
Обзор сервиса Словоеб | Блог YAGLA
Сервис Словоеб известен как бесплатный аналог Key Collector. Тот же принцип работы, практически тот же интерфейс. Естественно, есть и ограничения. Однако функционала Словоеба вполне достаточно для небольших проектов, и в отличие от ручного сбора семантики здесь за вас всю работу сделает программа.
В этой статье вы увидите, как настраивать Словоеб и пользоваться им.
Ограничения программы
Первое ограничение – количество источников, по которым происходит парсинг. К ним относятся:
- Левая и правая колонки сервиса Wordstat
- Rambler.Adstat
- Поисковые подсказки Яндекса и Google.
В Key Collector, для сравнения, помимо этих поддерживаются также Google Ads, подсказки Mail, Wordstat полностью и системы аналитики, установленные на сайте.
Второе ограничение – Словоеб проверяет частоту запросов исключительно по Яндекс Wordstat, в то время как Key Collector – по Yandex Direct, Google Ads, LiveInternet, Rambler Adstat, APIShop. com.
com.
И третье ограничение – оценка конкурентоспособности запросов для Яндекс и Google. В Key Collector есть 4 формулы оценки KEI, которые можно менять вручную.
Таким образом, Словоеб собирает ключи только из Вордстата и поисковых подсказок и работает только для Яндекса. Если нужна семантика для других рекламных систем, придется платить за Key Collector.
В целом, Словоеб делает всю ту же самую работу, что и вы, когда собираете семантику в сервисе Yandex Wordstat, но делает это автоматически, за вас, освобождая вам время на выполнение других задач.
И, разумеется, при автоматическом парсинге вы получаете результаты за считанные минуты: несколько тысяч ключей – за 10-15 минут, десятки тысяч – от силы за полчаса. При ручном сборе могут уйти и недели, впрочем, всё зависит от объема семантики и знания темы.
С чего начать
1) Зайдите на официальный сайт программы по ссылке. Здесь можно её скачать в один клик.
2) Запустите скачанный файл, чтобы установить программу на компьютер. Обновите до новой версии, если выходит такое окно:
Обновите до новой версии, если выходит такое окно:
Далее переходим к настройке программы Словоеб.
3) Зайдите в «Настройки» в левом верхнем меню, которое появляется при нажатии значка программы:
4) В разделе «Парсинг» задайте его параметры. Уберите значок «+» из поля «Фильтрация символов». Остальное оставьте, как задано по умолчанию.
Не забудьте сохранить изменения (далее сохраняйте их отдельно на каждой вкладке).
5) Настройте аккаунты Яндекс.Директа специально для сбора семантики.
Обратите особое внимание на следующее.
Использовать нужно специально созданные под парсинг аккаунты, проще говоря – «фейковые». Пусть вас это не пугает: Яндекс лоялен к парсерам, так как с помощью них рекламодатели могут настроить более качественные рекламные объявления, что на руку самой системе – ведь она на этом тоже зарабатывает. Это с одной стороны.
С другой – рабочий аккаунт, в котором ведется реклама, использовать ни в коем случае нельзя. Яндекс может его забанить за нарушение правил пользования сервисом. В этом случае лучше рискнуть потерять доступ к «фейковому» аккаунту, а не к настоящему.
Яндекс может его забанить за нарушение правил пользования сервисом. В этом случае лучше рискнуть потерять доступ к «фейковому» аккаунту, а не к настоящему.
Итак, далее придется выполнить небольшую рутинную работу по регистрации почтовых ящиков аккаунтов в Яндексе.
Важно! Несмотря на то, что аккаунты «фейковые», задавайте им читабельные имена пользователей, чтобы впредь процесс не тормозили капчи Яндекса, и работа продвигалась быстрее.
Затем перейдите на вкладку «Yandex.Direct» и в поле «Настройки аккаунтов Yandex» задайте их, а здесь введите их логины и пароли в любом из форматов. Чем больше, тем лучше, но достаточно и 3-5 аккаунтов.
