
Быстрый сбор и кластеризация семантики от Megaindex — Сосновский.ру
* На правах рекламы
Привет, друзья! Современные тенденции в создании и продвижении сайта существенно отличаются от прежних. Если лет 5-6 назад оптимизаторы «пыхтели» над выбором площадок в sape и составлением уникальных околоссылочных текстов, то сейчас, в первую очередь, акцент делается на внутренних факторах.
Успех проекта во многом зависит от фундаментальных вещей: семантическое ядро, правильная структура ресурса, распределение ключевых слов по страницам, создание качественного контента. Сегодня я как раз остановлюсь на семантике и на способах ее сбора и кластеризации с помощью сервиса от Megaindex, который существенно экономит время, нервы и деньги.
«Подбор и кластеризация запросов» — так называется новое и актуальное приложение в системе Мегаиндекс, которое призвано помогать вебмастерам и оптимизаторам собирать и группировать семантическое ядро в автоматическом режиме.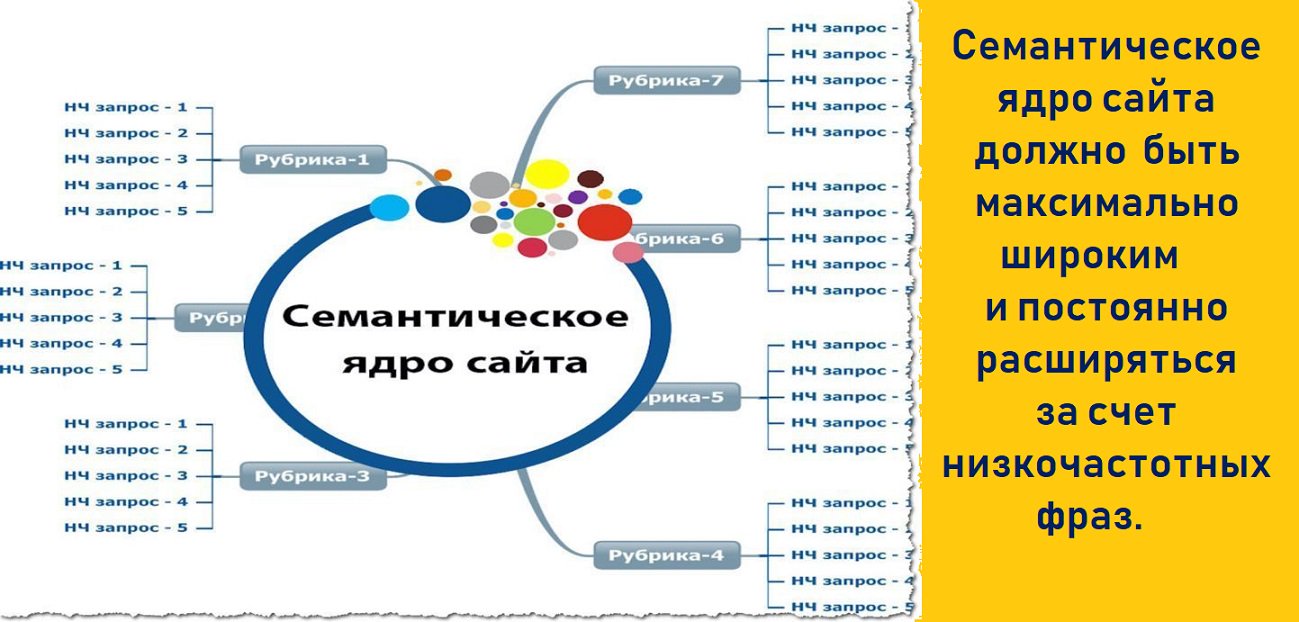
Кто-нибудь из вас хоть раз создавал семантику для более-менее крупного проекта (хотя бы на 100-200 страниц)? Если да, то знаете, насколько это долгая и кропотливая работа. Она занимает ни одни сутки. Автоматизация сбора ключевых слов для создания сайта развивается относительно давно. Распределение поисковых запросов по страницам также очень затратный по времени процесс, который сейчас можно автоматизировать с помощью сервиса от Megaindex.

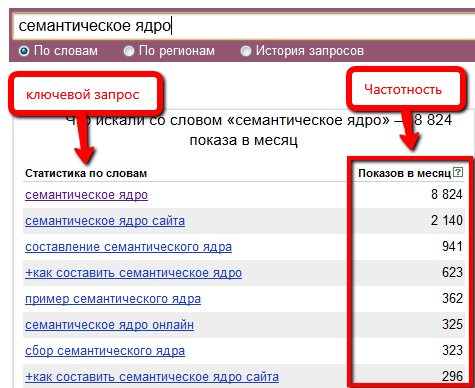
Давайте, я покажу вам все на примере . Вы даже можете повторять все за мной, перейдя по этой ссылке. Сейчас я в процессе поиска рулонных штор, поэтому решил, что пример буду показывать на основе этой тематики.
Сбор семантики на основе запросов конкурентов
Сервис позволяет собирать семантическое ядро, основываясь на ключевые слова ваших конкурентов. Как это делается? Вбиваете адрес вашего ресурса (если он только планируется, то URL ближайшего конкурента — как, например, сделал я), выбираете регион и нажимаете «Показать».
Система найдет ваших ближайших соперников по поисковой выдаче и предложит дополнительные варианты.
На этом этапе вы можете как добавить, так и убрать какие-то определенные проекты. Чем более схожи будут сайты конкурентов, тем более качественнее будут ключевые слова. После редактирования нажимаете «Продолжить». Приложение выдаст поисковые запросы, по которым ваши соперники ранжируются в поиске.
Буквально за минуту можно получить довольно широкий список ключевых слов для вашего сайта.
Этап выбора конкурентов можно пропустить и загрузить свои ключевые слова.
Для примера я собрал ключевые слова по рулонным шторам и отобрал те, которые имеют частотность («!») по wordstat больше 10 (система также умеет удалять запросы меньше определенной частотности). У меня получилось 856 ключей. Отличное количество для небольшого нишевого проекта. Нажимаю на «Запросы» и «Добавить». Далее перехожу к группировке «Перейти к кластеризации».
Кластеризация запросов на основе поисковой выдачи
На этом шаге необходимо выбрать количество совпадений страниц в ТОП 10. Важная особенность! Группировка ключевых фраз происходит, основываясь на результатах поисковой выдачи. То есть если запросы встречаются на нескольких страницах в серпе, то они относятся в один кластер.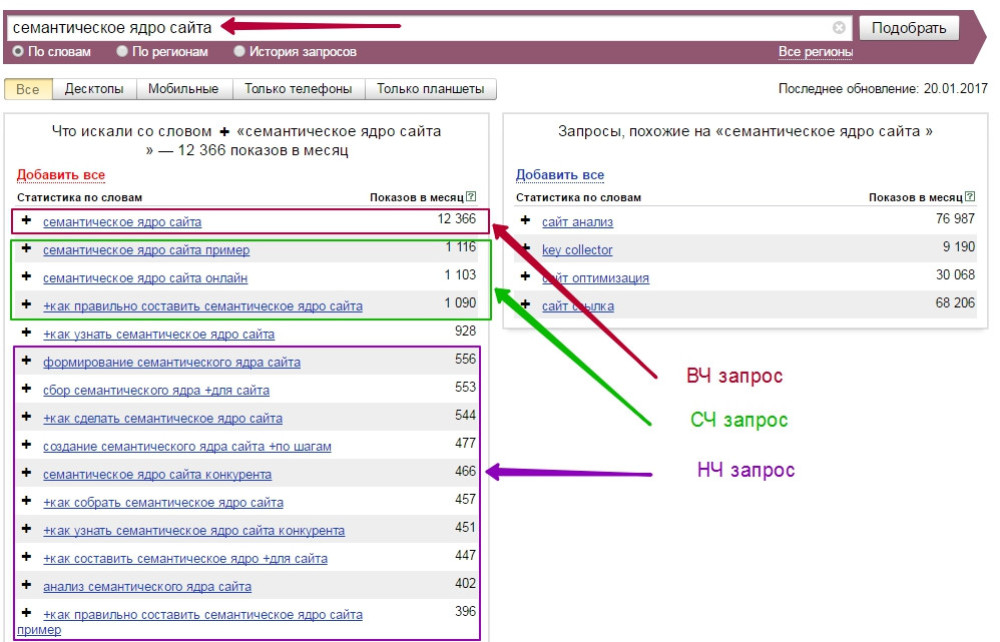 Значение 4 будет таким стандартным показателем (хотя можно и поиграться с ним, выбрав 3 или 5). Другими словами, распределение происходит не в разрез поисковым алгоритмам, а взаимодействуя с ними.
Значение 4 будет таким стандартным показателем (хотя можно и поиграться с ним, выбрав 3 или 5). Другими словами, распределение происходит не в разрез поисковым алгоритмам, а взаимодействуя с ними.
Дополнительно можно расширить кластеры связанными ключами, но также их можно будет добавить для каждой группы после кластеризации. Нажимаем кнопку «Кластеризовать», и ждем пока сервис обработает все данные. Моя группировка на 856 запросов заняла порядка 3-х минут. А сколько времени заняло бы ручное распределение ?
Получилось всего 432 кластера. Многие из них представляют собой готовые семантические ядра для отдельных посадочных страниц (пример на скриншоте). Напротив каждой группы есть общее число запросов, которое является суммой запросов отдельных фраз. Практически каждый кластер можно расширить дополнительными ключевыми словами.
Нажав на «Расширить», дополнительно получаем релевантные запросы, которые можно добавить в кластер и в будущем использовать на продвигаемых страницах.
Если какие-то кластеры не подходят или находятся не на своих местах, то их можно удалить, добавить в них ключи из другой группы или объединить выделенные запросы в отдельный кластер. На этом этапе необходима ручная работа. Как бы ни хотелось, но без человеческого вмешательства качественное семантическое ядро еще создать нельзя. Хотя Мегаиндекс приближает нас к этому моменту и существенно экономит время .
Вверху в уведомлениях вы всегда сможете найти ссылку на вашу группировку, что, несомненно, является удобным моментом. Все кластеры можно выгрузить в .csv файл и работать с ними уже в excel.
Тарифы
Нравится в Megaindex то, что многие сервисы и приложения являются бесплатными. Так и здесь самый первый тариф — бесплатный. Он предполагает кластеризацию до 1000 запросов. Для небольшого проекта этого будет вполне достаточно. Если же вы занимаетесь семантикой профессионально с большим объемом ключевых слов, то для вас существуют следующие тарифы (при оплате за несколько месяцев скидка до 20%).
Вполне адекватные цифры. Тем более, сколько экономят время . Уверен, что это еще не окончательный вариант сервиса и в будущем (надеюсь, ближайшем) у него появятся какие-нибудь дополнительные параметры. Например, вывод данных по конкуренции для отдельных кластеров/ключевых фраз, добавление минус-слов. Таким образом, можно было бы браться сначала за частотные запросы с невысокой конкуренцией. У Мегаиндекса есть огромные (точнее мега ) аналитические данные по ТОПу. Их можно использовать и при группировке.
Итак, регистрируйтесь в системе, пробуйте приложение и оставляйте ваши комментарии ниже. Мысли, отзывы, ошибки — все будет интересно, полезно не только мне, но и разработчикам . Для тех же, кто любит видео-формат, Михаил Шакин записал подробный ролик по работе кластеризатора. Приятного просмотра.
Формируем семантическое ядро за 15 минут — SEO на vc. ru
ru
{«id»:65983,»url»:»https:\/\/vc.ru\/seo\/65983-formiruem-semanticheskoe-yadro-za-15-minut»,»title»:»\u0424\u043e\u0440\u043c\u0438\u0440\u0443\u0435\u043c \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0435 \u044f\u0434\u0440\u043e \u0437\u0430 15 \u043c\u0438\u043d\u0443\u0442″,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/seo\/65983-formiruem-semanticheskoe-yadro-za-15-minut»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/seo\/65983-formiruem-semanticheskoe-yadro-za-15-minut&title=\u0424\u043e\u0440\u043c\u0438\u0440\u0443\u0435\u043c \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0435 \u044f\u0434\u0440\u043e \u0437\u0430 15 \u043c\u0438\u043d\u0443\u0442″,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.

12 888 просмотров
подробный гайд для новичков — Блог — Линкбилдер
Составление семантического ядра — это первый и очень важный этап перед стартом продвижения любого сайта. При этом не имеет значения, готовите ли вы рекламную кампанию в контекстной рекламе или собираетесь продвигать сайт в поисковых системах естественными ссылками, уже на начальном этапе очень важно понимать как потенциальные клиенты будут искать ваши товары и услуги в Интернете.
Под семантическим ядром понимается структурированный набор фраз, выражений, синонимов и вообще любых словосочетаний, которые максимально подробно описывают товары и услуги вашего сайта. Говоря простым языком, семантическое ядро — это те самые запросы, которые пользователи будут вводить в поисковую строку, чтобы попасть на ваш сайт, а если не повезет — то на сайт конкурентов.
Конечно, по-хорошему, прорабатывать «семантику» (так очень часто SEO-специалисты сокращают термин семантическое ядро) необходимо еще до создания сайта. Так, вы сможете заранее создать правильную структуру сайта и необходимые посадочные страницы (страницы, связанные с конкретными запросами). Это в значительной степени облегчит дальнейшее продвижение сайта и снизит трудозатраты на разработку. Но по естественным причинам, когда речь идет о первом опыте продвижения и тем более первом опыте создания сайта, вопросы о «семантически правильной» структуре проекта возникают далеко не сразу.
Основные виды запросов
Чтобы правильно собрать семантическое ядро, важно понимать, что не все запросы могут привести нужную аудиторию, поэтому их принято делить на три основные группы:
- Транзакционные (коммерческие)
- Информационные (некоммерческие)
- Навигационные
Для продвижения коммерческого сайта (интернет-магазина, сайта услуг) нам необходимо выбирать запросы, которые смогут привести на сайт клиентов, т. е. транзакционные запросы. К ним относятся фразы, в основе которых лежит покупательский интерес. Например, «квартиры до 3 млн», «магазин сантехники», «ламинирование волос в Москве». Такие фразы также часто содержат слова «купить», «цена», «заказать», «доставка», «недорого» и т. п. Например, доставка пиццы, заказать суши, ремонт холодильника недорого.
е. транзакционные запросы. К ним относятся фразы, в основе которых лежит покупательский интерес. Например, «квартиры до 3 млн», «магазин сантехники», «ламинирование волос в Москве». Такие фразы также часто содержат слова «купить», «цена», «заказать», «доставка», «недорого» и т. п. Например, доставка пиццы, заказать суши, ремонт холодильника недорого.
В отличие от транзакционных, информационные запросы имеют под собой другую основу и хоть и могут привести посетителей на ваш сайт, покупать они, скорее всего, ничего не будут. Такие запросы связаны с поиском информации и, как правило, не подразумевают транзакций. Например, «как поменять кран в ванной», «как удалить программу с компьютера», «как сварить кисель без комочков» и т.п. Если, конечно, вы мастер слова и можете продать снег даже эскимосу, то при определенном подходе вы сможете превратить посетителя, пришедшего по информационному запросу в вашего клиента, но! Здесь важно понимать, что поисковая система никогда не будет ранжировать коммерческий сайт (или страницу) по информационным запросам. Поэтому вам придется либо создавать на сайте отдельный блог, либо договариваться о размещении нужных статей с профильными блогерами, но это уже совсем другая история.
Поэтому вам придется либо создавать на сайте отдельный блог, либо договариваться о размещении нужных статей с профильными блогерами, но это уже совсем другая история.
Наконец, третий тип запросов (навигационные запросы) — это запросы, связанные с поиском конкретного места или бренда. Например, «Кафе Му-му адрес на бауманской» или «адреса всех магазинов Летуаль», «сервис Линкбилдер». Чтобы попасть в ТОП по названию вашего бренда достаточно указать его в заголовках страниц, а также составить подробную страницу контактов, с указанием адреса, схемы проезда и т.д. Не лишним будет добавить вашу организацию в справочник организаций Яндекс и Google, а также популярные сервисы отзывов, наподобие https://www.yell.ru. В этом случае, даже если пользователь промахнется мимо вашего сайта и выберет сайт популярного «отзовика», он сможет получить достоверную и правильную информацию о вашем бизнесе.
