
Способ, как найти ключевые слова в тексте онлайн
Home » Текстовые биржи » Находим ключевые слова в тексте через онлайн-сервис
Для людей, не разбирающихся в SEO-оптимизации и интернет-продвижении, непонятно, что значит выражение “ключевые слова”. Многие их путают с заголовками и подзаголовками, что еще больше усложняет взаимопонимание при заказе услуг SEO-продвижения. Найти ключевые слова в тексте онлайн понадобится любому человеку, который решил поднять свои сайт в ТОП поисковой выдачи Яндекса, Гугла или другой поисковой системы.
Содержание
- 1 Зачем нужны ключевые слова?
- 2 Как найти ключевые слова в тексте?
- 3 Сервисы и биржи, через которые можно проверить вхождения ключевых слов
- 4 Инструкция, как проверить вхождение ключевых слов в тексте
- 5 Как определить нужные ключевики для повышения ранжирования?
- 6 Заключение
- 6.
 1 Автор публикации
1 Автор публикации - 6.2 MasterCode
- 6.
 1 Автор публикации
1 Автор публикацииЗачем нужны ключевые слова?
Что же такое ключевые слова в тексте? Это наиболее часто употребляемые слова и словесные конструкции. Именно на них опираются поисковые машины при подборе сайтов по запросу пользователя. Чем больше в тексте встречается релевантных ключевых слов, тем выше будет ранжирование сайта. У ТОП-овых сайтов самый мощный поисковый трафик, ежедневно приносящий сотни и тысячи клиентов. Причем, в отличие от контекстной рекламы, трафик будет еще идти очень долго даже после того, как вы прекратите заниматься поисковой оптимизацией.
Для того чтобы понять, по каким запросам интернет-страница будет чаще всего выдаваться пользователю, необходимо определить основную словесную конструкцию.
Как найти ключевые слова в тексте?
Можно, конечно, найти все повторяющиеся конструкции самостоятельно, но этот вариант подходит только для проверки небольших отрывков. Поиск вручную в документе на 6000 символов займет не одну минуту, а что делать, если такие проверки нужно совершать по 10-20 раз в день? Тут не обойтись без специальных сервисов, которые помогут решать подобные задачи за 5-10 секунд. Рабочий интернет — вот все что для этого потребуется.
Поиск вручную в документе на 6000 символов займет не одну минуту, а что делать, если такие проверки нужно совершать по 10-20 раз в день? Тут не обойтись без специальных сервисов, которые помогут решать подобные задачи за 5-10 секунд. Рабочий интернет — вот все что для этого потребуется.
Сервисы и биржи, через которые можно проверить вхождения ключевых слов
Лучшие бесплатные сервисы для проверки вхождения ключевых слов в текст находятся на сайтах бирж копирайтинга. SEO-копирайтинг является одним из самых востребованных направлений на таких биржах. Для работы по этому направлению и нужны качественные сервисы анализа “ключей”.
Три лучших сервиса:
- Advego.
- Miratext.
- Программа Antiplagiarism.Net.
Пользоваться ими можно бесплатно и без регистрации. Программу можно скачать с сайта биржи Etxt либо с официального сайта, адрес которого является названием утилиты. Любой из этих вариантов полностью решит вопрос с поиском ключей, просто выберите, какой интерфейс вам удобней.
В Миратекст можно загрузить для анализа не только текст, но и сразу страницу сайта, что сильно ускорит и упростит работу с многостраничными порталами.
Инструкция, как проверить вхождение ключевых слов в тексте
Давайте убедимся, что определить частоту употребления слов и словесных конструкций можно быстро и легко. Для этого перейдем на Advego.
- Выбираем серую вкладку “Seo-анализ текста” в верхней шапке сайта.
- В открывшийся редактор вставляем нужный нам отрывок для проверки и запускаем процесс.
- Через несколько секунд получаем обширный отчет о предоставленном тексте. Нас интересует таблица “Семантическое ядро”. Показатель “Частота” показывает объем, который занимает то или иное слово от всего текста.
Как видите, провести моментальный поиск ключей онлайн может совершенно неподготовленный человек. Все что необходимо знать – адрес сервиса.
Как определить нужные ключевики для повышения ранжирования?
Чтобы лучше понять, какие ключевые фразы использовать, проанализируйте сайты ваших успешных конкурентов. Сняв “слепок” семантического ядра топовых сайтов, вы сможете использовать его как базу для наполнения своего интернет-проекта.
Сняв “слепок” семантического ядра топовых сайтов, вы сможете использовать его как базу для наполнения своего интернет-проекта.
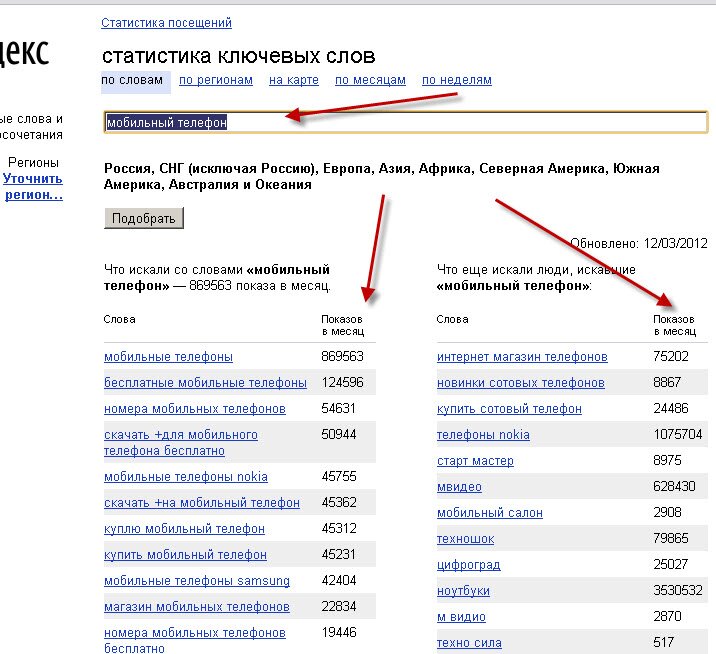
Альтернативным вариантом будет использование сервиса Yandex.WordStat, который предоставит информацию по поисковым запросам в любом регионе и за любой период. Также он подскажет аналогичные запросы, которые могут стать дополнительными ключевыми словами.
