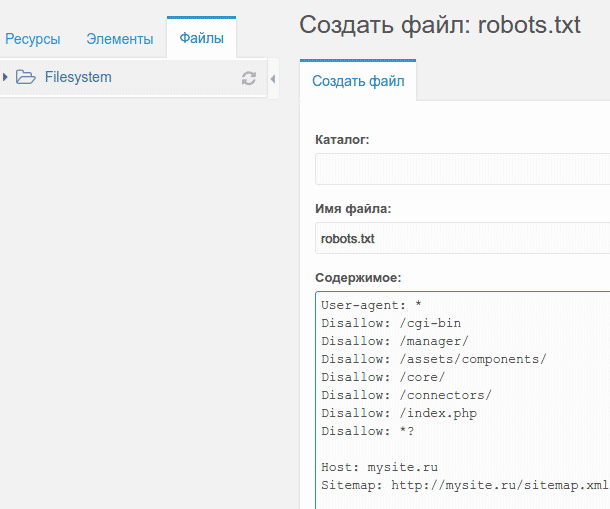
Как правильно создать и настроить robots.txt для сайта? FAQ
Robots.txt — текстовый документ, который размещается в корневом каталоге сайта и содержит запреты для поисковых роботов на индексацию технических страниц ресурса, с целью недопущения попадания них в поисковую выдачу.
Поисковые роботы используют сессионный принцип, во время каждой сессии робот формирует список страниц сайта, которые планирует загрузить. При заходе на сайт, робот первым делом смотрит файл robots.txt, чтобы знать что можно смотреть на сайте, а что нет.
Предлагаем посмотреть короткое видео от Яндекс, где при помощи простых сравнений наглядно рассказывается о задачах документа robots.txt:
Создание robots txt
01 При помощи любого текстового редактора (к примеру стандартного блокнота), создайте файл вида robots.txt.02 Пропишите в нем индивидуальные настройки, инструкция как это сделать описанная ниже.
Как правильно составить robots txt?
01Директива User-agent: содержит название поискового робота, к которому будут применены описанные ниже нее ограничения. Если использовано несколько разных директив User-agent, то перед каждой рекомендуется вставлять пустой перевод строки.Примеры User-agent: User-agent: YandexBot # для основного индексирующего робота Яндекс User-agent: Googlebot # для поискового робота компании Google User-agent: * #для всех роботов-индексаторов02Директивы Disallow и Allow: используются для запрета и разрешения доступа робота к конкретным разделам сайта. Примеры Disallow: Disallow: / # запрет на индексацию всего сайта
Disallow: / # запрещает индексировать весь сайт
Allow: /katalog # но разрешено индексировать страницы, которые начинаются с «/katalog» 03 Спецсимволы * и $ — используются для задавания определенных регулярных выражений при указании путей директив Allow и Disallow: используются для запрета и разрешения доступа робота к конкретным разделам сайта.

Disallow: /profile/*.aspx # запрещает «/profile/example.aspx» и «/profile/private/test.aspx»
Disallow: /*private # запрещает не только «/private», но и «/profile/private»
Disallow: /admin* # запрещает индексировать страницы начинающиеся с «/admin»
Disallow: /example$ # запрещает «/example», но не запрещает «/example.html» 04 Директива Sitemap — указывает местоположение xml карты сайта, которая содержит URL адреса всех допустимых к индексированию страниц сайта. используются для запрета и разрешения доступа робота к конкретным разделам сайта. Примеры использования: User-agent: YandexBot
Allow: /
Sitemap: http://www.
 site.com/sitemap.xml
site.com/sitemap.xmlHost: www.site.com 06 Директива Crawl-delay — используется для минимизации нагрузок на сервер, с ее помощью можно задать период времени в секундах, который должен быть между запросами роботами страниц сайта. Примеры использования: User-agent: YandexBot
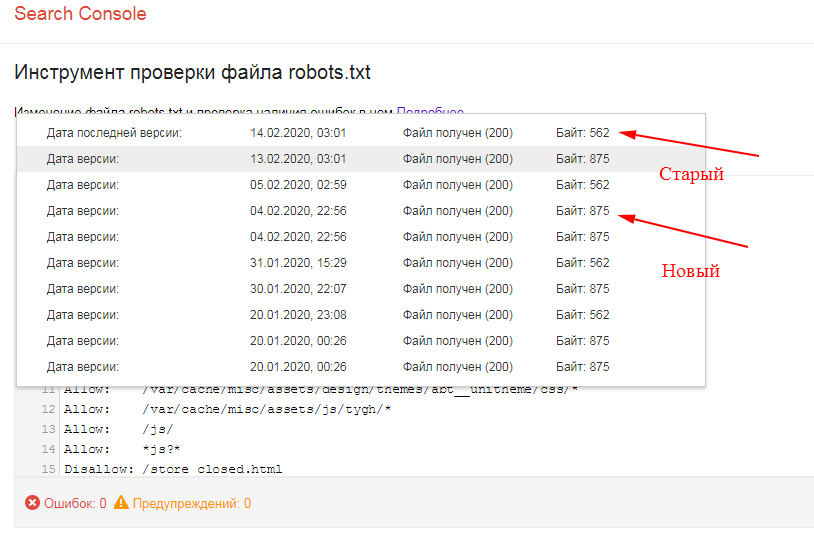
Рекомендуем проанализировать в ручном режиме страницы Вашего сайта, которые попали в индекс поисковых систем, сделать это можно при помощи нашего инструмента по анализу сайтов, в разделе “индексация сайта”, это поможет максимально быстро и эффективно найти все технические страницы и закрыть их посредством файла robots.txt и директивы Disallow.
Как оптимизировать Robots.txt для SEO в WordPress
Вы хотите оптимизировать свой файл robots.txt в WordPress? Не уверены, почему и каким образом файл robots.txt имеет важное значение для вашего SEO? В этой статье расскажем вам, как оптимизировать ваш файл robots.
В последнее время, пользователи спрашивают нас, нуждаются ли сайт в файле robots.txt и какова важность его? Файл robots.txt для вашего сайта играет важную роль в общей производительности и seo оптимизации вашего сайта. Это в основном позволяет вам общаться с поисковыми системами и дают им знать, какие части вашего сайта они должны индексировать.
Нужен ли файл robots.txt?
Отсутствие файла robots.txt не остановит поисковых систем от сканирования и индексирования вашего сайта. Тем не менее, настоятельно рекомендуется создать один. Если вы хотите представить на вашем сайте в XML карту сайта для поисковых систем, то в файле поисковые системы будут искать ваш XML Sitemap, если вы не указали его в Yandex webmaster или Google Webmaster Tools.
Мы настоятельно рекомендуем, если у вас нет файла robots.txt на вашем сайте, то вы должны сразу же создать.
Где находится файл robots.txt? Как создать файл robots. txt?
txt?
 txt?
txt?Файл robots.txt, как правило, находится в корневой папке вашего сайта. Вам нужно будет подключиться к вашему сайту с использованием клиента FTP или с помощью файлового менеджера CPanel для его просмотра.
Он такой же, как любой обычный текстовый файл, и вы можете открыть его с помощью обычного текстового редактора как Блокнота.
Как использовать файл robots.txt?
Формат файла robots.txt на самом деле довольно прост. Первая строка обычно называет User-Agent. Агент пользователя на самом деле имя бота поисковой системы, которые пытаются прочитать ваш сайт. Например, Googlebot или Yandexbot. Вы можете использовать звездочку *, чтобы проинструктировать всех ботов.
В следующей строке следует разрешить или запретить инструкции для поисковых систем, чтобы они знали, какие части вы хотите, чтобы индексировались, и какие из них вы не хотите индексировать.
Смотрите пример файла robots.txt:
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /readme.html
В этом примере файл robots.txt для WordPress, мы поручили всем ботам индексировать наш каталог загрузки изображения.
В следующих двух строках мы им запрещаем индексировать наш каталог плагинов WordPress и файл readme.html.
Оптимизация файла Robots.txt для SEO
В руководстве для веб-мастеров, Google советует веб-мастерам, не использовать файл robots.txt, чтобы скрыть содержание низкого качества. Если вы думаете об использовании файла robots.txt, чтобы остановить Google индексировать категории, даты и другие архивные страницы, то это не может быть мудрым выбором.
Помните, что цель robots.txt является поручить ботам, что делать с содержанием, когда они сканируют ваш сайт. Это не помешает ботам сканировать ваш сайт.