В поле «Количество потоков» впишите количество созданных аккаунтов:
6) Ту же самую цифру задайте на вкладке «Yandex.Wordstat»:
7) В разделе «Интерфейс» на вкладке «Экспорт» выберите, в каком формате будете экспортировать результаты парсинга:
Дополнительно можете подключить автораспознавание капчи, чтобы она вас не преследовала. Особенно если вы планируете парсить большие объемы ключей. Стоимость сервисов по автоматическому распознаванию символическая, актуальные цифры смотрите в разделе «Антикапча» по ссылкам:
Особенно если вы планируете парсить большие объемы ключей. Стоимость сервисов по автоматическому распознаванию символическая, актуальные цифры смотрите в разделе «Антикапча» по ссылкам:
На этом основные настройки парсинга готовы, Словоеб готов к сбору данных. Переходим к самому процессу.
Запуск парсинга в Словоебе
1) Создайте новый проект. Для этого на начальном странице есть специальная кнопка:
Задайте имя проекту и сохраните его в нужную папку на компьютере:
2) Укажите регионы для парсинга.
Например:
3) В блоке «Управление группами» для удобства можете создать разные группы, по которым можно будет распределять готовые маски ключевых слов.
Задайте группам названия, чтобы лучше ориентироваться в их содержимом.
Например, по разным тематикам, товарам, услугам и т.д.
Для добавления новой группы нажмите черный знак плюса, для сортировки по алфавиту – символ рядом с ним.
Наконец переходим к ключевым фразам, точнее – к базисам, по которым будем парсить более глубокую семантику. Предварительно вам нужно составить список базисов либо в блокноте, откуда удобно будет скопировать в программу.
Здесь ничего сложного: элементарно впишите варианты названий вашего продукта, по которым могут вас искать целевые пользователи, типа:
- пластиковые окна купить
- пластиковые окна пермь
- заказать пластиковые окна
- установка пластиковых окон
4) Добавьте список фраз, по которым программа Словоеб будет парсить новые маски ключевых фраз. На вкладке «Данные» кликните «Добавить фразы»:
Откроется такое окно:
В этом окне впишите все изначальные фразы и нажмите «Добавить в таблицу», либо загрузите из локального файла готовый список. Каждая новая фраза – с новой строки.
Отметьте, в какую группу добавлять фразы – в текущую активную или другие, созданные в блоке «Управление группами».
Также можно поставить галочку над полем с ключами, чтобы автоматически не добавлялись фразы, которые уже есть в выгружаемом списке.
Для примера добавим такие фразы:
5) Дополнительно вы можете добавить список стоп-слов, если он у вас уже сформирован. Программа сразу будет фильтровать запросы с этими словами и не включать их в результаты парсинга.
Выберите опцию «Стоп-слова» в верхнем меню:
Скопируйте минус-слова по одному или сразу добавьте списком из файла:
Внизу настройте, как алгоритм будет учитывать ваши минус-слова по вхождению и другим параметрам.
6) Начните сбор семантики. Он состоит из двух этапов – непосредственно парсинг ключей из Вордстата и сбор частотностей.
На вкладке «Сбор данных» выберите способ – пакетный сбор слов из левой колонки Вордстата (вместе со значениями частотностей).
Если вы настроили несколько аккаунтов под парсинг, для каждого из них Словоеб подберет одинаковую долю слов для анализа, чтобы затем обработать в классическом линейном режиме.
Чтобы активировать сбор, нажмите снова на список исходных ключей и нажмите в окне «Начать сбор»:
Когда процесс запущен, вы сможете им управлять – остановить полностью или приостановить на время, – кликнув по одной из иконок:
В нижнем блоке программы в журнале событий (вторая вкладка) вы увидите всю информацию о шагах парсинга по секундам – на каком этапе сейчас, какие ошибки когда возникали и т.д.
В процессе вы можете исправить все ошибки.
Если вы заметите, что программа «подвисает», нажмите на кнопку обновления:
Где смотреть результаты?
Когда парсинг завершится, вы увидите в журнале событий такую запись: «Процесс сбора левой колонки Yandex.Wordstat для фразы <…> завершен корректно. Опции «Остановка» и «Приостановка процессов» станут недоступными.