Заключение
Ключевые слова – базовый элемент для search engine optimisation. Определить их в статье на странице сайта по силу любому человеку, при помощи специальных сервисов и программ. Высокая частотность релевантных ключей повысит страницу в ранжировании, но важно не переборщить, иначе получится переспам, а заспамленные страницы быстро вылетают из Топа Yandex и Google.
Оцените текст:
Автор публикации
Поиск ключевых слов в тексте
2739
15. 06.2021
Скачать пример
06.2021
Скачать пример
Поиск ключевых слов в исходном тексте — одна из очень распространенных задач при работе с данными. Давайте рассмотрим её решение несколькими способами на следующем примере:
Предположим, что у нас с вами есть список ключевых слов — названия автомобильных марок — и большая таблица всевозможных запчастей, где в описаниях иногда могут встречаться один или сразу несколько таких брендов, если запчасть подходит больше, чем к одной марке автомобиля. Наша задача состоит в том, чтобы найти и вывести все обнаруженные ключевые слова в соседние ячейки через заданный символ-разделитель (например, запятую).
Способ 1. Power Query
Само-собой, сначала превращаем наши таблицы в динамические («умные») с помощью сочетания клавиш Ctrl+T или команды Главная — Форматировать как таблицу (Home — Format as Table), даём им имена (например Марки и Запчасти) и загружаем по очереди в редактор Power Query, выбрав на вкладке Данные — Из таблицы/диапазона (Data — From Table/Range). Если у вас старые версии Excel 2010-2013, где Power Query установлена как отдельная надстройка, то нужная кнопка будет на вкладке Power Query. Если у вас совсем новая версия Excel 365, то кнопка
Если у вас старые версии Excel 2010-2013, где Power Query установлена как отдельная надстройка, то нужная кнопка будет на вкладке Power Query. Если у вас совсем новая версия Excel 365, то кнопка
После загрузки каждой таблицы в Power Query возвращаемся обратно в Excel командой Главная — Закрыть и загрузить — Закрыть и загрузить в… — Только создать подключение (Home — Close & Load — Close & Load to… — Only create connection).
Теперь создадим дубликат запроса Запчасти, щёлкнув по нему правой кнопкой мыши и выбрав команду Дублировать запрос (Duplicate query), затем переименуем получившийся запрос-копию в Результаты и дальше будем работать уже с ним.
Логика действий следующая:
- На вкладке Добавление столбца выбираем команду
- Кнопкой с двойными стрелками в шапке добавленного столбца разворачиваем все вложенные таблицы. Строки с описаниями запчастей при этом размножатся кратно количеству марок, и мы получим все возможные пары-сочетания «запчасть-марка»:
- На вкладке Добавление столбца выбираем команду Условный столбец (Conditional column) и задаём условие на проверку вхождения ключевого слова (марки) в исходный текст (описание запчасти):
- Чтобы поиск был регистроНЕчувствительный, добавляем вручную в строке формул третий аргумент Comparer.OrdinalIgnoreCase к функции проверки вхождения Text.Contains (если строки формул не видно, то её можно включить на вкладке Просмотр):
- Фильтруем получившуюся таблицу, оставляя только единички в последнем столбце, т. е. совпадения и удаляем ненужный больше столбец Вхождения.
- Группируем одинаковые описания командой
- Чтобы извлечь марки для каждой запчасти, добавляем еще один вычисляемый столбец на вкладке Добавление столбца — Настраиваемый столбец (Add column — Custom column) и используем формулу, состоящую из таблицы (они у нас располагаются в столбце Подробности) и имени извлекаемого столбца:
- Щёлкаем по кнопке с двойными стрелками в шапке получившегося столбца и выбираем команду Извлечь значения (Extract values), чтобы вывести марки через любой желаемый символ-разделитель:
- Удаляем ненужный больше столбец Подробности.
- Чтобы добавить к получившейся таблице исчезнувшие из неё запчасти, где в описаниях не было найдено ни одной марки — выполним процедуру объединения запроса Результат с исходным запросом Запчасти кнопкой Объединить на вкладке Главная (Home — Merge queries). Тип соединения — Внешнее соединение справа (Right outer join):
- Останется удалить лишние столбцы и переименовать-переместить оставшиеся — и наша задача решена:
 После нажатия на ОК получим новый столбец, где в каждой ячейке будет вложенная таблица со списком наших ключевых слов — марок автопроизводителей:
После нажатия на ОК получим новый столбец, где в каждой ячейке будет вложенная таблица со списком наших ключевых слов — марок автопроизводителей: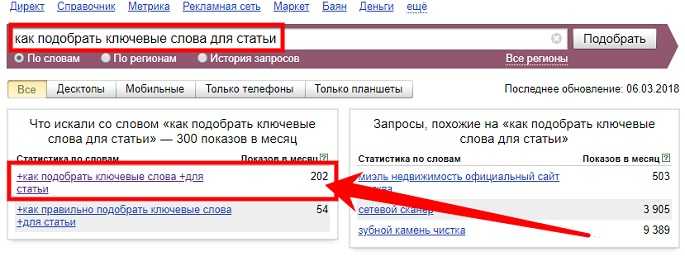 е. совпадения и удаляем ненужный больше столбец Вхождения.