Есть и другие плагины для WordPress, которые позволяют добавлять мета-теги, как NOFOLLOW и мета тег noindex в ваших страницах архива.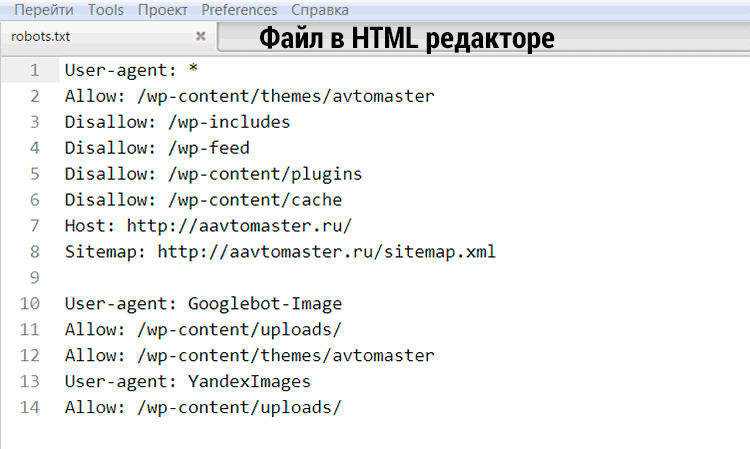 Плагин WordPress SEO также позволяет сделать это. Мы не говорим, что вы должны иметь ваши архивные страницы deindexed, но если вы хотите сделать это, то, что правильный способ сделать это.
Плагин WordPress SEO также позволяет сделать это. Мы не говорим, что вы должны иметь ваши архивные страницы deindexed, но если вы хотите сделать это, то, что правильный способ сделать это.
Вам не нужно добавлять страницу логина, каталога администратора или страницу регистрации в robots.txt, потому что логин и регистрационные страницы имеют теги NOINDEX, которые уже добавлены как мета-тег с помощью WordPress.
Он рекомендуется запретить readme.html файл в файле robots.txt. Этот файл readme может быть использован кем-то, кто пытается выяснить, какую версию WordPress вы используете. Если бы это было физическое лицо, то они могут легко получить доступ к файлу, просто просматривая его.
С другой стороны, если кто-то работает с вредоносными запросами, чтобы найти сайты на WordPress с использованием конкретной версии, то этот тег Disallow может защитить вас от этих массовых атак.
Вы также можете запретить ваш каталог плагинов WordPress. Это будет способствовать укреплению безопасности вашего сайта, если кто-то ищет конкретный уязвимый плагин, чтобы использовать его для массовой атаки.
Добавление вашей XML Sitemap в файл robots.txt
Если вы используете плагин Йоаст в WordPress SEO или какой – либо другой плагин для генерации XML Sitemap , то ваш плагин будет пытаться автоматически добавлять связанные строки в вашем файле Sitemap в файл robots.txt.
Однако, если это не удается, то ваш плагин покажет вам ссылку на XML Sitemaps, который вы можете добавить в свой файл robots.txt вручную следующим образом:
Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xml
Как должен выглядеть идеальный файл robots.txt?
Честно говоря, многие популярные блоги используют очень простые файлы robots.txt. Их содержание варьируются в зависимости от потребностей конкретного сайта:
User-agent: * Disallow: Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xml
Этот файл robots.txt просто сообщает всем ботам индексировать все содержание и предоставляет ссылки на XML Sitemaps сайта.
Вот еще один пример файла robots.txt, на этот раз это тот, который мы используем здесь на AndreyEx.ru:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /wp-login.php Disallow: /login.php Disallow: /wp-register.php Host: https://AndreyEx.ru User-agent: Googlebot Allow: /wp-content/plugins Allow: /wp-content/cache Sitemap: https://AndreyEx.ru/sitemap_index.xml
Это все. Мы надеемся , что эта статья помогла вам узнать , как оптимизировать ваш файл robots.txt для SEO. Вы также можете увидеть наш путеводитель по 9 лучшим WordPress SEO плагинам и инструментам, которые вы должны использовать.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как сделать robots.txt для WordPress.Создаем правильный robots.txt для сайта на WordPress
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет.
Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет.
Создание файла robots.txt
1. Создайте обычный текстовый файл с названием robots в формате .txt.
2. Добавьте в него следующую информацию :
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.
 php
Disallow: /wp-register.php
Disallow: */trackback
Disallow: */feed
Disallow: /cgi-bin
Disallow: /tmp/
Disallow: *?s=
Host: site.com
Sitemap: http://site.com/sitemap.xml
php
Disallow: /wp-register.php
Disallow: */trackback
Disallow: */feed
Disallow: /cgi-bin
Disallow: /tmp/
Disallow: *?s=
Host: site.com
Sitemap: http://site.com/sitemap.xml
3. Замените в в текстовом файле строчку site.com на адрес Вашего сайта.
4. Сохраните изменения и загрузите файл robots.txt (с помощью FTP) в корневую папку Вашего сайта.
5. Готово.
Для просмотра и скачки примера, нажмите кнопку ниже и сохраните файл (Ctrl + S на клавиатуре).
Скачать пример файла robots.txtРазбираемся в файле robots.txt (директивы)
Давайте теперь более детально разберем, что именно и зачем мы добавили в файл robots.txt.
User-agent — директива, которая используется для указания названия поискового робота. С помощью этой директивы можно запретить или разрешить поисковым роботам посещать Ваш сайт. Примеры:
Запрещаем роботу Яндекса просматривать папку с кэшем:
User-agent: Yandex Disallow: /wp-content/cache
Разрешаем роботу Bing просматривать папку themes (с темами сайта):
User-agent: bingbot Allow: /wp-content/themes
Allow и Disallow — разрешающая и запрещающая директива. Примеры:
Примеры:
Разрешим боту Яндекса просматривать папку wp-admin:
User-agent: Yandex Allow: /wp-admin
Запретим всем ботам просматривать папку wp-content:
User-agent: * Disallow: /wp-content
В нашем robots.txt мы не используем директиву Allow, так как всё, что не запрещено боту с помощью Disallow — по умолчанию будет разрешено.
Host — директива, с помощью которой нужно указать главное зеркало сайта, которое и будет индексироваться роботом.
Sitemap — используя эту директиву, нужно указать путь к карте сайта. Напомню, что карта сайта является очень важным инструментом при продвижении сайта! Обязательно указывайте её в этой директиве!
Если остались какие-то вопросы — задавайте их в комментарий. Если же информации в этом уроке для Вас оказалось недостаточно, рекомендую почитать подробнее о всех директивах и способах их использования перейдя по этой ссылке.
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет. Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет. Создание файла robots.txt 1. Создайте обычный текстовый файл с названием robots в формате .txt. 2. Добавьте в него следующую информацию : User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes…
Создание и настройка robots.txt
Рейтинг: 4. 5 ( 32 голосов ) 100 Оптимизация
5 ( 32 голосов ) 100 ОптимизацияWordPress Robots.txt (+ XML Sitemap) — посещаемость веб-сайта, поисковая оптимизация и повышение рейтинга — плагин WordPress
Better Robots.txt создает виртуальный файл robots.txt WordPress, помогает повысить SEO вашего сайта (возможности индексации, рейтинг Google и т. Д.) И производительность загрузки — Совместимость с Yoast SEO, Google Merchant, WooCommerce и сетевыми сайтами на основе каталогов ( МУЛЬТИСИТ)
С помощью Better Robots.txt вы можете определить, каким поисковым системам разрешено сканировать ваш сайт (или нет), указать четкие инструкции о том, что им разрешено (или нет), и определить задержку сканирования (для защиты вашего хостинг-сервера от агрессивные скребки).Better Robots.txt также дает вам полный контроль над содержимым файла robots.txt в WordPress с помощью окна пользовательских настроек.
Уменьшите экологический след своего сайта и выбросы парниковых газов (CO2), обусловленные его существованием в Интернете.
Краткий обзор:
ПОДДЕРЖИВАЕТСЯ НА 7 ЯЗЫКАХ
ПлагиныBetter Robots.txt переведены и доступны на следующих языках: китайский — 汉语 / 漢語, английский, французский — Français, русский –Руссɤɢɣ, португальский — Português, испанский — Español, немецкий — Deutsch
Знаете ли вы, что…
- Роботы.txt — это простой текстовый файл, размещаемый на вашем веб-сервере, который сообщает поисковым роботам (например, роботу Google), следует ли им обращаться к файлу.
- Файл robots.txt определяет, как пауки поисковых систем видят ваши веб-страницы и взаимодействуют с ними;
- Этот файл и боты, с которыми они взаимодействуют, являются фундаментальными частями работы поисковых систем;
- Первое, на что смотрит сканер поисковой системы при посещении страницы, — это файл robots. txt;
 txt;
txt;Роботы.txt — это источник сока SEO, который только и ждет, чтобы его разблокировали. Попробуйте Better Robots.txt!
