Индексация сайта и ее основные принципы
12 мин — время чтения
Фев 18, 2020
Поделиться
Когда-нибудь задумывались, как сайты попадают в выдачу поисковых систем? И как поисковикам удается выдавать нам тонны информации за считанные секунды?
Секрет такой молниеносной работы — в поисковом индексе. Его можно сравнить с огромным и идеально упорядоченным каталогом-архивом всех веб-страниц. Попадание в индекс означает, что поисковик вашу страницу увидел, оценил и запомнил. А, значит, он может показывать ее в результатах поиска.
Предлагаю разобраться в процессе индексации с нуля, чтобы понимать, как сайты попадают в выдачу, можно ли управлять этим процессом и что нужно знать про индексирование ресурсов с различными технологиями.
Что такое сканирование и индексация?
Сканирование страниц сайта — это процесс, когда поисковая система отправляет свои специальные программы (мы знаем их как поисковых роботов, краулеров, спайдеров, пауков) для сбора данных с новых и измененных страниц сайтов.
Индексация страниц сайта — это сканирование, считывание данных и добавление их в индекс (каталог) поисковыми роботами. Поисковик использует полученную информацию, чтобы узнать, о чем же ваш сайт и что находится на его страницах. После этого он может определить ключевые слова для каждой просканированной страницы и сохранить их копии в поисковом индексе. Для каждой страницы он хранит URL и информацию о контенте.
В результате, когда пользователи вводят поисковый запрос в интернете, поисковик быстро просматривает свой список просканированных сайтов и показывает только релевантные страницы в выдаче. Как библиотекарь, который ищет нужные вам книги в каталоге — по алфавиту, тематике и точному названию.
Индексация сайтов в разных поисковых системах отличается парой важных нюансов. Давайте разбираться, в чем же разница.
Индексация сайта в GoogleКогда мы гуглим что-то, поиск данных ведется не по сайтам в режиме реального времени, а по индексу Google, в котором хранятся сотни миллиардов страниц. Во время поиска учитываются разные факторы ― ваше местоположение, язык, тип устройства и т. д.
Во время поиска учитываются разные факторы ― ваше местоположение, язык, тип устройства и т. д.
В 2019 году Google изменил свой основной принцип индексирования сайта — вы наверняка слышали о запуске Mobile-first. Основное отличие нового способа в том, что теперь поисковик хранит в индексе мобильную версию страниц. Раньше в первую очередь учитывалась десктопная версия, а теперь первым на ваш сайт приходит робот Googlebot для смартфонов — особенно, если сайт новый. Все остальные сайты постепенно переходят на новый способ индексирования, о чем владельцы узнают в Google Search Console.
Еще несколько основных отличий индексации в Google:
- индекс обновляется постоянно;
- процесс индексирования сайта занимает от нескольких минут до недели;
- некачественные страницы обычно понижаются в рейтинге, но не удаляются из индекса.
В индекс попадают все просканированные страницы, а вот в выдачу по запросу — только самые качественные. Прежде чем показать пользователю какую-то веб-страницу по запросу, поисковик проверяет ее релевантность по более чем 200 критериям (факторам ранжирования) и отбирает самые подходящие.
Что поисковые роботы делают на вашем сайте, мы разобрались, а вот как они попадают туда? Существует несколько вариантов.
Как поисковые роботы узнают о вашем сайте
Если это новый ресурс, который до этого не индексировался, нужно «представить» его поисковикам. Получив приглашение от вашего ресурса, поисковые системы отправят на сайт своих краулеров для сбора данных.
Вы можете пригласить поисковых ботов на сайт, если разместите на него ссылку на стороннем интернет-ресурсе. Но учтите: чтобы поисковики обнаружили ваш сайт, они должны просканировать страницу, на которой размещена эта ссылка. Этот способ работает для обоих поисковиков.
Также можно воспользоваться одним из перечисленных ниже вариантов:
- Создайте файл Sitemap, добавьте на него ссылку в robots.txt и отправьте файл Sitemap в Google.
- Отправьте запрос на индексацию страницы с изменениями в Search Console.
Каждый сеошник мечтает, чтобы его сайт быстрее проиндексировали, охватив как можно больше страниц. Но повлиять на это не в силах никто, даже лучший друг, который работает в Google.
Но повлиять на это не в силах никто, даже лучший друг, который работает в Google.
Скорость сканирования и индексации зависит от многих факторов, включая количество страниц на сайте, скорость работы самого сайта, настройки в веб-мастере и краулинговый бюджет. Если кратко, краулинговый бюджет — это количество URL вашего сайта, которые поисковый робот хочет и может просканировать.
На что же мы все-таки можем повлиять в процессе индексации? На план обхода поисковыми роботами нашего сайта.
Как управлять поисковым роботом
Поисковая система скачивает информацию с сайта, учитывая robots.txt и sitemap. И именно там вы можете порекомендовать поисковику, что и как скачивать или не скачивать на вашем сайте.
Файл robots.txtЭто обычный текстовый файл, в котором указаны основные сведения — например, к каким поисковым роботам мы обращаемся (User-agent) и что запрещаем сканировать (Disallow).
Указания в robots.txt помогают поисковым роботам сориентироваться и не тратить свои ресурсы на сканирование маловажных страниц (например, системных файлов, страниц авторизации, содержимого корзины и т. д.). Например, строка Disallow:/admin запретит поисковым роботам просматривать страницы, URL которых начинается со слова admin, а Disallow:/*.pdf$ закроет им доступ к PDF-файлам на сайте.
д.). Например, строка Disallow:/admin запретит поисковым роботам просматривать страницы, URL которых начинается со слова admin, а Disallow:/*.pdf$ закроет им доступ к PDF-файлам на сайте.
Также в robots.txt стоит обязательно указать адрес карты сайта, чтобы указать поисковым роботам ее местоположение.
Чтобы проверить корректность robots.txt, воспользуйтесь отдельным инструментом в Google Search Console.
Файл SitemapЕще один файл, который поможет вам оптимизировать процесс сканирования сайта поисковыми роботами ― это карта сайта (Sitemap). В ней указывают, как организован контент на сайте, какие страницы подлежат индексации и как часто информация на них обновляется.
Если на вашем сайте несколько страниц, поисковик наверняка обнаружит их сам. Но когда у сайта миллионы страниц, ему приходится выбирать, какие из них сканировать и как часто. И тогда карта сайта помогает в их приоритезации среди прочих других факторов.
Также сайты, для которых очень важен мультимедийный или новостной контент, могут улучшить процесс индексации благодаря созданию отдельных карт сайта для каждого типа контента. Отдельные карты для видео также могут сообщить поисковикам о продолжительности видеоряда, типе файла и условиях лицензирования. Карты для изображений ― что изображено, какой тип файла и т. д. Для новостей ― дату публикации. название статьи и издания.
Чтобы ни одна важная страница вашего сайта не осталась без внимания поискового робота, в игру вступают навигация в меню, «хлебные крошки», внутренняя перелинковка. Но если у вас есть страница, на которую не ведут ни внешние, ни внутренние ссылки, то обнаружить ее поможет именно карта сайта.
А еще в Sitemap можно указать:
- частоту обновления конкретной страницы — тегом <changefreq>;
- каноническую версию страницы ― атрибутом rel=canonical;
- версии страниц на других языках ― атрибутом hreflang.


Карта сайта также здорово помогает разобраться, почему возникают сложности при индексации вашего сайта. Например, если сайт очень большой, то там создается много карт сайта с разбивкой по категориям или типам страниц. И тогда в консоли легче понять, какие именно страницы не индексируются и дальше разбираться уже с ними.
Проверить правильность файла Sitemap можно в Google Search Console вашего сайта в разделе «Файлы Sitemap».
Итак, ваш сайт отправлен на индексацию, robots.txt и sitemap проверены, пора узнать, как прошло индексирование сайта и что поисковая система нашла на ресурсе.
Как проверить индексацию сайта
Проверка индексации сайта осуществляется несколькими способами:
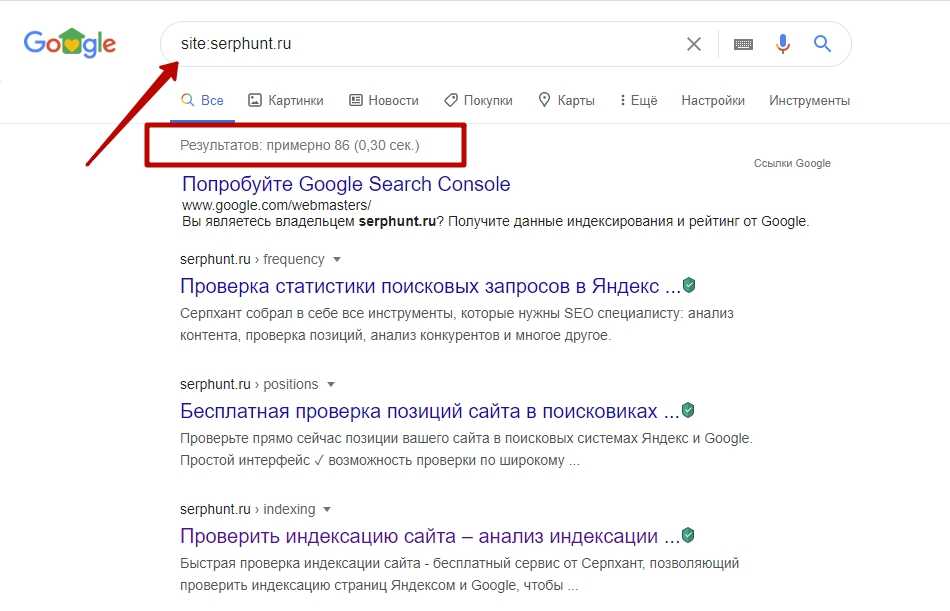
1. Через оператор site: в Google. Этот оператор не дает исчерпывающий список страниц, но даст общее понимание о том, какие страницы в индексе. Выдает результаты по основному домену и поддоменам.