е. совпадения и удаляем ненужный больше столбец Вхождения.
Способ 2. Формулы
Если у вас версия Excel 2016 или новее, то нашу проблему можно весьма компактно и изящно решить с помощью новой функции ОБЪЕДИНИТЬ (TEXTJOIN):
Логика работы этой формулы проста:
- Функция ПОИСК (FIND) ищет вхождение по очереди каждой марки в текущее описание запчасти и выдаёт либо порядковый номер символа, начиная с которого марка была найдена, либо ошибку #ЗНАЧ! если марки в описании нет.
- Затем при помощи функции ЕСЛИ (IF) и ЕОШИБКА (ISERROR) мы заменяем ошибки на пустую текстовую строку «», а порядковые номера символов — на сами названия марок.
- Полученный массив из пустых ячеек и найденных марок собирается в единую строку через заданный символ-разделитель с помощью функции ОБЪЕДИНИТЬ (TEXTJOIN).

Сравнение быстродействия и буферизация запроса Power Query для ускорения
Для тестирования быстродействия возьмем в качестве исходных данных таблицу из 100 000 описаний запчастей. На ней получаем следующие результаты:
- Время пересчета формулами (Способ 2) — 9 сек. при первом копировании формулы на весь столбец и 2 сек. при повторном (сказывается буферизация, видимо).
- Время обновления запроса Power Query (Способ 1) гораздо хуже — 110 сек.
Само-собой, многое зависит от «железа» отдельно взятого ПК и установленной версии Office и обновлений, но общая картина, думаю, понятна.
Для ускорения запроса Power Query давайте буферизуем таблицу-справочник Марки, т.к. она у нас не меняется в процессе выполнения запроса и постоянно пересчитывать её (как это де-факто делает Power Query) не нужно. Для этого используем функцию Table.Buffer из встроенного в Power Query языка М.
Для этого откроем запрос Результаты и на вкладке Просмотр нажмём на кнопку Расширенный редактор (View — Advanced Editor). В открывшемся окне добавим строку с новой переменной Марки2, которая будет буферизованной версией нашего справочника автопроизводителей и используем эту новую переменную далее в следующей команде запроса:
После такой доработки скорость обновления нашего запроса возрастает почти в 7 раз — до 15 сек. Совсем другое дело :)
Ссылки по теме
- Нечёткий текстовый поиск в Power Query
- Массовая замена текста формулами
- Массовая замена текста в Power Query функцией List. Accumulate
 Accumulate
AccumulateИзвлечение ключевых слов из текста с использованием nlp и машинного обучения
В двух словах, извлечение ключевых слов — это метод автоматического обнаружения важных слов, которые можно использовать для представления текста и для тематического моделирования.
Это очень эффективный способ получить представление о большом количестве неструктурированных текстовых данных. Возьмем пример: интернет-порталы розничной торговли, такие как Amazon, позволяют пользователям просматривать продукты. Мы хотим получить представление о конкретном продукте, скажем, о популярном смартфоне, мы можем не просматривать каждый обзор. Скорее, мы могли бы использовать методы извлечения ключевых слов, чтобы найти обзоры, в которых конкретно упоминается камера, батарея, производительность или любой другой атрибут.
Это полностью зависит от вариантов использования, и количество приложений может быть безграничным.
Здесь, в этой статье, мы возьмем реальный набор данных и выполним извлечение ключевых слов с использованием контролируемых алгоритмов машинного обучения. Мы попытаемся извлечь теги фильма из текста синопсиса сюжета данного фильма.
Мы попытаемся извлечь теги фильма из текста синопсиса сюжета данного фильма.
Реальный вариант использования упомянутой задачи — пометить фильм дополнительными тегами, отличными от жанров. Это может быть очень полезной информацией для зрителя, чтобы решить, смотреть фильм или нет. Такая автоматизированная система извлечения тегов/ключевых слов также поможет создать более совершенные системы рекомендаций для прогнозирования похожих фильмов и поможет пользователям узнать, чего ожидать от фильма.
Теги в фильмах основаны на сходстве элементов повествования или эмоциональной реакции на фильм. Мы можем получить хорошее представление об элементах повествования и возможных эмоциональных реакциях, просто проанализировав синопсис сюжета фильма.
В этом упражнении мы будем использовать набор данных, предоставленный лабораторией RiTUAL (Исследования в области понимания текста и анализа языка). Более подробная информация доступна здесь: http://ritual.uh.edu/mpst-2018/.
Этот набор данных содержит около 14 000 синопсисов фильмов, полученных в виде обучающих, проверочных и тестовых наборов. Все графики разбиты на один или несколько тегов. Здесь есть 71 уникальный тег.
Все графики разбиты на один или несколько тегов. Здесь есть 71 уникальный тег.
Сначала мы импортируем набор данных во фрейм данных pandas. Данные можно скачать отсюда. Ниже показано, как набор данных выглядит в необработанном виде:
1. Понимание набора данных
В приведенном выше наборе данных давайте внимательно рассмотрим различные столбцы:
- imdb_id: Интернет-база данных фильмов (IMDb) является самой популярной и авторитетный источник, чтобы узнать о фильмах или сериалах. Для каждого цифрового контента IMDb генерирует уникальный идентификатор, который принимается во всем Интернете. Здесь imdb_id — это уникальный идентификатор, который должен быть уникальным для каждой точки данных. Если есть повторяющиеся imdb_id, это просто означает, что у нас есть повторяющиеся точки данных в наших данных, и нам нужно их удалить.
