
Сбор семантики для контекстной рекламы — руководство от Ильи Исерсона — Офтоп на vc.ru
Владелец базы ключевых слов MOAB и спикер конференции Baltic Digital Days о том, что важно учесть при составлении семантического ядра.
57 491 просмотров
Как собрать правильное семантическое ядро
Если вы думаете, что собрать правильное ядро способен некий сервис или программа, то вы будете разочарованы. Единственный сервис, способный собрать правильную семантику, весит около полутора килограмм и потребляет около 20 ватт мощности. Это мозг.
Причем в этом случае у мозга есть вполне конкретное практическое применение вместо абстрактных формул. В статье я покажу редко обсуждаемые этапы процесса сбора семантики, которые невозможно автоматизировать.
Существует два подхода к сбору семантики
Подход первый (идеальный):
- Вы продаете заборы и их монтаж в Москве и Московской области.
- Вам нужны заявки из контекстной рекламы.

- Вы собираете всю семантику (расширенные фразы) по запросу «заборы» откуда угодно: от WordStat до поисковых подсказок.
- Получаете много запросов — десятки тысяч.
- Затем несколько месяцев чистите их от мусора и получаете две группы: «нужные» запросы и «минус-слова».

Плюсы: в этом случае вы получаете 100% охват — вы взяли все реальные запросы с трафиком по главному запросу «заборы» и выбрали оттуда всё, что вам нужно: от элементарного «заборы купить» до неочевидного «установка бетонных парапетов на забор цена».
Минусы: прошло два месяца, а вы только закончили работать с запросами.
Подход второй (механический):
Бизнес-школы, тренеры и агентства по контексту долго думали, что с этим делать. С одной стороны, действительно проработать весь массив по запросу «заборы» они не могут — это дорого, трудозатратно, людей не получится научить этому самостоятельно. С другой стороны, деньги учеников и клиентов тоже надо как-то забрать.
С другой стороны, деньги учеников и клиентов тоже надо как-то забрать.
Так было придумано решение: берем запрос «заборы», умножаем на «цены», «купить» и «монтаж» — и вперед. Ничего не надо парсить, чистить и собирать, главное — перемножить запросы в «скрипте-перемножалке». При этом возникающие проблемы мало кого волновали:
- Все придумывают плюс-минус одинаковые перемножения, поэтому запросы вида «монтаж заборов» или «заборы купить» моментально «перегреваются».
- Тысячи качественных запросов вида «заборы из профнастила в Долгопрудном» вообще не попадут в семантическое ядро.
Подход с перемножениями себя полностью исчерпал: наступают трудные времена, победителями выйдут только те компании, которые смогут для себя решить проблему качественной обработки действительно большого реального семантического ядра — от подбора базисов до очистки, кластеризации и создания контента для сайтов.
Задача этой статьи — научить читателя не только подбирать правильную семантику, но и соблюдать баланс между трудозатратностью, размером ядра и личной эффективностью.
Что такое базис и как искать запросы
Для начала договоримся о терминологии. Базис — это некий общий запрос. Если вернуться к примеру выше, вы продаете любые заборы, значит, «заборы» — главный для вас базис. Если же вы продаете только заборы из профнастила, то вашим главным базисом будет «заборы из профнастила».
Но если вы один, запросов много, а кампании надо запускать, то можно взять в качестве базиса «заборы из профнастила цена» или «заборы из профнастила купить». Функционально базис служит не столько как рекламный запрос, сколько как основа для сбора расширений.
Например, по запросу «заборы» более 1,3 млн показов в месяц по РФ
Это — не пользователи, не клики и не запросы. Это количество показов рекламных блоков «Яндекса» по всем запросам, включающим слово «заборы». Это мера охвата, применимая к некоему большому массиву запросов, объединенных вхождением в него слова «заборы».
В то же время по запросу «заборы из профнастила» — только 127 тысяч показов, то есть охват сжался в десять раз. Сопоставимым образом уменьшится и количество запросов, и трафик на сайт.
Сопоставимым образом уменьшится и количество запросов, и трафик на сайт.
Таким образом, можно сказать, что базис — это общий запрос, описывающий товар, услугу или нечто иное, за счет самой своей формулировки определяющий меру охвата потенциальной аудитории.
- Хотим «геноцида» конкурентов — берем огромный массив запросов по базису «забор», несколько лет его чистим и группируем — и вуаля — у вас лучшая рекламная кампания на рынке.
- Хотим сделать скромно, но эффективно, продавая только высокомаржинальные заборы из профнастила ограниченной аудитории — берем меньшую в десять раз выборку по запросу «заборы из профнастила» и работаем только с ней.
Итак, первый этап любой рекламной кампании — подбор семантики. А первый этап подбора семантики — это подбор базисов. Важно подобрать базисные запросы, которые:
- Описывают товар или услугу.
- Дадут такой объем расширенных запросов, который вы можете обработать в приемлемые для себя сроки.

Теперь попробуем разобраться с проблемой поиска базисов как таковых.
1. Как вы сами называете товар или услугу
Если вы — подрядчик, то спросите об этом у клиента. Например, заказчик говорит вам: «Я продаю спортивные покрытия в Москве и области». Выбросьте из формулировки заказчика Москву и область, а также подберите синонимы.
Базисы в таком случае будут такими
Цифры — это данные частотности по Москве и области по WordStat. Нетрудно заметить, что каждый из запросов при парсинге WordStat в глубину даст разную выборку расширенных запросов, и каждая выборка — это сегмент целевого спроса.
Пример с синонимами посложнее: «небольшой» медиаплан на сотню с лишним базисов с частотностью по Москве для продажи элитной недвижимости:
Вывод: собирать семантику сложно. Но сам сбор низкочастотных запросов довольно прост — есть куча сервисов от Key Collector до MOAB и других. Дело не в сервисе.
Итак, мы уже вспомнили определения товара или услуги «из головы» и привели их к укороченным формам. То есть если мы продаем «грузовики камаз», то пишем в файл просто — «камаз».
2. Посмотрите сайты конкурентов
Важно понять ключевой принцип — выборка по запросу «камаз» и по запросу «65115 -камаз» дает разные запросы, частично непересекающиеся. Это разные сущности.
Поэтому не нужно мучительно читать тайтлы конкурентов или анализировать их в сомнительных сервисах. Расслабьтесь, включите фантазию, налейте бокал хорошего коньяка и почитайте сайты конкурентов. Вот список артикулов, каждый из которых — отдельная выборка.
3. Сервисы поисковых систем
Здесь буду краток: проверяйте найденные в первых пунктах базисы вручную через правую колонку WordStat и блок «искали вместе с этим»
Пример: в правой колонке WordStat содержатся так называемые запросы, которые пользователи искали вместе с указанным.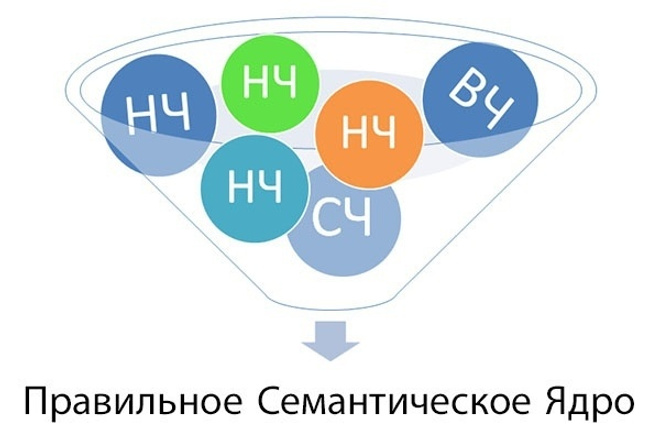 Глядя на правую колонку по запросу из примера выше, можно увидеть запрос с вхождением слова «самосвал».
Глядя на правую колонку по запросу из примера выше, можно увидеть запрос с вхождением слова «самосвал».
Отлично. Запрос «купить камаз самосвал» нам не нужен, так как он и так попадет в расширенные запросы по базису «камаз», а вот запрос «самосвал» — это новый сегмент с отдельными новыми запросами, новым спросом и новой семантикой.
