
проверка правописания — взгляд изнутри (часть 1) / Хабр
Читавшие мои предыдущие публикации знают, что пишу я достаточно редко, но обычно сериями. Хочется собраться с мыслями на заданную тему и разложить их по полочкам, не втискивая себя в прокрустово ложе одной короткой статейки.
На сей раз появился новый повод поговорить об обработке текстов (natural language processing то бишь). Я разрабатываю модуль проверки правописания для одной конторы. На выходе должна получиться функциональность, аналогичная встроенной в MS Word, только лучше 🙂 Не могу пока назвать себя крупным специалистом в этой области, но стараюсь учиться. В заметках постараюсь рассказать о том, куда движется наш проект, как устроен тот или иной этап обработки текста. Может, в комментариях услышу что-нибудь новое/интересное и для себя. Если проекту с этого будет польза — прекрасно. Как минимум, устаканю данные у себя в голове, а это тоже неплохо.
Понятно, что без оглядки на существующие решения изобретать свою систему трудно. Однако гигантов вокруг нас как-то не особенно наблюдается. Есть MS Word, который все мы знаем, а ещё… а кто ещё? Вот пусть комментаторы поправят, но кроме модуля LanguageTool для Open Office (о нём мы ещё поговорим) даже в голову ничего не приходит. Штучный товар. (Да, вспомнил ещё о пакете Grammarian Pro X для макинтоша, но он тоже погоды не делает). Соответственно, ориентироваться на «отцов» сложновато. Проверка орфографии худо-бедно много где реализована, а вот с грамматикой совсем беда.
Однако гигантов вокруг нас как-то не особенно наблюдается. Есть MS Word, который все мы знаем, а ещё… а кто ещё? Вот пусть комментаторы поправят, но кроме модуля LanguageTool для Open Office (о нём мы ещё поговорим) даже в голову ничего не приходит. Штучный товар. (Да, вспомнил ещё о пакете Grammarian Pro X для макинтоша, но он тоже погоды не делает). Соответственно, ориентироваться на «отцов» сложновато. Проверка орфографии худо-бедно много где реализована, а вот с грамматикой совсем беда.
В языках программирования отчётливо видны две модели выявления ошибок в тексте. Во-первых, ошибки можно выявить на этапе компиляции, то есть при попытке соединить слова языка в осмысленные, допустимые в соответствии с языковой грамматикой конструкции. Во-вторых, можно произвести статический анализ кода, то есть разыскать в тексте программы некие паттерны, связываемые с потенциально опасными действиями.
В теории «модель компиляции», конечно, выглядит очень заманчиво: попытаемся «откомпилировать» текст. Если в нём присутствуют ошибки, анализируемый фрагмент попросту «не склеится», причём системе будет сразу же ясно почему — как это ясно компилятору компьютерного языка. К сожалению, на данный момент полноценных «компиляторов естественного языка» не существует. Это как раз то направление, которое я копаю на досуге, но пытаться встроить сырые идеи в коммерческий продукт я пока не готов. Лучше уж сделать хороший state-of-the-art модуль, заодно понять, как он в наши времена устроен.
Если в нём присутствуют ошибки, анализируемый фрагмент попросту «не склеится», причём системе будет сразу же ясно почему — как это ясно компилятору компьютерного языка. К сожалению, на данный момент полноценных «компиляторов естественного языка» не существует. Это как раз то направление, которое я копаю на досуге, но пытаться встроить сырые идеи в коммерческий продукт я пока не готов. Лучше уж сделать хороший state-of-the-art модуль, заодно понять, как он в наши времена устроен.
Если вы откроете настройки правописания в MS Word, то увидите, что грамматическая проверка действует как раз по принципу статического анализатора. Есть некий набор проверок, и система последовательно прогоняет через них текст:
По правде говоря, рассуждать о «модуле проверки правописания в MS Word» не совсем корректно: в действительности модули для разных языков делались разными командами и на различных алгоритмах. Однако общая идея «прогона» текста через сито проверок вроде как справделива для каждого модуля.