Результаты парсинга отобразятся в таблице программы Словоеб. Выглядит это примерно так (в примере тематика – доставка пиццы):
Источник
Обратите внимание: это пока предварительные результаты, так как в них вы видите только базовую частотность – то есть общая сумма запросов ключа + по его низкочастотному «хвосту». Для дальнейшей работы нужна точная цифра по запросам в месяц по каждому базису. Иначе как спрогнозировать, сколько трафика мы будем получать с каждого ключевика?
Для дальнейшей работы нужна точная цифра по запросам в месяц по каждому базису. Иначе как спрогнозировать, сколько трафика мы будем получать с каждого ключевика?
В помощь – сбор частотностей из сервиса Yandex.Wordstat.
Он нужен, чтобы узнать точное количество запросов по ключам.
Нажмите кнопку с таким значком:
Программа предлагает разные варианты – собрать:
- Все виды частотностей
- Базовые виды частотности
- Частотности фраз в кавычках (то есть в фразовом соответствии)
- Частотности фраз в точном соответствии (конкретно по данном словоформе).
Выберите последний вариант и дождитесь окончания сбора данных. Результат будет выглядеть примерно так (на том же примере с пиццей):
Источник
Далее вы можете сразу очистить результаты от явно нецелевых запросов прямо в программе Словоеб, или оставить это на потом – удалить мусорные фразы из экспортированного Excel-файла.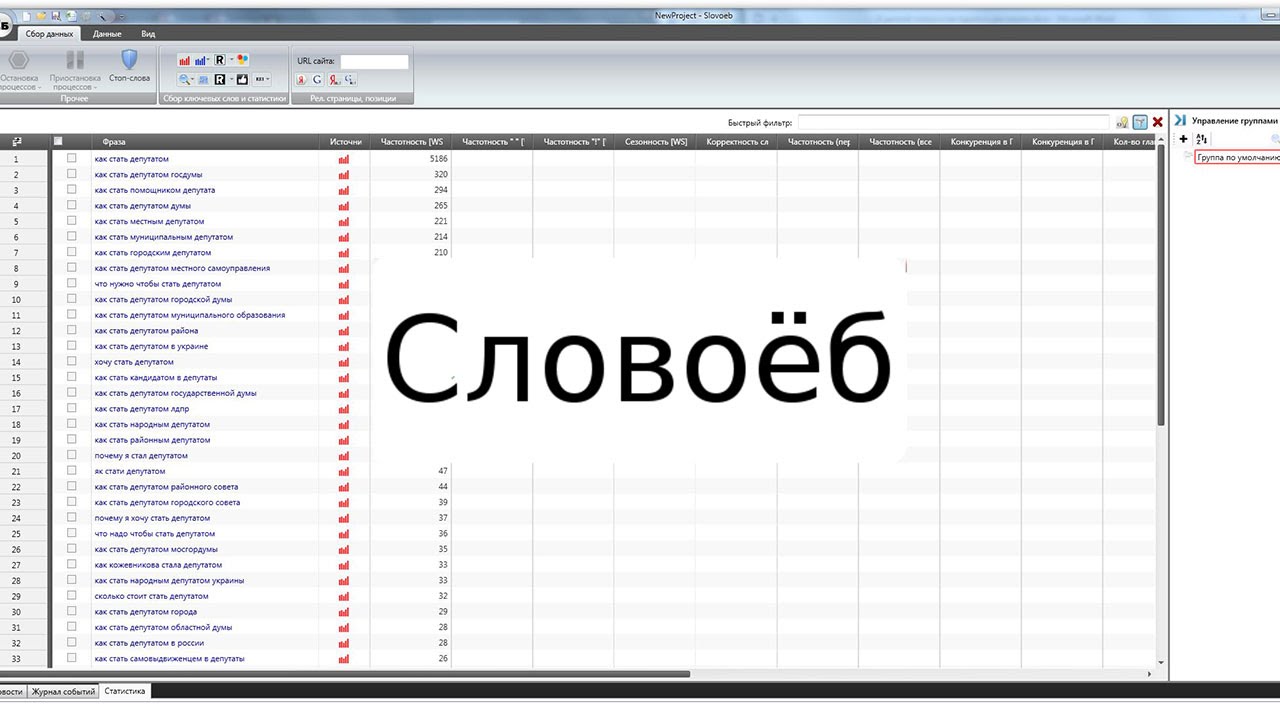
Итак, сбор семантики завершен. Результаты парсинга можно сохранить на свой компьютер для дальнейшего использования в рекламных кампаниях.