Берем его в проект. Аналогичным образом анализируем и блок «искали вместе с этим» в выдаче «Яндекса» и Google.
Google, к примеру, подсказывает запрос «сельхозник»
Вот что можно получить по нему в WordStat
Проверим, что говорит «Яндекс». Даже если предположить, что вы не продаете ничего, кроме «КамАЗов», то ваши усилия все равно не пропадут даром.
Можно взять запрос «тягач» и получить новый спрос на ваши грузовики и по нему
В целом, думаю, принцип понятен: задача — найти как можно больше целевых базисов, которые выступают инициаторами, драйверами новых длинных семантических хвостов.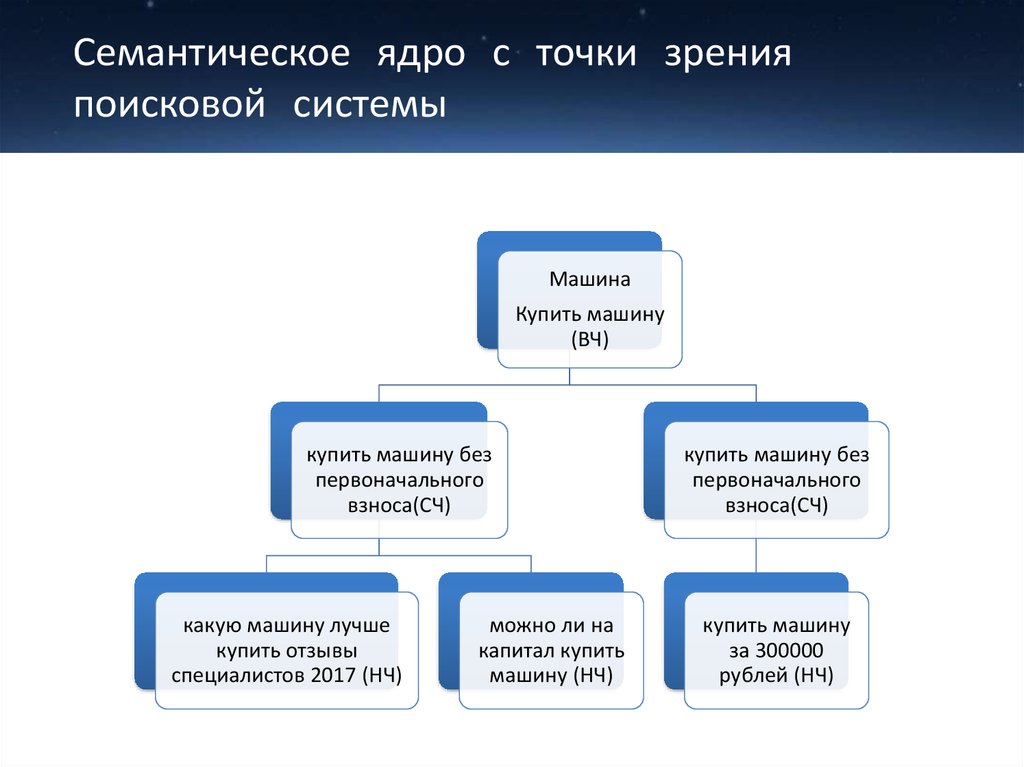
Конечно, тут можно дать ещё много советов: посмотреть анкор-файл конкурентов, посмотреть выгрузки из SpyWords или Serpstat. Всё это, конечно, хорошо. Вернее, было бы хорошо, если бы не было так грустно. Потому что в сущности работа еще даже не началась: насобирать каждый может, а попробуйте-ка всё это очистить, сгруппировать и грамотно управлять.
Вышеописанного вполне достаточно, чтобы, имея светлую голову, собрать семантику на порядок качественнее и лучше, чем у 99% ваших конкурентов.
Как не потратить всю жизнь на сбор ключевых слов
Многие спрашивают: как грамотно управлять семантикой, как её «резать». Если вы продаете могильные камни из буйволиного рога в Нарьян-Маре, вы вряд ли столкнетесь с этой проблемой — у вас семантики всегда будет мало. В то же время, в «горячих» популярных тематиках семантики всегда валом: названия брендов, категорий, моделей, их синонимы и так далее.
Мы решаем эту проблему за счет многоуровневой приоритизации семантики.
1. Приоритизация семантики до сбора запросов
Посмотрите на разделы и категории, по которым собираете семантику, оцените среднюю маржинальность каждой категории. Выкиньте те разделы, где маржинальность меньше 20%. Чаще всего (почти всегда в b2c и чуть реже в b2b) на марже 20% вы будете крутить рекламу в ноль.
Если всё равно остается много — уберите и те разделы, где маржинальность меньше 25-30%, там вы тоже, скорее всего, много не заработаете — максимум немного мелочи в карман плюс покажете производителю больше оборота и выбьете новые скидки. Зарабатывать интересные деньги получается на товарах и услугах с маржой от 30% — не всегда и не везде конечно, но эти цифры я видел десятки раз на самых разных проектах.
2. Сбор базисов и расширенной семантики по ним
Собрали? Все равно получается много? Проранжируйте запросы. Ставьте 1, 2 или 3 рядом с каждым базисом. Заставьте себя это сделать, вот так:
Я специально ограничиваюсь тремя значениями — это просто. Если у вас будет десять уровней приоритета, вы сойдете с ума, думая о том, поставить 6 или 7 конкретному базису, — а так решения очень простые и очевидные.
Если у вас будет десять уровней приоритета, вы сойдете с ума, думая о том, поставить 6 или 7 конкретному базису, — а так решения очень простые и очевидные.
Кроме того, это помогает структурировать свой бизнес для самого себя — взглянуть на него сквозь призму спроса и маржинальности: фильтруем по столбцу «Приоритет» и видим, что поставили «1» тем базисам, по которым мало спроса.
Значит, надо либо активнее работать с другими товарными направлениями, снижать закупочные цены, либо стимулировать спрос — но это уже другая история.
3. Отсекли всё неприоритетное и всё равно семантики слишком много
Когда говорят про «резать» семантику, те, кто с этим поработал, как правило, имеют в виду удаление низкочастотных запросов с частотностью ниже определённой отсечки. В тематических дискуссиях в Facebook и на форумах я регулярно вижу цифры от 5 до 10 (имеется в виду общая частотность по запросу).
То есть намеренно убирается из массива всё, что по частотности меньше 10.
Понятно, что так делать можно, если у вас всё равно очень много семантики. Но это всегда вопрос выбора между поеданием рыбы и сидением на неудобных для сидения предметах. Слишком много уберете — недосчитаетесь каких-то минус-слов, получите больше «грязного» трафика на запуске, но выиграете в трудозатратности.
Моё мнение таково: условная точка баланса здесь находится на уровне «убираем всё, что не имеет частотности». Это позволяет выкинуть примерно половину массивов, полученных из различных источников, в то же время трафик на запуске остается очень чистым, с погрешностью буквально 1-3% и быстро дочищается.
Что значит «дочищается»
Представьте, что вы собрали рекламную кампанию для поискового размещения в «Яндекс.Директе», запустили ее, и вам нужно оценить эффективность проделанной работы. Как это сделать? Оценивать по продажам? Не совсем правильно, ведь продажи — это результат работы цепочки «кампания-сайт-менеджеры».
Звонки? Тоже нет, ведь огромное влияние на количество звонков оказывает сайт: может быть, с кампанией всё хорошо, просто сайт сделан неправильно.
Быстро проверить эффективность поисковой кампании можно в «Яндекс.Метрике». Для этого нам надо через два-три дня после запуска кампании получить отчет о фразах, послуживших источниками перехода. Как найти этот отчет в «Метрике»:
А затем:
Кликаем на крестик на всех группировках, кроме «Поисковая фраза», и нажимаем «Применить». Мы получим отчет о тех фразах, по которым пользователи увидели наши объявления, кликнули по ним и перешли к нам на сайт. Что делать с этим отчетом?