А вот теперь обсудим вот такой важный вопрос: откуда берутся те самые проверки, о которых только что шла речь? Почему в MS Word встроен именно тот набор правил, который показан на скриншоте выше? Кстати, в справке доступна более развёрнутая информация по каждому виду анализа:
Качество проверки грамматики Вордом не пинал только ленивый. Достаточно изучить хотя бы вот эту известную подборку материалов, чтобы убедиться, что ваш негативный опыт разделяют многие 🙂 Я думаю, недостатки всех грамматических модулей вызваны тремя основными причинами. Во-первых, сам принцип «статической проверки» подразумевает неполное покрытие ошибок правописания. Имя этим ошибкам — легион, и надо обладать недюжинным талантом тестера, чтобы вбить в систему все мыслимые и немыслимые несуразности, потенциально возможные в предложениях. Во-вторых, наши технологии ещё не столь хороши, как хотелось бы. Многие ошибки тестер осознаёт, но не имеет возможности их запрограммировать. Понятно, что не все ошибки одинаково легко ловятся. В-третьих, по всей видимости, ошибки ищутся в соответствии с известной шуткой — «под фонарём», где светло, а не там, где они водятся на самом деле.
Понятно, что не все ошибки одинаково легко ловятся. В-третьих, по всей видимости, ошибки ищутся в соответствии с известной шуткой — «под фонарём», где светло, а не там, где они водятся на самом деле.
На сегодняшний день не так уж легко отыскать частотный перечень ошибок, встречающихся в обычной переписке. Одно из немногочисленных исследований перечисляет двадцать наиболее частых ошибок, замеченных в сочинениях студентов (на английском языке). Речь идёт о носителях языка, поэтому список может показаться нам неочевидным. Думаю, для иностранцев мы получим совершенно другую выборку (причём сильно зависящую от родного языка пишущего).
Автор другой статьи не поленился и прогнал тексты с указанными ошибками через различные модули проверки грамматики. Результаты оказались совершенно неутешительными. Если вкратце, всё плохо (а Word 97 почему-то оказался гораздо лучше всех последующих версий; впрочем, для нас это не имеет значения). Тест наиболее популярных ошибкок либо слишком сложен для программирования, либо попросту упущен разработчиками по недосмотру.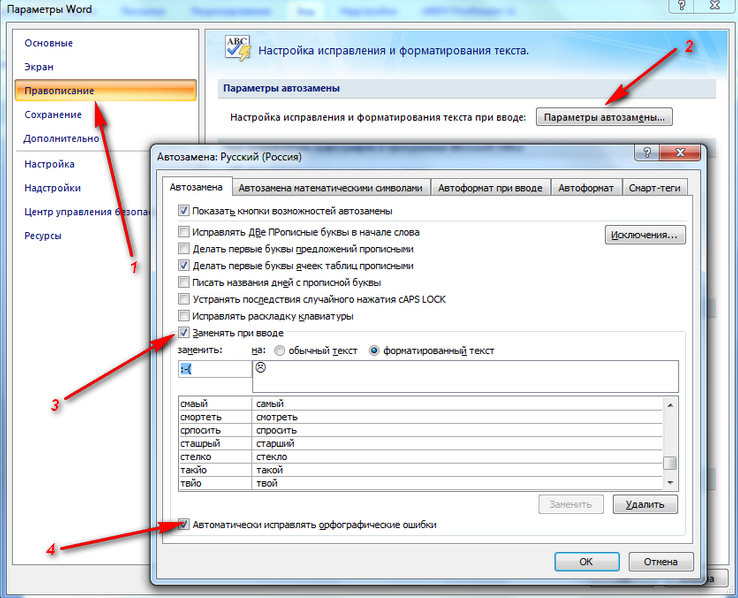
Разумеется, заказчик хочет иметь самый лучший грамматический модуль в мире. По крайней мере, не хуже, чем у MS Word. И мы попытаемся это ему обеспечить, но я, по правде говоря, не надеюсь далеко уйти от нынешних стандартов качества. Слишком многое играет против нас. Действительно, не существует хорошей классификации возможных ошибок с указанием их реальной частотности (как для носителей, так и для иностранцев), а без такого списка любые проверки превращаются в стрельбу по хмурому небу в надежде попасть в пролетающую где-то за тучами дичь. Да и ошибки из списка (я их внимательно изучил) действительно по большей части сложны для отлова. Что ж, будем работать. Да, я не упомянул пока, что начинаем мы с английского, далее по плану немецкий, а там жизнь покажет.