Кликните кнопку экспорта:
Допустим, вы в самом начале настройки выбрали для экспорта формат csv – на выходе получаете CSV-файл с семантикой.
Если вы распределяли ключи по группам, в этом файле каждый лист соответствует отдельной группе.
Вот и всё, что нужно знать про Словоеб и как с ним работать.
Хотите тоже написать статью для читателей Yagla? Если вам есть что рассказать про маркетинг, аналитику, бизнес, управление, карьеру для новичков, маркетологов и предпринимателей. Тогда заведите себе блог на Yagla прямо сейчас и пишите статьи. Это бесплатно и просто
настройки программа, как правильно пользоваться парсером
Программа Словоеб предназначена для автоматического сбора ключевых слов и частотностей из Яндекс Вордстата. Она бесплатная и устанавливается на компьютер. Это урезанный вариант Кей Коллектора.
Это урезанный вариант Кей Коллектора.
Плюсы и минусы программ
Преимущества:
- Не требует оплаты. Это единственная программа, которая парсит Вордстат абсолютно бесплатно.
- Собирает поисковые подсказки – хороший способ расширить семантическое ядро.
- Поддерживает парсинг в несколько потоков благодаря добавлению прокси.
- Парсит поисковую выдачу Яндекса и Гугла.
- Дает выбор региона.
- Поддерживает несколько сервисов антикапчи.
- Позволяет делить запросы на группы, формируя в итоге структуру сайта.
Недостатки.
- Словоеб не собирает частоты из Яндекс Директа, это замедляет процесс работы.
- Не парсит Гугл Адвордс.
- Не поддерживает платные API, если нужно снимать больше данных, например, показатели конкуренции ключевых слов в сервисе Мутаген или еще что-либо.
- Не устанавливает обновления автоматически, придется делать это вручную.
Обратите внимание на эти особенности, они важны для сбора и работы с СЯ.
Где скачать и как установить
Программа распространяется бесплатно, для ее активации не нужен лицензионный ключ.
Достаточно скачать программу и распаковать на ПК:
- Скачайте файлы с официального сайта.
- Распакуйте архив в нужную папку.
- Откройте программу, запустив файл с логотипом СловоЕб с расширением .EXE.
- Создайте проект и настройте программу.
Настройки Словоеба
Большинство настроек можно оставить по умолчанию, нужно только добавить e-mail с доменом yandex.ru. Добавляется все, что идет до значка @.
Кроме того, стоит оставить 1 поток с основного IP-адреса. Если задействованы прокси, нужно использовать столько же потоков, сколько прокси-серверов.
Остальные настройки необязательны.
К примеру, Антикапча желательна, но может не использоваться, если парсинг идет с одного основного IP-адреса.
Если ядро большое (5 000 запросов и более), для ускорения можно использовать прокси. Тогда нужно добавить и антикапчу.
Для сбора частот из Вордстата можно использовать и шаред прокси, и бесплатные сервера, если они не забанены Яндексом.
Настройки антикапчи в Словоебе
Для подключения антикапчи нужно зарегистрироваться в одном из поддерживаемых сервисов:
- Antigate (anti-captcha.com).
- CaptchaBot.
- RIPCaptcha.
- RuCaptcha.
Остается добавить API ключ системы в поле «Key» и сохранить изменения.
Прокси в Словоебе
Прокси помогают ускорить процесс сбора частотностей в разы.
Чтобы добавить прокси, зайдите в настройки, перейдите в раздел «Сеть», поставьте галочку напротив «Использовать прокси-серверы».
Нажмите «Добавить из буфера» и вставьте прокси в формате: АдресПрокси:Порт@Логин:Пароль. Нажмите «Ок» и «Сохранить изменения».
Купить прокси можно на сайте Proxy6.net →
Как пользоваться парсингом Вордстата в программе Словоеб
Первым делом определитесь с регионом. Если он не важен, ничего не делайте, а если важен – выберете нужный вариант в нижней панели.