- название: название фильма
- plot_synopsis: Синопсис сюжета — это повествовательное объяснение сюжета фильма, означающее краткое изложение сценария. Он представил главного героя и то, что он делает в фильме. Ниже представлен сюжетный синопсис фильма «Гензель и Гретель» (imdb_id: tt1380833):
 Он представил главного героя и то, что он делает в фильме. Ниже представлен сюжетный синопсис фильма «Гензель и Гретель» (imdb_id: tt1380833):
Он представил главного героя и то, что он делает в фильме. Ниже представлен сюжетный синопсис фильма «Гензель и Гретель» (imdb_id: tt1380833):‘Гензель и Гретель — маленькие дети бедного дровосека. Когда на земле наступает сильный голод, вторая жестокая жена дровосека решает увести детей в лес и оставить их там на произвол судьбы, чтобы она и ее муж не умерли с голоду, потому что дети есть слишком много. Дровосек возражает против этого плана, но, в конце концов, неохотно подчиняется плану своей жены. Они не знали, что в детской спальне Гензель и Гретель…»
- split: этот столбец определяет, принадлежит ли точка данных поезду, тесту или набору проверки.
- synopsis_source: предоставляет информацию об источнике синопсиса, будь то IMDb или Википедия.
- тегов: Теги — это теги для фильма. Для одного фильма может принимать несколько значений. Это будет наша метка предсказания. Если мы посмотрим поближе, один тег может иметь пробел или «-». Мы хотим, чтобы наши теги были похожи по форме, поэтому мы заменим пробелы и тире символом подчеркивания (‘_’). Кроме того, мы будем разделять теги пробелом вместо запятой. Вот как это выглядит:
 Мы хотим, чтобы наши теги были похожи по форме, поэтому мы заменим пробелы и тире символом подчеркивания (‘_’). Кроме того, мы будем разделять теги пробелом вместо запятой. Вот как это выглядит:
Мы хотим, чтобы наши теги были похожи по форме, поэтому мы заменим пробелы и тире символом подчеркивания (‘_’). Кроме того, мы будем разделять теги пробелом вместо запятой. Вот как это выглядит:2. Проверить наличие отсутствующих и повторяющихся данных
К счастью, ни в одном из столбцов нет отсутствующего текста, но в наборе данных наверняка есть повторяющиеся данные.
Как обсуждалось ранее, если столбец imdb_id имеет дубликаты, то и данные должны дублироваться. Но здесь есть несколько точек данных, где «imdb_id» отличается, но содержание для «title», «plot_synopsis» и «synopsis_source» одинаково. Взгляните на изображение ниже:
Мы будем удалять такие повторяющиеся точки с кодом ниже:
data= mpst_df.drop_duplicates([‘title’,’plot_synopsis’, ‘ptags’])
Приведенный выше код удалит все повторяющиеся строки с одинаковыми ‘title’,’plot_synopsis’ и ‘ptags’, за исключением первая запись.
3. Исследование данных
3.
 1 Теги на фильм
1 Теги на фильмКак обсуждалось ранее, фильм может состоять из более чем одного тега, и эту информацию будет интересно изучить.
# tags_count — это массив, содержащий количество тегов для каждого фильма
sns.countplot(tags_count)
plt.title(«Количество тегов в синопсисе»)
plt.xlabel(«Количество тегов»)
plt.ylabel(«Количество синопсиса»)
plt.show()
Всего 5516 фильмов которые содержат только один тег и 1 фильм, который помечен для 25 тегов.
3.2 Анализ частоты тегов
Было бы неплохо проанализировать частоты тегов, чтобы узнать о частых и редких тегах. Здесь мы можем заключить, что «убийство» является наиболее частым тегом (5782 случая), а «христианский фильм» — наименее частым тегом (42 случая).
sorted_freq_df=freq_df.sort_values(0, по возрастанию=False)
sorted_freq_df.head(-1).plot(kind=’bar’, figsize=(16,7), legend=False)
i=np.arange( 71)
plt.title(‘Частота всех тегов’)
plt. xlabel(‘Теги’)
xlabel(‘Теги’)
plt.ylabel(‘Количество’)
plt.show()
Если рассматривать только первые 20 теги, ниже показано, как это выглядит:
3.3 WordCloud для тегов
Создание облака слов текста синопсиса сюжета для определенного тега поможет нам понять наиболее часто встречающиеся слова для этого тега. Мы создадим облако слов для тега убийства.
# Создание столбца, чтобы указать, существует ли тег убийства или нет для фильма
data[‘ptags_murder’]= [1 if ‘murder’ в tgs.split() else 0 для tgs в data.ptags]
# создание корпуса для фильмов с тегом убийства
kill_word_cloud=»
для сюжета в data[data[‘ptags_murder’]==1].plot_synopsis:
kill_word_cloud = plot + ‘ ‘
from wordcloud import WordCloud
#создание wordcloud
wordcloud = WordCloud (ширина = 800, высота = 800, словосочетания = ложь,
background_color=’white’).generate(murder_word_cloud)
plt.figure(figsize=(10,10))
plt. imshow(wordcloud)
imshow(wordcloud)
plt.title(«Слова в сюжетах для фильмов с тегом убийства»)
plt.axis(«off»)
plt.show()
Здесь мы видим, что такие слова, как убийство, полиция, попытки, обвинение и т. д., имеют семантическое отношение к тегу убийство. Мы можем провести такой анализ для всех тегов, но, поскольку нам нужно охватить множество других вещей, не будет хорошей идеей увеличивать длину блога, включая весь этот анализ тегов.
