
Что такое контекстная реклама? — WiKi UpMe
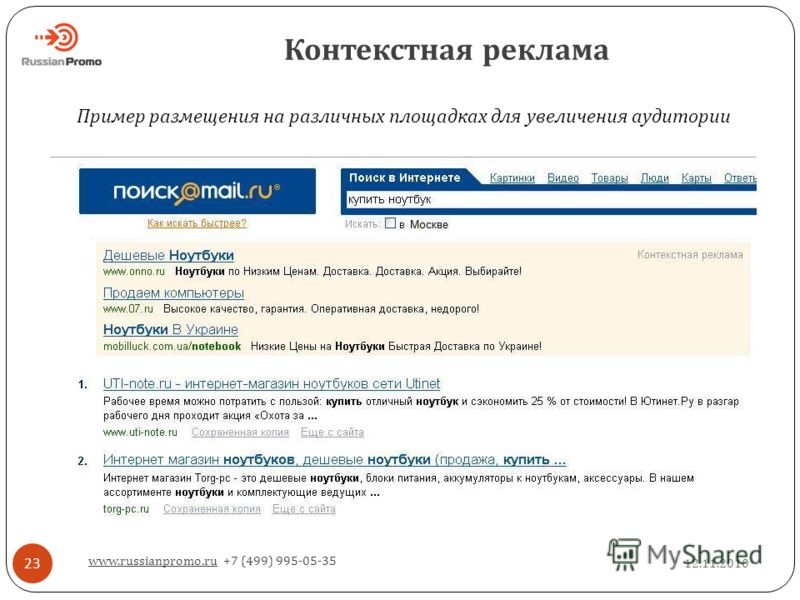
Контекстная реклама — вид рекламы в интернете, при котором рекламное объявление показывается в соответствии с содержанием, аудиторией, местом расположения, временем или иным контекстом страницы сайта.
Google AdWords существует следующие варианты контекстной рекламы:
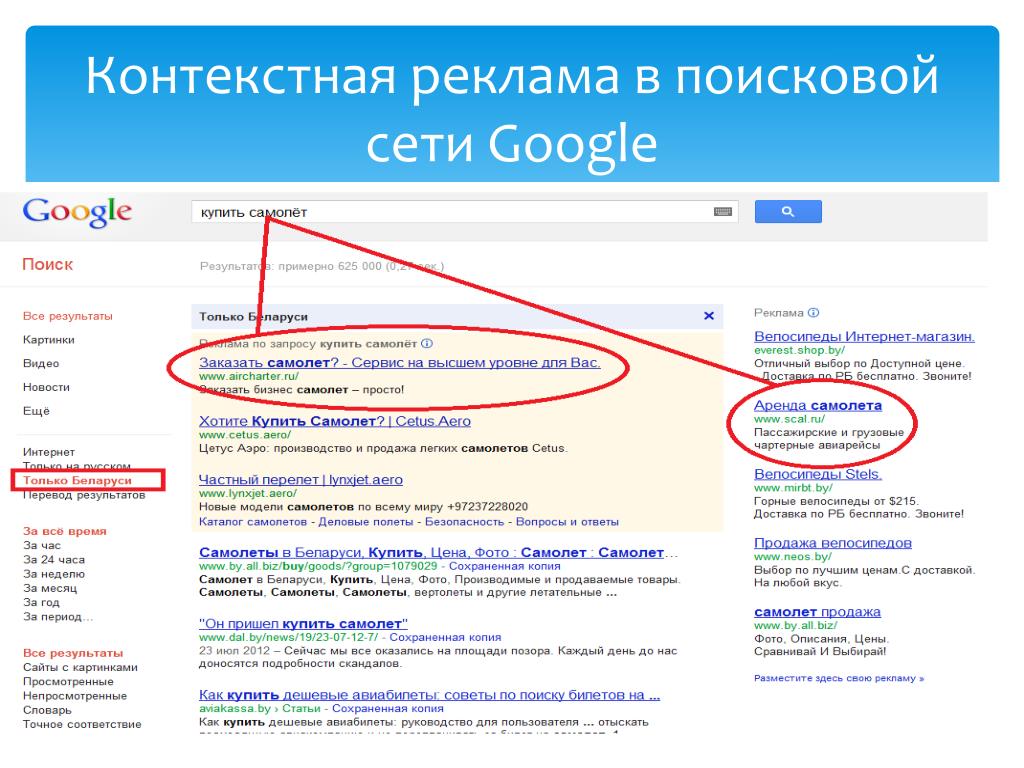
- В поисковой сети — вверху и под результатами органической выдачи. Пользователь ищет услугу в Гугле — в ответ на свой запрос видит объявления в результатах поиска. Такие объявления помечаются как реклама;
- Баннерная — зачастую встречается в блогах. На информационном портале о туризме будут контекстные объявления о продаже туров;
- Товарная — в результатах поисковой выдачи по товарным запросам в виде отбельного блока с карточками товаров.