Чтобы спарсить все хвосты по собранным маркерам, нужно нажать на значок Вордстата в панели инструментов и вставить маркеры в окно. Затем нажать «Начать сбор».
Если ранее в этом проекте были созданы группы с собранными ключами, лучше отметить чекбокс «Не добавлять фразу, если она уже есть в любых других группах». Это поможет избежать одинаковых ключей в разных группах.
Стоп-слова
Когда ключи будут собраны, можно удалить мусор с помощью стоп-слов.
Чтобы не удалить лишнего, выберите «Зависимый от словоформ стоп-слова», «Частичное вхождение» и «Искать совпадения только в начале слов».
В список добавьте те слова, которые точно не подходят. Например: «википедия», «ютуб», «форум», «картинки» и т. д. В зависимости от тематики они разнятся.
Далее удалите их с помощью кнопки в меню.
Сбор частотностей Вордстата в Словоебе
Теперь можно собрать частотности и в кавычках, и с восклицательным знаком. Для этого выберите в панели инструментов значок лупы.
В выпадающем меню выберите виды частот, которые вам нужны. Программа медленно, но верно пройдет по ним и добавит.
На этом этапе можно использовать прокси для ускорения сбора частот, например, 20 прокси ускорят процесс, соответственно, в 20 раз.
Учтите, что количество аккаунтов, указанных в настройках, должно быть равно количеству потоков. Т. е. прокси + 1 основной IP-адрес.
Обзор других функций программы
Помимо парсинга Вордстата, у Словоеба есть и другие функции.
Парсинг подсказок в Словоебе
Для начала нужно проверить настройки подсказок и задать их под себя. Находятся они в разделе «Парсинг» во вкладке «Подсказки».
Настройки:
- Глубину парсинга лучше оставить 0 – при большем значении найденные подсказки будут парситься по второму кругу. Соберется много мусора.
- Чекбокс в пункте «Собирать только ТОП подсказок без перебора пробела после фразы» лучше оставить пустым. И выбрать все возможные символы для перебора, как на скриншоте ниже.
 Так, к заданной фразе соберуться все возможные подсказки.
Так, к заданной фразе соберуться все возможные подсказки. - Если отметить «Выполнять подстановку выбранных групп перед заданной фразой», процесс затянется, а в итоге получится много мусора. Поэтому пользуйтесь функцией только тогда, когда без нее не обойтись.
- Остальные настройки можно оставить как есть, если не требуются подсказки из региональной выдачи.
 Так, к заданной фразе соберуться все возможные подсказки.
Так, к заданной фразе соберуться все возможные подсказки.Чтобы спарсить подсказки в программе, нажмите на соответствующий значок в панели инструментов и добавьте в открывшееся окно маркеры для парсинга.
Выберите, из каких поисковых систем нужны подсказки. Поставьте галочку, чтобы не добавлялись фразы, которые уже есть в других группах.
Теперь можно приступать к сбору подсказок.
Похожие фразы из Вордстата
В большинстве случаев нет смысла использовать эту функцию – для семантического ядра она может дать только мусор.
Но инструмент будет полезен, если нужны идеи первоначальных фраз для маркеров, которые в дальнейшем будут парситься.
Сезонность
Программа может проверить, является ли запрос сезонным. Словоеб анализирует историю запросов в Вордстате и выдает значение: да или нет.
Корректность словоформы
Функция проверяет, является ли словоформа корректной на основании поисковой выдачи.
Она пригодится, если в Словоеб добавлены ключевые слова из разных баз или выгрузки по конкурентам. С ее помощью можно избавиться от неправильных словоформ автоматически.
KEI в Словоебе
Опция для оценки конкурентности фразы в поисковых системах Яндекса и Гугла.
Позиции в Словоебе
Словоеб умеет определять, насколько страницы сайта релевантны запросам. За основу берутся данные поисковых систем Яндекса и Гугла. А также позиции сайта по этим ключам. Для проверки добавьте УРЛ сайта в строку меню.
Аналоги программы Словоеб
Бесплатный аналог программы – Магадан Lite. Другие продукты платные.
