
Количество символов в сообщении
SMS-сообщения имеют ограничение в 160 символов на текст, но вы по-прежнему можете отправлять и получать сообщения, длина которых превышает 160 символов.
Как это работает?
Мы используем процесс под названием Truncating , который позволяет пользователям отправлять SMS-сообщения длиной более 160 символов. Когда пользователь составляет сообщение, длина которого превышает 160 символов, его сообщение разбивается на несколько SMS-сообщений, известных как сегментов . Усечение автоматически объединяет эти сегменты, поэтому несколько сообщений будут отправляться как одно непрерывное сообщение.
Мы делаем это для непрерывности. Большинство людей думают, что одно длинное сообщение выглядит лучше, чем разделение сообщения на несколько сегментов. Большинство (не все) операторов мобильной связи следуют этому же процессу усечения сообщений. Например, если вы отправляете сообщение, содержащее 200 символов, оно будет отправлено в виде двух текстовых сегментов , но отображаться как одно сообщение.
Отправка нескольких сообщений
Отправка нескольких сообщений, которые были усечены вместе, требует дополнительных данных. В результате первое сообщение, которое вы отправляете, всегда будет иметь ограничение в 160 символов, но любое дополнительное сообщение после первого уменьшает максимум 9 символов каждого текста.0007 символов до 153 . Это означает, что сообщение, которое вы хотите считать не более чем тремя текстовыми сообщениями, должно иметь максимальное количество символов 459, а не 480. кодируется, уменьшая количество символов с 160 до 70 . Каждый эмодзи также считается как 2 символа в текстовом сообщении. Это означает, что вы можете отправить одно текстовое сообщение с максимальным количеством смайликов 35, если в сообщении нет других символов (мы не рекомендуем это делать).
Добавление запроса местоположения в текстовое сообщение создает ссылку для вашего контакта , по которой можно щелкнуть.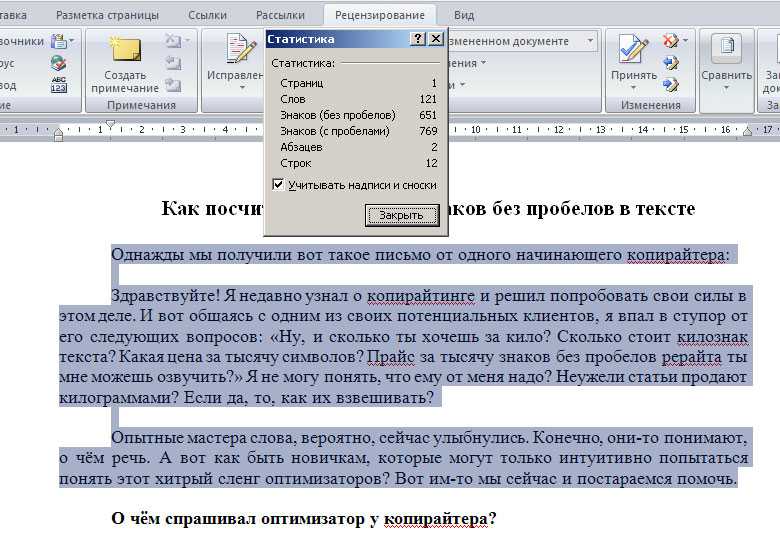
Любое Приложение , которое вы добавляете к сообщению, немедленно добавляет текст к вашему общему количеству текстовых сообщений. Например, если вы наберете сообщение длиной 123 символа, но добавите вложение к этому сообщению, то все сообщение будет считаться двумя текстами.