2. Через Google Search Console. В консоли вашего сайта есть детальная информация по всем страницам ― какие из них проиндексированы, какие нет и почему.
3. Воспользоваться плагинами для браузера типа RDS Bar или специальными инструментами для проверки индексации. Например, узнать, какие страницы вашего сайта попали в индекс поисковика можно в инструменте «Проверка индексации» SE Ranking.
Для этого достаточно ввести нужную вам поисковую систему (Google, Yahoo, Bing), добавить список урлов сайта и начать проверку. Чтобы протестировать работу инструмента «Проверка индексации», зарегистрируйтесь на платформе SE Ranking и откройте тул в разделе «Инструменты».
В этом месте вы можете поднять руку и спросить «А что, если у меня сайт на AJAX? Он попадет в индекс?». Отвечаем 🙂
Особенности индексирования сайтов с разными технологиями
AjaxСегодня все чаще встречаются JS-сайты с динамическим контентом ― они быстро загружаются и удобны для пользователей. Одно из основных отличий таких сайтов на AJAX — все содержимое подгружается одним сплошным скриптом, без разделения на страницы с URL. Вместо этого ― страницы с хештегом #, которые не индексируются поисковиками. Как следствие — вместо URL типа https://mywebsite.ru/#example поисковый робот обращается к https://mywebsite.ru/. И так для каждого найденного URL с #.
Вместо этого ― страницы с хештегом #, которые не индексируются поисковиками. Как следствие — вместо URL типа https://mywebsite.ru/#example поисковый робот обращается к https://mywebsite.ru/. И так для каждого найденного URL с #.
В этом и кроется сложность для поисковых роботов, потому что они просто не могут «считать» весь контент сайта. Для поисковиков хороший сайт ― это текст, который они могут просканировать, а не интерактивное веб-приложение, которое игнорирует природу привычных нам веб-страниц с URL.
Буквально пять лет назад сеошники могли только мечтать о том, чтобы продвинуть такой сайт в поиске. Но все меняется. Уже сейчас в справочной информации Google есть данные о том, что нужно для индексации AJAX-сайтов и как избежать ошибок в этом процессе.
Сайты на AJAX с 2019 года рендерятся Google напрямую — это значит, что поисковые роботы сканируют и обрабатывают #! URL как есть, имитируя поведение человека. Поэтому вебмастерам больше не нужно прописывать HTML-версию страницы.
Но здесь важно проверить, не закрыты ли скрипты со стилями в вашем robots.txt. Если они закрыты, обязательно откройте их для индексирования поисковыми роботам. Для этого в robots.txt нужно добавить такие команды:
User-agent: Googlebot Allow: /*.js Allow: /*.css Allow: /*.jpg Allow: /*.gif Allow: /*.pngФлеш-контент
С помощью технологии Flash, которая принадлежит компании Adobe, на страницах сайта можно создавать интерактивный контент с анимацией и звуком. За 20 лет своего развития у технологии было выявлено массу недостатков, включая большую нагрузку на процессор, ошибки в работе флеш-плеера и ошибки в индексировании контента поисковиками.
В 2019 году Google перестал индексировать флеш-контент, ознаменовав тем самым конец целой эпохи.
Поэтому не удивительно, что поисковик предлагает не использовать Flash на ваших сайтах. Если же дизайн сайта выполнен с применением этой технологии, сделайте и текстовую версию сайта. Она будет полезна как пользователям, у которых не установлена совсем или установлена устаревшая программа отображения Flash и пользователям мобильных устройств (они не отображают flash-контент).
Она будет полезна как пользователям, у которых не установлена совсем или установлена устаревшая программа отображения Flash и пользователям мобильных устройств (они не отображают flash-контент).
Фрейм это HTML-документ, который не содержит собственного контента, а состоит из разных областей ― каждая с отдельной веб-страницей. Также у него отсутствует элемент BODY.
Как результат, поисковым роботам просто негде искать полезный контент для сканирования. Страницы с фреймами индексируются очень медленно и с ошибками.
Вот что известно от самого поисковика: Google может индексировать контент внутри встроенного фрейма iframe. Именно iframe поддерживается современными технологиями, так как он позволяет встраивать фреймы на страницы без применения тега <iframe>.
А вот теги <frame>, <noframes>, <frameset> устарели и уже не поддерживаются в HTML5, поэтому и не рекомендуется использовать их на сайтах. Ведь даже если страницы с фреймами будут проиндексированы, то трудностей в их продвижении вам все равно не избежать.
Ведь даже если страницы с фреймами будут проиндексированы, то трудностей в их продвижении вам все равно не избежать.
Что в итоге
Поисковые системы готовы проиндексировать столько страниц вашего сайта, сколько нужно. Только подумайте, объем индекса Google значительно превышает 100 млн гигабайт ― это сотни миллиардов проиндексированных страниц, количество которых растет с каждым днем.
Но зачастую именно от вас зависит успех этого мероприятия. Понимая принципы индексации поисковых систем, вы не навредите своему сайту неправильными настройками. Если вы все правильно указали в robots.txt и карте сайта, учли технические требования поисковиков и позаботились о наличии качественного и полезного контента, поисковики не оставят ваш сайт без внимания.
Помните, что индексирование ― это не о том, попадет ваш сайт в выдачу или нет. Намного важнее ― сколько и каких страниц окажутся в индексе, какой контент на них будет просканирован и как он будет ранжироваться в поиске. И здесь ход за вами!
641 views
как краулер сканирует сайт и методы улучшения индексирования – Блог iSEO
В этой статье вы узнаете, что такое индексация сайтов, как индексируют сайты Google и Яндекс, как можно ускорить индексацию вашего сайта и какие проблемы встречаются чаще всего.
Кому полезна статья?
Начинающим SEO-специалистам и маркетологам, веб-разработчикам и владельцам сайтов, желающим разобраться в принципах индексирования и методиках его улучшения.
Оглавление
- Индексирование сайта — что это и для чего необходимо?
- Сканирование и индексация сайта — как протекает процесс?
- Наиболее популярные ошибки
- Сайт или страницы закрыты в robots.txt
- Бот не получает код ответа 200
- Бот не может получить код страницы
- Страницы закрыты метатегом robots или заголовком X-Robots-Tag
- Как управлять сканированием и индексацией?
- Файл robots.txt
- Метатег robots
- HTTP-заголовок X-Robots-Tag
- Тег и HTTP-заголовок canonical
- HTTP-код ответа сервера, отличный от 200
- Удаление страниц в Яндекс.Вебмастере и Google Search Console
- Как отправлять страницы на индексацию/переиндексацию?
- Как улучшить сканирование и индексацию?
- Используйте XML-карту сайта
- Оптимизируйте перелинковку
- Внедрите поддержку IndexNow и Google Indexing API
- Анонсируйте новый контент в социальных сетях
- Выводы
Индексирование сайта — что это и для чего необходимо?
Прежде чем касаться вопроса индексации, необходимо вспомнить о целях любой поисковой системы. Главная задача поиска — ответ на запрос пользователя. Чем точнее и качественнее он будет, тем чаще пользователи будут пользоваться поисковиком.
Главная задача поиска — ответ на запрос пользователя. Чем точнее и качественнее он будет, тем чаще пользователи будут пользоваться поисковиком.
Поисковая система ищет подходящую информацию в своей базе данных, куда сайты попадают после их индексирования, а значит, только корректное индексирование может обеспечить попадание в выдачу.
Процесс можно разделить на 3 этапа:
Из схемы можно увидеть, что процесс сканирования и индексирования — это база для ранжирования любого сайта. Если возникают существенные проблемы на любом из указанных этапов, то можно забыть о высоких позициях, росте трафика и лидов. Рассмотрим эти этапы детальнее.
Сканирование и индексация сайта — как протекает процесс?
Сканирование сайта (или crawling) — процесс, при котором поисковые роботы обходят сайт и загружают страницы с целью определения внутренних ссылок и контента.
Источники, из которых поисковые системы могут узнавать о новых страницах на сайте:
- Из XML-карт сайта — ссылки на них, как правило, есть в robots.
- Из данных счетчиков — Яндекс.Метрика, Google Analytics.
- Из данных браузеров — Яндекс.Браузер, Google Chrome.
- Из сервисов для веб-мастеров — отправка на переобход в Яндекс.Вебмастере, запрос на индексацию URL в Google Search Console.
- Из RSS-фида — XML-файл в специальном формате.
- По протоколу IndexNow.

Уже просканированные страницы сайтов боты поисковых систем периодически переобходят для выявления изменений, способных повлиять на их ранжирование.
Алгоритм сканирования сайтов следующий:
После сканирования поисковые роботы добавляют страницы в поисковый индекс. Сама по себе индексация представляет собой процесс, при котором поисковые системы упорядочивают информацию перед поиском, чтобы обеспечить максимально быстрый ответ пользователю на запрос.
Каждый из этапов сканирования важно контролировать, так как любые ошибки могут критически влиять на индексацию страниц.
Наиболее популярные ошибки
При работе с сайтом каждый оптимизатор или маркетолог сталкивались с проблемами индексирования сайтов. Далее разберем примеры самых частых проблем.
Далее разберем примеры самых частых проблем.
Сайт или страницы закрыты в robots.txt
Наиболее популярная проблема, встречающаяся у всех типов сайтов.
Файл robots.txt — это текстовый документ, содержащий разрешающие и запрещающие директивы для ботов поисковых систем.
Если ваш robots.txt содержит строку «Disallow: /», это повод проверить, видит ли ваш сайт поисковый бот. Сделать это можно с помощью инструмента https://webmaster.yandex.ru/tools/robotstxt/.
Бот не получает код ответа 200
Вторая наиболее часто встречающаяся проблема индексирования — наличие кодов ответа 4XX или 5XX.