Частотность запросов
Частотность запроса отражает количество раз, которое запрос был набран в поисковой системе за месяц. Особенно подчеркиваем, что речь идет именно про показы запроса, а не про трафик. Наличие вашего сайта даже на первом месте не гарантирует, что 100% пользователей, набравших этот запрос, перейдут на ваш сайт. Некоторые пользователи могут уйти по контекстной рекламе, некоторые на другие сайты, потому что у конкурента, например, указана привлекательная цена в заголовке. Кроме того, часть статистики накручена различным SEO-софтом по сбору позиций и т.д., поэтому при прогнозе трафика старайтесь избегать завышенных ожиданий. Различные исследования показывают, что сайты, стоящие на первой строчке поисковой выдачи собирают не более 25% всего трафика по запросу, последним же (на 9-10-ом местах) достается 2-3%, не более. На второй и тем более третьей странице выдачи живут одни боты, реальных людей там практически нет.
Проверить частотность запроса можно в сервисе https://wordstat.yandex.ru/
Как правило, по частотности запросы также делят на три группы:
- Высокочастотные (ВЧ)
- Среднечастотные (СЧ)
- Низкочастотные (НЧ)
Точного деления по частотности не существует, для каждой тематики эти показатели свои. Например, для фильмов онлайн, низкочастотными можно назвать запросы ниже 1000 показов в месяц, а для условных глубоководных сварочных аппаратов запросы выше 100 показов — уже запредельная радость.
Также учитывайте, что по умолчанию, Wordstat выдает цифру, которая включает в себя статистику показов всех словоформ искомого запроса. Если вы запросите данные, например, по слову «смартфон» (без кавычек), то узнаете суммарное количество раз, где это слово было использовано, например, в запросах «купить смартфон», «смартфоны эппл» и т.д. Чтобы получить «чистый» показатель, запрос необходимо взять в кавычки и добавить восклицательный знак, т.е. вот так: «!смартфон».
Почему важно собрать полное семантическое ядро?
Полное семантическое ядро даже среднего по величине интернет-магазина может достигать десятки тысяч фраз. Соберите воедино все товарные группы, сами товары, артикулы, фильтры по цвету / году / размеру / полу и т.д., популярные теги и вы поймете, откуда берутся такие масштабы. Безусловно, в зависимости от тематики эти цифры могут сильно разниться.
Безусловно, в зависимости от тематики эти цифры могут сильно разниться.
Имея в своем распоряжении полную «семантику», вы будете видеть:
- Общую динамику роста сайта по запросам (сайт растет или падает).
- Какие группы товаров получают мало трафика (точки роста).
- Тренды и сезонность спроса.
- Возможные проблемы на сайте (просели позиции по определенным группам запросов).
- Товары (услуги), на которые есть стабильный спрос, но у вас они не продаются (но могут).
Эти данные, во-первых, помогут раскрыть потенциал вашего сайта, слабые места над которыми стоит поработать в первую очередь, во-вторых, вовремя зафиксировать и устранить проблемы. Мы практически ежедневно сталкиваемся с ситуациями, когда по ошибке разработчиков на сайте пропадают целые разделы, что непременно сказывается на позициях и трафике по определенным группам товаров. Поисковые системы реагируют достаточно быстро и удаляют из выдачи пустые (битые) страницы.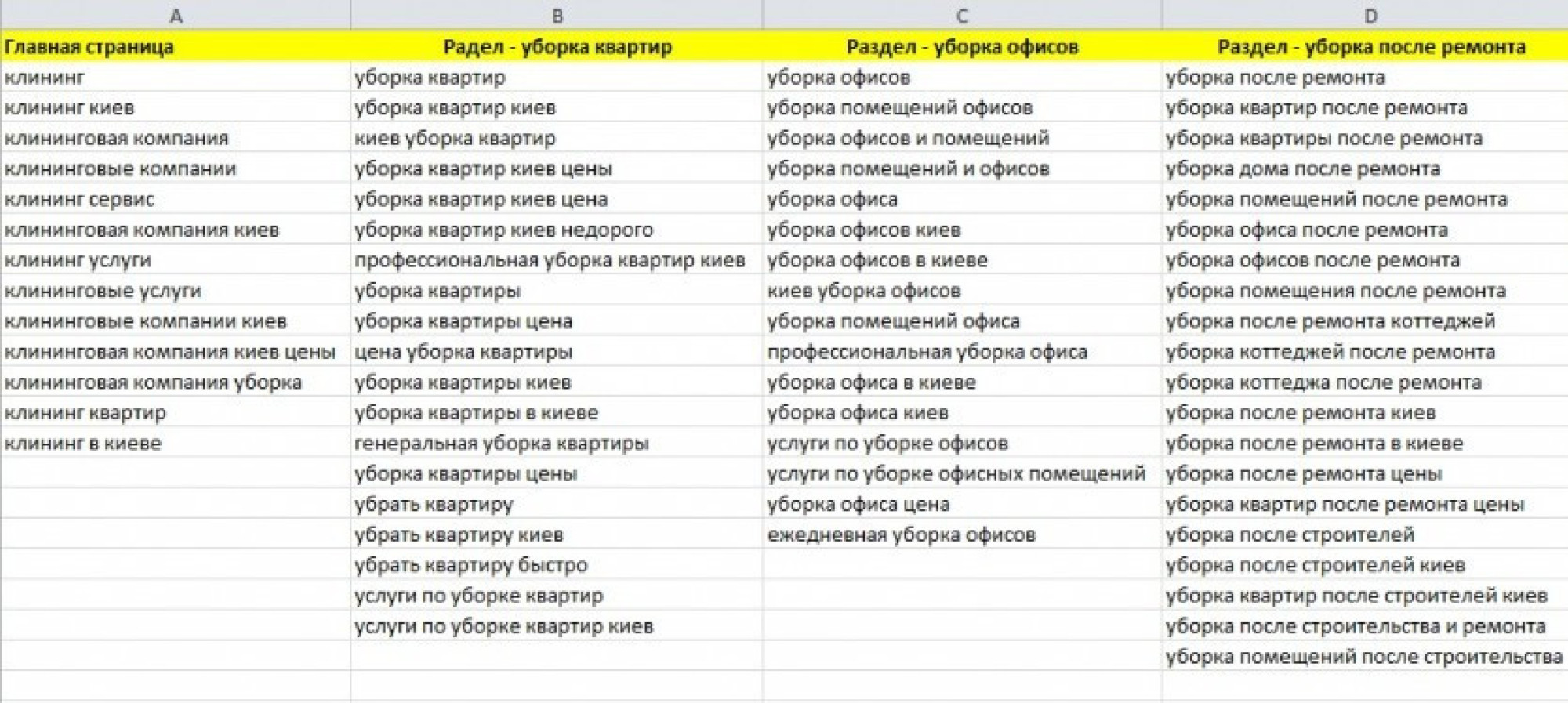 Имея перед собой полную картину видимости сайта по запросам, вы сможете понять, где следует «копать» в первую очередь.
Имея перед собой полную картину видимости сайта по запросам, вы сможете понять, где следует «копать» в первую очередь.
Как собирать запросы для семантического ядра
Сбор полного ядра — процесс не быстрый и требует значительных временных затрат и концентрации. Старайтесь не поручать работу одному человеку или делать все самому. Лучшим решением будет разделить задания между несколькими людьми по товарным категориям и желательно, чтобы каждый специалист обладал хорошими знаниями в той области, которую ему доверяют. Часто бывает, что сотрудник с низкой компетенцией может пропустить или удалить важный запрос. Например, запрос «смартфоны nfc» неподготовленный человек может отнести к какому-нибудь китайскому бренду и исключить его из списка, поскольку на сайте такого бренда нет. Но на деле под этим запросом понимаются смартфоны, имеющие на борту чип для бесконтактной оплаты NFC. И таких смартфонов в любом специализированном интернет-магазине наберется ни один десяток. Возможно, пример с NFC и не самый показательный, но думаем, что суть вы уловили..jpg) Особенно будьте осторожны, когда доверяете сбор семантики фрилансерам и вдвойне осторожней, когда речь идет о сложных B2B-тематиках, где без специальных знаний совсем тяжело.
Особенно будьте осторожны, когда доверяете сбор семантики фрилансерам и вдвойне осторожней, когда речь идет о сложных B2B-тематиках, где без специальных знаний совсем тяжело.
Теперь мы пробежимся по наиболее распространенным способам сбора «семантики».
Wordstat
Сервис https://wordstat.yandex.ru/ можно считать первоисточником, любые другие инструменты так или иначе взаимодействуют с данными «поисковика». Для начала выберите несколько запросов, которые характеризуют ваш бизнес максимально точно. Предположим, вы владелец интернет-магазина смартфонов. Отталкивайтесь от того, как бы вы сами искали любой подобный магазин в поисковой системе. Возьмем для примера запрос «купить смартфон».
В левой колонке мы видим фразы, которые пользователи искали вместе со словом «купить смартфон».
Помните, что из списка полученных фраз необходимо исключить все некоммерческие запросы, например, «какой смартфон купить в 2018 году», а также запросы, несвязанные с вашим бизнесом, для примера, «мтс купить смартфон по акции» (если, конечно, вы не сотрудник МТС).
Если вы сомневаетесь к какому типу относится запрос (коммерческий или нет), просто «вбейте» его в «поисковик» и посмотрите на результаты выдачи. Если в выдаче преобладают блоги и журналы, то запрос, скорее всего, информационный.
Выдача по запросу «какой смартфон купить в 2018 году», одни информационные сайты
В правой колонке «Яндекс» показывает нам фразы, похожие на искомый запрос, но мусора здесь однозначно больше. Используйте только те фразы, которые реально отражают суть вашего бизнеса, естественно также, исключая информационные запросы, вроде «хороший смартфон». Правую колонку хорошо использовать для поиска синонимов. Например, редкий человек может сходу правильно написать бренд китайской компании Xiaomi. Можно встретить и «ксиоми», и «сиаоми» и «сяоми». Все эти варианты также следует включить в состав ядра.
Перебирая запрос за запросом, вы непременно заметите, что потенциальные клиенты ищут смартфоны по нескольким критериям:
- Цена (купить недорогой смартфон)
- Бренд (купить смартфон xiaomi, купить смартфон samsung)
- Модель (купить смартфон xiaomi redmi)
- Характеристики (смартфон 32gb купить)
- Регион (купить смартфон в москве, купить смартфон в спб)
Благодаря этим данным, вы можете составить так называемые маски запросов, такие как:
- Смартфон + действие (купить, заказать, с доставкой по России).
- Смартфон + цена (недорого, дешево, по акции, до 10 тыс, до 20 тыс, до 30 тыс).
- Смартфон + бренд (Samsung, Apple).
- Смартфон + бренд + модель (Samsung Galaxy S9+, Apple iPhone X).
- Смартфон + характеристика (32 гб, с NFC, 6 дюймов, с 2мя sim-картами).
- Смартфон + что-то еще (для бабушки, с большой автономностью и т.п.).

Выделив основные маски запросов, вы сможете:
- Корректно распределить посадочные страницы на сайте по группам товаров и их характеристикам.
- Создать страницы под популярные поисковые запросы (как, например, смартфон для бабушки).
- Тиражировать выбранные маски запросов на все остальные товарные категории.
- Шаблонизировать сбор семантического ядра.
На данном этапе мы не рекомендуем придавать особое значение частотности запроса, включайте в список любые непустые фразы (с частотой от 1), которые связаны с вашим бизнесом. Какие фразы вы используете непосредственно для продвижения и рекламы — вопрос вторичный.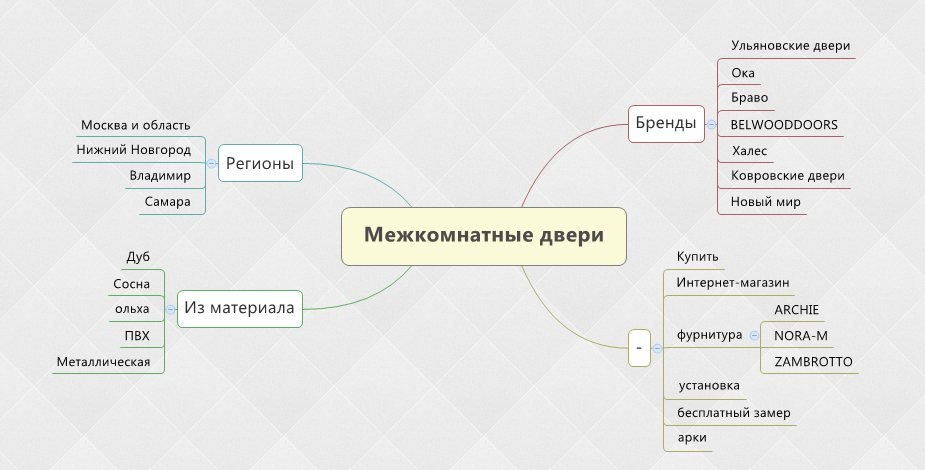 На первом этапе главное собрать полноценное семантическое ядро, почему это важно мы уже сказали ранее.
На первом этапе главное собрать полноценное семантическое ядро, почему это важно мы уже сказали ранее.
Rush Analytics
Сервис Rush Analytics позволяет в значительной степени автоматизировать сбор запросов из левой колонки Wordstat и выгрузить данные в таблицу Excel.
Для нашего примера достаточно запустить сбор ключевых слов по запросам «смартфон» и «телефон». Правда, здесь есть один важный нюанс. По умолчанию, Wordstat отдает всего 41 страницу результатов. Как вы понимаете, все запросы таким методом мы не получим. Чтобы обойти ограничение, существует метод сбора частотности для запросов заданной длины (до 7 слов).
Для этого добавляем запросы в сервис следующим образом (кавычки обязательны):
- «смартфон смартфон»
- «смартфон смартфон смартфон»
- «смартфон смартфон смартфон смартфон»
и так далее до 7 слов.
Тоже самое следует проделать и с запросом «телефон».
С помощью этого метода вы сможете собрать максимальное количество запросов в вашей тематике.
Мы не будем подробно останавливаться на интерфейсе сервиса, для этого наши коллеги подготовили понятную инструкцию вместе с видео: https://www.rush-analytics.ru/faq/sbor-yandex-wordstat-rukovodstvo
Spywords.ru
Сервис spywords.ru позволяет немного схитрить и собрать семантику не с нуля, а с помощью ваших конкурентов.
Суть работы предельно проста: вы выбираете 3-4 лидера в нише и собираете все фразы, по которым они ранжируются в поисковых системах в пределах ТОП100.
Запросы конкурента в ПС Яндекс
Безусловно, таким образом, вы вряд ли соберете полноценное семантическое ядро, но процентов 60 охватить вполне возможно и для старта этого может быть достаточно.
Где еще можно подсмотреть запросы?
В прошлой статье ТОП-10 ошибок на старте продвижения сайта мы уже говорили, что нужно не пренебрегать статистикой собственного сайта. Если ваш проект уже запущен и собирает небольшой трафик, изучите статистику переходов из поисковых систем и включите эти запросы в семантическое ядро.
Узнать по каким запросам ранжируется ваш сайт можно в системах Яндекс.Метрика или Google Analytics, а также в сервисах Яндекс.Вебмастер и Google Search Console.
Статистика переходов по поисковым фразам из Яндекс.Метрики
Статистика поисковых запросов из панели Яндекс.Вебмастер
Если на вашем сайте также есть поиск, попросите ваших разработчиков сохранять историю запросов ваших клиентов.
Кластеризация запросов
Предположим, что вы собрали все необходимые фразы, почистили дубли, избавились от лишних запросов. Теперь перед вами огромный файл с тысячами ключевых слов. Все эти ключевые фразы нужно распределить по группам.
Последние годы широкую популярность получил метод автоматизированной кластеризации запросов на основе сравнения поисковой выдачи. Говоря простым языком, кластеризация показывает, какие запросы можно продвигать на одну страницу, а какие нет. С помощью кластеризации вы увидите, что, например, запросы «мобильные телефоны» и «сотовые телефоны» можно продвигать на одну страницу, а запросы «смартфоны Apple» и «дешевые смартфоны» не стоит.
Произвести кластеризацию можно с помощью все того же сервиса Rush Analytics. Интерфейс данного функционала также очень простой, но если что инструкция прилагается: https://www.rush-analytics.ru/faq/klasterizaciya-zaprosov-semanticheskogo-yadra-rukovodstvo
Что делать дальше?
Теперь, когда ядро собрано, а запросы разделены по группам, самое время заняться оптимизацией вашего сайта. Ваша цель — обеспечить каждой группе запросов посадочную страницу. Позаботьтесь, чтобы на сайте была четкая структура каталога и понятная навигация по разделам. Каждый бренд, товар, фильтр и интерес пользователя должны получить отдельную посадочную страницу с уникальными мета-тегами и описанием. В ближайших статьях мы обязательно поговорим о том, как создать идеальную, с точки зрения поисковой системы, посадочную страницу.