4. Предварительная обработка текста
Текст в необработанном формате содержит такие элементы, как теги HTML, специальные символы и т. д., которые необходимо удалить перед использованием текста для построения модели машинного обучения. Ниже приведена процедура, которую я использовал для обработки текста.
- Удаление тегов HTML
- Удаление специальных символов, таких как #, _ , — и т. д.
- Преобразование текста в нижний регистр
- Удаление стоп-слов
- Операция забоя
## функция для удаления тегов html 9A-Za-z]+’,’ ‘,syn_processed) # удаление спецсимволов
words=word_tokenize(str(syn_processed. lower())) # устройство в слова и преобразование в младшие
lower())) # устройство в слова и преобразование в младшие
#syn_processed=’ ‘.join( str(stemmer.stem(j)) for j в словах, если j не в стоп-словах и len(j)!=1) #Удаление стоп-слов и объединение в предложение
return syn_processed
5. Обучение, проверка и тестовое разделение
Это довольно просто, так как стратегия разделения уже упоминается в самом наборе данных.
поезд = данные[данные[‘разделить’]==’поезд’]
val = data[data[‘split’]==’val’]
test = data[data[‘split’]==’test’]
6. Обозначение текста
Мы можем использовать несколько методов очерчивания текста например набор слов с n-граммами, TFIDF с n-граммами, Word2vec (усредненный и взвешенный), Sentic Phrase, TextBlob, тематическое моделирование LDA, NLP/текстовые функции и т. д.
Дополнительный ресурс для изучения text featurization
Для простоты я использовал TFIDF с 1,2,3-граммовыми признаками, что на самом деле дает довольно хороший результат.
vectorizer = TfidfVectorizer(min_df=0. 00009, smooth_idf=True, tokenizer = lambda x: x.split(), sublinear_tf=False, ngram_range=(1,3))
00009, smooth_idf=True, tokenizer = lambda x: x.split(), sublinear_tf=False, ngram_range=(1,3))
x_train = vectorizer.fit_transform(train[‘processed_plot’] )
x_val = vectorizer.transform(val[‘processed_plot’])
x_test = vectorizer.transform(test[‘processed_plot’])
TFIDF с (1,3) грамм сгенерировал менее 7 миллионов признаков. Следующие 2 ресурса помогут вам узнать больше о TFIDF:
- https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
- https://www.onely.com/blog/what-is-tf-idf/
7. Моделирование машинного обучения
Прежде чем перейти к моделированию, давайте обсудим показатели оценки. Выбор метрики оценки является наиболее важной задачей, так как это немного сложно в зависимости от цели задачи.
Наша проблема представляет собой проблему классификации с несколькими метками, где может быть несколько меток для одной точки данных. Мы хотим, чтобы наша модель предсказывала правильные категории, насколько это возможно, избегая при этом неправильного предсказания. Точность не очень хороший показатель для этой задачи. Для этой задачи микроусредненная оценка F1 является лучшей метрикой. 9-1)
Точность не очень хороший показатель для этой задачи. Для этой задачи микроусредненная оценка F1 является лучшей метрикой. 9-1)
Давайте разберемся, как рассчитать микросреднюю точность и вспомним на примере. скажем, для набора данных система
Истинный положительный (TP1) = 12
Ложноположительный (FP1) = 9
Ложноотрицательный (FN1) = 3
Тогда точность (P1) и отзыв (R1) будут 57,14 и 80, а для другого набора данных система равна
Истинный положительный результат (TP2) = 50
Ложноположительный результат (FP2) = 23
Ложноотрицательный результат (FN2) = 9
Затем точность (P2) и отзыв (R2) будет 68,49и 84,75
Теперь средняя точность и полнота системы с использованием метода микросреднего составляет
Микросреднее значение точности = (TP1+TP2)/(TP1+TP2+FP1+FP2) = (12+50) /(12+50+9+23) = 65,96
Микросреднее значение отзыва = (TP1+TP2)/(TP1+TP2+FN1+FN2) = (12+50)/(12+50+3+9) = 83,78
Приведенное выше объяснение взято из этого замечательного блога.
Еще кое-что, прежде чем перейти к моделированию.
Давайте рассмотрим исследовательскую работу издателя набора данных, о которой я уже упоминал (ссылка на статью) в начале. В качестве показателей оценки они использовали микросчет F1, а также вспоминание тегов и усвоение тегов. Ниже приведен снимок их результата:
Максимальное F1-микро в списке 37,8. Давайте посмотрим, сколько мы сможем получить с помощью простой модели.
Чтобы решить проблему классификации с несколькими метками, мы будем использовать классификатор OneVsRest, который одновременно итеративно классифицирует один класс. Узнайте больше здесь.
Я пробовал использовать метод опорных векторов и логистическую регрессию. Логистическая регрессия оказывается лучшим вариантом.
классификатор = OneVsRestClassifier(SGDClassifier(потеря=’log’, альфа=1e-5, штраф=’l1′), n_jobs=-1)
classifier.fit(x_train, y_train)
прогнозы = classifier. predict(x_test)print(«микро оценка f1:», metrics.f1_score(y_test, прогнозы, среднее = ‘микро’))
predict(x_test)print(«микро оценка f1:», metrics.f1_score(y_test, прогнозы, среднее = ‘микро’))
print(«потери Хэмминга:» ,metrics.hamming_loss(y_test,predictions))——выход——
Оценка микро-F1: 0,34867686650469504
Потеря Хэмминга: 0,04710189661231041
Мы получили довольно хороший микро-F1 (0,349 против 0,378, лучший результат, упомянутый в статье) с моделью LR.
Последний трюк!