Узнайте больше об этих функциях, посетив Справочный центр:
Смайлики
локаций
Вложения
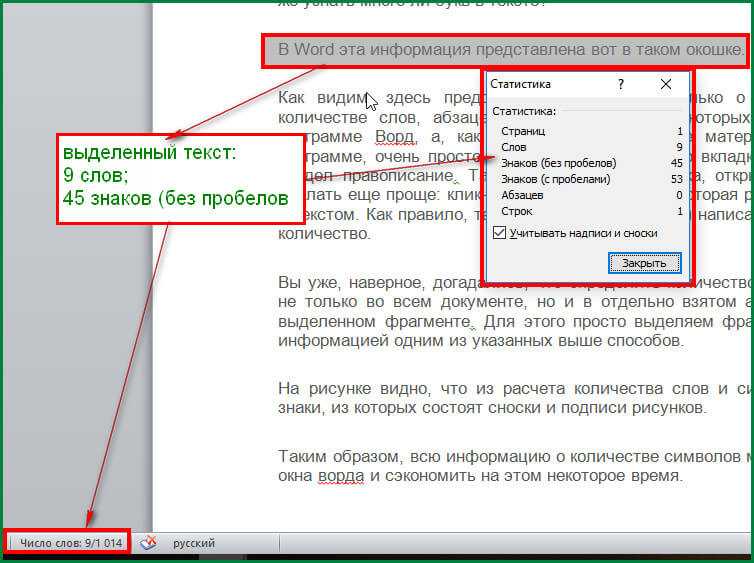
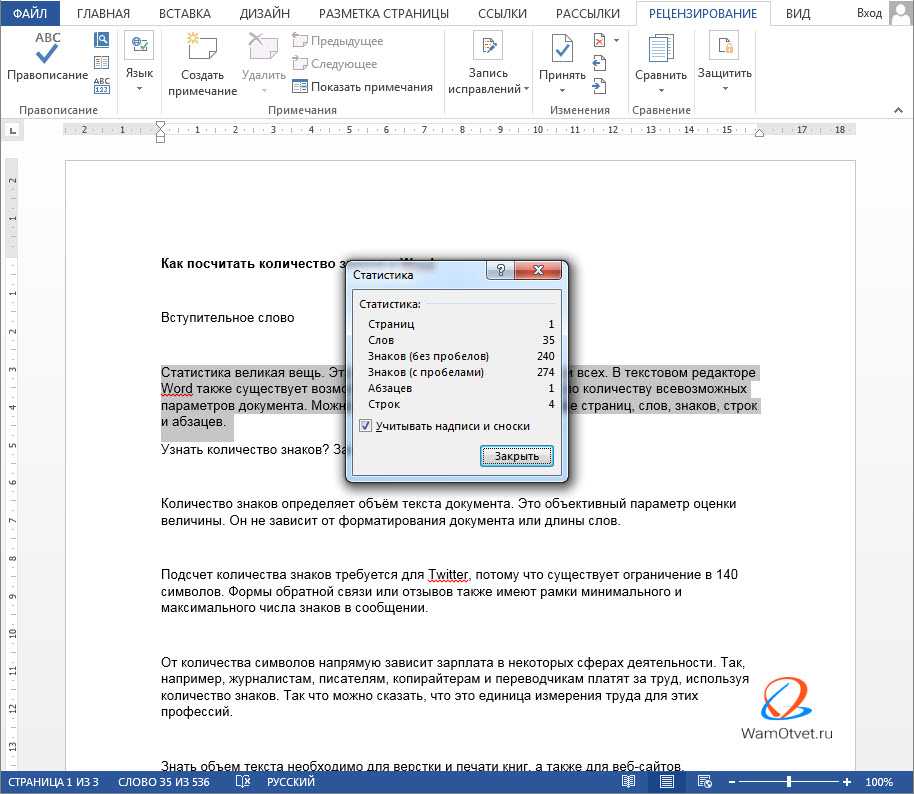
Превышение максимального количества символов
Текст каждого текстового запроса может содержать не более 160 символов, а общее сообщение может содержать не более 10 сегментов. Это дает абсолютный максимум 1600 символов на общее сообщение.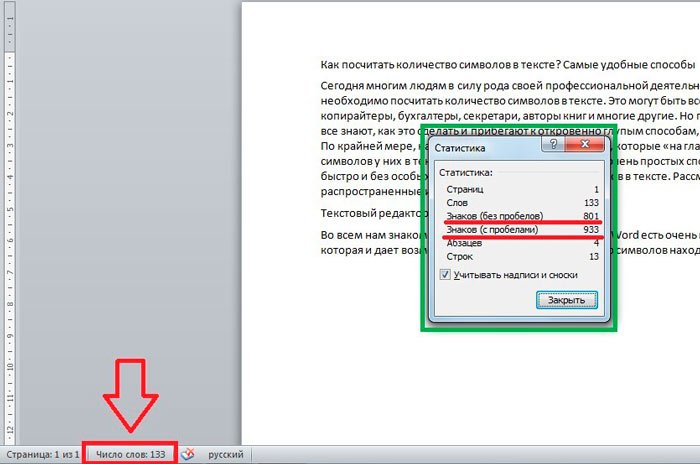 Если вы начнете приближаться к этому максимуму или даже превышать его, Text Request предупредит вас в счетчике символов сообщения.
Если вы начнете приближаться к этому максимуму или даже превышать его, Text Request предупредит вас в счетчике символов сообщения.
Около 1600 символов
Более 1600 символов
Уведомление об отказе
Обратите внимание, что каждый раз, когда вы отправляете сообщение Контактному лицу в первый раз, уведомление об отказе будет автоматически прикреплено к концу сообщения. сообщение. Это уведомление имеет номер . Текст STOP для отказа и имеет длину 22 символа. Это означает, что он добавит 22 символа к вашему общему сообщению. Если вы хотите, чтобы при использовании вами учитывался только один текст, вам необходимо учесть это уведомление об отказе, сохранив остальную часть вашего сообщения на уровне 9.0007 138 символов .
wc — количество новых строк, слов, байтов и символов
туалет [ -с | -м ]
[ -лв ]
[ -U [[[ c ][ lb8oa ]][ p [ lb8oa ]]]]
[ файл . ..]