Заключение
Важно понимать, что ежедневно появляются новые товары, меняются интересы и предпочтения пользователей, поэтому очень важно оставаться на гребне волны и вовремя реагировать на новые тренды.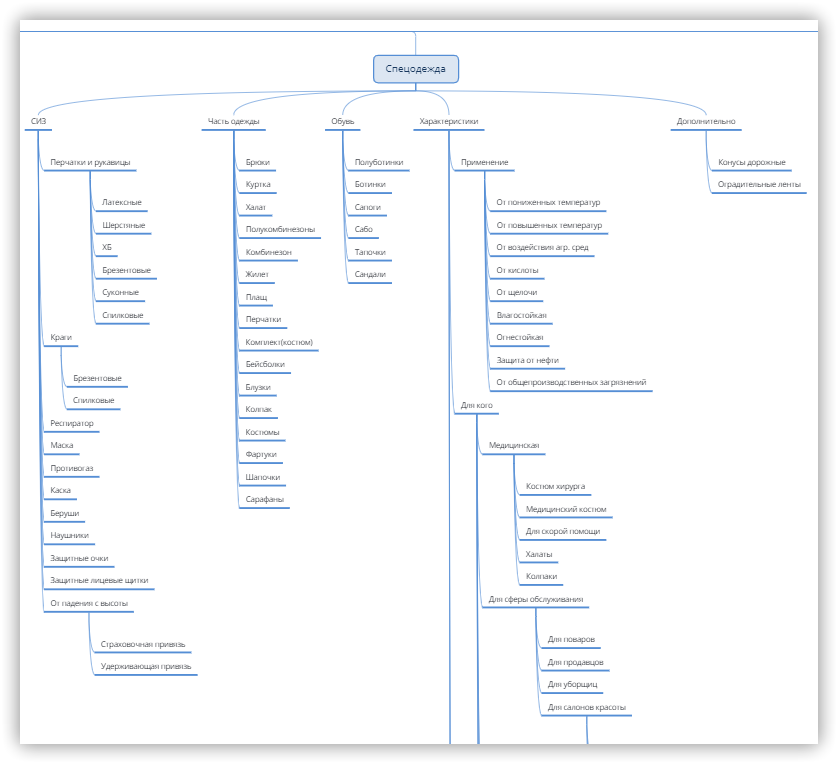 Понятно, что в ежедневном потоке дел не всегда удается посветить все время аналитике, но собрать «семантику» лишь один раз и не работать дальше в этом направлении — решение без перспектив.
Понятно, что в ежедневном потоке дел не всегда удается посветить все время аналитике, но собрать «семантику» лишь один раз и не работать дальше в этом направлении — решение без перспектив.
Старайтесь больше внимания обращать на ваших конкурентов. Как на тех, кто уже присутствует на рынке давно, так и на новичков. На последних мы бы рекомендовали смотреть даже более пристально, ведь им приходится заходить на конкурентный рынок и сделать это без каких-либо даже минимальных инноваций крайне сложно. Конкурировать одной лишь ценой крайне сложно. На том же рынке смартфонов появляется все больше игроков, которые предлагают Trade-In (обмен старого смартфона на новый с доплатой), а также продажу смартфона по подписке. Постепенно потенциальные покупатели привыкнут к новым сервисам, а игрокам, которые не пожелают модернизировать бизнес, придется уйти с рынка. Надеемся, что вы будете не из их числа.
Успешного продвижения!
Как собрать семантическое ядро для сайта: подробный гайд
РекламаЕсли вы решили развивать сайт самостоятельно, эта статья — это то, что вам нужно, поскольку поисковое продвижение нужно будет начать именно с построения семантического ядра.
Оглавление:
1. Что такое семантическое ядро сайта
2. Как построить структуру сайта
3. Что нужно знать о ключевых словах
3.1. Какие ключи использует аудитория
3.2. Что нужно знать об анатомии поисковых запросов
4. Сервисы для составления семантического ядра:
- Key Collector
- SlovoEB
- Сервис подбора ключевых слов «Яндекс»
- Планировщик ключевых слов Google
- Статистика запросов «Поиск Mail.ru»
- Serpstat
- «Мутаген»
- SemRush
- Keyword Tool
- Rush Analytics
- SEMparser
- Системы аналитики
- Сервисы анализа сайтов-конкурентов
5. Как подобрать ключевые слова для семантического ядра
5.1 Определяем базовые ключи
5.2 Расширяем семантическое ядро
5.3 Удаляем неподходящие поисковые фразы
6. Как группировать ключевые слова и строить карту релевантности
7. Что делать с семантическим ядром
8. Что нельзя делать с семантическим ядром, или Как все-таки не превратиться в олдскульного сеошника
9. Семантическое ядро: маркетинг или SEO
Семантическое ядро: маркетинг или SEO
Самый эффективный источник привлечения трафика — естественный поиск. Необходимо сделать сайт интересным и видимым для пользователей «Яндекса» и Google. Достаточно определить, чем интересуется ваша аудитория и как она ищет информацию. Эта задача решается при построении семантического ядра.
Теперь разберемся, что же такое семантическое ядро.
Семантическое ядро — набор слов и словосочетаний, отражающих тематику и структуру сайта. Семантика — раздел языковедения, изучающий смысловую наполненность единиц языка. Поэтому термины «семантическое ядро» и «смысловое ядро» тождественны.
Какую информацию можно найти на вашем сайте, а главное, с помощью каких поисковых запросов пользователи ищут информацию, которая будет опубликована на сайте — к этим вопросам нужен серьезный подход при составлении смыслового ядра, поскольку одним из главных принципов бизнеса и маркетинга считается клиентоориентированность.
Распределении поисковых фраз по страницам ресурса — еще одна из задач, которую решает построение смыслового ядра. Вы определяете, какая страница точнее всего отвечает на конкретный поисковый запрос или группу запросов.
Вы определяете, какая страница точнее всего отвечает на конкретный поисковый запрос или группу запросов.
К решению этой задачи можно подойти с разных сторон.
- Создание структуры сайта по результатам анализа поисковых запросов пользователя. Семантическое ядро будет определять каркас и архитектуру ресурса.
- Предварительное планирование структуры ресурса до анализа поисковых запросов. Семантическое ядро будет распределяться по готовому каркасу.
Конечно, логичнее сначала планировать структуру сайта, а потом определять запросы, по которым пользователи смогут найти ту или иную страницу. В этом случае вы сами выбираете, что хотите рассказывать потенциальным клиентам, то есть остаетесь проактивным. Если же вы подгоняете структуру ресурса под ключи, то остаетесь объектом и реагируете на среду, а не активно ее меняете. Так что оба подхода работают, вопрос только в эффективности и рациональности.
«Сеошный» и маркетинговый подходы к построению ядра резко различаются. Вот логика «сеошника»: чтобы создать сайт, нужно найти ключевые слова и выбрать фразы, по которым просто попасть в топ выдачи. После этого необходимо создать структуру сайта и распределить ключи по страницам. Контент страницы нужно оптимизировать под ключевые фразы.
Бизнесмен или маркетолог будут рассуждать так: нужно решить, какую информацию транслировать аудитории с помощью сайта. Для этого необходимо хорошо знать свою отрасль и бизнес. Сначала нужно запланировать приблизительную структуру сайта и предварительный список страниц. После этого при построении семантического ядра надо узнать, как аудитория ищет информацию. С помощью контента необходимо отвечать на вопросы, которые задает аудитория.
В первом случае падает информационная ценность ресурса. SEO необоснованно отсеивают часть перспективных поисковых запросов. Это объясняется высокой конкурентностью или низким коэффициентом KEI, низкой частотностью, «мусорностью» ключей и т.д. А бизнес должен формировать тренды и выбирать, что говорить клиентам. Бизнес не должен ограничиваться реакциями на статистику поисковых фраз и создавать страницы только ради оптимизации сайта под какой-то ключ.
Бизнес не должен ограничиваться реакциями на статистику поисковых фраз и создавать страницы только ради оптимизации сайта под какой-то ключ.
Список ключевых запросов, распределенных по страницам сайта, который, собственно, является результатом построения семантического ядра, содержит URL страниц, поисковые запросы и указание их частотности.
Структура сайта — иерархия страниц. С помощью иерархической схемы решается несколько задач. Вы планируете информационную политику и логику подачи информации, обеспечиваете юзабилити ресурса, обеспечиваете соответствие сайта требованиям поисковых систем.
Для того, чтобы построить структуру, воспользуйтесь удобным вам инструментом: редакторами таблиц, MS Word, другим ПО, либо взять лист бумаги и нарисовать структуру на нем.
Ответьте на два вопроса:
- Какую информацию вы хотите сообщить пользователям?
- Где следует опубликовать тот или иной информационный блок?
Например, что планируете структуру сайта небольшой кондитерской. Ресурс включает информационные страницы, раздел публикаций и витрину или каталог продуктов. Визуально структура может выглядеть так:
Ресурс включает информационные страницы, раздел публикаций и витрину или каталог продуктов. Визуально структура может выглядеть так:
Далее оформите структуру сайта в виде таблицы. В ней укажите названия страниц и обозначьте их подчиненность. Также включите в таблицу:
- колонки для указаний URL страниц,
- ключевых слов
- их частотности.
Таблица может выглядеть так:
Колонки URL, «Ключи» и «Частотность» вы заполните позже. Сейчас переходите к поиску ключевых слов.
Вы должны понимать, что такое ключевые слова и какие ключи использует аудитория. С этими знаниями вы сможете корректно использовать один из инструментов для подбора ключевых слов.
Какие ключи использует аудитория
Чтобы найти необходимую информацию потенциальные клиенты используют определенные слова и фразы. Это и есть ключи.
Например, чтобы приготовить торт, пользователь вводит в поисковую строку запрос «наполеон рецепт с фото».
Ключевые слова классифицируются по нескольким признакам. По разным данным, поисковые фразы объединяются в группы так:
- К низкочастотным относятся запросы с частотой показов до 100 в месяц. Некоторые специалисты включают в группу запросы с частотой до 1000 показов.
- К среднечастотным относятся запросы с частотой до 1000 показов. Иногда эксперты увеличивают порог до 5000 показов.
- К высокочастотным запросам относятся фразы с частотой от 1000 показов. Некоторые авторы считают высокочастотными ключи, имеющие от 5000 или даже 10 000 запросов.
Ну а по популярности выделяют высоко-, средне- и низкочастотные запросы.
Разница в оценке частотности связана с разной популярностью тематик. Если вы создаете ядро для интернет-магазина, торгующего ноутбуками, фраза «купить ноутбук samsung» с частотой показа около 6 тыс. в месяц будет среднечастотной. Если вы создаете ядро для сайта спортивного клуба, запрос «секция айкидо» с частотой показов около 1000 запросов будет высокочастотным.
По разным данным, от двух третьих до четырех пятых всех запросов пользователей относятся к низкочастотным. Поэтому вам нужно строить максимально широкое семантическое ядро. На практике оно должно постоянно расширяться за счет низкочастотных фраз.
Однако, без высоко- и среднечастотные запросов вы не обойдетесь. Но в качестве основного ресурса привлечения
Сбор семантического ядра — экспертные мнения, этапы, тонкости в гиде SEO-услуг
Вначале я думал сделать обзор этой довольно популярной и одной из самых важных услуг примерно на уровне прошлой статьи, но и спросить экспертное мнение известных специалистов, которое бы добавляло эксклюзивной ценности. Получив отклики, я понял, что не имею права сделать обычный обзор и выложил максимум по этой теме, уместно разместив мнения специалистов.
Перед тем как приступить к чтению об услуге, советую ознакомиться с временными рисками, о которых рассказывает практикующий специалист
Александр Павлуцкий — практикующий специалист, более 500 выполненных заказов по сбору семантического ядраЕсли человек собирается делать ядро только под один проект (или несколько в год), то гораздо эффективнее потратить время на другие вещи, а само ядро заказать у компетентного специалиста.
Ведь чтобы с ноля понять механику сбора (на какие кнопки тыкать), надо минимум 20 часов чистой работы. А чтобы понять стратегию сбора (зачем тыкать сюда, и почему не туда) — нужно же перелопатить огромный массив информации: научиться составлять маски запросов, определять конкуренцию и качество запросов, грамотно кластеризировать, сделать ТЗ копирайтеру — и за каждым этим пунктом стоит десяток-второй подпунктов, выливающихся в сильную потребность в общем понимании SEO.
И даже если сопоставить человека со знаниями, но без опыта и исполнителя со знанием и хорошим опытом работы (лично мне мои ядра начали нравится где-то после 300-ого заказа), то в итоге всё равно выйдут качественно разные ядра. Не легче ли потратить 100-200$ на хорошее СЯ, чем тратить минимум 100 часов обучения на освоение навыка сбора? А плохое ядро вам ничего кроме убытков не принесёт. Подумайте =)Для кого
Для всех владельцев сайтов, которые задумали продвигаться в поисковых системах. Сбор семантического ядра не так актуален для владельцев информационных сайтов, там актуальнее контент-план, который включает семантическое ядро.
Для чего
- Для того, что бы знать под какие запросы оптимизировать страницы
- Для создания корректной структуры сайта
- Для контент-плана
- Для оценки ниши, предварительного прогноза посещаемости и затрат
Что такое семантическое ядро
Семантическое ядро — список поисковых запросов кластеризованные (разбитые) по поисковым группам.
Без грамотного семантического ядра невозможно результативно продвигать сайт. Это ответственный этап, за которым стоит ответ об успешном продвижение.
Представляет из себя Exel файл с разбитыми на листы большие группы, внутри которых конкретные кластеры или поисковые группы
По-мимо поисковых фраз и групп по-дефолту добавляют частотность определяемую в wordstate. Так же в семантическом ядре по-желанию и запросу добавляют: конкурентность, текущее место сайта, точную частотность, цена клика в директе, adwords или бегуне, релевантную страницу на сайте. Однако все эти данные отношу к дополнительным и востребованным по-ситуации.
Пример, когда такие данные используются для определения «вкусных запросов» привел следующий эксперт
Игорь — автор блога altblog.ru
Трудно придумать что-то новое.
Для оценки популярности запроса надо смотреть не только «точное вхождение», но и статистику без кавычек.
Потом можно сравнить общую частотность с точной. Для меня, если первое больше второго в ~100 раз, то это «вкусный» запрос.
Также не стоит забывать про наличие витального сайта в выдаче. Если он есть — добиться топа будет трудновато, но даже наличие в топе может не давать необходимого количества трафика, т.к. большая часть будет уходить на витальный сайт, который не редко занимает более 1 позиции.
Стандартное правило: учитывать количество документов в выдаче и количество главных страниц.
Частотность запроса не влияет на трудность продвижения. Неоднократно были случаи, когда запрос с точной частотностью 20-30 тысяч продвигался намного легче и быстрей, чем с 5000.
СЯ должно охватывать как можно больше вопросов из тематики и раскрывать ее. Запросы должны быть правильно распределены на страницы/разделы, чтобы не мешали друг-другу в продвижении. Включайте спектральные синонимы в тексты статей.
Как делается сбор семантического ядра
Для начала разобьем на этапы сбора:
- Мозговой штурм или подбор семантической основы
- Технический парсинг и раскрытие семантической основы
- Кластеризация
1. Мозговой штурм
Или подбор семантической основы, это подбор опорных выражений, по которым мы будем дальше парсить поисковые фразы.
Например для магазина постельного белья это: постельное белье, простыни, наволочки для подушек, пододеяльники и т.д.
Если сайт у нас уже есть, то мы чаще всего берем начальную основу исходя из существующих разделов и страниц, если нет, то смотрим конкурентов или сами додумываем предполагаемые разделы и страницы.
Для информационных сайтов этот этап особо сложный, т. к. тяжело находить общие опорные выражения, из которых выделяются остальные, тут чаще остальных используется подбор поисковых фраз на основе конкурентного анализа и реже используется сбор сторонним специалистом. Сбор семантического ядра сопряжен с составлением контент-плана и представляет из себя локальный поиск по конкретной темы, а не сбор на основе опорного слова. Это не касается разделов, тегов и главной страницы.
к. тяжело находить общие опорные выражения, из которых выделяются остальные, тут чаще остальных используется подбор поисковых фраз на основе конкурентного анализа и реже используется сбор сторонним специалистом. Сбор семантического ядра сопряжен с составлением контент-плана и представляет из себя локальный поиск по конкретной темы, а не сбор на основе опорного слова. Это не касается разделов, тегов и главной страницы.