Примеры ошибок:
| Код ответа | Ошибка | Описание |
|---|---|---|
| 400 | Неверный запрос / Bad Request | Запрос не может быть понят сервером из-за некорректного синтаксиса. |
| 401 | Неавторизованный запрос / Unauthorized | Для доступа к документу необходимо вводить пароль или быть зарегистрированным пользователем. |
| 402 | Необходима оплата за запрос / Payment Required | Внутренняя ошибка или ошибка конфигурации сервера. |
| 403 | Доступ к ресурсу запрещен / Forbidden | Доступ к документу запрещен. Если вы хотите, чтобы страница индексировалась, необходимо разрешить доступ к ней. |
| 404 | Ресурс не найден / Not Found | Документ не существует. |
| 405 | Недопустимый метод / Method Not Allowed | Метод, определенный в строке запроса (Request-Line), не дозволено применять для указанного ресурса, поэтому робот не смог его проиндексировать. |
| 406 | Неприемлемый запрос / Not Acceptable | Нужный документ существует, но не в том формате (язык или кодировка не поддерживаются роботом). |
| 407 | Требуется идентификация прокси, файервола / Proxy Authentication Required | Необходима регистрация на прокси-сервере. |
| 408 | Время запроса истекло / Request Timeout | Робот не передал полный запрос в течение установленного времени, и сервер разорвал соединение. |
| 410 | Ресурс недоступен / Gone | Затребованный ресурс был окончательно удален с сайта. |
| 500 | Внутренняя ошибка сервера / Internal Server Error | Сервер столкнулся с непредвиденным условием, которое не позволяет ему выполнить запрос. |
| 501 | Метод не поддерживается / Not Implemented | Сервер не поддерживает функциональные возможности, требуемые для выполнения запроса. |
| 502 | Ошибка шлюза / Bad Gateway | Сервер, действуя в качестве шлюза или прокси-сервера, получил недопустимый ответ от следующего сервера в цепочке запросов, к которому обратился при попытке выполнить запрос. |
| 503 | Возникла ошибка из-за временной перегрузки или отключения сервера. | |
| 504 | Время прохождения через межсетевой шлюз истекло / Gateway Timeout | Сервер при работе в качестве внешнего шлюза или прокси-сервера своевременно не получил отклик от вышестоящего сервера. |
Наличие HTTP-кодов ответа сервера, отличных от 200, может стать серьезной проблемой на пути сканирования и индексации сайта.
Проверить ответ сервера вы можете с помощью внутренних инструментов поисковых систем: https://webmaster.yandex.ru/tools/server-response/ и https://search.google.com/search-console/. Или с помощью внешних сервисов, например https://bertal.ru/.
Бот не может получить код страницы
Главное для поисковика — наличие исходного HTML-кода, который он сможет прочесть. С развитием JavaScript технологий сайты стали функциональнее и быстрее, однако из-за фреймворков может происходить их некорректная индексация и снижение трафика.
Основная проблема JS-фреймворков в том, что они развиваются быстрее поисковых систем. Особенно это было заметно в Яндексе, где у сайтов на JavaScript часто возникали проблемы с индексированием контента (но есть надежда, что в ближайшем будущем ситуация изменится).
Да и у Google процесс сканирования и индексирования JS-сайтов несколько отличается от обработки классического HTML.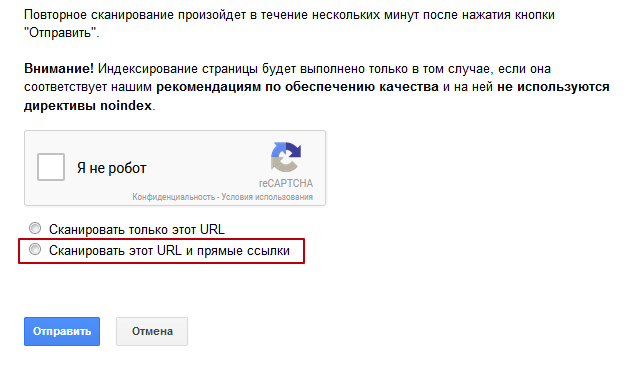
Поскольку рендеринг требует гораздо больше вычислительных ресурсов, чем разбор HTML, то возникают следующие проблемы:
- Этап рендеринга может длиться значительно дольше, чем индексация HTML-страницы. Он может занять несколько недель.
- Не все страницы сайта в принципе могут дойти до этапа рендеринга.
При работе с JS-сайтами учитываете требования поисковиков: https://yandex.ru/support/webmaster/yandex-indexing/rendering.html и https://developers.google.com/search/docs/advanced/javascript/javascript-seo-basics?hl=ru.
Проверить, как индексируется ваш сайт и настроен ли корректно рендринг, вы можете:
Используя сервис https://bertal.ru/ или аналогичный, выставив настройки «отображать HTML-код» и подходящий тип поискового робота:
Анализируя текстовую сохраненную копию страницы в выдаче Яндекса и Google.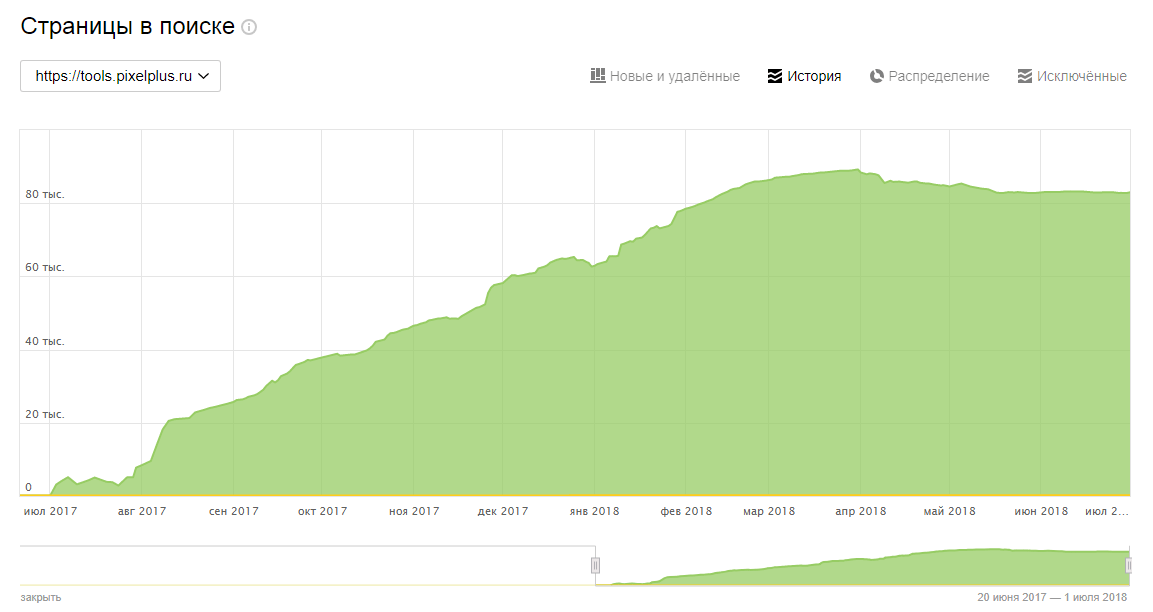 В случае, если вы наблюдаете проблемы с видимостью страниц на JS-фреймворках, проверьте сохраненную текстовую копию страницы прямо из выдачи:
В случае, если вы наблюдаете проблемы с видимостью страниц на JS-фреймворках, проверьте сохраненную текстовую копию страницы прямо из выдачи:
Анализируя страницы непосредственно в сервисах Яндекса и Google для веб мастеров — Яндекс.Вебмастере и Google Search Console. Рекомендуем обращать внимание не только на те страницы, что попали в индекс, но и на те, что не попали. Важно понять, должны ли эти страницы индексироваться и если должны, то по какой причине этого не происходит.
Страницы закрыты метатегом robots или заголовком X-Robots-Tag
Кроме файла robots.txt, поисковик может не получить доступ к конкретной странице, если на ней указан метатег robots, запрещающий её индексацию:
<meta name="robots" content="noindex, nofollow" />
Данный тег размещается внутрь тега…и дает поисковику команду не индексировать страницу (noindex) и не переходить по ее внутренним ссылкам (nofollow).
Аналогом метатега может быть блокировка сканирования страниц с помощью HTTP-заголовка X-Robots-Tag.
Проверить доступность страниц вы можете в инструментах для веб мастеров, например https://webmaster.yandex.ru/tools/server-response/, либо с помощью парсинга сайта программами Screaming Frog SEO Spider, Netpeak Spider и т. д.
Отметим, что отсутствие вышеперечисленных ошибок не может гарантировать корректного сканирования и индексирования сайта. Негативно могут влиять:
- мусорные страницы — например, страницы результатов сортировок или работы фильтров;
- дубли страниц — один и тот же контент, доступный по разным URL;
- технические/служебные страницы без полезного для пользователей контента;
- дубли страниц в формате PDF и т. д.
Как управлять сканированием и индексацией?
Для того чтобы сайт индексировался корректно, необходимо контролировать, как поиск видит сайт и расходует краулинговый бюджет.
Краулинговый бюджет — это квота страниц сайта, подлежащих индексированию в рамках одного обращения робота к сайту. Например, если краулер вместо целевых и полезных страниц ходит по мусорным документам, то индексация ухудшается, новые страницы не попадают в поиск, а потенциал трафика уменьшается.
Например, если краулер вместо целевых и полезных страниц ходит по мусорным документам, то индексация ухудшается, новые страницы не попадают в поиск, а потенциал трафика уменьшается.
Чтобы направлять краулер туда, куда необходимо, важно использовать следующие методы управления индексацией.
Файл robots.txt
Самый простой метод управления индексацией — текстовый файл robots.txt в корневой папке сайта. Как мы уже отметили ранее, поисковые роботы всегда обращаются к содержимому файла для понимания, какие страницы доступны к добавлению в поисковый индекс, а какие нет. Вы можете использовать файл для блокировки тех страниц, которые вы считаете неважными и ненужными к индексированию.