Внимательно просмотреть и выделить нерелевантные фразы, которые не относятся к вашему бизнесу. На жаргоне их называют «мусором». В профессионально сделанных кампаниях в первое время после запуска доля «мусора» может составлять от 1 до 4%, в кампаниях, собранных «на коленке», — до 20-40%.
Как вы уже, наверное, поняли, процедуру с дополнительной очисткой от мусора стоит проводить регулярно — как минимум, два-три раза в месяц. Почему так часто?
У нас был интересный пример из практики. Мы работали с кампанией, в которую включили для клиента высокомаржинальный запрос «черный дым дизель». Клиент работал с дизельными двигателями, и такой запрос означает, что у клиента есть серьезная проблема с двигателем, и, вероятно, потребность в квалифицированных услугах.
Мы работали с кампанией, в которую включили для клиента высокомаржинальный запрос «черный дым дизель». Клиент работал с дизельными двигателями, и такой запрос означает, что у клиента есть серьезная проблема с двигателем, и, вероятно, потребность в квалифицированных услугах.
Одновременно с этим в сентябре 2016 года, когда группировка российского флота направилась в Сирию, ТАКР «Адмирал Кузнецов» привлек внимание международных СМИ сильным черным дымом из выхлопной трубы. Это неизбежно спровоцировало запросы вроде «черный дым дизель адмирал кузнецов».
Ранее таких запросов просто не было, поэтому и не было минусов формата «–адмирал, –кузнецов». Поэтому мало того, что наше объявление показалось по таким запросам, так оно ещё и сгенерировало бессмысленные переходы, не имеющие для бизнеса никакой ценности.
Отследить такие запросы оперативно можно только в «Метрике»: поэтому возьмите себе за правило на старте кампании почаще (позже — реже) проверять семантику и дополнительно минусовать новый мусор.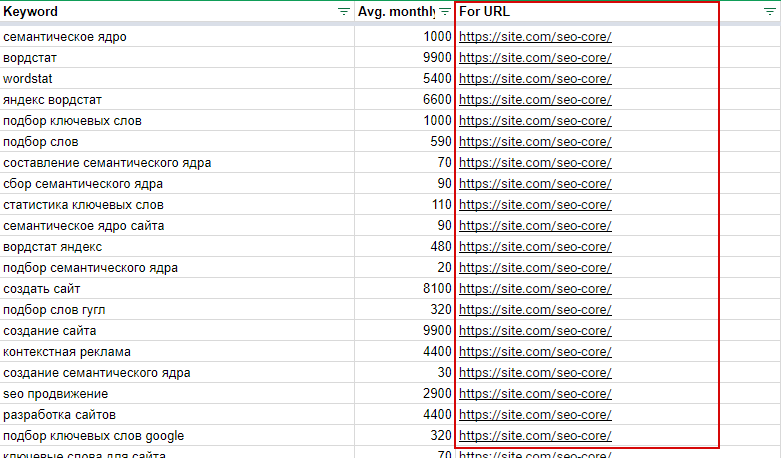
Разумеется, возникает вопрос: а что вообще влияет на количество мусора. Всё просто — статистическая достоверность семантики.
На что влияет объем семантики
Далеко не всегда люди понимают, о чем говорят, когда обсуждают влияние обширного семантического ядра на цену клика, качество кампании и прочее. Сама по себе обширная семантика не вызывает ни снижения цены клика, ни увеличения качества кампании. На что же реально влияют сотни и тысячи собранных НЧ-запросов?
1. Чистота трафика на запуске кампании
Чем больше запросов вы соберете — тем больше найдете минус-слов. На бесконечно большой выборке запросов вы найдете все возможные минус-слова, потратив на это бесконечный период времени.
На практике стоит ограничиться запросами, как я уже говорил, с частотностью от 1 по нужному региону — это даст «мусорность» в районе 3-4% при запуске, после чего вы быстро дочистите оставшиеся мусорные запросы, минусы, по которым почему-то не попали в выборку.
При этом стоит использовать и WordStat, и советы поисковых систем, собирая подсказки для каждого запроса, полученного в WordStat. Использование одного только WordStat даст высокую мусорность — 10-15% на запуске как минимум (если не больше). Но все мы понимаем — чем больше мусора, тем больше расход средств, тем меньше лидов на единицу расхода.
2. Релевантность объявлений запросам
Здесь важно понять системообразующий принцип: запросы, которые вы добавили в кампанию, по большому счету, ничего не значат. Они не важны.
Реальный трафик, который будет попадать к вам на сайт, приходит большей частью не по тем запросам, которые вы добавили в кампанию, а по расширениям от них. На один запрос, добавленный в кампанию, приходится как минимум три-четыре расширенных варианта — это ультра-НЧ, которые вообще никак не предскажешь, пользователи генерируют их прямо в момент поиска.
Поэтому не столь важен сам запрос: так много стало трафика по ультра-НЧ с частотой перехода в один-два раза в месяц или в год, что привязываться к конкретному запросу нет смысла. Важно собрать статистически значимую семантику, разбить её на мелкие группы похожих запросов и составить под них объявления.
Важно собрать статистически значимую семантику, разбить её на мелкие группы похожих запросов и составить под них объявления.
Больше семантика — больше групп, больше точность соответствий и ниже цена кампаний на поиске. В конкретной группе похожих ультра-НЧ, из которых сформируется объявление, может быть пять-десять запросов — а если вы выудите из «Метрики» фразы по этому объявлению через полгода, получите список на 30-40 фраз как минимум.
Повторюсь: семантика — не панацея от всего и не божество. Семантика влияет на многое: на чистоту трафика, на релевантность объявлений запросам — но не на всё. Не имеет смысла собирать огромные выборки «нулевок» в надежде получить трафик дешевле — этого не будет.
Семантика влияет:
- На охват рекламной кампании.
- На чистоту трафика.
- На релевантность «запрос-объявление».
Вот те факторы, про которые вам стоит помнить в первую очередь. Впрочем, попробуем суммировать итоги в двух словах.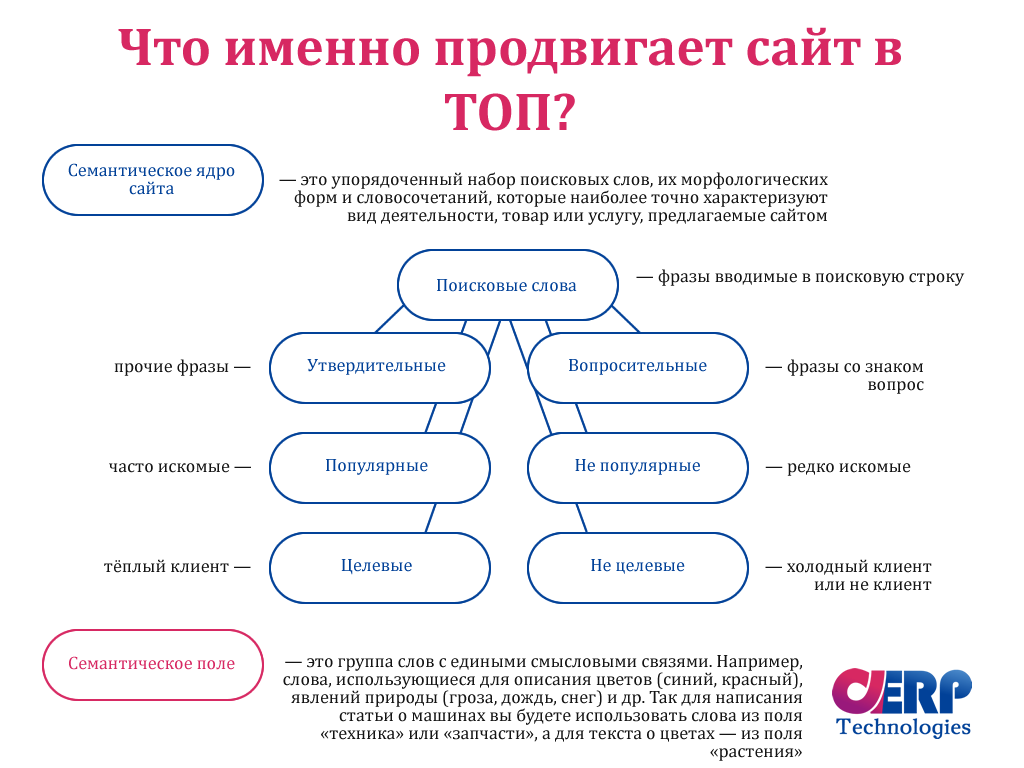
Кратко
- Соберите базисные запросы — общие фразы, описывающие ваши товары и услуги.