Для коммерческих сайтов опорный список чаще всего состоит из ассортимента и услуг самой компании, а так же дополнительные сортировочные запросы, перефразирование ассортимента и услуг и их глубокого дробления. При сборе для контентного раздела коммерческих сайтов учитываются прямые вопросы связанные с деятельностью и затрагиваются проблемы, которые помогает решить компания. Тут уже задействуются принципы поиска тем при классическом контент-маркетинге
Для сервисов (доски объявления, порталы, агрегаторы) подключается максимально внимательный мозговой штурм, при котором по-мимо самих опорных фраз с особой тщательностью анализировать выдачу Яндекса, что бы быть уверенным в возможности соответствовать поисковой фразе и дать корректный ответ.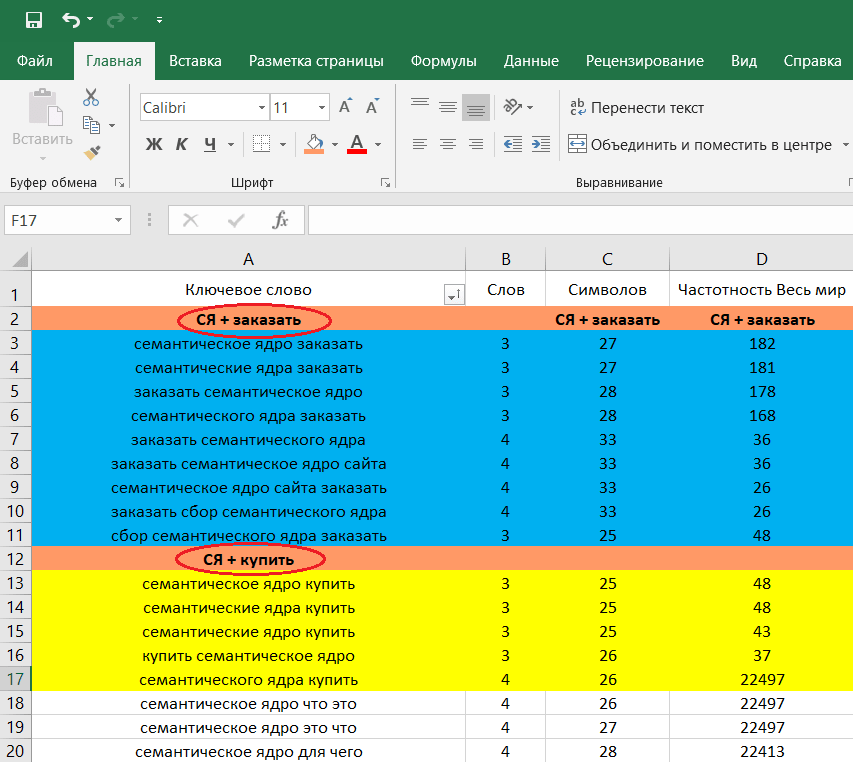 Это трудозатратный этап, т.к. слабо автоматизируется и для крупного сайта это становиться большой проблемой
Это трудозатратный этап, т.к. слабо автоматизируется и для крупного сайта это становиться большой проблемой
Самое важное в семантическом ядре — понимать, для чего собираются запросы и как они дальше будут использоваться. Чаще всего собирают их для корректировки (или проектирования) структуры сайта или контента страниц, поэтому уже при подборе ядра нужно мысленно рисовать себе структуру и основные элементы, представлять, будет ли это удобно для пользователей, это также может дать идеи для поиска новой семантики, и затем оформить мысли как-то визуально, например, с помощью mind-map.
Лишние фразы при подборе сами будут отсеиваться, если глубоко вникнуть в тему, поэтому важно при сборке полистать сайты схожей тематики, обратить внимание на их структуру, меню, хлебные крошки, заголовки, фильтры, оценить, насколько это удобно для использования или можно что-то улучшить, представить себя на месте клиента с его потребностями.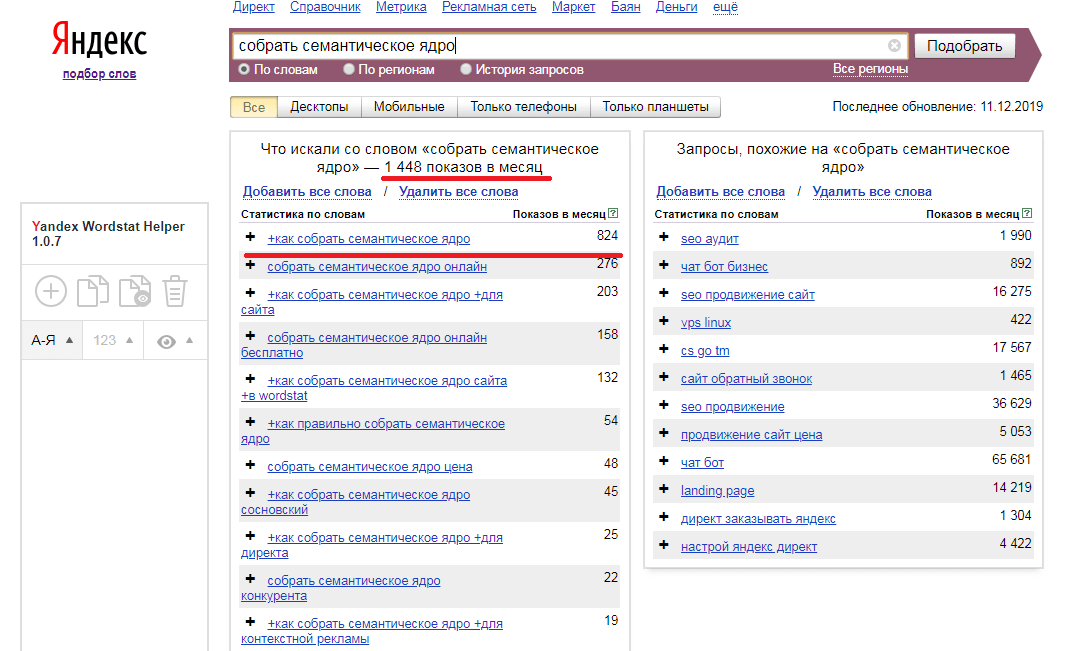 В таком случае семантику будет собирать намного проще.
В таком случае семантику будет собирать намного проще.
2. Технический парсинг
Этот этап ассоциируют с сбором семантического ядра. Есть бесплатные и платные сервисы, которые имеют собственные базы, парсят wordstat, поисковые подсказки и т.д. и т.п. Списков таких инструментов в статье devaka.ru
Сам я использую для основного семантического ядра Keycollector с парсингом wordstat и rookee + Базы Пастухова. Надо так же учитывать, что такой способ не подойдет для событийных запросов, где надо собрать поисковые подсказки и парсить прямой эфир поисковой системы.
Процесс незамысловат, однако имеет кучу тонкостей, которые позволяет быть на шаг вперед конкурентов и максимально автоматизировать процесс. Мы вводим по очереди запросы из нашей семантической основы, учитывая региональность при необходимости, и парсим результаты любым доступным методом.
Непосредственное использование любого инструмента можно с легкостью найти в интернете, т.к. техническое использование каждого инструмента достойна отдельной статьи.
При сборе так же всплывают новые слова, которые не были найдены на первом этапе, так что об этом не надо забывать.
По этому этапу было три экспертных мнений, которые расскажут о тонкостях намного лучше меня.
Денис Савельев — директор агенства Texterra
При работе с семантическим ядром можно выявить два — на первый взгляд разнонаправленных, — тренда: фокусировка и максимальное расширение.
Что значит «фокусировка»? Сегодня инструментов по сбору семантики множество, и сейчас «модно» создавать большие ядра. Но важен не сам размер ядра, как таковой: нужно собирать запросы, которые напрямую связаны с вашей тематикой, с вашим семантическим кластером. Всегда есть соблазн начать уходить в смежную тематику, и логика такого решения понятна — чем больше запросов, тем выше трафик. Но все, что не связано с вашим семантическим кластером напрямую, в итоге будет давать нецелевой трафик, с низкими поведенческими характеристиками — высокий процент отказов, низкая длина сессии и так далее.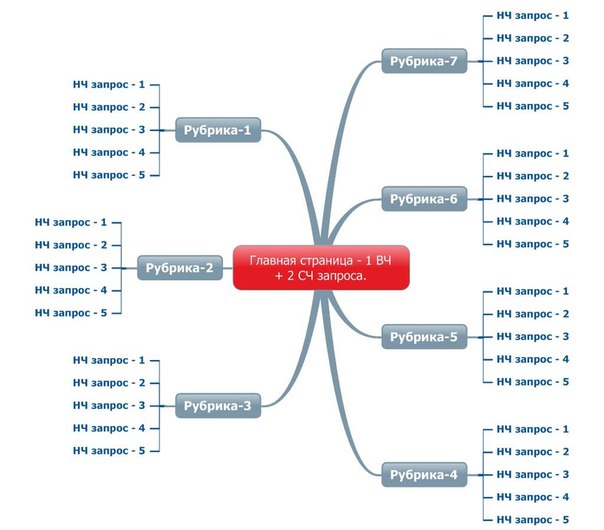 А, как следствие, все это негативно повлияет на продвижение сайта целиком.
А, как следствие, все это негативно повлияет на продвижение сайта целиком.
Второй важный тренд — это максимальное расширение семантического ядра. Да, все верно. Нужно фокусироваться на семантическом кластере, не распыляясь на смежные запросы, но в нем, в своем семантическом кластере, нужно «пылесосить» вообще все! Конкуренция сегодня очень высокая, уже нет практически ни в одной тематике НЧ-запросов, по которой не было бы конкуренции. Выход один — уходить в микро-низкочастотку. А это те запросы, которые генерят 1-2 перехода в три месяца. Все они по вордстату будут так называемыми «нулевками». Умение правильно прогнозировать микро-низкочастотные запросы — одно из очень важных умений современного специалиста по поисковому продвижению. Но это уже совсем другая тема, и здесь не так просто дать короткий и емкий ответ.
Дмитрий Шахов — автор блога bablorub и директор группы компаний РЕМАРКА
Семантика в некоторых нишах очень небольшая. Большинство же советов по составлению ядра ориентировано на ниши из десятков тысяч ключей, где полнота ядра компенсирует прочую работу с текстом. А вот в небольших нишах приходится работать не столько над расширением ядра — где большая часть посещаемости сосредоточена всего в нескольких сотнях или даже десятках ключей — а в поиске слов-сателлитов к ключам в тематике.
А вот в небольших нишах приходится работать не столько над расширением ядра — где большая часть посещаемости сосредоточена всего в нескольких сотнях или даже десятках ключей — а в поиске слов-сателлитов к ключам в тематике.
Грамотно искать такие слова не умеют зачастую даже весьма опытные специалисты. Также нет хороших инструментов для выявления синонимов с точки зрения поиска. Нет четкого алгоритма по выявлению привязки ключей к тематике: например «гостевой дом» поиск отличает от «гостиница», а «гостиница» и «отель» считает синонимами — в итоге гостевой дом не будет хорошо ранжироваться по запросу «гостиница» или «отель». Это вызовы, с которыми оптимизаторам, работающим в нише составления семантических ядер еще предстоит плотно столкнуться.
Илья Русаков — автор блога SEOinSoul.ru и владелец студии «impulse»Мы всегда стараемся составлять максимально детальное семантическое ядро, чтобы даже все микро НЧ с единичной частотностью были в нем. И начинаем продвижение именно с них.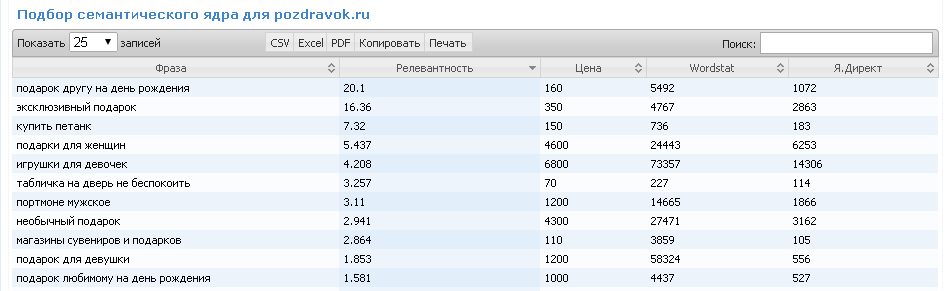
Важно использовать как можно больше источников. Стандартные: Wordstat, подсказки, бесплатные сервисы используют все ваши конкуренты! Таким образом вы никак не отделитесь от них и не найдете фразы с невысокой конкуренцией. Мы же собираем запросы из десятка источников: сервисы статистик, синонимы и ряд платных сервисов.
Очень важна кластеризация или группировка запросов, которую многие делают «спустя рукава». Просто группируют по наличию того или иного слова в запросе. Хотя все запросы надо группировать по смыслу, чтобы по ним выводилась действительно нужная страница.
Сейчас есть автоматические сервисы по кластеризации, которые частично решают эту задачу, но все равно за ними приходится доделывать ручками, из-за чего задача остается одной из самых трудоемких.
От себя добавлю важность составления грамотного стоп-листа, который уменьшит время ручного отсева «лишних» запросов до минимума, но не урежет нужные запросы.
3. Кластеризация
Важнейший этап, без которого семантическое ядро сложно назвать полноценным. Кластеризация или по другому распределение полученного списка на поисковые группы или по страницам целевого сайта.
Кластеризация или по другому распределение полученного списка на поисковые группы или по страницам целевого сайта.
Получив список запросов, нам важно их разделить, учитывая несколько правил:
- Возможность продвижения на одной странице. Здесь есть исключение, когда например запрос вида «»модель телевизора» инструкция» не продвигается на карточке товара, однако мы его оставляем для углубления семантики, но учитываем, что для его целевого продвижения создается отдельная группа
- Смысловая многозначность. Когда запрос «рукав» используется в строительном смысле, а не одежда, мы должны внимательно разделить нужные нам запросы, а несвязные удалить. Тут так же стоит обратить внимание что запрос «рукав» не продвигается на странице со строительным рукавом, его конкретизируют до нужного смысла.
- Поисковая ассоциация. Когда запрос по смыслу и по поисковой ассоциации отличается. Например для нас запросы «Фотограф» и «Свадебный фотограф» имеют разные значения, а для Яндекса эти запросы близкие, т. к. преобладающее большинство по запросу «фотограф» подразумевали именно свадебного, из-за чего произошла синонимизация этих запросов и возможность продвигать на одной странице.
 к. преобладающее большинство по запросу «фотограф» подразумевали именно свадебного, из-за чего произошла синонимизация этих запросов и возможность продвигать на одной странице.
к. преобладающее большинство по запросу «фотограф» подразумевали именно свадебного, из-за чего произошла синонимизация этих запросов и возможность продвигать на одной странице.Сбор семантического ядра (или просто семантики) – дело чуть ли не самое ответственное, при работе с сайтом. И хотелось бы свое повествование начать со слайда одной из моих презентаций для лекции в местной школе интернет-маркетинга.
Студиям, продвигающим клиентские сайты, это не интересно, ведь это долго, дорого…и пусть, что это ох**нно, но такой подход окупится только при длительном сотрудничестве и хорошем чеке. С точки зрения бизнеса такой подход не оправдан.
Задача звучит просто – надо собрать максимально большой список запросов по тематике и разбить на группы. Для несезонных запросов достаточно даже одного источника – wordstat.yandex. Самое сложное дальше – разбивка на группы по смыслу. Есть множество сервисов для автоматической кластеризации запросов, но лично у меня ни один не прижился, потому рулят Excel + прямые руки и голова.
Есть множество сервисов для автоматической кластеризации запросов, но лично у меня ни один не прижился, потому рулят Excel + прямые руки и голова.
Берем исходный список, убираем из него все лишнее и начинаем фигачить, разбрасывая запросы по группам. Никакой магии – только хардкор. Да, это долго, утомительно и вообще та еще рутина. Зато на выходе ох**нно, отвечаю! 🙂
Магия тут только в оптимизации процесса и в сборе самого списка запросов. Например, если запросов много, то еще перед парсингом вордстата стоит позаботиться о минус-словах, разбить основной запрос для парсинга по группам (направления, отраслям или как там еще). Все это упростит дальнейшую постобработку и сэкономит массу времени. Во общем-то, это и не магия, а просто опыт…
Подводные камни
Если вы заказываете семантическое ядро или хотите предоставлять качественную услугу, то надо знать особенности:
- Часто 2 этап технического парсинга выдают за работу над полноценным семантическим ядром, что на деле далеко не так
- При прогнозе посещаемости не учитывается регион, операторы точных запросов «запрос» и «!запрос», сезонный коэффициент
- Неопределенность клиента с его аудиторией, полным списком тем и целью сбора семантического ядра. Эта опасность подстерегает большие сервисы и порталы.
- «Бесконечность» некоторых ниш, особенно это касается информационных ниш, когда семантическое ядро раздувают до огромных размеров. Для этого надо провести «фокусировку» на определенных темах и сконцентрироваться на них
- Концентрация на темах, где невозможно дать полностью релевантный ответ. Например брендовый сайт дорогих рубашек, который хочет продвинуться по всему спектру запросов «рубашки»
 Эта опасность подстерегает большие сервисы и порталы.