О версии Pro (дополнительные возможности):
1. Повысьте свой контент в поисковых системах с помощью карты сайта!
Убедитесь, что ваши страницы, статьи и продукты, даже самые последние, принимаются во внимание поисковыми системами!
Плагин Better Robots.txt был создан для работы с плагином Yoast SEO (вероятно, лучшим плагином SEO для веб-сайтов WordPress).Он определит, используете ли вы в настоящее время Yoast SEO и активирована ли функция карты сайта. Если это так, то он автоматически добавит инструкции в файл Robots.txt, предлагая ботам / сканерам прочитать вашу карту сайта и проверить, внесли ли вы последние изменения на свой сайт (чтобы поисковые системы могли сканировать новый доступный контент).
Если вы хотите добавить свою собственную карту сайта (или если вы используете другой плагин SEO), вам просто нужно скопировать и вставить URL-адрес вашей карты сайта и Better Robots. txt добавит его в ваш WordPress Robots.txt.
txt добавит его в ваш WordPress Robots.txt.
2. Защитите свои данные и контент
Не позволяйте плохим ботам сканировать ваш сайт и коммерциализировать ваши данные.
Плагин Better Robots.txt помогает заблокировать сканирование и очистку ваших данных наиболее популярными вредоносными ботами.
Когда дело доходит до сканирования вашего сайта, есть хорошие и плохие боты. Хорошие боты, такие как бот Google, сканируют ваш сайт, чтобы проиндексировать его для поисковых систем. Другие сканируют ваш сайт по более гнусным причинам, таким как удаление вашего контента (текст, цена и т. Д.)) для переиздания, загрузки целых архивов вашего сайта или извлечения ваших изображений. Сообщалось, что некоторые боты даже закрывали целые веб-сайты в результате интенсивного использования широкополосного доступа.
Плагин Better Robots.txt защищает ваш сайт от пауков / парсеров, которые Distil Networks определили как плохих ботов.
3. Скрыть и защитить обратные ссылки
Скрыть и защитить обратные ссылки
Не позволяйте конкурентам определять ваши прибыльные обратные ссылки.
Обратные ссылки, также называемые «входящими ссылками» или «входящими ссылками», создаются, когда один веб-сайт ссылается на другой.Ссылка на внешний веб-сайт называется обратной ссылкой. Обратные ссылки особенно ценны для SEO, потому что они представляют собой «вотум доверия» от одного сайта к другому. По сути, обратные ссылки на ваш сайт являются сигналом для поисковых систем о том, что другие ручаются за ваш контент.
Если многие сайты ссылаются на одну и ту же веб-страницу или веб-сайт, поисковые системы могут сделать вывод, что контент стоит ссылки и, следовательно, также стоит показывать в поисковой выдаче. Таким образом, получение этих обратных ссылок оказывает положительное влияние на позицию сайта в рейтинге или видимость в поисковой сети.В индустрии SEM специалисты очень часто определяют, откуда берутся эти обратные ссылки (от конкурентов), чтобы отсортировать лучшие из них и создать высококачественные обратные ссылки для своих клиентов.
Учитывая, что создание очень прибыльных обратных ссылок для компании занимает много времени (время + энергия + бюджет), позволяя вашим конкурентам так легко идентифицировать и дублировать их, это чистая потеря эффективности.
Better Robots.txt помогает блокировать все поисковые роботы (aHref, Majestic, Semrush), чтобы ваши обратные ссылки не обнаруживались.
4. Избегайте спамовых обратных ссылок
Боты, заполняющие формы комментариев на вашем веб-сайте, говорят вам «отличная статья», «нравится информация», «надеются, что вы скоро сможете подробнее рассказать о теме» или даже предоставляют персональные комментарии, в том числе имя автора. Спам-боты со временем становятся все более умными, и, к сожалению, ссылки на спам в комментариях могут действительно повредить вашему профилю обратных ссылок. Улучшенный Robots.txt поможет вам избежать индексации этих комментариев поисковыми системами.
5.SEO инструменты
При улучшении нашего плагина мы добавили ссылки на 2 очень важных инструмента (если вас беспокоит ваш рейтинг в поисковых системах): Google Search Console и Bing Webmaster Tool.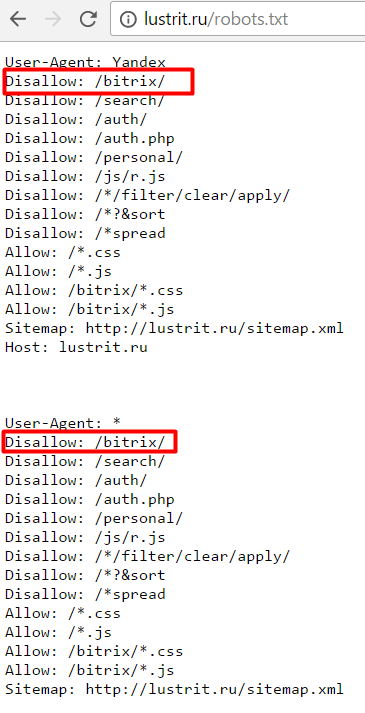 Если вы еще не используете их, теперь вы можете управлять индексированием своего сайта, оптимизируя robots.txt! Также был добавлен прямой доступ к инструменту массового пинга, который позволяет пинговать свои ссылки в более чем 70 поисковых системах.
Если вы еще не используете их, теперь вы можете управлять индексированием своего сайта, оптимизируя robots.txt! Также был добавлен прямой доступ к инструменту массового пинга, который позволяет пинговать свои ссылки в более чем 70 поисковых системах.
Мы также создали 4 ярлыка, относящиеся к лучшим онлайн-инструментам SEO, прямо доступным на Better Robots.txt SEO PRO. Так что теперь, когда вы захотите, вы теперь можете проверить производительность загрузки вашего сайта, проанализировать свой рейтинг SEO, определить свой текущий рейтинг в поисковой выдаче с помощью ключевых слов и трафика и даже просканировать весь сайт на наличие мертвых ссылок (ошибки 404, 503, …) Прямо из плагина.
6. Будьте уникальны
Мы подумали, что можем добавить немного оригинальности в Better Robots.txt, добавив функцию, позволяющую «настраивать» ваш файл robots.txt WordPress с помощью вашей собственной уникальной «подписи».«Большинство крупных компаний в мире персонализировали свой robots.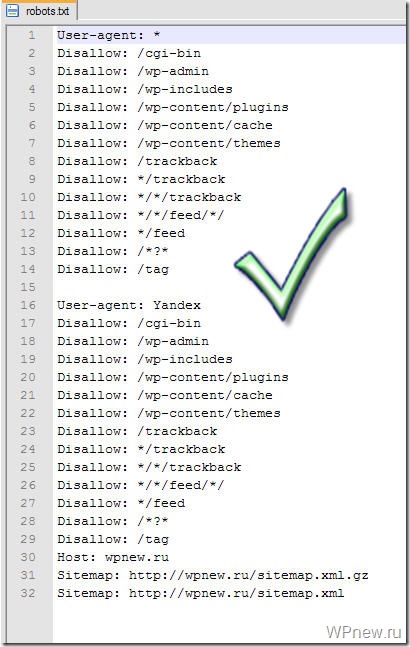 txt, добавив пословицы (https://www.yelp.com/robots.txt), слоганы (https://www.youtube.com/robots.txt) или даже рисунки (https://store.nike.com/robots.txt — внизу). И почему не ты тоже? Вот почему мы выделили специальную область на странице настроек, где вы можете писать или рисовать все, что хотите (действительно), не влияя на эффективность работы robots.txt.
txt, добавив пословицы (https://www.yelp.com/robots.txt), слоганы (https://www.youtube.com/robots.txt) или даже рисунки (https://store.nike.com/robots.txt — внизу). И почему не ты тоже? Вот почему мы выделили специальную область на странице настроек, где вы можете писать или рисовать все, что хотите (действительно), не влияя на эффективность работы robots.txt.