Пример:
Disallow: /folder-you-want-to-block/
Плюсы
- Как правило, легко внедрять корректировки.
- Быстро принимается и учитывается поиском.
- Есть возможность проверки файла с помощью Яндекс.Вебмастера и Google Search Console.
Минусы
- Google может проигнорировать директивы в robots. txt и добавить страницы в индекс. Google считает, что файл robots.txt управляет только сканированием сайта, а не его индексацией.
- Ссылки на страницы, закрытые в robots.txt, расходуют т. н. «статический вес» страниц (PageRank, ВИЦ и подобные алгоритмы).
- С заблокированных страниц не передается вес на другие страницы сайта.
 txt и добавить страницы в индекс. Google считает, что файл robots.txt управляет только сканированием сайта, а не его индексацией.
txt и добавить страницы в индекс. Google считает, что файл robots.txt управляет только сканированием сайта, а не его индексацией.Важный факт. Для Яндекса существует полезная директива «Clean-param», где вы можете указать параметры URL, которые поиск должен игнорировать. Например, результаты сортировки или работы фильтра товаров. Плюс такого решения — передача сигналов ранжирования (например поведенческих метрик) на страницы без параметров, что очень важно для Яндекса.
Метатег robots
Метатег robots позволяет эффективнее блокировать страницы к индексированию. В частности, для Google это более важный сигнал, чем инструкции в файле robots.txt.
<meta name="robots" content="noindex, nofollow" />
Внедрив тег на страницу, вы сможете без участия файла robots.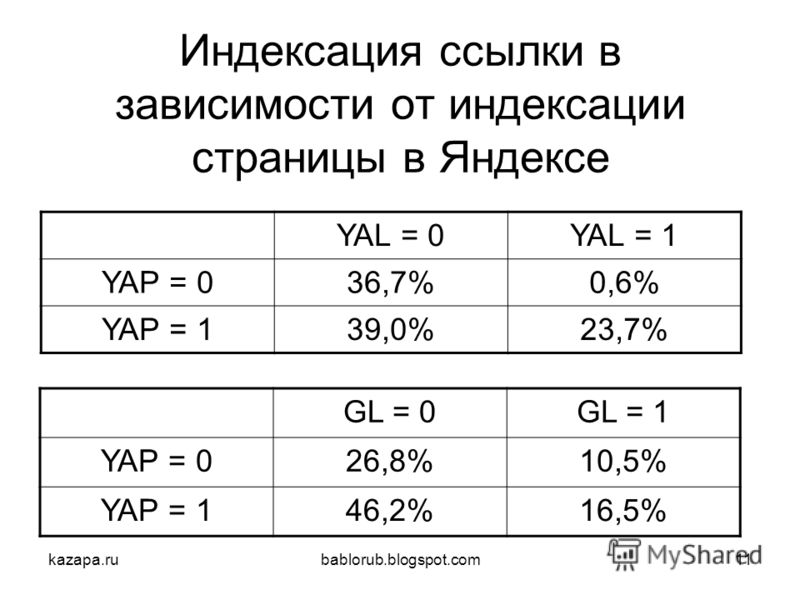 txt заблокировать её индексацию.
txt заблокировать её индексацию.
Плюсы
- Может эффективнее работать для блокировки страниц в Google, чем robots.txt.
- Хорошо воспринимается поисковыми ботами.
Минусы
- Более трудоемко, чем блокировка в robots.txt, если нужно заблокировать много страниц.
- Применим только для HTML-страниц.
- Ссылочный вес не передается на другие страницы.
При использовании метатега robots обращайте внимание на содержимое robots.txt. Чтобы Google увидел метатег robots на странице, она не должна быть заблокирована в файле robots.txt.
Аналог метатега robots. Вы можете использовать тот или иной метод.
Плюсы
- Может эффективнее работать для блокировки страниц в Google, чем robots.txt.
- Хорошо воспринимается поисковыми ботами.
Минусы
- Более трудоемкая реализация, чем использование файла robots. txt или метатега robots.
 txt или метатега robots.
txt или метатега robots.На практике X-Robots-Tag применяется реже, чем предыдущие два метода. При этом данный метод отлично работает для документов, отличных от HTML. К примеру, с помощью X-Robots-Tag можно легко блокировать PDF и другие документы, изображения и скрипты, что метатег сделать не может.
Тег и HTTP-заголовок canonical
Метатег, применяемый для указания среди двух или более одинаковых страниц одной канонической, которую поисковик должен проиндексировать и добавить в поиск, при этом другие страницы будут признаны неканоническими и добавляться в индекс не будут. Пример тега:
<link rel="canonical" href="https://www.iseo.ru/blog/" />
По сравнению с другими методами, тег canonical не является блокирующим. Вы можете поменять каноническую страницу или полностью удалить тег.
Плюсы
- Передает сигналы ранжирования (например ссылочные факторы) с неканонических на каноническую страницу. Аналогично 301-му редиректу.
- Позволяет бороться с дублями страниц внутри сайта.
- Может быть использован для указания скопированного контента, если вы размещаете один и тот же контент на нескольких доменах. Но некоторые поисковые системы могут не поддерживать межхостовый canonical.
- Легко обратим, если править теги canonical позволяет ваша CMS.
 Аналогично 301-му редиректу.
Аналогично 301-му редиректу.Минусы
- Тег носит рекомендательный характер. Если страницы заметно различаются, то поисковый бот может сменить каноническую страницу и добавить в индексе не ту копию, что вам нужна.
- Не экономит краулинговый бюджет. Бот реже обходит неканонические URL, но не прекращает это делать.
Чтобы тег canonical работал, страницы-дубли не должны быть закрыты в robots.txt или метатегом robots, в противном случае он будет проигнорирован. Также не следует помещать на одну страницу два или более тегов canonical.
В качестве альтернативы тегу canonical можно использовать HTTP-заголовок. В частности, для указания канонических документов (не HTML-страниц). Пример:
В частности, для указания канонических документов (не HTML-страниц). Пример:
Link: <http://www.iseo.ru/downloads/some-file.pdf>; rel="canonical"
HTTP-код ответа сервера, отличный от 200
Альтернативным решением по исключению страниц из индекса является настройка HTTP-кодов ответа сервера отличных от 200.
К примеру, у вас большое количество мусорных страниц или страниц дублей, созданных по ошибке. Они не имеют ни трафика, ни ссылок. Для таких страниц можно настроить код ответа сервера 404 или 410.
Или же на сайте были созданы две похожих по интенту страницы, мешающих друг другу ранжироваться. В таком случае для сохранения ссылочного веса и передачи прочих сигналов ранжирования (например поведенческих факторов) вы можете использовать 301-ый редирект. Таким образом, одна из страниц со временем будет удалена из выдачи.
Частный случай этого метода — закрытие доступа к сайту, папке или странице/файлу с помощью пароля. При этом боты будут получать код ответа 403.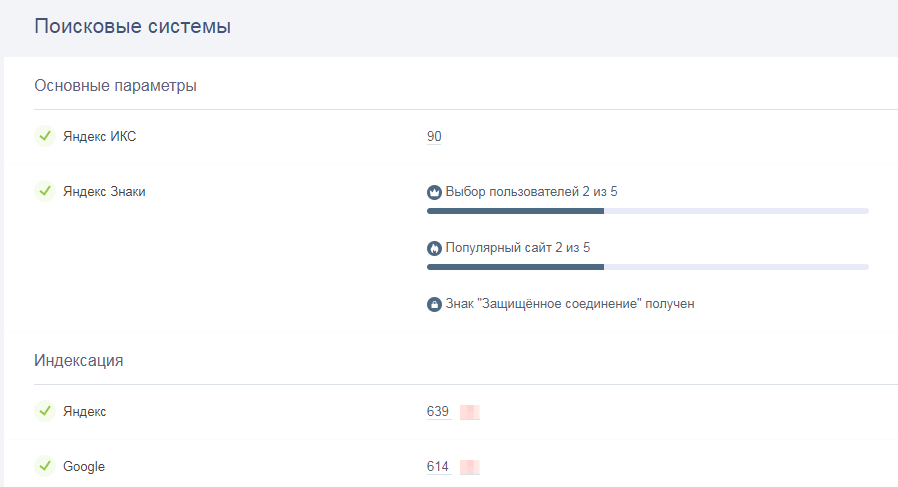 Например, таким образом можно закрыть от индексации новую версию сайта на тестовом домене.
Например, таким образом можно закрыть от индексации новую версию сайта на тестовом домене.
Плюсы
- Высокая эффективность. В отличии от метатегов и директив в robots.txt, код ответа сервера воспринимается ботом всегда, а значит, вы наверняка сможете предотвратить появление лишних страниц в индексе.
- Возможность сохранить внешние ссылки при использовании 301-х редиректов.
- Высокая скорость индексирования изменений. В отличии от индексации тегов, поисковые роботы, как правило, очень быстро принимают и учитывают новый код ответа сервера.
Минусы
- Потеря веса внешних ссылок в случае настройки 5ХХ или 4ХХ ответов сервера.
- Долгая обратимость. В случае, если вы ошибетесь при настройке, возврат 200-го кода ответа сервера может не гарантировать возврат страницы на старые позиции, а значит, может быть потерян трафик.
Удаление страниц в Яндекс.Вебмастере и Google Search Console
Для ускорения удаления страниц из поиска вы можете воспользоваться инструментами Яндекса и Google для веб мастеров:
- Для Яндекса — https://webmaster. yandex.ru/site/tools/del-url/
- Для Google — https://search.google.com/search-console/removals
 yandex.ru/site/tools/del-url/
yandex.ru/site/tools/del-url/Плюсы
- Высокая оперативность. К примеру, из Google страницы удаляются в течение двух дней.
Минусы
- Страницы блокируются от индексации не навсегда. Блокировка возникает на 6 месяцев для Google или на время присутствия запрещающих директив или кодов 403/404/410 для Яндекса.