- Видео — в роликах на Youtube.
- В мобильных приложениях — из Google Play Market.
Как работает контекстная реклама
В контекстной рекламы оплачиваются клики по объявлению, иногда — показы (только для медийной рекламы) и просмотры (для видео-рекламы на Ютубе). Проще говоря, рекламодатель покупает переходы на сайт.
Проще говоря, рекламодатель покупает переходы на сайт.
Стоимость клика зависит от конкуренции в нише. Каждый рекламодатель устанавливает ставку (максимальную цену за клик). У кого ставки выше — те и показываются. Есть и другие факторы, которые влияют на показ объявления, но это уже детали.
В контекстной рекламе много гибких настроек. Можно показывать рекламу только в определенные дни или часы. Или выделить конкретные города/районы и ориентировать рекламу только на них.
Google AdWords
Google — лидер не только в Украине, но и в мире по контекстной рекламе. Так-что размещая контекстную рекламу в Гугле, можно охватить большую часть потенциальных клиентов.
В Google AdWords можно размещать поисковые и медийные объявления, запускать видео-рекламу на Ютубе. У Google есть своя сеть для медийной рекламы — КМС (контекстно-медийная сеть), куда входят миллионы сайтов, среди которых: Gmail, YouTube, ukr.net. Медийные объявления в AdWords могут быть в виде текста, картинки или анимированного баннера.
Принцип работы контекстной рекламы
Контекстная реклама работает по принципу оплаты за клики (отсюда и сокращение PPC — Pay Per Click). В этом ее фишка — вы платите только результат, а именно за переход на сайт. Но стоимость кликов динамическая и зависит от того, как хорошо вы поработали с рекламной кампанией.
Механизм аукциона и принцип ставок
В поисковой контекстной рекламе есть 7 мест для объявлений. Очевидно, что желающих показать свои объявления больше 7. Поэтому Google показывает тех, кто готов платить больше. И чем больше он заработает, тем выше покажет. Если ставка слишком низкая, то объявления будет показываться внизу или вообще на второй странице поиска.
Это может показаться сложным, но на самом деле все просто. Подобные «аукционы» система проводит каждый раз, когда пользователь вводит запрос в поиск. Система смотрит на установленные ставки в данный момент и автоматически отбирает объявления с наивысшими ставками и сортирует их по этому фактору.
На что обращать внимание
Кроме ставки, есть и другие факторы, которые влияют на позицию объявлений. Например: CTR и показатель качества.
CTR (click-trough rate)
CTR — это показатель «кликабельности» объявлений. Вычисляется он очень просто: количество показов делится на количество кликов. Допустим, было 100 показов и 15 кликов, значит CTR = 15%. Все очень просто.
Так вот, если этот показатель высокий, цена за клик будет ниже. Ведь, чем больше будет кликов по объявлению — тем больше заработает система. Ее алгоритм будет автоматически снижать стоимость клика по объявлениям с высоким CTR.
Показатель качества ключевого слова
У каждого ключевого слова в аккаунте AdWords есть свой показатель качества. Он измеряется от 1 до 10. Чем больше — тем лучше (хорошим показателем считается 7 и выше). Показатель качества ключевого слова складывается из многих факторов, среди которых:
- качество посадочной страницы;
- релевантность (соответствие) ключевого слова объявлению;
- ожидаемый CTR (оценивается системой по истории ключевого слова).


Посадочная страница
Этот показатель зависит от того, насколько соответствует ключевое слово посадочной страничке. Если ключевое слово «ноутбуки Sony», а объявление ведет на главную страничку интернет-магазина электроники, то показатель качества будет низкий.
Google AdWords определяет релевантность странички через ее содержание (в т.ч. теги title, description, keywords) и если оно не соответстует ключевому слову, то занижается показатель качества.
Таким образом система стимулирует рекламодателей более качественно подбирать целевые странички под разные ключевые слова.
Релевантность объявления
AdWords оценивает ваши объявления на предмет того, насколько оно соответвует ключевому слову. На этот показатель влияет наличие ключевых слов в тексте объявления, а также его CTR.