В следующих частях перейду к техническим деталям того, как устроена наша система (на данный момент по большей части существующая только у меня в голове, но процесс движется быстро), а на сегодня предлагаю закончить.
Заказать исправление ошибок в тексте — ФРИЛАНС.ру
Фрилансеры
исправление ошибок в текстеРекламный копирайтинг. Продающие тексты
Сео SEO копирайтинг, тексты
Посты и продающие тексты для социальных сетей
Презентации, КП, LP, рассылки
SEO-тексты, посты для соцсетей
Описания для WB, OZON, Авито
Описание тура лёгким слогом
 Бонусы»>
Креатив, юмор. Бонусы
Бонусы»>
Креатив, юмор. БонусыСтатья о технологии. Экспертность + понятный язык
Преподавание в НИУ ВШЭ
Дистанционные курсы
Преподавание в Московской школе кино
Коммерческое предложение на английском языке
Продающий текст
Прототипы, тексты для лендингов, презентации
Переводы, веб-контент, лонгриды
SEO\LSI-тексты, внутренняя оптимизация
SEO
11 лет в копирайтинге
SEO
Гамбит — грозное оружие на шахматной доске
Бухта Бугас

Деревообработка
Продающие карточки
Рекламная статья
Корректура книги #15греховрекламиста
Нейминг-петербургский ресторан средиземноморской кухни
Название для SEO-агентства
Монтаж систем вентиляции
Оборудование для нефтегазовой и химической промышленности
Надежный девелопмент с компанией «DV group»
Визитка «Мир шапок»
Визитка Ресторан «Азия»
Дизайн этикетки для элитного соевого соуса Ukomai
Редактирование и корректировка текстов — Freelance.
 Ru
RuКаждый автор, который пишет текст, обязательно перечитывает его на наличие ошибок. Но даже это не уберегает от мелких опечаток, стилистических ошибок и других нелепостей. Лучше всего вычитывать текст спустя время, а еще лучше — нанять для этого другого человека, который сможет оценить материал свежим взглядом.
У фрилансеров, которых вы видите на этой странице каталога, вы можете заказать подготовку текста к публикации: исправить текст, доработать, поднять уникальность, исправить ошибки, добавить объем или наоборот, убрать воду.
В том числе и такие Редактирование/корректировка как исправление ошибок в тексте.
Обработка текстов
Оцифровка текста, устрание орфографических ошибок
1 000 Руб 1 День
Корректура текстов. Цена за 1000 знаков
Исправление ошибок в художественных и не только текстах. 100% грамотность никто гарантировать не может, особенно если текст имеет большой объём и имеет высокую сложность. Если ошибок слишком много (более 10 на 1000 знаков), то цена возрастёт до 40 и т.д.
100% грамотность никто гарантировать не может, особенно если текст имеет большой объём и имеет высокую сложность. Если ошибок слишком много (более 10 на 1000 знаков), то цена возрастёт до 40 и т.д.
30 Руб 30 Дней
Правка/доработка сайта
Доработка вашего сайта (формы, блоки, вёрстка, адаптивность под моб устройства, попапы, фильтры и т.д.) — от 800руб (цена оговаривается индивидуально, зависит от сложности и объёма.)
800 Руб 1 День
Написание текстов (рефератов, проектов) и исправление ошибок в текстах
Мне 16 лет, я регулярно занимаюсь написанием рефератов и проектов в учебной деятельности. Помогу вам написать текст и исправить ошибки.