- Есть разница в работе функционала. Для Google страница должна быть доступна для сканирования. При коде ответа 404, 502 или 503 блокировка отключается, а это значит, что если страница позже появится с кодом 200, то она может быть снова добавлена в поиск. Для Яндекса же наоборот, удаление может коснуться только тех страниц, что заблокированы в robots.txt или имеют код ответа 403, 404 или 410. Если страница отдает код 200 и открыта в robots.txt, запрос будет отклонен.
- Возможен расход краулингового бюджета на переобход заблокированных страниц.

Как отправлять страницы на индексацию/переиндексацию?
Можно не только удалять мусорные страницы, но и ускорять индексацию приоритетных. Воспользуйтесь Яндекс.Вебмастером и Google Search Console, чтобы сообщить поиску о новых страницах на вашем сайте или о появлении новых.
Для Яндекса — https://webmaster.yandex.ru/site/indexing/reindex/.
Добавьте URL в список страниц и отправьте его на переобход. Обратите внимание: для каждого сайта предусмотрен свой дневной лимит.
Для Google — https://search.google.com/u/3/search-console/inspect.
Добавьте адрес страницы в строку и запросите индексирование:
Используя данные инструменты, вы сможете:
- Оперативно уведомлять поисковые системы о появлении новых страниц, не дожидаясь обхода краулера.
- Сообщать ботам об изменениях на странице с целью ускоренной переиндексации контента.
Как улучшить сканирование и индексацию?
Добавление вручную страниц в консолях веб мастеров — хорошее решение для небольших сайтов. Но если у вас крупный сайт, лучше довериться поисковым роботам и упростить им работу за счет следующих решений.
Но если у вас крупный сайт, лучше довериться поисковым роботам и упростить им работу за счет следующих решений.
Используйте XML-карту сайта
XML-карта сайта — это файл со ссылками на все страницы, которые необходимо индексировать поисковым системам.
Поисковые системы разрабатывают алгоритмы, по которым краулеры узнают о сайтах и новых страницах, к примеру, переходя по внутренним и внешним ссылкам. Но иногда боты могут пропустить какие-то страницы, или же на целевые страницы мало или нет ссылок. XML-карта решает такие проблемы, отдавая полный список URL, доступных к индексации.
Рекомендации по использованию файлов XML-карт сайта:
- Не размещайте ссылки на закрытые от индексирования страницы.
- Не размещайте ссылки на страницы с кодом ответа сервера, отличным от 200.
- Используйте кодировку UTF-8.
- Не размещайте более 50 000 ссылок в одном файле. Если страниц больше, используйте индексный файл.
- Файл с XML-картой должен отдавать код 200 и быть доступным к обходу в robots. txt.
- Укажите ссылку на XML-карту сайта в robots.txt. Либо добавьте ссылку на XML-карту в инструменты для вебмастеров Яндекса и Google.
 txt.
txt.После создания файла sitemap.xml следует отправить его на индексацию в Яндекс.Вебмастер и Google Search Console.
Оптимизируйте перелинковку
Внутренние ссылки — это главная артерия любого сайта. Именно по гиперссылкам переходят краулеры поисковых систем, оценивая ссылочный вес и релевантность страниц, а пользователи совершают внутренние переходы, улучшая поведенческие показатели. Далее приведем несколько примеров перелинковки.
HTML-карта сайта
Это аналог sitemap.xml, но с некоторыми отличиями:
- В HTML-карте не всегда выводят ссылки на все страницы. Иногда только на самые важные. Например, если у вас большой интернет-магазин, то имеет смысл вывести ссылки на основные листинги товаров (категории, подборки и т. п.), но не на страницы товаров.
- В отличие от XML-карты сайта, HTML-карта передает по ссылкам сигналы ранжирования (PagRank и т. п.). Также учитываются анкоры ссылок.
- Сокращается вложенность страниц. Все страницы, на которые ссылается карта сайта, становятся доступны в два клика от главной страницы.
 п.). Также учитываются анкоры ссылок.
п.). Также учитываются анкоры ссылок.Пример небольшой карты сайта: https://www.iseo.ru/sitemap/.
Хлебные крошки
Навигационная цепочка, показывающая путь в структуре сайта от главной страницы к текущей. Пример со страницы https://shop.mts.ru/product/smartfon-apple-iphone-12-pro-max-256gb-tikhookeanskij-sinij:
Хлебные крошки решают следующие задачи:
- Передают статический вес страницам более высокого уровня.
- Улучшают юзабилити за счет понятного расположения страницы в иерархической структуре сайта.
- Могут быть размечены с помощью Schema.org и улучшить сниппет.
Ссылки на похожие товары или статьи
Блок перелинковки похожего контента — один из вариантов ускорения индексирования новых карточек товаров, статей и новостей.
Пример блока: https://www. iseo.ru/clients/internet-magazin-mts/
iseo.ru/clients/internet-magazin-mts/
Чаще всего данный блок работает автоматически. В контенте уже добавленных в индекс страниц выводятся ссылки на новые страницы. На это обращает внимание краулер и совершает их обход.
Ссылки с главной страницы
Как правило, главная страница обладает самым большим статическим весом по мнению поиска, так как чаще всего на нее ведет самое большое количество ссылок. Поэтому внедрение элементов перелинковки на главной странице имеет следующие плюсы:
- Высокая ценность таких ссылок. Страницы со ссылками с главной часто ранжируются лучше аналогичных без них.
- Ускорение индексации новых страниц.
Рекомендуем вам пользоваться главной страницей по максимуму при построении схем перелинковки.
Внедрите поддержку IndexNow и Google Indexing API
Кроме классических решений по ускорению индексации, вы можете подключить дополнительные протоколы типа IndexNow для Яндекса или Google Indexing API.
С их помощью вы можете не дожидаться, пока бот обнаружит все ваши страницы с помощью sitemap.xml или внутренней перелинковки. Вы сами можете уведомлять поисковики об обновлении, создании новых или удалении старых страниц. Причем делать это тысячами, не расходуя лимиты и время. Однако внедрение поддержки этих протоколов, скорее всего, потребует дополнительной разработки на стороне вашего сайта.
Подробнее о технологиях:
- Справка Яндекса по IndexNow — https://yandex.ru/support/webmaster/indexing-options/index-now.html
- Протокол IndexNow — https://www.indexnow.org/locale/ru_ru/index
- Справка по Google Indexing API — https://developers.google.com/search/apis/indexing-api/v3/using-api?hl=ru
Еще одним решением по ускорению индексации являются соцсети.
Делитесь свежим контентом с пользователями в социальных сетях. Такие ссылки поисковики замечают быстрее, а значит, и контент будет проиндексирован раньше. Бонусом здесь выступает трафик, который вы можете получить из социальных сетей.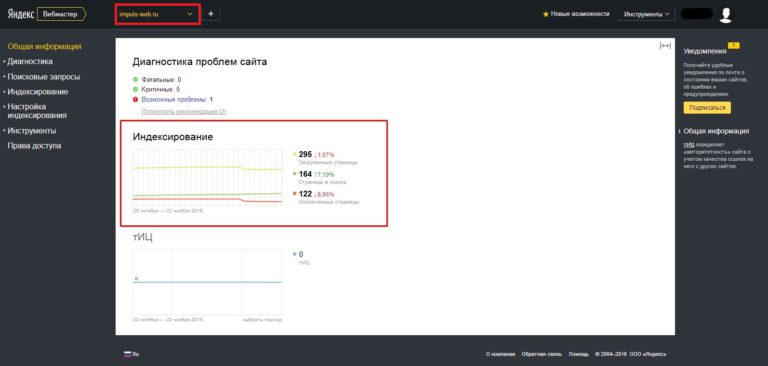
Выводы
Индексация — это отправная точка для органического трафика и продаж любого сайта. Если вы знаете, что у вас есть проблемы с индексированием, то исправляйте ошибки очень аккуратно и перепроверьте трижды результаты ваших решений.
А если вам нужна помощь экспертов, обращайтесь в нашу компанию за SEO-аудитом или поисковым продвижением вашего сайта.
Денис Яковенко
Руководитель группы SEO-специалистов
Что такое проиндексированные страницы? — Wiredelta
Индексированные страницы относятся к веб-страницам, которые данная поисковая система содержит в своей базе данных, другими словами, в своем «индексе». Индексация страниц — это процесс, посредством которого боты определенной поисковой системы сканируют Интернет в поисках новых страниц или обновлений на уже проиндексированных страницах.
Роботы, также известные как сканеры, обычно изучают каждую страницу веб-сайта, подробно анализируют все ее аспекты, а затем включают эти данные в свой индекс. Кроме того, поисковые роботы периодически возвращаются на веб-сайты, чтобы проверить наличие обновлений, хороших или плохих, которые они добавляют в свои реестры. Они также используют эти периодические обходы для оценки рейтинга веб-сайта. Таким образом, чем чаще веб-сайт обновляется — добавляется новый контент для поддержания актуальности сайта, исправляются проблемы с отзывчивостью, внедряются новые SEO-изменения и т. д. — тем выше рейтинг веб-сайта.
Кроме того, поисковые роботы периодически возвращаются на веб-сайты, чтобы проверить наличие обновлений, хороших или плохих, которые они добавляют в свои реестры. Они также используют эти периодические обходы для оценки рейтинга веб-сайта. Таким образом, чем чаще веб-сайт обновляется — добавляется новый контент для поддержания актуальности сайта, исправляются проблемы с отзывчивостью, внедряются новые SEO-изменения и т. д. — тем выше рейтинг веб-сайта.
Напротив, сайт, который долгое время оставался без должного обслуживания, будет становиться все менее и менее актуальным. И чем более она устаревает, тем менее интересна и достоверна информация, а значит, и ниже ранг.
Почему проиндексированные страницы важны?
Взаимосвязь между индексацией страниц и поисковой оптимизацией сложнее, чем кажется на первый взгляд. Начнем с того, что индексация URL-адреса необходима, если вы мечтаете о достижении целей позиционирования в результатах поиска. Как бы вы ни оптимизировали страницу, если она не проиндексирована, вы не получите никакого рейтинга в поисковой системе или посещений пользователей.