Эта опасность подстерегает большие сервисы и порталы.Итог
После этой статьи вы не сможете сразу собрать семантическое ядро, однако теперь вы с полной уверенностью можете его заказать, с возможностью оценить результат и помочь исполнителю, или изучить техническую сторону и уже знать, для чего и что вам надо делать
P.S. выражаю огромную благодарность, всем откликнувшимся специалистам и потратившим свое личное время для адекватного мнения
А какие вы знаете тонкости при сборе семантического ядра?
Семантическое ядро бесплатно – своими руками
Основа оптимизации сайта – это подбор подходящих запросов, по которым в дальнейшем продвигается ресурс.
На первый взгляд может показаться, что выделять ключевые слова легко, но оптимизаторам платят за их составление деньги не просто так.
Подобрать качественные запросы сложно и требует серьезных затрат времени.
Как составить семантическое ядро? Платить за подбор ключевых слов не обязательно, ядром можно составить своими руками и абсолютно бесплатно.
Если вы хотите повлиять на раскрутку своего сайта и получать как можно больше трафика с поисковых систем, обязательно воспользуйтесь нашей инструкцией по составлению семантического ядра.
Семантическое ядро бесплатно – своими руками
Естественно нам потребуется сервис WordStat, через который мы будем подбирать запросы. Первым делом оптимизатору нужно определиться с несколькими ключевиками, от которых можно оттолкнуться. Подобрать их может быть сложно, поэтому данную процедуру лучше облегчить.
Получить основу ядра можно за счет популярного сервиса по продвижению сайтов Rookee. От этой системы можно получить первую сотню запросов, чтобы потом использовать их для поиска других ключей.
Конечно, можно и самому найти эти слова, но у Rookee есть несколько явных преимуществ:
- анализируется частота запроса не только в Яндексе;
- всё производится на автомате;
- оценивается конкурентность ключевых слов.
А самое главное, что вы потратите на сбор необходимых запросов всего несколько минут. Как воспользоваться этим сервисом? Для начала пройдите регистрацию Rookee, а после этого переходите к созданию рекламной компании. Дальше выполняете 3 шага:
- Вводите адрес своего сайта:
- Устанавливаете некоторые параметры для продвижения:
- Получаете готовый список слов для продвижения вашего сайта:
Список содержит 104 запроса, а вы можете скопировать список и перенести его в таблицу Excel. На этом этапе вы уже владеете небольшим ядром, но его нужно улучшать и развивать. Первым делом после переноса слов, внимательно их читаем и удаляем всё, что вам не подходит:
Ядро из 100 слов, по которым частично у вас уже должны быть страницы для продвижения, это незначительный результат. Как его развивать? Выбирайте каждый запрос и отправляйтесь в WordStat, чтобы подбирать связанные ключевые слова.
Низкочастотные и среднечастотные запросы вы сможете быстро собирать и копировать их в другой файл Excel:
Чтобы не терять много времени, после ввода каждого слова просто копирайте строчки из результатов и добавляйте в таблицу. Потом, отсортируете записи по количеству показов в месяц и удалите те, что меньше определенного количества показов.
Сколько показов нужно вам?
Если сайт молодой, то можете сначала продвигать его по низкочастотным запросам до 5000 просмотров в месяц. Если же сайт уже давно существует, активно наполняется и развивается, то лучше брать запросы с более серьезными показателями.
Всего за несколько минут нам удалось пройтись по нескольким ключам из полученного ядра и собрать немного запросов:
Из 100 полученных от Rookee ключевых слов, как минимум по 5 среднечастотных вы найдете связанных, через WordStat, а это 500 запросов – готовое ядро.
Каждый вебмастер должен задумываться над тем, как ему составить семантическое ядро, так как это очень важно для продвижения сайта.
Если вы уже занимаетесь блоггингом и у вас есть готовые ресурсы, попробуйте поменять стратегию и составьте ядро, это поможет улучшить позиции в поисковых системах и увеличить посещаемость.
Вам также будет интересно:
— Сервис Topvisor для вебмастеров
— Как правильно составить анкор-лист?
— Заработок на семантических ядрах
— Проблемы семантического ядра
Что такое семантическая поисковая система и как ее создать?
Мы живем в мире данных, который одновременно и фантастичен, и сложен. Преимущество наличия огромных объемов информации в нашем распоряжении заключается в том, что мы можем получить глубокие знания об определенных вещах и принимать более обоснованные решения на основе данных. Однако недостатком является то, что становится трудно получить доступ к необходимой информации, поскольку пул данных постоянно увеличивается.
Однако недостатком является то, что становится трудно получить доступ к необходимой информации, поскольку пул данных постоянно увеличивается.
Следовательно, поиск подходящих записей в огромной базе данных похож на поиск иголки в стоге сена.
К счастью, существуют семантические поисковые системы, которые могут облегчить эту задачу. Технология может обрабатывать большие данные быстро и эффективно, извлекая нужные нам записи, обрабатывая поисковые запросы, сделанные на естественном языке.
Поскольку многие компании ежедневно имеют дело с огромными объемами данных, технология семантических поисковых систем жизненно важна для поддержания эффективного рабочего процесса и проведения исследований как можно быстрее. Благодаря постоянно растущему объему информации такое решение скоро станет идеальным решением для любого бизнеса.Но что в этом особенного?
Ниже вы найдете пример того, как мы создали семантический механизм для компании, специализирующейся на разработке диагностических (IVD) и биофармацевтических продуктов. Это отличный пример того, как эту технологию можно использовать в реальной жизни.
ПРОВЕРИТЬ НАШЕ ПРИМЕРНОЕ ИССЛЕДОВАНИЕ:
Заголовок: Система семантического поиска для компании по биоинформатике
Азати спроектировал и разработал систему семантического поиска на основе машинного обучения.Он извлекает реальный смысл из поискового запроса и ищет наиболее релевантные результаты в огромных наборах научных данных.
ЧТО ТАКОЕ СЕМАНТИЧЕСКИЙ ПОИСК?
Прежде всего, давайте определим, что такое семантика — в основном это определение значения слов. Чтобы объяснить подробно, семантическая поисковая машина обрабатывает введенный поисковый запрос, понимает не только прямой смысл, но и возможные интерпретации, создает ассоциации и только затем ищет соответствующие записи в базе данных.
Поскольку программа всегда пытается найти синоним по содержанию для выполнения задачи, результаты намного более точны и значимы. Конечно, такие поисковые машины более сложные. В отличие от более простых программ, которые получают только результаты, содержащие точные ключевые слова, технология семантического поиска «думает» как реальный человек и обнаруживает записи, которые могут быть релевантными, даже если они не включают исходное ключевое слово.
КАК МОДУЛЬ СЕМАНТИЧЕСКОГО ПОИСКА ОТЛИЧАЕТСЯ ОТ ОБЫЧНОГО ПОИСКА?
Традиционные поисковые системы используют следующий алгоритм — пользователь вводит ключевое слово, и система возвращает результаты, которые его содержат.Например, вы вводите «большое зеркало» в поле поиска, и движок выбирает все файлы с этой фразой в тексте. Этот подход эффективен, когда набор данных состоит из хорошо организованной и «очищенной» информации. Таким образом, чтобы найти записи в кратчайшие сроки, кому-то сначала нужно будет обработать все записи и убедиться, что информация зарегистрирована в правильной и подходящей форме.
Но когда дело доходит до больших данных, нам нужен более сложный инструмент, который мог бы работать с неструктурированной информацией, потому что человеку практически невозможно просмотреть все записи и систематизировать их.Технология поиска по ключевым словам просто не сможет обработать сложные базы данных, потому что она будет искать только точные ключевые слова. С другой стороны, семантическая поисковая система попытается понять ваш запрос и фактически удовлетворить его, анализируя контекст и ища синонимы. Следовательно, пользователи получат более точные результаты, чем в случае с традиционным поиском.
ПОСМОТРИМ СЕМАНТИЧЕСКИЙ ПОИСК GOOGLE
Google Search — отличный пример этой технологии.Хотя он возвращает результаты, содержащие само ключевое слово, он также ищет информацию, которая не содержит точной ключевой фразы, но все же может быть полезной. Вот почему вы всегда будете получать релевантные результаты поиска — страницы результатов поисковых систем. Кроме того, существуют расширенные функции, такие как интеллектуальный поиск, который распознает ключевые слова, когда пользователь вводит запрос, и предлагает возможные его варианты.
Более того, поиск соответствия изображений Google также основан на семантике — система анализирует изображение и пытается не только понять, что изображено на картинке, но и найти похожие изображения.Это приложение технологии семантического поиска. Google пытается понять смысл запроса пользователя и максимально точно удовлетворить его.
КАК СОЗДАТЬ ДВИГАТЕЛЬ СЕМАНТИЧЕСКОГО ПОИСКА?
Результаты семантического поиска основаны на онтологиях и машинном обучении. Система ищет отношения между терминами и находит дедуктивные сходства. Например, слова «прибыль» и «финансы» связаны между собой. Но также слово «прибыль» — это термин. Таким образом, в процессе семантического сопоставления система сделает вывод, что «прибыль» должна быть финансовым термином.
Для создания системы с семантическим «мышлением» разработчики используют машинное обучение. Они предоставляют программе значительный объем данных для изучения моделей машинного обучения семантического поиска. Затем система ищет запрограммированные отношения и учится находить необходимые синонимы, чтобы в дальнейшем предоставлять пользователям достоверные результаты. Самым значительным преимуществом семантических двигателей является то, что они всегда будут возвращать релевантную поисковую выдачу. Даже если нет записей, которые на 100% соответствуют запросу, система все равно будет извлекать записи, связанные с семантическими ключевыми словами.
По сути, основная технология, на которой основана семантическая поисковая машина, структурирует необработанные данные с использованием различных методов онтологии. К сожалению, сейчас невозможно мгновенно создать идеальную онтологию. Хорошая новость в том, что со временем его можно улучшить. Но даже несмотря на то, что этот процесс занимает много времени и требует много ресурсов, результаты впечатляют.
Программа семантического анализа может обрабатывать и понимать не только сами ключевые слова, но и определенные лингвистические нюансы.Другими словами, эта система работает почти как человек. Более того, многие инструменты могут упростить разработку системы.
КАКИЕ ИНСТРУМЕНТЫ ВЫ МОЖЕТЕ ИСПОЛЬЗОВАТЬ ДЛЯ СОЗДАНИЯ СЕМАНТИЧЕСКОГО ПОИСКА?
Существует множество инструментов, которые вы можете использовать для создания поисковой системы на основе онтологий — в Интернете полно различных библиотек для обучения системы. Просто зайдите на GitHub, и велика вероятность, что там будет много необходимых данных. Также вы легко найдете инструменты для сбора исходных данных, если нет библиотеки или базы данных для обучения.Например, вы можете использовать платформу Akka для создания поискового робота, который будет очищать необходимый контент.
После сбора данных их необходимо обработать, чтобы их можно было использовать для машинного обучения. Поэтому его нужно разобрать на пары. Отличный инструмент, который может оказаться здесь полезным, — это AST в библиотеке Python. Он извлекает код, оставляя комментарии. Затем очищенные данные должны быть организованы в три набора: обучение, проверка и тестирование. Стоит отметить, что на всякий случай следует также сохранить исходные данные.
Чтобы обучить основанную на онтологии семантическую поисковую машину, нам нужно создать саму онтологию, которая будет представлена в виде файлов OWL. Они состоят из концепций, созданных с помощью Resource Description Framework. RDF хранит информацию в тройках — сущность данных. Это набор из трех компонентов, описывающих утверждение. Например, «У собаки пушистые уши» — это объект данных. Он состоит из трех компонентов: «Собака» — это подлежащее, «Имеет» — сказуемое и «Пушистые уши» — это объект.
Эти тройки создают концепции для онтологии. Чтобы его создать, специалисты по данным могут использовать различные инструменты, такие как Protege, чтобы ускорить процесс. Впоследствии эти структурированные данные используются для обучения системы. Однако доступно множество предварительно обученных моделей, и ими довольно удобно пользоваться. Они экономят много времени и усилий, предоставляя разработчикам готовую основу для будущей технологии семантического поиска. Но в случае предметно-ориентированных проектов лучше обучать кастомную модель.
СВОДКА
Машинное обучение и искусственный интеллект становятся важной частью нашей жизни. И лучше начать использовать эти технологии сейчас, чтобы не только облегчить работу с данными и упростить исследования, но и чувствовать себя увереннее в этом быстро меняющемся мире.
Многие отрасли могут воспользоваться преимуществами технологии семантических поисковых систем — от биотехнологий и фармацевтики до электронной коммерции. Некоторые компании используют семантические поисковые системы для улучшения работы команды на этапе исследований и разработок.В то время как другие внедряют технологию для поиска покупателей, особенно если онлайн-компания имеет огромную базу данных товаров, которые она продает.
Несмотря на то, что эта технология является новой, все же возможно построить почти идеальную систему семантического поиска на базе ИИ даже для самых сложных областей данных. А поскольку технологии развиваются быстрыми темпами, мы можем ожидать, что такие двигатели будут быстро развиваться.
10. Анализ смысла предложений
1.1 Запрос базы данных
Предположим, у нас есть программа, которая позволяет нам вводить вопрос на естественном языке и дает нам вернули правильный ответ:
| (1) |
|
Насколько сложно написать такую программу? И можем ли мы просто использовать те же методы, что и мы уже встречались в этой книге, или это связано с чем-то новым? В этом разделе мы покажем, что решение задачи в ограниченной области довольно просто. Но мы также увидим, что для решения проблемы более в общем, мы должны открыть целый ряд новых идей и методов, включая представление смысла.
Итак, давайте начнем с предположения, что у нас есть данные о городах и страны в структурированной форме. Чтобы быть конкретным, мы будем использовать базу данных таблица, первые несколько строк которой показаны в 1.1.
Примечание
Данные, показанные в 1.1, взяты из системы Chat-80. (Уоррен и Перейра, 1982). Числа населения даны в тысячах, но обратите внимание, что данные, используемые в этих примерах, датируются как минимум к 1980-м годам, и на тот момент уже был несколько устаревшим когда было опубликовано (Warren & Pereira, 1982).
| Городской | Страна | Население |
|---|---|---|
| Афины | греция | 1368 |
| Бангкок | Таиланд | 1178 |
| барселона | испания | 1280 |
| Берлин | восточная_германия | 3481 |
| Бирмингем | United_kingdom | 1112 |
Очевидный способ получить ответы из этих табличных данных включает написание запросов на языке запросов к базе данных, таком как SQL.
Примечание
SQL (язык структурированных запросов) — это язык, разработанный для получение и управление данными в реляционных базах данных. Если вы хотите узнать больше о SQL, http://www.w3schools.com/sql/ — удобный онлайн Справка.
Например, при выполнении запроса (2) будет выведено значение ‘greece’:
Обзор технологий семантических датчиков в архитектурах Интернета вещей
Интеллектуальные датчики должны легко, безопасно и надежно соединяться между собой, чтобы обеспечить автоматизацию интеллектуальных приложений высокого уровня.Семантические метаданные могут предоставлять контекстную информацию для поддержки доступности этих функций, облегчая машинам и людям обработку сенсорных данных и обеспечение взаимодействия. Уникальный обзор онтологий датчиков в соответствии с семантическими потребностями слоев IoT-решений может служить руководством для инженеров и исследователей, заинтересованных в разработке интеллектуальных решений на основе датчиков. Изученные тенденции показывают, что онтологии будут играть еще более важную роль во взаимосвязанных системах IoT, поскольку совместимость и создание контролируемых связываемых источников данных должны основываться на семантически обогащенных сенсорных данных.
1. Введение
Системы на основе Интернета вещей (IoT) распространяются быстрыми темпами, обещая улучшить качество нашей жизни [1, 2] и эффективность производственных систем [3]. Приложения IoT часто выполняют анализ данных и прогнозную аналитику в реальном времени [4], которые требуют информативных автоматических измерений. Сенсорные решения на основе Интернета вещей пытаются поддерживать повсеместные вычисления [5] и функциональную совместимость [6–8] путем преобразования данных датчиков низкого уровня в знания высокого уровня, понятные людям и машинам [9].
Обогащение необработанных сенсорных данных становится все более и более важным, поскольку строгое управление цифровыми ресурсами и управление ими являются предварительными условиями, поддерживающими открытие знаний и инновации. Следовательно, системы, управляемые данными, должны обеспечивать свойства руководящих принципов FAIR (находимость, доступность, функциональная совместимость и возможность повторного использования) [10].