Самые популярные программы и сервисы для сбора семантического ядра:
- Кей Коллектор – мощная программа с расширенным набором функций. Устанавливается на ПК. Стоит 1 800 р. Заплатить нужно один раз.
- Магадан – расширенный аналог программы Магадан Lite, по функционалу схож с Кей Коллектор, на немного уступает. Так же устанавливается на ПК, лицензия стоит 1 500 р.
- Мутаген – недорогой онлайн-сервис, 1 запрос стоит 0,02 р.
- Rush Analytics – онлайн-сервис с широким функционалом и тарифными планами от 500 до 3 000 р./месяц.
 Устанавливается на ПК. Стоит 1 800 р. Заплатить нужно один раз.
Устанавливается на ПК. Стоит 1 800 р. Заплатить нужно один раз.Заключение
Словоеб подойдет новичкам, у которых пока нет доступа к более профессиональному софту, и тем, кому нужно собирать небольшие ядра от 100 до 3 000 ключей.
А если начекать штук 20 рабочих прокси и добавить столько же аккаунтов, то программа сможет собрать частотности и для больших ядер в приемлемый срок. Скажем, за 3–5 дней для ядра в 10 000 фраз и более.
Как использовать слова — зарабатывать на жизнь писательством
«Не могли бы вы взглянуть на то, что я пишу, и сказать, достаточно ли я хорош, чтобы заниматься этим профессионально?»
Я получил этот вопрос на прошлой неделе, во время моего марафона 5-часового бесплатного менторского звонка для подписчиков моего блога. (Извините более 100 человек, которые не смогли дозвониться!)
(Извините более 100 человек, которые не смогли дозвониться!)
Я всегда волнуюсь, когда люди говорят это. Во-первых, потому что я не чувствую себя вправе говорить кому-либо, хороши их тексты или нет.
Но также и потому, что если у вас нет ощущения, что вы хороши в этом деле, у вас как у фрилансера проблемы. В конечном итоге вы будете брать слишком мало и не будете выкладываться и получать хорошие концерты.
Есть так много разных видов письма. Мое общее ощущение таково, что где-то существует писательский рынок для большинства писателей, стремящихся зарабатывать этим на жизнь.
Но мы все всегда можем улучшить наше письмо.
Даже после 12 лет работы штатным сотрудником, пишущим по 3-4 статьи каждую неделю, я читаю отличные тематические статьи и думаю: «Черт. Я даже близко не там».
2 лучших совета от профессора письма Недавно у меня был Бен Ягода, профессор письма и автор новой книги Как не писать плохо , в качестве гостя на одном из моих подкастов.
Мы обсудили много настоящих грамматических тонкостей, но Бен говорит, что если у вас есть всего несколько минут, чтобы послушать, его совет:
Прочтите (работы других людей). Чем больше вы читаете, тем больше вы естественным образом усваиваете правила письма и понимаете, как работает игра слов и стиль.
Прочтите вслух (ваша собственная работа). Часто это поможет вам быстро найти предложения или слова, которые слишком длинны или не подходят.
Размышляя о том, как улучшить свои письменные работы, у меня есть семь принципов, которые помогают мне улучшить свои письменные работы.
Как использовать слова?
1. ЭкономноУ каждого читателя сейчас мало времени. Объем нашего внимания сокращается с каждой минутой.
Итак, когда вы пишете, подумайте, как наиболее лаконично выразить свою мысль. Ваши читатели будут вам за это благодарны.
После того, как вы напишете первый черновик, вернитесь и уменьшите его. Можно ли обрезать абзац или предложение, не теряя при этом ничего существенного? Отрежьте это.
Можно ли обрезать абзац или предложение, не теряя при этом ничего существенного? Отрежьте это.
Есть ли у вас слово или фраза, которыми вы часто пользуетесь? Патрулируйте и уничтожайте его повторения.
Затем фраза за фразой и слово за словом. Удалите все лишнее. Выберите более короткое слово, если оно выполняет свою работу.
Здесь меньше значит больше.
2. ВдумчивоЕсли мы пишем в полудумах о чем-то другом или в безумной спешке, мы не делаем все возможное.
Мы с Ягодой говорили об искусстве писать осознанно — полностью погружаясь в работу, которую делаем.