Таким образом, только проиндексированные страницы получают определенную позицию в поисковой выдаче. Но точная позиция будет зависеть от остальных внутренних и внешних факторов SEO, над которыми вы работали до и после этого момента. Правильно, ваша индексация изменится, если вы оставите свой сайт без присмотра.
К этим факторам присоединяются другие, которые мы можем контролировать в большей или меньшей степени, в зависимости от каждого из факторов. Факторы, о которых мы говорим:
- Скорость публикации контента;
- Качество контента;
- Обновления сайта;
- Существующие конкуренты
При этом индексация на количественном уровне также влияет на SEO-позиционирование страницы. Больше URL-адресов, проиндексированных в одном и том же домене, имеют больший вес в поисковой системе, чем конкуренты. Конечно, это только до тех пор, пока эти URL-адреса также являются качественными, поскольку количество не является единственным релевантным фактором.
Как сделать индексацию страниц в Google?
Google — самая используемая поисковая система в мире. Даже в странах с сильной внутренней ориентацией, таких как Россия, где нарицательным для долгой связи был Yandex.com, Google уже превысил 50% использования. Поэтому понятно, что веб-мастера заинтересованы в том, чтобы их страницы, статьи и индексация Google были как можно скорее.
Представьте, что вы предлагаете срочный контент или сезонные продукты, например. в начале учебного года, на Рождество или на летние каникулы — и вы только что запустили новый интернет-магазин или провели его ребрендинг и перенесли на новый домен. Насколько приветствуется раннее индексирование Google, когда от этого зависит будущее вашего бизнеса?
Есть несколько способов быстро проиндексировать ваши страницы или новый контент, которые помогут вам в этой ситуации. однако самыми быстрыми и, вероятно, наиболее эффективными из всех являются следующие две стратегии. Так что либо выберите один из шагов ниже, либо объедините их. Что бы вы ни делали, эти шаги позволят вам создать предпосылки для быстрой индексации контента — основного условия для получения раннего трафика.
Так что либо выберите один из шагов ниже, либо объедините их. Что бы вы ни делали, эти шаги позволят вам создать предпосылки для быстрой индексации контента — основного условия для получения раннего трафика.
Индексирование с помощью Инструментов для веб-мастеров и Google Search Console
Google может получать уведомления о создании новых страниц не только с помощью инструментов, которые обычно называют инструментами для веб-мастеров. Но поисковые системы Bing и Yahoo, например, используют свои собственные инструменты для веб-мастеров.
Однако наиболее интересующий нас набор инструментов Google когда-то назывался Google Webmaster Tools (GWM) и теперь разделен на отдельные блоки в зависимости от вашей направленности. В частности, для управления сайтами Google предоставляет Search Console, бесплатный сервис для администраторов, которые хотят отслеживать сайты, которыми они управляют, и их позиции в результатах поиска.
Веб-мастера могут предоставить Google точный URL-адрес страницы, в которую они внесли изменения, и гарантировать, что он проиндексирует ее как можно быстрее. Это особенно помогает в классических ситуациях, возникающих после переименования URL-адреса идентификатора, когда Google начинает индексировать ошибку 404 — страница не найдена по предыдущей ссылке. В худшем случае сканерам потребуется несколько месяцев, чтобы понять, что вы изменили идентификатор уже проиндексированных страниц. Но добавляя ссылку в Google Search Console, вы ускоряете процесс, избегая этих проблем.
Это особенно помогает в классических ситуациях, возникающих после переименования URL-адреса идентификатора, когда Google начинает индексировать ошибку 404 — страница не найдена по предыдущей ссылке. В худшем случае сканерам потребуется несколько месяцев, чтобы понять, что вы изменили идентификатор уже проиндексированных страниц. Но добавляя ссылку в Google Search Console, вы ускоряете процесс, избегая этих проблем.
То же самое касается как уже проиндексированных страниц, которые были просто обновлены, так и новых страниц. Веб-мастера просто уведомляют Google об изменениях, а затем Google отправляет своих поисковых роботов для анализа и индексации нового контента. Опять же, это не обязательный процесс, так как боты Google в конечном итоге доберутся до вашего контента — нового или обновленного — и проиндексируют его. Это просто система ускорения, позволяющая быстрее проиндексировать страницы.
Индексация по ссылкам
Еще один эффективный способ быстро проиндексировать веб-сайт — использовать внутренние ссылки, когда вы связываете новый контент с уже проиндексированными страницами.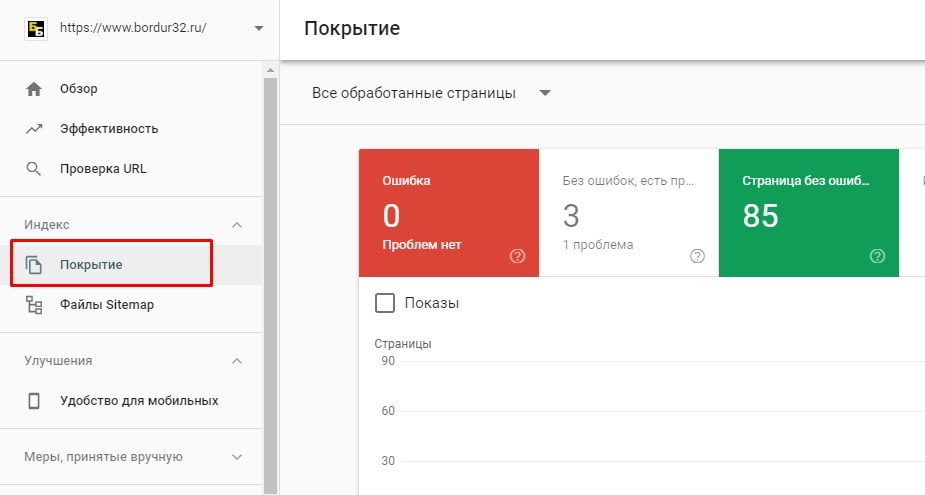 Чаще всего роботы посещают проиндексированные блоги или форумы с возможностью RSS-каналов, потому что их содержание часто меняется. Если вы управляете такой страницей и ее направленность позволяет это сделать, убедитесь, что вы всегда используете ссылки с сайта на новые страницы, и роботы поисковых систем легко найдут и проиндексируют ваш контент.
Чаще всего роботы посещают проиндексированные блоги или форумы с возможностью RSS-каналов, потому что их содержание часто меняется. Если вы управляете такой страницей и ее направленность позволяет это сделать, убедитесь, что вы всегда используете ссылки с сайта на новые страницы, и роботы поисковых систем легко найдут и проиндексируют ваш контент.
В качестве альтернативы поработайте над обратными ссылками и попросите ссылку у других, которые управляют интересными и связанными сайтами с уже проиндексированными страницами, похожими на ваши. Это поможет еще не проиндексированным страницам привлечь внимание ботов Google, но вы также привлечете больше трафика, и ваше общее SEO выиграет, поскольку Google рассматривает обратные ссылки как показатель авторитета.
10 способов заставить Google проиндексировать ваш сайт (которые действительно работают)
Джошуа Хардвик
Руководитель отдела контента @ Ahrefs (или, говоря простым языком, я отвечаю за то, чтобы каждый пост в блоге, который мы публикуем, был EPIC ).
СТАТИСТИКА СТАТЬЯ
Ежемесячный трафик 6 591
Связывание веб -сайтов 376
твиты 119
Показывает приблизительный месячный поисковый трафик к этой статье по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3-5 раз больше.
Сколько раз этой статьей поделились в Твиттере.
Поделиться этой статьей
Подпишитесь на еженедельные обновления
Подписка по электронной почте
Подписаться
Содержание
Если Google не индексирует ваш веб-сайт, вы практически невидимы. Вы не будете появляться ни по каким поисковым запросам, и вы не получите никакого органического трафика. пшик. Нада. Нуль.
Вы не будете появляться ни по каким поисковым запросам, и вы не получите никакого органического трафика. пшик. Нада. Нуль.
Учитывая, что вы здесь, полагаю, для вас это не новость. Итак, давайте сразу к делу.
В этой статье рассказывается, как решить любую из этих трех проблем:
- Весь ваш веб-сайт не проиндексирован.
- Некоторые из ваших страниц проиндексированы, а другие нет.
- Недавно опубликованные веб-страницы недостаточно быстро индексируются.
Но сначала давайте удостоверимся, что мы находимся на одной странице и полностью понимаем эту ошибку индексации.
Что такое сканирование и индексирование?
Google обнаруживает новые веб-страницы путем сканирования веб-страниц, а затем добавляет эти страницы в свой индекс . Они делают это с помощью веб-паука под названием 9.0156 Гуглбот .
Запутались? Давайте определим несколько ключевых терминов.
- Сканирование : Процесс перехода по гиперссылкам в Интернете для обнаружения нового контента.
- Индексирование : Процесс хранения каждой веб-страницы в обширной базе данных.
- Веб-паук : Программное обеспечение, предназначенное для выполнения процесса сканирования в масштабе.
- Googlebot : веб-паук Google .
Вот видео от Google, в котором более подробно объясняется процесс:
Когда вы что-то ищете в Google, вы просите Google вернуть все соответствующие страницы. из их индекса. Поскольку часто есть миллионы страниц, которые соответствуют всем требованиям, алгоритм ранжирования Google делает все возможное, чтобы отсортировать страницы, чтобы вы сначала увидели лучшие и наиболее релевантные результаты.
Важным моментом, на который я здесь обращаю внимание, является то, что индексация и ранжирование это две разные вещи .
Индексация выставлена на гонку; Рейтинг выигрывает.
Вы не сможете победить, не придя на первое место в гонке.
Как проверить, проиндексированы ли вы в Google
Зайдите в Google, затем выполните поиск site:yourwebsite.com
Это число примерно показывает, сколько ваших страниц проиндексировано Google.