200 Руб 3 Дня
Редактирование, перепечатка текстов
Редактирование, обработка, перепечатка текста с любого источника, в т. ч. с аудио, корректировка, исправление ошибок.
ч. с аудио, корректировка, исправление ошибок.
600 Руб 1 День
Редактирование/корректировка
Срок и Цена за редактирование и корректировку определяется исходя из объема текста. Тематика тоже играет роль,но не особо. Возьму любые тексты.
500 Руб 7 Дней
Помощь с исправлением текста – Газетный проект штата Иллинойс – Библиотека U of I
Введение
Какова цель исправления текста?
Исправление текста повышает точность поиска по ключевым словам в коллекциях цифровых газет штата Иллинойс (IDNC). Модуль исправления текста позволяет пользователям IDNC исправлять ошибки, допущенные в процессе оцифровки газеты. Со временем, благодаря усилиям наших добровольных корректоров текста, эти исправления текста повышают точность текста, доступного для поиска.
Принять участие в исправлении текста может любой желающий (инструкции о том, как начать работу, см. ниже).
Зачем нужна коррекция текста?
Когда мы оцифровываем газету, мы используем программное обеспечение оптического распознавания символов (OCR) для создания текста с возможностью поиска. Полученный текст часто называют «текст OCR », чтобы отличить его от текста, который пользователи видят на оцифрованном изображении газеты.
В большинстве оцифрованных газетных коллекций (например, Newspapers.com) OCR 9Текст 0008 остается скрытым, и пользователи никогда не видят текст, который они на самом деле ищут. То, что вы видите в этих коллекциях, по сути является цифровыми фотографиями газетных страниц. Без OCR эти страницы останутся недоступными для поиска.
OCR позволяет пользователям выполнять поиск в большом количестве полнотекстовых данных, но никогда не обеспечивает 100% точность. Уровень точности зависит от ряда факторов, в том числе от качества исходного отпечатка, его состояния на момент микрофильмирования, уровня детализации, зафиксированного сканером, и качества 9Программное обеспечение 0015 OCR . Такие проблемы, как грязные или поврежденные страницы, тонкая бумага, мелкий шрифт, смешанные шрифты и сложные макеты страниц, могут снизить точность OCR .
Уровень точности зависит от ряда факторов, в том числе от качества исходного отпечатка, его состояния на момент микрофильмирования, уровня детализации, зафиксированного сканером, и качества 9Программное обеспечение 0015 OCR . Такие проблемы, как грязные или поврежденные страницы, тонкая бумага, мелкий шрифт, смешанные шрифты и сложные макеты страниц, могут снизить точность OCR .
Модуль исправления текста IDNC позволяет одновременно просматривать текст OCR и оцифрованное изображение страницы. Ниже приведен пример плохого OCR :
Пример текста OCR (слева) и исходного изображения (справа), из New York Clipper , 2 июня 1865 г., с. 2, кол. Д На правой панели модуля исправления текста находится оцифрованное изображение настоящей газеты; слева текст OCR , который отображается в интерфейсе исправления текста. Модуль исправления текста IDNC позволяет просматривать текст OCR , даже если вы решили не участвовать в исправлении текста.
Модуль исправления текста IDNC позволяет просматривать текст OCR , даже если вы решили не участвовать в исправлении текста.
В приведенном выше примере первая строка текста OCR была попыткой программного обеспечения отобразить заголовок статьи «THE RING»:
9Г .Изображение статьи справа достаточно сложно для чтения человеком, так что вы можете себе представить, насколько это сложно для компьютерного программного обеспечения, которое начинает с попытки идентифицировать отдельные формы и сопоставлять их с буквами.
Инструкции по исправлению текста
Как начать коррекцию текста?
-Создать учетную запись
Чтобы начать исправлять текст, вы должны сначала зарегистрироваться как пользователь. Нажмите «Зарегистрироваться» в правом верхнем углу экрана. На ваш адрес электронной почты будет отправлено письмо с подтверждением. После проверки вы можете войти в IDNC и начните исправлять текст.