7. Запретить роботам сканировать бесполезные ссылки WooCommerce
Мы добавили уникальную функцию, позволяющую блокировать определенные ссылки («добавить в корзину», «заказать», «заполнить», «корзина», «аккаунт», «оформить заказ» и т. Д.) От сканирования поисковыми системами.Для большинства этих ссылок требуется много ресурсов ЦП, памяти и полосы пропускания (на сервере хостинга), поскольку они не кэшируются и / или создают «бесконечные» циклы сканирования (пока они бесполезны). Оптимизация вашего файла robots.txt в WordPress для WooCommerce при наличии интернет-магазина позволяет увеличить вычислительную мощность для действительно важных страниц и повысить производительность загрузки.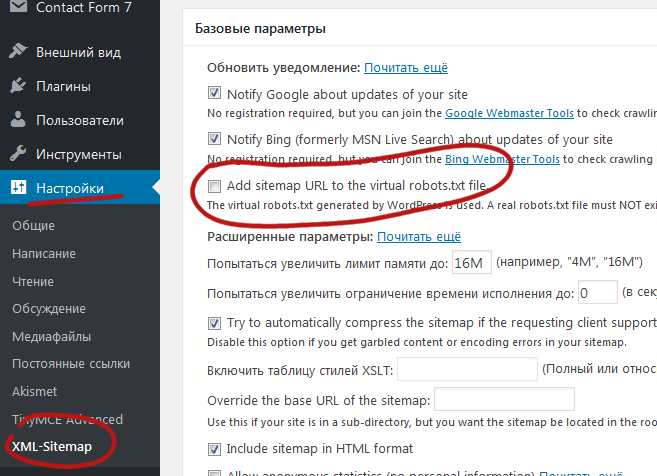
8. Избегайте ловушек на гусеничном ходу:
«Ловушки поискового робота» — это структурная проблема на веб-сайте, которая заставляет сканеры находить практически бесконечное количество нерелевантных URL-адресов.Теоретически сканеры могут застрять в одной части веб-сайта и никогда не завершить сканирование этих нерелевантных URL-адресов. Улучшенный файл Robots.txt помогает предотвратить ловушки роботов, которые сокращают бюджет сканирования и вызывают дублирование контента.
9. Инструменты взлома роста
Сегодня самые быстрорастущие компании, такие как Amazon, Airbnb и Facebook, добились резкого роста, объединив свои команды вокруг высокоскоростного процесса тестирования / обучения. Речь идет о взломе роста. Взлом роста — это процесс быстрого экспериментирования и реализации маркетинговых и рекламных стратегий, которые направлены исключительно на эффективный и быстрый рост бизнеса.Better Robots.txt предоставляет список из 150+ инструментов, доступных в Интернете, чтобы ускорить ваш рост.
10. Robots.txt Post Meta Box для ручных исключений
Этот мета-блок сообщения позволяет установить «вручную», должна ли страница быть видимой (или нет) в поисковых системах, введя специальное правило «запретить» + «noindex» в файл robots.txt WordPress. Почему это полезно для вашего рейтинга в поисковых системах? Просто потому, что некоторые страницы не предназначены для сканирования / индексации. Страницы с благодарностью, целевые страницы, страницы, содержащие исключительно формы, полезны для посетителей, но не для поисковых роботов, и вам не нужно, чтобы они отображались в поисковых системах.Кроме того, некоторые страницы, содержащие динамические календари (для онлайн-бронирования) НИКОГДА не должны быть доступны для поисковых роботов, поскольку они имеют тенденцию заманивать их в бесконечные циклы сканирования, что напрямую влияет на ваш бюджет сканирования (и ваш рейтинг).
11. Возможность сканирования Ads.txt и App-ads.txt
Чтобы гарантировать, что файлы ads. txt и app-ads.txt могут сканироваться поисковыми системами, плагин Better Robots.txt гарантирует, что они по умолчанию разрешены в файле Robots.txt независимо от вашей конфигурации.Для вашего сведения, авторизованные цифровые продавцы для Интернета или ads.txt — это инициатива IAB, направленная на повышение прозрачности автоматизированной рекламы. Вы можете создать свои собственные файлы ads.txt, чтобы определить, кто имеет право продавать ваши ресурсы. Эти файлы общедоступны и могут сканироваться биржами, платформами поставщиков (SSP) и другими покупателями и сторонними поставщиками. Авторизованные продавцы для приложений или app-ads.txt — это расширение стандарта авторизованных цифровых продавцов. Он расширяет совместимость для поддержки рекламы, отображаемой в мобильных приложениях.
txt и app-ads.txt могут сканироваться поисковыми системами, плагин Better Robots.txt гарантирует, что они по умолчанию разрешены в файле Robots.txt независимо от вашей конфигурации.Для вашего сведения, авторизованные цифровые продавцы для Интернета или ads.txt — это инициатива IAB, направленная на повышение прозрачности автоматизированной рекламы. Вы можете создать свои собственные файлы ads.txt, чтобы определить, кто имеет право продавать ваши ресурсы. Эти файлы общедоступны и могут сканироваться биржами, платформами поставщиков (SSP) и другими покупателями и сторонними поставщиками. Авторизованные продавцы для приложений или app-ads.txt — это расширение стандарта авторизованных цифровых продавцов. Он расширяет совместимость для поддержки рекламы, отображаемой в мобильных приложениях.
Как всегда, еще больше…
Узнайте, как оптимизировать файл Robots.txt
Итак, вы хотите стать рок-звездой robots.txt, а? Что ж, прежде чем вы сможете заставить этих пауков танцевать в вашем ритме, вам следует ознакомиться с несколькими основными принципами. Неправильно создав файл robots.txt, вы попадете в мир боли. Сделайте это правильно, и поисковые системы полюбят вас.
Неправильно создав файл robots.txt, вы попадете в мир боли. Сделайте это правильно, и поисковые системы полюбят вас.
Что такое файл robots.txt?
Это «инструкция» для поисковых роботов (Google, Bing и т. Д.).) использовать при посещении вашего сайта.
Файл robots.txt указывает различным роботам / сканерам / паукам поисковых систем, где они могут и не могут заходить на ваш сайт. Вы сообщаете этим ботам (Google, Bing и т. Д.), Что им разрешено «видеть» на вашем веб-сайте, а что запрещено.
Ваш файл robots.txt — это полицейский на остановке, а автомобили — это веб-сканеры / пауки .
Имеет смысл? Хорошо.
Зачем мне нужен файл Robots.txt?
Роботы.txt — это то, что люди, как правило, поспешно собирают вместе. Может быть, это потому, что он имеет тенденцию быть одним из последних пунктов в списке запуска веб-сайта (не должно быть… но вы знаете…. ) Или, может быть, люди в целом просто ленивы. Вы ленивый веб-мастер? Надеюсь, что нет…
) Или, может быть, люди в целом просто ленивы. Вы ленивый веб-мастер? Надеюсь, что нет…
Что может пойти не так, если я не буду использовать этот файл Robots.txt?
Без файла robots.txt ваш сайт будет :
- Не оптимизирован с точки зрения возможности сканирования
- Более подвержен ошибкам SEO
- Открыт для просмотра конфиденциальных данных
- Злоумышленникам проще взломать веб-сайт
- Пострадает от конкуренции
- Будут проблемы с индексацией
- Будет беспорядок, чтобы разобраться в инструментах для веб-мастеров
- Будет испускать сбивающие с толку сигналы поисковым системам
- и другие…
Давайте Начало: создание ваших роботов.txt
Минута №1: у вас уже есть файл robots.txt?
Было бы неплохо определить, есть ли на вашем веб-сайте в настоящее время файл robots.txt для начала. Возможно, вы не захотите отменять что-либо, что есть в данный момент. Если вы не знаете, есть ли на вашем веб-сайте файл robots, просто зайдите на свой веб-сайт и введите robots. txt. Пример того, как это будет выглядеть:
txt. Пример того, как это будет выглядеть:
www.mywebsite.com/robots.txt
Конечно, замените часть «mywebsite» на свое собственное доменное имя.
* Примечание : Местоположение файла robots.txt всегда должно быть в «корневом» или «домашнем» уровне вашего веб-сайта, то есть он должен находиться в той же папке, что и ваша домашняя страница или страница индекса.
Если вы ничего не видите при посещении этого URL-адреса, на вашем веб-сайте нет файла robots.txt. Однако если вы ДЕЙСТВИТЕЛЬНО видите информацию, значит, у вас ДЕЙСТВИТЕЛЬНО есть текущий файл robots. В этом случае, когда вы собираетесь редактировать или добавлять какие-либо правила (как показано ниже), не удаляйте все, что у вас есть в данный момент, поскольку это может «испортить» ваш сайт.
На всякий случай сделайте резервную копию файла robots.txt перед тем, как приступить к его редактированию. Когда дело доходит до работы с цифровыми файлами, у меня есть для вас три слова: ВСЕГДА СОЗДАВАЙТЕ РЕЗЕРВНЫЕ КОПИИ
Минута №2: Запуск файла Robots. txt
 txt
txt Создать файл robots.txt так же просто, как встать с постели. Ладно, мне трудно встать с постели, но я отвлекся.