Если вы хотите проверить статус индекса определенного URL-адреса, используйте тот же site:yourwebsite.com/web-page-slug оператор.
Если страница не проиндексирована, результатов не будет.
Теперь стоит отметить, что если вы являетесь пользователем Google Search Console, вы можете использовать отчет Покрытие , чтобы получить более точное представление о статусе индекса вашего веб-сайта. Просто перейдите по ссылке:
Просто перейдите по ссылке:
Google Search Console > Индекс > Покрытие
Посмотрите на количество действительных страниц (с предупреждениями и без них).
Если сумма этих двух чисел не равна нулю, то Google проиндексировал по крайней мере некоторые страницы вашего веб-сайта. Если нет, то у вас серьезная проблема, потому что ни одна из ваших веб-страниц не проиндексирована.
Примечание.
Не являетесь пользователем Google Search Console? Подписаться. Это бесплатно. Каждый, кто управляет веб-сайтом и заботится о получении трафика от Google, должен использовать Google Search Console. Это , что важно.
Вы также можете использовать Search Console, чтобы проверить, проиндексирована ли конкретная страница. Для этого вставьте URL-адрес в инструмент проверки URL-адресов.
Если эта страница проиндексирована, на ней будет написано «URL находится в Google».
Если страница не проиндексирована, вы увидите слова «URL не находится в Google».
Как проиндексироваться Google
Обнаружили, что ваш веб-сайт или веб-страница не проиндексированы в Google? Попробуйте:
- Перейдите в Google Search Console
- Перейдите к инструменту проверки URL
- Вставьте URL-адрес, который Google должен проиндексировать, в строку поиска.
- Подождите, пока Google проверит URL.
- Нажмите кнопку «Запросить индексирование». Вы фактически сообщаете Google, что добавили что-то новое на свой сайт и что они должны на это взглянуть.
Однако запрос на индексацию вряд ли решит основные проблемы, мешающие Google индексировать старые страницы. В этом случае следуйте приведенному ниже контрольному списку, чтобы диагностировать и устранить проблему.
Вот несколько быстрых ссылок на каждую тактику — на случай, если вы уже пробовали:
- Удалить блоки сканирования в файле robots.txt
- Удалить мошеннические теги noindex
- Включить страницу в карту сайта
- Удалить мошеннические канонические теги
- Убедитесь, что страница не потеряна 91 ) Удалите блоки сканирования в файле robots. txt
Google не индексирует весь ваш веб-сайт? Это может быть связано с блокировкой сканирования в файле robots.txt.
Чтобы проверить наличие этой проблемы, перейдите по адресу yourdomain.com/robots.txt .
Найдите любой из этих двух фрагментов кода:
User-agent: Googlebot Запретить: /
User-agent: * Disallow: /
Оба они сообщают роботу Googlebot, что им не разрешено сканировать какие-либо страницы на вашем сайте. Чтобы устранить проблему, удалите их. Это , что просто.
Блокировка сканирования в файле robots.txt также может быть причиной, если Google не индексирует ни одну веб-страницу. Чтобы проверить, так ли это, вставьте URL-адрес в инструмент проверки URL-адресов в Google Search Console. Нажмите на блок «Покрытие», чтобы открыть более подробную информацию, затем найдите «Сканирование разрешено? Нет: заблокировано ошибкой robots.txt».
Это указывает на то, что страница заблокирована в robots.
txt.В этом случае еще раз проверьте файл robots.txt на наличие каких-либо правил «запрета», относящихся к странице или соответствующему подразделу.
Удалить при необходимости.
2) Удалите мошеннические теги noindex
Google не будет индексировать страницы, если вы запретите им это делать. Это полезно для сохранения конфиденциальности некоторых веб-страниц. Есть два способа сделать это:
Способ 1: метатег
Страницы с любым из этих метатегов в своих
Это мета robots, и он сообщает поисковым системам, могут ли они индексировать страницу.
Примечание.
Ключевой частью является значение «noindex». Если вы это видите, значит для страницы установлено значение noindex.
Чтобы найти все страницы с метатегом noindex на вашем сайте, запустите сканирование с помощью аудита сайта Ahrefs.
Перейти к Индексируемость отчет. Ищите предупреждения «Noindex page».Нажмите, чтобы увидеть все затронутые страницы. Удалите метатег noindex со всех страниц, которым он не принадлежит.
Способ 2: X-Robots-Tag
Искатели также учитывают заголовок HTTP-ответа X-Robots-Tag. Вы можете реализовать это с помощью языка сценариев на стороне сервера, такого как PHP, или в вашем файле .htaccess, или изменив конфигурацию вашего сервера.
Инструмент проверки URL-адресов в Search Console сообщает, заблокирован ли Google от сканирования страницы из-за этого заголовка. Просто введите свой URL-адрес, а затем найдите «Индексирование разрешено? Нет: «noindex» обнаружен в http-заголовке «X-Robots-Tag»
Если вы хотите проверить наличие этой проблемы на своем сайте, запустите сканирование в инструменте аудита сайта Ahrefs, а затем используйте фильтр «Информация о роботах в заголовке HTTP» в проводнике страниц:
Попросите вашего разработчика исключить нужные вам страницы.
индексация от возврата этого заголовка.Рекомендуемая литература: Спецификации метатега Robots и заголовка HTTP X-Robots-Tag
3) Включите страницу в карту сайта
Карта сайта сообщает Google, какие страницы на вашем сайте важны, а какие нет . Это также может дать некоторые рекомендации о том, как часто их следует повторно сканировать.
Google должен иметь возможность находить страницы на вашем веб-сайте независимо от того, находятся ли они в вашей карте сайта, но рекомендуется включать их. В конце концов, нет смысла усложнять жизнь Google.
Чтобы проверить, есть ли страница в вашей карте сайта, используйте инструмент проверки URL в Search Console. Если вы видите ошибку «URL не находится в Google» и «Карта сайта: Н/Д», значит, его нет в вашей карте сайта или он не проиндексирован.
Не используете Search Console? Перейдите по URL-адресу вашей карты сайта — обычно это yourdomain.com/sitemap.xml 9.0157 — и найдите страницу.
Или, если вы хотите найти все сканируемые и индексируемые страницы, которых нет в вашей карте сайта, запустите сканирование в аудите сайта Ahrefs. Перейдите к Page Explorer и примените следующие фильтры:
Эти страницы должны быть в вашей карте сайта, поэтому добавьте их. После этого сообщите Google, что вы обновили карту сайта, проверив этот URL:
http://www.google.com/ping?sitemap=http://yourwebsite.com/sitemap_url.xmlЗаменить последняя часть с URL-адресом вашей карты сайта. Вы должны увидеть что-то вроде этого:
Это должно ускорить индексацию страницы Google.
4) Удаление мошеннических канонических тегов
Канонический тег сообщает Google, какая версия страницы является предпочтительной. Это выглядит примерно так:
Большинство страниц либо не имеют канонического тега, либо так называемого канонического тега, ссылающегося на себя.
Это сообщает Google. сама страница является предпочтительной и, возможно, единственной версией, другими словами, вы хотите, чтобы эта страница была проиндексирована.0003Но если на вашей странице есть мошеннический канонический тег, то он может сообщать Google о предпочтительной версии этой страницы, которой не существует. В этом случае ваша страница не будет проиндексирована.
Чтобы проверить наличие канонического URL, используйте инструмент Google для проверки URL. Вы увидите предупреждение «Альтернативная страница с каноническим тегом», если канонический указывает на другую страницу.
Если этого не должно быть, и вы хотите проиндексировать страницу, удалите тег canonical.
Если вам нужен быстрый способ найти мошеннические канонические теги на всем сайте, запустите сканирование в инструменте аудита сайта Ahrefs. Перейдите в Проводник страниц. Используйте эти настройки:
Поиск страниц в вашей карте сайта с каноническими тегами, не ссылающимися на самих себя.
Поскольку вы почти наверняка захотите проиндексировать страницы в своей карте сайта, вам следует дополнительно изучить, возвращает ли этот фильтр какие-либо результаты.Весьма вероятно, что эти страницы либо имеют мошеннический канонический код, либо вообще не должны быть в вашей карте сайта.
5) Убедитесь, что страница не потеряна.
Страницы-сироты – это те страницы, на которые не указывают внутренние ссылки .
Поскольку Google обнаруживает новый контент путем сканирования Интернета, он не может обнаружить бесхозные страницы с помощью этого процесса. Посетители сайта также не смогут их найти.
Чтобы проверить наличие потерянных страниц, просканируйте свой сайт с помощью аудита сайта Ahrefs. Затем проверьте отчет Links на наличие ошибок «Бесхозная страница (нет входящих внутренних ссылок)»:
Здесь показаны все страницы, которые одновременно индексируются и присутствуют в карте сайта, но не имеют внутренних ссылок, указывающих на них.
Не уверены, что все страницы, которые вы хотите проиндексировать, есть в вашей карте сайта? Попробуйте:
- Загрузите полный список страниц вашего сайта (через вашу CMS)
- Просканируйте свой сайт (используя такой инструмент, как Site Audit от Ahrefs)
- Сопоставьте два списка URL-адресов
Любые URL-адреса, не найденные во время сканирования, являются потерянными страницами.
Исправить страницы-сироты можно двумя способами:
- Если страница не важна , удалите ее и удалите из карты сайта.
- Если страница важна , включите ее во внутреннюю структуру ссылок вашего веб-сайта.
6) Исправление внутренних ссылок nofollow
Ссылки Nofollow — это ссылки с тегом rel=“nofollow”. Они предотвращают передачу PageRank на целевой URL. Google также не сканирует nofollow-ссылки.
Вот что Google говорит по этому поводу:
По сути, использование nofollow заставляет нас удалять целевые ссылки из нашего общего графа сети.
Однако целевые страницы могут по-прежнему отображаться в нашем индексе, если другие сайты ссылаются на них без использования nofollow или если URL-адреса отправляются в Google в файле Sitemap.Короче говоря, вы должны убедиться, что все внутренние ссылки на индексируемые страницы переходят.