Старайтесь полностью присутствовать, когда пишете, а не писать в полусне или на автопилоте, а также проверять Facebook каждую минуту. Качество того, что вы производите, сразу подскочит.
3. Творчески Нет ничего нового под солнцем. Мы все это читали раньше. Вот почему вы должны приложить немного больше усилий к своему письму и найти новый способ сказать это. Именно так все великие писатели делают себе имя благодаря своему уникальному подходу к языку.
Именно так все великие писатели делают себе имя благодаря своему уникальному подходу к языку.
Я знаю, что больше всего восхищаюсь писателями, которые могут удивить меня своими творческими оборотами речи.
Я думаю, что это часто происходит в окончательном варианте. Приложите еще немного усилий и придумайте новый поворот, просветляющую метафору, необычное наблюдение. Этот последний штрих делает работу уникальной и заставляет клиентов-фрилансеров говорить: «Нам просто нужно вас для этого задания».
4. ЧастоПисьмо – это мышца, как и любая другая в вашем теле. Много тренируйтесь, и он придет в прекрасную форму.
Я знаю, что мои писательские способности были отточены сотнями статей, которые я написал в качестве штатного писателя. Качество моего письма в начале этого длинного отрезка было откровенно смущающим по сравнению с тем, что я написал в конце.
Найдите свой собственный способ написать большой объем текста, будь то блог, журнал или добровольное написание информационного бюллетеня. Или все это и многое другое.
Или все это и многое другое.
Чем больше вы играете со словами, тем лучше и легче писать.
5. ПравильноВам неясно, следует ли использовать их или там, или вам следует писать Питтсбург, Пенсильвания или Питтсбург, Пенсильвания? Это веб-сайт или веб-сайт, десять миллионов долларов или 10 миллионов долларов?
Если сомневаетесь, посмотрите. Возьмите словарь, тезаурус, книгу Бена, Элементы стиля или книгу стилей AP и узнайте, что считается подходящим для вашей ситуации.
Это особенно важно, если вы пишете на английском как на втором языке. Небольшие ошибки в грамматике и словоупотреблении сигнализируют редакторам о том, что у вас недостаточно навыков, которые им нужны.
Так что найдите минутку и убедитесь, что вы правильно поняли эти тонкости.
6. Разговорный Жесткий, старомодный язык является серьезной проблемой в современном письме. Многие писатели до сих пор создают веб-страницы и маркетинговые электронные письма, которые читаются как деловые письма начала 1960-х годов.
Деловой тон сегодня разговорный. В блогах тон очень разговорный.
Прочитайте то, что вы пишете, и посмотрите, похоже ли это на то, что вы разговариваете с людьми. Если нет, расслабьте его. Прочтите это вслух.
Вложите в него свою индивидуальность и речевые ритмы. Используйте фрагменты предложений — они работают в блогах.
Внимательно подумайте, кто ваш читатель, и убедитесь, что вы говорите на его языке.
7. С уважениемПишите с осознанием того, что ваши слова обладают огромной силой.
Подумай: не заденут ли кого-нибудь мои слова? Являются ли они легкомысленными, небрежными, грубыми, излишне неуважительными? Если это так, внесите изменения.
Если вы пишете что-то намеренно провокационное, подумайте, какие чувства это вызовет у людей. Это то что ты хочешь? Будьте очень уверены, прежде чем нажимать «опубликовать» или «отправить».
Как добиться успеха Недавно мне написала по электронной почте одна писательница, в которой сообщила, что у нее возникли проблемы с публикацией, потому что ее пугали «все остальные писатели».
Не беспокойтесь о конкуренции. Вместо этого посвятите себя улучшению вашего письма. Это верный способ продвинуться в качестве фрилансера и получать более качественные задания и более высокую оплату.
Всегда нужны писатели, владеющие своим делом.
Что вы делаете, чтобы улучшить свое письмо? Оставьте комментарий и добавьте новые советы.