- Проверьте, все ли синонимы и переформулировки вы собрали: в помощь вам WordStat и блок «похожие запросы» в SERP.
- Соберите расширения по полученным запросам: WordStat, поисковые подсказки, база MOAB — всё идет в дело.
- Составьте табличку, где рядом с каждым базисом будет указана его частотность и количество расширенных запросов.
- Если запросов слишком много, и вы не успеваете их обработать — выполните приоритизацию базисов в зависимости от маржи, частотности и количества запросов.
- Окончательный семантический план сформирован. Теперь дело за очисткой и кластеризацией семантики.
Как вручную собрать семантику?, видеосовет 12
Один из способов сборки семантического ядра — ручной. Он не имеет никакой автоматизации. Рассмотрим этот способ на конкретном примере.
Рассмотрим этот способ на конкретном примере.
Возьмем простой сайт с тематикой лотерейных автоматов. Уже из беглого обзора сайта очевидны основные ключевые слова: «лотерейный автомат», «лотерейные автоматы» или перефразированное «автоматы для лотереи». Для удобства поместив эти запросы в Excel-файл, продолжаем изучение сайта. Изучаем разделы меню на предмет сбора семантических данных. В пункте меню «оборудование» в заголовках видим слова, которые могут нам подойти. Это «игровое оборудование», «лотерейное оборудование», «продажа оборудования для лотереи». Вносим их в Excel -файл.
К запросу «игровое оборудование», который можно отнести также к детской тематике, нужно задать специфическое слово, потому меняем этот запрос на «игровое лотерейное оборудование» и добавляем вариацию «игровое оборудование для лотереи». Возвращаемся к сайту и продолжаем поиски. Изучаем подразделы «терминалы», «лотерейные аппараты» и «консоли», которые также подходят к тематике. Аналогичным образом продолжаем искать запросы и добавляем слова, встречающиеся в каждом запросе коммерческого сайта, такие как «цена», «купить», «продажа». Объединяем эти типичные запросы с ранее найденными ключевыми словами, превращая их в соответствующие словосочетания, например: «купить лотерейные автоматы», «автоматы для лотерей купить» и т.п.
Объединяем эти типичные запросы с ранее найденными ключевыми словами, превращая их в соответствующие словосочетания, например: «купить лотерейные автоматы», «автоматы для лотерей купить» и т.п.
Что еще может помочь нам в ручном сборе семантики? Конечно, это сервис Яндекса — WordStat. Выбираем регион продвижения, например «Москва и область», и вводим запрос «лотерейные автоматы». Сервис показывает нам вариации запросов с ключевыми словами, которые вводились пользователем.
WordStat выдает информацию в двух колонках — левой и правой. В основном семантика собирается из левой колонки, но если у запроса есть какая-то другая форма — она будет отражена в правой. Ищем по колонке запросы, подходящие под нашу тематику. Находим запросы, которые ранее упустили, и добавляем в список. Сервис также показывает частотность запросов, которую мы вписываем отдельно по каждому ключу. С помощью частотности можно определить вид запроса, она также пригодится в чистке семантического ядра и в целом поможет в продвижении.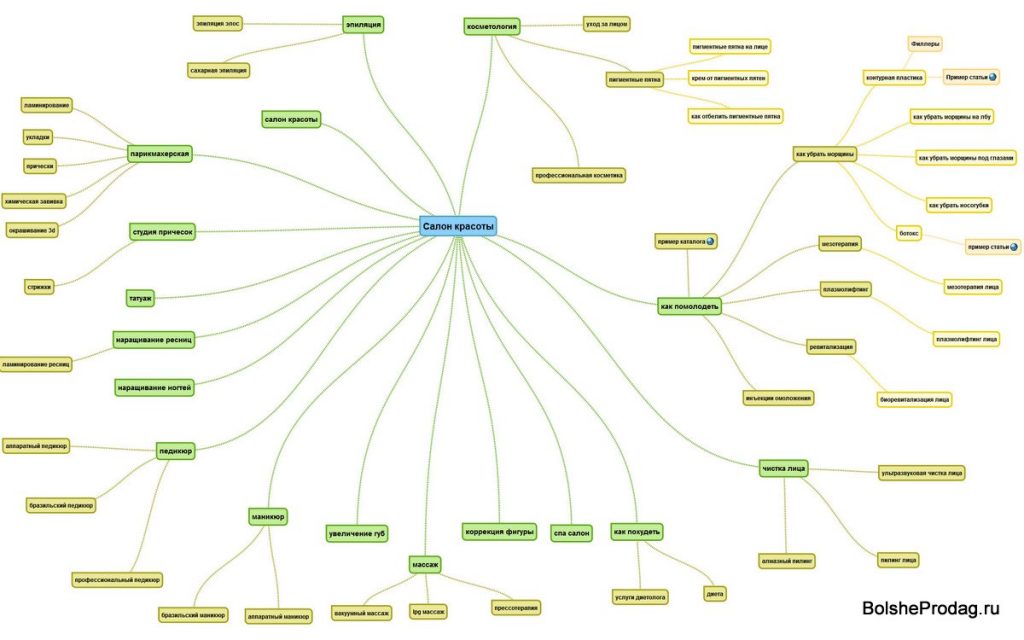
Частотность бывает общая и точная. Общая частотность показывает, сколько раз в месяц запрос, содержащий ключевое слово, был введен пользователями, а точная частотность показывает, сколько раз был введен именно такой запрос «лотерейные автоматы», а не вариации, например: «лотерейных автоматов», «купить лотерейные автоматы» и т.п. Чтобы получить точную частотность, достаточно заключить нашу фразу в кавычки и поставить перед каждым словом восклицательный знак.
Полученную информацию включаем в файл с семантикой. Помочь со сбором семантики могут также подсказки и подсветки самого поиска Яндекса. Чтобы получить подсказку, вводим в поиск ключевое слово и из всплывающего окна, предлагающего похожие запросы, выбираем подходящие. Для того чтобы собрать информацию при помощи подсветки, вводим ключевое слово и смотрим на выдачу. Отсеиваем все, что уже внесено в наш список, ищем слова, которые расширят его. Например, «лотомат». Добавляем его и вариации вроде «купить лотомат» и «продажа лотоматов» в список. В итоге получаем семантическое ядро с запросами, общей и точной частотностью.
В итоге получаем семантическое ядро с запросами, общей и точной частотностью.
Как это работает и для кого это
Для простых пользовательских запросов поисковая система может надежно найти правильный контент, используя только сопоставление ключевых слов.
Запрос «красный тостер» извлекает все продукты со словом «тостер» в заголовке или описании и красным цветом в атрибуте цвета.
Добавьте синонимы, например темно-бордовый к красному, и вы сможете найти еще больше тостеров.
Но все быстро становится сложнее: вы должны добавить эти синонимы самостоятельно, и ваш поиск также выдаст тостеры.
Здесь на помощь приходит семантический поиск.
Семантический поиск пытается применить намерение пользователя и значение (или семантику) слов и фраз для поиска нужного контента.