Для этого используйте инструмент аудита сайта Ahrefs для сканирования вашего сайта. Проверьте Ссылки Отчет для индексируемых страниц с ошибками «Страница имеет nofollow только входящие внутренние ссылки»:
Удалите тег nofollow из этих внутренних ссылок, предполагая, что вы хотите, чтобы Google проиндексировал страницу. Если нет, либо удалите страницу, либо не индексируйте ее.
Рекомендуем прочитать: Что такое ссылка Nofollow? Все, что вам нужно знать (без жаргона!)
7) Добавьте «мощные» внутренние ссылки
Google обнаруживает новый контент, сканируя ваш веб-сайт. Если вы пренебрегаете внутренней ссылкой на рассматриваемую страницу, они могут не найти ее.
Простое решение этой проблемы — добавить на страницу несколько внутренних ссылок. Вы можете сделать это с любой другой веб-страницы, которую Google может сканировать и индексировать. Однако, если вы хотите, чтобы Google проиндексировал страницу как можно быстрее, имеет смысл сделать это с одной из ваших наиболее «мощных» страниц.
Почему? Потому что Google, скорее всего, будет повторно сканировать такие страницы быстрее, чем менее важные страницы.
Для этого перейдите в Site Explorer от Ahrefs, введите свой домен, а затем перейдите на страницу Best by links 9отчет 0170.
Здесь показаны все страницы вашего веб-сайта, отсортированные по URL-рейтингу (UR). Другими словами, в первую очередь отображаются наиболее авторитетные страницы.
Просмотрите этот список и найдите релевантные страницы, с которых можно добавить внутренние ссылки на рассматриваемую страницу.
Например, если бы мы хотели добавить внутреннюю ссылку в наше руководство по размещению гостевых сообщений, наше руководство по созданию ссылок, вероятно, предложило бы подходящее место для этого.
И так случилось, что эта страница является 11-й по авторитетности страницей в нашем блоге:Google увидит эту ссылку и перейдет по ней при следующем повторном сканировании страницы.
8) Убедитесь, что страница ценна и уникальна.
Google вряд ли будет индексировать некачественные страницы, потому что они не представляют никакой ценности для пользователей. Вот что Джон Мюллер из Google сказал об индексации в 2018 году:
Мы никогда не индексируем все известные URL-адреса, это вполне нормально. Я бы сосредоточился на том, чтобы сделать сайт потрясающим и вдохновляющим, тогда все обычно работает лучше.
— 🍌 Джон 🍌 (@JohnMu) 3 января 2018 г.
Он подразумевает, что если вы хотите, чтобы Google проиндексировал ваш веб-сайт или веб-страницу, они должны быть «потрясающими и вдохновляющими».
Если вы исключили технические проблемы из-за отсутствия индексации, то причиной может быть отсутствие ценности.
По этой причине стоит взглянуть на страницу свежим взглядом и спросить себя: действительно ли эта страница ценна? Найдет ли пользователь ценность на этой странице, если он нажмет на нее из результатов поиска?Если ответ отрицательный на любой из этих вопросов, то вам необходимо улучшить свой контент.
Вы можете найти больше потенциально некачественных страниц, которые не проиндексированы, с помощью инструмента аудита сайта Ahrefs и профилировщика URL. Для этого перейдите в Page Explorer в Ahrefs Site Audit и используйте следующие настройки:
Это вернет «тонкие» страницы, которые индексируются и в настоящее время не получают органического трафика. Другими словами, есть неплохая вероятность, что они не проиндексированы.
Экспортируйте отчет, затем вставьте все URL-адреса в URL Profiler и запустите проверку индексации Google.
Проверьте все неиндексированные страницы на наличие проблем с качеством. При необходимости улучшите, а затем запросите переиндексацию в Google Search Console.
Вы также должны стремиться устранить проблемы с дублирующимся содержимым. Google вряд ли проиндексирует повторяющиеся или почти повторяющиеся страницы. Используйте отчет Duplicate content в аудите сайта, чтобы проверить эти проблемы.
9) Удалите некачественные страницы (для оптимизации «краулингового бюджета»)
Слишком много некачественных страниц на вашем веб-сайте приведет только к трате краулингового бюджета.
Вот что говорит Google по этому поводу:
Трата ресурсов сервера на [страницы с низкой добавленной стоимостью] приведет к уменьшению активности сканирования со страниц, которые действительно имеют ценность, что может привести к значительной задержке в обнаружении отличного контента на сайте. .
Думайте об этом как об учителе, оценивающем эссе, одно из которых ваше. Если им нужно оценить десять сочинений, они довольно быстро доберутся до вашего. Если у них есть сотня, это займет у них немного больше времени.
Если их тысячи, их рабочая нагрузка слишком высока, и они могут никогда не оценить ваше эссе.Google заявляет, что «краулинговый бюджет […] — это не то, о чем стоит беспокоиться большинству издателей», и что «если на сайте меньше нескольких тысяч URL-адресов, в большинстве случаев он будет сканироваться эффективно».
Тем не менее, удаление некачественных страниц с вашего сайта никогда не помешает. Это может только положительно сказаться на краулинговом бюджете.
Вы можете использовать наш шаблон аудита контента , чтобы найти потенциально некачественные и нерелевантные страницы, которые можно удалить.
10) Создавайте высококачественные обратные ссылки
Обратные ссылки сообщают Google, что веб-страница важна. В конце концов, если кто-то ссылается на него, то он должен иметь какую-то ценность. Это страницы, которые Google хочет проиндексировать.
Для обеспечения полной прозрачности Google индексирует не только веб-страницы с обратными ссылками.
Существует множество (миллиарды) проиндексированных страниц без обратных ссылок. Однако, поскольку Google считает страницы с качественными ссылками более важными, они, скорее всего, будут сканировать и повторно сканировать такие страницы быстрее, чем без них. Это приводит к более быстрой индексации.У нас есть много ресурсов для создания высококачественных обратных ссылок в блоге.
Взгляните на несколько руководств ниже.
Дальнейшее чтение
Индексация ≠ рейтинг
Индексация вашего веб-сайта или веб-страницы в Google не означает рейтинга или трафика.
Это две разные вещи.
Индексирование означает, что Google знает о вашем веб-сайте. Это не значит, что они будут ранжировать его по любым релевантным и стоящим запросам.
Вот где на помощь приходит SEO — искусство оптимизации ваших веб-страниц для ранжирования по определенным запросам.
Короче говоря, SEO включает в себя:
- Поиск того, что ищут ваши клиенты;
- Создание контента на эти темы;
- Оптимизация этих страниц под ваши целевые ключевые слова;
- Создание обратных ссылок;
- Регулярная перепубликация контента, чтобы он оставался «вечнозеленым».
Вот видео, которое поможет вам начать работу с SEO:
… и некоторые статьи:
Дополнительная литература
Заключительные мысли
Есть только две возможные причины, по которым Google не индексирует ваш веб-сайт или сеть. страница:
- Технические проблемы мешают им это делать
- Они считают ваш сайт или страницу некачественными и бесполезными для своих пользователей.
Вполне возможно, что существуют обе эти проблемы. Однако я бы сказал, что технические проблемы встречаются гораздо чаще. Технические проблемы также могут привести к автоматической генерации индексируемого контента низкого качества (например, проблемы с фасетной навигацией).
 txt
txt txt.
txt. Перейти к Индексируемость отчет. Ищите предупреждения «Noindex page».
Перейти к Индексируемость отчет. Ищите предупреждения «Noindex page». индексация от возврата этого заголовка.
индексация от возврата этого заголовка.
 Это сообщает Google. сама страница является предпочтительной и, возможно, единственной версией, другими словами, вы хотите, чтобы эта страница была проиндексирована.0003
Это сообщает Google. сама страница является предпочтительной и, возможно, единственной версией, другими словами, вы хотите, чтобы эта страница была проиндексирована.0003 Поскольку вы почти наверняка захотите проиндексировать страницы в своей карте сайта, вам следует дополнительно изучить, возвращает ли этот фильтр какие-либо результаты.
Поскольку вы почти наверняка захотите проиндексировать страницы в своей карте сайта, вам следует дополнительно изучить, возвращает ли этот фильтр какие-либо результаты.
 Однако целевые страницы могут по-прежнему отображаться в нашем индексе, если другие сайты ссылаются на них без использования nofollow или если URL-адреса отправляются в Google в файле Sitemap.
Однако целевые страницы могут по-прежнему отображаться в нашем индексе, если другие сайты ссылаются на них без использования nofollow или если URL-адреса отправляются в Google в файле Sitemap.
 И так случилось, что эта страница является 11-й по авторитетности страницей в нашем блоге:
И так случилось, что эта страница является 11-й по авторитетности страницей в нашем блоге: По этой причине стоит взглянуть на страницу свежим взглядом и спросить себя: действительно ли эта страница ценна? Найдет ли пользователь ценность на этой странице, если он нажмет на нее из результатов поиска?
По этой причине стоит взглянуть на страницу свежим взглядом и спросить себя: действительно ли эта страница ценна? Найдет ли пользователь ценность на этой странице, если он нажмет на нее из результатов поиска?
 Если их тысячи, их рабочая нагрузка слишком высока, и они могут никогда не оценить ваше эссе.
Если их тысячи, их рабочая нагрузка слишком высока, и они могут никогда не оценить ваше эссе. Существует множество (миллиарды) проиндексированных страниц без обратных ссылок. Однако, поскольку Google считает страницы с качественными ссылками более важными, они, скорее всего, будут сканировать и повторно сканировать такие страницы быстрее, чем без них. Это приводит к более быстрой индексации.
Существует множество (миллиарды) проиндексированных страниц без обратных ссылок. Однако, поскольку Google считает страницы с качественными ссылками более важными, они, скорее всего, будут сканировать и повторно сканировать такие страницы быстрее, чем без них. Это приводит к более быстрой индексации.