Семантическое моделирование дает явное описание значения данных структурированным способом путем объединения знаний предметной области и контекстно-релевантной информации с необработанными измеренными данными [11].Семантика включает онтологии, контексты и структурированные метаданные. Поскольку онтологии могут описывать знания, относящиеся к проблеме [12–14], отвечая на вопрос 4W1H (что, где, когда, кто и как) [15, 16], онтологическое моделирование обеспечивает гибкую структуру управления знаниями (Ontohub https: //ontohub.org и DAML http://www.daml.org/ перечисляют около 5536 и 282 онтологий соответственно).
Онтологии могут обогащать сенсорные данные [17] и обеспечивать совместимость, предоставляя уровень абстракции [18].
Взаимодействие — одна из наиболее серьезных проблем в интеллектуальной среде Интернета вещей, где связаны различные продукты, процессы и организации. Разработка IoT-решений на основе онтологий может позволить разработчикам получать универсальные решения, обеспечивающие успех IoT. Развитие этих семантических моделей должно следовать тенденциям решений IoT. Коллаборативный Интернет вещей (C-IoT) набирает обороты, что также способствует совместимости [19]. Увеличивая степень взаимосвязанности, можно разработать дополнительные функции, которые превзойдут отдельные приложения; е.g., умные автомобили могут реагировать на основе совместно используемой информации [20], а совместное использование контекстной информации значительно повышает производительность алгоритмов вспомогательного / автономного вождения [21]. Слияние контекстной информации позволяет извлекать новые типы знаний [22]. Интеллектуальное соединение датчиков, исполнительных механизмов и элементов знаний позволяет разрабатывать решения, необходимые для решений типа «умный город» и киберфизических систем (CPS) [23] в дополнение к автономным решениям в реальном времени на основе периферийных вычислений. [24, 25].Поскольку рассуждения и решения основаны на данных, одним из ключевых инструментов этих технологий являются семантические модели, которые поддерживают управление сенсорными измерениями [26].
Согласно [27], можно выделить три типа онтологий IoT: (i) Онтология устройств , которая описывает исполнительные механизмы и датчики на основе их подробных характеристик. (Ii) Онтология домена , которая представляет реальные физические концепции, основаны на наблюдениях, измерениях и их отношениях друг с другом на высоком уровне.(iii) Онтология оценки , которая описывает качество обслуживания и предоставляет информацию, необходимую для состава службы.
Хотя технологии IoT [28] и соответствующие методологии внедрения / установки [29], базы данных [30], требования [31] и конфиденциальность, а также аспекты безопасности [32], производственная архитектура [33] и связь стандарты [34] уже были рассмотрены, а также были представлены структуры доступа к сенсорным данным, обнаружения сервисов, архитектуры и неоднородности [35], подробное обсуждение семантических моделей решений IoT еще предстоит.
Хотя некоторые аспекты технологий семантических датчиков уже были рассмотрены, систематический обзор, который следует за структурой решений IoT, еще предстоит провести. Историческое исследование эволюции онтологий до 2014 года представлено в [36]. Возможные методы семантической аннотации рассмотрены в [37], где также сравниваются высокоуровневые прикладные онтологии управления контекстом. Вклад Открытого геопространственного консорциума (OGC) в семантические сенсорные сети, несомненно, значителен, поскольку большинство онтологий, разработанных после 2012 года, основаны на их концепции [38].
Обзор структурирован аналогично стандарту ITU-T Y.2060 [39], который описывает эталонную модель IoT и определяет высокоуровневые требования к решениям IoT. Сенсор, устройство, сеть (мы называем ее шлюзом), поддержка сервисов и приложений, а также прикладные уровни систем IoT показаны на рисунке 1. Технологии, обеспечивающие реализацию этих уровней, такие как стандарты связи [1, 40], протоколы [40, 41], высокоуровневые рассуждения [42] и связанные возможности обогащения открытых данных [43] развиваются быстрыми темпами и требуют стандартизации на основе семантических моделей, которые будут рассмотрены в этой статье.
В этой работе представлен уникальный обзор семантики IoT как технологий, так и моделей для поддержки разработки сенсорных сетей и решений IoT. Обзор структурирован в соответствии с преобразованными слоями и представляет их функции и детали связанных онтологий. Эта структурированная разбивка обеспечивает понимание и отправную точку для проектов исследований и разработок, в которых рассматриваются семантические приложения на любом этапе процесса.
Этот систематический обзор основан на изучении литературы в Google Scholar, Scopus и Web of Science в соответствии с протоколом PRISMA-P [44].Рабочий процесс PRISMA-P (Предпочтительные элементы отчетности для систематических обзоров и метаанализ для протоколов) состоит из контрольного списка из 17 пунктов, предназначенного для облегчения подготовки и составления надежного протокола для систематического обзора. Далее приведены только основные детали процесса. В последний раз полный опрос источников информации проводился в октябре 2018 года. Поскольку главный вопрос исследования заключался в том, как онтологии и семантические модели могут быть использованы на уровнях решений IoT («семантическая модель» ИЛИ «сенсорная« онтология ») и (« Интернет вещей «ИЛИ Интернет вещей») были ключевыми словами поиска, в результате которого было найдено около 750 статей.
Критерии включения и приемлемости заключались в том, насколько тесно публикации связаны с семантическими моделями и онтологиями датчиков. Как показано на рисунке 2, процесс выбора поддерживался сетевым анализом ключевых слов. Этот метаанализ был полезен для объединения данных из разных работ и поиска наиболее важных тем и их связей. После того, как исчерпывающий список рефератов был сгруппирован и проанализирован, были получены и проанализированы документы, которые соответствовали критериям включения.Также отслеживалась эволюция технологий, поэтому в дополнение к последним тенденциям также представлены корни семантических моделей и стандартов.
Чтобы сосредоточиться на семантическом контексте, в этой работе цитируются и обсуждаются только наиболее тесно связанные 162 публикации. С целью минимизировать систематическую ошибку мы включили все соответствующие онтологии, которые были определены как общие или широко применяемые в конкретной области. В результате синтеза результатов извлеченная информация была структурирована в соответствии с уровнями решений IoT, что обеспечивает уникальность и применимость нашей работы.Полученный в результате обзор может служить руководством для инженеров, заинтересованных в разработке легко подключаемых и совместимых решений IoT, а также для исследователей, заинтересованных в поиске полезных областей исследования. Ограничения этого обзора исходят из его целенаправленной точки зрения. Отнесение онтологий к уровням решений IoT субъективно. Новые алгоритмы, которые были разработаны для поддержки извлечения информации из семантических данных датчиков, не обсуждаются, поскольку результаты быстро развивающихся областей семантического анализа данных, больших и связанных данных заслуживают еще одного обзора.
2. Семантические представления сенсорных данных
Поскольку семантика играет важную роль в организации знаний [45], она может поддерживать обогащение измерений и получение знаний из систем IoT. На рисунке 3 показано, как семантические метаданные, такие как контекст, описание датчика и его конфигурация (например, оптимальный диапазон), улучшают понимание отдельного измерения. В следующем разделе представлен обзор развития этих онтологий и того, как следует применять этот подход с точки зрения проектирования уровней систем IoT.
Эволюция онтологий сенсорных сетей мотивируется проблемой создания контекста для измерений. Первые новаторские приложения OWL-кодированной контекстной онтологии (CONON) уже продемонстрировали, что онтологии могут поддерживать логическое обоснование контекста [83] и могут использоваться для разработки контекстно-зависимых приложений, таких как iMuseum [84]. Не перечисляя эти контекстные онтологии, ниже мы рассмотрим эволюцию онтологий сенсорных сетей, разработанных для поддержки описания сенсора, описания измерения, описания состояния сенсора и обнаружения сенсора.Эти онтологии приведены в Таблице 1 и на Рисунке 4. Наиболее интересные свойства этих онтологий базового уровня обсуждаются следующим образом: (i) Avancha et al. описал одну из первых онтологий для датчиков для определения условий и ожидаемого поведения сенсорной сети [46]. (Ii) Pedigree Ontology обрабатывает информацию об уровне обслуживания различных датчиков (например, магнитных, акустических, электрооптических, и т. д.) [50]. (iii) Sensor Web for Autonomous Mission Operations (SWAMO) обеспечивает динамическую совместимость сенсорных сетей и описывает автономных агентов для общесистемного совместного использования ресурсов, распределенного принятия решений и автономных операций.НАСА использует эту онтологию во время звездных миссий. SWAMO основан на языке моделей датчиков (SensorML) [51] и использует унифицированный код единиц измерения (UCUM) [85] для описания измерений. (Iv) Онтология беспроводных сенсорных сетей (WISNO) является очень простым доказательством концепция использования языка веб-онтологий (OWL) и языка правил семантической сети (SWRL), основанная на IEEE 1454.1 и SensorML [52]. (v) описывает подход промежуточного программного обеспечения на основе агента устройства для сред смешанного режима (A3ME) среды с различными измерениями неоднородности на основе онтологии устройств Foundation for Intelligent Physical Agents (FIPA), OntoSensor и контекстной онтологии SOPRANO [53, 86].(vi) SEEK (http://seek.ecoinformatics.org/) -Extensible Observation Ontology (OBOE) обеспечивает автоматическое объединение и обнаружение данных, закодированных с использованием логики описания языка веб-онтологий (OWL-DL) [54]. (vii) Онтология ISTAR описывает задачи, датчики и платформы развертывания для поддержки автоматического распределения задач. Интерфейс к физической среде сенсора позволяет мгновенно конфигурировать сенсор [55]. (Viii) CSIRO -Sensor Ontology, созданная Организацией научных и промышленных исследований Содружества (CSIRO), опубликовала ряд онтологий, которые можно использовать для интеграции данных, поиска и т.д. и управление рабочим процессом [56, 57].(ix) OntoSensor основан на предложенной верхней объединенной онтологии (SUMO) Института инженеров по электротехнике и электронике (IEEE), ISO 19115 Международной организации по стандартизации (ISO) и SensorML. Хотя онтология не обновляется, она может служить хорошей отправной точкой для дальнейших разработок, поскольку поддерживает обнаружение, обработку и анализ данных измерений датчиков; геолокации наблюдаемых значений и содержит явное описание процесса, посредством которого было получено наблюдение [58–60].(x) Ontonym-Sensor охватывает основные концепции местоположения, людей, времени, события и восприятия. Ontonym-Sensor содержит восемь классов для обеспечения высокоуровневого описания датчика и его возможностей (частота, охват, точность и пары точности) в дополнение к описанию наблюдений датчика (информация, относящаяся к наблюдениям, метаданные, датчик, временная метка, и период времени, в течение которого значение действительно, скорость изменения) [61]. (xi) SENSEI O&M — аннотация метаданных, назначенная шлюзу, который получает необработанные данные и обертывает значение аннотациями, взятыми из шаблона ( я.например, семантическая модель), поскольку аннотированные данные могут быть затем переданы информационным подписчикам [62]. (xii) W3C Semantic Sensor Network (SSN) -Ontology (https://w3c.github.io/sdw/ssn /) — первый стандарт W3C. Группа инкубаторов семантических сенсорных сетей (SSN-XG) представляет модель «стимул-сенсор-наблюдение» (SSO) [56]. Три части SSO — это стимул, имеющий отношение к наблюдаемому свойству, сенсоры, которые преобразуют поступающий стимул в цифровое представление, в то время как наблюдение связывает стимул с сенсором, который дает символическое представление явления, давая начало контексту [ 65].Шаблоны проектирования онтологий — полезные ресурсы и методы проектирования для алгоритмов сопоставления шаблонов, визуализации, рассуждений и создания на основе знаний [87]. SSN не предоставляет средств для абстракции, категоризации или рассуждений, предлагаемых семантическими технологиями [56]. (Xiii) Онтология WSSN расширяет онтологию SSN, описывая контекст и политику связи узлов. Потребность в этой онтологии возникла из-за низкоэнергетических узлов и управления их нерешенными потоками данных.WSSN решает проблему управления потоками данных путем реализации политик обмена данными непосредственно в онтологии [70]. (Xiv) Прибрежные сети экологического зондирования (CESN) построены на основе взаимодействия морских метаданных (MMI), SensorML и CSIRO и предоставляют типы датчиков, a логика описания (DL) и основанный на правилах механизм рассуждений, позволяющий делать выводы об аномалиях измерений [64]. (xv) DOLCE Ultra Light (DUL) — это описательная онтология для лингвистической и когнитивной инженерии (DOLCE), которая различает физические, временные и абстрактные качества (http: // www.loa.istc.cnr.it/ontologies/DUL.owl) [88]. DUL построен на онтологии W3C SSN-XG, поэтому также реализован и соблюдается шаблон проектирования онтологии Stimulus-Sensor-Observation (SSO). DOLCE Ultra Light — это ориентированное на стимулы расширение шаблона проектирования онтологий [65]. DUL можно либо напрямую использовать, например, для связанных данных датчиков, либо интегрировать в более сложные онтологии в качестве общей основы для согласования, сопоставления, перевода или взаимодействия в целом. (Xvi) Сетки семантических датчиков для быстрой разработки приложений для управления окружающей средой (SemSorGrid4Env) был введен для прогнозирования чрезвычайных ситуаций, связанных с наводнениями [66].Онтология разделена на четыре уровня: онтология в конкретных областях, информационная онтология, верхние онтологии и внешние онтологии. Слои удовлетворяют различным требованиям, касающимся представления знаний. (Xvii) Онтология веб-ресурсов датчиков для атмосферных наблюдений (SWROAO) Онтология включает добавление таксономии местоположения к данным датчиков для атмосферных наблюдений [67]. (Xviii) Онтология ядра датчика ( SCoreO) расширяет онтологию SSN такими модулями, как компонентный модуль, сервисный модуль и контекстный модуль.В контекстном модуле добавлены три важных класса: пространство, время и тема [68]. (Xix) Онтология измерения датчиков (SenMESO) автоматически преобразует измерения разнородных датчиков в семантические данные [89]. (Xx) Wireless Semantic Онтология сети датчиков (WSSN) является расширением SSN с дескрипторами состояний узлов датчиков. WSSN использует шаблон проектирования онтологии Stimulus-WSNnode-Communication (SWSNC), который рассматривает стимул как отправную точку любого процесса и триггер датчика или коммуникационного оборудования [56].(xxi) Онтология данных датчиков была создана для поддержки поиска соответствующих данных датчиков в распределенных и гетерогенных сетях датчиков. Онтология использует предложенную верхнюю объединенную онтологию (SUMO) и субонтологию иерархии датчиков, которая описывает датчики и данные датчиков, а также субонтологию данных датчиков, которая описывает контекст сенсорных данных по отношению к пространственным и / или временным наблюдениям [90]. (xxii) Онтология Национального института стандартов и технологий (NIST) также основана на SSN.Онтология NIST описывает подробные размеры, вес и разрешение датчиков; возможности системы; и сенсорная сеть в производственных средах [71]. (xxiii) Онтология Агентства государственной метеорологии (AEMET) используется для метеорологического прогнозирования Испанского метеорологического бюро. Поскольку онтология следует концепции связанных данных, измерения можно легко преобразовать в связанные данные [72]. (Xxiv) Sensor Cloud Ontology (SCloudO) — еще одно расширение SSN с целью составления семантического описания датчика. данные в сенсорном облаке [73].(xxv) IoT-Lite (https://www.w3.org/Submission/2015/SUBM-iot-lite-20151126/) позволяет представлять и использовать платформы IoT, не занимая слишком много времени обработки при выполнении запросов. онтология. IoT-Lite описывает концепции Интернета вещей в трех классах: объекты, системы или ресурсы и службы. IoT-Lite ориентирован на зондирование и подходит для динамических сред благодаря функции обнаружения датчиков в реальном времени [74, 75]. (Xxvi) MyOntoSens подробно описывает процесс измерения, включая входы, выходы, описание, калибровку, дрейф и т. Д. латентность, единица измерения и точность [76].(xxvii) Описание сенсора в системе контекстной осведомленности: новинка онтологии заключается в том, что машины могут идентифицировать различные сенсоры в соответствии с их технологическими возможностями, отмеченными в онтологии [78]. (xxviii) Динамическое связывание сенсоров на основе онтологии: интересно все онтологии расширяются и добавляют информацию, увеличивая доступность данных, эта онтология мыслит в обратном направлении; он вычитает из онтологий; например, OntoSensor [79]. (xxix) Smart Onto Sensor. Это онтология для сенсоров на базе смартфонов, основанная на SSN и SensorML [80]. Онтология сети мультимедийных семантических датчиков (MSSN-Onto) может эффективно моделировать сети мультимедийных датчиков (поток аудио; видео) и мультимедийные данные, определять сложные события, а также обеспечивать механизм запросов событий для сети мультимедийных датчиков [81] (xxx) Онтология датчика, наблюдения, образца и исполнительного механизма (SOSA). Облегченная онтология, ориентированная на события, построена на основе SSN [82].