Он выходит за рамки сопоставления ключевых слов, используя информацию, которая может не присутствовать непосредственно в тексте (сами ключевые слова), но тесно связана с тем, что хочет искатель.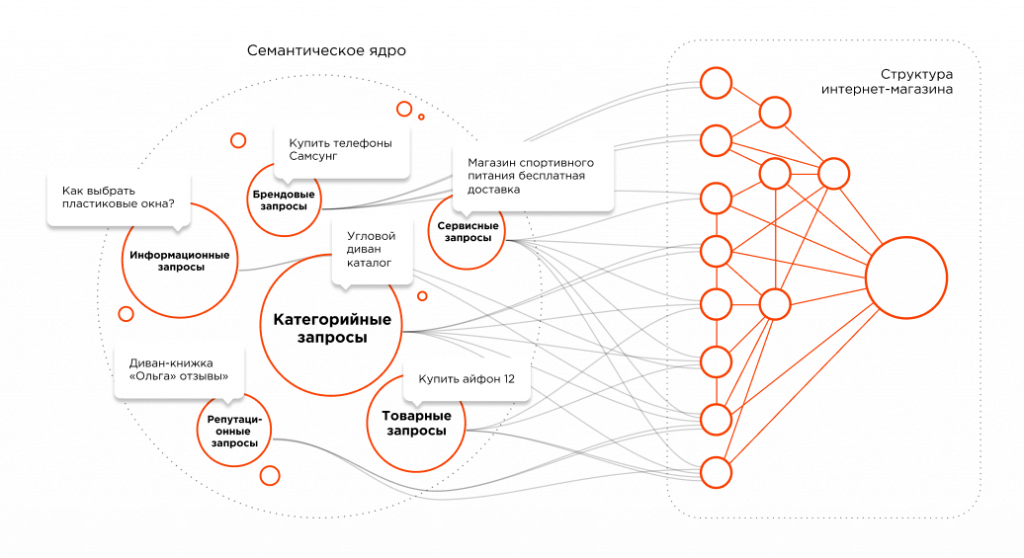
Например, найти свитер по запросу «свитер» или даже «слаще» не составит труда для поиска по ключевым словам, а запросы «теплая одежда» или «как согреться зимой?» лучше обслуживаются семантическим поиском.
Как вы можете себе представить, попытка выйти за пределы информации поверхностного уровня, встроенной в текст, является сложной задачей.
Его пробовали многие, и он включает множество различных компонентов.
Кроме того, как и все, что подает большие надежды, семантический поиск — это термин, который иногда используется для поиска, который на самом деле не соответствует названию.
Чтобы понять, применим ли семантический поиск к вашему бизнесу и как лучше всего воспользоваться преимуществами, полезно понять, как он работает, и компоненты, входящие в состав семантического поиска.
Что такое элементы семантического поиска?
Семантический поиск применяет намерение пользователя, контекст и концептуальные значения для сопоставления запроса пользователя с соответствующим содержимым.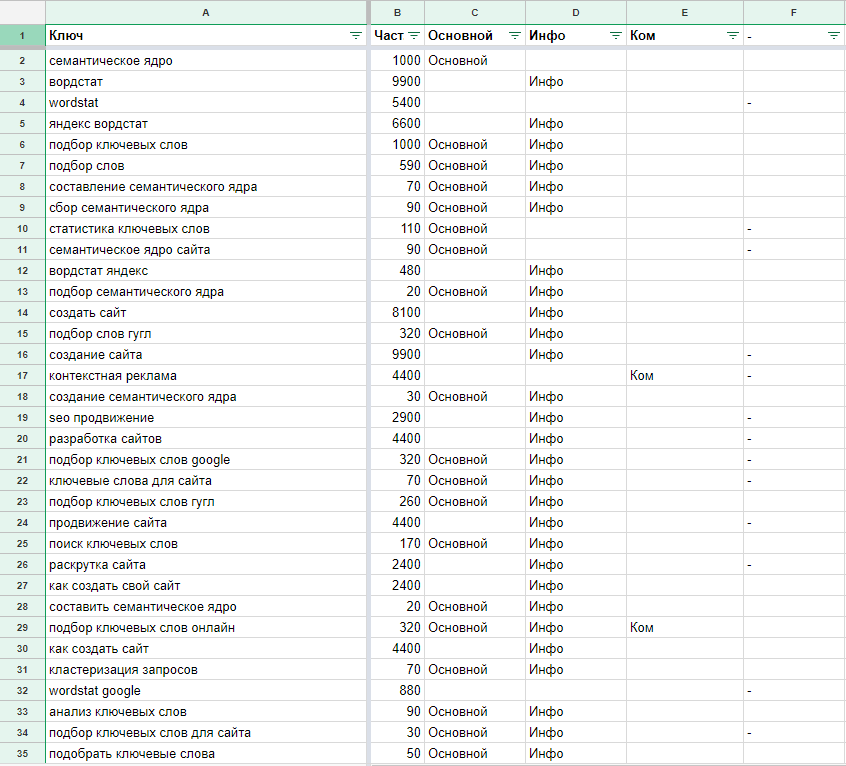
Он использует векторный поиск и машинное обучение для возврата результатов, которые должны соответствовать запросу пользователя, даже если нет совпадений слов.
Эти компоненты совместно извлекают и ранжируют результаты на основе их значения.
Одним из самых фундаментальных элементов является контекст.
Контекст
Контекст, в котором происходит поиск, важен для понимания того, что ищущий пытается найти.
Контекст может быть таким же простым, как место действия (американец, ищущий слово «футбол», хочет чего-то другого, чем британец, ищущий то же самое), или гораздо более сложным.
Интеллектуальная поисковая система будет использовать контекст как на личном, так и на групповом уровне.
Воздействие на результаты на личностном уровне вполне уместно называется персонализацией.
Персонализация будет использовать сходство этого отдельного искателя, предыдущие поиски и предыдущие взаимодействия, чтобы вернуть контент, который лучше всего подходит для текущего запроса.
Он применим ко всем видам поиска, но семантический поиск может пойти еще дальше.
На групповом уровне поисковая система может повторно ранжировать результаты, используя информацию о том, как все пользователи взаимодействуют с результатами поиска, например, какие результаты чаще всего нажимаются, или даже сезонность, когда одни результаты более популярны, чем другие.
Опять же, это показывает, как семантический поиск может привнести интеллект в поиск, в данном случае интеллект через поведение пользователя.
Семантический поиск также может использовать контекст в тексте.
Мы уже обсуждали, что синонимы полезны во всех видах поиска и могут улучшить поиск по ключевым словам, расширяя соответствие запросов к связанному контенту.
Но мы также знаем, что синонимы не универсальны – иногда два слова эквивалентны в одном контексте, а не в другом.
Когда кто-то ищет «футболисты», какие результаты правильные?
Ответ в Кенте, штат Огайо, будет другим, чем в графстве Кент, Великобритания.
Запрос типа «футболисты тампа-бэй», однако, вероятно, не должен знать, где находится искатель.
Добавление общего синонима, который сделал бы футбол и футбол эквивалентными, привело бы к плохому опыту, когда этот искатель увидел бы футбольный клуб Tampa Bay Rowdies рядом с Роном Гронковски.
(Конечно, если мы знаем, что искатель предпочел бы увидеть Tampa Bay Rowdies, поисковая система может принять это во внимание!)
Это пример понимания запроса с помощью семантического поиска.
Намерение пользователя
Конечной целью любой поисковой системы является помощь пользователю в успешном выполнении задачи.
Этой задачей может быть чтение новостных статей, покупка одежды или поиск документа.
Поисковая система должна выяснить, что пользователь хочет сделать или что пользователь намерение есть.
Мы можем увидеть это при поиске на веб-сайте электронной коммерции.
Когда пользователь вводит запрос «Jordan», поиск автоматически фильтруется по категории «Обувь».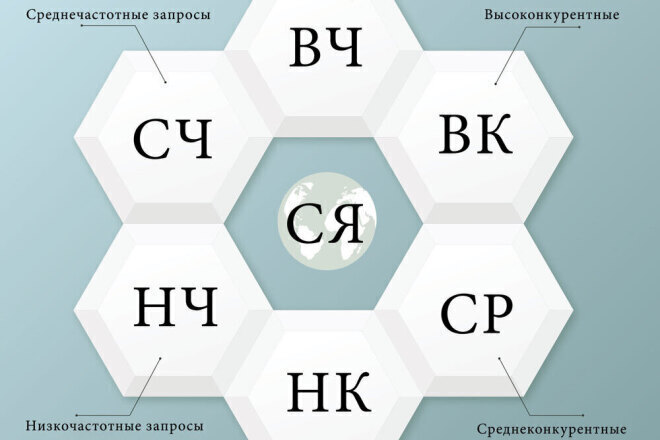
Предполагается, что целью пользователя является поиск обуви, а не иорданского миндаля (который будет в категории «Еда и закуски»).