Этим показателем Google мотивирует рекламодателей работать над CTR. Ведь чем чаще кликают на объявлениях, тем больше его заработок. Ну и самим рекламодателям тоже неплохо — ведь высокий CTR означает высокий показатель качества, а значит и ниже цены за клик.
Зачем нужны CTR и показатель качества
Все эти показатели нужны для того, чтобы контекстная реклама была максимально качественной и релевантной (соответствующей) поисковому запросу пользователя. Это прямой интерес поисковой системы — чтобы пользователь получал то, что ищет. А показатель качества и CTR — это индикаторы того, насколько соответствует объявлений запросу пользователя.
Если же игнорировать эти факторы и настраивать контекстную рекламу поверхностно (как делает большинство начинающих рекламодателей), то завышенные цены за клик будут обеспечены. И наоборот — если подходить к процессу настройки контекстной рекламы щепетильно, можно добиться снижения стоимости контекстной рекламы.
Как повысить показатель качества контекстной рекламы?
Показатель качества — один из важнейших составляющих экономной и эффективной контекстной рекламы в Google AdWords. Есть три основных фактора, которые влияют на показатель качества:
- релевантность объявления ключевому слову;
- качество посадочной странички;
- ожидаемое значение CTR.

Каждый параметр может получить оценку: «выше среднего», «средний» и «ниже среднего». Пройдемся по каждому из пунктов подробнее.
Релевантность объявления ключевому слову
Релевантность объявления ключевому слову показывает насколько соответствует рекламное объявление ключевому запросу. Чтобы поднять уровень релевантности нужно поработать над объявлениями — составить более узкоспециализированные объявления, которые будут максимально подходить под ключевое слово.
Пример
Допустим, есть ключевое слово «замена дисплея iphone 5s». Пример плохого, нерелевантного заголовка объявления будет нечто вроде: «Ремонт айфонов». Такое объявление слишком общее и можно говорить о том, что контекстную рекламу настраивал аматор.
Хорошим заголовком под указанное ключевое слово будет «Замена дисплея на iPhone 5s». Такой заголовок максимально релевантен запросу пользователя и поэтому обеспечит максимальный CTR.
Такой вариант более затратен по времени, ведь надо создать много похожих объявлений под ключевые запросы, но все это окупается высоким CTR и низкой ценой за клик.

Качество посадочной странички
Качество посадочной странички говорит о том, насколько она подходит под запрос пользователя. Возьмем пример из предыдущего блока — «замена дисплея iphone 5s».
Чтобы добиться показателя выше среднего, посадочная страничка должна быть о ремонте дисплеев на iphone 5s или, как минимум должна иметь часть текста по этой теме. Выбрав для такого запроса главную или общую страничку, добиться хорошей оценки по качеству посадочной странички будет сложно.
Критерии, по которым AdWords оценивает страничку, официально не указаны, но специалисты сходятся во мнении, что это: содержание, тег title и мета-теги description, заголовок h2.
Ожидаемое значение CTR
Если на первые 2 фактора еще можно повлиять, то на ожидаемое значение CTR повлиять не получится. AdWords анализирует исторические данные по выбранному ключевому слову и определяет шансы объявления получить клик. Особенность в том, что система анализирует эффективность данного ключевого слова у всех рекламодателей.
Низкую оценку по этому параметру получают слишком общие однословные ключевые слова (дизайн, отдых, ремонт, авто, ноутбук). Поскольку повлиять на ожидаемое значение CTR нельзя, все, что можно сделать — исключить такие слова из рекламной кампании. Тем более, что зачастую они действительно имеют низкий CTR и низкий показатель конверсии.
Для того, чтобы поднять показатель качества нужно работать по двум направлениям: улучшать объявления и оптимизировать посадочные странички. Объявления стоит делать максимально заточенными под выбранные ключевые слова, а странички оптимизировать под выбранные запросы. Нелишней будет работа над юзабилити. Вполне возможно, что Google анализирует поведенческие факторы и берет их в расчет.
От ключевых фраз с низкой оценкой по ожидаемому CTR в большинстве случаев стоит отказываться — это повысит общий показатель качества аккаунта, но в любом случае нужно обращать внимание на конверсии.