Чтобы создать файл robots.txt, просто откройте любой текстовый редактор. Важно, чтобы вы не использовали программное обеспечение WYSIWYG (программное обеспечение для дизайна веб-страниц), поскольку эти инструменты могут добавлять дополнительный код, который нам не нужен.Сделайте это простым и используйте текстовый редактор. Наиболее распространенные из них:
- Блокнот
- Блокнот ++
- Скобки
- TextWrangler
- TextMate
- Sublime Text
- Vim
- Atom
- и т. Д.
Подойдет любая из этих программ, так как ваш компьютер поставляется с Блокнот по умолчанию, вы также можете использовать его для этого урока.
Откройте Блокнот и начните вводить свои «правила». После того, как вы ввели свои правила, вы сохраняете файл, называя его «роботами», и убедитесь, что он сохранен с расширением «Текстовые документы (*. текст)».
текст)».
Какие «правила» вы должны ввести в свой файл robots.txt? Это зависит от того, чего вы хотите достичь. Прежде чем вводить правила, вам нужно решить, что вы хотите «заблокировать» или «скрыть» от сканирования на вашем веб-сайте. Папки на вашем веб-сайте, которые не нужно сканировать и индексировать в результатах поиска, включают в себя такие вещи, как:
- страницы поиска по сайту
- Разделы оформления заказа / электронной торговли
- Области входа пользователя
- Конфиденциальные данные
- Тестирование / Staging / Дубликаты данных
- и т. Д..
Имея эту информацию под рукой, легко настроить правила. Давайте посмотрим, как именно мы это делаем.
Понимание правил файла Robots.txt
Что касается файла robots.txt, существует стандартный формат для создания правил.
1) Звездочки используются в качестве подстановочного знака: *
2) Чтобы разрешить сканирование областей вашего веб-сайта, используется правило «Разрешить»
3) Чтобы запретить сканирование областей вашего веб-сайта, выберите «Запретить» используется правило
Допустим, у вас есть веб-сайт (что, вероятно, у вас есть ??). На вашем веб-сайте (назовем его mywebsite.com) у вас была подпапка, содержащая дублирующуюся информацию / тестовые материалы / материалы, которые вы хотите сохранить в тайне. Возможно, у вас была настройка этой подпапки в качестве промежуточной или тестовой области. Назовем эту папку «постановкой». Ваш файл robots.txt будет выглядеть примерно так:
На вашем веб-сайте (назовем его mywebsite.com) у вас была подпапка, содержащая дублирующуюся информацию / тестовые материалы / материалы, которые вы хотите сохранить в тайне. Возможно, у вас была настройка этой подпапки в качестве промежуточной или тестовой области. Назовем эту папку «постановкой». Ваш файл robots.txt будет выглядеть примерно так:
User-agent: *
Disallow: / staging /
Довольно просто, не правда ли? Давайте посмотрим, что здесь происходит.
Начнем с наших роботов.txt с User-agent: *
Определение User-agent обращается к паукам поисковой системы, а звездочка используется как подстановочный знак. Таким образом, это правило инструктирует ВСЕХ пауков из ВСЕХ поисковых систем, что они должны следовать ВСЕМ правилам, которые появятся позже.
Так будет до тех пор, пока другое объявление User-agent не будет объявлено далее в robots. txt (если вам придется использовать его снова). Что будет потом?
txt (если вам придется использовать его снова). Что будет потом?
Следующее правило:
Disallow: / staging /
Это правило запрета сообщает паукам поисковых систем, что им не разрешено сканировать что-либо на вашем веб-сайте, которое находится в промежуточной папке.Используя название нашего воображаемого веб-сайта, это местоположение будет выглядеть так: www.mywebsite.com/staging/
* Совет : имейте в виду, что только потому, что вы запрещаете сканирование определенного раздела вашего веб-сайта, это может по-прежнему отображаться в индексе поисковых систем IF ранее сканировалось И , если вы разрешили индексирование этих страниц .
Чтобы этого не произошло, лучше всего объединить правило запрета с метатегами «noindex», добавленными на ваши веб-страницы (подробнее об этом ниже).Если страницы, которые вы не хотите сканировать, уже отображаются в индексе поисковой системы, возможно, вам придется удалить их вручную с помощью области инструментов для веб-мастеров соответствующих поисковых систем (Google / Bing).
Все просто, не правда ли?
Несколько примеров, которые вы можете использовать
Ниже вы видите несколько примеров из файла robots.txt, показывающих различные правила для различных ситуаций. Не все файлы robots.txt будут одинаковыми. Некоторые люди могут захотеть заблокировать сканирование всего своего веб-сайта.У других может быть потребность ограничить только определенные разделы своего веб-сайта.
Разрешение сканирования и индексации всего на веб-сайте
Агент пользователя: *
Разрешить: /
Блокировка сканирования всего веб-сайта
Пользователь-агент: *
Disallow: /
Блокировка определенной папки от сканирования
User-agent: *
Allow: / myfolder /
Allow A Specific в данном случае Google) для доступа к вашему сайту и запрета всем остальным
User-agent: Googlebot
Allow: /
User-agent: *
Disallow: /
Extra: Роботы, специфичные для WordPress. txt File
 txt File
txt File Что касается WordPress, то при каждой установке WP есть три основных стандартных каталога. Это:
- wp-content
- wp-admin
- wp-includes
Папка wp-content содержит подпапку, известную как «загрузки». Это место содержит медиа-файлы, которые вы используете (изображения и т. Д.), И мы НЕ должны блокировать этот раздел. Зачем вам это нужно?
Ну, когда вы «запрещаете» папку в robots.txt, по умолчанию — все подпапки под ней также по умолчанию блокируются.Итак, мы должны создать уникальное правило для этой подпапки мультимедиа.
Ваш файл robots.txt в WordPress теперь может выглядеть примерно так:
User-agent: *
Disallow: / wp-admin /
Disallow: / wp-includes /
Disallow: / wp-content / plugins /
Disallow: / wp-content / themes /
Разрешить: / wp-content / uploads /
Теперь у нас очень простой файл robots.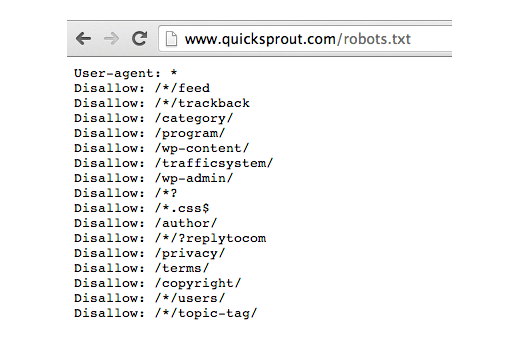 txt, который блокирует выбранные нами папки, но по-прежнему позволяет сканировать подпапку «uploads» в пределах «wp-content». Есть смысл?
txt, который блокирует выбранные нами папки, но по-прежнему позволяет сканировать подпапку «uploads» в пределах «wp-content». Есть смысл?
Если вы запрещаете папку «xyz», каждая папка, находящаяся под / помещенная внутри «xyz», также будет запрещена. Чтобы указать отдельные папки, которые следует сканировать, необходимо указать явное правило.
Вот что вы можете использовать для запуска файла robots.txt WordPress. Странный шар в этой группе, которого вы, возможно, не видели раньше, — «Disallow: / 20 *». Это отключает архивы дат, начиная с 20 года.
User-agent: *
Disallow: / wp-admin /
Disallow: / wp-includes /
Disallow: / wp-content / plugins /
Disallow: / wp content / cache /
Disallow: / wp-content / themes /
Disallow: /xmlrpc.php
Disallow: / wp-
Disallow: / feed /
Disallow: / trackback /
Disallow: * / feed /
Disallow: * / trackback /
Disallow: / *?
Disallow: / cgi-bin /
Disallow: / wp-login /
Disallow: / wp-register /
Disallow: / 20 *Разрешить: / wp-content / uploads /
Карта сайта: http: // example.
* Совет : всегда рекомендуется включать ссылку на карту сайта из файла robots.txt. Карта сайта также должна быть размещена в «корне» вашего веб-сайта (в той же папке, что и файл домашней страницы).
Минутка № 3: осторожное предупреждение / проверка на наличие ошибок
Вы должны убедиться, что вы не сделали никаких опечаток. Простая опечатка может испортить ваш файл, поэтому убедитесь, что вы написали все правильно и поставили правильный интервал.