Опередив намерения пользователя, поисковая система может вернуть наиболее релевантные результаты и не отвлекать пользователя элементами, которые соответствуют тексту, но не релевантны.
Это может быть еще более уместно, если применить сортировку в верхней части поиска, например, цену от самой низкой до самой высокой.
Это пример классификации запроса .
Категоризация запроса и ограничение набора результатов гарантируют отображение только релевантных результатов.
Разница между поиском по ключевому слову и семантическим поиском
Мы уже видели, как семантический поиск является интеллектуальным, но стоит подробнее рассмотреть, чем он отличается от поиска по ключевым словам.
Хотя поисковые системы по ключевым словам также вводят обработку естественного языка для улучшения этого сопоставления слов — с помощью таких методов, как использование синонимов, удаление стоп-слов, игнорирование множественного числа — эта обработка по-прежнему зависит от сопоставления слов со словами.
Но семантический поиск может возвращать результаты, в которых нет совпадающего текста, но любой, кто знаком с предметной областью, может увидеть, что есть явно хорошие совпадения.
Это связано с большой разницей между поиском по ключевым словам и семантическим поиском, которая заключается в том, как происходит сопоставление между запросом и записями.
Чтобы упростить некоторые вещи, поиск по ключевым словам происходит путем сопоставления текста.
«Soap» всегда будет соответствовать «soap» или «soapy» из-за перекрытия текстового качества.
Более конкретно, имеется достаточно совпадающих букв (или символов ), чтобы сообщить движку, что пользователь, ищущий одно, захочет другое.
Это же соответствие сообщит движку, что запрос мыла более вероятно соответствует слову «суп», чем слову «моющее средство».
То есть, если владелец поисковой системы не сообщил машине заранее, что мыло и моющее средство являются эквивалентами, и в этом случае поисковая система будет «притворяться», что моющее средство на самом деле является мылом, когда она определяет сходство.
Поисковые системы на основе ключевых слов также могут использовать такие инструменты, как синонимы, альтернативы или удаление слова из запроса — все типы расширения и ослабления запроса — для облегчения этой задачи поиска информации.
Инструменты NLP и NLU, такие как устойчивость к опечаткам, токенизация и нормализация, также улучшают поиск.
Хотя все это помогает улучшить результаты, они могут потерпеть неудачу из-за более интеллектуального сопоставления и сопоставления концепций.
Семантический поиск соответствует понятиям
Поскольку семантический поиск соответствует понятиям, поисковая система больше не может определять, являются ли записи релевантными, исходя из того, сколько символов разделяет два слова.
Опять же, подумайте о «мыле», «супе» и «моющем средстве».
Или более сложные запросы, такие как «чистка прачечной», «удаление пятен с одежды» или «как вывести пятна от травы с джинсовой ткани?»
Вы даже можете включить поиск изображений!
Реальной аналогией этого может быть клиент, спрашивающий сотрудника, где находится «чистый туалет».
Сотрудник, который понимает запрос только на уровне ключевых слов, не выполнит его, если магазин явно не называет свои плунжеры, очистители стоков и шнеки для унитазов «средствами для прочистки унитазов».
Но, хотелось бы надеяться, у сотрудника хватит ума, чтобы связать разные термины и направить покупателя в нужный отдел.
(Возможно, сотрудник знает различные термины или синонимы, которые клиент может использовать для любого продукта).
Кратко подытоживая то, что делает семантический поиск, можно сказать, что семантический поиск повышает интеллект, чтобы сопоставлять понятия больше, чем слова, за счет использования векторного поиска.
С таким интеллектом семантический поиск может выполняться более по-человечески, подобно тому, как искатель находит платья и костюмы при поиске модных вещей, но в поле зрения нет джинсов.
Чем не является семантический поиск?
К настоящему моменту семантический поиск должен стать мощным методом повышения качества поиска.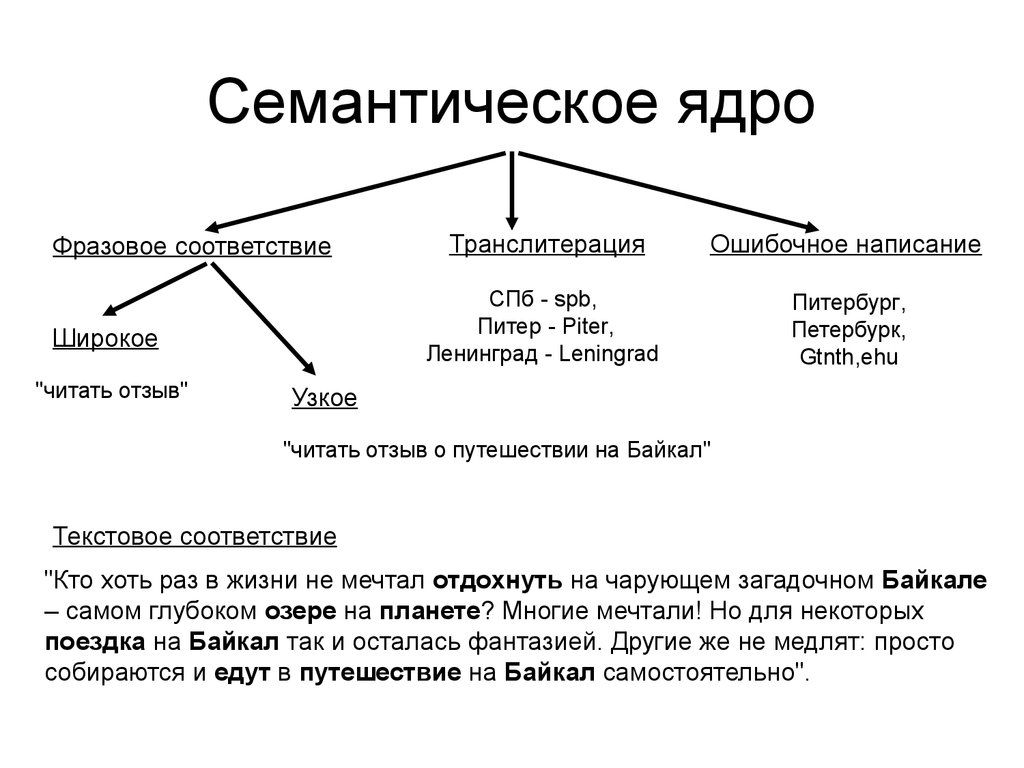
Таким образом, вы не должны удивляться, узнав, что значение семантического поиска применяется все шире и шире.
Часто такие возможности поиска не всегда оправдывают название.
И хотя официального определения семантического поиска не существует, мы можем сказать, что это поиск, выходящий за рамки традиционного поиска по ключевым словам.
Он делает это, используя знания из реального мира для определения намерений пользователя на основе значения запросов и контента.
Это приводит к выводу, что семантический поиск — это не просто применение НЛП и добавление синонимов в индекс.
Это правда, токенизация требует некоторых реальных знаний о конструкции языка, а синонимы применяют понимание концептуальных соответствий.
Однако в большинстве случаев им не хватает искусственного интеллекта, необходимого для того, чтобы поиск поднялся до уровня семантического.