Отличительной особенностью контекстной рекламы является возможность трансляции рекламы на целевую аудиторию.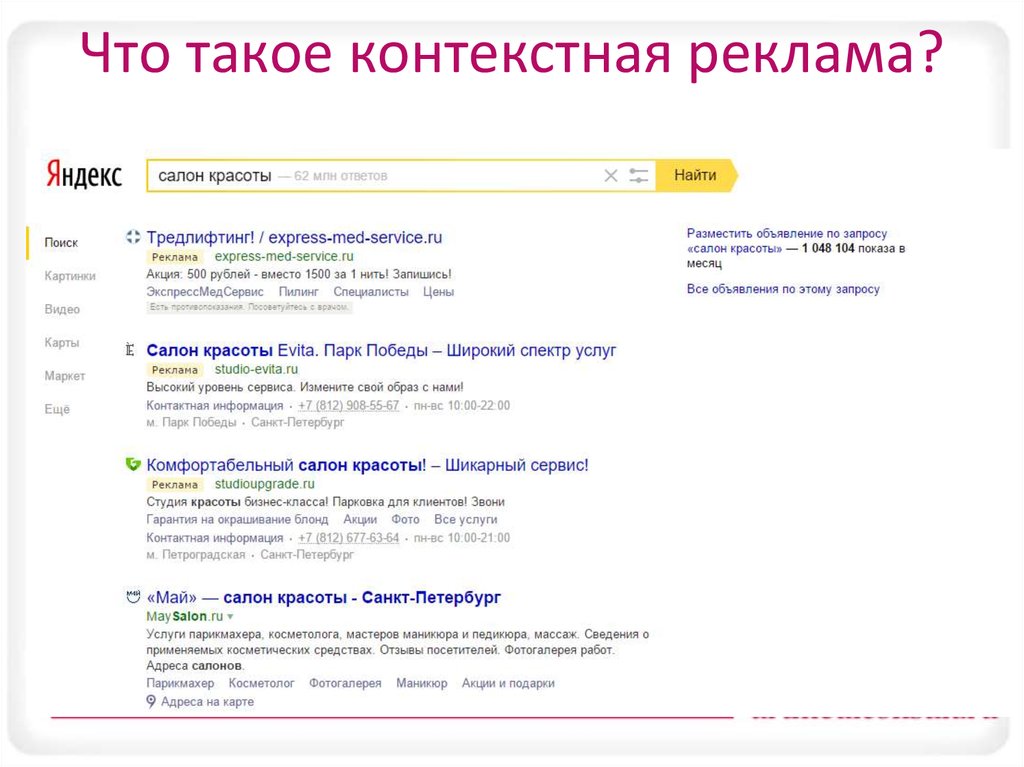
- Такой вид рекламы значительно дороже трафика из органической выдачи.
- Позиции объявлений и частота показа зависят от конкурентов и ставок на рекламу.
- Нет возможности получать стабильный результат за фиксированную сумму.
- При нулевом бюджете, реклама не работает.
- Существуют ограничения для типов товаров и услуг.
Но! Главный минус контекстной рекламы в том, что любая потраченная сумма на рекламу — не улучшает сайт в сравнение с поисковой оптимизацией, где необходимо улучшать сайт и постоянно его развивать.
Go to Top
SEO Википедия
SEO Википедия+7 (495) 789-84-05
Заказать звонок
+7 (495) 789-84-05
Заказать звонок
Заказать консультацию Консультация
Главная Вики
А
Апдейты поисковых систем Атрибут nofollow Алгоритм шинглов Алгоритм «Палех»
В
Внутренняя перелинковка сайта
Д
Директ Коммандер
З
Зеркало сайта
К
Контекстная реклама.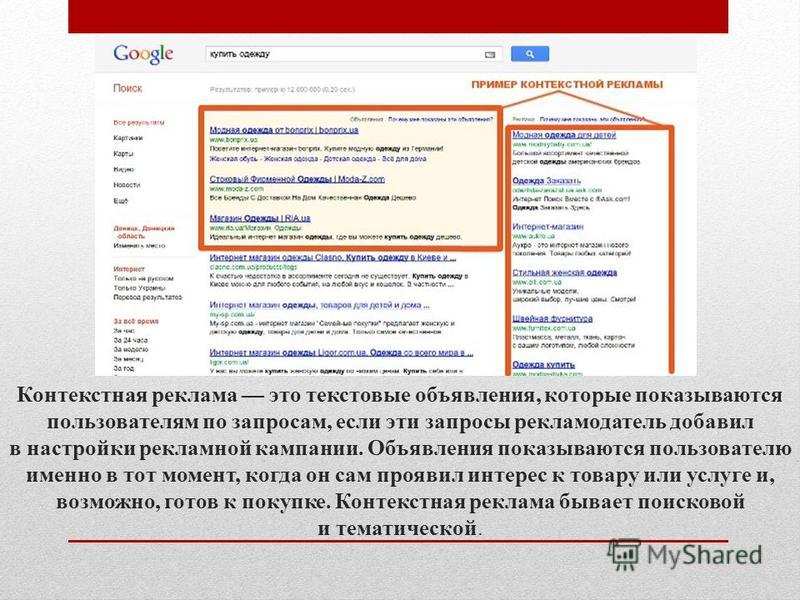 Конверсия
Конверсия
П
Показатели авторитетности сайта Поисковые алгоритмы Яндекса Поисковые системы
Р
Рекламная сеть Яндекса (РСЯ) Рерайтинг
С
Сервис контекстной рекламы «Бегун» Социальные закладки Сниппет
Т
Технология «Спектр»
Ф
Фильтры Яндекса Фильтры Google
Я
Яндекс. Директ
Яндекс.Вебмастер
Яндекс.Каталог
Яндекс.Вордстат
Директ
Яндекс.Вебмастер
Яндекс.Каталог
Яндекс.Вордстат
D
DMOZ (Open Directory Project)
G
Google Adwords Google Adsense
R
Robots.txt
S
Sitemap.xml
W
WebVisor (ВебВизор)
Категоризация контента для контекстной рекламы с использованием Википедии
- Идентификатор корпуса: 62929186
title={Категоризация контента для контекстной рекламы с использованием Википедии},
автор={Ингрид Гр\о}нли Гурен},
год = {2015}
} - Ingrid Grønlie Guren
- Опубликовано в 2015 г.
- Информатика

Автоматическая категоризация контента — важная функция онлайн-рекламы и автоматизированных рекомендаций контента, как для обеспечения контекстуальной релевантности мест размещения, так и для создания поведенческих профилей для пользователей, которые потреблять контент. В рекламном домене дерево таксономии, по которому классифицируется контент, определяется с учетом некоторого коммерческого приложения, чтобы каким-то образом отражать рекламные ресурсы рекламной платформы. Характер рекламного инвентаря и язык…
duo.uio.no
ПОКАЗЫВАЕТСЯ 1-10 ИЗ 13 ССЫЛОК