Точность и отзыв зависят от TP, FP, TN и FN. Все эти показатели зависят от прогнозов (0 или 1), но не от вероятности прогноза.
Что, если мы найдем способ использовать вероятность и проверить, улучшает ли это микро-счет F1 или нет. Для этого мы будем использовать тот факт, что пороговое значение для предсказания по умолчанию равно 0,5. Это просто означает, что мы присваиваем 1, если вероятность предсказания составляет 0,5 или выше, и 0 в противном случае.
Здесь мы попробуем разные пороговые значения, чтобы узнать порог, который максимизирует оценку микро-F1.
Давайте попробуем от 0,20 до 0,30 в качестве пороговых значений.
yhat_val_prob= classifier.predict_proba(x_val)
для t в списке (диапазон (20, 31, 1)):
print(t*0.01)
pred_lb=np.asarray(yhat_val_prob>t*0.01, dtype=’int8′)
print(«micro f1 scoore: ”,metrics.f1_score(y_val, pred_lb, average = ‘micro’))
—–output—–
0.2
micro f1 scoore : 0.37533010563380287
0.21
micro f1 scoore : 0.3761086785674189
0.22
micro f1 scoore : 0.3761457378551788
0,23
микро f1 оценка: 0,37720425084666587
0,24
микро f1 оценка: 0,37664962542
0.25
micro f1 scoore : 0.3773150950248154
0.26
micro f1 scoore : 0.378451509747248
0.27
micro f1 scoore : 0.3784528656435954
0.28
micro f1 scoore : 0.37878787878787873
0.29
micro f1 scoore : 0.377741831122614
0.3
micro f1 scoore : 0.3768382352941177
Из вышеизложенного видно, что, используя 0,28 в качестве порогового значения, мы можем получить наилучшую оценку микро-F1 около 0,379 в наборе данных проверки.
Посмотрим, какой результат может дать тот же порог для тестового набора данных.
pred_lb=np.asarray(yhat_test_prob>0.28, dtype=’int8′)
print(«микро f1 оценка:»,metrics.f1_score(y_test, pred_lb, среднее = ‘микро’))
print(«потери Хэмминга :», metrics.hamming_loss(y_test,pred_lb))
——output——
micro f1 score: 0,3737731458059294
hamming loss: 0,05899764066633302
2. .
Мы можем улучшить результат, используя меньше тегов, больше данных или сложные техники НЛП.
Извлечение ключевых слов помогает предприятиям обрабатывать очень большие текстовые данные за короткое время и извлекать из них ценную информацию. В случае отзывов клиентов мы можем получить данные о том, о чем говорят клиенты, что им нравится или не нравится.
Около 80% всех сгенерированных данных неструктурированы, и обнаружение ключевых слов — отличный способ узнать важные вещи, такие как тема или важные слова, из неструктурированных данных.
Первоисточник: https://anandborad. github.io/MPST/
github.io/MPST/
Топ-5 алгоритмов извлечения ключевых слов в НЛП
Когда вы просыпаетесь, первое, что вы делаете, это проверяете свой телефон на наличие сообщений. Ваш разум настроен на то, чтобы отклонять сообщения WhatsApp от лиц и групп, которые вам не нравятся. Ваш разум возьмет ключевые слова из названия группы WhatsApp или контакта и научит вас любить или игнорировать их. Такое же поведение можно имитировать с помощью машинного обучения. В НЛП это называется извлечением ключевых слов.
Обработка естественного языка (NLP) — это очень популярный метод искусственного интеллекта, который помогает компьютеру понимать человеческий язык. Это помогает преодолеть разрыв между машинами и людьми. Обработка естественного языка не является новой областью, но ее популярность растет в результате повышенного интереса к общению человека с машиной, а также доступности больших объемов данных, мощных вычислений и улучшенных алгоритмов.
В этой статье мы узнаем о концепции извлечения ключевых слов и узнаем список алгоритмов машинного обучения, которые помогают в извлечении ключевых слов.
Извлечение ключевых слов — это подход к анализу текста, который автоматически извлекает наиболее часто используемые и важные слова и выражения из документа. Это помогает в обобщении текстового материала и выявлении основных представленных вопросов.
Чтобы разбить человеческий язык, чтобы он мог быть понят и оценен машинами, извлечение ключевых слов сочетает машинное обучение искусственного интеллекта (ИИ) с обработкой естественного языка (НЛП). Его можно использовать для извлечения ключевых слов из широкого спектра текстов, включая стандартные статьи и бизнес-отчеты, комментарии в социальных сетях, интернет-форумы и обзоры, новости и многое другое.
Посмотрите на этот пример извлечения ключевых слов:
Инструмент извлечения Monkeylearn раскрывает все атрибуты отзыва клиента. Экстрактор ключевых слов можно использовать для извлечения отдельных слов (ключевых слов) или групп из двух или более слов, образующих фразу (ключевые фразы). Используйте экстрактор ключевых слов, чтобы найти отдельные слова (ключевые слова) или группы из двух или более слов, которые составляют фразу из вашего текста. Как видите, ключевые слова уже есть в исходном тексте. Это основное различие между извлечением ключевых слов и назначением ключевых слов, которое включает в себя выбор ключевых слов из списка ограниченного словаря или категоризацию текста с использованием ключевых слов из заранее определенного списка.
Извлечение ключевых слов позволяет быстро находить наиболее важные слова и фразы в больших наборах данных. И эти термины и фразы могут предоставить вам важную информацию о проблемах, которые обсуждают ваши клиенты.
И эти термины и фразы могут предоставить вам важную информацию о проблемах, которые обсуждают ваши клиенты.