Powered By Vector Search
Именно этот последний элемент делает семантический поиск одновременно мощным и сложным.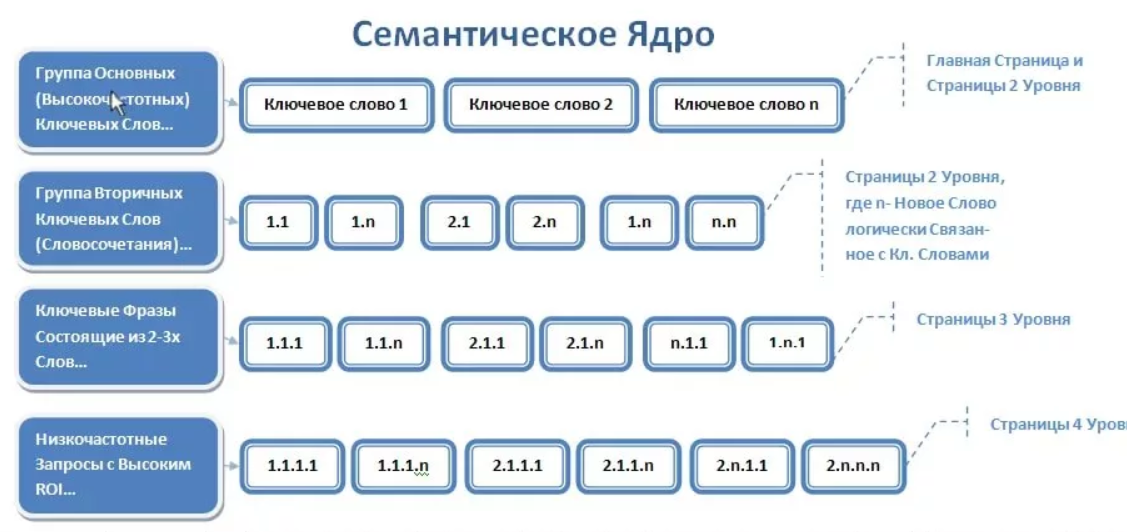
Как правило, с термином семантический поиск подразумевается некоторый уровень машинного обучения.
Почти так же часто это также включает векторный поиск .
Векторный поиск работает путем кодирования сведений об элементе в векторы и последующего сравнения векторов, чтобы определить, какие из них наиболее похожи.
Опять же, может помочь даже простой пример.
Возьмите два словосочетания: «Тойота Приус» и «стейк».
А теперь давайте сравним их с «гибридом».
Какие из первых двух больше похожи?
Ни один из них не соответствует тексту, но вы, вероятно, скажете, что «Toyota Prius» больше похожа на них.
Вы можете сказать это, потому что знаете, что «Prius» — это тип гибридного транспортного средства, потому что вы видели «Toyota Prius» в том же контексте, что и слово «гибрид», например, «Toyota Prius — это гибрид, заслуживающий внимания», или «гибридные автомобили, такие как Toyota Prius».
Вы уверены, однако, что никогда не видели «стейк» и «гибрид» в таком тесном пространстве.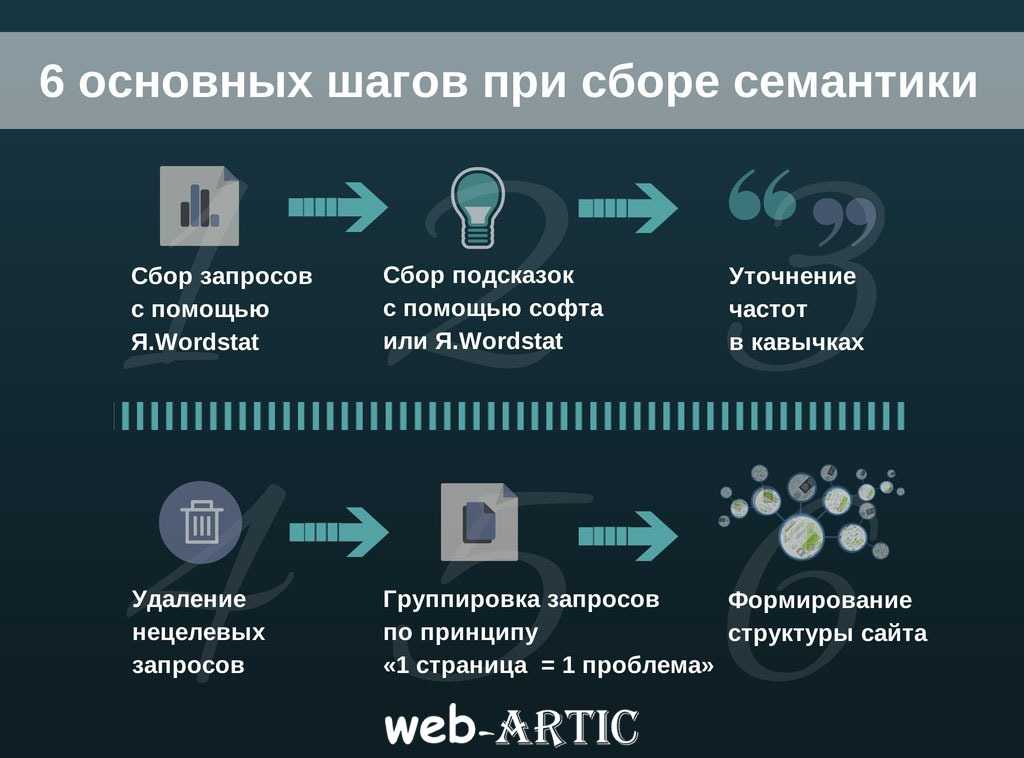
Построение векторов для поиска подобия
Обычно поиск векторов работает так же.
Модель машинного обучения берет тысячи или миллионы примеров из Интернета, книг или других источников и использует эту информацию, чтобы делать прогнозы.
Конечно, модели не могут сравниваться по отдельности («Часто ли Toyota Prius и гибрид видят вместе? Как насчет гибрида и стейка?»), поэтому вместо этого происходит то, что модели кодировать шаблоны , которые он замечает по разным фразам.
Это похоже на то, как вы смотрите на фразу и говорите: «это положительное» или «тот содержит цвет».
За исключением машинного обучения, языковая модель не работает так прозрачно (вот почему языковые модели могут быть трудны для отладки).
Эти кодировки хранятся в виде вектора или длинного списка числовых значений.
Затем векторный поиск использует математику для расчета степени сходства различных векторов.
Еще один способ представить измерения подобия, которые выполняет векторный поиск, — представить построенные векторы.
Это невероятно сложно, если вы попытаетесь представить себе вектор, представленный в сотнях измерений.
Если вы вместо этого представите вектор, построенный в трех измерениях, принцип тот же.
Эти векторы образуют линию при построении графика, и возникает вопрос: какие из этих линий ближе всего друг к другу?
Строки для «стейк» и «говядина» будут ближе, чем строки для «стейк» и «машина», и поэтому они более похожи.
Этот принцип называется векторным или косинусным сходством.
Сходство векторов имеет множество применений.
Он может давать рекомендации на основе ранее приобретенных продуктов, находить наиболее похожие изображения и определять, какие элементы лучше всего соответствуют семантически по сравнению с запросом пользователя.
Заключение
Семантический поиск — это мощный инструмент для приложений поиска, который вышел на передний план с появлением мощных моделей глубокого обучения и аппаратного обеспечения для их поддержки.
Хотя мы затронули здесь ряд различных распространенных приложений, существует еще больше, использующих векторный поиск и ИИ.
Под семантический поиск может подпадать даже поиск изображений или извлечение метаданных из изображений.
Нас ждут захватывающие времена!
И, тем не менее, его применение еще рано, и его известная сила может привести к неправильному присвоению термина.
Конвейер семантического поиска состоит из множества компонентов, и важно правильно определить каждый из них.
Если все сделано правильно, семантический поиск будет использовать реальные знания, особенно с помощью машинного обучения и подобия векторов, чтобы сопоставить запрос пользователя с соответствующим контентом.
Дополнительные ресурсы:
- Патент раскрывает, как Google может интерпретировать запросы на основе информации о сущности
- Семантическая кластеризация ключевых слов для более чем 10 000 ключевых слов [со сценарием]
- Как провести исследование ключевых слов для SEO: полное руководство
Рекомендуемое изображение: волшебные картинки/Shutterstock
Категория SEO
Руководство для начинающих по семантическому поиску: примеры и инструменты
Со времен Google Hummingbird термин «семантический поиск» часто использовался. Тем не менее, эта концепция часто неправильно понимается. Что такое семантический поиск и как он помогает усилиям SEO?
