" "${computedStyles.fontFamily}`
const textWidth = context.measureText(ref.current.textContent).width // ширина text
let fitLength = ref.current.textContent.length
let prefix = '' // символ с начала
let suffix = '' // символ с конца
let i = 0
let j = fitLength - 1
let current = middleChars || '' // т.е. '...'
let prev = current
while (i < j) {
prefix = prefix + ref.current.textContent.charAt(i)
current = prefix + middleChars + suffix
if (context.measureText(current).width > maxWidth) {
fitLength = prev.length
break
}
prev = current
suffix = ref.current.textContent.charAt(j) + suffix
current = prefix + middleChars + suffix
if (context.
FitLength = PREV.Length
Break
}
PREV = Current
I ++
J--
}
return {textWidth, charnumber: fitlength}
}
return {warnumb , charNumber: NaN }
}, [ref, maxWidth, middleChars])
}
export default useFitCharacterNumber
 current?.textContent && maxWidth) {
current?.textContent && maxWidth) {  measureText(current).width) {
measureText(current).width) {Как вы видите выше в строках 39 и 46, мы получаем один символ от начала и вычисляем ширину текста, и получаем один символ затем снова вычислите ширину текста, сравнивая текущую ширину текста с шириной содержимого contianer.
Почему мы не выбрали один символ с самого начала и не продолжили цикл? Поскольку целью здесь является обрезание текста от середины, а также поскольку некоторые символы занимают разную ширину, нам также нужно было выбрать символ с конца, чтобы получить более точное количество символов, которые помещаются в элемент кнопки.
Таким образом, решение может быть четным числом и нечетным числом, если это нечетное число, у нас есть один дополнительный символ с самого начала.