После проверки вы можете войти в IDNC и начните исправлять текст.
-Доступ к интерфейсу исправления текста
Как только вы войдете в программу просмотра газет (либо с экрана результатов поиска, либо с экрана просмотра), вы увидите, что программа просмотра газет разделена на две части: правая часть отображает страницу изображений, а левая сторона — это интерфейс исправления текста, где вы можете просматривать и исправлять текст OCR .
Средство просмотра газетПри наведении указателя мыши на изображения страниц на правой панели выделяются блоки, из которых состоит страница. Вы можете прокручивать это представление, перетаскивая мышью, или увеличивать/уменьшать масштаб с помощью кнопок над средством просмотра. Щелчок по выделенному блоку выделит его и загрузит форму для редактирования этого блока на левой панели.
-Как исправить текст
Есть два способа исправить текст из средства просмотра документов:
- Выберите статью или страницу, которую вы хотите исправить.
 Это отобразит текст на левой панели средства просмотра документов. Нажмите на ссылку «Исправить этот текст», которая появляется над этим текстом.
Это отобразит текст на левой панели средства просмотра документов. Нажмите на ссылку «Исправить этот текст», которая появляется над этим текстом.
ИЛИ, - Щелкните правой кнопкой мыши статью или изображение страницы и выберите «Исправить текст статьи» или «Исправить текст страницы» во всплывающем окне параметров. Исправьте текст построчно. На правой панели отображается красное поле, помогающее определить, какой текст должен быть включен в строку.
 Это отобразит текст на левой панели средства просмотра документов. Нажмите на ссылку «Исправить этот текст», которая появляется над этим текстом.
Это отобразит текст на левой панели средства просмотра документов. Нажмите на ссылку «Исправить этот текст», которая появляется над этим текстом. Исправьте текст построчно. На правой панели отображается красное поле, помогающее определить, какой текст должен быть включен в строку. После того, как вы закончите коррекцию текста, нажмите «Сохранить». Внесенные вами изменения вступят в силу немедленно. Кроме того, нажав кнопку «Отмена», вы отмените все несохраненные изменения, которые вы сделали.
Затем вы можете внести дополнительные исправления в тот же блок, перейти к следующему блоку, нажав кнопку «Сохранить и далее», выбрать другой блок на правой панели или выйти из режима исправления текста, нажав кнопку «Вернуться в режим просмотра». » связь. Нажатие «Сохранить и выйти» вместо «Сохранить» сохранит изменения, а затем автоматически вернет вас в обычный режим просмотра.
» связь. Нажатие «Сохранить и выйти» вместо «Сохранить» сохранит изменения, а затем автоматически вернет вас в обычный режим просмотра.
-Сохранить вашу работу
После того, как вы закончите коррекцию текста, нажмите «Сохранить». Внесенные вами изменения вступят в силу немедленно. Затем вы можете внести дополнительные исправления в тот же блок, перейти к следующему блоку, нажав кнопку «Сохранить и далее» или «Далее», выбрать другой блок на правой панели или выйти из режима редактирования текста, нажав кнопку «Выход». » связь.
Если нажать «Сохранить и выйти» вместо «Сохранить», изменения будут сохранены, а затем вы автоматически вернетесь в обычный режим просмотра.
Рекомендации по исправлению текста
Введите то, что вы видите: слова, знаки препинания и переносы. Ваша транскрипция должна сохранять орфографию, грамматику и порядок слов оригинального документа.
Вам не нужно исправлять пробелы или различные знаки препинания и символы, но вы можете это сделать, если хотите.