..]
wc подсчитывает количество новых строк, слов, символов и байт в текстовых файлах. Если вы укажете несколько файлов, wc производит подсчеты для каждый файл плюс итоги по всем файлам.
Помимо обычных текстовых файлов ASCII, wc также работает с кодировкой UTF-8. файлы и 16-битные файлы Unicode. Такие файлы обычно начинаются с многобайтовый маркер, указывающий, является ли содержимое файла Unicode с прямым порядком байтов, Unicode с прямым порядком байтов или UTF-8. Такие файлы обнаруживаются автоматически по
Обычно формат вывода wc по умолчанию соответствует формату первого файла, который он отображает, если только опция
 Дополнительные сведения об этой и других проблемах с обработкой файлов, связанных с Unicode, см.
см. unicode справочная страница.
Дополнительные сведения об этой и других проблемах с обработкой файлов, связанных с Unicode, см.
см. unicode справочная страница.Если вы не указали никаких параметров, wc создает следующий вывод:
newline_count word_count byte_count имя файла
При указании параметров wc отображает только выбранные подсчитывается в том же порядке, что и вывод по умолчанию. Если вы укажете
Словом считается символ или символы, разделенные белое пространство.
- Примечание:
Параметр -c команды wc подсчитывает байты, не персонажи.
 Это изменение по сравнению с предыдущими версиями wc , в соответствии со стандартом POSIX.2, который обеспечивает
опция
Это изменение по сравнению с предыдущими версиями wc , в соответствии со стандартом POSIX.2, который обеспечивает
опция
 Это изменение по сравнению с предыдущими версиями wc , в соответствии со стандартом POSIX.2, который обеспечивает
опция
Это изменение по сравнению с предыдущими версиями wc , в соответствии со стандартом POSIX.2, который обеспечивает
опция Опции
- -с
отображает количество байтов. Вы не можете указать эту опцию с -m .
- -л
отображает количество новой строки.
- -м
отображает количество символов. Вы не можете указать эту опцию с помощью
- -U [[[ c ][ lb8oa ]][ p [ lb8oa ]]]
определяет входной формат любого файла, в котором отсутствует начальный многобайтовый маркер, созданный выходной формат или и то, и другое.
Если указано c , применяются спецификаторы, следующие за ним. к потребляемому входу.
Когда указан p , применяются спецификаторы, следующие за ним. к произведенной продукции.
Если не указаны ни c , ни
Когда указаны оба c и p , остальные аргументы -U применяются как к вводу, так и к выводу.
Остальные спецификаторы указывают формат символов, считываемых из вход или запись на выход (как определено c и р ):
l 16-битных символов с прямым порядком байтов b 16-битные символы с обратным порядком байтов 8 символов UTF-8 a символов ASCII из кодовой страницы ANSI или символов ASCII из кодовой страницы OEM
Когда несколько спецификаторов формата могут быть связаны с любым c или p, последнее подходящее значение, заданное по команде для каждого из c и p используются.
-Ucoapl8
такой же как:
-Ucap8
Когда спецификатор p задан без c спецификатор и спецификаторы формата даются перед p спецификатор, эти спецификаторы формата применяются к входным данным. Например:
-Уопл
такой же как:
-Укопл
Когда c или p указаны без указания формата, 16-битные символы с прямым порядком байтов используются по умолчанию для либо ввод, либо вывод, в зависимости от обстоятельств.
В качестве альтернативы указанию форматов как для ввода, так и для вывода той же опцией -U можно указать -U вариант несколько раз. Например, следующие идентичны:
-Уца -Упб -Укапб
- Примечание:
Спецификаторы -U на самом деле нечувствительны к регистру.
Для
Например, все следующие действия идентичны по своему поведению:-Укл -UCL -UCl -УКЛ
- -ш
отображает количество слов.
 Для
Например, все следующие действия идентичны по своему поведению:
Для
Например, все следующие действия идентичны по своему поведению:- TK_STDIO_DEFAULT_INPUT_FORMAT
Устанавливает формат ввода по умолчанию для файлов, которые не имеют начального многобайтовый маркер. Значение должно быть одним из перечисленных в Форматы символов файлов раздела юникод справочная страница.
- TK_STDIO_DEFAULT_OUTPUT_FORMAT
Устанавливает формат вывода по умолчанию. Обычно в качестве вывода по умолчанию используется формат первого прочитанного файла. формат. Значение должно быть одним из перечисленных в
Возможные значения состояния выхода:
- 0
Успешное завершение.