СОРТИРОВАТЬ ПО Релевантности Наиболее влиятельные документыНедавность
Извлечение сущностей, связывание, классификация и тегирование для социальных сетей: подход на основе Википедии
С. Ламба, А. Доан
Информатика
Proc. ВЛДБ Эндоу.
В этом документе подробно описывается сквозная промышленная система, которая решает эти проблемы для социальных данных и использует основанную на Википедии глобальную базу знаний «в реальном времени», которая хорошо подходит для социальных данных.
Определение тем документов с помощью сети категорий Википедии
- Петер Шёнхофен
Информатика
2006 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2006 Main Conference Proceedings) (WI’0906)
Показано, что даже простой алгоритм, использующий только заголовки и категории статей Википедии, может на удивление хорошо характеризовать документы по категориям Википедии.
Автоматическое извлечение онтологий для классификации документов
- Н. Козлова, Г. Вейкум, М. Теобальд
Информатика
- 2005
дальнейшее исследование, в том числе программное средство, разработанное с учетом заявленных принципов.
Преодоление узкого места хрупкости с помощью Википедии: улучшение категоризации текста с помощью энциклопедических знаний
- Э. Габрилович, Шауль Маркович
Информатика
AAAI
- 2006
Предлагается обогатить представление документов за счет автоматического использования обширного сборника человеческих знаний и эмпирического подтверждения — циклопедии что это наукоемкое представление выводит категоризацию текста на качественно новый уровень производительности в разнообразном наборе наборов данных.
Введение в поиск информации
- Christopher D. Manning, P. Raghavan, Hinrich Schütze
Информатика
- 2005
В этом учебнике рассказывается о классическом и веб-поиске информации, включая веб-поиск и смежные области базовой классификации текста и кластеризации текста. концепции, что делает его идеальным для вводных курсов по поиску информации для студентов старших курсов и аспирантов компьютерных наук.
Расшифровка категорий Википедии для получения знаний
- Виви Настасе, М. Струбе
Информатика
AAAI
- 2008
Результаты подтверждают идею о том, что названия категорий Википедии являются богатым источником полезных и точных знаний.
Извлечение семантических взаимосвязи между категориями Википедии
- Сергей Чернов, Тереза IOFCIU, W. Nejdl, Xuan Zhou
Компьютерная наука
Semwiki
- 2006
Semwiki
- 2006
Semwiki
- 2006
.