Учитывая, что более 80% данных, которые мы генерируем каждый день, неструктурированы, т. е. не организованы заранее определенным образом, что делает их чрезвычайно сложными для анализа и обработки, предприятиям требуется автоматическое извлечение ключевых слов, чтобы помочь им в более эффективно обрабатывать и анализировать данные о клиентах.
При работе с текстом одной из самых важных задач является извлечение ключевых слов. Ключевые слова помогают читателям быстрее определить, стоит ли читать материал. Ключевые слова полезны для разработчиков веб-сайтов, поскольку они позволяют упорядочивать сопоставимую информацию по темам. Ключевые слова полезны для программистов алгоритмов, поскольку они сжимают размерность текста до наиболее значимых элементов.
Ниже приведены три основных компонента типичного алгоритма извлечения ключевых слов:
В зависимости от задания мы извлекаем все подходящие слова, фразы, термины или понятия, которые могут быть ключевыми словами.

Для каждого кандидата мы должны вычислить характеристики, которые указывают, является ли это ключевым словом. Кандидат, который появляется в названии книги, например, является вероятным ключевым словом.
Все кандидаты могут быть оценены либо путем включения качеств в формулу, либо с использованием подхода машинного обучения для оценки вероятности того, что кандидат является ключевым словом. Затем выбирается окончательный набор ключевых слов с использованием порога оценки или вероятности или ограничения на количество ключевых слов.
Вот шаги, которые необходимо выполнить для извлечения ключевых слов с помощью обработки естественного языка:
- Загрузите набор данных и найдите текстовые поля, которые вы хотите просмотреть:
Нажмите кнопку «Выполнить» в первой ячейке кода записной книжки «text-analytics. ipynb». Убедитесь, что файлы «rfi-data.tsv» и «custom-stopwords.txt» находятся на рабочем столе; скрипт будет искать их там.
ipynb». Убедитесь, что файлы «rfi-data.tsv» и «custom-stopwords.txt» находятся на рабочем столе; скрипт будет искать их там.
- Составьте список терминов, которых следует избегать:
Стоп-слова – это регулярно используемые слова, такие как «the», «a», «an», «in» и другие, которые часто встречаются в естественном языке, но не содержат важной информации о содержании или теме сообщения. Мы импортируем список наиболее распространенных стоп-слов английского языка из модуля NLTK.
- Чтобы получить очищенный, нормализованный текстовый корпус, предварительно обработайте набор данных следующим образом:
Предварительная обработка включает удаление из текста пунктуации, тегов и специальных символов, а затем нормализацию того, что осталось, до понятных слов. «Стемминг», который удаляет суффиксы и префиксы из корней слов, и «лемматизация», которая переводит оставшиеся корневые формы (которые могут быть или не быть действительными словами) обратно в реальное слово, встречающееся в естественном языке, являются частями процесс нормализации.
- Получите наиболее часто используемые термины и N-грамму:
Теперь мы подошли к моменту, когда можем построить список ключевых слов и n-грамм или фраз из двух и трех слов в нашем примере (биграммы и триграммы). Конечно, эти списки и графики — лишь часть информации, которую можно найти в этом текстовом корпусе, но они могут помочь нам понять, где нам следует копнуть глубже или провести дальнейшее исследование.
- Составьте список наиболее важных терминов TF-IDF:
Статистика TF-IDF, которая расшифровывается как «Частота термина – обратная частота документа», представляет собой числовую меру того, насколько важен термин для документа в коллекции. Значение TF-IDF термина возрастает пропорционально количеству раз, которое он встречается в документе, и затем компенсируется количеством документов в корпусе, содержащих этот термин. Это компенсирует тот факт, что одни термины используются чаще, чем другие.
Это компенсирует тот факт, что одни термины используются чаще, чем другие.
От графов до подходов извлечения на основе преобразователей, все алгоритмы, представленные в этом блоге, являются экстрактивными.
- Текстовый рейтинг:
С помощью этой методики были проведены эксперименты с несколькими окнами совместной встречаемости в диапазоне от 2 до 10, причем 2 дали сравнительно лучшие результаты. Кроме того, чтобы уменьшить шум, они используют синтаксические фильтры для удаления только существительных и прилагательных в качестве вероятных узлов-кандидатов при создании графов.
После создания графа они используют Page Rank до сходимости для ранжирования каждого узла в графе. Неизвешенная форма алгоритма распознавания рисунков показана в приведенном ниже уравнении-
Уравнение 1. 1
1
Здесь, D, DAMPLING SACTRING (это DAMPLING (это DAMPLING SPEE (DAMPLING STTO STET STET STET STET STET STET STET STET STET STET STET STET STET STET STET STET STET STET STET STET STET STET EM. чтобы гарантировать, что PR не попадет в циклы графа и может легко «телепортироваться» на другой узел в сети). In(V) — это входная степень узла V, Out(V) — исходящая степень узла V, а S(V) — рейтинг страницы для любого заданного узла. На приведенном ниже рисунке показано вычисление рейтинга страницы для узла на графике с использованием ранее заданного уравнения. Стоит отметить, что, поскольку граф неориентированный, In-степень==Out-степень для каждого узла в графе.
После сходимости каждому узлу в сети присваивается числовая оценка, отражающая его оценку PageRank (PR). Все ключевые слова, которые изначально существуют как соседи в реальных текстах, объединяются для создания одного ключевого слова в рамках этапа постобработки, чтобы также извлечь фразы из нескольких слов.