Также важно отметить, что не все пауки / сканеры следуют стандартному протоколу robots.txt. Вредоносные пользователи и спам-боты будут просматривать ваш файл robots.txt и искать конфиденциальную информацию, такую как личные разделы, папки с конфиденциальными данными, административные области и т. Д. Хотя многие люди ДОЛЖНЫ перечислять эти папки / области своего веб-сайта в файле robots.txt. (и это нормально в 99% случаев), чтобы сделать дополнительный шаг вперед, вы можете не помещать их в файл robots.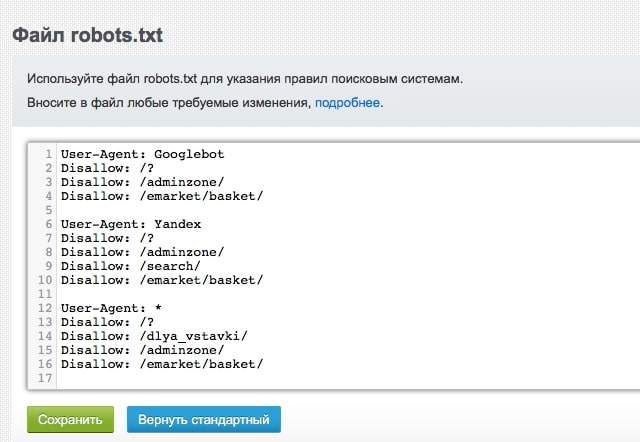 txt и просто скрыть их с помощью метатега robots.
txt и просто скрыть их с помощью метатега robots.
Итак, если вы хотите быть в большей безопасности и использовать блокировку конфиденциальных страниц с помощью метатегов, вот как вы это делаете:
- Откройте программу редактирования вашего веб-сайта (что бы вы ни использовали для разработки / редактирования реального веб-сайта)
- Используя «представление кода» или «представление текста» вашего программного обеспечения для редактирования, вы должны ввести следующий код между тегами «заголовок» страницы (верхняя часть страницы).
Теперь при просмотре исходного кода вашей страницы он должен выглядеть примерно так:
…
… и именно так вы легко блокируете свои страницы от индексации и сканирования!
Минута №4: Загрузка на ваш веб-сайт
Конечно, ничего из этого не будет служить никакой цели, если вы не загрузите и не сохраните файл обратно на свой веб-сайт.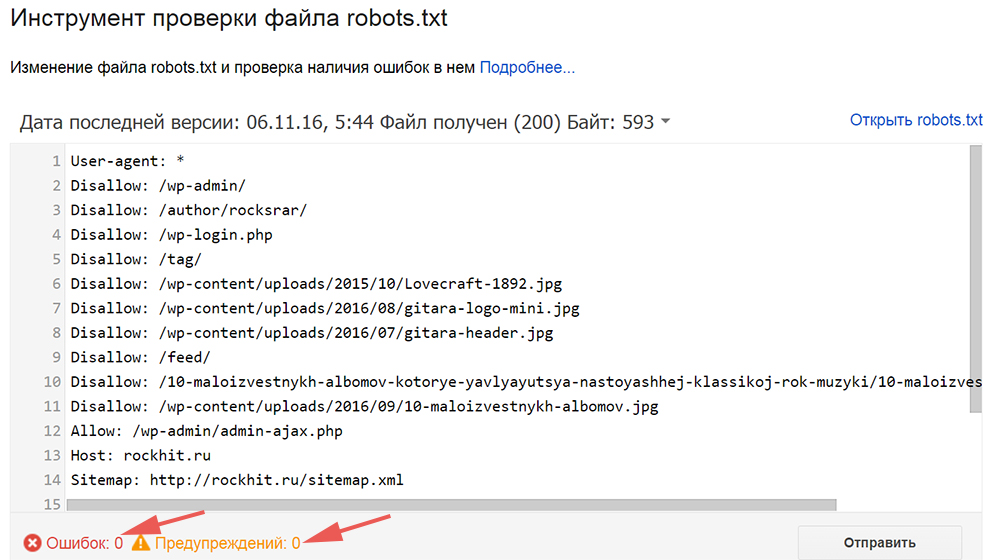 Поэтому обязательно сохраните свой файл роботов как robots.txt, и если вы также решили использовать опцию метатега, обязательно повторно загрузите эти веб-страницы после того, как вы их отредактировали и сохранили.
Поэтому обязательно сохраните свой файл роботов как robots.txt, и если вы также решили использовать опцию метатега, обязательно повторно загрузите эти веб-страницы после того, как вы их отредактировали и сохранили.
Минута №5: Просмотр файла в Интернете
Последним шагом в этом простом процессе является просмотр файла robots.txt в вашем веб-браузере, а также проверка того, что ваши недавно сохраненные страницы (если вы использовали метатег) также обновляются. На всякий случай обновите страницу или очистите кеш и файлы cookie на своем компьютере, прежде чем делать это.
Полезный ресурс:
Чтобы получить хороший список имен пользовательских агентов веб-сканера, посетите: http://www.robotstxt.org/db.html. Здесь вы можете найти любое «имя» сканера и добавить его в свой список разрешенных / запрещенных… но большинству людей это не понадобится.
Заключение и заключительные мысли
Итак, теперь у вас есть возможности и знания, чтобы эффективно создавать и оптимизировать файл robots. txt для вашего веб-сайта — потрясающе! Однако есть еще много чего узнать. Роботы.txt — это только один из сотен элементов, которые мы ежедневно используем для наших клиентов и стараемся опережать их.
txt для вашего веб-сайта — потрясающе! Однако есть еще много чего узнать. Роботы.txt — это только один из сотен элементов, которые мы ежедневно используем для наших клиентов и стараемся опережать их.
Если вы хотите, чтобы мы проанализировали оптимизацию вашего веб-сайта и резко повысили рейтинг вашего сайта, обязательно свяжитесь с нами, чтобы получить бесплатную 25-минутную маркетинговую оценку. Мы всегда рады помочь!
Есть вопросы? Обязательно оставьте свой комментарий ниже, и я свяжусь с вами как молния.
Как идентифицировать роботов с помощью журналов Apache
Получите глубокое представление о роботах, сканирующих ваш веб-сервер Apache
Ваш сайт сканируют два типа роботов: хорошие и плохие.
Хорошие боты идентифицируют себя в строке своего пользовательского агента и подчиняются правилам, изложенным в вашем файле robots.txt . Они также приносят определенную пользу вашей компании в обмен на пропускную способность, необходимую для их обслуживания. Например, вы обычно хотите, чтобы робот Googlebot просканировал ваш сайт, чтобы он отображался в результатах поиска.
Например, вы обычно хотите, чтобы робот Googlebot просканировал ваш сайт, чтобы он отображался в результатах поиска.
Плохие боты, с другой стороны, не играют по правилам. Они не только потребляют ресурсы сервера в ущерб вашим пользователям, но и часто собирают конфиденциальную информацию для собственного использования.Их намерения могут быть даже более злонамеренными, включая атаки типа «отказ в обслуживании» и автоматическую проверку уязвимостей безопасности.
Определение потенциального трафика ботов в Sumo Logic В этой статье мы рассмотрим несколько методов определения как хороших, так и плохих ботов путем анализа данных журнала Apache. После того, как вы определили ботов на своем сайте, вы можете оптимизировать хороших, изменив robots.txt , или заблокировать плохих по IP-адресу в .htaccess .
Полная видимость для DevSecOps
Сократите время простоя и перейдите от реактивного мониторинга к упреждающему.
Поиск роботов — это более сложное приложение для анализа показателей трафика, поэтому в этой статье предполагается, что вы уже ознакомились с основами анализа трафика Apache.
Определение хороших ботов
Боты с хорошим поведением идентифицируют себя — это часть пользовательского агента в объединенном формате журнала. Это делает относительно простым изолировать записи журнала, созданные хорошими ботами:
_sourceCategory = Apache / Access ("Googlebot" ИЛИ "AskJeeves" ИЛИ "Digger" ИЛИ "Lycos" ИЛИ "msnbot" ИЛИ "Inktomi Slurp" ИЛИ "Yahoo" ИЛИ "Nutch" ИЛИ "bingbot" ИЛИ "BingPreview" ИЛИ " Медиапартнеры-Google ИЛИ "Ближайший" ИЛИ "AhrefsBot" ИЛИ "AdsBot-Google" ИЛИ "Ezooms" ИЛИ "AddThis.\ "] +?) \" "| синтаксический анализ поля регулярного выражения = агент" (? 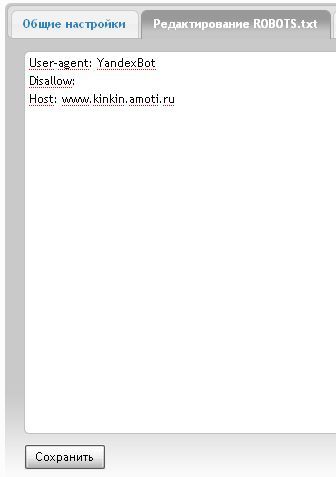 +" nodrop | parse regex field = agent "(?