категории Википедии и показывает, что коэффициент связности положительно коррелирует с силой семантической связи.Large-Scale Taxonomy Mapping for Restructuring and Integrating Wikipedia
- Simone Paolo Ponzetto, R. Navigli
Computer Science
IJCAI
- 2009
We present a knowledge-rich methodology for disambiguating Wikipedia categories with WordNet synsets и использование этой семантической информации для реструктуризации таксономии, автоматически сгенерированной из…
Устранение неоднозначности именованных объектов путем использования семантических знаний Википедии
- Xianpei Han, Jun Zhao
Информатика
CIKM
- 2009
Предложена новая мера сходства для использования обширных семантических понятий Википедии для устранения неоднозначности, которая превосходит другие семантические понятия. информацию и актуальный контент и был протестирован на стандартных наборах данных WePS.
Устранение неоднозначности крупномасштабных именованных объектов на основе данных Википедии
- Silviu Cucerzan
Информатика
EMNLP
- 2007
Путем максимального согласования контекстной информации, извлеченной из Википедии, с контекстом документа, а также согласования тегов категорий, связанных с Объекты-кандидаты, реализованная система демонстрирует высокую точность устранения неоднозначности как в новостях, так и в статьях Википедии.
Начальная загрузка крупномасштабного мелкозернистого классификатора контекстной рекламы из Википедии
Ипин Цзинь, Вишакха Кадам, Dittaya Wanvarie
Abstract
Контекстная реклама предоставляет рекламодателям возможность нацеливаться на контекст, наиболее релевантный их объявлениям. Большое разнообразие потенциальных тем делает очень сложным сбор учебных документов для построения контролируемой модели классификации или составления написанных экспертами правил в системе классификации, основанной на правилах. Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предлагаемый метод сравнивается с различными базовыми уровнями на основе обучения и ключевых слов и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий.- Идентификатор антологии:
- 2021.TextGraphs-1. 1
- Том:
- Слушания пятнадцатого семинара на графических методах для натурального языка (Textgraphs-15)
- МЕДЖДОМ: 919191919191919191919191919191919191919191919191919191919 гг.
- 2021
- Адрес:
- Мехико, Мексика
- Места проведения:
- NAACL | ТекстГрафы | WS
- SIG:
- Издатель:
- Ассоциация компьютерной лингвистики
- Примечание:
- Страницы:
- 1–9
- Язык:
- URL:
- HTTPS://aclanthology.org/2021. textgraphs-1.1
- Bibkey:
- Cite (ACL):
- Ипин Джин, Вишакха Кадам и Диттая Ванвари. 2021. Самозагрузка крупномасштабного мелкозернистого классификатора контекстной рекламы из Википедии. In Proceedings of the Fifteenth Workshop on Graph-Based Methods for Natural Language Processing (TextGraphs-15) , страницы 1–9, Мехико, Мексика. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- Начальная загрузка крупномасштабного мелкозернистого классификатора контекстной рекламы из Википедии (Джин и др. , TextGraphs 2021)
- Копирование цитирования:
- PDF:
- https://aclanthology.org/2021.textgraphs-1.1.pdf
- Code
- YipingNUS/contextual-eval-dataset
- BibTeX
- MODS XML
- Сноска
- Предварительно отформатированный
@inproceedings{jin-etal-2021-bootstrapping, title = "Создание крупномасштабного детализированного классификатора контекстной рекламы из {W}ikipedia", автор = "Джин, Ипин и Кадам, Вишакха и Ванвари, Диттайя", booktitle = "Материалы пятнадцатого семинара по графическим методам обработки естественного языка (TextGraphs-15)", месяц = июнь, год = "2021", address = "Мехико, Мексика", издатель = "Ассоциация вычислительной лингвистики", url = "https://aclanthology.org/2021.textgraphs-1.1", doi = "10.18653/v1/2021.textgraphs-1.1", страницы = "1--9", abstract = "Контекстная реклама предоставляет рекламодателям возможность настроить таргетинг на контекст, наиболее релевантный их объявлениям. Большое разнообразие потенциальных тем делает очень сложным сбор учебных материалов для построения контролируемой модели классификации или составления правил, написанных экспертами, в система классификации на основе правил.Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию.В этой работе мы предлагаем wiki2cat, метод для решения крупномасштабной мелкозернистой классификации текста путем нажатия на граф категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графе. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для проблемы крупномасштабной классификации, поскольку для этого не требуется никакого документа с маркировкой вручную, правил или ключевых слов, выбранных вручную. помечены различными базовыми показателями на основе обучения и ключевых слов и обеспечивают конкурентоспособную производительность в общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий».