Тем не менее, эта концепция часто неправильно понимается. Что такое семантический поиск и как он помогает усилиям SEO?
Когда люди разговаривают друг с другом, они понимают больше, чем просто слова. Они понимают контекст, невербальные сигналы (мимику, нюансы голоса и т. д.) и многое другое.
Это происходит естественным образом, поэтому мы не очень понимаем, насколько сложно объяснить, что сообщается, без помощи всех «запредельных слов».
Факторы, которые усложняют жизнь как Google, так и SEO
- Google пытается (и часто изо всех сил пытается) понять, чего хотят их пользователи (на самом деле не видя и не слыша их)
- оптимизаторы пытаются реконструировать то, что Google удалось понять из запросов своих пользователей, и как создавать страницы, соответствующие этим загадочным критериям. По мере того, как алгоритм Google становится все более зрелым, становится все труднее расшифровать то, что нужно Google, или, что более важно, то, что Google считает нужным своим пользователям при использовании любого конкретного поискового запроса.
Здесь в игру вступает семантический поиск.
«Семантика» относится к концепциям или идеям, передаваемым словами, а семантический анализ упрощает понимание любой темы (или поискового запроса) для машины.
Проще говоря (и я не являюсь профессиональным экспертом по семантическому анализу, хотя у меня есть степень в области когнитивной лингвистики), Google (и, следовательно, оптимизаторы) имеют дело с двумя основными концепциями семантического поиска:
- Семантическое отображение, то есть изучение связей между любым словом/фразой и набором связанных слов или понятий.
- Семантическое кодирование, то есть использование кодирования, чтобы лучше объяснить Google, какие типы информации можно найти на каждой странице.
Поскольку в нашей отрасли мы склонны метать термины направо и налево (и часто в процессе изобретаем свои собственные), возникает много путаницы, когда речь заходит о семантическом поиске и о том, как его выполнять.
Итак, эта статья — моя попытка прояснить эту путаницу и помочь вам лучше понять семантический анализ и его применение в поисковой оптимизации.
Семантическое отображение
Семантическое отображение — это визуализация отношений между понятиями и объектами (а также отношений между связанными понятиями и объектами).
Вот пример семантической карты (или модели), взятой из документа Раманатана Гуха из Google, будущего создателя проекта Schema: Yo Ma] поисковый запрос]
Эта модель помогает Google лучше понимать любые связанные запросы и предоставлять полезные поисковые подсказки (например, график знаний, быстрые ответы и другие).
Источник изображения: Скриншот создан автором (декабрь 2019 г.)
Семантический анализ также помогает Google лучше обслуживать пользователей голосового поиска, предоставляя им немедленные ответы на основе их общего понимания темы.
Но как можно использовать семантический анализ в поисковой оптимизации?
Лучший способ понять семантику предлагается оптимизатору текста, инструменту, помогающему понять эти взаимосвязи.
Если кто-то ищет [пицца], он может искать:
- Заказать пиццу
- Приготовить пиццу
Благодаря многолетнему предоставлению результатов поиска пользователям и анализу их взаимодействия с этими результатами поиска Google, кажется, знает, что большинство людей, которые ищут [пицца], заинтересованы в заказе пиццы.
Источник изображения: Скриншот, созданный автором (декабрь 2019 г.)
Следовательно, все, что нам нужно сделать, это расшифровать понимание Google любого запроса, на создание и уточнение которого у них ушли годы.
Таким образом, Text Optimizer захватывает эти результаты поиска и группирует их по связанным темам и объектам, давая вам четкое представление о том, как лучше оптимизировать результаты поиска.
Источник изображения: Скриншот, созданный автором (декабрь 2019 г.)
Идея состоит в том, что использование нескольких из этих терминов в вашем тексте помогает поместить его прямо в семантическую модель Google.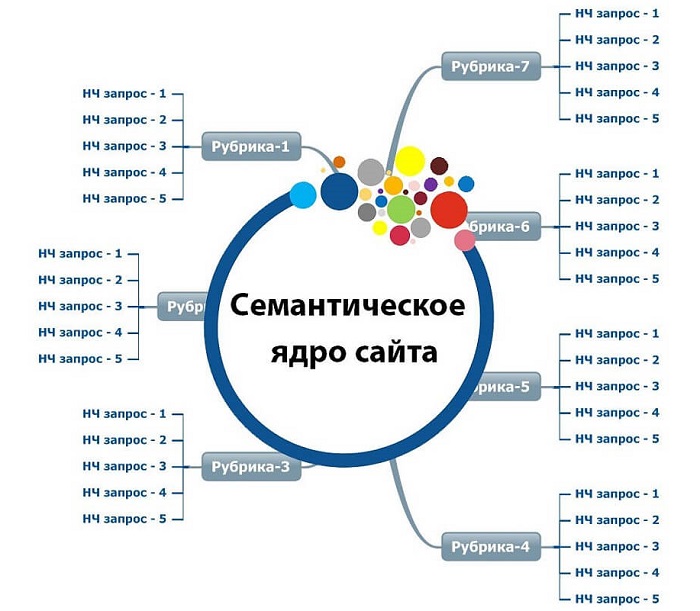 Таким образом, Google знает, что ваш документ будет хорошо соответствовать намерениям искателя.
Таким образом, Google знает, что ваш документ будет хорошо соответствовать намерениям искателя.
Семантическое кодирование
Идея использования кода для выражения смысла (а не только представления) возникла много лет назад, задолго до запуска проекта Schema.org.
В течение многих лет мы использовали семантический HTML для передачи смысла содержания:
- Подзаголовки h2-H6 отображали основные темы документа
- Другие теги HTML выражают больше семантики, в том числе:
Эти теги помогают всем типам машин лучше понимать и передавать информацию, которую они находят на веб-странице.
Например, для доступности рекомендуется использовать следующую разметку для вспомогательных технологий, чтобы знать, где начинается (и заканчивается) цитата и кто цитируется.
Источник изображения: Скриншот создан автором (декабрь 2019 г.)
Вот как HTML-теги добавляют смысл документа, и почему мы называем их семантическими тегами.
Когда в 2011 году была создана Schema.org, владельцам веб-сайтов было предложено еще больше способов передать смысл документа (и его различных частей) машине. С этого момента мы можем указать поисковому роботу автора страницы, тип контента (статья, часто задаваемые вопросы, обзор и другие подобные страницы) и его цель (проверка фактов, контактные данные и т. д.). .
Так зачем кому-то интересоваться семантическим кодированием?
Семантическая разметка существует по одной причине –
Желание общатьсяМы хотим объяснить поисковой системе цель и структуру нашего контента.
С помощью семантической разметки Google может идентифицировать и использовать ключевую информацию со страницы. Взамен веб-издатели получают «расширенные фрагменты», то есть поисковые списки, которые являются более подробными, чем те, которые не используют семантику.
Чтобы помочь вам с семантическим кодированием, существует множество инструментов:
- Приложение Schema помогает практически с любой существующей разметкой структурированных данных
- Для пользователей WordPress создано множество подключаемых модулей, в том числе схема просмотра, схема часто задаваемых вопросов и многое другое.

Наконец, недавний проект под названием inLinks помогает добавлять структурированные данные на ваши страницы на основе их собственного семантического анализа.
Источник изображения: Скриншот создан автором (декабрь 2019 г.))
Заключение
Проще говоря, семантический анализ — это попытка преодолеть разрыв между алгоритмом поиска, веб-страницами, которые он возвращает, и пользователями поисковой системы:
- Человек хочет что-то найти, и у поисковой системы есть две задачи. решить — понять, чего хочет пользователь, и сопоставить это намерение с веб-документами, которые лучше всего справляются с этой задачей .
- Поисковик должен понимать, что он хочет найти. Семантический анализ используется для лучшего понимания цели поискового запроса
- Поисковая система должна сопоставить это намерение запроса с веб-страницами, имеющимися в индексе. Семантическое кодирование можно использовать, чтобы объяснить поисковой системе, что находится на странице и соответствует ли это намерению запроса.