+" nodrop | parse regex field = agent "(? 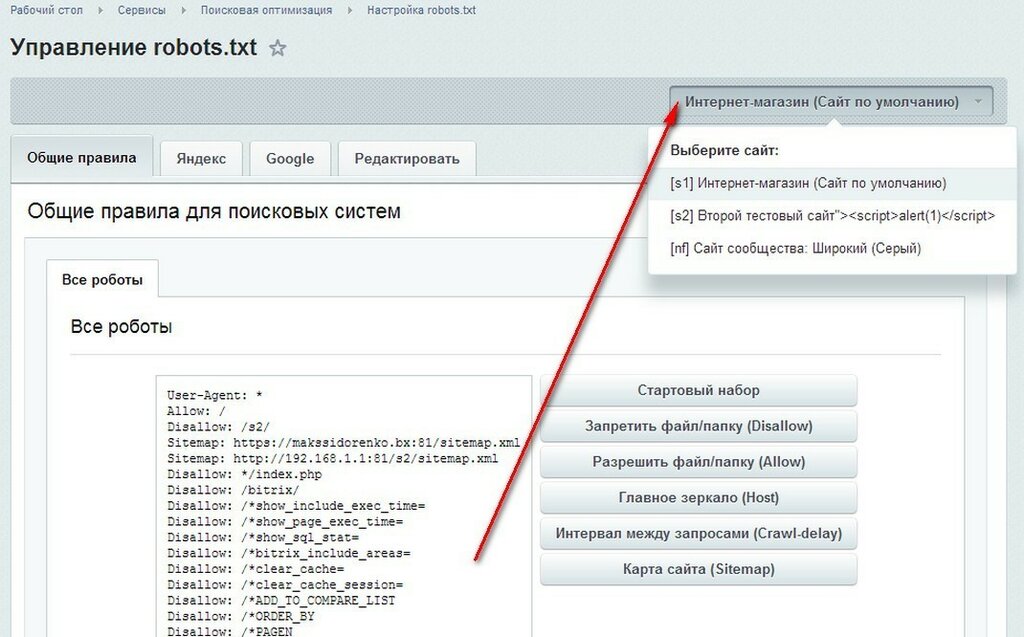 + "nodrop | parse regex field = agent" (?
+ "nodrop | parse regex field = agent" (?
Это длинный запрос, но не пугайтесь. Все, что он делает, — это извлекает пользовательский агент из каждого сообщения журнала и ищет специфичные для бота строки. Выполнение этого запроса в Sumo Logic вернет список из 20 самых популярных ботов, сканирующих ваш сайт:
Все, что он делает, — это извлекает пользовательский агент из каждого сообщения журнала и ищет специфичные для бота строки. Выполнение этого запроса в Sumo Logic вернет список из 20 самых популярных ботов, сканирующих ваш сайт:
Очевидно, вам не захочется переписывать этот запрос каждый раз, когда вы хотите анализировать трафик ботов. Вместо этого вы можете просто записать его в свою библиотеку Sumo Logic, нажав кнопку Сохранить как под строкой поиска.
Анализ объема трафика ботов
Приведенный выше запрос дает вам некоторое представление о том, кто сканирует ваш сайт, но чтобы сделать что-нибудь полезное с этой информацией, нам нужно копнуть глубже.\ «] +?) \» «| синтаксический анализ поля регулярного выражения = агент» (? 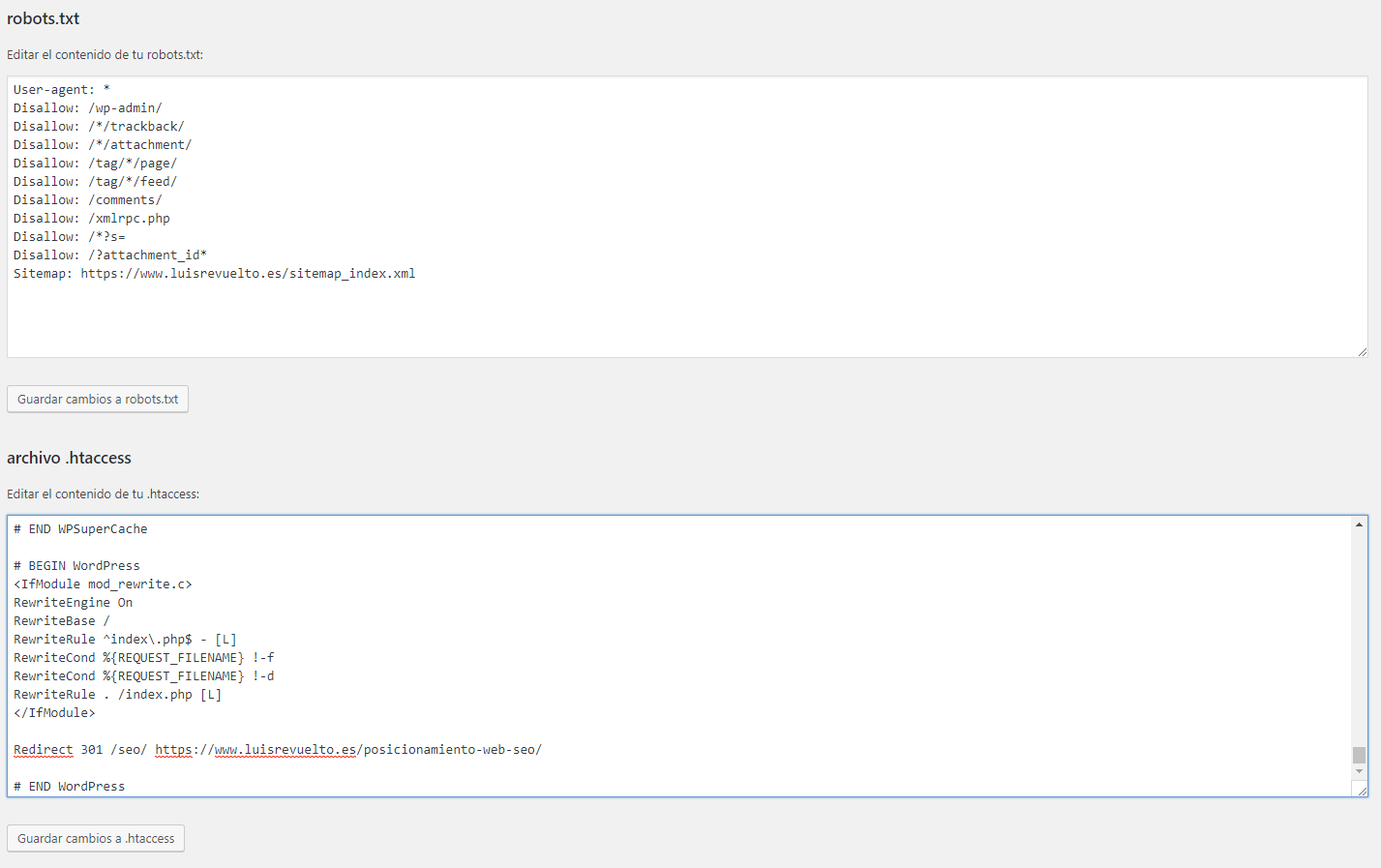 +» nodrop | parse regex field = agent «(?
+» nodrop | parse regex field = agent «(? 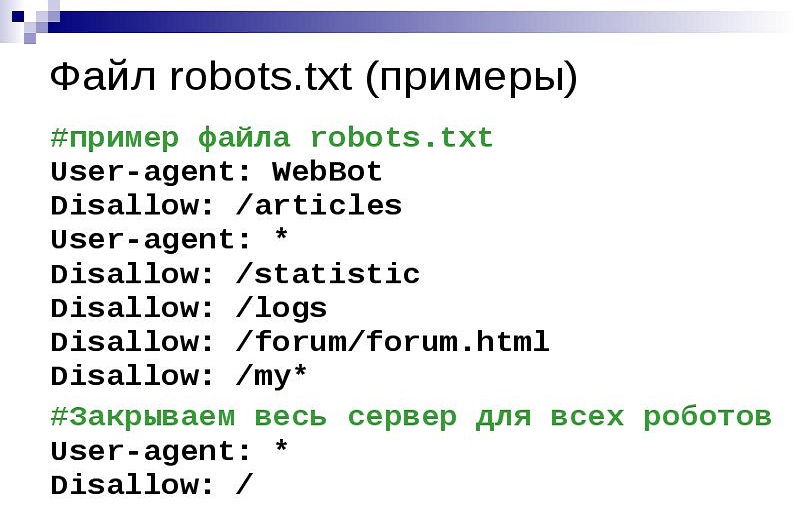 + «nodrop | parse regex field = agent» (?