}
<моды> <информация о заголовке> Создание крупномасштабного мелкозернистого классификатора контекстной рекламы из Википедии <название типа="личное">Ипин Джин <роль>автор <название типа="личное">Вишакха Кадам <роль>автор <название типа="личное">Диттайя Wanvarie <роль>автор <информация о происхождении>2021-06 текст <информация о заголовке> Материалы пятнадцатого семинара по графическим методам обработки естественного языка (TextGraphs-15) <информация о происхождении>Ассоциация компьютерной лингвистики <место>Мехико, Мексика публикация конференции Контекстная реклама предоставляет рекламодателям возможность ориентироваться на контекст, наиболее релевантный их объявлениям. Большое разнообразие потенциальных тем делает очень сложным сбор учебных документов для построения контролируемой модели классификации или составления написанных экспертами правил в системе классификации, основанной на правилах. Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предложенный метод сравнивается с различными базовыми показателями, основанными на обучении и ключевых словах, и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий. jin-etal-2021-начальная загрузка 10.18653/v1/2021.textgraphs-1.1 <местоположение>https://aclanthology.org/2021.textgraphs-1.1 <часть> <дата>2021-06 <единица экстента="страница"> <начало>1 <конец>9%0 Материалы конференции %T Начальная загрузка крупномасштабного мелкозернистого классификатора контекстной рекламы из Википедии %А Джин, Ипин %A Кадам, Вишакха %A Ванвари, Диттайя %S Материалы пятнадцатого семинара по основанным на графах методам обработки естественного языка (TextGraphs-15) %D 2021 %8 июня %I Ассоциация компьютерной лингвистики %C Мехико, Мексика %F jin-etal-2021-начальная загрузка %X Контекстная реклама предоставляет рекламодателям возможность настроить таргетинг на контекст, наиболее релевантный их объявлениям.
Большое разнообразие потенциальных тем делает очень сложным сбор учебных документов для построения контролируемой модели классификации или составления написанных экспертами правил в системе классификации, основанной на правилах. Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предлагаемый метод сравнивается с различными базовыми уровнями на основе обучения и ключевых слов и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий.
 категории Википедии и показывает, что коэффициент связности положительно коррелирует с силой семантической связи.
категории Википедии и показывает, что коэффициент связности положительно коррелирует с силой семантической связи.
 Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предлагаемый метод сравнивается с различными базовыми уровнями на основе обучения и ключевых слов и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий.
Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предлагаемый метод сравнивается с различными базовыми уровнями на основе обучения и ключевых слов и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий.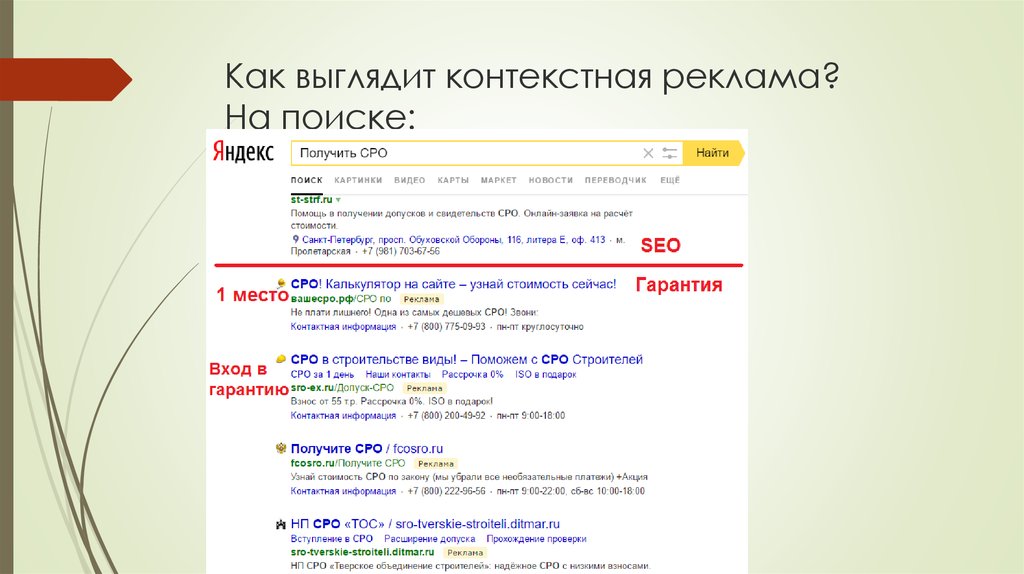 1
1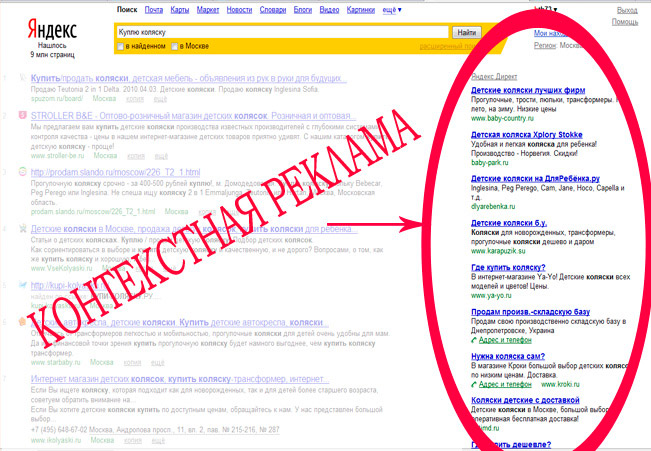 , TextGraphs 2021)
, TextGraphs 2021) Большое разнообразие потенциальных тем делает очень сложным сбор учебных материалов для построения контролируемой модели классификации или составления правил, написанных экспертами, в система классификации на основе правил.Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию.В этой работе мы предлагаем wiki2cat, метод для решения крупномасштабной мелкозернистой классификации текста путем нажатия на граф категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графе. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для проблемы крупномасштабной классификации, поскольку для этого не требуется никакого документа с маркировкой вручную, правил или ключевых слов, выбранных вручную. помечены различными базовыми показателями на основе обучения и ключевых слов и обеспечивают конкурентоспособную производительность в общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий».