- Расширить ранг:
В этом алгоритме мы сначала генерируем набор похожих документов D для данного документа, чтобы предоставить больше информации и, в конечном итоге, улучшить извлечение ключа отдельного документа. Идея создания аналогичного набора документов состоит в том, чтобы позволить модели использовать глобальную информацию в дополнение к локальной информации, присутствующей в любом заданном документе. Чтобы найти K-ближайших соседей, они используют косинусное сходство на основе TF*IDF.
После этого шага они используют алгоритм ранжирования на основе графа для вычисления глобальной оценки значимости для каждого слова в графе слов, построенном на этом расширенном наборе. Поскольку не все слова в документах являются хорошими индикаторами ключевых слов, при построении графа слов используются определенные синтаксические фильтры. Вес ребра между двумя словами рассчитывается путем умножения количества совпадений двух слов во всем наборе документов на сходство исходного документа с соседним рассматриваемым документом, как показано в уравнении:
Уравнение 2. 1
1
Поскольку этот график основан на всем наборе документов, он известен как график глобального сходства. Как только алгоритм ранжирования достигает точки сходимости, ключевые слова-кандидаты объединяются в фразу из нескольких слов. Они используют дополнительное правило для сокращения окончаний фраз прилагательных и выбирают только окончание фраз существительных. Общий балл фразы рассчитывается путем сложения баллов значимости отдельных слов.
- Должность Ранг:
Метод PageRank для интеграции информации обо всех местах вхождения слова в большой текст. Фундаментальное понятие PositionRank состоит в том, чтобы придать больший вес (или вероятность) словам, расположенным в начале текста, по сравнению со словами, которые появляются в более позднем разделе документа. Их алгоритмы в основном состоят из трех основных этапов.
Создание графа на уровне слов. Они используют существительные и прилагательные в качестве кандидатов на создание узлов в своем неориентированном графе слов. Если ребра, соединяющие узлы, основаны на скользящем окне совпадения заданного размера
Они используют существительные и прилагательные в качестве кандидатов на создание узлов в своем неориентированном графе слов. Если ребра, соединяющие узлы, основаны на скользящем окне совпадения заданного размера
Разработка PageRank с позицией — Они взвешивают каждое предложенное слово с его противоположным положением в тексте. Например, если слово находится на следующих позициях: 2-я, 5-я и 10-я, то вес, связанный с этим словом, равен 1/2 + 1/5 + 1/10 = 4/5 = 0,8. Формируется вектор, которому присваиваются нормализованные веса для каждого потенциального слова, как показано ниже —
Уравнение 3.1
Уравнение 3,2 (Источник) . .
Формирование фраз-кандидатов — Слова-кандидаты, имеющие смежные места в тексте, объединяются для создания фраз-кандидатов. Они используют еще один фильтр регулярных выражений [(прилагательное)*(существительное)+] длиной до трех (т. е. униграммы, биграммы и триграммы) поверх этих фраз-кандидатов, чтобы получить окончательный список ключевых фраз. Наконец, фразы оцениваются путем сложения баллов слов, составляющих фразу. (Совет — вы также можете поиграть с «Новой стратегией оценки ключевых слов из нескольких слов», указанной выше)
Они используют еще один фильтр регулярных выражений [(прилагательное)*(существительное)+] длиной до трех (т. е. униграммы, биграммы и триграммы) поверх этих фраз-кандидатов, чтобы получить окончательный список ключевых фраз. Наконец, фразы оцениваются путем сложения баллов слов, составляющих фразу. (Совет — вы также можете поиграть с «Новой стратегией оценки ключевых слов из нескольких слов», указанной выше)
- Яке:
Подход к извлечению ключевых слов, использующий статистические характеристики для обнаружения и ранжирования наиболее важных терминов. Ему нужен только список стоп-слов, чтобы он был нейтральным к языку. Полный алгоритм состоит из 4 этапов —
Сначала они выполняют разделение на уровне предложений, используя segtok, который представляет собой сегментатор предложений на основе правил. Затем предложения разделяются на термины на основе пробелов и других специальных символов (разрыв строки, запятая, точка) в качестве разделителей, и в зависимости от максимальной длины ключевых слов, которые нас интересуют, мы можем разделить 2, 3, 4 слова соответствующим образом. .
.
- Условия использования
Здесь они заложили 5 качеств для оценки каждой единицы, в частности, регистр (Tcase: больше внимания к заглавным буквам и аббревиатурам) (Tcase: больше внимания к заглавным буквам и аббревиатурам), положение слова в тексте (Tcase: больше внимания уделяется к терминам, которые присутствуют в начале документа), Частота слов (Tnorm), Отношение термина к контексту (Trel: Проверяет разнообразие контекста, в котором это слово появляется. Чем лучше разнообразие, тем выше возможности для него становится популярным термином. Его можно рассматривать как метрику для сокращения регулярно встречающихся терминов, таких как стоп-слова) и, наконец, термин «различное предложение» (предложение: эта характеристика оценивает, как часто слово-кандидат встречается с разными фразами. Более высокий балл присваивается терминам, которые регулярно появляются в различных фразах).
- Подсчет сроков
Он использует следующий алгоритм для вычисления оценки для каждой единицы.
- Дедупликация
Чрезвычайно реально получить сопоставимые морфологические термины при оценке в соответствии с методом предварительной оценки. Чтобы предотвратить избыточность, они предлагают стратегию дедупликации на основе расстояния Левенштейна, цель которой не состоит в том, чтобы выбрать слово, если оно имеет короткое расстояние Левенштейна с ранее выбранными терминами.
- Финальные места
Минимум баллов, лучше ключевые слова. Выберите топ-к.
- KeyBERT:
KeyBERT — это базовый и простой в использовании подход к извлечению ключевых слов, который использует встраивания BERT для создания ключевых слов и ключевых фраз, которые наиболее сопоставимы с текстом.