Обучение словам и их работе 9780807763179
Исследования показывают, что словарный запас является лучшей поддержкой для понимания учащимися повествовательных и информационных текстов. Часто обучение словарному запасу сосредотачивается на нескольких целевых словах в конкретных текстах. Однако, чтобы понять много новых слов в сложных текстах, учащиеся должны знать, как работают слова. Эта книга, написанная отмеченным наградами авторитетом в области обучения чтению, показывает учителям, как вносить небольшие изменения, чтобы учить больше слов, а также как слова работают. Многие из этих небольших изменений связаны с обогащением существующих словарных практик, таких как стены слов и беседы со студентами.
Обучение словам и тому, как они работают показывает учителям, как:
- Определять наиболее важные группы слов для обучения.
- Научите учащихся использовать начальный текст в качестве основы для понимания остального текста.
- Используйте стены слов с большей целью и большей вовлеченностью учащихся.
- Выберите правильные слова для обучения из новых информационных текстов.
- Лучше понять ограничения выровненных текстов и способы их настройки.
- Используйте активы и решайте проблемы, чтобы поддержать изучающих английский язык.
- Получите доступ к бесплатным онлайн-ресурсам для наставников и учителей на сайте textproject.org.

Эльфрида Х. Хиберт — президент и главный исполнительный директор TextProject, Inc., лауреат премии Оскара С. Кози Ассоциации исследования грамотности за выдающийся вклад в исследования чтения и соавтор (вместе с П. Дэвидом Пирсоном) книги
“ Teaching Words может быть инструментом для информирования начинающих и поздних педагогов, ищущих фундаментальные знания о преподавании словарного запаса в классе. Историческая основа в сочетании с такими важными вопросами, как языковое разнообразие, многоязычие учащихся и преднамеренный выбор материалов, предлагает учителям эмпирически обоснованное, но доступное руководство по укреплению словарного запаса в своих классах.
— Отчет Педагогического колледжа
«Последний том Хиберта (2020), Обучение словам и тому, как они работают: небольшие изменения для больших результатов словарного запаса », рассматривает сложность и необходимость обучения словарному запасу с прагматической точки зрения и предлагает преподавателям и то, и другое. возможность узнать больше об отношениях между словами и открыть для себя практические педагогические приемы для применения в классе».
— Journal of Language and Literacy Education
«Эта книга обязательна к прочтению учителями, которые хотят выйти за пределы еженедельного списка слов. Внедряя небольшие конкретные изменения, Hiebert помогает вам добиться устойчивых улучшений в вашей учебной программе. Она создала жизнеспособный процесс, который может оказать значительное долгосрочное влияние на развитие словарного запаса ваших учеников, не подавляя при этом вас. Она должна быть на книжной полке у каждого педагога».
Она создала жизнеспособный процесс, который может оказать значительное долгосрочное влияние на развитие словарного запаса ваших учеников, не подавляя при этом вас. Она должна быть на книжной полке у каждого педагога».
« Обучение словам и их работе» призван внести значительный вклад в эту область. Ожидается, что учителя будут манипулировать многочисленными приоритетами, а поддержка обучения детей словесному обучению часто оказывается недостатком. Эта книга дает учителям небольшие, но действенные предложения по включению обучения словарному запасу в уже установленную классную практику, чтобы учителя могли решать сразу несколько задач. Внося небольшие изменения, которые предлагает Хиберт, учителя могут существенно изменить словарный запас детей и тем самым поддержать их обучение на протяжении всех школьных лет».
Содержание
Предисловие ix
1. L зарабатывание слов и как работают слова 1
L зарабатывание слов и как работают слова 1
Лексика и тексты: двусторонние отношения 2
Словарная инструкция: фокус на отношениях между словами, а не на отдельных словах 4 булярная инструкция 11
Небольшие изменения = большие результаты: ПОЧЕМУ 12
Небольшие изменения = большие результаты: КАК 15
Последнее слово 20
Доказательства 25
Небольшие изменения = большие результаты 35
Последнее слово 38
4. Краткая история английского языка и почему это важно 41 9
Последнее слово 53
5. Переработка и повторное смешивание: Многозначность и использование слов 54
Свидетельства 56
Маленькие изменения = большие результаты 61
Последнее слово 64
6. Словарные сети повествовательных текстов 66
Свидетельства 67
Мелкие изменения s = Большие результаты 77
Последнее слово 80
7 .