Большое разнообразие потенциальных тем делает очень сложным сбор учебных материалов для построения контролируемой модели классификации или составления правил, написанных экспертами, в система классификации на основе правил.Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию.В этой работе мы предлагаем wiki2cat, метод для решения крупномасштабной мелкозернистой классификации текста путем нажатия на граф категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графе. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для проблемы крупномасштабной классификации, поскольку для этого не требуется никакого документа с маркировкой вручную, правил или ключевых слов, выбранных вручную. помечены различными базовыми показателями на основе обучения и ключевых слов и обеспечивают конкурентоспособную производительность в общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий». }
}
 Большое разнообразие потенциальных тем делает очень сложным сбор учебных документов для построения контролируемой модели классификации или составления написанных экспертами правил в системе классификации, основанной на правилах. Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предложенный метод сравнивается с различными базовыми показателями, основанными на обучении и ключевых словах, и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий.
Большое разнообразие потенциальных тем делает очень сложным сбор учебных документов для построения контролируемой модели классификации или составления написанных экспертами правил в системе классификации, основанной на правилах. Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предложенный метод сравнивается с различными базовыми показателями, основанными на обучении и ключевых словах, и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий.
 Большое разнообразие потенциальных тем делает очень сложным сбор учебных документов для построения контролируемой модели классификации или составления написанных экспертами правил в системе классификации, основанной на правилах. Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предлагаемый метод сравнивается с различными базовыми уровнями на основе обучения и ключевых слов и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий.
Большое разнообразие потенциальных тем делает очень сложным сбор учебных документов для построения контролируемой модели классификации или составления написанных экспертами правил в системе классификации, основанной на правилах. Кроме того, в мелкозернистой классификации разные категории часто перекрываются или встречаются одновременно, что затрудняет точную классификацию. В этой работе мы предлагаем wiki2cat, метод для крупномасштабной мелкозернистой классификации текста путем касания графа категорий Википедии. Категории в таксономии IAB сначала сопоставляются с узлами категорий на графике. Затем метка распространяется по графу, чтобы получить список помеченных документов Википедии, чтобы вызвать классификаторы текста. Этот метод идеально подходит для крупномасштабных задач классификации, поскольку он не требует никаких документов с маркировкой вручную, правил или ключевых слов, подобранных вручную. Предлагаемый метод сравнивается с различными базовыми уровнями на основе обучения и ключевых слов и обеспечивает конкурентоспособную производительность на общедоступных наборах данных и новом наборе данных, содержащем более 300 подробных категорий.