Если вы столкнулись с орфографической ошибкой, введите слово в том виде, в котором оно напечатано, и укажите правильное написание в квадратных скобках [ ], чтобы упростить поиск. В следующем примере три орфографические ошибки:
из Монмута Daily Atlas , 7 октября 1922 г., с. 5, кол. DТекстовое исправление для приведенного выше текста должно быть следующим:
из Монмута Daily Atlas , 7 октября 1922 г., с. 5, кол. DВы можете найти слова, которые кажутся написанными с ошибками, но это не так. Орфография, как и сами языки, меняется и даже варьируется в течение одного периода времени. Обращайтесь со старыми или вариантными вариантами написания так же, как и со словами с ошибками: сохраняйте исходное написание, как вы видите его на странице, но также не стесняйтесь добавлять в квадратных скобках модернизированное или вариантное написание, которое, по вашему мнению, более вероятно для поисковых запросов. для использования в запросе.
из Эдвардсвилля Зритель , 31 мая 1825 г. , с. 2, кол. A.
, с. 2, кол. A.В приведенном выше примере слово «соединение» написано не с ошибкой: это старое написание слова «соединение».
Названия мест и личные имена в старых газетах часто пишутся иначе, чем сегодня. Например, «Урбанна» обычно встречается в газетах девятнадцатого века как общепринятое написание города Урбана. Миннесота, с другой стороны, часто пишется с одной буквой «н»: Минесота. Племя американских индейцев сауков часто называли «сак» или «сак-индейцы». Как и в случае слов с ошибками, вы должны сохранить написание, которое вы видите в оригинале, и, если хотите, добавить модернизированное (или стандартизированное) написание в скобках.
Используйте комментарии или теги для более сложных вставок. Например, к замужней женщине обычно обращаются по имени мужа даже после его смерти:
из Berkshire World и Cornbelt Stockman , апрель 1917 г., с. 74 Очевидно, что вы не всегда будете знать собственное имя человека, даже если напечатанное имя является именем мужа или жены. Однако, если вы можете быть уверены, что знаете, подумайте над тем, чтобы добавить ее настоящее имя в качестве тега: «Берта Палмер».
Однако, если вы можете быть уверены, что знаете, подумайте над тем, чтобы добавить ее настоящее имя в качестве тега: «Берта Палмер».
Индейцев мескваки обычно называли индейцами «лис». Опять же, рассмотрите возможность добавления стандартизированной формы имени в качестве тега, а не исправления текста, поскольку «Fox», строго говоря, не является вариантом написания.
Если вы не можете разобрать исходное слово, используйте квадратные скобки для обозначения [неразборчивого] текста.
Если строка текста OCR была полностью пропущена, добавьте недостающую строку текста в конец строки выше. Если предыдущей строки нет, добавьте текст в начало следующей строки. По возможности убедитесь, что начало каждой строки совпадает с началом исходной строки текста.
Расшифруйте текст в правильном порядке чтения.
В ситуациях, когда невозможно воспроизвести текст в том виде, в котором он отображается на странице, просто убедитесь, что слова представлены в ближайшем доступном поле для исправления текста.
После исправления блока текста установите флажок «Этот блок полностью правильный». Блок по-прежнему должен быть помечен как «полностью правильный», даже если он содержит текст, помеченный как [неразборчиво].
Иногда изображение без текстового содержимого сканируется как текст, и вам будет предложено исправить его. Если рисунок не содержит текста, просто удалите текст, который появляется в поле исправления текста, и пометьте его как правильный.
Если вы хотите добавить комментарии, используйте раздел комментариев левого окна в конце исправляемого текста (Добавить комментарии). Не добавляйте комментарии в области транскрипции. Область транскрипции должна содержать только то, что находится на странице газеты (с исправлениями/неразборчивыми разделами, отмеченными в скобках).
Если вы хотите добавить теги, используйте раздел тегов левого окна в конце исправляемого текста (Добавить теги). Теги можно просматривать и использовать для сужения поиска в тематических областях.
Если вы обнаружите исправления, не относящиеся к исходному тексту, вы можете исправить их обратно в исходный текст. Если исправления кажутся преднамеренным вандализмом, сообщите о вандализме по адресу [email protected].
Предложение по автоматическому исправлению ошибок в тексте
NASA/ADS
Предложение по автоматическому исправлению ошибок в тексте
- Луна-Рамирес, Вульфрано А. ;
- Хаймес-Гонсалес, Карлос Р.