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Онтологии постоянно развиваются, оставляя все больше места для рассуждений и упрощений.Появляются специальные, ориентированные на приложения онтологии, которые интегрируются в стандарты. Легкие и чрезвычайно расширяемые онтологии также поддерживают разработку специализированных приложений и конвертируемость между форматами в дополнение к передаче информации между приложениями.
Предшественником этой тенденции является онтология SOSA, благодаря ее связанной структуре, подобной данным.
3. Послойный обзор семантических моделей измерительных систем
3.1. Уровень датчика / устройства
Уровень датчика обычно называют уровнем наблюдения и измерения (O&M) [56].Онтология сети семантических датчиков Консорциума World Wide Web (W3C SSN) содержит большинство аннотаций, необходимых для описания датчиков и наблюдений. Расширенная онтология SSN SOSA, которая является текущей версией SSN, визуализирована на рисунке 5, который можно рассматривать как одну из наиболее общих структур семантических моделей датчиков. Наиболее важные функции этого уровня следующие [91, 92]: (i) Описание датчика позволяет удаленно настраивать и управлять активами, а также обнаруживать датчик.Описание датчиков может содержать физические характеристики (например, интерфейс, источник энергии и т. Д.), Иерархию, развертывание и информацию о производителе. (Ii) Описание измерения поясняет и поясняет данные измерения, определяя его единицу измерения. , значение и процесс измерения. Унифицированный код единиц измерения (UCUM) [85] широко используется для описания измерений (http://ontolog.cim3.net/cgi-bin/wiki.pl?UoM).(iii) Обнаружение датчика является сложной задачей в динамических системах Интернета вещей [93].Обнаружение датчиков стандартизировано связанными протоколами уровня уровня, такими как протокол обнаружения канального уровня (LLDP), который соответствует стандарту IEEE 802.1AB, дескрипторы развертывания веб-служб (WSDD) (http://docs.oasis-open.org/ws -dd / discovery / 1.1 / wsdd-discovery-1.1-spec.html), сеть конфигурации Bonjour (https://developer.apple.com/bonjour/) или Simple Service Discovery Protocol (SSDP) как часть универсального Набор протоколов Plug and Play (UPnP) (http://quimby.gnus.org/internet-drafts/draft-cai-ssdp-v1-03.txt). (iv) Описание состояния датчика играет ключевую роль в работе, настройке и обслуживании устройства.
Коммуникационные технологии и стратегии сложно разместить на одном уровне. Поскольку обсуждение очень сильно уведет от семантических технологий, мы очень кратко остановимся на этой теме. Семантические технологии часто легко адаптируются к другим технологиям; мы должны упомянуть три основных коммуникационных стратегии: MQTT «публикация-подписка», специальный протокол веб-передачи CoAP и потоковая передача.Адаптация семантики к этим технологиям заключается в управлении доступом на основе контекста.
3.2. Уровни инфраструктуры
Уровни инфраструктуры используются для управления сложностью и неоднородностью сенсорных сетей. Эти уровни разделены на уровень шлюза, который обеспечивает разнородную дуплексную связь, и уровень поддержки услуг и приложений (промежуточное ПО), который служит интерфейсом для приложений и обеспечивает следующие расширенные функции: (i) Управление контекстом соответствует описанию и маркировка ситуаций, объектов, мест или людей, которая играет ключевую роль с точки зрения авторизации и адаптирует операцию к среде [94].Контекст может отличаться в разных областях применения. Однако операция одинакова для всех приложений, а именно: получение контекста, моделирование, рассуждение и распределение [95]. Получение контекста выражается в форме пяти факторов: (1) процесс получения, (2) частота, (3) ответственность, (4) тип датчика и (5) источник [96]. Эти пять факторов также соответствуют ранее описанным онтологиям. Однако на нижнем уровне не был учтен интересный фактор, а именно ответственность.Наиболее актуальный вопрос: «Что измеряет датчик?» Контекстное моделирование определяется как представление контекста, которое помогает понять свойства, отношения и детали измеряемых объектов. Обсуждение высокого уровня будет обсуждаться на прикладном уровне. Возникающей и важной частью взаимодействия являются меры безопасности и конфиденциальности, которые часто связаны с огромными узкими местами в потоках информации. Однако уже используются общие технологии, такие как временные, пространственные, связанные с риском и событиями роли [97].(ii) Комплексная обработка событий (CEP) и Stream Reasoning объединяют наблюдения в сложные события, часто определяемые несколькими источниками данных. Системы CEP нацелены на эффективную обработку данных и немедленное распознавание интересных ситуаций, когда они возникают. Управление контекстом и обработка контекста имеют решающее значение в отношении CEP [98]. CEP не только предоставляет информацию в форме событий от поставщиков к потребителям, но также поддерживает обнаружение взаимосвязей между событиями и обнаруживает временные правила корреляции событий, называемые шаблонами событий [99].Поскольку IoT поддерживает модульную разработку решений в реальном времени, то же самое делает рассуждение CEP и Stream [100]. Текущие высокоуровневые потоковые процессоры с возможностью получения информации для системы по прибытии или неприбытии данных — это C-SPARQL, CQELS и ACEIS [101]. С помощью специальных архитектур и методов также могут быть реализованы решения на основе машинного обучения [102]. (Iii) Конфигурация службы является ключом к видению автономных вычислений [103, 104]. IBM заявила, что системы должны быть самоуправляемыми, что означает самоконфигурацию, самооптимизацию, самозащиту и самовосстановление.Идея далека от этого, но удаленная конфигурация и удаленный доступ уже существуют в виде платформы подключенных устройств (CDP), которая гарантирует, что устройства и датчики могут быть легко подключены и удаленно управляться [105]. (Iv) Совместимость позволяет автоматические службы обнаружения и устройства, использующие новые инструменты, такие как Semantic Markup for Web Services (OWL-S iot ) [106] и Multistage Semantic Service Matching [107], скрывающие детали служб разнообразия и распределения каналов путем предоставления простого, единого уровень интерфейса прикладного программирования (API) и обеспечение функций безопасности и конфиденциальности [108].(v) Управление устройством Функции , такие как инициализация устройства, конфигурация устройства, управление программными модулями, операции управления жизненным циклом (например, установка, обновление и удаление) и управление сбоями [109]. (vi) Программно-определяемая сеть ( SDN) позволяет управлять сетевыми активами через интегрированный интерфейс. (Vii) Хранилище данных в основном полагается на графические базы данных, параллельные базы данных, хранилища ключей и значений, хранилища с широкими столбцами, хранилища документов и т. Д.Ключ всегда — скорость и масштабируемость; Таким образом, экосистемы IoT, как правило, всегда добавляют датчики и все больше и больше конечных узлов. Правильное хранилище данных управляет и обрабатывает отдельные точки измерения, а также семантические описания. Таксономия хранилищ метаданных представлена на рисунке 7. (viii) Уведомление SWE-Sensor Alert Service (SAS) — это стандартный интерфейс веб-службы для публикации и подписки на предупреждения от датчиков [91].
3.2.1. Уровень шлюза / сети
Шлюз разделяет службы [110] и служит мостом между сенсорными сетями и обычными сетями связи [109], поэтому уровень шлюза обладает следующими функциональными возможностями: (i) Предоставление позиционной информации нуждается в более высоком уровне Возможно, шлюзы в качестве точек слияния будут иметь информацию о периферийных узлах, которая может применяться к позиционированию на основе датчиков глобальной системы позиционирования (GPS), геолокации IP [111] или систем позиционирования внутри помещений [112, 113].(ii) Предоставление временных атрибутов нетривиально, поскольку пассивные устройства и устройства с очень низким энергопотреблением сами по себе не могут предоставлять временные атрибуты, поэтому эта задача должна выполняться на уровне шлюза на основе ISO 8601 и является стандартом для представления даты. и время в модели времени [114], которая описывает и определяет семь взаимосвязей между интервалами (продолжительность, начало, конец, до, после, соответствует и равно) или словарём времени OWL (https://www.w3.org/ TR / owl-time /) используется для выражения отношений между моментами и интервалами вместе с информацией о продолжительности, дате и времени.(iii) Выравнивание онтологий низкого уровня — это первый шаг к знанию предметной области, поскольку он означает точку слияния с онтологиями более высокого уровня или предметной области. У шлюзов гораздо больше энергии, чем у устройств. Поэтому первая энергия, требующая обработки вопреки семантике, может иметь место именно в этот момент.
3.2.2. Уровень поддержки сервисов и приложений (промежуточное ПО)
С точки зрения шаблона проектирования архитектуры, уровень поддержки сервисов и приложений промежуточное ПО, рассматриваемое как основная часть серверной части, также называемое обработчиком данных, также можно представить как классическое извлечение -Transform-Load (ETL) ПО.В промежуточном программном обеспечении есть несколько интересных идей, позволяющих не отставать от масштабируемости, обработки данных как есть, взаимодействия, распространения данных и т. Д. Семантику часто критикуют, поскольку она может быть серьезным узким местом для производительности [115]. Тем не менее, шаблоны, которые мы представляем в этом разделе, получат скорость, безопасность и надежность благодаря семантике.
Уровень промежуточного программного обеспечения объединяет разнородные сенсорные данные для прикладного уровня [121]. На рисунке 6 показано, что шаблоны проектирования могут быть основаны на подходах, ориентированных на контекст, устройства, данные и приложения.В таблице 2 суммированы эти подходы на основе их семантических, вычислительных требований и требований к хранению. Основанные на событиях в дополнение к подходам, ориентированным на службы и базы данных, основаны на конкретных семантических моделях, как показано ниже: (i) промежуточное ПО на основе событий должно обрабатывать метаданные спецификации событий и правила обработки событий [122]. Онтология SenaaS [116] поддерживает создание событий на основе наблюдений. (Ii) Сервисно-ориентированный подход к проектированию облегчает динамическую разработку приложений на основе компонентов [123].Следовательно, сервис-ориентированные онтологии должны обрабатывать свойства сервисов для измерений так же, как Распределенная Интернет-подобная архитектура для вещей (DIAT) поддерживает автономный сбор и обработку данных и имеет контекстные выводы для общего управления устройствами, а также ситуационную осведомленность для минимальных вмешательство человека и нулевая конфигурация [124]. (iii) Ориентированные на базы данных архитектуры промежуточного программного обеспечения используют распределенные базы данных [120] и стандартизованные языки запросов (например,g., SPARQL, язык структурированных запросов (SQL), Cypher и т. д.). Простой подход состоит в том, чтобы собрать данные стандартизированным способом и немедленно сохранить их в необработанном виде. Важно учитывать, что большинство датчиков передают непрерывные данные, также называемые потоковыми данными. Для хранения потоковых данных доступны два основных решения: (1) Жестко запрограммированный метод: соответствие между потоковыми данными и онтологией определяется в программах. Различные поля и форматы потоковых данных требуют разных типов кодирования.Потоковые данные будут постоянно записываться в файлы RDF в соответствии с программным кодом. Жестко запрограммированный метод является молниеносным, если он написан, но каждый отдельный объект должен быть закодирован вручную, что делает его очень жестким и быстрым, с другой стороны, расширение потока или применение другой онтологии заставляет отображение создаваться с самого начала. Объектно-ориентированный метод включает использование объектно-реляционного сопоставителя (ORM) (например, Entity Framework от Microsoft [125] и Hibernate для Java [126]).(2) Метод языка отображения: языки отображения (например, D2RQ [73, 127], R2O [128], R2RML [128–130] и On top [131]) предоставляют набор четко определенных семантических примитивов для описания отображения. отношения. Отображение потоковых данных и онтологию можно добавить вручную или автоматически с помощью программирования. Существуют альтернативные подходы для уменьшения объема кодирования. Пример сопоставления сообщений из широко используемого протокола обмена сообщениями публикации / подписки Message Queuing Telemetry Transport (MQTT) непосредственно в нотацию объектов JavaScript для связанных данных (JSON-LD) (https: // github.com / w3c / json-ld-syntax) с шаблонами Grok через конвейер обработки Logstash (https://www.elastic.co/products/logstash) показан в [132].
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Как уже было сказано, хорошо спроектированные уровни инфраструктуры должны быть ориентированы на взаимодействие.Для этой цели могут использоваться несколько семантических методов, например, согласование онтологий, несколько точек слияния, шлюзы, специальные архитектуры.
3.3. Уровень приложения
Успешные приложения требуют, чтобы все необходимые фрагменты атомарных данных были под рукой, были семантически описаны, а также все правила, чтобы делать выводы из данных. Таким образом, проблемы онтологий на прикладном уровне состоят в повторном использовании знаний предметной области, взаимосвязи между предметными областями знаний и рассуждениях.Вот почему управление знаниями предметной области по-прежнему очень важно. В прошлом для ссылки на знания предметной области использовались следующие инструменты: (i) Расширение онтологии — это широко используемый метод при построении новых онтологий, начиная с фиксированной, часто стандартной базовой онтологии [133]. В Разделе 2 мы представили, как онтологии происходят в основном из стандартов W3C. (Ii) Выравнивание онтологий высокого уровня Цель метода — найти соответствие между двумя или более онтологиями [134].Он имеет множество инструментов и готовых к использованию структур, представленных в обзорах отображения онтологий [134, 135]. (Iii) Объединение онтологий , где целью является объединение двух или более онтологий в одну [134]. Этот процесс требует глубоких знаний обеих онтологий, чтобы избежать дублирования хранимых данных и создать глубокие взаимосвязи между логическими элементами. (Iv) Каталог онтологий, каталог наборов данных , поддерживаемый семантическими поисковыми системами, является одной из групп инструментов для отображения данных и его значение из нескольких источников.(v) Ручная ссылка — это инструмент с наибольшим уровнем многоуровневости в этом списке, где каждое сопоставление онтологии описывается и сопоставляется вручную [136]. (vi) Графы знаний — это неструктурированные или полуструктурированные связанные данные для обработки всего домена и междоменное знание [137].
Поскольку информация, предоставляемая семантическим обогащением данных сенсора, может быть обработана без каких-либо знаний о сенсорной системе [91], прикладной уровень может обрабатывать эффективно интерпретируемые контекстуализированные высокоуровневые абстракции сенсорных данных [138] для генерации основанных на ситуации уведомления и решения [38].Основываясь на этой концепции, онтологии прикладного уровня должны обрабатывать информацию, которая связана со следующими функциями: (i) Situation Awareness объединяет информацию для принятия лучших решений. Предсказание событий и распознавание человеческой деятельности (HAR) — особые типы осведомленности о ситуации [139, 140]. Базовыми онтологиями, которые поддерживают понимание ситуации, являются временная онтология языка правил семантической паутины (SWRLTO) [141] и онтология временных абстракций (TAO) [142]. TAO разработан для захвата семантических временных абстракций, в то время как SWRLTO обеспечивает временное моделирование и рассуждения.Наиболее известными встроенными онтологиями, поддерживающими осведомленность о ситуации, являются следующие: (a) Situation Awareness Core (SAW-CORE) Онтология формализует представление знаний об объектах, отношениях и их темпоральном развитии, что приводит к хорошей производительности. Базовыми элементами SAW-CORE являются: SituationObject s и Relation s. Каждый SituationObject состоит из атрибутов , которые участвуют в Relation s, атрибут запускает Relation s как true или false [143].(b) Стандартная онтология для повсеместных и повсеместных приложений (SOUPA) обеспечивает пространственно-временное представление для охвата таких понятий, как момент времени ( TimeInstant ), интервалы ( TimeInterval ), подвижные пространственные объекты ( SpecialTemporalThing ) и географические объекты. [144]. (C) Event-Model-F поддерживает участие объектов в событиях, временную длительность событий, а также отношения между событиями в мереологических (события основаны друг на друге), причинных и корреляционных формах [145] .(d) SNAP / SPAN , где SNAP и SPAN обрабатывают отношения между пространственными и временными событиями соответственно [146]. (ii) Отслеживание — частая проблема приложений IoT. Помимо информации о состоянии, онтология I2oTonology также обрабатывает проблемы доступности и совместимости объектов [147]. (Iii) Запросы высокого уровня дополняют результаты запросов из облачных источников, таких как облако связанных открытых данных (https: // lod-cloud. net /), в результате чего возникла Семантическая сеть вещей (SWoT) [42].Двумя основными технологиями запросов высокого уровня являются семантические запросы, основанные на вариантах SPARQL [36] и доступ к данным на основе онтологий (OBDA) [148]. Технологии контроля доступа будут иметь большее значение в будущем [149]. Контекстные условия создают новые проблемы для контекстно-зависимого управления доступом, поскольку контекстная информация будет играть решающую роль в динамически изменяющейся среде [150]. В качестве многообещающего примера недавно был представлен подход, основанный на онтологии, который фиксирует такие контекстные условия и включает их в политики, используя языки онтологий и рассуждения на основе нечеткой логики [151].(iv) Интеграция и анализ потоковых данных Интернета вещей с помощью методов машинного обучения. приобретают все больший интерес, поскольку большинство моделей потоковых решений должны работать в средах с учетом ресурсов и обнаруживать изменения в среде и реагировать на них, и многим организациям необходимо иметь дело с огромными наборами данных разные форматы из разных источников. Наилучшая практика для оценки производительности моделей машинного обучения приведена в [152], а проблемы интеграции потоковых данных IoT суммированы в [153].