+ «nodrop | parse regex field = agent» (?
Обратите внимание, что мы добавили параметр nodrop в последнюю строку синтаксического анализа . Это гарантирует, что записи журнала, не относящиеся к ботам, не будут удалены из результатов, как в предыдущем запросе.
Это гарантирует, что записи журнала, не относящиеся к ботам, не будут удалены из результатов, как в предыдущем запросе.
Визуализация результатов в виде столбчатой диаграммы с накоплением позволяет легко увидеть, когда боты наводняют ваш сайт. Это важно, потому что это может замедлить время отклика ваших пользователей.
Сравнение обычного трафика с трафиком ботов с течением времени Поскольку этот запрос ищет только хороших ботов, вы должны иметь возможность контролировать частоту их сканирования и блокировать нерелевантные URL-адреса, настраивая роботов .txt файл. Хотя не все боты (особенно Googlebot) будут соблюдать инструкции по задержке сканирования, это все же хорошее начало для оптимизации трафика ботов.
Выявление ботов с неправильным поведением
Тем не менее, для хороших ботов можно провести лишь определенную оптимизацию, потому что они, ну, с самого начала хороши. По самой своей природе они не должны наводнять ваш сайт запросами или посещать страницы, которые вы объявили «закрытыми».
Как системный администратор, вы действительно должны больше беспокоиться о некорректном поведении ботов.Плохие боты обычно не идентифицируют себя в строке своего пользовательского агента, а это означает, что единственный способ их обнаружить — это проанализировать их поведение.
В оставшейся части этой статьи представлены несколько способов обнаружения подозрительного поведения с определенных IP-адресов. Независимо от того, являются ли эти пользователи ботами или людьми, их ненормальное поведение при просмотре страниц часто является достаточной причиной, чтобы заблокировать эти IP-адреса от посещения вашего сайта.
Частота запроса по IP
Давайте начнем с общего обзора поведения посетителей.Следующий запрос возвращает количество обращений каждую минуту с разбивкой по IP-адресам.
_sourceCategory = Apache / Access | синтаксический анализ регулярного выражения "(?
Отображение этой информации в виде линейной диаграммы позволяет легко увидеть, как каждый пользователь взаимодействует с вашим веб-сайтом:
Линейная диаграмма, показывающая совпадения по IP-адресу с течением времени
Эта диаграмма содержит много информации, поэтому стоит потратить немного времени, чтобы понять, как ее интерпретировать. Каждая строка представляет собой один IP-адрес, а по оси Y показано количество запросов, которые они выполняли каждую минуту. Обе оси предоставляют ключи для идентификации ботов.
Каждая строка представляет собой один IP-адрес, а по оси Y показано количество запросов, которые они выполняли каждую минуту. Обе оси предоставляют ключи для идентификации ботов.
Люди обычно просматривают веб-страницы по одной, что означает, что они должны быть ближе к нижней части оси y. Они также проводят некоторое время, читая каждую страницу, и в конечном итоге покидают ваш сайт, поэтому вы также должны видеть интервалы без взаимодействия. Другими словами, люди представлены в виде неправильной зубчатой линии внизу диаграммы.
Поведение бота может отличаться по нескольким причинам. Во-первых, они могут запрашивать несколько страниц параллельно, и в этом случае у них будет намного больше запросов за интервал времени, чем у их коллег-людей. Во-вторых, они делают запросы с относительно постоянным интервалом. В-третьих, они часто сканируют большую часть вашего сайта, а не просто посещают несколько страниц. Это будет отображаться в виде высоких значений по оси Y или относительно постоянных линий, которые периодически не опускаются до нуля.
Коричневые и пурпурные линии в верхней части диаграммы выше являются примерами потенциального поведения ботов.
Отслеживание IP-адреса
Целью предыдущего запроса было обнаружение подозрительных IP-адресов для расследования. Когда у вас есть эти IP-адреса, вы можете отслеживать их путь через свой веб-сайт с помощью следующего запроса (обязательно измените предложение where , чтобы использовать IP-адрес, который вы нашли в собственных данных журнала):
_sourceCategory = Apache / Access | синтаксический анализ регулярного выражения "(?
Это возвращает каждый URL-адрес, который пользователь с IP-адресом 166. запрашивал каждую минуту. Визуализируя это в виде столбчатой диаграммы, вы увидите, где они проводили время. 94.146.84
94.146.84
Опять же, есть подсказки в обоих измерениях. Одновременные запросы лежат по оси y, а частота запросов может быть найдена по оси x.Кроме того, вы можете точно видеть, какие страницы и медиаресурсы они посещали.
Эта последняя часть — мощный инструмент для определения поведения соскабливания. Например, если ваша компания агрегирует цены в реальном времени для конкретной отрасли, вы хотите знать, крадут ли люди эту ценную информацию. Если вы видите, что URL-адрес цены всплывает снова и снова (как на скриншоте выше), вы знаете, что этот IP-адрес постоянно посещает эту страницу, чтобы узнать, опубликовали ли вы новые данные.
Проверка соотношения изображения и HTML
Предыдущие примеры идентифицируют поведение ботов только по количеству обращений / громкости. Это отлично подходит для выявления потенциальных DoS-атак, проблем с производительностью и действий по очистке, но другие боты с низким трафиком также могут быть проблемой. Например, спам-боты, собирающие адреса электронной почты или отправляющие спам через формы контактов и комментариев, не будут отображаться как пользователи с высоким трафиком, но они могут быть такими же проблемными.
Например, спам-боты, собирающие адреса электронной почты или отправляющие спам через формы контактов и комментариев, не будут отображаться как пользователи с высоким трафиком, но они могут быть такими же проблемными.
Многие из этих ботов избегают загрузки изображений и других медиаресурсов, что означает, что мы можем идентифицировать их, сравнивая количество медиа-запросов с запросами HTML-контента.
_sourceCategory = Apache / Access | синтаксический анализ регулярного выражения "(? \ d {1,3} \. \ d {1,3} \. \ d {1,3} \. \ d {1,3})" | синтаксический анализ регулярного выражения "\" [AZ] + (?. +) HTTP "nodrop | where url! =" - "| синтаксический анализ поля регулярного выражения = url" (? jpg | jpeg | png | gif) "nodrop | if (type == "", 1, 0) как content_resource | if (type! = "", 1, 0) as media_resource | sum (content_resource) as content_resource, sum (media_resource) as media_resource by client_ip | (media_resource / content_resource) as media_to_content_ratio | sort по media_to_content_ratio asc | fields - media_resource, content_resource
Этот запрос вычисляет соотношение изображения и HTML для каждого IP-адреса. Само по себе это число мало что скажет, но установление базового уровня для пользователей-людей и сравнение их с потенциальными выбросами может помочь идентифицировать ботов. Простая гистограмма значительно упрощает это:
Само по себе это число мало что скажет, но установление базового уровня для пользователей-людей и сравнение их с потенциальными выбросами может помочь идентифицировать ботов. Простая гистограмма значительно упрощает это:
IP-адрес в верхней части диаграммы загружает значительно меньше статических медиаресурсов, чем остальные ваши пользователи. Это может указывать на бота, но это также может быть человек, использующий только текстовый браузер.
Сводка
Важно понимать, что методы, которые мы обсуждали в этой статье, представляют собой всего лишь эвристику для выявления ботов с плохим поведением.Они не определяют магический числовой порог, который отличает ботов от людей.
Есть потенциальные последствия для блокировки IP-адресов, поэтому важно быть очень осторожным при анализе трафика ботов. Излишне говорить, что принятие лучших клиентов за ботов не пойдет на пользу бизнесу. К сожалению, это сделать проще, чем вы думаете.
Например, пользователь-человек, открывающий несколько ссылок на отдельных вкладках, получит несколько одновременных обращений, что также является контрольным признаком ботов.Почти всегда требуется более глубокий анализ, чтобы принять обоснованное решение о том, стоит ли блокировать определенный IP-адрес.
Дополнительные ресурсы
Полная видимость для DevSecOps
Сократите время простоя и перейдите от реактивного мониторинга к упреждающему.
.