Аннотация
Ежедневно увеличивается объем информации, которую можно хранить на электронных носителях. Многие из них набираются в основном путем набора текста, например, огромное количество информации, полученной с сайтов веб 2.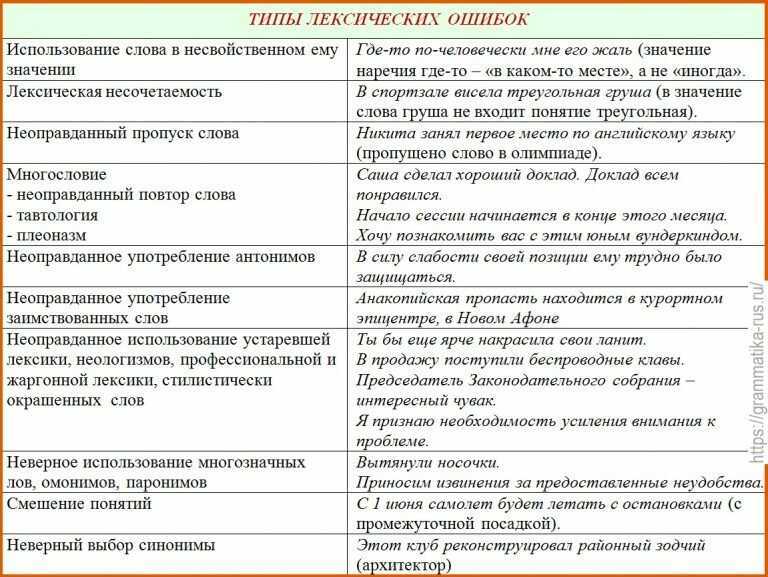 0; или сканируются и обрабатываются программным обеспечением оптического распознавания символов, например, тексты библиотек и государственных учреждений. Оба процесса вносят ошибки в тексты, поэтому трудно использовать данные для других целей, кроме как просто для их чтения, то есть для обработки этих текстов другими приложениями, такими как электронное обучение, изучение языков, электронные учебные пособия, анализ данных, поиск информации. и даже более специализированные системы, такие как тифлологическое программное обеспечение, специально ослепленные приложения, ориентированные на людей, такие как автоматическое чтение, где текст будет максимально безошибочным, чтобы упростить задачу преобразования текста в речь, и так далее. В данной статье показано применение автоматического распознавания и исправления орфографических ошибок в электронных текстах. Эта задача состоит из трех этапов: а) обнаружение ошибок; b) генерация возможных поправок; в) коррекция – выбор лучшего кандидата. Предложение основано на категоризации речевого текста, сходстве слов, словарях слов, статистических показателях, морфологическом анализе и языковой модели испанского языка на основе n-грамм.
0; или сканируются и обрабатываются программным обеспечением оптического распознавания символов, например, тексты библиотек и государственных учреждений. Оба процесса вносят ошибки в тексты, поэтому трудно использовать данные для других целей, кроме как просто для их чтения, то есть для обработки этих текстов другими приложениями, такими как электронное обучение, изучение языков, электронные учебные пособия, анализ данных, поиск информации. и даже более специализированные системы, такие как тифлологическое программное обеспечение, специально ослепленные приложения, ориентированные на людей, такие как автоматическое чтение, где текст будет максимально безошибочным, чтобы упростить задачу преобразования текста в речь, и так далее. В данной статье показано применение автоматического распознавания и исправления орфографических ошибок в электронных текстах. Эта задача состоит из трех этапов: а) обнаружение ошибок; b) генерация возможных поправок; в) коррекция – выбор лучшего кандидата. Предложение основано на категоризации речевого текста, сходстве слов, словарях слов, статистических показателях, морфологическом анализе и языковой модели испанского языка на основе n-грамм.
- Публикация:
Электронные распечатки arXiv
- Дата публикации:
- сентябрь 2021
- DOI:
- 10.48550/архив.2112.01846
- архив:
- архив: 2112.01846
- Биб-код:
- 2021arXiv211201846L