Разработка платформ облачных вычислений должна быть сосредоточена на обеспечении масштабируемости и надежности [154, 155], управлении устройствами и данными, мониторинге [156, 157], скорости поступления информации и гибкости [158]. Общие платформы Интернета вещей, такие как Google Cloud IoT (https://cloud.google.com/solutions/iot/), Microsoft Azure IoT Suite (https://azure.microsoft.com/en-us/services/iot-hub/ ) и Siemens-MindSphere (https://www.siemens.com/global/en/home/products/software/mindsphere.html), изначально не поддерживают семантические описания; вместо этого они используют расширяемые внутренние модели данных и функции для реализации ранее упомянутых функций.Orion Context Broker, OCB (https://fiware-orion.readthedocs.io/en/master/), является особенным на этом рынке платформы как услуги (PaaS), поскольку он изначально поддерживает семантику NGSI-LD. описание, основанное на JSON-LD (JSON для связывания данных), предназначенное для представления знаний в триплетах RDF из сущностей , свойств и отношений .
Расширение моделей данных до информационных моделей обеспечивает функциональную совместимость и полезность для оценки качества обслуживания (QoS) [159, 160] и качества информации (QoI) [161].Каталог онтологий LOV4IoT в связанных открытых словарях (LOV) (https://lov.linkeddata.es/) ссылается на 510 исследовательских проектов на основе онтологий для IoT и его прикладных областей (https://lov4iot.appspot.com/?p = онтологии), относящиеся к здравоохранению (159), окружающей среде, например, умной энергии, погоде и т. д. (95), универсальному Интернету вещей (86), умным городам (24), умным домам (59), робототехнике (28), сельскому хозяйству ( 24), туризм (31), транспорт (58), другие, например, безопасность, измерения и т. Д. (49). Каталог LOV4IoT является исчерпывающим источником для выбора онтологий, ориентированных на приложения, поэтому в оставшейся части этого раздела основное внимание уделяется тому, как семантические технологии используются в некоторых из наиболее часто применяемых решений.
Общие семантические технологии Интернета вещей в основном используются для обеспечения взаимосвязи между платформами и рабочими доменами: (i) Hypercat — это как формат, так и экосистема API, разработанная для взаимодействия, выборки и поиска в каталогах Интернета вещей [162]. Hypercat был разработан для устранения различий в приложениях на основе Интернета вещей путем определения универсального языка адаптера. Hypercat описывает функции и использование API, при этом не нужно создавать новый или универсальный API для существующих.Hypercat может указывать на любой ресурс с URL-адресом или URI; общие типы ресурсов в Hypercat в приложениях IoT — это объекты SenML для представления временных рядов [163]. (ii) OpenIoT (http://www.openiot.eu/) — это платформа на основе W3C SSN, которая фокусируется на подключении сенсорных устройств к программное обеспечение, позволяющее обнаруживать контекст и семантику, а также управлять датчиками. OpenIoT использует Hypercat для взаимодействия API высокого уровня. Возможности визуального мониторинга и настройки метаданных датчиков, предлагаемые Интегрированной средой разработки (OpenIoT IDE), позволяют разрабатывать приложения без программирования [164].OpenIoT также является хорошим примером парадигмы Sensing-as-a-Service (SaaS) [165] [166]. (Iii) FIESTA-IoT обращается к семантической совместимости на всех уровнях IoT. FIESTA-IoT использует ранее описанную структуру OpenIoT для управления взаимодействием аппаратного уровня на уровне датчиков. Онтология обеспечивает взаимодействие на уровне данных на уровне устройства посредством семантических аннотаций необработанных данных, взаимодействие на уровне модели на уровне шлюза путем согласования онтологий с существующими онтологиями IoT, взаимодействие на уровне запросов на уровне поддержки сервисов и приложений посредством запросов к унифицированным базам знаний, взаимодействия на уровне рассуждений, на основе вывода значимой информации и взаимодействия на уровне прикладной области на уровне службы / приложения для поддержки связанных открытых служб и междоменных приложений [167].(iv) Фреймворк Inter-IoT основан на аппаратных и программных инструментах с открытым исходным кодом, обеспечивающих многоуровневое взаимодействие между уровнями системы IoT (устройства, сети, промежуточное ПО, сервисы приложений и данные / семантика). Функциональная совместимость данных и семантики решена введением новой онтологии GOIoTP (Generic Ontology of IoT Platform) [168]. Взаимодействие между онтологиями решается с помощью процедур сопоставления и слияния онтологий инструмента межплатформенного семантического посредника (IPSM) [169].
Медицинские приложения на основе Интернета вещей очень разнообразны, включая мониторинг когнитивных функций (помощь при деменции, вспомогательные средства ухода за больными), электрокардиографию и всесторонний индивидуальный мониторинг здоровья с помощью носимых устройств. Уникальные факторы медицинских онтологий заключаются в том, как они управляют медицинскими датчиками и измерительным оборудованием, управляют диагностикой и путями, а также обеспечивают взаимосвязь информационных систем больниц. Далее мы обсудим роль онтологий через представление деталей некоторых из этих решений.(i) Smart Appliances REFerence for Health (SAREF4Health) был разработан для работы с электрокардиографией (ЭКГ) в реальном времени с упором на носимые устройства. Онтология основана на Справочнике по интеллектуальным устройствам (SAREF) (http://ontology.tno.nl), который также включает расширения для интеллектуальной энергетики, окружающей среды и зданий. В этом расширении онтология предназначена для сериализации сообщений SAREF4Health как JSON-LD для представления временных рядов сигналов ЭКГ и обеспечения совместимости с HL7 Fast Healthcare Interoperability Resources (FHIR) [170].(ii) Онтология здоровья и тревог — это основанная на онтологии система управления контекстом, разработанная для поддержки ухода на дому. Используемое рассуждение на основе правил оценивает риски на основе условий окружающей среды, сигналов тревоги,
Семинар 6. СЕМАНТИЧЕСКИЕ ИЗМЕНЕНИЯ
1. Смысловое изменение. Экстралингвистические изменения (изменение понятия, ослабление первого значения, развитие новых значений) и языковые изменения (конфликт синонимов, многоточие). Герман Пауль.Prinzipien des Sprachgeschichte.
2. Основные пути: постепенные семантические изменения (специализация и обобщение) и мгновенные сознательные семантические изменения (метафора и метонимия). Вторичные пути: постепенное (возвышение и деградация), мгновенное (гипербола и литотес).
Упражнения к семинару 6
I. Найдите синонимы в списке:
1. Улучшение 2. Различение синонимов 3.деградация 4. расширение 5. возвышение 6. ухудшение 7. ограничение 8. мелиорация 9. уничижение 10. обобщение 11. различение синонимов 12. расширение 13. ухудшение 14. расширение 15. специализация 16. вырождение 17. сужение 18. улучшение.
II. Прочтите словесные рассказы и определите результаты их смыслового развития. Результаты: a. обобщение; б. специализация; c. улучшение; d. уничижительное отношение.
1. Существительное изображение используется для обозначения только изображения, сделанного краской.Сегодня это может быть фотография или изображение, выполненное углем, карандашом или любым другим способом.
2. Прилагательное хороший от латинского nescius для невежественного в разное время до того, как нынешнее определение стало установленным, означало глупый, затем до глупости точный, затем педантично точный, затем точный в хорошем смысле и его текущее определение.
3. Червь — термин для любого ползающего существа, включая змей.
4. С 1550 по 1675 год глупый очень широко использовался в смысле «заслуживающий жалости и сострадания, беспомощный». Это производное от среднеанглийского seely от немецкого selig , что означает «счастливый, блаженный, благословенный, святой, а также пунктуальный, соблюдающий время года».
5. Самое раннее записанное значение слова pipe — музыкальный духовой инструмент. В настоящее время им можно обозначать любое полое продолговатое цилиндрическое тело.
6. Радиатор использовался для всего, излучающего тепло или свет, прежде чем он был применен специально для нагрева пара или транспортного средства и самолета.
7. Рассмотрим blackguard . В свите лордов средневековья служили, в частности, охранником железных горшков и другой черной от копоти кухонной утвари. Из безнравственных черт, приписываемых этим слугам их хозяева, происходит нынешнее пренебрежительное значение слова негодяй негодяй.
8. Революционный , который когда-то ассоциировался в сознании капиталистов с нежелательным ниспровержением статус-кво, теперь широко используется рекламодателями как сигнал желаемой новизны.
9. Слово saloon первоначально относилось к любому большому залу в общественном месте. К 1841 году был создан пивной бар sense a public.
10. Lewd начал обозначать тех, кто был мирянами, а не духовенством.Поскольку духовенство было образованным, а миряне мало-помалу — нет, тогда оно стало обозначать невежественных, а оттуда — непристойных, явно с худшими коннотациями.
11. Глагол похитить вошел в широкое употребление в значении «забирать ребенка незаконно и обычно силой, чтобы требовать денег для их безопасного возвращения». Теперь это любой человек, а не только ребенок.
12. Crafty , ныне пренебрежительный термин, изначально был словом похвалы.
13. Мишень изначально означала все, во что стреляют, и, образно говоря, любой результат, на который нацеливается.
14. Слово « худой» больше напоминает не об исхудании, а о спортивности и красоте.
15. Voyage на раннем английском языке означало путешествие, как и французский рейс voyage , но теперь он ограничен в основном путешествиями по морю.
16. Слово hussy сегодня означает женщину с плохим поведением, нефрит, флирт.Однако в среднеанглийском языке это обозначало женщину с хорошей репутацией (домохозяйку).
17. Мясник датируется 13 веком как термин, обозначающий человека, который готовил и нарезал любое мясо. Раньше это относилось к специалисту по козьему мясу, часто соленому, потому что оно было жестким. Этот факт указывает на то, насколько низким было потребление говядины в средние века.
18. Прилагательное проницательный раньше означало злой, злой; хитрый, лживый.Тогда это стало означать «остроумный»; имея практический здравый смысл.
III. Одно и то же слово может иметь как метафорические, так и метонимические значения. Проанализируйте эти фразы со словами из тематической группы «Части тела» и в каждом случае определите тип значения, который слово реализует во второй фразе: а) метафорический, б) метонимический.
Головка
1. голова девочки кочан
2.голова девушки для подсчета голов
3. Глава девушки глава семьи
Глаз
4. глаз человека глаз картофеля
5. Мужской взгляд на моду
Горловина
6. устье мальчика устье пещеры
7. рот мальчика другой рот для кормления
Язык
8.язык ребенка его родной язык (испанский)
9. язык ребенка язык колокола
10. Язык ребенка Ни один язык не должен раскрывать секреты
Сердце
11. сердце человека суть дела
12. сердце человека храброе сердце
Рука
13.руки человека заводские руки
14. рука человека стрелка часов
Фут
15. стопа солдата у подножия горы
16. стопа солдата пешая (пехотная)
IV. Метафоры основаны на различном типе сходства. Определите признак или признаки сходства в каждом случае:
а) форма; б) функция; в) возраст; г) цвет; д) положение.
1. капля молочного алмаза
2. сердце человека сердце города
3. черные туфли черное отчаяние
4. горлышко мужчины горлышко бутылки
5. зеленая трава зеленый человечек
6. зубы мальчика зубы гребня
7. ключ от двери ключ от тайны
8.хвост животного хвост пальто.
V. Метонимическое изменение может быть обусловлено различными связями, такими как пространственные, временные, причинные, символические, инструментальные, функциональные и т. Д. Установите модель переноса в каждом случае:
а) материальные изделия из нее; б) часть целиком; в) приборный продукт; г) символ вещи, символизируемой; д) содержимое емкости; е) разместить занимающих его людей.
1. отличный конь отряд конный
2.чайник новый Чайник кипит
3. никель (металл) никель (монета)
4. красивая корона Отказалась от короны
5. вести его за руку Имеет разборчивую руку
6. Большой промышленный город. Весь город в ярости от политики муниципальных образований.
VI. Проанализируйте значения слов, выделенных курсивом. Выявить результат изменения денотационного аспекта лексического значения данных слов.
Модель: кредит : подарок от начальника; вещь взяла взаймы денежную сумму, которая заимствована, часто в банке, и должна быть возвращена, как правило, вместе с дополнительной суммой денег, которую вы дали в качестве платы за заем.
Результатом изменения денотационного аспекта лексического значения слова «заем» стало то, что слово стало более специализированным по значению (ограничение значения, специализация).
1) лагерь : место размещения войск в палатках место проживания людей в палатках или охоты; 2) девочка : малолетний ребенок любого пола малолетний ребенок женского пола; 3) птица : молодая птица существо с крыльями и перьями, которое обычно может летать в воздухе; 4) прибытие: достигнуть берега после рейса, достигнуть места в конце пути или этапа путешествия; 5) олень : любое четвероногое () копытное пасущееся или пасущееся животное с разветвленными костными рогами, которые сбрасываются ежегодно и обычно переносятся только самцом; 6) коврик : грубая шерстяная ткань небольшой коврик; 7) сарай : место для хранения ячменя — крупное хозяйственное строение, используемое для хранения зерна, сена, соломы или содержания скота; 8) glide : плавное движение и плавный полет без двигателя; 9) , комната : помещение, часть или перегородка либо здание, ограниченное стенами, полом и потолком; 10) fly : движение с крыльями для перемещения по воздуху или в космическом пространстве; 11) художник: магистр гуманитарных наук () лицо, занимающееся рисованием или рисованием в качестве профессии или хобби; 12) чемпион : боец - лицо, которое победило или превзошло всех соперников в соревновании, особенно в спортивном; 13) кампания : полевые операции армии — связанный набор действий, направленных на получение определенного результата, в военных действиях, в политике и бизнесе.
VII. Проанализируйте значения слов, выделенных курсивом. Выявить результат изменения коннотационного аспекта лексического значения в данных словах.
Модель: негодяй: крепостной-феодал, крестьянин-земледелец в подчинении господину лицо, виновное или способное к преступлению или злу.
Результатом изменения коннотационного аспекта лексического значения слова злодей стало то, что слово приобрело уничижительный эмоциональный заряд (ухудшение значения).
1) хитрость: обладающая эрудицией или умением ловко обманывать; 2) рыцарь: человек слуга благородный мужественный; 3) любит: глупый, увлеченный () любящий, ласковый; 4) банда : группа людей, собирающаяся организованной группой преступников; 5) маршал — слуга, обслуживающий лошадей, офицер высшего ранга в вооруженных силах; 6) грубый : обыкновенный, обыкновенный грубый или вульгарный; 7) министр: служащий заведующий государственным учреждением; 8) энтузиазм : пророческое или поэтическое безумие (,) интенсивное и страстное наслаждение, интерес или одобрение; 9) насильственные: имеющие выраженный или мощный эффект с использованием физической силы или с ее использованием, предназначенной для нанесения вреда, повреждения или убийства кого-либо или чего-либо; 10) сплетня : крестный, родственник того, кто в Боге говорит скандал; рассказывает клеветнические истории о других людях.
VIII. Ниже приведен список выражений со словом красный. В каждом случае попытайтесь найти правдоподобную мотивацию для использования этого слова и поспорите, имеем ли мы больше отношения к лингвистической метафоре или метонимии или более к концептуальной метафоре или метонимии.
(a) рыжий (= кто-то с рыжими волосами)
(b) отвлекающий маневр (= что-то неважное, но отвлекающее от важных вещей)
(c) Он был пойман с поличным (= совершал что-то неправильное).
(d) Он начал краснеть (= он очень злился).
(e) Это был раскаленный (= очень захватывающий) проект.
(е) красная политика (= крайне левые, коммунистические идеи)
IX. Какое слово в каждом из следующих коротких отрывков, кажется, изменило свое значение с момента написания отрывка?
Голова твоя полна ссор, как яйцо полно мяса.(Шекспир, Ромео и Джульетта, III. I.20)
И когда я принесла печеные яблоки из туалета и надеялась, что наши друзья будут так любезны, чтобы взять их, О! — прямо сказал он, — нет ничего более хорошего в фруктах, и это самые прекрасные домашние яблоки, которые я когда-либо видел в своей жизни.